6. Objectif du projet
L'objectif principal de ce mémoire est le
suivant :
Protéger les objets vulnérables d'un
réseau domotique en mettant en oeuvre le filtrage du trafic au niveau de
la passerelle grâce à l'apprentissage automatique.
Nous proposons de protéger un réseau d'objets
connectés d'attaques très connus en créant des
modèles d'apprentissage automatique qui vont permettre de filtrer le
trafic réseau. Notre proposition serait, grâce à
l'intelligence artificielle, de nous servir d'algorithmes pour
reconnaître beaucoup plus facilement et surtout plus rapidement le trafic
malveillant spécifiques aux objets connectés et pouvoir ainsi
accepter ou rejeter un paquet. Tout en identifiant les objets du réseau
et reconnaître plus rapidement les objets piratés ou malveillants.
Nous allègerons le travail d'un pare-feu.
Pour cela nous pouvons définir plusieurs sous objectifs
qui sont :
? Pouvoir analyser un réseau d'objets connectés
à travers la passerelle pour identifier les différents types
d'objets
? Analyser le trafic et détecter les paquets
malveillants en se basant sur quelques attaques connues des objets
connectés
? Bloquer les connexions malveillantes
en se basant sur des prédictions faites par le modèle
CHAPITRE 2 :
MÉTHODOLOGIE
Introduction
Dans ce chapitre nous allons principalement aborder notre
méthodologie de travail pour atteindre les objectifs posés,
proposer des modèles et suggérer une solution de filtrage des
paquets. Nous allons présenter les concepts sur les algorithmes
d'apprentissage profond et d'empreinte digitale. Nous allons présenter
la méthodologie de créations des modèles de la collecte
des données jusqu'à la création des réseaux de
neurones. Enfin nous allons parler de l'implémentation d'un filtre qui
fonctionne avec le kernel et qui permet de filtrer des paquets.
1. Définition de concepts
clés
1.1. Algorithme d'apprentissage profond
L'apprentissage profond est un sous domaine d'intelligence
artificielle qui s'appuie sur un réseau de neurones artificiels. Il
permet globalement « d'apprendre à reconnaître,
d'identifier ou prédire ». La particularité
intéressante de l'intelligence artificielle est d'apprendre de ses
erreurs à peu près comme un être capable de penser
à beaucoup encourager les recherches dans le but de développer
cette discipline. Il est présent aujourd'hui dans plusieurs domaines
différents tels que la reconnaissance d'image, la traduction
automatique, la voiture autonome, le diagnostic médical, des
recommandations personnalisées dans nos e-commerces, les
modérateurs automatique, les chatbots, l'exploration spatiale et bien
évidement la sécurité informatique dans la
détection de malware [25].
Les réseaux de neurones artificiels sont
inspirés de l'architecture des réseaux de neurones humains.
C'est une combinaison de plusieurs neurones connectés sous la forme d'un
réseau. Ces neurones sont interconnectés pour traiter et
mémoriser des informations, comparer des problèmes ou situations
quelconque avec des situations (informations en entrée, erreurs, etc)
similaires passées, analyser les solutions et résoudre le
problème de la meilleure façon possible. La figure
ci-dessous nous montre un exemple basique d'un réseau neuronal. Un
réseau neuronal artificiel a une couche d'entrée, une ou
plusieurs couches cachées intermédiaires et une couche de sortie.
Sa forme la plus simple est le perceptron simple où on retrouve deux
couches. La couche d'entré et la couche de sortie.
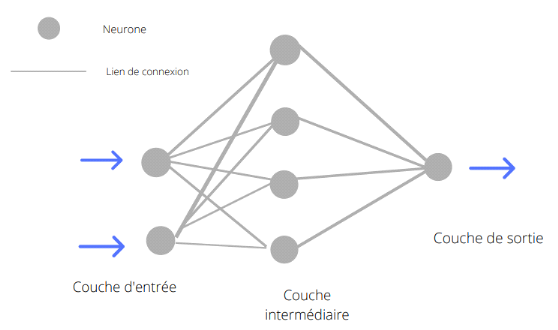
Figure 14 : un réseau de
neurone avec trois couches
Tel que montré à la
figure ci-dessus chaque couche possède un ensemble de neurones
connectés aux neurones de la couche suivante excepté la couche de
sortie.
