|
BASE DE DONNEES ORIENTEE-GRAPHE : MIGRATION DU
RELATIONNEL VERS LE NOSQL
Mémoire présenté et défendu par
Gradi KAMINGU LUBWELE
(Gradué en Sciences)
en vue de l'obtention du Titre de Licencié en Sciences
Groupe : Informatique
Option : Informatique de Gestion
Directeur :
Pierre KAFUNDA KATALAY,
Professeur Associé, Université de Kinshasa,
Faculté des Sciences, Département de
Mathématiques et Informatique
Année académique : 2014 - 2015
Epigraphie
«Nul ne peut contester que le cosmos et ses
composantes forment un graphe.»
Gradi L.Kamingu
«N'ayez aucun style comme style,
n'ayez aucune limitation comme limitation.»
Bruce LEE
In memoriam
A ma Tante, MALOU EKAKOLA pour l'orientation efficace pour
mon bien-être ; j'en suis reconnaissant de tous ses biens faits.
Gradi L.Kamingu
Remerciements
C'est pour nous un honneur et un réel plaisir de
réaliser un tel travail. Son élaboration traduit, à sa
juste valeur, le dévouement le plus soutenu et l'intérêt
que nous lui avons accordé.
Sur ce, nous nous en voudrais si nous manquions de
témoigner notre gratitude à tous ceux qui, par leur soutien tant
financier, moral, intellectuel que spirituel ont contribués de
près ou de loin à sa réalisation.
Nos sentiments de gratitude s'adressent de prime abord au
Très haut, le Dieu Créateur de cieux et la terre,
Générateur de souffle, la Bonté Absolue, l'Au-delà,
l'Infini, l'Eternel, Celui qui nous fait compter parmi les vivants.
La réalisation de ce travail n'aurait pas
été possible sans le soutien scientifique et la rigueur
exprimée de notre directeur, le Professeur Pierre KAFUNDA KATALAY, qui
malgré ses multiples occupations a accepté de diriger cet humble
travail.
Nos remerciements s'adressent au Professeur Léonard
MANYA NDJADI, celui qui nous a donné le goût de la théorie
des graphes en particulier et la Recherche opérationnelle en
général, et au Professeur Eugène MBUYI MUKENDI, qui a
investi son temps pour nous donner le plaisir de travailler dans le domaine des
bases de données, raison pour laquelle nous manquons même de
tournure de rhétorique pour exprimer notre gratitude.
Que tous les professeurs, chefs des travaux et assistants du
département des Mathématiques et Informatique trouvent ici nos
sentiments de gratitude, qui nous ont transmis pendant cinq longues
années les fondamentaux de la Science de l'Informaticien tout autour des
mathématiques.
Plaise à Dieu de permettre que notre gratitude
s'énonce à l'adresse d'Innocent KAMINGU et Lydie EKAKOLA,
respectivement notre père et notre mère, à qui nous devons
tout.
Nous noussentons dans le devoir de remercier Monsieur Koffi
SANI, Ingénieur Concepteur en Informatique de l'Institut Africain
d'Informatique à Libreville (Gabon).
Nous remercions également Glodi KAMINGU, L'or LUKELU,
Pitsho EKOKOLA, Bébé EKAKOLA, Nesta KINENE, Sephora KINENE,
Joëlle KINENE, Aninya NGE, Aminata AKWANI, Marguerite MUJINGA, Coen
FUNDATELA, Trésor BADIBANGA, Christian NTUMBA, Patrick
SHUNGU,Cédrick TOMBOLA,Jean-Paul TSASA, Moïse MBIKAYI et
Josée NKIKUpour leur fraternité dont ils ont montré
vis-à-vis de notre égard;
Nos reconnaissances s'adressent aussi à l'égard
de Sarah BENDELO; elle qui nous a toujours inspirée et nous a offert son
affection.
Nous dédions ce travail à l'avenir de Bethlehem
Corp./SARL, notre chère entreprise.
Avant-propos
Le présent travail est le fruit de cinq années
d'études universitaires. En plus de sa vertu de témoignage de
nos cinq longues années, il nous couronne du titre de second cycle.
Telle oeuvre, doit être lue avec grand intérêt, non
seulement par les scientifiques, mais aussi par des professionnels.
La théorie des graphes est un domaine bien ancien des
mathématiques discrètes, généralement
rattachée à la Recherche opérationnelle et l'Informatique
(surtout pour son importance en Algorithmique), qui trouva sa naissance par un
article du mathématicien suisse Leonhard Euler, qu'il
présenta à l'Académie de Saint-Pétersbourg en
1735 puis publié en 1741, qui traitait du problème des sept ponts
de Königsberg. Bien qu'étant une théorie ancienne, ses
applications continuent à se multiplier du jour le jour.
Nombre d'applications sont à compter aujourd'hui en
informatique (réseau social, réseau informatique, réseau
de télécommunications, etc.), y compris dans le domaine de base
de données.
Cependant, dans le présent travail, on met en
évidence une application beaucoup plus intéressante de la
théorie des graphes pour représenter des données qui
seront stockées sur un support physique. Ce qui fait que ce travail
revêt d'un bon outil pour la présentation d'une application
informatique de la théorie des graphes qui reste encore un peu
assombrie dans notre pays.
Enfin, ce travail propose de doter à nos concitoyens
des notions de base de base de données orientées-graphe qui est,
évidemment, encore en évolution. Nous avons proposé de
présenter les concepts clés liés à la notion de
base de données orientées-graphes ainsi qu'une étude de
cas pour une présentation matérielle des concepts
théoriques.
Nous remercions d'avance tous les utilisateurs qui voudront
bien nous faire parvenir leurs remarques, suggestions pour
l'amélioration tant syntaxique que sémantique de cet humble
travail.
Liste des abréviations utilisées
|
Abréviation
|
Signification
|
|
AGPL
|
Affero General Public Licence
|
|
API
|
Application Programming Interface
|
|
BD / BDD
|
Base de données
|
|
BI
|
Business Intelligence
|
|
DB
|
Database
|
|
CD
|
Centralité de degré
|
|
CDE
|
Centralité de degré entrante
|
|
CDS
|
Centralité de degré sortante
|
|
CI
|
Centralité d'intermédiarité
|
|
CIE
|
Centralité d'intermédiarité entrante
|
|
CIS
|
Centralité d'intermédiarité sortante
|
|
CODASYL
|
Conference on data system Language
|
|
CP
|
Centralité de proximité
|
|
CPE
|
Centralité de proximité entrante
|
|
CPS
|
Centralité de proximité sortante
|
|
DBTG
|
Data Base Task Group
|
|
EA
|
Entité-Association
|
|
GPL
|
GNU1(*)
General Public Licence
|
|
HA
|
High availability
|
|
http
|
Hypertext transfer protocol
|
|
IBM
|
International Business Machine
|
|
IS - IS
|
Intermediate system to intermediate system
|
|
JDK
|
Java Development Kit
|
|
JVM
|
Java Virtual Machine
|
|
MCD
|
Modèle conceptuel des données
|
|
Merise
|
Méthode de recherche en informatique pour les
systèmes d'entreprise
|
|
MPD
|
Modèle physique des données
|
|
NASA
|
National Aeronautics and Space Administration
|
|
NoSQL
|
Not only SQL
|
|
OLAP
|
Online Analytical Processing
|
|
OLTP
|
Online Transaction Processing
|
|
OMT
|
Object Modeling Technique
|
|
ORM
|
Object-Relational Mapping
|
|
OSPF
|
Open Shortest Path Protocol
|
|
SQL
|
Structured Query Language
|
|
SGBD
|
Système de gestion de base de données
|
|
SGBDR
|
Système de gestion de base de données
relationnelle
|
Liste des notations
|
Notation
|
Description
|
|
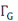 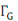 (x) (x)
|
Ensemble des voisins du sommet x dans G
|
|
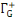 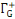 (x) (x)
|
Ensemble des successeurs du sommet x dans G
|
|
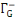 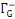 (x) (x)
|
Ensemble des prédécesseurs du sommet x dans G
|
|
Ø
|
Ensemble-vide
|
|
X
|
Ensemble des sommets (noeuds)
|
|
U
|
Ensemble des arêtes (arcs)
|
|
N
|
Ensemble des entiers naturels
|
|
N*
|
Ensemble des entiers naturels non-nuls
|
|
R
|
Ensemble des nombres réels
|
|
R*
|
Ensemble des nombres réels non-nuls
|
|
|X| ou #X
|
Cardinal de l'ensemble X
|
|
Degré d'un sommet x
|
|
Demi-degré extérieur d'un sommet x
|
|
Demi-degré intérieur d'un sommet x
|
|
Kn
|
Graphe complet d'ordre n
|
|
Km,n
|
Graphe biparti-complet d'ordre m,n
|
|
ñ(G)
|
Rayon d'un graphe G
|
|
ä(G)
|
Diamètre d'un graphe G
|
|
In×1
|
Vecteur colonne de dimension n ne contenant que des 1
|
|
On×1
|
Vecteur colonne de dimension n ne contenant que des 0
|
0
INTRODUCTION
A
Ujourd'hui, les problèmes ayant trait au stockage des
données sont très récurrents et sont dus
généralement aux structures et à la masse des informations
à stocker. Il faut alors reconnaitre que les bases de données
sont un élément très important dans l'informatique
moderne, car elles ont permis un bon stockage de données et de
manière structurée. Ces dernières années, le
modèle relationnel s'est imposé comme la norme. En effet ce
dernier permet un respect des propriétés ACID (Atomicité,
Consistance, Isolation, Durabilité) que nous expliquerons plus tard et
garanti ainsi la sécurité des données.
Cependant, ces propriétés demandent des
prérequis importants, ce qui peut impacter grandement les performances
de la base. A terme cela peut se traduire par une difficulté de mise en
échelle. Certaines entreprises ont donc décidé de se
pencher sur une nouvelle technologie afin de pallier aux problèmes de
performances, quitte à sacrifier la consistance des données comme
tel est le cas dans les NoSQL.
Pour y arriver, les scientifiques ont utilisé la
théorie des graphes, initiée par Euler avec son fameux
problème de 7 ponts de la ville de Königsberg. Cette théorie
bien qu'ancienne, a bien permis de trouver une application en Informatique
qu'est la base de données orientées-graphe. Dans le souci de
montrer une application importante de la théorie des graphes et de
montrer la nécessité des bases de données
orientées-graphes, nous avons pu choisir ce domaine encore en gestation.
On remarque aussi que la théorie des graphes est
utilisée dans un grand nombre de disciplines (mathématiques,
informatique, physique, économie, chimie, etc.). Les recherches
actuelles en théorie des graphes sont essentiellement menées par
des informaticiens, du fait de l'importance des aspects algorithmiques
(structures de données). D'où la nécessité
d'étudier ses applications.
Eu égard à tous ces qui précédent,
il ressort le désir de savoir s'il n'y a toujours la solution des bases
de données orientées-graphe qui peut résoudre les
problèmes liés aux stockages de l'information. Peut-on trouver
une approche pouvant nous permettre de migrer des bases de données
relationnelle vers les bases de données orientées-graphe ?
C'est dans ce contexte que nous avons alors choisi le sujet
intitulé Base de données orientées-graphe :
Migration du relationnel vers le NoSQL.
Etant donné que la gestion de la masse de
données est à la base même de l'Informatique de
gestion, l'intérêt principal et nécessaire de ce sujet
réside dans ces implications qui sont à la fois scientifique,
théorique, pratique, personnelle et didactique. En effet, ce travail
peut être vu selon plusieurs niveaux dont les principaux sont :
Ø Au niveau scientifique: ce travail
permet de mieux appréhender les mécanismes et méthodes mis
en oeuvre pour proposer une nouvelle approche de migration d'une base de
données de type quelconque vers une autre de type
différent du premier;
Ø Au niveau théorique: ce
travail constitue un support intéressant explicitant brièvement
et clairement les notions de base de données, de la théorie de
graphes, des différents types des bases de données du type NoSQL
et l'application de la théorie des graphes dans le domaine de base de
données ;
Ø Au niveau pratique : ce travail
montre clairement notre capacité à résoudre un
problème tout en appliquant les concepts théoriques
assimilés à l'université tout au long de nos
études, ainsi notre habilité à résoudre un
problème récurrent ;
Ø Au niveau personnel : ce
travail nous a permis de passer en revue des notions encore récentes et
encore moins traiter dans notre université. De plus il nous mis en
confiance que la théorie des graphes n'a pas encore fini ses
applications dans la science de l'informaticien ;
Ø Au niveau didactique : ce
travail constitue un support beaucoup plus intéressant pour
l'apprentissage de base de données NoSQL en général et les
bases de données orientées-graphe en particulier.
Proposer une approche de migration d'une base de données
relationnelle vers une base de données orientées-graphe, nous
avons délimité notre travail dans un espace d'octobre 2015
à janvier 2016.
Nous avons alors eu recours à la technique documentaire
consistant à consulter les ouvrages, les thèses, les
mémoires d'études, les revues techniques et les articles traitant
du domaine des bases de données orientées-graphe, de la
théorie de graphe, de la théorie des réseaux sociaux, et
du NoSQL. Nous avons également consulté un certain nombre de
documents disponibles sur Internet.
Ainsi pour arriver à nos fins, nous avons
subdivisé notre travail en quatre chapitres outre la présente
introduction et la conclusion, nous avons :
Ø Le chapitre premier qui est intitulé
Généralités sur les bases de données et les
graphes ;
Ø Le deuxième chapitre parlant de
NoSQL ;
Ø Le troisième chapitre intitulé
Base de données orientées-graphe ;
Ø Enfin le troisième chapitre qui décrit
l'Application.
CHAPITRE1
GENERALITES SUR LES BASES DE
DONNEES
ET LES GRAPHES
D
ans ce chapitre, il ne sera question que de présenter
d'une manière moins détaillée la notion de base de
données orientées graphe ou tout simplement base de
données graphe.
Une base de données orientées-graphe permet de
résoudre donc des problèmes très difficiles, voire
impossibles à résoudre dans une base de données
relationnelle. Un cas pratique est dans un réseau social, si nous nous
mettons à stocker les relations entre différentes personnes du
réseau, les manipulations seront fastidieuses et la base serait
très grosse et donc longue à parcourir pour rechercher les amis
d'une personne.
Cependant, nous allons nous atteler sur les notions abstraites
de base de données orientées-graphe. C'est à cette juste
raison que nous allons donner une aperçu général sur les
fondamentaux de base de données orientées graphe tels que la
notion générale de base de données et enfin la notion de
la théorie des graphes.
Pour clore ce chapitre, nous allons donner d'une
manière simple l'importance de la représentation des
données sous forme des graphes et son bienfondé lors des diverses
manipulations.
I.1.
BASE DE DONNEES
I.1.1. Définition de la base de données
Le terme Base de données est un mot
créer par Charles Bachmann, originairement de l'anglais Data
Base en 1960 dans un de ses livres intitulé « The
Evolution of Storage Structure ».
Une base de données (son abréviation BD ou BDD
ou encore DB, pour l'anglais Data Base) est un ensemble structuré des
données enregistrées sur des supports accessibles par
l'ordinateur, représentant des informations du monde réel, pour
satisfaire un ou une communauté d'utilisateurs simultanément en
un temps opportun. [MB13]
I.1.2. Critères d'une base de données
Une base de données doit répondre à
plusieurs critères dont trois sont les plus importants, à savoir
[MK10]:
(i) La structuration :
c'est-à-dire une base de données doit avoir une structure propre
à lui de façon à rendre donner la souplesse et la
rapidité dans son exploitation.
(ii) Non redondance :
c'est-à-dire une base de données ne doit pas avoir en son sein
des informations répétitives. Ainsi, Il y a alors deux types de
redondances :
§ La synonymie : c'est lorsque deux
ou plusieurs objets renvoient à la même signification.
Exemple 1.1:Titre et
Intitulé ; Désignation et Libellé.
§ La polysémie : c'est
lorsqu'un objet renvoie a plusieurs significations.
Périphérique
Animal
Exemple 1.2 : Souris :
(iii) Exhaustivité :
c'est-à-dire une base de données doit contenir toutes les
informations possibles et nécessaires pouvant faire objet de
répondre aux besoins des utilisateurs. Ainsi, nous parlons de la
complétude.
I.1.3. Types d'utilisateurs
· L'administrateur de la base de données : Il
assure la commande ou le contrôle de la base de données. Il est
chargé d'assurer la sécurité de la base de données,
en permettant accès aux données qu'aux applications et
différents individus qui ont le droit. Il est aussi chargé de
conserver des bonnes performances d'accès à ces données,
d'assurer les sauvegardes de données à la base de
données ;
· Le programmeur d'application : Il est
chargé d'écrire des applications qui utilisent la base de
données. Il crée des tables et les structures associées
(vues, index,...) utilisées par ses applications.
· L'utilisateur final : N'a accès qu'aux
données qui lui sont utilisés par l'intermédiaire des
applications ou en interrogeant directement les tables ou vues sur lesquelles
l'administrateur de base de données lui a accordé des droits.
I.4.1. Types de base de données
I.1.4.1. Base de données hiérarchique
Pour une base de données hiérarchique, les
données sont mises sous forme d'une structure d'arborescence de la
manière suivante :
· Les enregistrements sont mis dans les noeuds de
l'arborescence en notant que chaque noeud n'a qu'un seul possesseur. Chaque
noeud représente une classe d'entité du monde réel, Chaque
noeud peut avoir un ou plusieurs pointeurs déterminant le chemin
d'accès. Les noeuds n'ayant pas de pointeur sont des feuillets ;
· Les arcs représentent le lien existant entre
enregistrements. Ce lien est défini par un pointeur qui pointe sur le
noeud suivant.
Les structures de données hiérarchiques ont
été largement utilisées dans les premières bases de
données conçues pour la gestion de données du programme
Appolo de NASA.
Il sied de noter que les bases de données
hiérarchiques possèdent des limites considérables que leur
utilisation est en voie de disparition actuellement.
La représentation du modèle peut se faire de la
manière suivante :
Figure 1.1. Représentation des données du
type hiérarchique
I.1.4.2. Base de données réseau
La base de données est juste une
généralisation de la base de données hiérarchique
en levant certaines incapacités très délicates des bases
de données dites hiérarchiques. En effet, dans ces bases de
données, il y a possibilité d'avoir la relation du genre
un noeud peut avoir plusieurs possesseurs. En termes simples,
on peut dire que dans ces types de base de données, « une
fille à plusieurs mères ».
Ainsi, comme le modèle hiérarchique, ce
modèle est conçu avec des pointeurs déterminant le chemin
d'accès au (x) noeud(x) suivant(x).
Le modèle fut mis initialement proposé par le
groupe nommé DBTG du comité CODASYL fut alors mis au point par
Charles Bachmann. Ce qui lui value le prix Turing en 1973. Donc, ce
modèle se conforme aux normes fixées par le groupe CODASYL
(Conference On Data System Languages) en 1971.
On peut représenter ce modèle de la
manière suivante :
Figure 1.2. Représentation des données du
type réseau
I.4.1.3. Base de données relationnelle
La base de données relationnelle est alors
structurée sur les principes de l'Algèbre relationnelle, une
théorie inspiré de la théorie des ensembles et la logique
de prédicats du premier ordre. La théorie de l'Algèbre
relationnelle fut alors inventée par le mathématicien Edgar Frank
Codd.
En 1970, Edgar Frank Codd (1923 - 2003), programmeur
d'applications mathématiques chez IBM, proposa dans une thèse de
Mathématiques d'utiliser les tables pour représenter les
enregistrements au lieu d'utiliser les noeuds du graphe comme le faisaient la
base de données hiérarchiques et la base de données
réseaux. Ces informations utilisent maintenant le formalisme
entité-association pour être modélisées.
