|

Aout 2025
Page | I
MINISTERE DE L'ENSEIGNEMENT SUPERIEUR ET UNIVERSITAIRE ET
DE LA RECHERCHE SIENTIFIQUE

UNIVERSITE DE KANANGA
«
UNIKAN»

Faculté Des Sciences
Informatiques
MODELISATION ET IMPLEMENTATION D'UN
SYSTÈME
DECISIONNEL POUR L'ANALYSE DE
PERFORMANCE DES AGENTS. « CAS DE LA
DIRECTION
PROVINCIALE DE LA FONCTION
PUBLIQUE KASAI CENTRAL »

Par
TSHIBUANDA TSHIMANGA Adrien JP
Mémoire rédigé et défendu en vue de
l'obtention du titre de licencié en Sciences Informatiques
Option : Conception de Systèmes
d'Information
Page | II

République Démocratique du
Congo
MINISTERE DE L'ENSEIGNEMENT SUPERIEUR, UNIVERSITAIRE ET
DE LA RECHERCHE SCIENTIFIQUE
UNIVERSITE DE KANANGA
«
UNIKAN»

Faculté Des Sciences
Informatiques

MODELISATION ET IMPLEMENTATION D'UN
SYSTÈME
DECISIONNEL POUR L'ANALYSE DE
PERFORMANCE DES AGENTS. « CAS DE
LA
DIRECTION PROVINCIALE DE LA FONCTION
PUBLIQUE KASAI CENTRAL
»

Par
Année Académique 2024 -2025
TSHIBUANDA TSHIMANGA Adrien JP
Mémoire rédigé et défendu en vue
de l'obtention du titre de licencié en Sciences Informatiques
Option Conception de Systèmes
d'Information
Directeur : Prof. Jean Didier BATUBENGA
Co-Directeur : ASS ANACLET MIANGALA

La performance ne se
devine pas, elle s'analyse,
se mesure et se décide.
Peter Drucker
Page | III
EPIGRAPHE
Page | IV
IN MEMORIAM
À la mémoire de BEYA Jonas,
décédé le 17 mars 2021. Ton souvenir demeure vivant dans
nos coeurs.
Ta gentillesse, ton sourire et ton dévouement
continuent de nous inspirer chaque jour.
Que la paix éternelle t'accompagne, et que ton
souvenir reste à jamais gravé dans nos mémoires.
Avec respect et affection.
Adrien Jean Pierre TSHIBUANDA
Page | V
DEDICACE
À mes Parents MONGAME Anny et TSHIMANGA
Théodore pour tant d'amour, sacrifices et soutient inestimable durant
tout notre parcours académique.
Que ce modeste travail vous est profondément
dédié avec tout coeur.
Adrien Jean Pierre TSHIBUANDA
Adrien Jean Pierre TSHIBUANDA
Page | VI
REMERCIEMENTS
Nous voici donc franchi une des étapes tant
rêvée dans notre vie couronnée par cette synthèse de
nos réflexions sur le thème en couverture. Selon le programme
académique régissant les études universitaires dans notre
pays, l'obtention d'un diplôme de fin du deuxième cycle est
sanctionnée par la rédaction d'un travail qui sera
présenté au jury. Qu'il nous soit permis d'exprimer notre
profonde gratitude à toutes les personnes qui de loin ou de près,
ont contribué à la réalisation de cette recherche
scientifique, et nous ont aidé, en plus à devenir des grandes
personnalités.
Nos remerciements à notre Directeur le Professeur
Jean Didier BATUBENGA pour son entière disponibilité, son aide
inestimable et ses conseils, sans lesquels ce mémoire n'aurait pu
aboutir.
Nous remercions de tout coeur le co-directeur de ce
mémoire en la personne de l'Ingénieur Anaclet MIANGALA pour ses
différentes remarques et orientations dans l'élaboration ; qu'il
trouve ici l'expression de nos sentiments de gratitude.
Nos vifs remerciements sont ensuite adressés
à toutes les autorités académiques de l'Université
de Kananga, représentées par son Recteur monsieur le Professeur
TSHISANDA NTABALA Emery de nous avoir instruits à travers ses vifs et
braves enseignants durant tout notre parcours académique à cette
chère institution.
À mes Oncles, Grands-mères et Tantes :
Angélique KUBI, Monique BUKUMBA, Jonas BEYA, tantine Aimé BAKOLE,
Victor KABASELE, Marie Josée TABANDITA, MIANDA Clémence, pour
leurs participations à notre encadrement et formation pour qu'un jour
nous puissions être ce qu'ils ont toujours envisagé en notre
personne : responsable.
Nos remerciements s'adressent à mes soeurs et
frères : Yadid André, Cécile Tshibola, Monique Bukumba,
Théoricien Tshimanga, Sandrine Kanku, Augustin Ngalamulume, Chadrack
Lobo Tshimanga Sauvé, Rose Bubanji, Tshibola Marie, Marie José
ngalula, Olga mputu, Anny Mbuyi, Nathan, Dominique SHIKAYI et José
MBUYI.
Nos sentiments de reconnaissance s'adressent aussi
à l'endroit de nos ami(e)s : Agnès Kayaya, Jérémie
Kabasele, Ben K, Simon, L Dan, Sans oublier mes Purs de MBUJI MAYI.KGA vous
êtes dans nos coeurs.
Nous remercions de tout coeur nos combattants de lutte, et
amis de la promotion, entre autres : Michel Mutombo, Ambroise kamuabu, John
Mukendi, David Ilunga, Mayombo Belvine Victorine Kapinga, Santos Sakaji,
grâce Nasandi et Léonard Diyoka.
Nos sentiments de reconnaissance vont également
à tous mes Pasteurs, à tous les choristes de la chorale
Jérusalem, à tous les fidèles de l'église
adventiste, la Bénédiction de Dieu pour leur prière. Ainsi
qu'à tous mes amis et connaissances qui de loin ou de près, ont
contribué à la réalisation de cette recherche
scientifique, et nous ont aidé, nous pensons à : Ir Boss
Man.
À tous, nous disons merci.
Page | VII
SIGLES ET ABRÉVIATIONS
BD : Base de Données
DPFP : Direction Provinciale de la Fonction Publique
DWH : Data Warehouse (Entrepôt de Données)
ETL : Extract Transform Load
KPI : Key Performance Indicator (Indicateur Clé de
Performance)
OLAP : Online Analytical Processing (Traitement Analytique en
Ligne)
RH : Ressources Humaines
SAD : Système d'Aide à la Décision
SI : Système d'Information
SID : Système d'Information Décisionnel
SIG : Système d'Information de Gestion
SQL : Structured Query Language
UML : Unified Modeling Language
Page | VIII
LISTE DES FIGURES ET TABLEAUX 4 LISTE DES
FIGURES
Figure I-1 : Architecture Générale d'un
système décisionnel
Figure II-1 architecture d'un data werahouse
Figure II-2 Data werahouse avec ETL
Figure II-3 : schéma en étoile
Figure II-5 : Exemple de schéma
multidimensionnel
Figure II-6 : Architecture d'un Data Mart
Figure III-2 Conception de diagramme de cas
d'utilisation
Figure III-1 Organigramme de la Division provinciale de la
Fonction Publique
Figure IV-1: Diagramme de classe pour l'analyse de
performance des agents
Figure IV-2 : Modèle en étoile pour l'analyse
de performance des agents
Figure IV-3 : Schéma relationnel de la base de
données
Figure IV-4 : Base de données
multidimensionnelle
Figure IV-5 : Formulaire MDI (Multiple Document
Interface)
Figure IV-6 : Formulaire d'identification de l'agent
Figure IV-7 : Formulaire d'assignation des
tâches
Figure IV-8 : Formulaire de suivi des
réalisations
Figure IV-9 : Formulaire d'analyse des performances
4 LISTE DES TABLEAUX
Tableau I-1 Différences entre un SAD et un SIG
Tableau II-1 : Différence entre SGBD et
entrepôts de données
Tableau 2 : compare les caractéristiques des
systèmes
Tableau IV-1 : Critères d'évaluation de la
performance des agents
Tableau IV-2 : Grille d'appréciation globale de la
performance des agents en
fonction du score
Tableau IV-3 : Schéma relationnel de la base de
données transactionnelle
Tableau IV-4 : Schéma multidimensionnel de
l'entrepôt de données ;
Page | 1
0. INTRODUCTION GÉNÉRALE
Dans un environnement administratif on constante
évolution, la performance des agents publics est devenue un enjeu
stratégique majeur pour assurer une gestion efficace et responsable des
services de l'État. La Direction Provinciale de la Fonction Publique,
comme toute institution publique, se doit de disposer d'outils modernes
permettant non seulement le suivi rigoureux de ses agents, mais aussi l'aide
à la prise de décision basée sur des données
fiables.
Or, la gestion manuelle des performances, encore très
répandue, limite la réactivité, la transparence et
l'objectivité dans l'évaluation des ressources humaines. C'est
dans ce contexte que les systèmes décisionnels prennent tout leur
sens. Ils permettent de transformer les données brutes issues de
l'activité quotidienne en informations stratégiques, facilitant
ainsi l'évaluation des agents, le suivi de leurs réalisations et
l'amélioration continue de la performance institutionnelle.
0.1. CHOIX ET INTÉRÊT DU SUJET
0.1.1. CHOIX DU SUJET
Le choix du présent sujet, intitulé «
Modélisation et implémentation d'un système
décisionnel pour l'analyse de performance des agents à Direction
Provinciale de la Fonction Publique », se justifie par la
nécessité d'améliorer la gestion des ressources humaines
dans l'administration publique.
En effet, la performance des agents de l'État est
souvent difficile à mesurer objectivement à cause de la
dispersion des informations, du manque d'outils informatisés fiables et
de l'absence d'indicateurs clairs. Le recours à un système
décisionnel apparaît comme une solution moderne et efficace pour
pallier ces difficultés.
0.1.2. INTÉRÊT DU SUJET
L'intérêt de ce travail est multiple :
? Il nous permet d'obtenir le grade de Licencié en
Sciences Informatiques dès qu'il est défendu et accepté
;
? Il offre à l'administration provinciale un outil
capable de centraliser les données, d'automatiser l'évaluation de
la performance et de faciliter la prise de décision.
Page | 2
? Il participe à la promotion d'une gestion
transparente et équitable des agents de la Fonction Publique,
renforçant ainsi la confiance entre l'État et ses
fonctionnaires.
0.2. ÉTAT DE LA QUESTION
Plusieurs études ont déjà montré
l'importance de l'informatisation dans la gestion des ressources humaines. Les
systèmes décisionnels (ou Data Warehouses) sont utilisés
dans de nombreuses organisations pour analyser la performance et orienter la
prise de décision. Cependant, peu de travaux se sont
intéressés spécifiquement au contexte de la Fonction
Publique provinciale en République Démocratique du Congo,
où les méthodes traditionnelles demeurent dominantes.
