Etude des méthodes de reconnaissances d'empreinte digitale a l'aide du deep learningpar Jean-Edmond DASSE Université Félix Houphouet-Boigny - Master 2 Recherche option informatique 2019 |

CHAPITRE III : MACHINE LEARNINGDéfinition Le Machine Learning est une technologie d'intelligence artificielle permettant aux ordinateurs d'apprendre sans avoir été programmés explicitement à cet effet. Pour apprendre et se développer, les ordinateurs ont toutefois besoin de données à analyser et sur lesquelles s'entraîner. De fait, le Big Data est l'essence du Machine Learning, et c'est la technologie qui permet d'exploiter pleinement le potentiel du Big Data. Machine Learning et Big Data : définition et explications de la combinaison ( lebigdata.fr) https://www.lebigdata.fr/machine-learning-et-big-data I - LES DIFFÉRENTS CATÉGORIES DE MACHINE LEARNING Trois categories de machine learning:
dit « très important », cela peut signifier jusqu'à plusieurs millions d'images pour la base Image Net. C'est à partir de cette base que l'algorithme peut apprendre ans le cadre de l'apprentissage supervisé, la machine connaît déjà les réponses qu'on attend d'elle. Elle travaille à partir de données étiquetées Cette méthode permet de réaliser deux types de tâches : Ces tâches consistent à attribuer une classe à des objets. Par exemple, dans le milieu bancaire, on peut identifier si une transaction est frauduleuse ou non frauduleuse de manière automatique. On parle de détection d'anomalie. Dans l'industrie, on peut déterminer si oui ou non une machine est susceptible de tomber en panne. Ici, on n'attribue pas une classe mais une valeur mathématique : un pourcentage ou une valeur absolue. Par exemple, une probabilité pour une machine de tomber en panne (15 %, 20 %, etc.)
ou le prix de vente idéal d'un appartement en fonction de critères comme la surface, le quartier, etc. II- APPRENTISSAGE NON SUPERVISEUne différence lorsqu'on parle du type d'apprentissage non-supervisé, c'est que les réponses que l'on cherche à prédire ne sont pas disponibles dans les jeux de données. Ici, l'algorithme utilise un jeu de données non étiquetées. On demande alors à la machine de créer ses propres réponses. Elle propose ainsi des réponses à partir d'analyses et de groupement de données. Pour y voir plus clair, voici des exemples de tâches réalisables grâce à cette méthode. Mémoire de Master option Bases de Données et Génie Logiciel 28 Ici, on demande à la machine de grouper des objets dans des ensembles de données les plus homogènes possibles. Cette technique peut sembler proche de celle de la classification dans l'apprentissage supervisé, mais à la différence de cette dernière, les classes ne sont pas préremplies par un humain, c'est la machine qui «invente» ses propres classes, à un niveau de finesse pas toujours évident pour un humain. Une technique très utile dans le marketing pour faire de la segmentation client notamment. 1- Deep learning Définition Le deep learning ou apprentissage profond est un type d'intelligence artificielle dérivé du machine learning (apprentissage automatique) où la machine est capable d'apprendre par elle-même, contrairement à la programmation où elle se contente d'exécuter à la lettre des règles prédéterminées. 2 - Le fonctionnement du deep learning Le deep Learning s'appuie sur un réseau de neurones artificiels s'inspirant du cerveau humain. Ce réseau est composé de dizaines voire de centaines de « couches» de neurones, chacune recevant et interprétant les informations de la couche précédente. Le système apprendra par exemple à reconnaître les lettres avant de s'attaquer aux mots dans un texte, ou détermine s'il y a un visage sur une photo avant de découvrir de quelle personne il s'agit.
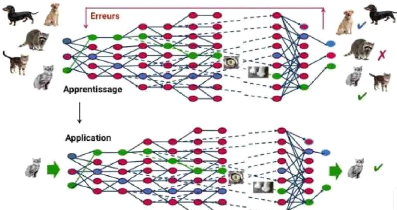
23 Figure 1.21: À travers un processus d'autoapprentissage, le deep Learning est capable d'identifier un chat sur une photo. À chaque couche du réseau neuronal correspond à un aspect particulier de (l'image MapR, C.D, Futura). Explications: À chaque étape, les « mauvaises» réponses sont éliminées et renvoyées vers les niveaux en amont pour ajuster le modèle mathématique. Au fur et à mesure, le programme réorganise les informations en blocs plus complexes. Lorsque ce modèle est par la suite appliqué à d'autres cas, il est normalement capable de reconnaître un chat sans que personne ne lui ait jamais indiqué qu'il n'ai jamais appris le concept de chat. Les données de départ sont essentielles : plus le système accumule d'expériences différentes, plus il sera performant. 3-Les Réseaux de neurons artificiels 4-Définition Un réseau de neurones artificiels ou Neural Network est un système informatique s'inspirant du fonctionnement du cerveau humain pour apprendre. 5-Les différents types de réseau de neurone Il existe de nombreux types de réseaux neuronaux, on peut les diviser en deux grandes catégories selon la nature de leur algorithme d'apprentissage. Les réseaux de neurones les plus populaires sont:
24 - Les réseaux de neurone convolutionnels - Les réseaux de neurone récurent - Réseau de neurone artificiel Ce sont des réseaux de neurones spécialisés qui utilisent le contexte des entrées lors du calcul de la sortie. La sortie dépend des entrées et des sorties calculées précédemment. Ainsi, les RNN conviennent aux applications où les informations historiques sont importantes. Ces réseaux nous aident à prévoir les séries chronologiques dans les applications commerciales et à prévoir les mots dans les applications de type chatbot. Ils peuvent fonctionner avec différentes longueurs d'entrée et de sortie et nécessitent une grande quantité de données.
