CHAPITRE IV: MATERIELS ET METHODES
I - LE MATERIELS
Ici nous parlerons :
- de l'architecture qui a été crée
- de la base de SOCOFING utilisée ensuite nous utiliserons
les bibliothèques Tensorflow et Keras pour l'apprentissage et la
classification à partir de python dans un environnement de Deep learning
créé à cet effet.
I.1 - L'Environnement de travail
1- Matériel
La machine utilisée est une machine personnelle, elle
possède : - un processeur Intel core i7 de fréquence 4.2 Mhz V
pro, - 8 Go de RAM,
- Carte graphique Intel® UHD Graphics
2- Logiciels et librairies Utilisés dans
l'implémentation
- Windows 10 est le système d'exploitation de notre
machine qui a servi à élaborer notre projet.
I.2 - Langages de programmation
L'environnement logiciel utilisé pour la
réalisation de notre application est python. Python est
un puissant outil de calcul numérique, de programmation et de
visualisation graphique. Python est un langage de programmation de haut niveau
interprété (il n'y a pas d'étape de compilation) et
orienté objet avec une sémantique dynamique. Il est très
sollicité par une large communauté de développeurs et de
programmeurs. Python est un langage simple, facile à apprendre et permet
une bonne éduction du cout de la maintenance des codes. Les
bibliothèques (packages) python encouragent la modularité et la
réutilisabilité des codes. Python et ses bibliothèques
sont disponibles (en source ou en binaires) sans charges pour la
majorité des plateformes et peuvent être redistribués
gratuitement.
Mode exécutif : il exécute ligne par ligne un
"fichier PY" (programme en langage Python).
Fenêtres Graphique : comme Spyder elle permet de faire
des graphiques dans ces fenêtres. Fichiers PY : Ce sont des programmes en
langage Python (écrits par l'usager),

|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
33
Figure 1.27 : Logo de spyder
Figure 1.28 : Environnement Python /spyder
I.3 - Quelques bibliothèques de python.
3- NumPy
NumPy est une bibliothèque pour langage de programmation
Python, destinée à manipuler des matrices ou tableaux
multidimensionnels ainsi que des fonctions mathématiques opérant
sur ces tableaux
4- TENSORFLOW
TensorFlow est un framework de programmation pour le calcul
numérique qui a été rendu Open Source par Google en
Novembre 2015. Depuis son release, TensorFlow n'a cessé de gagner en
popularité, pour devenir très rapidement l'un des frameworks les
plus utilisés pour
le Deep Learning et donc les réseaux de neurones. Son nom
est notamment inspiré du fait que les opérations courantes sur
des réseaux de neurones sont principalement faites via des tables de
données multi-dimensionnelles, appelées Tenseurs (Tensor). Un
Tensor à deux dimensions
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
34
est l'équivalent d'une matrice. Aujourd'hui, les
principaux produits de Google sont basés sur TensorFlow: Gmail, Google
Photos, Reconnaissance de voix.
Et La raison pour laquelle TensorFlow a été la
librairie choisie pour la réalisation de ce travail, est que cette
librairie est la plus utilisée en ce moment dans le monde du deep
learning. TensorFlow est une librairie codée en C++ afin d'obtenir une
performance élevée lors des phases d'apprentissage de nouveaux
modèles statistiques mais elle propose quelques APIs dans d'autres
langages, comme Python, R, Java et C# (Unruh, 2017). Il est important de noter
que Google propose plusieurs APIs, mais qu'elle recommande que l'apprentissage
soit fait avec le langage Python et qu'ensuite la mise en production se fasse
sur d'autres langages, comme Java par exemple (TensorFlow, 2018b).
5- THEANO
Theano est une bibliothèque logicielle Python
d'apprentissage profond développé par Mila - Institut
québécois d'intelligence artificielle, une équipe de
recherche de l'Université McGill et de l'Université de
Montréal.
6- KERAS
Keras est une API de réseaux de neurones de haut
niveau, écrite en Python et capable de fonctionner sur TensorFlow ou
Theano. Il a été développé en mettant l'accent sur
l'expérimentation rapide. Être capable d'aller de l'idée
à un résultat avec le moins de délai possible est la
clé pour faire de bonnes recherches. Il a été
développé dans le cadre de l'effort de recherche du projet
ONEIROS (Open-ended Neuro-Electronic Intelligent Robot Operating System), et
son principal auteur et mainteneur est François Chollet, un
ingénieur Google. En 2017, l'équipe TensorFlow de Google a
décidé de soutenir Keras dans la bibliothèque principale
de TensorFlow. Chollet a expliqué que Keras a été
conçue comme une interface plutôt que comme un cadre
d'apprentissage end to end. Il présente un ensemble d'abstractions de
niveau supérieur et plus intuitif qui facilitent la configuration des
réseaux neuronaux indépendamment de la bibliothèque
informatique de backend. Microsoft travaille également à ajouter
un backend CNTK à Keras aussi.