Quant à nous, nous allons nous basés sur «
la modélisation et l'implémentation d'un système
décisionnel pour l'analyse de performance des agents à Direction
provinciale de la fonction publique », tout en se focalisant sur l'analyse
de performance et l'évaluation du personnel de Division provinciale de
la fonction publique.
0.3. PROBLÉMATIQUE ET
HYPOTHÈSES
0.3.1. PROBLÉMATIQUE
La gestion des agents de la Fonction Publique au Kasaï
Central se fait encore de manière manuelle et dispersée. Cette
situation entraîne des difficultés telles que : lenteur dans le
traitement des dossiers, absence d'indicateurs fiables de performance, erreurs
fréquentes et manque de transparence dans les affectations.
Dès lors, plusieurs questions de recherche se posent :
1. quel système mettre en place en vue de fournir aux
décideurs des indicateurs clairs et précis sur base auxquels ils
pourront se pencher afin de prendre des décisions jugées
rationnelles, à ce qui concerne la gestion leur personnel ?
0.3.2. HYPOTHÈSES
Il est évident qu'un système décisionnel
serait une solution idéale pour répondre pour répondre
à la préoccupation ci-dessus.
1. La mise en place de ce système décisionnel
contribuerait à améliorer l'évaluation de la performance
des agents en fournissant des indicateurs clairs et fiables, et à
renforcer la prise de décision des responsables grâce à des
tableaux de bord dynamiques et des analyses multidimensionnelles.
Page | 3
0.4. MÉTHODES ET TECHNIQUES
0.4.1. MÉTHODES
Ce travail s'appuie sur une approche méthodologique
mixte :
+ Analytique, pour étudier les pratiques actuelles de
gestion des agents et identifier leurs limites ;
+ UML, pour modéliser le système à l'aide
des diagrammes UML et décrire son fonctionnement ;
+ Expérimentale, pour implémenter et tester le
système décisionnel proposé.
0.4.2. TECHNIQUES
En vue de récolter les données
nécessaires et correspondantes à notre problématique, nous
nous sommes référés aux techniques ci-dessous :
+ Technique d'interview : elle nous a servi à
interviewer les agents de la place avec une série des questions plus
détaillées et face auxquelles des réponses nous ont
été données et ont aidé à
l'élaboration de ce mémoire ;
+ Technique d'observation : cette dernière nous a
permis quant à elle d'observer le déroulement des
activités faisant l'objet de notre étude.
0.5. OBJECTIF DE LA RECHERCHE
L'objectif général est de concevoir et
d'implémenter un système décisionnel permettant d'analyser
et d'améliorer la performance des agents de la Fonction Publique
provinciale.
De manière spécifique, il s'agit de :
+ Centraliser les données relatives aux agents dans un
entrepôt de données ;
+ Définir des indicateurs pertinents de performance ;
+ Automatiser l'évaluation à travers un
algorithme et des tableaux de bord ;
+ Faciliter la prise de décision grâce à
des rapports fiables et rapides.
Page | 4
0.6. DÉLIMITATION DE LA RECHERCHE
La présente étude se limite à la
Direction Provinciale de la Fonction Publique du Kasaï Central,
située dans la ville de Kananga. Elle se concentre uniquement sur les
aspects liés à l'analyse de la performance des agents, sans
aborder d'autres dimensions de la gestion publique (finances, infrastructures,
etc.).
Dans le temps : notre étude va de janvier au mois
août 2025.
0.7. SUBDIVISION DU TRAVAIL
Outre l'introduction générale et la conclusion,
ce mémoire est structuré en quatre chapitres :
Chapitre I : Généralités sur le
système décisionnel ;
Chapitre II : Data Warehouse ;
Chapitre III : Analyse préalable et spécification
des besoins ;
Chapitre IV : Conception et implémentation du
système décisionnel.
Page | 5
CHAPITRE I : GÉNÉRALITÉS SUR LE
SYSTÈME DÉCISIONNEL
1.0. INTRODUCTION
Toute entreprise qui veut atteindre des performances est
censée prendre des décisions rationnelles en se basant sur un
système décisionnel. La faillite de bon nombre d'entreprises est
due au manque d'un personnel qualifié, à une mauvaise gestion et
à une prise de décisions non adéquate.
1.1 DÉFINITION DU SYSTÈME
DÉCISIONNEL
Un système décisionnel est un ensemble de
processus et d'outils technologiques permettant aux décideurs d'analyser
des données et d'en tirer des conclusions pour prendre des
décisions stratégiques et opérationnelles. Dans le cadre
de l'analyse de la performance des agents de la fonction publique, un
système décisionnel permet de collecter, traiter et analyser des
données relatives aux agents afin de fournir des indicateurs de
performance et des recommandations pour une gestion plus efficace.
Le système décisionnel peut être
intégré dans des outils de Business Intelligence (BI), qui
utilisent des techniques de collecte de données, de traitement, et de
visualisation pour aider les décideurs à mieux comprendre les
tendances et à prendre des décisions éclairées.
Un système décisionnel permet de
répondre aux questions suivantes :
? Que s'est-il passé ? (Tableau de bord) ;
? Pourquoi cela s'est-il passé ? (Analyse) ;
? Que va-t-il se passé ? (Prédiction) ;
? Que se passe-t-il en ce moment ? (Aide opérationnelle)
;
? Que devrait- il se passer ou que faire ? (Prise de
décision).
1.1.1 ARCHITECTURE DE SYSTÈMES
DÉCISIONNELS1
L'architecture générale d'un système
décisionnel se décompose en trois processus : extraction et
intégration, organisation et interrogation.
Le processus d'extraction et intégration, situé
les sources de données et l'entrepôt est responsable de
l'identification des données dans les
1 Dihia LANASRI, AI et Data analytics
Manager,2015, P.10
Page | 6
diverses sources internes et externes dans l'extraction de
l'information et de la préparation et de la transformation (nettoyage,
filtrage, etc..) des données à l'intérieur de
l'entrepôt, nous trouvons le processus d'organisation. Il est responsable
de la structuration des données par rapport à leur niveau de
granularité (agrégats).
Différents outils permettent de réaliser
l'analyse des données, pour les différents utilisateurs de
l'entreprise.
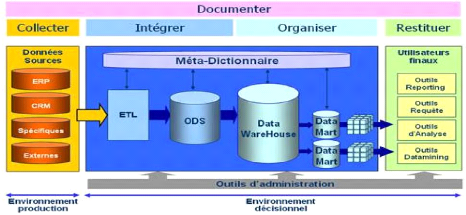
Figure I-1 : Architecture Générale d'un
système décisionnel
Les sources de données sont nombreuses, variées,
distribuées et autonomes. Elles peuvent être internes (bases de
production) ou externes (Internet, bases des partenaires) à
l'entreprise.
L'entrepôt de données est le lieu de stockage
centralisé des informations utiles pour les décideurs. Il met en
commun les données provenant des différentes sources et conserve
leurs évolutions.
Les magasins de données sont des extraits de
l'entrepôt orientés sujet. Les données sont
organisées de manière adéquate pour permettre des analyses
rapides à des fins de prise de décision.
Les outils d'analyse permettent de manipuler les
données suivant des axes d'analyses. L'information est visualisée
au travers d'interfaces interactives et fonctionnelles dédiées
à des décideurs souvent non informaticiens (directeurs, chefs de
services, ...).
Page | 7
1.2 OBJECTIFS PRINCIPAUX D'UN SYSTEME DECISIONNEL DANS LE
CADRE DE LA GESTION PUBLIQUE.
Dans le cadre de la gestion publique, un système
décisionnel (ou système d'information décisionnel) vise
à optimiser les processus de décision en fournissant des
informations fiables, précises et pertinentes. Voici les objectifs
principaux d'un tel système dans ce contexte :
1.2.1 Améliorer la prise de décision
Un système décisionnel permet aux responsables
de la gestion publique de prendre des décisions éclairées
en se basant sur des données objectives et des analyses précises
plutôt que sur des impressions ou des conjectures. Cela permet de mieux
orienter les politiques publiques, les stratégies de gestion des
ressources humaines et la répartition des budgets.
1.2.2 Optimiser la gestion des ressources humaines
Dans le cadre de la gestion publique, un système
décisionnel peut aider à :
> Suivre la performance des agents de la fonction publique
en temps réel (productivité, absences, évaluations,
etc.).
> Identifier les besoins de formation ou de
perfectionnement pour les agents.
> Gérer les carrières et les promotions sur
la base de critères objectifs et d'indicateurs de performance.
> Favoriser la transparence dans les processus
d'évaluation des agents, réduisant ainsi les risques de
partialité ou de favoritisme.
1.2.3 Favoriser la transparence et la
responsabilité
La gestion publique nécessite un niveau
élevé de transparence. Un système décisionnel
permet de :
> Suivre l'utilisation des ressources publiques
(financières, humaines, matérielles) de manière
détaillée et claire.
> Vérifier la conformité des décisions
avec les réglementations en vigueur et les objectifs de la politique
publique.
> Offrir des rapports clairs et accessibles à la
direction, aux citoyens et aux parties prenantes, ce qui renforce la
responsabilité des gestionnaires publics.
Lors de crises (économiques, sanitaires,
sécuritaires, etc.), un système décisionnel peut
être crucial pour :
Page | 8
1.2.4 Support à la planification et à la
prévision
Un système décisionnel permet de réaliser
des analyses prédictives et des simulations pour anticiper les besoins
futurs, par exemple :
V' Prévoir l'évolution des besoins en
personnel (recrutement, départs à la retraite, mutations,
etc.).
V' Prévoir l'impact des politiques publiques sur
des indicateurs sociaux, économiques ou environnementaux.
V' Identifier des zones de risque (financier, humain,
opérationnel) et proposer des mesures préventives.
1.2.5 Améliorer la gestion financière
Dans un environnement public, la gestion budgétaire est
un défi majeur. Un système décisionnel aide à :
V' Suivre les dépenses publiques et à
analyser l'utilisation des budgets dans différents départements
ou projets.
V' Identifier les zones de gaspillage et les
inefficacités dans l'utilisation des fonds publics.
V' Fournir des rapports détaillés pour
soutenir la prise de décisions financières concernant
l'allocation des ressources.
1.2.6 Faciliter la gestion des projets publics
Les projets publics impliquent souvent plusieurs parties
prenantes et ressources à gérer. Un système
décisionnel permet de :
> Suivre l'avancement des projets publics en temps
réel.
> Assurer un suivi des délais et des budgets
des projets en cours.
> Identifier les risques ou les retards qui
pourraient affecter la réalisation des projets et mettre en place des
mesures correctives rapidement.
1.2.7 Soutenir la gestion des crises et des situations
exceptionnelles
2 EFRAIM TURBAN Et JAY E. ARONSON, Decision
Support Systems and Intelligent Systems, Ed.7è, 2005, P.33
Page | 9
V' Analyser rapidement les données relatives
à la crise et à son évolution.
