|
UNIVERSITÉ AUBE NOUVELLE

INSTITUT SUPERIEUR D'INFORMATIQUE ET DE
GESTION
ISIG High Tech
MEMOIRE DE MASTER RECHERCHE en Informatique
OPTION :
Imagerie Numérique pour le Développent Durable

MOUVEMENT D'OBJET DANS UNE IMAGE : DETECTION D'OBJET EN
MOUVEMEN
THÈME : VERS LA RECONNAISSANCE
DE
Présenté par : Sous la direction de
:
Ali OUCHAR CHERIF Dr Aime METCHEBON
Année : 2013 - 2014
II
Résumé
La reconnaissance de mouvement suspect d'objet ou de personne
dans une image a une grande importance et constitue un challenge dans le
domaine de la surveillance via les caméras. Cette reconnaissances de
mouvement suspect d'objet passe par plusieurs phases à savoir : la
détection, le suivi, la création d'une base de données ou
vocabulaire par rapport à laquelle les mouvements pourront être
comparés afin d'être reconnus et qualifiés de suspects ou
non. Dans ce travail, nous nous intéressons à la phase de
détection d'objet ou de personne en mouvement dans une image. Nous
faisons une étude comparative de méthodes de détection de
mouvement d'objet ou de personnes dans une séquence vidéo. En
nous basons sur les méthodes existantes de détection de
mouvement, nous justifions le choix et faisons l'implémentation de trois
d'entre elles.
Abstract
The recognition of suspect movement of object or anybody in an
image has great importance and constitutes a challenge in the field of the
monitoring via the cameras. This recognitions of suspect movement of object
passes by several phases to knowing: detection, the follow-up, the creation of
a data base or vocabulary compared to which the movements could be or not
compared in order to be recognized and qualified suspects. In this work, we are
interested in the phase of target detection or anybody moving in an image. We
make a comparative study of methods of detection of movement of object or
people in a video sequence. In we let us base on the existing methods of
detection of movement, we justify the choice and make the implementation of
three of them.
III
Dédicaces
Je dédie le fruit de ce travail à mon
père
OUCHAR CHERIF que son âme repose en paix
et ma très chère mère,
SOUAD ALI AKACHA
pour leurs amour, leurs sacrifices acquiescés
à mon égard, pour leurs soutiens
indéfectibles,
leurs confiances,
leurs conseils, leurs orientations et la gratitude
de leur amour pour moi et pour mes frères.
Que Dieu les combles au-delà de leurs
attentes.
iv
Remerciements
Nous tenons à présenter nos sincères
remerciements à Université Aube Nouvelle ex ISIG (Institut
Supérieur de l'informatique et de Gestion) pour nous avoir offert un
cadre d'étude supérieure adéquat, répondant
à nos attentes et critères de formation.
Nos remerciements s'adressent aussi à l'endroit du corps
professoral de l'université Aube Nouvelle pour sa disponibilité,
sa qualité, son effort et sa rigueur dans l'optique de nous inculquer
une formation d'excellence.
Nos vifs remerciements vont à l'endroit de :
Docteur Aimé METCHEBON, qui n'a jamais refusé une
seconde de son temps à suivre mes travaux avec ses orientations,
conseils et par-dessus tout le temps qu'il a sacrifié pour la
réalisation du présent travail malgré ses multiples
occupations;
- M. Mbainadijel ALEXIS, chef de service informatique de la GMIP
Allemagne ;
- Mon père OUCHAR Cherif, que son âme repose en paix
;
- Ma chère maman SOUAD Ali Akacha, une mère unique
en son genre, pour son
amour, son soutien, ses sacrifices, ses conseils et ses efforts
robustes concédés pour la
réussite de mes études ;
- Toute ma famille, mes jeunes frères à savoir :
Cherif, Oumar, Mahadi et sans oublie
mon petit adorable Mahamoud pour leurs concours, soutiens et
amour.
- À AHMAT Hassan Mahamat, BRAHIM Adoum Ahmat et ABOUBAKAR
Djimé des
amis exceptionnels ;
- À la famille OUCHAR et AKACHA pour leurs soutiens tout
au long de mes années
d'études ;
- À Ahmat ALI AKACHA, un oncle pas comme les autres ;
- À KHADIDJA Herindji, une femme exceptionnelle et unique,
merci pour tout ;
- À tous ceux qui comptent pour moi ;
- À tous ceux pour qui je compte.
v
Sommaire
Résumé ii
Abstract ii
Dédicaces iii
Remerciements iv
Liste des figures vii
Liste des tableaux viii
Introduction 1
? Contexte et intérêt de l'étude
1
? Problématique 2
? Objectif 2
? Plan du travail 3
Chapitre 1 : Cadre de l'étude 4
1.1. Cadre théorique 4
1.1.1. Image 4
1.1.2. Définition d'une vidéo 12
Conclusion 14
Chapitre 2 : État de l'art 15
2.1. Détection par Différences entre deux images
consécutives 15
2.2. Flux optique 16
2.3. Soustraction de l'arrière-plan par
modélisation statistique 16
2.4. Détection par Histogramme 19
2.5. Détection par couleur 20
2.6. Méthode de détection par Technique du Gradient
22
2.7. Tableau comparatif de méthodes 23
Conclusion 25
Chapitre 3 : Choix de la méthode retenue et
modélisation 26
3.1. Soustraction d'arrière-plan par modélisation
statistique 26
3.2. Détection par différence d'images 29
Conclusion 33
Chapitre 4 : Le matériel utilisé 34
4.1. Les outils nécessaires pour la vision
artificielle 34
4.1.1. MinGW ou Mingw32 (Minimalist GNU for Windows) 34
4.1.2. CMakesFiles 34
4.1.3. Code::Blocks 35
4.1.4. OpenCv (Open Source Computer Vision) 35
4.2. Les étapes d'installation des
différentes applications 36
4.2.1. Étape 1: Installation de MinGW 36
4.2.2. Étape 2: Ajout de chemin d'accès de MinGW
au système 36
4.2.3. Étape 3: Installation Code :: Blocks (notre API
choisi) 38
4.2.4. Étape 4: Installer OpenCV 38
4.2.5. Étape 5: Ajout de OpenCV à la trajectoire
du système 40
4.2.6. Étape 6: Configuration du Code::Blocks avec OpenCV
40
4.3. Les fonctions utiles 44
Conclusion 46
Chapitre 5 : Implémentation et Discussions sur les
résultats 47
5.1. Implantation logicielle 47
5.1.1. Interface 47
5.1.2. Optimisations 48
5.2. Expérimentations 48
5.3. Performance 49
5.4. Implémentions de méthodes de
détection : Résultats et discussions 49
5.4.1. Détection par différence entre deux images
consécutives 49
5.4.2. Détection par soustraction d'arrière-plan
52
5.5. Élimination des ombres 55
Conclusion 56
Conclusion Générale 57
Bibliographie 58
Annexes 64
1. Programme en C ++ pour la détection par
différence d'images 64
2. Programme en C++ pour la détection par
soustraction d'arrière-plan 66
vi
« La meilleure façon d'apprendre est de
suivre des exemples ». A. Einstein
VII
Liste des figures
Figure 1: Histogramme d'une image en RGB 7
Figure 2: Image en niveau de gris et son histogramme
cumulé 8
Figure 3: Modification d'histogramme 9
Figure 4: Étirement et Histogramme de l'image
Étirée 9
Figure 5 : Égalisation et Histogramme de l'image
égalisée 10
Figure 6 : Dilatation d'image 11
Figure 7 : Érosion d'image 11
Figure 8: Exemple d'une séquence d'images 13
Figure 9: Technique de différence avec image de
référence, (a) l'image à l'instant t, (b) l'image
de
référence, (c) l'image de différence.
30
Figure 10: Technique de différence sans image de
référence, (a) image précédente, (b) image
courante, (c) image de différence. 32
Figure 11: Variable Environnement 37
Figure 12: Ajout de chemin 37
Figure 13 : Décompression OpenCv 38
Figure 14: installation de cmake 39
Figure 15: Ajout d'OpenCv à la variable 40
Figure 16: Test de mingw dans la variable path 40
Figure 17: Choix de l'application du projet 41
Figure 18: Interface de code::blocks 41
Figure 19: Interface de Configuration 42
Figure 20: Ajout du répertoire au compilateur
42
Figure 21: Ajout du répertoire OpenCv au Linker du
code::blocks 43
Figure 22: Ajout des librairies à l'IDE 43
Figure 23 : Image de détection 52
Figure 24 : Détection de mouvement par moyen mobile
54
VIII
Liste des tableaux
Tableau 1: Tableau comparative des méthodes
abordées 24
Tableau 2: Tableau comparatif de performance pour la
soustraction de l'arrière-plan à
différentes résolutions d'images et
fréquences de mise à jour du modèle 49
Introduction
? Contexte et intérêt de
l'étude
La vision par ordinateur est une branche d'intelligence
artificielle dont le but est de permettre à une machine de comprendre ce
qu'elle «voit ». Elle peut servir entre autre à la
reconnaissance de formes, qui consiste à reconnaitre une forme dans une
image après l'avoir enregistrée.
Une des particularités des êtres vivants est de
pouvoir acquérir des images, via l'oeil, comme une information, puis de
pouvoir l'interpréter via le cerveau. L'enjeu de la vision artificielle,
domaine dont est issu le sujet que nous allons traiter, est de permettre
à un ordinateur de »voir» ; C'est-à-dire, comme
l'homme, de récupérer l'information par l'intermédiaire
d'un dispositif d'acquisition d'image (une caméra ou bien un autre
support numérique) puis de l'exploiter à travers un programme
(exemple bibliothèque OpenCV), implémenter dans un langage de
programmation tel que (C, C++, Java, Matlab, Python, etc.).
La détection d'objet en mouvement est un domaine
très actif de la vision par ordinateur. De nombreux secteurs, et plus
particulièrement celui de la surveillance nécessitent une analyse
automatique de vidéos présentant des personnes ou des objets en
mouvement. De nombreux travaux ont été menés aux cours des
dernières décennies et de nombreuses approches ont
été mises en oeuvre, on peut citer les travaux de recherches de
(Benabbas, 2012) ; toutefois la plupart d'entre elles ne sont
valables que dans certaines situations spécifiques.
Une méthode fonctionnant parfaitement quel que soit le
type de situation n'existe pas encore. Des algorithmes robustes de
détection de personnes individuelles dans des scènes à
faible densité ont aussi été proposés. Nous allons
nous intéresser au cas de la reconnaissance d'actions et de mouvements
d'une ou plusieurs personnes dans une image obtenue via une caméra.
L'une des difficultés majeures dans ce genre
d'environnement est la forte ressemblance entre les différents
mouvements de personnes ainsi que le nombre important d'occultations partielles
ou totales de certaines détections ou reconnaissances appelées
fausses alertes.
La vidéosurveillance intelligente pour la
sécurité des personnes et d'espaces est une technologie
émergeante et encore peu connue qui change le paradigme d'utilisation
2
de la vidéosurveillance traditionnelle et ouvre de
nouvelles possibilités. C'est pourquoi elle laisse envisager
l'éclosion de nouveaux segments de recherches dans le secteur de la
sécurité.
Dans ce contexte, l'analytique vidéo présente de
nombreux avantages :
- Elle est en fonction 24 heures par jours, sept jours par
semaine ;
- Elle peut enclencher une alarme qui sera traitée par
un opérateur humain, commander le déplacement ou zoom d'une
caméra pour une surveillance plus précise d'un
événement suspects ou pertinents, permettant ainsi une
intervention en temps réel, plutôt qu'après
l'événement ;
- Elle réduit la bande passante et l'espace d'archivage
nécessaires en ne transmettant ou n'enregistrant que les données
sur les événements pertinents ; - Elle libère le personnel
de sécurité d'une surveillance continue ;
- Elle permet la recherche rapide d'événements
pertinents dans les séquences vidéo archivées ;
- Elle permet d'identifier les objets dans une scène et de
suivre leur activité.
? Problématique
Le problème que nous nous proposons de résoudre
dans le cadre de ce travail de fin d'étude en vue d'obtention de
diplôme de Master de Recherches en Imagerie Numérique pour le
Développement Durable peut se formuler par la question suivante :
Comment détecter un objet ou une personne en mouvement dans une
séquence vidéo? La réponse à cette question
constitue une première étape dans la reconnaissance d'objet, de
personne ou de situation suspecte dans une image dans le cadre de la
vidéo surveillance.
? Objectif
L'objectif de ce travail de recherche est de mettre en
évidence le mouvement d'une personne dans une séquence
vidéo.
Pour arriver à cette fin les objectifs spécifiques
seront de :
- Faire un état de l'art des méthodes existantes de
détection d'objet en mouvement;
- Choisir avec justification de méthodes efficaces de
détection d'objet en mouvement eu égard au contexte
socio-économique ;
- Proposer une implémentation de quelques méthodes
efficaces de détection de personne ou d'objet en mouvement.
3
? Plan du travail
Notre travail est subdivisé en cinq chapitres.
- Le premier chapitre présente le cadre de
l'étude comprenant une étude sur le cadre conceptuel et la
méthodologie.
- Le deuxième chapitre fait l'état de l'art des
méthodes existantes de détection d'objets ou de personnes dans
une d'images en mettant en exergue leurs avantages et inconvénients dans
chaque cas étudié.
- Le troisième chapitre, met en exergue le choix de
l'étude de méthodes efficaces de détection d'objet en
mouvement.
- Le quatrième chapitre décrit l'ensemble du
matériel utilisé pour l'implémentation et l'obtention de
résultats, et présente quelques fonctions utiles d'OpenCv.
- Dans le cinquième chapitre, nous proposons une
implémentation de méthodes choisies suivi d'une discussion sur
les résultats obtenus.
Enfin dans la conclusion, nous avançons les
perspectives d'insertion de notre travail dans la reconnaissance de mouvement
suspect dans une séquence vidéo.
4
Chapitre 1 : Cadre de l'étude
Dans ce présent chapitre, nous présentons deux
grands aspects de nos recherches ; le cadre théorique définissant
les concepts clés de traitement d'images, ensuite le cadre
méthodologique. Les définitions utilisées ici sont
extraites de (MEDJAHED, 2012) et de (Maïtine,
2015).
1.1. Cadre théorique
Dans cette partie, nous présentons les notions
essentielles à la compréhension de techniques
développées dans le cadre de la détection de mouvement sur
une séquence vidéo.
1.1.1. Image
Une image numérique est une matrice de pixels
repérée par ces coordonnées (x, y). S'il s'agit d'une
image couleur, un pixel est codé par 3 composantes (R, G, B) (chacune
comprise au sens large entre 0 et 255 ou plus), représentant
respectivement les niveaux de rouge, vert et bleu qui caractérisent la
couleur du pixel. S'il s'agit d'une image en niveau de gris, il est codé
par une seule composante comprise au sens large entre 0 et 255,
représentant la luminosité du pixel.
Exemples de couleurs :
· (0, 0,0)=noir.
· (255, 0,0)=rouge.
· (0, 255,0)=vert.
· (0, 0,255)=bleu.
· (127, 127,127)=gris moyen.
· (255, 255,255)=blanc.
