|
TABLE DES MATIERES
Table des matières
TABLE DES MATIERES
Erreur ! Signet non
défini.
MEMORIAL
iii
DEDICACES
iv
REMERCIEMENTS
v
INTRODUCTION GENERALE
1
CHAPITRE I. SYSTEME D'INFORMATION
SANITAIRE
3
[9][10][11] [13]
3
0. Introduction
3
I.1. Système d'Information
4
I.1.1. Définition
4
I.1.2. Enjeux d'un système d'information
5
I.1.3. Qualités attendues des SI
6
I.1.4. Composition d'un système
d'information d'entreprise
6
I.2. Système d'information
Hospitalier
10
I.2.1. Définition
10
I.2.2. Les organisations concernées
10
I.2.3. Les enjeux du Système d'information
Hospitalier
11
I.2.4. Les Objectifs d'un
système d'information hospitalier
11
I.2.5. L'urbanisation du Système
d'Information Hospitalier
12
I.3. Système de gestion de l'unité de
soins
15
I.4. Présentation de la Gestion d'un Dossier
Patient
17
I.4.1. Le Dossier Patient
17
I.4.1.1. Définitions
17
I.4.1.2. Fonctions
17
I.4.1.3. Intérêt et utilisation dans
l'environnement hospitalier
18
I.4.2. Organisation du dossier
20
I.4.3. Conclusion
25
CHAPITRE II. LES BASE DE DONNEES [2]
[8] [12]
26
II.1. Introduction
26
II.1.1. Définition
26
II.2. Différents modèles de base de
données
26
II.2.1. Modèle Hiérarchique
26
II.2.2. Modèle Réseau
27
II.2.3. Modèle Relationnel
27
II.2.4. Modèle Objet
27
II.3. Modélisation d'une base de
Données
28
II.3.1. Modèle
28
II.3.2. Méthode de modélisation d'une
base de données
29
II.4.Système de Gestion de Base de
Données (SGBD)
35
II.4.1. Définition
35
II.4.3. Fonctions des
36
II.4.4. Illustration de SGBD
38
II.5. Le langage SQL (Structured Query
Language)
40
II.6. Conclusion
40
CHAPITRE III. MODELISATION ET
IMPLEMENTATION DU SYSTEME [1][2][3][4][5][6][7]
41
III.1. Présentation des CUK
41
III.2. Cahier de charge et spécification
initiale du système
44
III.3. Les technologies et outils
utilisés
45
III.4. Méthode de développements
46
III.4. Architecture du système
47
47
III.5. Modélisation du système
48
III.6. Présentation de l'application
54
Conclusion Générale
61
Référence
bibliographie
62
MEMORIAL
A toi ma très chère maman ANNIE NDONGO qui a
semé dans un grand champ sans pour autant moissonner. Que ton âme
repose en paix maman !
DEDICACES
A mes très chers parents : Dosithée MUYAKA
et Annie NDONGO pour l'amour et les sacrifices, sans lesquels ce travail
n'aurait pu voir le jour.
REMERCIEMENTS
Louange à notre Seigneur Jésus-Christ qui nous a
dotés de la merveilleuse faculté de raisonnement.
Gloire à Dieu notre créateur qui nous a
incité à acquérir le savoir.
Que le corps académique du département de
Mathématiques et Informatique, le potier dont nous sommes un des vases
d'honneur en pleine formation, et en particulier le professeur NTUMBA BADIBANGA
Simon pour le temps consenti à la direction de ce travail.
Nous remercions très sincèrement l'assistant
Barth KABALA MUBENGA pour son encadrement.
Ce travail marque la fin du deuxième cycle au
département de Mathématiques et Informatique de
l'Université de Kinshasa. C'est un fruit de plusieurs sacrifices et
d'efforts fournis par nous ainsi que de la contribution de plusieurs autres
personnes envers qui nous exprimons notre profonde gratitude.
Voilà pourquoi nous tenons à remercier tous ceux
qui, de près ou de loin, ont apporté leur pierre à
l'édification de cet oeuvre scientifique.
Nos remerciements très particuliers vont à
l'endroit de nos parents Dosithée MUYAKA et Annie NDONGO que le Dieu
créateur a décidé de reprendre, à notre grande
soeur chérie Carnel MUYAKA, à nos frères que j'aime bien
Guyaume, Henri, Jean Baptiste, Robert Patrick, Moïse, Roanne, Marceline
à mes neveu charmants Verdi et Guivier pour leur affection, amour,
considération, assistance tant matériel, financier et spirituel
à mon égard.
Nous tenons en estime remercié mes amis et
connaissance : Gloria ZAINA, Francis KIMANGA, Jean-Claude LWEMBE, Patrick
MOBIA, Gracia KIMWANGA, Fiston LEFIE, Herve EPUS, Ruphin KELEMBO, Eminence
MULEMA, Rodrigue MOSHI, Lina KALENGA, Brenda MWAMBA, Pamela KAPINGA, Joseph
LUTULA, King KISENGE, Jordan TSHILOMBO, Nathan MANZAMBI, Radine PUNGU, Francis
NGALULA, Djonive MUNENE, John BAKONGO, Henry GWANA, Pacifique KINKELA, Gaby
NGANGI, Oliver MUKEBA, Mike NKONGOLO , Hardy MIKESE, Urbain NGOYI, Serge
ILUNGA, Thys KAZAD, Christian MBOMA, Richy NGOMBO, Adrien MUYAKA, Emmanuel
MBULU, Julien BATU........
Ces quelques pages ne suffiront pas pour citer tous ceux qui
de loin ou de près ont d'une manière ou d'une autre
contribué à l'élaboration de ce travail, qu'ils trouvent
ici l'expression de notre profonde reconnaissance.
Liste des Abréviations
|
ANES. REA
|
ANESTHESIE ET REANIMATION
|
|
BD
|
BASE DE DONNEES
|
|
BIOMED
|
BIOLOGIE CLINIQUE, MEDICALE
|
|
BSD
|
BERKELEY SOFTWARE DISTRIBUTION LICENSE
|
|
CHIR.
|
CHIRURGIE
|
|
COBIT
|
CONTROL OBJECTIVES FOR INFORMATION AND RELATED TECHNOLOGY
|
|
CRM
|
CUSTOMER RELATIONSHIP MANAGEMENT
|
|
CUK
|
CLINIQUES UNIVERSITAIRES DE KINSHASA
|
|
DB
|
DATABASE
|
|
DCL
|
DATA CONTROL LANGUAGE
|
|
DP
|
DOSSIER PATIENT
|
|
DPI
|
DOSSIER PATIENT INFORMATISER
|
|
DPT
|
DEPARTEMENT
|
|
DSDM
|
DYNAMIC SOFTWARE DEVELOPPMENT METHOD
|
|
EA
|
ENTITE ASSOCIATION
|
|
ERP
|
ENTERPRISE RESOURCE PLANNING
|
|
ETL
|
EXTRACT TRANSFORM AND LOAD
|
|
G.O
|
GYNECO - OBSTETRIQUE
|
|
GCL
|
GESTION DE LA CHAINE LOGISTIQUE
|
|
GPRS
|
GENERAL PACKET RADIO SERVICE
|
|
GPU
|
GENERAL PUBLIC LICENSE
|
|
GRC
|
GESTION DE LA RELATION CLIENT)
|
|
HRM
|
HUMAN RESOURCE MANAGEMENT
|
|
IBM
|
INTERNATIONAL BUSINESS MACHINES
|
|
IHM
|
INTERFACE HOMME MACHINE
|
|
IP
|
INTERNET PROTOCOL
|
|
ITIL
|
IT INFRASTRUCTURE LIBRARY
|
|
KINE
|
KINESITHERAPIE
|
|
LDD
|
LANGAGE DE DEFINITION DE DONNEES
|
|
LMD
|
LANGAGE DE MANIPULATION DE DONNEES
|
|
M.I.
|
MEDECINE INTERNE
|
|
MCD
|
MODELE CONCEPTUEL DE DONNEES
|
|
MERISE
|
METHODE D'ANALYSE INFORMATIQUE
|
|
MLD
|
MODELE LOGIQUE DE DONNEES
|
|
MPD
|
MODELE PHYSIQUE DES DONNEES
|
|
OLAP
|
ON-LINE ANALYTICAL PROCESSING
|
|
OLTP
|
ON-LINE TRANSACTIONAL PROCESSING
|
|
ONATRA
|
OFFICE NATIONAL DE TRANSPORT
|
|
ORL
|
OTO-RHINO- LARYNGOLOGIE
|
|
OTRACO
|
OFFICE DE TRANSPORT DU CONGO
|
|
PC
|
PERSONAL COMPUTER
|
|
PED
|
PEDIATRIE
|
|
PGI
|
PROGICIEL DE GESTION INTEGRE
|
|
PHAR
|
PHARMACIE
|
|
PLM
|
PRODUCT LIFE CYCLE MANAGEMENT
|
|
RTC
|
RESEAU TELEPHONIQUE COMMUTE
|
|
SCM
|
SUPPLY CHAIN MANAGEMENT
|
|
SGBD
|
SYSTEME DE GESTION DE BASE DE DONNEES
|
|
SGBDR
|
SYSTEME DE GESTION DE BASE DE DONNEES RELATIONNELLE
|
|
SGBDRO
|
SYSTEME DE GESTION DE BASE DE DONNEES RELATIONNELLE ET OBJET
|
|
SGDT
|
SYSTEME DE GESTION DE DONNEES TECHNIQUES
|
|
SI
|
SYSTEME D'INFORMATION
|
|
SIH
|
SYSTEME D'INFORMATION HOSPITALIER
|
|
SQL
|
LANGAGE DE DEFINITION DE DONNEES
|
|
SSRS
|
SQL SERVER REPORTING SERVICES
|
|
SYNAMED
|
SYNDICAT NATIONAL DE MEDECIN
|
|
TCP/ IP
|
TRANSMISSION CONTROL PROTOCOL /INTERNET PROTOCOL
|
|
UML
|
UNIFIED MODELING LANGUAGE
|
|
UMTS
|
UNIVERSAL MOBILE TECOMMUNICATION SYSTEM
|
|
UNIKIN
|
UNIVERSITE DE KINSHASA
|
|
VPN
|
VIRTUAL PRIVATE NETWORK
|
|
WI-FI
|
WIRELESS FIDELITY
|
|
XRM
|
EXTENDED RELATIONSHIP MANAGEMENT
|
Liste des Tableaux
TAB.1 : TYPOLOGIE DES SYSTÈMES
D'INFORMATION
3
TAB. 2 : TABLEAU COMPARATIF ENTRE LE DP ET LE
DPI
20
Liste des Figures
FIG.I.1 : LE MODÈLE PYRAMIDAL
3
FIG.I.2 :
ARRIVÉ PATIENT ORDINAIRE
15
FIG.I.3 : ARRIVÉ PATIENT AUX
URGENCES
16
FIG.I.4 : CONTRÔLE DE SANTÉ
16
FIG.I.5 : DOSSIER PATIENT
19
FIG.II.1: MODÈLE HIÉRARCHIQUE
27
FIG.II.2: MODÈLE RÉSEAU
27
FIG.II.3: MODÈLE RELATIONNEL
27
FIG.II.4: MODÈLE OBJET
28
FIG.II.5: ENTITÉ
29
FIG.II.6: ASSOCIATION
30
FIG.II.7: ATTRIBUT
31
FIG.II.8: CARDINALITÉ
31
FIG.II.9: RÈGLES 2 MCD
32
FIG.II.10: RÈGLES 2 MLD
33
FIG.III.1. CYCLE DE VIE DSDM
47
FIG.III.2.
ARCHITECTURE DU SYSTÈME
47
FIG.III.3.
DIAGRAMME DE CAS D'UTILISATION
48
FIG.III.4.
DIAGRAMME DE CLASSE
49
FIG.III.5.
DIAGRAMME DE SÉQUENCE
50
FIG.III.6. DIAGRAMME DE SÉQUENCE
51
FIG.III.7. DIAGRAMME D'ACTIVITÉ
52
FIG.III.8.
DIAGRAMME D'ACTIVITÉ
52
FIG.III.9. DIAGRAMME DE COMPOSANT
53
FIG.III.10.
DIAGRAMME DE DÉPLOIEMENT
53
FIG.III.11.
PAGE D'ACCUEIL
54
FIG.III.12.
PAGE DE CONNEXION
54
FIG.III.13.
MENU ADMINISTRATEUR
54
FIG.III.14.
PAGE ENREGISTREMENT PATIENT
55
FIG.III.15.
LISTE RENDEZ-VOUS
55
FIG.III.17.
MENU MÉDECIN
56
FIG.III.16
CRÉATION DOSSIER PATIENT
56
FIG.III.18.
PRESCRIPTION ORDONNANCE
57
FIG.III.19
MENU INFIRMIER
58
INTRODUCTION GENERALE
L'hôpital de nos jours ne peut plus être
considéré comme un îlot isolé. Son image
traditionnelle est en train de changer avec la mise en place des réseaux
de soins, et le besoin de communiquer devient une priorité.
Le dossier patient (DP), est un outil fondamental et
indispensable pour la pratique médicale. Il est construit autour de
l'accumulation des données liées aux soins d'un patient au cours
du temps. Aujourd'hui, le DP apparaît comme un outil à facettes
multiples. Il évolue et se complexifie, à la fois sous
l'influence du développement des spécialités
médicales mais aussi sous le choc de l'explosion
technologique.
L'informatisation du DP est devenue incontournable, même
si le processus d'informatisation est difficile, car calquer le modèle
« papier » est insuffisant et le « zéro papier »
n'est pas une fin en soi.
Les démarches pour arriver à la mise en place
d'un tel dossier informatisé sont assez différentes d'une
institution hospitalière à une autre. Les raisons qui
peuvent amener à l'informatisation du DP sont
généralement communes : l'augmentation des volumes des
données ou informations, la nécessité de diminuer les
temps d'accès et d'acheminement des informations médicales
ainsi que les besoins de partager l'information entre les
différents partenaires de la santé et leurs différentes
institutions. Cette application va permettre l'amélioration de la
qualité et la sécurité de la prise en charge des
patients à l'hôpital.
