Industrialisation des développements web : cas du langage php( Télécharger le fichier original )par Jean-Luc NTA à NWAMEKANG Institut Supérieur de Technologie et du Design Industrielle - European Master of Computer Science 2010 |

A DIEU le père éternel et tout puissant, Et à mes adorables parents M. et Mme NTA, Une dédicace toute particulière à tous ceux qui participent à la croissance et à l'innovation technologique, et au respect de l'environnement. REMERCIEMENTS Le présent document est le fruit d'un travail de recherche. Cependant, il n'aurait pu être réalisé sans l'apport de certaines personnes. Du fait de leur apport sous quelque forme que ce soit, ainsi nous citerons : § Au Seigneur Jésus-Christ sans qui ce travail n'aurait pas été possible et pour tout : soutien moral et physique, l'énergie pour aller jusqu'au bout de cette étude. § Monsieur Stéphane Franco, administrateur général de l'entreprise Ringo SA qui nous a accueillis et offert un cadre de travail doté d'une technologie de pointe. § Monsieur Kameni Claude pour les conseils et l'assistance permanente qu'il nous a apporté. § Monsieur Kizito, Ingénieur en architecture logicielle qui nous a fait connaître des outils et notions déterminantes. § Monsieur Azogni Patrick, Administrateur serveur à Ringo SA pour le support technique qu'il nous a fournit. § A la famille NSANGOU de Mendong pour leur soutien et précieux conseils. § A Sarah Dauphiné pour ses bons repas français qui ont été une délicieuse source d'inspiration. A tous mes collègues du pool web, pour la solidarité et la complicité que nous avons les uns envers les autres en particulier : Guy-Cédric MBOUOPDA et Steve KEUTCHANKEU.
A tous ceux qui ont oeuvré de près ou de loin à la réalisation de ce mémoire. RESUME L'expansion des applications informatiques prend de plus en plus d'ampleur avec la variété des secteurs d'activités qui existe de nos jours. Il existe de nombreuses méthodes de développement informatique (conception de logiciel) connues, la plupart d'entre elles ont quelqu'un point commun que nous avons exploité dans notre travail. Dans la pratique les techniques de génie logiciel sont de moins en moins appliquées dans les entreprises donc l'activité principale ne repose pas sur le développement informatique. Il est de plus en plus difficile d'instaurer une certaine dose de discipline au sein d'une équipe de développeurs dans un projet surtout si celui-ci est bien avancé, mais une fois installée l'effort de maintenance est minime. Cette discipline devrait être une méthode qui se veut pragmatique que les méthodes traditionnelles. Elle devra impliquer au maximum le demandeur (client) et permettre une grande réactivité à ses demandes. Elle visera la satisfaction réelle du besoin du client et non les termes d'un contrat de développement. Pour appliquer cette technique, il faut d'abord que : le code source soit partagé (en utilisant des logiciels de gestion de versions); les développeurs intègrent (commit) quotidiennement (au moins) leurs modifications; des tests d'intégration soient développés pour valider l'application et ensuite, il faut un outil d'intégration pour éviter les intégrations pénibles et réduire le risque dans un projet. Il est donc question dans ce document d'examiner les méthodes de gestion de code source, d'implémentation de tests unitaires et d'explorer les techniques d'intégration continue et ensuite proposé et mettre en place une architecture qui permettra de suivre un projet de développement informatique dans une approche de production industrielle. LISTE DES FIGURES Figure 2 : Objectifs d'un système de gestion de version 15 Figure 3 : Arborescence de la copie locale 21 Figure 4 : Cycle de vie du gestionnaire de versions 23 Figure 5 : Architecture intégration continue 27 Figure 6 : Fichier Build.properties 38 Figure 7 : Description de la tâche dbdeploy de phing 38 Figure 8: Tableau de bord du Xinc 2.0 alpha 49 Figure 9 : détails présentant le statut du build et les builds précédents 50 Figure 10 : détails du build - Artefacts du navigateur 50 LISTE DES TABLEAUX Tableau 1: CruiseControl vs Xinc 29 Tableau 2 : liste des outils utilisables avec Phing 33 Tableau 3 : liste des attributs de la tâche DbDeploy 37 Tableau 4 : Xinc - dépendances logicielles 44 DEFINITION DES SIGLES
