|
République du Sénégal
Un peuple-Un but-Une foi

Ministère du Plan

CABINET
Unité de Suivi des Programmes
d'Investissements Territoriaux de l'État
(USPITE) École Nationale de la Statistique
et de l'Analyse Économique
Mémoire de fin de formation
Établissement d'une base de
données
socioéconomique territorialisée et d'un
tableau de bord
de suivi des programmes et projets publics de
l'État
Rédigé et présenté
par
Brice Baem BAGOA
Élève Ingénieur des Travaux
Statistiques
(Quatrième Année)
Pour l'obtention du diplôme d'Ingénieur des
Travaux Statistiques
Maître de Stage : M. Souleymane DIALLO
Directeur de Cabinet du Ministère du Plan
Encadreur USPITE : M. Chouaïbou SONKO
Conseiller Technique, Coordonnateur de l'USPITE
Encadreur académique : M. Souleymane
FOFANA Responsable de la filière ITS à l'ENSAE
Juin 2014
c Ecole Nationale de la Statistique et de l'Analyse
Economique
Juin 2014
Établissement d'une base de données
socioéconomique territorialisée et d'un tableau de
bord
de suivi des programmes et projets publics de l'État
Brice Baem BAGOA
Elève Ingénieur des Travaux Statistiques
<
brice.bagoa@outlook.com
>
I can do all things through him who strengthens me.
-
Philippians 4 : 13 -
A Fidèle Lebon et Angéline BAKAM, mes parents
dans la foi,
Et à tous les frères et soeurs de la
Communauté Missionnaire Chrétienne Internationale
à
Dakar ...
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page i
Sommaire
Liste des tableaux iii
Table des figures iv
Sigles et abréviations vi
Avant propos vii
Remerciements viii
Résumé ix
Abstract x
Introduction Générale 1
1 Cadre général du suivi des projets de l'Etat
4
2 Bilan des approches et réalisations en matière
de bases de données 13
3 Approche Méthodologique et sources de données
24
4 Analyse du cadre socioéconomique du
Sénégal 43
5 Implémentation et déploiement du
système 54
6 Opérationnalisation du système, limites de
l'étude et recommandations 67
Conclusion générale 75
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page ii
Sommaire
Annexes et fiches techniques I
A Fiches techniques II
B Quelques graphiques et tableaux utiles VIII
Bibliographie XIII
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page iii
Liste des tableaux
|
2.1
|
Les modèles de la méthode Merise
|
20
|
|
2.2
|
Les diagrammes d'UML 2
|
21
|
|
3.1
|
Aperçu du cahier de charges
|
24
|
|
3.2
|
Indicateurs sociaux retenus pour le calcul de l'ISP suivant les
secteurs
|
32
|
|
3.3
|
Multiplicités et types d'associations
|
37
|
|
4.1
|
Pouvoir explicatif du premier axe factoriel : ISPA et ISPE
|
51
|
|
5.1
|
Recensement des classes du modèle
|
57
|
|
5.2
|
Établissement des associations entre les classes
|
58
|
|
A.1
|
Dictionnaire des données
|
II
|
|
A.2
|
Technologie utilisée pour la conception du
système
|
VI
|
|
B.1
|
Evolution de l'ISPA suivant les régions
|
VIII
|
|
B.2
|
Evolution de l'ISPE suivant les région
|
VIII
|
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page iv
Table des figures
|
1.1
|
Chaîne de résultats d'un projet de type GAR
|
6
|
|
1.2
|
Présentation allégée du SNSPITE (cas de la
casamance)
|
12
|
|
2.1
|
Représentation de l'architecture Client-Serveur
|
23
|
|
3.1
|
Architecture globale du système
|
34
|
|
3.2
|
Démarche générale d'implémentation
du système
|
35
|
|
3.3
|
Fonctionnement du site web
|
40
|
|
3.4
|
Présentation du design pattern MVC
|
41
|
|
4.1
|
Évolution du rendement de mil entre 2005 et 2012
|
44
|
|
4.2
|
Évolution du rendement d'arachide entre 2005 et 2012
|
45
|
|
4.3
|
Évolution du ratio Élèves/Classes entre
2005 et 2012
|
46
|
|
4.4
|
Évolution du ratio Élèves/Maîtres
entre 2005 et 2012
|
47
|
|
4.5
|
Corrélations des indicateurs de l'agriculture entre 2005
et 2012
|
48
|
|
4.6
|
Corrélations des indicateurs de l'éducation entre
2005 et 2011
|
49
|
|
4.7
|
Carte de proximité des régions pour l'agriculture
|
50
|
|
4.8
|
Carte de proximité des régions pour
l'éducation
|
50
|
|
4.9
|
L'ISPA et l'ISPE des régions pour 2005 et 2012
|
52
|
|
5.1
|
Diagramme de cas d'utilisation du système
|
55
|
|
5.2
|
Présentation du Modèle Conceptuel de
Données
|
59
|
|
5.3
|
Présentation du Modèle Logique de Données
|
62
|
|
5.4
|
Présentation du Modèle Physique de Données
|
64
|
|
6.1
|
Page d'accueil du site
|
68
|
|
6.2
|
Page d'authentification des utilisateurs
|
68
|
|
6.3
|
Page d'accueil de l'administration du site
|
69
|
|
6.4
|
Page d'accueil de la gestion des projets
|
70
|
|
6.5
|
Assignation des objectifs spécifiques et des indicateurs
de suivi
|
71
|
|
6.6
|
Page d'accueil de la BD socioéconomique
|
72
|
|
6.7
|
Mise à jour des indicateurs sociaux
|
72
|
|
B.1
|
Evolution des rendements du mil suivant les régions
|
IX
|
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page v
Table des figures
B.2 Evolution des rendements de l'arachide suivant les
régions IX
B.3 Evolution de l'ISPA suivant les régions X
B.4 Evolution de l'ISPE suivant les régions X
B.5 Consultation des détails d'un projet XI
B.6 Création d'un projet XI
B.7 Calcul d'un ratio XII
B.8 Publication d'un article par les membres de l'unité
XII
Sigles et abréviations

Agence Canadienne de Développement International
Agence Nationale de la Statistique et de la Démographie
Base de Données
Base de Données Objet-Relationnelle
Direction de la Coopération Economique et
Financière
Direction de la Planification Nationale et de la Coordination
avec la Planification Régionale
Document de Stratégie de Réduction de la
Pauvreté
Gestion Axée sur les Résultats
Interface Homme Machine
Indice Synthétique de Performances
Indice Synthétique de Performances Agricoles
Indice Synthétique de Performances Éducatives
Ministère de l'Economie et des Finances
Multidimensional Online Analytical Processing
Model View Controller
Online Analytical Processing
OnLine Transactionnal Processing
Orienté Objet
Plan d'Actions Stratégiques de l'Etat dans les
Départements
Plan d'Actions Stratégiques de l'Etat dans les
Régions
Programmation Orientée Objet
Plan Sénégal Emergent
Programme Triénal d'Investissements Publics
Relational Online Analytical Processing
Système de Gestion de Bases de Données
Systèmes de Gestion de Fichiers
Système d'Information Géographique
Stratégie Nationale de Développement Economique et
Social
Système National de Suivi des Programmes d'Investissements
Territoriaux de l'Etat
Unité de Suivi des Programmes d'Investissements
Territoriaux de l'Etat
ACDI
ANSD
BD
BDOR
DCEF
DPNCPR
DSRP
GAR
IHM
ISP
ISPA
ISPE
MEF
MOLAP
MVC
OLAP
OLTP
OO
PASED
PASER
POO
PSE
PTIP
ROLAP
SGBD
SGF
SIG
SNDES
SNSPITE
USPITE
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page vi
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page vii
Avant propos
L'Ecole Nationale de la Statistique et de l'Analyse Economique
(ENSAE) de Dakar est une école sous régionale membre du
réseau des Ecoles de Statistique Africaines (ESA) avec l'ENSEA d'Abidjan
et l'ISSEA de Yaoundé. Elle forme des Techniciens Supérieurs de
la Statistique (TSS), des Ingénieurs des Travaux Statistiques (ITS) et
des Ingénieurs Statisticiens Economistes (ISE).
La philosophie de toute grande est de concilier théorie
et pratique afin de former des cadres qui ont une bonne maîtrise des
outils théoriques et qui sont opérationnels dès leur
sortie. L'ENSAE ne déroge pas à cette règle. Ainsi, en
quatrième année, les élèves Ingénieurs des
Travaux Statistiques effectuent un stage de quatre mois au sein d'une
institution afin d'appliquer concrètement les connaissances acquises
aucours de leur formation. Ce stage est soldé par la rédaction
d'un mémoire de fin de formation.
La présente étude consiste en l'
«Établissement d'une base de données socioéconomique
ter-ritorialisée et d'un tableau de bord de suivi des programmes et
projets publics de l'État». Elle a été
réalisée au sein de l'Unité de Suivi des Programmes
d'Investissement Territoriaux de l'Etat (USPITE) qui est un service
attaché au Cabinet du Ministère du Plan. L'auteur assume
l'entière responsabilité des propos qui y sont tenus.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page viii
Remerciements
Au terme de ce stage, qu'il nous soit permis de remercier tous
ceux qui, de près ou de loin ont participé à sa
réalisation effective.
Nos remerciements vont d'abord à l'endroit de Monsieur
Abdoulaye BALDE, Ministre Sénégalais du Plan qui a bien voulu
nous accueillir dans sa structure en qualité de stagiaire. Nous
espérons avoir été à la hauteur de ses attentes.
Nos vives remerciements vont également à
l'endroit de Monsieur Souleymane DIALLO, Directeur de Cabinet du
Ministère du Plan et Maître de ce stage. Nous lui exprimons toute
notre reconnaissance en ce que, malgré un emploi du temps très
chargé, il s'est rendu disponible en nous écoutant et s'assurant
que ce stage se déroule dans de bonnes conditions.
Monsieur Chouaïbou SONKO, Conseiller Technique au
Ministère et Coordonnateur de l'USPITE a sans doute été
l'une des personnes ayant activement participé à la
réalisation de cette étude. Nous lui exprimons une vive
reconnaissance pour ses précieux conseils et sa présence
inconditionnelle dans tout le processus ayant abouti à l'éclosion
de cette oeuvre. En nous fournissant toute la documentation dont nous avions eu
besoin, il a largement facilité la tâche qui était la
nôtre au sein de l'Unité qu'il dirige.
Ce travail est également le fruit d'une étroite
collaboration avec les membres de l'USPITE. Il s'agit notamment de M. Ahmadou
Habib KANE, M. Ibrahima NDIAYE et Mme Marième BA. Qu'ils
reçoivent ici toute notre gratitude en ce qu'ils ont non seulement
facilité notre intégration au sein de leur équipe, mais
aussi se sont rendus disponibles et attentifs à nos diverses
inquiétudes et y ont apporté toutes les clarifications
nécessaires.
Les données utilisées dans ce rapport ont
été obtenues avec le concours de M. Mamadou DIENG, Conseiller
à l'Action Régionale de l'Agence Nationale de la Statistique et
de la Démographie. Qu'il reçoive ici nos remerciements les plus
vifs.
C'est le moment pour nous de remercier tout le personnel de
l'ENSAE en général et son Directeur M. Bocar TOURE en particulier
qui ne ménage aucun effort pour nous mettre dans de bonnes conditions
d'apprentissage. Nous faisons une mention spéciale à M.
Souleymane FOFANA notre encadreur académique durant ce stage et
responsable de la filière ITS, pour sa disponibilité et son
engagement à faire de nous l'élite de cette
génération. Merci à tous nos enseignants de l'ENSAE,
particulièrement à notre professeur de Programmation Web, M.
Abdel Kader FALL pour sa disponibilité et ses conseils qui ont
positivement orienté et impacté ce travail.
Nous remercions nos camarades Kodjo KOUDAKPO, Karl-Augustt
Novikan ALAHASSA et Augustin AKAKPO pour la relecture de ce document ainsi que
leurs diverses suggestions techniques qui nous ont été
très utiles. A tous nos camarades de la troisième promotion des
Ingénieurs des Travaux Statistiques à l'ENSAE, nous disons merci
pour leur soutien au cours de ces quatre années de formation. Nous
espérons leur avoir été utile autant qu'ils l'ont
été pour nous en leur souhaitant pleins succès pour leurs
projets futurs.
A nos parents, famille et amis, nous disons merci pour leur
soutien financier et moral tout au long de cette formation. Qu'ils voient en ce
document le fruit de la confiance qu'ils ont placé en nous.
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page ix
Résumé
Cette étude porte sur l'élaboration d'une base
de données socioéconomique territorialisée et d'un tableau
de bord pour le suivi des programmes et projets publics de l'État du
Sénégal. Elle vise l'objectif de mettre à la disposition
de Unité de Suivi des Programmes et Investissements Publics
Territauriaux de l'État (USPITE, Ministère du Plan) un ensemble
d'outils lui permettant de mener à bien ses activités quant
à la coordination du suivi des projets au plan national. Mais avant
cela, il est important pour l'USPITE de disposer d'un premier aperçu du
cadre social du Sénégal.
Pour mener à bien l'étude sur le secteur social
sénégalais, nous utilisons les méthodes factorielles pour
faire ressortir les corrélations entre les principaux indicateurs puis
les cartes auto-organisatrices de Kohonen pour établir les liens de
proximité entre les régions. La méthode l'analyse
factorielle dynamique est aussi utilisée pour la construction d'un
indice sectoriel de performances. Compte tenu des données à notre
disposition et les besoins prioritaires de l'USPITE, l'étude sociale a
porté sur les secteurs de l'agriculture et de l'éducation.
Les analyses ont montré que d'une manière
générale, les rendements des cultures (mil et arachide) sont en
baisse dans la plupart des régions, notamment celles du bassin
arachidier. On note par ailleurs que les indicateurs liés à
l'éducation s'améliorent d'année en année compte
tenu des projets entrepris par l'État dans les différentes
régions. L'étude a également fait ressortir l'existence de
corrélations entre les rendements de mil et de niebé d'une part
puis entre les rendements du maïs et de l'arachide d'autre part. Dans le
secteur de l'éducation, les corrélations sont marquées
entre les ratios élèves/classes et
élèves/maître puis entre les taux bruts de scolarisation et
de pré-scolarisation. Les indicateurs construits dans ce document nous
renseignent sur les performances des régions au fil des années
concernant l'agriculture et l'éducation.
Pour ce qui est du système informatisé, il est
constitué d'une base de données objet-relationnelle
PostgreSQL/PostGIS et d'une application web permettant aux utilisateurs d'y
accéder. L'application web est construite selon la convention MVC (Model
View Controller) et basé sur le framework Cake PHP. Cette application
présente entre autres les fonctionnalités suivantes : la gestion
des projets suivant l'approche classique et la Gestion Axée sur les
Résultats (GAR), la création, la mise à jour et l'analyse
des indicateurs sociaux, la gestion des utilisateurs, la publication d'articles
etc. Comme recommandation à l'USPITE, ce système doit faire
l'objet d'une migration vers un serveur web accessible via le réseau
internet pour une meilleure efficacité.
Mots Clés : Base de données,
Programmation Web, Suivi-évaluation des projets, Indicateur social.
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page x
Abstract
This study focuses on the development of a place-based
socio-economic database and a dashboard to monitor public programs and projects
of the State of Senegal. It is the objective of making available to USPITE
(Ministry of Planning) a set of tools to carry out its activities on the
coordination of monitoring projects at national level. But before that, it is
important for USPITE to have a first glimpse of the Senegal social
framework.
To carry out the study on the Senegalese social sector, we use
factor analysis to highlight the correlations between the main indicators and
the self-organizing Kohonen maps to establish close links between regions. the
dynamic factor analysis method is also used for the construction of a sector
index of performance. Given the data available to us and the priority needs of
the USPITE, social studies focused on agriculture and education.
The analyzes showed that in general, the yields of crops
(millet and groundnuts) are falling in most regions, including the groundnut
basin. We also note that the indicators related to education are improving year
on year given the projects undertaken by the state in different regions. The
study also revealed the existence of correlations between yields of millet and
cowpea on the one hand and between the yields of maize and groundnuts on the
other hand. In the education sector, correlations are marked between
students/classes and student/teacher ratios and between gross-enrollment and
pre-enrollment. Indicators constructed in this document tell us about the
performance of regions over the years concerning agriculture and education.
In terms of the computer system, it is constituted by an
object-relational database PostgreSQL/-PostGIS and a web application that
allows users to access it. The web application is built using the MVC
convention (Model View Controller) and based on the Cake PHP framework. This
application has several features : managing projects following the conventional
approach and the Results Based Management (RBM) approach, the creation,
updating and analysis of social indicators, user management, publication of
articles etc. As a recommendation to USPITE, this system must be migrated to an
accessible web server via internet network for greater efficiency.
Key Words : Database, Web Programming,
Monitoring and evaluation of projects, Social index.
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page 1
Introduction Générale
0.1 Contexte
Après la mise en oeuvre des deux
générations de Documents de Stratégie de Réduction
de la Pauvreté (DSRP) de 2003 à 2010, le Sénégal
fait toujours face à d'importants défis socioécono-miques.
En effet, la croissance économique est restée faible en 2011
(1,7%) et la tendance à la reprise de l'année 2012 a
été très limitée (3,6%). En outre, le pays connait
une forte croissance démographique avec une jeunesse confrontée
aux difficultés d'entrée sur le marché du travail. La
demande d'accès aux services sociaux de base reste également
forte, de même que les disparités sociales.
Dans ce contexte, les autorités ont adopté en
2012 une Stratégie Nationale de Développement Economique et
Sociale (SNDES). Cette stratégie repose sur la vision du Plan
Sénégal Emergent qui vise l'émergence d'ici 2035. Pour
l'étape intermédiaire 2018 présentée dans le Plan
d'Actions Prioritaires 2014-2018, la stratégie est
déclinée en trois axes principaux :
Axe 1 : Transformation structurelle de l'économie et
croissance
Axe 2 : Capital humain, protection sociale et
développement durable
Axe 3 : Gouvernance, institutions, paix et
sécurité
La vision du PSE sous-tend une territorialisation des
interventions de l'Etat dans les collectivités locales au travers de
l'Acte 3 de la décentralisation. De façon pratique, cette
territorialisation permettra une prise en compte des spécificités
de chaque région et département dans la mise en oeuvre des
politiques publiques. Ainsi, chaque collectivité locale sera
dotée d'un Plan d'Actions Stratégiques de l'Etat (PASER pour les
régions et PASED pour les départements). Les PASER/-PASED sont
des documents qui retracent l'ensemble des projets de l'Etat dans la
région ou le département.
0.2 Problématique
Le Sénégal consacre chaque année une part
importante de son budget aux dépenses d'inves-tissements à
travers des projets de développement. La mise en oeuvre du Programme
Triennal d'Investissements Publics (PTIP) 2014-2016 nécessite par
exemple un coût global de 3 467,889 milliards de francs CFA dont 52% sur
fonds propres. Cependant, force est de constater que ces projets, compte tenu
de leur complexité (acteurs multiples aux intérêts souvent
divergents, poids de
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 2
0.3. Objectifs de l'étude
l'environnement immédiat et lointain..) se
déroulent rarement tels que planifiés. D'où l'importance
du suivi rapproché de ces projets qui doit permettre de déceler
les difficultés et de leur apporter des solutions pour leur bonne mise
en oeuvre. Un bon suivi permet de relever très sensiblement
l'efficacité des ressources publiques investies dans les projets.
Toutefois, l'expérience a montré que par le
passé le suivi des projets publics n'a pas obtenu l'attention qu'il
mérite. Le suivi, éclaté dans diverses administrations
n'est fait que de manière sporadique et souvent à la demande des
partenaires techniques et financiers 1. Cette situation a
entrainé l'allongement de plusieurs projets avec des surcouts que cela
entraine voire des échecs dans la mise en oeuvre. Le Gouvernement a donc
décidé d'accorder plus d'attention au suivi des projets publics
à travers la création de l'USPITE. Cette dernière
établira dorénavant tous les ans un rapport portant sur
l'exécution physique et financière des projets de l'Etat. Le
système de suivi mis en place au niveau de l'USPITE permet une
remontée des données à partir du site du projet jusqu'au
niveau national en passant par le niveau régional (Gouverneurs) et le
filtre sectoriel (ministères). La mise en application de ce
système de suivi nécessite une centralisation des données
issues de l'activité de suivi des projets sur le terrain.
Pour plus d'efficacité dans la coordination des
PASER/PASED, l'USPITE doit disposer de la situation actuelle des principaux
indicateurs socioéconomiques des régions et départements
afin d'établir les tendances du développement de ces
collectivités. En outre, il est intéressant de mesurer les
disparités régionales et départementales et de tenir une
base de données actualisée à la disposition des usagers,
en particulier des administrations centrales et déconcentrées
pour leurs travaux de planification.
Il ressort donc la nécessité pour l'USPITE de
disposer d'un système informatisé en vue de garantir son bon
fonctionnement. Ce système doit aider à la coordination des
activités de suivi des projets et programmes de l'Etat d'une part et
d'autre part, permettre de disposer d'une base de données
territorialisée portant sur les principaux indicateurs sociaux.
0.3 Objectifs de l'étude
L'objectif général de la présente
étude est de mettre à la disposition de l'USPITE un
système informatisé fiable et cohérent constitué
d'une base de données socioéconomique territorialisée et
d'un tableau de bord de suivi des projets et programmes de l'Etat. De
façon spécifique, ce système doit répondre aux
exigences suivantes :
1. Source : USPITE
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 3
0.4. Structuration de ce document
Pour la base de données socioéconomique
:
~ Elle doit permettre de disposer de l'information pertinente
sur les régions et départements en perspective des travaux de
planification et d'analyses de disparités (régionales et
départementales);
~ Cette base de données doit pouvoir être jointe
à des ressources cartographiques afin de permettre la visualisation de
cartes portant sur tel ou tel indicateur;
~ La possibilité doit également être
offerte aux utilisateurs d'ajouter, de supprimer et de mettre à jours
des indicateurs.
Pour le tableau de bord de suivi des projets et
programmes de l'Etat :
~ Structuré selon les secteurs d'activités
2 , le tableau de bord doit permettre de disposer de la fiche
synoptique de chaque projet et programme mis en oeuvre dans chacune des
collectivités locales.
~ De par sa conception, le tableau de bord doit permettre de
consigner dans des compartiments à prévoir les données
issues des activités de suivi (indicateurs et activités).
~ Cet outil doit également permettre une prise en
charge des programmes qui sont des groupements de projets apparentés
dont le management est coordonné.
En marge de la conception de ce système, il convient
d'établir un panorama sur la situation économique et sociale du
Sénégal afin de poser les bases des analyses de disparités
sociales.
0.4 Structuration de ce document
Pour mener à bien cette étude, le présent
document sera structuré en six chapitres dont le premier sera
consacré à la présentation du cadre général
du suivi des projets au Sénégal. Une revue de littérature
sur les bases de données fera l'objet du second chapitre qui sera suivi
de l'approche méthodologique adoptée. Le quatrième
chapitre sera consacré à l'étude de l'évolution du
cadre socioéconomique du Sénégal depuis l'année
2005 à travers l'étude de quelques indicateurs sociaux et la mise
en place d'un indice sectoriel de performances permettant une comparaison des
régions dans les différents secteurs sociaux. Dans le
cinquième chapitre, nous proposons la modélisation et
l'implémentation des structures de données ainsi que d'une
application d'interaction avec ces données. Le dernier chapitre sera
consacré à la présentation et à l'utilisation
pratique des fonctionnalités du système ainsi mis en place ainsi
qu'aux limites et recommandations de l'étude.
2. Primaire, secondaire, tertiaire et quaternaire.

Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page 4
Chapitre 1
Cadre général du suivi des projets de
l'Etat
Un des objectifs de cette étude est la mise à
disposition de l'USPITE d'un système de suivi des différents
projets mis en oeuvre par l'Etat. La mise en place d'un tel système
passe naturellement par l'appropriation des concepts propres au domaine du
suivi des projets. Hormis les concepts d'ordre généraux, il est
aussi important de s'approprier la mise en oeuvre de ceux-ci dans le cas
spécifique du Sénégal. Ceci constitue l'objet de ce
premier chapitre. Il présente d'abord les concepts de projet et de
suivi-évaluation avant de proposer une analyse du système
sénégalais de suivi des projets. La dernière section sera
consacrée à la présentation du dispositif
opérationnel de l'USPITE.
1.1 La notion de projet
Un projet peut être défini comme une combinaison
de ressources humaines et matérielles réunies au sein d'une
organisation pour l'atteinte d'un objectif bien précis. CADENET et KING
donnent une définition plus exhaustive de la notion de projet. Pour eux:
« Un projet est un ensemble optimal d'actions à
caractères d'investissements fondé sur une planification
sectorielle globale et cohérente grâce auquel une combinaison
définie de ressources engendrent un développement
économique et social d'une valeur déterminée »
(Voir [47]). De ces deux définitions, il ressort que le projet doit
nécessairement aboutir à l'atteinte d'un objectif bien
déterminé en passant par la réalisation d'un certain
nombre d'activités ou tâches. Pour mener à bien un projet,
ce dernier doit faire l'objet d'un suivi et d'éventuelles
évaluations (au début, à mi-parcours ou a la fin). Deux
principales approches sont utilisées de nos jours dans la gestion des
projets : l'approche traditionnelle et la gestion axée sur les
résultats (GAR)
1.1.1 Suivi et évaluation des projets
Par définition le suivi est un processus
itératif de collecte et d'analyse d'informations pour repérer les
anomalies en vue de les corriger. Il fournit donc aux gestionnaires et aux
participants un retour d'information régulier qui peut aider à
déterminer si l'avancement du projet est conforme à
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 5
1.1. La notion de projet
la programmation. Aussi, les activités de suivi
permettent de comparer le rendement prévu avec le rendement atteint.
L'évaluation est une opération sélective
qui vise à apprécier systématiquement et de manière
objective les progrès dans la réalisation d'un effet au regard
des ressources engagées. Il peut survenir soit à un moment
donné pendant la mise en oeuvre (évaluations intérimaires,
et évaluation finale), soit après l'achèvement des
activités du projet/programme (Evaluation ex- post). Elle vise
ordinairement à déterminer la pertinence, l'efficience,
l'efficacité, l'impact et la durabilité d'un projet.
Le suivi-évaluation est basé sur les indicateurs
qui sont des outils destinés à mesurer l'avan-cement des projets
et à évaluer la qualité des résultats et
bénéfices que peuvent en dégager les parties-prenantes.
Ils représentent un des moyens essentiels pour améliorer la
qualité et l'impact sur le développement des projets. C'est un
facteur ou variable, de nature quantitative ou qualitative qui doit respecter
les conditions suivantes définies par le sigle SMART :
~ Spécifique : l'indicateur doit être clairement
défini et sans ambigüité pour les parties prenantes du
projet.
~ Mesurable : l'indicateur chiffré doit être
incontestable et reconnu comme tel par l'ensemble des parties prenantes.
~ Atteignable : il doit être acceptable et
réalisable lors de la mise en oeuvre du projet.
~ Réaliste : il doit être réalisable et ne
reposer que sur la motivation du collaborateur ou être
réajusté si le contexte change.
~ Temporellement défini : il doit être inscrit
dans le temps, avec une date de fin et éventuellement des points
intermédiaires.
1.1.2 La gestion axée sur les résultats
Le concept de Gestion axé sur les résultats est
attribué à Peter Druker dans son ouvrage "Managing for results"
[17]. Quelque peu éclipsé jusqu'à la fin des années
80, ce principe de gestion revient à l'avant plan dans les années
90. Partant du constat que l'aide publique au développement était
de moins en moins efficace, les dirigeants internationaux vont entreprendre une
série de consultations dans le but de trouver les moyens pour veiller
à ce que les fonds d'aide au développement soient efficacement
utilisés. C'est ainsi que le concept de GAR commence par prendre place
dans la gestion des projets.
Selon l'ACDI, la GAR est « un moyen d'améliorer
l'efficacité et la responsabilité de la gestion en faisant
participer les principaux intervenants à la définition de
résultats escomptés, en évaluant les
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page 6
1.2. Le système national de planification
risques, en suivant les progrès vers l'atteinte de ces
résultats, en intégrant les leçons apprises dans les
décisions de gestion et les rapports sur le rendement ». La
démarche en GAR est représentée par la chaîne de
résultats (Voir graphe 1.1). Des ressources matérielles et
humaines (Intrants) sont combinées pour la réalisation d'un
certain nombre d'actions (Activités) entrant dans le cadre du projet.
Les fruits issus de ces activités (Extrants) produisent un effet
à court ou moyen terme et un impact à long terme. Le suivi et
l'évaluation portent sur les effets et les impacts. Il est
effectué à travers les indicateurs respectant les conditions
SMART.
Graphique 1.1 -- Chaîne de
résultats d'un projet de type GAR
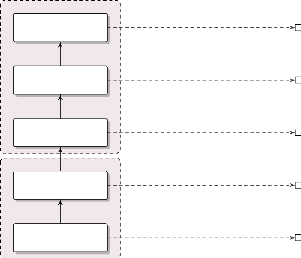
Ressources
Résultats
Activités
Extrants
Intrants
Impact
Effets
Actions entreprises dans le cadre du projet
Changements escomptés à long terme
Ressources financières et matérielles
Effets à court et moyen terme
Produits issus des activités
Source: Nos recherches
1.2 Le système national de planification
Les projets étant les principaux objets des
dépenses publiques, il est impératif qu'ils puissent s'inscrire
dans la stratégie de développement de l'État. En effet,
tout État, à travers sa politique de dépenses publiques,
vise l'atteinte de l'un au moins des quatre objectifs de la politique
économique (croissance, stabilité des prix, le plein emploi et
l'équilibre extérieur). Il est donc impératif de choisir
les projets qui sont un mode de gestion caractérisé par leurs
aspects temporels et tournés vers l'atteinte des objectifs ou des
résultats.
La planification étant indissociable de la gestion de
projet, le Sénégal s'est doté d'un système de
planification qui repose sur trois instruments couvrant trois horizons
temporels différents :
Une étude prospective à l'horizon d'une
génération (25 ans) : Elle procure un cadre
général
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 7
1.3. Processus d'instruction des projets
publics
de référence, par sa vision globale des
composantes économique, sociale et culturelle. L'Etude constitue une
réflexion prospective sur le Sénégal et son environnement,
explorant à l'horizon d'une génération le champ des
futures possibilités, afin d'éclairer les choix
stratégiques de développement. Ce premier maillon de la
chaîne du système de planification s'élabore en trois
phases : une étude rétrospective, une analyse structurelle et
l'élaboration de scénario pour aider à un choix de
société à long terme.
Le Plan d'Orientation pour le Développement
Economique et Social : Élaboré pour six ans, il
s'inscrit dans le cadre des axes stratégiques proposés par le
scénario constituant le choix de société retenu par les
sénégalais dans l'Etude Prospective. Il fournit des
repères et des critères pour la sélection et la
programmation des projets de l'Etat et pour le choix des mesures d'impulsion
des initiatives privées. Il constitue la référence pour
les politiques sectorielles.
Le Programme Triennal d'Investissements Publics (PTIP)
: Il rassemble les projets et études à réaliser
au cours des trois années couvertes par le programme. Il constitue le
budget d'in-vestissement prévisionnel de l'État et vise de ce
fait à rationaliser l'effort d'investissement public selon des
procédures d'acceptation de projets et d'arbitrage définies.
Ainsi, sont du domaine de la programmation triennale, les projets de
l'État ( mis en oeuvre par les ministères techniques
essentiellement ) , les projets des établissements publics, des
collectivités locales et sociétés nationales pour le
financement desquels l'État est sollicité soit pour subvention ou
prise de participation soit pour aval ou rétrocession d'emprunts. La
première année du PTIP qui constitue le Budget Consolide
d'Investissement (BCI) fait partie intégrante de la loi de finances. Le
PTIP est ajustable chaque année.
1.3 Processus d'instruction des projets publics
Le cadre institutionnel de définit une
évaluation ex-ante, un suivi physico-financier et une évaluation
ex-post des projets proposés par les ministères techniques.
1.3.1 L'évaluation ex-ante
Cette évaluation est effectuée depuis 2014 par
la DPSEP sur la base d'un dossier proposé par les ministères
techniques. La pertinence des projets est jugée en fonction de l'apport
dans l'atteinte des objectifs de politique économique fixée par
le Gouvernement. Cette évaluation est très importante dans la
mesure où elle permet de garantir la qualité des actions
publiques, notamment des investissements. Les projets ayant satisfait aux
conditions du suivi ex-ante sont classés par degré de
priorité.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 8
1.3. Processus d'instruction des projets
publics
1.3.2 L'exécution et le suivi physico-financier
Pour le suivi rapproché des programmes, les
Ministères techniques, en charge de l'exécution physique des
projets produisent des rapports trimestriels et un rapport annuel à
l'attention de la Direction de la Coopération Economique et
Financière (DCEF). Sur la base de ces rapports, la DCEF élabore
annuellement le Bulletin d'Exécution des Projets et Programmes du PTIP.
Dans le but de mesurer le niveau d'atteinte des objectifs et d'en tirer des
leçons, le MEF procède à une évaluation des projets
et programmes immédiatement à la fin de leur exécution.
1.3.3 L'évaluation ex-post
Elle consiste à évaluer les projets et
programmes quelques années après leur exécution en vue
d'en mesurer les impacts et surtout la contribution à l'atteinte des
objectifs stratégiques.
1.3.4 Les limites du système existant
Le système présenté ci dessus
présente des insuffisances liées à sa mise en oeuvre et
à la remontée des informations issues des activités de
suivi.
~ Le manque d'un dispositif centralisé permettant une
remontée rapide des informations est l'une des principales lacunes du
présent système. En effet, le suivi physique des projets ne
s'effectue que sur la base d'une constatation subjective de la part des agents.
Ceci est la cause d'un manque d'informations concrètes à la fois
pour les décideurs et les acteurs directement impliqués dans la
mise en oeuvre de ces projets.
~ Dans le présent dispositif de suivi, la
responsabilité de la réussite des projets et programmes incombe
uniquement au Gouvernement (MEF et Ministères Techniques). On note un
faible degré d'implication des acteurs locaux (régions et
départements) et des responsables de la mise en oeuvre des projets
(chefs et responsables des projets sur le terrain). Ceci ne permet pas une
gestion satisfaisante des difficultés rencontrées ainsi qu'une
prise en compte des réalités du terrain.
~ L'évaluation ex-post des projets et programmes reste
encore confrontée à des problèmes tels que les coûts
souvent élevés pour sa réalisation, la faiblesse des
compétences dans la plupart des agences et ministères techniques
et surtout la quasi absence d'archives.
~ On note par aillieurs l'absence d'un schéma de suivi
global et partagé, la faible collaboration entre les parties
impliquées ainsi que la modicité et l'affectation
inappropriée des ressources affectées au suivi.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 9
1.4. Présentation du SNSPITE
Pour palier les insuffisances du présent dispositif de
suivi, l'USPITE a mis sur pied un Système National de Suivi des
Programmes d'Investissements Territoriaux de l'Etat (SNSPITE).
1.4 Présentation du SNSPITE
Le Système National de Suivi des Programmes
d'Investissements Territoriaux de l'Etat (SNS-PITE) poursuit deux objectifs
principaux :
~ Permettre aux autorités et aux autres responsables
d'avoir une information continue sur l'état de la mise en oeuvre des
orientations, projets et programmes de l'Etat
~ Permettre aux décideurs situés aux
différents échelons d'apporter les remèdes
nécessaires pour permettre une bonne mise en oeuvre des programmes et
projets de l'Etat.
Pour l'atteinte de ses objectifs, le SNSPITE est doté
de trois niveaux complémentaires. Il s'agit des intervenants sur le
terrain, les ministères de tutelle et l'USPITE.
1.4.1 Les Unités de Gestion des Projets (UGP)
C'est le niveau opérationnel de la mise en oeuvre des
projets. Il est essentiellement constitué des gestionnaires de projets
et programmes dont le rôle principal est l'exécution effective des
dits projets. Les UGP ont la mission de veiller au suivi rapproché du
projet dont ils ont la charge. Ces unités établissent un rapport
trimestriel adressé aux ministères de tutelle (ou
ministères techniques en charge du projet) et aux autorités
administratives. Ce rapport s'arrête notamment sur le niveau de
réalisation des outputs, l'absorption des ressources etc. en tenant
compte des délais prévus. Les membres des UGP participent chaque
semestre aux Conférences Régionales de Suivi des Projets et
Programmes Territoriaux de l'Etat.
1.4.2 Les ministères techniques
Les projets et programmes de l'Etat sont rattachés
à des ministères techniques. Les rapports des UGP leur sont
destinés. La Cellule d'Etude et de Planification (CEP) centralise,
valide, fait la synthèse sectorielle des rapports de suivi.
L'exploitation du rapport au sein du ministère permet au
département :
- de connaître de l'état de mise en oeuvre des
projets à sa charge;
- d'apporter des réponses aux obstacles à sa
portée;
- de planifier ses nouvelles actions en connaissance de cause.
Les rapports de suivi des ministères sont par la suite
transmis à l'USPITE.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 10
1.4. Présentation du SNSPITE
1.4.3 L'USPITE
L'USPITE est l'organe national de suivi des projets et
programmes territoriaux de l'Etat. L'US-PITE est chargée de centraliser
et d'exploiter les rapports de suivi provenant des ministères techniques
et du niveau territorial, de rendre compte aux autorités et aux organes
compétents à l'in-tention de qui elle peut faire des
recommandations et de veiller au bon fonctionnement du système de suivi.
Le rapport de l'USPITE à l'attention des autorités vise :
- à les informer de l'état de mise en oeuvre des
projets et programmes;
- à porter à leur connaissance les
difficultés éventuelles;
- à faire des suggestions dans le but de leur trouver
des solutions
1.4.4 Les organes Ad Hoc du SNSPITE
Trois institutions ad-hoc sont également mises en place.
Il s'agit de :
Les conférences régionales de suivi des
projets et programmes territoriaux de l'Etat (CRSPPE) Les CRSPPE
procèdent à la revue régionale semestrielle des projets et
programmes de l'Etat. Dans chaque région, la CRSPPE est placée
sous l'autorité du Gouverneur, représentant du Chef de l'Etat et
du Gouvernement dans la dite région. Ces conférences regroupent
les services techniques régionaux et les UGP. Elles reçoivent les
rapports élaborés par les UGP, les valident et proposent, le cas
échéant, les solutions à apporter aux difficultés
rencontrées. La CRSPPE peut organiser des missions de suivi sur place et
son secrétariat est assuré par le Service Régional de la
Planification (SRP).
la Conférence Technique de Suivi des Projets et
Programmes territoriaux de l'Etat (CTSPPE) La CTSPPE est l'instance
technique ad hoc de suivi des projets et programmes. Elle regroupe le
Ministère du Plan (l'USPITE et la Direction de la Planification
Territoriale), le Ministère de l'Economie et des Finances, le
Ministère de l'Intérieur et les Ministères techniques.
Elle passe en revue les portefeuilles sectoriels de projets et programmes,
valide les rapports sectoriels, se prononce sur les difficultés
rencontrées et propose les outils adéquats. Elle cherche à
couvrir les besoins des parties (dont les Partenaires Techniques et Financiers)
en matière de suivi des projets.
la Conférence Nationale de Suivi des Projets et
Programmes territoriaux de l'Etat (CNSPPE) La CNSPPE est
présidée par le représentant de la Présidence de la
République. Elle comprend en outre les représentants de la
Primature, du Ministère du Plan, du Ministère de l'Economie et
des Finances , du Ministère de l'Intérieur (DGAT), du
Ministère de l'Aménagement du Territoire et des
Collectivités locales. C'est l'instance supérieure de pilotage du
système national
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 11
1.4. Présentation du SNSPITE
de suivi des projets et programmes de l'Etat. La CNSPPE
reçoit le rapport de l'USPITE et formule des recommandations y compris
pour le bon fonctionnement du système de suivi des projets et programmes
de l'Etat. Elle fournit l'information détenue par ses membres et pouvant
être utile dans le cadre du suivi des projets et programmes. Le rapport
de l'USPITE étudié par la CNSPPE est transmis aux
autorités.
De par son organisation, le SNSPITE est un système
permettant une meilleure appropriation par l'Etat de l'avancement de la mise en
oeuvre de ses orientations dans les collectivités locales. Le diagramme
de 1.2 donne une vue allégée de ce système pour le cas du
pôle territoire casamance.
Conclusion partielle
Somme toute, la mise en oeuvre des stratégies de
développement définies par l'Etat passe par la réalisation
de projets et programmes. Ceux-ci sont des ensembles d'actions
coordonnées faisant concourir des ressources matérielles et
humaines pour l'atteinte d'objectifs bien définis. La mesure de
l'atteinte de ces objectifs se fait à travers le suivi et
l'évaluation au moyen d'indicateurs fiables. Le système de suivi
existant au niveau du MEF présente des limites en termes de
données et d'implication des acteurs à différents niveaux
de la chaine. L'objectif du SNPITE est donc de renforcer ce dispositif en
responsabilisant les acteurs impliqués et en mettant à la
disposition des utilisateurs des données fiables sur l'exécution
des projets de l'Etat.
Source : USPITE
Graphique 1.2 -- Présentation
allégée du SNSPITE (cas de la casamance)
|
|
|
|
|
|
Rapports sectoriels
|
|
|
Ministère Technique
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Assurer la coordiation de tous les projets relevant de son
domaine
|
|
|
|
|
|
|
|
|
|
USPITE
Mission :
|
Proposition de solutions
|
Rapport Annuel
|
Appuyer l'élaboration des documents de planification
territoriale et d'assurer le suivi des programmes et projets d'investissements
territoriaux de l'Etat.
r
CSPT (Conférence de suivi du Pôle
Territoire)
Rôle :
Bilan de la mise en oeuvre des orientations, programmes et
projets d'investissements de l'Etat à l'échelle du pôle
territorial.
Membres :
Gouverneurs, ARD, SRP, ANSD, SRAT, Elus locaux,
Société civile, OCB/ONGs
Rapport semestriel
Rapport semestriel
Rapport Trimestriel
UGP (Unité de Gestion du Projet)
CRSPPE
Rôle :
Exécution du projet
Rapport trimestriel
Rôle :
Revue régionale et semestrielle des projets et programmes
de l'Etat
Responsables :
Coordinateur ou Chef de projet et programme
Propositions de solutions
Membres :
Gouverneurs, autorités administratives, SRP, ANSD,
SRAT.

Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page 13
Chapitre 2
Bilan des approches et réalisations en
matière de bases de
données
Ce chapitre se donne pour objectif de passer en revue toute la
théorie développée autour des bases de données. Il
sera question d'étudier les différents modèles
d'organisation ainsi que les méthodes d'analyse conceptuelle des bases
de données. La dernière section de ce chapitre est
réservée à la présentation des Systèmes de
Gestion de Bases de Données (SGBD). Avant tout, il est important de
s'interroger sur ce qu'est exactement une base de données.
2.1 La notion de base de données
2.1.1 Motivation et définition
Chaque jour, de grosses quantités d'information sont
partagées par des millions d'usagers à travers le monde. Ceci se
fait à travers des milliards de transactions allant de la plus simple
à la plus complexe. Mais d'où viennent ces informations que nous
recevons et où vont celles que nous transmettons?
L'invention du disque dur en 1956 a ouvert la voie à la
possibilité de stocker, d'organiser et de gérer de grandes
quantités d'informations sur les ordinateurs. De là, il va
naître une première approche des bases de données. Il a
fallu cependant attendre 1964 pour voir apparaître le terme « base
de données » qui désignait alors une collection
d'informations partagées par différents utilisateurs d'un
système d'informations. De nos jours, il existe plusieurs formulations
de cette définition. Nous retenons celle de J. AUBERT [3] : «
une base de données est un ensemble homogène et
structuré d'informations non redondantes enregistrées sur un
support informatique ».
Cette définition laisse entrevoir un certain nombre de
propriétés intrinsèques aux bases de données. Il
s'agit notamment de la bonne structuration, la non redondance, la
cohérence et de la persistance des données. De manière
formelle, ces propriétés sont connues sous le nom de
propriétés ACID.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 14
2.1. La notion de base de données
2.1.2 Les propriétés ACID d'une base de
données
Pour garantir l'intégrité et la fiabilité
des informations enregistrées, une base de données doit
être soumise à un certain nombre de contraintes. Vers la fin des
années 1970, Jim Gray a défini les propriétés qui
garantissent cette fiabilité des données puis il a
développé des technologies pour les mettre en oeuvre de
façon automatique. L'acronyme ACID (Atomicité, Cohérence,
Isolation et Durabilité) apparait en 1983 avec Andrea REUTER et Theo
HÄRDER pour désigner ces propriétés. De façon
concrète, les propriétés ACID signifient :
Atomicité : une transaction doit se
faire au complet ou pas du tout. En d'autres termes, tout ajout, modification
ou suppression d'informations dans une base de données doit
nécessairement arriver à terme. La conséquence de
l'interruption d'une transaction est naturellement la perte
d'intégrité des données enregistrées.
Cohérence : aucune modification ne
doit entraîner la perte de cohérence du système. Autrement
dit, chaque transaction doit amener le système d'un état valide
à un autre état valide ceci, à travers le respect d'un
certain nombre de contraintes d'intégrité 1 .
Isolation : cette règle assure que
l'exécution simultanée de plusieurs transactions n'a d'effet sur
aucune des transactions en cours. En fait, chaque interaction entre un
utilisateur et la base de données s'effectue comme si celui-ci
était seul à travailler sur cette base de données. Il n'y
a pas d'inférences avec les autres utilisateurs.
Durabilité : lorsqu'une transaction
s'est bien produite, les modifications apportées à la base
doivent être enregistrées de façon pérenne et
être capables de résister à tout choc externe (panne
d'ordinateur, coupure de courant etc.).
Il apparaît clairement que la violation de l'une de ces
règles entraine automatiquement la perte de fiabilité des
informations enregistrées. De nos jours, les logiciels
spécialisés dans la gestion de bases de données prennent
en compte ces quatre aspects fondamentaux de la fiabilité de
l'information. La dernière section de ce chapitre sera consacrée
à un bref aperçu de ces logiciels.
2.1.3 Terminologie des bases de données
Cette sous-section est réservée à
l'étude de quelques concepts fondamentaux du champ sémantique des
bases de données. Les définitions qui suivent serviront donc de
base à la suite du document.
Modèle de données : Le
schéma ou modèle de données, est la description de
l'organisation des données. Il se trouve à l'intérieur de
la base de données, et renseigne sur les caractéristiques
1. Les contraintes d'intégrité seront
étudiées au chapitre 3 de ce document
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 15
2.2. Évolution des modèles de bases de
données
de chaque type de donnée et les relations entre les
différentes données qui se trouvent dans la base de
données. La section suivante sera consacrée à
l'étude des différents types de modèles de
données.
Modèle logique et modèle physique de
données : Le modèle logique est la description des
données telles qu'elles sont dans la pratique, tandis que le
modèle de physique est un modèle dérivé du
modèle logique qui décrit comment les données seront
techniquement stockées dans la base de données.
Enregistrement : Un enregistrement est une
donnée composite qui comporte plusieurs champs dans chacun duquel est
enregistrée une donnée. Cette notion a été
introduite par le stockage dans des fichiers dans les années 1960.
2.2 Évolution des modèles de bases de
données
2.2.1 Les systèmes de gestion de fichiers
A l'origine, les informations étaient stockées
dans des fichiers directement sur les disques durs des ordinateurs.
L'accès ainsi que la manipulation se faisaient par
l'intermédiaire des SGF. Dans l'approche gestion de fichiers, ceux-ci
sont définis pour un ou plusieurs programmes de traitement. Les
données d'un fichier sont directement associées à un
programme (Basic, Cobol, DBase par exemple) par une description contenue dans
le programme de traitement lui-même. Il n'existe aucune
indépendance entre le programme et les données. Toute
modification de la structure des données nécessite la
réécriture du programme. La première difficulté
inhérente à cette approche est naturellement la lourdeur des
fichiers et la redondance de l'information qui y est contenue. Ajouté
à cela, l'approche SGF ne facilitait pas la manipulation (ajout,
suppression et mise à jour) de l'information contenue dans les fichiers.
Les requêtes simples (recherche de l'éditeur d'un article
donné par exemple) pouvaient être mises en oeuvre, cependant il
était impossible d'effectuer les requêtes faisant intervenir
plusieurs clés (comme la recherche de tous les articles d'un
éditeur donné). Face à ces lacunes, les acteurs du monde
informatique à l'époque vont penser à mettre en place des
systèmes de stockage d'informations beaucoup plus flexibles des avec des
liens entre les enregistrements. Ce fut la naissance des modèles
hiérarchiques et des modèles en réseau qui constituent la
deuxième génération de modèles de
données.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 16
2.2. Évolution des modèles de bases de
données
2.2.2 Des modèles hiérarchiques aux
modèles en réseau
Les modèles hiérarchiques font leur apparition
dans les années 1965. Ils sont basés sur une architecture
où certaines entités sont indépendantes (les racines), les
autres étant dépendantes des premières (les feuilles).
Dans ce type de structure, les données sont organisées sous la
forme d'arbres qu'on parcourt de la racine vers les feuilles. Chaque
enregistrement est composé donc récursivement d'autres
enregistrements et l'accès à l'information est conditionné
par la connaissance de son chemin d'accès. La compagnie
américaine IBM, précurseur de ces modèles a conçu
un SGBD nommé IMS (Information Management System) basé sur les
modèles hiérarchiques. Ce dernier développé dans le
cadre du projet Apollo 11 2 est encore utilisé de nos jours
dans la gestion de très grosses bases de données à haute
performances et à haute fiabilité, notamment dans le secteur
bancaire. Malgré sa popularité d'antan, IMS est de moins en moins
utilisé à cause de de son manque de flexibilité, sa
lourdeur et sa complexité. Les modèles hiérarchiques
seront ainsi progressivement délaissés au profit des
modèles en réseau.
Contrairement aux modèles hiérarchiques, les
modèles en réseau sont constitués d'entités
reliées les unes aux autres par un réseau de relations binaires.
Ils ont été développés par le groupe CODASYL DGTG
3 . Ici, les données sont organisées en
enregistrements dont les types sont bien définis. Les SGBD CODASYL
étaient dotés de compilateurs DDL (Data Description Language) et
DML (Data Management Language) permettant respectivement la définition
des schémas et la mise à jour des données via un langage
spécialisé. Ces SGBD ont largement été
utilisés pour la gestion d'applications batch et OLTP. Leur
simplicité d'usage - par rapport à leurs concurrents des
modèles hiérarchiques - ainsi que le langage très intuitif
leur ont valu une grande popularité dans le développement
d'applications complexes. Cependant les systèmes CODASYL souffrent d'un
manque de flexibilité pour ce qui est de l'évolution des
schémas ainsi que de l'absence d'un langage prédictif natif tel
que le SQL. En effet, Les langages proposés par les SGBD CODASYL
étaient tels que toute nouvelle requête devrait se traduire par un
nouveau programme. Ces aspects vont pousser leurs utilisateurs à les
remplacer par des SGBD relationnels.
2.2.3 Le modèle relationnel
Ce modèle est dû à E. F. CODD en 1970.
Grace à sa simplicité technique, il a pris une importance de plus
en plus grande dans le domaine du traitement et le stockage des données
informatiques. En effet, à l'inverse des modèles
hiérarchiques et des modèles en réseau, les relations
2. A l'origine, IMS a été conçu pour le
North American Rockwell dans le cadre du projet Apollo 11 qui avait pour
objectif d'envoyer l'homme sur la lune.
3. Le CODASYL (Conference on Data System Languages) est un
groupe d'utilisateurs et de fournisseurs de logiciels - dont IBM - qui fut
créé en 1959. Le Database Task Group (DBTG) en est un
sous-groupe.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 17
2.2. Évolution des modèles de bases de
données
manipulées par ce modèle sont des tableaux
à deux dimensions, avec lignes et colonnes, les informations
étant stockées à l'intersection de celles-ci. Le
modèle relationnel repose sur deux concepts fondamentaux : les domaines
de valeurs et les relations entre domaines. La puissance de ce modèle
réside non seulement dans sa simplicité technique, mais aussi
dans sa complétude et sa rigueur de mise en oeuvre. En effet, le
modèle relationnel est une variante de la théorie des ensembles
et des relations. Il revêt ainsi toute la rigueur des
mathématiques discrètes. En plus, ses structures sont suffisantes
pour représenter tout ce que les modèles concurrents pouvaient
offrir et bien plus.
Au fil des années, le modèle a connu de
profondes améliorations notamment en ce qui concerne la couverture
d'autres domaines (tels que les BD déductives, actives, les
données spatiales, temporelles etc.), l'adoption d'un langage standard
(le SQL) et enfin le développement de SGBD de plus en plus performants.
Oracle fut le premier SGBD construit sous ce modèle. De nombreux autres
ont suivi au fil des années. Les SGBDR sont aujourd'hui le modèle
le plus utilisé à travers le monde. Ils trouvent leurs
applications dans des domaines très variés.
Le modèle relationnel n'est cependant pas adapté
pour le développement d'applications utilisant les langages
orientés-objet comme C++, Java, Python etc. En effet, ces langages
traitent les informations en termes de classes alors que le modèle
relationnel stocke les données dans des tables. L'utilisation de ces
données en POO nécessite donc un mapping Objet/Relationnel qui
non seulement est couteux en développement mais ralentit
considérablement l'exécution des programmes. En plus de cela, le
modèle relationnel n'est pas très adapté pour la gestion
des données multimédia, qui, de nos jours deviennent de plus en
plus importantes. Une nouvelle génération de modèles vient
ainsi pallier ces manquements. Il s'agit des modèles de BD
Orientées-Objet.
2.2.4 L'ère post-relationnelle : Les BD objet
Les bases de données à objet apparaissent au
milieu des années 1980 pour pallier les insuffisances du modèle
relationnel notamment en ce qui concerne le stockage de données de type
complexe et l'intégration de langages orientés-objet dans les
applications de bases de données. Elles sont définies par Yamine
AÏT-AMEUR et Christophe GARION comme une « organisation
cohérente d'objets 4 persistants et partagée par des
utilisateurs concurrents ». Il ressort de cette définition que les
SGBD à objets manipulent non seulement les objets mais aussi et surtout
ils veillent à la persistance de ces objets. En effet, en POO, les
objets sont non persistants, c'est-à-dire que leur durée de vie
n'excède pas celle du programme qui les a créés. Le
schéma conceptuel d'une base de données objets est défini
par l'ensemble des classes et des associations décrivant la
réalité à modéliser. Suivant la technologie
utilisée, on peut distinguer deux approches de bases de
données
4. Un objet est une instance d'une classe elle-même
étant un type complexe défini par ses attributs et ses
méthodes
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 18
2.2. Évolution des modèles de bases de
données
objet : l'approche orientée-objet et l'approche
objet-relationnel.
Dans l'approche orientée-objet, les objets
représentent la base de la modélisation. On retrouve ici la
définition classique des objets en POO. Les objets qui partagent les
mêmes caractéristiques sont classifiés dans un même
type. Chaque objet possède un identifiant unique et il existe des
attributs permettant de définir des relations entre les objets. Les SGBD
orientés-objets sont dotés d'un langage ODL 5 pour la
définition des objets, d'un langage OML 6 pour la
manipulation des objets et d'un langage OQL 7 pour l'interrogation
des objets. Ces SGBD peuvent être mis en interface avec des langages de
POO come C++.
L'approche relationnelle-objet quant à elle est une
extension du modèle relationnel. Ce dernier étant basé sur
le langage SQL, la prise en compte des objets implique donc une extension de ce
langage en lui ajoutant une couche objet. Cette extension de SQL est connue
sous le nom de « norme SQL3 ». Cette extension réduit donc le
recours aux langages de POO dans l'écriture des programmes et
applications de bases de données. Le modèle objet-relationnel
apport une légère modification aux concepts fondamentaux du
modèle relationnel. Ainsi, on fait intervenir ici le concept de tables
typées similaire aux objets dans une BDOO et intégrant les
concepts de la POO tels que l'héritage, l'encapsulation etc. Les lignes
constituant ces tables typées possèdent des identifiants uniques
permettant la mise en place de relation entre ces tables. Parmi les SGBDOR, on
peut citer les géants Oracle et PostgreSQL.
2.2.5 Les défis contemporains: le business
intelligence et le Big Data
Aujourd'hui, les capacités de stockage sont quasi sans
limite et le volume de données produit chaque jour dans les
systèmes d'informations ne cesse de croître. En effet, selon IBM,
la quantité de données produite dans le monde tous les deux jours
est équivalente à celle qui a été
générée depuis le début de l'histoire jusqu'en
2003. Un autre fait marquant est qu'en 2012, 90% de toute la quantité de
données existante depuis l'avènement de l'histoire avait
été créée durant les deux années
précédentes. Les enjeux contemporains consistent donc à
tirer parti de cet immense stock d'informations pour fournir les indicateurs
pertinents à la prise une prise de décision fiable. Cependant,
face à cette vague importante d'informations, les modèles de
données classiques restent impuissants. De nouvelles technologies
viennent donc pallier ces insuffisances.
Le Business Intelligence encore appelé Informatique
Décisionnelle est définie comme l'ensemble des moyens permettant
de collecter, consolider modéliser et restituer les données
issues de sources
5. Object Definition Language
6. Object Manipulation Language
7. Object Query Language
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 19
2.3. Les méthodes d'analyse
variées au sein d'une même organisation en vue
d'offrir une aide à la décision. Ces informations sont
stockées sous forme agrégées dans une base de
données appelé entrepôt de donnes ou datawa-rehouse. Bill
IMNON, père de l'informatique décisionnelle définit un
entrepôt de données comme « une collection de données
thématiques, intégrées, non volatiles et
historisées pour la prise de décisions ». Ces bases de
données sont constituées de tables principales (les tables de
faits) reliées à des tables secondaires qui sont les dimensions
d'analyse. Les tables de faits peuvent prendre la forme de cubes (OLAP, ROLAP,
MOLAP) suivant les besoins et la réalité des organisations. Les
entrepôts de données sont généralement basés
sur le modèle relationnel.
Plus évoluée que le BI, le Big Data est un
ensemble de technologies permettant de traiter des informations non
structurées possédant les caractéristiques décrites
sous l'acronyme 3V. Il s'agit du volume très important de ces
données, de leur variété et de leur
vélocité. Cette dernière représente la
fréquence à laquelle les données sont
générées, capturées et partagées. Les bases
de données relationnelles classiques ne permettent pas de gérer
les volumes de données du Big Data. De nouveaux modèles de
représentation permettent de garantir les performances sur les
volumétries en jeu. Ces technologies, dites de Business Analytics and
Optimization (BAO) sont proposés les principaux acteurs de ce
marché que sont IBM, Google, Microsoft etc. Avec ce système les
requêtes sont séparées puis exécutées en
parallèles. Les résultats sont ensuite rassemblés et
récupérés. Ces volumes sont stockés dans le cloud
et sur des supercalculateurs. Bien que son avènement soit assez
récent et que les recherches sur le sujet continuent de nos jours, le
Big Data trouve déjà son application dans plusieurs domaines tels
que la recherche scientifique, la politique et surtout le secteur
privé.
2.3 Les méthodes d'analyse
Il existe plusieurs méthodes de conception. Les plus
importantes sont les méthodes systémiques à travers Merise
et les méthodes objet à travers UML.
2.3.1 La methode MERISE et le modèle
Entité-Association
Merise est le résultat des travaux menés par
Hubert TARDIEU dans les années 1970 et s'insère dans le sillage
du modèle relationnel. La méthode propose un cadre d'analyse qui
distingue nettement trois approches : communications, traitements et
données. Pour chacune de ces approches, Merise propose quatre niveaux
d'abstraction : les niveaux conceptuel, organisationnel, logique et physique.
Ce découpage donne ainsi naissance aux douze modèles qui
constituent Merise.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 20
2.3. Les méthodes d'analyse
Tableau 2.1 -- Les modèles de la
méthode Merise
|
Niveau
|
Communications
|
Traitements
|
Données
|
|
Conceptuel
|
MCC
|
MCT
|
MCD
|
|
Organisationnel
|
MOC
|
MOT
|
MOD
|
|
Logique
|
MLC
|
MLT
|
MLD
|
|
Physique
|
MPC
|
MPT
|
MPD
|
Source: Nos recherches
L'approche communications sert à décrire les
échanges de flux et d'informations au sein de l'organisation. Les
modèles de traitement comme leur nom l'indique ont pour objectif de
décrire les tâches effectuer à la réception ou pour
l'émission d'un flux d'informations. Enfin, l'approche données se
charge de la modélisation de ces informations en vue de leur stockage
sur un support informatique. Nous nous intéresserons donc ici à
cette dernière approche.
Les niveaux d'abstraction représentent chacune une
étape dans la conception d'un système d'information. Le niveau
conceptuel est l'étape où sont définies les fonctions
réalisées au sein de l'organisme. A ce niveau, la
représentation schématique adoptée par Merise est le
modèle Entité-Association. Ce modèle permet de
représenter le domaine d'application sous la forme d'un schéma
conceptuel composé de classes d'entités possédant des
propriétés propres à chacune d'elles. Ces entités
sont reliées entre elles par des associations servant à
définir les différentes relations et interactions entre elles.
Le niveau organisationnel quant à lui définit
l'organisation de ces fonctions et leur répartition entre les acteurs.
Le modèle logique représente la structure des données sans
faire référence au langage ou au SGBD à utiliser. Enfin le
niveau physique consiste juste à une implémentation du SI sur un
support informatique. La conception d'un SI se fait donc par succession de ces
étapes. On parle de cycle d'abstraction. Les résultats de chaque
étape doivent être clairement définis et la transition
d'une étape à la suivante est conditionnée par la
validation des résultats de l'étape précédente via
un contrôle formel de cohérence.
Méthode essentiellement française, Merise est
utilisée dans l'implémentation de nombreux systèmes
d'informations. On lui reproche néanmoins la lourdeur de sa mise en
oeuvre ainsi que son incapacité à modéliser des structures
utilisant des objets. Ces critiques sont progressivement prises en compte par
les améliorations apportées par la version Merise/2.
2.3.2 L'Unified Modeling Laguage (UML)
UML n'est pas une méthode d'analyse au sens propre du
terme. C'est un « langage de modélisation graphique et textuel
destiné à comprendre et décrire des besoins,
spécifier et documenter
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 21
2.4. Les Systèmes de Gestion de Bases de
Données (SGBD)
des systèmes, esquisser des architectures logicielles,
concevoir des solutions et communiquer des points de vue » (Pascal ROQUES
2008). UML unifie à la fois les notations et les concepts
orientés objet. Il peut cependant représenter aussi bien des
applications OO ou non.
La version récente d'UML (UML 2) propose treize types
de diagrammes, chacun d'eux étant dédié à la
représentation des concepts particuliers d'un système. Ces types
de diagrammes sont répartis en cinq vues. Chaque vue et chaque
modèle spécifie clairement un aspect particulier su
système
Tableau 2.2 -- Les diagrammes d'UML 2
Vues Diagrammes
Vue utilisateur Diagramme de cas d'utilisation
Diagramme de classes
Vue structurelle Diagramme d'objets
Diagramme de structures composites
Diagramme de packages
|
Vue comportementale
|
Diagramme de séquence Diagramme d'interaction Diagramme
d'état
Diagramme d'activités
Diagrammes de communications Diagramme temporel
|
Vue d'implémentation Diagramme de composants
Vue environnementale Diagramme de déploiement
Source: Nos recherches
Les diagrammes de classes UML décrivent les classes
d'objets, leurs propriétés ainsi que les relations entre ces
classes. Ils sont de plus en plus utilisés comme outil de
modélisation des bases de données. Ceci est dû au fait
qu'UML 2 reprend les concepts du modèle entité-association et
propose en plus des artifices pour améliorer la sémantique d'un
schéma conceptuel. De ce fait, cette notation est très
complète et puissante et peut s'adapter parfaitement à la
description d'une base de données.
2.4 Les Systèmes de Gestion de Bases de
Données (SGBD)
Les SGBD sont des logiciels spécialisés dans la
manipulation des structures de données. Ils s'adressent non seulement
aux concepteurs ayant des connaissances avérées en informatique
mais aussi aux utilisateurs non spécialisés. Dans cette section
nous proposons de passer succinctement en revue les fonctionnalités
supportées par ces logiciels pour garantir l'intégrité et
la fiabilité des données. Il sera aussi question dans
d'étudier les différentes architectures de fonctionnement des
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 22
2.4. Les Systèmes de Gestion de Bases de
Données (SGBD)
SGBD.
2.4.1 Les principales fonctions des SGBD
D'une manière générale, un SGBD doit pouvoir
garantir au minimum les fonctionnalités sui-
vantes :
~ Une description des données indépendante des
traitements
~ Une maintenance de la cohérence de données
~ Le recours à des langages non procéduraux,
interactifs et structurants
De façon spécifique, les SGBD devraient permettre
la concrétisation des aspects suivants :
Indépendance physique des données :
Le changement des modalités de stockage de l'informa-tion
n'implique pas de changements des programmes.
Indépendance logique des données :
L'évolution de la structure d'une partie des données
n'influe pas sur l'ensemble des données.
Manipulation des données par des
non-informaticiens: L'utilisateur n'a pas à savoir comment
l'information est stockée et calculée par la machine, mais juste
à pouvoir la rechercher et la mettre à jour à travers des
IHM.
Optimisation de l'accès aux données :
Les temps de réponse et de débits globaux sont
optimisés en fonctions des questions posées à la BD.
Contrôle de cohérence
(intégrité sémantique) des données : Le
SGBD doit assurer à tout instant que les données respectent les
règles d'intégrité qui leurs sont imposées.
Gestion des accès concurrentiels aux
données : Les données sont simultanément
consultables et modifiables.
Sécurité des données :
La confidentialité des données est assurée par
des systèmes d'authentifi-cation, de droits d'accès, de cryptage
des mots de passe, etc.
Sûreté des données : La
persistance des données, même en cas de panne, est assurée,
grâce typiquement à des sauvegardes et des journaux qui gardent
une trace persistante des opérations effectuées.
2.4.2 Architecture des SGBD
Il existe deux grandes familles de systèmes de gestion
de base de données de par leur fonctionnement : Les SGBD
centralisés et les SGBD client-serveur. Les premiers ont un
fonctionnement basique et le traitement de l'information se limite au niveau de
la seule machine ou même du fichier
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 23
2.4. Les Systèmes de Gestion de Bases de
Données (SGBD)
de la BD. Access de Microsoft est un exemple typique de SGBD
centralisé. Ils sont généralement utilisés pour des
applications bureautiques simples et ne supportent pas un volume
conséquent de données.
Les SGBD client-serveur pour leur part, sont constitués
d'un moteur de base de données et d'une (ou plusieurs) station(s)
cliente(s) qui ne sont pas forcément sur le même poste de travail.
Des requêtes sont envoyées aux moteurs de données par les
stations clientes qui reçoivent en retour une réponse. Cette
architecture, beaucoup plus élaborée que la
précédente renforce la sécurité des données
et permet un stockage massif. Ce type de SGBD est le plus utilisé dans
les applications faisant intervenir des bases de données. Oracle, MySQL,
SQL Server, PostgreSQL sont quelques exemples de SGBD client-serveur.
Graphique 2.1 -- Représentation de
l'architecture Client-Serveur
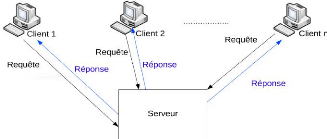
Source: Nos recherches
Conclusion partielle
En somme, l'importance des bases de données de nos
jours n'est plus à démontrer. Au fil des années, les
approches de modélisation des BD ont profondément
évolué avec l'apparition de nouveaux enjeux. Chacune d'elle
possédant ses avantages et ses limites, il conviendra aux concepteurs de
choisir l'approche la mieux adaptée compte tenu des
réalités du domaine d'application. Bien au-delà des
modèles théoriques, l'implémentation physique d'une base
de données nécessite une démarche à la fois
méthodique et très rigoureuse. Merise et UML sont les
méthodes d'analyse les plus utilisées afin de garantir une
cohérence des structures de données. Aujourd'hui, les
Systèmes de Gestion de Base de Données permettent la
création et la manipulation des BD. Ces systèmes peuvent
être centralisés ou non (client-serveur). De cette revue, la
question naturelle qui se pose est de savoir quelle est l'approche la plus
pertinente pour la réalisation de la présente étude.

Chapitre 3
Approche Méthodologique et sources de
données
Le présent chapitre a pour objectif de poser les bases
méthodologiques de notre étude. De façon
résumée, la réalisation de la présente étude
passe par l'atteinte des objectifs que nous pouvons décrire à
travers les deux points suivants :
1' Analyse du cadre socioéconomique du
Sénégal et élaboration d'un indicateur sectoriel;
1' Élaboration d'un système
informatisé constitué d'une BD socioéconomique
territorialisée (intégration de ressources SIG) et d'un tableau
de bord des projets.
Dans ce qui suit, nous spécifions pour chacun de ces
points, les objectifs spécifiques à atteindre.
Tableau 3.1 -- Aperçu du cahier de
charges
|
Etude statistique
|
Système informatisé
|
Objectif Général
Donner à l'USPITE une vue panoramique du paysage
socioéconomique au Sénégal
Mettre à la disposition de l'USPITE un système
informatique de suivi des projets de l'Etat
1' Étudier l'évolution des principaux
indicateurs depuis 2005 suivant les régions
Tâches spécifiques
1' Rechercher les corrélations entre les
différents indicateurs sociaux et établir une carte de
proximité des collectivités locales
1' Élaborer un indicateur annuel de
performances socioéconomiques
1' Élaborer une structure de données
prenant en charge la BD so-cioéconomique territorialisée et le
tableau de bord de suivi des projets
1' Mettre au point une interface servant de pont
entre les utilisateurs et la structure de données ainsi mise sen
place
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 24
Source: Nos travaux
Considérant le tableau ci-dessus, il sera d'abord
question dans ce chapitre, de présenter les méthodes
utilisées pour l'apprentissage statistique de liens entre indicateurs.
Il s'agira ensuite de décrire la méthodologie
d'élaboration de l'Indice Sectoriel de Performances (ISP). La
troisième section de ce chapitre sera consacrée à la
démarche d'implémentation des structures de données pour
le système constitué de la BD socioéconomique et du
tableau de bord de suivi des projets. La présentation de la
modélisation de l'interface fera l'objet de la cinquième section.
La dernière partie de ce chapitre sera réservée à
la présentation des sources de données.
3.1. Analyse exploratoire
|
1 E Im =
n j#k
|
d2(Zj, Zk)
= 1 E
n j#k
|
En i=1
|
(Zij - Zik)2
(3.3)
|
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 25
3.1 Analyse exploratoire
Pour la description des données, nous utilisons, en
plus des méthodes usuelles de statistiques descriptives, des
méthodes d'apprentissage non supervisé. Compte tenu de la
problématique et de la performance, nous retenons l'analyse en
composantes principales pour l'étude des corrélations entre les
variables et le réseau de KOHONEN pour la classification des
collectivités locales.
3.1.1 L'analyse en composantes principales
L'Analyse en Composantes Principales (ACP) cherche à
expliquer la structure des corrélations d'un ensemble de variables en
utilisant un plus petit ensemble de combinaisons linéaires de ces
dernières. Il s'agit donc de représenter l'information contenue
dans un tableau de m variables par un plus petit nombre de facteurs
(généralement 2). Par ses méthodes, l'ACP cherche à
établir une carte des variables en fonction de leurs corrélations
et une carte des individus en fonction de leur proximité. Dans cette
étude nous nous intéressons aux variables (les indicateurs
socioéconomiques).
3.1.1.1 Présentation théorique :
Soit X = (X1, ... , Xm)
une matrice n x m, chacun des Xi, i = 1, ... , n étant
ainsi un vecteur n x 1 décrivant une certaine caractéristique des
individus étudiés. Les composantes principales
représentent un nouveau système de coordonnées qui
s'obtient par maximisation de la variabilité (ou inertie) totale
contenue dans le tableau X. Avant de réaliser une ACP, il convient de
standardiser les variables de sorte à ce que leurs moyennes soient
nulles et leurs écart-types égales à l'unité. Cette
normalisation permet d'une part de centrer le nuage des individus autour de
l'individu moyen et d'autre part de restreindre le nuage N des variables au
cercle trigonométrique. Cette dernière restriction a le
mérite d'éliminer l'effet des unités des variables dans
l'analyse. Posons donc :
|
Xj - uj
Zj =
ój
|
,Vj = 1,...,m (3.1)
|
uj et ój étant
respectivement la moyenne et l'écart-type de la variable
Xj. L'espace Rn des variables est
muni de la distance euclidienne :
d2(Zj, Zk)
= En (Zij -
Zik)2 (3.2)
i=1
L'inertie totale du nuage des variables est donc donnée
par :
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 26
3.1. Analyse exploratoire
Nous recherchons un espace à k dimensions de
sorte que l'inertie du nuage projeté sur cet espace soit maximale. Le
premier axe factoriel est donc dirigé par le vecteur u1 tel
que
u1 = arg max(Im,
uá) (3.4)
uá
(Im,
uá) est l'inertie obtenue après
projection du nuage N sur le vecteur
uá. On montre que la solution
u1 de l'équation 3.4 est le vecteur propre associée
à la valeur propre la plus élevée A1 de la
matrice de covariances (1/n)Z'Z. Le second axe factoriel
est engendré par le vecteur associé à la deuxième
valeur propre la plus élevée A2 et ainsi de suite. Le
plan factoriel recherché est donc le sous-espace engendré par les
vecteurs propres associées aux valeurs propres A1,...,Ak
de la matrice (1/n)Z'Z.
Hk = V ect(u1,...,uk)
(3.5)
Notons d'une part que Aá
est l'inertie expliquée par l'axe
uá. D'autre part, pour á
=6 â, nous avons (uá,
uâ) = 0 et donc Im
= iá
Aá. Le nombre d'axes
factoriels k à retenir se détermine à l'aide de
la règle du coude de Catel et du pourcentage d'inertie expliquée
par le plan sous-jacent (Voir annexes).
3.1.1.2 Application de l'ACP
Dans notre étude, nous appliquons l'ACP sur l'ensemble
des régions du Sénégal décris par les indicateurs
sociaux étudiés. Pour cerner l'évolution de la structure
de corrélation entre ces indicateurs, l'analyse sera effectuée
à l'année 2005 et sur la période 2005-2012.
L'interprétation des résultats se fait à l'aide des aides
tels que le Cos2 (Voir Annexes).
3.1.2 La classification automatique par le réseau de
KOHONEN
Nous utilisons le réseau de KOHONEN 1 pour
la classification des régions en différentes classes au vu des
valeurs prises pour les indicateurs socioéconomiques
considérés. Cette méthode est l'une des plus
utilisées dans la littérature pour l'apprentissage statistique
non supervisé 2. L'objectif est de produire une carte de
proximité des individus étudiés (dans notre cas il s'agit
des régions) de sorte que les plus semblables soient le plus proche
possible. Cet algorithme d'apprentissage est une version
améliorée de la méthode des K-Means (Voir
[34]).
1. Encore appelé carte auto-organisée.
2. Pas de variable à prédire.
3.1. Analyse exploratoire
3.1.2.1 Présentation théorique :
Le réseau de KOHONEN fonctionne comme un réseau
de neurones à deux couches (entrée et sortie) sans variable
cible. Les noeuds de la couche d'entrée sont constitués par les
variables de classification et servent à présenter les individus.
Ceux de la couche de sortie sont disposés sur une grille ayant
généralement une forme rectangulaire. Chaque noeud
xk(k = 1, ... , n) d'entrée est
connecté à tous les noeuds (i,
j)i<N,j<M
de la carte via une pondération
Wijk. Le noeud qui sera retenu pour
représenter xk est le noeud
(i*, j*) tel que
|
(i*, j*) = arg min
i,j
|
n k=1
|
(xk -
Wijk)2 (3.6)
|
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 27
Celui-ci est appelé noeud gagnant. Après
détection du noeud gagnant, le réseau ajuste automatiquement les
poids des connections neuronales suivant la relation :
|
{
|
Wijk(t + 1) =
Wijk(t) + ç(t)
(xk - Wijk)
si (i,j) E
A(i*,j*)(t)
Wijk(t + 1) =
Wijk(t) si (i,j) E6
A(i*,j*)(t)
|
(3.7)
|
où
A(i*,j*)(t)
est le voisinage du noeud gagnant au temps t. Ce voisinage
décroit avec le temps, de sorte qu'à la fin de l'apprentissage
chaque noeud sera l'unique élément de son propre voisinage.
ç(t) est la fonction de voisinage qui contient une fonction de
taux d'apprentissage á(t) décroissante en fonction du
temps et qui détermine le taux d'adaptation des neurones situés
à l'intérieur de
A(i*,j*)(t).
Cette fonction est un moyen plus simple de stimuler les connexion
latérales entre les neurones. Généralement on se place
dans le cadre d'une fonction de voisinage gaussienne autour du neurone gagnant.
ç(t) s'exprime alors comme suit :
d2(Gij,
G*i,j)
ç(t) = á(t) exp L- 2ó(t)2
] (3.8)
d2(Gij,
G*i,j) désigne la
distance euclidienne entre le neurone gagnant et un autre neurone appartenant
au voisinage. L'encadré ci-dessous présente l'algorithme de
Kohonen dans son utilisation pratique.
3.2. Elaboration de l'ISP

