4.1.2.
Préparation et nettoyage des données
L'étape qui suit est de nettoyer les données
qu'on a téléchargées afin qu'elles puissent être
manipulables par l'algorithme.
En effet dans notre jeu de donnée, il y'a des valeurs
incomplètes, incohérentes, inexactes (contiennent des erreurs ou
des valeurs aberrantes) et des valeurs qui ne peuvent pas être
traités par l'algorithme car elles sont brutes et ne sont pas
compréhensible ou lisible pour celui-ci. Le prétraitement des
données permet d'améliorer la qualité des données
afin de favoriser l'extraction d'informations significatives à partir
des données.
Le prétraitement des données fait
référence à la technique de préparation (nettoyage
et organisation) des données brutes pour les adaptées à la
formation de modèles d'apprentissage profond. Ce processus aide à
nettoyer, formater et organiser les données brutes, les rendant ainsi
prêtes à l'emploi pour les modèles d'apprentissage
automatique.
Nous avons utilisés des bibliothèques Python
pour effectuer des tâches de prétraitement de données
spécifiques:
? NumPy : NumPy est le package
fondamental pour le calcul scientifique en Python. Par conséquent,
il est utilisé pour insérer tout type d'opération
mathématique dans le code
? Pandas : Pandas est une
bibliothèque Python open source pour la manipulation et l'analyse de
données. Nous l'avons utilisé pour importer et gérer
nos ensembles de données. Il intègre des structures de
données et des outils d'analyse de données hautes performances et
faciles à utiliser pour Python. Il nous a permis de manipuler nos
données, d'avoir une vue d'ensemble et de comprendre beaucoup plus
facilement nos données.
? Sklearn : Scikit-learn est
une bibliothèque libre Python destinée
à l'apprentissage automatique [34]. le
sklearn.preprocessing package, que nous avons beaucoup
utilisé, fournit plusieurs fonctions d'utilité communes et
classes de transformateurs pour changer les vecteurs de caractéristiques
bruts en une représentation qui convient mieux aux estimateurs en aval
[35]. Elle fait partie des bibliothèques majeures qui nous ont
aidés avec Pandas à faire le prétraitement des
données.
? Matplotlib : Matplotlib est une
bibliothèque du langage de programmation Python
complète pour créer des visualisations statiques, animées
et interactives en Python [36]. Elle peut être combinée avec
la bibliothèque python de calcul scientifique NumPy
[36].
Le jeu de données est dans le format texte pour le
premier modèle sur la détection de la nature du trafic. Avant
d'importer il faut spécifier que certaines valeurs manquantes dans mon
jeu de données sont spécifiées par le caractère ` -
'. Pour qu'il le remplace par un ` NaN '.
Nous avons séparé le jeu de données en
trois. Le jeu d'entraînement, le jeu de validation et le jeu de test.
L'ensemble du jeu d'entraînement de nos modèles
de machine learning représente 60% du jeu de donnée. Celui
de test pour mesurer la performance des modèles sur des données
non apprises représente 20% du jeu de données. La performance
d'un modèle sur l'ensemble de test correspond à une mesure de ce
modèle sur des données réelles, qui permettent
d'évaluer la capacité de généralisation du
modèle.
Un ensemble de validation pour s'assurer que notre
modèle ne se « sur ou sous entraine pas » et
effectuer des réglages des hyper paramètres du modèle.
Tout ceci pour que le modèle puisse faire une bonne
généralisation c'est-à-dire des prédictions justes
sur des données qu'il n'a jamais vues.
L'Overfitting (sur-apprentissage), et
l'Underfitting (sous-apprentissage) sont les causes
principales des mauvaises performances des modèles prédictifs
générés par les algorithmes d'intelligence
artificielle.
La notion d'overfitting désigne
le fait que le modèle choisi
est « habitué » aux données
d'entraînement. Le modèle prédictif produit par
l'algorithme de Machine Learning s'adapte très bien au jeu
d'entraînement. Par conséquent, le modèle
capturera tous les «aspects» et détails qui
caractérisent les données du jeu
d'entraînement. Dans ce sens, il capturera toutes les
fluctuations et variations aléatoires des données lors de
l'apprentissage. En d'autres termes, le modèle prédictif
capturera les corrélations généralisables beaucoup trop
bien.