Afin
de pouvoir traiter les problèmes cité ci - haut nous avons
subdivisé notre travail en trois chapitres :
Le premier chapitre intitulé «SYSTEME
D'INFORMATION SANITAIRE» dans lequel nous avons
présenté les concepts théoriques liés au
système d'information général, au système
d'information hospitalier qui est un cas particulier du SI, au système
de gestion des unités de soins, du dossier patient d'une manière
général, de ses différentes éléments
constitutif, de son organisation, du processus d'informatisation dudit dossier
et des enjeux auxquels ils doivent faire face dans le mécanisme de prise
en charge du patient.
Le deuxième chapitre intitulé
«LES BASE DE DONNEES» dans lequel nous
avons abordé les concepts théoriques sur les bases de
données et système de gestion de base de données (SGBD),
tout en précisant la force d'une base de données dans une
organisation.
Le troisième chapitre intitulé
«MODELISATION ET IMPLEMENTATION DU SYSTEME» : ce
chapitre est un cas pratique. Il montre étape par étape les
différents choix effectués pour la conception de notre
système.
CHAPITRE I. SYSTEME
D'INFORMATION SANITAIRE
[9][10][11] [13]
0.
Introduction
Au-delà de la recherche permanente d'un
équilibre entre la maîtrise des dépenses de
santé et la qualité des soins apportés aux
patients, les établissements de santé sont confrontés
à un certain nombre d'enjeux majeurs concrets pour lesquels la
performance et la qualité des systèmes d'information
constituent aujourd'hui, et de plus en plus, une nécessité
incontournable.
Ces enjeux sont liés à des
évolutions de natures diverses : évolutions
réglementaires, exigence de sécurité et de qualité,
nécessité de disposer d'un accès aisé à
l'information, évolution des organisations... Sans prétendre
à une exhaustivité, il n'est pas inutile de rappeler
certaines de ces exigences fortes qui s'imposent de façon
croissante aux établissements de santé :
- L'accès du patient à son dossier,
- Le développement des réseaux de
santé associés à la prise en charge du patient dans
le cadre de réseaux coordonnés, auxquels sont
nécessairement associés les établissements de
santé, lorsqu'ils n'en sont pas eux-mêmes les initiateurs,
- La généralisation d'une politique de
prévention, d'identification et de suivi des risques à tous les
niveaux de l'activité des Etablissement Public de Santé et bien
évidemment en relation directe avec la prise en charge des patients
a) Définition
C'est un système d'information global, regroupant tous
les types d'acteurs et ressources de santé.
Le système d'information de santé peut
être considéré comme une mère, qui regroupe en son
sein deux grands systèmes, à savoir : le système
d'information hospitalier et le système de gestion des unités des
soins.
b) Typologie
Le système d'information de santé peut
être caractérisé par plusieurs sous-systèmes qui
montrent comment les informations sont organisées et traitées en
spécifiant le type de données traitées dans chaque
sous-système indépendamment des autres.
|
Système d'information
extra- hospitalier
|
Système d'Information
Hospitalier
|
|
Système
d'information
administratif
|
Données administratives
|
Données administratives
|
|
Système
d'information
clinique
|
- Données médicales
- Données de soin
|
- Données médicales
- Données de soin
|
Tab.1 : Typologie des
systèmes d'information
I.1.
Système d'Information
I.1.1.
Définition
Un système d'information (SI) est un ensemble
organisé de ressources qui permet de collecter, stocker, traiter et
diffuser de l'information.
Il s'agit d'un système sociotechnique composé de
2 sous-systèmes, l'un social et l'autre technique. Le
sous-système social est composé de la structure organisationnelle
et des personnes liées au SI. Le sous-système technique est
composé des technologies (hardware, software et équipements de
télécommunication) et des processus concernés par le
SI.
L'apport des nouvelles technologies de l'Information est
à l'origine du regain de la notion de système d'information.
L'utilisation combinée de moyens
informatiques,
électroniques
et de procédés de
télécommunication
permet aujourd'hui, selon les besoins et les intentions exprimés,
d'accompagner, d'
automatiser et de
dématérialiser
quasiment toutes les opérations incluses dans les activités ou
procédures d'entreprise.
Ces capacités de traitement de volumes importants de
données, d'interconnexion de sites ou d'opérateurs
géographiquement éloignés, expliquent qu'elles sont
aujourd'hui largement utilisées (par exemple dans les activités
logistiques) pour traiter et répartir l'information en temps
réel, en lieu et place des moyens classiques manuels - plus lents - tels
que les
formulaires sur papier
et le
téléphone.
Ces capacités de traitement sont également
fortement appréciées par le fait qu'elles renforcent le
caractère «
systémique »
des données et traitements réalisés : la
cohérence et la consolidation des activités lorsqu'elle est
recherchée et bien conçue permet d'accroître la
qualité du
contrôle
interne de la gestion des organisations, même lorsque celles-ci sont
déconcentrées ou décentralisées.
I.1.2.
Enjeux d'un système d'information
Un système d'information est un véhicule des
entités d'une organisation. Sa structure est constituée de
l'ensemble des ressources (les personnels, le matériel, les logiciels,
les procédures) organisées pour : collecter, stocker,
traiter et communiquer les informations. Le système d'information
coordonne, grâce à la structuration des échanges, les
activités de l'organisation et lui permet ainsi d'atteindre ses
objectifs.
Un système d'information se construit à partir
de l'analyse des
processus
"métier" d'une organisation et de leurs interactions/interrelations, et
non simplement autour des solutions informatiques plus ou moins
standardisées par le marché. Le système d'information doit
réaliser l'alignement stratégique de la stratégie
d'entreprise par un
management
spécifique.
La gouvernance des systèmes d'information ou
gouvernance informatique (IT gouvernance) renvoie aux moyens de gestion et de
régulation des systèmes d'information mis en place dans une
organisation en vue d'atteindre ses objectifs. À ce titre, la
gouvernance du SI fait partie intégrante de la gouvernance de
l'organisation. Les méthodes ITIL (IT infrastructure Library) et
COBIT (Control Objectives for
Information and related Technology) sont par exemple des supports permettant de
mettre un SI sous contrôle et de le faire évoluer en fonction de
la stratégie de l'organisation.
I.1.3.
Qualités attendues des SI
Le système d'information désigne ici
l'ensemble des applications, vu comme un tout, et dans sa
capacité à supporter et exécuter les processus de
l'entreprise.
Les propriétés essentielles pour qu'un
système d'information joue son rôle sont :
ü La rapidité,
ü La fiabilité
ü L'agilité,
ü La maintenabilités,
ü L'extensibilité
I.1.4.
Composition d'un système d'information d'entreprise
I.1.4.1. Composition classique
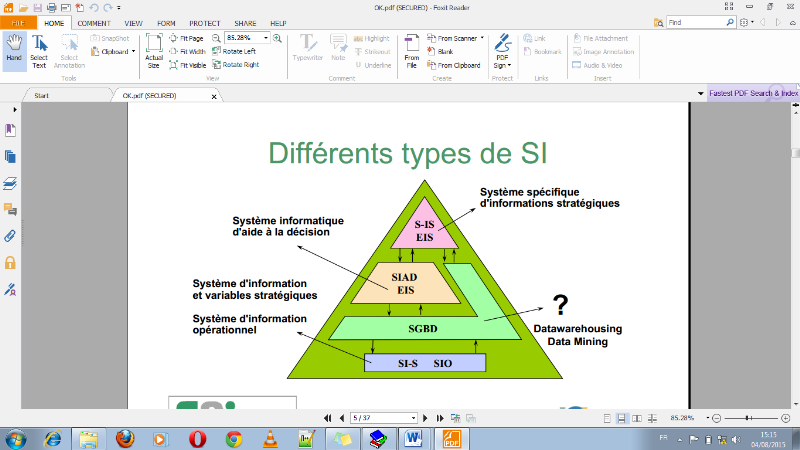
Fig.I.1 : Le modèle
pyramidal
Dans les oeuvres des années 1980 - 1990, la composition
« classique » des systèmes de l'information d'une
entreprise était comme une pyramide des systèmes d'information
qui reflétait la hiérarchie de l'entreprise.
Les systèmes qui traitent les transactions
fondamentales (TPS) au fond de la pyramide, suivis par les systèmes pour
la gestion de l'information (MIS), et après les systèmes de
soutien des décisions (DSS) et se terminant par les systèmes
d'information utilisés par la direction la plus supérieure (EIS),
au sommet.
Bien que le modèle pyramidal reste utile, un certain
nombre de nouvelles technologies ont été
développées et certaines nouvelles catégories de
systèmes d'information sont apparues et ne correspondent plus aux
différentes parties du modèle pyramidal.
I.1.4.2. Composition actuelle
Dans un système d'information d'une grande entreprise,
on trouve :
· un ERP - Enterprise Resource Planning (en
français : PGI pour progiciel de gestion intégré) -
qui intègre théoriquement tous les systèmes
informatisés transactionnels dont les modalités de fonctionnement
sont désormais bien connues des informaticiens et des hommes de l'Art de
chaque métier. Les ERP permettant de soutenir le fonctionnement de
l'entreprise ;
· des systèmes appelés autres dits les
intégrés métiers, où les verticalisés qui
sont des progiciels métiers, et qui couvrent aussi bien le front office,
que le middle, puis le back-office et qui ne sont pas de conception maison,
mais ont été bâti par un éditeur
spécialisé sur un métier et dont les modes de
fonctionnement logiciels correspondent aux meilleurs pratiques
constatées à un moment donné chez les plus performant dans
leur secteur d'excellence ;
· des systèmes restants appelés
« spécifiques » (ou encore : non standards, de
conception « maison », développés sur mesure,
que l'on ne trouve pas sur le marché, ...), où l'on rencontrera
davantage d'applications dans les domaines du calcul de coûts, de la
facturation, de l'aide à la production, ou de fonctions annexes.
La proportion entre ERP et systèmes spécifiques
est très variable d'une entreprise à l'autre.
L'
urbanisation
traite de la cartographie des systèmes de l'entreprise et donc de la
manière d'organiser son système d'information pour parvenir
à le faire évoluer de manière prévisionnelle, en
accord avec la stratégie générale de l'entreprise. La
stratégie de l'entreprise est menée par la direction
générale et l'urbanisation permet de mener l'alignement du SI sur
la stratégie.
Dans les ERP, on trouve des modules couvrant différents
domaines d'activité (comme la gestion de la production, la gestion de la
relation commerciale avec la clientèle, la gestion des ressources
humaines, la comptabilité, les finances, les fusions, les
intégrations comptables d'acquisitions récentes, ...) autour
d'une base de données commune et unifiée.
Il est fréquent qu'une entreprise soit
équipée de plusieurs progiciels différents selon ses
domaines d'activité. Dans ce cas, les progiciels ne sont pas totalement
intégrés comme dans un PGI, mais interfacés entre eux
ainsi qu'avec des applications spécifiques. On trouvera par exemple des
applications de :
· CRM - Customer Relationship Management (en
français : GRC pour Gestion de la relation client) : regroupe
toutes les fonctions permettant d'intégrer les clients dans le
système d'information de l'entreprise
· XRM - eXtended
Relationship Management (en français : Gestion de la Relation
Tiers) : est un système d'information d'entreprise, imaginé
par Nelis XRM en 2005, dont les processus relationnels constituent le socle de
l'organisation de l'information.
· SCM - Supply Chain Management (en
français : GCL pour Gestion de la chaîne logistique) :
regroupe toutes les fonctions permettant d'intégrer les fournisseurs et
la logistique au système d'information de l'entreprise
· HRM - Human Resource Management (en
français : SIRH pour la
GRH)
· PDM - Product Data Management (en français la
notion qui s'en rapproche le plus :
SGDT pour Système de
gestion de données techniques) : fonctions d'aide au stockage et
à la gestion des données techniques. Surtout utilisé par
les bureaux d'études. En fait le PDM est l'évolution de la
fonction SGDT, jusqu'à de nouvelles manières de gérer le
cycle de vie des données.
· PLM - Product Life cycle Management (en
français : gestion du cycle de vie du produit). Il s'agit d'une
notion qui comprend en plus du PDM, la conception et l'aide à
l'innovation, et la fin de vie du produit, donc son recyclage).
I.2.
Système d'information Hospitalier
I.2.1.
Définition
C'est un ensemble d'informations, de leurs règles de
circulation et de traitement nécessaires à son fonctionnement
quotidien, à ses modes de gestion et d'évaluation ainsi
qu'à son processus de décision stratégique.
Le système d'information hospitalier exclut
implicitement les organisations et processus implémentés.
Le système d'information hospitalier est
inséré dans l'organisation hôpital en perpétuelle
évolution ; il est capable, selon des règles et modes
opératoires prédéfinis, d'acquérir des
données, de les évaluer, de les traiter par des outils
informatiques ou organisationnel, de distribuer des informations contenant une
forte valeur ajoutée à tous les partenaires internes ou externes
de l'établissement, collaborant à une oeuvre commune
orienté vers un but spécifique, à savoir la prise en
charge d'un patient et le rétablissement de celui -ci.
I.2.2.
Les organisations concernées
Le terme système d'information hospitalier renvoie
explicitement au système d'information interne à une organisation
de santé. Les établissements sont les suivants :
Ø Les hôpitaux
Ø Les cliniques
Cependant il est moins fréquent et probablement abusif,
de parler de système d'information hospitalier pour d'autres types
d'organisations de santé, bien que celles-ci soient également
dotées de système d'information :
ü Les centres de radiologie ;
ü Les centres d'analyses ;
ü Les centres de soins ;
ü Les cabinets médicaux.
Les utilisateurs finaux du système d'information
hospitalier sont :
· Les patients ;
· Les professionnels de santé ;
· Le personnel soignant
· Le personnel médico-technique
· Le personnel administratif
I.2.3.
Les enjeux du Système d'information Hospitalier
Le Système d'Information Hospitalier couvre l'ensemble
des informations utilisées dans un établissement de santé.
