EPIGRAPHE
Merci Dieu tout puissant, car tu m'avais dit :
« je rendrai ton nom grand. Sois en bénédiction. Je
bénirai ceux qui te béniront, qui te bafouera je le maudirai. En
toi seront bénies toutes les familles de la terre ».
Genèse 12 :2-3
DEDICACE
A mes chers parents Marcel KAPUPA TAYULA et maman
Hélène KODJELA OMALOKENGE, pour la dignité de qui vous
vous battez et l'affection que vous ne cessez de témoigner plusieurs
années durant. Je vous dis grand merci pour le soutien inlassable
à l'ultime combat.
LOHAMBA
OMATOKO Séraphin
REMERCIEMENTS
Entre le passé ou sont enfouis nos souvenirs et le
futur ou germe notre espérance, il y a le présent où se
situe notre devoir. Dans cette perceptive s'approprier le prix d'une oeuvre
d'aussi passionnante serait sans doute une marque d'ingratitude dont le poids
fait grève aux mots. Dans ce contexte, il est digne qu'un tel travail
ne puisse pas prendre forme qu'avec les contributions des un et des
autres.
A vous monsieur le possesseur le prof Simon NTUMBA, je le
remercie d'avoir accepté apporter les premières briques de
l'édifice. En outre, de la confiance qu'il m'a témoignée
en m'intégrant au sein de son équipe de travail.
Nous tenons à remercier le corps académique de
l'université notre dame du kasayi en général et en
particulier la Faculté des sciences informatiques pour le savoir et
opportunités offertes au profit de notre formation.
Nous pensons modestement à toute la famille qui n'a pas
arrêté de nous donner toute l'affection et soutien
nécessaires : Rebecca KAPUPA, Me Junior KAPUPA, François
KAPUPA, Me OKUNDJI O et Mme Cathy KAPUPA , Papa Djonga N. et Christine KAPUPA .
A mes cousins et cousines ; nièces et
neveux ; tantes et oncles ainsi qu'à mes grands parents.
Très reconnaissant de votre soutien tant financier, moral que
matériel.
Nos pensées à toutes les autres personnes qui
nous sont d'une portée particulière : Dr DJAMBA LAMA, Maman
LOSOKOLA, famille Célestin DJONGA LOKANDU, maman Antoinette AHONDJU, les
anciens du Collège d'Amitié Wetshikoy, et ceux qui ne sont pas
cités en cet instant, qu'ils savent que nous gardons un très bon
souvenir de leur apport.
Nous tenons particulièrement à l'Ir Dadou
Tedia ; de sa bonne volonté de mettre à notre disposition
son imprimante pour l'impression de ce texte.
A tous mes amis et connaissances, sans oubliés les
compagnons de situations difficiles, pour de raison de modestie, je me
réserve de citer les noms. Très reconnaissant de vos conseils,
encouragement, et encadrement.
GLOSSAIRE
Ø AuC : Authentification Center
Ø BI: Business Intelligence
Ø CAH: Classification Automatique Hierarchique
Ø CHURN :Change Turn (expiration de la ligne
téléphonique d'un client due à son arrêt de son
activité
Ø DM :DataMart
Ø DM: Data Mining
Ø DW :Dataware House
Ø ECD: Exctration des connaissances à partir des
Données
Ø ED : Entrepôt de Données
Ø ETL: Extraction transformation Load
Ø GSM :Global System for Mobile
Ø HOLAP: Hybrid OLAP
Ø UML :Unified Methodl angage
Ø KDD: Knowledge Discovery in Databases
Ø MDX: Multidimensional Expression
Ø MOLAP: Multidimensional OLAP
Ø OLAP: On Line Analytical Processing
Ø OLTP: On Line Transaction Processing
Ø ROLAP : Relationnal OLAP
Ø SGBD : Système de Gestion de Base de
Données
Ø SIM : Subscriber Identity Module (carte à
puce identifiant l'abonné sur le réseau GSM)
Ø SMS :Short Message Service
Ø SQL: Structured Query Language
Ø SSAS: SQL Server Analysis Services
LISTE DES FIGURES
Fig.01 : architecture de dataware house
Fig.2 : schéma en étoile
Fig.3 : schéma d'un modèle en flocon
Fig.4 :Les arbres de décision
Fig.5 : L' Algorithme de CART
Fig.6 : Diagramme de cas
d'utilisation
Fig.7 : Diagramme de classes
Fig. 8 : architecture cliente serveur
FIG.9 : Création de la base source en SQL Server
avec le management
Studio
Fig 10 :Crétion de vues de source de
données avec le visual studio
Fig 11 : ajout de la dimension temps
Fig 12 : création des cubes de données
Fig 13 : Déploiement du cube
Fig 14 : visualisation des abonnés en Excel à
partir des cubes des données
Fig.15 Filière Attrition
Fig . 16 Représentation de l'arbre
hiérarchique
Fig. 17 Représentation de la partition en 4
classes
0. INTRODUCTION GENERALE
Depuis ces deux dernières décennies, les
entreprises commerciales sont en possession d'une remarquable quantité
de données concernant leurs clients (passés et présents)
à tel point que ce potentiel n'est pas exploité de manière
optimale. Or, c'est justement cette capacité à en tirer parti qui
peut vous démarquez dans la situation de concurrence.
Certes, il est arrivé alors la nécessité
de fouiller, torturer les données des clients dans les entrepôts
pour en dégager les corrélations, relations entre les
clients pour une prise de décision.
Face à de telles constations, il est évident de
constituer un support d'aide à la décision pour
s'imprégner de toutes les données de clients en se basant sur
l'exploitation de bases de données évoluées à
l'aide des techniques de datamining qui mettent en oeuvre de puissants outils
d'extraction des connaissances à partir des données.
0.1 PROBLEMATIQUE
La perte des clients d'une entreprise appelée
communément « attrition (churn) »
constitue un vrai problème pour les entreprises évoluant dans les
différents secteurs d'activité surtout en situation de
concurrence.
Nul n'ignore que ce phénomène n'a pas
épargné le secteur de la télécommunication.
Vodacom évoluant dans ce secteur est buttée
aussi à ce phénomène pour ses abonnés, très
surtout en situation de concurrence.
A cet effet, la prise de décision pour la Direction des
Marketing pour la réduction de ce phénomène suscite trop
d'interrogations pour l'éradiquer:
Ø Quels sont les abonnés fragiles au vu de leurs
profils d'utilisation du réseau ?
Ø Quelle est la zone géographique la plus
affectée par l'attrition de la clientèle ?
Ø Sur quel facteur agir pour modifier les
comportements des abonnés ?
Ø Quelles sont les causes de la perte des clients?
Ø Quels sont les abonnés
fidèles ?
0.2 HYPOTHESES
Ce travail s'inscrit dans le cadre de la fouille de
données et des méthodes de traitement de l'information de
l'entreprise. Basé sur des études récentes sur les
comportements des abonnés afin de maitriser l'attrition de la
clientèle.
Du fait que dans la téléphonie
prépayée, les clients ne sont pas engagés
contractuellement et peuvent cessez leur activité sans préavis.
Afin d'estimer l'effort de la fidélisation qui peut être
engagé au cas par cas, l'opérateur doit donc distinguer les
clients fidèles et fragiles et sur quels facteurs ajuster pour modifier
leurs comportements.
Pour y parvenir, nous pensons mettre sur pied un
entrepôt de données regroupant tous les abonnés à
une période donnée avec leurs différentes
caractéristiques en utilisant les techniques de datamining qui met en
oeuvre des outils pointus permettant de maitriser ce phénomène
c'est-à-dire les profiler afin de dégager les tendances,
relations inconnues a priori. La méthode de classification
hiérarchique automatique répond à cette
problématique d'exploitation de bases de données volumineuses.
Cette technique Opère des partitions dynamiques (classes
homogènes)en terme de comportements d'un ensemble d'abonnés en
définissant un critère de ressemblance ( par rapport à la
zone géographique, durée d'appels entrants, durée d'appels
sortant...).
0.3.
CHOIX ET INTERET DU SUJET
Notre travail s'intitule
''analyse et détection de l'attrition de la clientèle
dans une entreprise de télécommunication, étude
menée au sein de Vodacom Congo/Kananga''
En effet, L'heure est la gestion de la relation avec les
clients pour favoriser leur fidélisation à long terme. Les
opérations de marketing étant très couteuses, les
décideurs ont besoin d'avoir la clarté sur les abonnés
afin de savoir sur quels facteurs agir pour les fidéliser.
Combattre le coût élevé de la perte de la
clientèle, il est possible d'employer des techniques de plus en plus
sophistiquées pour analyser les raisons de la perte de la
clientèle et quels clients sont les plus fragiles et fidèles. Ces
informations peuvent être utilisées par les services de marketing
d'une entreprise de télécommunication (notamment de
Vodacom-Congo/Kananga) pour mieux cibler les campagnes de recrutement et
permettre une surveillance active de la base d'appels des abonnés afin
de repérer leurs comportements.
0.4.
DELIMITATION DU SUJET
Nous nous sommes donné une mission de :
Ø Profiler les clients avec objectif d'avoir une
idée sur leurs caractéristiques (comportements) afin de les
cibler;
Ø Concevoir un entrepôt de données
regroupant tous les abonnés et utiliser les outils de datamining
permettant de les torturer et en dégager des mesures;
Ø Réduire le taux d'attrition au sein de
l'entreprise dans une période de 6 mois ;
Ø Appliquer la classification automatique
hiérarchique qui consiste à opérer un regroupement des
abonnés par rapport à critère. Regrouper les
abonnés par rapport à la zone géographique, nombre
d'appels sortants, nombre d'appels entrants, nombre de messages sortants et
entrants... afin d'avoir une idée sur le
facteur à agir pour les fidéliser.
0.5 METHODES ET TECHNIQUES
UTILISEES
Dans le cadre de ce travail, nous avons utilisé les
méthodes suivantes :
Ø Technique documentaire : Elle
nous a permis d'élaborer notre approche théorique en consultant
les ouvrages, les mémoires, les travaux de fin de cycle et les notes de
cours qui cadrent avec notre sujet.
Ø Technique d'interview : Cette
technique nous a permis d'obtenir les informations fiables auprès des
personnes et agents qui travaillent dans les entreprises commerciales.
Ø Méthode historique :
cette méthode nous a permis à connaitre les
activités des années passées sur les ventes.
Ø Méthode statistique :
elle nous a aidés à réaliser divers calculs
(classification des différentes variables comparatives d'une
période à l'autre) de toutes les activités de vente
possibles. cette l'application de cette méthode a été
possible grâce à quelques techniques dont nous avons fait
usage :
Ø Internet : C'est une
bibliothèque universelle, elle nous a procuré des informations
nécessaires à la réalisation du présent travail.
0.6
CANEVAS DU TRAVAIL
Hormis l'introduction générale et la
conclusion générale, notre mémoire comporte quatre
chapitres, à savoir :
Ø Chapitre I : Généralités
sur le data ware house;
Ø Chapitre II : Techniques de datamining
Ø Chapitre III : Modélisation en UML
Ø Chapitre IV : Application
CHAPITRE I : GENERALITES SUR
LE DATA WARE HOUSE (ENTREPOT DE DONNEES) [3],[5],[4]6],[8],[9], [17]
Ce chapitre explicite de manière claire les concepts
fondamentaux et arguments généralement utilisés dans les
discussions ayant trait au data ware house. Ceux-ci y sont
présentés concernant l'entrepôt de données mais en
général ils seront autant que possible étayés par
des exemples provenant du secteur de la télécommunication
notamment dans son volet de la réduction de l'attrition.
I.1 INTRODUCTION
Le concept d'entrepôt de données a
été formalisé pour la première fois en 1990 par
Bill Immon. Il s'agissait de constituer une base de données
orientée sujet, intégrée et contenant des informations
historisées, non volatiles et exclusivement destinés aux
processus d'aide à la décision.
En effet, la simple logique de production (produire pour
répondre à une demande) ne suffit plus pour pérenniser.
Elle est un système ouvert sur son environnement au coeur des
systèmes d'informations confrontées à des
phénomènes économiques et sociaux lourds de
conséquences. Pour faire face aux nouveaux enjeux , l'entreprise doit
collecter , traiter , analyser les informations de son environnement pour
anticiper le changement.
Il devient fondamental de rassembler et
d'homogénéiser les données afin de permettre l'analyse des
indicateurs pertinents pour faciliter la prise de décision. L'objet de
l'entrepôt de données est de définir et d'intégrer
une architecture qui serve de fondation aux applications
décisionnelles.
I.1.1 Définition
Un entrepôt de données ou data warehouse se
définit comme un ensemble des données orienté sujet non
volatile, historisée, résumée, disponible pour
l'interrogation et l'analyse et organisée pour le support d'un processus
d'aide à la décision. « Bill Inmon ».
Les données d'un data warehouse possèdent les
caractéristiques suivantes :
a) Intégrées
Les données de l'entrepôt proviennent de
différentes sources éventuellement
hétérogènes. L'intégration consiste à
résoudre les problèmes
d'hétérogénéité des systèmes de
stockage, des modèles de données, de sémantique de
données.
b) Orientées sujet
Le Data Warehouse est organisé au tour des sujets
majeurs de l'entreprise. L'intérêt de cette organisation est de
disposer de l'ensemble des informations utiles sur un sujet le plus souvent
transversal aux structures fonctionnelles et organisationnelles de
l'entreprise.
c) Non volatiles
Tout se conserve, rien ne se perd : cette
caractéristique est primordiale dans les entrepôts de
données. En effet, et contrairement aux bases de données
classiques, un entrepôt de données est accessible en ajout ou en
consultation uniquement. Les modifications ne sont autorisées que pour
des cas particuliers (correction d'erreurs...etc.).
d) Historisées
La conservation de l'évolution des données dans
le temps, constitue une caractéristique majeure des entrepôts de
données. Elle consiste à s'appuyer sur les résultats
passés pour la prise de décision et faire des prédictions
; autrement dit, la conservation des données afin de mieux
appréhender le présent et d'anticiper le futur.
e) Résumées
Les informations issues des sources de données doivent
être agrégées et réorganisées afin de
faciliter le processus de prise de décision.
f) Disponibles pour l'interrogation et l'analyse
Les utilisateurs doivent pouvoir consulter les données
en fonction de leurs droits d'accès. L'entrepôt de données
doit comporter un module de traitement des requêtes, exprimées
dans un langage, doté d'opérateurs puissants, pour l'exploitation
de la richesse du modèle.
I.2 LE ROLE DU DATA WAREHOUSE
Le rôle primordial d'un data warehouse apparaît
ainsi évident dans une stratégie descensionnelle. L'alimentation
du data warehouse en est la phase la plus critique, En effet, importer des
données inutiles apportera de nombreux problèmes. Cela consommera
des ressources système et du temps. De plus, cela rendra les services
d'analyses plus lents. Autre point à prendre en compte et la
périodicité d'extraction des données.