A l'inverse,
l'underfitting désigne une situation où le
modèle n'est pas du tout assez complexe pour capturer le
phénomène dans son intégralité. Cela sous-entend
que le modèle prédictif généré lors de la
phase d'apprentissage, s'adapte mal aux données
d'entraînement. Autrement dit, le modèle prédictif
n'arrive même pas à capturer les corrélations du jeu
d'entraînement. Par conséquent,
le coût d'erreur en phase d'apprentissage reste
grand. Bien évidemment, le
modèle prédictif ne se généralise pas bien non
plus sur les données qu'il n'a pas encore vues. Finalement, le
modèle ne sera pas viable car les erreurs de prédictions seront
grandes.
Lorsqu'on veut généraliser un modèle,
nous avons besoin qu'il n'overfit pas et qu'il
n'underfit pas, qu'il soit pile entre les deux [37].
Les attributs utilisés dans le jeu de donnée
pour entraîner le modèle sont :
Tableau
4 : Attributs utilisés dans notre jeu de donnée
|
Attributs
|
Type
|
Utilité
|
|
Ts
|
Time
|
Horodatage de la mesure
|
|
Uid
|
String
|
Un identifiant unique de la session
|
|
id.orig_h
|
Adresse
|
Adresse IP du point de terminaison d'origine
|
|
id.orig_p
|
Port
|
Port TCP / UDP du point final d'origine
|
|
id.resp_h
|
Adresse
|
Adresse IP du point de terminaison répondant
|
|
id.resp_p
|
Port
|
Port TCP / UDP du point final en réponse
|
|
Proto
|
Transport-proto
|
Protocole de connexion de la couche de transport
|
|
Service
|
String
|
Protocole d'application détecté dynamiquement,
le cas échéant
|
|
orig_bytes
|
Count
|
Octets de charge utile de l'expéditeur; à partir
des numéros de séquence si TCP
|
|
resp_bytes
|
Count
|
Octets de charge utile du répondeur; à partir
des numéros de séquence si TCP
|
|
conn_state
|
Count
|
Code indiquant l'état de la session.
|
|
local_orig
|
Booléen
|
Indique si la session est lancée localement.
|
|
local_resp
|
Booléen
|
Indique si la session reçoit une réponse
localement.
|
|
missed_bytes
|
Count/Long
|
Nombre d'octets manquants dans les espaces de contenu
|
|
history
|
String
|
Drapeaux indiquant l'historique de la session.
|
|
orig_ip_bytes
|
Count
|
Nombre d'octets IP ORIG (via le champ d'en-tête IP
total_length)
|
|
resp_pkts
|
Count
|
Nombre de paquets RESP
|
|
resp_ip_bytes
|
Count
|
Nombre d'octets IP RESP (via le champ d'en-tête IP
total_length
|
|
label
|
String
|
L'étiquette
|
|
Duration
|
Interval
|
Durée de la session représentant le temps entre
le premier message et le dernier, en secondes.
|
|
orig_pkts
|
Count
|
Nombre de paquets ORIG
|
L'état des connexions peuvent prendre les valeurs
suivantes :
Tableau
5 : Valeurs possibles du champ conn_state
|
Etat
|
Description
|
|
S0
|
Tentative de connexion vue, pas de réponse
|
|
S1
|
Connexion établie, non terminé (0 octets )
|
|
SF
|
Établissement et terminaison normaux (> 0 octets)
|
|
REJ
|
Tentative de connexion rejetée
|
|
S2
|
Établi, ORIG tente de fermer, pas de réponse du
RESP.
