Le traitement des données manquantes pour l'établissement des comptes économiques du Burkina Faso( Télécharger le fichier original )par Lassana DOUCOURE ENSEA Abidjan - Ingénieur Statistiques 2005 |

Annexes
Annexe1 : Etat de non-réponse et constitution de l'échantillon. Tableau 8: Etat de non-réponses selon le statut des entreprises
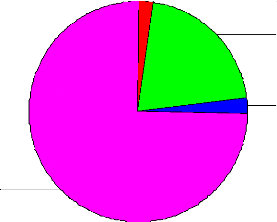
Source : INSD, nos calculs Graphique 2: Répartition de l'échantillon selon la résidence des entreprises BAN FO RA
BOBO KDG Ouaga Source; INSD, nos estimations.
Tableau 9: Répartition des entreprises selon leur vocation
Source : INSD, nos calculs.
Annexe 2 : Test de classification de donnée et d'autocorélation Tableau 10: Table de prédiction du modèle1 Logistic model for VDSF
Total | 232 157 | 389 Classified + if predicted Pr(D) >=0,5 Sensitivity Pr( +| D) 95,26% Specificity Pr( -|~D) 5,73% Positive predictive value Pr( D| +) 59,89% False + rate for true ~D Pr( +|~D) 94,27% False - rate for true D Pr( -| D) 4,74% Correctly classified 59,13% Source: INSD, nos calculs et estimations 1 Dans ce tableau, D désigne que VDSF=1, le signe "+" désigne VDSF estimé =1 tandis que VDSF estimé=0 est désigné par le signe " -".
Annexe 3 : test d'adéquation du modèle Tableau 11: Test de Hosmer-Lemeshow de bon calibrage du modèle
Source : INSD, nos calculs et estimations
Annexe 4 : caractéristique de groupes de réponse construits Tableau 12: Quintiles de probabilité de réponse
Source : INSD, nos estimations
Annexe5 : Résultats de l'estimation pour l'année 2000 Tableau 13: Résultat de l'estimation de probabilité de réponse de l'année 2000.
Source : INSD, nos estimations Tableau 14: Table de prédiction du modèle pour la base de 2000. True Classified | D ~D | Total + + + | 162 145 | 307 - | 14 18 | 32 + + Total | 176 163 | 339 Classified + if predicted Pr(D) >=0,5 Sensitivity Pr( +| D) 92,05% Specificity Pr( - |~D) 11,04% Positive predictive value Pr( D| +) 52,77,% Negative predictive value Pr(~D| -) 5 6,25% False + rate for true ~D Pr( +|~D) 88,96% False - rate for true D Pr( -| D) 7,95% False + rate for classified + Pr(~D| +) 47,23% Correctly classified 53,10% Source: INSD, nos estimations
Tableau 15: Test de Hosmer-Lemeshow de bon calibrage du modèle pour l'année 2000.
Source : INSD, nos estimations La p-value associée à ce test de Hosmer-Lemeshow est supérieure au seuil théorique que nous nous sommes fixés. On peut donne conclure à un bon reflet de la réalité par le modèle. C'est-à-dire que le modèle est bien calibré. On donne ci-dessous les groupes de réponse homogène. Tableau 16: Caractéristique de groupes (probabilité estimée) de réponse de 2000.
Source : INSD, nos estimations Ces classes (groupes) ont servi dans les estimations des grandeurs de comptabilité nationale pour l'année 2000. Comme se fut le cas pour l'année 2001 dans le dernier chapitre du document. Tableau 17: Odds Ratio des variables explicatives de l'année 2000.
Source : INSD, nos estimations
Annexe 6 : Résultats de l'estimation pour l'année 1999. Tableau 18: Résultat de l'estimation de probabilité de réponse de l'année 1999
Source : INSD, nos estimations Tableau 19; Table de prédiction du modèle de la base 1999 True Classified | D ~D | Total + + + | 156 53 | 209 - | 12 22 | 34 + ---+ Total | 168 75 | 243 Classified + if predicted Pr(D) >=0,5 Sensitivity Pr( +| D) 92,8 6% Specificity Pr( -|~D) 29,33% Positive predictive value Pr( D| +) 74, 64% Negative predictive value Pr(~D| -) 64,71% False + rate for true ~D Pr( +|~D) 70,67% False - rate for true D Pr( -| D) 7,14% False + rate for classified + Pr(~D| +) 25,3 6% Correctly classified 73,25% Source : INSD, nos estimations
Tableau 20: Test de Hosmer-Lemeshow de bon calibrage du modèle pour l'année 1999.
Source: INSD, nos estimations Tableau 21: Caractéristique de groupes (probabilité estimée) de réponse de 1999.
Source: INSD, nos estimations Tableau 22: Odds Ratio des variables explicative de l'année 1999.
