2. Système proposé
2.1. Description générale
Le système de reconnaissance de mots manuscrits se base
sur une approche analytique par partitionnement. La vue globale de cette
approche est présentée sur la figure 8. On a en entrée une
image d'une lettre manuscrite qui correspond à une lettre de l'alphabet
arabe, cette dernière sera nettoyer par un processus de
prétraitement qui comporte trois sous modules : un sous module de
binarisation qui se charge de la conversion de l'image en une image bitonale,
pour obtenir image nettoyée, ensuite nous allons passer cette même
image à un autre sous module qui se charge de l'encadrement et de la
sélection des cordonnées du mot dans l'image et enfin nous allons
passer ce mot à un sous module de prétraitement qui se charge de
la normalisation afin d'obtenir un mot adapté à une dimension
fixée par le système. Cependant, l'image prétraitée
va passer à un sous système d'apprentissage pour qu'elle puisse
être traité, ce dernier se charge de la construction de la matrice
de distribution sur une dimension de NxN, et d'enregistrer ces
caractéristiques avec l'identité du scripteur sur une base de
données d'apprentissage. Chaque lettre est représentée sur
la base de données d'apprentissage sous quatre formes différentes
(début, milieu, fin, isolée).
En ce qui concerne, le sous système de reconnaissance
son objectif est la reconnaissance du mot: On a en entrée une image
bruitée d'un mot manuscrit qui sera nettoyer par un processus de
nettoyage comportant les mêmes modules cités ci-dessus, ensuite
nous allons passer cette image à un autre sous module qui se charge de
l'encadrement (détermine les cordonnées du mot dans l'image) et
enfin l'image prétraitée sera envoyer pour le traitement.
Une fois que nous avons eu une image prétraitée,
nous commençons par l'extraction des trames de tailles fixes du
début jusqu'à la fin du mot de droite à gauche en
tranchant de manière incrémentale une partie du mot ensuite nous
allons faire une opération de normalisation de cette trame pour
l'adapter à une dimension de 64*64 pixels et enfin nous allons
construire la matrice de distribution qui va être comparer avec tous les
graphèmes qui sont dans la base de données d'apprentissage. La
comparaison se fait de manière efficace par exemple lorsqu'on est
positionné au début du mot on fait la comparaison avec tous les
modèles de toutes les graphèmes qui commencent au début
afin de minimiser le temps de comparaison et d'éviter le parcours total
de toute la base de données. Le processus de reconnaissance
possède deux états: non dans le cas où on n'a pas abouti
à une reconnaissance, cependant on revient à nouveau au processus
d'acquisition d'une nouvelle trame. Mais dans le cas inverse (oui) où on
a obtenu une reconnaissance (nous allons identifier le scripteur à
partir de la première lettre reconnue et enfin nous ferons une
modification sur la requête de sélection des graphèmes afin
d'éviter le parcours total de toute la base de données), on
vérifie si on a atteint la fin du mot, si s'est pas le cas on recommence
le processus d'acquisition d'une nouvelle trame, alors dans le cas inverse on
met fin au processus de traitement et on obtient en sortie le mot en solution.
Ce dernier va passer au post-traitement afin de valider le mot en solution et
de l'évaluer.
Nous allons par la suite expliquer en détail chaque
composant et son processus de fonctionnement.
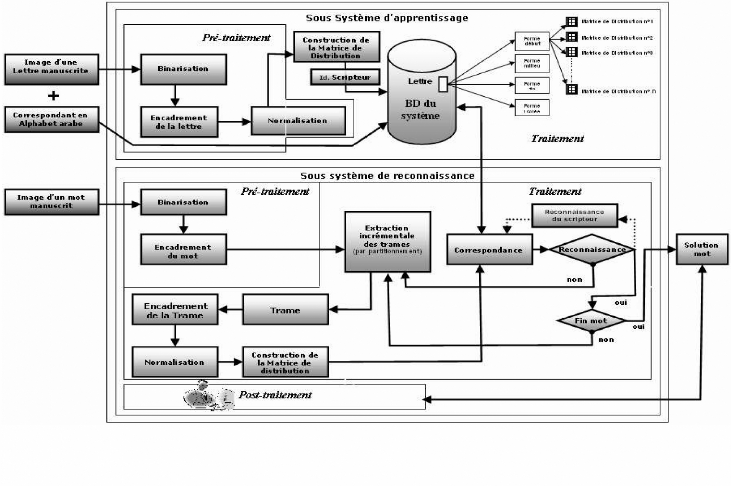
Figure 8 : Architecture globale du système
36
| 
