4.1.2 La fouille de textes
Les données textuelles disponibles sur support
infomatique représentent près de 70 pourcent des données
numériques et se retrouvent sous forme de rapport, de courriers, de
publications, de manuels, etc.
La fouille de données textuelles est un ensemble de
traitements informatiques consistant à extraire des connaissances selon
un critère de similarité. On y distingue deux niveau de
traitement :
1. Le premier niveau porte sur la recherche
d'information dans les bases de données textuelles. Par exemple
rechercher les textes qui contiennent les mots X et Y ou
Z. Grâce au developpement des technologies du traitement de la
langue naturelle, on peut également formuler des requêtes plus ou
moins complexes contenant des expressions ou même des textes.
2. Le segond niveau porte sur l'extraction de
connaissences à partir d'une base de données textuelles. En
effet, certaines recherches peuvent paraître extrêmement difficiles
pour l'utilisateur car il ne saura toujours pas comment formuler la bonne
requête en vue d'avoir des réponses pertinentes pour sa recherche.
Par exemple comment rechercher dans un document les textes qui incitent
à la violence dans les stades. Des tels réponses sont difficiles
à trouver étant donné que ces textes peuvent ne contenir
aucun des mots « violence » ou « stade ». C'est
là qu'interviennent les méthodes de data mining qui
peuvent aider l'usager à déterminer certaines règles qui
permettent de reconnaître ces textes.[14][11][15]
42
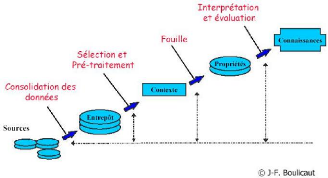
FIGURE 4.1 - Chaîne d'extraction de connaissances
4.1.3 La fouille du web
Les réseaux électroniques, de l'intranet
à internet, constitue une formidable source d'informations de par son
large volume de données. Les interêts de fouiller dans ces
données sont multiples et variés mais se heurtent à deux
problématiques majeurs; l'une concernant « l'internaute »
et l'autre concernant « le diffuseur » des
informations.
- La problématique de l'internaute peut se
résumer à celle de la recherche et de l'analyse d'informations
pertinentes;
- La problématique du diffuseur ou
propriétaire de sites web consiste à déterminer les
différents profils d'internautes en fonction de leur parcours sur le
site afin de pouvoir cibler ses offres, orienter son discours et donc proposer
rapidement les informations rechérchées par des clients
potentiels.
- les propriétaires de sites internet sont
quant à eux intéresser par des visiteurs. A chaque passage sur
les pages web, un internaute laisse ses traces. Outre la date et l'heure de la
visite, le site hôte enregistre le numéro de la machine, le
navigateur utilisé, l'ensemble de pages visitées, etc. En
s'appuyant sur ces données, les techniques de data mining,
text mining et d'image mining peuvent offrir des solutions
intéressantes.[14][16]
| 