Mais IBM, qui travaillait avec un autre type de modèle
de base de données n'y prêta pas attention si vite. Il a fallu
qu'on attende jusqu'en 1978 lorsque le concept intéressa Lawrence
Ellison, le fondateur d'une Startup qui est devenue Oracle Corporation.
|
...
|
...
|
...
|
|
...
|
...
|
...
|
|
...
|
...
|
...
|
|
|
|
|
...
|
...
|
...
|
Tableau 1.1. Représentation du modèle
relationnel
I.4.1.4. Base de données orientées-objet
La base de données orientées-objet utilise donc
une notion fondamentale qu'est l'objet au sens de la
Programmation orientée-objet.
Selon ce type de modèle de données, une base de
données est un lot d'objets de différentes classes, chaque objet
possède des propriétés : des caractéristiques
propres, et des méthodes qui sont des opérations en rapport avec
l'objet, une classe est une catégorie d'objets et reflète
typiquement un sujet concret.
Figure 1.3. Représentation des données du
type objet
I.1.4.5. Base de données orientées-colonne
Une base de données orientées-colonne est un
type de base de données qui ne diffère pas architecturalement
avec des bases des données relationnelles. La grande différence
entre les deux types de bases de données est la façon d'agencer
les informations dans la mémoire.
En effet, dans une base de données relationnelle, les
informations sont stockées en ligne tandis que dans une base de
données orientées-colonne, les informations sont stockées
en colonne. De ce fait, lorsqu'il s'agit de faire une requête portant
sur peu de lignes mais beaucoup de colonnes, le système de base de
données relationnelle sera rapide tandis que lorsqu'il s'agit de faire
une requête portant sur peu de colonnes mais beaucoup de lignes, le
système de base de données orientées-colonne sera
rapide.
I.1.4.6. Base de données orientées-graphe
Les bases de données orientées-graphe sont
celles qui stockent les enregistrements dans les noeuds et les relations entre
les enregistrements par les arêtes. Elles sont modélisées
à l'aide de la théorie des graphes qu'on verra dans le paragraphe
II.6.
C'est ainsi, une base de données
orientées-graphe stocke les informations d'une manière
très optimisée sous forme de graphe. Les liens entre
différentes informations sont aussi faits de manière
optimisée.
Ce type de base de données est très performant
surtout dans des domaines où les données sont très
nombreuses. Il est accès sur les données (entités2(*)) pendant que la plupart des
types de bases de données sont axés sur les modèles
(types-entités) ce qui fait que trouver les relations d'une
entité est très rapide.
I.1.4.7. Base de données
orientées-clé-valeur
Les bases de données orientées-clé-valeur
permettent de stocker une valeur, cette valeur peut être de tout type
(entier, chaine de caractères, flux binaire, etc.). En revanche les
requêtes ne portent que sur la clé associée à cette
valeur. Ce système de base de données est conçu pour
être très fortement répliqué de manière
à augmenter la disponibilité et les performances. La
réplication de données est plus ou moins partielle pour trouver
un bon compromis entre nombre de serveurs, disponibilité et espace
disque.
I.1.4.8. Base de données orientées-document
Les bases de données orientées-document sont une
extension des bases orientées clé-valeur, à la place de
stocker une valeur, nous stockons un document. Un document peut contenir
plusieurs valeurs et d'autres documents, qui peuvent à leur tour en
contenir d'autres et ainsi de suite. Un document peut donc posséder
plusieurs niveaux de profondeur. Tous les documents de niveau 0 sont
identifiés par une clé et sont regroupés dans une
collection.
Ce système est capable de faire des recherches sur les
valeurs d'un ou plusieurs documents, le système étant
partiellement répliqué, la requête va être
envoyée à tous les serveurs simultanément et chacun va
effectuer celle-ci et rendre des résultats différents, car toutes
les données ne sont pas présentes sur tous les serveurs, ces
résultats vont être ré-agrégés pour former le
résultat finale à la requête.
Nota :
Les quatre derniers types de base de données sont dits
du type NoSQL (Not Only SQL). Ces types de bases de données NoSQL
permettent de rendre le système beaucoup plus performant et
résistants aux pannes, en revanche comme celles-ci ne permettent pas de
cohérence des données, elles ne sont que très rarement
utilisées seule : une base de données relationnelle va contenir
les informations où une cohérence est vitale et une base de
données de type NoSQL va contenir tout le reste.
Les bases de données de type NoSQL n'ont pas encore des
normes définissant une architecture type ; cela se justifie par le
fait que les bases de données NoSQL sont des types de bases de
données très récentes dont l'évolution est encore
en cours.
I.2. GRAPHES
I.2.1. Définition d'un graphe
On appelle graphe G le couple (X, U) où :
· X est un ensemble non vide et au plus
dénombrable dont les éléments sont appelés
sommets) ou noeuds.
· U est une famille d'éléments du produit
cartésien X×X={(x,y)|x, y 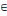 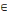 X} dont les éléments sont appelés arcs
ou arêtes. Ces éléments
représentent des liaisons entre sommets du graphe. X} dont les éléments sont appelés arcs
ou arêtes. Ces éléments
représentent des liaisons entre sommets du graphe.
En terminologie des graphes,
· On appellera arc une liaison
orientée d'un sommet x vers un autre sommet y. On dit que y
est un successeur de x s'il existe un arc (x,y); on
dit aussi que x est un prédécesseur de
y, c'est-à-dire x est un extrémité initiale
et y est un extrémité terminale
(finale). On appellera y voisin de x dans le graphe
G=(X, U) s'il est soit un successeur, soit un prédécesseur de x.
Nota : Dans la vie pratique, on peut
interpréter extrémité terminale par
« descendant », « fils ou fille»,
« origine », « ... » et on peut
interpréterextrémité initiale par
« ascendant », « père ou
mère », « cible »,
« ... ».
· On appellera arête une liaison
non-orientée d'un sommet x et un autre sommet y. Dans ce cas x et y sont
des extrémités.
Nota : Dans la vie pratique, on
l'interprète une extrémité par « un
noeud » ou un « bout ».
On notera alors :
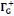 · · 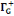 (x) = L'ensemble des successeurs du sommet x dans G (x) = L'ensemble des successeurs du sommet x dans G
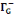 · · 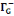 (x) = L'ensemble des prédécesseurs du
sommet x dans G (x) = L'ensemble des prédécesseurs du
sommet x dans G
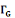 · · 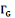 (x) = L'ensemble des voisins du sommet x dans G (x) = L'ensemble des voisins du sommet x dans G
Ainsi, 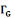 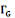 (x) = (x) = 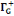 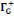 (x) + (x) + 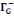 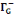 (x) (x)
Un sommet x dans 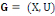 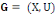 est un sommet isolé ssi est un sommet isolé ssi 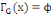 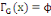 c'est-à-dire si et seulement si le sommet x n'a pas de voisin
c'est-à-dire qui n'a ni successeur, ni prédécesseur.
(1) c'est-à-dire si et seulement si le sommet x n'a pas de voisin
c'est-à-dire qui n'a ni successeur, ni prédécesseur.
(1)
b
a
d
e
f
c
u7
u2
u5
u6
u1
u4
u8
u3
Figure 1.4 : Représentation sagittale d'un
graphe
Exemple 1.3 : Soit le graphe G
Dans cet exemple, on a la représentation sagittale d'un
graphe d'ordre 6.
X = {a, b, c, d, e, f}
U = {u1, u2, u3,
u4, u5, u6, u7, u8}
Si le cardinal de U est égal à a (|U|=#U=a),
alors on dit que le graphe G = (X, U) est de taille a.
Dès lors nous considérons U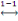 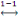 I I  N est fini. L'exemple 1.3 est de taille a=8, car il y a 8 arcs. N est fini. L'exemple 1.3 est de taille a=8, car il y a 8 arcs.
Si le cardinal de X est égal à n (|X|=#X=n),
alors on dit que le graphe G = (X, U) est d'ordre n.
Dès lors nous considérons X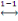 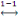 J J  N est fini. L'exemple 1.3 est d'ordre n=6, car il y a 5 sommets. N est fini. L'exemple 1.3 est d'ordre n=6, car il y a 5 sommets.
L'arc u7 est une boucle parce que
l'extrémité initiale coïncide avec l'extrémité
terminale.
L'arc u3 et l'arc u8 sont de la
même forme, car ils ont même extrémité initiale et
même extrémité finale. On dira que G (de l'exemple 1.3) est
un 2-graphe d'ordre 6.
Ainsi, un p-graphe d'ordre n est un graphe
d'ordre n dont le maximum d'arcs de même est le naturel p.
Un graphe simple est un 1-graphe
sans boucle. En d'autres termes, un graphe est dit simple s'il n'y a ni boucle,
ni d'arcs de même forme.
Dans un graphe simple, on pourra donc noter un arc à
l'aide de ses extrémités initiale et finale.
Un multigraphe est un p-graphe (avec p>1)
sans boucle.
Deux arcs sont dits adjacents s'ils
ont une extrémité en commun.
Deux sommets sont dits adjacents si un arc les relie.
Le demi-degré
extérieur d'un sommet x
(noté dG+(x)) est
égal au nombre d'arcs qui « partent » de x.
Le demi-degré
intérieur d'un sommet x
(noté dG-(x)) est
égal au nombre d'arcs qui « arrivent » en x.
Le degré du sommet x
(noté dG(x)) est égal à
la somme des demi-degrés, c'est-à-dire :
  + + 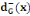 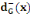
En particulier :
· Si 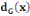 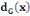 = 0, on dit que le sommet est
isolé ; (2) = 0, on dit que le sommet est
isolé ; (2)
· Si 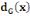 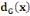 = 1, on dit que le sommet est
pendant. = 1, on dit que le sommet est
pendant.
Remarque : Les propositions (1) et (2) sont
équivalentes.
Lemme 1.1 : Lemme de poigné de
main
Soit G = (X, U) un graphe sans boucle, alors :
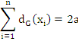
Où n le nombre des sommets et a le nombre
d'arêtes.
Exemple 1.4 : Soit le graphe G
b
a
d
e
f
c
u2
u5
u6
u1
u4
u3
Figure 1.5 : Représentation sagittale d'un
graphe simple
On notera que rien n'interdit la présence dans le
graphe de l'arc (e,f) et (f,e).
· d est un sommet
isolé parce qu'il n'est ni extrémité
initiale, ni extrémité terminale d'aucun arc ;
· a et b sont adjacents ;
· l'arc 4
est incident à f ;
· b et e sont des prédécesseurs de
f ;
· b et e sont des successeurs de a ;
· le demi-degré extérieur de e
dG+(e)= 1 ;
· le demi-degré intérieur de e
dG-(e)= 2 ;
· le degré de e dG(e) = 3.
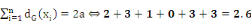 · · 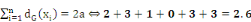 (Lemme de poignée de main) (Lemme de poignée de main)
I.2.2. Graphe complet
Un graphe est dit complet si tous
ses sommets sont reliés et par conséquent ils sont tous de
même degré.
On parle aussi de clique pour un
graphe complet. Ainsi, un graphe complet d'ordre n est appelé
n-clique, on note généralement
Kn, c'est-à-dire un graphe complet d'ordre n
est appelé n-clique.
Quand un graphe n'est pas complet, et que l'ensemble de
sommets peut être partitionné en cliques :
On notera ù le nombre
maximal de sommets d'une clique sous-graphe.
On notera è le nombre
minimal de cliques nécessaires pour partitionner l'ensemble des sommets
du graphe.
Exemple 1.5 : Soit le graphe
K5
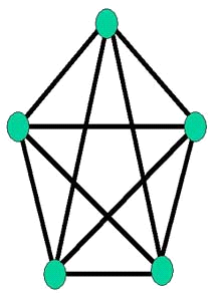
Figure 1.6 : Représentation sagittale d'un
graphe complet
I.2.3. Graphe biparti
Un graphe est dit biparti si
l'ensemble de sommets peut être partitionné en deux classes de
sorte que les sommets d'une même classe ne soient jamais adjacents.
Les graphes de fonctions, applications, bijections sont des
graphes bipartis
On définit aussi des graphes bipartis complets,
notés Km,n
a
b
c
d
e
f
Exemple 1.6 : Soit le graphe
K3,3
Figure 1.7 : Représentation sagittale d'un
graphe biparti
On
appelle sous-graphe engendré par A (partie de
X) le graphe obtenu en ne conservant que les sommets de A et les arcs les
reliant.
On appelle graphe partiel un graphe
obtenu en supprimant un nombre quelconque d'arcs au graphe initial.
On appelle chaîne une
succession d'arcs dont l'extrémité chaque arc
intermédiaire a une extrémité en commun avec l'arc
précédent l'autre extrémité en commun avec l'arc
suivant.
Une chaîne ne rencontrant pas deux fois le même
sommet est dite élémentaire.
Une chaîne ne rencontrant pas deux fois le même
arc est dite simple.
On appelle chemin une succession
d'arcs dont l'extrémité terminale coïncide avec
l'extrémité initiale de son suivant à l'exception du
dernier i.e. un chemin est une chaîne « bien
orientée », car tous les arcs de la chaîne sont
parcourus dans le bon sens.
On appelle cycle une chaîne
simple qui rentre dans son extrémité de départ.
On appelle circuit un cycle
« bien orienté », à la fois cycle et
chemin.
b
a
d
e
f
c
u6
u2
u5
u1
u4
u3
u7
Exemple 1.7 : Soit le graphe G
Figure 1.8 : Graphe ayant une chaine, un chemin, un
circuit et un cycle
· (u1, u4, u5) est une
chaîne dont les arcs 1 et 4 sont directs et 5 inverse
· (u7, u2, u1,
u4) est un chemin : tous les arcs sont parcourus dans le bon
sens.
· (u1, u4, u5,
u2) est un cycle, les extrémités
« libres » des arcs 1 et 2 sont égales; (a,b) puis
(b,f) puis (e,f) puis (e,a).
· (u6, u7, u2) est un
circuit.
On appelle
chaîne eulérienne une chaîne qui
passe une et une seule fois par toutes les arêtes du graphe.
On appelle
chaîne hamiltonnienne une chaîne qui
passe une et une seule fois par tous les sommets du graphe.
On peut bien évidemment étendre les deux notions
précédentes aux chemins, cycles, circuits.
Ainsi, en particulier,
· Le problème consistant à passer, d'une
manière minimale, par tous les sommets du graphe une et une seule fois
en revenant au sommet du départ s'appelle problème du
voyageur de commerce.
· Le problème consistant à parcourir, d'une
manière minimale, tous les arcs du graphe une et une seule fois en
revenant au sommet du départ s'appelle problème du
postier chinois.
I.2.4. Connexité
Un graphe sera dit connexe si, pour
tout couple (x, y) de sommets, il existe une chaîne reliant deux de ses
sommets x et y.
a
d
e
f
c
b
u1
u2
u4
u5
u6
u3
Exemple 1.8 : Soit le graphe G
Figure 1.9 : Graphe non connexe
· Ce graphe n'est pas connexe car le sommet d est
isolé
Si un graphe n'est pas connexe, on
appellera composante connexe, chacun de ses
« morceaux » connexes.
Plus formellement :
On définit une relation entre les sommets de la
manière suivante :
x R y si et seulement si x=y ou x et y
sont reliés par une chaîne.
On démontre aisément que cette relation R
est réflexive, symétrique et transitive,
donc que c'est une relation d'équivalence.
Qui dit « relation d'équivalence »,
dit « classes d'équivalence ». On appellera ces
classes des composantes connexes.
Nota : Lorsqu'il s'agit d'un graphe
orienté, on parle de la forte connexité.
On notera en général : p, le nombre de
composantes connexes d'un graphe.
On peut s'intéresser au nombre de sommets à
supprimer pour « disconnecter » un graphe connexe (i.e.
faire qu'il ne soit plus connexe).
Remarque : Quand on enlève un sommet,
on supprime aussi tous les arcs dont ce sommet est extrémité.
Le nombre minimum de sommets pour ce faire sera
noté ê, on l'appellera
la connectivité du graphe.
On qualifiera d'ensemble d'articulation, un
ensemble de sommets dont la suppression disconnecte le graphe.
La connectivité est donc le cardinal minimal d'un
ensemble d'articulation.
Remarque :
Une connectivité égale à k signifie
qu'on peut trouver k sommets dont la suppression
disconnecte le graphe, cela ne veut pas dire que ce sera le cas avec k sommets
quelconques.
Exemple 1.9 :
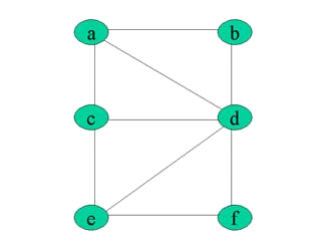
Figure 1.11 : Graphe connexe
· Ce graphe est connexe.
· Quel que soit le sommet qu'on retire, il reste
connexe.
· Si on retire b et d, le graphe est toujours connexe.
· Si on retire c et d le graphe n'est plus connexe.
· Le Graphe est donc 2-connexe.
· {c,d} est un ensemble d'articulation du graphe.
Remarque : Si un graphe est 3-connexe,
il est 2-connexe.
Un point d'articulation est un
sommet dont la suppression disconnecte le graphe, c'est-à-dire un sommet
sont la suppression augmente la connexité du graphe.
Un isthme est une arête dont
la suppression disconnecte le graphe, c'est-à-dire une arête sont
la suppression augmente la connexité du graphe. On parle aussi de
pont en lieu et place d'isthme. Ainsi, les
extrémités d'un pont dont appelé pieds du
pont.
Exemple 1.10 :
Figure 1.11 : Graphe ayant deux points d'articulations
et un isthme
· Ce graphe est connexe ;
· Il possède deux points d'articulation ;
· L'arc central est un isthme (pont) ;
· Les deux points d'articulation sont les pieds du
pont ;
· Il n'y a aucun autre isthme.
Soit G=(X, U) un graphe. On dit que ce graphe est
k-sommet-connexe s'il reste encore connexe après avoir
en ôté (k-1) sommets.
Soit G=(X, U) un graphe. On dit que ce graphe est
k-arête-connexe s'il est possible de le
déconnecter (augmenter le nombre de connexité) en supprimant k
arêtes et tel que k est minimal.
N.B : Un graphe régulier de
degré r est au plus r-arête-connexe, r-sommet-connexe et
r-régulier. S'il est effectivement r-arête-connexe,
r-sommet-connexe, il est donc optimalement connecté.
I.2.5. Distances
La distance entre deux sommets d'un
graphe connexe (ou entre 2 sommets d'une même composante connexe d'un
graphe non connexe) est le nombre minimum d'arcs (on dit
aussi la longueur) d'une chaîne allant de l'un à l'autre.
Dans l'exemple 1.9 la distance de a à f est de 2 : on
peut aller de a à f en 2 arcs, mais pas en 1 arc.
L'écartement d'un sommet est la
distance maximale existant entre ce sommet et les autres sommets du graphe. (Si
le graphe n'est pas connexe, l'écartement est infini).
Dans l'exemple 1.9, l'écartement de a est de 2, comme
d'ailleurs pour tous les autres sommets, sauf d dont l'écartement vaut
1.
On appelle centre d'un graphe, le
sommet d'écartement minimal. (Le centre n'est pas
nécessairement unique).Par exemple, dans une clique, tous les sommets
sont « centres »
On appelle rayon d'un graphe G,
noté ñ(G), l'écartement d'un centre
de G. Le rayon est de 1 dans l'exemple 1.9. d est le seul centre de ce
graphe.
On appelle diamètre d'un
graphe G, noté ä(G), la distance maximale
entre deux sommets du graphe G. Le diamètre est de 2 dans l'exemple
1.11.