1.1.1.1. Les images couleur
L'espace couleur est basé sur la synthèse des
couleurs, c'est-à-dire que le mélange de trois composantes donne
une couleur. Un pixel est codé par trois valeurs numériques. La
signification de ces valeurs dépend du type de codage choisi. Le plus
utilisé pour manier les images numériques est l'espace couleur
"Rouge-Vert-Bleu" (R, V, B) (RGB en anglais).
5
La restitution des couleurs sur écran utilise cette
représentation. C'est une synthèse additive. Il en existe
beaucoup d'autres : Cyan -Magenta-Jaune (ou CMY en anglais),
Teinte-Saturation-Luminosité (ou HSL en anglais), YUV, YIQ, Lab, XYZ
etc. La restitution des images sur papier utilise cette représentation :
c'est une synthèse soustractive.
Dans ce qui suit nous ne considérerons que des images
en niveaux de gris. En effet, chaque calque (ou canal) couleur peut être
considéré comme une image en niveaux de gris
séparément et on peut lui appliquer les transformations et
méthodes décrites dans l'état de l'art. Toutefois, les
techniques de recalage propres aux images couleur sont délicates et
sortent largement du cadre que nous nous sommes fixés ici.
1.1.1.2. Chrominance
C'est l'information portée par la lumière qui a
probablement la fréquence d'une onde lumineuse influençant la
couleur que nous percevons lorsque le rayon vient frapper notre rétine :
du rouge au violet en passant par tous les tons de l'arc-en-ciel.
1.1.1.3. Les images en niveaux de gris
En général, les images en niveaux de gris
renferment 256 teintes de gris. Par convention la valeur zéro
représente le noir (intensité lumineuse nulle) et la valeur 255,
le blanc (intensité lumineuse maximale). Le nombre 256 est lié
à la quantification de l'image. En effet chaque entier
représentant un niveau de gris est codé sur 8 bits. Il est donc
compris entre 0 et (28-1) = 255. C'est la quantification la plus
courante. On peut coder une image en niveaux de gris sur 16 bits (0 =n
=216-1) ou sur 2 bits : dans ce dernier cas le " niveau de
gris" vaut 0 ou 1.
1.1.1.4. Les images binaires (noir-blanc)
C'est l'exemple des images les plus simples : un pixel peut
prendre uniquement les valeurs noir ou blanc. C'est typiquement le type d'image
que l'on utilise pour numériser du texte quand celui-ci est
composé d'une seule couleur.
1.1.1.5. Luminance
C'est l'information relative à l'intensité de la
lumière. Cela revient à considérer la lumière comme
porteuse d'une seule information, descriptible par un seul nombre : le niveau
de gris. Si l'on raisonne en termes d'ondes lumineuses, on peut
considérer, grosso-modo, que cette information se traduit par
l'amplitude de l'onde.
6
1.1.1.6. Masque
Un masque est un outil pour le traitement d'image ; c'est lui
qui définit la surface des pixels qui va être utilisée pour
un traitement. Imaginons que nous souhaitons effectuer une opération
entre un pixel et ses voisins. Nous allons définir un masque qui
contiendra les pixels dont nous avons besoin pour faire notre calcul.
1.1.1.7. Binarisation
La binarisation consiste à transformer un pixel sur
plusieurs bits (2, 4, 8 ou plus) en une image sur 1 seul bit. Pour ça,
nous allons faire un seuillage. Si la valeur du pixel est en dessous du seuil,
nous lui associons la valeur 0. Si la valeur du pixel est égale ou
supérieure au seuil nous lui donnons la valeur 1. Si l'image est en
niveau de gris, il n'y a qu'une seule composante de couleur.
En ce qui concerne les images couleurs, c'est
différent. En effet nous avons 3 composantes de couleur (rouge bleu
vert), La première étape consiste donc à transformer une
image en couleur en niveau de gris puis en image binaire.
1.1.1.8. Seuillage
Pour exploiter une image numérique, elle a
généralement besoin d'être simplifiée, c'est le but
du seuillage. Ce dernier consiste à transformer l'image codée sur
6, 8 ou 16 bits, en une image binaire ou les pixels à 1 correspondent
aux objets et les pixels à 0 au fond de l'image. À la
différence des différents traitements de l'image
numérique, le seuillage est un passage obligatoire pour toute analyse
morphologique ultérieure. Le seuillage permet de sélectionner les
parties de l'image qui intéressent l'opérateur, par exemple 2
types de grains (blancs et sombres) dans un mélange. On
peut donc, par exemple, attribuer à tous les pixels de l'image
numérique qui ont un niveau de gris compris entre i1 et
i2, choisies par l'opérateur, la valeur 1; à
tous les autres pixels est attribuée la valeur 0. Après
seuillage, les parties de l'image sélectionnées seront traduites
en noir et blanc. L'image, digitalisée par l'ordinateur (0 et 1), est
appelée image binaire. Cette dernière, tout comme l'image
numérique contient des informations superfétatoires, qu'il
convient d'éviter, ou masquées qu'il faut révéler.
Les traitements suivants permettent de modifier l'image binaire à ces
fins.
7
1.1.1.9. Histogramme
Un histogramme est un ensemble de données statistiques
permettant de représenter la distribution des intensités
lumineuses des pixels d'une image, c'est à-dire le nombre de pixels pour
chaque niveau de gris. Pour une image en couleur, il est possible soit de faire
un histogramme par composante (RGB en français rouge, vert et bleue),
soit de faire l'histogramme de la moyenne des trois composantes pour chaque
pixel, soit de faire l'étirement et l'égalisation.

Image originale
a)Histogramme en R (Rouge) b) Histogramme en G (vert) c)
Histogramme en B (Bleue)

Figure 1: Histogramme d'une image en RGB
La figure 1 représente une image couleur filmée,
en 1.a) nous avons une représentation de l'histogramme en fonction du
canal rouge. 1.b) représente la forme de la représentation
graphique en fonction du canal vert. Et enfin 1.c) c'est représentation
de l'histogramme en fonction du canal bleu.
1.1.1.10. Histogramme cumulé
L'histogramme cumulé représente la distribution
cumulée des intensités des pixels d'une image. En plus de
l'histogramme classique, il peut être intéressant dans certains
cas
8
de travailler sur l'histogramme cumulé. Ce dernier
s'obtient en associant à chaque niveau de gris i le nombre
hi de pixels de l'image qui ont une valeur
inférieure ou égale à i.
En quelque sorte, cela revient à calculer l'histogramme de
l'image et d'associer à chaque niveau i la somme des
hi (nombre de pixel de l'image qui ont une valeur
égale à j) pour ] = ~.
En formule :
hti~ = Eo<1<tihti= ho + h1 +
·
·
· ..............hti (1)
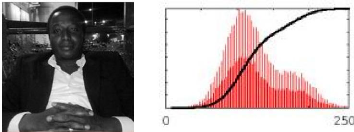
Figure 2: Image en niveau de gris et son histogramme
cumulé
La figure 2 est en niveau de gris, c'est une
représentation sur un seul canal ; c'est la quantification la plus
courante. L'histogramme est la représentation graphique de cette image
en niveau de gris.
a) Modification de l'histogramme
L'histogramme est un outil très utile pour
étudier la répartition de composantes d'une image mais il permet
également de corriger le contraste et l'échelle des couleurs pour
des images surexposées ou sous-exposées : On parle dans ce cas
d'exemples des images qu'on n'arrive pas à identifier ou qu'on n'arrive
pas à lire compte tenu des pixels non lumineux.
En outre sa modification n'altère pas les informations
contenues dans l'image mais les rend plus ou moins visibles. La modification
d'un histogramme est généralement représentée sur
une courbe (appelée courbe tonale) indiquant la modification globale des
composantes de l'image avec en abscisse les valeurs initiales et en
ordonnée les valeurs après modification.
9
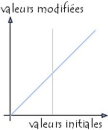
|
Figure 3: Modification d'histogramme
La figure ci-contre montre l'histogramme lorsqu'aucun mouvement
n'a eu lieu.
|
Comme illustre la figure suivante, la diagonale indique la
courbe telle que les valeurs initiales sont égales aux valeurs finales,
c'est-à-dire lorsque aucune modification n'a eu lieu. Les valeurs
à gauche de la valeur moyenne sur l'axe des abscisses
représentent les pixels "clairs" tandis que ceux à droite
représentent les pixels foncés.
b) Étirement de l'histogramme
L'étirement d'histogramme (aussi appelé
"linéarisation d'histogramme" ou "expansion de la dynamique") consiste
à répartir les fréquences d'apparition des pixels sur la
largeur de l'histogramme.
Ainsi il s'agit d'une opération consistant à
modifier l'histogramme de telle manière à répartir au
mieux les intensités sur l'échelle des valeurs disponibles. Ceci
revient à étendre l'histogramme afin que la valeur
d'intensité la plus faible soit à zéro et que la plus
haute soit à la valeur maximale.
De cette façon, si les valeurs de l'histogramme sont
très proches les unes des autres, l'étirement va permettre de
fournir une meilleure répartition afin de rendre les pixels clairs
encore plus clairs et les pixels foncés proches du noir. Il est ainsi
possible d'augmenter le contraste d'une image. Par exemple une image trop
foncée pourra devenir plus "visible".

a) Image Originale b) Image Étirée c)
Histogramme
Figure 4: Étirement et Histogramme de l'image
Étirée
10
L'image 4.a) est l'origine ou la source, en 4.b), nous avons une
image étirée de l'image originale en niveau de gris. En 4.c)
c'est une représentation de l'histogramme de l'image
étirée.
c) Égalisation d'histogramme
Il peut arriver que les pixels d'une image, bien qu'occupant tout
l'espace de valeurs disponible entre 0 et 255, soient « agglutinés
», c'est-à-dire que l'histogramme n'est pas uniforme. C'est le cas,
par exemple, sur les images suivantes :
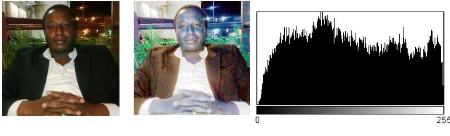
a) Image Originale b) Image Égalisée c)
Histogramme
Figure 5 : Égalisation et Histogramme de l'image
égalisée
L'image 5.a) est l'originale ou la source, l'image 5.b) nous
donne la forme égalisée de l'image originale. On remarque que la
couleur est devenue vive. Enfin en 5.c) une présentation de
l'histogramme. Ce qui nous saute très vite aux yeux, c'est que cette
image contient beaucoup de pixels très sombres ou très clairs, et
relativement peu de pixels d'une luminosité « moyenne ».
1.1.1.11. Morphologie Mathématique
La morphologie mathématique est une méthode de
description de la forme des objets par comparaisons avec des objets de formes
connues, les éléments structurants. Les éléments
structurants les plus employés sont les éléments convexes
tels que le segment et surtout le disque isotrope. Concrètement, si le
réseau régulier de pixels choisi pour représenter une
image binaire est hexagonal, un élément structurant,
assimilé dans cet exemple à un disque, sera parfaitement
déterminé par les valeurs attribuées (1 ou 0) à son
centre et plus proches voisins de ce dernier, répartis selon un
hexagone. L'ensemble des plus proches voisins constitue le voisinage du
centre.
a) Dilatation et Érosion
Une érosion permet de supprimer les pixels «
isolés » qui ne correspondent pas à notre objet
détecté. Ensuite vient l'étape de la dilatation qui nous
permet de renforcer les groupes denses de pixels notamment l'objet suivi.

a) Image originale b) image dilatée
Figure 6 : Dilatation d'image
L'image a) de la figure 5, nous montre l'image originale
acquise via une caméra. L'image 5.b) est l'image dilatée de
l'image 5.a).
a) 
11
Image originale b) image érodée
Figure 7 :
Érosion d'image
L'image a) de la figure 6, nous montre l'image originale
acquise via une caméra. L'image 6.b) est l'image érodée de
l'image 6.a).
b) Ouverture
L'ouverture de I par S notée IoS est
le résultat d'une érosion de I suivie d'une
dilatation de l'ensemble érodé par le même
élément structurant.
loS = (lOS) S (2)
12
L'ouverture adoucit les contours et élimine les pics
aigus.
c) Fermeture
C'est l'opération duale de l'ouverture, notée
I
·S, c'est le résultat d'une dilatation suivie d'une
érosion en utilisant le même élément structurant.
I
· S = (I ED S)0S (3)
La fermeture fusionne les coupures étroites,
élimine les petits trous, et comble les vides sur les contours.
1.1.1.12. Étiquetage des composantes
L'étiquetage des composantes connexes1 d'une
image binaire consiste à attribuer un label, étiquette ou
numéro différent pour chaque composante connexe et identique pour
tous les pixels d'une même composante. Il existe de nombreux algorithmes
réalisant cette fonction. Ils dépendent de la connexité
considérée et se différencient aussi par leur approche
séquentielle ou parallèle. Une composante connexe peut alors
être extraite par l'intermédiaire de son étiquette pour
faire un traitement spécifique. L'image des étiquettes est une
formulation implicite des composantes connexes; l'extraction aura pour but la
transformation de cette formulation implicite en une formulation explicite
(liste des composantes connexes avec des attributs par exemple).
1.1.2. Définition d'une vidéo
La vidéo est une succession d'images animées
défilant à une certaine cadence afin de créer une illusion
de mouvement pour l'oeil humain. Elle peut être analogique (signal
continu d'intensité de luminance) ou numérique (suite de trames
ou images). On peut distinguer deux types de vidéo:
La vidéo entrelacée: où
chaque image est formée de deux champs entrelacés. Le premier
champ contenant uniquement les lignes impaires de l'image, le second champ,
quant à lui, contenant les lignes paires (les signaux de
télévision nord-américain et européen sont
entrelacés).
La vidéo progressive: dans une
vidéo progressive, contrairement au mode entrelacé, toutes les
lignes d'une image sont lues en une passe (vidéo numérique).
1 C'est l'ensemble des éléments
constituants la connexité d'un graphe
13
1.1.2.1. Résolution temporelle d'une
vidéo
La résolution temporelle d'une vidéo est
définie par le nombre d'images défilant par seconde. Afin
d'éviter les désagréments dus aux papillotements, et
prenant en considération les spécificités de l'oeil humain
qui garde une image environ 10 micro secondes au niveau de sa rétine ;
les images doivent défiler à une certaine cadence:
Environ 24 images/s pour un film de cinéma ;
25 images/s pour la télévision européenne
;
Environ 30 images/s pour la télévision
nord-américaine et japonaise.
1.1.2.2. Séquence d'images
Une séquence d'images est une succession d'images
bidimensionnelles qui montre l'évolution temporelle d'une scène.
La cadence est de 25 images par seconde, ce qui correspond au seuil à
partir duquel l'oeil humain perçoit la séquence comme un stimulus
continu, grâce à la persistance rétinienne. Par la suite,
nous appellerons « trame » ou « plan » chaque image
bidimensionnelle correspondant à un instant donné de la
séquence.

Figure 8: Exemple d'une séquence d'images
La figure 8, nous montre les captures d'images du
déplacement d'une personne dans une séquence vidéo.
Par ailleurs, il est important de bien définir le terme
détection du mouvement afin d'éliminer les ambigüités
qui pourraient survenir.
14
Conclusion
Dans ce chapitre, nous avons rappelé les
différentes notions essentielles à la compréhension. Dans
ce que suit, nous allons faire l'état de l'art de méthode de
détection d'objet en mouvement.