V' Aider à coordonner les actions des
différentes entités publiques impliquées
(ministères, collectivités locales, etc.).
V' Fournir des recommandations immédiates pour
minimiser les impacts de la crise et optimiser la gestion des ressources
allouées à la gestion de la situation.
1.2.8 Renforcer la coopération
interinstitutionnelle
Dans le cadre de la gestion publique, de nombreuses agences et
institutions interagissent. Un système décisionnel favorise :
V' La centralisation de l'information provenant de
différentes sources (agences locales, ministères, etc.) pour
obtenir une vue d'ensemble.
V' Le partage de données et la coordination
des actions entre les institutions, ce qui permet d'améliorer
l'efficacité collective des politiques publiques.
1.2.9 Améliorer la qualité des services
publics Les systèmes décisionnels aident à :
V' Analyser la satisfaction des citoyens
vis-à-vis des services publics fournis (éducation, santé,
sécurité, etc.).
V' Identifier les domaines d'amélioration dans
la prestation des services publics et prendre des mesures correctives.
V' Suivre les résultats des réformes
administratives ou des changements dans la manière de fournir des
services publics.
1.3 DIFFERENCE ENTRE UN SYSTEME D'AIDE À LA DECISION
(SAD) ET UN SYSTEME D'INFORMATION DE GESTION (SIG).
Un système d'aide à la décision (SAD) et
un système d'information de gestion (SIG) sont deux types de
systèmes informatiques qui aident les organisations à prendre des
décisions et à gérer les informations de manière
plus efficace. Bien qu'ils aient des objectifs complémentaires, ils
jouent des rôles distincts dans la gestion d'une organisation. 2
Page | 10
1.3.1 Système d'Aide à la Décision
(SAD)
Un Système d'Aide à la Décision (SAD) est
un ensemble de processus, de technologies et d'outils utilisés pour
soutenir les décideurs dans la prise de décisions complexes. Les
SAD sont particulièrement utiles lorsqu'il s'agit d'analyses
basées sur des données et des scénarios multiples.
I Objectifs d'un SAD :
? Analyser des données complexes :
Le SAD est conçu pour traiter de grandes
quantités de données provenant de différentes sources afin
d'aider les décideurs à comprendre des phénomènes
complexes et à prendre des décisions stratégiques.
? Faciliter les prévisions :
Un SAD aide à la prévision et à la
simulation de différents scénarios basés sur des tendances
passées ou des modèles statistiques.
? Améliorer la prise de décision :
En fournissant des rapports, des tableaux de bord, des
graphiques et des analyses, le SAD soutient les gestionnaires en leur
permettant de prendre des décisions basées sur des faits et non
sur des intuitions.
? Gérer l'incertitude :
Lors de la prise de décision, le SAD peut gérer
des éléments d'incertitude et de risque en simulant
différents scénarios et en offrant des options possibles.
Exemples de SAD dans le secteur public :
I Dans une direction provinciale de la fonction publique, un
SAD peut être utilisé pour analyser la performance des agents,
identifier les besoins en formation, ou optimiser les ressources humaines en
fonction des projets à venir.
Page | 11
1.3.2 Système d'Information de Gestion (SIG)3
Un Système d'Information de Gestion (SIG) est un
système qui aide à la gestion des opérations quotidiennes
d'une organisation en facilitant la collecte, le stockage, le traitement et la
distribution de l'information. Il soutient la gestion opérationnelle et
tactique et se concentre principalement sur les informations qui sont
essentielles pour les processus administratifs et logistiques
internes.4
? Objectifs d'un SIG :
? Collecter et organiser les données : Un SIG
centralise les données opérationnelles provenant des
différents services (ressources humaines, finance, etc.) pour en
faciliter l'accès et l'exploitation.
? Automatiser les processus internes : Un SIG aide à
automatiser des tâches courantes, comme la gestion des dossiers des
agents, le suivi des dépenses, ou l'enregistrement des performances.
? Soutenir la gestion quotidienne : Contrairement au SAD qui
est plus axé sur la décision stratégique, le SIG soutient
la gestion quotidienne de l'organisation en fournissant des outils pour
gérer les opérations, comme la comptabilité, la
planification, les ressources humaines et la gestion des stocks.
? Optimiser l'efficacité : En réduisant la
duplication des efforts et en rationalisant les processus, un SIG aide à
améliorer l'efficacité des opérations.
1.3.3 Composants principaux d'un SIG :
1. Base de données : Contient toutes les informations
relatives à la gestion quotidienne de l'organisation.
2. Module d'application : Permet de gérer
différentes fonctions comme la gestion des ressources humaines, la
gestion des finances, la logistique, etc.
3. Interface utilisateur : Permet aux employés de
saisir et d'extraire des informations à partir du système.
3 R SHARDA, D DELEN, E TURBAN, Business
intelligence: a managerial perspective on analytics, Ed. Third 2014,
P. 37-42
4 C. LAUDON et JANE P. LAUDON, Management
information systems: managing the Digital Firm Ed.seventeenth, 2008,
P.122.
Page | 12
4. Outils de gestion : Ces outils permettent de suivre les
opérations, de générer des rapports et de prendre des
décisions opérationnelles. 1.3.4 Différences entre
un SAD et un SIG5
|
CRITERE
|
SYSTEME D'AIDE A LA
DECISION (SAD)
|
SYSTEME D'INFORMATION DE GESTION (SIG)
|
|
Objectif principal
|
Aider à la prise de décision stratégique et
tactique
|
Gérer les opérations
quotidiennes et le
fonctionnement interne
|
|
Type de données traitées
|
Données analytiques et
stratégiques
|
Données opérationnelles,
administratives et
fonctionnelles
|
|
Utilisation
|
Décisions complexes et
analyses de scénarios
multiples
|
Gestion de l'information
quotidienne, gestion des
tâches
opérationnelles
|
|
Orientation temporelle
|
À long terme, avec des
prévisions et des projections
|
À court et moyen terme, orienté vers les
activités quotidiennes
|
|
Exemple
|
Prise de décision sur
l'allocation des ressources
humaines, prévisions
budgétaires
|
Suivi des heures de travail des agents, gestion des
dépenses quotidiennes
|
|
Composants principaux
|
Outils d'analyse, bases de
données décisionnelles,
rapports interactifs
|
Applications de gestion, bases
de données opérationnelles,
outils de suivi
|
Tableau I-1 Différences entre un SAD et un SIG6
1.3.5 Relation entre un SAD et un SIG
Un SAD et un SIG peuvent être utilisés de
manière complémentaire dans une organisation. Tandis que le SIG
permet de gérer les opérations quotidiennes et d'assurer le bon
fonctionnement de l'administration, le SAD permet d'exploiter les
données provenant du SIG pour effectuer des analyses
stratégiques. Par exemple :
? Un SIG collectera des données sur les performances
des agents, les budgets alloués et les tâches accomplies.
? Un SAD prendra ces données et effectuera des
analyses, des simulations ou des prévisions pour aider à la
réallocation des
5 Laudon, K. C., & Laudon, J. P., Management
Information Systems: Managing the Digital Firm 15e Edition,
2018.
6 Laudon, K. C., & Laudon, J. P., Management
Information Systems: Managing the Digital Firm 15e Edition,
2018.
Les principales fonctions d'un système
décisionnel dans la gestion des ressources humaines sont les suivantes
:
Page | 13
ressources, à la formation des agents, ou à
l'optimisation des performances.
Le Système d'aide à la Décision (SAD) est
utilisé pour prendre des décisions stratégiques complexes
à partir de données analytiques et des prévisions, tandis
que le Système d'information de Gestion (SIG) soutient la gestion des
processus administratifs et opérationnels quotidiens.
1.3.6 Types de systèmes décisionnels
:
? Système d'Information Décisionnelle (SID) : Un
SID regroupe des technologies, des processus et des outils permettant de
traiter des données pour faciliter la prise de décision.
? Système de Support à la Décision (DSS)
: Un DSS est un système interactif qui permet de soutenir les prises de
décision complexes en analysant de grandes quantités de
données.
1.4 COMPOSANTS D'UN SYSTEME DECISIONNEL
Un système décisionnel efficace se compose
généralement de plusieurs éléments :
1. Sources de données : Les
données brutes provenant de différentes sources qui alimenteront
le système.
2. Système d'intégration des
données : La manière dont les données sont
collectées, intégrées et nettoyées pour être
utilisées efficacement.
3. Base de données décisionnelle :
Un entrepôt de données (Data Warehouse) qui permet de
stocker et d'organiser les informations historiques et actuelles.
4. Outils d'analyse : Des outils permettant
de traiter et d'analyser les données (ex. : SQL, Python, R, Tableau,
Power BI).
5. Interface utilisateur : La plateforme
où les gestionnaires et responsables RH peuvent accéder aux
informations et visualiser les résultats des analyses (rapports,
graphiques, tableaux de bord).
1.5. LES FONCTIONNALITÉS D'UN SYSTÈME
DÉCISIONNEL
Page | 14
? Collecte et stockage des données :
Le système recueille des données relatives aux
agents (par exemple, évaluations de performance, absences, formations
suivies).
? Traitement des données :
Il traite les données pour en extraire des informations
pertinentes sur la performance des agents.
? Analyse et visualisation des données :
Le système permet d'effectuer des analyses
statistiques, de générer des rapports et des graphiques
permettant aux responsables RH de mieux comprendre la performance des
agents.
? Prise de décision :
Sur la base des informations analysées, le
système fournit des recommandations ou alertes pour améliorer la
gestion des agents.
1.6 LES DIFFÉRENTS ÉLÉMENTS
CONSTITUTIFS DU SYSTÈME DÉCISIONNEL
1.6.1 Les sources de données :
Les sources de données sont souvent diverses et
variées et le but est de trouver des outils et en fin de les extraire,
de les nettoyer, de les transformer et de les mettre dans l'entrepôt de
données. Ces sources de données peuvent être de fichiers de
type Excel, des bases de données opérationnelles d'une entreprise
ou fichiers plats.
1.6.2 L'entrepôt de données :
Il est le coeur du système décisionnel et
demande une analyse profonde de la part de maitre d'ouvrage.
La conception d'un data Waterhouse diffère de la
conception d'une base de données relationnelles.
En effet, alors que les bases de données relationnelles
tendant le plus souvent à être normalisées, les bases des
données multidimensionnelles, elles sont normalisées en
respectant le modèle en étoile ou en flocon.7
7 Bertino E., Ferrari E., Guerrini G., Merlo I.,
"Extending the ODMG Object Model with Composite Objects", OOPSLA'98,
Vancouver (Canada), 1998, p.56
Page | 15
1.6.3. Le service OLAP ou serveur d'analyse
Le serveur OLAP est opposé à OLTP et a pour but
d'organisé les données à analyser par domaine ou par
thème et d'en ressortir des résultats pertinents pour le
décideur. Les résultats sont obtenus par différents
algorithmes de datamining (fouille de données) du serveur d'analyse. Ces
résultats peuvent amener l'organisation à prendre de très
bonnes décisions en vue d'améliorer le rendement de leurs
entreprises.