SOMMAIRE 3- Rappel : Cycle de vie logiciel 11 Chapitre I. LA GESTION DU CODE SOURCE 14 I.2 Les deux types de gestion de version 16 I.3 Principe de fonctionnement 16 I.6 Avantage de l'architecture 24 Chapitre II. L'INTEGRATION CONTINUE 25 Chapitre III. DEPLOIEMENT AUTOMATISEE 34 III.2 Règles d'utilisation de dbdeploy 35 ETUDE D'UNE SOLUTION D'INDUSTRIALISATION 38 Chapitre IV. L'ENVIRONNEMENT DE TRAVAIL 39 IV.1 Configuration matérielle et logicielle 40 Chapitre V. Installation et configuration de SVN 41 V.1 Installation du serveur SVN 42 V.2 Mise en place des clients SVN 42 Chapitre VI. Mise en place du serveur d'intégration 43 VI.1 Installation du serveur Xinc 44 VI.2 Fichier de configuration .ini 45 VI.3 Interface web d'administration 46 Chapitre V. Paramétrage du système de build avec Phnig 48 VII.1 Installation de Phing 49
Le travail en équipe est un aspect incontournable pour le développement de toute activité devant produire le résultat attendu. De ce fait l'organisation de l'exécution des tâches et la synchronisation entre tâches effectuées par les différents intervenants doivent être normalisées selon des standards bien établis afin d'améliorer la productivité de l'équipe. L'industrialisation est le processus de fabrication de produits manufacturés avec des techniques permettant une forte productivité du travail et qui regroupe les travailleurs dans des infrastructures constantes avec les horaires fixes et une réglementation stricte. De manière analogue il est possible d'organiser le code fournit par une équipe de développeurs selon des procédés industriels. Au delà de l'organisation, on pourra aussi envisager l'automatisation des stockages et même des livraisons d'un projet quelconque. Cette étude (Industrialisation des développements PHP) est effectuée dans le cadre de la conduite du projet « Implémentation des serveurs de déploiement automatique « visant à implémenter un système de suivi des projets de développement effectués par le Pool web. Le dit travail nous est confié à l'occasion d'une période de test effectuée au sein de l'entreprise RINGO SA. Cette dernière est spécialisée dans la fourniture des solutions internet aux entreprises, aux particuliers et aux grands publics. Le pool web est le département en charge du développement, du webdesign, de l'intégration des gestionnaires de contenus et de la mise en ligne du site web. En outre ce dernier reçoit des commandes de travail internes, issues d'autres services de l'entreprise. Et pour ce qui concerne notre travail, le demandeur interne c'est la Direction générale qui souhaite avoir ce système qui tourne sur des serveurs internes et aussi accessibles depuis l'extérieur.
Le développement (programmation) informatique est l'ensemble des activités qui permettent la rédaction du code source des programmes informatiques. C'est une étape importante de la conception d'applications. La question qui a conduit cette étude nait d'une question posée par le directeur générale : Serait-il possible d'implémenter un environnement de développement sûr de telles sortes que les projets en test soient consultables à partir d'une seule adresse et accessible au fur et a mesure de l'avancement du projet ? Dans de gros projets de développement informatique le travail s'organise autour d'une équipe de développeurs qui ne programme pas de la même façon, alors il serait bénéfique pour les programmeurs de connaître les méthodes de programmation de chacun, ainsi que les méthodes de débogages. Il est aussi important pour la conduite du projet de savoir quelles sont les modifications apportées par chacun des acteurs. Une pratique à mettre en place pour archiver les codes sources et adopter la méthode XP : Je pars d'un programme simple que j'enrichis petit à petit. Le processus idéal est de construire automatiquement le projet au fur et à mesure qu'il y aura des modifications sur le code source, cette construction doit inclure l'interprétation (PHP étant un langage interprété) du code source ainsi on pourra avoir une visibilité sur l'évolution entière du projet avec chaque de ces versions. Pour ce qui est de la base de données elle suivra aussi ce même procédé d'industrialisation donc elle sera déployé sur un serveur de test. Par la suite d'autres questions ont émergées et ont été déterminantes tant dans l'élaboration de la solution proposée que dans la détermination des enjeux : § Comment automatiser le déploiement des tests ? § Comment travailler à plusieurs sur un même code source ? § Comment réduire le temps d'une mise en production? § Comment faire des tests de performance, de robustesse d'une application ? § Serait-il possible de déployer sur plusieurs serveurs avec une seule action ? § Comment s'assurer qu'une nouvelle fonctionnalité, nouvelle correction de bogue n'introduit pas de régression ?