7- Scikit-learn
Scikit-learn est une bibliothèque libre Python
dédiée à l'apprentissage automatique. Elle est
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
35
développée par de nombreux contributeurs
notamment dans le monde académique par des instituts français
d'enseignement supérieur et de recherche comme Inria et
Télécom ParisTech. Elle comprend notamment des fonctions pour
estimer des forêts aléatoires, des régressions logistiques,
des algorithmes de classification, et les machines à vecteurs de
support. Elle est conçue pour s'harmoniser avec des autres
bibliothèques libre Python, notamment NumPy et SciPy.
8- OS
OS est un module fournit par Python dont le but d'interagir
avec le système d'exploitation, il permet ainsi de gérer
l'arborescence des fichiers, de fournir des informations sur le système
d'exploitation processus, variables systèmes, ainsi que de nombreuses
fonctionnalités du système.
9- OPENCV
OpenCV est une bibliothèque libre de vision par
ordinateur. Cette bibliothèque est écrite en C et C++ et peut
être utilisée sous Linux, Windows et Mac OS X. Des interfaces ont
été développées pour Python, Ruby, Matlab et autre
langage. OpenCV est orientée vers des applications en temps réel.
Un des buts d'OpenCV est d'aider les gens à construire rapidement des
applications sophistiquées de vision à l'aide d'infrastructure
simple de vision par 57 ordinateurs. La bibliothèque d'OpenCV contient
près de 500 fonctions. Il est possible grâce à la «
licence de code ouvert » de réaliser un produit commercial en
utilisant tout ou partie d'OpenCV. La version d'Opencv que nous avons
utilisé est opencv 3.4
10- MAXPOOLING
Maxpooling est un processus de discrétisation
basé sur des échantillons. L'objectif est de
sous-échantillonner une représentation d'entrée (image,
matrice de sortie de couche cachée, etc.), en réduisant sa
dimensionnalité et en permettant de faire des hypothèses sur les
caractéristiques contenues dans les sous-régions
regroupées.
Ceci est fait en partie pour aider à sur-ajuster en
fournissant une forme abstraite de la représentation. De plus, il
réduit le coût de calcul en réduisant le nombre de
paramètres à apprendre et fournit une invariance de traduction de
base à la représentation interne.
11-
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
36
RELU
ReLU ( Rectified Linear Unit ) : Ce sont les fonctions les
plus populaires de nos jours. Elles permettent un entrainement plus rapide
comparé aux fonctions sigmoid et tanh, étant plus
légères.
12- SOFMAX
La fonction softmax est utilisée pour transformer les
logits dans un vecteur de probabilités, indiquant la
probabilité que x appartienne à chacune des classes de
sortie T. Mais on peut travailler sur d'autres caractéristiques, et
ainsi obtenir d'autres probabilités, afin de déterminer l'animal
sur la photo. Au fur et à mesure que l'intelligence artificielle aura
d'exemples, plus la matrice de poids s'affinera, et plus le système sera
performant.
II - METHODES DE RECONNAISSANCES
II.1 - Base de données d'empreinte
digitale
Les problèmes de sécurités se sont
multipliés et le marché de la biométrie a connu une
croissance rapide. Aujourd'hui il existe différents types
de biométries technologies tels que les
empreintes digitales, l'iris, les veines, les voix
identification. Ici dans notre contexte, notre étude
consistera à utiliser le deep Learning pour la
résolution de nos problèmes.
L'identification des empreintes digitales a été
utilisée dans notre étude. Une gigantesque
base de données d'empreintes digitales existantes a
été déjà établie et fut donné par nos
différents
encadreurs.
Cette base de données est constituée d'empreinte
digitale de plusieurs individus repartis
dans plusieurs fichiers :
- Altered-easy
- Altered-hard
- Altered-medium
Ici, nous avons utilisé la base de données
d'empreinte digital SOCOFING comprenant Sokoto
Coventry Fingerprint Dataset (SOCOFing) qui est une base de
données biométrique
d'empreintes digitales conçue à des fins de
recherche universitaire. SOCOFing est composé de
6 000 images d'empreintes digitales de 600 sujets africains et
contient des attributs uniques tels
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
que des étiquettes pour le sexe, le nom des mains et des
doigts ainsi que des versions modifiées
synthétiquement avec trois niveaux différents
d'altération pour l'effacement.