Exemple 1.11 :
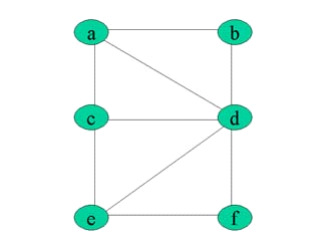
Figure 1.11 : Représentation sagittale d'un
graphe illustrant la notion de distance
1.2.6. Graphe planaire
Un Graphe sera dit planaire s'il
admet une représentation sagittale planaire, c'est à dire une
représentation dans le plan où les sommets du graphe sont des
points du plan et les arcs des courbes simples ne se rencontrant qu'en un
sommet.
Remarque : Pour qu'un graphe soit planaire,
il faut qu'il admette au moins une représentation planaire.
Exemple 1.12 :
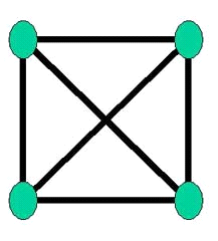
Figure 1.12 : Graphe planaire
K4 est-il planaire ?
Si on se fonde sur sa représentation sagittale
classique ci-contre, il semblerait que non.
Pourtant, on pourrait représenter le graphe autrement,
en faisant passer l'arc 2,4 par l'extérieur, on aurait alors une
représentation planaire.
K4 est donc bien un graphe
planaire.
Dans la représentation planaire d'un graphe, on
appellera face toute région du plan non
traversée par des arcs.
Dans l'exemple 1.12, il y a 6 faces (n'oubliez pas la face
infinie), 12 sommets et 16 arcs.
Exemple 1.13 :
6
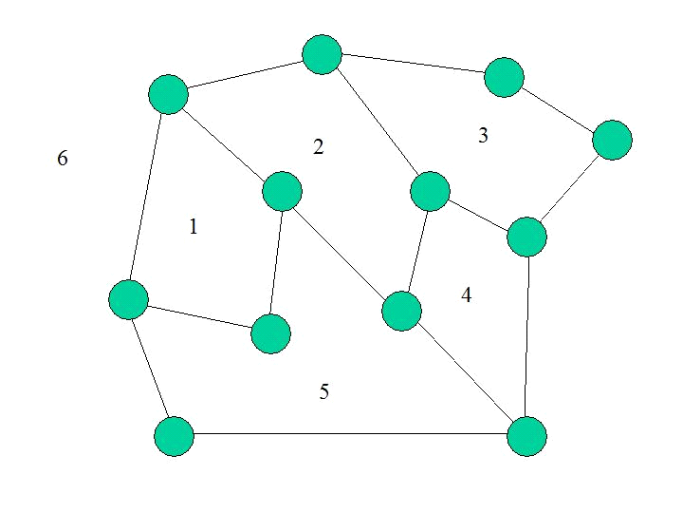
Figure 1.13 : Faces d'un graphe planaire
Propriété 1.1 (Formule
d'Euler): Dans un graphe planaire d'ordre n avec m arcs, on
a:
f = a - n + 2.
Démonstration : par
récurrence sur a,
C'est vrai pour le graphe contenant 2 sommets et un
arc : f=1, n=2, a=1 d'où :
f-a+n= 2
Quand on rajoute un arc, deux cas de figure peuvent se
présenter : soit on rajoute un sommet dans une face et le nombre de
faces ne change pas; soit on ne rajoute pas de sommet, l'arc ajouté
arrive donc sur un sommet déjà existant, mais alors, on a
coupé une face en 2, donc ajouter une face.
Dans tous les cas, le nombre f-a+n ne varie pas, reste donc
égal à2. 
Propriété 1.2
: K5 n'est pas planaire
Démonstration : S'il
était planaire, sa représentation planaire comporterait
(d'après la Formule d'Euler) 10-5+2 = 7 faces.
Or, il faut au moins 3
arcs pour fermer une face et un arc pouvant servir de frontière à
2 faces, avec 10 arcs, il ne peut y avoir plus de 20/3 faces, d'où une
contradiction.  
Propriété 1.3
: K3,3 n'est pas planaire
Démonstration : S'il
était planaire, sa représentation planaire comporterait
(d'après la Formule d'Euler) 9-6+2 = 5 faces.
Or, il faut au moins 4
arcs (dans le cas d'un graphe biparti, on ne peut pas fermer une face avec un
nombre impair d'arcs!) pour fermer une face et un arc pouvant servir de
frontière à 2 faces, avec 9 arcs, il ne peut y avoir plus de 18/4
faces, d'où une contradiction. 
Nota : Il existe une réciproque
à ces deux propriétés, connue sous le nom
de Théorème de Kuratowski, dont la
démonstration est assez difficile.
Propriété 1.4 (Théorème de
Kuratowski) :
Les seuls graphes non planaires sont ceux admettant
K5 ou K3,3 comme sous-graphes.
I.2.7. Graphe pondéré - Réseau -
Réseau de transport
a. Graphe pondéré
Soit G = (X, U) :
· On dit que G est pondéré à tout
arc (xi, xj) 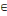 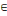 U, si on associe le nombre cij U, si on associe le nombre cij 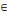 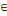 R ; R ;
· La matrice C=(cij) (i, j)  U est appelé matrice de pondération. U est appelé matrice de pondération.
· On note alors le triplet G=(X, U, C) le graphe
pondéré.
A savoir que la pondération ou la valeur c
(xi, xj) est une valeur résultant d'une mesure.
Cette mesure peut être :
· Une distance du sommet xi au sommet
xj ;
· Un coût sur l'arc (xi,
xj) ;
· Une pénalité, par exemple : Paiement
associé à l'arc (xi, xj) ;
· Une probabilité de transition du sommet
xi au sommet xj ;
· Une durée (temps) entre xi et
xj ;
· Une consommation (de carburant, etc.) à
effectuer du xi au sommet xj ;
· Etc.
Exemple 1.14 : Soit le graphe G=(X, U,
C).
Le graphe ci-contre est pondéré dans la mesure
où, de chaque, on a associé une valeur numérique
quelconque.
a
-5
c
5
19
e
13
d
2
3
b
1
1
g
-2
3
f
9
2
Figure 1.14 : Illustration d'un graphe
pondéré
b. Réseau
Un réseau est un graphe pondéré sans boucle.
Pour ce faire, on note
R=(X, U,?) un graphe pondéré sans boucle ni circuit
à valeur négative.
c. Réseau de transport
(i) R=(X, U,?) est un réseau de transport si et seulement
si c'est un graphe pondéré sans boucle ni circuit à valeur
négative et c (xi,xj) = 0, 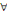 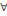 (xi,xj) (xi,xj) 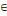 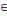 U. U.
(ii) R=(X, U,?) est un réseau de transport si et seulement
si c'est un graphe pondéré sans boucle ni circuit à valeur
négative et c (xi,xj) = 0, 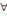 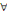 xi,xj xi,xj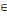 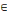 X. X.
NOTA : La définition (i) et
(ii) sont équivalentes ;
I.2.8. Problème de Cheminement optimale
a. Valeur d'un chemin
Soit G=(X,U) un graphe. Si à chaque arc
(xi,xj) 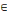 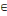 U, on associe le nombre le nombre cij U, on associe le nombre le nombre cij 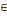 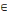 R*, tel que cij = valeur (xi,xj) = c
(xi,xj). R*, tel que cij = valeur (xi,xj) = c
(xi,xj).
Considérons la loi de composition interne binaire +
dans R*. On appelle valeur d'un chemin (xi1,
xi2, ..., xik), le nombre noté
« l », tel que :
l = ci1, ci2 + ci2,
ci3 + ... + cik - 1, cik
Exemple 1.15 : Considérons le
graphe suivant :
b
a
c
e
f
d
z
5
2
10
30
40
90
100
6
11
8
7
11
Figure 1.15 : Graphe pondéré
On a : cab=c(a,b)=5 ;
cbd=c(b,d)=8 ; cdc=c(d,c)=4 ;
cce=c(c,e)=3
  l (a, b, d, c, e) = 20 l (a, b, d, c, e) = 20
Remarque
S'il existe un chemin qui correspond à la plus grande (ou
petite) valeur de l, on l'appelle « plus long (ou court)
chemin » du graphe.
b. Types d'algorithmes de cheminement optimal
Il existe deux types de cheminement optimal, se basant toutes sur
le principe d'optimalité de Richards Bellman. On cite :
· Les algorithmes constructeurs d'arbre (Tree
builder) qui consistent à construire l'arbre à
valeur optimale entre la racine (source) et les autres noeuds du
réseau ;
· Les algorithmes matriciels qui
consistent à trouver le chemin à valeur optimale entre tous les
couples de sommet (xi,xj) 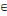 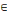 U. U.
Dans ce travail, on s'intéressera qu'à un
algorithme Tree builder de plus court chemin, appelé Algorithme de
Dijkstra, car c'est cet algorithme qui est utilisé dans
l'implémentation des bases de données orientées-graphe.
c. Algorithme de Dijkstra (pour le plus court
chemin)
c.1. Origine
Cet algorithme est dû aux recherches de l'Informaticien
et Mathématicien néerlandais (alors qu'il était
diplômé en Physique théorique, mais trop
intéressé à l'Informatique notamment le Système
d'exploitation et les principes de programmation) appelé Edsger
Dijkstra. Cet algorithme fut publié en 1959.
Cet algorithme est plus utilisé dans le calcul des
itinéraires routiers. Une autre application les plus courantes de cet
algorithme est le protocole Open Shortest Path Fist (OSPF) qui est
utilisé pour le routage internet ; il permet des informations. Les
routeurs tels que IS-IS sont implémentés en algorithme de
Dijkstra. [Wiki1]
c.2. Principe
L'algorithme de Dijkstra s'appuie directement sur le
principe d'optimalité de Richards Bellman selon
lequel : « dans un graphe, tout chemin optimal comprenant au
plus r arcs est formé des sous-chemins contenant au plus k arcs (k=r) et
qui sont eux aussi optimaux entre leurs sommets
extrémités ».
Algorithme 1.1
1. (Numérotation)
Numéroter les sommets du graphe dans un ordre
quelconque, en observant toutefois que le sommet de départ doit
être marqué x0 et celui d'arrivé xn-1
si n est le nombre total de sommets du graphe.
2. (Initialisation)
Pour tout sommet xi (i?0)
On affecte provisoirement à tous les xi une
étiquette de poids (xi)
une valeur 8, c'est-à-dire :
poids (xi)   8 8
Fin pour
3. poids (x0)   0 0
4. S   X X
5. Tant que ð?S
Choisir un sommet xj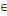 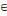 ð / poids (xj) = ð / poids (xj) = 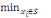 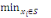 poids (xj) poids (xj)
ð   ð ð  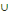 { xj } { xj }
Pour tout voisin xj de
xi de ð
Sipoids (xj) + v
(xi,xj) < poids (xj) Alors
Mémoriser en xj que l'on vient de
xi
Fin si
Fin pour
Fin tant que
6. Fin
1.2.9. Calcul de centralité [CH10]
Un réseau social est un ensemble
d'individus ou d'organisations reliés par des interactions
sociales régulières. Un domaine scientifique nommé
analyse des réseaux sociaux, les étudie en se basant sur la
théorie des graphes et l'analyse sociologique.Le calcul de
centralité est depuis plusieurs décennies une
problématique importante dans le domaine de l'analyse des réseaux
sociaux [WF94]. Le calcul de centralité est une notion qui a
été mise en oeuvre pour rendre compte de la popularité ou
la visibilité d'un acteur (noeud) au sein d'un groupe (graphe). Cette
notion représente l'une des contributions les plus importantes dans le
domaine de l'analyse de réseaux sociaux. Ces contributions sont
traitées dans l'article « Centrality in social networks:
Conceptual clarification [FR79]. Dans son article, Freeman propose trois
définitions formelles du concept de centralité que nous
présentons ci-dessous.
Dans le but de quantifier cette notion d'importance d'un noeud
dans un graphe, les chercheurs ont proposé plusieurs définitions
connues sous le nom de mesures de centralité. En effet, l'identification
des noeuds centraux dans un graphe représente un enjeu important dans
plusieurs domaines. Prenons le cas des réseaux de communication ;
le fait de connaitre les noeuds importants permet d'adopter des
stratégies afin de mieux protéger ces noeuds qui jouent un
rôle essentiel dans la communication au sein du réseau.
Considérons à titre d'exemple le réseau de communication
de la figure 1.16.
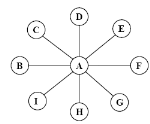
Figure 1.16 : Exemple d'un réseau de
communication
On remarque que si le noeud B tombe en panne, la communication
entre les différents noeuds ne sera pas affectée. Par contre, si
le noeud A (point d'articulation du graphe) tombe en panne, cela engendrerait
un grand problème de communication puisque tous les noeuds se
retrouveront isoles.
Lors de l'étude de la notion de centralité, il
est important de distinguer le cas des graphes orientés du cas des
graphes non-orientés. Dans les graphes orientés, les noeuds
possèdent deux types de liens, à savoir des liens entrants et des
liens sortants. Pour une définition donnée de la notion de
centralité, chaque noeud aura alors deux mesures d'importance : une
mesure relative à ses liens sortants, appelée mesure de
centralité, d'influence, d'hubité ou de centralité
sortante, et une autre mesure relative à ses liens entrants,
appelée mesure de prestige, de popularité, d'autorité ou
de centralité entrante. Dans un graphe non-orienté, chaque noeud
possède un seul type de liens ou de relations avec les autres noeuds.
Chaque noeud possède alors une seule mesure d'importance (correspondant
à une définition précise) appelée mesure de
centralité [WF94].
Dans la suite de ce chapitre, nous décrivons quelques
mesures de centralité dans les graphes orientés et
non-orientés. Nous commençons par rappeler les principales
mesures proposées dans le domaine de l'analyse des
réseaux sociaux (qui sont des applications très
rependue des bases de données graphe). Celles-ci incluent les
centralités de degré, d'intermédiarité ainsi que de
proximité.
a. Centralité de degré
La centralité de degré [FR79] représente
la forme la plus simple et la plus intuitive de la notion de centralité.
Elle est basée sur l'idée qu'un noeud (individu) occupe une place
importante dans un graphe (groupe) s'il est à plus des voisins (s'il a
plusieurs personnes qu'il connait ou interagit directement). Cela consiste
alors à calculer le nombre de ses sommets voisins, ou de manière
équivalente, à calculer le nombre de liens qui lui sont incidents
qu'on appelle évidemment degré du noeud, d'où
l'appellation de centralité de degré.
Soit G = (X, U) un graphe d'ordre n représente par sa
matrice d'incidence sommets-sommets de A. Dans le cas où le graphe G est
non-orienté, la centralité de degré d'un noeud
xi? X est définie par :
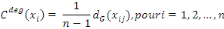
En notation matricielle, le vecteur de la centralité de
degré est donne par :
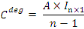
Où 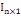 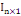 est un vecteur-colonne de dimension n necontenant des que 1. est un vecteur-colonne de dimension n necontenant des que 1.
Au lieu d'utiliser la matrice d'adjacence A (qu'on appelle
aussi matrice d'incidence sommet-sommet), on peut aussi utiliser la matrice de
degrés D.
Ce qui implique que le vecteur calcul de centralité de
degré en notation matricielle peut s'écrire :
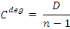
Dans le cas où le graphe G est orienté, chaque
noeud xi?X possède alors deux mesures de centralité de
degré : une par rapport aux arcs incidents extérieurement et une
par rapport aux arcs incidents extérieurement.
Elles sont définies respectivement par :
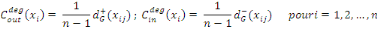
En termes de matrices, les vecteurs de centralité de
degré sortant et de degré entrant sont donnés
respectivement par :
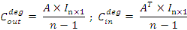
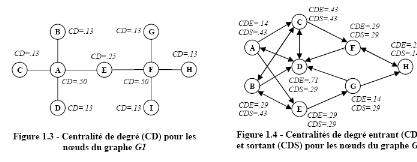
Les figures 1.17 et 1.18 indiquent respectivement la
centralité de degré pour les noeuds graphes G1 et
G2. Les résultats fournis par cette analyse de la
centralité de degré montrent que les noeuds A et F, ayant quatre
liens chacun, sont les plus importants dans le graphe G1. Pour le
graphe G2, les noeuds A, B et C possèdent la plus forte
centralité par rapport aux liens sortants, tandis que le noeud D
possède la plus forte centralité par rapport aux liens entrants.
La centralité de degré est aussi appelée
mesure de centralité locale car elle ne prend pas en compte la structure
globale du graphe et n'est calculée qu'à partir du voisinage
immédiat d'un sommet. Bien qu'elle soit pertinente dans certaines
situations, la centralité de degré s'avère être peu
informative dans d'autres cas, comme par exemple pour l'analyse des graphes de
pages web. Les mesures que nous présentons dans la suite sont toutes des
mesures de centralité globales.
|
Figure 1.17 : Centralité de degré (CD)
pour les noeuds du graphe G1
|
Figure 1.18 : Centralité de proximité
entrante (CDE) et sortante (CDS) pour les noeuds du graphe
G2
|
Source : [CH10]
b. Centralité de proximité
La centralité de proximité [FR79] est une mesure
de centralité globale basée sur l'intuition qu'un noeud occupe
une position stratégique (ou importante) dans un graphe s'il est
globalement proche des autres noeuds de ce graphe. Par exemple dans un
réseau social, cette mesure correspond à l'idée qu'un
acteur est important s'il est capable de contacter facilement un grand nombre
d'acteurs avec un minimum d'effort (l'effort ici est relatif à la taille
des chemins). En pratique, la centralité de proximité d'un noeud
est obtenue en calculant sa proximité moyenne vis-à-vis des
autres noeuds du graphe.
Soit G = (X, U) un graphe (orienté ou non) d'ordre n
représente par sa matrice d'adjacence A. Dans le cas où le graphe
G est non-orienté, la centralité de proximité d'un noeud
xi? X est définie par :
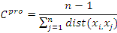
Où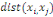 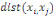 est la distance entre les deux sommets est la distance entre les deux sommets 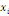 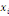 et et 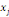 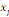
Dans le cas où le graphe G est orienté, chaque
noeud xi? X possède alors deux mesures de centralité
de proximité : une par rapport aux liens sortants et une par rapport aux
liens entrants. Elles sont définies respectivement par :
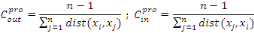
Où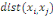 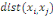 est la distance entre les deux sommets est la distance entre les deux sommets 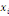 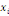 et et 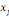 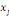
Pour le calcul des distances entre sommets, plusieurs
métriques peuvent être utilisées. Freeman propose par
exemple d'utiliser la distance géodésique entre les noeuds.
D'autres mesures de distance telle que la distance euclidienne peuvent
également être utilisées pour le calcul de la
centralité de proximité.
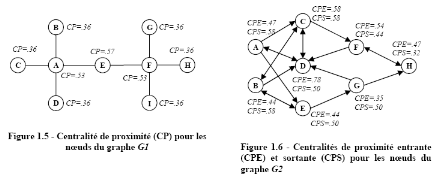
Les figures 1.19 et 1.20 indiquent respectivement la
centralité de proximité (de Freeman) pour les noeuds des graphes
G1 et G2.
|
Figure 1.19 : Centralité de proximité
(CP) pour les noeuds du graphe G1
|
Figure 1.20 : Centralité de proximité
entrante (CPE) et sortante (CPS) pour les noeuds du graphe
G2
|
Source : [CH10]
Remarque : La centralité
d'intermédiarité a pour inconvénients de ne pas fournir
des bons résultats lorsque le graphe n'est pas connexe. Il n'est par
conséquent pas possible de calculer la centralité de
proximité puisque les distances géodésiques entre certains
noeuds sont indéfinies, c'est-à-dire elles ont des valeurs   puisqu'il n'existe aucun chemin entre ces noeuds. puisqu'il n'existe aucun chemin entre ces noeuds.
c. Centralité d'intermédiarité
La centralité d'intermédiarité [FR79] est
une autre mesure de centralité globale proposée par Freeman.