Effectivement, le plus souvent, les opérations de
collecte de données sont coûteuses en ressource. Il faut donc
trouver un équilibre entre le délai acceptable entre deux mises
à jours des tables du data warehouse et les ressources
consommées. Comme nous l'avons indiqué, le Data warehouse est le
centre de chaîne décisionnelle, les utilisateurs n'auront
accès qu'aux outils de requête et d'analyse. Toutes parties de
l'alimentation et celles de restitution des données sont
gérées par une équipe informatique interne ou externe
à l'entreprise spécialisée en gestion de base de
données et en décisionnel.
La chaîne décisionnelle est composée de
trois parties :
Ø Alimentation du Data Warehouse
Ø La Modélisation
Ø Et la Restitution des données : Analyse et
prise des décisions*
I.3 OBJECTIFS DU DATA
WAREHOUSE
L'important d'une entreprise réside dans les
informations qu'elle possède. Les informations se présentent
généralement sous deux formes : les systèmes
opérationnels qui enregistrent les données et le Data Warehouse.
En bref, les systèmes opérationnels représentent
l'emplacement de saisie des données, et l'entrepôt de
données l'emplacement de restitution.
Les objectifs fondamentaux du Data Warehouse sont :
a) Rendre accessibles les informations de
l'entreprise : le contenu de l'entrepôt doit être
compréhensible et l'utilisateur doit pouvoir y naviguer facilement et
avec rapidité. Ces exigences n'ont ni frontières, ni limites. Des
données compréhensibles sont
pertinentes et clairement définies. Par données navigables, on
n'entend que l'utilisateur identifie immédiatement à
l'écran le but de ses recherches et accède au résultat en
un clic.
b) Rendre cohérente les informations d'une
l'entreprise : les informations
provenant d'une branche de l'entreprise peuvent être mise en
corrélation avec celles d'une autre branche. Si deux unités de
mesure portent le même nom, elles doivent alors signifier la même
chose. A l'inverse, deux unités ne signifiant pas la même chose
doivent être définie différemment. Une information
cohérente suppose une information de grande qualité. Cela veut
dire que l'information est prise en compte et qu'elle est complète.
c) Constituer une source d'information souple et
adaptable : l'entrepôt de données est conçu
dans la perspective de notifications perpétuelle, l'arrivé de
question nouvelles ne doit bouleverser ni les données existantes ni les
technologies. La conception de Data Mart distincts composant un entrepôt
de données doit être répartie et incrémentielle.
d) Représenter un bastion
sécurisé qui protège la capitale
information : l'entrepôt de
données ne contrôle pas seulement l'accès aux
données, mais il offre à ses gestionnaires une bonne
visibilité des utilisations.
e) Constituer la base décisionnelle de
l'entreprise : l'entrepôt de
données recèle en son sein les informations propres à
faciliter la prise de décisions.
I.4 ARCHITECTURE DE DATA WARE
HOUSE
Méta données
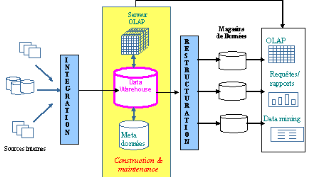
Fig.01 architecture de dataware
house
L'architecture d'un ED, représentée dans la
figure ci - dessus, s'articule autour de trois phases : l'intégration,
la restructuration, et l'exploitation (Inmon, 1996b).
Les systèmes opérationnels, bases de
données indispensable à la vie d'une entreprise, permet d'avoir
une activité journalière (gestion de stocks, base des
fournisseurs/clients, etc.). Ceci n'est pas le rôle d'un Data warehouse,
couplé à des outils de datamining, il n'a pour unique but de
faciliter la prise de décision en apportant une vue
synthétisée de l'ensemble des données de l'entreprise
éparpillées dans toutes ces bases opérationnelles.
Les données ayant été identifiées,
elles doivent être extraites de leurs système sources,
transformées puis acheminées jusqu'aux serveurs de
présentation. Elles sont en suite mise à disposition dans le but
d'être utilisées efficacement par les clients du Data warehouse.
L'élaboration de l'architecture et
l'établissement des priorités doivent en premier lieu être
piloté par les besoins métier. L'architecture du Data warehouse
présente les processus et les outils qui s'appliquent aux
données. Elle répond aux questions : comment
récupérer les données sources, comment leur donner une
forme répondant aux besoins et comment les placer à un endroit
accessible ? Les outils, les utilisateurs, le code, tout ce qui donne vie
à l'entrepôt de données fait partie de l'architecture. Ces
composants constituent les pompes et les canalisations qui régulent les
flux des données et les dirigent au bon endroit au bon moment. Les
emplacements d'origine et de destination des données font
également partie de l'architecture. Cette dernière répond
aux questions suivantes :
Ø Comment récupérer les
données sources ?
Ø Comment leur donner une forme répondant aux
besoins ?
Ø Comment les placer à un endroit
accessible ?
Ø Les outils, les utilisateurs, le code, tout ce qui
donne vie à l'entrepôt de données fait partie de
l'architecture. Cette dernière s'articule aussi autour de trois
phases :
- L'intégration : cette étape est assez
délicate, car elle consiste à extraire et regrouper les
données provenant des sources multiples et
hétérogènes. Certain nombre des problèmes est
à résoudre à ce niveau : les données doivent
être filtrées, tirées, homogénéisées
et nettoyées ;
- La restitution : cette étape consiste à
réorganiser les données dans des magasins afin d'apporter
efficacement les processus d'analyses et d'interrogations, et d'offrir aux
différents utilisateurs, des vues appropriées à leurs
besoins ;
- Interrogation et analyse : l'exploitation de
l'entrepôt, pour l'aide à la décision peut se faire des
différentes façons, dont :
- L'interrogation à travers un langage de
requêtes ;
- La connexion à des composants de report, pour des
représentations graphiques et tabulaires ;
- L'utilisation des techniques OLAP (Online Analytical
Process) ;
- L'utilisation des techniques de fouille de données
(Datamining).
I.4.1 Caractéristique d'un
Data Warehouse
a. Un Data Warehouse est une collection de données
conçue pour l'interrogation et l'analyse plutôt que le traitement
de transactions. Il contient généralement des données
historiques dérivées de données transactionnelles, mais il
peut comprendre des données d'autres origines. Les Data Warehouse
séparent la charge d'analyse de la charge transactionnelle. Ils
permettent aux entreprises de consolider des données de
différentes origines. Au sein d'une même entité
fonctionnelle, le Data Warehouse joue le rôle d'outil analytique.
b. En complément d'une base de données, un Data
Warehouse inclut une solution d'extraction, de transformation et de chargement
(ETL), des fonctionnalités de traitement analytique en ligne (OLAP) et
de Data mining, des outils d'analyse client et d'autres applications qui
gèrent le processus de collecte et de mise à la disposition de
données.
I.4.2 Les composants de base du
Data Warehouse
a. Le système source : est
le système d'opération d'enregistrement, dont la
fonction consiste à capturer les transactions liées à
l'activité.
b. Zone de préparation des
données : ensemble des processus qui nettoient,
transforment, combinent, archivent, suppriment les doublons,
c'est-à-dire prépare les données sources en vue de leur
intégration puis de leur exploitation au sein du Data Warehouse. La zone
de préparation des données ne doit offrir ni service des
requêtes, ni service de présentation.
c. Serveur de présentation :
machine cible sur laquelle l'entrepôt de données est stocké
et organisé pour répondre en accès direct aux
requêtes émises par des utilisateurs, les
générateurs d'état et les autres applications.
d. Data Mart : sous-ensemble logique
d'un Data Warehouse, il est destiné à quelques utilisateurs d'un
département.
e. Entrepôt de données :
source de données interrogeable de l'entreprise. C'est tout
simplement l'union des Data Marts qui le composent. L'entrepôt de
données est alimenté par la zone de préparation des
données. L'administrateur de l'entrepôt de données est
également responsable de la zone de préparation des
données.
f. OLAP (On Line Analytic Processing) :
Activité globale de requêtage et de présentation de
données textuelles et numériques contenues dans l'entrepôt
de données ; style d'interrogation et de présentation
spécifiquement dimensionnel.
g. ROLAP (Relational OLAP) : ensemble
d'interface utilisateur et d'applications donnant une vision dimensionnelle des
bases de données relationnelles.
h. MOLAP (Multidimensional OLAP) :
ensemble d'interface utilisateur et d'applications dont l'aspect dimensionnel
est prépondérant.
i. Application utilisateur : ensemble
d'outils qui interrogent, analysent et présente des informations
répondant à un besoin spécifique. L'ensemble des outils
minimal se compose d'outil d'accès aux données, d'un tableur,
d'un logiciel graphique et d'un service d'interface utilisateur, qui suscite
les requêtes et simplifie la présentation de l'écran aux
yeux de l'utilisateur.
j. Outil d'accès aux
données : client de l'entrepôt de données.
k. Outil de requête : types
spécifique d'outil d'accès aux données qui invite
l'utilisateur à formuler ses propres requêtes en manipulant
directement les tables et leurs jointures.
l. Application de modélisation :
type de client de base de données sophistiqués
doté de fonctionnalités analytiques qui transforment ou mettent
en forme les résultats obtenus ; on peut
avoir :
- les modèles prévisionnels, qui tentent
d'établir des prévisions d'avenir ;
- les modèles de calcul comportemental, qui
catégorisent et classent les comportements d'achat ou d'endettement des
clients ;
- la plupart des outils de Data mining.
g. Métadonnées : toutes
informations de l'environnement du Data Warehouse qui ne constituent pas les
données proprement dites.
I.4.3 Différence entre les
Systèmes OLTP et le Data Warehouse
Les Data Warehouse et les Systèmes OLTP (On Line
Transaction Processing) répondent à besoins très
différents. Les Data Warehouse conçu pour prendre en charge des
interrogations. La taille du Data Warehouse n'est pas connue à
l'avance. Par conséquent, celui-ci doit être optimisé pour
offrir de bonnes performances dans le cadre d'opérations d'interrogation
très diverses.
Les systèmes OLTP prennent généralement
en charge des opérations prédéfinies. Les applications
peuvent être réglées ou conçues
spécifiquement pour ces opérations. Un Data Warehouse est mise
à jour régulièrement par les processus ETL (Extraction,
Transformation and Loading), un système de chargement de données
en masse soigneusement défini et contrôlé. Il n'est pas
mise à jour directement par les utilisateurs.
Dans les systèmes OLTP, les utilisateurs
exécutent régulièrement des instructions qui modifient les
données de la base. La base de données OLTP est à jour en
permanence et elle reflète l'état actuel de chaque transaction.
Les Data Warehouse utilisent souvent des schémas
dénormalisés ou partiellement dénormalisés (tels
que le schéma en étoile) pour optimiser les performances des
interrogations. A l'inverse, les systèmes OLTP ont souvent recours
à des schémas totalement normalisés pour optimiser les
performances des opérations de mise à jour, d'insertion et de
suppression, et pour garantir la cohérence des données. Il s'agit
là des différences générales, elles ne doivent pas
être considérées comme des distinctions strictes et
absolues.
De manière générale, une interrogation
portant sur un Data Warehouse balaye des milliers voire des millions de lignes.
En revanche, une opération OLTP standard accède à quelque
enregistrement seulement. Le Data Warehouse contient généralement
des données correspondant à plusieurs mois ou années.
Cela permet d'effectuer des analyses historiques. Les systèmes OLTP
contiennent généralement des données quelque semaine ou
mois. Ils conservent uniquement des données historiques
nécessaires à la transaction en cours.
I.5. MODELISATION
DIMENSIONNELLE
Cette modélisation est une
méthode de conception logique qui vise à présenter les
données sous une forme standardisée intuitive et qui permet des
accès hautement performants. Elle adhère totalement à la
dimensionnalité ainsi qu'à une discipline qui exploite le
modèle relationnel en le limitant sérieusement. Chaque
modèle dimensionnel se compose d'une table contenant une clé
multiple, table des faits, et d'un ensemble de tables plus petite
nommées, tables dimensionnelles. Chacune de ces dernières
possède une clé primaire unique, qui correspond exactement
à l'un des composants de la clé multiple de la table des faits.
Dans la mesure où elle possède une clé
primaire multiple reliée à au moins deux clés externes, la
table des faits exprime toujours une relation n,n (plusieurs à
plusieurs).
I.5.1 Relation entre la
Modélisation Dimensionnelle et la Modélisation
Entité/Relation
Pour mieux appréhender la relation qui existe entre la
modélisation dimensionnelle et la modélisation
entité/relation, il faut comprendre qu'un seul schéma
entité/relation se décompose en plusieurs schémas de table
des faits.
La modélisation dimensionnelle ne se met pas à
son avantage en représentant sur un même schéma plusieurs
processus qui ne coexistent jamais au sein d'une série de données
et à un moment donné. Ce qui le rend indûment complexe.
Ainsi, la conversion d'un schéma entité/relation en une
série de schémas décisionnels consiste à scinder le
premier en autant de sous schémas qu'il y a de processus métier
puis de les modéliser l'un après l'autre.
La deuxième étape consiste à
sélectionner les relations n,n (plusieurs à plusieurs)
contenant des faits numériques et additifs (autres que les clés)
et d'en faire autant de table des faits.
La troisième étape consiste à
dénormalisés toutes les autres tables en table non
séquentielle dotées de clés uniques qui les relient
directement aux tables des faits. Elles deviennent ainsi des tables
dimensionnelles. S'il arrive qu'une table dimensionnelle soit reliée
à plusieurs tables des faits, nous représentons cette table
dimensionnelle dans les deux schémas et dirons des tables
dimensionnelles qu'elles sont conformes d'un modèle à l'autre.
I.5.2 Avantages de la
modélisation dimensionnelle
Le modèle dimensionnel possède un grand nombre
d'avantages dont le modèle entité/relation est dépourvu.
Premièrement, le modèle dimensionnel est une structure
prévisible et standardisée. Les générateurs
d'états, outils de requête et interfaces utilisateurs peuvent
reposer fortement sur le modèle dimensionnel pour faire en sorte que les
interfaces utilisateurs soient plus compréhensibles et que le traitement
soit optimisé. La deuxième force du modèle dimensionnel
est que la structure prévisible du schéma en étoile
réside aux changements de comportement inattendus de l'utilisateur.
Toutes les dimensions sont équivalentes. Le troisième avantage du
modèle dimensionnel réside dans le fait qu'il est extensible
à pour accueillir des données et des besoins d'analyse non
prévus au départ. Ainsi, il est possible d'accomplir :
Ø Ajouter des faits nouveaux non prévus
initialement ;
Ø Ajouter des dimensions totalement nouvelles ;
Ø Ajouter des attributs dimensionnels nouveaux non
prévus initialement ;
Ø Décomposer les enregistrements d'une dimension
existante en un niveau de détail plus fin à partir d'une date
déterminée ;
I.6 SCHÉMAS D'UN DATA
WAREHOUSE
Un schéma est un ensemble d'objets de la base de
données tels que les tables, des vues, des vues
matérialisé, des index et des synonymes. La conception du
schéma d'un Data Warehouse est guidée par le modèle des
données source et par les besoins utilisateurs. L'idée
fondamentale de la modélisation dimensionnelle est que presque tous les
types de données peuvent être représentés dans un
cube de données, dont les cellules contiennent des valeurs
mesurées et les angles les dimensions naturelles de données
.
