|
A DIEU le père éternel et tout puissant,
Et à mes adorables parents M. et Mme NTA,
Une dédicace toute particulière à tous ceux
qui participent à la croissance et à l'innovation technologique,
et au respect de l'environnement.
REMERCIEMENTS
Le présent document est le fruit d'un travail de
recherche. Cependant, il n'aurait pu être réalisé sans
l'apport de certaines personnes. Du fait de leur apport sous quelque forme que
ce soit, ainsi nous citerons :
§ Au Seigneur Jésus-Christ sans qui ce travail
n'aurait pas été possible et pour tout : soutien moral et
physique, l'énergie pour aller jusqu'au bout de cette étude.
§ Monsieur Stéphane Franco, administrateur
général de l'entreprise Ringo SA qui nous a accueillis et offert
un cadre de travail doté d'une technologie de pointe.
§ Monsieur Kameni Claude pour les conseils et l'assistance
permanente qu'il nous a apporté.
§ Monsieur Kizito, Ingénieur en architecture
logicielle qui nous a fait connaître des outils et notions
déterminantes.
§ Monsieur Azogni Patrick, Administrateur serveur à
Ringo SA pour le support technique qu'il nous a fournit.
§ A la famille NSANGOU de Mendong pour leur soutien et
précieux conseils.
§ A Sarah Dauphiné pour ses bons repas
français qui ont été une délicieuse source
d'inspiration.
A tous mes collègues du pool web, pour la
solidarité et la complicité que nous avons les uns envers les
autres en particulier : Guy-Cédric MBOUOPDA et Steve KEUTCHANKEU.
A tous ceux qui ont oeuvré de près ou de loin
à la réalisation de ce mémoire.
RESUME
L'expansion des applications informatiques prend de plus en
plus d'ampleur avec la variété des secteurs d'activités
qui existe de nos jours. Il existe de nombreuses méthodes de
développement informatique (conception de logiciel) connues, la plupart
d'entre elles ont quelqu'un point commun que nous avons exploité dans
notre travail.
Dans la pratique les techniques de génie logiciel sont
de moins en moins appliquées dans les entreprises donc l'activité
principale ne repose pas sur le développement informatique. Il est de
plus en plus difficile d'instaurer une certaine dose de discipline au sein
d'une équipe de développeurs dans un projet surtout si celui-ci
est bien avancé, mais une fois installée l'effort de maintenance
est minime. Cette discipline devrait être une méthode qui se veut
pragmatique que les méthodes traditionnelles. Elle devra impliquer au
maximum le demandeur (client) et permettre une grande réactivité
à ses demandes. Elle visera la satisfaction réelle du besoin du
client et non les termes d'un contrat de développement.
Pour appliquer cette technique, il faut d'abord que : le code
source soit partagé (en utilisant des logiciels de gestion de versions);
les développeurs intègrent (commit) quotidiennement (au moins)
leurs modifications; des tests d'intégration soient
développés pour valider l'application et ensuite, il faut un
outil d'intégration pour éviter les intégrations
pénibles et réduire le risque dans un projet.
Il est donc question dans ce document d'examiner les
méthodes de gestion de code source, d'implémentation de tests
unitaires et d'explorer les techniques d'intégration continue et ensuite
proposé et mettre en place une architecture qui permettra de suivre un
projet de développement informatique dans une approche de production
industrielle.
LISTE DES FIGURES
Figure 1 : Architecture
10
Figure 2 : Objectifs d'un système de gestion
de version
15
Figure 3 : Arborescence de la copie locale
21
Figure 4 : Cycle de vie du gestionnaire de
versions
23
Figure 5 : Architecture intégration
continue
27
Figure 6 : Fichier Build.properties
38
Figure 7 : Description de la tâche dbdeploy de
phing
38
Figure 8: Tableau de bord du Xinc 2.0 alpha
49
Figure 9 : détails présentant le
statut du build et les builds précédents
50
Figure 10 : détails du build - Artefacts du
navigateur
50
LISTE DES TABLEAUX
Tableau 1: CruiseControl vs Xinc
29
Tableau 2 : liste des outils utilisables avec
Phing
33
Tableau 3 : liste des attributs de la tâche
DbDeploy
37
Tableau 4 : Xinc - dépendances
logicielles
44
DEFINITION DES SIGLES
|
Sigle
|
Définition
|
|
Ant
|
Compilateur de tâches
|
|
BD
|
Base de données
|
|
BDB
|
Berkeley DataBase
|
|
Checkout
|
Transfert du référentiel vers le dépôt
local
|
|
CMS
|
Content Management System
|
|
Commit
|
Transfert du dépôt local vers le
référentiel
|
|
CVS
|
Concurrent Versions System
|
|
http
|
Protocole réseau de navigation internet
|
|
Phing
|
Outil de build de projets développement PHP
|
|
RSS
|
Really Simple Syndication
|
|
Shell
|
Scripts, ligne de commandes
|
|
SQL
|
Structured Query Language
|
|
SSH
|
Secure Shell
|
|
SVN
|
Subversion, gestionnaire de version
|
|
Target
|
Tâche Ant ou Phing
|
|
Xinc
|
Serveur d'intégration continue écrit en PHP
|
SOMMAIRE
INTRODUCTION
8
1- Cadre de l'étude
9
2- Problématique
10
3- Rappel : Cycle de vie
logiciel
11
PRESENTATION DE LA METHODE
13
Chapitre I. LA GESTION DU CODE
SOURCE
14
I.1 Définition
15
I.2 Les deux types de gestion de
version
16
I.3 Principe de fonctionnement
16
I.4 Les tests unitaires
22
I.4 Les tests unitaires
22
I.6 Avantage de l'architecture
24
Chapitre II. L'INTEGRATION
CONTINUE
25
II.1 Contexte
26
II.2 Objectifs
27
II.3 Serveur
d'intégration
28
II.4 Système de build
29
Chapitre III. DEPLOIEMENT
AUTOMATISEE
34
DE LA BASE DE DONNEES
34
III.1 Problématique
35
III.2 Règles d'utilisation de
dbdeploy
35
III.3 DbDeployTask
36
ETUDE D'UNE SOLUTION
D'INDUSTRIALISATION
38
Chapitre IV. L'ENVIRONNEMENT DE
TRAVAIL
39
IV.1 Configuration matérielle et
logicielle
40
IV.2 Les outils
40
Chapitre V. Installation et configuration
de SVN
41
V.1 Installation du serveur
SVN
42
V.2 Mise en place des clients
SVN
42
V.3 Création d'un
projet
42
Chapitre VI. Mise en place du serveur
d'intégration
43
VI.1 Installation du serveur
Xinc
44
VI.2 Fichier de configuration
.ini
45
VI.3 Interface web
d'administration
46
Chapitre V. Paramétrage du
système de build avec Phnig
48
VII.1 Installation de Phing
49
VII.2 Utilisation de Phing
49
CONCLUSION
55
1- Rappels sur le travail
56
2- Problèmes non
résolus
57
3- Perspectives
57
Bibliographie
58
Annexes
60
INTRODUCTION
Le travail en équipe est un aspect incontournable pour
le développement de toute activité devant produire le
résultat attendu. De ce fait l'organisation de l'exécution des
tâches et la synchronisation entre tâches effectuées par les
différents intervenants doivent être normalisées selon des
standards bien établis afin d'améliorer la productivité de
l'équipe. L'industrialisation est le processus de fabrication de
produits manufacturés avec des techniques permettant une forte
productivité du travail et qui regroupe les travailleurs dans des
infrastructures constantes avec les horaires fixes et une réglementation
stricte. De manière analogue il est possible d'organiser le code
fournit par une équipe de développeurs selon des
procédés industriels. Au delà de l'organisation, on pourra
aussi envisager l'automatisation des stockages et même des livraisons
d'un projet quelconque.
1- Cadre de
l'étude
Cette étude (Industrialisation des
développements PHP) est effectuée dans le cadre de la conduite du
projet « Implémentation des serveurs de déploiement
automatique « visant à implémenter un système de
suivi des projets de développement effectués par le Pool web. Le
dit travail nous est confié à l'occasion d'une période de
test effectuée au sein de l'entreprise RINGO SA. Cette dernière
est spécialisée dans la fourniture des solutions internet aux
entreprises, aux particuliers et aux grands publics.
Le pool web est le département en charge du
développement, du webdesign, de l'intégration des gestionnaires
de contenus et de la mise en ligne du site web. En outre ce dernier
reçoit des commandes de travail internes, issues d'autres services de
l'entreprise. Et pour ce qui concerne notre travail, le demandeur interne
c'est la Direction générale qui souhaite avoir ce système
qui tourne sur des serveurs internes et aussi accessibles depuis
l'extérieur.
Figure 1 : Architecture
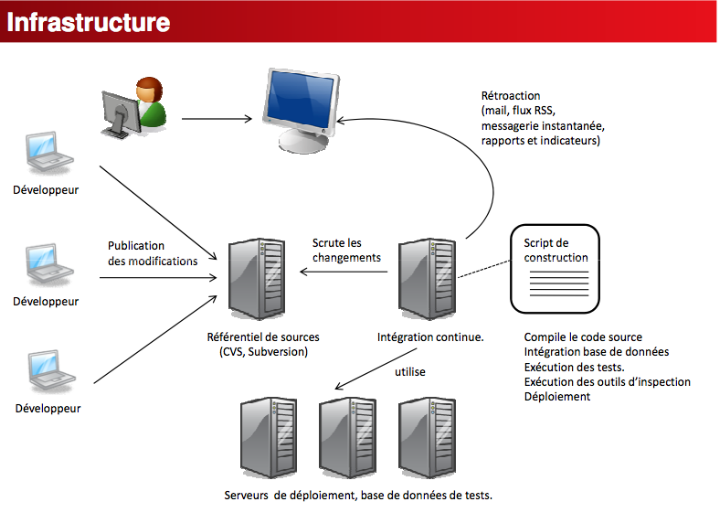
2-
Problématique
Le développement (programmation) informatique est
l'ensemble des activités qui permettent la rédaction du code
source des programmes informatiques. C'est une étape importante de la
conception d'applications.