15
Chapitre 2 : État de l'art
Dans ce présent chapitre, plusieurs méthodes de
détection de mouvement par vision numérique seront
présentées. Pour celles-ci, la performance varie en fonction du
temps de traitement et de la qualité des résultats produit.
À partir d'un modèle de l'environnement et d'une
observation ou d'une série d'observations successives, on cherche
à détecter et suivre ce qui a changé.
Il existe plusieurs méthodes dans la
littérature, faire une étude comparative détaillée
de toutes les au-delà du cadre de ce travail. Nous avons eu à
nous baser sur les méthodes les plus récentes de détection
de mouvement dans une séquence vidéo.
2.1.Détection par Différences entre deux
images consécutives
Elle représente une solution très
intéressante et peu complexe. Comme son nom l'indique, elle consiste
à soustraire une image acquise au temps tn
d'une autre au temps tn + k, où
k est habituellement égal à 1. On utilise des
méthodes qui calculent une différence temporelle, pixel par
pixel, entre deux ou trois images successives. On peut citer les travaux de
(Lipton et al., 1998) et de
(Huwer et Niemannqui.,
2000) qui traitent de la détection par différence d'images. La
valeur absolue de cette différence est seuillée pour
détecter les changements. Ensuite, les pixels " labellisés en
mouvement" sont regroupés en objets avec une analyse en composantes
connectées. Cette méthode présente l'avantage d'être
adaptée aux environnements dynamiques puisqu'elle n'est pas
influencée par les variations de luminosité mais ne permet pas de
récupérer tous les pixels de l'objet en mouvement.
Ainsi, l'image résultante sera vide si aucun mouvement
ne s'est produit pendant l'intervalle de temps observé car
l'intensité et la couleur des pixels seront presque identiques.
Par contre, si le mouvement a lieu dans le champ de vue, les
pixels frontières des objets en déplacement devraient changer
drastiquement de valeurs, révélant alors la présence
d'activité dans la scène. Cette technique nécessite
très peu de ressources, car aucun modèle n'est nécessaire.
Cela implique donc qu'il n'y a pas de phase d'initialisation obligatoire avec
une scène statique, ce qui procure une très grande
flexibilité d'utilisation. De plus, une opération de soustraction
d'images requiert très peu de puissance de calcul,
16
lui conférant un avantage supplémentaire.
Par ailleurs, les résultats obtenus par cette
méthode ne sont pas aussi précis que ceux
générés en utilisant un modèle statistique de
l'arrière-plan. En effet, certains traitements supplémentaires
sont nécessaires afin de déterminer la zone en mouvement (zone
intérieure et contours des objets en mouvement), car l'information
disponible ne concerne que les contours des régions en
déplacement.
2.2.Flux optique
Similaire à l'approche précédente,
l'utilisation du flux optique ou flot optique procure une information de
mouvement pour chaque pixel de l'image. Ainsi, il mesure les vecteurs de
déplacement à partir de l'intensité des pixels de deux
images consécutives ou temporellement rapprochées. Dans un
contexte de détection de mouvement, les pixels inactifs
possèderont alors une vélocité nulle contrairement aux
pixels appartenant à des objets dynamiques. Une classification sous
forme de regroupement est donc nécessaire afin d'isoler et de localiser
les zones représentant du mouvement. Cette technique a notamment
été utilisée pour la détection de piétons
(Kunret et al.,
2001). Il y a finalement plusieurs méthodes pour
calculer le flux optique, mentionnons entre autres celle de (Lucas
et Kanade, 1981).
L'inconvénient majeur de l'utilisation du flux optique est la somme
importante de calculs à réaliser pour l'estimation du
mouvement.
Par ailleurs, une variante utilisant le block
matching2 peut bénéficier de certaines instructions
optimisées MMX (MultiMedia eXtension ou MatriX Math), ce qui peut
accélérer le traitement global. Néanmoins, une tâche
supplémentaire de classification et d'interprétation est
nécessaire. De plus, si certaines parties d'un objet ne sont pas en
mouvement, elles seront complétement ignorées par cette
méthode. Ça peut être le cas par exemple d'une
séquence vidéo contenant une personne assise par terre et agitant
les bras. Dans cette situation bien précise, le corps de la personne ne
serait pas détecté contrairement à ses bras.
2.3.Soustraction de l'arrière-plan par
modélisation statistique
La présente technique est la moins récente et
l'une les plus utilisées, probablement grâce à sa
simplicité théorique ainsi qu'à sa faible
complexité algorithmique. Le principe fondamental repose sur une
estimation statistique de la scène observée.
2 Le block matching est algorithme utilisé dans
plusieurs algorithmes de compression vidéo pour l'estimation du
mouvement entre différentes images d'une vidéo.
17
Le mouvement est détecté en comparant une image
test (image de référence) avec le modèle
d'arrière-plan calculé auparavant. Certaines hypothèses de
base doivent par contre être respectées pour un fonctionnement
adéquat de cette méthode.
Tout d'abord, la caméra utilisée est fixe et ne
doit bouger à aucun moment. Une caméra à l'épaule
ou une caméra sur pied est un bon exemple de situation non applicable
à la Soustraction d'Arrière-Plan (SAP). Pour ce qui est de la
scène observée, elle doit être relativement constante et
conserver la même apparence. Un paysage observé à partir
d'une voiture à une vitesse constante est donc une bonne
représentation d'une scène non statique. Il est important de
noter qu'aucune limite n'est utilisée pour la quantité d'objets
en mouvement. De plus, des variations de luminosité sont
tolérées en autant qu'elles ne soient pas trop brusques.
Le modèle statistique calculé lors de la phase
d'initialisation est constamment mis à jour, lui permettant ainsi de
s'adapter aux changements qui peuvent se produire dans la scène
observée (par ex : soleil levant). Cette capacité d'adaptation
est commune à toutes les techniques de SAP par modélisation
statistique et leur confère un atout majeur qui sera abordé en
détails tout au long de nos recherches. Par ailleurs, cette
méthode connaît plusieurs implantations différentes qui
varient principalement selon le type de capteur utilisé.
2.3.1. Visibilité sur deux dimensions (2D)
La première catégorie de méthodes de
soustraction d'arrière-plan regroupe les techniques basées sur
l'utilisation d'images 2D dans le spectre visible. Un des modèles de
couleurs le plus fréquemment utilisé pour la modélisation
statistique est le RGB, soient le rouge (R), le vert (G) et le bleu (B).
La technique de base consiste à modéliser
l'arrière-plan à partir de plusieurs images acquises
séquentiellement. Pour chaque pixel de l'image, ainsi que pour chacun
des canaux (R, G et B), une moyenne et une variance sont calculées.
Lorsqu'un pixel test doit être classifié, il faut tout d'abord lui
soustraire la moyenne correspondante dans le modèle statistique. Il sera
alors étiqueté comme un pixel contenant du mouvement seulement si
la valeur absolue du résultat dépasse un certain multiple de
l'écart-type correspondant.
Les travaux de (Horprasert et
al.,2000) ont proposé un nouveau
modèle de couleurs basé sur le RGB. Leur technique permet la
classification des pixels en quatre catégories, soient
l'arrière-plan original, illuminé, ombré et un pixel en
mouvement. Pour
18
ce faire, deux mesures sont ajoutées à la
méthode de base en RGB : la distorsion chromatique
(á) et la luminosité
(CD). Les points faibles de cette approche
résident surtout dans la somme d'opérations
supplémentaires nécessaires pour calculer ces deux mesures ainsi
que les seuils associés. En pratique, certaines erreurs de
classifications peuvent également se produire entrainant, par exemple,
l'identification d'un objet en mouvement comme étant de l'ombre. Il y a
finalement un très grand nombre de méthodes de SAP par
modélisation statistique non abordées dans le cadre de ce travail
(McIvor, 2000), notamment pour des raisons de
complexité et pour lesquelles les gains en performance sur la technique
de base sont relativement négligeables.
2.3.2. Informations de profondeur à trois dimensions
(3D)
L'utilisation d'informations tridimensionnelles (par. ex :
webcam ou bien une caméra classique) permet la réalisation d'une
soustraction d'arrière-plan très efficace. Tout comme les
méthodes précédentes, cette technique nécessite un
modèle statistique de l'arrière-plan. Mais contrairement aux
autres, elle renferme des valeurs de distances entre la caméra et les
différentes composantes de la scène. Le mouvement sera donc
détecté lorsque des points seront à des distances
différentes de celles retrouvées dans le modèle
statistique.
Une implantation en temps réel de cet algorithme
requiert cependant énormément de puissance de calcul ou de
l'équipement matériel spécialisé tel que
souligné par (Kanade et
al.,1996).
Par ailleurs, (Ivanov et
al., 2000) ont proposé un modèle hybride
utilisant la couleur et les informations 3D pour accomplir la SAP. Dans ce cas,
les informations de profondeurs sont modélisées et
calculées hors-ligne en générant un modèle de
disparité de l'arrière-plan nécessaire à la
validation. Il est ensuite utilisé pour étiqueter un pixel qui ne
respecte pas la couleur d'une image de référence comme
étant de l'ombre ou un objet en mouvement.
Les avantages majeurs de cette méthode reposent sur sa
robustesse à l'illumination et sa capacité à
éliminer les ombres.
19
2.4.Détection par Histogramme
La détection de mouvement par histogramme comprend deux
types de reconnaissance.
Le premier : l'image de référence est toujours
la même, alors que dans le second type : l'image est modifiée
à chaque photogramme. Dans chacun des cas, on va comparer, les
histogrammes de chacune des couleurs, entre l'image de référence
et la particule. Une moyenne sera effectuée, puis inversée de
façon à ce que la différence la plus petite possède
le poids le plus grand.
L'image de référence peut être une image
sélectionnée de la bibliothèque ou une sélection
faite à la main sur le premier photogramme de la vidéo. En effet
il est possible de changer le photogramme d'origine à chaque instant de
traitement, ceci peut être intéressant si l'objet change de forme
ou de couleur. Dans notre cas, les personnes peuvent marcher, courir, se
courber ou s'agiter.
Avec un changement d'image de référence, l'objet
se perd peu à peu. Avec une image fixe, l'objet sera toujours
présent mais si cet objet change de couleur alors il sera impossible de
le repérer. Il faut donc trouver un compromis, permettant de
repérer l'objet à chaque changement de couleur. Lorsque le choix
de l'image de référence se fait à la main sur le premier
photogramme, les particules ne sont alors pas placées
aléatoirement sur tout le frame, mais autour de la particule
sélectionnée. De cette façon, l'objet est
détecté tout de suite, et si les paramètres sont corrects
alors l'objet est correctement suivi à chaque frame. Les
paramètres de tracking3, en particulier avec la
méthode de l'histogramme, sont difficiles à obtenir.
En effet, ces paramètres peuvent dépendre de la
taille de la particule de référence mais aussi des informations
qu'elle contient. De ce fait, il est très difficile avec une
sélection du photogramme référence, de trouver les bons
paramètres car la sélection ne sera pas identique à chaque
fois. Plus le nombre d'information sur l'objet est important, moins les erreurs
sont possibles, plus il y a d'informations, meilleurs sont les
résultats. Mais si ces informations concernent «le
background» en majorité, c'est la particule qui
3 Enregistrement et analyse discrète de toutes
les activités d'un individu, à des fins plus ou moins
honnêtes.
20
correspond le plus au «background» qui sera
reconnue. Si tout le « background » est éliminé, une
partie des informations de l'objet sera également
éliminée.
Si l'image de référence est fixe et que l'objet
change de taille, de forme ou de couleur au cours de la vidéo, la
reconnaissance ne se fera pas. En changeant le frame d'origine et donc
l'histogramme de comparaison, le risque est moindre car l'histogramme varie de
la même manière que l'objet. En revanche si on utilise le
changement de frame il y aura un risque de décalage à chaque
changement et de ne reconnaître que le fond à la fin de la
vidéo. Il est donc nécessaire de trouver un bon équilibre
et de ne changer le frame et l'histogramme que lorsque la particule et
l'histogramme sont très proche mais pas à chaque frame. Les
paramètres sont difficiles à mettre en place, il y a un manque de
précision et les résultats ne sont pas toujours ceux
espérés. Cet algorithme n'est pas idéal dans
l'étude de détection des personnes.
2.5.Détection par couleur
La détection par la couleur est devenue une
méthode rapide de détection des visages. Il a en effet
été montré que l'utilisation de la couleur de la peau pour
détecter la présence d'un visage est un critère fiable, la
peau ayant une couleur caractéristique pouvant aisément
être distinguée des autres couleurs. De plus, l'attribut couleur
est plus robuste que l'attribut contour étant données les
variations géométriques d'un visage ou d'une main. La
construction d'un détecteur de couleur doit répondre à
trois problèmes. Il est tout d'abord nécessaire de choisir un
espace de couleur, puis la représentation à utiliser pour
modéliser la couleur, et enfin la manière d'exploiter le
résultat produit par le détecteur. L'utilisation de cet attribut
induit bien entendu certaines contraintes que nous détaillerons.
2.5.1. Espaces de couleur
De nombreux espaces de couleur ont été
conçus dans les recherches en colorimétrie, synthèse
d'image et transmission du signal vidéo.
RGB
L'espace de couleur RGB fut à l'origine conçu
pour la formation des images dans les tubes cathodiques (cathode-ray tube CRT),
qui supposait pouvoir décomposer la couleur en trois rayons (rouge, vert
et bleu). C'est un des espaces le plus utilisé dans le traitement et le
stockage des images numériques. Par contre la haute corrélation
entre les trois
21
canaux, la non-uniformité perceptuelle, le mélange
des données de chrominance et de luminance font de ce système un
choix peu heureux pour l'analyse d'images d'après leurs couleurs.
RGB normalisé.
Dans le but de diminuer la corrélation des canaux avec la
luminance, il est possible de les normaliser.
Perceptuels.
Les systèmes perceptuels distinguent trois informations
: la Teinte, la Saturation et la Luminance, notés HSV (Hue Saturation
Value). Ils fournissent des informations numériques sur les
propriétés de la couleur et la décrivent de manière
plus intuitive (que les systèmes RGB par exemple). La teinte
dénie la composante chromatique dominante de la région
analysée, la saturation donne la proportion de cette composante de la
région par rapport à sa luminosité. L'intensité, la
valeur et la luminance définissent la luminosité de la
région. Leur capacité à distinguer la chrominance de la
luminance en ont fait des espaces de couleur populaires dans les travaux de
segmentation par la couleur.
Perceptuel uniforme
Un espace perceptuel uniforme est un espace où une
petite perturbation d'un composant est perceptible de manière
égale sur l'ensemble des valeurs du composant.
2.5.2. Modélisation de la couleur de la peau
Le but final d'un détecteur de couleur de peau est de
construire une règle de décision pour faire la différence
entre les pixels de couleur peau et les autres. On introduit habituellement une
métrique pour mesurer la distance (au sens général) entre
la couleur d'un pixel et la couleur de la peau.
Modélisation non-paramétrique.
L'idée principale dans la réalisation
non-paramétrique est d'estimer la distribution de couleur à
partir de données d'apprentissage sans en dériver explicitement
un modèle. Le résultat de ces méthodes est souvent
appelé `' carte de probabilité de couleur `'
détaillée par (Brand et
Mason, 2000) et (Gomez et
Morales 2002) où une probabilité est
associée à chaque point d'un espace de couleur.