1.7 LES SOURCES DE DONNÉES DANS UN SYSTÈME
DÉCISIONNEL
Les données utilisées dans un système
décisionnel proviennent de diverses sources internes et externes
à l'organisation. Dans le cadre de l'analyse de la performance des
agents à la direction provinciale de la fonction publique, les sources
de données peuvent inclure :
1.7.1 Sources internes
1. Systèmes de gestion des ressources humaines
(SIRH) :
Ce sont des logiciels qui gèrent toutes les
données relatives aux employés, comme les dossiers des agents,
les évaluations de performance, les historiques de formation, et les
absences. Ces informations sont cruciales pour le suivi des performances des
agents au quotidien.
2. Rapports de performance :
Les évaluations annuelles de performance, les rapports
de superviseurs et les auto-évaluations des agents permettent de
collecter des informations qualitatives et quantitatives sur la performance
individuelle.
3. Système de gestion des congés et
absences :
Ce système enregistre toutes les absences des agents
(congés, maladies, retards), qui peut être un indicateur
clé de la performance d'un agent, en particulier pour évaluer son
assiduité et son engagement.
4. Données salariales :
Les informations relatives à la
rémunération, aux primes et aux avantages sociaux des agents
peuvent également faire partie du système décisionnel. Ces
données peuvent être croisées avec les performances pour
déterminer si la rémunération est proportionnelle à
la performance.
Page | 16
5. Système de gestion des formations :
Les données liées aux formations suivies par les
agents sont importantes pour évaluer les compétences acquises et
leur impact sur les performances professionnelles. La gestion des
compétences et de la formation continue est un facteur essentiel pour
l'amélioration de la performance des agents.
1.7.2 Sources externes
1. Données sectorielles et comparatives :
Les comparaisons avec d'autres directions provinciales ou
d'autres institutions publiques permettent d'avoir une vision comparative des
performances. Ces données peuvent provenir d'enquêtes
sectorielles, de rapports gouvernementaux ou d'études de
benchmarking.
2. Normes et standards externes :
Les indicateurs de performance (KPI) peuvent aussi être
influencés par des normes externes, telles que les directives de la
fonction publique, les lois sur la gestion des ressources humaines, et les
meilleures pratiques dans le secteur public.
3. Sondages de satisfaction des citoyens :
Les enquêtes de satisfaction des citoyens ou des usagers
peuvent fournir des données externes sur la qualité du service
fourni par les agents, ce qui peut être un indicateur indirect de leur
performance.
1.7.3 Intégration des sources de données
Le système décisionnel doit être capable
de collecter, intégrer et structurer les données provenant de ces
différentes sources de manière cohérente. Cela
nécessite une intégration des systèmes (par exemple, SIRH,
outils de gestion des congés) et l'utilisation de bases de
données centralisées qui stockent et organisent ces informations
pour les rendre accessibles et utilisables.
1.8 AVANTAGES D'UN SYSTÈME DÉCISIONNEL DANS
LA GESTION DE LA PERFORMANCE DES AGENTS
Un système décisionnel bien conçu
présente plusieurs avantages pour l'analyse de la performance des
agents, notamment :
Page | 17
1. Objectivité dans l'évaluation des
performances : En utilisant des données et des indicateurs
quantifiables, le système permet d'avoir une évaluation plus
objective et plus précise des performances des agents.
2. Suivi de la progression : Il permet de suivre les
performances des agents dans le temps et de détecter les
évolutions (améliorations ou détériorations), ce
qui facilite les ajustements dans la gestion des ressources humaines.
3. Optimisation de la prise de décision : Les
responsables RH peuvent prendre des décisions éclairées en
utilisant les rapports générés par le système,
qu'il s'agisse de promotions, de formations, ou d'actions correctives pour
améliorer la performance des agents.
4. Amélioration continue : Grâce à une
collecte et une analyse régulières des données, le
système favorise l'amélioration continue de la gestion des
ressources humaines, en fournissant des données concrètes sur
lesquelles baser les futures actions.
I.9. LES APPORTS DES SYSTÈMES
DÉCISIONNELS
Dans beaucoup de nos entreprises ; il est difficile
d'expliquer aux dirigeants que l'on doit parfois dépenser beaucoup
d'argent pour analyser et manipuler des données existant dans le
système d'information de l'entreprise8.
Les apports de systèmes décisionnel sont aussi
défais réels. Ils peuvent être classés en deux
catégories.
? L'amélioration de l'efficacité de la
communication et de la distribution des informations de pilotage ;
? L'amélioration du pilotage des entreprises
résultant de meilleures décisions à prendre plus
rapidement ;
Si le premier point est aisément compréhensible,
présente peu de risque de mise en oeuvre et pose peu de problème
d'évaluation ce n'est clairement pas en revanche une source de gains
significative. Il sera difficile le plus souvent de justifier les couts d'un
projet sur cette seule promesse.
La seconde catégorie a nettement plus de potentiel de
gains. Mais il faut bien reconnaitre que le risque de ne pas atteindre les
objectifs initiaux
8 S. Kelly, John Wiley & Sons « Data
Warehousing - The Route to Mass Customization », 1996, p.13.
Page | 18
sont réels sans parler d'énormes
difficultés d'évaluation des bénéfices
escomptés.
Les bénéfices de ce type le plus souvent
cités sont les suivants :
V' Unicité des chiffres, une seule
vérité acceptée par tous ;
V' Meilleure planification ;
V' Amélioration de la prise de décision
;
V' Amélioration de l'efficacité des
processus ;
V' Amélioration de la satisfaction des clients et
des fournisseurs ;
V' Amélioration de la satisfaction des
employés.
1.10 LES ENJEUX DE L'INFORMATIQUE DÉCISIONNELLE
De nos jours, les données applicatives métier
sont stockées dans une ou plusieurs bases de données
relationnelles ou non relationnelles. Ces données sont extraites,
transformées et chargées par un outil de type ETL.
Un entrepôt de données (data Waterhouse) peut
prendre la forme d'un data Mart. En règle générale, le
data Waterhouse globalise toutes les données applicatives de
l'entreprise tandis que les data Marts, généralement
alimentés à partir des données du data Waterhouse sont des
sous-ensembles d'information concernant un métier particulier de
l'entreprise.
1.11 LES FONCTIONS ESSENTIELLES DE
L'INFORMATIQUE
DÉCISIONNELLE
Un système d'information décisionnel assure
quatre fonctions fondamentales, à savoir : la collecte,
l'intégration, la diffusion et la présentation des
données. A ces quatre fonctions s'ajoute une fonction de contrôle
du système d'information décisionnelle lui-même,
l'administration.9
a) Collecte
La collecte est l'ensemble des taches consistant à
détecter, sélectionner, extraire et à filtrer les
données brutes issues des environnements pertinents compte tenu du
périmètre du système d'information décisionnel
(SID).
9 Bret F., Teste O., "Construction Graphique
d'Entrepôts et de Magasins de Données", INFORSID'99, La Garde
(France), Juin 1999.
10 Chaudhuri S., Dayal U., "An Overview of Data
Warehousing and OLAP Technology", ACM SIGMOD Record, 26(1), 1997, p.112
Page | 19
b) Intégration
L'intégration consiste à concentrer les
données collectées dans un espace unifié, dont le socle
informatique essentiel est l'entrepôt.
Élément central du dispositif, il permet aux
applications décisionnelles de bénéficier d'une source
d'information commune, homogène, normalisée et fiable,
susceptible de masquer la diversité de l'origine des données.
Une synchronisation (d'intégrer en même temps ou
à la même date de valeur des événements reçus
ou constatés de manière décalée ou
déphasée).
c) La diffusion ou la distribution
L'objectif prioritaire est de segmenter les données en
contextes informationnels fortement cohérents, simples à utiliser
et correspondant à une activité décisionnelle
particulière.
Très souvent, un contexte de diffusion est
multidimensionnel, c'est-à-dire modélisable sous la forme d'un
hyper cube, il peut alors être mis à disposition à l'aide
d'un outil OLAP.10
d) Présentation
Cette quatrième fonction, la plus visible pour
l'utilisateur, régit les conditions d'accès de l'utilisateur aux
informations. Elle assure le fonctionnement du poste de travail, le
contrôle d'accès, la prise en charge des requêtes, la
visualisation des résultats sous une forme ou une autre.
e) Administration
C'est la fonction transversale qui supervise la bonne
exécution de toutes les autres ; elle pilote le processus de mise
à jour des données, la documentation sur les données et
sur les métadonnées, la sécurité, les sauvegardes,
la gestion des incidents.
1.12. DÉFINITION DES MODÈLES DE
DONNÉES DÉCISIONNELS
Un modèle de données s'applique
généralement à une application ou à un ensemble
d'applications dont le périmètre et la définition sont
arrêtés en amont du projet. Ceci est valable pour toute
application informatique.
Page | 20
Mais ce principe s'applique d'une manière
particulière dans les projets décisionnels.
Consommateur de données et producteur d'informations,
un SID est nécessairement un dispositif à double face puisque
:
? Il combine des données d'origines diverses,
généralement opérationnelles ;
? Il met des données à disposition selon des
objectifs informationnels.
Par rapport aux sources de données qui l'alimentent, le
data Waterhouse est sous-tendu par un modèle fédérateur ou
intégrateur. Mais ce modèle n'est pas directement
représentatif des points de vue informationnels éventuellement
multiples et changeants des utilisateurs du SID. Or le SID ne vaut que pour les
restitutions informationnelles qu'il offre. Le véritable modèle
de données décisionnel est donc celui qui reflète la mise
à disposition ou encore la diffusion des données, et non leur
concentration.
Un SID comporte donc en réalité au moins deux
Modèles Conceptuels de Données. L'un des deux représente
l'intégration des sources opérationnelles à partir
desquelles s'alimente le système. Il se conçoit et se normalise
selon une démarche traditionnelle de génie logiciel, qui n'a pas
lieu d'être développée ici. L'autre, celui que nous
examinons dans ce chapitre, correspond à la structure informationnelle
destinée à supporter les requêtes des utilisateurs. C'est
le MCD de diffusion. C'est ce dernier qui représente la structure selon
laquelle l'information doit être mise à disposition ; il constitue
la spécification fonctionnelle du SID11.
Conclusion partielle
Dans ce chapitre, nous avons traité les
généralités sur les systèmes décisionnels
(Business Intelligence) ; avons défini l'informatique
décisionnelle, l'architecture de systèmes décisionnels et
ses différents enjeux avec leurs fonctions ; et avons abordé les
systèmes décisionnels qui sont des systèmes qui permettent
aux décideurs des entreprises de prendre des décisions optimales
et importantes pour une meilleure gestion des leurs entreprises. Le chapitre
suivant abordera les notions de Data werahouse.