(c) Modification de la taille du voisinage et du coefficient
d'apprentissage ç(t);
(d) t = t + 1; end
(1) Data: Entrée X =
(x1,...,xn)
(2) Initialisation des poids ùijk
avec de petites valeurs aléatoires;
(3) t = 1;
(4) while Tous les noeuds ne sont pas
représentés do
(a) Sélection du neurone le plus proche :
(c) Modification des poids pour le neurone
(i*,j*) et ses plus proches voisins
:
Encadré 1 : Algorithme de Kohonen
ùijk(t + 1) =
ùijk(t) + ç(t) (xk -
ùijk)
(i*, j*) = arg min
i,j
Xn k=1
(xk -
ùijk)2
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 28
3.1.2.2 Application :
Pour notre étude, nous considérons comme
variables d'entrée les couples indicateurs-années portant sur les
régions. Nous aurons donc en sortie une carte présentant la
proximité des régions sur toute la période d'étude
(1005-2012). Rappelons que pour l'utilisation d'un réseau de neurones,
les valeurs d'entrées doivent être normalisées de sorte
à être comprises entre 0 et 1. Pour chaque valeur de l'indicateur
social I(·) nous faisons correspondre la valeur normalisée
I'(·) donnée par
I(k) - Imin
I'(k) = (3.9)
Imax - Imin
k représente la région étudiée.
3.2 Elaboration de l'ISP
L'objet de cette section est de présenter la
démarche d'élaboration de l'Indice Sectoriel de Performances
(ISP) qui constituera une base de comparaisons entre collectivités
locales suivant les secteurs sociaux. l'ISP étant un indicateur
synthétique, il convient de recourir aux méthodes
factorielles.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 29
3.2. Elaboration de l'ISP
3.2.1 Les limites de l'analyse en composantes
principales
L'analyse en composantes principales est
généralement utilisée dans le calcul d'indicateurs
synthétiques à travers les coordonnées factorielles. En
effet, l'ACP effectuée sur plusieurs variables permet de recueillir les
valeurs propres ëá ainsi que les
coordonnées factorielles Gá(i) de
chaque individu i sur l'axe factoriel á. L'indicateur est ainsi
donné par
> á ëá
× Gá(i)
Ii = > (3.10)
á ëá
á variant jusqu'au nombre d'axes factoriels retenus.
Cet indicateur est très pertinent dans la mesure où les
données sont en coupe instantanée. Dès qu'intervient le
facteur temps, il lui devient difficile de rendre compte de la
réalité. En effet, il ne tient pas compte de l'aspect
autoregressif des variables. De plus, l'indicateur issu de l'ACP n'est pas
applicable aux données de panel. Spécifiquement, dans notre
étude, il s'agit de construire un indicateur annuel pour chaque
région du pays. Le cadre fournit par l'ACP nous permet jute d'avoir un
indicateur pour chaque région et pour une année donnée en
ne tenant pas compte des autocorrélations d'une année à
l'autre. Pour palier ces insuffisances, les modèles d'analyse
factorielle dynamique ont été développés et
permettent d'obtenir des indicateurs synthétiques mieux adaptés
aux données temporelles.
3.2.2 L'analyse factorielle dynamique
L'analyse factorielle dynamique a été introduite
par Geweke en 1977 [22] puis reprise par Sargent et Sims en 1977. C'est un
modèle permettant de résumer l'information de larges ensembles de
données temporelles par des variables inobservables appelées
facteurs tout en décrivant la structure des séries
étudiées. Ce type de modèle est utilisé pour
obtenir des indicateurs synthétiques de même fréquence que
les séries composites. Par exemple, Stock et Watson [49] utilisent l'AFD
pour la construction et la prévision d'un indicateur synthétique
à partir de données macroéconomiques. M. Scrati et G.
Arnisano [43] appliquent l'AFD à l'élaboration d'un indicateur du
marché du pétrole aux États-Unis et pour résumer le
climat des affaires dans l'industrie française, l'INSEE [7] calcule un
indice mensuel en se basant sur l'AFD. Dans chacun de ces cas, les
résultats se sont révélés concluants et les
prévisions étaient de bonne précision.
3.2.2.1 Cadre théorique de l'AFD
On considère que les données sur l'individu
étudié sont représentées par un vecteur
yjt où j = 1,...,J représente
l'indice des variables et t = 1,...,T représente le temps. Le
modèle présente yjt en fonction de p
facteurs fpt, commune aux séries et d'un
terme d'erreur ujt. Fpt et
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 30
3.2. Elaboration de l'ISP
ujt sont supposés suivre des
processus AR(1) de sorte que le modèle s'écrive :
|
{ yjt = a ·
fpt + ujt
fpt = b ·
fpt-1 + åt
upt = c ·
upt-1 + åt
|
(3.11)
|
Dans la formulation 3.11, a est une matrice (J
x p) de paramètres; b, une matrice (p x
p) des auto-corrélations des facteurs et c la matrice
(p x p) d'auto-corrélation des erreurs. L'estimation
de ces paramètres se fait par passage à la formulation
espace-état du modèle qui rend le calcul de la vraisemblance plus
aisé. À l'aide de cette représentation, il sera possible
d'utiliser le filtre de Kalman pour calculer la vraisemblance (Voir [31] pour
plus de précision sur les modèles espace-état).
3.2.2.2 Extension aux données de panel
Le modèle présenté ci-dessus
étudie un ensemble de variables temporelles pour un seul individu. Qu'en
est-t-il d'une spécification des données de panel comme dans le
cas de notre étude? Nikolaos Zirogiannis et Yorghos Tripodis [54]
proposent une généralisation du modèle d'analyse
factorielle dynamique pour répondre à cette interrogation. Il
utilisent ensuite les résultats pour le calcul d'un indice
synthétique annuel de performances pour la comparaison des
collectivités locales par rapport aux performances dans le secteur de
hydraulique.
Dans le cadre de cette extension, on considère
Yij,t comme l'ensemble des données
disponibles sur chacun des i = 1, ... , N observations et pour chacune
des j = 1, ... , J variables. t = 1, ... , T
représente toujours le temps. Nous adoptons les notations suivantes
:
(i) Yij est une matrice
(T x 1) des observations pour i et j
fixés;
(ii) Yt est une matrice (NJ x
1) des observations pour t fixé. Le modèle
s'écrit sous la forme suivante :
Yt = A ·
Ft + ít
ít ^-> ./V(0,D)
(3.12)
Ft = B ·
Ft-1 + çt
çt ^-> ./V(0, Q)
(3.13)
Dans cette approche, A est la matrice (NJ x
J) des paramètres ; B, une matrice (N x
N) des auto-corrélations des facteurs. Dans cette
représentation de type espace-état, la relation 3.12 est
l'équation de mesure et la relation 3.13 est l'équation
d'état (ou de transition). Par hypothèse, on pose
E(Ft ·
ít) = E(Ft ·
çt) = E(ít
· çt) = 0 (3.14)
L'estimation de ce modèle est plus délicate
à cause de la grande taille de la matrice des données
Yt. Les paramètres à estimer
étant les matrices A, B, D et Q, la
vraisemblance du modèle se met
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 31
3.2. Elaboration de l'ISP
sous la forme
L(A,B,D,Q,Y1,...,YT) =
YT f (Y1) ·
fY (Yt, A, B, D,
Q|It-1) (3.15)
t=2
où It-1
est la ó-algèbre des valeurs passées
(Y1,...,Yt-1). Les auteurs de cette
extension de l'analyse factorielle dynamique aux données de panel ont
introduit un algorithme d'estimation du modèle défini par les
équations 3.12 et 3.13. Celui-ci nommé Two-Cycle Conditional
Expectation-Maximization (2CCEM) algorithm procède à une
estimation par deux cycles d'itérations, le premier cycle consistant
à estimer les paramètres A et D et le second
permettant d'estimer les matrices B et Q. Les détails
sur l'algorithme 2CCEM peuvent être consultés dans [54].
3.2.2.3 Construction de l'ISP par AFD
Une fois l'estimation des paramètres achevée,
les facteurs Ft peuvent être bien
déterminés. L'indicateur sectoriel de performances est donc
l'espérance de ces facteurs communs, conditionnellement à
l'information disponible à la date t - 1.
ISP(t) = E(Ft|It)
(3.16)
Pour chaque secteur, il convient de bien choisir les variables
qui entrent dans la constitution de l'indice, autrement dit les variables de la
matrice Y . Pour notre étude, nous calculons l'ISP pour les
régions. Selon les besoins de l'USPITE, nous retenons les secteurs de
l'agriculture et de l'éducation (ISPA et ISPE) . Le tableau 3.2
résume les variables sélectionnées pour chacun de ces
secteurs selon la disponibilité et la pertinence. Pour finir,
l'indicateur obtenu sera normalisé de sorte à ce qu'il soit
compris entre 0 et 1 :
ISP(t)i -
ISP(t)min
ISP (t)norm =
(3.17)
ISP(t)max -
ISP(t)min
Notons que cette normalisation est susceptible d'introduire
des fluctuations importantes d'une année à l'autre pour une
même région. L'ISP doit donc être interprété
en terme de note relative d'une région par rapport aux autres et non en
terme absolu.
L'application de l'AFD exige que les séries en
entrée soient stationnaires. Au cas contraire une autre approche devra
être adoptée.
3.2.3 Approche par décomposition de la
variabilité totale
Alessando Federici et Andrea Mazzitelli [18] ont
proposé une forme de modélisation AFD non probabiliste pour
prendre en compte les données temporelles dans le cadre d'une ACP. Ils
appliquent
3. Notons que l'ISP peut être construit pour tous les
secteurs sociaux et même au niveau départemental
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 32
3.2. Elaboration de l'ISP
leur méthode pour construire un indicateur
synthétique à partir des données socioéconomiques
de l'OCDE. Considérant la matrice
d'entréeYij,t, on décompose
la variabilité totale S comme suit :
S = St + S*
(3.18)
T
où St représente la
matrice de la dispersion intra-années (variabilité intra),
modélisée par une ACP et S* T
représente la dispersion entre les années qui peut donc
être modélisée par une relation linéaire du type
z
·jt = aj
+ bj · t +
åjt, ?t = 1,...,T (3.19)
où les variables z découlent de la
standardisation de la matrice Yij,t.
L'indice synthétique peut être obtenu à partir de la
matrice S* T dans le cas où la
régression 3.19 donne des résultats significatifs pour chaque
région. Au cas contraire l'ISP est obtenu à partir d'une ACP sur
la matrice St. Cette dernière approche sera
utilisée ici compte tenu de la fluctuation des données (Voir les
graphiques B.1 et B.2). L'ISP est donc donné par :
i2k h=1 a' h
· St ·
ah
ISP (t) = (3.20)
trace(St)
où ah représente le
vecteur des coordonnées factorielles et k le nombre d'axes
considérés. Bien entendu l'ISP obtenu devra être
normalisé selon l'équation 3.17 de sorte à être
compris entre 0 et 1.
3.2.4 Sélection des variables d'étude
Dans cette étude, nous construisons l'ISP pour
l'agriculture (ISPA) et pour l'éducation (ISPE). Pour chacun de ces
secteurs, les variables considérées sont
représentées dans le tableau 3.2. Il s'agit essentiellement de
ratios permettant de mesurer l'efficience d'un aspect donné du secteur
considéré.
Tableau 3.2 -- Indicateurs sociaux retenus
pour le calcul de l'ISP suivant les secteurs
Secteurs sociaux Variables composites de l'indicateur
|
Agriculture
|
Rendement du mil Rendement du sorgho Rendement du maïs
Rendement de l'arachide Rendement du niebé Rendement du manioc
|
Ratio élèves/maîtres au primaire
Éducation Ratio élèves/classes au
primaire
Taux Brut se Pré-scolarisation Taux Brut de Scolarisation
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 33
3.3. Généralités sur la conception
du système
3.3 Généralités sur la conception
du système
3.3.1 Quel type de système?
Plusieurs travaux ont été réalisés
dans le cadre de la mise en place soit d'une base de données
socioéconomique, soit d'une base de données de suivi des projets.
Nous pouvons dans ce cadre citer les travaux de Sandrine Nguiakam qui ont
porté sur la « Conception d'une base de données
socio-économique des Etats de l'UEMOA [36] » et de Abdul Dosso
sur la « Mise en place d'un système d'information pour le suivi
des activités liées aux projets de santé à la DIPE
[14] ». Ces systèmes étaient basés sur le
modèle relationnel supporté par un SGBD centralisé
(Access). Cette approche, bien que simple d'utilisation et de mise en oeuvre
présente plusieurs inconvénients. En effet, elle ne permet pas un
accès concurrentiel aux données. Dans cette approche, une seule
machine a le contrôle sur le système rendant ainsi l'accès
distant impossible. En outre, la perte de données y est un risque
permanent 4 et les types de données pris en charge sont
limités 5.
Pour cette étude, nous proposons un système
commun englobant la BD socioéconomique et le tableau de bord de suivi
des projets. Ceci permet d'optimiser en ressources dans la mesure où
certaines entités sont communes aux deux sous-systèmes. Pour
palier les insuffisances de l'ap-proche précédente, ce
système reposera sur un modèle objet-relationnel mis en interface
avec une application Web, le tout reposant sur une architecture client-serveur
à 3 composantes 6 (Clients, serveur Web et serveur de
données. Voir Graphique 3.1). Ce choix se justifie. D'une part,
l'approche objet-relationnel permet la prise en charge de données
complexes (shapefiles, images, fichiers pdf etc.) devant être
sauvegardées par notre système et aussi l'automatisation de
certaines procédures via les déclencheurs (ou triggers). En
outre, la mise en place d'une interface web permet aux utilisateurs
d'accéder aux informations et d'effectuer des mises à jour via
une connexion internet ou un réseau local, ceci même en
n'étant pas physiquement présents à leur lieu de
travail.
Au vu de ce qui précède, la présente
étude consiste donc en l'élaboration d'une application web
permettant l'enregistrement, la mise à jour et la consultation de
données portant sur les indicateurs socioéconomiques du
Sénégal et sur les activités de suivi-évaluation
des projets de l'État. La section suivante présente la
démarche générale que nous utilisons pour la mise en place
de ce système.
4. Il suffit que le fichier Access soit altéré
suite à une mauvaise manipulation.
5. Impossibilité de stocker des données SIG par
exemple.
6. Cette structuration est encore connue sous le nom
d'architecture 3-tiers.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 34
3.3. Généralités sur la conception
du système
Graphique 3.1 -- Architecture globale du
système
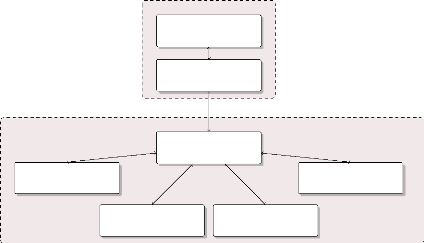
Station Cliente
Client1
Client2
Machine Serveur
Serveur BD (Post-greSQL/PostGIS)
Réseau (Local ou Internet)
Serveur Web (Apache)
Client3
Client4
Source: Nos travaux
3.3.2 Démarche générale de
conception
La première étape dans la conception de toute
application informatique est le recueil et l'analyse des besoins des
utilisateurs. Ces besoins s'expriment en termes de données et
d'applications (besoins fonctionnels). La conception du système se
divise ainsi en deux composantes: les données et l'IHM (Interface
Homme-Machine) dont la combinaison aboutit au système
opérationnel attendu par les utilisateurs. Il sera donc question dans
notre étude de procéder à la mise en place de ces deux
composantes en insistant à chaque étape sur les influences
réciproques qu'ils entretiennent 7. Notre démarche est
représentée par le graphique 3.2.
D'une part, l'implémentation de l'IHM commence par une
étape d'analyse fonctionnelle qui a pour objectif de définir les
interactions entre les utilisateurs et le système. En termes clair, il
s'agira ici de recueillir les fonctionnalités que doit proposer
l'application à concevoir. L'analyse fonctionnelle aboutira au
développement informatique des programmes et applications qui doivent
assurer ces fonctions. D'autre part, l'implémentation des structures de
données commence par les échanges avec les utilisateurs pour
aboutir à un modèle conceptuel de données (MCD). De ce MCD
découlera un modèle logique (MLD) puis un modèle physique
de données (MPD). Ces deux sous-systèmes (données et IHM),
une fois mis en place seront combinés dans une dernière
étape d'implémentation des transactions dont l'objectif est de
relier les données aux applications. Les sections suivantes
7. En effet, les besoins en données conditionnent
l'ossature de l'IHM. Inversement, le besoin fonctionnel joue un rôle
important dans la structuration des données.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 35
3.4. Démarche d'implémentation des
structures de données
Graphique 3.2 -- Démarche
générale d'implémentation du système
Système
IHM
Étape 8
Système Opérationnel
Étape 2
Analyse Fonctionnelle
Étape 7
Implémentation des
Transactions
Étape 4
Conception des programmes et
Applications
Étape 1
Recueil et Analyse des
bésoins
Données
Application Web (HTML, CSS, JavaScript, PHP, SQL)
Étape 3
Analyse conceptuelle des
données
Étape 6
Conception Physique
Étape 5
Conception Logique
Déploiment et utilisation du système
Discussions et échanges avec les commanditaires
Modèle Conceptuel de Données (MCD)
Modèle Logique de Données (MLD)
MPD (PostgreSQL/PostGIS)
Source: Nos travaux
présentent les méthodes d'élaboration des
structures de données et de l'IHM.
3.4 Démarche d'implémentation des
structures de données
Comme nous l'avons vu à la section 2.3, il existe deux
formalismes généralement utilisés pour la
représentation schématique des phases de conception d'une BD.
Dans la présente étude, nous utiliserons le formalisme UML. Ce
choix se justifie d'une part, par le souci d'harmonisation des notations dans
notre document. En effet, nous aurons à utiliser plusieurs diagrammes de
types UML parmi ceux présentés à la sous-section 2.3.2
pour présenter des réalités non prises en compte par
Merise (Voir [45]). D'autre part, les diagrammes de classes UML
présentent des extensions les rendant mieux adaptés pour la
modélisation de BDOR que les diagrammes EA de Merise.
3.4.1 Le niveau conceptuel
Le MCD cherche à représenter une vue abstraite
de la base de données à travers des représentations
graphiques indépendantes du support informatique à utiliser.
Cette étape de la conception
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 36
3.4. Démarche d'implémentation des
structures de données
est très importante dans la mesure où elle
conditionne la structure de la base de données qui sera déduite
des différents éléments du schéma conceptuel :
entités (ou classes), associations et contraintes. En UML, nous
parlerons de classes et d'associoations entre ces classes. Une classe est une
description abstraite d'un ensemble d'objets de même structure et de
même comportement extraits du monde à modéliser. C'est
l'équivalent de l'entité dans un formalisme de type EA.
3.4.1.1 Définition des concepts
utilisés
La modélisation en UML repose sur un ensemble de
concepts. Dans ce qui suit, nous présentons ceux qui seront
utilisés dans le cadre de notre étude. Soient A et B deux
classes.
Attribut : donnée
élémentaire servant à caractériser les classes et
les relations. Association : l'association permet de relier
une classe à plusieurs autres classes.
Multiplicité : chaque
extrémité d'une association porte une indication de
multiplicité. Elle exprime le nombre minimum et maximum d'objets d'une
classe qui peuvent être reliés à des objets d'une autre
classe. Ce nombre est soit 0, 1 ou N. Ainsi, on a les multiplicités
suivantes en UML : (0,...,1), (0,...,N), (1,...,1), (1,...,N) et (N,...,N).
Ici, les contraintes de multiplicités d'une entité donnée
sont lues à partir des autres entités de l'association. Sur le
schéma ci dessous par exemple, un élément de la classe A
peut être relié à 0 ou plusieurs éléments de
la classe B (l'astérisque désigne N).

.
Classe-association : cette notion,
spécifique à UML permet d'associer des attributs à une
association. L'association entre les classes 'région' et 'indicateur'
peut par exemple avoir l'année comme attribut.
Identifiant : L'identifiant d'une classe est
un attribut (ou groupe d'attributs) qui permet de définir chaque objet
de cette classe de façon unique.
Le MCD provient d'une certaine organisation des
éléments ci-dessus de sorte à bien représenter les
besoins du domaine d'application. Les multiplicités sont très
importantes à cette étape puisqu'elles déterminent la
nature des associations entre les classes.
3.4.1.2 Les différents types d'associations
Suivant les multiplicités, on distingue trois types
d'associations :
Les associations un-à-un : On utilise
une association un-à-un entre les classes A et B si tout objet de A est
en rapport au plus avec un objet de B et inversement.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 37
3.4. Démarche d'implémentation des
structures de données
Les associations un-à-plusieurs : On
utilise une association un-à-plusieurs entre les classes A et B si un
objet de A peut être en rapport avec plusieurs objets de B et pas
inversement.
Les associations plusieurs-à-plusieurs :
On utilise une association plusieurs-à-plusieurs entre les
classes A et B si un objet de A peut être en rapport avec plusieurs
objets de B et inversement.
Le tableau 3.3 ci-dessous présente les types
d'associations en correspondant aux différentes multiplicités.
Tableau 3.3 -- Multiplicités et types
d'associations
Types d'associations Multiplicités
|
Un-à-un (1, 1)
|
(0,...,1) -- (0,...,1)
(0,...,1) -- (1,...,1)
(1,...,1) -- (1,...,1)
|
|
Un-à-Plusieurs (1, n)
|
(0,...,1) -- (0,..., *) (0,...,1) -- (1,..., *) (1,...,1) --
(0,..., *) (1,...,1) -- (1,..., *)
|
|
Plusieurs-à-Plusieurs (n, n)
|
(0,...,*) -- (0,..., *) (0,...,*) -- (1,..., *) (1,...,*) --
(0,..., *) (1,...,*) -- (1,..., *)
|
Source: Nos recherches
3.4.1.3 Règles de validation du modèle
conceptuel
Un MCD cohérent doit respecter un certain nombre de
règles. Celles-ci permettent de limiter considérablement les
risques d'erreurs de modélisation lourdes de conséquences au
niveau de la base de données.
Attribut élémentaire : Tous les
attributs sont élémentaires en ce sens qu'ils doivent être
non décomposables;
Non-redondance : Un attribut doit
apparaître une seule fois dans le diagramme, soit au sein d'une classe,
soit dans une ou classe-association.
Hormis le caractère élémentaire des
attributs et la non redondance, les MCD doivent vérifier un certain
nombre de contraintes.
Contrainte de partition : Toutes les
occurrences d'une classe participent à l'une des deux associations, mais
pas aux deux, ni à aucune des deux;
Contrainte d'exclusivité : Toutes les
occurrences d'une classe peuvent participer à l'une des deux
associations, mais pas aux deux à la fois;
3.4. Démarche d'implémentation des
structures de données
Contrainte de totalité : Toutes les
occurrences d'une classe participent au moins à une association;
Contrainte d'inclusion : Toutes les
occurrences d'une association doivent être incluses dans les occurrences
d'une autre association ;
Contrainte de simultanéité :
Entre plusieurs associations, toute occurrence d'une classe
liée à une association participe également aux autres.
On distingue aussi les règles de normalisation qui
reposent sur les propriétés des dépendances
fonctionnelles. Par définition, un attribut b dépend
fonctionnellement d'un attribut a si à une valeur de a correspond au
plus une valeur de b.
Première Forme Normale : Chaque attribut
d'une classe, d'une association ou d'une classe-association possède au
plus une seule valeur à un instant donné. Cette normalisation ne
sera pas faite dans notre cas puisque pour BD objet-relationnelle, un attribut
est susceptible d'avoir plusieurs valeurs 8 ;
Deuxième Forme Normale : Chaque attribut
d'une classe doit dépendre fonctionnellement de l'identifiant de la
classe. Chaque attribut d'une classe-association doit dépendre
simultanément des identifiants des classes connectées à la
classe-association ;
Troisième Forme Normale : Chaque attribut
doit dépendre d'un identifiant dans le cas d'une
classe, ou de plusieurs identifiants dans le cas d'une
classe-association et non d'un autre attribut voisin, lui-même
dépendant d'un ou de plusieurs identifiants;
La Forme Normale de Boyce Codd : Aucun
attribut d'une classe-association ne doit être en dépendance avec
un identifiant d'une des classes connectée à l'association.
De façon pratique, pour l'élaboration du MCD,
nous procédons par les étapes suivantes comme le propose
Christian SOUTOU ([45]) :

(1) Établir la liste des classes;
(2) Déterminer les attributs de chaque classe en
choisissant un identifiant;
(3) Établir les relations entre les différentes
classes;
(4) Déterminer les attributs de chaque relation et
définir les multiplicités;
(5) Mettre en place les contraintes et vérifier le
modèle par la normalisation.
Encadré 2 : Les étapes de la construction
du MCD
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 38
8. Par exemple l'adresse d'une maison peut être
constituée du numéro de la rue, de la villa etc.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 39
3.5. Démarche d'implémentation de
l'IHM
3.4.2 Le passage au niveau logique
Le modèle logique de données (MLD) est la
description de l'architecture des données telles qu'elles seront
représentées dans la pratique, indépendamment du support
informatique. Le MLD découle directement du MCD par application d'un
certain nombre de règles :
Règle 1 : Chaque classe, hormis les
classes-associations, devient une table du schéma. L'identifiant de la
classe constituera alors la clé primaire de la table.
Règle 2 : Pour les associations
un-à-plusieurs, la clé primaire de la classe père
9 migre vers la classe fils où elle devient une clé
étrangère.
Règle 3 : Les associations
plusieurs-à-plusieurs deviennent des tables dont la clé primaire
est constituée des deux clés étrangères provenant
de chacune des classes de l'association.
Règle 4 : Une association binaire de
type un-à-un est traduite comme une telle quel. Cependant, la clé
étrangère se voit imposer une contrainte d'unicité en plus
d'une éventuelle contrainte de non vacuité (cette contrainte
d'unicité impose à la colonne correspondante de ne prendre que
des valeurs distinctes).
Les classes associations : Elles deviennent
des tables dont la clé est constituée des identifiants des
classes en relation.
3.4.3 Le niveau physique
Le modèle physique est simplement obtenu par la
transcription du modèle logique en langage SQL. Le SGBD utilisé
pour notre étude est PostgreSQL qui, en plus d'être gratuit
propose des extensions pour la prise en compte des données complexes
intervenant dans les BD objet-relationnelles.
3.5 Démarche d'implémentation de
l'IHM
Les utilisateurs du futur système n'étant pas
forcément des informaticiens, il convient de concevoir une Interface
Homme Machine afin de faciliter les interactions avec le système. De
plus, cette IHM prendra en charge des fonctionnalités non
proposées par le SGBD comme la réalisation de graphiques, de
cartes et constituera un outil d'échange entre l'USPITE et le monde
extérieur (décideurs et public).
9. Celle dont les éléments peuvent être mis
en relation avec plusieurs éléments de l'autre classe dite
fils.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 40
3.5. Démarche d'implémentation de
l'IHM
3.5.1 Généralités sur
l'application
L'IHM de notre étude est une application WEB
basée sur le design pattern Model View Controller (MVC). Ce choix n'est
pas fortuit. D'une part une application web est plus flexible et accessible
à n'importe quel utilisateur, quelle que soit sa position
géographique, tant qu'il est connecté au réseau internet
(ou plus généralement le réseau sur lequel se trouve la
machine hôte de l'application). D'autre part, le design pattern MVC est
une manière de présenter les codes de sorte à
séparer les couches constituant l'application. Ceci permet de travailler
sur chacune d'elles indépendamment des autres. Cette technique est
très répandue dans le monde du développement web. Certains
auteurs comme [40] en font d'ailleurs la méthodologie centrale pour
l'écriture de leurs livres.
Le graphique 3.3 présente le fonctionnement du futur
site web. Les utilisateurs, représentés par la station cliente
accèdent au systèmes via des navigateurs (Internet Explorer,
Google Chrome, Firefox etc.) et un réseau (internet ou local). Ces
utilisateurs transmettent des requêtes qui sont
interprétées par le serveur d'application et transmises au moteur
de données. La réponse de ce dernier est ensuite
interprétée toujours par le serveur d'applications et transmise
à la station cliente (utilisateur).
Graphique 3.3 -- Fonctionnement du site web