La question qui a conduit cette étude nait d'une question
posée par le directeur générale : Serait-il possible
d'implémenter un environnement de développement sûr de
telles sortes que les projets en test soient consultables à partir d'une
seule adresse et accessible au fur et a mesure de l'avancement du projet ?
Dans de gros projets de développement informatique le
travail s'organise autour d'une équipe de développeurs qui ne
programme pas de la même façon, alors il serait
bénéfique pour les programmeurs de connaître les
méthodes de programmation de chacun, ainsi que les méthodes de
débogages. Il est aussi important pour la conduite du projet de savoir
quelles sont les modifications apportées par chacun des acteurs. Une
pratique à mettre en place pour archiver les codes sources et adopter la
méthode XP : Je pars d'un programme simple que j'enrichis petit
à petit. Le processus idéal est de construire automatiquement le
projet au fur et à mesure qu'il y aura des modifications sur le code
source, cette construction doit inclure l'interprétation (PHP
étant un langage interprété) du code source ainsi on
pourra avoir une visibilité sur l'évolution entière du
projet avec chaque de ces versions. Pour ce qui est de la base de
données elle suivra aussi ce même procédé
d'industrialisation donc elle sera déployé sur un serveur de
test.
Par la suite d'autres questions ont émergées et
ont été déterminantes tant dans l'élaboration de
la solution proposée que dans la détermination des enjeux :
§ Comment automatiser le déploiement des tests ?
§ Comment travailler à plusieurs sur un même
code source ?
§ Comment réduire le temps d'une mise en
production?
§ Comment faire des tests de performance, de robustesse
d'une application ?
§ Serait-il possible de déployer sur plusieurs
serveurs avec une seule action ?
§ Comment s'assurer qu'une nouvelle fonctionnalité,
nouvelle correction de bogue
n'introduit pas de régression ?
Nous essayerons d'apporter solution à ces interrogations
en explorant les enjeux dans un processus d'industrialisation du
développement en langage PHP.
3- Rappel :
Cycle de vie logiciel
Les projets relatifs à l'ingénierie logicielle
sont généralement de grande envergure et dépassent souvent
les 10 000 lignes de code. C'est pourquoi ces projets nécessitent
une équipe de développement bien structurée. La gestion de
tel projet se trouve intimement liée au génie logiciel. Le
génie logicielle s'intéresse particulière à la
manière dont le code source d'un logiciel est spécifié
puis produit.
Le cycle de vie désigne toutes les étapes de la
validation du développement d'un logiciel, de sa conception à sa
disparition. L'objectif d'un tel découpage est de permettre de
définir des jalons intermédiaires permettant la validation du
développement logiciel, c'est-à-dire la conformité du
logiciel avec les besoins exprimés, et la vérification du
processus de développement, c'est-à-dire l'adéquation des
méthodes mises en oeuvre.
Le cycle de vie du logiciel comprend
généralement à minima les activités
suivantes :
§ Définition des objectifs,
consistant à définir la finalité du projet et son
inscription dans une stratégie globale.
§ Analyse des besoins et
faisabilité, c'est-à-dire l'expression, le recueil et la
formalisation des besoins du demandeur (le client) et de l'ensemble des
contraintes.
§ Conception générale. Il
s'agit de l'élaboration des spécifications de l'architecture
générale du logiciel.
§ Conception détaillée,
consistant à définir précisément chaque
sous-ensemble du logiciel.
§ Codage (Implémentation
ou programmation), soit la traduction dans un langage de programmation des
fonctionnalités définies lors de phases de conception.
§ Tests unitaires, permettant de
vérifier individuellement que chaque sous-ensemble du logiciel est
implémenté conformément aux spécifications.
§ Intégration, dont
l'objectif est de s'assurer de l'interfaçage des différents
éléments (modules) du logiciel. Elle fait l'objet de tests
d'intégration consignés dans un document.
§ Qualification (ou recette),
c'est-à-dire la vérification de la conformité du logiciel
aux spécifications initiales.
§ Documentation, visant à
produire les informations nécessaires pour l'utilisation du logiciel et
pour des développements ultérieurs.
§ Mise en production,
§ Maintenance, comprenant toutes
les actions correctives (maintenance corrective) et évolutives
(maintenance évolutive) sur le logiciel.
La séquence et la présence de chacune de ces
activités dans le cycle de vie dépend du choix d'un modèle
de cycle de vie entre le client et l'équipe de développement.
PRESENTATION DE LA
METHODE
Chapitre I. LA GESTION DU
CODE SOURCE
Nous allons définir la gestion des versions du
code source et présenter les opérations qu'elle permet aux
utilisateurs d'effectuer. Par la suite, nous allons parcourir des techniques de
construction du projet voir d'intégration continue.
I.1
Définition
Un logiciel de gestion de versions agit sur une
arborescence de fichiers afin de conserver toutes les versions des fichiers,
ainsi que les différences entre les fichiers.
Ce système permet par exemple de mutualiser un
développement. Un groupe de développeurs autour d'un même
développement se servira de l'outil pour stocker toute
l'évolution du code source. Le système gère les mises
à jour des sources pour chaque développeur, conserve une trace de
chaque changement. Ceux-ci sont, en bonne utilisation, chaque fois
accompagnés d'un commentaire. Le système travaille par fusion de
copies locale et distante, et non par écrasement de la version distante
par la version locale. Ainsi, deux développeurs travaillant de concert
sur une même source, les changements du premier à soumettre son
travail ne seront pas perdus lorsque le second, qui a donc travaillé sur
une version non encore modifiée par le premier, renvoie ses
modifications.
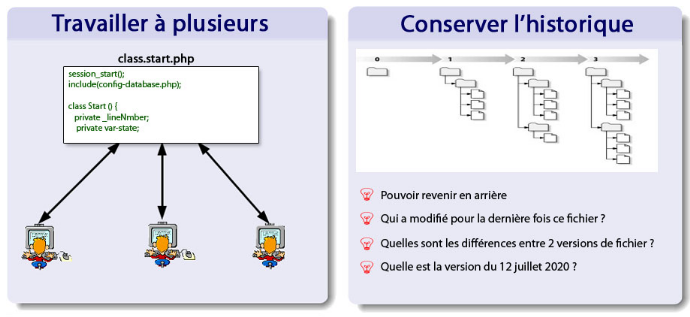
Figure 2 : Objectifs d'un
système de gestion de version
I.2 Les deux types de
gestion de version
Pendant très longtemps l'unique logiciel libre et
sérieux de gestion de versions était CVS. Il reste aujourd'hui la
référence. Mais depuis que ce vénérable logiciel
atteint ces limites et que la créativité bouillonne dans ce
domaine, il est temps de présenter les solutions rivales.
Pour remplacer CVS, il existe deux sortes de logiciel de
gestion de version, centralisés ou décentralisés.
Les logiciels de gestion de versions centralisée
permettent de n'avoir qu'un seul dépôt des versions,
dépôt qui fait référence, cela simplifie la gestion
des versions mais est contraignant pour certains usages (travail sans connexion
au réseau ou tout simplement travail sur des branches
expérimentales ou contestées). On peut citer CVS et
Subversion.
Avec l'arrivée des logiciels libres et leur
développement communautaire, une autre façon de voir la gestion
de versions est apparue. Cette autre vision consiste à voir l'outil de
gestion de versions comme un outil permettant à chacun de travailler
à son rythme, de façon désynchronisée des autres,
puis d'offrir un moyen à ces développeurs de s'échanger
leur travaux respectifs. C'est ce que l'on nomme la gestion de versions
décentralisée. On peut citer Mercurial, Darcs, Bazaar, Git,
Monotone, GNU Arch et BitKeeper (propriétaire) sont des logiciels de
gestion de versions décentralisée. Avec ceux-ci, il existe
plusieurs dépôts de versions.
Dans notre cas d'étude le travail de chaque
développeur doit être sur un même référentiel
le dépôt doit donc être centralisée, ce qui
détermine notre choix du système de gestion de versions
centralisée : Subversion.
I.3 Principe de
fonctionnement
Subversion est un outil de gestion de versions. Il autorise
plusieurs personnes à travailler de concert sur un même code
source, et historise les différentes évolutions validées
par ces développeurs. Subversion peut être séparée
en deux éléments: Le dépôt et le client.
I.3.1 Le dépôt
Le dépôt est ce que l'on appelle parfois le
"serveur" Subversion. Il contient le code source et son historique. Un
dépôt peut être accéder par plusieurs
méthodes, suivant sa configuration:
· http:// ou https:// : Subversion est
associé à un serveur HTTP (Apache). C'est la méthode la
plus fréquente, car elle permet de voir le contenu du dépôt
à l'aide d'un navigateur Web.
· ssh:// : Cette méthode est
aussi rencontrée de temps en temps. Subversion est alors associée
à un serveur SSH (Secure Shell). Bien qu'elle soit plus difficile
à mettre en oeuvre, elle apporte une meilleure sécurité
des données que le https, et évite d'avoir un serveur Web
installé sur la machine du dépôt Subversion.
· svn:// : Subversion possède son
propre protocole, qui peut être activé via un serveur.
Le dépôt utilise une base de données
Bekerley (BDB pour les intimes) pour stocker les différentes versions de
votre code source. A l'aide de Subversion, vous pouvez:
· Voir d'anciennes versions de votre code source.