A. les objets d'un schéma de Data
Warehouse
Les deux types d'objet les plus courants dans les
schémas de Data Warehouse sont les tables de faits et les tables de
dimension.
a) Tables de faits
La table de faits est la clef de voûte du modèle
dimensionnel où sont stockés les indicateurs de performances. Le
concepteur s'efforce de considérer comme indicateurs les informations
d'un processus d'entreprise dans un système d'information. Les
indicateurs étant les données les plus volumineuses d'un
système d'information, on ne peut se permettre de les dupliquer dans
d'autres tables mais de les rationaliser au sein de la table de faits.
Une table de faits comprend généralement des
colonnes de deux types : celles qui contiennent des faits
numériques (souvent appelés indicateurs) et celles qui servent de
clé étrangère vers les tables de dimension. Une table de
faits peut contenir des faits détaillés ou
agrégées. Les tables contenant des faits agrégés
sont souvent appelées tables agrégées. Une table
de faits contient généralement de faits de même niveau
d'agrégation. La plupart des faits sont additifs, mais ils peuvent
être semi additifs ou non additifs.
Les faits additifs peuvent être agrégés
par simple addition arithmétique. C'est par exemple le cas des ventes.
Les faits non additifs ne peuvent pas être additionnés du tout.
C'est le cas des moyennes. Les faits semi additifs peuvent être
agrégés selon certaines dimensions mais pas selon d'autres. C'est
le cas, par exemple des niveaux de stock. Une table de faits doit être
définie pour chaque schéma. Du point de vue de la
modélisation, la clé primaire de la table de faits est
généralement une clé composée qui est formée
de toutes les clés étrangères associées.
b) Tables de dimensions
Une dimension est une structure comprenant une ou plusieurs
hiérarchies qui classe les données en catégories. Les
dimensions sont des étiquettes descriptives fournissant des informations
complémentaires sur les faits, qui sont stockées dans les tables
de dimension. Il s'agit normalement de valeurs textuelles descriptives.
Plusieurs dimensions distinctes combinées avec les faits permettant de
répondre aux questions relatives à l'activité de
l'entreprise.
Les données de dimension son généralement
collectées au plus bas niveau de détail, puis
agrégées aux niveaux supérieurs en totaux plus
intéressants pour l'analyse, ces agrégations ou cumuls naturels
au sein d'une table de dimension sont appelés des
hiérarchies. Les hiérarchies sont des structures
logiques qui utilisent les niveaux ordonnées pour organiser les
données.
Pour une dimension temps, par exemple, une hiérarchie
peut agréger les données selon le niveau mensuel, le niveau
trimestriel, le niveau annuel. Au sein d'une hiérarchie, chaque niveau
est connecté logiquement aux niveaux supérieurs et
inférieurs. Les valeurs des niveaux inférieurs sont
agrégées en valeurs de niveau supérieur.
I.6.1 Le Schéma en
Etoile
Le schéma en étoile peut être le type le
plus simple de schéma de Data Warehouse, il est dit en étoile
parce que son diagramme entité/relation ressemble à une
étoile, avec des branches partant d'une table centrale.
Un schéma en étoile est
caractérisé par une ou plusieurs tables de faits, très
volumineuses, qui contiennent les informations essentielles du Data Warehouse
et par un certain nombre de tables de dimension, beaucoup plus petites, qui
contiennent chacune des informations sur les entrées associées
à un attribut particulier de la table de faits. Une interrogation en
étoile est une jointure entre une table de faits et un certain nombre de
table de dimensions. Chaque table de dimension est jointe à la table de
faits à l'aide d'une jointure de clé primaire à clé
étrangère, mais les tables de dimension ne sont pas jointes entre
elles.
Dans un schéma en étoile, une table centrale de
faits contenant les faits à analyser, référence les tables
de dimensions par des clefs étrangères. Chaque dimension est
décrite par une seule table dont les attributs représentent les
diverses granularités possibles.
Dimensions 1
Id_dim1
Dimensions 1
Id_dim1
Table des Faits
Id_f (Pk)
Id_dim1 (Fk)
Id_dim2 (Fk)
Id_dim3 (Fk)
Id_dim4 (Fk)
Dimensions 2
Id_dim2
Dimensions 3
Id_dim3
Dimensions 4
Id_dim4
Les schémas en étoile présentent les
avantages suivants : ils fournissent une correspondance directe et
intuitive entre les entités fonctionnelles analysées par les
utilisateurs et la conception du schéma. Ils sont pris en charge par un
grand nombre d'outils décisionnels. La manière la plus naturelle
de modéliser un Data Warehouse est la représenter par un
schéma en étoile dans lequel une jointure unique établit
la relation entre la table de faits et chaque table de dimension. Un
schéma en étoile optimise les performances en contribuant
à simplifier les interrogations et à raccourcir les temps de
réponse. Les schémas en étoile présentent
néanmoins quelques limites.
Fig.2 schéma en
étoile
I.6.2 Le Schéma en
Flocon
Les schémas en flocons normalisent les dimensions pour
éliminer les redondances. Autrement dit, les données de dimension
sont stockées dans plusieurs tables et non dans une seule table de
grande taille. Cette structure de schéma consomme moins d'espace disque,
mais comme elle utilise davantage de tables de dimension, elle nécessite
un plus grand nombre de jointures de clé secondaire. Les interrogations
sont par conséquent plus complexes et moins performantes.
Dans un schéma en flocon, cette même table de
faits, référence les tables de dimensions de premier niveau, au
même titre que le schéma en étoile. La différence
réside dans le fait que les dimensions sont décrites par une
succession de tables (à l'aide de clefs étrangères)
représentant la granularité de l'information. Ce schéma
évite les redondances d'information mais nécessite des jointures
lors des agrégats de ces dimensions.
Le principal avantage du schéma en flocons est une
amélioration des performances des interrogations due à des
besoins réduits en espace de stockage sur disque et la petite taille
des tables de dimension à joindre.
Dimensions 1
Id_dim1
Dimensions 1
Id_dim1
Table des Faits
Id_f (Pk)
Id_dim1 (Fk)
Id_dim2 (Fk)
Id_dim3 (Fk)
Id_dim4 (Fk)
Dimensions 2
Id_dim2
Id_dim 5
Dimensions 3
Id_dim3
Id_dim 6
Dimensions 4
Id_dim4
Dimensions 6
Id_dim 6
Dimensions 5
Id_dim5
Le principal inconvénient de ce schéma est le
travail de maintenance supplémentaire imposé par le nombre accru
de tables de dimension.
Fig 3 : schéma en flocon
1.6.3 Les schémas en
constellation de faits
Dans un schéma en constellation, plusieurs
modèles dimensionnels se partagent les mêmes dimensions,
c'est-à-dire, les tables de faits ont des tables de dimensions en
commun.
Pour conclure, les différences entre ces trois
modèles sont faibles et ne peuvent donner lieu à des comparaisons
de performance. Ce sont des schémas issus de la modélisation
dimensionnelle utilisés par les outils décisionnels.
1.7 CONSTRUCTION DU DATA
WAREHOUSE
Supposons que votre entreprise ait décidée de
construire un Data Warehouse. Vous avez défini les besoins et la
portée de votre application et vous avez crée un projet
conceptuel. Vous devez ensuite traduire vos besoins en une solution
système. Pour ce faire, vous créez la conception logique et la
conception physique du Data Warehouse.
1.7.1 La Conception logique
Une conception logique est conceptuelle et abstraite. A ce
stade, il n'est pas nécessaire de s'intéresser aux détails
de l'implémentation physique. Il suffit de définir les types
d'informations correspondant à vos besoins. L'une des techniques
utilisée pour modéliser vos besoins logiques en matière
d'informations est la modélisation entité/relation (E/R).
La modélisation E/R consiste à identifier les
données importantes (entités), leurs propriétés
(attributs) et les liens entre entités (relations). Dans le cadre de la
modélisation, une entité représente une tranche
d'informations. Dans les bases de données relationnelles, une
entité correspond souvent à une table, un attribut est un
composant d'une entité qui permet de définir l'unicité de
cette entité. Dans les bases de données relationnelles, un
attribut correspond à une colonne. Pour garantir la cohérence des
données, vous devez utiliser des identifiant uniques. Un identifiant
unique est ajouté aux tables pour permettre de distinguer les
éléments qui apparaissent à différents endroits.
En pratique, il s'agit habituellement d'une clé
primaire. La technique de modélisation entité/relation est
traditionnellement associée à des modèles très
normalisés comme les applications OLTP. Elle est néanmoins utile
pour la conception de Data Warehouse, sous la forme d'une modélisation
multidimensionnelle.
Dans le cadre d'une telle modélisation, vous identifiez
les informations qui appartiennent à une table de faits centrale et
celles qui appartiennent à une table de dimension associées. Vous
identifiez les sujets ou champs de données, vous définissez les
relations entre ces sujets et vous nommez les attributs correspondant à
chaque sujet.
La conception logique doit inclure un ensemble
d'entités et d'attributs correspondant à des faits et des tables
de décision, un modèle de transformation des données
opérationnelles source en informations orientées sujet dans le
schéma de Data Warehouse cible.
1.7.2 La Conception Physique
Pendant le processus de la conception physique, vous
convertissez les données collectées pendant la phase de la
conception logique en une description de la structure physique de la base de
données. Les principaux aspects qui orientent les décisions
relatives à la conception physique sont les performances des
interrogations et la maintenance de la base de données. Le processus de
conception physique consiste à convertir les schémas
prévus en structures de base données réelles. A ce
stade, vous devez associer :
Ø Les entités à des tables ;
Ø Les relatons à des contraintes de clé
étrangère ;
Ø Les attributs à des colonnes ;
Ø Les identifiants uniques à des contraintes de
clé primaire ;
Ø Les identifiants unique à des contraintes de
clé unique ;
1.7.3 Alimentation du Data
Warehouse par les outils ETL
Les données contenues dans un data warehouse sont
issues des différentes bases de données de l'entreprise. Ces
bases de production, systèmes opérants de l'entreprise,
correspondent à l'ensemble des applications informatiques
utilisées au quotidien dans l'entreprise pour son activité
(gestion de production, gestion bancaire, gestion commerciale,...). Les
informations qui y sont stockées, propres à chaque application,
peuvent parfois être utilisées par d'autres programmes, par
l'intermédiaire de transferts de données, couramment
appelés interfaces.
Nous allons donc voir les outils et les méthodes
permettant d'alimenter un data warehouse tout en minimisant l'impact sur les
systèmes de productions.
La majorité des systèmes d'information
d'entreprise sont de nature hétérogène car les
systèmes d'informations de l'entreprise s'élaborent le plus
souvent sur de longues périodes. Bien que la standardisation des
échanges entre les divers outils informatiques avance à grand
pas, la disparité des formats des données en circulation est
toujours une réalité. C'est le principal obstacle technologique
aux échanges d'informations.
Avant d'être utilisables, les données de
l'entreprise doivent être mises en forme, nettoyées et
consolidées. Les outils ETL (Extract, Transform, Load)
permettent d'automatiser ces traitements et de gérer les flux de
données qui alimentent l'entrepôt. Ces outils d'alimentation
permet aussi de paramétrer des règles de gestion, propres
à l'entreprise et à son secteur d'activité. Ces
règles visent elles aussi à assurer la cohérence entre les
données et à ne stocker dans l'entrepôt de données
que des informations préalablement mises en relation les unes avec les
autres.
Les outils ETL font référence à plusieurs
opérations qui s'articulent autour de trois axes majeurs :
Ø Extraction ;
Ø Transform ;
Ø Chargement ;
a. Extraction
L'extraction des données est la
première des étapes des systèmes ETL. Le but de cette
étape, est comme son nom l'indique , la lecture et l'extraction des
données du système source. On imagine facilement que cette
étape s'avère être critique. En effet, dans le cas ou le
système source doit fonctionner en permanence (24h/24 et 7jours sur 7),
il faut que l'extraction, opération coûteuse en ressources, doit
être fait le plus rapidement possible et souvent durant un laps de temps
précis (souvent nommé « extract window »),
décidé en collaboration des équipes chargés de la
gestion et/ou de l'exploitation de ce système source.
La complexité de l'extraction n'est pas dans le
processus de lecture, mais surtout dans le respect de l'extract window. Cette
contrainte est la principale raison de la séparation extraction /
transformation. D'autre part, on essaye au maximum d'extraire seulement les
données utiles (Mise à jour ou ajoutée après la
dernière extraction) et pour ce faire on pourrait s'entendre avec le
responsable du système source pour ajouter soit un flag ou encore des
dates dans chacune des tables extraites, au moins deux dates : Date de
création de l'enregistrement dans la table et la date de mise à
jour (En général la plupart des systèmes sources disposent
de ces deux dates).
Par ailleurs pour ne pas perdre des données suites
à des problèmes d'extraction, il est important de s'assurer que
le système source ne purge pas les données avant que
l'entrepôt ne les ait extraits. Le processus d'extraction est une des
taches ETL les plus consommatrices de temps car, outre la complexité des
différents systèmes source, la détermination exacte des
données à extraire est difficile. De plus, ce processus est
répétitif, parfois dans des intervalles de temps très
rapprochés. La définition du processus d'extraction revient
à choisir une méthode d'extraction des données source, un
processus de transport et un processus de mise à jour de
l'entrepôt (Data Warehouse).
b. Transformation
c' est l'opération qui réalise le
déplacement des données du système source vers le
système cible. Par exemple, le transport s'effectue :
ü D'un système source vers l'entrepôt ou
vers une zone de préparation (zone intermédiaire de
stockage) ;
ü D'une zone de préparation vers
l'entrepôt ;
ü de l'entrepôt vers un Data mart ;
ü etc.
La transformation est la tâche la plus
complexe et qui demande beaucoup de réflexion.
Voici les grandes fonctionnalités de transformation
:
- Nettoyage des données
- Standardisation des données.
- Conformité des données.
- gestion des tables de fait
- gestion des dimensions
- affectations des clés de substitution (surrogate
key)
- gestion de l'évolution lente (Slowly changing
dimension)
- gestion des faits arrivants en retard ( Late arriving
fact)
- gestion des lookups
c. Chargement
Le chargement permet de transférer
les données vers leur destination finale. 3 cas de figures se
présentent, celons l'architecture mise en place.
Ø De charger les données dans
l'entrepôt de données :si la politique retenue a
été de construire un entrepôt de données avec une
base de données, alors les données seront chargées dans
l'entrepôt. Cette approche est proche à celle de Bill Inmon. Il
sera dés lors possible d'utiliser des fonctionnalités analytiques
comme Oracle le permet.
Ø De les charger dans des cubes de
données la deuxième possibilité est de
charger les données directement dans des cubes de données sans
les stocker dans un DW. Cette approche est certainement la plus proche à
celle de Ralph Kimball. Un bon exemple est l'utilisation directe des cubes de
données.