L'intuition de cette mesure est que, dans un graphe, un noeud est d'autant plus
important qu'il est nécessaire de le traverser pour aller d'un noeud
quelconque à un autre. Plus précisément, un sommet ayant
une forte centralité d'intermédiarité est un sommet par
lequel passe un grand nombre de chemins géodésiques le graphe.
Dans un réseau social, un acteur ayant une forte centralité
d'intermédiarité est un sommet tel qu'un grand nombre
d'interactions entre des sommets non adjacents dépend de lui [BE06].
Dans un réseau de communication, la centralité
d'intermédiarité d'un noeud peut être
considérée comme la probabilité qu'une information
transmise entre deux noeuds, qui passe par ce noeud intermédiaire
[BE06].
|
Figure 1.21 : Centralité
d'intermédiarité (CI) pour les noeuds du graphe
G1
|
Figure 1.22 : Centralité
d'intermédiarité entrante (CI) pour les noeuds du graphe
G2
|
Source : [CH10]
Soit G = (X, U) un graphe (orienté ou non) d'ordre n.
La centralité d'intermédiarité d'un noeud xi? X
est définie par :
où  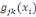 est le nombre total de chemins géodésiques entre les
noeuds est le nombre total de chemins géodésiques entre les
noeuds 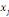 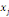 et et 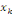 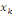 qui passent par le noeud qui passent par le noeud 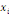 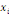 , et , et 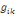 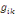 est le nombre total de chemins géodésiques entre les
noeuds est le nombre total de chemins géodésiques entre les
noeuds 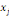 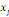 et et 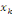 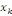 . .
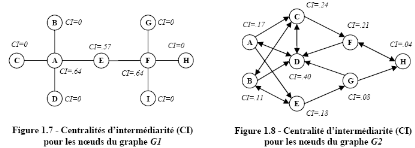
Les figures 1.21 et 1.22 indiquent respectivement la
centralité d'intermédiarité pour les noeuds des graphes
G1 et G2. Nous remarquons que les noeuds A et F sont les
plus importants dans le graphe G1; ces deux noeuds sont en effet les
plus traverses par les chemins géodésiques entre les noeuds du
graphe. Pour le graphe G2, le noeud D est celui par lequel passe le
plus grand nombre de chemins géodésiques entre les noeuds du
graphe; il possède par conséquent la plus forte
centralité. Il est également intéressant de noter pour le
graphe G2, que les noeuds E et F possèdent des
centralités d'intermédiarité différentes bien
qu'ils aient le même nombre de liens entrants et de liens sortants.
La centralité d'intermédiarité est
basée sur l'hypothèse que les noeuds ne communiquent où
interagissent entre eux qu'à travers les chemins les plus courts.
Certains chercheurs ont alors proposé de modifier cette hypothèse
afin de prendre en compte le fait que les noeuds peuvent interagir en utilisant
des chemins autres que les chemins géodésiques. Par exemple,
Freeman [FR91] a proposé la centralité du flux
d'intermédiarité qui n'utilise pas que les chemins
géodésiques mais plutôt tous les chemins
indépendants entre deux noeuds c'est-à-dire les chemins dont les
ensembles d'arcs sont disjoints.
I.3. IMPORTANCE DE LA THEORIE DES GRAPHES EN BASE DE
DONNEES
Les graphes sont d'une importance en base de données,
car une base de données orientées-graphe utilise les
structures de graphes (noeuds, arêtes et propriétés) pour
représenter et stocker les données.
Par définition, une base de données
orientées-graphe correspond à un système de stockage
correspondant à un graphe G=(X, U) tel que :
· X est l'ensemble des noeuds qui représentent les
enregistrements ;
· U est l'ensemble des liens entre noeuds qui
représentent les relations entre enregistrements.
C'est une base de données orientées-objet
adaptée à l'exploitation des structures de données de type
graphe ou dérivée, comme des arbres. [Wiki3]
Exemple 1.16:
En base de données relationnelle:
Table Client contient un identifiant, un nom, un
prénom, une adresse, un numéro client, correspondant aux noms des
colonnes respectives. Considérons le client « id01 Badibanga
Trésor 96 quartier Ngufu 010203 »
Cette table client est rattachée à une table
entreprise, avec un numéro de SIRET, un nom, et un domaine
d'activité par exemple. Considérons l'entreprise « 1221
Bcorp TIC ».
La relation entre les tables se nomme a pour client, et bien
évidemment Bcorp a pour client Trésor.
En base de données
orientées-graphe, la table client sera
représentée par un ensemble de noeuds pour chaque instance, donc
le même client sera représenté par un noeud
suivant :
"Client :
identifiant : id01
nom : Badibanga
prénom : Trésor
adresse : 96 quartier Ngufu
numéro client : 010203".
L'entreprise sera représentée de la même
manière par un noeud :
"Entreprise :
siret : 1221
nom : Bcorp
domaine : TIC"
Et la relation entre les deux sera matérialisée
par un arc partant du noeud Entreprise Bcorp vers le noeud Badibanga
Trésor, nommée "a pour client".
Aussi, l'entreprise aura autant de pointeurs que de clients
(chaque arc partant de l'entreprise vers le noeud correspondant avec comme nom
a pour client).
De la même manière, le noeud client pourra
pointer vers un noeud véhicule, lequel véhicule pourra pointer
vers un noeud typeClavier, par exemple.
Il sera ainsi beaucoup plus facile d'accéder au type
d'ordinateur du client no id01 par le biais du graphe
puisqu'en parcourant les arcs on retrouvera directement le client, puis son
ordinateur, et enfin son type de clavier. En base de données
relationnelle, en revanche, il aurait fallu faire des jointures entre la table
Client, la table Ordinateur, et la table Clavier ce qui aurait
été très couteux.
L'intérêt de cette structure devient donc
évident dans le cas de données complexes. C'est ainsi une
structure idéale pour des recherches du type « partir d'un
noeud et parcourir le graphe » plutôt que « trouver
toutes les entités du type X », plus adaptées aux
bases
de données relationnelles traditionnelles.
Elle est particulièrement appropriée lorsqu'il
s'agit d'exploiter les relations entre les
données (par exemple des connaissances entre des personnes, la
description de l'ensemble des pièces d'une machine industrielle et de la
manière dont elles sont liées entre elles).
Les bases de données orientées-graphes sont
utilisées aujourd'hui dans la
modélisation des
réseaux
sociaux : LinkedIn utilise par exemple ce système avec un
graphe représentant les personnes et leur relations, et parvient ainsi
facilement à afficher le degré de séparation entre chaque
contact, qui n'est finalement que la distance entre les noeuds.
Elles sont de même utilisées dans le stockage de
masse de données ou
Big data, avec ainsi un
enjeu important à l'heure actuelle dans l'exploitation des
données par leur structure adaptée.
Une telle base de données se caractérise donc par
les critères suivants :
· stockage des données
représentées sous forme d'un graphe, avec des
noeuds et des arêtes;
· lecture et parcours des données
sans recours à un index, en utilisant les arêtes
pour passer d'un noeud à l'autre ;
· flexibilité du modèle de
données ; il n'est pas nécessaire de créer
une entité pour les noeuds ou les arêtes contrairement au
modèle d'une base de données relationnelle ;
· intégration d'une
API utilisant
des algorithmes classique de la
Théorie
des graphes (
Algorithme de
plus cours chemin (Dijkstra), A*, parcours en largeur, parcours en
profondeur, calcul de centralité,...) permettant une exploitation
différente des bases de données relationnelles.
CHAPITRE 2
NOSQL
I
l peut paraître un peu absurde de parler de NoSQL dans
un environnement où quasiment tout le monde parle de SQL, jusqu'ici le
SQL est le langage qui se trouve dans presque tous les lieux où l'on
parle de base de données. Bien que les bases de données utilisant
le SQL battent son plein, cela ne nous empêche en aucune façon de
parler son homologue qu'est le NoSQL.
Etant donnée une augmentation très rapide des
données à travers des différents types de stockage,
notamment les données du web. On est alors arrivé à mettre
en place des nouvelles organisations des données pouvant répondre
à ces nouvelles contraintes et exigences.
De grands acteurs d'Internet, notamment Google (BigTable),
Amazon (Dynamo), LinkedIn (Projet Voldemort), Facebook (Cassandra Project puis
HBase), SourceForge.net (MongoDB), Ubuntu One (CouchDB), etc.,
conçoivent et exploitent des bases de données de type NoSQL.
D'autres acteurs plus modestes sont à l'origine de grands succès,
notamment dans le domaine des stockages clé-valeur (Redis,...). Une
proportion importante de ces projets est
open source et
sous licence libre. [Wiki2]
C'est la raison pour laquelle, dans ce chapitre on mettra
aussi un accent sur les différents principes que doivent respecter les
différents types de bases de données. Cependant, on parlera
essentiellement des nouvelles organisations des données qui sont les
bases de données du type NoSQL.
Enfin, on mettra un accent sur les défis majeurs que
peuvent rencontrer les bases de données du type NoSQL,
c'est-à-dire les problèmes que doivent résoudre les
développeurs de bases de données NoSQL.
II.1. TERMINOLOGIE
Le terme NoSQL (de l'anglais Not only SQL) est apparu
en 1989. C'est à cette année-là que Carlo Stozzi le
prononça pour la première fois en public ; c'était
lors de la présentation de son système de gestion de base des
données relationnelles open source. Il l'a appelé ainsi à
cause de l'absence de l'interface SQL pour communiquer.
Plus tard en 2009, le mot réapparait lorsqu'Eric Evans
l'utilisa pour spécifier le nombre grandissant des bases de
données distribuées open source.
NoSQL désigne une catégorie de
systèmes de gestion de base de données (SGBD) qui n'est plus
fondée sur l'architecture classique des bases relationnelles.
L'unité logique n'y est plus la table, et les données ne sont en
général pas manipulées avec le langage
d'interrogation qu'est le SQL.
Selon Shashank Tiwari dans son livre Professional
NoSQL, « les auteurs de ce néologisme ont
probablement voulu signifier non-relationnel, mais ont
préféré le mot NoSQL parce qu'il sonne
mieux » que, par exemple, NoREL (pour Not only Relational). En
bref, le mot est aujourd'hui utilisé pour exprimer tous les SGBD et les
logiciels de stockage de données qui ne sont ni relationnels, ni objets,
ni hiérarchiques et ni réseaux. [Wiki2]
II.2. CONCEPTS DE BASE
II.2.1. Théorème du CAP (d'Eric Brewer)
Actuellement, il sied de savoir que le mouvement des bases de
données NoSQL contient plusieurs approches qui ont une architecture qui
leur est propre et qui traitent des cas d'utilisation bien définis. Il
convient donc de choisir l'outil qui répond le mieux au problème
posé, à la fois en termes de modélisation mais aussi de
répartition des données.
Le théorème énonce donc qu'il est
impossible pour un système distribué de fournir
les trois propriétés suivantes à la fois :
· Consistency: Tous les noeuds du
système voient les mêmesdonnées au
même moment quelques soient les modifications ;
· Availability: Les requêtes
d'écriture et de lecture sont toujours satisfaites, donc il y a
disponibilité pour la lecture et l'écriture ;
· Partition tolerance: La seule raison
qui pousse un système à l'arrêt est la coupure totale du
réseau. Autrement dit si une partie du réseau n'est pas
opérationnelle, cela n'empêche pas le système de
répondre. Le système tolère même
une partie du réseau.
Afin de créer une architecture distribuée on doit
donc se résoudre à choisir deux de ces propriétés,
laissant ainsi trois conceptions possibles :
· CP : Les données sont
consistantes entre tous les noeuds et le système possède une
tolérance aux pannes, mais il peut aussi subir des problèmes de
latence ou plus généralement, de disponibilité ;
· AP : Le système répond
de façon performante en plus d'être tolérant aux pannes.
Cependant rien ne garantit la consistance des données entre les
noeuds ;
· CA : Les données sont
consistantes entre tous les noeuds (tant que les noeuds sont onlines). Toutes
les lectures/écritures des noeuds concernent les mêmes
données. Mais si un problème de réseau apparait, certains
noeuds seront désynchronisés au niveau des données (et
perdront donc la consistance).
Le design CA n'est pas vraiment une option cohérente
car un système qui n'est pas tolérant aux pannes (partition du
réseau) sera, par définition, obligé d'abandonner la
consistance ou la disponibilité lors d'un problème de partition.
C'est pourquoi il existe une version plus moderne du théorème :
« Durant un problème de partition, il faut choisir
entre la disponibilité et la consistance.».
II.2.2. Principes ACID et BASE
Hormis le théorème CAP ci-haut
énoncé, nous pouvons aussi parler de deux principes qui sont
alors liés à la répartition des données et qui sont
à la base des architectures actuelles des systèmes de gestion de
bases de données, notamment les systèmes du type NoSQL.
ACID et BASE représentent deux principes de conception
aux extrémités opposées du spectre
cohérence-disponibilité. Les propriétés ACID se
concentrent sur la cohérence et sont l'approche traditionnelle des bases
de données. Le principe BASE était créé à
la fin des années 90 pour saisir les concepts émergents de la
haute disponibilité et rendre explicite à la fois le choix et le
spectre. Les systèmes étendus modernes et à grande
échelle, y compris le Cloud, utilisent une combinaison des deux
approches.
Bien que les deux acronymes soient plus mnémoniques que
précis, l'acronyme BASE (étant le second apparu) est un peu plus
délicat : Basically Available, Soft state, Eventually consistent
(Simplement disponible, état souple, finalement consistant). Soft state
et Eventual consistency sont des techniques qui fonctionnent bien en
présence de partitions réseau et donc améliorent la
disponibilité.
La relation entre CAP et ACID est plus complexe et souvent
incomprise, en partie parce que les C et A d'ACID représentent des
concepts différents des mêmes lettres dans CAP et en partie parce
que choisir la disponibilité affecte seulement certaines des garanties
ACID. Les quatre propriétés ACID sont :
· Atomicity : Tout système
bénéficie d'opérations atomiques. Quand l'objectif est la
disponibilité, toutes les parties de la partition doivent toujours
utiliser des opérations atomiques. De plus, des opérations
atomiques de plus haut niveau (celles qu'impliquent ACID) simplifient la
restauration ;
· Coherence: Dans ACID, le C signifie
qu'une transaction préserve toutes les règles des bases de
données, telles que les clés uniques. En comparaison, le C de CAP
ne se réfère qu'à une cohérence de copie unique, un
sous-ensemble strict de la cohérence ACID. Plus
généralement, maintenir des invariants durant les partitions peut
être impossible, d'où le besoin de bien choisir quelles
opérations interdire et comment ensuite restaurer les
invariants ;
· Isolation : L'isolation est au
coeur du théorème CAP : si un système nécessite
l'isolation ACID, il peut opérer sur au plus une partie durant une
partition réseau. La possibilité de sérialiser les
transactions nécessite des communications en général et
échoue durant les séparations réseau. Des
définitions plus faibles de l'exactitude sont viables durant les
partitions en compensant durant la phase de restauration ;
· Durability : Comme pour
l'atomicité, il n'y a pas de raison d'abandonner la durabilité,
bien que le développeur puisse choisir d'éviter d'en avoir besoin
grâce à un état flexible (dans le style de BASE) à
cause de son coût. Une subtilité est que durant la restauration il
est possible d'inverser les opérations durables qui violent un invariant
pendant l'opération. Néanmoins, au moment de la restauration,
avec un historique durable de toutes les parties de la partition, de telles
opérations peuvent être détectées et
corrigées. En général, effectuer des transactions ACID
dans chaque partie de la partition rend la restauration plus simple et fourni
un cadre pour compenser les transactions qui peut être utilisé
pour récupérer d'une partition.
Il est à noter que le principe BASE abandonne donc la
consistance au profit de ces nouvelles propriétés :
· Basically available : Le
système garantie bien la disponibilité dans le même sens
que celle du théorème de CAP ;
· Soft-State : Indique que l'état
du système peut changer à mesure que le temps passe, et c'est
sans action utilisateur. C'est dû à la propriété
suivante ;
· Eventually consistent :
Spécifie que le système sera consistent à mesure
que le temps passe, à condition qu'il ne reçoive pas une action
utilisateur entre temps.
NOTA :
ACID est nécessaire si :
· Beaucoup d'utilisateurs ou processus qui travaillent
sur une même donnée au même moment ;
· L'ordre des transactions est très
important ;
· L'affichage de données dépassées
n'est pas une option ;
· Il y a un impact significatif lorsqu'une transaction
n'aboutit pas (dans des systèmes financiers en temps réel par
exemple).
BASE est possible si :
· Les utilisateurs ou processus ont surtout tendances
à faire des mises à jour ou travailler sur leurs propres
données ;
· L'ordre des transactions n'est pas un
problème;
· L'utilisateur sera sur le même écran
pendant un moment et regardera de toute façon des données
dépassées ;
· Aucun impact grave lors de l'abandon d'une
transaction.
Il est ainsi à remarquer que s'agissant des
systèmes AC, il s'agit des bases des données relationnelles
implémentant les propriétés de Cohérence et de
Disponibilité. Ce qui signifie que les bases des données NoSQL
sont généralement des systèmes CP et AP. [KO12].
C
A
P
Les systèmes CP sont du groupe NoSQL
Les systèmes AC renferment tous les systèmes qui
obéissent au principe ACID
Les systèmes AP sont du groupe NoSQL
Figure 2.1 : Guide visuelle au Théorème
CAP
II.3. CRITERES DE MIGRATION VERS LE NOSQL
C'est une évidence de dire qu'il convient de choisir la
bonne technologie en fonction du besoin. Il existe cependant certains
critères déterminants pour basculer sur du NoSQL.
· Taille : Nous sommes dans un monde
où il y a des données ayant une masse considérable (qu'on
appelle infobésité). Il sied d'avoir alors un système
pouvant supporter un nombre important des opérations, d'utilisateurs,
des données, etc. de manière optimale. Bien que tous les
systèmes NoSQL ne soient pas conçus pour cette
problématique, il est possible d'en trouver sans problème.
· Performance en écriture :
Intérêt principal du géant Google, Facebook (135
milliards de messages par mois), Twitter (7TB de données par jour). Des
données qui augmentent chaque année. A 80MB/s cela prend une
journée pour stocker 7TB, donc l'écriture doit être
distribuée sur un cluster, ce qui implique du MapReduce,
réplication, tolérance aux pannes, consistance,... Pour des
performances en écriture encore plus puissante, il convient de se
tourner vers les systèmes in-memory.
· Performance en lecture clé-valeur :
Certaines solutions NoSQL ne possèdent pas cet avantage mais
comme il s'agit d'un point clé, la plupart d'entre elles en sont
dotées.
· Type de données flexibles : Les
solutions NoSQL supportent de nouveaux types de données et c'est une
innovation majeure. Divers types de données, souvent des données
complexes ne peuvent pas être mis sous forme de données
relationnelles, d'où l'adaptation à un nouveau type des
données.
· ACID : Bien que ce ne soit pas le but
premier du NoSQL, il existe des solutions permettant de conserver certains
(voire tous) aspects des propriétés ACID. Se
référer au théorème CAP plus haut et aux
propriétés BASE.