Source: INSD, nos estimations
Annexe 7: Résultats de test de Marasculo1 $$ Comparaison des proportions de "type" pour la modalité "DSF existe" de disponibilité DSF ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~~~~
$$ Comparaison des proportions de "type" pour la modalité "DSF n'existe" de disponibilité DSF ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
1 sur 6 Proportions sont égales 1 La commande utilisée a été développée sous un logiciel de la place par Chitou Bassirou Ph. D enseignant à permanent l'ENSEA Bibliographie
REFERENCES BIBLIOGRAPHIQUES Gujarati Damodar N. (2004) - Econométrie, 4e édition américaine: Traduction Par Bernier B., Col. Ouvertures Economiques, De Boeck, Bruxelles. Donzé L. (2003) - Théorie et pratique des enquêtes : analyse de données d'une enquête complexe, Université de Fribourg, Fribourg, Suisse. Hurlin C. (2003) - Econométrie des variables qualitatives: modèles à variables endogènes qualitatives, Université d'Orléans, Orléans, France. INSD (Burkina Faso) - (2003) - Note méthodologique sur l'élaboration des comptes à l'aide du module ERETES, Document de travail, Ouagadougou. Jacqemin-Gadda H. (2003) - Analyse de données longitudinales avec des données manquantes, INSERMU, Bordeaux, France. Document disponible en ligne www.bordeaux.inserm.fr Luminet D. (2003) - L'enquête sur les Forces de travail: calibrage et autres développements, Institut National de la Statistique éditeur, Louvain. Valliant R. (2003) - Application de nouvelles techniques statistiques, Statistique Canada, Ottawa, Document disponible en ligne www.statcan.ca Bernier J et al. (2002) - traitement des données manquantes: une étude de cas, Société statistique du Canada, Ottawa. Bialès M. et al. (2002) - Notions fondamentales de l'économie, Col. Notions fondamentales, Foucher, Paris. La revue Prescrire (2002) - tenir comptes de données manquantes dans les essais cliniques, Tome 2 N° 225, inconnu. AFRISTAT (Rép. MALI) - (2001) - Guide méthodologique pour l'élaboration des comptes nationaux dans les Etats membres d'AFRISTAT, Document de travail, Bamako. Tood R. W. (2001) - Flexible matching imputation: combining hot-deck imputation with model-based methodology, American Statistical Association, U. S bureau of census, Washington. BRION P. et CLAIRIN R. (1997) - Manuel de sondages : Applications aux pays en développement, INSEE et CPED, Paris. Séruzier M. (1996) - Construire les comptes de la nation selon le SCN 1993, Col. Economie et statistiques avancées, ECONOMICA, Paris. ONU et al. (1995) - Système de Comptabilité Nationale 1993 (SCN 1993), Manuel préparé par un groupe de travail intersecrétariat sur la comptabilité nationale, Washington. Heckly C. (1990) - Eléments d'économie pratique, Harmattan, Paris. Gourieroux C. (1989) - Econométrie des variables qualitatives, Col. Economie et Statistiques avancées, ECONOMICA, Paris. Rubin D.B. (1987) - Multiple imputation for nonresponse in surveys, Wiley, New- York.
TABLE DES MATIÈRES Dédicace et remerciements 2 Sigles et abréviations 3 Sommaire. 4 Liste des tableaux 5 Liste des graphique. 5 Avant-propos 6 Présentation de la structure 7 Introduction 9 Chapitre 0. Concepts et définitions 10 I. Comptabilité nationale 10
II. Secteur moderne DSF et secteur moderne non DSF 11 III. Les sources de données 12 Chapitre 1. Généralités et problématique de l'étude 14
4.1. Méthode de repondération 18 Mise en application 18 4.2. Méthode d'imputation. 20 a. Généralité sur l'imputation 20
b. Technique d'imputation 20 Chapitre 2. Méthodologie d'estimation des déclarations manquantes 24
b.1 Estimations des probabilités de réponses 31 b.2 Diagnostics du modèle 34 b.3 Odds ratio 36 b.4 Groupes de réponses 38 Chapitre 3. : Estimation des DSF des entreprises du secteur moderne. 39 I. Estimation de la production et de la CI 39
II. Estimation de la rémunération des salariés et de l'impôt sur production 40
Recommandations 42 Conclusion. 43 Annexes 44 Annexe1 : Etat de non-réponse et constitution de l'échantillon. 45 Annexe 2 : Test de classification de donnée et d'autocorélation 47 Annexe 3 : test d'adéquation du modèle 48 Annexe 4 : caractéristique de groupes de réponse construits 49 Annexe5 : Résultats de l'estimation pour l'année 2000 50 Annexe 6 : Résultats de l'estimation pour l'année 1999 52
Annexe 7: Résultats de test de Marasculo 54 Références bibliographiques 55 Table des matières 56 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||