La performance d'un système d'information dépend de multiples
facteurs. Un de ceux-ci est le facteur humain. Celui-ci va percevoir plus ou
moins les enjeux d'une mise en commun d'informations vers un même
objectif : une réponse adaptée, sécurisée
à la demande de soins de la population dans un contexte
économique tourné dorénavant vers l'effet positif.
Le Système d'Information Hospitalier doit être
conçu pour faciliter l'intégration en temps réel des
informations entre l'opérationnel et le décisionnel. Le
Système d'Information Hospitalier peut regrouper plusieurs fonctions
nécessaires à la gestion des plannings, à la gestion de la
paye, la facturation, le suivi budgétaire, le relevé
d'activités médicales, la communication (internet, intranet,
protocoles, messagerie, forum, bon de commande, etc.). La tendance actuelle se
tourne vers l'extérieur de l'hôpital : le
développement de réseaux de santé, le
Dossier
médical personnel, la télémédecine.
I.2.4.
Les Objectifs d'un système d'information hospitalier
I.2.4.1. Objectifs Principaux
a) Amélioration de la Qualité des
soins
- Amélioration des communications
- Réduction des délais d'attente
- Aide à la prise de décision
b) Maîtrise des coûts
- Réduction des durées des séjours
- Réduction des tâches administratives
- Diminution du personnel
I.2.4.2. Objectifs Spécifiques
Permettre le suivi du déploiement ou l'état
d'avancement d'une politique et d'en évaluer la pertinence dans le cadre
d'une démarche qualité. La production des tableaux de bord.
La mise en place d'un Système d'Information Hospitalier
performant demande une véritable politique d'information
hospitalière menée par une direction du système
d'information. Elle doit être à long terme évolutive et
réaliste, car en informatique la mutation est permanente, il faut
concilier opportunisme et vision à long terme. Les solutions techniques
sont une chose mais le plus important est de mettre en place un réel
management.
I.2.5.
L'urbanisation du Système d'Information Hospitalier
L'urbanisation est l'évolution naturelle des
méthodologies de construction de parcs applicatifs. C'est un ensemble
d'idées et des concepts développés depuis 30 ans
dans le monde informatique. Des idées et des concepts tels que
l'analyse fonctionnelle, les processus, la formalisation des interfaces, la
définition des rôles, l'analyse des flots de données, etc.
il permet, entre autres, de décrire le système d'information
de façon complète, générique et fournit une
articulation judicieuse des couches. On peut catégoriser l'urbanisation
des systèmes d'information en plusieurs couches telles que :
- Couche métier
- Couche fonctionnelle
- Couche applicative
- Couche technique
a) Couche métier
Au niveau de description le plus général,
l'architecture métier du SIH (Système d'Information
Hospitalier) est décrite en 3 grandes séries de
processus :
- les processus métier, sous-entendu les processus de
prise en charge du patient
- les processus associés, essentiellement processus de
supervision (pilotage) et de contrepartie (financement)
- les processus support, chargés de gérer et
mettre à la disposition des processus métier les ressources
nécessaire à leurs activités. Il s'agit notamment des
processus achats, logistiques, de gestion de l'information et de la
connaissance.
b) Couche fonctionnelle
Les grands ensembles fonctionnels fréquemment
identifiés dans les SIH sont :
- Pilotage et supervision, facturation et contrepartie
- Gestion de vente
- Production clinique et médico-technique
- Gestion partagée des informations du patient
- Partage de la connaissance
- Partage des informations de vigilance
- Planification des rendez-vous
- Gestion des ressources logistiques
- Fonctions liées à l'administration de
l'information de production de soins (administration des informations du
patient, de la connaissance, vigilances, annuaires)
- Un certain nombre de fonctions et services techniques
(gestion des flux, gestion des services de sécurité, etc.)
c) Couche applicative
La couche applicative implémente dans des applications
informatiques les fonctions nécessaires à la réalisation
des activités métier. Chaque SIH particulier dispose de sa propre
carte applicative, reflétant l'état des applications
déployées dans l'établissement. Il est assez
délicat de décrire de grand type d'architecture applicative mise
en oeuvre dans les établissements de santé.
d) Couche technique
La couche technique du SIH n'est pas spécifique au
secteur de la santé, à l'exception notable des équipements
biomédicaux (
imagerie
médicale, centrales de surveillance par exemple).
Elle est composée :
ü D'un réseau local informatique (typiquement un
réseau Ethernet TCP/IP, topologie en étoile) :
· Des câbles (fils cuivrés pour les courtes
distances, fibres optiques pour les distances supérieures à 100
m.) ou de la radio (réseau
Wi-Fi, ou GPRS UMTS et 3G
pour les grandes distances)
· Des éléments actifs, dits
concentrateurs et
répartiteurs (hub et Switch)
· Des serveurs, groupés (et de plus en plus
virtualisés) dans une salle machine avec de 1 à des dizaines de
serveurs, assurant la gestion du réseau et faisant fonctionner les
applications
· Des postes de travail : des ordinateurs
individuels, type
PC (plus
rarement des Macintosh), des consoles (terminaux passifs), des terminaux
mobiles (Smartphones, tablettes tactiles, etc.)
ü Des connexions à un ou des réseaux
extérieurs
· Par le réseau
Internet
· Par ligne RTC,
Transpac,
Numeris,
notamment pour se connecter aux organismes publics comme les
Caisses
Primaires d'Assurance Maladie.
· Par des liaisons louées pour relier des sites
distants (hôpitaux multi sites par VPN, par exemple)
ü D'un système de téléphonie
complet
· Réseau téléphonique privé,
plus ou moins sophistiqué
· Connexion au réseau téléphonique
public
· Téléphonie IP
I.3.
Système de gestion de l'unité de soins
Les unités de soins dans une institution
hospitalière sont regroupées en termes de service ou
département, celles -ci constituent le coeur de l'hôpital. Voici
les différentes unités de soins qu'on retrouve dans les
hôpitaux :
ü Consultations externes, urgences
ü Services médicaux
ü Services chirurgicaux
ü Soins intensifs, réanimation
ü Rééducation, etc.
Le but de tous ces départements dans une institution de
santé est d'offrir une meilleure qualité de soins aux patients
qui y sont et de réduire les délais d'attente de résultat.
Nous allons illustrer les cas de circulation des informations
entre différentes unités de gestion de soins.
Il existe deux types de cas :
ü Cas ordinaire
ü Cas urgent
1. Arrivée du patient ordinaire
Fig.I.2 : Arrivé
patient ordinaire
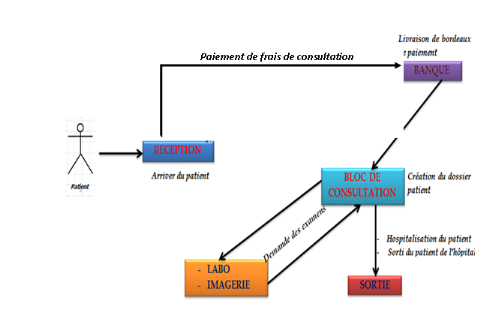
2. Arrivée du patient aux urgences
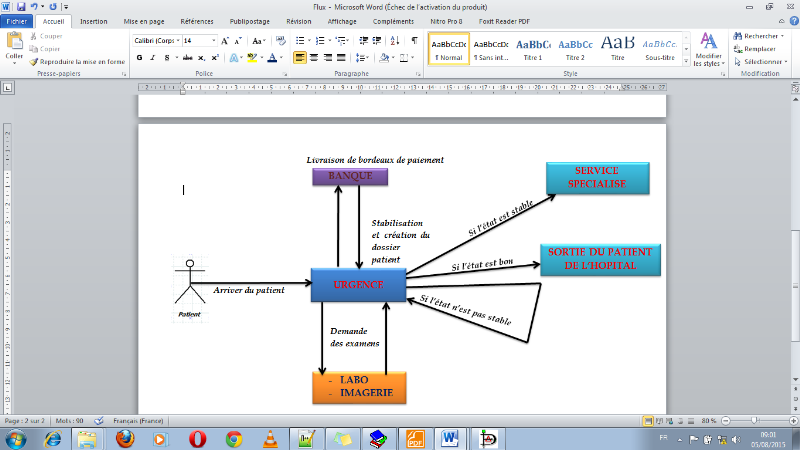
Fig.I.3 : Arrivé
patient aux urgences
3. Contrôle
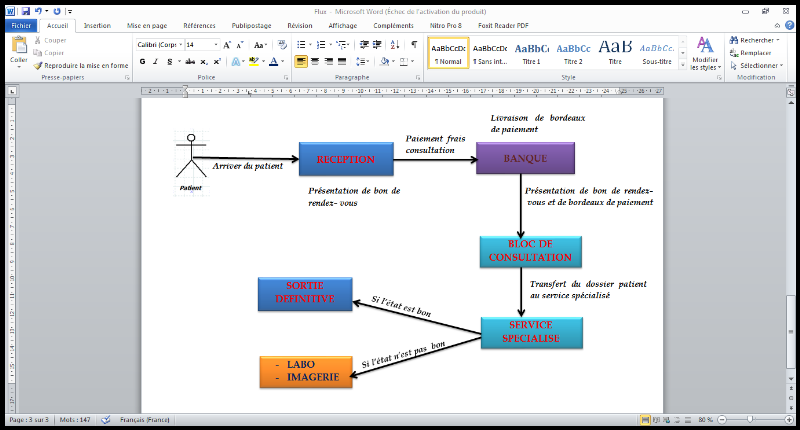
Fig.I.4 : Contrôle de
santé
I.4.
Présentation de la Gestion d'un Dossier Patient
I.4.1.
Le Dossier Patient
I.4.1.1. Définitions
Le dossier patient est la mémoire écrite de
toutes les informations (informations administratives, cliniques, biologiques,
diagnostiques et thérapeutiques) concernant un malade, constamment mis
à jour, et dont l'utilisation est à la fois individuelle et
collective.
I.4.1.2. Fonctions
La tenue du DP (Dossier Patient) est une partie
intégrante de l'acte de soin ainsi qu'une obligation légale. Il a
les fonctions suivantes :
1. D'aide-mémoire pour le suivi du
patient : Le DP est le résultat d'un flux
documentaire qui accompagne le patient dans son parcours de santé
(hospitalier et ambulatoire). Dans le dossier se trouve toute
l'information nécessaire de l'ensemble de la prise en charge du
patient.
2. De document médico-légal :
La tenue d'un DP permet d'établir les faits tant pour le
patient que pour le médecin. Les données du dossier peuvent
servir de preuves légales dans les affaires juridiques où la
responsabilité du patient, du médecin ou de l'institution est
engagée.
3. De facturation : La tenue de
la trajectoire du patient est indispensable au processus de la facturation des
prestations fournies au patient.
4. De communication : Le DP
permet de stocker des informations relatives au patient, les
problèmes médicaux rencontrés, les décisions
médicales prises et les résultats de ces décisions.
Tout élément mémorisé dans le dossier est un acte
potentiel de communication avec les différents partenaires du
système de santé.
I.4.1.3. Intérêt et utilisation dans
l'environnement hospitalier
Le DP présente un grand intérêt dans
l'évolution de son parcours et peut être constitué de
plusieurs points :
1. Pour noter, pour garder une trace de
:
- Tout ce qui s'est passé,
- Tout ce qui a été dit,
- Tout ce qui a été fait.
2. Pour regrouper tout ce qui est connu d'un
patient
- Documents papiers, photocopies
- Courriers
- Ordonnances
- Radiographies
- etc.
a) Utilisation dans l'environnement hospitalier
Aujourd'hui le DP a de nombreuses autres utilisations :
- C'est un outil d'évaluation de l'activité
médicale. Avec les données récoltées, il est
possible d'évaluer une pratique ou un acte de soin ;
- Il permet de classer les patients en groupes
homogènes de malades dans un objectif d'évaluation
d'activité et de tarification ;
- C'est un outil de calcul de coûts par séjour
(comptabilité analytique) ;
- C'est une source d'informations sur l'état de
santé de la population, utilisée pour effectuer de la
recherche épidémiologique ;
- C'est également un outil de recherche clinique : il
permet d'effectuer des études rétrospectives et de
générer les hypothèses à vérifier pour des
études prospectives.
Dans un milieu hospitalier, le DP est l'union des dossiers de
tous les intervenants du système de soins de l'hôpital.
A l'origine de chaque document se trouve un acte
médical, dans le sens large du terme. Il peut s'agir de l'admission
du patient, de la réalisation d'un examen, d'une consultation,
d'un transfert d'un service à l'autre, etc.
Le contenu d'un DP comprend au moins les trois volets
: dossier administratif, dossier médical et dossier infirmier.
Dossier patient
Dossier Administratif
Dossier soins infirmiers
Dossier médical
Fig.I.5 : Dossier Patient
Le dossier administratif : la
fiche d'identification du patient (données administratives et
sociales), couverture d'assurance, documents de facturation.
- Le dossier médical :
anamnèse (histoire clinique du patient), résultats d'examens
cliniques, résultats d'examens complémentaires, prescriptions
diagnostiques ou thérapeutiques, traitements, notes de suite, avis de
spécialistes, différents rapports (radiologie, pathologie,
etc.), comptes rendus opératoires, les lettres de sortie (rapport
définitif produit à la fin du traitement du patient), les fiches
d'information au patient, etc.
- Le dossier infirmier : feuilles de
surveillances (signes vitaux), notes de soins, etc.
Ces trois parties principales du DP peuvent être
créées lorsque le patient se présente à
l'hôpital en cas d'urgence (dossier
d'urgence), pour une consultation (dossier
ambulatoire) ou encore pour un séjour hospitalier
(dossier d'hospitalisation).