La figure ci-dessous nous montre les détails des liens
entre les neurones de la couche précédente et un neurone de la
couche suivante. Chaque lien connectant un neurone à un autre est
associé à un poids wi
représentant la force de la connexion.
La somme (poids wi multiplié par la valeur de
l'entrée précédente du lien xi)
ou fonction d'agrégation des liens de la couche précédente
est multipliée par la fonction d'activation du neurone de la couche
suivante ce qui donne une sortie représentative de l'activation du
neurone. La figure ci-dessous nous montre que chaque neurone d'une couche
effectue des calculs en fonction des sorties des couches
précédentes.
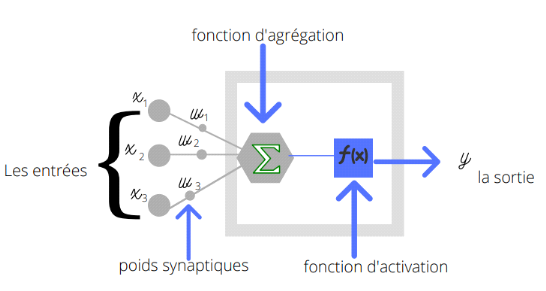
Figure 15 : Connexion des
entrées d'une couche précédente vers un neurone de la
couche suivante
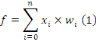
- f est la fonction
d'agrégation
- x est la valeur de la sortie d'un des neurones de la couche
précédente
- w est le poids synaptique d'un lien
Une fonction d'activation est une fonction mathématique
appliquée à un signal de sortie d'un neurone [25]. Il correspond
à un seuil d'activation qui une fois atteint entraine une réponse
du neurone. Il existe plusieurs fonctions d'activation. Par exemple la fonction
rampe ou identité f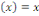 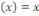 (2), la fonction logistique ou sigmoïde (2), la fonction logistique ou sigmoïde 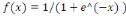 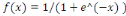 (3), la fonction relu ou unité de rectification
linéaire (3), la fonction relu ou unité de rectification
linéaire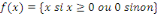 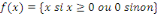 (4)ou encore fonction tangente hyperbolique (4)ou encore fonction tangente hyperbolique 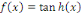 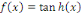 (5). (5).
Nous remarquons qu'il existe dans la plupart des cas un seuil
pour activer le neurone. Par exemple pour la fonction sigmoïde x elle se
trouve entre -1 et 1 ou encore celle de la fonction Relu où x doit
être supérieur à zéro.
Dans le cadre de notre projet deux types de réseau de
neurone nous ont intéressés, le perceptron multicouche et le
réseau récurrent LSTM.
Le perceptron multicouche (PMC en français ou MLP pour
MultiLayer perceptron) est un algorithme d'apprentissage dans lequel
l'information circule dans un seul sens et qui apprend une fonction en
s'entraînant à partir d'un jeu de donnée ou dataset avec
des attributs en entrées, plusieurs couches intermédiaires et des
classe/labels à prédire en sortie.
L'apprentissage du MLP se fait généralement par
rétro-propagation. Cela permet de trouver les poids minimisant une
fonction d'erreur globale. Elle permet de calculer le gradient de l'erreur pour
chaque neurone du réseau, de la dernière couche vers la
première.
Il y'a deux étapes principales dans la rétro
propagation. Nous avons en premier lieu la propagation
« avant » avec un ensemble d'opérations qui
permettent de calculer des valeurs d'activation des neurones de sorties. Nous
déterminons ainsi l'erreur d'apprentissage.