Ø le mode hybride :la
troisième possibilité est celle qui offre le plus d'avantages
mais demande par contre plus d'effort. Le chargement des données
s'effectue à la fois sur le data warehouse et les data marts
: Un premier chargement des données dans un
entrepôt de données.
Un deuxième chargement dans des cubes de
données : par contre cette approche ajoute une charge de travail
très considérable pour l'équipe de développement
(Aucun impact sur les utilisateurs) :Une base de données à
créer et à maintenir,un exercice de réflexion sur le
modèle de données du data warehouse, un autre exercice de
réflexion sur le modèle des méta-données.
Ø La transformation de données consiste
à :
Ø la constitution des historiques ;
Ø l' homogénéisation des nomenclatures
des différentes sources ;
Ø l' i ntégration de données
externes ;
Ø Filtrage, agrégation, mise à la
granularité ;
Ø Nettoyage, suppression d'erreurs.
Le schéma suivant illustre une transformation de
données par étapes successives avec création d'une table
intermédiaire après chaque modification.
Quand au chargement de données, il consiste à
insérer les données dans le Data Warehouse, elles sont ensuite
disponibles pour les différents outils d'analyse et de
présentation que son le Data mining, l'analyse multidimensionnelle OLAP,
les analyses géographiques, les raquetteurs et autres reportings.
I.8 LE DATA MART
Un Data Mart est un entrepôt qui stock des
données provenant de systèmes opérationnels ou d'autre
sources, conçu pour répondre aux besoins spécifiques d'un
département ou d'un groupe d'utilisateurs en termes d'analyse, de
contenu, de présentation et de facilité d'emploi. Les
informations y sont stockées dans un format qui est familier aux
utilisateurs. Un Data Mart ressemble en fait à un Data Warehouse sauf
qu'il est moins générique. Une approche courante consiste
à maintenir des informations détaillées au niveau du Data
warehouse et à les synthétiser dans un Data mart pour chaque
groupe ou département fonctionnel. Un autre choix de conception consiste
à créer des Data marts pour chaque département puis
à fusionner ultérieurement ces données dans
l'entrepôt global. Chacune de ces méthodes présente
l'avantage de centraliser les informations pour les utilisateurs finaux.
Les caractéristiques propres aux Data Mart
sont :
Ø Les données sont spécialisées
pour un groupe ou département particulier ;
Ø Ils sont conçus pour un accès
facile ;
Ø Le temps de réponse est optimal pour un volume
de requêtes moindre ;
Ø Les différents Data Marts indépendants
peuvent être dynamiquement couplé pour se métamorphoser en
Data Warehouse ;
Ø Les Data Marts sont plus flexibles que les Data
Warehouse.
En raison de la nature simplifiée et
spécialisée des Data Marts, les entreprises choisissent ces
magasins de données comme solution rapide à leurs besoins en
matière d'aide à la décision.
Data Warehouse versus Data Mart
|
Data Warehouse
|
Data Mart
|
|
Utilisation globale de l'entreprise
|
Utilisé par un département ou une unité
fonctionnelle
|
|
Difficile et plus long à implémenter
|
Plus facile et rapide à implémenter
|
|
Volume de données plus important
|
Volume de données plus petit et
spécialisé
|
|
Développé sur la base de données
actuelle
|
Développé sur les bases des besoins
utilisateurs
|
Les Data Marts représentent de toute évidence
une réponse rapide aux besoins des différents départements
de l'entreprise. Leur coût moindre et leur facilité d'emploi
permettent une implémentation rapide et un retour à
l'investissement presque immédiat. Il faut toute fois être prudent
lorsque des Data marts sont ainsi crées pour plusieurs divisions. Ces
dernières utilisent souvent des représentations
différentes de certains concepts de gestion. Par exemple, les
départements finances et marketing peuvent tous deux effectué un
suivi des ventes réalisées par l'entreprise, mais défini
différemment ce concept. Plus tard, si un employé du marketing a
besoin de recueillir certaines informations à partir du Data Marts des
finances, l'entreprise sera confrontée à un problème. Par
conséquent, une vision unifiée est nécessaire même
pour concevoir des Data marts par département.
I.9 OLAP
I.9.1 Introduction
OLAP signifie « On
Line Analytical
Processus » repose sur une base de données
multidimensionnelle, destinée à exploiter rapidement les
dimensions d'une population de données. Le modèle OLAP sera celui
du Data Warehouse, il sera construit pour sélectionner et croiser
plusieurs données provenant des sources diverses afin d'en tirer une
information implicite. Ceci a évolué pour aboutir à une
méthode d'analyse permettant aux décideurs un accès rapide
et de manière pertinente présentée sous divers angles,
dimensions sous forme de cube. L'outil OLAP repose sur la restructuration et le
stockage des données dans un format multidimensionnel issues de fichiers
plats ou de bases de données relationnelles. Ce format multidimensionnel
est connu sous le nom d'hyper cube, ce dernier organise les données le
long de dimensions. Ainsi, les utilisateurs analysent les données
suivant les axes propres à leur métier. OLAP est un mode de
stockage prévu pour l'analyse statistique des données. Une base
de données OLAP peut se représenter comme un cube à N
dimensions où toutes les intersections sont pré
calculées.
I.9.2 les différents
outils OLAP
1. Multidimensionnel OLAP (MOLAP)
Il est plus facile et plus cher à mettre en place, il
est conçus exclusivement pour l'analyse multidimensionnelle avec un mode
de stockage optimisé par rapport aux chemins d'accès
prédéfinis. MOLAP repose sur un moteur spécialisé,
qui stocke le données dans format tabulaire propriétaire (Cube).
Pour accéder aux données de ce cube, on ne peut pas utiliser le
langage de requête SQL, il faut utiliser une API
spécifique.
2. Relationnal OLAP (ROLAP)
Il est plus facile et moins cher à mettre en place, il
est moins performant lors des phases de calculs. En effet, il fait appel
à beaucoup de jointure et donc les traitements sont plus
conséquents. Il superpose au dessus des SGBD/R bidimensionnels un
modèle qui représente les données dans un format
multidimensionnel. ROLAP propose souvent un composant serveur, pour optimiser
les performances lors de la navigation dans les données. Il est
déconseillé d'accéder en direct à des bases de
données de production pour faire des analyses tout simplement pour des
raisons des performances.
3. Hybride OLAP (HOLAP)
HOLAP est une solution hybride entre les deux (MOLAP et
ROLAP) qui recherche un bon compromis au niveau du coût et de la
performance. HOLAP désigne les outils d'analyse multidimensionnelle qui
récupèrent les données dans de bases relationnelles ou
multidimensionnelles, de manière transparente pour l'utilisateur. Ces
trois notions se retrouvent surtout lors du développement des solutions.
Elles dépendent du software et hardware. Lors de la
modélisation, on ne s'intéresse qu'à concevoir une
modélisation orientée décisionnelle, indépendamment
des outils utilisés ultérieurement.
I.10 LA NAVIGATION DANS LES
DONNEES
Les différentes possibilités de navigation dans
les bases de données sont :
I.10.1 Drill-Down et Drill-Up
Le Drill-Down et Drill-up désigne la faculté
d'aller du niveau global vers le niveau détaillé, et inversement.
Ce mécanisme est totalement basé sur la notion de
hiérarchie.
Chacun des axes d'analyse se décompose en attributs
reliés entre eux par des relations père /fils. Une dimension
doit normalement pouvoir comporter plusieurs hiérarchies. Par exemple,
la dimension produits peut contenir une hiérarchie
marque-article et une hiérarchie secteur-segment-article.
Le mécanisme de Drill-Down se fera ainsi de la marque vers
l'article et du secteur vers le segment puis vers l'article. La mise en oeuvre
de cette fonctionnalité n'est cependant pas toujours aussi simple.
I.10.2 Data Surfing
Le Data Surfing est la possibilité de laissée
à l'utilisateur de circuler librement, de manière intuitive et
ergonomique dans un modèle dimensionnel, au-delà d'un simple
Drill-Down ou Slice and dice. L'utilisateur peut alors modifier dynamiquement
ses axes d'analyse ou appliquer un nouveau filtre à ses données.
Ces mécanismes s'appliquent sur le modèle défini soit par
l'administrateur, soit par l'utilisateur.
I.10.2 Conclusion
Ainsi, un data warehouse correctement alimenté permet
aux décideurs, au service de marketing d'établir des statistiques
d'évolution ou de construire des plans. Cela est rendu possible par le
fait qu'un data warehouse regroupent l'ensemble des données de
l'entreprise. Celles-ci sont Historisées et non modifiable. Mais
extraire une synthèse à partir d'un tel volume de donnée
(souvent de l'ordre de plusieurs téraoctets) n'ai pas chose
aisée. Il faut une architecture du système adéquate. Les
données peuvent être séparées par vue métier
au sein de mini data warehouse nommé data marts et couplé avec un
mode de stockage en cube OLAP. Chaque dimension d'un cube OLAP contenant une
famille de donnée. Mais cela ne suffit pas, des outils de recherche
spécialisés dans la recherche et l'élaboration de
schéma logique (corrélation sur les évolutions des
données ) doivent être utilisés.
CHAPITRE II: LES TECHNIQUES DE
DATA MINING [1], [8], [11], [10],[12], [14]
II.1 INTRODUCTION
Le terme Data mining est souvent employé pour
désigner un ensemble d'outils permettant aux utilisateurs
d'accéder aux données de l'entreprise et des analyses. Les
outils d'aide à la décision, qu'ils soient relationnels ou OLAP,
laissent l'initiative à l'utilisateur de choisir les
éléments qu'il veut observer ou analyser. Au contraire, dans le
cas du data mining, le système a l'initiative et découvre
lui-même les associations entre les données, sans que
l'utilisateur ait à lui dire de rechercher plutôt dans telle ou
telle direction ou à poser des hypothèses. Les modèles
classiques de recherche d'informations ne sont pas adaptés pour traiter
des masses gigantesques de données, souvent
hétérogènes. C'est ce constat qui a permis au data mining
d'émerger et vulgariser les méthodes d'analyse.
Le data mining (ou la fouille de données) a pour objet
l'extraction d'un savoir à partir de grandes quantités de
données, par des méthodes automatiques ou semi-automatiques. La
fouille de données repose sur un ensemble de fonctions mais aussi sur
une méthodologie de travail.
Le terme de data mining signifie littéralement
exploitation des données. Comme dans toute exploitation, le but
recherché est de pouvoir extraire de la richesse. Ici, la richesse est
la connaissance de l'entreprise. Fort du constat qu'il existe au sein des bases
de données de chaque entreprise une ressource de données
cachées et surtout inexploitée, le data Mining permet de faire
les apparaître, et cela grâce à un certain nombre de
techniques spécifiques. Nous appellerons data mining l'ensemble des
techniques qui permettent de transformer les données en connaissances.
Le périmètre d'exploitation du data mining ne se limite pas
à l'exploitation des Data warehouse. Il veut d'être capable
d'exploiter toutes bases de données contenant de grandes
quantités de données telles que des bases relationnelles, des
entrepôts de données mais également des sources plus ou
moins structurées comme internet. Dans ces cas, il faut néanmoins
construire une base de données ou un entrepôt de données
qui sera dédié à l'analyse.
Le data mining est un processus itératif qui met en
oeuvre un ensemble de techniques hétéroclites tel que le data
warehouse , de la statistique, de l'intelligence artificielle, de l'analyse des
données et des interfaces de communication homme - machine. Le
résultat du datamining peut se présenter sous différent
format : texte plat, tableau, graphique...
Le datamining est un ensemble d'outils d'analyse
d'entrepôt de données et de cube apportant aux décideurs
des éléments supplémentaire de prise de décisions
qui ne sont pas forcement visible aux premiers abords.
II.1.1 Définition
La fouille de données consiste à rechercher et
extraire de l'information (utile et inconnue) de gros volumes de données
stockées dans des bases ou des entrepôts de données.
L'exploration se fait sur l'initiative du système, par
un utilisateur métier, et son but est de remplir l'une des tâches
suivantes : classification, estimation, prédiction, regroupement par
similitudes, segmentation (ou clustérisation), description et, dans une
moindre mesure, l'optimisation.
II.1.2 Triple objectif du data
mining
Ø Expliquer :le data mining
pourra tenter d'expliquer un événement ou un incident
indiscernable. Par la consultation des informations contenues dans
l'entrepôt de données de l'entreprise, on peut être en
mesure de formuler la question suivante :pour qu'elle raison perd-t-on des
clients pour tel produit spécifique dans telle région? tout en se
basant sur des données collectées ou des mises en signification
de paramètres liés, le data mining va essayer de trouver un
certain nombre d'explication à cette question. Le Data Mining va aider
à trouver des hypothèses d'explications.
Ø Confirmer : le data Mining
aidera à confirmer un comportement ou une hypothèse.
Dans le cas où le décideur aurait un doute concernant
une hypothèse, le data Mining pourra tenter de confirmer cette
hypothèse en la vérifiant en appliquant des méthodes
statistiques ou d'intelligence artificielle.
Ø Explorer :enfin, le data mining
peut explorer les données pour découvrir un lien "inconnu" jusque
là. Quand le décideur n'as pas d'hypothèse ou
d'idée sur un fait précis, il peut demander au système de
proposer des associations ou des corrélations qui pourront aboutir a une
explication. Il est utopique de croire que le data mining pourrait remplacer la
réflexion humaine. Le data mining ne doit être vu et utiliser
uniquement en tant qu'aide à la prise de décision. Par contre,
l'informatique décisionnelle dans son ensemble, et plus
particulièrement le data mining permet de suggérer des
hypothèses. La décision finale appartiendra toujours au
décideur.
II.2 LES DIFFERENTES ETAPES
D'EXTRATION DE CONNAISSANCES
a. Etape 1 : identification du (ou des)
problème(s) :les systèmes de Business
Intelligence ne se construisent sur des données techniques,
mais sur la compréhension des objectifs métiers de l'entreprise.
Cette recherche préliminaire aboutit à la définition de
problèmes auxquels la fouille de données tentera d'apporter une
réponse.
b. Etape 2 : rassemblement de
données :la plupart du temps, les projets data mining
assemblent une grande quantité de données en combinant plusieurs
sources de données hétérogènes. Lorsque la source
n'est pas directement un entrepôt de données, une première
phase consiste à repartir les données brutes et à les
stocker localement sous forme d'une base de données.
c. Etape 3 : préparation des
données : dans la réalité, les
données extraites doivent être filtrées, mise en forme,
traitées avant de pouvoir être exploitées par les
algorithmes de data mining. La préparation des données est donc
un point crucial, et les développeurs doivent pouvoir s'appuyer sur les
fonctionnalités d'une base de données pour effectuer les
traitements préliminaires tels que l'élimination des valeurs
erronées ou régénération de valeurs manquantes.
d. Etape 4 : modélisation des
données
e. Les fonctions de data mining se répartissent en deux
grandes catégories :
Ø Les fonctions supervisées :
elles travaillent avec une cible, permettent de prédire une
valeur. La modélisation et la décision se fondent sur
l'observation du passé. Les fonctions supervisées sont aussi
désignées par les termes fonctions distinctes ou fonctions
prédictives.