Tableau comparatif entre le DP et le DPI
(Dossier Patient Informatiser)
|
Caractéristique
|
DP papier
|
DPI
|
|
Intégration des données (données
multimédias)
|
+
|
+++
|
|
Stockage
|
+
|
+++
|
|
Rapidité d'accès aux informations
|
+
|
+++
|
|
Accès à distance
|
-
|
+++
|
|
Disponibilité de l'information
|
+
|
++
|
|
Lisibilité
|
+
|
++
|
|
Regroupement pour la recherche clinique
|
+
|
+++
|
|
Evaluation des soins
|
+
|
+++
|
|
Traitement des données multimédia
|
-
|
+++
|
|
Connexion à de bases de données documentaires ou
de connaissances médicales
|
-
|
+++
|
|
Sécurité de l'information
|
+
|
+++
|
|
Confidentialité
|
++
|
+
|
Tab. 2 : Tableau
comparatif entre le DP et le DPI
Légende
· N'existe pas (-)
· Peu satisfaisant (+)
· Satisfaisant (++)
· Très satisfaisant
(+++)
I.4.2.
Organisation du dossier
a) Organisation de la
consultation sur place
La consultation du dossier se fait sur rendez-vous au niveau
du service. La mention de la date de la consultation doit être
notée dans le dossier. Si la consultation se fait en présence
d'une tierce personne, la confidentialité du dossier doit être
préservée lors de sa consultation, sauf avis contraire du
patient. Un accompagnement psychologique par un médecin peut être
prévu.
a) Conservation du dossier du patient
Le dossier du patient est conservé dans des conditions
permettant son accessibilité, son intégrité et la
préservation de la confidentialité des informations qu'il
comporte.
Dans les établissements de santé privés,
les informations sont conservées dans l'établissement sous la
responsabilité d'un ou de plusieurs médecins
désignés à cet effet par le syndicat national de
médecin(SYNAMED). Dans tous les cas, le directeur de
l'établissement veille à ce que les dispositions soient prises
pour assurer la garde et la confidentialité des informations de
santé conservées dans l'établissement.
b) Durée de conservation des dossiers (toutes
pathologies)
Ø Patient majeur :
· 20 ans à compter du dernier
séjour/consultation
· 10 ans à compter du décès du
patient
Ø Patient mineur :
· âgé de moins de 8 ans : jusqu'au 28e
anniversaire du patient
· âgé de plus de 8 ans : 20 ans
· 10 ans à compter du décès du
patient
I.4.2.1. Processus
d'informatisation de la gestion des dossiers patients
L'informatisation permet d'améliorer significativement
la qualité du contenu des dossiers médicaux. Un dossier
médical informatisé est à la fois plus lisible et plus
précis qu'un dossier manuel. S'il est souvent moins exhaustif, sa
complétude est plus élevée pour les sujets traités,
en particulier lorsque sa structure externe est sous forme de questionnaires
standardisés.
Cette informatisation permet de potentialiser les
différentes fonctions du dossier traditionnel mais elle nécessite
au préalable une analyse approfondie de ces fonctions, de la structure
du langage médical et la recherche de modèles appropriés
de représentation des données et des connaissances
médicales.
I.4.2.2. La modélisation des informations
médicales
a) Comment standardiser la terminologie
médicale ?
La modélisation des données médicales
passe par une modélisation du discours médical, dont deux
étapes revêtent une importance particulière : la
définition des éléments du discours (étape de
standardisation de la terminologie) et l'organisation de ces
éléments dans un modèle approprié (étape de
structuration).
La standardisation correspond à la définition
précise des catégories sémantiques du langage
médical, à l'organisation des termes à l'intérieur
de chaque catégorie et à la définition précise de
chaque terme.
b) Comment structurer le dossier médical
?
La structuration peut être définie comme le
regroupement d'éléments isolés pour former des objets plus
complexes. C'est presque depuis qu'elle existe que la médecine a reconnu
la nécessité d'une structuration du dossier médical.
Cette structuration, nous amène à citer deux types
de dossier médical :
v Le dossier médical orienté suivant
la source
Le dossier médical actuel reste traditionnellement
orienté suivant la source (ou l'origine), c'est-à-dire que les
données obtenues à partir de l'interrogatoire
(antécédents, symptômes) et de l'examen clinique, les
examens complémentaires, les données diagnostiques,
thérapeutiques et pronostiques sont regroupées en sections
distinctes. La section diagnostique est la section la plus importante puisque
sa fonction est d'intégrer le maximum de données de façon
à déduire les décisions correctes. Les données
d'évolution sont constituées de sous-ensembles des sections
précédentes. Le risque de négliger la partie de
synthèse aux dépens de la partie analytique, en particulier lors
de la surveillance au long cours d'un patient, est ainsi
élevé.
v Le dossier médical orienté suivant
les problèmes
L'idée de base du dossier orienté suivant
les problèmes est de structurer le plan et les notes
d'évolution suivant une hiérarchie ayant comme racine la liste
des problèmes.
Le concept de problème est un concept plus large que le
concept de diagnostic puisqu'incluant toute condition nécessitant une
attention ultérieure pour le diagnostic, le traitement ou la
surveillance (un problème peut être aussi bien un symptôme
qu'un diagnostic).
Cependant, elle inclut un certain nombre de contraintes, en
partie inhérentes au modèle hiérarchique choisi, et qui en
limitent la diffusion. Pour être efficace un tel modèle
nécessite une relative indépendance des branches de l'arbre,
c'est-à-dire des données associées à chaque
problème, ce qui est rarement le cas pour des problèmes
concernant le même patient. Les données d'évolution sont
rattachées à des éléments (les problèmes)
dont la définition est instable dans le temps, fonction de
l'évolution du profil des problèmes d'un patient, mais aussi de
l'expérience du médecin ou de l'évolution des concepts
médicaux
I.4.2.3. Informatisation de la
gestion des dossiers patients
I.4.2.3.1. Définitions
ü Le DPI consiste en l'utilisation des outils
permettant à tout usager autorisé, d'enregistrer, de retrouver,
de consulter et d'exploiter des données relatives au patient. A cette
base s'ajoute de cas en cas d'autres informations telles que les
résultats d'analyses de laboratoires, des résultats d'examens
radiologiques, des prescriptions médicamenteuses, etc.
ü Le dossier patient informatisé est une des
composantes d'un système d'information en réseaux.
I.4.2.3.2. Modèles et
procédures
De nos jours, il n'existe pas de modèle parfait
répondant en même temps à tous les besoins d'une
institution donnée. Cependant, il existe plusieurs modèles de
DPI :
· Le DPI de documents non structurés,
· Le DPI de documents structurés,
· Le DPI semi-structuré (tous les documents ne
sont pas structurés),
· Le DPI qui suit un modèle mixte (les mêmes
dossiers existent sous forme structurée et non structurée)
Dans le cas de notre travail, nous allons nous concentrer sur
le DPI de documents structurés car il permet de représenter
explicitement l'information et de la manipuler. Ce modèle
s'intéresse aux propriétés structurales et
comportementales des données, des informations et des connaissances.
C'est à dire que les données de laboratoires par exemple,
n'existent pas en tant que chiffres sur une feuille mais en tant que valeur
ayant un sens dont on pourra spécifiquement demander l'évolution
dans le temps.
I.4.2.3.3. Importance et avantage
de l'informatisation de la gestion des dossiers patients
Les raisons d'informatiser le DP sont multiples. Le DPI est
considéré comme une ressource importante à
l'activité de soins, à la gestion des problèmes dans le
domaine de la santé ainsi qu'à l'extension des connaissances
médicales. L'informatisation du DP permet de stocker dans un volume
réduit des quantités considérables d'informations, y
compris des données multimédias.
Parallèlement à la quantité,
l'informatisation permet d'améliorer la qualité du contenu de
dossier. Le DPI est plus lisible que le DP sous forme papier et l'accès
aux informations recherchées est plus rapide. Avec le DPI, le partage
des informations entre partenaires de soins se fait plus facilement aussi bien
à l'intérieur qu'à l'extérieur de l'hôpital.
Cela implique une meilleure continuité de soins et une diminution des
coûts de la prise en charge globale du patient en évitant la
répétition des examens. Les DPI facilitent le regroupement des
données pour pouvoir effectuer différents types de recherches
(statistiques, épidémiologiques, cliniques) ainsi qu'une
évaluation des soins.
Un DPI peut être connecté à des bases de
données documentaires (recherche des références
bibliographiques) et/ou à des bases de connaissances (informations
pour la prise de décision). Les dossiers informatisés
sont mieux protégés et les moyens techniques se mettent
en place pour assurer la confidentialité des données. Les
avantages offerts par le DPI vont ainsi au-delà de celles du DP papier,
tel que :
v Gain de temps (absence de saisies redondantes et
automatisations des ordonnances...)
v Faciliter la continuité des soins
v Amélioration de la qualité des dossiers
(lecture aisée, contrôles à la saisie...)
v Facilité de contenir des annexes (Documents patients)
dans un dossier patient
v Pas de perte du dossier qui est consultable sur les 24 h
dans tous les bureaux
v Sécurisation de la prescription
médicamenteuse
v Partage info possible au sein d'un centre ou de la
région
v Meilleur suivi des complications y compris à long
terme
v Evaluation interne et rapports d'activités (tableaux
de bords d'indicateurs automatisés) et évaluation externe
favorisée
v Études épidémiologiques
I.4.3.
Conclusion
Dans ce chapitre, on a parlé de tous les concepts
théoriques liés au système d'information
général, de système d'information hospitalier qui est un
cas particulier du SI, de système de gestion des unités de soins,
du dossier patient d'une manière général, de
différentes éléments constitutif, son organisation, de
processus d'informatisation de la dite dossier et les enjeux auxquels ils
doivent faire face dans le mécanisme de prise en charge du patient.
Ceci nous amène à aborder le concept de base de
données qui fera l'objet du second chapitre de notre travail.
CHAPITRE II. LES BASE DE DONNEES [2] [8] [12]
II.1.
Introduction
Les Bases de Données occupent aujourd'hui une place de
plus en plus importante dans les systèmes informatiques. Les
Systèmes de Gestion de Bases de Données (SGBD) remplacent
les anciennes organisations où les données, regroupées
en fichiers, restaient liées à une application
particulière. Ils assurent le partage, la cohérence, la
sécurité d'informations qui, de plus en plus, constituent le
coeur de l'entreprise. Des premiers modèles hiérarchiques et
réseaux au modèle relationnel, du mainframe au micro, du
centralisé au réparti, les ambitions des SGBD augmentent
d'année en année.
II.1.1. Définition
Une Base de Données (son abréviation est BD, en
anglais DB, DataBase) est un ensemble structuré de données
archivées dans des mémoires accessibles à l'ordinateur
pour satisfaire un ou plusieurs utilisateurs simultanément en un temps
opportun et qui répond aux trois critères suivants :
l'exhaustivité, la non-redondance et la
structure.
ü L'exhaustivité implique la
présence dans la base de données, de tous les renseignements qui
ont trait aux applications en question.
ü La non - redondance implique la
présence d'un renseignement donné une fois et une seule.
ü La structure implique l'adaptation du
mode de stockage des renseignements aux traitements qui les exploiteront et les
mettrons à jour, ainsi qu'au coût de stockage dans
l'ordinateur.
II.2.
Différents modèles de base de données
II.2.1. Modèle Hiérarchique
Les données sont représentées sous forme
d'une structure arborescente d'enregistrements. Cette structure est
conçue avec des pointeurs et détermine le chemin d'accès
aux données.
Chaque noeud de l'arbre correspond à une classe
d'entités du monde réel et les chemins entre les noeuds
représentent les liens existant entre les objets.
Les données sont donc classées
hiérarchiquement selon un graphe arborescent descendant où on a
un segment racine unique, des segments internes et des segments feuilles. Le
niveau d'un segment caractérise sa distance à la racine.
Fig.II.1: Modèle
Hiérarchique
II.2.2. Modèle Réseau
La structure des données peut être
visualisée sous la forme d'un graphe quelconque. Comme pour le
modèle hiérarchique, la structure est conçue avec des
pointeurs et détermine le chemin d'accès aux données.
Toutefois la structure n'est plus forcément arborescente dans le sens
descendant.
Fig.II.2: Modèle
Réseau
II.2.3. Modèle Relationnel
II est fondé sur la théorie mathématique
des relations (Union, Différence, Produit cartésien, ...). Il
conduit à une représentation très simple des
données sous forme de tables constituées de lignes et de
colonnes. II n'y a plus de pointeurs qui figeaient la structure de la base.
Fig.II.3: Modèle
Relationnel
II.2.4. Modèle Objet
Les données sont représentées sous forme
d'objets au sens donné par les langages orientés objet : pour
simplifier, les données (au sens habituel) sont enregistrées avec
les procédures et fonctions qui permettent de les manipuler.
L'organisation des données est faite sous forme d'instances de classes
hiérarchisées qui possèdent leurs propres méthodes
d'exploitation. Les champs sont des instances de ces classes.
Fig.II.4: Modèle Objet
II.3.
Modélisation d'une base de Données
La modélisation est la démarche qui consiste
à produire des modèles, soit pour décrire un
système existant (analyse), soit pour élaborer un nouveau
système (conception) à partir des perceptions du monde
réel.
II.3.1. Modèle
ü Un modèle est une représentation
partielle de la réalité.
ü Abstraction de ce qui est intéressant pour un
contexte donné, Vue subjective et simplifiée d'un
système.
Le modèle nous facilite la compréhension, la
communication et voire simuler le fonctionnement d'un système.
Pourquoi il est important de modéliser une
base de données ?
Il est bien connu qu'avant d'entreprendre la
réalisation informatique d'un problème, il est nécessaire
de réfléchir aux tenants et aboutissants du système
à réaliser. Il s'agit de passer du monde réel, complexe et
confus au monde informatique où les structures et les
propriétés des objets doivent être identifiées.
Cette tâche classique est essentielle dans la conception du schéma
d'une base de données.
II.3.2. Méthode de modélisation d'une base de
données
Nous allons utiliser la méthode Merise qui est une
Méthode d'Étude et de Réalisation Informatique par les
Sous-ensembles ou pour les Systèmes d'Entreprise.
Cette méthode présente comme avantage
indéniable de permettre une définition claire et précise
de l'ensemble du
Système et d'en définir correctement le
périmètre.