Nous essayerons d'apporter solution à ces interrogations en explorant les enjeux dans un processus d'industrialisation du développement en langage PHP. 3- Rappel : Cycle de vie logiciel
Les projets relatifs à l'ingénierie logicielle sont généralement de grande envergure et dépassent souvent les 10 000 lignes de code. C'est pourquoi ces projets nécessitent une équipe de développement bien structurée. La gestion de tel projet se trouve intimement liée au génie logiciel. Le génie logicielle s'intéresse particulière à la manière dont le code source d'un logiciel est spécifié puis produit. Le cycle de vie désigne toutes les étapes de la validation du développement d'un logiciel, de sa conception à sa disparition. L'objectif d'un tel découpage est de permettre de définir des jalons intermédiaires permettant la validation du développement logiciel, c'est-à-dire la conformité du logiciel avec les besoins exprimés, et la vérification du processus de développement, c'est-à-dire l'adéquation des méthodes mises en oeuvre. Le cycle de vie du logiciel comprend généralement à minima les activités suivantes : § Définition des objectifs, consistant à définir la finalité du projet et son inscription dans une stratégie globale. § Analyse des besoins et faisabilité, c'est-à-dire l'expression, le recueil et la formalisation des besoins du demandeur (le client) et de l'ensemble des contraintes. § Conception générale. Il s'agit de l'élaboration des spécifications de l'architecture générale du logiciel. § Conception détaillée, consistant à définir précisément chaque sous-ensemble du logiciel. § Codage (Implémentation ou programmation), soit la traduction dans un langage de programmation des fonctionnalités définies lors de phases de conception. § Tests unitaires, permettant de vérifier individuellement que chaque sous-ensemble du logiciel est implémenté conformément aux spécifications. § Intégration, dont l'objectif est de s'assurer de l'interfaçage des différents éléments (modules) du logiciel. Elle fait l'objet de tests d'intégration consignés dans un document. § Qualification (ou recette), c'est-à-dire la vérification de la conformité du logiciel aux spécifications initiales. § Documentation, visant à produire les informations nécessaires pour l'utilisation du logiciel et pour des développements ultérieurs. § Mise en production, § Maintenance, comprenant toutes les actions correctives (maintenance corrective) et évolutives (maintenance évolutive) sur le logiciel. La séquence et la présence de chacune de ces activités dans le cycle de vie dépend du choix d'un modèle de cycle de vie entre le client et l'équipe de développement.
Chapitre I. LA GESTION DU CODE SOURCE
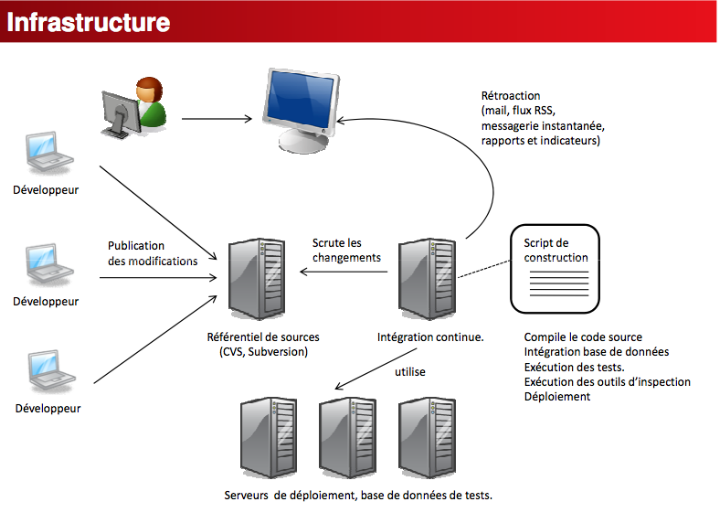
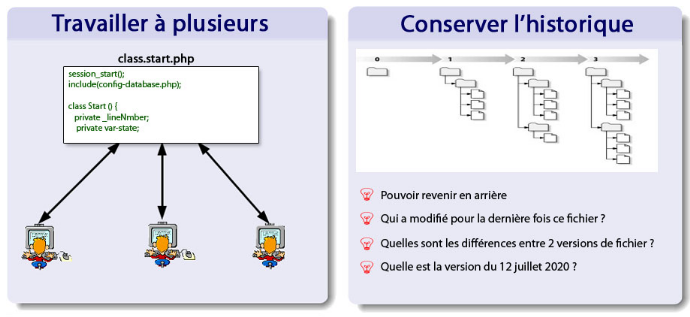
Nous allons définir la gestion des versions du code source et présenter les opérations qu'elle permet aux utilisateurs d'effectuer. Par la suite, nous allons parcourir des techniques de construction du projet voir d'intégration continue. Un logiciel de gestion de versions agit sur une arborescence de fichiers afin de conserver toutes les versions des fichiers, ainsi que les différences entre les fichiers. Ce système permet par exemple de mutualiser un développement. Un groupe de développeurs autour d'un même développement se servira de l'outil pour stocker toute l'évolution du code source. Le système gère les mises à jour des sources pour chaque développeur, conserve une trace de chaque changement. Ceux-ci sont, en bonne utilisation, chaque fois accompagnés d'un commentaire. Le système travaille par fusion de copies locale et distante, et non par écrasement de la version distante par la version locale. Ainsi, deux développeurs travaillant de concert sur une même source, les changements du premier à soumettre son travail ne seront pas perdus lorsque le second, qui a donc travaillé sur une version non encore modifiée par le premier, renvoie ses modifications.
