Caractérisation et extraction informatique de la structure d'un tableau par une méthode implémentant un réseau de neurones( Télécharger le fichier original )par Pacifique BISIMWA MUGISHO Institut Supérieur Pédagogique - Licence en Informatique de Gestion 2011 |

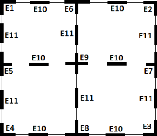
CHAPITRE II. LE PROBLEME DE LA RECONNAISSANCE DE TABLEAUX2.1. ObjectifsCe chapitre constitue un exposé succinct de notre manière d'appréhender le problème de la reconnaissance de tableaux. En fait, l'objectif étant de donner une lumière sur la démarche que nous avons adoptée, à travers ce chapitre, nous nous proposons d'examiner à fond la question de la reconnaissance de tableaux afin de découvrir les voies et moyens susceptibles d'apporter une idée sur la solution à adopter en termes de méthodologie et de technique. Pour ce faire, nous débutons d'abord par quelques considérations théoriques concernant le problème de la reconnaissance de tableaux. Ensuite, nous étalons la solution que nous avons choisie pour résoudre ce problème avant de donner un aperçu succinct de l'algorithme que nous implémenterons dans le système de reconnaissance de tableaux. 2.2. Quelques considérations théoriques du problème2.2.1. Postulat :De prime abord, nous considérons qu'un tableau n'est visible - ou, du moins, détectable à l'oeil humain - qu'à travers ses traits caractéristiques, notamment : ses lignes droites horizontales ou verticales le constituant. Nous n'allons donc pas considérer un tableau «imaginaire» dont les lignes droites horizontales et verticales sont hypothétiques car non définies ou invisibles. Ainsi, dans la suite de notre travail, c'est à ces types de tableaux auxquels nous ferons toujours allusion et sur lesquels nous travaillerons. 2.2.2. Considérations :- Soit le tableau de la figure suivante :
Fig. 3. Eléments de structuration d'un tableau - Soit A, l'ensemble des éléments pouvant constituer un tableau T. On a :
43 A = {E1,E2,E3,E4,E5,E6, E7,E8,E9,E10,E11} = {Ei|i E [1,11] C N} - Les éléments de A sont appelés «éléments de structuration » de T car ils donnent l'idée de la structure du tableau T. - Pour que ces éléments représentent réellement la structure d'un tableau T, ils doivent être rangés selon un certain ordre dans un espace à deux dimensions. Appelons donc M, la matrice d'éléments de structuration de T, constituée par les indices de ces éléments. Pour le tableau de la figure précédente, nous aurons donc la matrice :
- Notons que, dans la matrice ci-dessus, la présence des 0 (zéro) signifie l'absence d'éléments de structuration. - La composition de la matrice M est une expérience essentiellement aléatoire car, d'une part, il est impossible de prévoir de quels éléments de structuration le tableau à détecter sera constitué et, d'autre part, cette matrice est variable d'un tableau à un autre. - Notre espace fondamental û sera constitué par l'ensemble de toutes les possibilités de combinaison d'éléments de structuration pouvant composer un tableau. - Une matrice M sera donc un sous - ensemble de l'espace fondamentale û, c'est - à - dire qu'il est un ensemble de résultats possibles. - En considérant la probabilité de détecter un tableau dans un document (c'est-à-dire, de créer une matrice M associée à ce tableau), à chaque occurrence de la matrice M, nous associons un nombre réel P(M). La valeur de P(M) est une mesure de la chance que la matrice M représente bel et bien la structure d'un tableau lors du processus de reconnaissance. - Le cardinal de M sera donné par sa dimension NM= n X m (avec n : nombre de lignes et m : nombre de colonnes). - En postulant que l'ordre des éléments importe peu (car des faux tableaux seraient ainsi détectés !), le cardinal de û sera la combinaison avec répétition des 11 éléments de structuration pris 11 à 11, c'est-à-dire : 21! - 11)! ?ii *11= ?ii+ii--i 11 = ?2i 11= = 352 716 = NOE
44 - Ainsi la probabilité P(M) sera égale à : Nç n x m = (*) 6 P(M) = N 352 71 - Etant donné que nous devons tout mettre en oeuvre pour que la matrice M représente bel et bien la configuration structurelle d'un tableau, sachant aussi que 0 = P(M) = 1 (2 *), la première manche du problème consiste donc à déterminer les valeurs optimales de n et m qui maximisent (*) . Et, en langage mathématique, cela se traduit par :
Or, d'après l'inégalité (2 *), nous trouvons que la valeur maximale de (*) est atteinte lorsque P(M)=1. D'où l'inégalité (*) devient alors : n x m 352 716 = 1 ? n x m = 352 716 (4 *) L'équation (4 *) nous donne le produit de n et m ; ce qui revient à dire que n=m ou n=m en vertu de(3 *). Les valeurs de n et m sont donc des éléments de l'ensemble des diviseurs de 353 716. Pour notre part, nous avons choisi deux valeurs optimum de n et m, à savoir : 663 et 532 (car 663 x 532 = 352 716). Ainsi, la valeur de (3 *) devient :
- Soit B, l'ensemble d'éléments présents sur l'image du tableau. Afin de reconnaître un tableau, notre système devra déterminer les caractéristiques de l'image représentant le tableau. Ces caractéristiques ne sont pas observables directement et peuvent être représentées par un élément x de l'espace B. De plus, ces caractéristiques sont observées à partir d'autres caractéristiques observables de l'image et qui sont représentées par un élément y de l'espace û. Ici, nous supposerons qu'il n'existe pas de liens déterministe entre les x et les y - c'est-à-dire, plusieurs x possibles peuvent correspondre à un y observé. Cependant, bien qu'il n'existe aucun lien déterministe entre les y et les x, l'observation de y doit apporter une certaine information sur x. Cette information est donnée par une loi de probabilité sur B, compréhensible grâce à la loi des grands nombres, de la manière suivante : si la situation de produit un certain nombre de fois (à y donné), la probabilité p(F|y) (dépendant de y) d'un ensemble F?B est la proportion des x se trouvant dans F.