22
Modélisation paramétrique
Les modélisations non paramétriques utilisant
des histogrammes nécessitent beaucoup d'espaces et leur pouvoir
discriminant dépend directement de la représentativité de
l'ensemble d'apprentissage. La nécessité de pouvoir disposer de
représentations plus compactes avec des possibilités de
généralisation et d'interpolation des données
d'apprentissage a motivé le développement de modèles
paramétriques de couleur de peau.
Table de correspondance.
Plusieurs algorithmes de détection d'objet en mouvement
(Chen et al., 1995),
(Sigal et al. 2000))
utilisent des histogrammes pour segmenter les pixels de couleur peau. L'espace
de couleur (habituellement l'information de chrominance seule est
utilisée) est quantifié dans les cases de l'histogramme, chacune
correspondant à un certain ensemble de composants de couleur. Ces cases
forment un histogramme 2D ou 3D selon la table de mise en correspondance.
Chaque case contient le nombre d'occurrence d'une couleur dans les images de
l'ensemble d'apprentissage. Après l'apprentissage, l'histogramme est
normalisé, convertissant les valeurs de l'histogramme en distribution de
probabilité discrète.
Pskin(c) = ~~~~|~|
~~~~ (4)
où skin|c| est la valeur de la case de
l'histogramme correspondant à la couleur c, et
Norm le coefficient de normalisation, soit la somme de toutes
les cases de l'histogramme soit la valeur maximum. Les valeurs
normalisées de la table de correspondance constituent la
probabilité que la couleur correspondante soit de la couleur de la
peau.
2.6.Méthode de détection par Technique du
Gradient
Le gradient est une grandeur vectorielle qui indique comment
une grandeur physique varie en fonction de ses différents
paramètres. Dans notre cas, nous voulons analyser la variation
d'intensité entre chaque pixel de l'image. Intuitivement, le gradient
indique la direction de la plus grande variation du champ scalaire, et
l'intensité de cette variation. Par exemple, le gradient de l'altitude
est dirigé selon la ligne de plus grande pente et sa norme augmente avec
la pente. On peut donc considéré qu'un point de l'image (pixel)
correspond à un maximum local de la norme du gradient. La normale du
contour est
23
donnée par le gradient. Si la valeur du gradient est non
nulle on peut donc déduire que l'on se situe dans une zone de transition
entre une partie claire et une partie sombre.
Cette méthode n'a pas été suffisamment
investiguée dans le cadre de ce travail. 2.7.Tableau
comparatif de méthodes
Le tableau ci-dessous fait un résumé comparatif des
différentes méthodes ci-dessus abordées.
24
Tableau 1: Tableau comparative des méthodes
abordées
|
Type
|
Avantages
|
Inconvénients
|
|
Soustraction par arrière-plan
|
SAP (visible 2D)
|
- Algorithme peu complexe
- Classification simple
- Résultats clairs
|
- Initialisation/scène
statique
- Ombres non rejetées
|
|
SAP (visible 3D)
|
- Robustesse aux ombres
- Informations de profondeur
|
- Initialisation/scène
statique
- Complexité et calculs - Plusieurs caméras
|
|
Différences
d'images consécutives
|
- Flexibilité d'utilisation
- Faible complexité de
l'algorithme de base
- Souplesse d'initialisation
|
- Mouvement obligatoire - Ombres non rejetées -
Détection incomplète
|
|
Flux optique
|
- Informations précises sur le mouvement
- Suivi/prédiction possible
|
- Complexité et calculs - Ombres non rejetées -
Mouvement obligatoire - Interprétation difficile
|
|
Couleur
|
- Simplicité
d'implémentation
- Reconnaissance de la
couleur à
détectée
|
- Base de données
couleurs 2653
- Perte de détection par changement de couleur.
|
|
Histogramme
|
- Identification de particule
- Facilité de choix de
particules de
références
- Des informations, moins
d'erreurs
|
- Décalage de
reconnaissance
- Manque d'équilibre
- Difficulté de mise en
oeuvre
|
25
Conclusion
Ce chapitre a présenté, la revue de la
littérature des techniques de détection du mouvement les plus
utilisées et les plus robustes. Une comparaison des méthodes
(voir tableau) est fournie au tableau 1. Dans le chapitre suivant nous
justifions le choix de méthodes de détection qui feront l'objet
d'implémentation. La bibliothèque OpenCv sera un atout avec
certaines de ses fonctions que nous jugeons utiles et indispensables pour tout
traitement d'image ; de la reconnaissance au suivi en passant par la
détection d'objet en mouvement qui est l'objet de notre étude.
26
Chapitre 3 : Choix de la méthode retenue et
modélisation
Il est impératif de faire un choix après une
étude comparative faite à l'état de l'art sur les
avantages et les inconvénients de chacune des approches
envisagées. Parmi toutes les méthodes étudiées et
comparées, peu d'entre elles respectent l'ensemble des exigences et des
besoins de l'objectif que nous avons fixé.
Dans ce qui suit, nous proposons une démarche nous
permettant de choisir les méthodes de détection les plus
adaptées à notre problème eu égard au contexte.
Les contraintes matérielles excluent l'utilisation
d'informations tridimensionnelles ou d'équipements d'imagerie
infrarouge. Pour ce qui est du flux optique, l'importante somme de calculs
nécessaire ainsi que l'interprétation difficile des
résultats générés nuisent à sa
sélection. Ensuite, grâce à leur faible complexité
et leur temps de traitement raisonnable, deux approches différentes sont
finalement sélectionnées, la SAP par modélisation
statistique (visibilité en 2D) et la détection de mouvement par
différence d'images consécutives. Cette dernière
méthode, quoique possédant un avantage certain sur le plan de
l'initialisation, souffre de certaines limitations du côté de la
classification, favorisant finalement la sélection de la méthode
par soustraction d'arrière-plan par modélisation statistique 2D
dans le spectre visible.
3.1.Soustraction d'arrière-plan par
modélisation statistique
La soustraction de l'arrière-plan permet de simplifier
le traitement ultérieur en localisant les régions
d'intérêt dans l'image. À partir d'un modèle de
l'environnement et d'une observation, on cherche à détecter ce
qui a changé. Pour notre application, les régions
d'intérêt sont les régions de l'image où il y a une
forte probabilité qu'il y ait une personne.
L'algorithme utilisé pour la soustraction de
l'arrière-plan par modélisation statistique comporte trois
étapes importantes : l'initialisation, l'extraction du mouvement
(avant-plan) et la mise à jour du modèle.
D'après les résultats présentés
lors de l'étude comparative dans l'état de l'art, il
apparaît clairement que le meilleur compromis entre la qualité de
la détection, le temps de calcul et la mémoire utilisée
sont obtenus avec des méthodes de soustraction de
27
l'arrière-plan simple. Nous avons choisi de
modéliser chaque pixel de l'arrière-plan par une densité
de probabilité Gaussienne.
3.1.1. Initialisation
La première étape consiste à
modéliser l'arrière-plan à partir des N
premières images (N 30) d'une
séquence vidéo. Une moyenne d'intensité est donc
calculée à partir de ces images pour chaque pixel et pour chacun
des canaux (R, G, B). La moyenne d'intensité d'un pixel donné se
résume alors à l'équation suivante :
~
Itc(X, Y) = ~ ~ ? ~~,~(~, ~)
~~~ (5)
Où Ii est la
ième image d'initialisation,
N la quantité d'images utilisées et
c le canal sélectionné.
L'étape suivante consiste à calculer un
écart-type o pour chaque pixel (et pour chaque
canal) afin d'être utilisé comme seuil de détection. Cette
opération nécessite habituellement le stockage des N
premières images. Or, une équation modifiée
permet de contourner cette contrainte de façon incrémentale et
ainsi réduire la consommation d'espace mémoire. Pour ce faire,
deux accumulateurs sont utilisés, soient S(x, y)
pour stocker la somme des intensités des pixels et
SC(x, y) pour emmagasiner la somme des carrés.
Les écarts-types peuvent alors être calculés à
l'aide de l'équation suivante.
~
o(x, ,,) = I (SCc(x,Y)
~ ~ - ~sc(x,Y)
~ ~ (6)
Par ailleurs, il est intéressant de remarquer que
S(x, y) peut être réutilisée pour
le calcul de la moyenne, ce qui évite des opérations
supplémentaires et superflues.
3.1.2. Extraction de l'avant-plan
Afin d'extraire le mouvement dans une image, le modèle
de l'arrière-plan doit tout d'abord lui être soustrait. Chaque
pixel, dont la différence en valeur absolue dépasse la valeur
á × o, est ensuite classifié comme
étant un pixel en mouvement. Dans l'expression précédente,
la variable á représente une certaine
fraction de l'écart-type o. En pratique, ce
paramètre se situe dans l'intervalle [2.0, 4.0] et dépend du
niveau d'exclusion désiré. Un masque binaire de mouvement peut
alors être généré pour chaque canal à l'aide
de l'équation ci-après :
28
mc(x,Y) = f1 si IIc(x,Y) -
uc(x,Y)I > a. oc(x, Y) (7)
0 autrement
Où mc(x, y) représente
le masque de mouvement pour un canal c et
Ic(x, y) l'image d'entrée à
analyser.
L'équation mc(x, y)
représente le calcul du masque de mouvement pour un seul
canal. Pour utiliser cet algorithme avec les 3 canaux (RGB) des images
utilisées, les masques individuels doivent tout d'abord être
générés indépendamment et combinés par la
suite à l'aide d'un opérateur OU logique. Par conséquent,
si un mouvement est détecté pour un pixel dans un seul canal,
cela sera suffisant pour en modifier l'état. L'équation suivante
représente cette combinaison produisant ainsi un masque de mouvement
à un seul canal :
M(x,Y) = mr(x,Y) u mg(x,Y) u mb(x,Y)
(8)
Une fois cette opération complétée,
certaines opérations de morphologie mathématique
(Gonzalez et Richard, 2002)
doivent être appliquées afin d'éliminer le bruit et les
fausses détections. Pour ce faire, 2 érosions et 2 dilatations
sont appliquées respectivement dans cet ordre sur le masque de
mouvement. Finalement, l'image d'entrée est combinée avec le
masque pour produire une image à 3 canaux (avant-plan) contenant
seulement les pixels représentant du mouvement. Cette opération
peut se résumer à l'équation suivante :
F(x, Y) = M(x, Y). I(x, Y)
(9)
Où F(x, y) représente
l'image d'avant-plan (mouvement ou foreground) et I(x, y)
l'image d'entrée. Les deux images sont combinées
grâce à une multiplication pixel à pixel pour chacun des
canaux.
3.1.3. Mise à jour du modèle
Au cours de la période d'acquisition, certaines
régions de la scène peuvent subir des modifications
d'éclairage, ce qui rend la mise à jour du modèle
statistique de l'arrière-plan primordiale. Ainsi, un changement graduel
de luminosité (p. ex. : lever du soleil) sera donc intègre au
modèle et ne sera pas considère comme du mouvement. Pour ce
faire, l'extraction de l'avant-plan est réalisée avec l'image
courante, ce qui génère un masque de mouvement
M.
29
Le modèle de l'arrière-plan est ensuite mis
à jour à partir du complément de
M, c'est-à-dire en utilisant tous les pixels
qui sont étiquetés comme faisant partie de l'arrière-
plan. Les changements brusques dans l'image ne sont donc pas ajoutés au
modèle.
L'équation ci-après illustre ce processus de mise
à jour :
I2' (X, y) = (1 - 77). I.Lc(X, y) + 77. I(x,
y).M~ (x,y) (10)
Où u'(x, y) représente
un pixel de l'arrière-plan moyen mis à jour et ç
le taux d'apprentissage. L'expression Ic(x,
y).M~ (x, y) représente les pixels statiques de
l'image courante, c'est-à-dire ceux pour lesquels aucun changement n'est
associé.
Afin de ne pas modifier radicalement le modèle
d'arrière-plan, seulement une fraction i de
l'image temporaire Ic(x, y).M~ (x, y) est
utilisée. En pratique, ce taux d'apprentissage peut prendre des valeurs
comprises dans l'intervalle [0.05, 0.25]. Plus la valeur de ce paramètre
est élevée, plus les changements s'intègreront rapidement.
Cela revient alors à oublier rapidement le modèle construit lors
de la phase d'initialisation. Il est conseillé d'utiliser des valeurs
relativement faibles (p. ex. : 0.05).
Finalement, l'écart-type n'est pas ajusté ou mis
à jour pendant l'exécution de l'algorithme (c.-à-d.. : une
fois l'initialisation effectuée) afin de réduire la somme de
calculs nécessaire. Certaines expérimentations
supplémentaires devraient cependant être réalisées
pour vérifier l'utilité et l'impact de cette mise à jour
sur les résultats.
3.2. Détection par différence
d'images
La détection du mouvement contient les méthodes
de différences d'images (approche directe), de corrélation ou de
recherche dans l'espace des paramètres. Les méthodes basses
niveaux exploitent la comparaison pixel à pixel, ou petite région
à petite région entre deux images consécutives d'une
séquence. Elles permettent de déterminer les régions de
variations de l'image dans le temps. Elles nécessitent soit une
caméra fixe, soit un recalage préalable dans le cas d'un
observateur mobile, afin de détecter uniquement les zones de mouvement
dans la scène. Elles sont généralement limitées aux
mouvements d'objets rigides et au cas de petits déplacements.
3.2.1. Avec image de référence
Dans certaines applications (acquisition avec caméra
fixe en particulier), il peut être possible de disposer d'une image dans
laquelle seuls les éléments stationnaires sont
30
présents. Cette image est alors utilisée comme une
image de référence R(x, y) notée
R. Cette image doit posséder les
caractéristiques suivantes :
- Être exempte de tout objet mobile ;
- Avoir été acquise sous les mêmes conditions
d'éclairement que les images avec lesquelles elle sera
comparée.
L'image de différence notée D
devient alors :
D = II - RI (11)
Où I représente
l'image à l'instant t et R
est l'image de référence. Les régions en
mouvement sont obtenues après seuillage de l'image de différence
(nécessaire à cause du bruit). Cette image de différence
fait apparaître 2 types de régions :

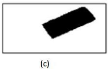
Source : (MEDJAHED, 2012)
Figure 9: Technique de différence avec image de
référence, (a) l'image à l'instant t, (b) l'image de
référence, (c) l'image de différence.
- La première zone est constituée des points
appartenant aux objets mobiles dans leur position courante ;
- La seconde zone est constituée des points
stationnaires présents dans les deux images I(x, y, t)
et R(x, y).
Cette méthode est très utilisée dans le
domaine de détection d'objet en mouvement mais la plus grande
difficulté consiste à obtenir l'image de la
référence (du fond). Dans certains cas, cette image peut
être obtenue en sélectionnant manuellement une image ou aucun
objet n'apparait, mais ce n'est pas toujours le cas. La construction d'une
image de
31
référence est donc une question délicate
abordée dans la littérature par de nombreux auteurs tels qu'avec
(Evelet et Bolles,1998), et
(Long et Yang,1990).L'image de
référence doit en permanence être identique à
l'environnement statique perçu dans chaque image de la séquence.