· Simplicité de développement :
L'accès aux données est simple. Bien que le
modèle relationnel soit simple pour les utilisateurs finaux (les
données sont restituées selon la structure de la base), il n'est
pas très intuitif pour les toujours être celle d'embauche d'un
administrateur de base de données, le développeur devrait pouvoir
être en mesure de le résoudre.
· Parallel Computing : Les solutions
NoSQL améliorent les calculs parallèles.
II.4. CRITERES DE CHOIX POUR MIEUX CHOISIR LE TYPE DE BASE DE
DONNEES [LE14]
Nous avons décrit les types des bases des
données NoSQL au chapitre précédent. Certaines comme
HBase, MongoDB ou Neo4j apparaissent régulièrement dans
l'actualité et sont toutes libellées en tant que NoSQL. Il existe
cependant des différences significatives entre elles, liées
notamment au théorème de CAP. Ainsi, nous proposons le
critère de choix suivant lorsque nous sommes buttés au choix d'un
système de gestion de base de données du type NoSQL :
Ø Choisir une base de données
orientées-document car elle s'adapte aux données non
planes (type profil utilisateur).
Document
|
Champ1
|
Valeur
|
|
Champ2
|
valeur
|
Document
|
Champ1
|
Valeur
|
|
Champ2
|
valeur
|
|
Champ3
|
Valeur
|
Document
Document
|
Champ1
|
Valeur
|
|
Champ2
|
Valeur
|
|
Champ3
|
Valeur
|
|
Champ4
|
Valeur
|
|
Champ5
|
Champ5.1
|
Valeur
|
|
Champ5.2
|
valeur
|
|
Clé
|
|
CLE2012
|
|
CLE2013
|
|
CLE2014
|
|
CLE2015
|
|
CLE...
|
Figure 2.2 : Illustration d'une base de données
orientées-document
Quelques SGBD orientées-document :
· MongoDB : Développé en
C++. Les API officielles pour beaucoup de langages.Protocole
personnalisé BSON. Réplication master/slave. Licence AGPL
(commercial et libre) ;
· CouchDB : Développé en
Erlang. Protocol http. Réplication master/master. Licence Apache.
Ø Choisir une base de données
orientées-colonne car elle s'adapte mieux au stockage des
listes (messages, postes, commentaires, ...).

Figure 2.3 : Illustration d'une base de
données orientées-colonne
Source : [LE14]
Quelques SGBD orientées-colonnes :
· HBase : Utilise un API Java. Adopte un
design CA. Présence de quelques SPOF.
· Cassandra : Beaucoup d'API
disponibles. Adopte un design AP avec consistance éventuelle. Aucun
SPOF3(*) car
réplication master/master. Moins performant que HBase sur les insertions
de données.
Ø Choisir une base de données
orientées-graphe car pour mieux gérer les relations
multiples entre objets (comme des relations dans un réseau social).
Figure 2.4 : Illustration d'une base de
données orientées-graphe
Source : [LE14]
Quelques SGBD orientées-graphe :
· Neo4J : Développé en
Java. Supporte beaucoup de langages. Réplication master/slave.
Propriétés ACID possibles. Langage de requêtes
personnalisé «Cypher».
· Titan : Haute disponibilité
avec réplication master/master. Prise en compte d'ACID avec consistance
éventuelle. Intégration native avec le framework
TinkerPop.
Ø Choisir une base de données
orientées-clé-valeur car elle permet d'accéder
rapidement aux informations pour la gestion des caches.
Valeur 2012
Valeur 2013
Valeur 2014
Valeur 2015
Clé
|
|
CLE2012
|
|
CLE2013
|
|
CLE2014
|
|
CLE2015
|
|
CLE...
|
Figure 2.5 : Illustration d'une base de
données orientées-clé-valeur
Quelques SGBD orientées-clé-valeur :
· DynamoDB : Solution d'Amazon à
l'origine de ce type de base. Design de type AP selon le théorème
de CAP mais peut aussi fournir une consistance éventuelle.
· Voldemort : Implémentation
open-source de Dynamo. Il y a possibilité d'en faire une base
embarquée.
II.5. DEFIS MAJEURS DES NOSQL [KO12]
La plupart des organisations cherchant à migrer vers
les NoSQL se révèlent des grandes organisations traitant
d'énormes masses de données, ainsi ayant d'énormes besoins
de stockage. Il faut aussi le signaler que, les petites organisations ne
regardent presque pas à la même direction ce concept qu'est le
NoSQL.
Dans une enquête menée par une communauté
d'enquêté appelée Information Week, 44% des professionnels
en activité de l'informatique n'ont pas entendu parler de NoSQL. En
outre, seulement 1% des répondants ont indiqué que NoSQL est une
partie de leur orientation stratégique. De toute évidence, NoSQL
a sa place dans notre monde connecté, mais devra continuer à
évoluer pour obtenir l'appel de masse que beaucoup pensent qu'elle
pourrait avoir. La technologie NoSQL ne cesse de faire parler d'elle et semble
avoir le vent en poupe. Attrayante, la barrière d'entrée pour un
nouveau développement est d'ailleurs assez peu élevée pour
tout développeur ayant bien compris les sous-jacents de la solution
retenue. Néanmoins, il est essentiel de garder à l'esprit que
NoSQL apporte une réponse à des besoins bien spécifiques.
Dit autrement, il est nécessaire d'avoir identifié au
préalable la nécessité d'utiliser cette technologie dans
vos services et pas uniquement avec une motivation : « et si on a autant
de succès demain que Twitter».
Cependant, il faut se mettre d'accord que bien que robuste, le
NoSQL reste encore une technologie en gestation et doit par conséquent
ne pas cesser d'évoluer d'une manière quantitative que
qualitative (en se dotant par exemple de solutions ORM
éprouvées, en gommant l'absence d'un langage de requêtage
commun et capitaliser sur l'utilisation, comme nos chers SGBDR l'ont fait sur
les 20 dernières années).
Les bases de données NoSQL ont suscité beaucoup
d'enthousiasme, mais il y'a de nombreux obstacles à surmonter avant de
pouvoir faire appel aux principaux acteurs de l'industrie des bases de
données. Voici quelques-uns des principaux défis.
II.5.1. Maturité et stabilité
Les outils permettant l'exploitation de ce type de bases de
données sont encore très peu matures tout au moins pour la
plupart. Si l'on se place au niveau des outils de développements, ils
n'intègrent pas encore des Framework ou plugin compatibles au NoSQL.
Pour ce qui est des outils d'administration (outils de sauvegarde, monitoring,
...), quand ils existent, ils sont spécifiques à des moteurs
NoSQL particuliers. C'est le cas de Google qui a mis sur pieds son propre outil
d'administration de bases de données orientées-colonne. Aussi,
les bases de données de type NoSQL étant des technologies encore
très récentes, il n'y a pas encore de normes qui permettent de
définir une architecture type pour tel ou tel type de base de
données, ni de syntaxe particulière ; bien que le mouvement tende
vers une convergence pour des requêtes basées sur le langage
JavaScript. Il manque vraiment des standards, comme JDBC et SQL le sont pour
les SGBDR, mais cela s'explique sans doute par la jeunesse du mouvement et
l'hétérogénéité des types de bases.
II.5.2. Assistance et maintenance
Les entreprises veulent avoir l'assurance que si un
système de clés échoue, les fournisseurs de la base NoSQL
seront en mesure d'offrir un soutien rapide et compétent ; la
documentation sur les bases de données NoSQL ne sont pas à la
portée de plusieurs personnes. Tous les fournisseurs de SGBDR font de
grands efforts pour fournir un niveau élevé de soutien aux
entreprises. En revanche, la plupart des systèmes NoSQL sont des projets
open source, et bien qu'il existe généralement une ou plusieurs
entreprises qui offrent un soutien pour chaque base de données NoSQL,
ces entreprises sont souvent des startups sans portée mondiale et n'ont
pas les ressources de soutien, ou la crédibilité d'un Oracle, de
Microsoft, ou IBM.
II.5.3. Outils d'analyse et administration
Les bases de données NoSQL offrent peu d'installations
pour des requêtes ad-hoc et d'analyse de données. Même une
simple requête nécessite une expertise significative de
programmation. Certains de secours sont fournis par l'émergence de
solutions telles que le HIVE ou PIG, qui peuvent fournir un accès plus
facile aux données détenues dans les clusters Hadoop et
peut-être à terme, d'autres bases de données NoSQL. Quest
Software a développé un produit dénommé « Toad
» pour les bases de données qui peut fournir des capacités
de requête ad-hoc à une variété de bases de
données NoSQL. L'objectif de la conception des bases de données
NoSQL était de fournir une solution zéro-administration, mais la
réalité actuelle est bien loin de cet objectif [wika]. Pour
administrer une base NoSQL aujourd'hui, il faut beaucoup d'habileté non
seulement pour l'installer et beaucoup d'efforts pour la maintenir.
Les outils d'analyse et de calculs (qu'on appelle graph
processing) ne sont pas très développés, et les recherches
se font encore en ce sens, c'est-à-dire les chercheurs cherchent encore
des outils nécessaires adaptés au BI et à l'Analyse des
données.
II.5.4 Expertise
Bien qu'à travers le monde entier, il existe environ
des millions des développeurs, il sied de reconnaitre que dans chaque
secteur d'activités, les développeurs sont presque tous familiers
avec les concepts de programmation et gestion de bases de données
relationnelles. En revanche, presque tous les développeurs des bases de
données de type NoSQL sont en phase d'apprentissage. Cette situation se
penchera naturellement au fil du temps, mais pour l'instant, c'est beaucoup
plus facile de trouver des programmeurs expérimentés ou les
administrateurs SGBDRque par un expert NoSQL.
CHAPITRE 3
BASE DE DONNEES
ORIENTEES-GRAPHE
L
a base de données
orientées-graphe étant le noeud de la question, nous allons
alors nous appesantir sur la vue globale des bases de données
orientées-graphe. A cet effet, on parlera de sa puissance et de ses cas
d'usage, c'est-à-dire les différentes applications des bases de
données orientées-graphe ainsi que leur performance au niveau de
l'implémentation de certaines applications.
Après avoir passé en revue de sa puissance et
ses cas d'usage, on parlera d'outils des différents outils qui utilisent
les graphes pour l'utilisation des données, notamment les outils de
stockage de données (graph storage) et de traitement et analyse de
données (graph processing).
De plus, on donne une comparaison entre les bases de
données orientées-graphe et les autres bases de données
notamment les bases de données relationnelles et les bases de
données réseau. Ces comparaisons se justifient car les bases de
données relationnelles sont encore beaucoup plus utilisées et il
existe plusieurs confusions entre les bases de données réseau et
les bases de données orientées-graphe.
A la fin de ce chapitre, nous parlerons alors d'un
système de gestion de base de données qui nous permet de mettre
en oeuvre les bases de données orientée-graphe, le Neo4j.
III.1. VUE GLOBALE
III.1.1. Définition
Une base de données
orientée-graphe est une base de données utilisant
les structures de graphes (noeuds, arcs et propriétés) pour
représenter et stocker les données.
En effet, d'une manière plus formelle, une base de
données orientées-graphe correspond à un système de
stockage correspondant à un graphe G=(X, U) tel que :
· X est l'ensemble des noeuds qui représentent les
enregistrements de la base de données;
· U est l'ensemble des arêtes (liens) entre noeuds
qui représentent les relations entre différents enregistrements.
Exemple 3.1.
Figure 3.1 : Exemple d'une structure de base de
données graphe
Dans cet exemple :
· X = {différents noeuds formant le graphe}
· U = {DONNA NAISSANCE (Confidentialité: Public),
FORME PAR(Age: 3ans), CONNAIT(Age: 6ans), CONNAIT (Age :
3mois, Confidentialité : Secret), CONNAIT (Age : 4 ans,
Confidentialité : Public)}
Nota : Les différentes
relations peuvent être unidirectionnelles (dans un seul sens) ou
bidirectionnelles (dans les deux sens).
III.1.2. Puissance des bases de données
orientées-graphe
Eu égard au chapitre précédent, nul ne
peut douter de la puissance des bases de données du type NoSQL en
général et des bases de données orientées-graphe en
particulier. En effet, La puissance de l'utilisation des bases de
données orientées-graphe peut se résumer en trois notions
suivantes: [SA]
Ø Performance : se
référant à l'expérience de Partner et Vukovic dans
leur publication intitulée Neo4j in Action, une base de données
orientées-graphe est plus performent que les autres types de base de
données, notamment la base de données relationnelle ;
Ø Flexibilité : dans une base
de données orientée-graphe, les ajouts de noeuds, des relations
et propriétés sans perturber les requêtes existantes;
Ø Agilité : dans une base de
données orientée-graphe, le développement se fait sans
friction et il est contrôlé. De plus, la maintenance est
gracieuse. Il n'y a pas de complication pour assurer sa maintenance.
Faisant référence à la puissance des
bases de données orientées-graphe ci-haut, la migration des
autres modèles de bases de données vers les bases de
données orientées-graphe est plus que souhaitée, surtout
pour les bases de données disposant d'une masse de données
importantes et voulant bénéficier des avantages qu'offrent les
algorithmes des graphes.
III.1.3. Cas d'usage des bases de données
orientées-graphe
Il existe plusieurs cas d'usage des systèmes de gestion
des bases de données orientées-graphes, mais les plus
fréquents peuvent se résumer en assertions suivantes [Wiki3]:
· La gestion de
réseau: Migration vers les bases de données pour
gérer la forte connectivité de leurs clients. La
multiplicité des clients dans les entreprises fait que les entreprises
cherchent à migrer vers les bases de données
orientées-graphe, étant donnée il y a forte
connectivité entre différents clients. Dans ce cas, on stocke
dans les noeuds les différents clients;
· La logistique : Calculer le
meilleur chemin pour livrer un client. Dans ce cas précis, les clients
et les marchandises sont stockés dans les noeuds ;
· Le Social, la
collaboration : Gestion de la connectivité
grâce aux graphes. Rechercher très facilement les amis de mes amis
qui ne sont pas mes amis. Ce type de bases de données est beaucoup plus
utilisé dans les réseaux sociaux électroniques. C'est ce
qui a d'ailleurs fait sa commodité dans l'implémentation de
plusieurs réseaux sociaux les plus utiliser des nos jours. Ici, les
différents acteurs du réseau social et les informations les
concernant sont stockés dans les noeuds ;
· La
recommandation : Définir en temps réel la
liste des produits achetés par mes amis que je n'ai pas moi-même
achetés. Dans les noeuds, on stockera les clients et les
produits ;
· Le Master Data Management / la gestion de
configuration : Construction d'un référentiel
standardisé performant et sans redondance pour vos données
critiques hiérarchisées : hiérarchie d'entreprise et
de produit. Les noeuds contiendront donc les produits et l'entreprise ;
· La sécurité est l'accès
aux données : Gestion des groupes, utilisateurs et
droits rapidement et sans redondance. Relier les détails
d'authentification des clients et administrateurs. C'est un bon choix à
adapter pour le Cloud Computing ;
· Le géo-Spatial/Système
d'information géographique : Modélisation
d'une carte routière et calculs d'itinéraires. Les
différents carrefours et leurs informations seront stockés dans
les noeuds et les différentes routes et leurs informations dans les
arêtes ;
· La biologie, interactions
moléculaires : Réduire les risques d'effets
secondaires des médicaments en calculant en temps réel les
interactions entre une protéine et une future molécule. Il
est clair que les molécules seront stockées dans les noeuds et
les arêtes représenteront leurs interactions.
III.2.
OUTILS DES BASES DE DONNEES ORIENTEES-GRAPHE
Comme pour les autres types de bases de données,
notamment les bases de données relationnelles, les bases de
données orientées-graphe (bien que pas encore normalisé)
on distingue les outils de stockage (graph storage) et les outils de
traitements (graph processing).
Une comparaison qu'on est amené à faire est
celle des bases de données graphes par rapport aux outils de
« large-scale graph processing » (traitement de graphe en
grande échelle) comme Google's Pregel ou BSP.
Une première différence importante est qu'on a
affaire à des outils aux objectifs assez différents, bien qu'ils
partagent les mêmes modèles de données. Jim Webber de
NeoTechnology donne un point de vue intéressant bien qu'assez
partisan :
· Les outils de graph processing,
comme leur nom l'indique, adressent uniquement
des problématiques de calcul et d'analyse (OLAP),
tandis que les graphs storages'adressent essentiellement
des problématiques de stockage et de calculs
transactionnels (OLTP).
· Les outils de graph processing impliquent, de la
même manière que des outils comme Hadoop, une certaine
latence dans les calculs (plusieurs secondes), tandis que le
graph storage vise des lectures plutôt temps réel
(de l'ordre de la ms).
· Les deux n'adressent pas la même échelle
de calculs, et n'ont pas non plus les mêmes exigences matérielles:
un outil de graph storage adresse essentiellement la problématique du
volume par scale-in sur un seul serveur là où un outil comme
Pregel l'adresse par scale-out en distribuant les traitements sur plusieurs
machines.
· Les outils de graph processing sont entièrement
distribués, possibilité que n'offrent pas la plupart des outils
de graph storage.
On a donc affaire à deux familles
d'outils qui adressent des types et des échelles de
problèmes différents : en terme
d'usages, on utilisera plus facilement un outil de graph storage pour la
navigation dans le graphe ou une recherche de plus court chemin, tandis qu'un
outil de graph processing adressera plutôt du
clustering de
graphe, de la recherche de
centralité ou
encore une recherche globale de tous les chemins (problème de
cheminement, d'une manière générale).
Les bases des données orientées-graphe
connaissent toutefois une limite liée à leur structure, celle de
la taille : il est complexe de partitionner un graphe,
particulièrement en tenant compte de la latence réseau, des
patterns récurrents de parcours du graphe (quelles relations sont les
plus parcourues) et surtout de l'évolution en temps réel du
graphe. Certains systèmes de gestion de base de données graphes,
OrientDB et InfiniteGraph, s'affichent comme facilement partitionnables, tandis
que le SGBD comme de Neo4j n'offre pas encore cette possibilité. Les
chercheurs travaillent encore sur ce sujet. Ce qui n'empêche pas que dans
un avenir plus ou moins moyen qu'on introduise les notions comme la coloration
des graphes (Algorithme de coloration, b-coloration, etc.), la connexité
des graphes (Algorithme de Tarjan, Algorithme de Kusaraju).
Par ailleurs, on peut alors résumer (selon Marko
Rodriguez) très bien le positionnement des différents outils de
traitements de graphes dans ce graphique, en fonction de la taille des
données à utiliser par rapport à l'objectif de vitesse des
parcours du graphe : plus la taille du graphe à exploiter est
grande (et surtout la portion du graphe à parcourir), moins les
outils adaptés permettent un traitement en temps réel.
Figure 3.2 : Classification des outils de
traitement de graphes
Source : [Octo]
III.3. COMPARAISON DE BASE DE DONNEES ORIENTEES-GRAPHE AVEC
LES AUTRES
BASES DE DONNEES
II.3.1. Comparaison avec les bases de données
relationnelles
En règle générale, une base de
données orientée-graphe permet l'exploitation des structures de
type graphe ou dérivé, tels que les arbres, les arborescences,
etc., plus particulièrement s'il s'agit d'exploiter les relations entre
les données. Pour effectuer une recherche par exemple, il est possible
de partir d'un ou plusieurs noeuds et effectuer les opérations de
parcours d'un graphe. Il offre ainsi la possibilité d'effectuer des
lectures qui permet de trouver toutes les entités d'un
type.
Mais, il faut toutefois noter que les bases de données
relationnelles sont très adaptées à de requêtes du
genre trouver toutes les entités grâce aux
structures internes des tables, d'autant plus s'il s'agit de réaliser
des opérations d'agrégations sur toutes les lignes d'une
table.