· Annuler des modifications pour revenir à une
ancienne version fonctionnelle.
· "Tagguer" les versions stables de votre projet, c'est
à dire enregistrer l'état de votre code pour une version de votre
logiciel.
· Et bien d'autre chose.
Subversion utilise une mécanique de "révision"
pour stocker les informations de versions de votre code. Une
révision correspond à un ensemble de
modifications validées par un "commit". A tout moment,
vous pouvez obtenir les informations associées à une
révision donnée.
I.3.2 Le client
Le client est un outil en ligne de commande : svn. Il vous
permet de manipuler le contenu de votre copie de travail ainsi que celui du
dépôt Subversion. C'est aussi lui qui gère la
synchronisation entre votre copie de travail et le serveur Subversion.
I.3.3 Les opérations
courantes
· Créer une copie de travail
Pour travailler sur un projet, on doit créer une copie
de travail du code source de ce projet. La copie de travail est l'endroit ou
sera modifié le code du projet. Une fois le code modifié et
testé, les modifications peuvent être ajouté au
dépôt Subversion à l'aide d'un commit.
Pour créer une copie de travail à partir d'un
dépôt, il faut utiliser la commande "checkout" ou "co" pour faire
court. Pour ce faire, il faut d'abord récupérez l'URL du
dépôt et exécutez :
- svn co http://svn.web-srv-yde.com/test/trunk
Projet1
· Mettre à jour une copie de travail
Il est important de synchroniser la copie de travail avec la
version présente dans le dépôt. C'est
particulièrement le cas lorsqu'on travaille en équipe avec
d'autres développeurs. Pour ce faire, il faut se placer à la
racine de la copie du répertoire de travail et exécutez :
- svn update
Subversion récupère alors les modifications
présentes dans le dépôt.
Remarque: Les modifications des autres sont
fondues avec vos modifications, mais dans certains cas, un conflit peut
apparaitre. Vous devez alors corriger manuellement les fichiers posant
problèmes (les conflits sont en général affichés
entre des <<<< et >>>>).
· Gestion des conflits
Un conflit apparaît lorsque deux personnes (ou plus)
décident de modifier un fichier au même moment. La plus rapide va
commiter son changement sans aucun problème, mais la deuxième va
devoir gérer le fait que, sur le serveur, se trouve une version plus
récente que celle sur laquelle elle a travaillé. Il existe trois
options pour contourner les conflits :
§ Diff :
Cette commande permet de ne pas se perdre. Quand la
quantité de codes écrit arrive à être énorme
et que vous ne savez plus ce que vous avez modifié depuis le dernier
update. Pas de problème, cette option est là pour vous expliquer
ce que vous avez fait.
- svn diff
§ Revert :
Cette commande va enlever la plupart des modifications
effectuées sur les éléments (fichiers ou dossiers) depuis
le dernier update. Dans un projet, la plupart du temps, cette commande est
utilisée parce que quelqu'un a édité un fichier binaire,
".doc" par exemple, alors que ce n'était pas son tour dans le planning.
Or le problème, c'est que SVN ne sait pas fusionner des fichiers
binaires ! et il va donc falloir tout refaire.
- svn revert [chemin] [--targets fichier_darguments] [-R]
§ Resolved :
Cette commande a "deux fonctions". Elle ne permet que
d'indiquer qu'un conflit est résolu (comme on aurait pu s'en douter),
seulement, subtilité, il y a deux façons de s'en servir.
- svn resolved [chemin] [--targets fichier_darguments] [-R]
· Ajouter un fichier au dépôt
Pour ajouter un nouveau fichier au dépôt,
placez-vous dans votre copie de travail et exécutez (en remplacement la
valeur en gras par le chemin vers le nouveau fichier):
- svn add chemin/vers/le/fichier
· Supprimer un fichier du dépôt
Pour supprimer un fichier présent dans le
dépôt, il faut être dans la copie de travail, et
exécutez :
- svn del chemin/vers/le/fichier
· Renommer ou déplacez un fichier
Pour renommer ou déplacer un fichier présent
dans le dépôt, placez-vous dans votre copie de travail, et
exécutez :
- svn mv chemin/vers/le/fichier chemin/vers/le/nouveau/fichier
· Poster vos modifications
Une fois que les modifications que vous avez
effectuées sont fonctionnelles, vous pouvez envoyer vos changements sur
le dépôt. Pour se faire, placez-vous à la racine de votre
copie de travail, et exécutez la commande :
- svn commit -m "Mon résumé de mes changements"
· Créer un Tag de version du logiciel
Une fois que vous estimez que le "tronc" (trunk) courant est
stable, vous pouvez créer un tag pour une nouvelle version de votre
logiciel. Généralement, cela se fait à chaque livraison au
client. Pour ce faire, exécutez la commande :
- svn cp http://svn.web-srv-yde.com/projet2/trunk
- http://svn.web-srv-yde.com/projet2/tags/numero.de.version
Une convention assez courante de numérotation de
version est une numérotation à 3 chiffres : 1.2.3 ou :
· 1 est le numéro de version majeur. Il change
lorsque le logiciel subit de grosses modifications de fond, et n'est plus
compatible avec la version précédente.
· 2 est le numéro de version mineur. Il
représente l'ajout de nouvelle fonctionnalités, ou la
modification d'existantes, tout en restant compatible avec la version
précédente du logiciel.
· 3 est le numéro de correctif. Il
représente le nombre de mise à jour correctives appliquées
sur le logiciel depuis la dernière version mineure.
· Afficher la liste des modifications entre 2
révisions
La commande suivante:
- svn diff -r 310 :304 -- summarize
Affiche la liste des fichiers modifiés entre la
révision 304 et la révision 310.
I.3.4 Tronc, branches,
tags
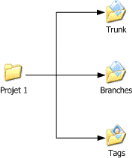
Les notions de tronc, de branches et de tags sont
assez spécifiques aux logiciels de contrôle de versions. C'est ce
qui explique que les arborescences des répertoires de projet contiennent
souvent comme premier niveau de sous-répertoires les dossiers trunk,
branches et tags.
En général, on définit par
« tronc » la version centrale du programme, le
développement principal « officiel ».
Une
« branche » est en général
créée lorsqu'un développement
« secondaire » est mis en route, que ce soit pour ajouter
une nouvelle fonctionnalité ou parce que certains développeurs
souhaitent essayer de prendre une autre direction pour certains aspects du
développement. Une branche peut, au bout d'un certain temps, soit
être à nouveau fusionnée dans le
« tronc », soit disparaître, soit donner lieu
à un nouveau programme.
La notion de tags correspond en
partie à celle de release, c'est à dire de marquage
d'une certaine révision du projet comme composant une version du projet.
Une fois que le développement a atteint une certaine stabilité,
on pourra par exemple créer un tag pour marquer la sortie de la
version 1.0. Ceci permettra de revenir facilement à cette version,
indépendamment du numéro de révision sous-jacent
correspondant.
Nous n'entrerons pas dans le détail de ces concepts et
commandes ici, mais on peut juste citer que la création de
branches ou de tags ne sont en fait que des copies
créées par la commande svn copy. La commande svn switch, elle,
permet de faire passer la copie de travail d'une branche à une autre.
Figure 3 : Arborescence de la copie
locale
I.4 Les tests unitaires
Le but des tests unitaires est d'automatiser les tests de
non-régression. Quand on développe un logiciel, on peut
facilement faire des modifications sans se rendre compte qu'elles introduisent
des bugs dans certains cas particuliers. C'est ce qu'on appelle des bugs de
régression, en ce sens qu'on introduit de nouveaux bugs à la
suite d'une évolution fonctionnelle. Comme il n'est pas humainement
possible de tester systématiquement tous les cas d'utilisation possible,
ces bugs peuvent se retrouver déployés en production, avec tous
les problèmes que cela comporte.
Une des notions importantes, quand on fait du
développement, est de savoir que plus un bug est détecté
tôt, plus il sera facile à corriger. Les gros soucis arrivent
quand on fait du "sur-développement" par-dessus un bug de
régression ; il devient très difficile de faire un retour en
arrière sur le code incriminé, car cela impliquerait de supprimer
des fonctionnalités. Il faut alors corriger ce nouveau code, en essayant
de trouver une aiguille dans une botte de foin.
Concrètement, les tests unitaires consistent en un
ensemble de scripts, qui ont chacun en charge la validation d'un morceau de
code (ou d'une classe lorsqu'il d'agit de la programmation orientée
objet). Il est assez évident de tester de la sorte les
bibliothèques de fonction : les "librairies" peuvent être
vues comme des boîtes noires, avec des entrées et des sorties. Il
suffit d'injecter certaines données en entrée, et vérifier
la conformité de ce qu'on obtient en sortie.
Pour du code applicatif,
c'est un peu plus délicat, car on est parfois obligé de mettre en
place un environnement de test sophistiqué (bases de données avec
lots de test, génération de données aléatoires,
gestion des tentatives de hack, ...). Mais bien heureusement il existe de
très nombreux Framework pour nous aider à y arriver ;
suivant la plate-forme de développement, on distingue :
§ Java : JUnit,
§ PHP : SimpleTest, PHPunit
§ C++ : CppUnit,
§ JavaScript : JSUnit,
§ ActionScript : ASUnit,
§ Ruby : Test::Unit,
§ Perl : Test::Unit,
§ Python : unittest ,
§ .NET: NUnit.
Au cours du développement, il faut évidemment
prendre le temps de réaliser les tests équivalents à
chaque nouvelle fonctionnalité, à chaque nouveau cas particulier.
Mais ce temps se récupère au moment du test et du
débogage. Il suffit de lancer les tests unitaires pour savoir rapidement
où les bugs se situent, ce qui permet de les corriger sans perdre de
temps.