(Jain, 1984), propose un algorithme qui repose sur l'analyse
de différence d'image. (Makarov,1996) construit l'image
de référence en se fondant sur l'analyse de la moyenne du niveau
de gris d'un pixel donné sur une séquence de N
images. À chaque acquisition d'une nouvelle image
I de la séquence, une nouvelle image de
référence R est construite. Le niveau
de gris de chaque pixel de l'image de référence est
déterminé par la relation suivante :
t1
R(x, y, t) = N 1 ? ~(~, ~, t)
~~t_~ (12)
Où N : le nombre d'images
dans la séquence. Cette méthode nécessite une
mémorisation de N images successives de la
séquence, mais cette opération est assez coûteuse. Une
autre difficulté vient de changements de luminosité ; même
si l'hypothèse du faible changement entre deux images successives est
respectée, le changement à long terme peut être important
sur une séquence très longue.
3.2.2. Sans l'image de référence
La différence temporelle s'exprime par :
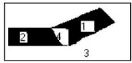
FD (Ic ,Ip) = |Ic - I,,| (13)
Où : FD : image de
différence, IC image courante, et
IP image précédente.
L'image FD (IC, IP) ainsi obtenue
est nulle en tout point où le signal d'entrée I
est constant. Les points où un changement temporel s'est
produit sont détectés par simple seuillage de
FD. Le seuillage est nécessaire à cause
du bruit présent dans les 2 images. Le résultat du seuillage est
une image binaire indiquant les zones en mouvement.

32
Source : (MEDJAHED, 2012)
Figure 10: Technique de différence sans image de
référence, (a) image précédente, (b) image
courante, (c) image de différence.
- La zone `1' située à l'avant
de l'objet dans le sens du déplacement est constituée de points
qui appartenaient au fond de l'image précédente et qui sont
recouverts par l'objet dans l'image courante. L'amplitude de différences
de niveaux de gris y est fonction du contraste entre l'objet et le fond.
- La zone `2' située à
l'arrière de l'objet est constituée de points qui appartenaient
à l'objet dans l'image précédente et qui ont
été découverts suite au mouvement. Ils appartiennent au
fond de l'image courante. L'amplitude de différences de niveaux de gris
y est fonction du contraste entre l'objet et le fond.
- La zone `3' constituée de points
appartenant au fond et aux objets stationnaires dans les deux images.
L'amplitude des différences de niveaux de gris y est faible.
- La zone '4' qui n'existe que lorsqu'il y a
chevauchement des positions de l'objet et qui est constituée de points
appartenant à l'objet en mouvement dans les deux images. L'amplitude de
différences de niveaux de gris y est faible.
Ainsi, les régions `1' et `4'
retracent l'objet dans l'image à l'instant t,
et les régions `2' et `4' à
l'instant t- dt, les régions `1'
et `2' sont détectées comme des
régions en mouvement, par contre, la région `4'
l'est rarement et le problème est d'extraire cette
région.
33
Conclusion
Dans ce chapitre, nous avons justifié le choix de deux
méthodes de détection de mouvement d'objet ou de personne dans
une séquence vidéo. Il d'agit de la méthode par
soustraction de l'arrière-plan et la méthode différence
d'image consécutive. Nous avons aussi présenté les
techniques d'implémentation de ces dernières. Dans le chapitre
suivant nous présentons le matériel nécessaire à
l'implémentation des modèles de détection de mouvement
retenus.
34
Chapitre 4 : Le matériel utilisé
Pour la réalisation de nos travaux, nous avons
utilisé plusieurs méthodes et techniques dont l'objet de ce
chapitre est de décrire les différentes applications et
bibliothèques utilisées. Une description sur les étapes
utilisées de la mise en place de la plateforme de lecture,
d'écriture et de manipulations de données séquences
images. L'avantage de ces outils est qu'ils sont tous libres de licence GNU.
4.1. Les outils nécessaires pour la vision
artificielle
Nous avons utilisé plusieurs outils et techniques pour
préparer notre plate-forme IDE Code::Block, afin de pouvoir faire les
manipulations sur des séquences d'images.
4.1.1. MinGW ou Mingw32 (Minimalist GNU for Windows)4
Elle est une adaptation des logiciels de développement
et de compilation du GNU (GCC - GNU Compiler Collection), à la
plate-forme Win32. Contrairement à d'autres applications, les programmes
générés avec MinGW n'ont pas besoin de couche
intermédiaire de compatibilité (sous forme d'une
bibliothèque dynamique, DLL (Dynamic Link Library)). L'appellation
Mingw32 a été abandonnée depuis que MinGW supporte les
environnements d'exécution 64 bits en plus de 32 bits.
D'autre part, sa licence libre n'exige pas que les
applications développées avec MinGW soient publiées sous
licence GNU GPL5.
4.1.2. CMakesFiles6
Il sert principalement à faciliter la compilation et
l'édition de liens puisque dans ce processus le résultat final
dépend d'opérations précédentes. Le système
de langage utilisé dans le cmakefiles est de la programmation
déclarative. À l'inverse de la programmation impérative,
cela signifie que l'ordre dans lequel les instructions doivent être
exécutées n'a pas d'importance.
4 Source :
http://sourceforge.net/projects/mingw/files/
5Source :
http://www.linux-france.org/article/these/gpl.html
6Source :
http://www.cmake.org/cmake/resources/software.html
35
4.1.3. Code::Blocks
C'est notre IDE (Environnement de Développement
Intégré) libre et multiplateforme. Il est écrit en C++
grâce à la bibliothèque wxWidgets. Pour le moment,
Code ::Blocks est orienté C et C++, mais il peut aussi être
supporté par d'autres langages.
La liberté de Code::Blocks implique la
possibilité du contrôle par l'utilisateur de l'ajout de librairie
ou par personnalisation des compilateurs par exemple. De plus, sa
gratuité a permis de créer une communauté de
programmateurs suffisamment conséquente pour que le logiciel soit mis
à jour régulièrement et qu'il soit très simple de
trouver quelques explications complémentaires en cas d'erreurs dans la
compilation. Les principaux avantages de ce logiciel sont la possibilité
de création de projet et la mise en forme automatique (auto
complétion et colorisation du code) qui permet de repérer
rapidement les erreurs.
4.1.4. OpenCv (Open Source Computer Vision)7
OpenCV (Open Computer Vision) est une librairie open source
d'algorithmes de vision assistée par ordinateur, elle est accessible
pour les langages C, C++ et aussi Python. Il s'agit d'une bibliothèque
libre, ce qui présente les avantages précédemment
évoqués, qui se spécialise dans le traitement et l'analyse
d'images ou vidéos en temps réel au moyen d'interfaces.
Grâce à cette bibliothèque, il est
possible de charger, afficher et modifier des images, travailler à
partir d'histogrammes et d'appliquer des transformations de base (seuillage,
segmentation, morphologie...).
OpenCV est composée de 5 librairies différentes
: CV, CVAUX, CXCORE, HIGHGUI et ML. Chacune a sa
spécificité, HIGHGUI par exemple permet la manipulation
des fichiers et l'affichage d'une interface graphique alors que ML
permet la classification des données. On trouve de nombreuses
applications à cette librairie, les ordinateurs à
déverrouillage par reconnaissance faciale par exemple, de même que
le tracking d'objet sur une vidéo. Au moyen d'OpenCV, il est possible de
contrôler une machine par les mouvements oculaires et les clignements
pour des personnes handicapées parmi tant d'autres
possibilités.
7
http://opencv.org/&usg=ALkJrhiMsrQo2SmvZH4Ghd1Cg0bDejVm-Q
36
4.2. Les étapes d'installation des
différentes applications
Pour une bonne vision artificielle, nous allons d'abord
préparer notre propre environ de travail. A cette raison nous allons
suivre quelques étapes ci-après :
4.2.1. Étape 1: Installation de MinGW
MinGW est un compilateur C/C++, qui doit être
intégré dans notre API. L'installation se fera à la racine
et à l'emplacement par défaut
C:\MinGW. Dans les options
d'installation, nous allons choisir mingw32-base et mingw32-gcc-g
+ +, mais tout en sachant que nous pouvons également installer les
autres composants si besoin sera faites mais nous n'avons besoin que de
compilateur C + + (g+ +).
NB : Une attention particulière
sera portée sur ce passage car l'installation de différents
paquets se fait via un téléchargement, alors il peut ou n'est pas
être correcte, cela posera un grave souci et l'installation n'aura jamais
lieu. Tel est le problème que nous avons rencontré lors de nos
premières manipulations avec les outils de la vision artificielle.
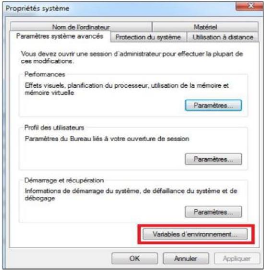
4.2.2. Étape 2: Ajout de chemin d'accès de
MinGW au système Nous allons accéder à :
Panneau de configuration -> Système ->
Paramètres système avancés puis comme montre la figure
ci-dessous: Nous allons ajouter le lien C : \MinGW\bin à la
suite des Variables d'Environnement.
37
Figure 11: Variable Environnement
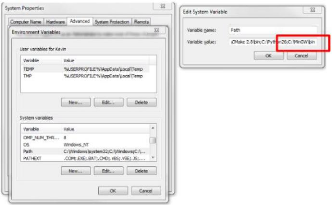
Figure 12: Ajout de chemin
Nous devons mettre évidement un point-virgule après
la dernière entrée dans le "chemin", puis le chemin MinGW
à ajouter (il devrait être
C:\MinGW\bin si nous
avons respecté (effectivement le choix de l'emplacement par
défaut).
Nous allons ouvrir un "chemin" invite de commande et tapons "
mingw" pour s'assurer qu'il a été bien installé
et prêt pour travailler. Les programmes devront être
redémarrés pour que cette modification prenne effet.
38
4.2.3. Étape 3: Installation Code :: Blocks (notre
API choisi)
L'installation devra se faire à l'emplacement par
défaut :
C:\ProgramFiles(x86)\CodeBlocks.
Lorsque le programme d'installation terminé, un clic sur Oui est
nécessaire afin d'exécuter Code::Blocks, puis nous irons dans
l'interface de l'IDE pour paramétrer : Paramètres ->
Compiler et Debugger. Selon les exécutables
Toolchain, pour notre cas ci, nous allons sélectionner GNU
compilateur GCC dans le menu déroulant, puis nous appuyons sur
AutoDetect afin de vérifier que si Code::Blocks a trouvé
MinGW comme compilateur par défaut sur la machine.
4.2.4. Étape 4: Installer OpenCV
La bibliothèque OpenCV met à notre disposition
de nombreuses fonctionnalités très diversifiées permettant
de créer des programmes, des données brutes pour aller
jusqu'à la création d'interfaces graphiques basiques.
Il est disponible sur le site officiel en version compression,
la décompression se fera comme suit: Nous allons faire un double clic
sur le fichier téléchargé OpenCV-2.4.2.exe et
choisissez C: \ comme répertoire extrait.
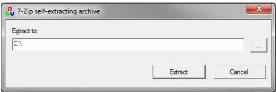
Figure 13 : Décompression OpenCv
OpenCV est maintenant installé mais pas
configuré avec Code::Blocks. Il nous reste d'abord l'application
CmakeFiles. Une fois téléchargé le fichier, nous
effectuons de la manière suivante : ouvrons le fichier CmakeFiles
et nous sélectionnons C: \ OpenCV qui serait le
répertoire source et
C:\OpenCV\build\x86\mingw
sera le répertoire cible pour construire les binaires (nous
pourrons sélectionner n'importe quel répertoire mais choisir
celui-ci écrase les fichiers binaires de OpenCV préconstruits).
Un clic sur Configurer ensuite nous choisissons makefiles MinGW,
après un temps de patience et ensuite un clique sur
Générer. Voir figure ci-dessous.
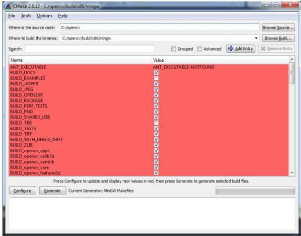
39
Figure 14: installation de cmake
Lorsque CmakeFiles est correctement installé,
nous devons ouvrir une invite de commande dans le même répertoire
de construction (build), de sorte a accédé à
C:\opencv\build\x86\mingw,
nous passerons ensuite un clic droit et tout en choisissant la
fenêtre de commande ouverte puis saisissons "mingw32-make".
Mingw va maintenant commencer à compiler OpenCV. Une fois la compilation
de cmake dans OpenCv terminée, nous allons ressaisir une
nouvelle commande qui permet l'installation de cmake et mingw dans opencv :
"mingw32-make install. L'installation prendra aussi un peu temps, la
patience est beaucoup plus sollicitée.
40
4.2.5. Étape 5: Ajout de OpenCV à la
trajectoire du système
C:\opencv\build\x86\mingw
\bin (utiliser le même procédé que mingw)
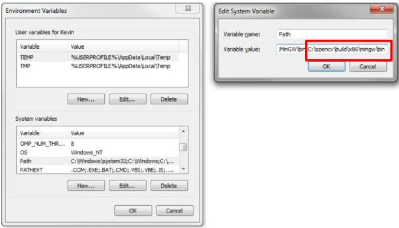
Figure 15: Ajout d'OpenCv à la variable
Figure 16: Test de mingw dans la variable path
Il nous reste que la vérification, de MinGW et OpenCV sont
dans le chemin d'accès système. Une fois la configuration
terminée, un redémarrage de l'application de l'IDE Code::Blocks
est nécessaire avant toute utilisation.
4.2.6. Étape 6: Configuration du Code::Blocks avec
OpenCV
En ouvrant Code::Blocks et en sélectionnant Nouveau
projet, c'est la première fenêtre que nous devons en avoir, avant
de choisir le modèle du projet que nous voulons mettre en place. Ici,
nous avons d'abord Console Application comme montre la figure :
41
Figure 17: Choix de l'application du projet
Une fois sélectionnée, nous validons et poursuivons
la suite de notre configuration.
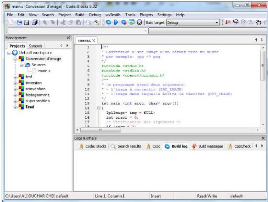
Figure 18: Interface de code::blocks
Il existe deux possibilités de modifier les
paramètres, soit en modifiant les paramètres de chaque projets,
soit en modifiant les paramètres globaux du compilateur qui se trouve
sur la barre de menu en haut à droite. Nous avons choisi la
deuxième possibilité. La fenêtre ci-après:
42
Figure 19: Interface de Configuration
D'abord, nous allons faire entrer les différents
paramètres dans le Compilateur comme montre la figure ci-après :
C:\opencv\build\include.
Cette étape consiste à définir le repertoire dans
lequel OpenCv est sauvegardé. Ajoutons le repertoire comme montre la
figure.
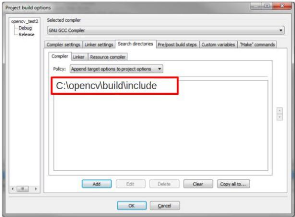
Figure 20: Ajout du répertoire au compilateur
Nous passerons à la séconde étape qui
consiste à ajouter les répertoires à prendre en compte par
le linker de CodeBlocks. Voir figure ci-dessous.
