
BURKINA FASO
Unité Progrès Justice
MINISTERE DE
L'ECONOMIE ET DU
REPUBLIQUE DE COTE D'IVOIRE
Union Discipline Travail
MINISTERE DE
L'ENSEIGNEMENT
SUPERIEUR
DEVELOPPEMENT
ECOLE NATIONALE SUPERIEURE
DE STATISTIQUE ET
D'ECONOMIE
APPLIQUEE (ENSEA)
INSTITUT NATIONAL DE LA
STATISTIQUE ET DE LA
DEMOGRAPHIE
(INSD)
MEMOIRE DE FIN DE CYCLE
Maître de stage :
PARE
Lassina
Ingénieur statisticien
économiste
Service des Comptes Economiques
et des Analyses
Macroéconomiques
(SCEAM)
Présenté et soutenu par:
DOUCOURE
Lassana
Elève ingénieur
des travaux
statistiques
Septembre 2005.

DEDICACE ET REMERCIEMENTS
"Rendons la grâce à Allah le Tout Puissant,
le Clément le Très Miséricordieux qui a guidé nos
pas depuis l'aube de notre vie, loué soit Allah. Et que la paix, la
miséricorde et la bénédiction d'Allah soient sur Muhammad,
celui qui nous a apporté la vérité de la part de son
Seigneur ainsi que sur sa famille et ses compagnons".
Je dédie cette modeste oeuvre à la
mémoire de mon oncle feu Sékou DOUCOURE (dit Sékou
Bléh). Je la dédie également à ma petite soeur,
Fatoumata (Maman) dont le décès est survenu au cours de ce stage.
Qu'Allah aie pitié d'eux.
Qu'il me soit permis de dire ceci à mes parents qui
n'ont ménagé aucun effort pour m'aider dans mes études.
"N'bâ N'mânou ka nari ar na atouga ".
Je pense en ce moment précis à tous ceux qui
m'ont apporté leur aide principalement dans ce travail et pendant tout
mon parcours scolaire. Je tiens à remercier particulièrement mes
frères Sidiki et Mahamet. Je remercie la LIEEMA au Mali et tous ses
membres.
Tout au long de la présente étude j'ai
bénéficié de l'aide, du soutien et des conseils de mon
enseignant d'économétrie CHITOU Bassirou, et de mon maître
de stage PARE Lassina. Qu'ils trouvent l'expression de ma reconnaissance et mes
remerciements les plus sincères. Je tiens à remercier le
Directeur de l'ENSEA M. KOFFI N'guessan et le Directeur des études de
division ITS M. KOUAKOU N'Gorang Jean Arnaud, ainsi que le corps enseignant et
le personnel de l'Ecole. Je remercie aussi le Directeur Général
de l'INSD, M. Bamory OUATTARA, le Directeur des études
économiques M. YAGO Namaro, le chef de service des comptes
économiques et des analyses macroéconomiques M. KABORE Barbi sans
oublier le personnel de l'INSD. Qu'il me soit aussi permis de remercier M.
Malik LANKOANDE et M. Adama TIENDREBEOGO du service de démographie de
l'INSD.
Au cours de notre séjour à Abidjan et au Burkina
Faso, de bonnes volontés nous ont rendu la vie facile. Pour cela je
remercie MM. Boussiré et Kandé DOUCOURE ainsi que leur famille
à Abidjan, la famille YAGO, M. Ahmed GUENDA et sa famille ainsi que Mme
Fatoumata NOMBRE et sa famille à Ouagadougou. Qu'il me soit enfin permis
de conclure par cette citation populaire :
"Etre doué n'est pas ce qui est le plus important,
mais faire mieux avec ce qu'on a".

SIGLES ET ABREVIATIONS ABB : Approximate
Bayesian Boostrap.
CI : Consommation Intermédiaire.
DGI : Direction Générale des
Impôts.
DSF : Déclaration Statistique et
Fiscale.
Entreprise non DSF : entreprise n'ayant pas
déposé sa DSF ou ne produisant pas de DSF.
ERE : Equilibre Ressources Emplois.
INS : Institut National de Statistique.
INSD : Institut National de la Statistique et de
la Démographie du Burkina Faso. KDG : La ville de
Koudougou.
MAR : Missing At Random.
MCAR: Missing Completely At Random.
NMAR: Non Missing At Random.
Ouaga : La ville de Ouagadougou.
PIB : Produit Intérieur Brut.
SCN : Système de Comptabilité
Nationale. SYSCOA : Système Comptable Ouest Africain.
TOFE : Tableau des Opérations Financières de
l'Etat.

SOMMAIRE
Dédicace et remerciement 2
Sigles et abréviations. 3
Sommaire 4
Liste des tableaux 5
Liste des graphique 5
Avant-propos 6
Présentation de la structure 7
Introduction 9
Chapitre 0. Concepts et définitions 10
I. Comptabilité nationale 10
II. Secteur moderne DSF et secteur moderne non DSF
11
III. Les sources de données 12
Chapitre 1. Généralités et
problématique de l'étude 14
I. Contexte et problématique de l'étude.
14
II. Cadre théorique 14
Chapitre 2. Méthodologie d'Estimation des
déclarations manquantes. 24
I. Méthode utilisée par INSD 25
II. Critique de la méthode présentée
26
III. Proposition de méthode. 27
Chapitre 3. : estimation des dsf des entreprises du secteur
moderne. 39
I. Estimation de la production et de la CI 39
II. Estimation de la rémunération des
salariés et de l'impôt sur production 40
Recommandations 42
Conclusion 43
Annexes 44
Références bibliographiques 55
Table des matières 56

LISTE DES TABLEAUX
Tableau 1: Etat de taux de réponse globale 28
Tableau 2: Répartition de non-réponses par
localité 29
Tableau 3: Taux de non-réponse selon la structure des
entreprises 30
Tableau 4: Résultat de l'estimation de
probabilités de réponses. 33
Tableau 5: Les observations ayant de distance
élevée 35
Tableau 6: Odds ratio des variable explicatives 37
Tableau 7: Caractéristique de groupe de réponse
homogène pour la repondération 38
Tableau 8: Etat de non-réponses selon le statut des
entreprises 45
Tableau 9: Répartition des entreprises selon leur
vocation 46
Tableau 10: Table de prédiction du modèle
47
Tableau 11: Test de Hosmer-Lemeshow de bon calibrage du
modèle 48
Tableau 12: Quintiles de probabilité de réponse
49
Tableau 13: Résultat de l'estimation de
probabilité de réponse de l'année 2000. 50
Tableau 14: Table de prédiction du modèle pour
la base de 2000. 50
Tableau 15: Test de Hosmer-Lemeshow de bon calibrage du
modèle pour l'année 2000. 51
Tableau 16: Caractéristique de groupes
(probabilité estimée) de réponse de 2000. 51
Tableau 17: Odds Ratio des variables explicatives de
l'année 2000. 51
Tableau 18: Résultat de l'estimation de
probabilité de réponse de l'année 1999 52
Tableau 19; Table de prédiction du modèle de la
base 1999 52
Tableau 20: Test de Hosmer-Lemeshow de bon calibrage du
modèle pour l'année 1999. 53
Tableau 21: Caractéristique de groupes
(probabilité estimée) de réponse de 1999. 53
Tableau 22: Odds Ratio des variables explicative de
l'année 1999. 53
LISTE DES GRAPHIQUE
Graphique 1: Résidu standard par entreprise 34
Graphique 2: Répartition de l'échantillon selon
la résidence des entreprises 45

AVANT-PROPOS
L'Ecole Nationale Supérieure de Statistique et
d'Economie Appliquée, L'ENSEA est une école nationale à
vocation sous régionale. A cet effet, elle a pour mission la formation
des cadres statisticiens pour les pays d'Afrique francophone. Ces cadres issus
de toute l'Afrique francophone sont formés dans plusieurs domaines de la
statistique et de l'économie.
Pour mener à bien sa mission, l'ENSEA a réparti
la formation entre cinq divisions : deux de techniciens, deux
d'ingénieurs et une division de diplôme d'étude
supérieure spécialisée. La division des ingénieurs
des travaux statistiques est une de ces cinq divisions. La formation y est
dispensée à travers les cours théoriques couplés de
ceux pratiques. Après deux années de formations
théoriques, les élèves doivent effectuer un stage qui
donne lieu à une rédaction d'un document qui sera soutenu devant
un jury. Le stage constitue une partie du volet pratique de la formation. Il a
pour objectif d'une part de familiariser les élèves avec le monde
professionnel et d'autre part de leur donner l'occasion de confronter les
théories acquises à l'école aux réalités
pratiques de terrain. Ce présent stage d'environ trois mois s'inscrit
dans ce cadre.
Par rapport aux objectifs cités dans le paragraphe
précédent, nous avons été reçus à la
direction de l'Institut National de la Statistique et de la Démographie
(INSD) du Burkina Faso, dans sa direction des études économiques
et plus précisément au service de comptabilité nationale.
Il nous a été demandé de proposer une méthode
de traitement des entreprises du secteur moderne non DSF (Déclarations
Statistiques Fiscales) pour la comptabilité nationale du Burkina
Faso.
Le présent document est la résultante d'un stage
qui s'est déroulé du 13 juin au 9 septembre 2005 à l'INSD
du Burkina Faso.

PRESENTATION DE LA STRUCTURE
Officiellement Burkina Faso, le Burkina est un pays
situé en Afrique de l'Ouest. Il est enclavé et limité au
nord et à l'ouest par le Mali, à l'est par le Niger et au sud par
le Bénin, le Togo, le Ghana et la Côte d'Ivoire. Le Faso comme on
le désigne par fois couvre une superficie de 275 000 km2 avec
une population estimée en 2003 à plus de treize millions
d'habitants. La population croît à un taux de 2,6% par an selon la
même estimation de 2003. Le Burkina a pour capitale, l'ancien centre du
royaume mossi, la ville de Ouagadougou. Sur le plan économique, le PIB
par habitant est estimé à 220 dollars américains par an en
2001. Ce pays nous a servi d'accueil pour le déroulement de notre stage
de fin de formation. Ce stage s'est déroulé à l'Institut
National de la Statistique et de la Démographie.
Comme tous les INS (Institut National de la Statistique) des
pays africains, l'INSD est chargé de produire
régulièrement des statistiques sur les caractéristiques
socioéconomiques, sur la situation démographique et sur bien
d'autres domaines. D'une façon générale les attributions
de la direction générale de l'INSD peuvent être
résumées en un certain nombre de points. Ces points sont:
y' La réalisation d'enquêtes, de recensement et
d'études dans le domaine social, économique et
démographique, et réalisation des études statistiques au
compte des autres utilisateurs;
y' La collecte, la centralisation, le traitement, l'analyse et
l'organisation des statistiques provenant de sources diverses dans des banques
de données;
y' Le développement et promotion du système
national statistique.
Conscient que le regroupement des hommes requiert un minimum
d'organisation, l'INSD s'est subdivisé en directions techniques : une
Direction de la Coordination et de la Coopération statistiques, une
Direction de la Démographie, une Direction des Statistiques
générales et une Direction des Etudes Economiques. C'est dans
cette dernière que nous avons été accueillis en tant que
stagiaire. Elle est structurée en trois services : le Service de la
Prévision et de l'Analyse conjoncturelle, le Service des Statistiques
d'Entreprise et du Commerce et le Service des Comptes Economiques et des
Analyses Macroéconomiques. C'est ce dernier service qui nous a offert un
environnement de travail. Cet environnement nous a permis d'effectuer notre
stage avec les moyens de bord. Ce service est chargé essentiellement de
l'élaboration et de la publication des comptes nationaux du Burkina.
Les études que le SCEAM entreprend, sont axées
sur la publication des résultats des collectes entreprises par
l'institut. Ces publications portent sur les comptes nationaux du pays, la
situation de la pauvreté, la situation économique... Elle
procède aussi à des études de prévision de certaine
caractéristique de la vie économique du Faso (Prévision de
production des entreprises, des loyers fictifs,...).
C'est donc ce service qui est chargé de la collecte et
de suivi des DSF des entreprises opérant sur le territoire
économique du Burkina. A cet effet, il se doit de veiller non seulement
à la bonne marche de la collecte mais aussi à l'utilisation
judicieuse des informations pour une bonne estimation des grandeurs
nécessaires à l'élaboration des comptes nationaux.
La tâche qui incombe à la structure statistique
nationale devenant de plus en plus importante, le besoin d'une
décentralisation des forces d'intervention se fait sentir. C'est dans ce
cadre que dans le futur l'INSD entend se rapprocher davantage de la population
pour mener à bien la mission qui lui incombe. Cette volonté se
manifeste par la mise en place des directions régionales. Ces directions
représenteront l'appareil statistique dans leur région

d'intervention. Pour l'instant il s'agit de Bobo et de Fada.
Cette décentralisation concernera plus tard les autres régions du
Faso.

INTRODUCTION
Dans un contexte de mondialisation où le suivi des
projets, des programmes et des politiques économiques se fait de plus en
plus sentir, l'information statistique et économique a une importance
majeure aussi bien pour les entreprises, la population que pour les
décideurs politiques. Il importe de chercher non seulement à
comprendre l'évolution de ces informations mais aussi à
maîtriser les évolutions de ces dernières par les
méthodes statistiques. La comptabilité nationale occupe une place
de choix dans un tel contexte. Car elle comprend non seulement toutes les
données économiques de la nation, mais aussi elle prend en compte
toutes ces informations économiques dans le but de les
synthétiser dans un cadre cohérent. Ce cadre cohérant
permettrai de mieux rendre compte les performances économique de la
nation. Nul ne doute de l'abondance et de la complexité d'un tel
travail. Aussi il demande d'être exécuté dans un
délai important en dépit des pressions pour avoir les
informations le plutôt possible.
Par ailleurs les difficultés de collecte à
laquelle se heurtent les instituts de statistiques des pays africains ne sont
pas de nature à résoudre le problème. A l'issue des
enquêtes organisées pour la collecte, il n'est pas rare que l'INSD
du Burkina Faso se retrouve avec un nombre important d'entreprises du secteur
moderne qui ne font pas des déclarations statistiques et fiscales. Ces
déclarations servent comme pierre angulaire dans la constitution et
l'élaboration des comptes nationaux. Les publications sur les
agrégats économiques sont donc fortement influencées par
ces Déclarations Statistiques et Fiscales (DSF) "manquantes". Car c'est
à partir des comptabilités des entreprises que l'on
procède à une agrégation des données pour obtenir
les indicateurs de dimension globale (Produit Intérieur Brut, revenu
national, niveau de consommation, ...).
Consciente de l'importance de ces DSF dans l'économie
nationale, la direction de l'INSD du Burkina Faso à travers son service
de comptabilité a accordé un stage à l'Ecole Nationale
Supérieure de Statistique et d'Economie Appliquée. Ce stage avait
pour thème les traitements des entreprises du secteur moderne non
DSF (Déclarations Statistiques Fiscales) pour la comptabilité
nationale du Burkina Faso. Ce thème répond à un
besoin de réduire au minimum la sous estimation des grandeurs
économiques que le service en charge d'élaboration des comptes
économiques met à la disposition des décideurs.
Le présent document comportera quatre chapitres : le
premier a pour but de faire une présentation générale de
concepts et de sources de données de la comptabilité nationale,
le second traitera de problématique et de cadre théorique de
l'étude. Avant de procéder aux estimations des ces statistiques
(Production, Consommation intermédiaire, rémunération des
salariés et les impôts liés à la production), on
présentera la méthodologie d'estimations des déclarations
manquantes que le service utilise et on proposera une autre méthode.