Malgré l'adjectif
« relationnelle », il faut noter que les bases de
données relationnelles sont vraiment moins efficaces pour l'exploitation
des « relations», qui dans ce cas doit être par la mise en
place des clés étrangères (qui ne sont que des pointeurs
logiques). L'avantage est que nous utilisons des pointeurs physiques dans une
base de données orientées-graphe pour les parcours de relations
qui se représentent par des arêtes dans le cas des bases de
données graphe.
A titre illustratif, on se réfère de l'exemple
donné par
Michel Domenjoud dans un article
de blog posté le 18/07/2012 [Octo], dans lequel on modélise des
sociétés, les personnes qui y travaillent et depuis combien de
temps. On cherche par exemple à trouver les personnes qui travaillent
chez Google.
En utilisant une modélisation relationnelle, on
pourrait obtenir l'exécution décrite dans la figure 3.3, qui
nécessite a priori 3 lookups d'index, optimisés en fonction des
indexes et des clés étrangères déclarés.
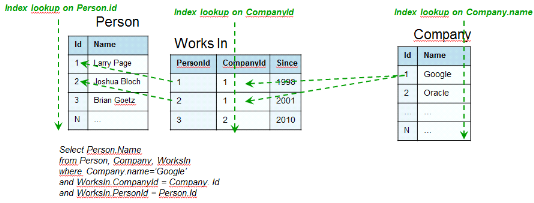
Figure 3.3. Exemple de la modélisation d'une base de
données relationnelle
Source : [Octo]
En utilisant une modélisation dans un graphe, la
requête nécessitera un lookup d'index, puis un parcours par
pointeurs physiques des relations dans le graphe.
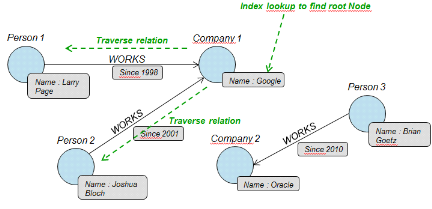
Figure 3.4. Exemple de la modélisation d'une base de
données graphe
Source : [Octo]
Il parait très clairement au travers de cet exemple que
l'utilisation d'une base de données orientée-graphes est
logiquement plus performante que l'utilisation d'une base de données
relationnelle.
La différence de performances sera d'autant plus
importante lorsque la quantité de données stockées
augmente, car hormis le lookup d'index pour trouver le(s) noeud(s) de
départ du parcours de graphe, la requête se fera en temps à
peu près constant dans un graphe, au contraire de la base de
données relationnelle dans laquelle chaque parcours d'index pour
récupérer une clé étrangère
coûtera O(log2N) du point de vue
algorithmique si l'index est stocké dans un
B-Tree (avec N le nombre
d'enregistrements dans la table parcourue).
Une base de données orientées-graphe surpassera
naturellement les performances en lecture d'une base de données
relationnelle sur son domaine de prédilection, les traversals, et
d'autant plus si la profondeur de ceux-ci est importante ou n'est pas
déterminée à l'avance (il serait dans ce cas impossible
d'optimiser le plan de la requête SQL à l'avance), ce que tendent
à montrer les
quelques
comparatifs existants sur le Web.
II.3.2. Comparaison avec les bases de données
réseaux
Pour rappel, le modèle réseau est en mesure de
lever de nombreuses difficultés du modèle hiérarchique
grâce à la possibilité d'établir des liaisons de
type n-m en définissant des associations entre tous les types
d'enregistrements. Pour retrouver une donnée dans une telle
modélisation, il faut connaître le chemin d'accès ceci rend
encore les programmes dépendants de la structure de données.
D'une manière plus claire, Ils permettent de modéliser des
articles stockés dans des fichiers ainsi que les liens entre ces
articles. Ces modèles dérivent avant tout d'une approche
système au problème des bases de données qui tend à
voir une base de données comme un ensemble de fichiers reliés par
des pointeurs. Ils privilégient l'optimisation des
entrées-sorties. C'est pourquoi nous les appelons aussi
modèles d'accès.
Dans un modèle orienté-graphe, on utilise le
langage de modélisation NoSQL utilisant les algorithmes de plus court
chemin, de calcul de centralité, etc. mais dans le modèle
réseau, sont associés des langages de manipulation de
données sont basés sur le parcours de fichiers et de liens entre
fichiers, article par article, appelés langages navigationnels. Ces
langages sont très caractéristiques des modèles
d'accès. L'utilisation de algorithmes de la Théorie de graphes
dans les bases de données graphe permet de faciliter la manipulation
qu'en utilisant les bases de données réseaux bien qu'utilisant
tous les pointeurs physiques.
Du point de vue de la performance, les bases de données
orientées-graphe sont beaucoup plus performantes que les bases de
données réseaux car la syntaxe utilisée pour faire des
requêtes utilisent les algorithmes efficaces de la théorie des
graphes. Dans le cas d'une base de données réseaux, on fera
plusieurs accès à l'aide de pointeurs pour chercher
l' « ami d'un ami », mais dans le cas d'une base de
données orientée-graphe, il suffira de calculer
déjà le chemin géodésique d'une source vers tous
les autres sommets voisins de l'ami et après, atteindre cet ami à
partir des arcs optimaux (Principe d'optimalité de Richards Bellman).
Il faut noter que du point de vue de la modélisation,
les bases de données orientées-graphe et les bases de
données réseaux se modélisent toutes à l'aide des
graphes, sauf qu'il existe certaines possibilités non offertes pour le
cas des bases de données réseaux, par exemple les liaisons
bidirectionnelles.
En effet, les possibilités offertes pour
modéliser les associations entre objets constituent un des
éléments importants d'un modèle de données.
Historiquement, le modèle réseau est issu d'une conceptualisation
de fichiers reliés par des pointeurs. De ce fait, il offre des
possibilités limitées pour représenter les liens entre
fichiers. Avec les recommandations du CODASYL, il est seulement possible de
définir des associations entre un article appelé
propriétaire et n articles membres. Une instance d'association est le
plus souvent une liste circulaire d'articles partant d'un article
propriétaire et parcourant n articles membres pour revenir au
propriétaire. Ces associations, qui sont donc purement
hiérarchiques mais qui, utilisées à plusieurs niveaux,
peuvent permettre de former aussi bien des arbres, des cycles que des
réseaux, sont appelées ici liens (en anglais
set).
NOTA : Un lien (set) est un
type d'association orientée entre articles de type T1 vers articles de
type T2 dans laquelle une occurrence relie un article propriétaire de
type T1 à n articles membres de type T2.
Un type de lien permet donc d'associer un type d'article
propriétaire à un type d'article membre; une occurrence de lien
permet d'associer une occurrence d'article propriétaire à n
occurrences d'articles membres. Généralement, les articles
membres seront d'un type unique, mais la notion de lien peut
théoriquement être étendue afin de supporter des membres de
différents types.
Un lien se représente au niveau des types à
l'aide d'un diagramme de Bachman. Il s'agit d'un graphe
composé de deux sommets et d'un arc. Les sommets,
représentés par des rectangles, correspondent aux types
d'articles ; l'arc représente le lien de 1 vers n [BA69]. L'arc est
orienté du type propriétaire vers le type membre. Il est
valué par le nom du type de lien qu'il représente et chaque
sommet par le nom du type d'article associé.
Par exemple, les types d'articles VINS et PRODUCTEURS
décrits ci-dessus seront naturellement reliés par le type de lien
RECOLTE, allant de PRODUCTEURS vers VINS. Une occurrence reliera un producteur
à tous les vins qu'il produit. La figure 2.4 schématise le
diagramme de Bachman correspondant à ce lien.
PRODUCTEURS
VINS
Récolte
Figure 3.5. Exemple de diagramme de Bachman
III.4.
MODELISATION
Un dernier point particulièrement important en faveur
d'une base de données orientées-graphe réside dans la
facilité de modélisation des données.
Ensuite, une fois qu'on a choisi un système de
stockage, il est temps de faire rentrer notre modèle de données
dedans.
Si nous choisissons une base de données relationnelle,
on commence généralement par normaliser notre modèle
afin de bien se conformer à la 3ème forme normale, et
ça pourrait donner quelque chose comme ça :
Figure 3.6. Modèle relationnel
Alors que si on choisit de modéliser nos données
dans une base de données graphes, ça pourrait naïvement
donner ceci :
Figure 3.7. Modèle graphe
La modélisation de données sous forme de
graphes est naturelle, et comporte donc l'avantage non
négligeable d'être lisible, même sans background technique.
Cet exemple reste néanmoins très simpliste, et de même
qu'un modèle relationnel normalisé est parfois
dénormalisé pour des raisons de performances, certaines
optimisations moins lisibles à « l'oeil nu » de
la modélisation du graphe peuvent être nécessaires.
III.5.
SYSTEME DE GESTION DES DONNEES ORIENTEES-GRAPHE : NEO4J
III.5.1. Qu'est-ce que Neo4j ?
C'est un système de gestion de bases de
données
NoSQL orienté-
graphe édité
par la société
NeoTechnology. Ce logiciel permet
de représenter les données connectées naturellement, en
tant qu'objets reliés par un ensemble de relations, chacun
possédant ses propres propriétés.
III.5.2. Caractéristiques de Neo4j
· Neo4j est un SGBD à code source libre (open
source);
· Neo4j utilise des transactions ACID (Atomiques,
Cohérentes, Isolées, Durables) ;
· Neo4j est un SGBD écrit en Java et
nécessite donc l'emploi d'une machine virtuelle Java (JVM : Java
Virtual Machine, version?1.7 obligatoire à partir de Neo4j
2.0) ;
· Le serveur d'application proposé par
défaut est Jetty. Toutefois, Neo4j n'a pas été
écrit pour Java son utilisation au travers de l'API REST n'est pas
triviale mais réellement pensée en ce sens. Le moteur
d'indexation utilisé par défaut est Lucène mais cette
technologie reste transparente du point de vue de l'utilisateur ;
· Neo4j est capable de manipuler d'énormes
quantités de données en un temps record, et ses limites sont sans
cesse repoussées. En outre, il peut être intégré
dans une grappe de serveurs (cluster) pour en augmenter les
performances ainsi que la disponibilité (HA : High
Availability) ;
· Les systèmes d'exploitation qui sont
concernés par ce SGBD sont le Windows, le Linux et le Mac OS X.
III.5.3. Installation rapide de Neo4j
Il suffit de le connecter sur le site de Neo4j et
télécharger la dernière version communautaire
(Community Edition) prévue pour votre système. Les
instructions données ici détaillent une installation sur un poste
de travail de type Windows. Elles ne signifient en aucun cas une limitation du
produit pour ce système, ni ne constituent une installation
pérenne en vue d'un lancement en production ou encore une installation
type pour un déploiement sur un serveur.
1. Installez le Java Development Kit (JDK) version?1.7+ si
celui-ci n'est pas disponible sur votre machine (une simple vérification
avec la ligne de commande > java -version répondra à
cette question). Notez que le programme d'installation sous Windows est
à présent pourvu de son JDK.
2. Lancez l'installeur de Neo4j et suivez les quelques
étapes proposées par l'assistant d'installation.
Nota : Le dossier racine
d'installation de Neo4j sera noté [NEO4J_HOME dans la suite de
cet ouvrage. De même, les chemins relatifs au système de fichiers
seront indiqués avec le caractère /.
III.5.4. Lancement de Neo4j
À partir de la boîte de dialogue du lanceur
Neo4j, cliquez sur le bouton START. Dès que la
barre STATUS sera passée du rouge au vert, votre
système Neo4j sera prêt à l'emploi.
Figure 3.8 : Lanceur Neo4j
III.5.5. Test d'installation de Neo4j
Lancez un navigateur web et entrez
l'adresse http://localhost:7474. Vous devriez obtenir l'écran
suivant?:
Figure 3.9 : http://localhost:7474
CHAPITRE4
APPLICATION
L
es bases de données relationnelles sont encore de plus
en plus utilisées dans la plupart des entreprises tant publiques que
privées, alors que beaucoup de ces entreprises ne savent pas encore rien
de l'importance et des cas d'usage des bases de données
orientées-graphe. Dans la plupart des cas, ces entreprises n'ont
même pas entendu parler de ces types de bases de données. Les
entreprises ou en général les organisations ayant entendu parler
de ces types des bases de données désirent ainsi migrer de leurs
bases des données pour rejoindre les grandes familles des bases
graphes.
Ainsi, dans ce chapitre, il sera question de montrer comment
peut-on passer des bases de données relationnelles vers les bases de
données orientées-graphe. On se propose une approche qui permet
de prendre une base de données existante comme entrée, en
utilisant évidemment son Modèle Entité-Association, plus
particulièrement le modèle conceptuelle des données et/ou
son modèle physique des données de la méthode Merise et
ensuite générer un Modèle de Graphe Attribué. Pour
rendre les choses plus claires, nous allons montrer à l'aide d'un
algorithme comment se fait cette migration.
Enfin du chapitre, on validera l'approche par une étude
de cas consistant à faire migrer une base de données conçu
par l'approche modèle relationnel vers l'approche modèle
graphe ; et valider l'approche par une étude de cas.
IV.1. PRESENTATION DE L'APPROCHE
IV.1.1. Introduction
Dans ce paragraphe, nous allons présenter l'approche de
migration que nous proposons pour quitter des bases des données
relationnelles vers les bases des données orientées-graphe. Les
types de bases des données étant différents ; les
exigences ainsi que les performances étant aussi différentes, il
ressort de savoir que le processus de migration d'une base des données
vers une autre est très complexe, et généralement pas
très direct.
De ce fait, quelques transformations à tous les niveaux
sont alors nécessaires pour avoir un modèle cohérent et
sans perte d'informations. Car, il suffit de voir d'une manière triviale
que les types de conception des bases de données sont différents
et on ne peut pas seulement faire des correspondances, mais il faut aussi
adjonction ou omission des certaines choses. Ainsi, il faut avoir la maitrise
du modèle de données source et du modèle de données
cible.
IV.1.2. Modèle de données source
Le modèle de données source que nous devons
parler ici est le modèle relationnelle. La conception d'une base de
données relationnelle, en utilisant la méthode Merise s'effectue
en quatre niveaux (conceptuel, organisationnel, logique et physique). Comme la
méthode Merise utilise le modèle Entité-Association, nous
allons alors utiliser le Modèle Entité-Association comme notre
modèle source.
On pouvait utiliser normalement comme schéma de
données source le modèle physique de données (MPD),
c'est-à-dire le scripte de la base de données relationnelle. Mais
l'inconvénient est que ce dernier peut varier d'un SGBD à l'autre
même si le langage standard reste le SQL. Par ailleurs, le modèle
de données relationnel, introduit par Codd représente une base de
données comme une collection de relations d'où le nom de base de
données relationnelle. [KO12] C'est la raison pour laquelle, on prend un
modèle plus général qu'est le modèle
Entité-Association, le Modèle conceptuel des données (MCD)
et le MPD seront utilisé d'une manière particulière et
pourront aussi nous aider.
Le modèle Entité-Association (qu'on note EA) est
aussi fréquemment nommé Entité-Relation et parfois
Entité-Relation-Attribut. Le modèle EA propose des concepts
(principalement les entités, les associations et les attributs)
permettant de décrire un ensemble de données relatives à
un domaine défini afin de les intégrer ensuite dans une base de
données. Le modèle EA a été inventé par
Peter Chen en 1975 ; il est destiné à clarifier
l'organisation des données dans les bases de données. Ce
modèle est à la base de plusieurs méthodes de
modélisation d'analyse/conception comme OMT, CASE, MERISE, etc. [KA13]
Les concepts clés de ce modèle sont :
· typeEntité
Une entité est un objet, une chose
concrète ou abstraite qui peut être reconnue distinctement. Un
type-entité est un ensemble d'entités qui
possèdent les mêmes caractéristiques.
Figure 4.1 : Représentation du diagramme type
entité
· Une association (ou une
relation) est un lien entre plusieurs entités. Un
type-association (ou un type-relation) est un
ensemble de relations qui possèdent les mêmes
caractéristiques ; c'est un lien existant entre plusieurs
types-entités.
· Un attribut (ou une
propriété) est une caractéristique
associée à une entité ou une association.
Attribut 1
Attribut 2
...
typeEntité 1
Attribut 1
Attribut 2
...
typeEntité 2
typeAssociation
Attribut 1
Attribut 2 ...
Figure 4.2 : Représentation des
types-entités et type-association avec les attributs
· Un identifiant d'un type-entité
ou d'un type-association est constitué par un ou plusieurs de ses
attributs qui doivent avoir une valeur unique pour chaque type-entité ou
type-association de ce type ;
· La cardinalité d'une
association est le nombre de fois minimal et maximal qu'une entité peut
intervenir dans une association de ce type.
L'expression de la cardinalité est obligatoire pour
chaque patte d'un type-association.
La cardinalité minimale peut-être :
§ 0 Cela signifie qu'une entité peut
exister tout en étant impliquée dans aucune
association ;
§ 1 Cela signifie qu'une entité ne peut
exister que si elle est impliquée dans au moins une
association ;
§ n Cela signifie qu'une entité ne peut
exister que si elle est impliquée dans plusieurs
associations.
De ce fait, on distingue trois types de
types-associations :
Ø Type-association du plusieurs à
plusieurs (many to many) : ici, deux types-entités 1 et 2
sont reliées et on peut correspondre plusieurs instances du
type-entité 2 et inversement.
Attribut 1
Attribut 2
...
Entité 1
Attribut 1
Attribut 2
...
Entité 2
typeAssociation
Attribut 1
Attribut 2 ...
1, n
1, n
Figure 4.2: Association many to many
Ø Type-association du plusieurs à un ou
un à plusieurs (many to one ou one to many) : ici, deux
types-entités 1 et 2 sont reliées et pour une instance
donnée du type-entité 1, peut correspondre plusieurs instances de
du type-entité 2. Et chaque entité de 2 correspond une et une
seule instance du type-entité 1.
Attribut 1
Attribut 2
...
typeEntité 1
Attribut 1
Attribut 2
...
typeEntité 2
typeAssociation
Attribut 1
Attribut 2 ...
1, 1
1, n
Figure 4.3: Association many to one
Ø Type-association du un à un (one to
one) : ici, deux types-entités sont reliées et
lorsque pour une instance donnée de du type-entité 1, correspond
une et une seule instance du type-entité 2 et inversement.
Attribut 1
Attribut 2
...
typeEntité 1
Attribut 1
Attribut 2
...
typeEntité 2
typeAssociation
Attribut 1
Attribut 2 ...
1, 1
1, 1
Figure 4.4: Association one to one
Nota : Par abus de langage, on
utilise souvent le mot entité en lieu et place du mot
type-entité, et on utilise souvent le mot association en lieu et place
du mot type-association, il faut cependant prendre garde à ne pas
confondre ces différents concepts.
Exemple 4.1 : Personne, Automobile,
Région, ... sont des types-entité tandis que Glodi Kamingu,
maVoiture, Kinshasa, ... sont des entités.
Exemple 4.2 : Le mariage de deux
personnes, le transport d'un produit vers un entrepôt, l'affectation d'un
employé à un service sont des types-association tandis que
mariage de Ronny et Marielle, le transport de la Clio 3333 XR 06 vers le
dépôt de Matete, le fait que Pupa travaille au service
Informatique sont des associations.
Ce que nous pouvons dire d'une manière très
simple, en terme de programmation orientée-objet, un type-entité
est vu comme une classe et une entité est vu comme un objet, ou instance
du type-entité.