II.3.2.1. Modèle entité Association
Le modèle E-A (ou E-R [Entity-Relationship] en anglais)
permet la modélisation conceptuelle des données. Il correspond au
niveau conceptuel de la méthode MERISE (méthode d'analyse
informatique), le MCD (Modèle Conceptuel de Données). La
conception E-A est issue des travaux de Chen, (Chen, "The entity-Relation sheep
Model - Towards a UnifiedView of Data", "ACM Transactions on Database systems",
mars-1976, n°.1) et se fonde sur deux concepts principaux et un
troisième sous-jacent : l'entité, l'association et l'attribut ou
propriété.
a) Entité
Une Entité est une représentation d'un
objet du monde réel (concret ou abstrait), perçu par le
concepteur comme ayant une existence propre, et à propos duquel on peut
enregistrer des informations, car n'ayant que des caractéristiques
comparables.
PATIENT
MEDECIN
Une entité existe indépendamment du fait qu'elle
puisse être liée à d'autres entités de la base de
données. Par exemple, dans un hôpital, on a l'entité
médecin, patient, etc. ...
Fig.II.5: Entité
b) Association
Une association est une représentation d'un lien entre
plusieurs entités, lien où chaque entité liée joue
un rôle déterminé. Si l'association lie deux (ou plusieurs)
entités du même type, elle est dite "cyclique" et, dans ce cas, la
spécification du rôle de chaque entité est indispensable
pour supprimer les ambiguïtés possibles.
Dans notre cas, l'association consulter met en relation
l'entité médecin et patient.
PATIENT
MEDECIN
Consulter
Fig.II.6: Association
c) Attribut
Un attribut est une propriété d'une
entité ou d'une association.
Un identifiant est un attribut sans doublons c'est
-à-dire qui ne prend pas deux fois la même valeur.
Remarque :
ü Un attribut est atomique, c'est à dire qu'il ne
peut prendre qu'une seule valeur pour une occurrence.
ü Un attribut est élémentaire, c'est
à dire qu'il ne peut être exprimé par (ou
dérivé) d'autres attributs.
ü Un attribut qui identifie de façon unique une
occurrence est appelé attribut clé.
Consulter
MEDECIN
Id_med
Nom_med
Postnom_med
Sexe_med
Spécialité
PATIENT
Id_pat
Nom_pat
Prenom_pat
Sexe_pat
Fig.II.7: Attribut
d) Cardinalité
Les cardinalités permettent de caractériser le
lien qui existe entre une entité et la relation à laquelle elle
est reliée. La cardinalité d'une relation est composée
d'un couple comportant une borne maximale et une borne minimale, intervalle
dans lequel la cardinalité d'une entité peut prendre sa
valeur :
ü la borne minimale (généralement 0 ou 1)
décrit le nombre minimum de fois qu'une entité peut participer
à une relation
ü la borne maximale (généralement 1 ou n)
décrit le nombre maximum de fois qu'une entité peut participer
à une relation
(0, n)
(1, n)
Consulter
Date
MEDECIN
Id_med
Nom_med
Postnom_med
Sexe_med
Spécialité
PATIENT
Id_pat
Nom_pat
Prenom_pat
Sexe_pat
Fig.II.8: Cardinalité
II.3.2.2. Modèle Logique de Données
(MLD)
Le Modèle Logique de Données (MLD) est la suite
du processus Merise. Son but est de nous rapprocher au plus près du
modèle physique. Pour cela, nous partons du modèle Conceptuel de
Données et nous lui enlevons les relations, mais pas n'importe comment,
il faut en effet respecter certaines règles.
Règle 1 :
Toute entité devient une table dans laquelle les
attributs deviennent des colonnes. L'identifiant de l'entité constitue
alors la clé primaire de la table.
Exemple: Médecin
(id_med,nom_med,postnom_med,sexe_med,....)
Règle 2:
Dans le cas de deux entités reliées par une
association de type 1 : n, on ajoute une clé
étrangère dans la table côté 0, 1 ou 1, 1, vers la
clé primaire de la table côté 0, n ou 1, n. les attributs
de l'association glissent vers la table côte 0, 1 ou 1, 1. Et si la
cardinalité est 1, 1 alors la clé étrangère ne peut
recevoir de valeur NULL (autrement dit, vide interdit).
Exemple :
Voici un modèle conceptuel de départ :
Elever
Mères
Numero_mère
Nom_mère
Prénom_mère
Enfants
Numero_enfant
Nom_enfant
Prénom_enfant
(1, n)
(1, 1)
Fig.II.9: Règles 2 MCD
Voici le Modèle Logique des Données
découlant du Modèle conceptuel précédent :
Mères
Numero_mère
Nom_mère
Prénom_mère
Enfants
Numero_enfant
Nom_enfant
Prénom_enfant
#Numero_mère
Règles 3 :
Fig.II.10: Règles 2 MLD
Dans le cas de deux entités reliées par une
association de type 1 : 1, on ajoute, aux deux tables, une clé
étrangère vers la clé primaire de l'autre. Afin d'assurer
la cardinalité maximale de 1, on ajoute une contrainte d'unicité
sur chacune de ces clés étrangères (la colonne
correspondante ne peut prendre que des valeurs distinctes). Les attributs de
l'association sont alors repartis vers l'une des deux tables. Et si la
cardinalité est 1, 1 alors la clé étrangère
concernée ne peut recevoir la valeur NULL (autrement dit, vide
interdit).
Cette alternative est sans doute préférable, car
plus évolutive (si le type 1 :1 est un jour converti en un autre
type).
Remarque :
D'autres techniques sont parfois proposées pour la
règle 3 (fusionner les tables, utiliser une clé primaire
identique) mais en pratique elles ne sont pas exploitables dans le cas
général
Règle 4 :
Une association entre deux entités de type n : m
est traduite par une table supplémentaire (parfois appelée table
de jointure) dont la clé primaire est composée de deux
clés étrangères vers les clés primaires des deux
tables en association. Les attributs de l'association deviennent des colonnes
de cette table.
Illustration :
Comme dans notre exemple précedent, l'association
consulter qui relie deux entités dont médecin et patient qui
sont de cardinalité père - père, l'association consulter
devient une table avec comme clé primaire la concatenation de la
clé de l'entité médecin et patient.
ü Médecin
(id_med,Nom_med,postnom_med,...)
ü Consulter (#id_med,#id_pat,date)
ü Patient (Id_pat,Nom_pat,Prenom_pat,..)
Règle 5:
Une association non binaire est traduite par une table
supplémentaire dont la clé primaire est composée d'autant
de clés étrangères que d'entités. Les attributs de
l'association deviennent des colonnes de cette table.
II.3.2.3. Modèle Physique de Données
(MPD)
Le modèle physique des données (MPD) est la
traduction du modèle logique des données (MLD) dans une structure
de données spécifique au système de gestion de bases de
données (SGBD) utilisé.
Le MPD est donc représenté par des tables
définies au niveau du système de gestion de bases de
données. C'est donc au niveau du MPD que nous quittons la
méthode générale de création d'un MCD et de sa
transformation en MLD, pour nous tourner vers la manipulation d'un SGBD
spécifique.
Passage du MLD au MPD
Le passage MLD vers MPD se fait par les étapes
suivantes :
- Implémentation physique de chaque table du MLD dans
le SGBD utilisé
- Pour chaque table, indiquer au SGBD quel(s) champ(s)
constitue(nt) la clé primaire
- Pour chaque table, indiquer au SGBD la (les) clé(s)
étrangère(s) et la (les) clé(s) primaire(s)
correspondant(s).
Pour ce faire, la plupart des SGBD actuellement sur le
marché nous offrent deux possibilités :
1) L'utilisation d'une ou de plusieurs interfaces graphiques,
qui nous aident dans la création des tables physiques, dans la
définition des clés primaires et dans la définition des
relations.
2) L'utilisation des commandes spéciales, faisant
partie d'un langage de définition de données (SQL).
II.4.Système de Gestion de Base de Données
(SGBD)
II.4.1. Définition
Un SGBD est un logiciel qui prend en charge la structuration,
le stockage, la mise à jour et la maintenance d'une base de
données. Il est l'unique interface entre les informaticiens et
les données (définition des schémas, programmation des
applications), ainsi qu'entre les utilisateurs et les données
(consultation et mise à jour).
II.4.2. Objectif principal
L'objectif principal d'un SGBD est d'assurer
l'indépendance des programmes aux données, c'est-à-dire la
possibilité de modifier les schémas conceptuels et interne des
données sans modifier les programmes d'applications, et donc, le
schéma externe vu par ces programmes.
II.4.2.1.Objectif spécifiques
Les objectifs spécifiques sont :
ü Indépendance physique des
données
Le changement des modalités de stockage de
l'information (optimisation, réorganisation, segmentation, etc.)
n'implique pas de changements des programmes.
ü Indépendance logique des
données
L'évolution de la structure d'une partie des
données n'influe pas sur l'ensemble des données.
ü Manipulation des données par des
non-informaticiens
L'utilisateurn'apasàsavoircommentl'informationeststockéeetcalculéeparlamachine,
mais juste à pouvoir la rechercher et la mettre à jour à
travers des IHM [Interface Homme Machine] ou des langages assertionnels
simples.
ü Administration facilitée des
données
Le SGBD fournit un ensemble d'outils (dictionnaire de
données, audit, tunning, statistiques, etc.) pour améliorer les
performances et optimiser les stockages.
ü Optimisation de l'accès aux
données
Les temps de réponse et de débits globaux sont
optimisés en fonctions des questions posées à la BD.
ü Contrôle de cohérence
(intégrité sémantique) des données
Le SGBD doit assurer à tout instant que les
données respectent les règles d'intégrité qui leurs
sont imposées.
ü Partage des données
Les données sont simultanément consultables et
modifiables.
ü Sécurité des
données
La confidentialité des données est
assurée par des systèmes d'authentification, de droits
d'accès, décryptage des mots de passe, etc.
ü Sûreté des
données
La persistance des données, même en cas de panne,
est assurée, grâce typiquement à des sauvegardes et des
journaux qui gardent une trace persistante des opérations
effectuées.
II.4.3. Fonctions des
Le SGBD sert donc d'interface entre les programmes
d'application et les fichiers de données physiques ; il libère
donc les programmeurs et les utilisateurs de la nécessité de
comprendre où et comment les données sont stockées.
Un SGBD doit garantir :
· la cohérence des données :
le SGBD doit permettre la définition des contraintes
d'intégrité au sein de la base de données,
· la concurrence des accès : lorsque
plusieurs utilisateurs désirent accéder en même temps aux
mêmes données ; le SGBD doit gérer cette concurrence
d'accès en ordonnançant les demandes,
· la confidentialité des données
: le SGBD doit permettre le contrôle des accès lors de la
création, la modification, la consultation et la suppression des
données ; ce contrôle est réalisé par l'utilisation
de mots de passe ou par le cryptage des données,
· la sécurité des données
: le SGBD doit assurer la sécurité des données
contre les incidents matériels ou logiciels.
Enfin, le SGBD doit également assurer le suivi
des opérations en fournissant d'une part des statistiques sur
les utilisations de la base et, d'autre part, des services de gestion.
Ce constat montre qu'il est nécessaire d'identifier
différents niveaux de modèles pour une base de données.
II.4.4. Illustration de SGBD
Il existe de nombreux systèmes de gestion de bases de
données, en voici une liste non exhaustive :
a) PostgreSQL
PostgreSQL est un système de gestion de base de
données relationnelle et objet (SGBDRO). C'est un outil libre disponible
selon les termes d'une licence de type BSD (Berkeley Software Distribution
License).
Ce système est concurrent d'autres systèmes de
gestion de base de données, qu'ils soient libres ou
propriétaires. Comme les projets libres Apache et Linux, PostgreSQL
n'est pas contrôlé par une seule entreprise, mais est fondé
sur une communauté mondiale de développeurs et d'entreprises.
b) MySQL
MySQL est un système de gestion de bases de
données relationnelles (SGBDR). Il est distribué sous une double
licence GPU (General Public License) et propriétaire. Il fait partie des
logiciels de gestion de base de données les plus utilisés au
monde, autant par le grand public (applications web principalement) que par des
professionnels.
MySQL est un serveur de bases de données relationnelles
SQL (Structured Query Language) développé dans un souci de
performances élevées en lecture, ce qui signifie qu'il est
davantage orienté vers le service de données déjà
en place que vers celui de mises à jour fréquentes et fortement
sécurisées. Il est multi-utilisateur.
c) Oracle
Oracle DataBase est un système de gestion de base de
données relationnelle (SGBDR) qui depuis l'introduction du support du
modèle objet dans sa version 8 peut être aussi qualifié de
système de gestion de base de données relationnel-objet (SGBDRO).
Fourni par Oracle Corporation, il a été développé
par Larry Ellison, accompagné d'autres personnes telles que Bob Miner et
Ed Oates.
d) Microsoft SQLSERVER
Microsoft SQL Server est un
système de gestion de base de données (abrégé en
SGBD) incorporant entre autres un SGBDR (SGBD relationnel »)
développé et commercialisé par la société
Microsoft. Il ne fonctionne que sous les OS Windows.
En fait MS SQL Server est une suite composée de cinq
services principaux :
· Le moteur relationnel (OLTP) appelé SQL
Server ;
· Le moteur décisionnel (OLAP) appelé
SSAS (SQL Server Analysis Services) incluant un
moteur de stockage pour les cubes, des algorithmes de forage (data
mining) et différents outils de BI (Business
Intelligence) ;
· Un ETL (Extract Transform and Load) appelé
SSIS (SQL Server Integration Services) destiné à
la mise en place de logiques de flux de données, notamment pour
alimenter des entrepôts de données (data warehouse) ;
· Un outil de génération d'état
appelé SSRS (SQL Server Reporting Services) permettant
de produire des rapports sous différentes formes et exploitant les
ressources du moteur décisionnel (bases "resport Server...") à la
fois pour y stocker les rapports mais aussi y cacher les données de ces
derniers afin de faire du "warmup" ;
· Un système de planification de travaux et de
gestion d'alerte appelé Agent SQL qui utilise lui aussi
les services du moteur SQL (base msdb).
e) Sybase
Sybase est un éditeur de logiciels
fondé en 1984. Sybase fournit des solutions d'infrastructure
d'entreprise, des solutions de mobilités de logiciel pour la gestion de
l'information, pour le développement, et pour l'intégration.