I.5 Le cycle d'un gestionnaire de
version
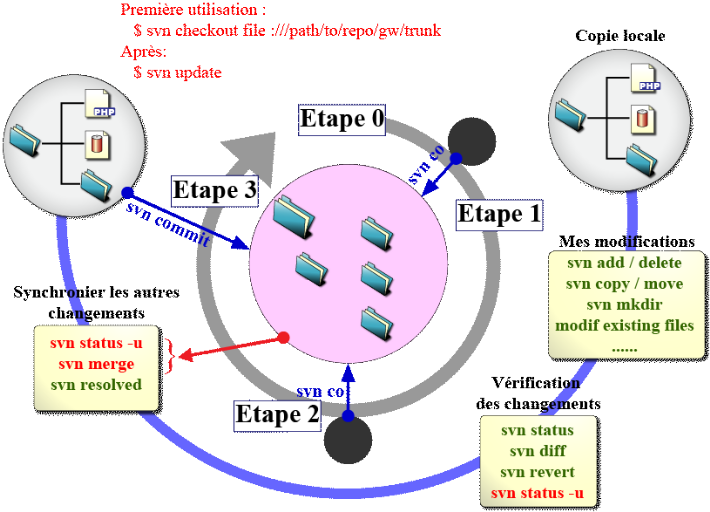
Figure 4 : Cycle de vie du
gestionnaire de versions
I.6 Avantage de
l'architecture
Les pratiques sont les suivantes :
§ Maintenir un dépôt unique de code source
versionné;
§ Automatiser les compilations ;
§ Rendre les compilations auto-testantes ;
§ Tout le monde commit tous les jours ;
§ Tout commit doit compiler le tronc sur une machine
d'intégration ;
§ Maintenir une compilation courte ;
§ Tester dans un environnement de test
cloné ;
§ Rendre disponible facilement le dernier
exécutable ;
§ Tout le monde doit voir ce qui se passe ;
§ Automatiser le déploiement.
Chapitre II.
L'INTEGRATION CONTINUE
II.1
Contexte
Avant de commencer avec l'intégration continue, il
faut comprendre l'architecture "idéale" de développement d'une
application (dans notre cas d'une application Web). Elle se compose de cinq
environnements :
§ Les postes des développeurs
(dits "locaux"), avec les différents outils traditionnels (IDE, outils
de modélisation de base de données, éditeurs XML, ...)
§ L'environnement de
développement. Il est réservé aux
développeurs qui en ont tous les droits (administrateurs). On verra que
c'est l'environnement cible de l'intégration continue. Il est ainsi
toujours à jour avec la dernière version disponible de
l'application. De plus son état est souvent plus ou moins stable
(redémarrage fréquent des applications, données volatiles
insérées par les développeurs dans le cadre de leurs
tests, ...)
§ L'environnement de test à
destination du client (par exemple le comité de direction). Ce dernier
valide le bon développement de l'application par rapport à ses
besoins. Dans le cadre d'un développement itératif, il permet
surtout de découvrir à temps les besoins réels du client
qui sont trop souvent mal exprimés ou incomplets. Une nouvelle version
de l'application est déployée depuis l'environnement de
développement dès que l'application est estimée stable et
qu'elle contient suffisamment de nouveautés ou corrections de bugs par
rapport à la version précédente. Ces déploiements
sont tout de même fréquents (toutes les 1 à 2 semaines) et
sont généralement effectués manuellement à la
demande du chef de projet. On offre alors généralement un fichier
changes.txt qui décrit les différentes évolutions et
corrections de bugs apportées depuis la version
précédente.
§ L'environnement de
pré-production pour tester la version finale de l'application.
Il reproduit à l'identique l'environnement de production (nombre de
machines, processeurs, mémoires, versions des applications, ...). Il
permet de réaliser les tests de charge et de valider la bonne
exécution de l'application lors du passage en production.
§ L'environnement de production
accessible par les clients.
§ Hormis les machines locales, ces environnements sont
indépendants entre eux et exécutent leurs propres serveurs
(Apache, conteneur J2EE, base de données, serveur de mail...). Seules
les machines locales et l'environnement de développement se partagent
quelques applications :
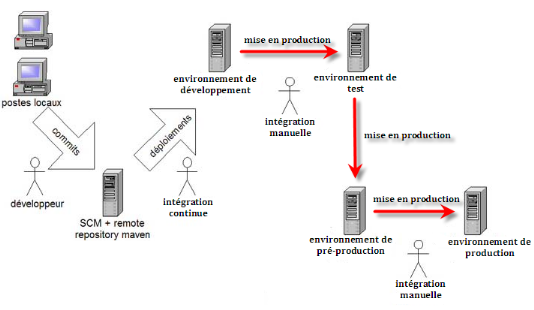
§ le serveur SCM (Source Control
Management) comme CVS ou Subversion. Il centralise toutes les sources des
différents projets et gère les notions liées au
versionning (branche, différences entre deux versions d'un même
fichier, ...).
Figure 5 : Architecture
intégration continue
II.2
Objectifs
L'intégration continue est un processus
d'automatisation de tâches récurrentes liées à
l'environnement de développement. Les plus connues sont :
· construction ("build") de l'application à partir
des données contenues dans le SCM. Cela comprend la compilation des
sources et la construction des releases (JAR, WAR, EAR, ...)
· déploiement de l'application sur l'environnement
de développement (copie des librairies, configuration et
redémarrage)
· exécution des tests unitaires et
d'intégration
· génération de rapports, par exemple
phpdocumentor
Tout l'intérêt de cette automatisation
réside dans sa fréquence d'exécution, qui doit être
au minimum quotidienne. On dispose alors régulièrement d'un
environnement mis à jour avec la toute dernière version de
l'application, mais surtout de l'état du projet (succès de la
compilation, des tests et du déploiement). Et c'est là un des
gros avantages de l'intégration continue : le fait que l'on sache
immédiatement qu'une tâche a échoué apporte une
certaine discipline au développeur. Finis les "ca
compile pas chez moi!" (mais chez le voisin oui). Ces problèmes prennent
toujours plus de temps à trouver leur origine qu'à les corriger
(oubli d'archivage de fichier, suppression d'un fichier encore utilisé
quelque part ailleurs, modification de code impactant un autre composant, ...).
Avec l'intégration continue on connaît tout de suite la nature et
l'origine du problème.
Un autre gros avantage est la réduction du
coût de correction des bugs, à condition bien entendu de
l'existence de tests... La fréquence élevée
d'intégration diminue le délai de détection d'un bug. Le
contexte est alors encore d'actualité pour les développeurs et
les modifications de code depuis l'insertion du bug sont peu nombreuses et
encore connues. En effet quoi de plus coûteux qu'un bug découvert
longtemps après son insertion ! (5% des bugs représentent
95% du coût de correction).
On peut encore trouver d'autres avantages à
l'intégration continue :
· gain de temps pour ceux qui avaient la longue et
laborieuse tâche de déployer en développement.
· connaissance plus concrète du chef de projet de
l'état d'avancement du développement.
Bien entendu vous aurez compris que l'intégration
continue n'a d'intérêt que dans le cadre d'un développement
itératif. Et elle peut être mise en place quelque
soit la taille du projet, même si il n'y a qu'un développeur...
II.3 Serveur
d'intégration
Parmi les serveurs d'intégration continue existants,
ceux qui répondent à nos attentes et dont les
caractéristiques intègrent les outils que nous avons choisis
sont :
§ CruiseControl + l'extension phpUnderControl.
§ Xinc.
|
CruiseControl
|
Xinc
|
|
Plateforme d'exécution
|
JVM
|
PHP
|
|
Programme d'installation
|
Installeur Windows
|
PEAR
|
|
Outil de build préférés
|
Ant, Maven
|
Phing
|
|
Autres outil de build supportés
|
Phing (intégration instable)
|
|
|
Support SCM
|
CVS, SVN, Perforce,...
|
SVN
|
|
Langages supportés
|
Tout ce qui peut être construit avec Ant
|
PHP
|
|
Web Front end_
|
Jetty
|
Apache
|
|
Extensible via
|
XSL, JSP, Java
|
Xinc Plugins (PHP)
|
Tableau 1: CruiseControl vs
Xinc
·
Rétroaction
§ Les résultats de l'intégration
sont notifiés à l'équipe développement et
publiés sur un site web accessible aux parties prenantes au projet.
§ La correction des constructions en erreur est
une priorité des membres de l'équipe de
développement :
Ø Gain de temps
Ø Diminution des coûts
Corriger les défauts détectés
avant qu'ils ne se manifestent.
·
Inspection
§ L'intégration continue permet d'obtenir
continuellement des indicateurs d'avancement et d'état qualitatif d'un
projet en cours de développement.
§ Les outils d'assurance de qualité
participent au contrôle des risques :
Ø Risques de faible qualité
logicielle
Ø Risques de découverte tardive des
défauts
Pour les projets de développement basé
sur le langage PHP, il existe un serveur d'intégration continue
écrit en PHP 5 : Xinc. Il comprend nativement le
support de Subversion et de Phing (et donc PHPUnit). Il peut aussi être
étendu pour travailler avec d'autres outils de gestion de code source ou
de build.
II.4 Système de
build
Pour un petit programme avec une douzaine de fichiers,
la construction de l'application peut être juste une question de commande
unique pour un compilateur. Des projets plus importants ont besoin d'un peu
plus que la compilation fichier par fichier : tests, compilation
simultanée, déplacement de fichiers compilés,
création d'auto-docs, compression, mise en ligne avec CVS/Subversion....
Dans ces cas, vous avez des fichiers dans plusieurs répertoires. Vous
devez vous assurer que le code objet qui en résulte est au bon endroit.