Ø Les fonctions non
supervisées : elles détectent des relations, des
analogies ou concordances entre les données. Ces fonctions n'utilisent
aucune cible. Ces fonctions s'appuient sur le clustering
hiérarchique, les centres mobiles, les règles
d'association, etc. pour extraire des similitudes dans les données. Les
fonctions non supervisées sont aussi désignées par les
termes fonctions indirectes ou fonctions descriptives.
Ø Etape 5 : évaluation des
modèles : l'évaluation du (ou des modèle(s)
est une étape importante qui permet de vérifier que les questions
posées lors de l'étape 1 ont bien trouvé une
réponse fiable. Une fois les modèles construits, il peut
s'avérer nécessaire de revoir les étapes 2 et 3 afin
d'affiner la collecte et la préparation des données. Le
succès de cette étape conditionne le déploiement.
Ø Etape 6 :
déploiement : après avoir été
validés, les modèle data mining sont déployés dans
leurs domaines d'application respectifs. Le déploiement couvre des
domaines aussi divers que la production de rapports ou l'automatisation de
l'acquisition de données dans l'entrepôt.
II.3 PRINCIPALES METHODES DU DATA
MINING
Pour arriver à exploiter ces quantités
importantes de données, le data mining utilise des méthodes
d'apprentissages automatiques. Une amalgame est faite à tord entre
toutes ces méthodes. Ces méthodes sont de deux types : les
méthodes descriptives et les méthodes prédictives, selon
qu'il existe ou non une variable "cible" que l'on cherche à
expliquer.
II.3.1 Méthodes descriptive
Le principe de ces méthodes est de pouvoir mettre en
évidence les informations présentes dans le data warehouse mais
qui sont masquées par la masse de donnée.
Parmi les techniques et algorithmes utilisés dans
l'analyse descriptive, on cite :
Ø Analyse factorielle (ACP et ACM)
Ø Méthode des centres mobiles
Ø Classification hiérarchique
Ø Classification neuronale (réseau de
Kohonen)
Ø Recherche d'association
II.3.2 Méthode
prédictive
Contrairement à l'analyse descriptive, cette technique
fait appels à de l'intelligence artificielle . L'analyse
prédictive, est comme son nom l'indique une technique qui va essayer de
prévoir une évolution des événements en se basant
sur l'exploitation de données stockés dans le data warehouse.
En effet, l'observation et l'historisation des
événements peuvent permettre de prédire une suite logique.
Le meilleur exemple est celui des prévisions
météorologiques qui se base sur des études des
évolutions météorologiques passées. En marketing,
l'objectif est par exemple de déterminer les profils d'individus
présentant une probabilité importante d'achat ou encore de
prévoir à partir de quel moment un client deviendra
infidèle.
Parmi les techniques et algorithmes utilisés dans
l'analyse prédictive, on cite :
Ø Arbre de décision
Ø Réseaux de neurones
Ø Régression linéaire
Ø Analyse discriminante de Fisher
Ø Analyse probabiliste
II.4 LES TACHES DU DATA MINING
Contrairement aux idées reçues, le data mining
n'est pas le remède miracle capable de résoudre toutes les
difficultés ou besoins de l'entreprise. Cependant, une multitude de
problèmes d'ordre intellectuel, économique ou commercial peuvent
être regroupés, dans leur formalisation, dans l'une des
tâches suivantes :
- Classification,
- Estimation,
- Prédiction,
- Groupement par similitudes,
- Segmentation (ou clusterisation),
- Description,
- Optimisation.
Afin de lever toute ambiguïté sur des termes qui
peuvent paraître similaires, il semble raisonnable de les
définir.
II.4.1 La classification
La classification se fait naturellement depuis
déjà bien longtemps pour comprendre et communiquer notre vision
du monde (par exemple les espèces animales, minérales ou
végétales).
« La classification consiste à examiner des
caractéristiques d'un élément nouvellement
présenté afin de l'affecter à une classe d'un ensemble
prédéfini. »
Dans le cadre informatique, les éléments sont
représentés par un enregistrement et le résultat de la
classification viendra alimenter un champ supplémentaire.
La classification permet de créer des classes
d'individus (terme à prendre dans son acception statistique). Celles-ci
sont discrètes : homme / femme, oui / non, rouge / vert / bleu, ...
Les techniques les plus appropriées à la
classification sont :
- les arbres de décision,
- le raisonnement basé sur la mémoire,
- éventuellement l'analyse des liens.
II.4.2 Estimation
Contrairement à la classification, le résultat
d'une estimation permet d'obtenir une variable continue. Celle-ci est obtenue
par une ou plusieurs fonctions combinant les données en entrée.
Le résultat d'une estimation permet de procéder aux
classifications grâce à un barème. Par exemple, on peut
estimer le revenu d'un ménage selon divers critères (type de
véhicule et nombre, profession ou catégorie socioprofessionnelle,
type d'habitation, etc ...). Il sera ensuite possible de définir des
tranches de revenus pour classifier les individus.
Un des intérêts de l'estimation est de pouvoir
ordonner les résultats pour ne retenir si on le désire que les n
meilleures valeurs. Cette technique sera souvent utilisée en marketing,
combinée à d'autres, pour proposer des offres aux meilleurs
clients potentiels. Enfin, il est facile de mesurer la position d'un
élément dans sa classe si celui-ci a été
estimé, ce qui peut être particulièrement important pour
les cas limitrophes.
La technique la plus appropriée à l'estimation
est : les réseaux de neurones.
II.4.3 La prédiction
La prédiction ressemble à la classification et
à l'estimation mais dans une échelle temporelle
différente. Tout comme les tâches précédentes, elle
s'appuie sur le passé et le présent mais son résultat se
situe dans un futur généralement précisé. La seule
méthode pour mesurer la qualité de la prédiction est
d'attendre !
Les techniques les plus appropriées à la
prédiction sont :
Ø L'analyse du panier de la ménagère
Ø Le raisonnement basé sur la mémoire
Ø Les arbres de décision
Ø les réseaux de neurones
II.4.4 Le regroupement par
similitude
Le regroupement par similitudes consiste à grouper les
éléments qui vont naturellement ensembles. La technique la plus
appropriée au regroupement par similitudes est : L'analyse du panier de
la ménagère
II.4.5 L' Analyse des
clusters
L'analyse des clusters consiste à segmenter une
population hétérogène en sous-populations
homogènes. Contrairement à la classification, les sous
populations ne sont pas préétablies.
La technique la plus appropriée à la
clustérisation est : L'analyse des clusters
II.4.6 La description
C'est souvent l'une des premières tâches
demandées à un outil de data mining. On lui demande de
décrire les données d'une base complexe. Cela engendre souvent
une exploitation supplémentaire en vue de fournir des explications.
La technique la plus appropriée à la description
est : L'analyse du panier de la ménagère
II.4.7 L' Optimisation
Pour résoudre de nombreux problèmes, il est
courant pour chaque solution potentielle d'y associer une fonction
d'évaluation. Le but de l'optimisation est de maximiser ou minimiser
cette fonction. Quelques spécialistes considèrent que ce type de
problème ne relève pas du data mining.
La technique la plus appropriée à l'optimisation
est : Les réseaux de neurones.
II.5 LA CONNAISSANCE
II.5.1 Définition
La connaissance peut être considérée
comme une combinaison d'intuitions, de modèles, de méthodes de
règles de gestion, de programme et de principes d'utilisation qui
guident les décisions et les actions.
II.5.2 La découverte de
connaissances
Il s'agit d'une approche ascendante : cette technique
consiste à partir des données pour tenter d'en extraire une
information pertinente et inconnue. La découverte de connaissances est
l'approche du data mining la plus significative et la plus souvent mise en
avant. On distinguera la découverte de connaissances dirigée et
non dirigée.
Nota : La découverte de connaissances non
dirigée sert à reconnaître les relations exprimées
par les données tandis que la découverte dirigée permet
d'expliquer ces relations une fois qu'elles ont été
trouvées.
Ø La découverte de connaissances non
dirigée :cette technique est
également appelée apprentissage sans supervision. Historiquement,
c'était la vocation des logiciels de data mining. On fournit au logiciel
une base de données et celui-ci recherche des structures significatives
et retourne un ensemble de connaissances. Celles-ci sont
généralement exprimées sous forme de règles, du
type :si achat de riz ET de vin blanc, alors achat de
poisson. A chaque règle est associé un
indicateur de confiance (ici : nombre de personnes ayant acheté riz, vin
blanc et poisson divisé par le nombre de personnes ayant acheté
riz et vin blanc) qui permet de quantifier la fiabilité de la
règle. Une valeur de 0.84 signifie que 84 % des gens qui ont
acheté du riz et du vin blanc ont acheté du poisson.
Ce critère n'est pas suffisant car il faut en outre que
l'effectif soit significatif. En effet, si une règle ne concerne qu'un
ou deux individus même avec 100 % de confiance, elle devra être
rejetée car non suffisamment significative.Les règles
d'association peuvent également se dérouler dans le temps : telle
action à un instant t entraînera tel résultat à un
autre instant t'. Il faut alors posséder suffisamment de données
Historisées pour avoir une bonne fiabilité des résultats.
La technique qui consiste à prévoir le comportement d'une
variable dans le temps en fonction du passé s'appelle le
« forecasting ».
Ø Méthodologie de connaissances non
dirigée :la découverte de connaissances non
dirigée se déroule en suivant les étapes suivantes :
- Identifier les sources de données disponibles
- Préparer les données pour l'analyse
- Construire et instruire le programme informatique
- Evaluer le modèle informatique
- Appliquer le modèle informatique à de
nouvelles données
- Identifier les cibles potentielles pour la découverte
de connaissances dirigée
- Générer de nouvelles hypothèses
à tester
a. Identifier les sources
de données disponibles
Les processus de découvertes de connaissances sont
basés sur le fait que la connaissance ou la réponse aux questions
que l'on se pose se trouve dans les données. Par conséquent, la
qualité des données est la première exigence de ce type
d'analyse.
L'idéal est de travailler à partir des
données archivées dans l'entreprise. Mais celles-ci sont
prévues généralement pour la production, avec des formats
adaptés aux meilleurs temps de réponse, voire même
conservés sur des bandes magnétiques. Il va donc falloir
identifier les données, les localiser, identifier les formats et
codages, ... Un travail organisationnel et logistique important est
nécessaire pour disposer des données sous une forme utile en vue
de la découverte de connaissances.
b. Préparer les
données pour l'analyse
Après le travail de repérage et
d'identification décrit dans l'étape précédente, il
faut préparer les données pour l'analyse. Cette étape est
de loin la plus importante car la qualité des résultats obtenus
est très fortement liée à la qualité de cette
préparation.
On distinguera plusieurs étapes dans cette
préparation : regrouper les données et les transformer. Enfin,
distribuer les donnée
1°) Regrouper les
données et les transformer
C'est la première étape qui consiste à
regrouper, rapatrier, transcoder, transformer les données. Il faut faire
face aux incompatibilités entre les différents systèmes
informatiques de l'entreprise, importer les données externes, regrouper
l'ensemble dans un format propice à l'exploitation par une application
de data mining.
Parfois, on souhaitera agréger les données ou
les regrouper.
Enfin, il est souvent utile de rajouter des champs
supplémentaires, issus de résultats de calculs ou transformations
depuis des champs existants. Ceci est particulièrement vrai si l'on
cherche des relations entre champs ou pour suivre des évolutions dans le
temps. A titre d'exemple, on pourrait citer :
-Index d'obésité = taille ² / poids
-Densité = population / surface
Ces travaux sont prévus voire automatisés dans
le cadre de la mise en oeuvre d'un data warehouse.
2°) Distribuer les
données
Une fois les données obtenues, il va falloir les
distribuer en trois parties :
-Ensemble d'apprentissage
-Ensemble de test
-Ensemble d'évaluation
Ces trois ensembles devront être distincts (n'avoir
aucun enregistrement en commun)
L'ensemble d'apprentissage est utilisé pour construire
le modèle initial. C'est depuis cet ensemble que le système va
calculer ses différents paramètres.
Une fois les paramètres calculés, il faut
vérifier comment ils se comportent sur l'ensemble de test. Celui-ci va
permettre d'ajuster les valeurs trouvées à l'étape
précédente et les rendre moins sensibles à l'ensemble
d'apprentissage.
Enfin, les paramètres seront testés sur
l'ensemble d'évaluation. Si les résultats obtenus sont proches de
ceux attendus, on pourra alors valider le système. Dans le cas
contraire, il faudra analyser les raisons de cette différence. Pour
mesurer la validité des résultats obtenus, on utilisera les
outils statistiques traditionnels (le khi2 par exemple).
Il faut cependant respecter quelques règles :
Dans une analyse statistique traditionnelle, il est
fréquent de choisir les variables à analyser pour tenter par
exemple de déterminer la corrélation de l'une par rapport
à une autre. De même, on supprime souvent certains champs trop
complexes ou insuffisamment alimentés (valeurs absentes). Dans une
approche de data mining, il est préférable de soumettre
l'ensemble des données et laisser l'outil déterminer
lui-même les données utiles car les champs absents ou complexes
peuvent déboucher sur des connaissances importantes.
II.6 LES TECHNIQUES DU DATA
MINING
Derrière ces analyses se positionnent des outils
basés sur des techniques différentes. Nous vous proposons une
présentation des plus importante de ces techniques.
- Analyse du panier de la ménagère
- Raisonnement basé sur la mémoire
- Détection automatique de clusters
- Analyse des liens
- Arbres de décision
- Réseaux de neurones
- Découverte de règles
- Signal Processing
- Fractales
II.6.1 Analyse du panier de la
ménagère
L'analyse du panier de la ménagère est un moyen
de trouver les groupes d'articles qui vont ensembles lors d'une transaction.
C'est une technique de découverte de connaissances non dirigée
(de type analyse de clusters) qui génère des règles et
supporte l'analyse des séries temporelles (si les transactions ne sont
pas anonymes). Les règles générées sont simples,
faciles à comprendre et assorties d'une probabilité, ce qui en
fait un outil agréable et directement exploitable par l'utilisateur
métier.
Exemple : Le client qui achète de la peinture
achète un pinceau
Le client qui achète du thé achète du
sucre
II.6.2 Analyse des liens
L'analyse des liens est une technique de description qui
s'inspire et repose sur la théorie des graphes. Elle consiste à
relier des entités entre elles (clients, entreprises, ...) par des
liens. A chaque lien est affecté un poids, défini par l'analyse,
qui quantifie la force de cette relation. Cette technique peut être
utilisée pour la prédiction ou la classification mais
généralement une simple observation du graphe permet de mener
à bien l'analyse.
II.6.3 Les arbres de
décision
Les arbres de décision sont utilisés dans le
cadre de la découverte de connaissances dirigée. Ce sont des
outils très puissants principalement utilisés pour la
classification, la description ou l'estimation. Le principe de fonctionnement
est le suivant : pour expliquer une variable, le système recherche le
critère le plus déterminant et découpe la population en
sous populations possédant la même entité de ce
critère. Chaque sous population est ensuite analysée comme la
population initiale. Le modèle rendu est facile à comprendre et
les règles trouvées sont très explicites. Ce
système est donc très apprécié.