IV.1.3. Modèle de données cible
Le modèle de données cible ici est le
modèle graphe que nous avons parlé en détail au chapitre
précédent. Il a été bien dit plus haut que ce
modèle se base principalement sur la théorie des graphes
initié par Leonhard Euler par ses fameux ponts de Königsberg. C'est
cette théorie qui est à la base de la conception d'une base de
données orientées-graphe.
Le domaine des bases de données
orientées-graphes étant encore en gestation, Il n'existe pas de
consensus général sur les concepts de base les concernant. Il
existe beaucoup de modèles de graphes différents. Cependant, un
certain effort est fait pour créer le Modèle de Graphe
Attribué (Property Graph Model), unifiant la plupart des
différentes implémentations de graphes. Selon celui-ci,
l'information dans un graphe attribué est modélisée
grâce à trois blocs de base :
· Un noeud est un sommet du graphe
représentant une partie du monde réel.
Noeud
Figure 4.5: Noeud d'une base de données
graphe
· Une arête est un lien entre
plusieurs noeuds, avec une orientation ou non et un type (orienté et
marqué).
· Noeud1
Attribut1 : valeur1
Attribut2 : valeur2
...
Noeud2
Attribut1 : valeur1
Attribut2 : valeur2
...
Arête
Attribut1 : valeur1
Attribut2 : valeur2
...
Un attribut (ou une
propriété) est une caractéristique
associée à un noeud ou un arc.
Figure 4.6: Noeuds, arête et leurs attributs
Plus spécifiquement, le modèle est un
multigraphe(p-graphe sans boucle) attribué,
marqué et orienté ou non-orienté. Il est attribué
car, les arêtes et les noeuds ont des attributs. Il est marqué
car, à une étiquette pour chaque arête qui est
utilisée comme type pour celle-ci. Il est orienté ou non, car les
arêtes du graphe ont des flèches montrant la direction de
l'origine vers la cible ou ils n'ont rien comme flèche.Ces graphes
autorisent une liste variable d'attributs pour chaque noeud et arête,
dans laquelle un attribut est une valeur associée à un nom,
simplifiant la structure du graphe.
Il sied de signaler que les graphes qu'on utilise pour les
bases des données sont des multigraphes, c'est-à-dire qu'il
autorise plusieurs arêtes entre deux noeuds (en théorie des
graphes, on parle des arêtes de même forme). Cela
signifie que deux noeuds peuvent être connectés plusieurs fois par
différentes arêtes, même si deux arêtes ont la
même extrémité initiale et extrémité
terminale.
IV.3. TRADUCTION DU MODELE DE DONNEES SOURCE VERS LE MODELE DE
DONNEES CIBLES
Pour passer d'un modèle relationnel vers un
modèle graphe, nous proposons les différentes étapes
suivantes :
IV.3.1. Traduction des types-entités (ou tables)
Il sied pour nous de rappeler que, la matérialisation
du modèle relationnel est le modèle physique de données
(MPD) si nous nous référons à la méthode Merise.
Alors dans ce cas, on parle des tables en lieu et place du type-entité.
De plus, le type-association du type many to many se transforme en table de
jointure, qui est évidement action très coûteux du point de
vue spatiotemporel.
Règle 4.1 : Lors de la migration du
relationnel vers le graphe, chaque table d'entité est
représentée par une étiquette sur des
noeuds
Exemple 4.3 :
En relationnelle, on a :
Matricule
Nom
Prenom
Personne
NumRegistre
Libelle
Status
Entreprise
Travailler _a
DateEmbauche
DureeContrat
1, n
1, n
Figure 4.6: Type-entité à traduire
: Personne
Matricule : valeur
Nom : valeur
Prenom : valeur
: Entreprise
NumRegistre: valeur
Libelle : valeur
Status : valeur
Travailler_a
DateEmbauche : valeur
DureeContrat: valeur
En graphe, on a :
Figure 4.7: Traduction du type-entité
IV.3.2. Traduction des enregistrements (lignes) d'une table
d'entité
Les enregistrements ou les lignes dans les bases de
données relationnelles sont les éléments qui font beaucoup
plus l'objet des requêtes. Ainsi, chacun de ses enregistrements se
transforment en noeud et les colonnes de ses enregistrements deviennent des
attributs du noeud correspondant. Les attributs à valeur nulle ne sont
pas répétés dans une base de données
orientées-graphe.
Règle 4.2: Lors de la migration du
relationnel vers le graphe, chaque enregistrement dévient un noeud, et
par conséquent chaque colonne sur ces tables devient attribut de
noeud.
IV.3.3. Traduction de la table de jointure
Une table de jointure (Join table ou jonction table) est une
table issue d'un type-association many to many. Cette table contient alors les
clés de chaque table qui agissent sur elle.
Règle 4.3 : Lors de la migration du
relationnel vers le graphe, chaque table de jointure devient une arête,
et ne comporte aucune clé comme attribut. Seuls les attributs du
type-association dont elle provenait sont maintenus comme attributs de
l'arête.
Exemple 4.4 :
En relationnelle, on a les tables suivantes:
|
Personne
|
|
Matricule
|
Nom
|
Prenom
|
|
001A
|
Kamingu
|
Gradi
|
|
002B
|
Pinshi
|
Jonathan
|
|
003C
|
Kadima
|
Gloire
|
|
004D
|
Lukelu
|
L'or
|
|
...
|
...
|
...
|
|
...
|
...
|
...
|
|
Travailler_a
|
|
Matricule
|
NumRegistre
|
DateEmbauche
|
DureeContrat
|
|
001A
|
1
|
1998
|
Ind.
|
|
002B
|
1
|
2003
|
20 ans
|
|
003C
|
2
|
2014
|
10 ans
|
|
004D
|
3
|
2015
|
4 ans
|
|
...
|
...
|
...
|
...
|
|
...
|
...
|
...
|
...
|
|
Entreprise
|
|
NumRegistre
|
Libelle
|
Status
|
|
1
|
Bcorp
|
SARL
|
|
2
|
Shibagu
|
SARL
|
|
3
|
Vodacom
|
SPRL
|
|
...
|
...
|
...
|
|
...
|
...
|
...
|
Figure 4.8: Tables à traduire
: Personne
Matricule : 001A
Nom : Kamingu
Prenom : Gradi
: Entreprise
NumRegistre : 1
Libelle : Bcorp
Statuts : SARL
Travailler_a
DateEmbauche : 1998
DureeContrat : Ind.
: Personne
Matricule : 002B
Nom : Pinshi
Prenom : Jonathan
Travailler_a
DateEmbauche : 2003
DureeContrat : 20 ans
: Personne
Matricule : 003C
Nom : Kadima
Prenom : Gloire
: Personne
Matricule : 004D
Nom : Lukelu
Prenom : L'or
: Entreprise
NumRegistre : 2
Libelle : Shibagu
Statuts : SARL
: Entreprise
NumRegistre : 3
Libelle : Vodacom
Statuts : SPRL
Travailler_a
DateEmbauche : 2014
DureeContrat : 10 ans
Travailler_a
DateEmbauche : 2015
DureeContrat : 4 ans
En graphe, on a :
Figure 4.9: Graphe issu des tables de la figure 4.8
IV.4. ALGORITHME DE MIGRATION DES DONNEES
Pour rappel, un algorithme est une suite finie
d'opérations permettant de résoudre un problème
donné. Pour ce faire, nous proposons alors l'algorithme suivant
permettant de faire la migration des bases de données relationnelles
vers les bases des données NoSQL du type graphe.
Algorithme 4.1
1. Début
2. Repérer le Modèle EA
3. Pour tout Type-association
3.1. Chaque type-association dévient une arête
3.2. Les types-associations réflexive engendrent deux
noeuds ayant le même étiquette
FinPour
4. Repérer le Modèle physique des données
4.1. Pour Toute Table
4.1.1. Si la Table est une table de jointure
Alors
4.1.1.1. La table dévient une arête (cela se
justifie parce que ladite table était une relation dans le Modèle
EA)
Sinon
4.1.1.2. Chaque ligne de table dévient un noeud dont
l'étiquette est le nom de la table ;
4.1.1.3. Chaque colonne de la table dévient un attribut
du noeud ;
4.1.1.4. Enlever toutes les clés techniques des tables,
ne garder que les clés faisant l'affaire ;
4.1.1.5. Ajouter les index ayant les attributs les plus
fréquents ;
4.1.1.6. Supprimer tous les attributs ayant des valeurs par
défaut, il n'est pas important d'avoir des valeurs comme NULL dans une
base de données graphe.
FinSi
FinPour
5. Ajouter les différentes relations non prises en
charge par le modèle relationnel
6. Fin
IV.5. VALIDATION DE L'APPROCHE PAR ETUDE DE CAS
Notre étude se basera sur l'étude d'un
réseau des entreprises. Ainsi, ce réseau nous permettra :
· De voir les différentes relations
existantes entre les entreprises, les dirigeants des entreprises et les
différentes agents des entreprises ;
· de voir toutes les entreprises remplissant une certaine
condition ;
IV.5.1. Modélisation relationnelle de la base des
données avec le modèle entité-association
L'algorithme commence par le repère du modèle
entité-association. Dans le cas de notre modélisation, le
modèle entité-association sera alors le suivant :
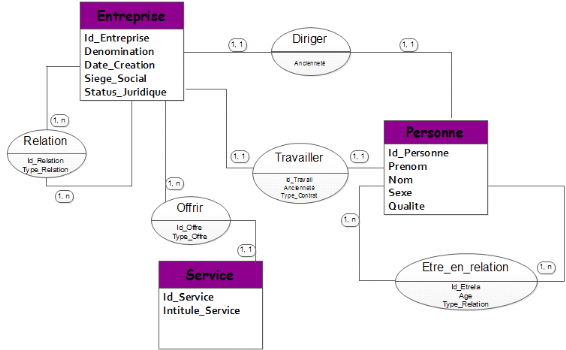
Figure 4.10: Modèle Entité-Association de
l'étude de cas
IV.5.2. Modélisation physique des données
Pour représenter physiquement notre base de
données relationnelle, nous avons utilisé le SGBD Microsoft
Access, dans sa version 2010 pour sa disponibilité dans l'ordinateur et
sa souplesse dans le stockage des données relationnelles. Nous avons
donc cinq tables qui sont :
· Table Entreprise
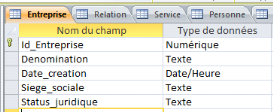
En mode feuille des données, on a :
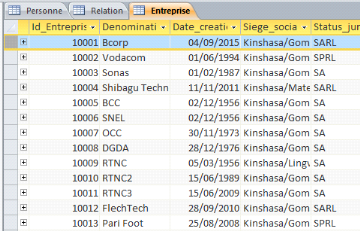
· Table Relation
· Table Service
· Table Personne
· Table Etre_en_relation
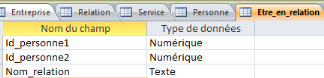
IV.5.3. Migration des donnéesrelationnelles vers
données orientées-graphe
Pour quitter du modèle relationnel vers le
modèle graphe de notre base de données, nous allons appliquer
l'algorithme 4.1. proposé un peu plus haut. Voici alors la trace pour
notre application :
1. Début
2. On repère le modèle EA, voir la figure
4.10
3. 3.1. Les relations Relation,
Diriger, Travailler, Offrir,
Etre_en_relation deviennent des arêtes.
3.2. Les relations réflexives comme Relation
et Etre_en_relation vont engendrer respectivement
deux noeuds. Pour l'arête Relation, on aura deux noeuds ayant tous les
deux comme étiquette Entreprise. Pour l'arête
Etre_En_Relation, on aura deux noeuds ayant tous les deux comme
étiquette Personne.
4. On repère le MPD explicité au point
IV.5.2.
4.1. Relation est une table de jointure, elle ne fera pas
objet de devenir un noeud, elle était déjà
transformée en arête.
Tous les enregistrements (ou toutes les lignes) deviennent des
noeuds. Pour la table Entreprise (en mode feuille des données), les
lignes de Denomination BCorp, Vodacom, ..., PariFoot
deviennent les noeuds dans notre modèle graphe.
5. On crée un nouvel étiquette
Dirigeant qui aura les mêmes attributs que le noeud
Personne.
D'où le modèle de graphe attribué se
présente alors de la manière suivante :
Est_en_relation
Age
Type_Relation
Travailler
Ancienneté
Type_Contrat
Diriger
Ancienneté
Offrir
Type_Offre
Relation
Type_Relation

Figure 4.11: Modèle de graphe
attribué
IV.5.3. Implémentation de la base de données par
l'approche Graphe
Nous avons pu implémenter en graphe en mode console
notre base de données. Pour l'implémenter, il s'agit
d'écrire des requêtes NoSQL du langage Cypher. Ainsi, le langage
Cypher est un standard des bases des données orientées-graphe
utilisé dans le SGBD orientées-graphe qu'on appelle Neo4j.
Les différentes requêtes du langage Cypher se
tapent dans la zone de fermeture qui se présente de la manière
suivante :

C'est dans la zone ci-haut que toutes les requêtes
Cypher s'écrivent. Chaque requête se trouve sur une ligne qui se
nomme automatiquement dès que nous passons d'une ligne à une
autre.
Après validation, on aura la feuille des
résultats suivants :

Le graphe de la base de données dans la console de
Neo4j se présente alors de la manière suivante:
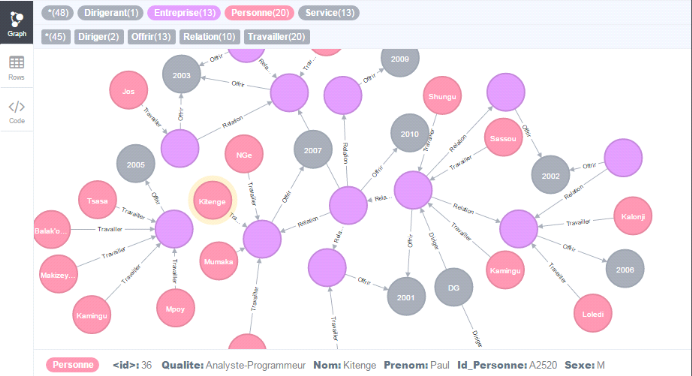
Chaque type de noeud porte une couleur différente des
autres.
1. Pour les noeuds de type Entreprise, la couleur est
violette ;
2. Pour les noeuds de type Dirigeant, la couleur est grise
foncée ;
3. Pour les noeuds de type Personne, la couleur est
rouge ;
4. Pour les noeuds de type Service, la couleur est
grise-claire.