37
II.2 - Le Prétraitement
L'étape du prétraitement devrait être
effectuée avant l'extraction des caractéristiques. Nous centrons
l'empreinte dans un canevas ensuite nous supprimons l'arrière-plan en
définissant les pixels d'arrière-plan sur un blanc et en laissant
les pixels du premier plan en niveau de gris. Certaines étapes de
prétraitements doivent être effectuées avant l'extraction
des données. Il s'agit de l'importation des bibliothèques
(numpy,os,sklearn,open cv...).
Apres importation des bibliothèques on importera la base
de données :
Sokoto Coventry Fingerprint Dataset (SOCOFing) | Kaggle
L'étape suivante consistera à pixeler les images
ensuite mettre les images dans une même
dimension compris entre 0 et 1.
Le Dataset sera subdivisé en deux étapes :
-Trainning(entrainement)
-Test(test)
Importation de la fonction Train_set(permet la division de la db
)

Figure 1.29 : Base de données SOCOFING
(empreinte digitale d'individu)
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
38
39
II.2.1 - La Binarisation
II.3. Méthodologie utilisée
Dans notre exercice nous allons utiliser un algorithme de Deep
Learning c'est-à-dire les réseaux de neurones convolutifs car ils
sont qualifiés comme étant les modèles les plus
performants pour la classification d'images.
II.3.1. Les réseaux de neurones convolutifs
II.3.1.1. Définition
Les réseaux de neurones convolutifs désignent
une sous-catégorie de réseaux de neurones et sont conçu
pour extraire automatiquement les caractéristiques des images
d'entrée. Ils reçoivent des images en entrée,
détectent les features de chacune d'entre elles, puis entraînent
un classifieur dessus. Leur architecture est alors plus spécifique :
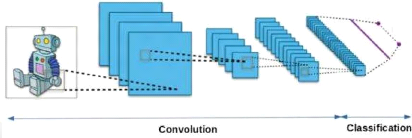
elle est composée de deux parties principales bien distinctes.
Ø La partie convolutive : en entrée, une image est
fournie sous la forme d'une matrice de
pixels. Elle a 2 dimensions pour une image en niveaux de
gris. La couleur est représentée par une troisième
dimension, de profondeur 3 pour représenter les couleurs fondamentales
[Rouge, Vert, Bleu].
La première partie d'un CNN est la partie convolutive
à proprement parler. Elle fonctionne comme un extracteur de
caractéristiques des images. Une image est passée à
travers une succession de filtres, ou noyaux de convolution, créant de
nouvelles images appelées cartes de convolutions. Certains filtres
intermédiaires réduisent la résolution de l'image par une
opération de maximum local. Au final, les cartes de convolutions sont
mises à plat et concaténées en un vecteur de
caractéristiques, appelé code CNN. [19]
Ø La partie classification : ce code CNN en sortie de la
partie convolutive est ensuite
branché en entrée d'une deuxième partie,
constituée de couches entièrement connectées (perceptron
multicouche). Le rôle de cette partie est de combiner les
caractéristiques du code CNN pour classer l'image.
La sortie est une dernière couche comportant un
neurone par catégorie. Les valeurs numériques obtenues sont
généralement normalisées entre 0 et 1, de somme 1, pour
produire une distribution de probabilité sur les catégories.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
Figure 1.30 : les deux parties de
l'architecture des réseaux de neurones convolutifs II.3.1.2. Les
différentes couches des CNN
Il existe quatre types de couches pour un réseau de
neurones convolutifs : la couche de convolution, la couche de pooling, la
couche de correction ReLU et la couche fully-connected :
» La couche de convolution (CONY) qui traite les
données d'un champ récepteur.
» La couche de pooling (POOL), qui permet de compresser
l'information en réduisant la taille de l'image intermédiaire
(souvent par sous-échantillonnage).
» La couche de correction (ReLU), souvent appelée
par abus 'ReLU' en référence à la
fonction d'activation (Unité de rectification
linéaire).
» La couche "entièrement connectée" (FC),
qui est une couche de type perceptron.
1- La couche de convolution
La couche de convolution est la composante clé des
réseaux de neurones convolutifs, et constitue toujours au moins leur
première couche.