II.5.
Le langage SQL (Structured Query Language)
Le modèle relationnel a été
inventé par E.F. Codd (Directeur de recherche du centre IBM de San
José) en 1970, suite à quoi de nombreux langages ont fait leur
apparition :
v IBM Sequel (Structured English Query Language) en 1977
v IBM Sequel/2
v IBM System/R
v IBM DB2
Ce sont ces langages qui ont donné naissance au
standard SQL, normalisé en 1986 par l'ANSI pour donner SQL/86. Puis en
1989 la version SQL/89 a été approuvée. La norme SQL/92 a
désormais pour nom SQL 2.
SQL est à la fois :
- Langage de définition de
Données
SQL
est un langage de définition de données (LDD),
c'est-à-dire qu'il permet de créer des tables dans une base de
données relationnelle, ainsi que d'en modifier ou en supprimer.
- Langage de manipulation de
données
SQL est un langage de manipulation de données
(LMD), cela signifie qu'il permet de sélectionner,
insérer, modifier ou supprimer des données dans une table d'une
base de données relationnelle.
- Langage de protections
d'accès
Il est possible avec SQL de définir des permissions au
niveau des utilisateurs d'une base de données. On parle de
DCL (Data Control Language).
II.6. Conclusion
Dans ce chapitre, nous avons abordé les concepts
théoriques sur les bases de données et système de gestion
de base de données (SGBD), tout en précisant la force d'une base
de données dans une organisation. Ceci nous a conduire à la
réalisation d'une application de gestion de dossier patient qui est
l'objet de notre prochain chapitre en précisant toutes les étapes
de l'analyse au développement du nouveau système.
CHAPITRE III. MODELISATION ET IMPLEMENTATION DU SYSTEME
[1][2][3][4][5][6][7]
III.1. Présentation des
CUK
a. Historique
C'est en 1957 que furent inaugurées les Cliniques
Universitaires de Kinshasa, pour les services curatifs médicaux du
personnel de l'Office de Transport du Congo (OTRACO, aujourd'hui ONATRA).
Vers 1958, une convention du Conseil d'administration confie
l'Institution à l'Université de Louvanium, actuellement
Université de Kinshasa (UNIKIN), spécialement gérée
par la Faculté de Médecine.
b. Situation Géographique
Situées sur le Mont - Amba, site universitaire, dans la
Commune de Lemba, les Cliniques Universitaires de Kinshasa occupent une
superficie de 27.110 m2. Deux voies d'accès y sont possibles :
l'avenue de l'Université et l'avenue de la Foire, au niveau du Rond-
Point Ngaba.
c. Structure et Organisation des
C.U.K
1. Structure
Actuellement, les Cliniques Universitaires de Kinshasa sont
dirigées par un Comité directeur : pour orientation et
coordination dans toutes les activités médico -
administratives.
Ce Comité est composé de :
· Médecin Directeur ;
· Médecin Directeur Adjoint ;
· Directeur Financier ;
· Directeur Administratif ;
· Directeur de Nursing ;
· Directeur de Pharmacie ;
· Directeur Technique.
2. Organisation
Les membres du Comité Directeur qui dirigent les
Cliniques Universitaires de Kinshasa sont nommés par le Recteur de
l'Université de Kinshasa.
Le Médecin Directeur qui préside le
Comité Directeur est aussi Vice - Doyen de la Faculté de
Médecine chargé des CUK. La gestion y est collégiale, sans
interférence sur l'autonomie de chaque Département médico
- technique.
3. Mission assignée aux
C.U.K
C'est une Institution médicale à
caractère social et éducatif.
Les Cliniques Universitaires de Kinshasa sont une entreprise,
elles ont une mission bien définie :
ü dispenser les soins dans le cadre de la santé
publique ;
ü les enseignements universitaires, supérieurs et
professionnels ;
ü cadre professionnel et de recyclage des stagiaires en
médecine ou autres professions de santé publique.
B.SECRET. DE DIR
B.INFORMATIQUE
B.STATISTIQUES
B.PLANIFICAT°
B.FINANCIER
B.ADMINISTRATIF
DPT MEDICAUX
(10)+ see URG
DIV.REL.PUB
DIV.GARDE
B.RENSEIGNEMENT
B.ENQUETES
B.ADMINISTRATION
B.PROTOCOLE
B.COURRIER
COMITE DIRECTEUR ELARGI
COMITE DIRECTEUR
MEDECIN DIRECTEUR
MEDECIN DIRECTEUR ADJ
DIV. CORDINAT°
(ASS. M.D)
DIV. PLAN.STR
&INFORMAT.
AUDIT INTERNE
B.SECRETARIAT
DIRECTION
ADMINISTRATIVE
DIV. DU PERS
B. GEST.ACTIFS
B.ARCHIVE DU PERS
B.REMUNERAT°
B.CONTENTIEUX
B.CONTROL PERS
B.SOCIAL
B.GEST.PASS+MED
DIV.COORD. DE STAGE
B.ENCAD.STAGE
B.FORM+SELECT
DIV.PATRIMOINE
B.ARCH.MED
B.INVENT.
DIV.HOTELLERIE
B.BUAND.
B.CUISINE
B.CAFETERIA.
DIV.APPROV
B.MAGASIN
B.ACHAT
DIRECTIONS DU NURSING
DIV.SOINS CHIR.
DIV.SOINS M.I. +RX
DIV.SOINS PED. +NUIT
DIV.SOINS ODONTOS-TS
DIV.SOINS GYN.OBS
DIV.SOINS SPECIALITE
DIV.LABO.BIOL.MED
DIV.ANESTH.REA.
DIV.SOINS MED.PYS.
B.SECRETARIAT
B.MEDICO-PHARMA
DIV.COORD.DE STAGE
B.COORD.ISTM
B.COORD.ITM
DIRECTIONS DES FINANCES
B.SECRET.
DIV.TARIF+FACT.
B.TARIFICAT°
B.FACTURAT°
DIV.BUD.CONT.
B.ORDON.
B.CONT.B.
DIV.RECOUV.
B.RECOUV.INT
B.RECOUV.EXT.
DIV.FINANCES
B.COMPT.
B.TRESOR.
B.PAIE.
DIRECTION TECHNIQUES
B.SECERT.
.
DIV.ENTRETIEN
.
B.DES TRAV.
.
B.JARDINAGE
.
B.ATELER CO
.
B.ASSAINISS
.
B.ELECTRICITE
.
B.ELECTRO-MEC
.
B.ELECTRO-MED
.
B.FROID+CLIM
.
DIVMOUVEMENT
.
B.GARAGE
.
B.TRATIF
.
B.CHARRIO+ASSU
.
B.MORGUE
.
DIRECTION DES PHARMACIE
B.SECRET.
DIV.ADM.&FIN.
B.TRS+CAIS
B.COMPT+REc
B.FACT.
DIV.PRODUCT°
B.INJECT.+SOLUT.
B.COMPT.+POM
B.G.STOCK M.
DIV.APPROV.
B.ACHATS
B.MAG.STOCK
B.OFF.VENTE
DIV.ANALYSE
B.ANAL/M.P
B.SUP.P.R
Organigramme
a. Organisation du
Départements Médico-chirurgical aux
CUK
Il s'agit de :
v Département de Chirurgie (Dpt. Chir.) ;
v Département de Médecine Interne (Dpt. M.I.) et
Nucléaire ;
v Département de Pédiatrie (Dpt.
Péd.) ;
v Département de Gynéco - Obstétrique
(Dpt G.O.) ;
v Département d'Anesthésie et Réanimation
(Dpt. Anes. Réa) ;
v Département de Biologie Clinique, médicale
(Dpt. Bioméd) ;
v Département des Spécialités
(Odontologie, Maxillo. - Faciale, Dermatologie, Ophtalmologie, ORL :
oto-rhino- laryngologie) ;
v Département de Pharmacie (Dpt, Phar) ;
v Département de Kinésithérapie (Dpt.
Kiné).
b. services présents dans le
département
ü Service de Radiologie ;
ü Service des Appareillages
Orthopédiques ;
ü Service Technique ;
ü Service de la garde universitaire (Police) ;
III.2. Cahier de charge et
spécification initiale du système
Ce travail consiste au développement d'une application
de gestion du dossier patient dans une institution hospitalière pour une
bonne prise en charge des patients. Cette application doit permettre aux
personnelles de l'hôpital de retrouver facilement la liste de tous les
patients, son parcours, les personnes qui ont exécuté un acte
pendant son passage à l'hôpital, la liste de tous le personnels
administrative et corps médicale, est aussi de faire le statistique de
patients selon des pathologies pendant une période donnée.
L'objectif principal de l'application est de faciliter la
sauvegarde des informations recueillies et produites auprès du patient
pendant son séjour à l'hôpital pour permettre de suivre son
évolution pour une prise efficace, avoir une bonne communication des
informations en interne pour améliorer la qualité de soins au
sein de l'hôpital et aussi permettre un suivis efficace de
l'évolution de patient pour assurer une amélioration de son
état.
L'application aura pour mission à long terme de servir
pour les études épidémiologiques, en classifier des
pathologies selon les critères bien déterminés par les
analystes. Cette application va aide l'hôpital à améliorer
la qualité de soins qu'il offre et à fonctionner efficacement
même en cas d'incendie car la disponibilité de donnée sera
assurée par un serveur de sauvegarde.
III.3.
Les technologies et outils utilisés
Pour la modélisation de notre système, nous
avons choisi le langage de modélisation UML dans sa version 2 toute en
choisissant quelque diagramme pour décrire efficacement notre
système.
Le choix de ce langage de modélisation a
été motivé par le fait que nous avions entrepris la
réalisation de notre système selon l'approche orienté
objet pour pouvoir tirer profil de nombreux avantages qu'il offre.
Nous avons choisi le langage de programmation php dans sa
version 7 pour sa capacité à être déployé
facilement dans un serveur d'application, sa souplesse, sa simplicité
à l'utilisation et aussi pour permettre l'accès à tous les
utilisateurs dans un simple navigateur web.
Le choix du serveur de base de données MySQL 5.5
à été motivé par le simple fait qu'il est open
source, gratuit et offre beaucoup de facilité à son utilisation
par les utilisateurs.
Le choix du serveur d'application Apache 2.5 à
été motivé par le simple fait qu'il est parmi les
meilleurs serveur d'application web libre et open source dans le monde.
III.4.
Méthode de développements
Le développement d'une application passe par
différentes phases appelés cycle de développement allant
de la spécification des besoins ou description plus ou moins exacte du
problème jusqu'à la réalisation et la mise en
fonctionnement du système.
Dans le cas de notre travail, nous allons utiliser les
méthodes agiles qui reprennent le principe du cycle en V mais avec un
séquencement itératif.
Cette méthode vise à réduire le cycle de
vie du logiciel en intégrant des évaluations des utilisateurs
durant tout le processus de développement. Il s'agit donc de
développer une version minimale, puis d'y intégrer chaque
fonctionnalité grâce à un processus itératif
basé sur une écoute client et des tests. La méthode
choisie pour notre projet est DSDM (Dynamic Software Developpment Method),
cette méthode a mis neuf principes complémentaires en avant.
Les neuf principes sont :
v Implication active des utilisateurs
v Autonomie et pouvoir de décision des
équipes
v Livraisons fréquentes
v Adéquation aux besoins des clients comme seul
critère d'acceptation du produit
v Développement itératif et
incrémental
v Modifications réversibles
v Définitions globale macroscopique des besoins
v Intégration des tests dans tout le cycle de vie
v Collaboration et coopération entre toutes les parties
prenantes.
Le cycle de vie proposé par DSDM est un cadre
général qui doit être adapté à chaque projet.
Il présente cinq étapes :
Etude de faisabilité
Etude du business
Modèle fonctionnel itératif
Mise en oeuvre
Conception et développements
itératifs
Fig.III.1. Cycle de vie DSDM
III.5.
Architecture du système
Dans le cas de notre nouveau système, nous avons
utilisé une architecture en 3 tiers.
Fig.III.2. Architecture du
système
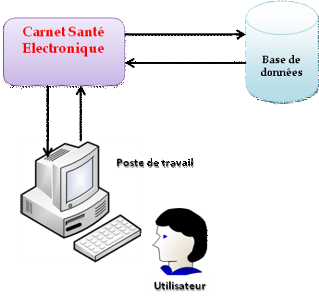
III.6.