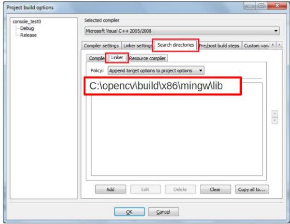
43
Figure 21: Ajout du répertoire OpenCv au Linker du
code::blocks
Remarque : Même si notre système est 64 bits parce
que le compilateur est 32-bit.
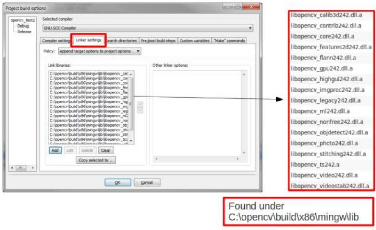
Figure 22: Ajout des librairies à l'IDE
Nous ajoutons les librairies de Linker qui se trouvent dans le
répertoire :
C:\opencv\build\x86\mingw\bin.
Maintenant, la configuration est terminée. Nous testons la
configuration en exécutant un programme simple OpenCV de lecture d'une
image "Lecture " pour vérifier que l'installation a fonctionné ou
pas.
44
4.3. Les fonctions utiles
Un des buts d'OpenCV est d'aider les gens à construire
rapidement des applications sophistiquées de vision à l'aide
d'infrastructure simple de vision par ordinateur. La bibliothèque
d'OpenCV contient près de 500 fonctions. Il est possible grâce a
la « licence de code ouvert » de réaliser un produit
commercial en utilisant tout ou partie d'OpenCV. Nous citons les
fonctionnalités utilisées pour la réalisation de ce
travail de mémoire.
4.3.1. Pour le traitement d'image
? IplImage* cvLoadImage( const char* filename,
int
iscolor=CV_LOAD_IMAGE_COLOR )
Cette ligne charge l'image. La fonction cvLoadImage
détermine le format de l'image à partir du nom passé
en argument, réserve la mémoire nécessaire pour la
structure de données de l'image et renvoi un pointeur. Ce pointeur
s'utilise pour manipuler tant l'image que les données. Le second
argument spécifie la couleur de l'image chargée (RGB, noir et
blanc ou échelle de gris).
? cvNamedWindow(«Name»,
CV_WINDOW_AUTOSIZE);
cvNamedWindow() ouvre une fenêtre qui peut
contenir et montrer une image. Le premier argument correspond au nom à
donner à la fenêtre. Le second défini les
propriétés de la fenêtre. Ici CV_WINDOW_AUTOSIZE, signifie
que la fenêtre prendra la taille de l'image.
? cvShowImage(«Name», img);
Cette fonction permet d'afficher une image de type «
IplImage » dans la fenêtre créée au
préalable.
· cvWaitKey(0);
Cette ligne de code interrompt, momentanément ou
indéfiniment, l'exécution du programme. La valeur positive,
entrée en argument, correspond au temps en millisecondes avant que le
programme ne s'exécute de nouveau. S'il s'agit d'une valeur nulle ou
négative, le programme attend que l'utilisateur tape une touche du
clavier pour s'exécuter de nouveau.
? cvReleaseImage(&img);
Cette fonction libère la mémoire
réservée pour contenir les données de l'image.
·
45
cvDestroyWindow(«Example»); Cette
fonction permet de détruire la fenêtre.
· IplImage* cvCloneImage( const IplImage* image
)
Cette fonction permet de créer une copie complète
de l'image passée en argument.
· IplImage* cvCreateImage( CvSize size, int depth,
int channels)
Crée un emplacement et enregistre les données de
l'image. Le premier argument spécifie la taille de l'image (hauteur et
largeur). Le second spécifie la profondeur en bits des
éléments (pixels) de l'image. Le troisième spécifie
le nombre de caractères par pixel.
· void cvCvtPixToPlane( const CvArr* src, CvArr*
dst0, CvArr* dst1, CvArr* dst2, CvArr* dst3 )
Cette fonction sépare une matrice multi-canaux(src)
vers plusieurs matrices n'ayant qu'un canal (dst0, dst1, dst2 y dst3).
4.3.2. Pour lire la video
· CvCapture* capture =
cvCreateFileCapture(argv[1]);
La fonction cvCreateFileCapture() prend en argument le nom de
du fichier AVI(Audio Video Interleave) à être chargé et
renvoi un pointeur à une structure de données CvCapture. Cette
structure contient toute les informations sur le fichier AVI qui a
été lu. Le pointeur pointe au début de la vidéo.
· cvReleaseCapture(&capture);
Libère la mémoire utilisée avec la
structure CvCapture. Cette fonction ferme également tous les fichiers
ouvert et qui font référence au fichier AVI.
· CvVideoWriter* cvCreateVideoWriter( const
char* filename, int fourcc, double fps, CvSize frame_size, int is_color=1
)
Cette fonction crée une structure pour écrire
une vidéo. Les arguments nécessaires sont :
- Filename. Nom de la vidéo de sortie.
- Fourcc. Code de quatre caractères du
codec utilisé pour comprimer le photogramme
46
- Fps. Nombre de photogrammes par seconde de la
vidéo que l'on veut créer.
- Frame_size. Taille du photogramme.
- Is_color. Permet de définir
l'échelle de couleur de l'image. RGB, gamme de gris ou noir
et blanc.
? IplImage* cvQueryFrame( CvCapture* capture
)
Lit puis renvoi le photogramme d'une caméra ou d'un
fichier.
? double cvGetCaptureProperty( CvCapture*capture,int
property_id);
Propriétés et vidéo spécifiées
en argument. Voici quelques exemples de propriétés utiles
au programme :
- CV_CAP_PROP_FPS. Nombre de photogramme par seconde.
- CV_CAP_PROP_FOURCC. Code de quatre caractères du codec
utilisé
- CV_CAP_PROP_FRAME_COUNT. Nombre de photogrammes dans la
vidéo ? int cvWriteFrame( CvVideoWriter* writer, const IplImage*
image)
Cette structure permet d'ajouter un photogramme à la
vidéo.
? void cvReleaseVideoWriter( CvVideoWriter** writer
)
Cette fonction finalise l'enregistrement de la vidéo et
libère la structure.
Conclusion
Nous avons présenté un ensemble de
matériel nécessaires à l'implémentation
d'algorithmes en traitement d'image en général et de
détection de mouvement en particulier. Ce matériel se
résume en deux outils, à savoir, l'environnement de
développement intégré (EDI) CodeBlock, la
bibliothèque Open CV qui sont tous deux de licence libre. Nous avons
proposé aussi une configuration de l'EDI CodeBlock afin de permettre son
interopérabilité avec Open CV. Dans le chapitre suivant nous
implémentons pratiquement les modèles de détection de
mouvement retenu (voir chapitre 3)
47
Chapitre 5 : Implémentation et Discussions sur
les résultats
L'expérimentation présente un grand
intérêt pour le présent travail de recherches. En effet,
l'algorithme de mise en correspondance entre les points d'intérêt
des différentes images, la détection de mouvement sont
basés sur une étude théorique, dont il est
nécessaire de situer la validité et la robustesse par
expérimentation.
5.1. Implantation logicielle
À l'usage, certaines particularités de la
méthode de base ont pu être simplifiées, notamment pour les
seuils de détection. En effet, il est courant d'utiliser une valeur
d'écart-type pour chaque pixel et pour chaque canal de l'image.
Cependant, des expérimentations ont démontrées que
l'utilisation d'un écart-type global pour chacun des canaux ne
dégradait nullement les résultats obtenus. En pratique ces
valeurs sont calculées à l'aide de la moyenne des
écarts-types de chaque canal correspondant. Cette simplification est
utilisée dans notre implémentation, représentant donc une
légère économie d'espace et d'accès mémoire
lors de la phase d'extraction du mouvement.
5.1.1. Interface
Afin d'interagir avec la classe, plusieurs fonctions
d'interface ont été créées. La liste suivante
résume les principales fonctions publiques accompagnées d'une
courte description pour chacune d'elle :
- init : Initialisation des
différents compteurs, accumulateurs et modèles nécessaires
à l'exécution des algorithmes ;
- update : Mise à jour du
modèle statistique. Cette fonction dépend essentiellement de
l'état du modèle statistique, c'est-à-dire du niveau
d'avancement de celui-ci. Le traitement exécuté dépend du
nombre d'images d'initialisation ajoutées au modèle et est
déterminé automatiquement lors de l'appel de la fonction. Les
deux modes sont :
? Modèle non complet : l'image d'entrée est
ajoutée aux différents accumulateurs et le compteur d'images
d'initialisation est incrémenté ;
? Modèle initialisé : le modèle
statistique de l'arrière-plan est modifié en ajoutant une
fraction des pixels statiques de l'image d'entrée;
- getMask : Extraction du masque des
pixels en mouvement;
48
- getForeground : Extraction de
l'avant-plan (ou pixels en mouvement). Cette opération implique un
calcul du masque du mouvement;
- getBackground : Extraction de
l'arrière-plan. En pratique, le modèle statistique
est simplement converti et copié dans l'image
passée par référence à la fonction ; -
reset : Réinitialisation des variables membres, compteurs,
modèles, etc. afin de
démarrer une nouvelle soustraction de
l'arrière-plan.
5.1.2. Optimisations
Finalement, plusieurs optimisations logicielles peuvent
contribuer à des gains de performance intéressants. Tout d'abord,
une modification à l'algorithme de base concernant le masque de
mouvement est déjà implémenté dans la classe
développée. Lorsque plusieurs accès au masque sont requis
(c.-à-d. : appel séquentiel des fonctions getForeground,
getMask et update), il est possible de le conserver en
mémoire afin de le réutiliser dans les fonctions
subséquentes. Cela évite alors le calcul du même masque
plusieurs fois de suite. Le seul inconvénient avec cette façon de
procéder est que nous devons prendre les précautions
nécessaires pour ne pas utiliser un masque obsolète.
Enfin, l'optimisation la plus facilement réalisable est
l'ajustement de la fréquence de mise à jour du modèle
statistique. En effet, il est inutile d'effectuer cette opération
à chaque acquisition d'image considérant que dans la
majorité des cas, la différence entre deux images
consécutives est minime (p. ex. : mise à jour d'une image sur
deux). Toutefois, il serait également envisageable, lorsque les
conditions sont contrôlées, d'éliminer totalement la phase
de mise à jour.
5.2. Expérimentations
La présente section illustre certains résultats
obtenus avec la méthode de SAP par modélisation statistique ainsi
que certaines expérimentations avec différents paramètres
de l'algorithme. Il est à noter que pour toutes les
expérimentations réalisées, la fonction d'ajustement
automatique (auto white balance) de la camera était
désactivée. De plus, les valeurs utilisées pour le temps
d'intégration ainsi que le gain du capteur étaient fixées
et non modifiées au cours d'une même acquisition. Nous avons fait
nos acquisitions avec de caméra HD afin d'avoir une résolution
correcte, nette et bien pixélisée.
49
5.3. Performance
Le tableau suivant résume la capacité de
traitement de l'algorithme à différentes résolutions et
pour certaines fréquences de mise à jour. Il est important de
noter qu'aucun affichage n'a été réalisé pendant
ces expérimentations. Donc, pour des images de dimensions 320 x
240, le système peut traiter jusqu'à 24 images par seconde
(FPS ou Frame Per Second).
Tableau 2: Tableau comparatif de performance
pour la soustraction de l'arrière-plan à
différentes résolutions d'images et fréquences de mise
à jour du modèle
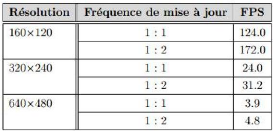
Source : Mémoire pour l'obtention du grade de
maître ès sciences, Alexandre Lemieux, 2003
Par ailleurs, lorsque la fréquence de mise à
jour est abaissée de moitié, le nombre d'images traitées
par seconde augmente rapidement (surtout à basses résolutions)
avec, par exemple, un gain de 48 FPS pour une résolution de 160 x
120 (c.-à-d. : passe de 124.0 à 172.0 FPS). Notons cependant
que la quantité d'images traitées ne double pas lorsque la
fréquence de mise à jour est abaissée de moitié.
Ceci s'explique simplement par le fait que les opérations
nécessaires à la mise à jour du modèle ne
constituent pas l'ensemble des étapes à effectuer à chaque
itération de l'algorithme.
5.4. Implémentions de méthodes de
détection : Résultats et discussions
Nous avons choisi trois méthodes parmi celles
étudiées à l'état de l'art pour faire une
implémentation et comparaison de résultats afin de mener une
discussion et souligner l'importance de la méthode choisie
définitivement pour l'étude et la rédaction de ce
mémoire.
5.4.1. Détection par différence entre deux
images consécutives
Étant peu complexe, la différence entre des
images consécutives représente une solution très
intéressante. Comme son nom l'indique, elle consiste à soustraire
une image
50
acquise au temps tn d'une autre au temps tn +
k, où k est habituellement égal à
1. Ainsi, l'image résultante sera vide si aucun mouvement ne
s'est produit pendant l'intervalle de temps observé car
l'intensité et la couleur des pixels seront presque identiques.
Par contre, si le mouvement a lieu dans le champ de vue, les
pixels frontières des objets en déplacement devraient changer
rapidement de valeurs, révélant alors la présence
d'activité dans la scène. Cette technique nécessite
très peu de ressources, car aucun modèle n'est nécessaire.
Cela implique donc qu'il n'y a pas de phase d'initialisation obligatoire avec
une scène statique, ce qui procure une très grande
flexibilité d'utilisation. Par ailleurs, les résultats obtenus
avec cette méthode ne sont pas aussi précis que ceux
générés en utilisant un modèle statistique de
l'arrière-plan.
En effet, certains traitements supplémentaires sont
nécessaires afin de déterminer la zone en mouvement, car
l'information disponible ne concerne que les contours des régions en
déplacement (ce qui inclut également les zones intérieures
d'un objet).
5.4.1.1. Technique étudiée
D'une manière générale, la détection
de mouvement se fait à l'aide de la différence
entre l'image courante à l'instant t et l'image de
référence Iref.
La formule générale est :
?I(x, y , t) = I(x, y) - Iref(x, y, t), V (x, y)
(14)
x, y sont les coordonnées respectives.
L'image de référence est
considérée ici comme celle du fond mobile dans le cas d'une
caméra fixe, mais peut aussi être estimée par la moyenne ou
la médiane des N images précédentes de la
séquence.
Comme dans le cas de la détermination des points de
contours d'une image, le seuillage se fait sur le module de la
différence d'images.
D(x,y,t) = I|?I(x,y,t)|I > seuil
(15)
D(t) est une image binaire où les
pixels en mouvement sont mis à 255, les autres à 0. Dans le cas
où l'image de référence est une image fixe du fond
immobile, les pixels en mouvement sont aisément détectés,
pour peu que les conditions d'éclairement de la scène ne varient
pas notablement :
Iref(x, y, t) = Iref(x, y, O), Vt
(16)
51
Si l'illumination de la scène varie brutalement, si la
caméra est déplacée durant la séquence, ou si
aucune image du fond n'est disponible, l'image de référence peut
être construite à partir d'images précédentes de la
scène : dans ce cas, c'est la silhouette des objets en mouvement qui est
généralement détectée, et pas leur
intérieur.