11 Groupe EVOLUTION. F. Bret. T. Cruanees. I.
Guessarian. E. Metais. M-C. Rousset. S. Schwer. O. Teste. G. Zurfluh,
Ingénerie des systèmes d'information, édition
HERMES, 2001, p.38
Page | 21
CHAPITRE II: LE DATA WAREHOUSE
2.0 INTRODUCTION
Les entrepôts des données intègrent des
informations en provenance de différentes sources, souvent reparties et
hétérogènes ayant pour objectif de fournir une vue globale
de l'information aux analystes et aux décideurs.
La construction et la mise en oeuvre d'un entrepôt de
données représentent une tâche complexe qui se compose de
plusieurs étapes.
La première est l'analyse des sources de données
et l'identification des besoins des utilisateurs, la deuxième correspond
à l'organisation des données à l'intérieur de
l'entrepôt. En fin, la troisième sert à établir
divers outils d'interrogation, d'analyse, et de fouille de données.
Chaque étape présente des problèmes
spécifiques. Ainsi, par exemple, lors de la première
étape, la difficulté principale consiste en l'intégration
des données, de manière à ce qu'elles soient de
qualité pour leur stockage. Pour l'organisation, il existe plusieurs
problèmes comme la sélection des vues à
matérialiser, le rafraichissement de l'entrepôt, la gestion de
l'ensemble de données courantes et historisées.
En ce qui concerne le processus d'interrogation, nous avons
besoin des outils performants et conviviaux pour l'accès et l'analyse de
l'information.
2.1 DÉFINITION D'UN DATA WAREHOUSE (DW)12
Un entrepôt de données est une collection de
données orientées sujet, intégrées, non volatiles
et historisées, organisées pour le support d'un processus d'aide
à la décision. Nous détaillons ces caractéristiques
:
V' Orientées sujet : les données des
entrepôts sont organisées par sujet plutôt que par
application, par exemple, une chaine de magasins d'alimentation organise les
données de son entrepôt par rapport aux ventes qui ont
été réalisées par produit et par magasin, au cours
d'un certain temps.
V' Intégrées : les données provenant de
différentes sources doivent être intégrées, avant
leur stockage dans l'entrepôt de données.
12 Jarke M., Lenzerini M., Vassiliou Y.,
Vassiliadis P., "Fundamentals of Data Warehouses", Ed. Springer Verlag,
ISBN 3-540-65365-1, 1999, p.187
Page | 22
L'intégration, c'est à dire la mise en
correspondance des formats, permet d'avoir une cohérence de
l'information.
V' Non volatiles : à la différence des
données opérationnelles, celles de l'entrepôt sont
permanentes et ne peuvent pas être modifiées. le rafraichissement
de l'entrepôt consiste à ajouter de nouvelles données, sans
modifier ou perdre celles qui existent.
V' Historisées : la prise en compte de
l'évolution des données est essentielle pour la prise de
décision qui, par exemple, utilise des techniques de prédication
en s'appuyant sur les évolutions passées pour prévoir les
évolutions futures.
2.2 OBJECTIF DU DATA WARE HOUSE
L'atout principal d'une entreprise réside dans les
informations qu'elle possède. Les informations se présentent
généralement sous deux formes : les systèmes
opérationnels qui enregistrent les données et le Data Warehouse.
En bref, les systèmes opérationnels représentent
l'emplacement de saisie des données, et l'entrepôt de
données l'emplacement de restitution13.
Ainsi voici les objectifs fondamentaux du data warehouse :
Rendre accessibles les informations de l'entreprise : le
contenu de l'entrepôt doit être compréhensible et
l'utilisateur doit pouvoir y naviguer facilement et avec rapidité. Ces
exigences n'ont ni frontières, ni limites. Des données
compréhensibles sont pertinentes et clairement définies. Par
données navigables, on n'entend que l'utilisateur identifie
immédiatement à l'écran le but de ses recherches et
accède au résultat en un clic.
Rendre cohérente les informations d'une l'entreprise :
les informations provenant d'une branche de l'entreprise peuvent être
mise en corrélation avec celles d'une autre branche. Si deux
unités de mesure portent le même nom, elles doivent alors
signifier la même chose. A l'inverse, deux unités ne signifiant
pas la même chose doivent être définie différemment.
Une information cohérente suppose une information de grande
qualité. Cela veut dire que l'information est prise en compte et qu'elle
est complète.
13 Samos J., Saltor F., Sistrac J., Bardés A.,
"Database Architecture for Data Warehousing: An evolutionary Approach",
DEXA'98, Vienna (Austria), 1998, p.72
14 AHMED T., MIQUEL M., LAURINI R., «
Continuous data warehouse: concepts, challenges and potentials »,
Proc. of the 12th International Conference on Geoinformatics, 2004, p.
157-164.
Page | 23
Constituer une source d'information souple et adaptable :
l'entrepôt de données est conçu dans la perspective de
notifications perpétuelle, l'arrivé de question nouvelles ne doit
bouleverser ni les données existantes ni les technologies. La conception
de Data Mart distincts composant un entrepôt de données doit
être répartie et incrémentielle.
Représenter un bastion sécurisé qui
protège la capitale information : l'entrepôt de données ne
contrôle pas seulement l'accès aux données, mais il offre
à ses gestionnaires une bonne visibilité des utilisations.
Constituer la base décisionnelle de l'entreprise :
l'entrepôt de données recèle en son sein les informations
propres à faciliter la prise de décisions.
2.3. LES COMPOSANTS DE BASE DU DATA WAREHOUSE14 ? Le
système source :
Système opération d'enregistrement, dont la
fonction consiste à capturer les transactions liées à
l'activité.
? Zone de préparation des données :
Ensemble des processus qui nettoient, transforment, combinent,
archivent, suppriment les doublons, c'est-à-dire prépare les
données sources en vue de leur intégration puis de leur
exploitation au sein du Data Warehouse. La zone de préparation des
données ne doit offrir ni service des requêtes, ni service de
présentation.
? Serveur de présentation :
Machine cible sur laquelle l'entrepôt de données
est stocké et organisé pour répondre en accès
direct aux requêtes émises par des utilisateurs, les
générateurs d'état et les autres applications.
? Data Mart :
Sous-ensemble logique d'un Data Warehouse, il est
destiné à quelques utilisateurs d'un département.
? Entrepôt de données :
Source de données interrogeable de l'entreprise. C'est
tout simplement l'union des Data Marts qui le composent. L'entrepôt de
Toutes informations de l'environnement du Data Warehouse qui
ne constituent pas les données proprement dites.
Page | 24
données est alimenté par la zone de
préparation des données. L'administrateur de l'entrepôt de
données est également responsable de la zone de
préparation des données.
+ OLAP (On Line Analytic Processing) :
Activité globale de requêtage et de
présentation de données textuelles et numériques contenues
dans l'entrepôt de données ; style d'interrogation et de
présentation spécifiquement dimensionnel.
+ ROLAP (Relational OLAP) :
Ensemble d'interface utilisateur et d'applications donnant une
vision dimensionnelle des bases de données relationnelles.
+ MOLAP (Multidimensional OLAP) :
Ensemble d'interface utilisateur et d'applications dont
l'aspect dimensionnel est prépondérant.
+ Application utilisateur :
Ensemble d'outils qui interrogent, analysent et
présente des informations répondant à un besoin
spécifique. L'ensemble des outils minimal se compose d'outil
d'accès aux données, d'un tableur, d'un logiciel graphique et
d'un service d'interface utilisateur, qui suscite les requêtes et
simplifie la présentation de l'écran aux yeux de
l'utilisateur.
+ Outil d'accès aux données : client de
l'entrepôt de données. + Outil de requête :
Types spécifique d'outil d'accès aux
données qui invite l'utilisateur à formuler ses propres
requêtes en manipulant directement les tables et leurs jointures.
+ Application de modélisation :
Type de client de base de données sophistiqués
doté de fonctionnalités analytiques qui transforment ou mettent
en forme les résultats obtenus ;
+ Métadonnées :
Page | 25
2.4. CARACTÉRISTIQUES D'UN DATA WAREHOUSE15
Un Data Warehouse est une base de données conçue
pour l'interrogation et l'analyse plutôt que le traitement de
transactions. Il contient généralement des données
historiques dérivées de données transactionnelles, mais il
peut comprendre des données d'autres origines.
Les Data Warehouse séparent la charge d'analyse de la
charge transactionnelle. Ils permettent aux entreprises de consolider des
données de différentes origines.
Au sein d'une même entité fonctionnelle, le Data
Warehouse joue le rôle d'outil analytique.
En complément d'une base de données, un Data
Warehouse inclut une solution d'extraction, de transformation et de chargement
(ETL), des fonctionnalités de traitement analytique en ligne (OLAP) et
de Data mining, des outils d'analyse client et d'autres applications qui
gèrent le processus de collecte et de mise à la disposition de
données.
2.5 ARCHITECTURE D'UN DATA WERAHOUSE16
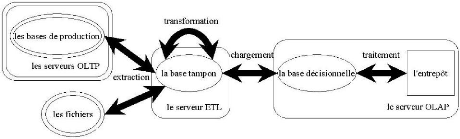
Figure II-1 architecture d'un data werahouse
3.6 L'ETL
Une fois la structure du datawarehouse définie, les
données doivent être insérées. L'outil qui va
permettre le remplissage de notre base est l'ETL (Extract-Transform-Loading).
Comme son nom l'indique, il commence par extraire les données provenant
de différentes sources (Excel, MySQL...), les transforme si besoin est,
puis les charge dans le data warehouse.
15 INMON W.-H., Building the data warehouse, QED
Publishing Group, 1992, p.57.
16 TSHIMANGA Célestin, Cours d'info
centre, UNIKAN L2 info, 2025, P32.
Page | 26
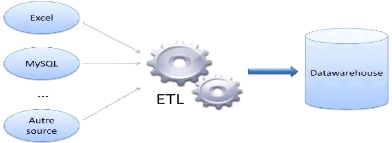
Figure II-2 Data werahouse avec ETL
2.7 ENTREPÔTS ET BASES DE DONNÉES
Dans l'environnement des entrepôts de données,
les opérations, l'organisation des données, les critères
de performance, la gestion des métadonnées, la gestion des
transactions et le processus de requêtes sont très
différents des systèmes de bases de données
opérationnels.
Les SGBD ont été créés pour les
applications de gestion de systèmes transactionnels. Par contre, les
entrepôts de données ont été conçus pour
l'aide à la prise de décision. Ils intègrent les
informations qui ont pour objectif de fournir une vue globale de l'information
aux analystes et aux décideurs.
Le tableau suivant résume les différences entre
les systèmes de gestion de bases de données et les
entrepôts de données.
