Reconnaissance des caractères arabes imprimés par l'approche neuro-génétique.( Télécharger le fichier original )par Marwa AMARA ECOLE NATIONALE DES SCIENCES DE L?INFORMATIQUE - Master 2012 |

CHAPITRE 4. EXPÉRIMENTATION ET ÉVALUATIONTABLE 4.2 - Paramètres finales de l'algorithme génétique
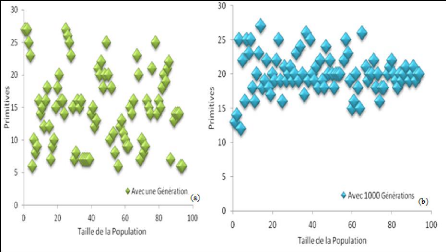
Après le choix final des paramètres de l'AG, la sélection des primitives se lance. La figure suivante représente la répartition des individus, qui représentent les vecteurs de primitives, d'une population de taille 100 pour une première génération figure-4.14(a) et après 1000 générations figure-4.14(b).
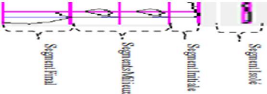
FIGURE 4.14 - Distribution des individus dans l'espace de recherche Nous observons que les individus deviennent de plus en plus ordonnés d'une génération 68 CHAPITRE 4. EXPÉRIMENTATION ET ÉVALUATIONà une autre. Le nombre de primitive sectionnée vari tend vers 20 après 1000 générations. L'objectif de la sélection des primitives pertinentes a été atteint car les résultats obtenus par l'approche de la sélection des primitives par les AGs sont satisfaisants. Nous avons pu supprimer 25% de nombre de primitives. En effet, le nombre de primitives a diminué de 7, passant de 27 à 20 primitives pertinentes. 4.2.5 ApprentissagePuisque un caractère arabe peut avoir des différentes formes en fonction de sa position dans un sous-mot (un mot) , alors, les segments résultants du processus de segmentation ont également de différentes formes selon leurs positions dans le sous-mot. Ils existent quatre types de segments, illustrés à la figure-4.15 :
FIGURE 4.15 - Les positions possibles des caractères dans un mot Les segments de caractères sont divisés en quatre ensembles en fonction de leurs positions dans le sous-mot (initiale, milieu, finale et isolée) comme mentionné dans l'annexe. Chaque segment de caractère est appris (puis reconnu) à l'aide d'un réseau de neurones distincts, d'où nous avons quatre réseaux de neurones (initiale - milieu - final - isolé) à former, pour être utilisées plus tard dans le processus de reconnaissance. Il existe de nombreuses techniques pour déterminer le choix de des paramètres du réseau de neurone. Dans tous les cas, un nombre d'essai est nécessaire pour déterminer la structure optimale. Pour l'apprentissage du perceptron multicouche nous avons utilisé l'algorithme de rétropropagation du gradient. Le réseau contient une seule couche caché car la plupart des chercheurs disent qu'avec une couche cachée, le réseau est capable, avec un nombre suffisant de neurones, d'approximer toute fonction continue1. Pour déterminer le nombre de noeuds dans cette couche nous avons utilisé l'heuristique suivante : \/ H = M2 + N2 (4.1) 1. http :// cict.fr/~stpierre/reseaux-neuronaux/node17.html 69 |
|