Modélisation du système
Diagramme de cas d'utilisation
Fig.III.3. Diagramme de cas
d'utilisation
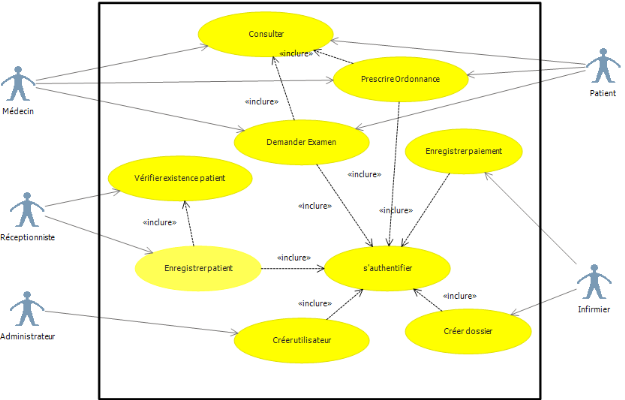
- Diagramme de classe
Durant l'analyse et la spécification du nouveau
système, nous avons pu identifier les classes suivantes :
· Patient
· Médecin
· Infirmier
· Ordonnance
· Rendez- vous
· Dossier
· Examen
· Tarif
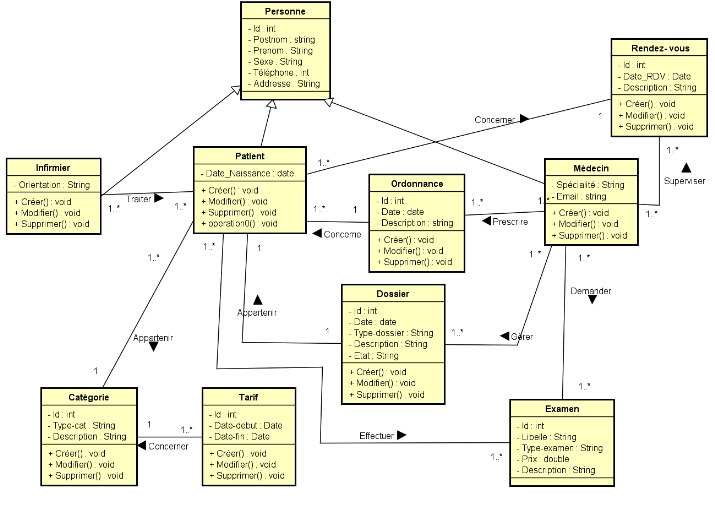
· Catégorie
· Preuve_Paiment
Fig.III.4. Diagramme de classe
- Diagramme de séquence
Le diagramme de séquence se rapportant au cas
d'utilisation « Enregistrer
patient »
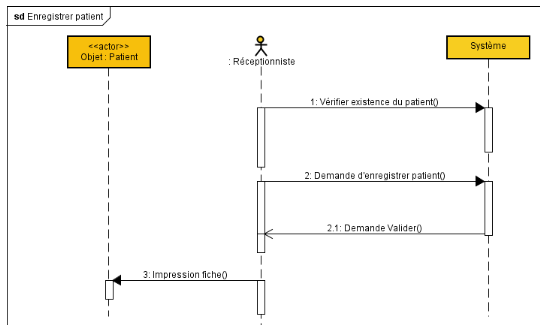
Fig.III.5. Diagramme de
séquence
Le diagramme de séquence se rapportant au cas
d'utilisation « Création dossier »
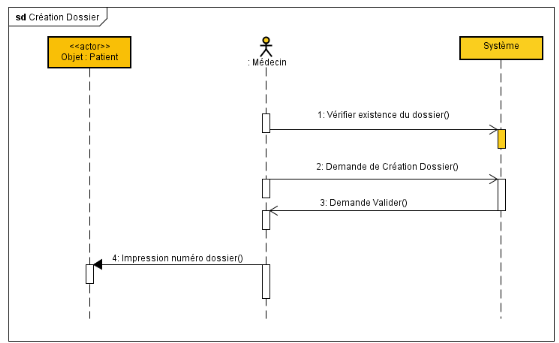
Fig.III.6. Diagramme de
séquence
- Diagramme d'activité
Enregistrer patient
Fig.III.7. Diagramme
d'activité
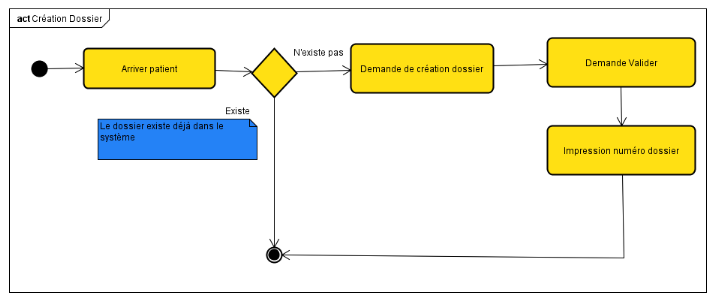
Cas d'utilisation Création Dossier
Fig.III.8. Diagramme
d'activité
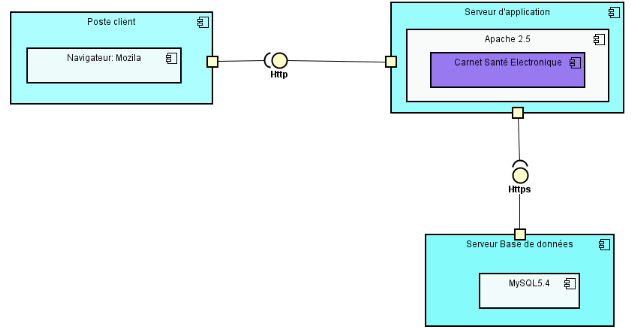
- Diagramme de composant
Fig.III.9. Diagramme de
composant
Diagramme de déploiement
Fig.III.10. Diagramme de
déploiement
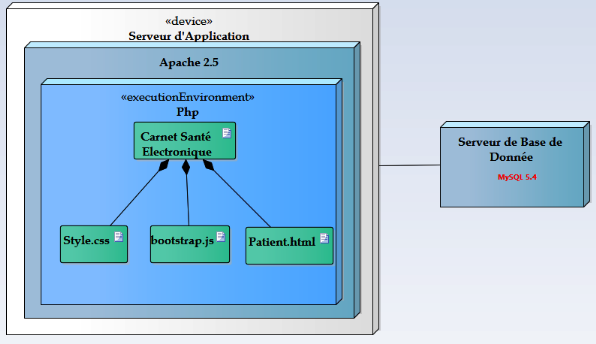
III.7. Présentation de l'application
- Interfaces
Page d'accueil du système
Fig.III.11. Page d'accueil
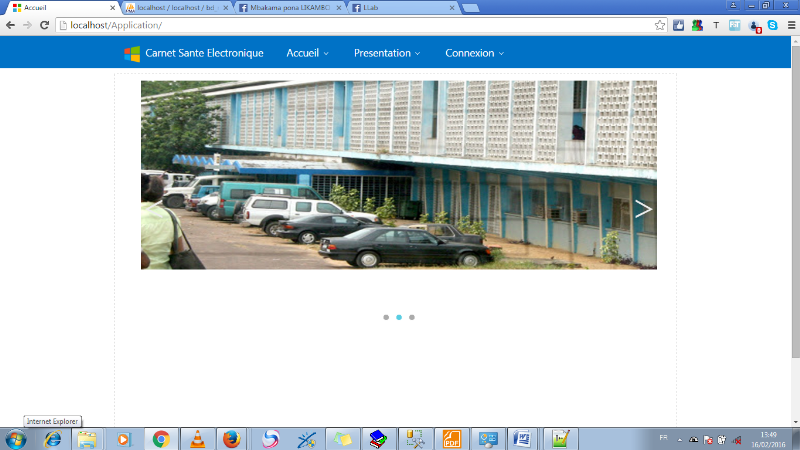
Pour permettre l'accès à l'application, il est
demandé aux utilisateurs de se connecté
Fig.III.12. Page de connexion
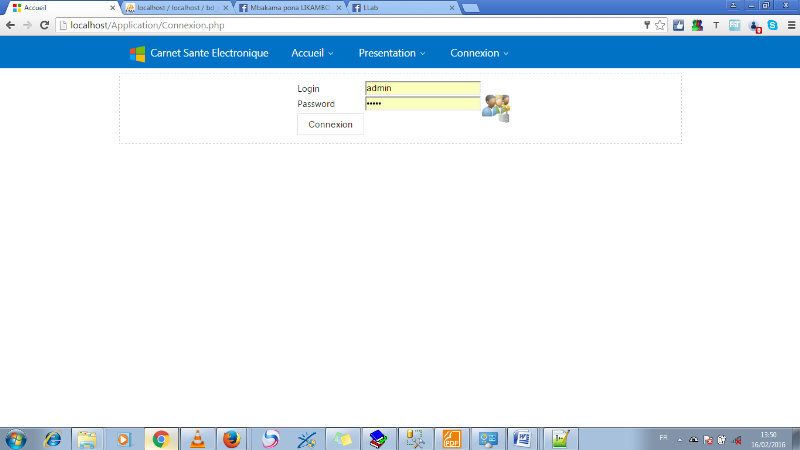
Nous avons 4 types d'utilisateurs dans notre
système :
- L'administrateur ;
- Les Médecins
- Les infirmiers
- Le réceptionniste
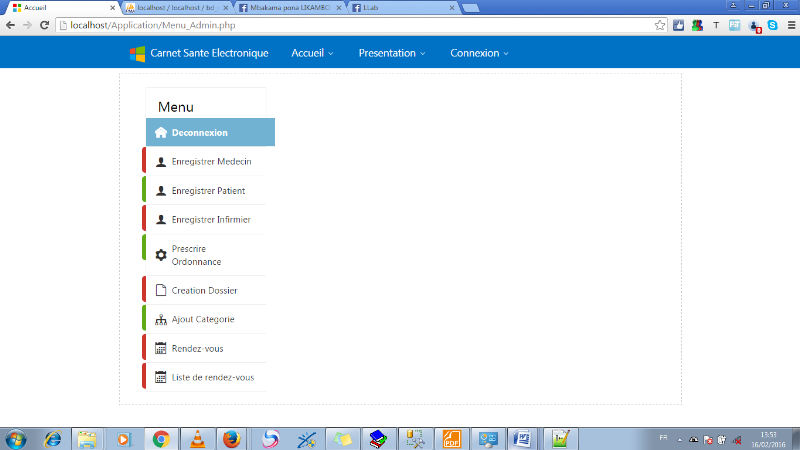
L'administrateur à doit à toutes les
fonctionnalités du système :
Fig.III.13. Menu Administrateur
En cliquant sur l'onglet Enregistrer patient nous avons cette
interface ;
Fig.III.14. Page Enregistrement Patient
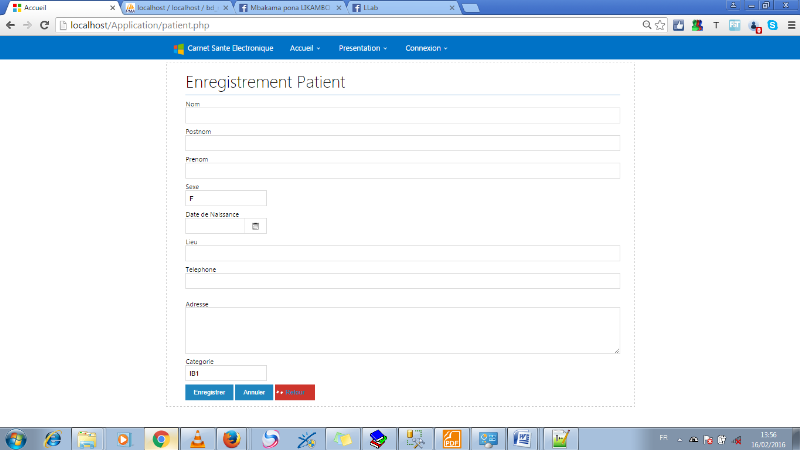
On peut revenir en arrière en cliquant sur le bouton
retour
L'admin peut voir la liste de ses rendez-vous de la
journée
Fig.III.15. Liste Rendez-vous
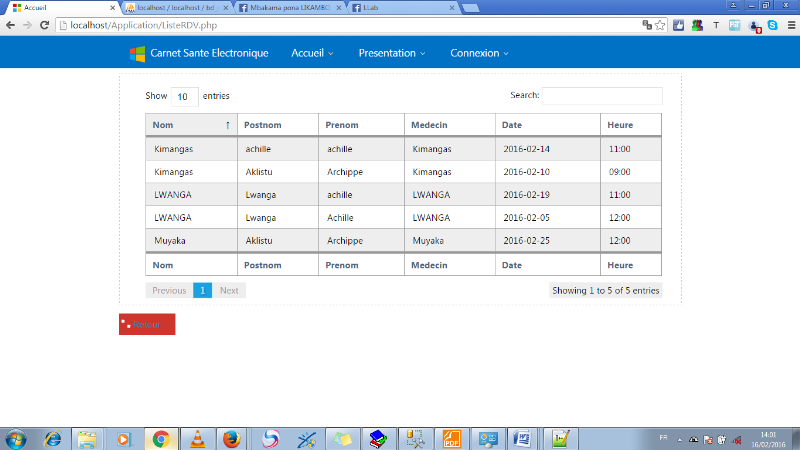
Il peut créer un Dossier patient :
Fig.III.17. Menu Médecin
Fig.III.16 Création dossier patient
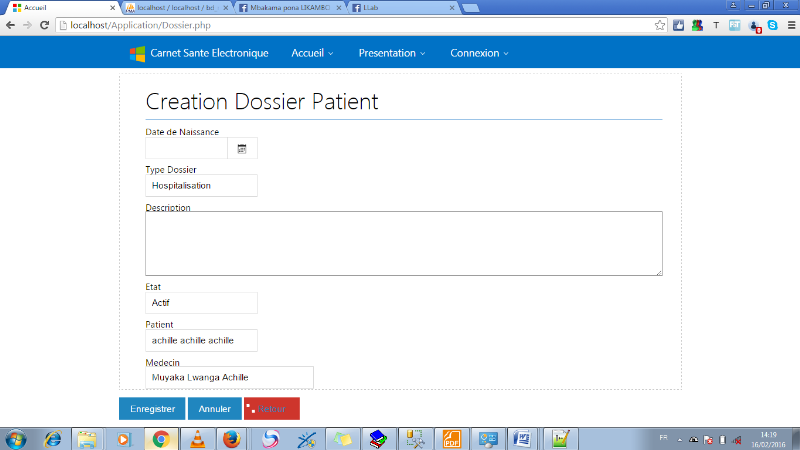
En se connectant comme médecin, nous avons 3
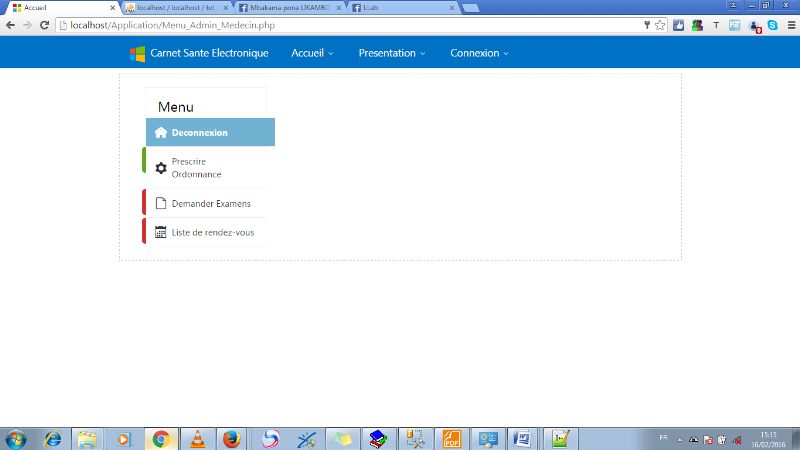
Les médecins à doit aux fonctionnalités
suivant :
- Prescrire ordonnance
- Demander les examens
- Liste de Rendez-vous
En cliquant sur prescrire ordonnance, il nous ramène
à cette interface :
Fig.III.18. Prescription Ordonnance
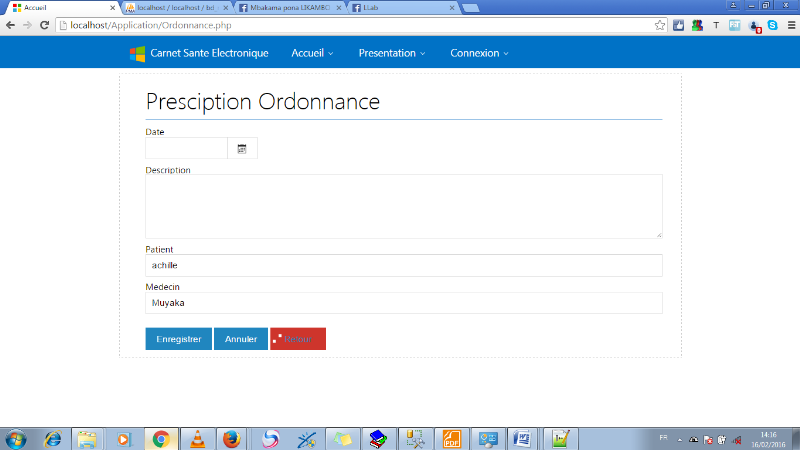
En cliquant sur Liste de Rendez-vous :
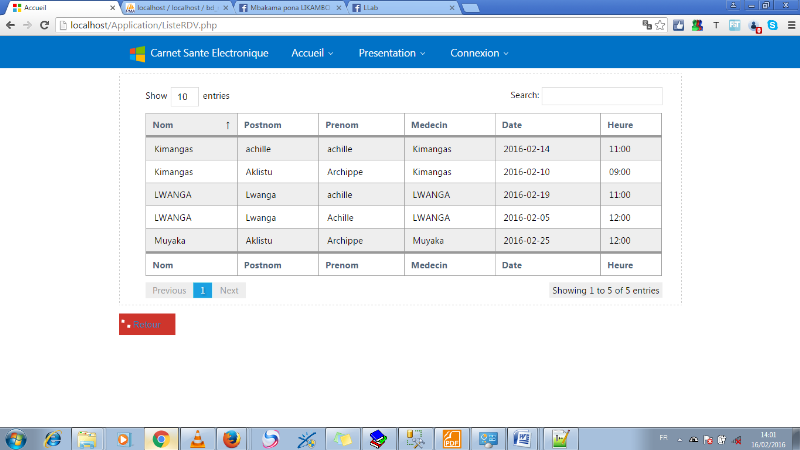
Le Réceptionniste à doit aux opérations
suivantes :
- Enregistrer le patient
- Lister les rendez-vous
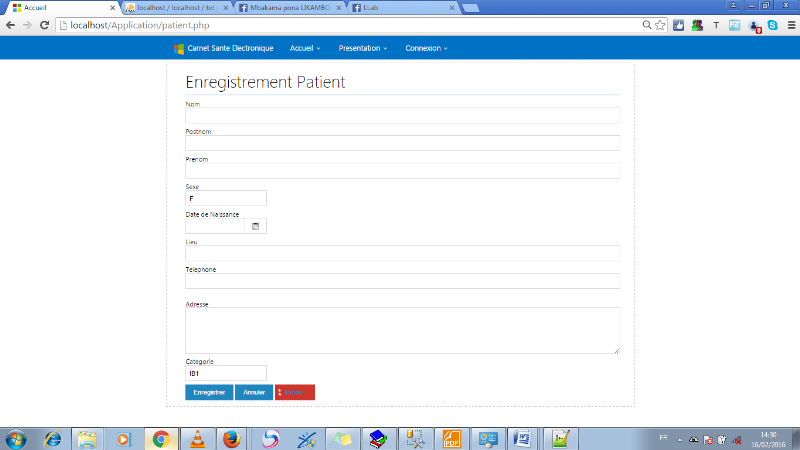
En cliquant sur liste de rendez-vous, on a cette
interface :
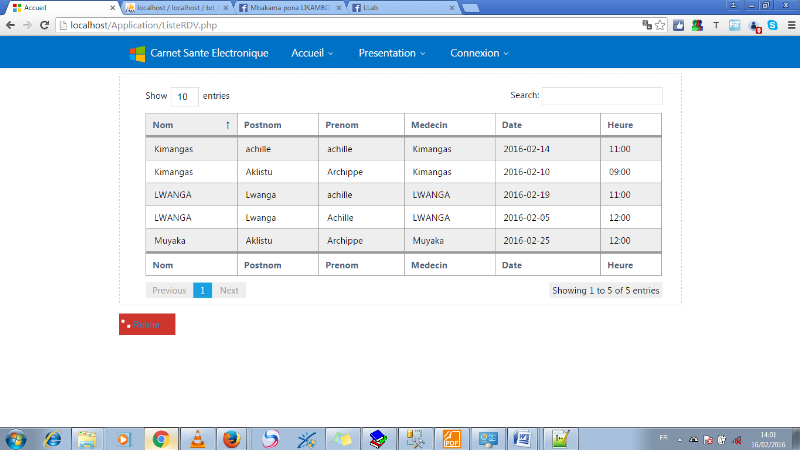
En se connectant comme infirmier, on a le menu
suivant :
Fig.III.19 Menu Infirmier
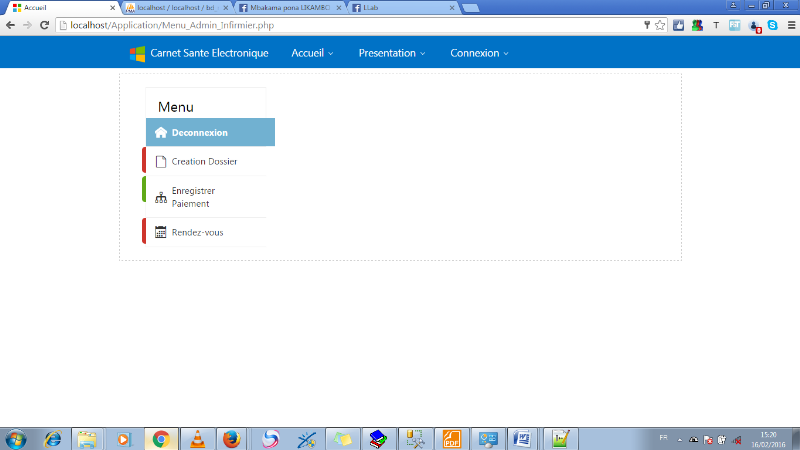
En cliquant sur création dossier, on a cette
interface :
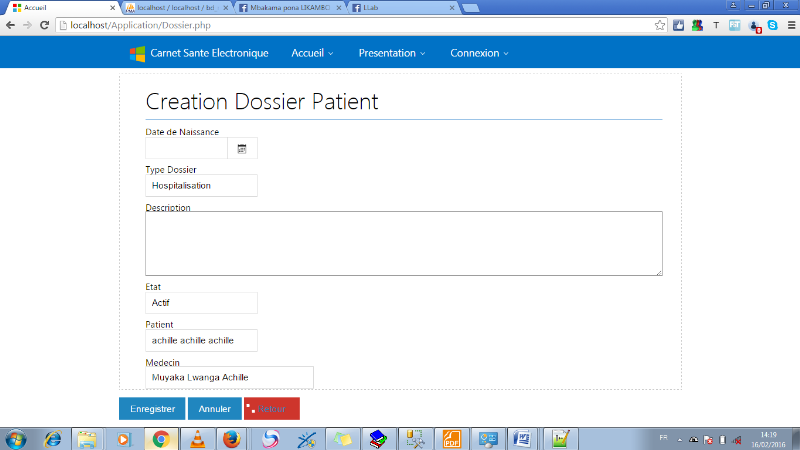
En cliquant sur Enregistrer Paiement, on a cette
interface :
Fig. III.20. Enregistrement
Patient
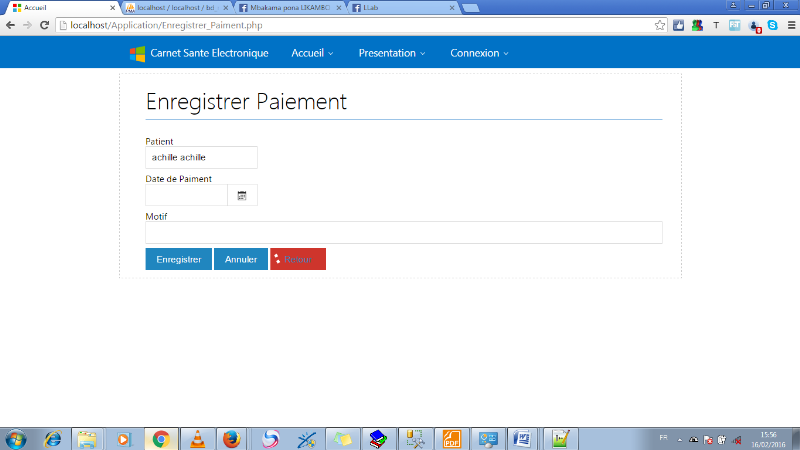
- Script de la Base de
données
CREATE DATABASE Gestion_Dossier;
CREATE TABLE `categorie` (
`Id` int(11) NOT NULL auto_increment,
`Libelle` varchar(50) NOT NULL,
`Description` varchar(200) NOT NULL,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=8 ;
CREATE TABLE `dossier` (