Chapitre 0. CONCEPTS ET DEFINITIONS
I. Comptabilité nationale
Dans cette section il s'agit pour nous de circonscrire notre
thème dans un cadre comptable. Ce document ne se veut pas non plus un
guide pour l'apprentissage de la discipline. Nous ne donnerons que des
définitions et des éclaircissements sur des concepts que nous
estimons importants pour mener à bien notre étude.
1. Définition
La comptabilité nationale peut être
appréhendée comme un outil ou un instrument de mesure qui, au
moyen des techniques statistiques, économiques et comptables informe de
manière très précise et synthétique sur la
situation économique d'un pays. C'est donc un instrument de mesure
privilégié au service de la science économique, en ce sens
qu'elle permet d'introduire la quantification non seulement dans les analyses
mais aussi dans les modèles économiques proposés.
En tant que science, elle enseigne les techniques et les
méthodes permettant de retracer dans un cadre comptable toutes les
opérations qu'effectuent les agents économiques résidents
pendant une année. L'expression cadre comptable signifie que les comptes
de la nation ne constituent pas une véritable comptabilité qui
serait issue de la consolidation de la comptabilité de tous les agents
économiques.
2. Objet
Dans les années 1930, il est apparu nécessaire
voire indispensable de connaître avec la plus grande certitude possible
les grands agrégats caractérisant l'économie nationale
(PIB, revenu national, niveau de consommation, ...) ainsi que
l'évolution de ces agrégats. Ces agrégats,
élaborés à partir d'un système cohérent,
permettraient de quantifier les interventions du pouvoir public pour un
éventuel coup de main au lancement de l'emploi et de la production. Les
premiers travaux sur les agrégats ont été orientés
vers ce sens.
Cette demande est devenue plus pressante au lendemain de la
seconde guerre mondiale, nécessitant une normalisation des
systèmes d'élaboration et de suivi des comptes. Ce système
qui, plus tard, aboutira à l'adoption d'un système uniforme et
universel de la comptabilité nationale, est aujourd'hui adopté
par presque tout les pays pour l'établissement de leurs comptes
économiques. La version la plus recommandée de ce système
a été élaborée en commun accord de cinq structures,
et est présentée comme le système de comptabilité
nationale des nations unies.
Par ce système, la comptabilité nationale aura
permis une unification de langage économique, du moins en ce qui
concerne les données macroéconomiques, en dépit des
différences qui subsistent dans la théorie économique.
Ainsi, ses définitions sont sans ambiguïté. Elle
élabore des agrégats économiques qui pour la plupart
donnent lieu à l'établissement des modèles d'estimations
et de prévision à court et à moyen terme.
La comptabilité nationale a donc pour objet de
décrire (rendre compte, analyser, ....) l'ensemble des opérations
à caractère économique qui ont lieu sur le territoire
économique d'un pays ou d'un Etat. Pour ce faire, elle procède
à un regroupement des agents économiques en des

unités qui auraient des comportements analogues. Ces
unités, qui sont des centres élémentaires de
décision jouissant d'une certaine autonomie, forment ce que l'on peut
appeler les secteurs institutionnels. On distingue ainsi selon le
SCN19931, cinq secteurs institutionnels (les sociétés
non financières, les sociétés financières, les
administrations publiques, les institutions sans buts lucratifs et les
ménages) et mutuellement exclusifs. A ces secteurs on adjoint le reste
du monde qui n'est pas un secteur à part entière, il permet
toutefois de retracer les relations économiques que le pays entretient
avec l'extérieur, c'est-à-dire les relations qu'entretiennent les
unités résidentes2 avec celles non-résidentes
de l'économie.
Cette nomenclature de secteur institutionnel est propre
à la comptabilité nationale et s'écarte de celle
utilisée par d'autres spécialistes, comme les sociologues. Ainsi
un individu peut à la fois appartenir aux sociétés et
quasi-sociétés (secteur des sociétés non
financières) pour son activité de production, (entant qu'ouvrier
par exemple) et aux ménages pour son activité de consommation.
Les opérations de ces secteurs sont enregistrées en des
différents postes que l'on appelle les comptes.
3. Les comptes
La comptabilité nationale enregistre chaque
opération effectuée par un secteur institutionnel en plusieurs
postes d'enregistrements. Ces postes constituent ce que l'on appelle les
comptes institutionnels. Pour un agent, les opérations peuvent
être de nature financière ou porter sur les biens et services.
Pour des opérations de biens et services, on les enregistre dans l'un
des cinq comptes intégrés qui sont: comptes de production,
d'exploitation, de revenu, d'utilisation de revenu et de compte de capital.
Pour plus de clarté, on peut éclater le compte d'utilisation de
revenu en trois comptes à savoir les comptes d'affectation de revenu
primaire, les comptes de distribution secondaire de revenu et le compte
d'utilisation du revenu disponible. Les comptes sont liés les uns aux
autres par leur solde. On inscrit à la ressource du second le solde du
premier, celui du second à la ressource du troisième et ainsi de
suite. Le dernier solde est celui de capacité ou de besoin de
financement pour l'unité concernée. Il renseigne sur la situation
de trésorerie de l'agent économique concerné.
Les comptes financiers renseignent sur la manière dont
les agents en besoin de financement ont financé leur besoin et dont ceux
en capacité de financement ont utilisé leurs ressources
disponibles. Ils portent sur les opérations relatives à la
création et à la circulation des moyens de paiement et de
financement dont a besoin l'économie pour son fonctionnement.
II. Secteur moderne DSF et secteur moderne non
DSF
Les DSF (Déclaration Statistique et Fiscale) sont des
documents officiels que déposent les entreprises du secteur moderne
à la Direction Générale des Impôts (DGI) à la
fin de chaque exercice comptable. Ces documents contiennent la
quasi-totalité de comptabilité des entreprises
dépositaires. En ce sens, elles permettent d'évaluer leurs
productions, leurs Consommations Intermédiaires (CI)... Les entreprises
concernées par le dépôt de DSF sont celles du secteur
moderne. Car ces sont elles qui sont supposées détenir de
comptabilité qu'elles produisent annuellement. Le constat de la
réalité a permis au service de la comptabilité nationale
de scinder ce secteur en deux sous-secteurs. Ces sous-secteurs sont
élaborés à la fois en fonction de leurs chiffres
d'affaires et de leurs statuts. Le statut évoqué n'est autre que
l'appartenance ou non d'une
1 Système de comptabilité nationale des Nations
Unies version révisée en 1993.
2 La résidence n'est pas définie selon la
nationalité, est résident d'une économie toute personne
physique ou morale qui effectue une activité à caractère
économique sur un territoire ou a l'intention d'y effectuer cette
activité pour une durée au moins une année. La
résidence retenue est donc un concept lié au centre
d'intérêt économique

entreprise au secteur dit moderne. Cette classification
donnera les deux sous secteurs à savoir "secteur moderne DSF"
et "secteur moderne non DSF".
Le secteur marchand moderne DSF regroupe toutes les grosses
entreprises1 du secteur moderne qui produisent un document comptable
de façon périodique. Le secteur marchand moderne non DSF
regroupe, quant à lui, les entreprises du secteur moderne non retenues
dans le classement cité supra. Ce sont des entreprises dont les DSF sont
inexploitables ou pour lesquelles l'on ne dispose pas du tout de DSF. Les
comptes de ce secteur doivent donc être estimés.
III. Les sources de données
Comme toute science quantitative, la comptabilité
nationale utilise des sources statistiques pour l'élaboration des
comptes et pour l'analyse et la projection de ceux-ci. Ces sources statistiques
proviennent en partie des enquêtes qu'organisent les services en charge
de la collecte d'information. On peut aussi faire recours aux sources
administratives disponibles pour l'élaboration des comptes. Parmi ces
sources, on a les liasses fiscales des entreprises et les déclarations
statistiques et fiscales déposées par celles-ci.
L'utilisation d'une ou d'autres sources est fonction des
comptes que nous devons élaborer. Ainsi pour les comptes nationaux du
Burkina, on peut avoir recours à plusieurs sources. Pour les comptes du
secteur primaire (agriculture et élevage), les ministères de
l'agriculture et de l'élevage constituent les partenaires clés
pour les statistiques agricoles. Le Tableau des Opérations
Financières de l'Etat (TOFE), les documents comptables des organismes de
sécurité sociale et des autres organismes de l'Etat, les comptes
de gestion des collectivités locales (communes et provinces) et la
balance du trésor sont des sources importantes pour l'élaboration
des comptes de l'administration publique. En ce qui concerne le reste du monde,
la balance des paiements et les statistiques du commerce extérieur
constituent la source de première place.
Pour l'élaboration des comptes des
sociétés financières et non financières, on
utilisera comme sources de données de première importance les
documents comptables des institutions de crédit et des
sociétés d'assurance, le recensement à caractère
industriel et commercial et les déclarations statistiques et
fiscales.
Au Burkina, les entreprises sont tenues de faire une
déclaration auprès de services des impôts. Ces
déclarations concernent toutes les entreprises du secteur moderne. A
partir des statistiques disponibles couplées avec celles
collectées par le service de comptabilité nationale, on disposera
d'une base d'informations. Cette base constitue la boussole du service dans
l'élaboration des comptes nationaux. Le document qui contient ces
déclarations est appelé la DSF (Déclaration Statistique et
Fiscale) des entreprises. Mais en pratique, il n'est pas fréquent de
coupler les informations reçues par la direction générale
des impôts (liasses fiscales) avec les données de l'INSD.
Compte tenu de l'importance que peuvent avoir ces DSF et de
nombre pléthorique des entreprises du secteur moderne, il a
été prévu que chaque entreprise de ce secteur
prévoira un exemplaire de ses déclarations fiscales annuelles -
qu'elle dépose à la DGI - pour le besoin de statistiques. Mais
dans les faits, ce principe est loin d'être respecté. Car la DGI
ne met pas toujours des DSF à la disposition des comptables nationaux et
il existe des entreprises qui n'en produisent point, obligeant l'INSD à
entreprendre des travaux de collecte pour se procurer de maximum de
données sur l'existence et l'activité de ces unités
institutionnelles. En sus, la démographie instable des entreprises fait
que l'on ne peut pas se passer de collecter des informations chaque
année sur à la fois leur existence que sur leur niveau
d'activité entre autres la production, le salaire versé aux
employés, la consommation nécessaire pour le fonctionnement
1 Raisonnement en terme de chiffre d'affaires.

de processus de production et les impôts sur la
production. De plus, ces données sont très variables d'une
année à une autre, même pour les entreprises stables sur le
territoire économique, faisant de la collecte un des moyens le plus
sûr pour avoir les informations sur les unités opérant des
activités économiques sur le territoire nationale.

Chapitre 1. GENERALITES ET PROBLEMATIQUE DE
L'ETUDE
Toute étude scientifique doit se baser sur les
théories tout en ne perdant pas de vue l'aspect pratique. Ce chapitre
aborde le cadre théorique de notre étude après avoir
situé le contexte et la problématique du stage.
I. Contexte et problématique de
l'étude
La présente étude, portant sur le traitement
des entreprises du secteur moderne non DSF en vue de l'élaboration des
comptes des sociétés non financières, intervient dans le
cadre du stage de fin de cycle d'ingénieur des travaux statistiques.
Elle répond d'une part à une demande du service de
comptabilité nationale de l'INSD du Burkina Faso, et d'autre part au
besoin de mise en pratique des théories acquises au cours de la
formation.
Au sein du Service de la comptabilité nationale, nous
avions pour tâche de proposer une méthodologie pour le traitement
des entreprises du secteur moderne "non DSF" en vue de compléter
l'information disponible fournie par les entreprises du moderne DSF.
Pour l'élaboration des comptes nationaux, el service
en charge de la Comptabilité nationale doit collecter des informations
assez précises et exhaustives en vue de produire les agrégats et
les indicateurs macroéconomiques avec la plus grande certitude possible.
Pour ce faire, on cherche à détenir le maximum d'informations sur
toutes les unités institutionnelles qui prennent part à
l'activité économique nationale. Les sociétés et
quasi sociétés non financières constituent une source
importante de données dans la production de ces agrégats. Il est
donc nécessaire de rassembler le maximum d'information chiffrée
sur ces unités. Le support qui permet de disposer de cette information
est la DSF qui est un document comptable dont les entreprises ont obligation de
déposer des copies à la Direction Générale des
Impôts (DGI). L'INSD devrait pouvoir entrer en possession de ces
documents auprès de la DGI mais la collaboration avec cette structure
n'est pas toujours aisée. C'est pourquoi des collectes directes sont
organisées par le Service de la Comptabilité nationale en vue de
disposer des DSF, tout au moins pour les grandes entreprises. Pour les
entreprises dont on ne peut pas disposer des DSF (soit que le document est
inaccessible ou soit qu'il n'existe pas du tout), des estimations sont faites
pour approcher leurs agrégats (production, consommations
intermédiaires, rémunérations des salariés et
impôts sur la production).
La prise en compte des DSF manquantes permet de
remédier au problème de sous estimations des grandeurs dans
l'élaboration des comptes nationaux. Le traitement des DSF manquantes
consiste à estimer les comptes de production et d'exploitation des
entreprises pour lesquelles on n'a pas pu disposer de documents pour une
année donnée.
L'objectif premier de notre étude est donc de proposer
une méthodologie adaptée d'estimation, en vue de réduire
le biais introduit par la non disponibilité des DSF pour certaines
entreprises du secteur moderne non financier. Mais avant de proposer notre
méthode d'investigation pour réaliser cet objectif, nous allons
passer succinctement en revue les principales méthodes d'estimation des
données manquantes disponibles dans la littérature.
II. Cadre théorique
Dans cette section, il sera question pour nous de
présenter la littérature sur les différentes
théories concernant le traitement de données manquantes.

Dans l'application des techniques de collecte (sondage),
plusieurs problèmes peuvent se poser, parmi lesquels on compte la
difficulté pour choisir une technique de sondage particulière. A
cette difficulté conceptuelle s'ajoutent plusieurs autres
problèmes d'ordres pratiques entre autres : l'absence de certaines
unités au moment de l'enquête, le refus de répondre, la
perte des questionnaires ou l'illisibilité de certains questionnaires.
Ces problèmes mentionnés entraînent la non-réponse
totale ou partielle dont la non prise en compte est susceptible
d'entraîner un biais dans l'estimation des paramètres.
Peu importe la rigueur que l'on se fixe, il y aura toujours
des non-réponses (comme le soulignaient BRION P. et CLAIRIN Rémy
- 1997)1 et il faut faire avec en trouvant une méthode
robuste pour leur traitement. Ainsi dans toute enquête un certain
degré de non- réponse est inévitable. A cet effet, il
convient alors de connaître les méthodes qui réduisent et
affaiblissent leur effet sur le résultat. Avant de définir les
méthodes appropriées aux traitements de ce
phénomène, il nous paraît nécessaire de faire une
distinction entre les différentes formes de non-réponses. Quand
parle - t - on d'une non-réponse totale ou partielle ? Cette distinction
sera suivie par une description des types de mécanismes susceptibles de
faire apparaître de données manquantes.
On considère une variable Y dont on veut estimer la
moyenne, le total ou toute autre fonction sur une population donnée.
Soit Y = (yj)1=j=k, l'ensemble des
observations de la
variable Y sur un échantillon s de cette population.
On appelle ensemble de réponses associées à
la variable d'intérêt y l'ensemble
suivant :
r = i i ? s y ji .
j { / et observée }
Avec s désignant l'échantillon. On remarque que
les rj ne sont pas forcément identiques pour tout
les individus.
De façon générale, le statisticien
d'enquête distingue deux sortes de non-réponses : la
non-réponse totale et la non-réponse partielle.
1. Non-réponse totale
La non-réponse est dite totale lorsque l'on rencontre
des problèmes qui nous empêchent d'avoir le questionnaire pour
l'analyse, peu importe ce qui aurait occasionné la non
disponibilité du questionnaire. Cette non disponibilité peut
être due au refus de l'unité statistique (l'enquêté)
à prendre part à l'interview, à la perte du questionnaire,
à l'illisibilité du questionnaire rempli,... Ainsi, on parlera de
non-réponse totale pour l'élément i si le vecteur entier
des variables de l'étude est manquant (non observé). Soit
l'ensemble suivant :
k
|
r r r
= ? ?
t 1 2
|
... . Ainsi désigne l'ensemble de réponse
totale.
? =J
r r r
k i t
|
i=1
L'ensemble de non-réponse totale s'obtient par
différence entre l'échantillon et l'ensemble de réponse,
d'où l'équation suivante :
r t = s -rt.
Dans cette équation, rt désigne
l'ensemble de non-réponse totale.
1 BRION P. et CLAIRIN R. (1997) - Manuel de sondages :
Application aux pays en développement, INSEE et CPED, Paris.

2. Non-réponse partielle
On parle de non-réponse partielle lorsque pour une
raison ou pour une autre l'on n'est pas capable d'avoir l'information pour une
ou plusieurs des questions particulières de l'enquête. Il s'agit
donc de l'absence de la valeur observée pour l'unité. C'est
lorsqu'une ou plusieurs variables sont manquantes. L'ensemble des
réponses partielles est donnée par :
k
r r r r r
= n n n =I
...
p 1 2 k i
i=1
Ainsi le rp nous donne les
éléments qui ont répondu à toutes les questions et
r t - rp donne l'ensemble de non-réponse
partielle.
Toutefois, le manque de cette valeur n'implique pas
automatiquement une non- réponse partielle pour l'observation. La
carence d'information peut être due par exemple au fait que l'individu
statistique n'est pas concerné par la question qui lui est posée
(exemple : le niveau d'étude d'un enfant de moins de six ans dans un
pays où l'age officiel d'aller à l'école est de sept ans).
On parlera alors de "sans objet" au lieu de non-réponse.
La non-réponse partielle se présente dans l'un des
cas suivants :
y' L'enquêté ne connaît pas la réponse
à la question qui lui a été posée; y' Il ne
souhaite pas répondre à la question pour une raison
quelconque;
y' La suppression des valeurs aberrantes par l'enquêteur
ou par l'analyste.
On retient donc que dans les deux cas de non-réponses
les données peuvent exister et être hors de portée du
statisticien. Pour des raisons de secret professionnel, par exemple, les firmes
peuvent bloquer l'accès aux données.
3. Les mécanismes de génération
des données manquantes
Par mécanisme de génération, on entend le
phénomène susceptible d'entraîner la non- réponse
des unités statistiques ou encore type de données manquantes.
Dans la théorie statistique, on distingue en général trois
mécanismes, selon Little et Rubin (1987), qui peuvent décrire le
phénomène de données manquantes. Ces mécanismes
sont: réponse manquant entièrement au hasard (MCAR, Missing
Completely At Random), réponse manquant au hasard (MAR, Missing
At Random) et réponse ne manquant pas au hasard (NMAR, Non
Missing At Random).
Avant d'expliciter ces mécanismes nous jugeons
nécessaire de faire une définition des concepts et des notations
que nous utiliserons dans la définition des types de
non-réponse.
Soit X = (x ij ) une matrice de
données d'ordre (n× k) d'éléments
xij où n est le nombre
d'observations de
la population cible U, k le nombre de variables et
xij est la valeur de la
variable j pour
l'observation i, avec i =1,..., n, et j =1,...,
k. Soit A = (aij), une matrice dont
les éléments valent l'unité lorsque la
valeur de la variable de l'observation est absente et zéro
sinon. Dit
autrement et de façon formelle, c'est une matrice indicatrice de
données
manquantes d'éléments aij
telle que aij = 1 si xij manque, et
aij = 0 sinon. La matrice A décrit donc la
structure des données manquantes. Il est utile de traiter A
comme une matrice stochastique. Soient , , et
X X
o no respectivement la partie observée
de données X, la partie
non observée et les paramètres caractérisant
le taux de réponse.