Son but est de repérer la présence d'un
ensemble de features dans les images reçues en entrée. Pour cela,
on réalise un filtrage par convolution : le principe est de faire
"glisser" une fenêtre représentant la feature sur l'image, et de
calculer le produit de convolution entre la feature et chaque portion de
l'image balayée. Une feature est alors vue comme un filtre : les deux
termes sont équivalents dans ce contexte.
Trois hyperparamètres permettent de dimensionner le
volume de la couche de convolution
» Profondeur de la couche : nombre de noyaux de
convolution (ou nombre de neurones associés à un même champ
récepteur).
» Le pas contrôle le chevauchement des champs
récepteurs. Plus le pas est petit, plus les
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
40
champs récepteurs se chevauchent et plus le volume de
sortie sera grand.
Ø La marge (à 0) ou zero padding : parfois, il est
commode de mettre des zéros à la frontière
du volume d'entrée. La taille de ce zero-padding est
le troisième hyperparamètre. Cette marge permet de
contrôler la dimension spatiale du volume de sortie. En particulier, il
est parfois souhaitable de conserver la même surface que celle du volume
d'entrée.
2- Couche de pooling (POOL)
Ce type de couche est souvent placé entre deux couches de
convolution : elle reçoit en entrée plusieurs feature maps, et
applique à chacune d'entre elles l'opération de pooling.
L'opération de pooling (ou sub-sampling) consiste
à réduire la taille des images, tout en préservant leurs
caractéristiques importantes.
Pour cela, on découpe l'image en cellules
régulière, puis on garde au sein de chaque cellule la valeur
maximale. En pratique, on utilise souvent des cellules carrées de petite
taille pour ne pas perdre trop d'informations. Les choix les plus communs sont
des cellules adjacentes de taille 2 × 2 pixels qui ne se chevauchent pas,
ou des cellules de taille 3 × 3 pixels, distantes les unes des autres d'un
pas de 2 pixels (qui se chevauchent donc). On obtient en sortie le même
nombre de feature maps qu'en entrée, mais celles-ci sont bien plus
petites.
La couche de pooling permet de réduire le nombre de
paramètres et de calculs dans le réseau. On améliore ainsi
l'efficacité du réseau et on évite le
sur-apprentissage.
Il est courant d'insérer périodiquement une
couche Pooling entre les couches Conv successives dans une architecture
ConvNet. Sa fonction est de réduire progressivement la taille spatiale
de la représentation afin de réduire la quantité de
paramètres et de calculs dans le réseau, et donc de
contrôler également le sur-ajustement. La couche de pooling
fonctionne indépendamment sur chaque tranche de profondeur de
l'entrée et la redimensionne spatialement, en utilisant
l'opération MAX.
Ainsi, la couche de pooling rend le réseau moins
sensible à la position des features : le fait qu'une feature se situe un
peu plus en haut ou en bas, ou même qu'elle ait une orientation
légèrement différente ne devrait pas provoquer un
changement radical dans la classification de l'image.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
41
3- Couches de correction (RELU)
Pour améliorer l'efficacité du traitement en
intercalant entre les couches de traitement une couche qui va opérer une
fonction mathématique (fonction d'activation) sur les signaux de sortie.
dans ce cadre on trouve ReLU (Rectified Linear Units) désigne la
fonction réelle non-linéaire définie par ReLU(x)=max(0,x).
La couche de correction ReLU remplace donc toutes les valeurs négatives
reçues en entrées par des zéros. Elle joue le rôle
de fonction d'activation.
Souvent, la correction Relu est préférable, mais
il existe d'autre forme
Ø La correction par tangente hyperbolique
f(x)=tanh(x),
Ø La correction par la tangente hyperbolique saturante :
f(x)=|tanh(x)|,
4- Couche entièrement connectée
(FC)
La couche fully-connected constitue toujours la
dernière couche d'un réseau de neurones, convolutif ou non - elle
n'est donc pas caractéristique d'un CNN.
Ce type de couche reçoit un vecteur en entrée et
produit un nouveau vecteur en sortie. Pour cela, elle applique une combinaison
linéaire puis éventuellement unefonction d'activation aux valeurs
reçues en entrée.
La couche fully-connected permet de classifier l'image en
entrée du réseau : elle renvoie un vecteur de taille N, où
N est le nombre de classes dans notre problème de classification
d'images. Chaque élément du vecteur indique la probabilité
pour l'image en entrée d'appartenir à une classe.