|
|
S3
|
Établi, les tentatives de RESP se ferment, aucune
réponse d'ORIG
|
|
RSTO
|
Établi, ORIG abandonné (RST)
|
|
RSTR
|
Établi, RESP abandonné (RST)
|
|
RSTOS0
|
ORIG a envoyé SYN puis RST; pas de RESP SYN-ACK
|
|
RSTRH
|
RESP a envoyé SYN-ACK puis RST; pas de SYN ORIG
|
|
SH
|
ORIG a envoyé SYN puis FIN; pas de RESP SYN-ACK
(«semi-ouvert»)
|
|
SHR
|
RESP a envoyé SYN-ACK puis FIN; pas de SYN ORIG
|
|
OTH
|
Pas de SYN, pas fermé. Trafic médian. Connexion
partielle.
|
Et l'historique d'une session peut aussi avoir
différentes valeurs :
Tableau 6 : Valeurs possibles
du champ history
|
Lettre
|
Description
|
|
S
|
un SYN sans le bit ACK défini
|
|
H
|
un SYN-ACK («handshake»)
|
|
A
|
un ACK pur
|
|
D
|
paquet avec charge utile («data»)
|
|
F
|
paquet avec jeu de bits FIN
|
|
R
|
paquet avec jeu de bits RST
|
|
C
|
paquet avec une mauvaise somme de contrôle (checksum)
|
|
I
|
Paquet incohérent (SYN et RST)
|
Les 05 classes que nous avons obtenues après un
nettoyage manuel du jeu de donnée sont :
? Malicious Attack
? Malicious C&C
? Malicious DDoS
? Malicious PartOfAHorizontalPortScan
? Begnin
Les étapes que nous avons suivies pour obtenir un jeu
de donnée lisible sont :
- Modification des classes : Les classes
listées ci-dessus sont les étiquettes correspondantes à
chaque paquet dans le jeu de données. Cependant il nous a fallu les
nettoyer elles aussi car la différence entre certaines classes
n'étaient pas « pertinentes » pour notre projet.
D'abord nous avions 3 labels tunnel_parents, label et detailed-label qui
formaient une seule colonne. Le detailed-label concernait les détails du
label comme DDoS ou C&C par exemple. Et le tunnel_parents était soit
vide soit manquant raison pour laquelle nous ne l'avons pas trouvé
utile et donc supprimer. Les trois labels sont devenus une seule nommée
label qui mélangeait les détails du label et sa nature
(bénigne ou malicieuse). Ensuite nous avions 03 classes bénignes
différentes. Puisque l'important est de différencier la nature du
trafic, la différence entre les différentes classes comme
« Begnin, begnin, - Begnin - » ou encore
« Malicious PartOfAHorizontalPortScan, - Malicious
PartOfAHorizontalPortScan» par exemple, ne sont pas importantes
sachant que ce sont juste des espaces vides ou non mis. La dizaine de classes
qu'on avait au début s'est transformée en 05 classes.
- Remplacer les valeurs manquantes :
Nous les avons remplacées soit par None pour les
attributs catégoriques ou alors par -1 pour les
attributs numériques qui ont beaucoup trop de lignes vides. Lorsqu'il
y'a beaucoup de valeurs vides dans une colonne, il est souvent courant de le
supprimer ou de remplacer les valeurs vides par les valeurs proches, les plus
fréquentes ou encore par la moyenne. Nous, nous sommes allés
selon la logique qu'une valeur d'un champ d'un paquet IP est
significative. Par exemple, nous pouvons prendre la moyenne dans la
colonne ``protocole''. Sauf qu'on pourrait obtenir un chiffre comme 80 ou 99
qui correspondent à des protocoles bien définis. Donc pour
éviter de se retrouver avec 50 ou 100 lignes consécutives avec un
même protocole et induire l'algorithme en erreur dans ses
prédictions, nous avons préféré adopter la
stratégie d'une valeur par défaut -1 pour justement montrer qu'il
n'y a pas de valeur mais qu'il reste lisible par une machine.
- Encoder les valeurs
catégoriques : les valeurs catégoriques ne sont pas
compréhensibles par un algorithme d'apprentissage profond. Il faut donc
les transformer en valeurs numériques. Nous avons utilisé le
LabelEncoder(). C'est une étape à faire
après avoir rempli les espaces vides.