Le but de cette technique est de créer un arbre de
décision procédant a une analyse critère par
critère. La détermination de ces critères significatifs
est faite selon les poids statistiques des valeurs. L'outil de data mining va
parcourir les différents critères possibles, dont la
finalité sera de trouver des liens entre les chemins qui ont une
signification par rapport à la problématique donnée.
On donne un ensemble X de N dont les éléments
sont notés xi et dont les P attributs sont quantitatifs. Chaque
élément de X est étiqueté, c'est-à-dire
qu'il lui est associé une classe ou un attribut cible que l'on note y
appartenant à Y.
A partir de ce qui précède, on construit un
arbre dit « de décision » tel que :
- chaque noeud correspond à un test sur la valeur d'un
ou plusieurs attributs ;
- chaque branche partant d'un noeud correspond à une ou
plusieurs valeurs de ce test ;
Les arbres de décisions ont pour objectif la
classification et la prédiction.
Leur fonctionnement est basé sur un enchaînement
hiérarchique de règles exprimées en langage courant.
Un arbre de décision est une structure qui permet de
déduire un résultat à partir de décisions
successives. Pour parcourir un arbre de décision et trouver une solution
il faut partir de la racine. Chaque noeud est une décision atomique.
Chaque réponse possible est prise en compte et permet de se diriger vers
un des fils du noeud. De proche en proche, on descend dans l'arbre
jusqu'à tomber sur une feuille. La feuille représente la
réponse qu'apporte l'arbre au cas que l'on vient de tester.
- Débuter à la racine de l'arbre
- Descendre dans l'arbre en passant par les noeuds de test
- La feuille atteinte à la fin permet de classer
l'instance testée.
Très souvent on considère qu'un noeud pose une
question sur une variable, la valeur de cette variable permet de savoir sur
quels fils descendre. Pour les variables énumérées il est
parfois possible d'avoir un fils par valeur, on peut aussi décider que
plusieurs variables différentes mènent au même sous arbre.
Pour les variables continues il n'est pas imaginable de créer un noeud
qui aurait potentiellement un nombre de fils infini, on doit discrétiser
le domaine continu (arrondis, approximation), donc décider de segmenter
le domaine en sous ensembles. Plus l'arbre est simple, et plus il semble
techniquement rapide à utiliser. En fait, il est plus intéressant
d'obtenir un arbre qui est adapté aux probabilités des variables
à tester. La plupart du temps un arbre équilibré sera un
bon résultat. Si un sous arbre ne peut mener qu'à une solution
unique, alors tout ce sous-arbre peut être réduit à sa
simple conclusion, cela simplifie le traitement et ne change rien au
résultat final.
L'algorithme ID3 fut proposé par Quinlan en 1979 afin
de générer des arbres de décisions à partir de
données. Imaginons que nous ayons à notre disposition un ensemble
d'enregistrements. Tous les enregistrements ont la même structure,
à savoir un certain nombre de paires attribut ou valeur. L'un de ses
attributs représente la catégorie de l'enregistrement. Le
problème consiste à construire un arbre de décision qui
sur la base de réponses à des questions posées sur des
attributs non cibles peut prédire correctement la valeur de l'attribut
cible. Souvent l'attribut cible prend seulement les valeurs vrai, faux ou
échec, succès.
Les principales idées sur lesquels repose ID3 sont les
suivantes :
Dans l'arbre de décision chaque noeud correspond
à un attribut non cible et chaque arc à une valeur possible de
cet attribut. Une feuille de l' arbre donne la valeur escomptée de
l'attribut cible pour l'enregistrement testé décrit par le chemin
de la racine de l'arbre de décision jusqu'à la feuille.
Dans l'arbre de décision, à chaque noeud doit
être associé l'attribut non cible qui apporte le plus
d'information par rapport aux autres attributs non encore utilisés dans
le chemin depuis la racine. (Critère d'un bon arbre de
décision)
L'entropie est utilisée pour mesurer la
quantité d'information apportée par un noeud. (Cette notion a
été introduite par Claude Shannon lors de ses recherches
concernant la théorie de l'information qui sert de base à
énormément de méthodes du data mining.)
Un arbre de décision peut être exploité de
différentes manières :
Ø En y classant de nouvelles données (un noeud
racine par lequel entre les enregistrements),
Ø En faisant de l'estimation d'attribut,
Ø En extrayant un jeu de règles de
classification concernant l'attribut cible,
Ø En interprétant la pertinence des attributs de
noeuds feuilles qui correspondent à un classement.
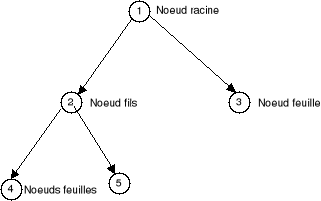
Fig.4 Les arbres de
décision
A. L' Algorithme de CART
Cet algorithme a été publié en 1984 par
L.Briemen. Il est utilisé dans de nombreux outils du marché.
Processus
Ø Trouver la première bifurcation,
Ø Développer l'arbre complet,
Ø Mesurer le taux d'erreur à chaque noeud,
Ø Calculer le taux d'erreur de l'arbre entier,
Ø Elaguer,
Ø Identifier les sous-arbres,
Ø Evaluer les sous-arbres,
Ø Evaluer le meilleur sous-arbre.
La première bifurcation est celle qui divise le mieux
les enregistrements en groupes. Ainsi pour déterminer le critère
qui effectuera le meilleur partage entre les éléments, un indice
de diversité est calculé, selon la formule suivante :
Max. de : diversité (avant division) -
(diversité fils gauche + diversité fils droit)
Il existe différents modes de calcul pour l'indice de
diversité :
Ø Min. (Probabilité(c1),
Probabilité(c2)),
Ø 2 Probabilité(c1)Probabilité(c2),
Ø
(Probabilité(c1)logProbabilité(c1))+Probabilité(c2)logProbabilité(c2))
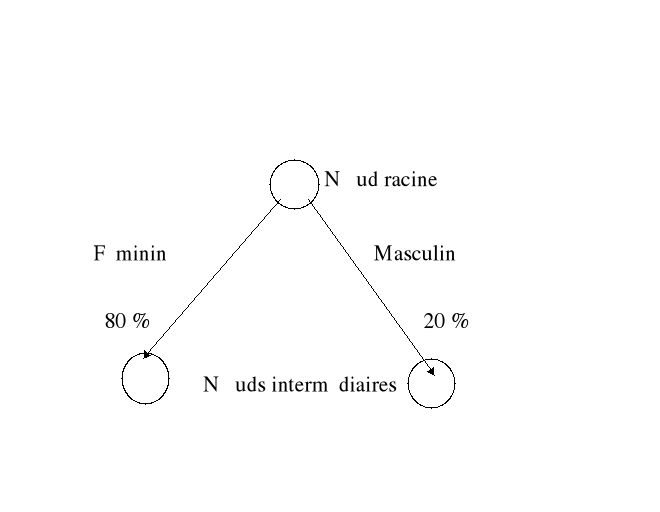
Fig : 5 L' Algorithme de
CART
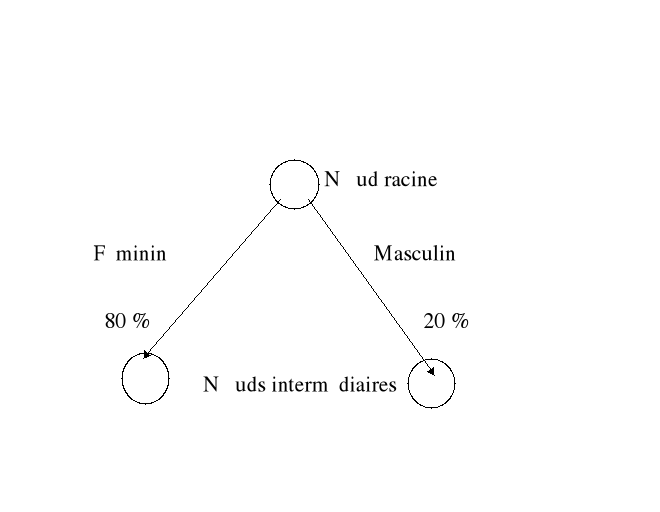
Une fois la première bifurcation établie, nous
avons donc le noeud racine qui se sépare en deux. L'étape
suivante est donc de développer l'arbre complet en divisant de la
même façon les nouveaux noeuds crées, et ainsi de suite
tant que le résultat de la division a une valeur significative. Le
dernier noeud étant le noeud feuille qui donne le classement final d'un
enregistrement.
L'arbre résultant n'est pas obligatoirement le
meilleur, la prochaine étape est de calculer le taux d'erreur pour
chaque noeud. Si nous supposons que 11 enregistrements sur 15 sont
classés correctement d'après l'ensemble d'apprentissage, la
probabilité pour ce noeud est de 11/15 soit 0,7333. Le taux d'erreur
attribué est de 1 - 0,7333 = 0,2667.
Le calcul du taux d'erreur de chaque noeud étant fait,
il est possible de calculer le taux d'erreur de l'arbre entier soit :
t : taux d'erreur d'un noeud
P : probabilité d'aller au noeud
Taux d'erreur de l'arbre = (t * P)
Soit dans l'exemple, avec un taux d'erreur de (15/17) pour le
noeud Masculin
((11/15) * 0,80) + ((15/17) * 0,20) = 0,763
Le danger de l'arbre de décision, tel qu'il est
constitué à l'issue du premier passage, est que certains noeuds
feuilles ne contiennent pas suffisamment d'enregistrements pour être
significatifs. Il faut élaguer, le plus complexe étant de trouver
la bonne limite à appliquer.
Le choix des branches à supprimer, se fait par
l'intermédiaire du taux d'erreur ajusté d'un arbre qui se
calcule, sur chaque sous arbre possible, comme suit :
Soit le compte des feuilles
Taux d'erreur ajusté = taux d'erreur + compte des
feuilles
Un premier sous arbre est candidat lorsque son taux d'erreur
ajusté devient plus petit ou égal au taux d'erreur ajusté
de tout l'arbre. Toutes les branches, qui n'en font pas partie, sont
élaguées, et le processus recommence ainsi de suite jusqu'au
noeud racine.
Il faut donc maintenant choisir parmi tous les sous arbres
candidats. Pour cela, chaque sous arbre va être exécuter avec un
ensemble de test, celui qui aura le plus petit taux d'erreur sera
considéré comme le meilleur.
Enfin pour contrôler l'efficacité du sous arbre
sélectionné, un ensemble d'évaluation va lui être
soumis. Son taux d'erreur obtenu donnera une estimation des performances de
l'arbre.
Tout d'abord, CHAID utilise pour choisir les bifurcations le
test du chi-2, que l'on ne détaillera pas ici.
Et enfin, contrairement aux autres il ne développe pas
l'arbre complet, pour ensuite l'élaguer, mais tente dès le
premier passage de limiter sa croissance.
B. L'Algorithme ID3
Le principe de l'algorithme ID3 pour déterminer
l'attribut à placer à la racine de l'arbre de décision
peut maintenant être exprimée : rechercher l'attribut qui
possède le gain d'information maximum, le placer en racine, et
itérer pour chaque fils, c'est à dire pour chaque valeur de
l'attribut. Cela étant dit, on peut donner L'ALGORITHME
ID3.
entrées : ensemble d'attributs A;
échantillon E; classe c
début
initialiser à l'arbre vide;
si tous les exemples de E ont la
même classe c
alors étiqueter la racine par
c;
sinon si l'ensemble des attributs A
est vide
alors étiqueter la
racine par la classe majoritaire dans E;
sinon soit a le meilleur
attribut choisi dans A;
étiqueter la racine par
a;
pour toute valeur v
de a
construire une branche
étiquetée par v;
soit Eav l'ensemble des exemples tels
que e(a) = v;
ajouter l'arbre construit par
ID3(A-{a}, Eav, c);
finpour
finsinon
finsinon
retourner racine;
fin
II.6.4 Les réseaux de
neurones
Les réseaux de neurones représentent la
technique de data mining la plus utilisée. Pour certains utilisateurs,
elle en est même synonyme. C'est une transposition simplifiée des
neurones du cerveau humain. Dans leur variante la plus courante, les
réseaux de neurones apprennent sur une population d'origine puis sont
capables d'exprimer des résultats sur des données inconnues. Ils
sont utilisés dans la prédiction et la classification dans le
cadre de découverte de connaissances dirigée. Certaines variantes
permettent l'exploration des séries temporelles et des analyses non
dirigées (réseaux de Kohonen). Le champ d'application est
très vaste et l'offre logicielle importante.
Cependant, on leur reproche souvent d'être une "boite
noire" : il est difficile de savoir comment les résultats sont produits,
ce qui rend les explications délicates, même si les
résultats sont bons.
Donc, Utiliser des technologies d'intelligence artificielle
afin de découvrir par l'apprentissage du moteur des liens non
procéduraux. Ces deux dernières techniques s'appuient sur des
algorithmes mathématiques et tentent à travers des
méthodes d'apprentissage de constituer des logiques non
procédurales.
II.6.4.1 Découverte des
règles
Le but étant de construire une règle logique et
empirique applicable dans un contexte précis. Le principe de cette
technique est double. On peut d'une part demande au système de valider
une règle en la justifiant ou l'invalidant grâce a ses
données, ou bien d'autre part demander au système
d'établir une règle en fonction des données qu'il
possède.
II.6. 4.2 Signal processing
Mise en évidence d'un comportement de données
en les filtrant. Cette technique consiste à appliquer un filtre à
travers une hypothèse afin de faire apparaître un lien entre ces
données.
II.6.4.3 Fractales
Technique se basant sur des algorithmes mathématique.
Composer des segmentations à partir de modèles
mathématiques basés sur des regroupements irréguliers de
données.
CHAPITRE III MODELISATION EN UML
[11],[12], [16], [17]
Ce chapitre a consisté à créer une
représentation simplifiée de l'attrition de la clientèle
dans une entreprise de télécommunication. Nous avons
utilisé la modélisation unifiée qui est l'UML (unified
modeling language). Grâce à l'UML, nous avons
représenté le problème sous forme des diagrammes( use
case, classes, et déploiement) afin de bien évidemment
simuler le problème et le comprendre.
III.1 OBJECTIF DU TRAVAIL
Le but de notre étude est de réduire le cout de
la perte de la clientèle. Sur ce, opérer des classes
homogènes des abonnés par rapport à un critère de
similarité à une période donnée pour dégager
les tendances afin de savoir sur quels facteurs agir pour les
fidéliser. Les abonnés modifiant continuellement leurs
comportements (la structure de leurs dépenses et l'utilisation
de leurs lignes).
Enfin, mettre en place un entrepôt de données et
l'utilisation des outils de datamining pour en dégager des connaissances
pour une prise de décision.
IV.1.1
Diagramme de cas d'utilisation (use case)
Le diagramme de cas d'utilisation recense les besoins des
utilisateurs. En d'autre terme modélise un service rendu par le
système.