`Id` int(11) NOT NULL auto_increment,
`Date_dossier` date default NULL,
`type_d` varchar(43) NOT NULL,
`Description` varchar(100) NOT NULL,
`Etat` varchar(40) NOT NULL,
`Id_pat` int(11) NOT NULL,
`Id_Med` int(11) NOT NULL,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=3 ;
CREATE TABLE `examen` (
`Id` int(11) NOT NULL auto_increment,
`Description` varchar(200) NOT NULL,
`Type_examen` varchar(40) NOT NULL,
`Date_exam` date NOT NULL,
`Id_Pat` int(11) NOT NULL,
`Id_Med` int(11) NOT NULL,
`Libelle` varchar(50) NOT NULL,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
Conclusion
Générale
L'objectif de ce travail était de réaliser une
application de gestion de dossier patient aux cliniques universitaires de
Kinshasa. Il était question de mettre à terme certaines
difficultés rencontrées notamment lors de la constitution du
dossier complet du patient et de retracer tout son parcours dans
l'hôpital. Le système permet l'enregistrement de tous les
patients, ainsi que tous les documents y afférant. Nous avons remarqué que le système
existant serait la cause majeure de plusieurs morts et diagnostics
incohérents des patients et nous avons proposés le DPI pour
pallier à ces difficultés.
Un aspect intéressant
à souligner est la rapidité entre l'avancement
technologique et l'évolution des habitudes humaines. Etant
donné que la technologie avance à grands pas alors que
les habitudes humaines changent à un rythme beaucoup plus lent, le
personnel médical reste encore attaché au support papier,
même s'il est devenu exigeant face au DPI. Afin de réduire cet
écart de vitesse entre la vitesse d'évolution de la technologie
et celle des habitudes humaines, l'accent devrait être mis plutôt
sur l'aspect humain.
Le succès du DPI dépend de son
intégration totale dans la pratique courante du personnel
médical de sorte qu'il soit considéré comme un outil de
travail convivial et non pas comme une contrainte, même si parfois il
est utile de contraindre les utilisateurs à changer leurs
habitudes pour apprivoiser les outils informatiques mis à leur
disposition (par exemple la prescription médicamenteuse), car dans
certains cas le fait de ne pas vouloir changer d'habitude nous fait
évoluer très lentement ou pas du tout et ne contribue pas
à mettre la pratique médicale en conformité avec la
loi.
Référence
bibliographie
1.
Ouvrages
- [1] BENOIT CHARROUX, AOMAR OSMANI,
YANN THIERRY-MIEG, UML 2 Pratique de la Modélisation, Edition
Pearson Education France, 2009.
- [2] GABAY J., UML 2 Analyse et conception, Edition
Dunod, 2008.
- [3] JEANLUC BAPTISTE., Merise
guide Pratique, Edition Eni, Paris, 2009
- [4] ROQUES P. & VALLEE F.,
UML en Action, Ed. Eyrolles, 4ème Edition,
2007.
2. Notes de cours
- [5]
DJUNGU S., « Cours de Génie Logiciel et Construction des
Programmes », Unikin, Notes de cours, 2013.
- [6] KASORO MULENDA N., «Programmation Orienté
Objet », Unikin, Notes de cours, 2013.
- [7] MBAKI LUZAYISU E., «Analyse et Modélisation de
Système », Unikin, Notes de cours, 2015.
- [8] MBUYI MUKENDI E., « Cours de Base de données
», Unikin, Notes de cours, 2009.
3. Articles
- [9] P. DEGOULET.,
« Système d'Information Medical», Ecole
d'été Corte, 2001, 45 p
- [10] P JARNO., « Les Systèmes d'Information
Hospitaliers (SIH) et la surveillance des infections associées aux
soins», Clinique Ouest, Décembre 2012, 63 p
4. Sites Web
- [11]
http://www.wikipedia.org, Juin
2016 -Janvier 2016
- [12]
https://www.google.cd/search,
Janvier 2016- Février 2016
- [13]
http://www.cadredesante.com/spip/profession/ntic/article/la-mise-en-place-du-dossier
, Septembre 2015 
| 