Station cliente
Requêtes
Réponses

Requêtes
Réponses
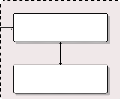
Informations
Serveur
Fichiers/Données
Programme Serveur
Réseau
Source: Nos recherches
Différents langages de programmation sont
utilisés pour la réalisation d'un tel système. Dans notre
étude, HTML et CSS seront utilisés respectivement pour la gestion
des contenus et de la forme du texte. Nous utiliserons PHP pour la
communication entre le serveur d'applications et le serveur de bases de
données. SQL est utilisé pour la manipulation des données
et JavaScript servira à la mise en place de contrôles pour
garantir la cohérence du système.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 41
3.5. Démarche d'implémentation de
l'IHM
3.5.2 Organisation du code : le design pattern MVC
3.5.2.1 Fonctionnement du MVC
Dans le cadre d'une architecture MVC, les données sont
gérées par le modèle, la présentation par la vue et
l'ensemble est coordonné par les contrôleurs. Le graphe 3.4
présente les interactions entre les composantes. Le contrôleur
reçoit la requête provenant du client et l'analyse puis la
transmet ensuite au modèle. Il récupère ensuite les
informations fournies par le modèle et les transmet à la vue pour
présentation à l'utilisateur. Dans la pratique, le
contrôleur frontal est représenté par un fichier
index.php.
Graphique 3.4 -- Présentation du design
pattern MVC
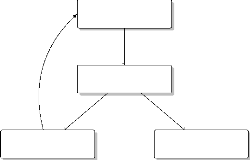
Réponse
Vue
Station cliente
Contrôleur
Requette
Modèle
Source: Nos recherches
3.5.2.2 Rôle des composantes
Le modèle : Le modèle
représente le coeur de l'application : traitements des données,
interactions avec la base de données, etc. Il décrit les
données manipulées par l'application. Il regroupe la gestion de
ces données et est responsable de leur intégrité. La base
de données sera l'un de ses composants. Le modèle comporte des
méthodes standards pour mettre à jour ces données
(insertion, suppression, changement de valeur). Il offre aussi des
méthodes pour récupérer ces données.
La vue : Sa première tâche est
de présenter les résultats renvoyés par le modèle.
Sa seconde tâche est de recevoir les requêtes de la part de
l'utilisateur. Celles-ci sont envoyées au contrôleur. La vue
n'effectue pas de traitement, affiche juste les résultats des
traitements effectués par le modèle et interagit avec
l'utilisateur.
Le contrôleur : Le contrôleur
prend en charge la gestion des événements de synchronisation pour
mettre à jour la vue ou le modèle. Il reçoit toutes les
requêtes de l'utilisateur et enclenche
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 42
3.6. Les sources de données
les actions à effectuer. Si une action nécessite
un changement des données, le contrôleur demande la modification
des données au modèle, et ce dernier notifie la vue que les
données ont changé pour qu'elle se mette à jour. Il
analyse la requête du client et se contente d'appeler le modèle
adéquat et de renvoyer la vue correspondant à la demande.
3.6 Les sources de données
Les données utilisées dans cette étude
sont des données administratives. Elles proviennent ma-joritairement des
Services Régionaux de la Statistique et de la Démographie ainsi
que des situations économiques et sociales des régions depuis
l'année 2005. Certaines données proviennent du Ministère
de l'éducation. Afin de mener à bien l'étude, ces
données ont été harmonisées et les indicateurs
utilisés dans ce rapport y ont été extraits pour chaque
année et pour chaque collectivité locale. Quelques valeurs
manquantes à certaines périodes ont été
imputées par la moyenne les valeurs aux années
précédente et suivante :
I(t) = I(t - 1) +
I(t + 1)
d (3.21)
2
|
|
|
Cette méthode se justifie par le fait que
|
I(t), étant à mi-chemin des
observations I(t - 1) et
|
I(t + 1) permet un certain lissage de a
série concernée et une moindre perte d'informations. Pour finir,
notons que les régions de Kaffrine, Kédougou et Sédhiou ne
disposent de données que pour les années 2010, 2011 et 2012. Nos
résultats sur ces régions se limitent donc à ces trois
années.
Conclusion partielle
En résumé, la présente étude est
constituée d'une première partie qui vise l'analyse du cadre
socioéconomique du Sénégal et d'une seconde partie dont le
but est de mettre à la disposition de l'USPITE un système
informatique. Les objectifs de ce système sont, d'une part, de doter
l'unité d'une BD socioéconomique du Sénégal et
d'autre part, de permettre la gestion des projets et programmes de l'Etat. Dans
la première partie de l'étude, l'analyse en composantes
principales et les réseaux de KOHONEN permettront d'établir une
carte des indicateurs en fonction de leur corrélations et une carte des
régions en fonction de leur proximité. Il sera ensuite question
d'élaborer un Indice Sectoriel de Performance (ISP) qui se fondera sur
une analyse factorielle dynamique. L'outil informatique faisant l'objet de la
seconde partie de l'étude est une application WEB de type MVC qui
interagira avec une BD objet-relationnelle (PostgreSQL/PostGIS). Cette BD sera
obtenue après élaboration d'un modèle conceptuel qui sera
traduit en modèle logique puis en modèle physique via le langage
SQL. Le cadre méthodologique de l'étude étant
défini, le chapitre suivant présente les résultats obtenus
de l'analyse statistique.

Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page 43
Chapitre 4
Analyse du cadre socioéconomique du
Sénégal
Comme annoncé dans les chapitres
précédents, une partie de cette étude sera
réservée à l'ana-lyse du cadre socioéconomique du
Sénégal. L'idéal aurait été que tous les
secteurs sociaux soient abordés. Cependant, compte tenu des contraintes
de temps et de données, nous abordons les secteurs essentiels de
l'agriculture et de l'éducation. Un panier d'indicateurs retenus pour
chacun de ces secteurs servira de base pour l'étude. Celle-ci
s'étale sur la période 2005 à 2012. Il sera d'abord
question d'étudier l'évolution ces principaux indicateurs
(agriculture et éducation) entre les années 2005 et 2012. La
seconde section sera consacrée à l'étude des
corrélations entre les indicateurs et de la proximité entre les
régions. La dernière section sera consacrée à
l'étude de l'ISP pour l'agriculture puis l'éducation.
4.1 Évolution des indicateurs entre 2005 et
2012
Dans cette section, nous comparons les valeurs des indicateurs
entre les années 2005 et 2012. Cette comparaison permettra de rendre
compte de l'écart de productivité pour l'agriculture et de la
disponibilité des ressources (humaines et matérielles) dans le
domaine de l'éducation pour chaque région. Signalons que les
régions de Kaffrine, Kédougou et Sédhiou n'étant
créées qu'en 2011 ne disposent pas de données pour
2005.
4.1.1 Agriculture
L'analyse du secteur agricole se fera à travers les
rendements des différentes cultures essentielles du pays. Le rendement
d'un produit agricole donné est le rapport de la production totale (en
kilogrammes) sur la superficie de terre consacrée à ce produit
(en hectares). Le rendement permet donc de mesurer l'efficacité du
système agricole par rapport à une culture donnée. Nous
analysons ici les cas du mil (culture vivrière) et de l'arachide
(culture de rente).
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 44
4.1. Évolution des indicateurs entre 2005 et
2012
4.1.1.1 Le rendement du mil
Le mil est avec le maïs et le sorgho les cultures
vivrières les plus importantes au Sénégal. Il est
très utilisé par les ménages pour la préparation de
plats locaux (généralement pour le diner en famille). La tendance
générale est à la baisse en ce qui concerne les rendements
du mil dans les régions. Comme le montre le graphique 4.1, le rendement
du mil a considérablement baissé pour la plupart des
régions entre 2005 et 2012. Cette situation pourrait s'expliquer par la
montée de la sécheresse durant ces dernières
années. En effet, le manque de pluie est davantage marqué
d'année en année. A cela s'ajoute la mauvaise gestion des
ressources d'eau de la part des paysans ainsi que la dégradation des
ressources productives (sols et intrants). Malgré ces difficultés
du secteur du mil, certaines régions sont su réaliser un
écart positif entre ces deux années. Il s'agit notamment de
Dakar, Kaolack, Diourbel, Louga et Matam.
Graphique 4.1 -- Évolution du rendement
de mil entre 2005 et 2012
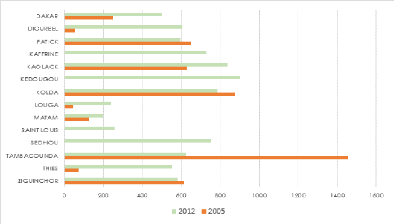
Source : ANSD, Nos calculs
4.1.1.2 Le rendement de l'arachide
L'arachide et le coton sont les principales cultures de rente
des paysans sénégalais. Du fait de la non disponibilité de
données pour toutes les régions, nous étudions le cas de
l'arachide. Cette culture est très développée dans le
pays, notamment dans le « bassin arachidier » (correspondant
aux régions administratives de Kaolack et Fatick). Ces dernières
années, le rendement de l'arachide a connu une tendance à la
baisse du fait de d'un contexte international défavorable (prix de
l'arachide ). Ainsi, entre 2005 et 2012, l'écart de rendement est
négatif pour la plupart des régions. Cet écart est
d'autant plus marqué dans les régions du Sine Saloum où
l'arachide demeure cependant
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 45
4.1. Évolution des indicateurs entre 2005 et
2012
la principale culture de rente. Les projets de l'État
en matière de développement de la culture d'arachide doivent donc
être orientés prioritairement vers cette zone afin de redonner
tout son sens au nom « bassin arachidier » et d'avoir ainsi
un pôle de production d'arachide pour le pays.
Graphique 4.2 -- Évolution du rendement
d'arachide entre 2005 et 2012
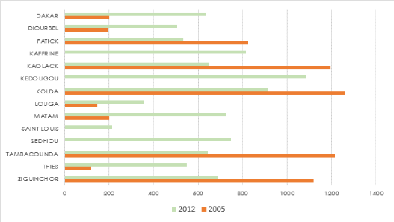
Source : ANSD, Noas calculs
4.1.2 Éducation
Tout comme pour l'agriculture, le développement de
l'éducation dans les pays africains revêt une importance capitale.
En effet, aucun pays ne peut viser l'émergence sans une ressource
humaine qualifiée et dont les aptitudes répondent aux besoins de
développement dudit pays sans accorder une place de choix à
l'éducation dans la mise en oeuvre des politiques. Nous étudions
ici l'évolution de la couverture des besoins par les ressources
allouées à l'éducation à travers les ratios
élèves/classes et élèves/maîtres au
primaire.
4.1.2.1 Le ratio élèves sur salles de
classes au primaire
Le ratio élèves sur salles de classes donne en
moyenne le nombre d'élèves par classe. Il fournit une information
très intéressante sur les besoins en termes de bâtiments
scolaires dans une collectivité locale donnée. Ainsi, cet
indicateur permet d'orienter les politiques de construction de salles de
classes vers les collectivités locales dont la valeur du ratio est la
plus élevée. D'une manière générale, ce
ratio est en baisse considérable pour la plupart des régions.
L'écart marqué entre les valeurs de 2005 et 2012 est d'autant
plus important pour les régions de Dakar, Thiès, Kolda, Kaolack
et Ziguinchor. Cette situation résulte sans doute de l'augmentation de
la population scolarisable
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 46
4.1. Évolution des indicateurs entre 2005 et
2012
surcompensée la mise en oeuvre des différents
projets de construction de bâtiments scolaires. Notons aussi que dans le
public, les infrastructures sont vieillissantes voire hors d'usage. Ceci
pourrait diminuer les capacités d'accueil pour la jeune
génération d'élèves.
Graphique 4.3 -- Évolution du ratio
Élèves/Classes entre 2005 et 2012
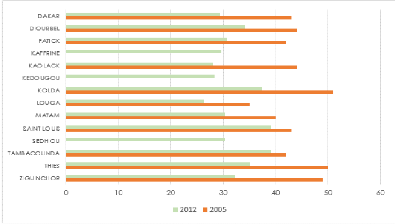
Source : ANSD & Ministère de l'éducation,
Nos calculs
4.1.2.2 Le ratio élèves sur maîtres
au primaire
Ici, il est question de mesurer le nombre moyen
d'élèves pris en charge par un enseignant au primaire. Ceci
permet de voir quelle collectivité locale (région ou
département) est prioritaire en matière de formation et
d'affectation d'enseignants. La tendance de cet indicateur est a la baisse pour
la période considérée dans toutes les régions
exceptée Dakar. Notons par ailleurs que l'écart observé
est beaucoup plus marqué pour la région de Dakar. Ceci
résulte sans doute de l'augmentation de la population de la capitale
sénégalaise dû à une forte natalité et
à un exode rural important. Il est donc urgent qu'une politique de
déconcentration soit mise en oeuvre pour palier cette hausse du ratio.
Aussi, il faudra former et affecter plus d'enseignants dans les écoles
primaires de la région.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 47
4.2. Analyse exploratoire
Graphique 4.4 -- Évolution du ratio
Élèves/Maîtres entre 2005 et 2012
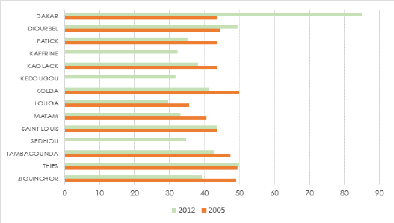
Source : ANSD & Ministère de l'éducation,
Nos calculs
4.2 Analyse exploratoire
4.2.1 Structure des corrélations entre les
indicateurs
Pour chaque secteur, nous faisons une analyse en 2005 puis une
analyse sur la période 2005 - 2012. Cette dernière se fait en
considérant pour chaque indicateur les couples
région-année comme individus statistiques.
4.2.1.1 Agriculture
Dans l'agriculture, nous étudions les corrélations
entre les rendements des différentes cultures principales. Les
données dont nous disposons se rapportent aux cultures suivantes: mil
(agric_01), sorgho (agric_02), maïs (agric_03), arachide (agric_04),
niebé (agric_05) et manioc (agric_06). Nous étudions dans un
premier temps les corrélations à l'année 2005 (nuage de
gauche) puis dans un second temps la structure des corrélations sur la
période considérée (nuage de droite).
En 2005, nous pouvons remarquer que sur l'ensemble des
régions tous les rendements sont positivement corrélés au
premier axe factoriel à l'exception du rendement du manioc. Cette
corrélation est d'autant plus importante pour le mil, l'arachide et le
niebé. Ceci se justifie puisque la plupart des paysans consacre la
même parcelle pour ces deux cultures voisines. Sur toute la
période 2005 à 2012, la structure des corrélations n'est
pas altérée. En effet, le rendement du mil
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 48
4.2. Analyse exploratoire
Graphique 4.5 -- Corrélations des
indicateurs de l'agriculture entre 2005 et 2012
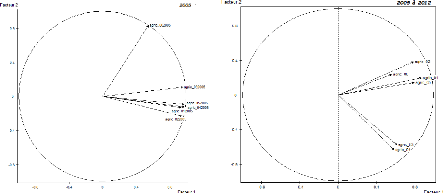
Source : ANSD, Nos calculs
reste positivement corrélé avec celui du
niebé. Le maïs et l'arachide évoluent aussi dans le
même sens. Ces résultats signifient que toute politique mise en
oeuvre pour le développement du mil par exemple sera favorable au
développement du niebé et vice versa. Il en est de même
pour le maïs et l'arachide.
4.2.1.2 Éducation
Les indicateurs de l'éducation que nous
considérons ici sont les deux ratios étudiés plus haut en
plus des taux brut de scolarisation et de pré-scolarisation (TBS et
TBPS). Que se soit en début de période ou tout au long de
celle-ci, l'analyse montre que les ratios élèves/classes et
élèves/maître sont positivement corrélés
(conformément à l'analyse descriptive effectuée plus haut)
d'une part et que d'autre part, le TBS est positivement corrélé
avec le TBPS.
Cette structure s'explique simplement par le fait que le
nombre d'enseignants augmente naturellement avec le nombre de salles de classes
d'une part et que d'autre part, l'entrée au primaire est
conditionnée par l'entrée au préscolaire. Toute politique
visant à améliorer d'un de ces indicateurs devra donc mettre en
oeuvre les ressources pour améliorer l'indicateur qui lui est
corrélé. Par exemple, un projet de construction de salles de
classes supplémentaires dans une localité doit disposer de
ressources pour recruter des enseignants supplémentaires.
4.2.2 Étude de la proximité des
régions
Ici, l'analyse consistera à établir une carte de
proximité des régions en utilisant le réseau de Kohonen
(Voir sous-section 3.1.2). Nous optons pour cette méthode à cause
de la faible représen-
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 49
4.2. Analyse exploratoire
Graphique 4.6 -- Corrélations des
indicateurs de l'éducation entre 2005 et 2011
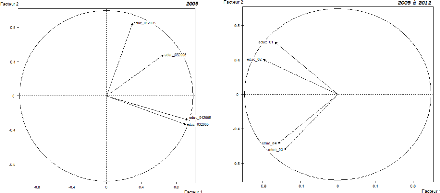
Source : ANSD & Ministère de l'éducation,
Nos calculs
tativité des variables sur les axes factoriels dans
l'analyse en composantes principales. Pour cette étude, nous
considérons comme variables d'entrée les couples
indicateurs-années pour chaque région.
4.2.2.1 Agriculture
En termes de performances agricoles, l'étude nous
permet de classer les régions en trois groupes comme indiqué sur
le graphique 4.7. En premier lieu, nous avons les régions à fort
potentiel agricole constituées du bassin arachidier et des autres
régions du sud (Fatick, Kaolack Ziguinchor, Kolda et Tabmacounda).
Celles-ci jouissent de conditions pluviométriques favorables au
développement des cultures et disposent aussi de très bonnes
techniques culturales. Elles pourraient, avec l'appui des autorités,
constituer un pôle agricole pour le pays. En second lieu, nous
distinguons les régions à potentiel agricole moyen. Il s'agit de
Dakar, Diourbel, Thies et Louga. Le dernier groupe de régions agricoles
est constitué essentiellement des nouvelles régions
(Sédhiou, Kaffrine et kédougou) en plus de la région de
Matam. Les efforts en termes d'appui au secteur agricole (fourniture de
machines, formation des techniciens etc.) doivent être orientées
prioritairement vers ces terroirs.
4.2.2.2 Éducation
Tout comme pour l'agriculture, nous distinguons trois
catégories de régions de part les valeurs prises pour les
indicateurs du secteur de l'éducation. Dakar et Ziguinchor se
distinguent des autres régions et forment ainsi le pôle le mieux
pourvu en termes de ressources pour l'éducation. Le pôle vers
lequel les efforts des autorités doivent se tourner est constitué
de Kaffrine, Kédougou et
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 50
4.2. Analyse exploratoire
Sédhiou. En effet, l'analyse montre que ces
régions disposent de moins d'atouts pour le développement de
l'éducation. Les performances des autres régions en
matière d'éducation peuvent être considérées
comme moyennes.
Graphique 4.7 -- Carte de proximité des
régions pour l'agriculture
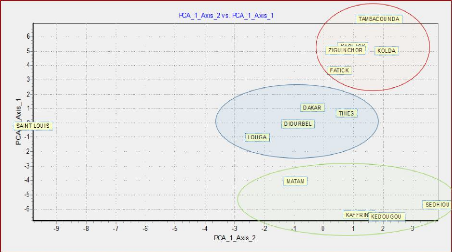
Source : ANSD, nos calculs
Graphique 4.8 -- Carte de proximité des
régions pour l'éducation
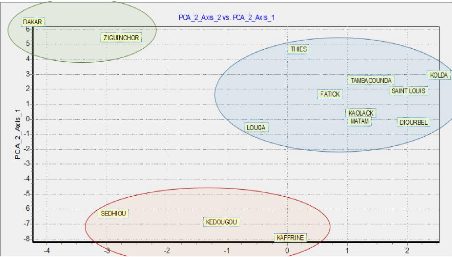
Source : ANSD & Ministère de l'Education
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 51
4.3. L'indice synthétique de
performances
4.3 L'indice synthétique de performances
L'indice synthétique de performances permet de
résumer l'information contenue dans l'ensemble des indicateurs relatifs
à un secteur donné et de présenter celle-ci en terme de
valeur numérique normalisée et comparable entre les
régions d'une année à l'autre. Nous utilisons l'approche
par décomposition de la variabilité présentée
à la section 3.2.3. En effet la courte longueur des séries ne
permet pas les différentiations exigées par l'AFD probabiliste.
Il en résulte une non convergence des algorithmes de maximisation de la
vraisemblance. Le tableau 4.1 montre le cumul la part de variabilité
expliquée par les axes factoriels pour l'éducation et
l'agriculture. Les résultats suggèrent de retenir deux axes pour
chaque secteur (plus de 60% de la variabilité est expliquée).
Tableau 4.1 -- Pouvoir explicatif du premier
axe factoriel : ISPA et ISPE
Agriculture
. mat list cum_variability
cum_variability[1,6]
e1 e2 e3 e4 e5 e6
r1 .42957225 .61003135 .76057473 .86355688 .94953262 1
Education
. mat list cum_variability
cum_variability[1,4]
e1 e2 e3 e4
r1 .5671387 .84556107 .96492399 1
4.3.1 Agriculture
Pour ce qui concerne l'agriculture, entre 2005 et 2012, l'ISPA
distingue les régions dont les performances se sont accrues des autres
régions. Par exemple, les régions de Matam, Diourbel, Thies et
Dakar qui avaient une faible note en 2005 ont vu leur performances s'accroitre
en 2012. Par contre, les régions de St Louis et Tambacouda ont
régressé par rapport à 2005. Notons cependant qu'au cours
de la période d'étude, certaines régions ont connu
d'importantes fluctuations pour l'ISPA (Voir Graphique B.3).
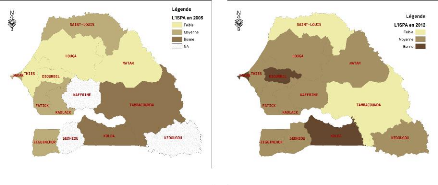
4.3. L'indice synthétique de
performances
4.3.2 Éducation
le constat est presque le même pour l'éducation.
Les régions de Matam, Thies, Fatick, Kaolack et Kolda ont
régressé par rapport à 2005. Par contre, les
régions de St Louis, Louga et Tamba-counda ont réalisé du
progrès aucours de la période. Notons ici aussi qu'au cours de
cette période, certaines régions ont connu d'importantes
fluctuations pour l'ISPA (Voir Graphique B.4).
Graphique 4.9 -- L'ISPA et l'ISPE des
régions pour 2005 et 2012
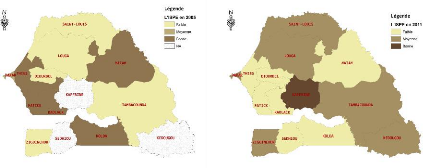
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 52
Source: Nos calculs
Conclusion partielle
De cette étude, nous pouvons retenir que d'une
manière générale, les rendements des cultures (mil et
arachide) sont en forte baisse dan la plupart des régions, notamment
celles du bassin arachidier. Ces dernières pourraient avec l'aide des
autorités constituer un pôle agricole à forte valeur
ajoutée pour le pays. Notons aussi que les indicateurs liés
à l'éducation s'améliorent d'année en année
compte tenu des projets entrepris par l'État dans les différentes
régions. Il faudrait cependant que ces projets prennent en compte les
nouveaux défis en termes d'augmentation de la population
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 53
4.3. L'indice synthétique de
performances
préscolarisable et scolarisable. Les indicateurs
construits dans cette partie nous renseignent sur les performances des
régions au fil des années concernant l'agriculture et
l'éducation. Signalons que pour une meilleure représentation de
la réalité, ces indicateurs doivent être
améliorés d'un point de vue méthodologique de sorte
à prendre en compte les fluctuations qui interviennent dans les
séries d'entrée.

Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page 54
Chapitre 5
Implémentation et déploiement du
système
La conception du système se déroule en deux
phases. La première est consacrée à l'élaboration
du schéma global d'organisation des données regroupant le tableau
de bord et la BD socioécono-mique. La deuxième phase abordera la
conception de l'IHM. Mais avant cela, il est important de fixer les
idées sur les possibilités que doit offrir le futur
système.
5.1 Quelles fonctionnalités pour le futur
système?
La figure 5.1 représente un diagramme de cas
d'utilisation
UML. IL est utilisé pour
représenter les interactions entre le système et les utilisateurs
finaux. On distingue trois types d'acteurs à savoir les visiteurs, les
membres de l'USPITE et l'administrateur du site. Les visiteurs, externes
à l'unité n'auront qu'un droit de consultation des informations,
les droits de modification et de mise à jour étant
réservés aux membres de l'unité. L'administrateur du
système (qui est aussi un membre de l'unité) aura le
contrôle total sur toutes les fonctionnalités proposées par
l'application. Au cours de la conception du système, nous nous
attelerons à developper les fonctionnalités suivantes :
BD socioéconomique :
~ Accès aux indicateurs par zone, par période et
par secteur
~ Cartes thématiques, graphiques (suivant le temps et
suivant les zones) ~ Exportation des graphiques générés
sous format image
~ Création et renseignement de nouveaux indicateurs
Tableau de bord des projets :
~ Consultation de la liste des projets et programmes (ensemble,
par zones, par période, par Ministère sectoriel/DG, etc.)
~ Consultation de chaque projet via une fiche synoptique
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 55
5.2. Implémentation des structures de
données
~ Mise à jour de chaque projet (création et
renseignement d'indicateurs de suivi dans le temps) ~ Gestion des programmes
(Consultation des projets de chaque programme et mise à jour)
Le site d'une manière
générale
~ Publication des articles et des rapports
~ Gestion des utilisateurs et des droits d'accès ~ Contact
de l'unité par les utilisateurs externes
Graphique 5.1 -- Diagramme de cas
d'utilisation du système
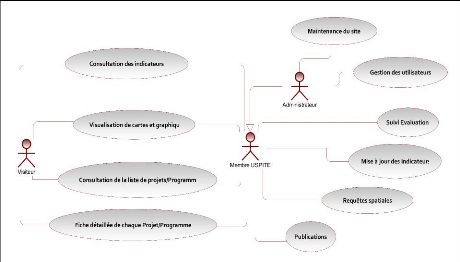
Source: Nos travaux
5.2 Implémentation des structures de
données
5.2.1 Élaboration du modèle conceptuel de
données
Au vu des fonctionnalités décrites plus haut et
après l'analyse du domaine d'application, nous avons recensé les
classes devant faire partie du modèle de données dans le tableau
5.1. Le dictionnaire de données, plus détaillé est
présenté au tableau A.1 en annexes. Les règles suivantes
permettent d'établir les associations entre les classes.
(i) Un projet a au moins un effet/objectif et un effet/objectif
est rattaché à un et un seul projet;
(ii) Un projet a au plus plusieurs extrants et un extrant est
rattaché à un et un seul projet (approche GAR) ;
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 56
5.2. Implémentation des structures de
données
(iii) Un projet a au plus plusieurs impacts et un impact est
rattaché à un et un seul projet (approche GAR) ;
(iv) Un projet appartient à au plus un programme et un
programme comporte au moins un projet;
(v) Une structure est attachée à un et un seul
Ministère et un Ministère peut en comporter plusieurs;
(vi) Un projet est pris en charge par au moins une structure
et une structure n'a pas forcément la charge d'un projet;
(vii) Un projet comporte au moins une activité et une
activité est inscrite à un et un seul projet;
(viii) Un projet possède un plan de financement qui
peut être révisé au fil du temps;
(ix) Un indicateur peut ou pas être disponible pour un
département donnée. Cet indicateur prend une valeur donnée
pour une année;
(x) Un bailleur finance soit aucun ou plusieurs projets
à un montant donné et un projet peut être financé
par plusieurs bailleurs;
(xi) Un indicateur de projet est relatif à un et un
seul effet/extrant/impact et un effet/extrant/im-pact peut être
capté par plusieurs indicateurs. Ceux-ci peuvent prendre une certaine
valeur à une période donnée;
(xii) Un indicateur est relatif à un seul secteur
social et un secteur social rassemble plusieurs indicateurs;
(xiii) Une information complémentaire concerne un et
un seul projet alors qu'un projet peut avoir plusieurs informations
complémentaires;
(xiv) Un projet s'effectue forcément dans un ou
plusieurs départements mais un département peu n'abriter aucun
projet;
(xv) Un projet s'effectue forcément dans une ou
plusieurs régions mais une région peu n'abriter aucun projet;
(xvi) Un utilisateur du système publie aucun ou
plusieurs articles et un article est publié par un et un seul
utilisateur;
(xvii) Une région comporte au moins un
département et un département appartient à une et une
seule région;
(xviii) Un indicateur peut ou pas être disponible pour
une région donnée. Cet indicateur prend une valeur donnée
pour une année;
(xix) A une activité, on affecte au moins une
ressource à une quantité donnée. Une ressource n'est pas
forcément affectée à une activité.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 57
5.2. Implémentation des structures de
données
Ces associations sont représentées dans le
tableau 5.2 en précisant s'il y a lieu des attributs pour les
classes-associations. De ces tableaux, découle le diagramme de classes
représenté par la figure 5.2. La vérification (manuelle et
automatique avec l'outil Power AMC) de ce diagramme permet de le valider le
tenant compte des critères énoncés dans la sous-section
3.4.1.3. Pour rappel, il s'agit d'abord de vérifier si les attributs
sont élémentaires et non redondants. Ensuite, on vérifie
si les contraintes de partition, d'exclusivité, de totalité,
d'inclusion et de simultanéité sont respectées. La
dernière étape consiste en l'application des trois
dernières formes normales.
Tableau 5.1 -- Recensement des classes du
modèle
Classe Attributs possibles Commentaire
Activites Identifiant, nom, debut, fin Les activités d'un
projet
article Titre, contenu, fichiers L'unité publie des
articles
Bailleur Nom du bailleur, commentaires Les bailleurs financent
les projets
Plan_Finance Identifiant, Commentaire Plan de financement du
projet
Contact Adresse, mail, tel, à propos Coordonnées de
l'unité
Departement Identifiant, nom Colectivité locale
Indicateur Social Identifiant, nom Liste des indicateurs
sociaux
Indicateurs Projet Identifiant, nom Indicateurs de suivi
Info Complementaire Identifiant, Commentaire Infos
complémentaires du projet
Messages Coordonnées, objet, contenu etc. Messages de la
part des utilisateurs
Ministères Techniques Identifiant, nom Les MT en charge
des projets
Extrants Id, Libelé Un projet a des extrants bien
définis
Effets Id, Libelé Un projet a des effets/objectifs bien
définis
Impact Id, Libelé Un projet vise un impact sur la
population
Programmes Id, libellé, début, fin, financement
etc. Ensemble de projets
Projets Matricule, libellé, debut, fin, financement etc.
La classe Projet
Region Identifiant et nom Collectivité locale
Ressource Id et type de ressource Ressources du projet
Secteur Social Identifiant et nom Agriculture,
l'éducation, santé etc.
Structure Identifiant et nom Structure du MT en charge du
projet
Users Login, Mot de passe, etc. Compte des membres de
l'unité
Source: Nos travaux
Tableau 5.2 -- Établissement des
associations entre les classes
|
Association
|
Classe A
|
Mult. A
|
Classe B
|
Mult. B
|
Attributs 1
|
|
Prj_ Extrants
|
Extrants
|
0..
|
Projets
|
1..1
|
Année, valeur, source, commentaire
|
|
Prj_ Effets
|
Effets
|
1..
|
Projets
|
1..1
|
Année, valeur, source, commentaire
|
|
Prj_ impact
|
Impact
|
0..
|
Projets
|
1..1
|
Année, valeur, source, commentaire
|
|
Appartient
|
Projets
|
1..
|
Programmes
|
1..1
|
|
|
attache
|
Ministeres Techniques
|
1..1
|
Structure
|
1..
|
|
|
charge
|
Projets
|
0..
|
Structure
|
1..
|
|
|
comporte
|
Activites
|
1..
|
Projets
|
1..1
|
|
|
prj_plan_ fin
|
Projets
|
1..1
|
Plan Finance
|
1..
|
Année, Dépense, Taux d'avancement, commentaire
|
|
d_relatif_ is
|
Departement
|
0..
|
Indicateur Social
|
0..
|
Année, valeur, source
|
|
Ficance
|
Bailleur
|
1..
|
Projets
|
0..
|
Montant
|
|
ind_relatif_ obj
|
Objectifs
|
0..1
|
Indicateurs Projet
|
0..
|
Date, valeur, source
|
|
is_relatif_ ss
|
Indicateur Social
|
1..
|
Secteur Social
|
1..1
|
|
|
Possede
|
Projets
|
1..1
|
Info Complementaire
|
0..
|
|
|
pr_localise_ dept
|
Projets
|
0..
|
Departement
|
1..
|
|
|
pr_localise_ reg
|
Projets
|
0..
|
Region
|
1..
|
|
|
publie
|
Users
|
1..1
|
article
|
0..
|
|
|
r_Contient_ d
|
Region
|
1..1
|
Departement
|
1..
|
|
|
reg_relatif_ is
|
Region
|
1..
|
Indicateur Social
|
0..
|
Année, valeur, source
|
|
res_affecte_ activite
|
Ressource
|
1..
|
Activites
|
0..1
|
Valeur
|
Source: Nos travaux
Graphique 5.2 -- Présentation du
Modèle Conceptuel de Données
prj_plan_fin
|
Plan Finance
|
|
|
|
- id Plan
- Planification
|
|
|
|
prj_plan_fin
|
Programmes
- id programme
- nom_programme
- Cout_Total
- Debut_programme
- Fin_programme
- Organisme_programme
ind mesure ext
ind mesure eff
0..* 0..*
Indicateurs Projet
- id ind p
- nom_ind_p
- Valeur Initaile
Date_Initiale - Valeur cible - Date_Cible
- Annee
- Dep_Effectiv
- Taux_avancement - Comment_Finan
1..* 1..1
prj_impact
- id Projet
- nom_projet
- Objectif_General
- Cout_Initial_rr
- Secteur act
- sous_secteur
- Secteur inst
- Etat finance
- Nature finance
- Nature_Engagement
- Debut_projet
- Fin_projet
- Organisme_Projet
- id service
- nom service
Projets
Structure
charge
1.*
ind_mesure_imp
Ministeres Techniques
- id ministere 1..1
- nom_ministere attache
ind mesure ext
- Annee - Valeurext - source_ext - Comm_Extr
Extrants
- id Extrant
- nom_Extrant - Etat Extrant
Appartient
PrjExtrants
0..1
Effets
- id Effet
- nom Effet - Etat Effet
Impact
- Id Impact
- nom_Impact
- Etat_Impact
0..1
0..1
ind mesure eff
- Annee_Eff
- Valeur eff
- Source_Eff
- Comment Effet
ind_mesure_imp
- Annee_imp - Valeur_imp - Source_imp - Comment_Imp
0..*

prj_Effet
Activites
res_affecte_activite
res_affecte_activite - Valeur_ressource
Users
|
pr_localise_reg
|
- username - password - statut
- user email
- nom
- prenom
|
Bailleur
- id bailleur
- nom bailleur
- commentBailleur

Ressource
- id ressource
- Type_ressurce
publie
article
- id article - Titre_Article - contenu - image
- fichier -
Contact
- id contact - Telephone - email - Adresse - About
Messages
- id message
- Nom auteur
- email auteur
- Tel auteur
- Motif_Message
- Contenu
- Date
|
comporte
|
- id activite
|
|
0..1
|
|
- nom activite - debut activite
- fin activite
- debut effectif
- fin effective
- Commentaire acti
|
|
|
1..*
|
|
|
|
|
|
|
|
0.
|
Ficanc
pr localise_dept
|
|
|
Ficance
|
|
- Montant
|
|
|
|
|
1..*
1..?ossede
|
Departement r_Contient_d
- id departement 1
- nom_departement
reg_relafrf is
Info Complementaire
|
- id info
|
d
|
relatif
|
is
|
|
reg_relatif_is
|
|
|
- Type_info
- Commentaire
|
- Annee_ind_reg
- Valeur_ind_reg
- Source_Ind_reg
|
|
|
|
|
|
|
Secteur Social
|
|
d_relatifis
|
- id sect social
|
|
- Annee_ind_dep
- Valeur_ind_dep
- Source_ind_dep
|
Indicateur Social
|
|
- nom sect social
|
|
id ind social
|
1." is_relatif_so
|
|
|
- nom_ind_social
|
11..1
|
Source : Nos travaux
I
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 60
5.2. Implémentation des structures de
données
5.2.2 Passage au modèle logique de
données
Le modèle logique de données et obtenu par
l'application des règles 1 à 4 énoncées dans la
sous-section 3.4.2. Toutes les classes sont d'abord transformées en
tables et les identifiants de chaque classe deviennent des clés
primaires des tables ainsi formées. Suivant les multiplicités
représentées au niveau des associations du MCD, nous obtenons les
transformations suivantes :
(i) La clé primaire de la table projet devient clé
étrangère de la table Extrants
(ii) La clé primaire de la table projet devient
clé étrangère de la table Effets
(iii) La clé primaire de la table projet devient
clé étrangère de la table Impacts
(iv) La clé primaire de la table programme devient
clé étrangère de la table Projet
(v) La clé primaire de la table MT devient clé
étrangère de la table Structure
(vi) L'association charge devient une table dont la
clé primaire est constituée des clés de chacune des deux
tables
(vii) La clé primaire de la table projet devient
clé étrangère de la table Activités
(viii) L'association d_relatif_is devient une table dont la
clé primaire est constituée des clés de chacune des deux
tables
(ix) L'association Finance devient une table dont la
clé primaire est constituée des clés de chacune des deux
tables
(x) L'association ind_relatif_obj devient une table dont la
clé primaire est constituée des clés de chacune des deux
tables
(xi) La clé primaire de la table Secteur Social
devient clé étrangère de la table Indicateur Social
(xii) La clé primaire de la table projet devient
clé étrangère de la table Infos Complementaires
(xiii) L'association pr_localise_dept devient une table dont
la clé primaire est constituée des clés de chacune des
deux tables
(xiv) L'association pr_localise_reg devient une table dont la
clé primaire est constituée des clés de chacune des deux
tables
(xv) La clé primaire de la table Users devient
clé étrangère de la table Article
(xvi) La clé primaire de la table région
devient clé étrangère de la table Département
(xvii) L'association reg_relatif_is devient une table dont la
clé primaire est constituée des clés de chacune des deux
tables
(xviii) L'association res_affecte_activite devient une table
dont la clé primaire est constituée des clés de chacune
des deux tables
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 61
5.2. Implémentation des structures de
données
(xix) L'association ind_mesure_eff devient une table dont la
clé primaire est constituée des clés de chacune des deux
tables
(xx) L'association ind_mesure_ext devient une table dont la
clé primaire est constituée des clés de chacune des deux
tables
(xxi) L'association ind_mesure_imp devient une table dont la
clé primaire est constituée des clés de chacune des deux
tables
(xxii) L'association prj_plan_fin devient une table dont la
clé primaire est constituée des clés de chacune des deux
tables
De ces transformations découle le modèle logique de
données représenté par la figure 5.3.
Graphique 5.3 -- Présentation du
Modèle Logique de Données
prj_plan_fin
id Proiet <pi fi2> <01
id Plan <pi fil> <0
Annee_SFin Dep_Effectiv Taux avancement Comment_Finan
Plan Finance
Ac
re.
id ressource <pi,fil>j.
· id activite <pi,fi2>
Valeur ressource
pr_localise_reg
· iC region <pi,f2> <0>
id Proiet <pi,fil> <0>
id activite `p <0
id_Projet
nom_activite
debut_acfivite fin_activite debut effectif fin
effective Commentaire _ad
·
Users
username 92 <0>
password statut user_email nom prenom
Source : Nos travaux
Ri
id ressource <pi> <0>
Type_ressurce
Programmes
id programme <pi> <O>
nom_programme Cout Total Debut_programme Fin_programme
Organisme_programme
ind_mesure_ext
cid Extrant <pi,fil~
id ind p 91fi2:
Annee_Ext Valeur_ext source_ext Comm_Extr
Extrants
·
id Extrant <0>
id_Projet <fi> <0>
nom_Extrant Etat_Extrant

Projets
id Proiet <pi> <O>
|
Ficance
|
|
|
|
|
|
id bailleur <pi fil>'
id Proiet <pi fi2>
|
Region
|
|
icon`r72 <0>
|
|
Montant
|
|
|
|
|
|
region
|
|
article
id article <pi> <O>
username <fi> <O>
Titre Article
contenu
image fichier
reg_relatif_is
id ind social <pi fi2, Contact
|
id region <pifil
|
|
id contact <pi> <O>
|
|
|
|
|
|
|
Annee_ind_reg
Valeur_ind_reg
Source_Ind_reg
|
|
|
Telephone email Adresse About
|
|
|
|
|
|
Messages
id message <p <O>
nom_projet Objecfif_General Cout_Initial_pr Secteur_act
sous_secteur Secteur inst Etat_f nance Nature finance Nature_Engagement
Debut_projet Fin_projet Organisme_Projet
ind_mesure_eff
cid Effet id ind p <pi fi2>
Annee_Eff Valeur_eff Source_Eff Comment Effet
Effets
id Effet <pi> <O>
id_Projet <fi> <O> nom Effet
Etat Effet
Info Complementaire id info <pi> <O>
id_Projet <fi> <
Type_info Commentaire
Indicateurs Projet
idindp 92 <0>
nom_ind_p <O>
Valeur Initaile Date Initiale Valeur cible Date Cible
ind_mesure_imp
rid Impact <pi fil>1
id ind p <pi fi2>
Annee_imp Valeur_imp Source_imp Comment_Imp
Impact
Id Impact <pi> <0>
id_Projet <f> <O>
nom_Impact Etat_Impact
·
|
|
|
Bailleur
|
|
|
pr_localise_dept
id departement <pi fi2> <O>
id Proiet <pi,fil> <O>
|
|
id bailleur <pi> <(
|
|
|
|
|
nom bailleur commentBailleur
|
|
|
|
|
|
1
|
|
|
|
|
|
Departement
|
|
|
|
|
|
id departement 92 <0>
|
|
|
|
|
id_region <fi> <O>
·
nom_departement
d_relatif_is
·
7- id ind social id departement
Annee_ind_dep
Valeur_ind_dep
,_Source_ind_dep
Indicateur Social
charge
id service <pi,fi2> <O>
id Proiet <pi fil> <O>
Structure
id service <pj <O>
id ministere <fi> <O> nom service
Nom_auteur email auteur Tel auteur Motif_Message Contenu
Date
Ministeres Techniques id ministere <pi> <0>
id ind social <pi> <O>
id_sect_social <fi> <O>
nom ind social
Secteur Social
id sect social <pi> <O>
nom_sect_social
nom_ministere
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 63
5.2. Implémentation des structures de
données
5.2.3 Implémentation du modèle physique de
données
Les tables du modèles logique sont transcrites sur un
support informatique via le langage SQL. Le code ci dessous présente
l'exemple de la table projet.
/*==============================================================*/
/* Table : PROJETS */
/*==============================================================*/
CREATE TABLE PROJETS (
ID_PROGRAMME INT4 NOT NULL,
ID_PROJET INT8 NOT NULL,
ID_SA INT4 NOT NULL,
NOM_PROJET VARCHAR(254) NULL,
OBJECTIFGENERAL VARCHAR(254) NULL,
COUT_INITIAL DECIMAL NULL,
SECTEURACT VARCHAR(254) NULL,
SOUSSECTEUR VARCHAR(254) NULL,
SECTEURINST VARCHAR(254) NULL,
ETATFINANCE VARCHAR(254) NULL,
NATUREFINANCE VARCHAR(254) NULL,
NATUREENGAGEMENT VARCHAR(254) NULL,
DEBUTPROJET DATE NULL,
FINPROJET DATE NULL,
ORGANISMEPROJET VARCHAR(254) NULL,
CONSTRAINT PK_PROJETS PRIMARY KEY (ID_PROGRAMME, ID_PROJET)
);
La migration des clés de la table programmes et
sous_secteur dans la table projet est représentée en SQL par les
code suivants. La même procédure est reprise pour toutes les
tables et relations du modèle logique, de sorte à obtenir le
modèle physique représenté par le graphique 5.4.
/*===== Exemple de migration de quelques clés vers la
table projets =========*/
ALTER TABLE PROJETS
ADD CONSTRAINT FK_PROJETS_APPARTIEN_PROGRAMM FOREIGN KEY
(ID_PROGRAMME)
REFERENCES PROGRAMMES (ID_PROGRAMME) ON DELETE RESTRICT ON UPDATE
RESTRICT;
Graphique 5.4 -- Présentation du
Modèle Physique de Données

pr1_plan_fin
Ressource
id Plan <pk>
Planification
Plan_Finance
id ressource Type_ressurce
id programme S
Projet yg
id Plan Annee SFin Dep_Effectiv Taux_avancement
|
|
|
Users
|
|
|
username
|
<pk>
|
|
Acthdtes
|
|
password statut user_email
|
|
|
|
id activite
|
<pk>
|
|
id_programme
|
<fk>
|
|
nom
|
|
|
id_Projet nom activite
|
<fk>
|
|
prenom
|
|
|
debut activite
|
|
|
|
res affecte activite
id ressource <pk,fkl>
id activite <pk fk2>
Valeur ressource
pr_localise_reg
id rection <pk,fk2>
H programme <pk,fkl>
id Projet <pk,fkl>
pr_localise_dept
id departement <pk fk2> id programme <pk
fkl>
id region <pk fk2>
kl Projet <pk,fkl>
Projets
id programme <pk,fk>
id Projet <pk>
id_sect_act nom_projet
Objectif_General Cout_Initial_pr Secteur_ act
- sous_secteur Secteur inst Etat finance
- Nature_finance Nature_Engagement Debut_projet
Fin_projet
Organisme_Projet
id bailleur <pk,fl
id programme <pk,fl
id Projet <pk,fl
Ficance
id bailleur <pk>
nom_bailleur commentBailleur
Bailleur
Region
id region <pk> region
in
A
article
id article <pk>
username <fk> Titre Article contenu image
fichier
Programmes
id programme nom_programme Cout_Total Debut_programme
Fin_programme Organisme_programme
|
|
|
|
|
|
Extrants
|
|
|
ind mesure ext
|
id Extant
|
<pk-
|
|
id Extrant
|
<pk,fk
|
|
id_programme
|
<fk>
|
|
<pk,fk
|
id_Projet nom_Extrant
|
<fk>
|
|
id ind_r
|
|
|
Annee Ext
|
|
Valeur ext souroe_ext
|
|
|
|
|
|
Comm_Extr
|
|
|
|
|
|
|
|
|
Effets
|
|
|
charge
|
Departement
|
|
ind mesure ef
|
|
|
|
|
|
|
|
|
|
Info Comp ementaire
|
|
|
|
|
|
|
|
id departement <pk>
id region <pk,fk>
nom_departement
|
|
I
|
|
|
|
id Effet <~k
id_programme <fk:
id_Projet <fk:
nom_Effet
|
id service <pk fk2>
id programme <pk,fkl>
id ministers <pk fk2>
id Projet <pk fkl>
|
|
id Effet id indp Annee_Eff Valeur eff Source_Eff Comment
Effi
|
|
|
|
|
|
id info <~k
id_programme <fk id Projet
Type_ info
|
|
|
|
|
|
|
|
|
1
|
|
Impact
|
reg_relatif_is
y
Indicateur Social
id ind social <pk>
id sect social <pk tk>
nom ind social
Contact
id contact <pk>
Telephone
email
Adresse
About
Messages
id message <pk>
Nom_auteur email auteur Tel_auteur Motif_Message Contenu
Date
id ind social <pkfk2>
id sect social <pk fk2>
id region <pk *1>
Annee_ind_reg Valeur_ind_reg Source_Ind_reg
Secteur Social
id sect social <pk>
nom_sect_social
Structure
id service <pk>
id ministere <pk tk>
nom_service
Source : Nos travaux
Id Impact <pk>
id_programme <fk>
d_relatif_is
id_Projet <fk>
nom_Impact
id ind social <pk,fk2>
id sect social <pk fk2>
id departement <pk fkl>
id region <pk,fkl>
Annee_ind_dep Valeur_ind_dep
Source_ind_dep
Indicateurs Projet
id indp <pk>
nom_ind_p Valeur Initaile
Id Impact d ind_r
ind_mesure_imp
<pk fk2>
Date Initiale
|
Valeur cible Date Cible
|
.11
|
Annee_imp Valeur_imp Source_imp Comment_Imp
|
|
|
|
Ministeres Techniques
id ministers <pk>
|
|
|
nom_ministere
|
4
|
|
|
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 65
5.3. Conception de l'IHM
5.3 Conception de l'IHM
Afin de mieux organiser le code suivant le design pattern MVC,
nous utilisons CakePHP. C'est est un framework de développement rapide
pour PHP, gratuit et open-source. C'est un ensemble d'outils de base pour la
création d'applications web. Cake PHP propose des classes
prédéfinies pour chaque composant de l'application
(modèle, vues, contrôleurs). Les objets sont donc
créées à partir de celles-ci.
Création des modèles : Il
s'agit ici de la création des variables intervenant dans le
système. Chaque table du modèle physique constitue donc un
modèle et ceux-ci sont reliés entre eux par des associations. Ici
on définit également les règles de validation des
données qui doivent être saisies dans les différents
formulaires.
Création des vues : Chaque
modèle est associé à une ou plusieurs vues. Celles-ci sont
généralement relatives à la saisie et à l'affichage
des informations recueillies des modèles.
La logique et les contrôleurs : Il
s'agit ici d'affecter à chaque modèle les actions et traitements
qui doivent être exécutés. C'est aussi le moment d'associer
les vues aux modèles pour répondre aux différentes
requêtes posées par les utilisateurs.
A cet ensemble est ajouté des feuilles de styles pour
organiser les vues et du code JavaScript. Le système obtenu est
présenté au chapitre 6.
5.4 Déploiement du système
La solution idéale pour un fonctionnement efficient de
ce système est de l'héberger sur un serveur web accessible par le
réseau internet. Pour l'heure, l'USPITE ne disposant pas de serveur, une
solution intermédiaire est la mise en place d'un réseau local
constitué des machines de l'unité. L'une d'entre elles servira de
station serveur. Les autres machines (postes clients) reliées au
réseau pourront donc accéder au système via une adresse
url comme indiqué au graphique 3.1. Le déploiement consiste donc
à l'installation du logiciel sur la machine hôte. Ceci se fera
à travers les étapes suivantes :
~ Installation du serveur de base de données:
Il s'agit dans cette partie d'installer le SGBD PostgreSQL, abritant le
serveur de BD. Il faudra ensuite y implémenter la base de données
physique.
~ Installation du serveur web: Nous utilisons ici le
serveur Apache pour PostgreSQL. Celui-ci permet d'interpréter les
scripts PHP qui assurent l'interaction avec la BD.
~ Installation de l'application sur le serveur web:
Il s'agit juste de copier le dossier contenant les codes sources de
l'application sur la racine du serveur web.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 66
5.4. Déploiement du système
Conclusion partielle
Au vu des fonctionnalités présentées,
nous avons mis en place une structure de données exhaustive prenant en
compte les besoins de l'USPITE. Cette application est le fruit de nombreux
échanges et séances de travail avec les membres de
l'unité. Le système repose sur une base de données de type
objet-relationnel PostgreSQL, les utilisateurs interagissant avec cette BD via
une application web. Celle ci est développée suivant le design
pattern MVC de sorte à séparer les traitements, les
données et l'affichage. Cette organisation permet une mise à jour
plus aisée de l'application. Les codes sont organisés selon le
framework Cake PHP qui fournit de nombreuses fonctionnalités et une
facilité de développement. Selon les réalités du
terrain, le présent système pourra facilement être mis
à jour par l'intégration de nouveaux modules.

Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page 67
Chapitre 6
Opérationnalisation du système, limites
de l'étude et
recommandations
Ce chapitre présente le système conçu au
travers de ses diverses fonctionnalités. Il sera principalement question
de donner un aperçu sur l'utilisation de la BD socioéconomique,
du tableau de bord de suivi des projets et aussi de quelques autres fonctions
globales du système. Ce chapitre pourrait aussi servir de guide
d'utilisateur pour les membres de l'USPITE. La dernière section est
réservée aux limites de l'étude puis recommandations et
perspectives pour l'amélioration de l'efficience du système.
6.1 Accueil et authentification
6.1.1 Présentation générale
Depuis un navigateur web (Google Chrome de
préférence), il est possible d'accéder au site web mis en
place en saisissant l'adresse
http://localhost:8091/uspite-plan/
dans la barre d'adresses. On obtient alors la page d'accueil du site
représentée par la capture d'écran à la figure 6.1.
Cette page d'accueil présente les 7 menus suivants :
Accueil : Page d'accueil du site
BD sociale : Accès des utilisateurs
externes aux informations de la BD socioéconomique
Suivi des projets : Accès des
utilisateurs externes à la liste des projets et programmes ainsi qu'aux
informations qui s'y rapportent
Analyses : Accès aux analyses de
disparités et quelques autres analyses effectuées par l'USPITE.
C'est ici que peuvent être disponibles les résultats des analyses
effectuées au chapitre 4.
Publications : Accès des utilisateurs
aux rapport et autres documents ou articles publiés par l'US-PITE.
Contact : Possibilité pour les
utilisateurs externes de contacter l'unité
6.1. Accueil et authentification
Administration : Réservé aux
membres de l'unité pour le suivi des projets et programmes, la gestion
de la BD socioéconomique et d'autres tâches d'administration.
L'accès à cette section du site est conditionnée par la
disposition d'un nom d'utilisateur et d'un mot de passe telle que
présentée à la figure 6.2.
Graphique 6.1 -- Page d'accueil du site
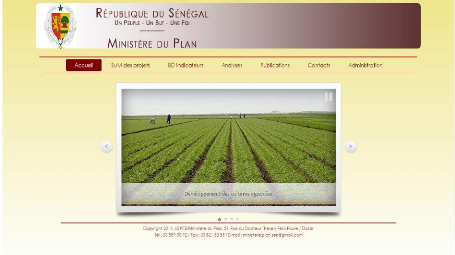
Source: Nos travaux
Graphique 6.2 -- Page d'authentification des
utilisateurs
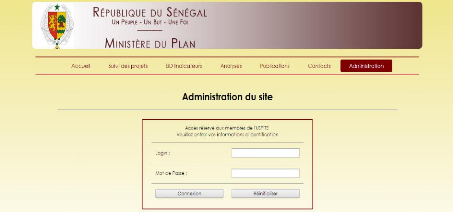
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 68
Source : Nos travaux
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 69
6.1. Accueil et authentification
6.1.2 Le menu Administrateur
Après l'authentification par login et mot de passe, le
membre de l'unité est dirigé vers la page
représentée par la figure 6.3. Il s'agit du menu de
l'administrateur. On y trouve les sous menus suivants :
Gestion des Projets : Il s'agit du menu
permettant à l'unité de gérer les projets. Ceci inclut la
création, le suivi, l'évaluation, la mise à jour
d'indicateurs et le renseignement de toutes les informations ayant trait aux
projets. Les fonctionnalités de ce menu sont détaillées
dans la section 6.2.
Gestion des programmes : page permettant la
coordination d'un ensemble d'un projets dans le cadre d'un programme
donné.
BD socioéconomique : C'est ici que
l'unité effectue toutes les opérations (Ajout, modification, mise
à jour etc.) sur les indicateurs sociaux ainsi que les analyses en vue
d'établir des rapports de disparités régionales et
départementales. Les fonctionnalités de ce menu sont
détaillés dans la section 6.3.
Modifier Contact : Comme son nom l'indique,
ce menu permet à l'USPITE d'actualiser ses coordonnées (en cas de
déménagement par exemple).
Publier un article : A partir de ce menu,
l'unité peut publier des articles, rapports etc.
Gestion des utilisateurs : L'administrateur
du système qui est le seul à avoir accès à ce menu
aura la possibilité de créer, supprimer et modifier les
autorisations des utilisateurs.
Graphique 6.3 -- Page d'accueil de
l'administration du site
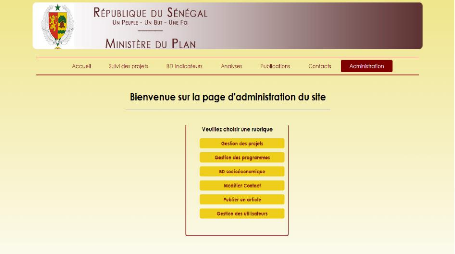
Source: Nos travaux
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 70
6.2. Utilisation du tableau de bord de suivi des
projets
Dans les sections 6.2 et 6.3, les fonctionnalités
présentées ne concernent que les membres de l'unité
disposant d'un nom d'utilisateur et d'un mot de passe pour accéder au
menu administrateur (Graphique 6.3).
6.2 Utilisation du tableau de bord de suivi des
projets
Un clic sur le sous menu Gestion des projets dirige
l'utilisateur vers la page d'accueil de la gestion des projets (Graphique 6.4).
La page est constituée de trois parties : à gauche, le menu
administrateur permet de naviguer sans avoir besoin de revenir à la page
d'accueil de l'adminis-tration. Au milieu, la liste de projets de l'État
avec leurs numéros matricules. Les libelles sont des liens hypertextes.
A droite, se trouve un menu du projet sélectionné par clic sur le
lien hypertexte (Graphique B.5).
Graphique 6.4 -- Page d'accueil de la gestion
des projets
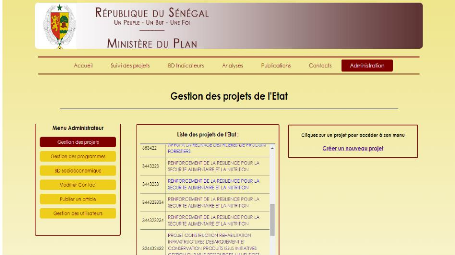
Source: Nos travaux
Lorsqu'aucun projet n'est sélectionné, le menu
de droite permet la création d'un nouveau projet par un clic sur le lien
qui s'y trouve. Lorsqu'un clic est effectué sur le libellé d'un
projet, le matricule et le libellé de celui-ci sont affichés dans
le menu de droite. Ce menu contient aussi des sous menus permettant d'effectuer
toutes les opérations possibles sur le projet en question. Ces sous
menus sont composés des fonctionnalités suivantes :
~ Modifier détails pour mettre à jour les
informations générales relatives au projet. Il s'agit
principalement de la localisation, des structures en charge du projet, le
programme qui abrite le projet - au cas échéant -, les
activités ainsi que des informations complémentaires
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 71
6.3. Utilisation de la BD
socioéconomique
qui n'auront pas été prises en compte plus haut.
~ Objectifs et Indicateurs pour affecter les objectifs
spécifiques - ou effets - au projet ainsi que les indicateurs
associés à ces objectifs (Graphique 6.5).
~ Suivi-Evaluation pour mettre jour les indicateurs dans la
cadre su suivi des objectifs, effectuer le suivi des activités et faire
l'évaluation du projet à un instant donné.
~ Fiche Complète pour afficher un rapport complet sur le
projet.
Graphique 6.5 -- Assignation des objectifs
spécifiques et des indicateurs de suivi
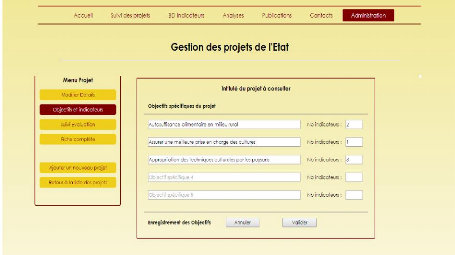
Source: Nos travaux
6.3 Utilisation de la BD socioéconomique
Le site présente plusieurs fonctionnalités dans
le cadre de l'utilisation de la BD socioéconomique dont la page
d'accueil est représentée par la figure 6.6.
~ Analyse statique permet d'avoir une vue sur un certain
nombre d'indicateurs pour les collectivités locales choisies à
une année donnée (figure 6.6). Les résultats sont
consignés dans un tableau comportant les indicateurs en ligne et les
collectivités locales en colonnes.
~ Analyse dynamique permet, à l'inverse de l'analyse
statique d'avoir l'évolution dans le temps de plusieurs indicateurs par
rapport à une collectivité locale. Les résultats se
présentent sous forme de tableau contenant les indicateurs en ligne et
les années en colonnes.
~ Carte thématique permet d'obtenir une carte du
Sénégal présentant un indicateur donné en fonction
des régions ou départements selon le choix de l'utilisateur.
~ Courbe d'évolution donne l'allure de
l'évolution d'un indicateur donné pour une collectivité
locale donnée. L'utilisateur sera invité à choisir la
période sur laquelle il veut visualiser
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 72
6.3. Utilisation de la BD
socioéconomique
la tendance de l'indicateur.
~ Nouvel indicateur permet de créer un nouvel
indicateur et de l'affecter à un secteur donné.
~ Création de ratio invite l'utilisateur à
sélectionner un numérateur et un dénominateur du ratio
à créer (Voir Graphique B.7). Celui-ci, une fois mis en place
figurera dans la liste des indicateurs disponibles.
~ Mise à jour donne l'occasion à l'utilisateur
de renseigner les valeurs des indicateurs sociaux nouvellement crées ou
dont les informations ont été obtenues après la mise en
place du
système (Voir Graphique 6.7).
Graphique 6.6 -- Page d'accueil de la BD
socioéconomique
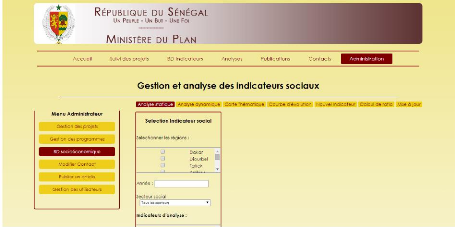
Source: Nos travaux
Graphique 6.7 -- Mise à jour des
indicateurs sociaux
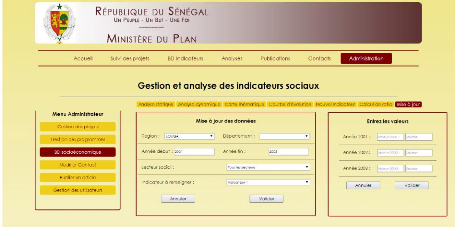
Source : Nos travaux
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 73
6.4. Limites de l'étude
6.4 Limites de l'étude
La principale limite à cette étude est la
fourniture des données pour l'alimentation de la BD
so-cioéconomique. Les données provenant des situations
économiques et sociales des régions n'étaient pas facile
à traiter. En effet, d'une région à l'autre la structure
des rapports ainsi que les indicateurs étudiés n'étaient
pas les mêmes. De même, dans une même région, la
structure des documents peut varier d'une année à l'autre. Cette
situation a été la cause du manque de temps pour approfondir
l'analyse statistique au chapitre 4.
La méthode proposée par Nikolaos Zirogiannis et
Yorghos Tripodis [54] bien que performante pour l'élaboration de l'ISP,
n'a pas été utilisée à cause de la longueur des
séries étudiées (8 années). En effet, un passage
aux différences premières pour rendre les séries
stationnaires ferait perdre une valeur sur huit pour chaque région et
chaque indicateur. Il en est de même pour un lissage quelconque. Notons
aussi que le panier de variables ayant servi pour notre étude aurait pu
être élargi de sorte à se rapprocher des
réalités de chaque région.
Pour finir, L'USITE ne disposant pas de serveur et les moyens
ne permettant pas la mise en place d'un réseau local, le système
est actuellement hébergé sur un serveur local qui n'est
accessible que depuis la machine hôte. Ceci limite les accès
concurrentiels à la BD.
6.5 Recommandations et perspectives
Après la réalisation de cette étude, nos
recommandations à l'endroit de l'USPITE sont les suivantes :
1 La possibilité de jumelage de certains
projets dans l'agriculture : l'analyse statistique des indicateurs de
l'agriculture et de l'éducation nous apporte un certain nombre
d'enseignements. D'abord, la structure des corrélations montre que le
rendement de certaines cultures évoluent dans le même sens. Ceci
étant, les projets de l'État pour améliorer les rendements
peuvent être jumelés en un seul projet prenant en compte ces
cultures voisines. Par exemple un projet de renforcement de la culture du mil
peut être jumelé avec un projet de renforcement de la culture du
niebé puisque les rendements de ces deux cultures évoluent dans
le même sens. de la même façon, l'arachide et le maïs
peuvent être rapprochés.
1 La prise en compte des ressources humaines dans
l'enseignement : pour ce qui concerne l'éducation, il est
important que les efforts de développement de tel ou tel aspect prennent
en compte les aspects connexes. Par exemple, notre étude a montré
que les ratios élèves/classes et
élèves/maîtres étaient positivement
corrélés. Cela signifie que tout programme ou projet
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 74
6.5. Recommandations et perspectives
visant à réduire le nombre
d'élèves par classe doit inclure le recrutement et la formation
d'enseignants pour ces nouvelles classes.
1 Le maintien et le développement
méthodologique de l'ISP : l'indicateur élaboré
dans ce document pourrait être étendu aux autres secteurs et
même aux départements. Cet indicateur doit aider l'unité,
année après année à établir ses rapports de
disparités. Pour améliorer sa fiabilité, il convient de
renseigner les autres indicateurs sociaux des différents secteurs. De ce
fait, l'ISP prendra mieux en compte les réalités
spécifiques aux régions/départements et gagnera en
robustesse.
1 La migration du système vers un serveur :
le système étant actuellement hébergé sur
un serveur local, son efficience serait plus importante si il est migré
vers un serveur distant accessible depuis le réseau internet. En effet,
les utilisateurs externes n'ont aucune vue sur le système actuel. En
plus, les membres de l'USPITE ne peuvent y accéder qu'à leur lieu
de travail sur des postes reliées à la machine serveur. Ces
insuffisances peuvent être surmontées par une migration vers un
serveur distant.
1 L'alimentation de la base de données :
une autre recommandation est celle relative au renseignement et
à la mise à jour des informations de la BD
socioéconomique. En effet, l'état actuel du système
nécessite le renseignement de plusieurs indicateurs afin d'être
pleinement opérationnel. Bien que les secteurs ayant fait l'objet de
l'étude statistique aient été renseignés, la BD
socioéconomique doit être davantage pourvue en données pour
être beaucoup plus utile.
1 L'intégration de nouvelles
fonctionnalités au système : à long terme, le
système devra être mis à jour de sorte à prendre en
compte les nouveaux besoins de l'unité. Les réalités du
terrain étant toutes autres, il est impératif de prévoir
une maintenance du logiciel.
Conclusion partielle
Dans ce chapitre, nous avons présenté les
fonctionnalités principales de l'application web. D'autres fonctions
telles que la publication d'articles, la modification des contacts, les
consultations par les utilisateurs externes etc. seront amplement
abordées lors de la formation des membres de l'unité. Pour une
utilisation du système au plein de ses capacités, l'unité
doit le faire migrer sur un serveur distant relié à internet puis
rechercher et renseigner les indicateurs relatifs aux secteurs sociaux qui
n'ont pas pu être abordés dans ce document, faute de temps et de
données. Pour finir, soulignons que l'élaboration annuelle de
l'ISP pour tous les secteurs, régions et départements doit
être maintenue et renforcée afin d'assurer à l'unité
une meilleure visibilité du cadre socioéconomique du
Sénégal.
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page 75
Conclusion générale
La présente étude avait un double objectif. Dans
un premier temps, il s'agissait de donner à l'UPITE un aperçu du
cadre socioéconomique du Sénégal depuis l'année
2005 aux travers des différents indicateurs sociaux. Les secteurs
abordés sont l'agriculture et l'éducation. Dans un second temps
l'étude devait déboucher sur un système informatisé
constitué d'une base de données so-cioéconomique
territorialisée et d'un tableau de bord de suivi des projets et
programmes de l'État. Ce système permettra à
l'unité d'accomplir pleinement sa mission qui est d'assurer un meilleur
suivi des projets et programmes puis d'accompagner l'élaboration des
PASER/PASED.
Dans la première partie de l'étude, l'analyse en
composantes principales et les réseaux de KO-HONEN ont permis
d'établir une carte des indicateurs en fonction de leurs
corrélations et une carte des régions en fonction de leurs
proximités. Pour l'agriculture, il est ressorti que les rendements de
certaines cultures évoluent dans le même sens. Il s'agit d'une
part du mil et du niebé et d'autre part de l'arachide et du maïs.
Les régions à fort potentiel agricoles sont celles du bassin
arachidier aux quelles s'ajoutent Tambacounda, Kolda et Ziguinchor. Les plus
faibles performances agricoles sont notées dans les régions de
Matam, Sédhiou, Kédougou et Kaffrine. L'indice synthétique
de performances agricoles (ISPA) construit dans ce rapport à partir de
méthodes factorielles a permis de classer les régions selon leurs
performances à chaque année. En ce qui concerne
l'éducation, les corrélations sont ressorties d'une part entre
les ratios élèves/classes et élèves/maîtres
puis d'autre part entre les taux bruts de scolarisation et de
pré-scolarisation. En termes de proximité, on note que la
région de Dakar est de loin la mieux pourvue en ressources suivie de la
région de Ziguinchor. L'urgence des interventions de l'Etat est plus
ressentie dans les régions de Kaffrine, Kédougou et
Sédhiou. De même que l'ISPA, l'indice synthétique de
performances éducatives (ISPE) a permi d'établir des cartes de
disparité régionales en matière d'éducation.
Dans la seconde partie de l'étude, nous avons mis en
place une structure de données exhaustive prenant en compte les besoins
de l'USPITE. Après l'analyse des besoins et échanges avec les
membres de l'USPITE, nous avons établi un modèle conceptuel de
données. De ce dernier nous avons déduit un modèle logique
puis un modèle physique de données. Parallèlement à
la mise en place des modèles de données, des applications ont
été développées selon les besoins fonctionnels
recueillis. Le système final repose sur une base de données de
type objet-relationnel PostgreSQL, les utilisateurs interagissant avec cette BD
via une application web. Celle ci est développée suivant le
design pattern MVC de sorte à séparer les traitements, les
données et l'affichage. Cette organisation permet une mise à jour
plus aisée de l'application. Les codes sont organisés selon le
framework Cake PHP qui fournit de nombreuses fonctionnalités et une
facilité de développement. Le système ainsi
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page 76
Conclusion Générale
mis en place propose un éventail de
fonctionnalités parmi les quelles gestion et le suivi-évaluation
des projets, la création, la mise à jour et l'exploitation de
données socioéconomiques.
Cette étude revêt une importance majeure dans la
mesure où elle a permis de mettre à disposition de l'unité
les outils nécessaires pour le démarrage effectif de ses
activités. L'utilisation et surtout le développement des outils
mis en place dans cette étude pourra permettre un meilleur suivi des
projets de l'État mais aussi une bonne orientation des financements vers
les localités les plus nécessiteuses. Le défi majeur pour
garantir la stabilité de ce système est la fourniture
régulière des données. Dans cette optique, des
partenariats doivent être mis en place entre l'USPITE et les structures
pourvoyeuses d'informations (ANSD, Ministères techniques etc.).
Brice Baem BAGOA, Elève Ingénieur
des Travaux Statistiques Page I
Annexes et fiches techniques

Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page II
Annexe A
Fiches techniques
A.1 Dictionnaire des données et compléments sur le
système
Tableau A.1 -- Dictionnaire des données
Classes et Attributs Type de données Description
Commentaire
Classe Programmes
id_programme Entier Identifiant du programme ----
nom_programme Chaîne de caractères Nom du programme
----
Cout_Total decimal Coût total du programme ----
Debut_programme DateTime Date de début du programme
----
Fin_programme DateTime Fin prévue pour le programme
----
Organisme_programme Chaîne de caractères Organisme
qui chapeaute l'exécution du programme ----
Classe Régions
id_region Entier Code de la région ----
region Chaîne de caractères Nom de la région
----
Classe Indicateur Social
id_ind_social Entier Cide de l'indicateur social ----
nom_ind_social Chaîne de caractères Nom de
l'indicateur social ----
id_ind_p Entier Code de l'indicateur de projet ----
nom_ind_p Chaîne de caractères Nom de l'indicateur
de projet ----
Valeur_cible float Valeur cible de l'indicateur de projet
----
Date_Cible date Date d'atteinte de la valeur cible ----
Classe Département
id_departement Entier Code du département ----
nom_departement Chaîne de caractères Nom du
département ----
Classe Messages
Suite à la page suivante
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page III
A.1. Dictionnaire des données et compléments sur
le système
Classes et Attributs Type de données Description
Commentaire
id_message Entier Numéro d'ordre du message Auto
Incrementé
Nom_auteur Chaîne de caractères Nom de l'auteur du
message ----
email_auteur Chaîne de caractères Email de l'auteur
du message ----
Tel_auteur Chaîne de caractères
Téléphone de l'auteur du message ----
Motif_Message Chaîne de caractères Motif du message
----
Contenu Chaîne de caractères Contenu du message
----
Date DateTime Date d'envoi du message ----
Classe Contact
id_contact Entier Numéro d'ordre du contact Auto
Incrementé
Telephone Entier Numéro de Téléphone de
l'Unité ----
email Chaîne de caractères Email de l'Unité
----
Adresse Chaîne de caractères Adresse
complète de l'Unité ----
About Chaîne de caractères Brève
présentation de l'Unité ----
Classe Article
id_article Entier Numéro d'ordre de l'article ----
Titre_Article Chaîne de caractères Titre de
l'article ----
contenu Chaîne de caractères Contenu de l'article
----
image Object Image relative à l'article ----
fichier Object Fichier relatif à l'article Peut
être téléchargé
Classe Ministère Technique
id_ministere Entier Code du Ministère ----
nom_ministere Chaîne de caractères Nom du
Ministère ----
Classe User
username Chaîne de caractères Identifiant de
l'utilisateur ----
password Chaîne de caractères Mot de passe ----
statut Chaîne de caractères Administrateur ou
simple membre ----
user_email Chaîne de caractères Email de
l'utilisateur ----
nom Chaîne de caractères Nom de l'utilisateur
----
prenom Chaîne de caractères Prénoms de
l'utilisateur ----
Classe Projet
id_Projet Entier Matricule du projet ----
nom_projet Chaîne de caractères Libellé du
projet ----
Objectif_General Chaîne de caractères Objectif
général du projet ----
Cout_Initial_pr decimal Coût initial du projet ----
Secteur_act Chaîne de caractères Secteur
d'activité auquel se rapport le projet ----
Suite à la page suivante
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page IV
A.1. Dictionnaire des données et compléments sur
le système
Classes et Attributs Type de données Description
Commentaire
sous_secteur Chaîne de caractères Sous Secteur
d'activité auquel se rapport le projet ----
Secteur_inst Chaîne de caractères Secteur
institutionnel auquel se rapport le projet ----
Etat_finance Chaîne de caractères Etat du
financement du projet ----
Nature_finance Chaîne de caractères Nature du
financement du projet ----
Nature_Engagement Chaîne de caractères Nature de
l'engagement ----
Debut_projet DateTime Date de début du projet ----
Fin_projet DateTime Date de fin du projet ----
Organisme_Projet Chaîne de caractères Organisme qui
chapeaute l'exécution du programme ----
Classe Structure
id_service Entier Code de la structure ----
nom_service Chaîne de caractères Nom de la
structure ----
Classe Extrant
id_Extrant Entier Numéro d'ordre de l'Extrant Auto
Incrementé
nom_Extrant Chaîne de caractères Econcé de
l'Extrant ----
Etat Chaîne de caractères Extrant
réalisé ou pas ----
Classe Effet
id_Effet Entier Numéro d'ordre de l'Effet Auto
Incrementé
nom_Effet Chaîne de caractères Econcé de
l'Effet ----
Etat Chaîne de caractères Effet atteint ou pas
----
Classe Impact
id_Impact Entier Numéro d'ordre de l'Impact Auto
Incrementé
nom_Impact Chaîne de caractères Econcé de
l'Impact ----
Etat Chaîne de caractères Impact
réalisé ou pas ----
Classe Secteur Social
id_sect_social Entier Code du secteur ----
nom_sect_social Chaîne de caractères
Libéllé du secteur ----
Classe Info Complémentaire
id_info Entier Numéro d'ordre de l'information Auto
Incrementé
Type_info Chaîne de caractères Type d'information
----
Commentaire Chaîne de caractères Commentaire
relatif à l'information ----
Classe-Association d_relatif_is
Annee_ind_dep Entier Année ----
Valeur_ind_dep float Valeur de l'indicateur à cette
année ----
Source_ind_dep Chaîne de caractères Source de
cette valeur ----
Classe-Association reg_relatif_is
Suite à la page suivante
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page V
A.1. Dictionnaire des données et compléments sur
le système
Classes et Attributs Type de données Description
Commentaire
Annee_ind_reg Entier Année ----
Valeur_ind_reg float Valeur de l'indicateur à cette
année ----
Source_Ind_reg Chaîne de caractères Source de cette
valeur ----
Classe-Association ind_mesure_ext
Annee DateTime Date ----
Valeur_ext Entier Valeur de l'indicateur à cette date
----
Source_ext Chaîne de caractères Source de cette
valeur ----
Comm_Extr Chaîne de caractères Commentaire sur le
suivi de l'extrant ----
Classe-Association ind_mesure_eff
Annee_eff DateTime Date ----
Valeur_eff Entier Valeur de l'indicateur à cette date
----
Source_eff Chaîne de caractères Source de cette
valeur ----
Comm_Eff Chaîne de caractères Commentaire sur le
suivi de l'effet ----
Classe-Association ind_mesure_imp
Annee_imp DateTime Date ----
Valeur_imp Entier Valeur de l'indicateur à cette date
----
Source_imp Chaîne de caractères Source de cette
valeur ----
Comm_imp Chaîne de caractères Commentaire sur le
suivi de l'impact ----
Classe Ressource
id_ressource Entier Identifiant de la ressource ----
Type_ressurce Chaîne de caractères Type de
ressource (humaines, financières etc.) ----
Classe Activité
id_activite Entier Numéro d'ordre de l'activité
Auto Incrementé
nom_activite Chaîne de caractères Enoncé de
l'activité ----
debut_activite DateTime Date de début de
l'activité ----
fin_activite DateTime Fin prévue pour l'activité
----
Debut_effectif DateTime Démarrage effectif de
l'activité Peut être vide
fin_effective DateTime Fin effective de l'activité Peut
être vide
Cmmentaire_act Chaîne de caractères Commentaires
relatifs à l'activité Peut être vide
Classe-Association res_affecte_activite
Valeur_ressource Chaîne de caractères Valeur de la
ressource affectée ----
Classe Bailleur
id_bailleur Entier Code du bailleur de fonds ----
nom_bailleur Chaîne de caractères Nom du bailleur
----
commentBailleur Chaîne de caractères Commentaire
relatif au bailleur ----
Suite à la page suivante
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page VI
A.2. Compléments de l'Analyse en composantes
principales
Classes et Attributs Type de données Description
Commentaire
Classe-Association Montant
Montant long Montant du financement d'un bailleur ----
Classe Plan_Finance
Id_Plan Entier Identifiant du plan de financement Auto
Incrementé
Planification Chaîne de caractères Planification du
financement ----
Classe-Association prj_plan_fin
Annee Entier Année de l'évaluation ou du suivi
----
Dep_Effectiv float Dépense à cette année
----
Taux_Avancement float Avancement du projet à cette
année ----
Comment_Fian Chaîne de caractères Commentaires
----
Source: Nos recherches
Tableau A.2 -- Technologie utilisée
pour la conception du système
Fonction Logiciel / Langages
SGBD PostgreSQL (v 9.3) /PostGIS (v 2.1)
Modélisation Power AMC
Notations UML
Langages HTML, CSS, JavaScript, PHP, SQL
Design du site Model View Controller
Serveur Web Apache Entreprise DB
Editeur Komodo Edit 8.5
Navigateur Web Google Chrome
Framework MVC Cake PHP
Librairies JS pour les graphes HightCharts
Librairies JS pour les cartes HightMaps
Analyses statistiques STATA, SPSS, R, Tanagra
A.2 Compléments de l'Analyse en composantes
principales
A.2.1 Les aides à l'interprétation
Pour interpreter les résultats de l'ACP sur un ensemble
d'individus, on définit les critères suivants :
~ Le cosinus Carré : Il constitue un
critère important permettant de mesurer la qualité de la
représentation d'un point Qi par
projection sur l'axe. Gá(i)
étant la coordonnée factorielle de l'individu i sur
l'axe á, on a :
Cos2 i = Gá(i)
(A.1)
d2(O,Qi)
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page VII
A.2. Compléments de l'Analyse en composantes
principales
Plus le Cos2 est proche de 1, plus l'individu est bien
représenté sur l'axe factoriel.
~ La qualité de représentation : Elle
est comprise entre 0 et 1. Mieux un point est représenté dans le
plan factoriel, plus elle est proche de 1. Si k est le nombre d'axes factoriels
sélectionnés, la qualité de représentation
s'exprime comme suit :
QLTk(i) = Xk
Cos2 á(i) (A.2)
á=1
~ La contribution : C'est la contribution de
l'individu à la formation de l'axe factoriel. Elle est donné par
:
Gá(i)
CRTá(i) = > (A.3)
â Gâ(i)
~ L'originalité d'un point : C'est la distance
d'un point i du centre de gravité du nuage des individus. Elle est
donnée par :
DISTO(i) = d(i, O) (A.4)
A.2.2 Le choix du nombre d'axes factoriels
Le choix du nombre d'aces factoriels n'est pas fortuit et doit
se faire de sorte à ce que le plan factoriel choisi puisse
représenter le maximum de l'information disponible dans le tableau de
départ. On définit les règles suivantes :
~ Le taux d'inertie: Il donne la part d'information
représentée par les k premiers axes factoriels
sélectionnés. Il est donné par :
>k á=1
ëá
Rk = × 100 (A.5)
Itotale
La valeur de k est fixée de sorte que Rk
= RSeuil, RSeuil étant
fixé à priori (généralement 60% à 80%).
~ La règle du coude de Cattel : Elle cherche
à identifier les axes les plus riches en information. Comme les
ëá forment une suite
décroissante, la règle du coude cherche à
déterminer sur l'histogramme des valeurs propres l'existence d'un coude
ou d'un palier. Le nombre d'axes à retenir correspond alors au coude
pour lequel on note une diminution de l'inertie.

Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page VIII
Annexe B
Quelques graphiques et tableaux utiles
Tableau B.1 -- Evolution de l'ISPA suivant les
régions
|
Région
|
2005
|
2006
|
2007
|
2008
|
2009
|
2010
|
2011
|
2012
|
|
DAKAR
|
0.3980
|
0.5135
|
0.1953
|
0.9974
|
0.3733
|
0.5440
|
0.6412
|
0.6320
|
|
DIOURBEL
|
0.2304
|
0.9829
|
0.3605
|
0.4004
|
0.4803
|
0.6203
|
0.6511
|
0.5677
|
|
FATICK
|
0.6131
|
0.8834
|
0.0000
|
0.8432
|
0.4292
|
0.6485
|
0.7261
|
0.2304
|
|
KAFFRINE
|
|
|
|
|
|
0.4807
|
0.6228
|
0.2307
|
|
KAOLACK
|
0.7671
|
0.9320
|
0.5224
|
0.0301
|
0.5056
|
0.5031
|
0.4830
|
0.3560
|
|
KEDOUGOU
|
|
|
|
|
|
0.1430
|
0.4628
|
0.4542
|
|
KOLDA
|
0.9050
|
0.8929
|
0.5219
|
0.5864
|
0.3745
|
0.0000
|
0.6869
|
0.6232
|
|
LOUGA
|
0.0658
|
0.2600
|
0.3550
|
0.2453
|
0.7494
|
1.0000
|
0.5929
|
0.4460
|
|
MATAM
|
0.0673
|
0.5698
|
0.6278
|
0.8430
|
0.4242
|
0.5600
|
0.8063
|
0.3081
|
|
SAINT-LOUIS
|
0.7174
|
0.7983
|
1.0000
|
0.0000
|
0.3610
|
0.2176
|
0.0000
|
1.0000
|
|
SEDHIOU
|
|
|
|
|
|
0.5292
|
0.9158
|
0.4126
|
|
TAMBACOUNDA
|
0.9879
|
0.9706
|
0.3860
|
0.2283
|
0.9747
|
0.4292
|
0.4657
|
0.0000
|
|
THIES
|
0.0000
|
0.2401
|
0.1750
|
1.0000
|
0.5225
|
0.7483
|
1.0000
|
0.4317
|
|
ZIGUINCHOR
|
0.6949
|
0.7244
|
0.3485
|
0.6891
|
0.0000
|
0.8190
|
0.3162
|
0.2296
|
Source: Nos claculs
Tableau B.2 -- Evolution de l'ISPE suivant les
région
|
Région
|
2005
|
2006
|
2007
|
2008
|
2009
|
2010
|
2011
|
|
DAKAR
|
0.6094
|
0.8053
|
0.0948
|
0.4614
|
0.1526
|
0.6104
|
0.2359
|
|
DIOURBEL
|
0.0982
|
0.8208
|
0.3939
|
0.9023
|
0.7435
|
0.4692
|
0.1631
|
|
FATICK
|
0.8069
|
0.6003
|
0.3353
|
0.4469
|
0.1202
|
0.2420
|
0.0619
|
|
KAFFRINE
|
|
|
|
|
|
0.8107
|
1.0000
|
|
KAOLACK
|
0.7154
|
0.5943
|
0.3514
|
0.4374
|
0.0989
|
0.3939
|
0.1299
|
|
KEDOUGOU
|
|
|
|
|
|
0.9298
|
0.3524
|
|
KOLDA
|
0.8204
|
0.4919
|
0.2319
|
0.4796
|
0.1934
|
0.3344
|
0.0100
|
|
LOUGA
|
0.0280
|
0.2958
|
0.0000
|
0.9548
|
0.8750
|
1.0000
|
0.2761
|
|
MATAM
|
0.7652
|
0.6934
|
0.3169
|
0.3933
|
0.0000
|
0.5304
|
0.0305
|
|
SAINT-LOUIS
|
0.0410
|
0.3903
|
0.5177
|
0.5735
|
1.0000
|
0.9015
|
0.2682
|
|
SEDHIOU
|
|
|
|
|
|
0.0000
|
0.0000
|
|
TAMBACOUNDA
|
0.0098
|
0.4779
|
0.6801
|
0.6537
|
0.6090
|
0.8568
|
0.3114
|
|
THIES
|
1.0000
|
0.8572
|
0.1867
|
0.0000
|
0.5898
|
0.0878
|
0.1441
|
|
ZIGUINCHOR
|
0.0648
|
0.2036
|
1.0000
|
0.4134
|
0.5961
|
0.9085
|
0.3153
|
Source : Nos calculs
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page IX
Graphique B.1 -- Evolution des rendements du
mil suivant les régions
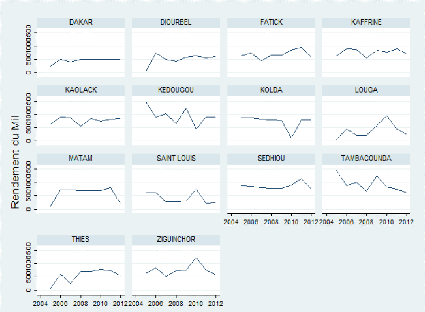
Source : ANSD, Nos calculs
Graphique B.2 -- Evolution des rendements de
l'arachide suivant les régions
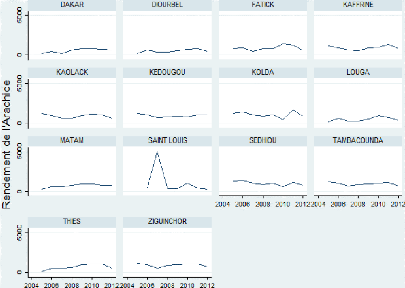
Source : ANSD Nos calculs
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page X
Graphique B.3 -- Evolution de l'ISPA suivant
les régions
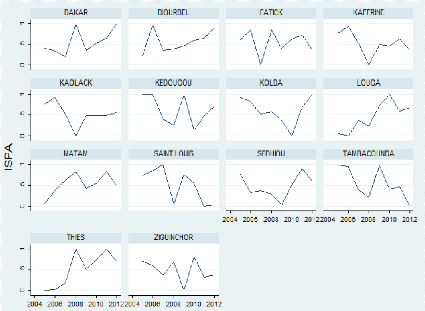
Source: Nos calculs
Graphique B.4 -- Evolution de l'ISPE suivant
les régions
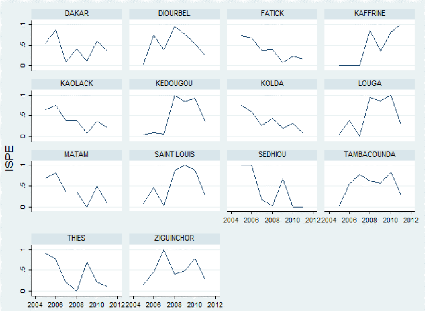
Source : Nos calculs
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page XI
Graphique B.5 -- Consultation des
détails d'un projet
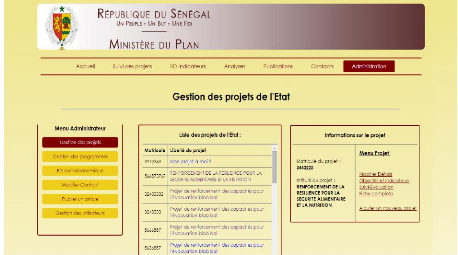
Source: Nos travaux
Graphique B.6 -- Création d'un
projet
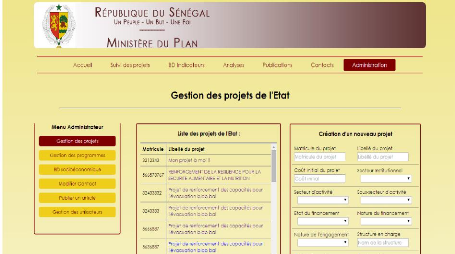
Source : Nos travaux
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page XII
Graphique B.7 -- Calcul d'un ratio
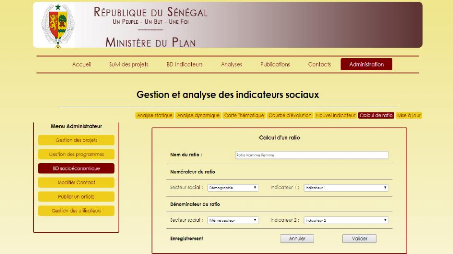
Source: Nos travaux
Graphique B.8 -- Publication d'un article par
les membres de l'unité
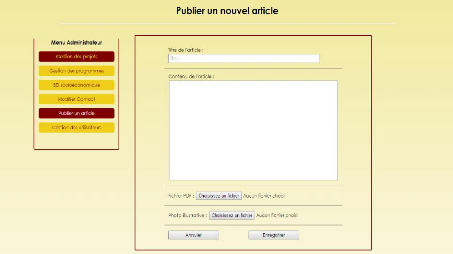
Source : Nos travaux
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page XIII
Bibliographie
[1] Stratégie Nationale de développement
Economique et Social 2013 - 2017.
[2] Plan Sénégal Emergent. 2014.
[3] Aubert, J. Bases de données :
implémentation avec Access. Technosup (Paris). Ellipses Marketing,
2004.
[4] Bersini, H. La programmation orientée objet.
Eyrolles, 2011.
[5] Casals, J., Jerez, M., and Sotoca, S. Exact smoothing for
stationary and non-stationary time series. International Journal of
Forecasting 16, 1 (2000), 59-69.
[6] Chawdhary, Z. PostGIS QuickStart : Introduction to
PostGIS. PostGIS. 2014.
[7] Cornec, M., and Deperraz, T. Un nouvel indicateur
synthétique mensuel résumant le climat des affaires dans les
services en france. Economie et statistique 395, 1 (2006), 13-38.
[8] Corti, P. e. A. PostGIS Cookbook:. Quick answers to
common problems. Packt Publishing
Ltd, 2014.
[9] Darie, C., Bucica, M., and Balanescu, E. Beginning
PHP and PostgreSQL E-Commerce : From Novice to Professional. The Expert's
Voice in Open Source. Apress, 2006.
[10] DCEF. Programme Triénal d'Investissements
Publics 2014-2016. Ministère de L'Economie et des Finances,
2013.
[11] De Jong, P. The likelihood for a state space model.
Biometrika 75, 1 (1988), 165-169.
[12] De Jong, P., et al. The diffuse kalman filter. The
Annals of Statistics 19, 2 (1991), 1073- 1083.
[13] de Jong, P., and Penzer, J. The arma model in state
space form. Statistics & probability letters 70, 1 (2004),
119-125.
[14] Dosso, A. Mise en place d'un système
d'information pour le suivi des activités liées aux projets de
santé à la dipe. Master's thesis, Ecole Nationale de la
Statistique et de l'Economie Appliquée (ENSEA), 2009.
[15] Douglas, K., and Douglas, S. PostgreSQL : A
Comprehensive Guide to Building, Programming, and Administering PostgresSQL
Databases. Developer's library. Sams, 2003.
[16] DPNCPR. Projet Plan d'Orientation pour le
développement Economique et Social 2002-2007 (Xe plan).
Ministère du Plan et du développement durable, 2004.
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page XIV
Bibliographie
[17] Drucker, P. Managing For Results. Taylor &
Francis, 2012.
[18] Federici, A., and Mazzitelli, A. Dynamic factor analysis
with stata. University of Rome La Sapienza (2009).
[19] Forni, M., Hallin, M., Lippi, M., and Reichlin, L. The
generalized dynamic-factor model : Identification and estimation. Review of
Economics and statistics 82, 4 (2000), 540-554.
[20] Gardarin, G. Bases de données: 5ème
tirage 2003. Best of Eyrolles. Eyrolles, 2012.
[21] Geschwinde, E., and Schönig, H. PostgreSQL
Developer's Handbook. Developer's Library. Sams, 2002.
[22] Geweke, J. The dynamic factor analysis of economic time
series models. University of Wisconsin, 1976.
[23] Hainaut, J. Bases de données - 2e éd. -
Concepts, utilisation et développement: Concepts, utilisation et
développement. Informatique. Dunod, 2012.
[24] Hall, B., and Leahy, M. Open Source Approaches in
Spatial Data Handling. Advances in Geographic Information Science.
Springer, 2008.
[25] Hamilton, J. D. State-space models. Handbook of
econometrics 4 (1994), 3039-3080.
[26] Hindrayanto, A. I. W. Periodic seasonal time series
models with applications to us macroeconomic data.
[27] JAUBERT, L. Conception d'une base de données
d'aide à la décision du patrimoine du C.E.A. de Grenoble.
CNAM, 2001.
[28] Kropla, B. Beginning MapServer : Open Source GIS
Development. Expert's Voice in Open Source. Apress, 2006.
[29] Lardière, S. PostgreSQL : administration et
exploitation d'une base de données. Ressources informatiques.
Editions ENI, 2007.
[30] Larrousse, N., and Innocenti, E. Création de
bases de données. Synthex, synthèse de cours et exercices
corrigés. Pearson Education, 2006.
[31] Lemoine, M., and Pelgrin, F. Introduction aux
modèles espace-état et au filtre de kalman. Revue de
l'OFCE, 3 (2003), 203-229.
[32] MEF. Eude prospective Sénégal
2035. Ministère de l'Economie et des Finances, 2011.
[33] MEF. Plan Sénégal Emergent: Plan
d'actions Prioritaires 2014-2018. Ministère de L'Econo-mie et des
Finances, 2014.
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page XV
Bibliographie
[34] Mingoti, S. A., and Lima, J. O. Comparing som neural
network with fuzzy c-means, k-means and traditional hierarchical clustering
algorithms. European Journal of Operational Research 174, 3 (2006),
1742-1759.
[35] Mitchell, T. Web Mapping Illustrated : Using Open
Source GIS Toolkits. O'Reilly Series. O'Reilly Media, 2005.
[36] Nguiakam, S. Conception d'une base de données
socio-économique des etats de l'uemoa. Master's thesis, Ecole Nationale
de la Statistique et de l'Economie Appliquée (ENSEA), 2009.
[37] PNUD. Guide du suivi et de l'évaluation
axés sur les résultats, 2002.
[38] Quah, D., and Sargent, T. J. A dynamic index model for
large cross sections. In Business cycles, indicators and forecasting.
University of Chicago Press, 1993, pp. 285-310.
[39] Richard, M. Coopération pour le
Développement: Rapport 2007. Coopération pour le
Développement : Rapport. OECD Publishing, 2008.
[40] Rigaux, P. Pratique de MySQL et PHP : Conception et
réalisation de sites web dynamiques. Etudes, développement,
intégration. Dunod, 2009.
[41] Roques, P. UML 2 : Modéliser une application
web. Les cahiers du programmeur. Eyrolles,
2008.
[42] Roy, G. Conception de bases de données avec
UML. Presses de l'Universite du Quebec, 2007.
[43] Serati, M., and Amisano, G. Building composite leading
indexes in a dynamic factor model framework : a new proposal. Liuc papers
(2008).
[44] Shekhar, S., and Xiong, H. Encyclopedia of GIS.
Encyclopedia of GIS. Springer, 2008.
[45] Soutou, C. UML 2 pour les bases de données:
Avec 20 exercices corrigés. Noire. Eyrolles, 2011.
[46] Soutou, C., and Brouard, F. ULM 2 pour les bases de
données: Modélisation, normalisation, génération,
SQL, outils - Avec 30 exercices corrigés. Noire. Eyrolles, 2012.
[47] Sow, S. Cours de suivi et Evaluation des
projets. ENSAE, 2014.
[48] Stinson, B. PostgreSQL Essential Reference.
Essential Reference Series. New Riders, 2001.
[49] Stock, J. H., and Watson, M. W. Dynamic factor models.
Oxford Handbook of Economic Forecasting. Oxford University Press, USA
(2011), 35-59.
[50] Stones, R., and Matthew, N. Beginning Databases with
PostgreSQL : From Novice to Professional. Books for professionals by
professionals. Apress, 2005.
Brice Baem BAGOA, Elève Ingénieur des Travaux
Statistiques Page XVI
Bibliographie
[51] Tardieu, H., Rochfeld, A., and Colletti, R. La
méthode MERISE. : Principes et outils. No. vol. 1. Editions
d'Organisation, 2000.
[52] Tufféry, S. Data mining et statistique
décisionnelle: l'intelligence des données. Technip, 2005.
[53] Watson, M. W., and Stock, J. New indexes of coincident
and leading economic indicators.
Macroeconomics Annual 4, 351-409.
[54] Zirogiannis, N., and Tripodis, Y. A generalized dynamic
factor model for panel data : Estimation with a two-cycle conditional
expectation-maximization algorithm. University of Massachusetts at Amherst
Department of Resource Economics, 2013-1 (2013).
[55] Zuur, A., Tuck, I., and Bailey, N. Dynamic factor analysis
to estimate common trends in fisheries time series. Canadian journal of
fisheries and aquatic sciences 60, 5 (2003), 542- 552.
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page XVII
Table des matières
Liste des tableaux iii
Table des figures iv
Sigles et abréviations vi
Avant propos vii
Remerciements viii
Résumé ix
Abstract x
Introduction Générale 1
0.1 Contexte 1
0.2 Problématique 1
0.3 Objectifs de l'étude 2
0.4 Structuration de ce document 3
1 Cadre général du suivi des projets de
l'Etat 4
1.1 La notion de projet 4
1.1.1 Suivi et évaluation des projets 4
1.1.2 La gestion axée sur les résultats 5
1.2 Le système national de planification 6
1.3 Processus d'instruction des projets publics 7
1.3.1 L'évaluation ex-ante 7
1.3.2 L'exécution et le suivi physico-financier 8
1.3.3 L'évaluation ex-post 8
1.3.4 Les limites du système existant 8
1.4 Présentation du SNSPITE 9
1.4.1 Les Unités de Gestion des Projets (UGP) 9
1.4.2 Les ministères techniques 9
1.4.3 L'USPITE 10
1.4.4 Les organes Ad Hoc du SNSPITE 10
Conclusion partielle 11
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page XVIII
|
|
Table des matières
|
|
2
|
Bilan des approches et réalisations en
matière de bases de données
2.1 La notion de base de données
2.1.1 Motivation et définition
2.1.2 Les propriétés ACID d'une base de
données
2.1.3 Terminologie des bases de données
2.2 Évolution des modèles de bases de
données
|
13
13
13
14
14
15
|
|
|
2.2.1 Les systèmes de gestion de fichiers
|
15
|
|
|
2.2.2 Des modèles hiérarchiques aux modèles
en réseau
|
16
|
|
|
2.2.3 Le modèle relationnel
|
16
|
|
|
2.2.4 L'ère post-relationnelle : Les BD objet
|
17
|
|
|
2.2.5 Les défis contemporains : le business intelligence
et le Big Data
|
18
|
|
2.3
|
Les méthodes d'analyse
|
19
|
|
|
2.3.1 La methode MERISE et le modèle
Entité-Association
|
19
|
|
|
2.3.2 L'Unified Modeling Laguage (UML)
|
20
|
|
2.4
|
Les Systèmes de Gestion de Bases de Données (SGBD)
|
21
|
|
|
2.4.1 Les principales fonctions des SGBD
|
22
|
|
|
2.4.2 Architecture des SGBD
|
22
|
|
Conclusion partielle
|
23
|
|
3
|
Approche Méthodologique et sources de
données
|
24
|
|
3.1
|
Analyse exploratoire
|
25
|
|
|
3.1.1 L'analyse en composantes principales
|
25
|
|
|
3.1.1.1 Présentation théorique :
|
25
|
|
|
3.1.1.2 Application de l'ACP
|
26
|
|
|
3.1.2 La classification automatique par le réseau de
KOHONEN
|
26
|
|
|
3.1.2.1 Présentation théorique :
|
27
|
|
|
3.1.2.2 Application :
|
28
|
|
3.2
|
Elaboration de l'ISP
|
28
|
|
|
3.2.1 Les limites de l'analyse en composantes principales
|
29
|
|
|
3.2.2 L'analyse factorielle dynamique
|
29
|
|
|
3.2.2.1 Cadre théorique de l'AFD
|
29
|
|
|
3.2.2.2 Extension aux données de panel
|
30
|
|
|
3.2.2.3 Construction de l'ISP par AFD
|
31
|
|
|
3.2.3 Approche par décomposition de la variabilité
totale
|
31
|
|
|
3.2.4 Sélection des variables d'étude
|
32
|
|
3.3
|
Généralités sur la conception du
système
|
33
|
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page XIX
|
|
Table des matières
|
|
3.4
|
3.3.1 Quel type de système?
3.3.2 Démarche générale de conception
Démarche d'implémentation des structures de
données
|
33
34
35
|
|
|
3.4.1 Le niveau conceptuel
|
35
|
|
|
3.4.1.1 Définition des concepts utilisés
|
36
|
|
|
3.4.1.2 Les différents types d'associations
|
36
|
|
|
3.4.1.3 Règles de validation du modèle conceptuel
|
37
|
|
|
3.4.2 Le passage au niveau logique
|
39
|
|
|
3.4.3 Le niveau physique
|
39
|
|
3.5
|
Démarche d'implémentation de l'IHM
|
39
|
|
|
3.5.1 Généralités sur l'application
|
40
|
|
|
3.5.2 Organisation du code : le design pattern MVC
|
41
|
|
|
3.5.2.1 Fonctionnement du MVC
|
41
|
|
|
3.5.2.2 Rôle des composantes
|
41
|
|
3.6
|
Les sources de données
|
42
|
|
Conclusion partielle
|
42
|
|
4
|
Analyse du cadre socioéconomique du
Sénégal
|
43
|
|
4.1
|
Évolution des indicateurs entre 2005 et 2012
|
43
|
|
|
4.1.1 Agriculture
|
43
|
|
|
4.1.1.1 Le rendement du mil
|
44
|
|
|
4.1.1.2 Le rendement de l'arachide
|
44
|
|
|
4.1.2 Éducation
|
45
|
|
|
4.1.2.1 Le ratio élèves sur salles de classes au
primaire
|
45
|
|
|
4.1.2.2 Le ratio élèves sur maîtres au
primaire
|
46
|
|
4.2
|
Analyse exploratoire
|
47
|
|
|
4.2.1 Structure des corrélations entre les indicateurs
|
47
|
|
|
4.2.1.1 Agriculture
|
47
|
|
|
4.2.1.2 Éducation
|
48
|
|
|
4.2.2 Étude de la proximité des régions
|
48
|
|
|
4.2.2.1 Agriculture
|
49
|
|
|
4.2.2.2 Éducation
|
49
|
|
4.3
|
L'indice synthétique de performances
|
51
|
|
|
4.3.1 Agriculture
|
51
|
|
|
4.3.2 Éducation
|
52
|
|
Conclusion partielle
|
52
|
Brice Baem BAGOA, Elève Ingénieur des
Travaux Statistiques Page XX
Table des matières
5 Implémentation et déploiement du
système 54
5.1 Quelles fonctionnalités pour le futur système?
54
5.2 Implémentation des structures de données
55
5.2.1 Élaboration du modèle conceptuel de
données 55
5.2.2 Passage au modèle logique de données 60
5.2.3 Implémentation du modèle physique de
données 63
5.3 Conception de l'IHM 65
5.4 Déploiement du système 65
Conclusion partielle 66
6 Opérationnalisation du système, limites
de l'étude et recommandations 67
6.1 Accueil et authentification 67
6.1.1 Présentation générale 67
6.1.2 Le menu Administrateur 69
6.2 Utilisation du tableau de bord de suivi des projets 70
6.3 Utilisation de la BD socioéconomique 71
6.4 Limites de l'étude 73
6.5 Recommandations et perspectives 73
Conclusion partielle 74
Conclusion générale 75
Annexes et fiches techniques I
A Fiches techniques II
A.1 Dictionnaire des données et compléments sur le
système II
A.2 Compléments de l'Analyse en composantes principales
VI
A.2.1 Les aides à l'interprétation VI
A.2.2 Le choix du nombre d'axes factoriels VII
B Quelques graphiques et tableaux utiles VIII
Bibliographie XIII
| 