III. ARCHITECTURE DE NOTRE RESEAU, ENTRAINEMENT ET
COMPILATION DU MODELE
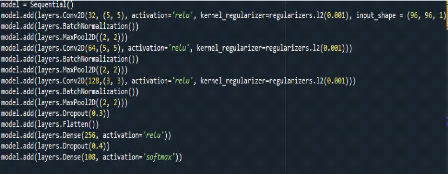
1. Architecture de notre réseau
Notre modèle est composé de trois couches de
convolution, trois couches maxpooling, trois couches et deux couches de fully
connect.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
42
Figure 1.31 : Définition du
modèle
» L'image en entrée est de taille 96*96, l'image
passe d'abord à la première couche de
convolution
» La première couche de convolution est
composée de 32 filtres de taille 5*5, la seconde
couche de convolution est composée de 64 filtres de
tailles 5*5 et la dernière est composée de 128 filtres de tailles
3*3 et ont toute la fonction ReLU comme fonction
d'activation.
» Une couche de Maxpooling est appliquée au 32
features obténues après l'application d'une
normalisation par lot (BatchNormalization), pour réduire
la taille des images tout
en préservant leurs caractéristiques
importantes.
» On répète la même chose avec les
couches de convolutions deux et trois. Une couche
de Maxpooling est appliquée après l'application
de la normalisation par lot (BatchNormalization) à la sortie de la
couche de convolution précédente. A la sortie de la
deuxième couche de Maxpooling on obtient 64 features et à la
sortie de la troisième couche de Maxpooling on obtient 128 features
» Après ces trois couches de convolution, nous
utilisons un réseau de neurones composé
de deux couches fully connected. La première couche a
256 neurones où la fonction d'activation utilisée est le ReLU, et
la deuxième couche a 108 neurones où la fonction d'activation
utilisée softmax qui permet de calculer la distribution de
probabilité des
108 classes (nombre de classe dans la base d'image).
» Nous avons utilisé la méthode Flatten qui a
permis de mettre bout à bout toutes les
images (matrices) que nous avons pour en faire un vecteur.
Ø
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
43
Et la méthode Dropout qui nous a permis d'éviter le
sur-apprentissage en éteignant temporairement et aléatoirement
certains neurones au cours de l'apprentissage.
2. Compilation
C'est au moment de la compilation que nous allons définir
le type d'algorithme d'optimisation et la fonction de coût à
utiliser.

Figure 1.32: La compilation
Dans le cadre de cette mise en pratique nous avons opté
pour l'algorithme d'optimisation Adam et une fonction de coût d'entropie
croisée catégorielle.
3. L'entrainement
Premier cas : Le modèle est entraîné pendant
05 époques Deuxième cas : Le modèle est
entraîné pendant 10 époques Troisième cas : Le
modèle est entraîné pendant 20 époques

Figure 1.33 : l'entrainement des deux
1er cas
Avec l'avènement du deeplearning, l'accent est
placé sur les méthodes d'apprentissage en profondeur dont les
réseaux de neurones à convolution (CNN),qui sont les premier dans
l'évolution de l'apprentissage en profondeur. La CNN se compose de
plusieurs couches, effectuant des opérations telles que les
convolutions, la mise en pool maximale et les produits dot (couches
entièrement connectées), où dans les couches convolutives
et les couches entièrement connectées ont des paramètres
prenables qui sont optimisés pendant la formation.
Le type d'architecture de CNN détermine comment sont
de nombreuses couches, quelle est la fonction de chaque couche et comment les
couches sont connectées.
Il existe quatre architectures pour les CNN, à savoir
:
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
44
LeNet, AlexNet, VGG et GoogleNet. Parmi ceux-ci, nous avons
étudié LeNet et AlexNet. Choisir une bonne architecture est
crucial pour un apprentissage réussi des CNN. L'Alex Net de
l'architecture CNN contient 11 couches comprenant la convolution, la mise en
commun et le couches entièrement connectées. Le réseau
choisi contient 7 couches.
Ce chapitre nous a permis de monter de manière
détaillée les différents outils et la méthode de
réseaux de neurones convolutifs qui ont été
utilisés durant ce travail. Aussi les réseaux de neurones
convolutifs sont adaptés aux images, sont composés de deux
parties qui sont la partie convolutive et la partie de classification et dans
leur architecture, on a quatre couches. Ils tiennent leur particularité
de leur couche clé qui est la couche convolutive. Nous avons par la
suite montré notre modèle construit, donner les paramètres
de notre compilation et de notre entrainement.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
RESULTATS ET DISCUSSIONS
45
| 