Vous avez le code généré à partir d'autres fichiers
qui doit être généré avant de pouvoir être
compilé. Les tests doivent être exécutés
automatiquement.
Une grande construction prend souvent du temps, vous ne
voulez pas faire toutes ces étapes si vous avez seulement fait un petit
changement. Ainsi, un bon outil de build analyse juste ce qui doit être
changé dans le cadre du processus. La façon courante de le faire
est de vérifier les dates du code source et des fichiers objets et ne
compiler que si le code source est plus ancien. La gestion des
dépendances devient alors compliquée : si on change de fichier
objet ceux qui en dépendent peuvent aussi avoir besoin d'être
reconstruit. Les compilateurs peuvent gérer ce genre de chose, ou
pas.
Tout dépend de ce que l'on veut, on peut avoir besoin de
différentes sortes de choses à la construction. Vous pouvez
construire un système avec ou sans code de test, ou à
différents jeux de tests. Certains éléments peuvent
être construits autonome. Un script de build devrait vous permettre de
construire des cibles (target) alternatives pour les différents cas.
Une fois que vous avez passé une ligne de commande simple, des
scripts prennent souvent en charge le reste. Ceux-ci peuvent être des
scripts shell ou utiliser un langage plus sophistiqué de script tel que
Perl ou Python. Mais plus tard il s'avère logique d'utiliser un
environnement conçu pour ce genre de chose, comme le font les outils
« Make » sous Unix.
Dans notre développement PHP nous avons
rapidement découvert que nous avons besoin d'une solution plus
appropriées. Phing est un outil inspiré d'apache Ant et
destiné à PHP. Nous pouvons l'utiliser pour nous assister dans la
réalisation de certaines tâches tout au long du cycle de vie de
nos projets tels que la génération de code, la construction des
releases, la génération de la documentation, la
génération de rapports (tests unitaires, couverture du code,
aspect du code...), le déploiement dans différents
environnements...
II.4.1 Les avantage de Phing
Phing a de nombreux avantages,
comparé à un système de build plus archaïque
construit à partir d'un ensemble de scripts de déploiement
(fichiers PHP, Shell ou batch).
· Il centralise les informations de build dans un seul
fichier :
Toutes les informations dont Phing a besoin pour fonctionner
sont rassemblées dans le fichier build.xml. Toutes les tâches que
l'on souhaite réaliser y seront décrites. Il est possible de
construire des groupes de tâches (appelés targets)
réutilisables. Le fichier build.xml est suffisamment verbeux pour
être, lors de sa lecture, compréhensible sans connaissance
préalable par un autre développeur.
· Il fonctionne sur toutes les plateformes où PHP
est disponible :
Phing est codé en PHP. Il est donc l'utilisable
dès lors que PHP est installé sur le système.
· Il supporte un grand nombre d'outils PHP :
Il existe un grand nombre d'applications destinées
à améliorer l'écriture du code PHP. Elles ont
l'inconvénient de ne pas suivre les mêmes conventions ou la
même logique. Phing intègre des tâches dédiées
à certaines d'entre elles. Ces tâches sont normalisées et
suivent une logique commune. Ce canevas est utile pour paramétrer,
efficacement et avec un minimum d'effort, chacune d'entre elles sans sacrifier
pour autant les possibilités de réglages avancés.
· Il est documenté :
La documentation est d'excellente qualité et
détaille avec précision le rôle et la configuration de
chaque tâche. Que celle-ci fasse partie du noyau de Phing ou soit
rattachée à un outil externe, vous trouverez fréquemment
des exemples clairs et concis.
· Il est extensible :
On peut étendre Phing pour y ajouter de nouvelles
tâches. Ainsi on pourra utiliser nos propres outils irremplaçables
ou non implémentés. Le système d'extension est
documenté. La documentation officielle a un chapitre entier
détaillant les possibilités, proposant des gabarits pour
travailler et expliquant pas-à-pas le processus de conception d'une
nouvelle tâche.
· Il facilite la mise en place d'un processus
d'intégration continue :
Il est utilisable avec la plupart des outils
dédiés à l'intégration continue : Cruise control,
Hudson, Xinc...
II.4.2 Outils utilisables avec
Phing
|
Type d'opération
|
Application(s) externe(s)
nécessaire(s)
|
Description
|
|
Couverture du code par les tests
|
PHPUnit et Xdebug
|
Pour utiliser cette fonction, PHPUnit et Xdebug sont
nécessaires. Cet outil génère un rapport sur la couverture
de votre code par les tests unitaires. Vous pouvez créer un rapport sur
quelques fichiers, par module ou sur l'application complète.
|
|
DbDeploy
|
Non
|
Cet outil intégré à Phing facilite la
migration et l'évolution des bases de données de vos projets.
|
|
Exécuter une commande console
|
Non
|
Vous pouvez exécuter une commande Shell à partir
de Phing. Cette fonctionnalité est intéressante lorsque l'outil
que vous souhaitez appeler n'a pas de tâche associée. Utilisez des
commandes aussi simples que possible. Dans l'idéal, ne cassez pas le
support multiplateforme. SVN est un très bon exemple où cette
fonctionnalité est indispensable. N'oubliez pas de gérer les
erreurs.
|
|
FtpDeploy
|
Non
|
Phing peut prendre en charge le déploiement de votre
application sur différents serveurs en utilisant le protocole FTP.
|
|
Ioncube Encoder
|
Ioncube Encoder
|
Cet outil commercial rend illisibles vos scripts PHP et en assure
la protection par licence.
|
|
JsLint
|
JsLint
|
Cet outil analyse le code JavaScript pour vérifier
l'usage des bonnes pratiques de développement.
|
|
JsMin
|
Non
|
JsMin est une application externe embarquée dans Phing.
Vous n'avez donc pas besoin de l'installer. Cet outil minimise la taille d'un
fichier JavaScript.
|
|
Outils XML
|
Non
|
Phing peut valider un ou plusieurs scripts XML à l'aide
d'un schéma XSD et transformer un fichier XML en utilisant une feuille
de style XSL.
|
|
PEAR Packager
|
Non
|
Phing crée un fichier XML permettant de déployer
votre application au moyen de PEAR (supporte la version 1 et la version 2 de
PEAR)
|
|
Phar Packager
|
PECL's Phar
|
Cet outil crée un package Phar. Tous les fichiers PHP
d'une application sont rassemblés en un seul fichier. Un package Phar
est utilisable dans PHP depuis la version 5.3. Ces packages sont
optimisés pour améliorer la vitesse d'exécution des
scripts.
|
|
Php_CodeSniffer
|
Php_CodeSniffer
|
Cet outil effectue une analyse statique de vos scripts pour
vérifier qu'ils respectent les conventions de code que vous avez
définies (PEAR, Zend, vos propres conventions...).
|
|
PhpCpd
|
phpCpd
|
PHP Copy/Paste detector est un script simple qui recherche les
lignes de code dupliquées dans vos fichiers PHP.
|
|
PhpDocumentor
|
PhpDocumentor
|
Cet outil génère la documentation de votre API
à partir des commentaires phpdoc écrits dans vos scripts. Vous
pouvez aussi compiler des tutoriels ou des articles à partir de
documents docbook.
|
|
phpLint
|
phpLint
|
Cet outil est un analyseur statique de code. Il vérifie
les erreurs les plus communes en PHP (par exemple, l'emploi de fonctions
déconseillées ou l'utilisation des short tags).
|
|
PHPUnit
|
PHPUnit
|
Vous pouvez exécuter vos tests unitaires et
générer un rapport résumant leur exécution.
|
|
Scp
|
Non
|
Scp est une fonction permettant de copier un fichier au
travers du protocole
SSH.
Vous pouvez déployer intégralement une application en utilisant
le protocole SSH à place du protocole FTP.
|
|
SVN
|
VersionControl_SVN
|
Phing supporte les opérations Subversion (en
abrégé SVN) checkout, commit, export et update. Vous pouvez
interagir avec un serveur de version SVN. On regrettera l'absence de certaines
commandes SVN (merge, import...). Vous pouvez exécuter SVN en utilisant
la tâche ExecTask qui permet d'exécuter une commande dans le Shell
de l'OS.
|
|
Zend code analyseur
|
Zend Code Analyseur
|
Zend code analyseur est livré avec Zend studio. C'est
un analyseur de code statique qui repère les erreurs les plus courantes
dans du code PHP.
|
|
Zip & Tar
|
Archive_Tar (pour les fichiers tar seulement)
|
Vous pouvez créer des archives compressées ou
décompresser des archives existantes au format Tar ou Zip.
|
Tableau 2 : liste des outils utilisables avec
Phing
Chapitre III. DEPLOIEMENT
AUTOMATISEE
DE LA BASE DE
DONNEES
La majorité des
projets de développements informatiques traitent, stockent et restituent
des données et ces données sont pour la plus part
organisées dans des bases de données. Nous avons
précédemment présentés les mécanismes utiles
pour le partage de codes sources et la construction automatique du projet. Le
projet sera construit entièrement si les mises à jour
apportées aux données sont parallèlement
intégrées.
Ainsi pour la migration de nos bases de données, nous
utiliserons un outil intégré à Phing qui facilite la
migration et l'évolution des bases de données d'un projet :
DbDeploy. C'est un outil de gestion des changements d'une base
de données. C'est pour les développeurs ou DBA qui veulent faire
évoluer leur schéma de base de données - ou refactoriser
leur base de données - d'une manière simple,
maîtrisé, flexible et fréquents.
III.1
Problématique
Le problème récurrent avec le
développement de bases de données, c'est qu'à un moment
donné, on devra mettre à jour la base de données existante
et préserver son contenu. Dans les environnements de
développement, il est souvent possible (et même souhaitable) de
balayer la base de données et de la reconstruire à partir de
zéro aussi souvent que le code est reconstruit.