De façon non formelle, on dira qu'un processus de
génération de données manquantes est dû au hasard
(MAR) si la probabilité de réponse dépend de certaines
variables auxiliaires, mais non de la variable d'intérêt.
Autrement dit, si ( / , , )
P A X X
o no est la
distribution conditionnelle de A étant
donné X et ne dépend que de variables qui se retrouvent
dans la base, o
X . On dira ainsi que :
( / , , ) ( / , )
o no = P A X o no
P A X X ? X .
C'est donc un processus pour lequel la probabilité de
répondre à une variable d'intérêt dépend
uniquement des variables auxiliaires.
Pour le processus dont les données manquantes ne sont
pas dues au hasard, on parlera de mécanisme de type NMAR. La
probabilité de réponse dépend de la variable
d'intérêt et éventuellement d'autres variables explicatives
non observées.
Si ( / , , ) ( / , )
o no = P A Y X on dit que la distribution
conditionnelle de A
no
P A X X
sachant X ne dépend pas d'un
phénomène aléatoire mais plutôt de la nature de la
variable d'intérêt. Par exemple pour des raisons de
méfiance dans un pays en conflit la population n'aime pas
répondre à la question concernant la religion et l'ethnie. Tout
comme, l'entrepreneur ne souhaite pas toujours donner des informations sur son
chiffre d'affaires.
Quant au mécanisme de type MCAR, il concerne des
données manquantes qui sont complètement dues au hasard. Pour ce
mécanisme la probabilité de répondre ne dépend ni
de la variable d'intérêt ni des variables explicatives et elle est
identique pour toutes les unités.
Formellement, lorsque l'on considère que P
(A / X,) est la distribution conditionnelle de la
matrice indicatrice A. Lorsqu'on connaît la matrice de
données X, on dira qu'il s'agit de
MCAR siP(A/X,)=P(A/)
? X.
4. Traitement de la non-réponse
Après un aperçu sur les mécanismes de
non-réponse nous aborderons dans cette sous section les méthodes
de traitement que prévoit la théorie statistique en cas de
présence de données manquantes. On note qu'il existe plusieurs
méthodes de traitement de données manquantes. Ces méthodes
s'appliquent selon la nature du processus et parfois compte tenu de nombre
d'observation voire de l'existence de variables auxiliaires.
Parmi les méthodes de traitement de non-réponse,
on dénombre deux qui sont plus faciles à mettre en oeuvre.
Cependant, elles ne sont pas les plus robustes. Il est apparu dans les services
statistiques des Etats en développement de ne rien faire face aux
données manquantes. Cette solution est aussi une méthode, elle
consiste à travailler avec la base sans se soucier des
non-réponses.
La non prise en compte de données manquantes est peu
commode pour un statisticien. D'abord, il se trouve face à une base qui
n'est pas présentable (incomplète); ensuite les moyennes et les
variances sont calculées sur toute la population en assimilant les
données manquantes à zéro. Enfin, ces estimateurs sont
alors influencés par les individus n'ayant pas répondu au risque
de rendre incohérents, les résultats assortis des analyses. En
effet, elle accroît le biais des estimations lorsque les non
répondants se distinguent des répondants dans leurs comportements
par rapport aux variables d'étude.
Une autre solution aussi facile à appliquer est la
suppression des individus pour lesquels il manque au moins une valeur d'une
variable de la base. La méthode de suppression permet d'utiliser un
fichier complet. Plus avantageuse que la première citée, cette
solution donne des

estimateurs de l'échantillon retenu sans biais si la
non-réponse ne dépend d'aucune variable d'intérêt.
Mais ces estimateurs peuvent ne pas refléter la réalité.
Car ils sont alors des fonctions des valeurs obtenues pour les
répondants qui ont fourni des données complètes
uniquement. Ce qui conduit au rejet de cas de non-réponse partielle et
entraîne une perte considérable d'information empêchant
ainsi l'utilisation du poids que le sondage aurait accordé aux
unités statistiques. Et le fait que la taille de l'échantillon se
trouve réduite, elle peut conduire à augmenter la variance des
estimateurs.
4.1. Méthode de repondération
C'est une méthode de redressement de données en
présence de non-réponse. Elle est utilisée, en
général, pour compenser la non-réponse totale. La
repondération vise à ajuster les poids de répondants en
vue de compenser la perte d'information due aux non répondants. En
d'autres termes c'est une méthode consistant essentiellement à
augmenter le poids de sondage de répondants afin de compenser les non
répondants. Cette méthode a cependant des principes et des
critères d'application. Il faut que la non-réponse soit totale,
qu'on ne dispose pas d'informations auxiliaires et que le mécanisme de
réponse soit homogène dans la population
Mise en application
Avant de procéder à l'ajustement de poids des
répondants, on effectue une classification des unités
statistiques en j classes. Ces j classes regroupent tous les individus de
j
l'échantillon, les répondants comme les non
répondants, de telle sorte qu'on ait
U = où s s s
i
i= 1
désigne l'échantillon et les si la
classe i de l'échantillon avec i=1, 2, ..., j. Cependant, on doit
s'assurer pour ces groupes que la variable d'intérêt n'a pas
d'influence sur la décision de répondre ou de ne pas
répondre. La constitution des classes doit être pertinente pour
l'analyse qu'on envisage mener. Par exemple, pour la production des
entreprises, on ne fera pas un regroupement par ordre alphabétique des
sigles ni des noms. On fera plutôt une catégorisation basée
sur le chiffre d'affaires ou sur la taille de celles-ci ou sur tout autre
critère pertinent.
Ayant les classes on pourra ainsi calculer le poids des
unités répondantes après ajustement pour la
non-réponse qui vaut:
Où Pc et wi
désignent respectivement le taux de réponse dans la classe c et
le poids de l'individus i avant l'ajustement.
On peut calculer l'estimateur par repondération en
considérant les c classes, comme
suit :
? ? ?
Y n y n w *
c i ri i i
= ? = ? .
où
i s i s
? ?
c c
Avec yri qui désigne la moyenne des
répondants dans la classe i. On démontre que le
biais de non-réponse est une espérance
conditionnelle de l'échantillon total et qu'il vaut zéro pour le
mécanisme de non-réponse uniforme à l'intérieur des
classes. En effet, le biais s'écrit selon l'expression suivante :
- 1
? ? j
B Y s E Y Y s P w P P y y
( / ) ( / ) ( )( )
= - = ? ? - -
i i
c i k k k i

Où Pi désigne la moyenne
pondérée, par le poids avant l'ajustement, des taux de
réponses de la classe i. Et yi
désigne la moyenne de la variable dans la classe
considérée et vaut :
? w y
k k
c
k s
?
yi
? .
w k
k s
? c
Lorsque l'expression du biais est nulle, on peut se retrouver
avec des classes à l'intérieur desquelles la repondération
serait uniforme c'est-à-dire que la probabilité de
répondre pour un individu serait identique à celle des autres
individus de la classe. Il s'agit de groupes homogènes. En effet, on
dira qu'il s'agit de groupes homogènes si pour tout l'échantillon
et toute classe c on a:
|
??? ??
|
P i r s i s
( / )
? = = Ö ? ?
i s c c
/
P i j r s P i r s P j r s i j s
( & / ) ( / ) ( / )
? = = ? ? ? ? ?
ij s
/
|
L'objectif est donc la construction de groupes d'individus
statistiques qui soient homogènes par rapport à la
probabilité de répondre afin d'éliminer ou tout au moins
de réduire le biais de la non-réponse. De façon pratique
on désire construire des groupes de sorte qu'on puisse décrire
autant que faire se peut le mécanisme de non-réponse.
Les classes des repondérations peuvent être
créées à partir de différentes méthodes dont
celle des "scores". Cette méthode consiste dans un premier temps
à prédire les probabilités de répondre pour toutes
les unités de l'échantillon à l'aide d'un modèle de
régression approprié (logistique, probit, probabilité
linéaire ou autre) tout en prenant le soin de bien choisir les facteurs
explicatifs. La deuxième étape est celle d'ordonnancement des
probabilités estimées en ordre croissant. La troisième
consiste à l'utilisation d'analyse par
?
groupe pour regrouper les unités ayant des
Pi similaires. Les classes étant constituées
la
dernière étape s'agirait tout simplement de
calculer à l'intérieur de chaque classe les poids ajustés
pour la non-réponse; ainsi on aura procédé à la
repondération à l'intérieur de chaque classe.
L'efficacité de cette méthode a été
démontrée en 2001 par D. Haziza et ses collaborateurs dans une
étude menée au Canada. Cette méthode a l'avantage de
rendre efficaces les estimateurs de grandeurs notamment la moyenne et le total.
La repondération par la non-réponse totale peut être le
moyen le plus simple de compenser la carence de certaines données
d'enquête.
Pour tenir compte de la non accessibilité du sondage
à certaines unités, soit parce qu'elles sont inadmissibles dans
une base de sondage ou parce qu'elles sont non répondantes lors de
l'enquête, on emploie des multiples formes d'ajustements (multiples
méthodes de repondération). Considérons toujours notre
population cible dont les unités sont regroupées en j
classes homogènes. L'estimateur du total s'écrira de la
façon suivante, après ajustement
au poids :
?
T w y
= ?
*
ci ci
ci s s
? ?
ad na
Où :
y' i et y c idésignent
respectivement une unité de la classe c et une valeur liée
à cette unité ci.

' sad et sna
désignent respectivement des répondants admissibles à
l'échantillon et l'ensemble des unités connues comme non
admissibles.
La repondération permet, avec l'utilisation judicieuse
des données, de compenser l'effet de la non-réponse totale en
formant des classes de repondération. Elle permet aussi d'avoir les
valeurs estimées des agrégats comme le total et la moyenne.
Cependant, elle devient plus compliquée à mettre en oeuvre dans
les cas des non-réponses partielles. Car il faudra procéder
à des repondérations qui seraient probablement différentes
pour chaque variable concernée. Pour cette raison, on lui
préfère d'autres méthodes plus appropriées comme
celles dites d'imputation.
4.2. Méthode d'imputation
a. Généralité sur
l'imputation
Loin d'être une nouvelle méthode, l'imputation
est une technique assez utilisée dans les traitements des
non-réponses. C'est une technique de redressement des estimateurs en
présence de non-réponse partielle, comme le soulignaient Little
et Schenker (1995). Le recours à l'imputation pour remplacer des
données manquantes à certaines questions est monnaie courante
dans bien des enquêtes. La non-réponse partielle peut introduire
des biais d'estimation ; il faut donc des traitements conséquents. On y
remédie par une méthode dite d'imputation qui consiste à
substituer aux données manquantes des valeurs calculées ou
tirées de la base de données. Ceci facilite l'analyse de micros
données. L'imputation permet d'estimer des agrégats de population
comme les moyennes ou les totaux sans faire d'ajustements aux poids qui
auraient été différents pour chaque variable.
L'imputation est une famille de méthodes de traitement
de non-réponse partielle. Pour sa bonne mise en oeuvre, il est important
de recenser et d'utiliser au maximum toutes les sources de données
disponibles lors de l'imputation. La mise en oeuvre de ses procédures
peut être basée sur les modèles implicites ou explicites.
Il est parfois souhaitable de combiner ses deux méthodes. Les
modèles implicites, par opposition aux modèles explicites qui
sont en général basés sur une théorie statistique,
sont basés sur les procédures permettant de résoudre de
façon pratique les problèmes de structures de données. Ces
sont des modèles qui sont souvent de type non paramétrique. Les
procédures "hot-deck" reposées sur une modélisation
implicite en constituent un exemple.
Les modèles, qu'ils soient implicites ou explicites,
peuvent aussi être regroupés sous la bannière de
modèle informatif ou non informatif. Le modèle est dit informatif
lorsqu'une
valeur Xk d'un non répondant est
systématiquement différente de celle d'un répondant
en
dépit de l'égalité entre les valeurs
X1 ,X2,..., Xk - 1 de la
variable. Par contre, on parlera de
modèle non informatif si on accepte que même si un
répondant et un non répondant ont un comportement commun par
rapport aux valeurs X1 , X2,..., Xk
- 1 leurs valeurs Xk ne peuvent
être égale stochastiquement. Ces modèles
peuvent être utilisés comme un départ pour les
procédures d'imputation.
b. Technique d'imputation Le plus proche
voisin
Parmi les méthodes les plus utilisées, on a
celle dite du "plus proche voisin". C'est une méthode qui consiste
à trouver pour l'individu qui n'a pas répondu un donneur
potentiel qui puisse lui être semblable le plus statistiquement possible.
Il s'agit de donner une valeur artificielle à l'individu n'ayant pas
répondu à la question qui lui aurait été
posée. Cette valeur artificielle proviendra d'une unité dont les
caractéristiques sont plus proches de l'unité ayant

introduit le biais de données manquantes. Pour l'imputer
on peut utiliser le formalisme suivant :
y i * = y k /j?
sr;(i,j)? classex
C'est-à-dire qu'on choisit l'individu donneur de telle
sorte que la distance d(x i ;x
j ) soit la plus petite possible, x étant la
variable auxiliaire. Où *
yi et yj
désignent respectivement la valeur imputée de la variable pour
l'individu i et la valeur observée de la même variable
pour l'individu donneur j. Et sr désigne
l'échantillon des répondants.
Il s'agit donc d'élaborer un critère quelconque,
à partir des caractéristiques qu'on a déterminées,
pour montrer et choisir lequel des individus répondants ressemble le
plus à celui pour lequel on ne détient pas l'information. Le plus
semblable des éléments tient lieu de donneur et est
considéré de ce fait comme le voisin le plus proche.
Imputation par moyenne ou par ratio
On compte aussi parmi les méthodes d'imputation,
l'imputation par moyenne et celle par ratio. Ces deux méthodes sont
basées sur l'affectation d'une valeur aux observations
incomplètes d'une variable. En ce qui concerne l'imputation par la
moyenne, sa mise en oeuvre ne nécessite pas que l'on dispose des
variables auxiliaires qui seraient pertinentes pour l'analyse de la variable
d'intérêt. Car elle consiste à remplacer les données
manquantes de la variable considérée par la moyenne des valeurs
données par les répondants. De façon analytique lorsqu'un
élément ne répond pas à la question qui lui est
posée, c'est à dire ne donne pas de valeur à la variable
d'étude, on applique la formule de la moyenne pour lui imputer une
valeur.
.
* 1
y y
i j
= ?
n ? r j s r
Cette valeur moyenne pour l'ensemble de réponses obtenues
est utilisée pour remplacer chacune de variables manquantes.
La méthode par ratio utilise à la fois la
moyenne de la variable d'intérêt pour les répondant et les
variables auxiliaires. Elle consiste à imputer une même valeur
pour toutes les unités non répondantes. C'est-à-dire pour
une variable donnée toute les observations manquantes auront un
remplaçant commun pour compenser la perte de donnée. Le
formalisme peut se présenter comme suit:

* r
y
y x
=
i i
xr
Où yr , xr et x
i désignent respectivement la moyenne de la variable
d'intérêt, de la variable auxiliaire pertinente pour
l'étude et la valeur de cette variable pour l'individu i
Imputation multiple
Jusqu'ici nous avons seulement, pour la correction de
non-réponse partielle, explicité le cas d'imputation unique.
C'est-à-dire pour chaque valeur manquante imputer une seule valeur. Une
autre technique est de procéder à un type d'imputation
appelé imputation multiple. La technique d'imputation multiple
a été principalement développée par Rubin. Elle
remplace chaque variable manquante par au moins deux valeurs tirées
d'une distribution pour les valeurs manquantes sous l'hypothèse que l'on
postule à propos de la non-réponse. On obtient donc comme
résultat de l'imputation au moins deux bases. Chacune des bases
étant analysée

selon une même méthode, on combine les analyses afin
de refléter la variabilité supplémentaire que peuvent
entraîner les données manquantes.
Du point de vue théorique on peut assimiler cette
méthode d'imputation multiple à une approche bayesienne. Lorsque
le nombre d'imputations est élevé, les estimateurs seront plus
précis. Pour qu'une procédure d'imputation multiple soit
appropriée, il faut qu'elle incorpore la variabilité
adéquate parmi les v ensembles d'imputations.
La procédure "Approximate Bayesian Boostrap" (ABB) est une
des procédures appropriées. Elle peut être décrite
comme suit:
Soit un groupe de n unités de même valeur
X1 , X2,..., Xk - 1 où
l'on trouve pour la valeur Xk, nsr
répondants. Avec n et nsr qui
désignent respectivement la taille de la
population cible et celle de l'échantillon de
répondants. Les non répondants sont naturellement de:
n sr = n- nsr.
On tire dans l'ensemble de répondants les n
valeurs possibles de Xk avec remise et de
façon aléatoire, et cela pour chacun des
v ensembles d'imputations. Après ce tirage on impute les
valeurs manquantes en procédant à un tirage aléatoire avec
remise de l'ensemble des n
possibles plutôt que dans l'échantillon de
répondants. Ce tirage de nsr génère entre
les
imputations une variabilité appropriée. La supposition
d'un groupe de n unités ayant les
mêmes valeurs X 1 ,X2,...,
Xk-1 permet de classer les répondants,
comme les non répondants
dans un même ensemble homogène comme nous l'avons
explicité dans la méthode de repondération.
Le principe est d'attribuer à une donnée
manquante une valeur observée chez un répondant. Il s'agirait
donc de trouver pour un receveur les potentiels donneurs parmi les
répondants. Une façon plus pratique est de faire des classes
homogènes comme nous l'avons explicité plus haut. On donnera
à un non répondant la valeur d'un répondant appartenant au
même groupe.
La procédure ABB est une méthode de type
hot-deck à qui on incorpore les techniques de Boostrap. Car le hot-deck
consiste aussi à imputer une valeur à l'observation qui fait
défaut selon une technique que l'on cherche à mettre en
oeuvre.
Bien que l'imputation améliore la qualité de
données finales par le fait qu'elle permet de compenser les
réponses manquantes, invalides ou incohérentes, il convient de
veiller à choisir la méthode d'imputation appropriée. En
effet, il existe une multitude de techniques d'imputation dont chacune aboutit
à une estimation particulière de la variance et à une
formule différente de celle des autres. De plus, certaines de ces
méthodes ne sont pas sans effet sur les liens qui existent entre les
variables. C'est-à-dire qu'il existerait des méthodes
d'imputation qui ne préserveraient pas les relations entre les variables
de l'étude ou, pourraient fausser les distributions sous-jacentes.
De façon générale on peut classer les
méthodes d'imputation parmi les groupes suivants :
V' Les méthodes déductives : elles utilisent les
informations des autres questions pour avoir des données déduites
susceptibles de remplacer les données manquantes;
V' Les méthodes "cold-deck" : on utilise des informations
d'une autre enquête pour compenser les non répondants

V' Les méthodes hot-deck: dans ces cas on donne la
valeur d'un individu répondant (le donneur) à la valeur manquante
selon une procédure qu'on se fixe. C'est donc une méthode qui
recourt à d'autres enregistrements pour répondre à la
question qui doit faire l'objet d'une imputation. Il existe une multitude de
procédures connues que l'on peut mettre en pratique. On a parmi ces
procédures le hot-deck aléatoire, le hot-deck séquentiel
hiérarchisé et le hot-deck métrique.
V' Il y a aussi des méthodes dites de prévision,
elles consistent à procéder à une régression
adéquate. Les résultats du modèle de régression
sont ensuite utilisés pour faire une prévision.

Chapitre 2. METHODOLOGIE D'ESTIMATION DES D ECLARATIONS
MANQUANTES
La théorie statistique prévoit plusieurs
méthodes pour l'estimation des valeurs des individus qui font
défaut à l'observation. Ainsi l'on rencontre plusieurs pratiques
dans les services statistiques. Ces pratiques sont plus ou moins basées
sur l'intuition et le bon sens, plutôt que sur une théorie
proprement dite. Surtout quand il s'agit des instituts des pays en voie de
développement. Pourtant, ce ne sont pas les méthodes les plus
robustes qui manquent en la matière.
Dans ce chapitre, l'accent sera mis sur la méthodologie
que nous utiliserons dans notre étude. Mais, nous commencerons par une
présentation des méthodes d'estimation que l'INSD du Burkina Faso
utilise. Cette partie sera suivie d'une critique de la méthode
d'estimation utilisée jusque là par le service de
comptabilité nationale de l'INSD.
La collecte des DSF constitue une étape importante dans
l'élaboration des comptes des sociétés non
financières. A cet effet on entreprend des collectes périodiques
dans les principales villes où l'activité économique est
intense. Ces villes sont Ouagadougou, Bobo-Dioulasso, Koudougou et Banfora. Les
renseignements contenus dans les DSF sont saisis à l'aide d'un micro
programme informatique que le service de comptabilité nationale a mis en
place. Ce programme tient compte de l'architecture des tableaux contenus dans
les DSF. Et à travers un ensemble de règles bien définies
par un manuel d'élaboration des comptes, on passe des données des
entreprises (selon le plan SYSCOA1) aux rubriques de la
comptabilité nationale.
A l'aide de ces formules de passage, on calcule les
données individuelles des entreprises comme le veut la
comptabilité nationale. Ainsi la production prendra en compte en outre
la production réalisée par l'entreprise (ventes de produits ou de
services produits par l'entreprise, production stockée,
immobilisée ou produits accessoires), les ventes des marchandises
desquelles il faut retrancher les achats de marchandises. La valeur
algébrique obtenue représente ainsi la production totale de
l'entreprise selon l'optique de la comptabilité nationale. Ce formalisme
peut être traduit par la formule suivante :
Pdt = PdtStk + PdtImm +PdtsAcc
+ Vtemdse + VtePdtsFabr - Ach mdse + TrSvc
Vend.
Où les termes désignent respectivement, et dans
l'ordre de leur apparition dans la formule, la production totale de
l'entreprise, la partie de la production stockée, celle
immobilisée, les produits accessoires, la vente de marchandises, la
vente des produits fabriqués, les achats de marchandises et les travaux
et services qu'aura vendus l'entreprise.
Lorsqu'il s'agit d'une entreprise commerciale, la production est
évaluée par la marge brute. C'est-à-dire la
différence entre les ventes et les achats de marchandises.
1SYSCOA: Système Comptable ouest africain,
c'est le système de comptabilité que utilisent les pays membres
de l'UEMOA.

De cette même règle on évalue la
consommation intermédiaire de l'unité soumise à
l'étude par les formules de passage entre ces deux types de
comptabilité. Cette formule est la suivante :
CI = AchMat1 + Tsprt + SvcExtr
+ FrechDev + AutAch ? ÄStk. Les termes de
cette équation se définissent comme suit:
CI: Consommation Intermédiaire;
AchMat1: Achat de matières premières;
Tsprt: Coût de Transport;
SvcExtr: Services Extérieurs;
FrechDev: Frais de recherche et de développement
c'est-à-dire les créations, les apports et les acquisitions;
AutAch: Autres achats et
ÄStk: Variation de stocks de matières
premières et des autres achats.
Quand à la rémunération des
salariés, elle correspond au poste « frais du personnel » du
SYSCOA. C'est donc une autre dénomination qui désigne le montant
que l'unité de production accorde à son personnel en contrepartie
du service qu'il fournit.
Après ces calculs de passage entre les deux
comptabilités, on obtient les indicateurs calculés pour chaque
entreprise ayant pris part à l'étude. Mais un certain nombre de
celles-ci a préféré s'abstenir. C'est pour ces
dernières que nous tentons de trouver des méthodes qui permettent
de réduire le biais qu'elles introduisent dans le calcul des
agrégats.
I. Méthode utilisée par
l'INSD
C'est une méthode basée sur le taux de croissance
de la production des entreprises d'une même branche au cours des 5
dernières années ayant précédé
l'année en cours.
Cette méthode suppose que les entreprises appartenant
à la même branche d'activité ont des taux de croissance
similaires. Ainsi la production constitue - t - elle l'élément
déterminant de l'estimation de toutes les grandeurs de la
comptabilité prises en compte lors de l'établissement des comptes
des sociétés non financières.
Par branche d'activité, il est constitué un
échantillon d'entreprises ayant transmis régulièrement
leurs DSF sur la période considérée. Cet
échantillon doit en outre être représentatif de l'ensemble
de la branche ; en d'autres termes il doit représenter au moins quatre
vingt pour cent (80%) de la production totale de la branche dont il est issu.
On calcule ensuite des taux de croissance moyens de la production pour
l'ensemble de la branche à partir de l'échantillon.
Pour une entreprise donnée et en fonction des
données disponibles sur cette entreprise, on utilise les taux de
croissance calculés pour estimer sa production.
Pour l'estimation de la consommation intermédiaire, il est
d'abord calculé un ratio CI Pdt pour chaque entreprise ayant
déposé une DSF au cours de la période de
référence.
Ensuite on constitue, par branche d'activité, un
échantillon d'entreprises dont les ratios CI Pdt
sont assez
stables sur la période. On calcule un ratio moyen à partir de cet
échantillon, et par

branche d'activité on applique cette moyenne CI
Pdt à la production estimée pour avoir les CI
estimées. On déduit la valeur ajoutée par
solde.
Pour l'estimation de rémunération des
salariés (RS) et des impôts sur la production, on procède
de la même façon que précédemment, mais selon le
niveau, on calcule des moyennes RS/VA ou I/VA.
Il faut souligner que cette méthode était
surtout utilisée dans l'ancienne méthodologie
d'élaboration des comptes sous le SCN 68 et aussi dans le cadre de
l'élaboration des comptes de l'année de base 1999 sous le SCN 93
à l'aide du module ERETES. Pour l'élaboration des comptes des
années courantes du module ERETES qui est en cours, l'estimation des
agrégats des entreprises du secteur moderne non DSF se fait directement
au sein du module à l'étape des comptes de branches. Toutefois,
cette estimation gagnerait à être effectuée en dehors du
module pour permettre d'aller plus vite dans les travaux internes au module
ERETES.
II. Critique de la méthode
présentée
La méthode explicitée ci-dessus a pour avantage
de permettre de combler les données manquantes. A cet effet, elle permet
de faire une analyse avec une base relativement complète. Cette
façon peut être considérée comme une imputation
simple. C'est-à-dire que l'on donne à toutes les observations
manquantes la valeur commune censée être leur valeur si elles
avaient participé à l'étude.
S'il est vrai qu'elle permet d'avoir les données
artificielles pour compenser le biais que pourraient introduire les
non-réponses, il n'en demeure pas moins vrai qu'elle ne prend pas en
compte ni la nature de non-réponse ni le type de mécanisme qui
pourrait occasionner cette non- réponse. En effet, la méthode
semble être une méthode d'imputation qui s'applique aussi bien
à la non-réponse totale qu'à la no n-réponse
partielle. Or, on sait que ces méthodes ne sont réellement
efficaces que lorsqu'il s'agit d'une non-réponse partielle. Toutefois,
même en présence de cette nature de non-réponse, il est
tout à fait préférable de connaître le type de
processus qui aurait généré la non-réponse. A
défaut de connaître ce type, l'on suppose que les données
manquantes suivent un processus que l'on doit tester.
Confondre la non-réponse totale avec celle partielle et
les traiter de la même manière sont susceptibles de porter
préjudice à la qualité de données et partant celle
des résultats qui seront assortis de l'étude. Car cela revient
à considérer que l'individu qui n'a pas répondu à
une moindre question de l'étude apporte la même perte
d'information que celui qui refuse d'y participer. Par exemple, dans
l'estimation de la production, même si l'entreprise n'a pas
participé à la collecte, il suffit d'avoir une information sur
son existence. Si tel est le cas sa production sera égale à la
production estimée, de même que celle qui n'aurait pas
répondu aux variables permettant d'évaluer sa production mais qui
aura toutefois participé aux autres questions.
En cas de non-réponse totale, il faut redéfinir
les poids que le sondage aurait accordés aux unités statistiques
qui devaient prendre part à l'interview. Car les poids de ces
unités ne tiennent plus et ne peuvent plus être utilisés
pour extrapoler les données sur l'ensemble de la population. Or, en
comptabilité nationale, les données n'étant
publiées que pour le pays, cette extrapolation ne doit en aucune
manière être négligée. On se rend compte que la
procédure développée dans la première partie de ce
chapitre ne prend pas en compte cette nécessité de
redéfinition des poids des unités.

Cette méthode utilise les données d'une autre
enquête ce qui permet d'avoir d'autres sources de traitement. Mais dans
une économie ou les entreprises se créent et disparaissent aussi
rapidement, il peut être non cohérent d'utiliser les
données provenant d'une enquête lointaine dans le temps (de plus
de dix ans par exemple). Car la démographie instable des entreprises
fait appelle à une veille statistique et sa non prise en compte risque
de rendre incohérentes les estimations. En effet, il est possible
d'utiliser une entreprise dans le calcul de ratio et des taux de croissance
alors que cette entreprise a disparu, ou a été
délocalisée ou tout simplement a changé d'activité
principale. En plus c'est une méthode d'imputation ponctuelle
appliquée aux données manquantes sans tenir comptes de leur type
(MCAR, NMAR ou MAR) ou de leur nature (partielle ou totale).
L'objectif n'est pas de donner des estimations dont il est
difficile - si ce n'est pas impossible - de mesurer le biais ou de donner une
formule de la variance. Il s'agit plutôt de compenser les carences
d'informations avec des méthodes assez simples et faciles à
mettre en oeuvre. Le critère de choix de ces méthodes reste
toutefois la traduction de la réalité le plus fidèlement
possible. C'est pourquoi pour mieux faire l'estimation des DSF manquantes il
est intéressant d'étudier et de savoir de quelle nature de
non-réponse avons-nous à faire. En fonction de cette nature?
Quelle est la méthode la plus appropriée et la plus possible
à envisager pour le traitement? Ces éclaircissements feront
l'objet de la prochaine partie.
III. Proposition de méthode
La méthodologie de traitement des données
d'enquête est confrontée à plusieurs problèmes qui
sont à la fois d'ordre pratique et théorique. La recherche de
remède à ces difficultés n'est pas une chose aisée.
En effet, le statisticien dans son travail de l'élaboration des
données est confronté à un besoin sans cesse grandissant
des acteurs de la vie économique et sociale. Ce besoin se manifeste par
une pression accrue pour l'obtention des indicateurs de niveau global de
l'activité dans un laps de temps. Cette pression est parfois
accompagnée par une exigence portée sur la qualité des
données que produit le statisticien.
La faiblesse de culture statistique au sein de la plus grande
partie de la population des pays en voie de développement est un
handicap majeur pour la bonne collecte. Ces deux aspects contradictoires (d'une
part une demande accrue pour avoir les statistiques et d'autre part la
méconnaissance de bien fondé de statistiques de la part de la
grande majorité) traduisant la vie statistique des pays de l'Afrique
subsaharienne peuvent parfois entraîner une diminution du taux de
réponse, comme nous l'avons explicité plus haut. Ce
phénomène qui introduirait un faible taux de réponse
amènerait à des estimations biaisées et parfois moins
précises. A ce problème de faible taux de réponse et
d'exposition à des risques d'introduction de biais dans les estimations,
nous comptons proposer une méthode de traitement qui en tiendra compte.
Cette méthode permettrait de réduire les effets de
non-réponse, à défaut de les éradiquer. Nous
présenterons notre méthode d'estimation après une analyse
exploratoire de notre source statistique. Cette analyse nous permettra de
définir les taux de réponse, le type de non-réponse,
etc.
1. Analyse exploratoire
La base de données que nous utiliserons est issue de la
collecte que le service a entreprise pour se procurer des informations sur
l'activité des entreprises. Cette base contient les données nous
permettant d'évaluer la production, la consommation
intermédiaire, l'impôt lié à la production et la
rémunération des salariés des entreprises DSF. Ces
variables d'intérêt sont calculées à l'aide de
formules de passage entre les deux comptabilités. Ces formules ont
été

explicitées dans la partie introductive de ce chapitre.
Les entreprises ont un poids proportionnel à leur chiffre d'affaires sur
celui du total. Ce poids était valable pour toutes les entreprises
recensées, lors du dernier recensement commercial et industriel de 1998,
qui devraient faire partie de l'échantillon. La collecte a lieu chaque
année. Et nous utiliserons les données de 2001 pour
l'illustration de la méthode que nous proposerons au service de
comptabilité. Pour les données issues des collectes de
l'année 2000 et de l'année 1999, on appliquera cette
méthode proposée. Les résultats pour ces années
sont représentés dans l'annexe du document.
A l'issue de la collecte en 2001, un certain nombre
d'entreprise ont pris part à l'interview, mais d'autres ne l'ont pas
fait. Une description de l'état de participation des entreprises se
dessine comme suit :
Tableau 1: Etat de taux de réponse
globale
|
Fréquence
|
Pour cent
|
|
Valide DSF existe
|
232
|
59,6
|
|
DSF n'existe pas
|
157
|
40,4
|
|
Total
|
389
|
100,0
|
Source: INSD, nos calculs.
Sur le plan général, l'analyse de ce tableau
permet de constater qu'en 2001, sur les 389 entreprises qui devraient prendre
part à l'étude cent cinquante sept ont fait défaut
à la collecte ou ont des DSF inutilisables. Cet effectif
représente un taux de non-réponse assez élevé (plus
de 40%). Cette classification concerne le taux de non-réponse totale. En
effet, dans une étude pareille, il est presque impossible d'avoir
affaire à des non-réponses partielles. Car les entreprises
élaborent les DSF qu'elles mettent à la disposition des agents
collecteurs. Ce qui signifie que le document n'est reçu que lorsqu'il
est prêt. Mais cette répartition ne donne que la situation
globale. Or, il serait intéressant de savoir quelle localité a
tendance à tirer ce taux vers le haut. Cette répartition de
niveau de réponse par grandes villes peut se résumer de la sorte
:

Tableau 2: Répartition de
non-réponses par localité1
|
|
|
Disponibilité de DSF
|
Total
|
|
DSF existe
|
DSF n'existe
pas
|
|
Localité de
|
BANFORA
|
Effectif
|
5
|
4
|
9
|
|
l'entreprise
|
|
taux de réponse
|
55,6%
|
44,4%
|
100,0%
|
|
BOBO
|
Effectif
|
47
|
34
|
81
|
|
|
taux de réponse
|
58,0%
|
42,0%
|
100,0%
|
|
KDG
|
Effectif
|
4
|
4
|
8
|
|
|
taux de réponse
|
50,0%
|
50,0%
|
100,0%
|
|
Ouaga
|
Effectif
|
176
|
115
|
291
|
|
|
taux de réponse
|
60,5%
|
39,5%
|
100,0%
|
|
Total
|
|
Effectif
|
232
|
157
|
389
|
|
|
taux de réponse
|
59,6%
|
40,4%
|
100,0%
|
Source: INSD, nos estimations
Il existe une relation entre la localité de
résidence de l'entreprise et sa décision de déposer sa
DSF. Comme l'indique le test de Fisher exact (P-value = 0,891). La
répartition des taux de non-réponse par localité permet de
constater une disparité entre les différentes localités
concernées par l'étude. Ainsi on peut remarquer qu'en dehors de
la ville de Ouagadougou, les autres ont un taux de réponse
supérieur à la moyenne. Parmi ces localités Koudougou
(KDG) vient en tête de liste avec cinquante pour cent de
non-réponse. Il faut signaler que pour un certain nombre d'entreprises,
la variable localité n'était pas renseignée. Pour
celles-ci, nous avons procédé à une interrogation par
proximité. Cette interrogation a consisté à demander aux
personnes ressources la localité de telle ou telle autre entreprise.
Elle nous a permis de connaître la résidence d'une grande partie
des centres élémentaires concernés. Pour ce qui est du
reste (environ 8% de l'ensemble); nous avons décidé de faire une
répartition entre les quatre localités au prorata de leur
effectif dans la base.
Au vu de cette répartition inégale des
non-réponses entre les localités on peut se poser la question
suivante: quel est le lien entre la non-réponse et une localité
particulière? Dit autrement, est ce que la résidence de
l'unité statistique influe sur sa décision de prendre part
à l'étude ?
Pour des besoins d'analyse, nous avons jugé
nécessaire de créer une variable "type". Cette variable renseigne
sur la vocation de l'entreprise. Nous lui avons affectée quatre
modalités. Elle permet par exemple de savoir si les entreprises
pharmaceutiques sont plus réticentes que les entreprises de transport ou
de transit. Cette distinction est résumée dans le tableau qui
suit.
1 Un test de marasculo est fait pour confirmer les proportions.
Un exemple de ce test est présenté dans l'annexe 7.

Tableau 3: Taux de non-réponse selon la
structure des entreprises
|
|
|
Disponibilité de DSF
|
Total
|
|
DSF existe
|
DSF n'existe
pas
|
|
Type de l'entreprise
|
Entreprise Pharmaceutique
|
Effectif
Taux de réponse
|
47
50,0%
|
47
50,0%
|
94
100,0%
|
|
Entreprise de Service ou Commerce
|
Effectif
Taux de réponse
|
147
63,1%
|
86
36,9%
|
233
100,0%
|
|
Industrie
|
Effectif
Taux de réponse
|
28
60,9%
|
18
39,1%
|
46
100,0%
|
|
Transport ou Transit
|
Effectif
Taux de réponse
|
10
62,5%
|
6
37,5%
|
16
100,0%
|
|
Total
|
|
Effectif
Taux de réponse
|
232
59,6%
|
157
40,4%
|
389
100,0%
|
Source : INSD, nos calculs
Un test de Chi 2 de dépendance aboutit à une
conclusion d'existence de relation entre le dépôt de DSF d'une
entreprise et la vocation de celle-ci (P-value 1= 0,182). A
l'exception des unités pharmaceutiques, on enregistre un taux de
non-réponse inférieur à 40% au sein des autres types
d'entreprises. Le taux élevé de non-réponse serait donc
fortement influencé par les entreprises pharmaceutiques (les
laboratoires, les grossistes de médicament et les pharmacies). Car les
entreprises de cette structure, qui ne représentent qu'environ 25 pour
cent de l'échantillon (voir annexe1), récoltent cinquante pour
cent de non-réponse en leur sein. Par contre, les entreprises qui
offrent des services (les cabinets d'étude par exemple) ou qui font le
commerce ont le taux de non-réponse le plus faible (36,9%) quoiqu'elles
constituent 59,9% de l'échantillon2.
Après toute cette analyse exploratoire de la base, on
s'aperçoit qu'il s'agit bel et bien d'un cas de non-réponse
totale. Les entreprises pour lesquelles on n'a pas pu évaluer la
production, la consommation intermédiaire, etc. sont celles qui n'ont
pas déposé de déclaration. Ou ces sont des entreprises
pour lesquelles on n'a pas pu disposer de DSF, peu importe la raison qui
justifie le non dépôt. Pour tenir compte de cette carence, nous
proposons de procéder par une repondération.
2. Proposition de méthode de
repondération
Il s'agit, ici, de justifier notre choix qui s'est porté
sur ce type de méthode. Cette justification sera suivie de la
présentation de la façon dont nous comptons le mettre en
pratique.
a. Justification
Comme nous l'avons fait remarquer, la non-réponse que
nous traitons dans la collecte des DSF est de nature totale. Cette
non-réponse concerne plus de quarante pour cent de l'échantillon
constitué par des entreprises. Ce taux faible de réponse est de
nature à affecter les estimateurs calculés sur la base de la
collecte. Pour pallier cette difficulté et cette insuffisance,
1 Il s'agit de la P-value associée à la statistique
de Pearson qui suit un chi 2 de trois degré de liberté.
2 On a effectué un test de proportion de marasculo sur ce
tableau. Les résultats sont dans le dernier annexe.

nous avons plusieurs méthodes en présence. Parmi
celles-ci, notre choix s'est porté sur la méthode de
repondération. En effet, la repondération s'avère facile
à mettre en oeuvre lorsqu'il s'agit de non-réponse totale. Ce
choix se justifie aussi par la nature de la base d'information. Nous n'avons
pas des variables auxiliaires qui puissent permettre d'estimer les grandeurs
économiques (production, CI, Impôt sur production,...) des
entreprises absentes de la collecte. En sus, nous supposons l'existence d'un
phénomène de réponse homogène au sein des groupes.
Cette supposition nous conduit dans cette repondération, à
procéder à la constitution de groupes de réponses
homogènes. L'hypothèse de mécanisme de réponse
homogène est en effet basée sur l'observation de la
répartition des taux de réponse selon les groupes
présentés dans la sous section supra.
Une autre raison est qu'en comptabilité nationale et
dans les études conjoncturelles, dont ces grandeurs peuvent faire
l'objet l'on a recours à l'agrégation des données. Cette
extrapolation (agrégation) incluant les réponses pour estimer le
niveau national des grandeurs, utilise des coefficients. Ces coefficients, que
l'on appelle coefficients d'extrapolation, ne sont autres que les poids que le
sondage aura accordés aux unités. Or ces poids ne sont plus
valides compte tenu de l'influence de la non-réponse. Il faut donc
réajuster ces poids. C'est à ce niveau que la
repondération se révèle nécessaire.
b. Spécification de la
méthode
Dans ce qui suit, nous allons déterminer la
procédure que nous adopterons lors de la mise en oeuvre de la
méthode de repondération.
A cet effet, nous n'allons pas faire directement l'ajustement
des poids des unités répondantes. On procède au
préalable à la définition des groupes de réponses
homogènes. Ces groupes seront définis à l'aide des
probabilités estimées de réponses. C'est donc à
l'intérieur de ces groupes que nous appliquerons l'ajustement au poids
des unités statistiques.
b. 1 Estimations des probabilités de
réponses
Nous allons prédire ces probabilités de
répondre pour chaque entreprise. Ainsi on pourra savoir la chance que
chaque unité aura de répondre en tenant compte des facteurs qui
agissent sur sa décision de répondre. En d'autres termes il
s'agit de modéliser la chance qu'une unité réponde en
tenant compte des informations sur celle-ci. Ces informations que nous
appellerons plus tard les facteurs explicatifs, sont sensés avoir un
effet sur la décision de l'entreprise de participer à la collecte
des DSF. Pour la prédiction des probabilités de réponses
de chaque unité, nous utiliserons un modèle d'estimation de
probabilité approprié, il s'agit d'un modèle
qualitatif.
Dans ces modèles et contrairement aux
régressions linéaires, où est associée à la
réalisation d'un événement une valeur quantitative, on
associe à la réalisation d'un événement sa
probabilité d'apparition. Cette probabilité est toute fois
conditionnelle aux variables exogènes. De façon formelle, on
écrira le modèle suivant:
P i =Prob(yi
=1/xi)=F(xi)
Où la fonction F(.) désigne une fonction
de répartition que l'on choisira, xi et
désignent respectivement le vecteur de variables
explicatives et le vecteur de coefficients du modèle. Il existe un choix
varié de fonctions de répartition mais deux sont les plus
utilisées (la loi normale et la loi logistique). Ainsi, on
désigne le modèle utilisant la loi normale par le modèle
probit et celle qui utilise la loi logistique est appelée logit.

Tout au long de notre étude nous choisirons le
modèle logit pour prédire les probabilités
associées au fait qu'une entreprise dépose sa DSF. Pour ce fait
nous avons créé une variable expliquée (variable
dépendante du modèle) qui prend la valeur "1" lorsque
l'on détient la DSF de l'entreprise. Cette variable prend la valeur
"0" dans le cas échéant. Il faut noter que pour tous les
tests économétriques que nous mettrons en oeuvre, le seuil
théorique est fixé à 5% sauf indication contraire.
Comme toute estimation, il faut des variables explicatives. En
ce qui nous concerne, trois variables ont retenu notre attention. Une sur le
secteur d'activité de l'entreprise, une sur sa localité et la
dernière sur son statut juridique. Nous rappelons que la variable sur le
secteur d'activité de l'entreprise a été
créée par nous. Et pour la renseigner nous avons
procédé par une interrogation par proximité.
Parmi ces variables, deux étaient catégorielles.
Pour les besoins d'études il a été jugé
nécessaire de dichotomiser leurs modalités. Ainsi chaque
modalité est devenue une variable dichotomique (qui prend la valeur 0 ou
1). En effet, cette dichotomisation facilite l'analyse et donne une
cohérence à l'interprétation. On peut ainsi dire que si
l'entreprise est dans telle localité au lieu et à la place de "si
l'entreprise a la valeur 4 de localité". Car cette valeur quatre n'est
qu'une codification. Un autre analyste pourrait affecter à la même
localité le code deux.
Ainsi pour la prédiction des probabilités nous
avons des variables explicatives suivantes :
1' Quatre variables dichotomiques liées à
chacune des quatre localités soumises à l'étude. Ces
variables sont VIOU (qui vaut 1 si l'entreprise est à
Ouagadougou et zéro sinon), VIBO (pour la ville de
Bobo-Dioulasso), VIBA (pour la ville de Banfora) et VIKD (la
ville de Koudougou).
1' Quatre variables correspondant au secteur d'activité
de l'entreprise. On a VIPH qui prend la valeur 1 lorsqu'il s'agit
d'une entreprise pharmaceutique. Ce secteur regroupe les pharmacies et les
grossistes pharmaceutiques. La variable VISC regroupe les entreprises
offrant des services d'études (bureau d'étude par exemple) et les
entreprises commerciales. La variable VIIN rassemble les entreprises
industrielles. Quand à la variable VITT, elle concerne les
unités qui offrent le service de transport, de transit ou de tourisme.
Il s'agit des compagnies de transports, des entreprises de transits et des
agence de voyage et tourisme On rappelle que toutes ces variables sont
dichotomiques. A cet effet, elles prennent l'unité comme valeur lorsque
le critère est respecté et zéro si tel n'est pas le
cas.
1' Et enfin une variable renseignant sur le statut juridique
de l'entreprise. Celle-ci permet de distinguer les unités privées
des unités publiques. Cette variable, Pub, prend la valeur 1
pour les entreprises et les sociétés d'Etat et prend 0 pour tout
autre type d'entreprises.
Pour estimer la probabilité qu'une entreprise
dépose sa DSF compte tenue de la connaissance sur les facteurs
explicatifs de sa décision on utilisera le modèle logit. La
variable expliquée est aussi dichotomique. Il s'agit de la variable
suivante:
|
?
VDSF i = ??
|
1 si la DSF existe 0 sinon
|

Il s'agit donc d'estimer le modèle suivant: P Prob
VDSF x F x
= = =
( 1/ ) ( ) Où la probabilité vaut la valeur de la
fonction de répartition
VDSFi i i i
de la loi logistique considérée au point et qui
peut s'écrire comme suit:
x i
|
F ( )
x = i
|
i
e x 1
= ? =
i 1,
1 1
+ +
e e
x x
i i
-
|
2,....,n.
|
Ce modèle permet d'estimer, à l'aide de logit,
la probabilité pour qu'une unité statistique soit
répondante à l'étude compte tenu des informations que l'on
détient sur elle. C'est donc une espérance conditionnelle que
VDSF soit égale à 1 connaissant les valeurs des autres
variables explicatives.
Après estimations on trouve des résultats qui sont
répertoriés dans le tableau ci-dessous :
Tableau 4: Résultat de l'estimation de
probabilités de réponses
|
VDSF
|
Coefficients
|
Std. Err.
|
Statistiques
|
P-value
|
Intervalle de confiance à 95%
|
|
|
|
|
|
Borne inférieure
|
Borne supérieure
|
|
VITT
|
0,0442354
|
0,6033469
|
0,07
|
0,942
|
-1,138303
|
1,226774
|
|
VISC
|
0,0784134
|
0,3355564
|
0,23
|
0,815
|
-0,5792651
|
0,7360918
|
|
VIPH
|
-0,4476894
|
0,3747968
|
-2,19
|
0,032
|
-1,01202278
|
-0,0868988
|
|
VIBA
|
0,0910208
|
0,9857771
|
0,09
|
0,926
|
-1,841067
|
2,023109
|
|
VIBO
|
0,1577487
|
0,7550015
|
2,21
|
0,014
|
0,037524
|
1,012027
|
|
VIOU
|
0,3017356
|
0,7261064
|
0,42
|
0,678
|
-1,121407
|
1,724878
|
|
Pub
|
0,1969121
|
0,5172728
|
0,38
|
0,703
|
-0,8169239
|
1,210748
|
|
Constante
|
0,184638
|
0,7871903
|
0,23
|
0,815
|
-1,358227
|
1,727503
|
Source: INSD, nos estimations
A l'issue de cette estimation par le modèle logit, on
constate qu'au sens statistique seules deux variables explicatives sont
significatives au seuil de 5% : il s'agit de VIPH et VIBO. Ce
qui signifie que statistiquement, ces deux variables ont une influence sur le
fait qu'une unité dépose sa déclaration statistique.
Autrement dit lorsqu'une entreprise est basée à Bobo-Dioulasso,
la chance que celle-ci dépose sa déclaration augmente. Tandis que
la structure pharmaceutique influence négativement la décision de
répondre de l'unité à la collecte. Il est à noter
que deux variables ont été supprimées. Car elles
risquaient d'introduire une colinéarité dans l'estimation. Il
s'agit de variables VIIN et VIKD.
Il vient d'après l'estimation que la probabilité de
réponse est:
+
P V D S F = ? ( 0 , 0 4 4 2 3 5 4 * 0 , 0 7 8 4 1 3 4 *
0 , 4 4 7 6 8 9 4 * 0 , 0 9 1 0 2 0 8 *
V I T T V I S C V I P H V I B A
+ - +
0 , 1 5 7 7 4 8 7 * 0 , 3 0 1 7 3 5 6 * 0 , 1 9 6 9 1 2 1 * 0 ,
1 8 4 6 3 8 ) .
V I B O V I O U P u b
+ + +
Avec ? qui désigne la fonction de répartition de la
loi logistique.
Cette non significativité des autres variables
mérite d'être soumise à des tests. Ces tests et diagnostics
permettront de détecter une présence éventuelle des
"outliers" ou de "leverages" ou d'autres types de problèmes susceptibles
d'affecter la qualité de l'estimation.