45 Pour calculer l'optimalité, considérons une fonction L : B2-- R/ qui modélise la gravité des erreurs ; L(x1,x2) représente le coût de l'erreur « nous pensons que x est x1 alors que le vrai x est x2 ». Nous appellerons la fonction L, la « fonction de perte » ou encore « fonction de coût ». Supposons que nous disposons d'une règle de décision d : Ù--B, qui associe à chaque y observé un x inobservable, et que nous souhaitions évaluer sa qualité. Connaissant la probabilité p(x|y), nous pouvons donc calculer le risque28 défini par : R(L,d,y) = J L(d(y),x)p(x|y)dx (5 *) C avec y : une caractéristique de tableau pouvant être observée sur l'image d : la fonction de décision qui associe un y observé à un x inobservable L : la fonction qui évalue la perte lorsqu'on associe un y observé à un x inobservable La fonction (5 *) exprime tout simplement le risque global qui est associé à la perte globale occasionnée par les erreurs d'observation des x, perte qui est pondérée par les probabilités d'occurrence de ces erreurs. 29 Les quantités x et y étant aléatoires, nous pouvons les considérer comme des variables aléatoires appartenant respectivement à B et Ù. La loi p(x,y) du couple (B, Ù) sera donc donnée par la loi p(y) de B et la loi p(x|y) de B conditionnel à Ù. En considérant que les variables aléatoires x et y sont discrètes, le risque moyen associé à L et d sera alors défini par : R(L, d) = E[L(d(Ù), B)] (6 *) L'équation (6 *) exprime l'espérance mathématique de la fonction de perte qui détermine le risque moyen ; et la décision Bayésienne30 associée à L sera la décision qui minimise ce risque moyen : E[L(d cents(Ù),B)] = arg min E[L(d(Ù),B)] (7 *) - Considérons donc le problème de reproduction d'un tableau comportant deux classes : la classe des pixels appartenant au tracé du tableau, notée T et la classe des pixels n'appartenant pas au tracé du tableau, notée Tf . Lorsque nous souhaitons travailler pixel par pixel, nous observons sur chaque pixel un niveau de gris y auquel nous devons attribuer un x de l'ensemble B = [T, Tf }. Nous nous trouvons dans un contexte probabiliste si un niveau de 28 http://en.wikipedia.org/wiki/Risk function, lien valide le 08/04/2012 à 20h09'. 29 http://www.cim.mcgill.ca/~friggi/bayes/decision/risk.html , lien valide le 08/04/2012 à 20h15'. 30 http://www.cim.mcgill.ca/%7Efriggi/bayes/decision/ &usg=ALkJrhiDn1gKh6g9e5FmoLjO6QdzT-EmwQ, , lien valide le 08/04/2012 à 21h15'. gris donné peut aussi bien correspondre au tracé d'un tableau qu'au tracé d'un autre objet sur le document (bruits, images, graphiques, etc.). C'est ce que nous observons fréquemment dans des images contenant du bruit tels que ceux des documents scannés comportant, en plus des tableaux, d'autres objets comme des images, des graphiques, des écritures manuscrites, etc. La loi p(x,y) du couple (B,û) peut alors être donnée par la loi p(x) de B, qui est une probabilité sur B = fT, fT } et désigne simplement la proportion de deux classes dans le document concerné, et par les deux lois p(y|T) et p(y|Tf) de û conditionnel à B. Notons que ces deux dernières lois modélisent simultanément la «variabilité naturelle » de deux classes et les diverses dégradations dues à l'acquisition des données ( cfr. la qualité des capteurs tels que le scanneur ainsi que les paramètres de capture tels que la résolution). Supposons que deux clients souhaitent se porter acquéreurs de logiciels de reconnaissance de tableaux. Le premier client, pour lequel la surévaluation de la classe «tracé de tableau» est plus grave que celle de la classe «pas tracé de tableau», perd 1 dollar quand un pixel « tracé » est classé à tort comme « pas tracé », et 10 dollars quand un pixel « pas tracé » est classé à tort comme étant « tracé ». Un deuxième client, pour qui la surévaluation de la classe « pas tracé de tableau » est plus grave que celle de la classe « tracé de tableau », perd 1 dollar quand