Iref(x, y, t) = Iref(x, y, t - I), Vt
(17)
Prendre la moyenne des N images
précédentes pour image de référence amène
à une détection de mouvement plus robuste qu'une
différence d'images consécutives :
Iref(x,y,t) = NENI Iref(x,y,t-i)
(18)
En effet, dans le cas d'une scène filmée par une
caméra fixe, les objets immobiles sont mis en valeur au détriment
de ceux en mouvement qui sont atténués par l'opération de
moyennage, et semblent effacés.
5.4.1.2. Schéma de l'implémentation
La détection peut se faire par seuillage de la
différence entre l'image courante (instant t) et l'image
précédente (à t-1) de la séquence. Dans le
programme précèdent, on propose d'implémenter un curseur
à glissière fixant le seuil à appliquer. La
détection de mouvement est définie dans la fonction
MotionDetection qui retourne l'image dst des pixels en
mouvement colorés en bleu. L'image silh est l'image binaire du
mouvement, codée sur 8 bits et composée d'un seul canal.
La fonction cvAbsDiff calcule la différence
entre deux images en valeur absolue pour chaque pixel. L'image
précédente curr_img est ensuite actualisée avant
le traitement de l'image suivante de la séquence : on lui affecte le
contenu de l'image courante prev_img à l'aide de la fonction
cvCopy utilisée de la bibliothèque OpenCv.
Le programme principal déclare les images couleur
video_image et motion servant à la lecture de la trame
vidéo et à l'affichage de la détection de mouvement. Ces
images ainsi que l'image courante et précédente (deux images
monochromes) doivent être créées une fois la
première trame de la vidéo lue. Après cette installation,
le flux vidéo est traité par l'appel au sous-programme comme
montre le programme principal.
La méthode la plus simple et la plus rapide est de
calculer l'image de différence de luminance en chaque pixel entre deux
images consécutives de la séquence vidéo. À
cause
52
du bruit induit par l'électronique et les capteurs de la
caméra, un seuil S doit être appliqué. L'image de
différence est ensuite binarisée suivant des relations de la
forme : pour un pixel. Le code source de programme implémenté
se trouve en annexe A.
5.4.1.3. Résultats et Discussions
En appliquant le programme en annexe, nous obtenons comme
résultats :

a) image de référence b) image
détectée c) image binarisée et seuiléee
Figure 23 : Image de détection
L'image a), représente l'image de
référence ; l'image à laquelle aucun mouvement n'est
détecté. On observe une image l'image du fond de la scène
filmée par la camera fixée.
L'image b), représente l'image détectée,
qui est caractérisée par la présence d'une personne en
mouvement comme on voit sur l'image. Cette situation explique la variation de
pixel : la personne détectée présente une variation de
pixel. La camera détecte une personne dans la scène alors qu'elle
est supposée être fixe.
L'image c), l'image binarisée et seuillée est le
résultat de la différence entre l'image a) et b). En faisant la
différence entre les pixels de ces deux images, nous obtiendrons l'image
c) qui sera affichée après deux opérations : la
binarisation et le seuillage.
5.4.2. Détection par soustraction
d'arrière-plan
La détection de personnes dans des séquences
vidéo consiste à déterminer, pour une image ou une
séquence d'images, si des personnes sont présentes, et
éventuellement à déterminer leur position. Elle permet de
repérer les objets mobiles de l'arrière-plan d'une
séquence vidéo, elle est une technique de segmentation
nécessaire et souvent très utilisée en vision
artificielle. La plupart des algorithmes de vision considèrent cette
étape comme une étape de prétraitement nécessaire
qui a pour but de réduire l'espace de recherche, et d'améliorer
la performance en terme de coût calculatoire d'une application
(possiblement de reconnaissance ou de tracking ou de détection) de plus
haut niveau d'abstraction. Cette
53
étape est nécessaire, plus
précisément, pour le suivi d'objet, la reconnaissance d'actions
humaines, la vidéosurveillance, la détection de chute, etc. On
trouve un ensemble de méthodes de détection d'objet basées
sur la technique de soustraction de fond. La détection d'objet par cette
technique se fait par une opération de soustraction de deux images,
l'image courante, et l'image qui représente la ou les partie(s) statique
de la scène. L'un des problèmes majeurs de cette technique est la
manière dont on peut obtenir automatiquement un arrière-plan de
la scène statique qui soit le plus robuste aux changements de
l'éclairage, aux ombres, et au bruit présent dans la
séquence vidéo. Il existe différents algorithmes dans la
littérature qui ont été conçus pour
modéliser tout ce qui est statique, d'éliminer les ombres, et de
récompenser l'évolution de l'arrière-plan. La performance
de ces algorithmes, pour estimer un arrière-plan plus robuste, est
variable d'un algorithme à l'autre.
5.4.2.1. Technique étudiée
L'image de référence peut être la moyenne
des N images précédentes de la séquence
(disponible publiquement). Pour calculer cette image, on crée un tableau
d'images buf dans lequel on copie ces N images. Ce tableau a
une taille fixe, il contient N images monochromes et la ieme
image buf[i] se manipule comme n'importe quelle image.
Pour accéder en lecture ou en écriture à
ces images, on déclare un entier last indexant l'instant t
: buf[last] est ainsi l'image courante. Une fois enregistrées les
N premières images du tableau buf, (buf[i]
pour i allant 0 à N-1), la N+Ieme image
de la séquence doit être stockée en début de tableau
écrasant l'ancienne valeur de buf[0], l'image suivante à
t=N+2 écrase buf[1] etc......L'image de la
séquence est donc à stocker à la position last +1
modulo N du buffer buf. On calcule ensuite la moyenne
mobile en deux étapes, la somme des N images cvAcc est
calculée en premier, ce qui nécessite une image codée sur
32 bits pour stocker ce résultat intermédiaire. Et puis la
division de cette image par l'entier N est réalisé en
même temps que sa conversion en image codée sur 8 bits.
5.4.2.2. Schéma d'implémentation
La modélisation de l'arrière-plan d'une
scène par la méthode proposée par (Kim et
al,2004) est devenue une référence de plus en
plus utilisée dans les domaines de la détection d'objets mobiles.
Cette méthode est robuste et efficace dans un grand nombre de cas
d'utilisation, y-compris les arrière-plans dynamiques (tels que les
feuillages, les fontaines, les bords de mers, les drapeaux...) et les
légers changements d'illumination.

54
L'observation préalable de cet algorithme est que les
fausses détections sont généralement situées dans
les zones sombres de l'image. Or, les couleurs sombres (et donc moins
lumineuses) sont par nature plus difficiles à différencier et
conduisent à une incertitude plus grande sur leur classification finale
(fond ou forme). Ainsi, on suppose que la luminosité devrait être
un facteur important dans la comparaison des ratios de couleurs entre deux
pixels. Le code source de programme implémenté se trouve en
annexe B.
5.4.2.3. Résultats et Discussions
On observe également au fil du temps que la couleur
d'un pixel donné est distribuée sur une droite alignée
avec l'origine (0,0,0). Ces observations motivent la création d'un
nouveau modèle de couleur permettant une évaluation
séparée de la distorsion de la couleur et de la luminosité
du pixel.

a) Images de références b) image en niveau de
gris
a) Image Moyen mobile de la scène d) image
détectée binarisée et seuillée
Figure 24 : Détection de mouvement par moyen
mobile
Les images issues de résultats de la méthode de
détection par la moyenne mobile, nous donne cinq images dont :
L'image a) est constituée de deux images
considérées comme image de référence a deux
instants différents : l'instant t, alors que l'image où
on ne détecte pas une personne en
55
mouvement et à l'instant t+1 ; où on
détecte une personne en nouement dans la scène. La
différence entre ces instants qui nous permettra de faire la moyenne
d'image acquise plus tard entre l'image à l'instant t et celle
à l'instant t+1.
L'image b) est celle transformée en niveau de gris. La
transformation d'image en niveau de gris a pour objectif de convertir les
images couleur en image binaire où la luminance et la chrominance sont
nulles.
L'image c) montre la moyenne de la différence entre
l'image de référence à l'instant t et celle
à l'instant t+1, notre objectif atteint ici est le fait de
n'est rien voir sur cette image alors qu'en réalité nous avons
des activités de détection. En faisant la moyenne entre les
images à l'instant t et à l'instant t+1, on appelle une fonction
spécifique de la bibliothèque OpenCv pour annuler l'ensemble de
pixel en mouvement et ainsi, nous aurons une image où ne bouche ;
appelée image de la moyenne d'images.
L'image d) est obtenue après la détection de la
moyenne d'image, comme étant présentée sur l'image c), le
résultat est binarisée et seuillée. Nous observons la
personne après détection, binarisation et seuillage mais avec une
tache qui ne permet pas de spécifier la personne comme dans les autres
cas.
Par contre la présence d'ombre peut entrainer une
fausse détection dans certain cas : la présence d'ombre est
considérée comme une seconde personne. Pour une bonne vision,
nous devons éliminer la présence de l'ombre par la méthode
de seuillage manuel tout en ajustant le niveau de seuillage voulu en fonction
de curseur.
5.5. Élimination des ombres
Des ombres peuvent parfois être
générées par l'effet de sources de lumière sur des
objets en mouvement comme nous montre les images issues de nos
différentes expériences réalisées. Ces cas
spéciaux peuvent alors produire des désagréments, par
exemple pour l'appariement des parties entre deux régions comme nous
montrent l'image c) de la figure 23 et les images c) et d) de la figure 24.
Cependant, les ombres ne sont pas trop dérangeantes dans un cadre de
reconnaissance de visage, car elles peuvent être éliminées
facilement par une opération de masquage.
Par ailleurs, les méthodes de détection
d'individu basées sur le corps en entier souffriront
énormément de ces effets secondaires. Certaines techniques
peuvent toutefois solutionner en majorité ou en partie ce
problème. Il y a notamment la méthode
de
56
(Horprasert et
al.,2000) abordée ci-dessus de
(Mikiæ et al.,2000)
et celle de (Cucchiara et
al.,2001), utilisent par exemple l'information de
couleur obtenue à l'aide du HSV afin d'éliminer les ombres. En
effet, un arrière-plan ombré devrait posséder en principe
une couleur identique avec une luminosité plus faible.
Outre les avantages incontestables de l'élimination des
ombres, il ne faut pas oublier que des fausses détections peuvent se
produisent lors de cette phase supplémentaire. Or, dans le cadre actuel
du projet, mieux vaut supprimer les zones inutiles que de voir une fausse
détection et ainsi les fausses alarmes seront multipliées.
Conclusion
Ce chapitre a présenté, l'implémentation
d'une part de la méthode de détection de mouvement par
soustraction de l'arrière-plan (SAP) par modélisation statistique
(visible 2D), et la méthode de détection par différence
d'image successive d'autre part. En particulier L'algorithme pour le
modèle SAP utilisé est une simplification de la technique de
base, notamment par rapport au calcul des seuils de détection. Aussi,
les deux modèles de détection d'objet en mouvement ont
été implémentés à travers notre
Environnement de Développement Intégré déjà
préparé et détaillé au chapitre 3.
L'implémentation des deux méthodes sélectionnées
procure de bons résultats. De plus, un grand nombre d'optimisations est
envisageable pour améliorer leur performance. Notons en particulier que
la méthode de différence donne des résultats satisfaisants
dans le cas d'un mouvement faible. Par contre en cas de mouvement rapide elle
ne donne pas de bon résultat contrairement à la méthode
soustraction de l'arrière-plan. Le désavantage majeur
relié à l'utilisation de la méthode deux méthodes
repose sur la sensibilité aux ombres des objets qui peuvent parfois
être générées par les objets en mouvement.
57
Conclusion Générale
Dans ce travail, on s'est intéressé à un
des problèmes majeurs d'analyse de mouvement dans une séquence
d'images; la détection d'objets en mouvement dans des scènes
simples. Après une revue de la littérature nous avons eu à
comparer des méthodes et justifier le choix de deux méthodes de
détection d'objet en mouvement à savoir le modèle de
détection par soustraction de l'arrière-plan et le modèle
de détection par différence d'images successives. Une
implémentation de ces deux méthodes, a été
effectuée sur des séquences vidéo diverses. Dans le cas
d'un mouvement lent, la méthode la plus efficace et la plus courante
dans la détection d'objets en mouvement est la méthode de
différence entre deux images successive. Dans le cas d'un mouvement
rapide c'est la méthode de soustraction de l'arrière-plan qui est
préconisé. Notons que pour plus d'efficacité les deux
méthodes précédentes pourraient être
utilisées conjointement avec les méthodes de segmentation d'image
dont nous n'avons pas fait cas dans le présent travail.
Rappelons que ce travail est la première phase d'un
projet de reconnaissance de mouvement suspect d'objet en mouvement dans une
image. Cette finalité nous ouvre les perspectives suivantes :
De chercher une méthode unique pour la détection
d'objets mobiles pour les deux types de mouvement (lent et rapide).
L'application des méthodes de détection sur les
séquences à fonds dynamiques (caméras mobiles).
Faire une étude de suivi de mouvement d'objet dans une
séquence vidéo ;
Faire une étude de reconnaissance d'objet après
l'avoir détecté et suivi.
Appliquer l'informatique pour l'appariement d'image qui est
une étape clé d'une grande partie des techniques de vision par
ordinateur et de photogrammétrie, que ce soit pour le recalage d'image,
l'estimation de poste , la reconnaissance de forme, l'indexation d'images ou la
reconnaissance tridimensionnelle, en imagerie terrestre, aérienne ou
satellitaire.
Électronique des détecteurs permet de
développer des logiques de gestion de l'éclairage en
détection de présence ou d'absence,
58
Bibliographie
1. A. Makarov, Comparison of background extraction based
intrusion detection algorithms, Dans International Conference On Image
Processing ICIP'96, pages 521-524, 1996
2. Benabbas Siavosh Département d'informatique,
Université de Toronto, Efficace Sum-Based hiérarchique Lissage
Sous \ ell_1-Norm, 2012 ;
3. B. Bascle et R. Deriche ,Region tracking through image
sequences, Rapport de recherche 2439, INRIA-Sophia Antipolis, 21 pages,
Décembre 1994.
4. B. Bascle, P. Bouthemy, R. Deriche, et F. Meyer, Suivi de
primitives complexes sur une séquence d'images, Rapport de recherche
2428, INRIA-Sophia Antipolis, Décembre 1994. 22 pages.
5. B. Lucas, T. Kanade, «An iterative image registration
technique with an application to stereo vision», in Proc. of the
International Joint Conference on Artificial Intelligence, pp 674-679, 1981.
6. B. Wu and R. Nevatia, «Tracking of multiple,
partially occluded humans based on static body part detection», in IEEE
Proc. Of the conference on Computer Vision and Pattern Recognition, pp.
951-958, 2006.
7. B.D. Lucas et T. Kanade : An iterative image registration
technique with an application to stereo vision. Dans IJCAI81, pages 674-679,
1981.] ainsi que celle de Horn et Schunck [B. K. P. Horn et B. G. Schunck :
Determining optical flow. Dans Artificial
Inteligence, volume 17, pages 185-203, 1981.
8. B.D. Zarit, B.J. Super et F.K.H. Quek. Comparison of five
color models in skin pixel classification. Dans Workshop on recognition,
analysis and tracking of faces
and gestures in Real-Time systems, pages 58-63, 1999.