- Transformer les classes : Nous avions
une seule colonne Label qui représente les différentes classes
que l'on peut avoir. Mais nous voulons que chacune de ces classes devienne une
colonne. Nous utilisons l'encodage
« Dummy », pour que le nombre de
catégories soit égal au nombre de colonnes. Les variables
« Dummy » prenant la valeur 0 ou 1 pour
indiquer l'absence ou la présence d'une catégorie.
- Extraire les variables : Nous avons
d'une part les valeurs indépendantes qui sont les attributs et d'autres
part les valeurs dépendantes qui sont les classes de sorties à
prédire.
- Séparer le jeu de
données : Nous avons séparé le jeu de
données en jeu de d'entraînement, jeu de validation et jeu de
test. Le jeu d'entraînement est utilisé pour entraîner le
modèle tandis que le jeu de test sert à tester celui-ci et
prédire les classes. Dans notre cas, le jeu d'entraînement
représente 60%, le jeu de validation 20% et le jeu de test 20% du jeu
de données initial.
- Feature scaling : C'est la fin du
prétraitement. Il permet de standardiser (dans notre cas avec
StandardScaler()) ou normaliser les variables
indépendantes du jeu de données dans une plage de valeur
spécifique. Cette pratique est utile car dans notre jeu de
données, nous nous retrouvons avec des données qui ont de grandes
différences de valeurs. Une colonne où nous avons des valeurs
autour de 10000 et une autre colonne où nous avons des valeurs autour de
52 par exemple. La première colonne dominera sur la seconde et donnera
des résultats incorrects. Raison pour laquelle la standardisation est
importante pour l'algorithme.
Pour le second modèle suggéré, même
si la même logique n'a pas été forcément
appliquée, il s'agit généralement des mêmes
étapes pour pouvoir obtenir à la fin un jeu de données
lisible. Les 23 attributs nécessaires qu'on peut voir à la figure
25 doivent aussi être transformés en valeur numérique.
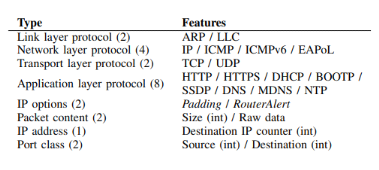
Figure 24 : description des 23
attributs utilisés pour former le modèle [16]
Contrairement au premier modèle où les
caractères ont été transformés en valeurs
numériques, ici la plupart des valeurs étaient binaires. Donc
dans le premier modèle nous avions une colonne
« history » ou « adresse » par exemple
avec différents valeurs possibles et ceux-ci étaient
transformés en valeurs numériques.
A l'inverse pour ce modèle, pas de transformation de
données catégorique en valeurs numériques. Les champs
prenaient pour la plupart des valeurs binaires en fonction de l'absence ou de
la présence de ce protocole. Des protocoles qui prenaient la valeur 1
lorsqu'ils étaient utilisés et 0 sinon. 16 des protocoles choisis
sont généralement utilisés durant la phase d'association
des appareils dans le wifi (entre l'objet et le point d'accès). Deux
attributs binaires représentent l'utilisation des entêtes IP
padding et router alert. La première adresse IP trouvée
démarre un compteur qui commence à 1 et celui-ci
s'incrémente au fur et à mesure que de nouvelles adresses sont
trouvées.
Les deux derniers attributs représentent les ports
sources et destinations utilisés :
? Si aucun port n'est utilisé, nous mettons 0
? Si un port connu dans la plage [0, 1023] est utilisé,
nous mettons 1
? Si c'est un port enregistré dans la plage [1024,
49151], nous mettons 2
? Si c'est un port dynamique, nous mettons 3
Les empreintes prennent en compte la dimension temporelle des
communications en les capturant et en les gardant dans leur ordre
séquentiel. Nous gardons les douze premiers paquets et on obtient un
vecteur d'attributs de dimension (12 paquets *23 attributs).
F0 = {f1,1, f2,1, . . . , f23,1, f1,2, f2,2, . . . , f22,et,
f23,i}
Nous avons créé un algorithme en python de
prétraitement des données pour effectuer ces tâches et
obtenir un fichier avec lequel le modèle peut identifier les objets.
| 