un pixel « pas tracé » est classé à tort comme étant « tracé », et 20 dollars quand un pixel « tracé » est classé à tort comme étant « pas tracé ». Nous aurons donc : L1(T,T) = L1(Tf,Tf) = 0, L1(Tf,T) = 10, L1(T,Tf) = 1, (a *) L2(T,T) = L2(Tf,Tf) = 0, L2(Tf,T) = 1, L2(T,Tf) = 20 (a **) Etant donné que nous nous trouvons dans le cas des variables aléatoires discrètes, à partir de (5 *) nous pouvons obtenir la fonction de risque encouru par les deux clients. Ainsi cette fonction sera : R(L,d1,2,y) = L(d(y),T)p(T|y) + L(d(y),Tf)p(Tf|y) (8 *) Ajoutons ici que les probabilités p(T|y) et p(Tf|y) peuvent être calculées- en vertu du théorème de Bayes31 - à partir de p(x), p(y|T) et p(y|Tf) par : p(T)p(y|T) p(T)p(y|T) + p(Tf)p(y|Tf) p(T|y) = p(T p(T)p(y|T) |y) = p(T)p(y|T) + p(Tf)p(y|Tf)
46 31 http://fr.wikipedia.org/wiki/Th%C3%A9or%C3%A8medeBayes, lien valide le 08/04/2012 à 20h30'.
47 Lorsque nous minimisons la fonction (8 *) par rapport au premier client, nous observons deux cas :
Dans ce cas, notre client devra minimiser le risque global de sa décision en excluant le risque de la décision « tracé » du risque de la décision «pas tracé». Ce qui se traduit mathématiquement par : d1(y)= Tf si L(T,Tf)p(Tf|y) - L(Tf,T)p(T|y) = 0 len vertu de (a *)) ? p(Tf |y) = 10p(T|y) En appliquant le même raisonnement (ci - dessus) de minimisation de (8 *) à la situation du second client, nous obtenons les décisions suivantes : d2(y)= T si L(Tf,T)p(T|y) - L(T,Tf)p(Tf|y) = 0 len vertu de (a **)) ? p(T|y) = 20p(T |y) d2(y)= Tf si L(T, Tf)p(Tf|y) - L(Tf, T)p(T|y) = 0 len vertu de (a **)) ? 20p(Tf |y) = p(T|y) 2.3. Notre démarche de solution De ce qui précède, nous constatons que le problème de la reconnaissance de tableaux est essentiellement un problème de classification bayésienne32 où la gestion du risque d'erreur joue un rôle capital. Cela est d'autant plus vrai que, comme nous l'avons remarqué, cette classification s'adapte parfaitement à la situation générale dans laquelle l'image d'un document à reconnaître peut contenir, en plus des tableaux, d'autres objets tels que des graphiques, des bruits, des schémas, des signatures, etc. Dans une telle situation, le risque d'erreur de classification est effectivement grand pour le système de reconnaissance de 32 Une classification essentiellement probabiliste.
48 tableau. D'où l'utilisation des probabilités s'avère d'une importance capitale pour la gestion de ce risque. Il est évident que ce problème pourrait être bien résolu par les méthodes bien connues de la classification bayésienne. Cependant, eu égard à notre problématique de base - celle de la reproduction de la structure d'un tableau - nous nous sommes proposés d'adopter une autre approche qui, quoique différente, se base aussi sur des calculs probabilistes. C'est l'approche neuronale. Au fait, bien que très peu ou presque pas utilisée en reconnaissance de tableau, l'approche par réseaux de neurones nous semble la mieux adaptée à notre problématique de base pour les raisons ci - après : - cette approche concorde avec l'hypothèse forte de l'intelligence artificielle ; celle de la « reproduction du comportement d'un être humain dans un domaine spécifique ou non »33 ; - comme nous le verrons dans la suite, un réseau de neurones est une combinaison d'éléments simples : les neurones ; - cette approche est non linéaire (par « opposition » aux autres méthodes classiques d'analyse de données.)34 ; - cette approche est essentiellement numérique (par opposition à l'Intelligence Artificielle symbolique - base de règles, raisonnement par cas, etc.) et donc, mieux adaptée aux capacités de calcul d'un ordinateur. - Nous pensons qu'un réseau de neurones est mieux adapté pour l'extraction des informations structurelles d'un tableau. Avant d'aborder de manière détaillée la méthodologie que nous avons adoptée, jetons d'abord un regard analytique sur les réseaux de neurones. |
|