Sur ce, l'entreprise Vodacom Congo et les responsables de
marketing en particulier ont besoin de savoir:
Ø Quels sont les abonnés fragiles au vu de leurs
profils d'utilisation du réseau ;
Ø Quelle est la zone géographique la plus
affectée par l'attrition de la clientèle;
Ø Sur quel facteur agir pour modifier les
comportements des abonnés
Ø Repérer les clients fidèles et
infidèles ,
« Étend »
Décideur
comportements
Temps
Le facteur à agir pour modifier les
comportements
Zone géographique fragile ou
rentable
Interroger le système pour connaitre
Les abonnés par rapport à leurs comportements
Antennes
Abonnés
« Inclut »
« Inclut »
« Inclut »
« Étend »
« Inclut »
« Inclut »
« Étend »
« Étend »
« Étend »
« Inclut »
Figure
n° 6 : Diagramme de cas d'utilisation
IV.1.2
Diagramme de classe
Le diagramme de classe exprime la structure statique du
système. Ils déscrivent l'ensemble des classes et leurs
associations.
Ici nous avons 5 entités :
Ø Abonné
Ø Sim
Ø Offre
Ø Zone géographique
SIM
N°tel
Codgéo
Durée apent
Durée apsort
SMSS
SMSE
Nbre jour
Activée()
Désactiver()
ABONNE
N°Tel
Nom
Sexe
Age
adresse
Connecter ()
Non connecter()
AVOIR
1 1 1 1
1...*
LOCALISER
USER
1...*
1
ZONE GEO
Cod_ Zgéo
Désign
Etendu
Enreg ()
Non Enreg ()
1...*
OFFRE
Num
Désign
spécialité
Date
1
LANCER 1...*
PRODUIT
Num
Nom
Sexe
Age
1...*
Figure n°7 : Diagramme de
classe
IV.1.3 Diagramme de
déploiement
Ce diagramme illustre la disposition physique des
différents matériels qui entre dans la composition du
système. La répartition des composants au sein des noeuds et
support des communications entre eux.
Généralement, de nombreuses applications
fonctionnent selon un environnement client/serveur, cela signifie que des
machines clientes (des machines faisant partie du réseau) contactent un
serveur, une machine généralement très puissante en termes
de capacités d'entrée-sortie, qui leur fournit des services. Ces
services sont des programmes fournissant des ressources telles que
données, des fichiers, une connexion et aussi des ressources
matériels. Les services sont exploités par des programmes,
appelés programmes clients, s'exécutant sur les machines
clientes. On parle ainsi de client (client FTP, client de messagerie, etc.)
Ø Serveurs : ordinateurs
spécialisés dans la fourniture et le stockage des ressources
partagées entre les utilisateurs du réseau.
Ø Clients : ordinateurs qui
accèdent aux ressources partagées fournies par un serveur du
réseau

SERVEUR

CLIENT


CLIENT
CLIENT
Figure
n° 8: architecture client serveur
Cette image illustre d'une manière moins technique la
disposition physique des différents matériels qui entre dans la
composition du sytème :
Ø Le client émet une requête
vers le serveur grâce à son adresse IP et le port, qui
désigne un service particulier du serveur.
Ø Le serveur reçoit la demande et répond
(réponse) à l'aide de l'adresse de la machine cliente et son
port.
CHAPITRE IV : APPLICATION
IV. 1 MISE EN PLACE DE L'ENTREPOT
DE DONNEES
Nous avons choisi Business Intelligence Développement
Studio, comme environnement de développement, permettant bien
évidemment de déployer des entrepôts de données avec
Analysis Services de Microsoft.
SQL Server Analysis Services (SSAS) est une plate forme de
développement et d'administration permettant de créer des
applications OLAP (On Line Analytical Processing) et de Datamining. Elle est
incluse dans SQL 2008 et a pour but d'aider les utilisateurs à analyser
les données historiques et à découvrir des
corrélations ou des modèles de comportement entre les
données.
Du coté client, un outil de requetage et filtrage doit
etre installé (Excel ou tout autre outil tiers: Proclarty, Panorama,
Powerplay, Crystal, Report builder, etc.). Du coté serveur, analysis
services doit être installé et correctement
paramétré au niveau de la sécurité afin d'autoriser
l'accès aux données selon le profil des utilisateurs.
Le composant central de l'infrastructure OLAP est le cube
multidimensionnel. Il s'agit d'une de données spécialement
conçue pour permettre un accès immédiat aux données
d'entreprise stockées dans les entrepôts de données.
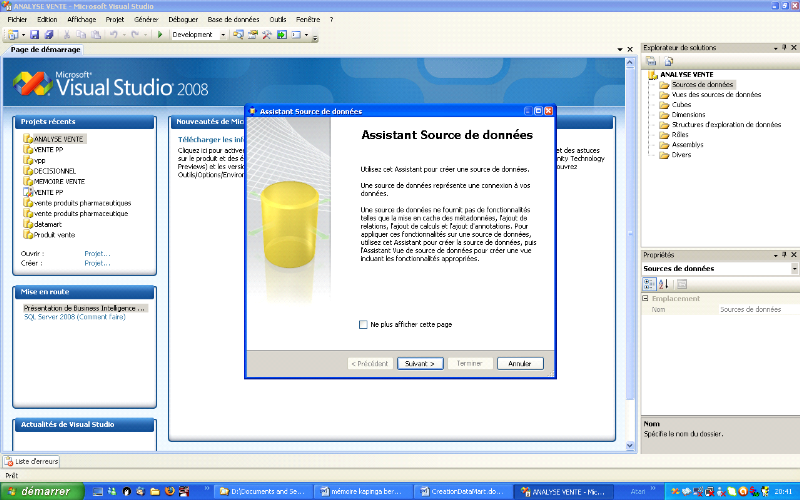
FIG.9 : Création de la
base source en SQL Server avec le management
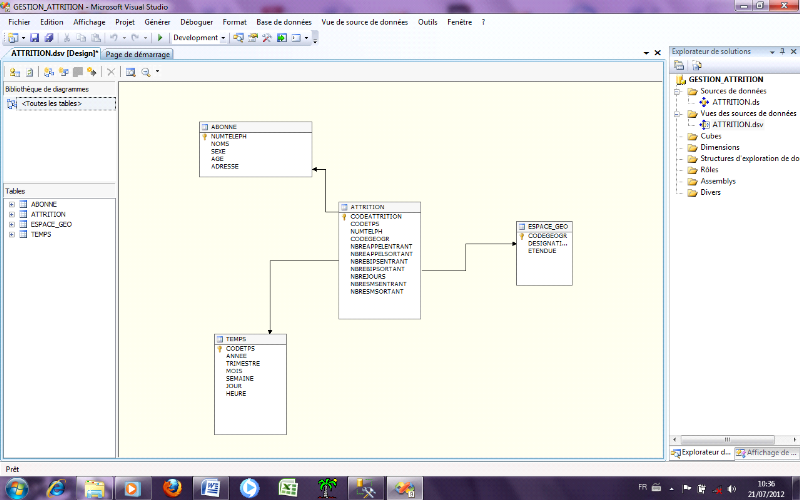
Fig10. Crétion de vues de source de
données avec le visual studio
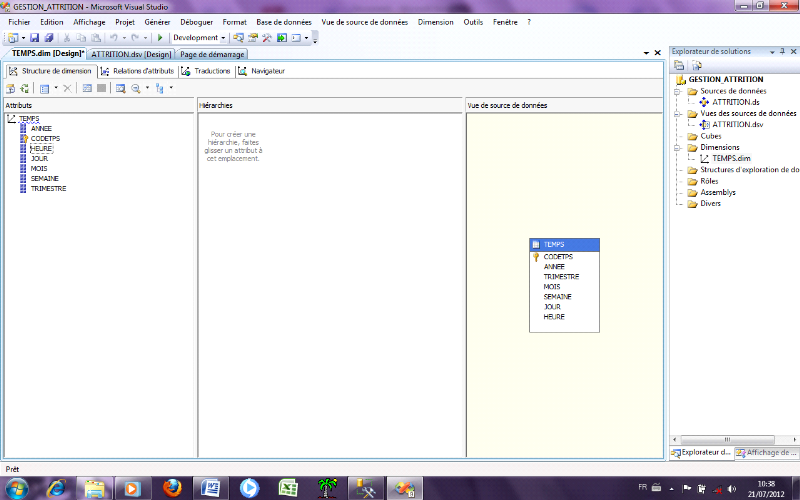
Fig11 : ajout de la dimension
temps
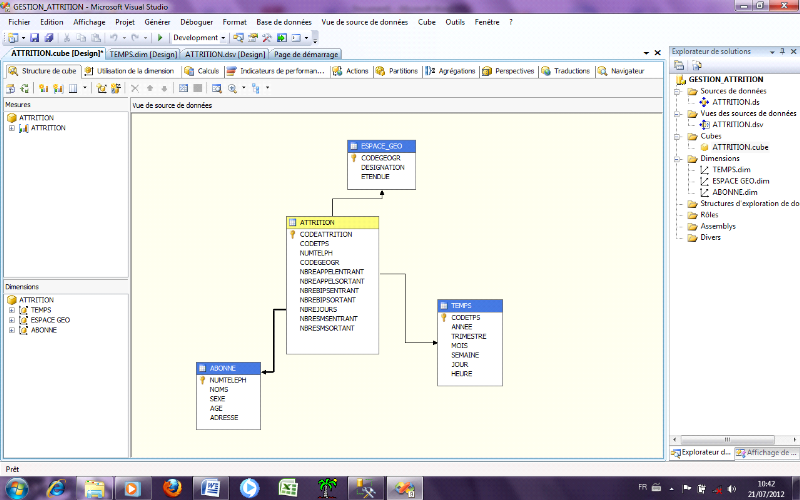
Fig12 : création des cubes de
données
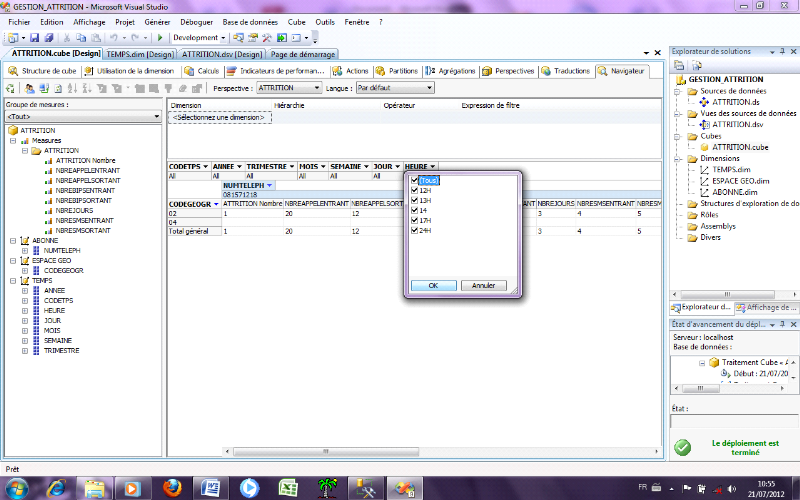
Fig13 : Déploiement du
cube
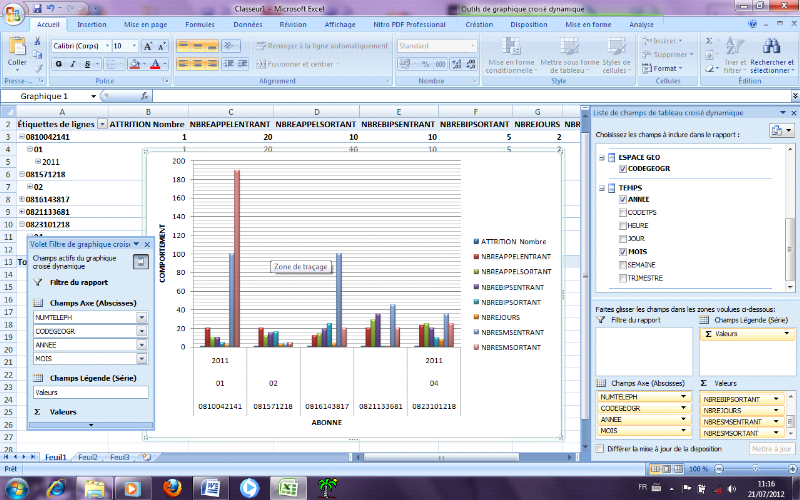
FIG 14 : visualisation des abonnés en
Excel à partir des cubes des données
IV.2 LA CLASSIFICATION
AUTOMATIQUE HIERARCHIQUE
IV.2.1 Introduction
La classification regroupe des techniques de synthèse
des grands volumes de données. Avec la multiplication actuelle des bases
de données et des entrepôts de données, on comprend le
regain d'intérêt pour ces techniques et parallèlement le
soin que les éditeurs de logiciels mettent à bien traiter le
problème. Pour l'essentiel, les techniques de classification font appel
à une démarche algorithmique et non à des techniques
mathématiques complexes : les résultats sont obtenus au terme
d'une série d'opérations simples et répétitives.
Autre avantage, la classification conduit à des résultats souvent
faciles à décrire et à caractériser : les classes.
Ces traits particuliers expliquent la présence en bonne place de la
classification dans les techniques pratiquées en Data mining et en
Analyses des données. Des logiciels majeurs dans ce domaine comme SAS et
SPAD lui consacrent une place privilégiée pour les
différentes analyses.
IV.2.2 Spad
Le SPAD est un logiciel de datamining et d'analyse
prédictive , permet à partir des données de l'entreprise
permettant d'anticiper les risques, d'identifier les opportunités , et
d'optimiser les différentes opérations métier.