Ensuite la propagation « arrière »,
on circule des sorties vers les entrées. L'erreur d'apprentissage va
être distribuée aux neurones de couches cachées afin de
pouvoir ajuster plus tard les poids du réseau.
Le nouveau poids est égal à la somme de l'ancien
poids ajouté au produit du taux d'apprentissage, de l'erreur du neurone
actuel et de la sortie de la couche précédente.
Les phases de rétro-propagation sont
répétées autant de fois que le nombre
d'échantillons du jeu de données. Une fois terminé on
calcule la somme des erreurs d'apprentissage.
Les réseaux de neurones récurrents sont quant
à eux un type de réseau de neurones artificiel où les
liens entre les neurones forment un cycle direct ou encore où il existe
des liens récurrents [26]. Cela crée un état interne du
réseau qui permet d'avoir un comportement dynamique et une
mémoire. La spécificité d'un RNN est qu'ils ont une
«mémoire» qui capture des informations sur ce qui a
été calculé jusqu'à présent. Les
données sont récupérées au niveau de la couche
d'entrée. L'ensemble des neurones d'entrées doivent correspondre
aux attributs du jeu de données.
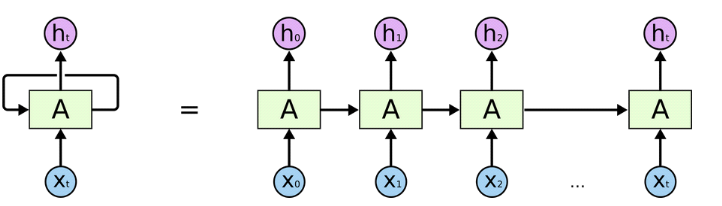
Figure 16 : Détail de
fonctionnement du réseau LSTM [26]
? Xt est l'entrée à un instant t
? Ht est la sortie à un instant t
? A est l'état caché à un instant t et
est calculé en fonction de l'état précédent
D'après la figure ci-dessus nous voyons que dans ce
type de réseau, chaque neurone peut utiliser sa mémoire interne
pour maintenir l'information concernant l'entrée
précédente. Cela signifie qu'en plus de pouvoir faire des
prédictions, ils peuvent apprendre les séquences d'un
problème et alors généré entièrement une
nouvelle séquence plausible du problème en question. Dans notre
cas par exemple, nous pourrions totalement générer de nouveaux
paquets plausibles ainsi que leurs classes. Cependant ce n'était pas le
but ici, nous voulions juste prédire la classe.
Le LSTM Les réseaux de mémoire à long
terme à court terme généralement appelés simplement
(LSTM : Long Short Term Memory) sont un type spécial de RNN. La cellule
LSTM est une adaptation de la couche récurrente qui permet aux signaux
plus anciens des couches profondes de se déplacer vers la cellule A du
présent.
L'apprentissage est une phase du développement d'un
réseau de neurones durant laquelle le comportement du réseau est
modifié jusqu'à l'obtention du résultat
désiré ou s'approchant de celui-ci !
Quelque soit le type de réseau, il existe plusieurs
types d'apprentissage :
? Apprentissage supervisé : Dans
ce type d'apprentissage, nous avons en entrées des données qui
sont associées à une étiquette ou une classe en sortie.
L'algorithme durant son entraînement va apprendre à
reconnaître ces données comme correspondant à ces
étiquettes particulières. Par la suite, il sera capable de
prédire une cible grâce à de nouvelles données
différentes de celles utilisées pendant l'entraînement.
? Apprentissage non supervisé :
Dans ce cas les données ne possèdent pas d'étiquettes.
l'algorithme pendant l'entraînement s'applique à trouver seul les
similarités et distinctions au sein de ces données et à
regrouper ensemble celles qui partagent des caractéristiques
communes.
? Apprentissage par renforcement : Elle
se base sur un cycle d'expérience / récompense et améliore
les performances à chaque itération. Donc lorsque
l'algorithme fait une bonne prédiction, il est récompensé
et ainsi encourager à en faire plus !
| 

