CHAPITRE 2. GÉNÉRALITÉS
«Les transformateurs» est une architecture qui
utilise l'attention pour augmenter la vitesse à laquelle ces
modèles peuvent être formés. Le plus grand avantage,
cependant, vient de la façon dont le transformateur se prête
à la parallélisation. Ils reposent sur une architecture
encoder-decoder (Figure 2.2). Le composant d'en-codage et de décodage
sont des piles du même nombre.
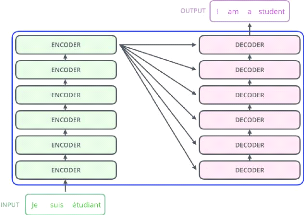
FIGURE 2.2: Architecture de base des transformateurs [Tra,
2018].
-- L'encodeur est composéde 6 couches identiques.
Chaque couche a deux sous-couches. La première est celle de
«Multi-head Self-Attention» [Voita et al., 2019] qui permet au
modèle de s'occuper des informations provenant de différentes
positions. La seconde est un simple réseau «feed-forward»
[Chen et al., 2001] entièrement connectéen fonction de la
position.
-- Le décodeur à son tour, composéde 6
couches identiques, contient également deux sous-couches similaires
à celles de l'encodeur, mais entre elles se trouve une troisième
sous-couche qui réalise une «Multi-head attention» sur
l'output de l'encodeur. Cette couche aide le décodeur à se
concentrer sur les parties pertinentes de la phrase d'entrée.
En phase d'encodage, comme le montre la Figure 2.3 :
1. L'entrée est l'encapsulation des mots pour la
première couche. Pour les couches suivantes, ce sera la sortie de la
couche précédente.
2. À l'intérieur de chaque couche, la Multi-head
self-attention est calculée en utilisant les entrées de la couche
comme vecteurs de clés, requêtes et valeurs; puis le
résultat est envoyéà la couche feed-forward.
21
CHAPITRE 2. GÉNÉRALITÉS
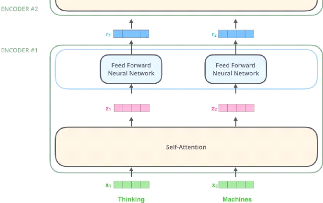
FIGURE 2.3: Architecture de l'encodeur du transformateur [Tra,
2018].
Le principe de «Self Attention» repose sur
l'idée que tous les mots seront comparés les uns aux autres afin
d'avoir le sens exact de l'input (Figure 2.4).

FIGURE 2.4: Principe de self-attention [Sel, 2020].
Et donc, contrairement aux RNN, les transformateurs n'exigent
pas que les données séquentielles soient traitées dans
l'ordre. Grâce à cette caractéristique, le Transformateur
permet une parallélisation beaucoup plus importante que les RNN et donc
des temps de formation réduits.
Les transformateurs sont devenus le modèle de choix
pour résoudre de nombreux problèmes en NLP. Cela a conduit au
développement de systèmes pré-entrainés tels que
BERT (Bidirectional Encoder Representations
CHAPITRE 2. GÉNÉRALITÉS
from Transformers) [Devlin et al., 2018] et GPT (Generative
Pre-trained Transformer) [Radford et al., 2018], qui ont
étéformés avec d'énormes ensembles de
données en langage général et peuvent être
adaptés à des tâches linguistiques spécifiques.
2.2.3 BERT (Bidirectional Encoder Representations from
Transformers)
Les transformateurs est une architecture
d'encodeur-décodeur, c-à-dire ils prennent une entrée et
produisent une sortie. BERT [Devlin et al., 2018] est une architecture qui
n'utilise que la partie d'encodeur des transformateurs pour réaliser de
multiples tâches. Ce processus est nomméle Transfer
Learning [Pan and Yang, 2010] qui est une méthode
d'apprentissage automatique dans laquelle un modèle
développépour une tâche est réutilisécomme
point de départ pour un modèle sur une deuxième
tâche. Cette approche est utilisée en Deep Learning avec les
modèles pre-trained comme BERT. Ils sont conçus pour
réaliser une des tâches spécifiques (de traitement
d'images, traitement de langage naturel...) avec changement de l'input suivant
la tâche à réaliser. Il existe deux modèle de BERT,
Base et Large:
-- BERT Base (Cased et Uncased) : contient 12
couches, hidden size=768 et 12 self-attention heads.
-- BERT Large (Cased et Uncased) : contient 24
couches, hidden size=1024 et 16 self-attention heads. «Uncased»
réalise une mise en minuscules avant la tokenisation (eq. John Smith
devient john smith) et supprime également tout marqueur d'accent.
«Cased» signifie que la casse et les accents sont conservés.
En général, le modèle «Uncased» est
préférable sauf si la casse est importante.
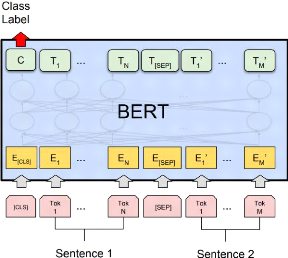
22
FIGURE 2.5: Représentation des entrées et sorties
du modèle BERT [Devlin et al., 2018].
23
| 

