CHAPITRE 3. CONCEPTION ET IMPLÉMENTATION DE
YOUTAQA
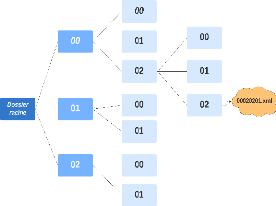
FIGURE 3.3: Arborescence des fichiers XML.
appliquéun formatage du texte en utilisant le script
WikiExtractor3 qui nous a permis de nous débarrasser de la
mise en page appliquée par Wikipédia.
3.4.2 Indexation des articles
Après avoir traitéles articles de
Wikipédia, nous avons indexéces articles en utilisant la
bibliothèque Py-Lucene. Dans cette étape, nous avons
procédéà l'implémentation d'un analyseur
personnalisépour notre index inversé4. Cet analyseur
sert à appliquer les transformations du texte telles que la suppression
des mots vides, la tokenisation, la normalisation et le stemming5
des mots de chaque article.
Pour but de faciliter la tâche de notre future module
d'extraction des réponses, et afin de booster les performances de notre
système en terme de temps d'exécution, au lieu de
considérer les articles en eux-mêmes comme des documents, nous
avons eu l'idée de considérer les sections des articles comme
documents afin de peaufiner la recherche suite à une requête
donnée. Pour éclaircir tout cela, nous avons illustrédans
la Figure 3.4 l'exemple d'une page Wikipédia et comment l'index va
considérer cet article en divisant le même article en trois
documents.
3. WikiExtractor : Un script Python qui permet
de convertir la mise en page appliquépar wikipédia en un text
pure
sans syntaxe.
4. Index inversé: C'est une structure de
données qui stocke la correspondance entre le contenu, tel que des mots
ou
des chiffres, et ses emplacements dans un document ou un
ensemble de documents.
5.
https://en.wikipedia.org/wiki/Stemming
CHAPITRE 3. CONCEPTION ET IMPLÉMENTATION DE
YOUTAQA
FIGURE 3.4: Schéma représentatif des sections
d'un article Wikipédia
30
Notre index est constituéde 5 champs essentiels:
-- L'identifiant de l'article qui est unique à chaque
article (Champs de type LongPoint).
-- Le titre de l'article (Champs de type StringField).
-- L'identifiant de la section (Champs de type LongPoint).
-- Le titre de la section (Champs de type StringField).
-- Le contenu de la section, c'est le contenu principal de chaque
document (Champs de type TextField).
3.4.3 Méthodes de recherche
adoptées
Pour le processus de recherche, nous avons optépour deux
méthodes de recherche différentes applicables sur notre index.
1. Méthode de recherche SimpleFieldSearch
: La première méthode de recherche, qui est la plus
basique, sera en fait une méthode de recherche qui, après avoir
extrait les mots clés d'une requête, permet de rechercher les mots
clés dans le contenu des documents seulement.
31
CHAPITRE 3. CONCEPTION ET IMPLÉMENTATION DE
YOUTAQA
2. Méthode de recherche MultifieldsSearch
: Cette méthode consiste à faire une recherche sur
à la fois le contenu et le titre.
3.5 Module de classification MC
Comme décrit dans la Section 2.2.3, BERT est un
modèle pré-entraînébasésur le »Transfer
Learning» capable de réaliser plusieurs tâches NLP. Parmi ces
tâches, nous retrouvons la classification de texte. Pour notre cas, nous
avons utiliséBERT Base Uncased dans le but de
réduire le temps d'exécution durant les
expérimentations.

FIGURE 3.5: La phase de tokenisation des entrées.
Pour ajouter une tâche de classification de texte
à BERT, nous intégrons à la fois la question et le passage
dans la saisie. Comme première étape, nous commençons par
la tokenisation de notre jeu de données afin de le coder suivant le
même format. La fonction de tokenisation parcourt les données et
concatène chaque paire de Question-Passage comme
illustrédans la Figure 3.5.
Chaque séquence (paire) commence par le token de
classification spécial [CLS] en plus d'un autre token spécial
[SEP] qui sépare les deux parties de l'entrée et permet ainsi
à BERT de différencier la question et le passage. Afin que tous
les tokens soient de la même taille, nous avons défini une taille
maximale aux séquences d'entrée égale à 300,
complétée avec un remplissage (padding) avec le mot
clé[PAD] dans le cas oùla taille du passage
concaténéà la question est inférieure à la
taille de l'entrée fixée. BERT utilise «Segment
Embeddings» afin de différencier la question du passage. Dans la
Figure 3.5, A et B représentent les «Segment Embeddings»
ajoutés aux tokens codés avant de les passer comme
paramètres d'entrée.
32
| 