Figure 2 : Objectifs d'un système de gestion de version I.2 Les deux types de gestion de version Pendant très longtemps l'unique logiciel libre et sérieux de gestion de versions était CVS. Il reste aujourd'hui la référence. Mais depuis que ce vénérable logiciel atteint ces limites et que la créativité bouillonne dans ce domaine, il est temps de présenter les solutions rivales. Pour remplacer CVS, il existe deux sortes de logiciel de gestion de version, centralisés ou décentralisés. Les logiciels de gestion de versions centralisée permettent de n'avoir qu'un seul dépôt des versions, dépôt qui fait référence, cela simplifie la gestion des versions mais est contraignant pour certains usages (travail sans connexion au réseau ou tout simplement travail sur des branches expérimentales ou contestées). On peut citer CVS et Subversion. Avec l'arrivée des logiciels libres et leur développement communautaire, une autre façon de voir la gestion de versions est apparue. Cette autre vision consiste à voir l'outil de gestion de versions comme un outil permettant à chacun de travailler à son rythme, de façon désynchronisée des autres, puis d'offrir un moyen à ces développeurs de s'échanger leur travaux respectifs. C'est ce que l'on nomme la gestion de versions décentralisée. On peut citer Mercurial, Darcs, Bazaar, Git, Monotone, GNU Arch et BitKeeper (propriétaire) sont des logiciels de gestion de versions décentralisée. Avec ceux-ci, il existe plusieurs dépôts de versions. Dans notre cas d'étude le travail de chaque développeur doit être sur un même référentiel le dépôt doit donc être centralisée, ce qui détermine notre choix du système de gestion de versions centralisée : Subversion. I.3 Principe de fonctionnement
Subversion est un outil de gestion de versions. Il autorise plusieurs personnes à travailler de concert sur un même code source, et historise les différentes évolutions validées par ces développeurs. Subversion peut être séparée en deux éléments: Le dépôt et le client. I.3.1 Le dépôt Le dépôt est ce que l'on appelle parfois le "serveur" Subversion. Il contient le code source et son historique. Un dépôt peut être accéder par plusieurs méthodes, suivant sa configuration: · http:// ou https:// : Subversion est associé à un serveur HTTP (Apache). C'est la méthode la plus fréquente, car elle permet de voir le contenu du dépôt à l'aide d'un navigateur Web. · ssh:// : Cette méthode est aussi rencontrée de temps en temps. Subversion est alors associée à un serveur SSH (Secure Shell). Bien qu'elle soit plus difficile à mettre en oeuvre, elle apporte une meilleure sécurité des données que le https, et évite d'avoir un serveur Web installé sur la machine du dépôt Subversion. · svn:// : Subversion possède son propre protocole, qui peut être activé via un serveur. Le dépôt utilise une base de données Bekerley (BDB pour les intimes) pour stocker les différentes versions de votre code source. A l'aide de Subversion, vous pouvez: · Voir d'anciennes versions de votre code source. · Annuler des modifications pour revenir à une ancienne version fonctionnelle. · "Tagguer" les versions stables de votre projet, c'est à dire enregistrer l'état de votre code pour une version de votre logiciel. · Et bien d'autre chose. Subversion utilise une mécanique de "révision" pour stocker les informations de versions de votre code. Une révision correspond à un ensemble de modifications validées par un "commit". A tout moment, vous pouvez obtenir les informations associées à une révision donnée. I.3.2 Le client Le client est un outil en ligne de commande : svn. Il vous permet de manipuler le contenu de votre copie de travail ainsi que celui du dépôt Subversion. C'est aussi lui qui gère la synchronisation entre votre copie de travail et le serveur Subversion. I.3.3 Les opérations courantes · Créer une copie de travailPour travailler sur un projet, on doit créer une copie de travail du code source de ce projet. La copie de travail est l'endroit ou sera modifié le code du projet. Une fois le code modifié et testé, les modifications peuvent être ajouté au dépôt Subversion à l'aide d'un commit. Pour créer une copie de travail à partir d'un dépôt, il faut utiliser la commande "checkout" ou "co" pour faire court. Pour ce faire, il faut d'abord récupérez l'URL du dépôt et exécutez : - svn co http://svn.web-srv-yde.com/test/trunk Projet1 |
|