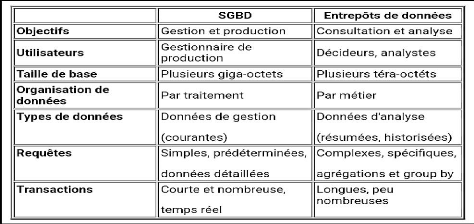
Tableau II-1 : Différence entre SGBD et
entrepôts de données
Page | 27
2.7.1 Rôle d'un entrepôt de données
Le rôle primordial d'un data warehouse apparait ainsi
évident dans une stratégie décisionnelle. L'alimentation
du data warehouse en est la phase la plus critique.
En effet, importer des données inutiles en portera de
nombreux problèmes, cela consommera des ressources système et du
temps. De plus, cela rendra le service d'analyse plus lent. Autre point
à prendre en compte est la périodicité d'extraction des
données ;
effectivement, le plus souvent, les opérations de
collecte de données sont couteuses en ressource pour la base
accédée.17
2.7.2 Systèmes transactionnels et systèmes
décisionnels
Les Système de Gestion de Base de Donnée (SGBD)
ont été créés pour gérer de grands volumes
d'information contenus dans les différents systèmes
opérationnels qui appartiennent à l'entreprise.
Ces données sont manipulées en utilisant des
processus transactionnels en ligne, parallèlement à
l'exploitation de l'information contenue dans ces systèmes
opérationnels, les dirigeants des entreprises ont besoin d'avoir une
vision globale concernant toute cette information pour faire des calculs
prévisionnels, des statistiques ou pour établir des
stratégies de développement et d'analyses des tendances.
Tableau 2 : compare les caractéristiques des
systèmes

17 Dayal U., Blaustein B. T., Buchmann A. P., Chakravarthy U.
S., Hsu M., Ledin R., McCarthy D. R., Rosenthal A., Sarin S. K., Carey M. J.,
Livny M., Jauhari R., "The HiPAC Project: Combining Active Databases and
Timing Constraints", ACM SIGMOD Record, 17(3), Chicago (Illinois, USA),
1988, p.312-322
18 R. Kimball, L. Reeves, M. Ross, W. Thornthwaite, Concevoir
et déployer un data warehouse, Eyrolles, Paris, 2000, p.79
Page | 28
II.4.3 Différence entre le système OLTP et le
Data warehouse
Les Data Warehouse et les Systèmes OLTP (On Line
Transaction Processing) répondent à besoins très
différents. Les Data Warehouse conçu pour prendre en charge des
interrogations ad hoc. La taille du Data Warehouse n'est pas connue à
l'avance. Par conséquent, celui-ci doit être optimisé pour
offrir de bonnes performances dans le cadre d'opérations d'interrogation
très diverses. Les systèmes OLTP prennent
généralement en charge des opérations
prédéfinies. Les applications peuvent être
réglées ou conçues spécifiquement pour ces
opérations.
Un Data Warehouse est mise à jour
régulièrement par les processus ETL (Extraction, Transformation
and Loading), un système de chargement de données en masse
soigneusement défini et contrôlé. Il n'est pas mis à
jour directement par les utilisateurs. Dans les systèmes OLTP, les
utilisateurs exécutent régulièrement des instructions qui
modifient les données de la base. La base de données OLTP est
à jour en permanence et elle reflète l'état actuel de
chaque transaction18.
De manière générale, une interrogation
portant sur un Data Warehouse balaye des milliers voire des millions de lignes.
En revanche, une opération OLTP standard accède à quelque
enregistrement seulement.
Le Data Warehouse contient généralement des
données correspondant à plusieurs mois ou années. Cela
permet d'effectuer des analyses historiques. Les systèmes OLTP
contiennent généralement des données quelque semaine ou
mois. Ils conservent uniquement des données historiques
nécessaires à la transaction en cours.
2.8 LA PROBLÉMATIQUE DE L'ENTREPRISE
L'entreprise construit un système décisionnel
pour améliorer sa performance, elle doit décider et anticiper en
fonction de l'information disponible et capitaliser sur ses
expériences.
? Entreprise : est une organisation
dotée d'une mission et d'un objectif métier. Elle doit sa raison
d'être ou sa pérennité au travers de différent
objectifs (sécurité, développement, rentabilité
...). Par voie de conséquence, cette organisation humaine est
dotée d'un centre décision.
Page | 29
? Rôle de décideur :
Il peut être le responsable de l'entreprise, le
responsable d'une fonction ou d'un secteur. Il est donc celui qui engage la
pérennité ou la raison d'être de l'entreprise. Pour ces
raisons, il doit s'entourer de différents moyens lui permettant une
prise de décision la plus pertinente. Parmi ces moyens, les Data
Warehouse ont une place primordiale.
2.9. SCHÉMAS D'UN DATA WAREHOUSE
Un schéma est un ensemble d'objets de la base de
données tels que les tables, des vues, des vues
matérialisées, des index et des synonymes. La conception du
schéma d'un Data Warehouse est guidée par le modèle des
données source et par les besoins utilisateurs.
2.9.1 Tables des faits :
Une table de faits comprend généralement des
colonnes de deux types : celles qui contiennent des faits numériques
(souvent appelés indicateurs) et celles qui servent de clé
étrangère vers les tables de dimension. Une table de faits peut
contenir des faits détaillés ou agrégées. Les
tables contenant des faits agrégés sont souvent appelées
tables agrégées. Une table de faits contient
généralement de faits de même niveau d'agrégation.
La plupart des faits sont additifs, mais ils peuvent être semi-additifs
ou non additifs. Les faits additifs peuvent être agrégés
par simple addition arithmétique. C'est par exemple le cas des ventes.
Les faits non additifs ne peuvent pas être additionnés du tout.
C'est le cas des moyennes. Les faits semi-additifs peuvent être
agrégés selon certaines dimensions mais pas selon d'autres.
2.9.2 Tables des dimensions :
Une dimension est une structure comprenant une ou plusieurs
hiérarchies qui classent les données en catégories. Les
dimensions sont des étiquettes descriptives fournissant des informations
complémentaires sur les faits, qui sont stockées dans les tables
de dimension. Il s'agit normalement de valeurs textuelles descriptives.
Plusieurs dimensions distinctes combinées avec les faits permettant de
répondre aux questions relatives à l'activité de
l'entreprise. Les données de dimension son généralement
collectées au plus bas niveau de détail, puis
agrégées aux niveaux supérieurs en totaux plus
intéressants pour l'analyse, ces agrégations ou cumuls naturels
au sein d'une table de dimension sont appelés des hiérarchies.
Les hiérarchies sont des structures logiques qui utilisent les niveaux
ordonnés pour organiser les données. Pour une dimension temps,
par exemple, une hiérarchie peut
19 TSHIMANGA Célestin, Cours d'info
centre, UNIKAN L2 info, 2025, P29.
Page | 30
agréger les données selon le niveau mensuel, le
niveau trimestriel, le niveau annuel. Au sein d'une hiérarchie, chaque
niveau est connecté logiquement aux niveaux supérieurs et
inférieurs. Les valeurs des niveaux inférieurs sont
agrégées en valeurs de niveau supérieur.
2.10. MODELISATION MULTIDIMENSIONNELLE
2.10.1 Le Schéma en Etoile19
Le schéma en étoile peut être le type le
plus simple de schéma de Data Warehouse, il est dit en étoile
parce que son diagramme entité/relation ressemble à une
étoile, avec des branches partant d'une table centrale. Un schéma
en étoile est caractérisé par une ou plusieurs tables de
faits, très volumineuses, qui contiennent les informations essentielles
du Data Warehouse et par un certain nombre de tables de dimension, beaucoup
plus petites, qui contiennent chacune des informations sur les entrées
associées à un attribut particulier de la table de faits. Une
interrogation en étoile est une jointure entre une table de faits et un
certain nombre de table de dimensions. Chaque table de dimension est jointe
à la table de faits à l'aide d'une jointure de clé
primaire à clé étrangère, mais les tables de
dimension ne sont pas jointes entre elles.
Le principal avantage du schéma en flocons est une
amélioration des performances des interrogations due à des
besoins réduits en espace de stockage sur disque et la petite
décisionnels. La manière la plus naturelle de modéliser un
Data Warehouse est la représenter par un schéma en étoile
dans lequel une jointure unique établit la relation entre la table de
faits et chaque table de dimension. Un schéma en étoile optimise
les performances en contribuant à simplifier les interrogations et
à raccourcir les temps de réponse.
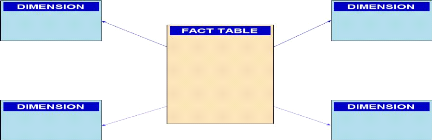
Figure II-2 : schéma en étoile
Page | 31
2.10.2 Le Schéma en Flocon20
Les schémas en flocons normalisent les dimensions pour
éliminer les redondances. Autrement dit, les données de dimension
sont stockées dans plusieurs tables et non dans une seule table de
grande taille. Cette structure de schéma consomme moins d'espace disque,
mais comme elle utilise davantage de tables de dimension, elle nécessite
un plus grand nombre de jointures de clé secondaire.
Dans un schéma en flocon, cette même table de
faits, référence les tables de dimensions de premier niveau, au
même titre que le schéma en étoile.
Cette figure présente un schéma
multidimensionnel pour les ventes qui ont été
réalisées dans les magasins pour les différents produits
au cours d'un temps donné (jour) taille des tables de dimension à
joindre.
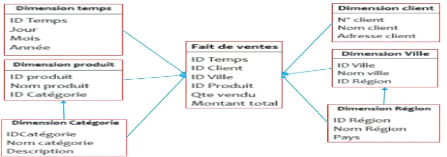
Figure II-3 : schéma d'un modèle en
flocon
2.10.3 schéma multi dimensionnel
Dans le modèle multi dimensionnel, le concept central
est le cube, lequel est constitué des éléments
appelés cellule qui peuvent contenir une ou plusieurs mesures. La
localisation de la cellule est faite à travers les axes, qui
correspondent chacun a une dimension.
20 TSHIMANGA Celestin, Op. Cit
Page | 32
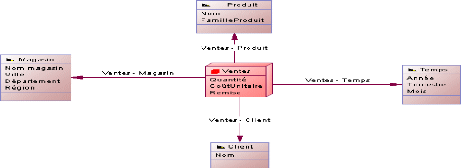
Figure II-4 : Exemple de schéma
multidimensionnel
2.11 LE DATA MART
2.11.1 Introduction
Un DataMart est un sous-ensemble d'un entrepôt de
données ; il est généralement exploité dans les
entreprises pour restituer des informations ciblées sur un métier
spécifique, constituant pour ce dernier un ensemble d'indicateurs
à vocation de pilotage de l'activité et d'aide à la
décision. Un DataMart, selon les définitions, est issu ou fait
partie d'un Data Warehouse, et en reprend par
conséquvééé2ent la plupart des
caractéristiques.
2.11.2 Les définitions
Le DataMart est un ensemble de données ciblées,
organisées, regroupées et agrégées pour
répondre à un besoin spécifique à un métier
ou un domaine donné. Il est donc destiné à être
interrogé sur un panel de données restreint à son domaine
fonctionnel, selon des paramètres qui auront été
définis à l'avance lors de sa conception.