9. C. Chesnaud. Techniques statistiques de segmentation par
contour actif et mise en oeuvre rapide. Thèse de Doctorat de
l'Université de d'Aix-Marseille), Février 2000.
10. C. Papageorgiou, M. Oren and T. Poggio, «A general
framework for object detection», in Proc. of the IEEE International
Conference on Computer Vision, pp. 555-562, 1999.
11.
59
C. Stauffer and W.E.L. Grimson. Adaptive background mixture
models for real-time tracking. international conference on Computer Vision and
Pattern Recognition, 2, 1999.
12. C. Wren, A. Azarbayejani, T. Darrell, and A. Pentland.
Pfnder : Real-time tracking of the human body. Pattern Analysis and Machine
Intelligence, 1997.
13. D.G. Lowe, Robust model-based motion tracking through the
intégration of search and estimation, International Journal of Computer
Vision, 8(2) :113-122, 1992.
14. Dee, H. M., Velastin, S. A. «How close are we to
solving the problem of automated visual surveillance? A review of real-world
surveillance, scientific progress and evaluative mechanisms». Machine
Vision and Applications, 19 (5-6). Septembre 2008. pp. 329-343.
15. E. François, Interprétation qualitative du
mouvement à partir d'une séquence d'images, Thèse de
Doctorat de l'Université de Rennes I, Juin 1991.
16. Fatiha MEDJAHED , Détection et Suivi d'Objets en
Mouvement Dans Une Séquence d'Images, Mémoire Magister,
Université Mohamed Boudiaf Faculté de Génie Electrique,
2012
17. F.G. Meyer et P. Bouthemy, Region-based tracking using
affine motion models in long image sequences, CVGIP : Image Understanding,
60(2) :119-140, September 1994.
18. G. Gomez et E. Morales. Automatic feature reconstruction
and a simple rule induction algorithm for skin detection. Dans ICML Workshop On
Machine Learning in Computer Vision, pages 31-38, 2002.
19. H. Nicolas et C. Labit, Motion and illumination variation
estimation using a hierarchy of models : application to image sequence coding,
Publication interne 742, IRISA, 1993.
20. H. Nicolas, Hiérarchie de modèles de
mouvement et méthodes d'estimation associées, application au
codage de séquences d'images, Thèse de doctorat,
IRISA-Université de Rennes 1, 1992.
21. Home Office Research, Development and Statistics
Directorate. Cité dans
http://www.youarebeingwatched.us/about/182/#footnote10]
et [Gill and Spriggs, Assessing the Impact of CCTV. (2005) Home Office Study.
Cité dans
http://www.youarebeingwatched.us/about/182/#footnote10].
22.
60
Ivana Mikiæ, Pamela C. Cosman, Greg T. Kogut et Mohan M.
Trivedi : Moving shadow and object detection in traffic scenes. Dans
International Conference on Pattern Recognition (ICPR), pages 321-324, 2000
23. Ismail Haritaoglu, David Harwood et Larry S. Davis. Ghost
: a human body part labelling system using silhouette. Dans Proceedings IEEE
Conf. On Pattern Recognition, volume 1, pages 77-82, 1998.
24. J. Kovac, P. Peer et F. Solina. Human skin color
clustering for face detection. EUROCON 2003 Computer as a Tool, 2 :144-148,
2003.
25. J. Shi and C. Tomasi, «Good features to track»,
in Proc. of the international conference on Computer Vision and Pattern
Recognition, pp. 593-600, 1994.
26. J.F. Gobeau, «Détecteurs de mouvement
à infrarouge passif (dé- tecteurs IRP)», Colloque Capteurs,
2007.
27. Jason Brand et John S. Mason. A comparative assessment of
three approaches to pixel-level human skin-detection. Dans 15th International
Conference on Pattern Recognition, volume 1, pages 1056-1059, 2000.
28. K. K. C. Evelet et R. Bolles, Background modeling for
segmentation of video-rate stereo sequences, Dans CVPR98, pages 266-272,
1998.
29. K. Kim, T. H. Chalidabhongse, D. Hanuood, et L. Davis.
Background modeling and substraction by codebook construction. 2004
30. K. Kim, T.H. Chalidabhongse, D. Harwood, and L. Davis.
Real-time foreground-background segmentation using codebook model. Real-Time
Ima- ging, 11 :172185, 2005.
31. L. Bonnaud, Schémas de suivi d'objets vidéo
dans une séquence animée : application à l'interpolation
d'images intermédiaires, Thèse de doctorat,
IRISA-Université de Rennes, 1998.
32. L. Bonnaudet C. Labit, Etude d'algorithmes de suivi
temporel de segmentation basée mouvement pour la compression de
séquences d'images, Publication interne 793, IRISAUniversité de
Rennes, 43 pages, Janvier 1994.
33. L. Sigal, S. Sclaroff et V. Athitsos. Estimation and
prediction of evolving color distributions for skin segmentation under varying
illumination,. Dans IEEE Conference on Computer Vision and Pattern Recognition,
volume 2, pages 152159,2000.
34.
61
Liang Zhao, «Dressed Human Modeling, Detection, and Parts
Localization», PhD thesis, The Robotics Institute, Carnegie Mellon
University, Pittsburgh, 2001.
35. M. Kass, A. Witkin, et D. Terzopoulos, Snakes : Active
contour models. International Journal of Computer Vision, 1 :321-331, 1998.
36. M. Kunert D. M. Gavrila et U. Lages : A multi-sensor
approach for the protection of vulnerable traffic participants - the protector
project. Dans Proc. of the IEEE Instrumentation and Measurement Technology
Conference, volume 3, pages 2044-2048, 2001.
37. Michael J. Jones et James M. Rehg. Statistical color
models with application to skin detection. Int. J. Comput. Vision, 46(1)
:81-96, 2002.
38. N. Dalal and B. Triggs, «Histograms of oriented
gradients for human detection», in IEEE Proc. of the conference on
Computer Vision and Pattern Recognition, pp. 886- 893, 2005.
39. N.K. Paragios, Geodesic active region and level set
methods : Contribution and applications in artificial vision, Thése de
doctorat, Sophia Antipolis, Janvier 2000.
40. N.M. Oliver, B. Rosario, and A.P. Pentland. A bayesian
computer vision system for modeling human interactions. Pattern Analysis and
Machine Intelligence, 22 :831p843, 2000.
41. P. Viola and M. Jones, «Rapid object detection using
a boosted cascade of simple features», in IEEE Proc. of the conference on
Computer Vision and Pattern Recognition, pp. 511-518, 2001.
42. P. Viola, M.J. Jones and D. Snow, «Detecting
pedestrians using patterns of motion and appearance», in International
Journal of Computer Vision, pp. 153-161, 2005.
43. Q. Zhao, J. Kang, H. Tao and W. Hua, «Part Based
Human Tracking In A Multiple Cues Fusion Framework», in Proc. of the
International Conference on Pattern Recognition, pp. 450-455,2006.
44. R. B. Church, K. Schonert-Reichl, N. Goodman, S. D. Kelly
et S. Ayman-Nolley. The role of gesture and speech communication as refections
of cognitive understanding. Journal of Contemporary, 63 :123-140, 1995.
45. R. Jain, Différence and accumulative difference
pictures in dynamic scene analysis, Image and Vision Computing, 2(2) :99-108,
may 1984
46.
62
R.E. Schapire, «The boosting approach to machine learning
: An overview,» in Workshop on N.E.C., 2002.
47. Rafael C. Gonzalez et Richard E. Woods : Digital Image
Processing (2nd Ed.), chapitre 10, Morphological Image Processing, pages
519-566. Prentice Hall, 2002.
48. Rita Cucchiara, Costantino Grana, Massimo Piccardi,
Andrea Pratti et Stefano Sirotti : Improving shadow suppression in moving
object detection with hsv color information. Dans Intelligent Transportation
Systems, pages 334- 339. IEEE, 2001
49. S. Jehan-Besson, Modèles de contours actifs
basés régions pour la segmentation d'images et de vidéos,
Thèse de Doctorat de l'Université de Nice - Sophia Antipolis,
Janvier 2003
50. S. Venegas-Martinez, Analyse et segmentation de
séquences d'images en vue d'une reconnaissance de formes efficace,
Thèse de Doctorat de l'Université René Descartes - Paris
V, 2001.
51. T. Horprasert, D. Harwood et L. Davis : A robust
background subtraction and shadow detection. In Proceedings of the ACCV,
2000
52. V. Caselles, F. Catte, T. Coll, et F. Dibos. A geometric,
model for active contours in image processing, Numerische Mathematik, 66 :1-
31, 1993.
53. V. Garcia-Garduno et C. Labit, Suivi de segmentation
spatiotemporelle pour la compression de séquences animées,
Quatorzième Colloque GRETSI, Juan-les-Pins, Septembre 1993.
54. W. Long et Y. Yang, Stationary background generation : An
alternative to the difference of two images, Pattern Recognition, 23
:1351-1359, 1990
55. Welsh, B. and Farrington, D., Crime Prevention Effects of
Closed Circuit Television: A Systematic Review (2002),
56. Y. Benezeth, P.M. Jodoin, B. Emile, H. Laurent, C.
Rosenberger, «Review and evaluation of commonly-implemented background
subtraction algorithms», in Proc. of the International Conference on
Pattern Recognition, 2008.
57. Y . Brookner, Tracking and Kalman Filtering Made Easy,
John Wiley & Sons, 1998.
58. Y R. Raquel, Pinho, R. S. Joao Manuel, Tavares, V.
Miguel. Correia, An Efficient and Robust Tracking System using Kalman Filter,
VIPSI- 2006 VENICE, 2006.
59. Y. Bar-shalom and T.E. Fortman, Tracking and Data
Association New York : Academic, 1988.
63
64
Annexes
1. Programme en C ++ pour la détection par
différence d'images
#include "highgui.h"
#include "cv.h"
int seuil_diff = 30;
IplImage *prev_img = 0;
IplImage *curr_img = 0;
void MotionDetection(IplImage* img, IplImage* dst, int
diff_threshold)
{
cvCvtColor(img, curr_img, CV_BGR2GRAY);
IplImage* silh = cvCreateImage(cvGetSize(img), IPL_DEPTH_8U,
1);
cvAbsDiff(prev_img, curr_img, silh);
cvThreshold(silh, silh, diff_threshold, 255,
CV_THRESH_BINARY);
cvCopy(curr_img, prev_img);
cvMerge(silh, 0,0,0, dst);
cvReleaseImage(&silh);
}
// programme principal
int main()
{
CvCapture* capture = 0;
IplImage *frame = 0;
capture = cvCreateFileCapture("video.avi");
IplImage *video_image = 0, *motion = 0;
for(;;)
{
frame = cvQueryFrame(capture);
if (!frame)
break;
// Création initiale des tableaux utiles
if (!video_image)
{
65
video_image = cvCreateImage(cvGetSize(frame),8,3);
motion = cvCreateImage(cvGetSize(video_image),8,3);
prev_img = cvCreateImage(cvGetSize(frame),IPL_DEPTH_8U,1);
curr_img = cvCreateImage(cvGetSize(frame),IPL_DEPTH_8U,1);
cvZero(prev_img);
}
// Origine de l'image = coin haut gauche
if (frame -> origin == 1)
cvFlip(frame, video_image, 1);
else
cvCopy(frame, video_image, 0);
// Detection de mouvement
MotionDetection(video_image, motion, seuil_diff);
// Affichage des resultats
cvNamedWindow("video_image", 1);
cvShowImage("video_image", frame);
cvNamedWindow("frame",0);
cvShowImage("frame", curr_img);
cvNamedWindow("motion", 0);
cvShowImage("motion", motion);
cvCreateTrackbar("seuil_diff", "motion", &seuil_diff, 60,
0);
int delay = 30;
if (cvWaitKey(delay)>= 0)
break;
}
// Sortie du programme
cvReleaseCapture(&capture);
cvReleaseImage(&video_image);
cvReleaseImage(&motion);
cvReleaseImage(&prev_img);
cvReleaseImage(&curr_img);
}
return 0;
66
2. Programme en C++ pour la détection par
soustraction d'arrière-plan
#include <stdio.h>
#include <stdlib.h>
#include <opencv/highgui.h>
#include <opencv/cv.h>
//void MotionDetection(IplImage* img, IplImage* dst, int
diff_threshold);
//IplImage *prev_img=0, *curr_img =0;
IplImage *video_image = 0, *motion = 0, *ref_img=0;
int seuil_diff = 50;
int N =20;
IplImage *buf[20];
int last=0;
void MotionDetection(IplImage* img, IplImage* dst, int
diff_threshold)
{
cvCvtColor(img, buf[last], CV_BGR2GRAY);//image courante int idx1
= last;// indice de l'image courante (à t) int idx2 = (last + 1)% N;
last = idx2; // indice de la prochaine image (à t+1)
IplImage* moyenne = cvCreateImage(cvGetSize(img),32,1); IplImage*
silh = cvCreateImage(cvGetSize(img),8,1); cvZero(moyenne);
int i;
for (i = 0;i<N;i++)
if (i!=idx1) //exclusion de l'image courante
cvAcc (buf[i],moyenne,0);// somme des N-1 images
précédentes cvConvertScale(moyenne, ref_img, 1./(N-1),0);
cvReleaseImage(&moyenne);
cvAbsDiff(buf[idx1], ref_img, silh);
cvThreshold(silh, silh, diff_threshold, 255, CV_THRESH_BINARY);
cvMerge(0, silh,0,0,dst); //mouvement en vert cvReleaseImage(&silh);
}
67
int main()
{
CvCapture* capture = 0;
IplImage* frame = 0;
capture = cvCreateFileCapture("video.avi");
for(;;)
{
frame = cvQueryFrame(capture);
if (!frame)
break;
//creation des tableaux utiles
if (!video_image)
{
video_image = cvCreateImage(cvGetSize(frame), 8, 3);
motion = cvCreateImage(cvGetSize(video_image),8,3);
ref_img = cvCreateImage(cvGetSize(frame),IPL_DEPTH_8U,1);
int i;
for(i=0;i<N;i++)
{
buf[i]=cvCreateImage(cvGetSize(frame),IPL_DEPTH_8U,1);
cvZero(buf[i]);
}
}
//origine de l'image = coin haut gauche
if (frame->origin == 1)
cvFlip(frame, video_image, -1);
else
cvCopy(frame, video_image,NULL);
//detection de mouvement
MotionDetection(video_image, motion, seuil_diff);
//affichage des résultats
cvNamedWindow("Vidéo_Source",0);
cvShowImage("Vidéo_Source", video_image);
68
cvNamedWindow("Moyenne",0); cvShowImage("Moyenne", ref_img);
cvNamedWindow("Icourante",1); cvShowImage("Icourante", buf[last]);
cvNamedWindow("motion",0); cvShowImage("motion", motion);
cvCreateTrackbar("seuil_diff", "motion", &seuil_diff, 100,0); int delay =
5;
if (cvWaitKey(delay)>=0)
break;
}
//sortie du programme
cvReleaseCapture(&capture); cvReleaseImage(&video_image);
cvReleaseImage(&motion); cvReleaseImage(&ref_img); int i;
for(i=0;i<N;i++)
cvReleaseImage(&buf[i]); return 0;
}
| 