Nous avons constaté que l'un des moyens les plus
faciles pour permettre aux gens de changer la base de données consiste
à utiliser un contrôleur de version scripts SQL delta. Nous avons
également jugé utile de faire en sorte que les scripts
utilisés pour construire des environnements de développement
soient exactement les mêmes utilisés lors de la production.
Maintenir et faire usage de ces deltas peut rapidement devenir une surcharge
importante - dbdeploy vise à combler cette lacune.
III.2 Règles
d'utilisation de dbdeploy
Lors de la création d'un fichier delta il sera important
de suivre les conventions suivantes :
1. Se rassurer que toutes les modifications de base de
données sont écrites comme des scripts delta qui seront
récupérées par dbdeploy.
2. Respecter les conventions de nom pour les scripts delta.
Les noms des scripts doivent commencés par un nombre qui indique l'ordre
dans lequel ils seront exécutés. Il est possible d'ajouter un
commentaire au nom du fichier pour décrire ce que fait le fichier
(exemple : 1Cree_table_client.sql),
3. On peut optionnellement ajouter une section undo à
nos scripts. Tout d'abord, il faut écrire le script qui va
exécuter l'action à faire; Une fois que le script de toutes les
actions à faire est rédigé, inclure dans une nouvelle
ligne le label --//@UNDO. Inclure les tâches d'annulation après
le label.
DbDeploy s'exécute en effectuant des
vérifications pour voir si un script delta particulier a
été exécuté sur une base de données
particulière. Pour ce faire, il utilise le nom du script delta plus le
nom de l'ensemble du delta (qui sera «All», sauf indication
contraire) et le compare avec le contenu de la table de version du
schéma. Si un script delta qui a déjà été
appliqué à une base de données est modifié par la
suite, cette modification ultérieure ne sera pas appliquée
à la base de données.
Tout cela fonctionne très bien tant que vous n'avez pas
besoin de corriger un bugg sérieux dans un script. Il ya deux
façons de réduire ce risque :
· Toujours effectuer
une génération locale avant les vérifications, de cette
façon le problème est constaté et peut être
fixé avant d'être versionner.
· Utilisez
l'intégration continue - si votre serveur de build s'interrompt, le
référentiel de code source ne sera pas étiqueté
jusqu'à ce que le problème soit résolu.
III.3
DbDeployTask
Dans le fichier de configuration de Phing (le build.xml), la
tâche que nous utiliserons est :
DbDeployTask. Lors de son exécution cette tâche
crée un fichier .sql pour effectuer les révisions de base de
données, basée sur les conventions dbdeploy qui sont
centrées autour d'une table changelog de la base de
données. la table changelog doit se présentée
ainsi:
CREATE TABLE changelog (
change_number BIGINT NOT NULL,
delta_set VARCHAR(10) NOT NULL,
start_dt TIMESTAMP NOT NULL,
complete_dt TIMESTAMP NULL,
applied_by VARCHAR(100) NOT NULL,
description VARCHAR(500) NOT NULL
)
· Exemple d'application
<taskdef name="dbdeploy"
classname="phing.tasks.ext.dbdeploy.DbDeployTask"/>
<dbdeploy
url="sqlite:${project.basedir}/data/db.sqlite"
userid="admin"
password="ringo"
dir="${project.basedir}/data/dbdeploy/deltas"/>
L'exemple ci-dessus utilise une base de données SQLite
et les scripts delta se trouvant dans le répertoire dbdeploy/deltas de
la racine du répertoire du projet.
· Attributs de la tâche
|
Name
|
Type
|
Description
|
Required
|
|
url
|
String
|
PDO connection url
|
Yes
|
|
userid
|
String
|
DB userid to use for accessing the changelog table
|
As required by db
|
|
password
|
String
|
DB password to use for accessing the changelog table
|
As required by db
|
|
dir
|
String
|
Directory containing dbdeploy delta scripts
|
Yes
|
|
outputfile
|
String
|
Filename in which deployment SQL will be generated
|
No
|
|
undooutputfile
|
String
|
Filename in which undo SQL will be generated
|
No
|
|
deltaset
|
String
|
deltaset to check within db
|
No
|
|
lastchangetoapply
|
Integer
|
Highest-numbered delta script to apply to db
|
No
|
Tableau 3 : liste des attributs de la tâche
DbDeploy
·
Déploiement
Dans l'architecture du projet en annexe (Annexe
2), le dossier «db« contient les fichiers
sql, le dossier «deploy« contient nos scripts de
build, le dossier «library«
contient le code de l'application et le dossier
«public« contiendra les scripts et fichiers
accessibles directement à partir du web. Le fichier de configuration
(propriétés) qui va permettre d'exécuter la migration de
la BD est formaté sous la forme : clé=valeur et
édité avec un quelconque éditeur de texte puis
enregistré sous : «deploy/build.properties«.

Figure 6 : Fichier
Build.properties
Ensuite la tâche de migration à insérer
dans notre construction est :
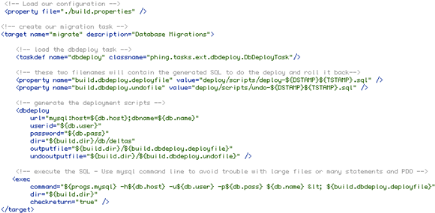
Figure 7 : Description de
la tâche dbdeploy de phing
ETUDE D'UNE SOLUTION
D'INDUSTRIALISATION
Chapitre IV.
L'ENVIRONNEMENT DE TRAVAIL
IV.1 Configuration
matérielle et logicielle
· Matériel
Ringo SA est dote d'un Datacenter serveur constitue de 2
blade center IBM type H, dont 28 lames. Chaque lame ayant les
caractéristiques suivantes :
- 2 Processeurs QuadCore, 2.5 Ghz cpu
- 8 Go de Ram
- 2 cartes réseaux broadcom
- 2 cartes HBA
D'une baie de disque constitue d'un contrôleur DS4700 et
d'une enclosure EXP810 d'une capacité totale de 8 TB. Le blade center
est connecté à la baie des disques via la technologie
san au travers des modules FC connectés.
· Logicielle
Ringo SA a mis en place une infrastructure de virtualisation
xen pour l'hébergement des serveurs. Ainsi, sur chaque
serveur est installé l'hyperviseur xen sur lesquels
sont déployés les pools de ressource et les machines virtuelles
elles mêmes. Ringo S.A a donc déployé une infrastructure
xen constituée de 3 principaux pools de
serveurs :
- Le pool production dans lequel sont
déployées les machines virtuelle utilisée pour la
production.
- Le pool test dans lequel sont
déployés les machines virtuelles utilises pour les tests.
- Le pool corporate dans lequel sont
déployés les machines virtuelles pour les corporates.
Le but de cette création de pool étant :
- La séparation étant de pouvoir
délimiter déjà de façon logique la communication
entre les différents pools, sauf ci cela est défini
implicitement. Un serveur de test ne doit communique pas avec un serveur de
production.
- La gestion efficace des machines virtuelles dans un pool en
permettant les migrations a chaud, le démarrage des machines virtuelle
sur l'hôte le plus disponible, ...
Dans le cas de notre travail, nous avons
bénéficie d'un serveur dans le pool de test d'un serveur debian
Lenny.
IV.2 Les
outils
Parmi les différents outils existants et que
nous avons explorés, nous avons fait un choix en fonction de
l'interopérabilité de chacun, ainsi on utilisera :
· Gestionnaire de version : Subversion
(gestion de codes sources)
· Test Unitaire : PHPUnit
· Test IHM : Selenium (Outil de tests de
recette pour applications web via navigateur)
· Scripts d'automatisation :
Phing
· Serveur d'intégration :
Xinc
Chapitre V. Installation
et configuration de SVN
V.1 Installation du
serveur SVN
Nous avons installe svn avec le module
webDav pour permettre l'accès au dépôt via
une interface web. Les commandes d'installation sont les suivantes :
- apt-get install subversion
- apt-get install libapache2-svn
Création du dépôt initial :
- svnadmin create -fs-type fsfs /var/depot
Nous devons autoriser l'acces au dépôt a apache
et aux autres utilisateurs
- groupadd subversion
- addgroup jeanluc subversion
- addgroup Patrick subversion
- chown -R www-data :subversion
/var/depot
- chmod -R 770 /var/dépôt/*
Maintenant, nous devons activer le module web pour permettre
la connexion au dépôt en http :
- a2enmod dav
- a2enmod dav_svn
Les modules étant actives, nous devons éditer le
fichier de configuration pour spécifier l'emplacement du
dépôt et la gestion des accès :
Le fichier de configuration est :
/etc/apache2/mods-available/dav_svn.conf
<Location /depot>
DAV svn
SVNPath /var/dépôt
AthzSVNAccessFile
/var/access-svn/access_authz
AuthType Basic
AuthName "Depot svn"
AuthUserFile /var/access-svn/access
Require valid-user
SSLRequireSSL
</Location>
Puis, tel qu'indiqué dans le fichier
dav_svn.conf nous gérons les accès à
partir de 2 fichiers :
- access pour contrôler les
accès au dépôt
- access_authz pour contrôler les
accès aux répertoires du dépôt pour les utilisateurs
étant authentifiés par le fichier access.
La création du fichier access se fait via les commandes
suivantes :
htpassword -c /var/access-svn/access
jeanluc
htpassword /var/access-svn/access Patrick
Ensuite, nous éditons le fichier contrôlant
l'accès à des dossiers spécifiques
access_authz
[/]
* = rw
.[/siteyaounde]
Patrick = rw
Jeanluc = r
Ici, jean-luc a accès à tout le
dépôt en lecture et en écriture sauf au dossier
« siteyaounde ».