Les codes-sources de la création de graphe sont
alors :
CREATE (d:Dirigerant{Id_Dirigerant:"1001", Prenom:"Coen",
Nom:"Fundatela", Sexe:"M",Qualite:"DG"})
CREATE (e1:Entreprise{Id_Entreprise:"10001",
Denomination:"BCorp", Date_Creation:"04/09/2015",
Siege_Sociale:"Kinshasa/Gombe", Status_Juridique:"SARL"})
CREATE (e2:Entreprise{Id_Entreprise:"10002",
Denomination:"Vodacom", Date_Creation:"01/06/1994",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SPRL"})
CREATE (e3:Entreprise{Id_Entreprise:"10003",
Denomination:"Sonas", Date_Creation:"01/02/1987",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SA"})
CREATE (e4:Entreprise{Id_Entreprise:"10004",
Denomination:"Shibagu Techology", Date_Creation:"11/11/2011",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SARL"})
CREATE (e5:Entreprise{Id_Entreprise:"10005", Denomination:"BCC",
Date_Creation:"02/12/1956",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SA"})
CREATE (e6:Entreprise{Id_Entreprise:"10006", Denomination:"SNEL",
Date_Creation:"02/12/1956",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SA"})
CREATE (e7:Entreprise{Id_Entreprise:"10007", Denomination:"OCC",
Date_Creation:"30/11/1973",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SA"})
CREATE (e8:Entreprise{Id_Entreprise:"10008", Denomination:"DGDA",
Date_Creation:"28/12/1976",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SA"})
CREATE (e9:Entreprise{Id_Entreprise:"10009", Denomination:"RTNC",
Date_Creation:"05/03/1956",
Siege_Sociale:"Kinshasa/Lingwala",Status_Juridique:"SA"})
CREATE (e10:Entreprise{Id_Entreprise:"10010", Denomination:"RTNC
2 Développement", Date_Creation:"15/06/1989",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SA"})
CREATE (e11:Entreprise{Id_Entreprise:"10011", Denomination:"RTNC
3 Institutions", Date_Creation:"15/06/2009",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SA"})
CREATE (e12:Entreprise{Id_Entreprise:"10012",
Denomination:"FlechTech", Date_Creation:"28/09/2010",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SARL"})
CREATE (e13:Entreprise{Id_Entreprise:"10013", Denomination:"Paris
Foot", Date_Creation:"25/08/2008",
Siege_Sociale:"Kinshasa/Gombe",Status_Juridique:"SARL"})
CREATE (s1:Service{Id_Service:"2001",
Intitule_Service:"Electricité"})
CREATE (s2:Service{Id_Service:"2002", Intitule_Service:"TIC"})
CREATE (s3:Service{Id_Service:"2003", Intitule_Service:"Radio et
Télévision"})
CREATE (s4:Service{Id_Service:"2004",
Intitule_Service:"Mécanique"})
CREATE (s5:Service{Id_Service:"2005",
Intitule_Service:"Assurance"})
CREATE (s6:Service{Id_Service:"2006",
Intitule_Service:"Réseaux des Télécommunications"})
CREATE (s7:Service{Id_Service:"2007",
Intitule_Service:"Contrôle"})
CREATE (s8:Service{Id_Service:"2008",
Intitule_Service:"Distribution d'Eau"})
CREATE (s9:Service{Id_Service:"2009",
Intitule_Service:"Impôts, douanes & assises"})
CREATE (s10:Service{Id_Service:"2010",
Intitule_Service:"Banque"})
CREATE (s11:Service{Id_Service:"2011",
Intitule_Service:"Industries"})
CREATE (s12:Service{Id_Service:"2012",
Intitule_Service:"Aviation"})
CREATE (s13:Service{Id_Service:"2012",
Intitule_Service:"Lotterie"})
CREATE (d)-[:Diriger{Anciennete:"5mois"}]->(e)
CREATE (p1:Personne{Id_Personne:"1002", Prenom:"Gradi",
Nom:"Kamingu", Sexe:"M",Qualite:"DGA"})
CREATE (p2:Personne{Id_Personne:"1003", Prenom:"Patrick",
Nom:"Shungu", Sexe:"M",Qualite:"Directeur Financier"})
CREATE (p3:Personne{Id_Personne:"1004", Prenom:"Bel-Ange",
Nom:"Kalonji", Sexe:"F",Qualite:"Conseiller Juridique"})
CREATE (p4:Personne{Id_Personne:"A250", Prenom:"Glodi",
Nom:"Kamingu", Sexe:"M",Qualite:"Conseiller Statistiques"})
CREATE (p5:Personne{Id_Personne:"A2880", Prenom:"Jean-Paul",
Nom:"Tsasa", Sexe:"M",Qualite:"Rédacteur en Chef"})
CREATE (p6:Personne{Id_Personne:"A5862", Prenom:"Trésor",
Nom:"Badibanga", Sexe:"M",Qualite:"Caméraman"})
CREATE (p7:Personne{Id_Personne:"BG586", Prenom:"Aninya",
Nom:"NGe", Sexe:"F",Qualite:"Chimiste"})
CREATE (p8:Personne{Id_Personne:"1008", Prenom:"Grace",
Nom:"Isolo", Sexe:"F",Qualite:"Secrétaire de Direction"})
CREATE (p9:Personne{Id_Personne:"A2520", Prenom:"Paul",
Nom:"Kitenge", Sexe:"M",Qualite:"Analyste-Programmeur"})
CREATE (p10:Personne{Id_Personne:"A2580", Prenom:"Moïse",
Nom:"Mbikayi", Sexe:"M",Qualite:"Administrateur Réseaux"})
CREATE (p11:Personne{Id_Personne:"2002", Prenom:"Onyx",
Nom:"Mpoy", Sexe:"M",Qualite:"Opérateur de saisie"})
CREATE (p12:Personne{Id_Personne:"2003", Prenom:"Josée",
Nom:"Jos", Sexe:"F",Qualite:"Opérateur de Saisie"})
CREATE (p13:Personne{Id_Personne:"2004", Prenom:"Levieux",
Nom:"Makizeyika", Sexe:"M",Qualite:"Conseiller stratégique"})
CREATE (p14:Personne{Id_Personne:"B250", Prenom:"Glodia",
Nom:"Sassou", Sexe:"F",Qualite:"Conseiller Statistiques"})
CREATE (p15:Personne{Id_Personne:"B2880", Prenom:"John",
Nom:"Loledi", Sexe:"M",Qualite:"Marketeur"})
CREATE (p16:Personne{Id_Personne:"B5862", Prenom:"Pupa",
Nom:"Balak'opandje", Sexe:"M",Qualite:"Réporteur"})
CREATE (p17:Personne{Id_Personne:"CG586", Prenom:"Anne",
Nom:"Mumaka", Sexe:"F",Qualite:"Chimiste"})
CREATE (p18:Personne{Id_Personne:"2008", Prenom:"Rony",
Nom:"Bope", Sexe:"M",Qualite:"Statisticien"})
CREATE (p19:Personne{Id_Personne:"B2520", Prenom:"Gloria",
Nom:"Mbombo", Sexe:"F",Qualite:"Chimiste"})
CREATE (p20:Personne{Id_Personne:"B2580", Prenom:"Moïse",
Nom:"Kabamba", Sexe:"M",Qualite:"Administrateur Système"})
CREATE (p1)-[:Travailler{Anciennete:"5mois",
Type_Contrat:"Durée Indeterminée"}]->(e1)
CREATE (p2)-[:Travailler{Anciennete:"5mois",
Type_Contrat:"Durée Indeterminée"}]->(e1)
CREATE (p3)-[:Travailler{Anciennete:"5mois",
Type_Contrat:"Durée Indeterminée"}]->(e2)
CREATE (p4)-[:Travailler{Anciennete:"2ans",
Type_Contrat:"Durée Indeterminée"}]->(e3)
CREATE (p5)-[:Travailler{Anciennete:"15ans",
Type_Contrat:"Durée Indeterminée"}]->(e3)
CREATE (p6)-[:Travailler{Anciennete:"5mois",
Type_Contrat:"2ans"}]->(e9)
CREATE (p7)-[:Travailler{Anciennete:"2ans", Type_Contrat:"8ans
"}]->(e7)
CREATE (p8)-[:Travailler{Anciennete:"6ans",
Type_Contrat:"4ans"}]->(e6)
CREATE (p9)-[:Travailler{Anciennete:"20ans",
Type_Contrat:"4ans"}]->(e7)
CREATE (p10)-[:Travailler{Anciennete:"1an",
Type_Contrat:"4ans"}]->(e13)
CREATE (p11)-[:Travailler{Anciennete:"5mois",
Type_Contrat:"Durée Indeterminée"}]->(e3)
CREATE (p12)-[:Travailler{Anciennete:"8mois",
Type_Contrat:"Durée Indeterminée"}]->(e10)
CREATE (p13)-[:Travailler{Anciennete:"15ans",
Type_Contrat:"Durée Indeterminée"}]->(e3)
CREATE (p14)-[:Travailler{Anciennete:"5mois",
Type_Contrat:"2ans"}]->(e1)
CREATE (p15)-[:Travailler{Anciennete:"2ans", Type_Contrat:"8ans
"}]->(e2)
CREATE (p16)-[:Travailler{Anciennete:"6ans",
Type_Contrat:"4ans"}]->(e3)
CREATE (p17)-[:Travailler{Anciennete:"20ans",
Type_Contrat:"4ans"}]->(e7)
CREATE (p18)-[:Travailler{Anciennete:"1an",
Type_Contrat:"4ans"}]->(e13)
CREATE (p19)-[:Travailler{Anciennete:"5mois",
Type_Contrat:"Durée Indeterminée"}]->(e7)
CREATE (p20)-[:Travailler{Anciennete:"8mois",
Type_Contrat:"Durée Indeterminée"}]->(e13)
CREATE (d)-[:Diriger{Anciennete:"5mois"}]->(e1)
CREATE (e1)-[:Offrir]->(s1)
CREATE (e2)-[:Offrir]->(s6)
CREATE (e3)-[:Offrir]->(s5)
CREATE (e4)-[:Offrir]->(s2)
CREATE (e5)-[:Offrir]->(s10)
CREATE (e6)-[:Offrir]->(s1)
CREATE (e7)-[:Offrir]->(s7)
CREATE (e8)-[:Offrir]->(s9)
CREATE (e9)-[:Offrir]->(s3)
CREATE (e10)-[:Offrir]->(s3)
CREATE (e11)-[:Offrir]->(s3)
CREATE (e12)-[:Offrir]->(s2)
CREATE (e13)-[:Offrir]->(s13)
CREATE (e1)-[:Relation{Type_Relation:"Partenariat"}]->(e2)
CREATE (e1)-[:Relation{Type_Relation:"Partenariat"}]->(e5)
CREATE (e12)-[:Relation{Type_Relation:"Partenariat"}]->(e2)
CREATE (e1)-[:Relation{Type_Relation:"Partenariat"}]->(e4)
CREATE (e10)-[:Relation{Type_Relation:"Extension"}]->(e9)
CREATE (e11)-[:Relation{Type_Relation:"Extension"}]->(e9)
CREATE (e5)-[:Relation{Type_Relation:" Partenariat"}]->(e6)
CREATE (e5)-[:Relation{Type_Relation:"Partenariat"}]->(e7)
CREATE (e5)-[:Relation{Type_Relation:"Partenariat"}]->(e8)
CREATE (e5)-[:Relation{Type_Relation:"Partenariat"}]->(e9)
CONCLUSION
Nous voici en fin de notre travail qui a consisté
à la proposition d'une approche de migration d'une base des
données relationnelles vers une base des données NoSQL
orientées-graphe.
Vu l'importance de stockage et des traitements des
données dans le support informatique et vu la grande masse des
données, il a été question de mettre en oeuvre une
approche nous permettant le migrer vers le modèle cible qu'est le
modèle graphe.
Cela s'est justifié par le simple fait que les graphes
modélisent très facilement et très clairement la
réalité et le traitement dévient beaucoup très
efficace lorsqu'on utilise les algorithmes de la Théorie des graphes.
En effet, les données se sont enregistrées dans les noeuds du
graphe et les liens entre ces différentes données par des
arêtes.
Sur ce, pour atteindre nos fins, nous avons parlé des
généralités sur les graphes et les bases des
données au premier chapitre. Au chapitre second, nous avons
traité les NoSQL ; ici nous avons parlé des
différentes bases des données NoSQL qui existent actuellement
graphe qui étaient d'ailleurs le noeud de notre question. Au chapitre
troisième, on a parlé des Bases des données
orientées-graphe.En dernier chapitre, on a pu proposer une approche
permettant de migrer d'une approche relationnelle vers une approche utilisant
la théorie des graphes tout en s'appuyant sur une étude de cas
à titre illustratif.
Sachant qu'il existe plusieurs technologies permettant de
résoudre les problématiques les bases de données
orientées-graphe, nous nous sommes permis d'utiliser le système
de gestion des bases des données orientées-graphes de la firme
Neo4j, qu'on appelle Neo4j.
Dans le souci d'amélioration, nous osons croire que le
présent mémoire n'est qu'un début d'un commencement, et
nécessite alors plusieurs enrichissements dans les années
à venir. Néanmoins, nous n'estimons pas avoir tout fait et tout
dit car l'Informatique évolue du jour le jour, mais nous ne croyons
simplement que nous avons pu avancer d'un premier pas car, dit
« Même un voyage de mille kilomètres commence par le
premier pas ».
BIBLIOGRAPHIE
I. OUVRAGES
[BE70] C. Berge : Graphes et
hypergraphes, Ed. Dunod, Paris 1970 ;
[BR15] R. BRUCHEZ: Les bases de données NoSQL
et le Big Data. Comprendre et mettre oeuvre, 2ème
Ed. EYROLLES, Paris, 2015;
[MK10] J.-A.K. MVIBUDULU, L.-D. I. KONKFIE: Technique
des bases de données, Etude et cas, 1ère Ed.
CRIGED, Kinshasa, janvier 2010;
[WF94] S. WASSERMAN and K. FAUST: Social Network
Analysis: Methods and Applications, Cambridge University Press,
1994;
II. NOTES DE COURS
[KM14] P. K. KAFUNDA, L. N. MANYA: Coursde Recherche
Opérationnelle Approfondie, Première licence en
Informatique de gestion, Département des Mathématiques et
Informatique, Faculté des Sciences, Université de Kinshasa, 2013
- 2014;
[MA08] L. N. MANYA: Cours de Recherche
Opérationnelle, Troisièmes Graduats en
Mathématiques et en Informatique, Département des
Mathématiques et Informatique, Faculté des Sciences,
Université de Kinshasa, 2007 - 2008;
[MA06] S. M. MAPHANA: Recherche Opérationnelle.
Module 1 : Théorie des graphes et ses applications,
Premières licences en Sciences de Gestion, Département des
Sciences de Gestion, Faculté des Sciences Economiques et de Gestion,
Université de Kinshasa, Mai 2006;
[MB12] E. M. MBUYI: Cours d'Informatique
appliquée : Base de données, Troisièmes
Graduats en Mathématiques et en Informatique, Département des
Mathématiques et Informatique, Faculté des Sciences,
Université de Kinshasa, 2012 - 2013;
[RI10] M. RIGO: Théorie des Graphes,
Deuxièmes bacheliers en sciences mathématiques,
Département des Mathématiques, Faculté des Sciences,
Université de Liège, 2009 - 2010;
[RWE] I. ROBINSON, J. WEBBER, and EMIL: Graph
Databases - The Definitive Book on Graph Databases.
III. ARTICLES, PAPIERS, CONFERENCES
[BA69] C. BACHMAN, «Data Structure
Diagrams»,Journal of ACM, SIGBDP Vol. 1, N° 2, pp.
4-10, mars 1969;
[BE06] S. P. BORGATTI and M. G. EVERETT: «A Graph
theoretic perspective on centrality. Social Networks»,
28(4):466-484, 2006;
[FR79] L. C. FREEMAN: «Centrality in social
networks conceptual clarification. Social Networks", 1(3):215-239,
1979;
[FR91] L. C. FREEMAN: «Centrality in valued
graphs: A measure of betweenness based on network flow. Social
Networks", 13(2):141-154, 1991 ;
[LE14] M. LEONARD : « L'avenir du
NoSQL. Quel avenir pour le NoSQL ? , 2014 ;
[RO] M. ROGER : Synthèse d'étude et
projets d'interlogiciels. Base NOSQL, IFR IMA ;
[SA] K. SANI : Graph databases : Les bases de
données orientées Graphes. Une brève présentation,
Etablissement Inter-Etats d'Enseignement Supérieur, Institut
Africain d'Informatique ;
[TO12] C. M. TOMBOLA: Construction d'une matrice
d'incidence et de la matrice laplacienne : Comment représenter
intelligemment un graphe.One pager Laréq, Vol. 4 Num.
005, novembre 2012.
IV. TRAVAILS DE FIN DE CYCLE, MEMOIRES,
THESES
[CH10] N.F. CHIKHI : Calcul de centralité
et identification de structures de communautés dans les graphes de
documents, Thèse de doctorat, spécialité
Intelligence Artificielle, Ecole doctorale de Mathématiques Informatique
Télécommunications (MITT), Université Toulouse 3 Paul
Sabatier, vendredi 17 décembre 2010 ;
[KA13] G. L. KAMINGU: Mise en place d'un
système d'information pour la gestion des concours et épreuves
spéciales d'entrée. Cas de la Faculté des Sciences de
l'Université de Kinshasa,Travail de Fin de Cycle,
Département des Mathématiques et Informatique, Faculté des
Sciences, Université de Kinshasa, 2012 - 2013;
[KL13] A. KHATIR, I. LABBAS : Conception et
réalisation d'un réseau social,Mémoire de Fin
d'Etudes Master, Option : Réseaux et systèmes
distribués, Département d'informatique, Faculté des
Sciences, Université Abou Bakr Belkiad-Tlemcen, 2012 - 2013;
[KO12] E. KOUEDI : Approche de migration d'une
base de données relationnelles vers une base de données NoSQL
orientée colonne, Mémoire de Master II
Recherche, Département d'Informatique, Faculté des Sciences,
Université de Yaounde I, Mai 2012 ;
[MA04] F. MATHIEU : Graphe du Web, mesure
d'importance à la PageRank, Thèse de doctorat,
Spécialité : Informatique, Ecole doctorale d'Information,
Structures, Systèmes, Université Montpellier II Sciences et
Technique du Languedoc, 2004 ;
[TR13] N. TROTIGNON: Graphes parfaits : structure
et algorithmes, Thèse de doctorat,
Spécialité : Mathématiques Informatique, Ecole
doctorale de Recherche Opérationnelle, Combinatoire et Optimisation,
Université Grenoble 1 Joseph Fourrier, 28 septembre 2004.
V. SITES WEB, BLOGS, FORUMS
[Dboo]
http://www.d-booker.fr/neo4j-1/156-prise-en-main.html(04/10/2015)
[Gisp]
http://gist.neo4j.org(04/10/2015)
[Grap]
http://www.graphes.fr/(04/10/2015)
[Img]
http://www-img.univ-mlv.fr/~dr/XPOSE2010/Cassandra/modèle.html(08/12/2015)
[Neo]
http://www.neo4j.org/(04/10/2015)
[Octo] http://blog.octo.com/author/mdo/ (Bases de
données graphes : un tour d'horizon.(04/10/2015)
[Wika]
http://wiki.apache.org/couchedb
(07/10/2015)
[Wiki1]
http://fr.wikipedia.org/Algorithme_de_Dijskstra
(18/01/2016)
[Wiki2]
http://en.wikipedia.org/wiki/Nosql(18/01/2016)
[Wiki3]
http://en.wikipedia.org/wiki/Graph_database(18/01/2016)
[Wiki4]
http://en.wikipedia.org/wiki/Document-oriented_database(18/01/2016)
[Wiki5]
http://en.wikipedia.org/wiki/Column-oriented_DBMS(18/01/2016)
[Wiki6]
http://en.wikipedia.org/wiki/Relational_database(18/01/2016)
TABLE DES MATIERES
Epigraphie
ii
In memoriam
iii
Remerciements
iv
Liste des abréviations utilisées
vi
Liste des notations
vii
0.
INTRODUCTION
1
Chapitre 1:
GENERALITES SUR LES BASES DE DONNEES
ET LES GRAPHES
3
I.1. BASE DE DONNEES
3
I.1.1. Définition de la base de
données
3
I.1.2. Critères d'une base de
données
4
I.1.3. Types d'utilisateurs
4
I.4.1. Types de base de données
4
I.1.4.1. Base de données
hiérarchique
4
I.1.4.2. Base de données réseau
5
I.4.1.3. Base de données relationnelle
6
I.4.1.4. Base de données
orientées-objet
6
I.1.4.5. Base de données
orientées-colonne
7
I.1.4.6. Base de données
orientées-graphe
7
I.1.4.7. Base de données
orientées-clé-valeur
7
I.1.4.8. Base de données
orientées-document
7
I.2. GRAPHES
8
I.2.1. Définition d'un graphe
8
I.2.2. Graphe complet
11
I.2.3. Graphe biparti
11
I.2.4. Connexité
13
I.2.5. Distances
15
1.2.6. Graphe planaire
16
I.2.7. Graphe pondéré - Réseau
- Réseau de transport
18
I.2.8. Problème de Cheminement optimale
19
1.2.9. Calcul de centralité [CH10]
21
I.3. IMPORTANCE DE LA THEORIE DES GRAPHES EN BASE
DE DONNEES
26
CHAPITRE 2 :
NOSQL
28
II.1. TERMINOLOGIE
29
II.2. CONCEPTS DE BASE
29
II.2.1. Théorème du CAP (d'Eric
Brewer)
29
II.2.2. Principes ACID et BASE
30
II.3. CRITERES DE MIGRATION VERS LE NOSQL
32
II.4. CRITERES DE CHOIX POUR MIEUX CHOISIR LE TYPE
DE BASE DE DONNEES [LE14]
33
II.5. DEFIS MAJEURS DES NOSQL [KO12]
35
II.5.1. Maturité et stabilité
36
II.5.2. Assistance et maintenance
36
II.5.3. Outils d'analyse et administration
36
II.5.4 Expertise
37
CHAPITRE 3 :
BASE DE DONNEES ORIENTEES-GRAPHE
38
III.1. VUE GLOBALE
38
III.1.1. Définition
38
III.1.2. Puissance des bases de données
orientées-graphe
39
III.1.3. Cas d'usage des bases de données
orientées-graphe
40
III.2. OUTILS DES BASES DE DONNEES
ORIENTEES-GRAPHE
41
III.3. COMPARAISON DE BASE DE DONNEES
ORIENTEES-GRAPHE AVEC LES AUTRES
BASES DE DONNEES
42
II.3.1. Comparaison avec les bases de
données relationnelles
42
II.3.2. Comparaison avec les bases de
données réseaux
44
III.4. MODELISATION
46
III.5. SYSTEME DE GESTION DES DONNEES
ORIENTEES-GRAPHE : NEO4J
47
III.5.1. Qu'est-ce que Neo4j ?
47
III.5.2. Caractéristiques de Neo4j
47
III.5.3. Installation rapide de Neo4j
47
III.5.4. Lancement de Neo4j
48
III.5.5. Test d'installation de Neo4j
48
CHAPITRE 4 :
APPLICATION
49
IV.1. PRESENTATION DE L'APPROCHE
49
IV.1.1. Introduction
49
IV.1.2. Modèle de données source
50
IV.1.3. Modèle de données cible
52
IV.3. TRADUCTION DU MODELE DE DONNEES SOURCE VERS
LE MODELE DE DONNEES CIBLES
53
IV.3.1. Traduction des types-entités (ou
tables)
53
IV.3.2. Traduction des enregistrements (lignes)
d'une table d'entité
54
IV.3.3. Traduction de la table de jointure
54
IV.4. ALGORITHME DE MIGRATION DES DONNEES
56
IV.5. VALIDATION DE L'APPROCHE PAR ETUDE DE CAS
57
IV.5.1. Modélisation relationnelle de la
base des données avec le modèle entité-association
57
IV.5.2. Modélisation physique des
données
58
IV.5.3. Migration des données relationnelles
vers données orientées-graphe
60
IV.5.3. Implémentation de la base de
données par l'approche Graphe
61
CONCLUSION
66
BIBLIOGRAPHIE
67
* 1 Ce nom est un
acronyme
récursif qui signifie en anglais
« GNU's Not UNIX »
(littéralement, « GNU n'est pas UNIX »).
* 2 Les notions d'entités
et de type-entités seront abordées d'une manière claire au
chapitre 4
* 3 C'est un point d'un
système informatique dont le reste du système est
dépendant et dont une panne entraîne l'arrêt complet du
système.
| 