De façon plus technique, le DataMart peut être
considère de deux manières différentes, attribuées
aux deux principaux théoriciens de l'informatique décisionnelle,
bill inmon et Ralph Kimball :
? Définition d'Inmon:
Le DataMart est issu d'un flux de données provenant du
Data Warehouse. Contrairement a ce dernier qui présente le détail
des données pour toute l'entreprise, il a vocation à
présenter la donnée de manière spécialisée,
agrégée et regroupée fonctionnellement.
Page | 33
? Définition de Kimball :
Le DataMart est un sous-ensemble du Data Warehouse, constitue
de tables au niveau détail et à des niveaux plus agrèges,
permettant de restituer tout le spectre d'une activité métier.
L'ensemble des DataMarts de l'entreprise constitue le Data Warehouse.
2.11.3 La place du datamart dans l'entreprise
Le DataMart se trouve en toute fin de la chaine de traitement
de l'information. En règle générale, il se situe en aval
d'un Data Warehouse plus global à partir duquel il est alimenté,
dont il constitue en quelque sorte un extrait.
Un DataMart forme la principale interaction entre les
utilisateurs et les systèmes informatiques qui gèrent la
production de l'entreprise (souvent des ERP).
Dans un DataMart, l'information est préparée
pour être exploitée brute par les personnes du métier
auquel il se rapporte. Pour ce faire, il est appelé à être
utilisé via des logiciels d'interrogation de bases de données
(notamment des outils de reporting) afin de renseigner ses utilisateurs sur
l'état de l'entreprise à un moment donné (stock) ou sur
son activité (flux).
Le retrait de données inutiles :
Le DataMart ne contient que les données qui sont
strictement utiles aux utilisateurs. L'historisation des données : le
DataMart contient seulement la période de temps qui intéresse les
utilisateurs.
2.11.4 Data warehouse Et Data mart
La première étape d'un projet busines
intelligent est de créer un entrepôt central pour avoir une vision
globale des données de chaque service. Cet entrepôt porte le nom
de Data Warehouse.
On peut également parler de DataMart, si seulement une
catégorie de services ou métiers est concernée.
Par définition, un DataMart peut être contenu
dans un Data Warehouse, ou il peut être seulement issu de celui-ci.
Page | 34
2.11.5. Architecture d'un Datamart
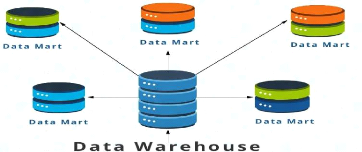
Figure II-5 : Architecture d'un Data Mart
2.11.6. Data Warehouse face à Data Mart
Les Data Marts représentent de toute évidence
une réponse rapide aux besoins des différents départements
de l'entreprise. Leur coût moindre et leur facilité d'emploi
permettent une implémentation rapide et un retour à
l'investissement presque immédiat. Il faut toutefois être prudent
lorsque des Datamarts sont ainsi crées pour plusieurs divisions.
Ces dernières utilisent souvent des
représentations différentes de certains concepts de gestion. Par
exemple, les départements finances et marketing peuvent tous deux
effectué un suivi des ventes réalisées par l'entreprise,
mais défini différemment ce concept. Plus tard, si un
employé du marketing a besoin de recueillir certaines informations
à partir du Data Marts des finances, l'entreprise sera confrontée
à un problème. Par conséquent, une vision unifiée
est nécessaire même pour concevoir des Datamarts par
département.
CONCLUSION PARTIELLE
Dans ce chapitre, nous avons traité l'entrepôt de
données et le data mart. Nous avons donné l'architecture d'un
entrepôt de données et celle du data mart. Nous avons
expliqué les différents composants qu'il intègre, les
types de données et les différents outils pour arriver à
la visualisation de l'information ; avons décrit les différents
modèles multidimensionnels pour la construction d'un entrepôt de
données, ainsi que les différentes opérations pour la
manipulation des données multidimensionnelles et le parallélisme
entre le deux, nous avons présenté
Page | 35
l'apport de DataMart dans les entreprises. Le chapitre suivant
abordera sur analyse préalable et spécification des besoins.
CHAPITRE III : ANALYSE PRÉALABLE ET
SPÉCIFICATION DES
BESOINS
3.0 INTRODUCTION
Pour garantir la réussite d'un projet informatique, il
est indispensable de procéder à une analyse rigoureuse des
besoins réels de l'organisation concernée. Le présent
chapitre se consacre à l'analyse préalable du contexte
organisationnel et fonctionnel de la Direction Provinciale de la Fonction
Publique, dans le but de définir clairement les exigences du
système décisionnel à mettre en place.
Cette étape permet non seulement de comprendre le
fonctionnement actuel du service, mais aussi d'identifier les faiblesses du
système existant en matière de suivi de la performance des
agents. À partir de cette analyse, les besoins fonctionnels et non
fonctionnels seront spécifiés avec précision, afin de
proposer une solution informatique cohérente, réaliste et
adaptée aux objectifs de performance de l'administration publique.
3.1. PRÉSENTATION DU CADRE D'ÉTUDE
3.1.1. Situation géographique
La Direction Provinciale de la Fonction Publique du Kasaï
Central est située dans la ville de Kananga, chef-lieu de la province du
Kasaï Central, en République Démocratique du Congo. Cette
ville se trouve au centre du pays, à une latitude d'environ 5° Sud
et une longitude de 22° Est. La ville de Kananga est un carrefour
administratif, commercial et politique de la région, facilitant ainsi la
centralisation des services publics provinciaux.
Elle est bornée par :
? Au nord par le bâtiment du fond social ;
? Au sud par l'hôtel de ville de Kananga ;
? À l'Est par le parquet général de
Kananga ;
? À l'Ouest par le bâtiment de ministère
provinciaux.
3.1.2. Historique
La Direction Provinciale de la Fonction Publique du Kasaï
Central est créé par l'ordonnance N° 80 du 28 août
1980 au même moment que le ministère de la fonction publique.
Page | 36
Elle a été mise en place à la suite de la
mise en oeuvre de la décentralisation prévue par la Constitution
de 2006. Autrefois centralisés à Kinshasa, les services de la
fonction publique ont progressivement été
déconcentrés puis décentralisés vers les provinces,
dans un souci de proximité administrative et de gouvernance locale. La
création de la direction provinciale visait à permettre une
gestion autonome et efficace des ressources humaines de l'État au niveau
local.
3.1.3. Statut juridique
La Direction Provinciale de la Fonction Publique est un
service public provincial rattaché au ministère de la Fonction
Publique au niveau national. Elle bénéficie d'une autonomie
administrative relative, tout en restant soumise aux orientations nationales.
Elle fonctionne conformément aux textes réglementaires en
vigueur.
3.1.4. Objet social de la DPFP
L'objet principal de la Direction Provinciale de la Fonction
Publique est d'assurer la gestion administrative, statutaire et technique des
agents de carrière des services publics de l'État au niveau
provincial. Cela comprend : l'enregistrement et la gestion des dossiers, la
régularisation des situations administratives, la planification des
besoins en personnel, l'organisation des concours, le suivi de la
carrière des agents, etc.
3.1.5. Durée d'existence de la DPFP
La Direction Provinciale de la Fonction Publique du Kasaï
Central existe depuis environ 2010. Sa mise en place s'inscrit dans la
dynamique de renforcement des institutions provinciales conformément
à la décentralisation.
3.1.6. Rôles de la Direction Provinciale de la
Fonction Publique Les principaux rôles de la direction sont :
V' La gestion des ressources humaines ;
V' L'élaboration des rapports de performance ;
V' La formation continue ;
V' Le contrôle de la discipline administrative, et
la transmission
régulière des données à
l'administration centrale.
3.1.7. Projets d'avenir de la DPFP
Parmi les projets d'avenir, on note : la digitalisation des
dossiers, la mise en place d'un système décisionnel, la
création d'une base de données centralisée, le suivi
automatisé des carrières, et l'amélioration des
compétences par des formations continues.
Page | 37
3.1.8. Organisation et fonctionnement
3.1.8.1. Organigramme de la DPFP
L'organigramme comprend : la Division des ressources humaines,
la Division des carrières, la Division de la planification, le Service
informatique, le Service d'accueil et le Service de contrôle
administratif. Chaque division est dirigée par un chef.
3.1.8.2. Fonctionnement de la DPFP
Le fonctionnement repose sur une hiérarchie bien
définie, des procédures rigoureuses et des réunions
périodiques. Le traitement des dossiers suit une chaîne de
validation avec plusieurs niveaux de contrôle. L'informatisation
progressive des services vise à améliorer l'efficacité
administrative.
Fonctions et responsabilités :
+ LE CHEF DE DIVISION
Le chef de division coordonne, supervise et contrôle les
activités de sa division ; fait des études, élabore les
rapports annuels des activités de service et en plus vise
préalablement tous les dossiers après traitement des services
concernés elles sont ouverts du ministère provincial des tutelles
sur les documents tels que :
> Son projet des commissions d'affectation ;
> Tout projet d'autorisation de sortie ; >
Tout projet de déclaration des créances. > LE
SECRÉTARIAT DE LA DIVISION
Charger de la rédaction, dactylographie saisie,
réception et expédition des courriers, classement et
maintenance.
> LE 1e BUREAU RESSOUCES HUMAINES :
Ce bureau est chargé de la gestion interne de la
division du budget de la division, gestion des fournitures des bureaux et des
mobiliers, maintenance et entretien des bâtiments abritant des services
de la division et enfin de la gestion des finances et ressources humaines.
> DEXIEME BUREAU
Il est chargé de la documentation et archives, grade
des dossiers administratif et des archives, organisation de la documentation
sur les actes administratifs.
Page | 38
> TROISIEME BUREAU
Il est chargé de contrôle, recours et
contentieux, contrôle les effectifs et de la paye de toutes les
divisions, récolte des données de gestion des ressources
humaines, régularisation des citations administratives relatives
à :
V' La paye, la gestion administrative, position
administrative...;
V' Examiner les enquêtes administratives sont
les faux documents, les actes douteux...
> LE QUATRIEME BUREAU
Il est chargé de l'organisation et fonction des points
identification des besoins en formation, service conseil en matière de
la formation, supervision ou fusion des structures d'un service provincial.
> LE 5e BUREAU
Il est chargé au suivi de la gestion du personnel
administratif de l'EPST et L'ESU et des services émargeant aux budgets
annexes :
V' Coordonner, superviser et contrôler les
activités du bureau.
V' Déterminer la masse salariale des
personnels administratifs relevant l'EPST et l'ESU ;
V' Traité et actualiser les dossiers des
agents de l'EPST et de L'ESU à la fonction publique ;
V' Suivi de la gestion du personnel relevant les
services émargeant aux budgets annexes.
> LE 6e BUREAU
Charger de l'inspection et contrôle de division provinciale
:
V' Contrôle physiquement et les agents de toutes
les divisions
provinciales ;
V' Vérification des agents administratifs ;
V' Intervention pour le respect de l'application des
dispositions
statutaires ;...