b.2 Diagnostics du modèle
Intéressons nous à expliquer le modèle
estimé ci-dessus. Cette explication se fera à l'appui des tests
numériques et graphiques sur les leverages, la distance de Cook, les
résidus de l'estimation et sur d'autres.
Pour les résidus, on s'attachera à
vérifier une éventuelle présence d'observations outliers.
Compte tenu du nombre d'observations, on peut supposer une normalité
asymptotique de ceux-ci. En effet, nous avons plus de trois cent observations.
Ceci permet de supposer que les résidus suivraient asymptotiquement une
distribution normale.
Une observation peut être considérée comme
outlier, si elle a un grand résidu. Dans la pratique la valeur absolue
de résidu standardisé est comparée à deux. Si pour
une observation ce résidu est supérieur en valeur absolue
à deux, on dira alors qu"il s'agit d'une observation outlier. En ce qui
nous concerne nous pouvons le vérifier à l'aide du graphique
suivant:
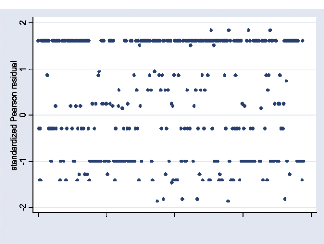
0 100 200 300 400
ident
Graphique 1: Résidu standard par
entreprise
Source: INSD, nos estimations
L'analyse de ce graphique laisse apparaître une
conclusion assez intéressante. Car elle permet de constater qu'on n'est
pas confronté aux observations outliers. En effet, tous les
résidus sont contenus entre les deux lignes horizontales
délimitées par 2 et -2. Cela signifie qu'aucune des unités
n'a une probabilité de réponse peu commune avec les autres
entreprises compte tenu des facteurs explicatifs. Cette situation pourrait
traduire une bonne disposition des chances de réponses. Quoique
importante, l'absence des outliers ne suffit pas pour conclure une absence de
problème.
Un autre type de problème auquel on peut être
confronté est celui des observations leverages. On dit qu'une
observation est leverage lorsque la valeur de sa puissance (leverage) devit
considérablement de sa moyenne. Ce leverage est donc comparé
à deux fois sa moyenne théorique. De façon formelle on
peut résumer comme suit:

? ?
r
h h r rst
1 Où , et désignent respectivement le leverage, le
résidu de l'estimationet le
i
ii = -? ? ii i i
? ?
rst i
|
résidu standard de l'individu . Cette valeur est
comparée à 2* i
|
? + ?
k 1
? ?
? ?
n
|
avec nombre de k
|
s variables
|
explivative et n celui de l'observation. Lorsque
ii dépasse cette valeur on parle de leverage
élevé.
h
Avant de faire ce test de "puissance élevée" sur
les unités de la base d'informations, nous chercherons d'abord à
déterminer les observations qui pourraient influencer les estimateurs.
Pour ce fait, on utilise la notion de distance de Cook. Compte tenu du nombre
impressionnant des observations de notre base de données, nous n'avons
pas jugé nécessaire de présenter la liste des observations
influentes. On a plutôt créé une variable "compteur". Cette
variable sert à compter le nombre de ces observations. Les
résultats sont consignés dans le tableau ci-dessous:
Tableau 5: Les observations ayant des distances
élevées
|
Candidats
|
Effectif
|
Pourcentage
|
|
Non
|
324
|
83,29
|
|
Oui
|
65
|
16,71
|
|
Total
|
389
|
100
|
Source: INSD, nos estimations
On constate d'après ce tableau, que sur les 389
observations qui constituent la base soixante cinq sont candidates pour
être des influences. Mais l'analyse la plus pointue des observations
laisse apparaître une absence de leverage. Ce qui signifie que sur
environ les dix sept pour cent des observations qui se
révéleraient high leverage (distance de Cook
élevée), aucune ne possède une puissance
élevée. Cette situation traduirait, que les données
sembleraient être bien classées. Toutefois, la non
significativité de certaines variables pourraient en partie être
due à ces observations qui ont une distance de Cook
élevée. Le test d'autocorélation de DurbinWatson conduit
à une absence dune éventuelle autocorélation entre les
résidus de l'estimation. En effet, la statistique de Durbin-Watson
calculée est de 1,997. Qui se situe dans l'intervalle correspondant
à l'absence d'autocorélation.
Nous nous sommes jusqu'ici intéresser aux
problèmes que peuvent entraîner les observations. Un autre
diagnostic consiste à tester la classification des données
prédites et à vérifier l'adéquation du
modèle avec les données. Pour le critère de classification
de données, nous utiliserons l'indicateur R2 count. C'est un
indicateur de bonne classification. C'est-à-dire pour la quelle la
valeur estimée serait égale à la valeur observée de
la variable d'étude.
Pour sa mise en oeuvre, on crée une variable qui prend
la valeur 1 lorsque la valeur estimée de VDSF> 0,5 et
zéro dans l'autre cas. Ainsi on construit un tableau1
permettant le
calcul de R2 count. L'indicateur peut
être donné de la façon suivante:
1 Ce tableau se trouve dans l'annexe 2, il est intitulé
table de prédiction du modèle.

2 00 11
n n
+
R=
count n
où n désigne (respectivement n 11 )
l'effctif des unités pour lesquelles = 0
VDSF
00
(respectivement 1) et estimée vaut 0 (respectivement
1).
VDSF
Après calcul on trouve R2 count=59, 13%. Ce
résultat signifie que le modèle est à environ plus de
cinquante neuf pour cent bien classifié. En d'autres termes nous avons
une classification de probabilité de réponse de bonne
qualité. L'analyse du tableau de l'annexe 2 permet de connaître
comment le modèle aurait prédit le classement pour chaque
individu de l'échantillon. Le jugement qu'on porte sur le modèle
peut en dépendre. En effet, plus les prédictions du modèle
sont conformes à la réalité plus est positif le jugement
qui lui est fait. Le tableau de l'annexe 2 résume ce test. Ainsi on
constate que la probabilité qu'une unité soit classée
répondante sachant qu'elle a répondu est de 95,26%. Cette
probabilité d'être classée non répondante sachant
que l'unité est non répondante est de 5,73%. Autrement dit, pour
une unité répondante le modèle le classe répondante
dans une très grande proportion. Alors que pour celle non
répondante, il la classe dans une proportion moins importante. L'on peut
lire aussi dans ce tableau que la probabilité pour qu'une unité
soit répondante sachant que sa probabilité prédite
d'être répondante est inférieure à 0,5 est de 55%. A
contrario, une unité dont la probabilité prédite est
supérieure à 0,5 a une probabilité de 0,4 d'être non
répondante. Mais ces chances de réponse ou de non-réponse
ne suffisent pas pour conclure à un bon calibrage du modèle. Pour
ce fait, nous utiliserons le test de Hosmer-Lemeshow.
Le test de Hosmer-Lemeshow est un test d'adéquation du
modèle. Il permet de se rendre compte sur le niveau de calibrage du
modèle qui est soumis à l'étude. C'est donc une
procédure qui consiste à tester l'adéquation entre les
valeurs prédites par le modèle et les valeurs observées de
la variable d'étude. Pour ce faire, on regroupe les individus en
classes1. On calcule une statistique de Hosmer-Lemeshow qui suit un
chi deux. Si la p-value associée à cette statistique est
inférieure au seuil théorique qu'on s'est fixé, on dira
que le modèle ne reflète pas la réalité. A
contrario, si cette p-value est supérieure à cinq pour cent, nous
pouvons affirmer un calibrage du modèle. C'est-à-dire qu'on peut
affirmer, avec un risque de cinq pour cent de se tromper, que le modèle
reflète la réalité (les données
observées).
Le résultat de Goodness of fit Test (Test de Hosmer-
Lemeshow) est répertorié dans le tableau de l'annexe 3 du
document. Dans ce tableau outre le regroupement, on a la p-value
associée à la statistique de Hosmer-Lemeshow. Cette p -
value = 0,8289, forts de ce résultat
nous pouvons affirmer que notre modèle est bien
calibré, qu'il reflète les données dont il prétend
expliquer. Il est à remarquer que l'on ne devrait pas surestimer
l'importance de l'ajustement dans les modèles où la variable
dépendante est dichotomique 2.
b.3 Odds ratio
Le odds ratio est un indicateur qui permet de tester
l'association entre deux variables, l'une étant une variable
d'intérêt et l'autre une variable explicative dans un
modèle CLDV donné. Il se calcule en général sur les
variables dichotomiques. Toutefois, on peut dichotomiser les
1 Pour plus d'amples de renseignement se reporter à
l'annexe 3 du document. Un tableau représente ce regroupement.
2 Gujarati. N. D. (2004) - Econométrie,
4ème édition américaine : Traduction
Par Bernier B., Col. Ouvertures Economiques, De Boeck, Bruxelles.

variables explicatives continues. Pour ce fait, on choisit une
caractéristique de tendance centrale1 comme critère.
Ainsi un odds ratio différent de 1 signifie qu'il y a association entre
les deux variables, un odds ratio égal à 1 signifie que les deux
variables ne sont pas en liaison. Le odds ratio est définis à
partir de rapport entre deux odds, lesquels sont définis ainsi qu'il
suit :
( )
VDSF X
= =
1/ 1
i
( )
VDSF X
= =
1/ 1
i
Odds1
P r
1-P r
p ( )
= =
Odds 2
1/ 0
VDSF X
r i
1 1/ 0
- = =
p VDSF X
r ( )
i
Ainsi le odds ratio peut être donné de la
façon suivante :
|
Oddsratio
|
=
|
Pr Pr
|
( ) ( ( ) )
VDSF X P VDSF X
= = - = =
1/ 1 / 1 1/ 1
i r i
( ) ( ( ) )
VDSF X P VDSF X
= = - = =
1/ 0 / 1 1/ 0
i r i
|
Après calcul, on trouve des résultats qui
aboutissent à la conclusion selon laquelle toutes les variables ont une
association avec la variable d'étude. Ces résultats sont
présentés dans le tableau qui suit :
Tableau 6: Odds ratio des variable
explicatives
|
Variables
|
Odds Ratio
|
|
VITT
|
1,045228
|
|
VISC
|
1,08157
|
|
VIPH
|
0,6391031
|
|
VIBA
|
1,095292
|
|
VIBO
|
1,570872
|
|
VIOU
|
1,352204
|
|
Pub
|
1,217637
|
Source : INSD, nos estimations
Comme on le voit dans le tableau, même si certaines
variables explicatives ne sont pas statistiquement significatives au risque de
cinq pour cent, elles auraient des liens avec la variable d'étude.
C'est-à-dire qu'il y a effectivement une association entre chacune des
variables choisies et la décision de l'entreprise de fournir ou de ne
pas fournir sa DSF. L'on constate que les entreprises pharmaceutiques ont une
propension plus grande à ne pas déposer leurs DSF toute chose
égale par ailleurs. Tandis que les entreprises offrant le service ou les
entreprise commerciales (variable VISC) ont une propension plus grande
à répondre favorable à l'étude.
La première étape de mise en oeuvre de la
méthode de repondération consistait à prédire les
probabilités de réponse aussi bien pour les répondantes
que pour les non répondantes. L'on devait se rassurer que ces
probabilités pouvaient être acceptées (pouvaient
refléter les données). Ce souci a nécessité des
tests et des diagnostics. A présent, on va ordonner ces chances de
réponse et on les regroupera en classe de réponses
homogènes.
1 La moyenne lorsque la variable suit une distribution normale
et dans le cas échéant on conseille la médiane. La
variable dichotomique prend zéro si la valeur de la variable
concernée est inférieure à la caractéristique sinon
elle prend un.

b.4 Groupes de réponses
Dans cette section l'idée motrice est de trouver un
regroupement des unités en des classes. Ce regroupement se fait de telle
sorte que les classes puissent être pertinentes pour l'analyse. De plus
ces classes doivent être basées sur les probabilités
prédites plus haut. Il s'agit donc de construire des groupes à
partir des probabilités qu'on a prédites avec le modèle
utilisé dans la section précédente. Pour notre part nous
utiliserons cinq classes de réponses. Ces classes sont définies
à partir des quintiles de la probabilité de réponse. En
effet, d'après Laurent Donzé - enseignant à
l'université de Fribourg (Suisse) - il est préférable lors
de construction de groupe de réponses homogènes de choisir un
nombre de classe limité. Pour cela il propose de "former cinq à
six classes à partir des probabilités estimées, en prenant
par exemple les quintiles1 ".
Nous avons constitué nos groupes de réponse
homogènes sur les quintiles des probabilités que nous avons
estimées pour les unités qui constituent la banque
d'informations. Mais ces groupes ne respectent pas toutes les hypothèses
de groupes homogènes. En effet, il existait deux classes qui ont la
même probabilité de réponse2. Or une des
hypothèses est qu'à l'intérieur des classes on ait des
probabilités identiques de réponses; cette probabilité
doit être différente selon les classes. Nous avons donc
utilisé quatre classes de réponse au lieu de cinq. Ces groupes
sont consignés dans le tableau qui suit :
Tableau 7: Caractéristique de groupe de
réponse homogène pour la repondération
|
N° de groupe
|
Probabilités
|
Observations manquantes
|
Observations non Manquantes
|
Observations totales
|
|
1
|
0,5654
|
49
|
48
|
97
|
|
2
|
0,6296
|
41
|
56
|
97
|
|
3
|
0,6376
|
36
|
61
|
97
|
|
4
|
0,6817
|
31
|
67
|
98
|
|
Total
|
157
|
232
|
389
|
Source: INSD, nos estimations
On constate que les probabilités estimées de
réponses varient avec les classes ce qui signifie que les chances de
réponses sont différentes d'une classe à une autre. C'est
à l'intérieur de ces groupes que nous allons procéder
à la repondération qui donne lieu à l'estimation de la
production, de la consommation intermédiaire, de l'impôt sur
production et de la rémunération des salariés des
entreprises.
1 Donzé L. (2003) - Théorie et pratique des
enquêtes : analyse de données d'une enquête complexe,
Université de Fribourg, Fribourg, Suisse.
2 Se référer à l'annexe 4 du document.