Apres avoir édité ce fichier, nous
redémarrons le serveur apache via la commande :
/etc/init.d/apache2 restart
V.2 Création d'un
projet
La première chose à faire lors de la
première utilisation est de créer un nouveau projet. Deux cas de
figure peuvent se présenter : ou bien le projet existe
déjà au sein d'un dépôt et il s'agit de
récupérer ce projet en local pour en faire une copie de travail,
ou bien ce projet existe en local et doit être importé au sein du
dépôt. Dans notre cas le projet se trouve en local et doit
être importé sur le référentiel de code source. Au
cas ou il existe plutôt sur le dépôt une seule commande
suffit pour effectuer un checkout et récupérer
la dernière version des fichiers : il s'agit de la commande
svn co.
· Import d'un projet déjà existant en
local
Si le projet n'existe pas dans le dépôt et qu'il
faut le créer à partir de fichiers locaux, la commande à
utiliser est svn import. Cette opération n'est en
théorie effectuée que par la personne chargée de
l'administration du dépôt.
>> svn import ./projetTest /var/svn/projetTest
-m "import initial de Jean-Luc"
Chapitre VI. Mise en place du serveur
d'intégration
Xinc
Le choix que
nous avons porté sur le serveur d'intégration continue Xinc est
tout à fait justifié car il correspond à ce qu'il faut
pour un projet de développement PHP. Ces caractéristiques sont
les suivantes : la plateforme d'exécution est PHP, il s'installe
à partir du Framework PHP PEAR, il supporte SVN et PHP (car
codé lui-même en PHP), l'interface web est supportée sous
Apache.
Xinc est un logiciel gratuit
distribué sous les termes de la licence LGPL. Pour une liste
détaillée des logiciels nécessaires et les
bibliothèques, consultez le tableau ci-dessous des dépendances de
logiciels :
Tableau 4 : Xinc -
dépendances logicielles
VI.1 Installation du
serveur Xinc
Xinc peut être installé grace au package PEAR de
deux manières:
>> pear channel-discover
pear.xinc.eu
>> pear channel-discover
pear.phing.info
>> pear channel-discover
components.ez.no
>> pear install xinc/Xinc
OU
>> pear channel-discover
pear.xinc.eu
>> pear channel-discover
pear.phing.info
>> pear channel-discover
components.ez.no
>> pear install
http://xinc.eu/api/deliverable/get/download/xinc-dev/latest-
successful/Xinc-Latest-Dev-2.0.1.tgz
Pour que xinc soit prêt à être
exécuter, on doit exécuter un script de
configuration:
>> pear runc-scripts
xinc-2.0.1/Xinc
Ce script permet de configurer les répertoires
spéciaux selon les besoins de Xinc ainsi que configurer l'interface Web
de Xinc:
1. Répertoire des fichiers de configuration Xinc:
/etc/xinc,
2. Répertoire des projets Xinc et des informations de
statut: /var/xinc,
3. Répertoire des fichiers journaux Xinc:
/var/log,
4. Répertoire du fichier de
démarrage/arrêt de Xinc: /etc/init.d,
5. Répertoire d'installation de l'application web de
Xinc: /var/www/xinc,
6. Adresse IP de l'application web de Xinc:
127.0.0.1,
7. Port de l'application web de Xinc:
8080.
Pour terminer l'installation Xinc.
- Inclure le fichier
/etc/xinc/www.conf dans les serveurs virtuels Apache :
>> sudo ln -s /etc/xinc/www.conf
/etc/apache2/sites-enabled/
>> sudo apache2ctl restart
- Activer le mode mod-rewrite : ajouter
la ligne suivante au fichier httpd.conf
LoadModule rewrite_module
/usr/lib/apache2/modules/mod_rewrite.so
- Pour ajouter des projets à Xinc, copier le projet
XML dans /etc/xinc/conf.d :
Ce fichier en question est :
etc/xinc/conf.d/xinc.xml (annexe 1)
- Pour démarrer xinc exécutez: sudo
/etc/init.d/start xinc
VI.2 Fichier de
configuration .ini
Xinc permet de configurer
certains paramètres, qui déterminent le comportement de
l'interface graphique et / ou de comportement des plugins. Ce qui suit est
notre fichier de configuration:
[xinc]
version = 2.0.1
etc = /etc/xinc
etc_conf_d = /etc/xinc/conf.d
dir = /var/xinc
status_dir = /var/xinc/status
project_dir = /var/xinc/projects
www_dir = /var/www/xinc
www_port = 8080
www_ip = 127.0.0.1
log_dir = /var/log
[web]
title = " Serveur Xinc"
logo = "/images/myServerLogo.png"
ohloh = 1
[phing]
path = /my/alternative/path/to/phing
[svn]
path = /my/alternative/path/to/svn
VI.3 Interface web
d'administration
Figure 8: Tableau de bord du Xinc
2.0 alpha
Figure 9 : détails
présentant le statut du build et les builds précédents
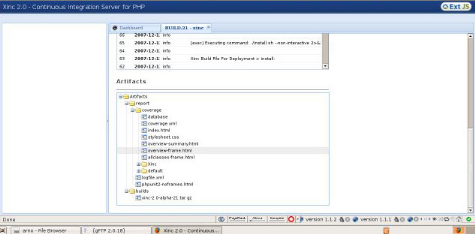
Figure 10 : détails du build
- Artefacts du navigateur
Chapitre V. Paramétrage du système de
build
Avec Phing
L'automatisation
des opérations répétitives dans un projet de
développement peut être résolue de multiples
manières allant du simple script lancé à la main au
système d'intégration continue.
La plupart des langages ont standardisé leurs outils,
make pour C, Ant pour Java... PHP bénéficie lui aussi d'un tel
outil : Phing.
Phing est un projet Open Source très inspiré de
Ant. Le concept est assez simple. Un fichier XML décrit une série
d'actions possibles pouvant ou non être dépendantes les unes des
autres et une ligne de commande permet de déclencher ces actions.
VII.1 Installation de
Phing
Phing est disponible sous la forme d'un package PEAR.
L'installation, la communication avec les applications tierces et la mise
à jour de votre environnement est plus facile par ce moyen.
>> pear channel-discover
pear.phing.info
>> pear install phing/phing
Installer Phing sans
utiliser PEAR est déconseillé, car Phing faisant appel à
des applications tierces fréquemment installées grâce
à PEAR, (par exemple, PHPunit ou PhpDocumentor), l'installation de
l'environnement de travail peut s'avérer délicate et souffrir
d'un manque de cohésion.
VII.2 Utilisation de
Phing
A Ringo SA, il existe plusieurs projets de
développement web, parmi lesquels un bon nombre sont encore en
développement. Dans le cadre de notre travail, il nous était
indsipensable d'avoir un projet dans lequel intervenait plusieurs
développeurs. L'effectif de l'équipe en place étant
réduit les projets sont conduits par une voire deux personnes (max). Le
projet sur lequel nous allions implémenter notre solution est le projet
de refonte du site web : www.ringo.cm. Nous présentons dans la
suite un prototype de de fichier XML de configuration de Phing :
Fichier build.xml
<?xml version="1.0" encoding="UTF-8"?>
<project name="php" default="help">
<!--
======================================================= -->
<!-- Properties (définition des valeurs
globales au build) -->
<!--========================================================
-->
<!-- *** Project General Properties
*********************************** -->
<property name="home"
value="${project.basedir}"/>
<property name="src.dir"
value="library"/>
<property name="test.dir"
value="tests"/>
<property name="doc.dir"
value="docs"/>
<property name="context.dir"
value="contexts"/>
<property name="config.dir"
value="config"/>
<property name=" svn.dir"
value="svn://w-dev-srv1.cm/svn/projetTest/trunk"/>
<property name="convention"
value="PEAR"/>
<!-- *** Project Custom Properties
************************************ -->
<property
file="${home}/${config.dir}/build.properties"
override="true"/>
<property
file="${home}/${config.dir}/${conf}.properties"
override="true"/>
<!-- *** Project Common Properties
************************************ -->
<property name="package.name"
value="${application.name}"/>
<!--
======================================================= -->
<!-- Targets (les tâches à executer)
-->
<!--
======================================================= -->
<!-- *** $ phing inits
************************************************ -->
<target name = "inits"
depends = ""
description = "Initializes the application
environment">
<!-- /library -->
<mkdir
dir="${home}/${src.dir}"/>
<!-- /tests -->
<mkdir
dir="${home}/${test.dir}"/>
<mkdir
dir="${home}/${test.dir}/phpunit"/>
<mkdir
dir="${home}/${test.dir}/selenium"/>
<mkdir
dir="${home}/${test.dir}/jsunit"/>
<!-- /docs -->
<mkdir
dir="${home}/${doc.dir}"/>
<mkdir
dir="${home}/${doc.dir}/api"/>
<!-- /contexts -->
<mkdir
dir="${home}/${context.dir}"/>
</target>
<!-- *** $ phing tests-unit
******************************************* -->
<target name = "tests-unit"
depends = "inits"
description = "Executes unit tests
(PHPUnit)">
<php expression="require_once
'${home}/${context.dir}/phpunit.php'"/>
<phpunit2 haltonfailure="false"
printsummary="true">
<batchtest
classpath="${home}/${src.dir}">
<fileset dir="${home}">
<include
name="${test.dir}/phpunit/**/*Test.php" />
</fileset>
</batchtest>
<formatter type = "xml"
todir =
"${home}/${report.dir}/phpunit"
outfile = "tests-report.xml"
/>
</phpunit2>
<phpunit2report
infile =
"${home}/${report.dir}/phpunit/tests-report.xml"
format = "frames"
todir = "${home}/${report.dir}/phpunit"
/>
</target>
<!-- *** $ phing tests-functional
************************************* -->
<target name = "tests-functional"
depends = "inits"
description = "Executes functional tests
(Fitnesse)">
</target>
<!-- *** $ phing tests-javascript
************************************* -->
<target name =
"tests-javascript"
depends = "inits"
description = "Executes javascript tests
(JSUnit)">
</target>
<!-- *** $ phing tests-gui
******************************************** -->
<target name = "tests-gui"