IV.3 ANALYSE ET RESULTATS
Tel est le tableau de contingence qui illustre les
données de notre entrepôt de données.
|
var
Num TEL
|
Durée d'ap sort
|
Durée d'ap ent
|
SMS Ent
|
SMS sort
|
Mgb
|
Bip entr
|
Bip sort
|
Zgéo
|
Tarif
|
|
813407865
|
76
|
45
|
167
|
123
|
23
|
23
|
34
|
2
|
1
|
|
082602345
|
372
|
26
|
13
|
1
|
10
|
16
|
19
|
3
|
1
|
|
825471230
|
119
|
22
|
27
|
13
|
24
|
32
|
21
|
4
|
1
|
|
810042141
|
278
|
354
|
35
|
45
|
31
|
11
|
79
|
3
|
|
|
813358298
|
32
|
97
|
14
|
74
|
19
|
39
|
98
|
4
|
2
|
|
819834560
|
80
|
39
|
239
|
39
|
231
|
12
|
731
|
2
|
2
|
|
815637882
|
65
|
83
|
15
|
63
|
78
|
43
|
11
|
1
|
2
|
|
815700380
|
7
|
15
|
40
|
2
|
6
|
10
|
3
|
5
|
1
|
|
823143387
|
500
|
276
|
80
|
4
|
57
|
52
|
12
|
3
|
2
|
|
810041143
|
19
|
24
|
9
|
12
|
36
|
52
|
35
|
2
|
2
|
|
816135454
|
46
|
0
|
13
|
45
|
89
|
45
|
23
|
5
|
1
|
|
813407865
|
76
|
45
|
37
|
123
|
23
|
23
|
34
|
2
|
2
|
|
826002545
|
26
|
26
|
13
|
29
|
10
|
37
|
56
|
1
|
1
|
|
825792386
|
119
|
22
|
27
|
13
|
24
|
32
|
21
|
4
|
2
|
|
10042141
|
278
|
41
|
35
|
45
|
31
|
11
|
79
|
3
|
1
|
|
13358298
|
32
|
97
|
14
|
74
|
46
|
39
|
98
|
5
|
1
|
|
819834567
|
49
|
313
|
35
|
95
|
231
|
12
|
37
|
2
|
2
|
|
1537882
|
167
|
83
|
15
|
63
|
78
|
43
|
78
|
3
|
2
|
|
19702387
|
7
|
15
|
40
|
2
|
18
|
10
|
89
|
1
|
1
|
|
829789237
|
321
|
29
|
90
|
4
|
57
|
52
|
6
|
3
|
2
|
|
|
|
|
|
|
|
|
|
|
|
813101218
|
103
|
25
|
9
|
12
|
36
|
46
|
76
|
3
|
1
|
|
816145317
|
14
|
26
|
7
|
2
|
27
|
58
|
90
|
4
|
1
|
|
813407865
|
76
|
34
|
21
|
123
|
85.000
|
78.000
|
34.000
|
2
|
2
|
|
826002345
|
179
|
40
|
89
|
29
|
10
|
37
|
36
|
3
|
2
|
Légende
Ø Zone geographique
- Kananga : 3,
- NDESHA : 2,
- KATOKA : 5,
- LUKONGA : 1,
- AEROPORT: 4
Ø Tarification
- TIC TAC PLUS 1
- STANDARD 2
V.3.1 Filière
d'exécution
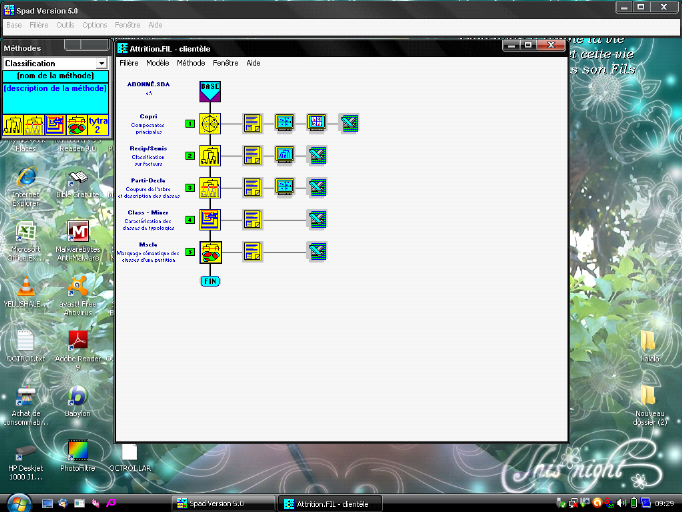
Fig.15 Filière Attrition
IV.3.2 Representation de l'arbre
hierarchique (Dendrogramme)
La méthode de classification hierarchique automatique
nous a permis ici de classifier les abonnés au vu de leurs comportements
sur le réseau afin de savoir sur quels facteurs s'appuyer pour les
cibler et les fideliser. Tel est le cas de l'illustration du dendrogramme
suivant qui regroupe les abonnés par rapport à leurs
durées d'appels sortants.
Fig . 16 Représentation de l'arbre
hiérarchique
Cet arbre hiérarchique classifie les abonnés
selon la durée d'appels sortant à une période. Ce qui
permettra aux décideurs les fidéliser par rapport à leurs
comportements. Car ce n'est pas seulement la classe fragile mais aussi
même la plus fidèle ; on pourra par exemple améliorer
la qualité de service pour n'est pas les perdre ultérieurement.
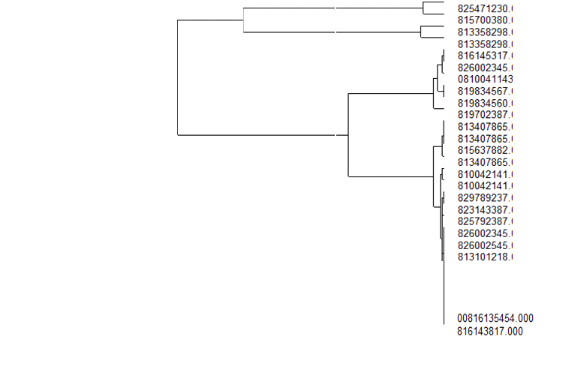
Fig. 17 Représentation la partition en 4
classes
La subdivision en quatre classes des abonnés les plus
homogènes toujours par rapport à la durée des appels
sortants. Et cela sans oublier de signaler que cette classification est
pratique pour tous les critères de regroupement qui vous semble utile.
Entre autres ; regroupement des abonnés selon leurs durées
d'appels entrants, par nombre des sms entrants, sms sortants, méga
téléchargé, ou bien évidemment la zone
géographique pour vérifier par exemple la plus rentable ou la
plus fragile afin justement procéder à une offre ciblée.
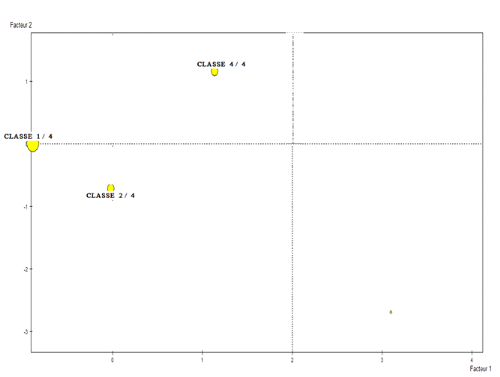

Classe 3/4





Classe 4/4
IV.3.3 Représentation de la
partition en 4 classes
CONCLUSION
Nous avons montré dans ce travail, les
spécificités de l'attrition de la clientèle dans une
entreprise de télécommunication et nous avons mise en place un
système décisionnel permettant de maitriser le
phénomène. Notre étude qui a porté sur
« l'analyse et détection de l'attrition des abonnés
dans une entreprise de télécommunication, étude
menée au sein de Vodacom Congo/Kananga ».Celle-ci a été menée dans
l'objectif d'étudier les comportements des abonnés afin de
réduire le cout de la perte de la clientèle ; les
opérations de marketing étant très couteuses, les
décideurs ont besoin d'avoir la clarté sur les abonnés
afin de savoir sur quels facteurs agir pour les fidéliser.
Ensuite, mettre en place un entrepôt de données
et l'utilisation des outils de datamining pour en dégager des
connaissances pour une prise de décision.
Pour y parvenir, nous avons subdivisé notre travail a
quatre chapitres ;dont le premier donne bien évidement une
idée sur les généralités sur les entrepôts de
données. Le deuxième sur les différentes techniques de
datamining ; celui-ci détaille les panoramas des techniques de
datamining de résolution. Suivi du troisième sur la
modélisation En UML ;qui est en fait, une image nous aidant
à comprendre le problème. et l'application qui présentent
les résultats trouvés par notre expérience.
Le logiciel coheris SPAD qui nous
a aidé de faire une classification automatique hiérarchique. La
classification est la technique de datamining retenue par notre étude
afin de regrouper les abonnés par rapport à un critère de
similarité dans une période de 6 mois pour s'imprégner sur
quel facteur agir pour maitriser ce phénomène.
Notre réflexion se « termine »
ainsi sur une ouverture, une enquête à poursuivre et à
approfondir par des études ultérieures.
BIBLIOGRAPHIQUE
1. Benzécri, J.P., Benzécri, F. (1985) -
Introduction à la Classification Ascendante
hiérarchique d'après un exemple de Données Economiques.
J. Soc.Stat. de Paris, 1, 14-34
2. Archaux C., Martin A. , Khenchaf A., Détection
par SVM-Application à la détection de churn en
téléphonie mobile prépayée, Extraction et Gestion
des connaissances (EGC), in Revue des Nouvelles Technologies de
l'Information, Vol 2, pp 597, Clérmont Ferrand, France,
20-23 Janvier 2004.
3. E. F. Codd, Providing OLAP to user-analysts: an
IT mandate, Technical Report, E. F. Codd and
associates, 1993;
4. Georges Gardarin, Internet, Intranet et bases
de données, Edition DUNOD, 2000 ;
5. Jean Michel Franco et Sandrine de
lignerolles, Piloter l'entreprise grâce au data
ware house, Ed Eyrolles, 2000, P25 ;
6. Kimball R.,Ross M. Entrepot de données.
Guide pratique de modelisation
dimensionnelle,2e éd.,
ISBN :Vuibert, 2003
7. R.E. Shannon, Systems Simulation, the art and
science, Prentice Hall 1975;
8. SEAN KELLY, DataWarehousing: the route to mass
customization, John Wiley & Sons, 1996;
9. W. Inmon. Building the Data Warehouse. QED
Technical Publishing Group, Wellesley, Massachusetts, U.S.A.,
1996
10. Zighed D.A., Rakotomala R., Extraction des
connaissances à partir des données
IBN :2746200724,Hermès,2000. BURQUIER
Bertrand, «Business Intelligence avec SQL server 2008,
DUNORD 2008.
III. NOTES DE COURS
11. CT.
Kafunda, « infocentre », U.KA, 2012 ;
12. CT. Kafunda, « Question Spéciale
du génie logiciel », U.KA, 2012 ;
13. CT. Muamba, « Note de cours d'analyse des
organisations », U.KA, 2010 ;
14. Prof. Ntumba, « Analyse de
données », U.KA, 2012 ;
III.SITES WEB
15.
http://www.datawarehouse.com/consulté le 12/03/2012 à 12h
01'
Portail dédié au datawarehouse
16. http://www.guideinformatique.com/consulté
le01/05/2012 à 16h 09'
L'information professionnelle des decideurs
17. http://www.decisionnel.net/ consulté le 26/06/2012
à 10h 47'
Site consacré à l'information
décisionnelle de l'entreprise.
TABLE DES MATIERES
EPIGRAPHE
I
DEDICACE
II
REMERCIEMENTS
III
GLOSSAIRE
V
LISTE DES FIGURES
VI
0. INTRODUCTION GENERALE
1
0.1 PROBLEMATIQUE
1
0.2 HYPOTHESES
2
0.3. CHOIX ET INTERET DU SUJET
3
0.4. DELIMITATION DU SUJET
3
0.5 METHODES ET TECHNIQUES UTILISEES
4
0.6 CANEVAS DU TRAVAIL
4
CHAPITRE I : GENERALITES SUR LE DATA WARE
HAUSE (ENTREPOT DE DONNEES)
5
I.1 INTRODUCTION
5
I.1.1 DEFINITION
5
I.2 LE ROLE DU DATA WAREHOUSE
7
I.3 OBJECTIFS DU DATA WAREHOUSE
7
I.4 ARCHITECTURE DE DATA WARE HOUSE
9
I.4.1 CARACTERISTIQUE D'UN DATA WAREHOUSE
11
I.4.2 LES COMPOSANTS DE BASE DU DATA WAREHOUSE
11
I.4.3 DIFFERENCE ENTRE LES SYSTEMES OLTP ET LE DATA
WAREHOUSE
13
I.5. MODELISATION DIMENSIONNELLE
14
I.5.1 RELATION ENTRE LA MODELISATION DIMENSIONNELLE
ET LA MODELISATION ENTITE/RELATION
15
I.5.2 AVANTAGES DE LA MODELISATION
DIMENSIONNELLE
16
I.6 SCHÉMAS D'UN DATA WAREHOUSE
16
A. LES OBJETS D'UN SCHEMA DE DATA
WAREHOUSE
17
I.6.1 LE SCHEMA EN ETOILE
18
I.6.2 LE SCHEMA EN FLOCON
19
1.6.3 LES SCHEMAS EN CONSTELLATION DE FAITS
21
1.7 CONSTRUCTION DU DATA WAREHOUSE
21
1.7.1 LA CONCEPTION LOGIQUE
21
1.7.2 LA CONCEPTION PHYSIQUE
22
1.7.3 ALIMENTATION DU DATA WAREHOUSE PAR LES
OUTILS ETL
23
I.8 LE DATA MART
27
I.9 OLAP
28
I.9.1 INTRODUCTION
28
I.9.2 LES DIFFERENTS OUTILS OLAP
29
I.10 LA NAVIGATION DANS LES DONNEES
30
I.10.1 DRILL-DOWN ET DRILL-UP
30
I.10.2 DATA SURFING
31
I.10.2 CONCLUSION
31
CHAPITRE II: LES TECHNIQUES DE DATA MINING
32
II.1 INTRODUCTION
32
II.1.1 DEFINITION
33
II.1.2 TRIPLE OBJECTIF DU DATA MINING
33
II.2 LES DIFFERENTES ETAPES D'EXTRATION DE
CONNAISSANCES
34
II.3 PRINCIPALES METHODES DU DATA MINING
36
II.3.1 METHODES DESCRIPTIVE
36
II.3.2 METHODE PREDICTIVE
36
II.4 LES TACHES DU DATA MINING
37
II.4.1 LA CLASSIFICATION
38
II.4.2 ESTIMATION
38
II.4.3 LA PREDICTION
39
II.4.4 LE REGROUPEMENT PAR SIMILITUDE
39
II.4.5 L' ANALYSE DES CLUSTERS
39
II.4.6 LA DESCRIPTION
40
II.4.7 L' OPTIMISATION
40
II.5 LA CONNAISSANCE
40
II.5.1 DEFINITION
40
II.5.2 LA DECOUVERTE DE CONNAISSANCES
40
II.6 LES TECHNIQUES DU DATA MINING
44
II.6.1 ANALYSE DU PANIER DE LA MENAGERE
44
II.6.2 ANALYSE DES LIENS
45
II.6.3 LES ARBRES DE DECISION
45
II.6.4 LES RESEAUX DE NEURONES
51
II.6.4.1 DECOUVERTE DES REGLES
52
CHAPITRE III MODELISATION EN UML
53
III.1 OBJECTIF DU TRAVAIL
53
IV.1.1 DIAGRAMME DE CAS D'UTILISATION (USE
CASE)
53
IV.1.2 DIAGRAMME DE CLASSE
54
IV.1.3 DIAGRAMME DE DEPLOIEMENT
55
CHAPITRE IV : APPLICATION
57
IV. 1 MISE EN PLACE DE L'ENTREPOT DE DONNEES
57
IV.2 LA CLASSIFICATION AUTOMATIQUE
HIERARCHIQUE
61
IV.2.1 INTRODUCTION
61
IV.2.2 SPAD
61
IV.3 ANALYSE ET RESULTATS
62
V.3.1 FILIERE D'EXECUTION
63
IV.3.2 REPRESENTATION DE L'ARBRE HIERARCHIQUE
(DENDROGRAMME)
64
IV.3.3 REPRESENTATION DE LA PARTITION EN 4
CLASSES
65
CONCLUSION
66
BIBLIOGRAPHIQUE
67
TABLE DES MATIERES
69
| 