Chapitre 3. : ESTIMATION DES DSF DES ENTREPRISES DU
SECTEUR MODERNE.
Dans ce chapitre, il sera question pour nous d'estimer la
production et la consommation intermédiaire (Première partie). En
suite on procède à l'estimation de la rémunération
versée aux salariés par les entreprises et l'impôt sur la
production. Ce qui fera l'objet de la seconde partie du chapitre.
I. Estimation de la production et de la
CI
Le statisticien dans sa quête de l'information, cherche
à fournir aux dirigeants et aux opérateurs économiques des
informations leur permettant de décider face à une politique
donnée et à un objectif précis. A l'issue d'une collecte
on met en pratique plusieurs techniques. Ces techniques ont pour but de
corriger les éventuelles incohérences qui pourraient affecter la
banque d'informations. A cet effet, elles permettent de donner des estimations
"plus réalistes" (qui ne seraient pas biaisées) des grandeurs.
Ainsi, en comptabilité nationale l'accent est beaucoup plus mis sur les
grandeurs économiques. C'est ainsi que nous allons estimer le total de
la production du secteur et celui de la consommation intermédiaire. Car
en comptabilité nationale, on s'intéresse plus aux
agrégats lors de l'établissement des comptes, plutôt qu'aux
données individuelles. En sus le type de non-réponse permet
d'estimer plus facilement le total que d'imputer une variable à chaque
unité non répondante.
1. Estimation de la production
Ici, il s'agit d'estimer le total de la production à
l'aide de l'ajustement au poids. Cet ajustement a été possible
grâce à la constitution de groupes de réponses
homogènes. On suppose donc qu'à l'intérieur des groupes
les unités ont le même taux de réponse (probabilité
estimée de réponse) et leur poids sera calculé en fonction
de ce nouveau taux de réponse. Ces poids seront ensuite utilisés
dans l'estimation de total d'une grandeur considérée. De
façon formelle, nous avons:
Pour chaque élément de l'échantillon, un
coefficient d'ajustement est calculé. Ce coefficient est proportionnel
à son poids et inversement proportionnel à la probabilité
de réponse du groupe auquel il appartient. Ainsi le coefficient, est
calculé selon la formule qui suit :
Pds
Pdsajusté i
i
= avec appartenant à la classe c.
i ?
Pc
Où Pdsajustéi représente
le poids ajusté de l'unité i pour la
repondération (coefficient d'ajustement). La variable
Pdsi représente le poids de l'unité avant
l'ajustement. Et le
dénominateur désigne la probabilité
estimée de réponse dans la classe c. Il est important de signaler
que lorsque le sondage n'aurait pas défini de poids pour les
unités, on peut prendre l'inverse de probabilité. Il s'agit en
effet, d'affecter un poids à chaque unité. Ce poids serait
égal à "l'inverse de la probabilité estimée de
réponse de la classe à la quelle appartient l'unité

statistique "1. C'est ce poids ainsi défini qui
sera considéré comme le poids ajusté pour la
repondération.
En utilisant ce résultat, on calcule la production
totale qui cette fois-ci tiendra compte de la non-réponse et de son
effet sur l'estimation. La production totale est donc estimée par la
formule qui suit:
Pdt = ? Pdsajusté Pdt
i * i
i
Après calcul on trouve comme production totale
estimée la valeur suivante : 772 497,573 millions de F CFA. Ce qui
signifie qu'avec la prise en compte de données manquantes la production
du secteur moderne s'élève à plus de sept cent soixante
dix milliards de FCFA.
Quand à la moyenne de la production nous la calculerons
par l'estimateur d'Horowitz et Thomson. Cet estimateur est donné par la
formule ainsi qu'elle suit :
= ?
n
PdtPdt
c *
n
c


c

Avec Pdtc désignant la production
moyenne des répondants d'une classe c donnée. On conserve les
notations précédentes. Cette moyenne vaut : 1 286,3 12 millions
de FCFA.
2. Estimation de la consommation
intermédiaire
Par consommation intermédiaire, nous entendons tous ce
qui a été utilisé par l'unité de production
concernée dans son processus de production. Cette définition
prendra donc en compte tous les frais nécessaires qui reviennent
à l'entreprise pour se procurer de l'intrant de production. C'est cette
définition qui a permis le calcul de la CI.
Pour l'estimation de la consommation intermédiaire, il
nous a semblé important de donner le total estimé. Comme pour la
production, on a utilisé la même formule de calcul de l'estimateur
du total et de celui de la moyenne. Pour le calcul, il suffit de remplacer dans
les formules ci-dessus les productions par les consommations
intermédiaires.
La mise en pratique de ces formules permet d'avoir des
résultats suivants. Pour la consommation intermédiaire totale, on
a une estimation qui s'élève à 508 064,642 millions de F
CFA. La moyenne vaut 842,663 millions de FCFA. Cette valeur permet aussi
d'estimer la valeur ajoutée de ce secteur qui regroupe divers types
d'entreprises. Il suffit simplement de faire une différence entre la
production et la consommation intermédiaire pour obtenir la VA
estimée.
II. Estimation de la rémunération des
salariés et de l'impôt sur production
Dans cette partie, conformément à la demande du
service d'accueil, nous allons estimer la rémunération que les
unités élémentaires de décision du secteur moderne
ont accordée à leur personnel pour l'année 2001. Sera
suivie de cette estimation, celle de l'impôt sur productions des
entreprises. A l'image de la partie précédente, cette partie
comportera deux sous parties. Chacune est consacrée à une
estimation précise.
1 Donzé L. (2003) - Théorie et pratique des
enquêtes : analyse de données d'une enquête complexe,
Université de Fribourg, Fribourg, Suisse

1. Estimation de la RS
La rémunération des salariés correspond
au traitement que les entreprises ont versé à leur personnel en
contre partie des services que ce denier leur fournisse. Elle comprend en outre
le salaire brute, les indemnités accordée par l'entreprise au
personnel, les congés payés, les cotisatio ns sociales
payées par l'entreprise pour le personnel auprès d'un service de
sécurité sociale. Il s'agit donc d'un concept qui va
au-delà du salaire. C'est cette définition qui a retenu notre
attention. A l'aide de celle-ci on a pu établir une évaluation
des RS pour les entreprises répondantes. Pour estimer le total de RS du
secteur, il faut donc faire une estimation du total.
Cette estimation du total, comme les deux
précédentes, sera faite à partir de la méthode de
repondération telle qu'explicitée plus haut. Après
estimation on trouve pour le secteur moderne une RS de 92 185,782 millions de F
CFA. Ce qui signifie que pour leur fonctionnement, les unités de
production ont du versé une somme de plus de 92 milliards de FCFA
à leur personnel en compensation du service que ce dernier leur apporte.
Sans pour autant connaître avec l'exactitude la répartition de ce
montant entre les secteurs institutionnels, on pourra établir un
équilibre ressources emplois de RS lorsqu'on connaît les emplois
des autres secteurs et la ressource des ménages. Car l'essentiel n'est
pas de savoir quel montant le ménage aura reçu de tel ou tel
autre secteur.
On cherche plutôt à faire un ERE de
l'opération en question (rémunération des
salariés). Ainsi pour les 92 185,782 millions de nos francs que le
secteur moderne a dépensé en rémunérant ses
salariés, une partie est versée au ménage, une autre
partie serait probablement versée au reste du monde. Il n'est toutefois
pas nécessaire de savoir combien ce secteur a offert au reste du monde
(ou au ménage) pour s'offrir son service.
Il sera aussi intéressant de savoir en moyenne combien
les entreprises dépenseront pour rémunérer leurs
salariés. Cette moyenne est estimée avec la même formule
que les deux précédentes dans la partie une de ce chapitre. On a
donc une moyenne de RS pour l'année 2001 qui s'élève
à 154,721 106 de F CFA.
2. Estimation de l'impôt sur
production
Dans cette sous section, il s'agit d'appliquer la
repondération pour avoir l'impôt sur production. Nous allons
estimer le total de l'impôt que les entreprises du secteur moderne
payeront sur leur production. En effet, cet impôt est important dans
l'établissement des comptes nationaux de façon
général. Il en est aussi important pour les comptes des
sociétés non financières en particulier.
A l'image des autres estimations susmentionnées, on
utilise les probabilités prédites de réponses pour faire
l'estimation du total de l'impôt sur production de l'ensemble des
entreprises du secteur concerné. Ainsi, on trouve comme impôt
estimé une valeur de 20 077,93373 millions de F CFA.
Les entreprises payent en moyenne (pour l'année 2001)
un impôt sur production de 33,554935 1 millions de FCFA. Ces estimations
permettront ainsi d'élaborer (ou de faciliter l'élaboration) des
comptes des entreprises concernée, et partant ceux de la nation.
Recommandation

RECOMMANDATIONS
Au cours de notre étude, il nous a été
demandé de proposer une méthode au service de la
comptabilité nationale du Burkina Faso. Cette méthode doit
permettre de faire une estimation des grandeurs économiques qui
prendrait en compte les éventuelles non réponses à l'issue
de la collecte. Après analyse exploratoire des sources de données
dont nous disposions, il nous a paru nécessaire de proposer la
méthode de repondération. Car cette méthode se montre
intéressante avec les non réponses globales (totales). Dit
autrement, c'est une méthode qui s'applique mieux aux données
manquantes, lorsque ce manque est dû à la non-réponse
totale.
Pour l'illustration de cette méthode nous avons
utilisé la base de données issue de la collecte des
déclarations statistiques et fiscales 2001. Outre cette base nous avons
appliqué la méthode proposée à deux bases
d'informations. Ces bases sont aussi des résultantes des collectes que
le service a entreprises au cours des années 1999 et 2000
A cet effet, nous proposons au service de veiller à
l'application de la méthode de repondération pour compenser les
manques de données de cette nature (non-réponse totale).
Concernant la collecte de DSF, nous recommandons une attention
particulière aux entreprises répondant aux
caractéristiques pour lesquelles les Odds ratio sont inférieurs
à l'unité. Car ces entreprises ont des chances importantes de ne
pas donner de DSF. Pour des années à venir, nous suggérons
de prendre en compte l'âge des entreprises. Cette prise en compte sera
possible dès lors qu'on demande aux entreprises de mentionner leurs
dates de création sur leurs DSF. Ainsi on pourra s'intéresser
à savoir si ce sont les entreprises les moins jeunes qui ont tendances
à ne pas faire de déclarations.
Nous pensons qu'il est préférable qu'une
entreprise n'aie qu'un identifiant unique quelque soit la localité. Cet
identifiant doit lui est être propre. Car cela permettra de faciliter le
contrôle de cohérence et aussi d'éviter les doublons. Pour
cela, on peut numéroter les localités par un ordre précis.
De même, on identifie les communes au sein d'une localité; ensuite
les entreprises auront un numéro par ordre croissant dans la commune.
Pour une entreprise, il suffit de faire une concaténation de ces trois
nombre pour avoir l'identifiant de l'entreprise.
Conclusion

CONCLUSION
Basée sur la collecte des DSF que l'INSD du Burkina
Faso a entreprise - à travers son service de comptabilité
nationale - au cours de trois années antérieures (1999, 2000 et
2001), cette étude avait pour but de déterminer le type de non
réponse des entreprises à la collecte. En d'autre terme quel type
de non réponse introduirait les entreprises du secteur moderne non DSF
dans la base d'informations dont on dispose. Après cette
détermination de type de non réponse, il fallait proposer une
méthode de traitement de ces carences d'informations par une technique
statistique. Après des études descriptives et des estimations des
chances de réponse via les techniques d'économétrie, on
aboutit aux résultats suivants :
Premièrement, les non réponses qui se
présentent dans les différentes bases de données sont des
non réponses totales
Deuxièmement, la régression logit a permis de
clarifier les relations qui pourraient exister entre les variables explicatives
retenues et la probabilité pour les entreprises de fournir les DSF.
Certaines se sont montrées influentes sur cette chance de collecter les
DSF des entreprises. Tans disque d'autres auraient simplement un lien avec
cette chance sans pour autant l'influencer. Ainsi, toutes les variables
explicatives auraient un lien avec la décision de participer ou non
à la collecte. Quoique certaines d'entre elles ne soient pas
statistiquement significatives au seuil théorique que nous nous sommes
fixés. En effet, les Odds Ratio sont différents de l'unité
pour chaque variable explicative. Cette différence des Odds Ratio avec
l'unité s'opère pour les trois années. Les données
estimées par le modèle reflétant la réalité
(test de Hosmer-Lemeshow), nous avons construit des groupes de réponses
homogènes.
Ces groupes ont permis de calculer les poids ajutés des
unités ayant accepté de fournir leurs DSF. Ainsi, on a pu
construire quatre groupes de réponses pour l'année 2001, cinq
pour l'année 2000. Et enfin six groupes ont pu être
distingués pour l'année 1999. Ce sont ces groupes qui ont ainsi
permis de faire des estimations des moyennes et des totaux des
différentes grandeurs. Ainsi, conformément à la demande du
service d'accueil nous avons fait des estimations des totaux des grandeurs de
comptabilité nationale.
Cette étude a donc permis d'estimer les grandeurs en
tenant compte des taux de réponses lors de la collecte. Les
caractéristiques de ces grandeurs, comme toute autre grandeur des bases
utilisées, peuvent être estimées en utilisant les formules
d'estimations qui conviennent.

Annexes

Annexe1 : Etat de non-réponse et constitution
de
l'échantillon.
Tableau 8: Etat de non-réponses selon le
statut des entreprises
|
Disponibilité de DSF
|
Total
|
|
DSF existe
|
DSF n'existe
pas
|
|
Statut des entreprises Privée Effectif
|
220
|
151
|
371
|
|
Taux de
réponse
|
59,3%
|
40,7%
|
100,0%
|
|
Publique Effectif
|
12
|
6
|
18
|
|
Taux de
réponse
|
66,7%
|
33,3%
|
100,0%
|
|
Total Effectif
|
232
|
157
|
389
|
|
Taux de
|
|
|
|
|
réponse
|
59,6%
|
40,4%
|
100,0%
|
Source : INSD, nos calculs
Graphique 2: Répartition de
l'échantillon selon la résidence des entreprises
BAN FO RA
BOBO
KDG
Ouaga
Source; INSD, nos estimations.

Tableau 9: Répartition des entreprises
selon leur vocation
|
Fréquence
|
Pourcentage
|
|
Valide Entreprise
Pharmaceutique
Entreprise de Service
ou Commerce
Industrie
Transport ou Transit Total
|
94
233
46 16 389
|
24,2
59,9
11,8
4,1
100,0
|
Source : INSD, nos calculs.

Annexe 2 : Test de classification de donnée
et
d'autocorélation
Tableau 10: Table de prédiction du
modèle1
Logistic model for VDSF
True
|
Classified |
|
D
|
~D
|
|
|
Total
|
|
+
|
|
|
|
+
|
|
|
+
|
|
|
221
|
148
|
|
|
369
|
|
-
|
|
|
11
|
9
|
|
|
20
|
|
+
|
|
|
+
|
|
Total | 232 157 | 389
Classified + if predicted Pr(D) >=0,5
True D defined as
VDSF ~= 0
Sensitivity Pr( +| D) 95,26%
Specificity Pr( -|~D) 5,73%
Positive predictive value Pr( D| +) 59,89%
Negative predictive
value Pr(~D| -) 4 5,00%
False + rate for true ~D Pr( +|~D) 94,27%
False - rate for true D Pr( -| D) 4,74%
False + rate for
classified + Pr(~D| +) 40,11%
False - rate for classified - Pr( D| -) 5
5,00%
Correctly classified 59,13%
Source: INSD, nos calculs et
estimations
1 Dans ce tableau, D désigne que VDSF=1, le signe "+"
désigne VDSF estimé =1 tandis que VDSF estimé=0 est
désigné par le signe " -".

Annexe 3 : test d'adéquation du
modèle
Tableau 11: Test de Hosmer-Lemeshow de bon calibrage du
modèle
|
Quantile of Risk
|
VDSF=0
|
VDSF=1
|
Total
|
H-L
|
|
Groupes
|
Low
|
High
|
Observé
|
Prédit
|
Observé
|
Prédit
|
|
Value
|
|
1
|
0,4346
|
0,5097
|
18
|
19,5415
|
20
|
18,4585
|
38
|
0,25034
|
|
2
|
0,5097
|
0,5097
|
20
|
19,1229
|
19
|
19,8771
|
39
|
0,07894
|
|
3
|
0,5097
|
0,5876
|
17
|
17,5671
|
22
|
21,4329
|
39
|
0,03332
|
|
4
|
0,5876
|
0,6037
|
18
|
15,5374
|
21
|
23,4626
|
39
|
0,64879
|
|
5
|
0,6037
|
0,6296
|
18
|
14,9998
|
21
|
24,0002
|
39
|
0,97515
|
|
6
|
0,6296
|
0,6376
|
12
|
14,2323
|
27
|
24,7677
|
39
|
0,55131
|
|
7
|
0,6376
|
0,6376
|
13
|
14,1352
|
26
|
24,8648
|
39
|
0,14299
|
|
8
|
0,6376
|
0,6376
|
14
|
14,1352
|
25
|
24,8648
|
39
|
0,00203
|
|
9
|
0,6376
|
0,6376
|
11
|
14,1352
|
28
|
24,8648
|
39
|
1,0907
|
|
10
|
0,6376
|
0,6817
|
16
|
13,5935
|
23
|
25,4065
|
39
|
0,65396
|
|
|
Total
|
157
|
157
|
232
|
232
|
389
|
4,42751
|
|
H-L Statistic: 4,4275 Prob. Chi-2(8) 0,8166
|
|
Andrews Statistic: 5,835 Prob. Chi-2(10) 0,8289
|
Source : INSD, nos calculs et
estimations

Annexe 4 : caractéristique de groupes de
réponse
construits
Tableau 12: Quintiles de probabilité de
réponse
|
N° de Groupe
|
Probabilités
|
Nombre de non répondantes
|
Nombre de répondantes
|
Observations totales
|
|
1
|
0,5097
|
40
|
37
|
77
|
|
2
|
0,6037
|
35
|
43
|
78
|
|
3
|
0,6376
|
29
|
49
|
78
|
|
4
|
0,6376
|
24
|
54
|
78
|
|
5
|
0,6817
|
29
|
49
|
78
|
|
Total
|
157
|
232
|
389
|
Source : INSD, nos estimations