depends = "inits"
description = "Executes graphical user
interface tests (Selenium)">
</target>
<!-- *** $ phing tests
************************************************ -->
<target name = "tests"
depends =
"tests-functional,tests-javascript,tests-gui"
description = "Generates all tests reports
for project">
</target>
<!-- *** $ phing builds-on-commit
************************************* -->
<target name = "builds-on-commit"
depends = "tests-unit"
description = "Continous integration
Light-build on svn commit">
</target>
<!-- *** $ phing docs
************************************************* -->
<target name = "docs"
depends = "docs-api"
description = "Generates all documentation
for project">
</target>
<!-- *** $ phing deploys-integ
**************************************** -->
<target name = "deploys-integ"
depends = "tests-unit"
description = "Executes unit tests and
deploys a tag of the application on integration">
<echo>Deploying on
integration...</echo>
<echo>@todo: specific integration
pre-deployment tasks...</echo>
<phingcall
target="_template-deploys">
<property name="${deploy.platform}"
value="integ"/>
</phingcall>
<echo>@todo: specific integration
post-deployment tasks...</echo>
<echo>Application deployed on
integration.</echo>
</target>
<!-- *** $ phing deploys-preprod
************************************** -->
<target name = "deploys-preprod"
depends = "tests-unit"
description = "Executes unit tests and
deploys a tag of the application on pre-production">
<echo>Deploying on
preproduction...</echo>
<echo>@todo: specific preproduction
pre-deployment tasks...</echo>
<phingcall
target="_template-deploys">
<property name="${deploy.platform}"
value="preprod"/>
</phingcall>
<echo>@todo: specific preproduction
post-deployment tasks...</echo>
<echo>Application deployed on
preproduction.</echo>
</target>
<!-- *** $ phing deploys-prod
***************************************** -->
<target name = "deploys-prod"
depends = "tests-unit"
description = "Executes unit tests and
deploys a tag of the application on production">
<echo>Deploying on
production...</echo>
<echo>@todo: specific production
pre-deployment tasks...</echo>
<phingcall
target="_template-deploys">
<property name="${deploy.platform}"
value="prod"/>
</phingcall>
<echo>@todo: specific production
post-deployment tasks...</echo>
<echo>Application deployed on
production.</echo>
</target>
<!-- *** internal task
************************************************ -->
<target name =
"_template-deploys"
depends = "tests-unit"
description = "Template - Executes unit tests
and deploys a tag of the application on a platform">
<if>
<isnotset
property="deploy.platform"/>
<then>
<fail>You must set the
deploy.platform property with the name of the platform to deploy
on</fail>
</then>
</if>
<if>
<isnotset property="tag"/>
<then>
<fail>You must provide a svn tag in
order to deploy this tag on ${deploy.platform}</fail>
</then>
</if>
<property
file="${home}/${config.dir}/platforms/${deploy.platform}.properties"
override="true" />
<property name="deploy.src.dir"
value="${home}/${build.dir}/${deploy.platform}/${tag}" />
<property name="svn.url"
value="${svn.repo}/tags/${tag}" />
<svnexport svnpath =
"${svn.bin}"
username =
"${svn.username}"
password =
"${svn.password}"
force = "true"
nocache = "true"
repositoryurl =
"${svn.url}"
todir =
"${deploy.src.dir}"/>
<echo>@todo : deployment (zip
${deploy.src.dir, then ftp, ...) </echo>
<fail>@remove: Not yet
implemented</fail>
</target>
</project>
CONCLUSION
Cette section achève notre document en
présentant des rappels sur le travail effectué et décrit
dans les sections précédentes et présente des perspectives
d'amélioration de ce travail.
1- Rappels sur le
travail
Tout au long de ce document, il a été question
d'examiner les méthodes et processus d'industrialisation des
développements web et particulièrement les développements
en langage PHP, en comparaison avec le modèle en cascade du cycle de vie
d'un logiciel. Les développements sont en général
effectués par les équipes en local, dans notre
démarche nous avons essayés de synchroniser les
développements, de définir des conventions, cadrer les
développements, améliorer les rendements grâce aux
feedbacks, améliorer la qualité avec l'écriture des tests
unitaires, des tests d'intégration, des tests fonctionnels et des tests
graphiques(IHM). Nous ne nous sommes pas appesantis sur l'écriture des
tests en générale. Le processus qui va rendre tout ce qui
précède industriel est l'intégration continue qui
vise à automatiser les tests, le déploiement et les
contrôles de qualités ; ces derniers sont effectués
grâce au suivi des métriques de qualité
générés par le serveur d'intégration continue.
Déployer en recette, en pré-production et production en
un seul clic. Le déploiement que nous avons
présenté concerne autant l'application que les données
qu'elles traitent. Pour le déploiement des données nous avons
utilisés une tâche propre à notre outil de construction de
projet : DbDeployTask. Après avoir décrit le fonctionnement
de subversion, de son environnement et présenté le principe
d'intégration continue, nous avons proposé dans la suite une
méthode d'industrialisation des développements web avec des
outils choisis rigoureusement parmi plusieurs. La section suivante a
consisté en la mise en oeuvre de cette industrie de développement
dont l'objectif est de permettre aux décideurs de suivre
l'évolution des projets développements.
2- Problèmes non
résolus
Ce travail n'a pas été effectué sans
difficultés. Parmi ces dernières nous citerons le fait qu'il est
difficile de changer les mentalités des développeurs, donc de
leur imposer une discipline de travail inhabituelle. Par ailleurs le site web
existant basé sur le CMS Joomla a une architecture assez
particulière et structuré en plusieurs répertoires et
sous-répertoires contenant une multitude de fichier, cela nous a
posé un problème car lors des déploiements (copie de
fichiers) sur les différents serveurs la copie étant
individuelle, elle grossie la taille de notre build et augmente la charge du
système. Le traitement à envisager serait d'implémenter de
nouvelles tâches à intégrer à Phing pour permettre
la copie itérative de la structure des dossiers de notre projet. La
structure physique des serveurs de pré-production et de production a
également été une difficulté pour nous.
3- Perspectives
Notre modèle
d'architecture proposé comme solution est un concept que nous pouvons
implémenter en un langage quelconque parce que c'est une pratique du
génie logicielle. Compte tenu de la diversité sans cesse
évolutive des plates formes de développements d'applications web,
il n'est pas évident de satisfaire la majorité des clients avec
le développement PHP. Une meilleure évolution serait de
construire une plate forme qui intègre tous les outils
nécessaires de mise en place d'une industrie de développement.
Elle devra intégrée, un gestionnaire de version, un serveur
d'intégration continue et un outil de construction de projet automatique
en s'assurant de la compatibilité entre ces différents outils.
Bibliographie
[1] MAJIOTSOP TIAYA Valérie,
Sécurité appliquées aux messages dans les services
financiers : Cas pratique Mobile to Mobile transfer,
Mémoire de Master professionnel, Douala 2008-2009.
[2] Feu FOTSO
Valery, Conception des systèmes des systèmes
d'informations informatisés (CS2i), il fut notre enseignant
à l'ISTDI au cours de l'année 2008-2009.
Webographie
[3] Introduction à subversion,
http://dev.nozav.org/intro_svn.html#htoc18,
lu le 11/04/2010 à 9H12.
[4] La
création d'une application web,
http://www.xul.fr/application-web.html,
lu le 19/05/2010 à 11H.
[5] PHP
Continuous Integration Server :
Xinc,
http://code.google.com/p/xinc/, lu le 25/05/2010 à 10H31.
[6] Install Xinc
From Pear Channel :
http://code.google.com/p/xinc/wiki/
InstallXincFromPearChannel, lu le 25/05/2010 à 12H.
[7] Phing
automatise les opérations répétives des
développements PHP :
http://labs.pimsworld.org/2009/01/phing-automatise-les-operations-repetitives-des-developpements-php/,
lu le 07/06/2010 à 09H13.
[8] Exemple de
fichier build.xml pour un projet utilisant l'intégration continue:
http://blog.phppro.fr/?post/2009/06/05/Exemple-de-fichier-buildxml-pour-un-projet-utilisant-l-integration-continue,
lu le 10/06/2010 à 14H17.
[9] How to simple
database migrations with phing and dbdeploy,
http://www.davedevelopment.co.uk/2008/04/14/how-to-simple-database-migrations-with-phing-and-dbdeploy/,lu
le 15/06/2010 à 08H25.
[10] FABIEN
ARCELLIER, Gérer le cycle de vie d'une application PHP avec
Phing, publié le 04 Mars 2010
http://farcellier.developpez.com/tutoriels/
php/phing-gerer-cycle-vie-projet/#LVI lu le 17/06/2010 à 19H.
[11] ARNO
SCHNEIDER, Continious integration and PHP - improve your development
process, Conférence Barcelona2008 publié le 23/02/2008,
http://www.slideshare.net/arnoschn/continuous-integration-and-php,
lu le 24/06/2010 à 20H42.
[12] Phing 2.X
User Guide,
http://phing.info/docs/guide/current/,
lu le 11 Avril 2010 à 9H12.
Annexes
Annexe 1 :
Xinc.xml

Annexe 2 : Structure de
l'application
  
| 