Ces réseaux reposent sur des filtres de convolution (matrices numériques). Les filtres sont appliqués aux entrées avant que celles-ci ne soient transmises aux neurones. Ces réseaux de neurones sont utiles pour le traitement et la prévision d'images. https://moncoachdata.com/blog/comprendre-les-reseaux-de-neurones/ 7- Les réseaux de neurone récurent Les réseaux récurrents (ou RNN pour Récurrent Neural Networks) sont des réseaux de neurones dans lesquels l'information peut se propager dans les deux sens, y compris des couches profondes aux premières couches. En cela, ils sont plus proches du vrai fonctionnement du système nerveux, qui n'est pas à sens unique. Ces réseaux possèdent des connexions récurrentes au sens où elles conservent des informations en mémoire : ils peuvent Mémoire de Master option Bases de Données et Génie Logiciel 30 prendre en compte à un instant t un certain nombre d'états passés. Pour cette raison, les RNNs sont particulièrement adaptés aux applications faisant intervenir le contexte, et plus particulièrement au traitement des séquences temporelles comme l'apprentissage et la génération de signaux, c'est à dire quand les données forment une suite et ne sont pas indépendantes les unes des autres. Néanmoins, pour les applications faisant intervenir de longs écarts temporels (typiquement la classification de séquences vidéo), cette « mémoire à court-terme » n'est pas suffisante. En effet, les RNNs « classiques » (réseaux de neurones récurrents simples ou Vanilla RNNs) ne sont capables de mémoriser que le passé dit proche, et commencent
25 à « oublier » au bout d'une cinquantaine d'itérations environ. Ce transfert d'information à double sens rend leur entrainement beaucoup plus compliqué, et ce n'est que récemment que des méthodes efficaces ont été mises au point comme les LSTM (Long Short Term Memory). Ces réseaux à large « mémoire court-terme » ont notamment révolutionné la reconnaissance de la voix par les machines (Speech Recognition) ou la compréhension et la génération de texte (Natural Langage Processing). D'un point de vue théorique, les RNNs ont un potentiel bien plus grand que les réseaux de neurones classiques : des recherches ont montré qu'ils sont « Turing-complet » (ou Turing-complete), c'est à dire qu'ils permettent théoriquement* de simuler n'importe quel algorithme. Cela ne donne néanmoins aucune piste pour savoir comment les construire pour cela dans la pratique. NB : Ne pas confondre les réseaux de neurones récurrents avec les réseaux de neurones aléatoires (Random Neural Network) aussi traduits par RNN. * Siegelmann, H. T. (1997). Computation beyond the Turing limit. Neural Networks and Analog Computation, 153164 Dans le cadre de notre étude nous utiliserons les réseaux de neurones convolution car ils sont plus adaptés au traitement ou la manipulation des images.
La conception des réseaux de neurones artificiels s'appuie sur la structure des neurones biologiques du cerveau humain. Les réseaux de neurones artificiels peuvent être décrits comme des systèmes composés d'au moins deux couches de neurones - une couche d'entrée et une couche de sortie - et comprenant généralement des couches intermédiaires (« hidden layers »). Plus le problème à résoudre est complexe, plus le réseau de neurones artificiels ne doit comporter de couches. Chaque couche contient un grand nombre de neurones artificiels spécialisés.
26 10- Traitement de l'information au sein du réseau de neurones Au sein d'un réseau de neurones artificiels, le traitement de l'information suit toujours la même séquence : les informations sont transmises sous la forme de signaux aux neurones de la couche d'entrée, où elles sont traitées. À chaque neurone est attribué un « poids » particulier, et donc une importance différente. Associé à la fonction dite de transfert, le poids permet de déterminer quelles informations peuvent entrer dans le système. À l'étape suivante, une fonction dite d'activation associée à une valeur seuil calculent et pondèrent la valeur de sortie du neurone. En fonction de cette valeur, un nombre plus ou moins grand de neurones sont connectés et activés. Cette connexion et cette pondération dessinent un algorithme qui fait correspondre un résultat à chaque entrée. Chaque nouvelle itération permet d'ajuster la pondération et donc l'algorithme de façon à ce que le réseau donne à chaque fois un résultat plus précis et fiable.
Figure 1.22: Couche de réseau de neurone |
|