Annexe5 : Résultats de l'estimation pour
l'année 2000
Tableau 13: Résultat de l'estimation de
probabilité de réponse de l'année 2000.
|
VDSF
|
Coefficient
|
Ecart type
|
Statistique
|
P-value
|
Intervalle de confiance
|
|
|
|
|
|
Borne Inférieure
|
Borne supérieure
|
|
VIOU
|
0,2187589
|
0,6951519
|
0,31
|
0,753
|
-1,143714
|
1,581232
|
|
VIBO
|
0,2370171
|
0,7279133
|
0,33
|
0,745
|
-1,189667
|
1,663701
|
|
VIKD
|
-0,3519532
|
1,14967
|
-2,31
|
0,045
|
-1,605264
|
-0,201358
|
|
VIPH
|
0,1486894
|
0,5138915
|
2,49
|
0,002
|
0,0585195
|
2,515898
|
|
VISC
|
-0,2257785
|
0,4039783
|
-2,06
|
0,017
|
-2,17561
|
-0,166004
|
|
VIIN
|
-0,4914565
|
0,5594179
|
-0,88
|
0,38
|
-1,587895
|
0,6049824
|
|
Pub
|
0,34226
|
0,3983209
|
2,14
|
0,039
|
0,4384345
|
2,152955
|
|
Constante
|
0,025991
|
0,7719421
|
0,03
|
0,973
|
-1,486988
|
1,53897
|
|
R2 count
|
= 53,10%
|
Source : INSD, nos estimations
Tableau 14: Table de prédiction du modèle
pour la base de 2000.
True
Classified | D ~D | Total
+ +
+ | 162 145 | 307
- | 14 18 | 32
+ +
Total | 176 163 | 339
Classified + if predicted Pr(D) >=0,5
True D defined as
VDSF~= 0
Sensitivity Pr( +| D) 92,05%
Specificity Pr( - |~D) 11,04%
Positive predictive value Pr( D| +) 52,77,%
Negative predictive value Pr(~D| -) 5 6,25%
False + rate for true ~D Pr( +|~D) 88,96%
False - rate for true D Pr( -| D) 7,95%
False + rate for classified + Pr(~D| +) 47,23%
False - rate
for classified - Pr( D| -) 43,75%
Correctly classified 53,10%
Source: INSD, nos estimations

Tableau 15: Test de Hosmer-Lemeshow de bon calibrage du
modèle pour l'année 2000.
|
Quantile of Risk
|
VDSF=0
|
VDSF=1
|
Total
|
H-L
|
|
Groupes
|
Low
|
High
|
Observé
|
Prédit
|
Observé
|
Prédit
|
|
Value
|
|
1
|
0,3655
|
0,5047
|
19
|
18,7421
|
14
|
14,2579
|
33
|
0,00821
|
|
2
|
0,5047
|
0,5047
|
17
|
16,8387
|
17
|
17,1613
|
34
|
0,00306
|
|
3
|
0,5047
|
0,5047
|
14
|
16,8387
|
20
|
17,1613
|
34
|
0,94814
|
|
4
|
0,5047
|
0,5047
|
20
|
16,8387
|
14
|
17,1613
|
34
|
1,17581
|
|
5
|
0,5047
|
0,5047
|
19
|
16,8387
|
15
|
17,1613
|
34
|
0,54958
|
|
6
|
0,5047
|
0,5047
|
19
|
16,8387
|
15
|
17,1613
|
34
|
0,54958
|
|
7
|
0,5047
|
0,5093
|
14
|
16,7229
|
20
|
17,2771
|
34
|
0,87249
|
|
8
|
0,5093
|
0,5609
|
12
|
15,803
|
22
|
18,197
|
34
|
1,70995
|
|
9
|
0,5609
|
0,5971
|
15
|
14,0705
|
19
|
19,9295
|
34
|
0,10475
|
|
10
|
0,5971
|
0,6427
|
14
|
13,4677
|
20
|
20,5323
|
34
|
0,03483
|
|
|
Total
|
163
|
163
|
176
|
176
|
339
|
5,95641
|
|
H-L Statistic: 5,9564 Prob. Chi-2(8) 0,6521
|
|
Andrews Statistic: 8,5668 Prob. Chi-2 (10) 0,5737
|
Source : INSD, nos estimations
La p-value associée à ce test de Hosmer-Lemeshow
est supérieure au seuil théorique que nous nous sommes
fixés. On peut donne conclure à un bon reflet de la
réalité par le modèle. C'est-à-dire que le
modèle est bien calibré. On donne ci-dessous les groupes de
réponse homogène.
Tableau 16: Caractéristique de groupes
(probabilité estimée) de réponse de 2000.
|
N° de groupes
|
Probabilité estimée
|
Nombre de non répondante
|
Nombre de répondantes
|
Observations totales
|
|
1
|
0,5047
|
111
|
100
|
211
|
|
2
|
0,5093
|
17
|
24
|
41
|
|
3
|
0,5609
|
7
|
14
|
21
|
|
4
|
0,5971
|
21
|
30
|
51
|
|
5
|
0,6427
|
7
|
8
|
15
|
|
|
|
|
|
|
Total
|
163
|
176
|
339
|
Source : INSD, nos estimations
Ces classes (groupes) ont servi dans les estimations des
grandeurs de comptabilité nationale pour l'année 2000. Comme se
fut le cas pour l'année 2001 dans le dernier chapitre du document.
Tableau 17: Odds Ratio des variables explicatives de
l'année 2000.
|
Variables explicatives
|
VIOU
|
VIBO
|
VIKD
|
VIPH
|
VISC
|
VIIN
|
Pub
|
|
Odds Ratio
|
1,244531
|
1,267463
|
0,7033131
|
1,160313
|
0,7978948
|
0,6117348
|
1,408126
|
Source : INSD, nos estimations

Annexe 6 : Résultats de l'estimation pour
l'année
1999.
Tableau 18: Résultat de l'estimation de
probabilité de réponse de l'année 1999
|
VDSF
|
Coefficient
|
Ecart type
|
statistiques
|
P-value
|
Intervalle de confiance
|
|
|
|
|
|
Borne inférieure
|
Borne Supérieure
|
|
VIOU
|
0,9516174
|
0,840293
|
1,13
|
0,257
|
-0,6953265
|
2,598561
|
|
VIBO
|
0,7322836
|
0,87846
|
2,83
|
0,005
|
0,9894663
|
3,454034
|
|
VIKD
|
-0,5342036
|
1,21781
|
-2,44
|
0,041
|
-2,921068
|
-0,052661
|
|
VIPH
|
-3,105719
|
1,107519
|
-2,8
|
0,005
|
-5,276417
|
-0,9350208
|
|
VISC
|
-1,712079
|
1,058649
|
-1,62
|
0,106
|
-3,786993
|
0,3628352
|
|
VITT
|
-0,2071229
|
1,482653
|
-0,14
|
0,889
|
-3,113069
|
2,698824
|
|
Pub
|
0,6049261
|
0,4838371
|
1,25
|
0,211
|
-0,3433772
|
1,553229
|
|
Constante
|
1,712079
|
1,336939
|
2,28
|
0,02
|
0,9082724
|
4,33243
|
|
R2 count =
|
73,25%
|
Source : INSD, nos estimations
Tableau 19; Table de prédiction du modèle
de la base 1999
True
Classified | D ~D | Total
+ +
+ | 156 53 | 209
- | 12 22 | 34
+ ---+
Total | 168 75 | 243
Classified + if predicted Pr(D) >=0,5
True D defined as
VDSF ~= 0
Sensitivity Pr( +| D) 92,8 6%
Specificity Pr( -|~D) 29,33%
Positive predictive value Pr( D| +) 74, 64%
Negative predictive value Pr(~D| -) 64,71%
False + rate for true ~D Pr( +|~D) 70,67%
False - rate for true D Pr( -| D) 7,14%
False + rate for classified + Pr(~D| +) 25,3 6%
False - rate
for classified - Pr( D| -) 35,29%
Correctly classified 73,25%
Source : INSD, nos estimations

Tableau 20: Test de Hosmer-Lemeshow de bon calibrage du
modèle pour l'année 1999.
|
N° Groupes
|
Quantile of Risk
|
VDSF=0
|
VDSF=1
|
Total
|
H-L
|
|
Low
|
High
|
Observé
|
Prédit
|
Observé
|
Prédit
|
|
Value
|
|
1
|
0,3404
|
0,3913
|
16
|
14,9799
|
8
|
9,02011
|
24
|
0,18484
|
|
2
|
0,3913
|
0,6753
|
11
|
12,1749
|
13
|
11,8251
|
24
|
0,23012
|
|
3
|
0,6753
|
0,6753
|
7
|
7,79265
|
17
|
16,2073
|
24
|
0,11939
|
|
4
|
0,6753
|
0,7214
|
6
|
7,2408
|
19
|
17,7592
|
25
|
0,29932
|
|
5
|
0,7214
|
0,7214
|
9
|
6,68543
|
15
|
17,3146
|
24
|
1,11073
|
|
6
|
0,7214
|
0,7214
|
7
|
6,68543
|
17
|
17,3146
|
24
|
0,02052
|
|
7
|
0,7214
|
0,7214
|
9
|
6,96399
|
16
|
18,036
|
25
|
0,82509
|
|
8
|
0,7214
|
0,792
|
2
|
6,54425
|
22
|
17,4557
|
24
|
4,33848
|
|
9
|
0,792
|
0,9035
|
6
|
4,17304
|
18
|
19,827
|
24
|
0,96819
|
|
10
|
0,9035
|
0,9633
|
2
|
1,75959
|
23
|
23,2404
|
25
|
0,03533
|
|
|
Total
|
75
|
75
|
168
|
168
|
243
|
8,13201
|
|
H-L Statistic:
|
8,132
|
Prob, Chi-2(8) 0,4207
|
|
Andrews Statistic:
|
17,5701
|
Prob, Chi-2(10) 0,0627
|
Source: INSD, nos estimations
Tableau 21: Caractéristique de groupes
(probabilité estimée) de réponse de 1999.
|
N° Groupes
|
Probabilité
|
Nombre de non répondantes
|
Nombre de répondantes
|
Observations totales
|
|
1
|
0,3913
|
22
|
11
|
33
|
|
2
|
0,6753
|
15
|
30
|
45
|
|
3
|
0,7214
|
30
|
84
|
114
|
|
4
|
0,7920
|
1
|
4
|
5
|
|
5
|
0,9035
|
6
|
17
|
23
|
|
6
|
0,9633
|
1
|
22
|
23
|
|
Total
|
75
|
168
|
243
|
Source: INSD, nos estimations
Tableau 22: Odds Ratio des variables explicative de
l'année 1999.
|
Variables explicatives
|
VIOU
|
VIBO
|
VIKD
|
VIPH
|
VISC
|
VITT
|
Pub
|
|
Odds Ratio
|
2,589895
|
2,079825
|
0,5861359
|
0,0447923
|
0,1804902
|
0,8129197
|
1,831117
|
Source: INSD, nos estimations

Annexe 7: Résultats de test de
Marasculo1
$$ Comparaison des proportions de "type" pour la modalité
"DSF existe" de disponibilité DSF
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~
|
Différence abs Valeur Seuil critique
|
Signif( 0,05)?
|
P_val
|
|
P entre - P entre =
|
0,431
|
0,115
|
Diff
|
0,000
|
|
P entre - P indus =
|
0,082
|
0,095
|
Egales
|
0,12 10
|
|
P entre - P trans =
|
0,159
|
0,083
|
Diff
|
0,000
|
|
P entre - P indus =
|
0,513
|
0,107
|
Diff
|
0,000
|
|
P entre - P trans =
|
0,591
|
0,096
|
Diff
|
0,000
|
|
P indus - P trans =
|
0,078
|
0,070
|
Diff
|
0,024
|
|
1 sur
|
6 Proportions sont égales
|
|
$$ Comparaison des proportions de "type" pour la modalité
"DSF n'existe" de disponibilité DSF
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
Difference abs Valeur
|
Seuil critique
|
Signif(.05)?
|
P_val
|
|
P entre - P entre =
|
0,248
|
0,151
|
Diff
|
0,000
|
|
P entre - P indus =
|
0,185
|
0,124
|
Diff
|
0,001
|
|
P entre - P trans =
|
0,261
|
0,111
|
Diff
|
0,000
|
|
P entre - P indus =
|
0,433
|
0,132
|
Diff
|
0,000
|
|
P entre - P trans =
|
0,5 10
|
0,119
|
Diff
|
0,000
|
|
P indus - P trans =
|
0,076
|
0,083
|
Egales
|
0,085
|
1 sur 6 Proportions sont égales
1 La commande utilisée a été
développée sous un logiciel de la place par Chitou Bassirou Ph. D
enseignant à permanent l'ENSEA
Bibliographie

REFERENCES BIBLIOGRAPHIQUES
Gujarati Damodar N. (2004) - Econométrie,
4e édition américaine: Traduction Par Bernier B.,
Col. Ouvertures Economiques, De Boeck, Bruxelles.
Donzé L. (2003) - Théorie et pratique des
enquêtes : analyse de données d'une enquête complexe,
Université de Fribourg, Fribourg, Suisse.
Hurlin C. (2003) - Econométrie des variables qualitatives:
modèles à variables endogènes qualitatives,
Université d'Orléans, Orléans, France.
INSD (Burkina Faso) - (2003) - Note méthodologique sur
l'élaboration des comptes à l'aide du module ERETES, Document de
travail, Ouagadougou.
Jacqemin-Gadda H. (2003) - Analyse de données
longitudinales avec des données manquantes, INSERMU, Bordeaux,
France. Document disponible en ligne
www.bordeaux.inserm.fr
Luminet D. (2003) - L'enquête sur les Forces de
travail: calibrage et autres développements, Institut National de
la Statistique éditeur, Louvain.
Valliant R. (2003) - Application de nouvelles techniques
statistiques, Statistique Canada, Ottawa, Document disponible en ligne
www.statcan.ca
Bernier J et al. (2002) - traitement des données
manquantes: une étude de cas, Société statistique du
Canada, Ottawa.
Bialès M. et al. (2002) - Notions fondamentales de
l'économie, Col. Notions fondamentales, Foucher, Paris.
La revue Prescrire (2002) - tenir comptes de données
manquantes dans les essais cliniques, Tome 2 N° 225, inconnu.
AFRISTAT (Rép. MALI) - (2001) - Guide
méthodologique pour l'élaboration des comptes nationaux dans les
Etats membres d'AFRISTAT, Document de travail, Bamako.
Tood R. W. (2001) - Flexible matching imputation: combining
hot-deck imputation with model-based methodology, American Statistical
Association, U. S bureau of census, Washington.
BRION P. et CLAIRIN R. (1997) - Manuel de sondages : Applications
aux pays en développement, INSEE et CPED, Paris.
Séruzier M. (1996) - Construire les comptes de la
nation selon le SCN 1993, Col. Economie et statistiques avancées,
ECONOMICA, Paris.
ONU et al. (1995) - Système de Comptabilité
Nationale 1993 (SCN 1993), Manuel préparé par un groupe de
travail intersecrétariat sur la comptabilité nationale,
Washington.
Heckly C. (1990) - Eléments d'économie
pratique, Harmattan, Paris.
Gourieroux C. (1989) - Econométrie des variables
qualitatives, Col. Economie et Statistiques avancées, ECONOMICA,
Paris.
Rubin D.B. (1987) - Multiple imputation for nonresponse in
surveys, Wiley, New-
York.

TABLE DES MATIÈRES
Dédicace et remerciements 2
Sigles et abréviations 3
Sommaire. 4
Liste des tableaux 5
Liste des graphique. 5
Avant-propos 6
Présentation de la structure
7
Introduction 9
Chapitre 0. Concepts et définitions
10
I. Comptabilité nationale 10
1. Définition 10
2. Objet 10
3. Les comptes 11
II. Secteur moderne DSF et secteur moderne non DSF
11
III. Les sources de données
12
Chapitre 1. Généralités et
problématique de l'étude 14
I. Contexte et problématique de
l'étude 14
II. Cadre théorique 14
1. Non-réponse totale 15
2. Non-réponse partielle 16
3. Les mécanismes de génération
des données manquantes 16
4. Traitement de la non-réponse.
17
4.1. Méthode de repondération
18
Mise en application 18
4.2. Méthode d'imputation. 20
a. Généralité sur l'imputation
20

b. Technique d'imputation 20
Chapitre 2. Méthodologie d'estimation des
déclarations manquantes 24
I. Méthode utilisée par l 'INSD
25
II. Critique de la méthode
présentée 26
III. Proposition de méthode
27
1. Analyse exploratoire. 27
2. Proposition de méthode de
repondération 30
a. Justification 30
b. Spécification de la méthode
31
b.1 Estimations des probabilités de
réponses 31
b.2 Diagnostics du modèle 34
b.3 Odds ratio 36
b.4 Groupes de réponses 38
Chapitre 3. : Estimation des DSF des entreprises du
secteur moderne. 39
I. Estimation de la production et de la CI
39
1. Estimation de la production 39
2. Estimation de la consommation
intermédiaire 40
II. Estimation de la rémunération des
salariés et de l'impôt sur production 40
1. Estimation de la RS 41
2. Estimation de l'impôt sur production
41
Recommandations 42
Conclusion. 43
Annexes 44
Annexe1 : Etat de non-réponse et constitution
de l'échantillon. 45
Annexe 2 : Test de classification de donnée et
d'autocorélation 47
Annexe 3 : test d'adéquation du modèle
48
Annexe 4 : caractéristique de groupes de
réponse construits 49
Annexe5 : Résultats de l'estimation pour
l'année 2000 50
Annexe 6 : Résultats de l'estimation pour
l'année 1999 52

Annexe 7: Résultats de test de Marasculo
54
Références bibliographiques
55
Table des matières 56