V' Coordonne, supervise et contrôle les
activités du bureau ;
V' Contrôle physiquement des agents ;
V' Vérification de l'authenticité des
agents administratifs.
> LE 6e BUREAU
Chargé d'Étude et planification.
Page | 39
3.1.9 ORGANIGRAMME
DIRECTEUR
SECRETAIRE
CHEF DE DIVISION RH

2er BUREAU
3er BUREAU

4er BUREAU
5er BUREAU
1er BUREAU

6er BUREAU
7er BUREAU
2er BUREAU
Figure III-1 Organigramme de la Division provinciale de la
Fonction Publique
Page | 40
3.2 ANALYSE DE L'EXISTANT
3.2.1 DEFINITION GLOBALE DU PROBLEME
La direction est dirigée par un chef, qui est
généralement un fonctionnaire expérimenté. Elle est
composée d'un certain nombre de services spécialisés, tels
que :
Service du personnel : Gère les dossiers des
fonctionnaires, les procédures de recrutement, etc.
Service des réformes : Suivi des réformes de la
fonction publique. Service de la formation : Organise les formations des
fonctionnaires.
La direction peut également avoir des
délégations dans les différentes villes et régions
de la province, pour assurer une présence sur le terrain.
Exemples d'actions :
Mise en place d'un système de gestion des talents :
Identification et développement des potentiels au sein de la fonction
publique provinciale.
Amélioration des conditions de travail : Mises en place
de projets pour améliorer les infrastructures et les
équipements.
Sensibilisation aux valeurs de la fonction publique :
Campagnes de communication pour promouvoir l'éthique et la
transparence.
Veille et application des lois :
Elle s'assure que les lois et règlements relatifs
à la fonction publique sont appliqués au niveau provincial.
Conseil et assistance :
Elle conseille les autorités provinciales et les services
publics sur les questions relatives à la fonction publique.
Développement professionnel :
Elle peut organiser des formations et des séminaires pour
les fonctionnaires provinciaux.
Suivi des réformes :
Elle suit l'évolution de la fonction publique et les
réformes en cours.
Page | 41
La Direction Provinciale de la Fonction Publique du Kasaï
Central est un acteur clé de la modernité et du redressement de
l'administration publique au niveau provincial. Selon le Portail de la Fonction
Publique, la direction provinciale est impliquée dans des initiatives
telles que l'identification biométrique des fonctionnaires et la
sensibilisation aux réformes de la sécurité sociale.
3.2.2 LANGAGE DE MODELISATION DE L'EXISTANT Pourquoi
et comment modéliser ?
1. Qu'est-ce qu'un modèle
?
Un modèle est une représentation abstraite et
simplifiée d'une entité (phénomène, processus,
système, etc.) du monde réel en vue de le décrire, de
l'expliquer ou de le prévoir. Modèle est synonyme de
théorie, mais avec une connotation pratique : un modèle, c'est
une théorie orientée vers l'action qu'elle doit servir.
Concrètement, un modèle permet de réduire
la complexité d'un phénomène en éliminant les
détails qui n'influencent pas son comportement de manière
significative. Il reflète ce que le concepteur croit important pour la
compréhension et la prédiction du phénomène
modélisé, les limites du phénomène
modélisé dépendant des objectifs du modèle.
Un modèle est avant tout une représentation
abstraite du monde réel. À ce titre, ce n'est pas le monde
réel et donc ce n'est pas, exactement le monde réel. Un
modèle offre donc une vision schématique d'un certain nombre
d'éléments que l'on veut décrire ; un dessin quoi ! On a
coutume de dire : « Un dessin vaut mieux qu'un beau discours » ; et
bien écoutons et tentons de comprendre nos ancêtres, nos parents
ou tout ceux qui ont pu nous répéter cette phrase.
Réaliser un modèle c'est avant tout dessiner ce que l'on a
compris d'un problème dans une syntaxe précise (la syntaxe UML ou
Merise).
Un modèle va donc nous servir à communiquer et
échanger des points de vue afin d'avoir une compréhension commune
et précise d'un même problème.
3.2.2.2 DIAGRAMME DE CAS D'UTILISTAION a.
Généralité
Bien souvent, la maîtrise d'ouvrage et les utilisateurs
ne sont pas des informaticiens. Il leur faut donc un moyen simple d'exprimer
leurs besoins. C'est précisément le rôle des diagrammes de
cas d'utilisation qui permettent de recueillir, d'analyser et d'organiser les
besoins, et de recenser les grandes
Page | 42
fonctionnalités d'un système. Il s'agit donc de
la première étape UML d'analyse d'un
système.21
Un diagramme de cas d'utilisation capture le comportement d'un
système, d'un sous-système, d'une classe ou d'un composant tel
qu'un utilisateur extérieur le voit. Il scinde la fonctionnalité
du système en unités cohérentes, les cas d'utilisation,
ayant un sens pour les acteurs. Les cas d'utilisation permettent d'exprimer le
besoin des utilisateurs d'un système, ils sont donc une vision
orientée utilisateur de ce besoin au contraire d'une vision
informatique.
Les diagrammes des cas d'utilisation identifient les
fonctionnalités fournies par le système (cas d'utilisation), les
utilisateurs qui interagissent avec le système (acteurs), et les
interactions entre ces derniers. Les cas d'utilisation sont utilisés
dans la phase d'analyse pour définir les besoins de "haut niveau" du
système. Les objectifs principaux des diagrammes des cas d'utilisation
sont :
? Fournir une vue de haut-niveau de ce que fait le système
;
? Identifier les utilisateurs ("acteurs") du système ;
? Déterminer des secteurs nécessitant des
interfaces homme-machine.
Les cas d'utilisation se prolongent au-delà des
diagrammes imagés. En fait, des descriptions textuelles des cas
d'utilisation sont souvent employées pour compléter ces derniers
et représentent leurs fonctionnalités plus en détail.
b. Éléments des diagrammes de cas d'utilisation
:
Les composants de base des diagrammes des cas d'utilisation
sont l'acteur, le cas d'utilisation, et l'association.
? Acteur
Un acteur est un utilisateur du système, et est
représenté par une figure filaire. Le rôle de l'utilisateur
est écrit sous l'icône. Les acteurs ne sont pas limités aux
humains. Si le système communique avec une autre application, et
effectue des entrées/sorties avec elle, alors cette application peut
également être considérée comme un acteur.
? Cas d'utilisation
Un cas d'utilisation représente une
fonctionnalité fournie par le système, (par exemple effacer
utilisateur).
21
https://www.memoireonline.com
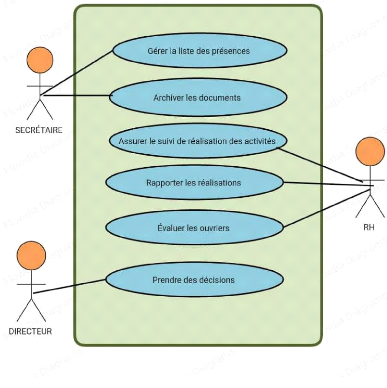
Figure III-2 Conception de diagramme de cas
d'utilisation
Page | 43
Les cas d'utilisation sont représentés par une
ellipse contenant leurs
noms.
? Association
Les associations sont utilisées pour lier des acteurs
avec des cas d'utilisation. Elles indiquent qu'un acteur participe au cas
d'utilisation sous une forme quelconque. Les associations sont
représentées par une ligne reliant l'acteur et le cas
d'utilisation.
Ce diagramme illustre les interactions entre les utilisateurs
(acteurs) et le système. Trois acteurs sont identifiés :
Directeur, Responsable de ressources humaines et le secrétaire.
Page | 44
3.2.3 DIAGNOSTIC DE L'EXISTANT, CRITIQUES ET PROPOSITIONS
DES SOLUTIONS
L'étude de l'existant vise à analyser les
mécanismes actuels utilisés par la Division Provinciale de la
Fonction Publique dans la gestion de la performance des agents, en mettant en
lumière les forces et les faiblesses du système en place.
Actuellement, la Division Provinciale de la Fonction Publique
ne dispose pas d'un système informatique intégré et
automatisé pour l'analyse de performance des agents. Les tâches de
contrôle, de suivi des dossiers et de gestion des ressources humaines se
font majoritairement de manière manuelle ou semi-informatisée
(utilisation basique de Word, Excel, dactylographie...).
Principales limites observées :
? Lenteur dans le traitement et la circulation des dossiers.
? Manque de traçabilité et de transparence dans
les processus d'évaluation et d'affectation des agents.
? Risque d'erreurs humaines liées à la gestion
manuelle des données.
? Difficultés d'accès aux archives physiques ou
égarées.
? Absence d'indicateurs de performance clairs, rendant
difficile toute évaluation objective des agents.
Opportunité de modernisation :
Face à ces constats, la mise en place d'un
système décisionnel performant s'avère nécessaire
pour centraliser les informations, automatiser l'analyse de performance,
faciliter les prises de décisions, produire des statistiques fiables et
améliorer l'efficience de la division.
Conclusion partielle
L'analyse menée dans ce chapitre a permis de cerner les
limites du système actuel de gestion des performances à la
Direction Provinciale de la Fonction Publique du Kasaï Central et
d'identifier les opportunités d'amélioration. Les constats
révèlent la nécessité d'une modernisation
axée sur la centralisation, l'automatisation et la fiabilisation des
données. Ainsi, la proposition d'un système décisionnel
intégrant des outils d'analyse et de suivi constitue une réponse
adaptée aux enjeux identifiés, préparant la voie à
sa conception et implémentation dans le chapitre suivant.
Page | 45
CHAPITRE IV. CONCEPTION ET IMPLEMENTATION
4.0 INTRODUCTION
La conception et l'implémentation constituent une phase
essentielle dans le processus de développement d'un système
décisionnel. Après avoir identifié les besoins
fonctionnels et techniques à travers les analyses
précédentes, il devient indispensable de passer à la
modélisation concrète du système et à sa
réalisation pratique. Ce chapitre présente l'ensemble des choix
techniques et conceptuels qui ont guidé la mise en oeuvre du
système décisionnel pour l'analyse de performance des agents au
sein de la Direction Provinciale de la Fonction Publique.
4.1 ANALYSE DES BESOINS
La conception et l'implémentation d'un système
décisionnel pour l'analyse de la performance des agents nécessite
une identification claire et structurée des besoins. Ces besoins sont
classés en deux grandes catégories : les besoins fonctionnels et
les besoins non fonctionnels.
3.2.1 Besoins fonctionnels
Les besoins fonctionnels décrivent les services
attendus du système. Il s'agit des fonctionnalités que doit
offrir le système pour satisfaire les utilisateurs.
a) Gestion des agents
V' Création, modification, suppression des fiches
individuelles des agents. V' Suivi de la carrière (affectations,
promotions, sanctions, formations). V' Archivage des documents administratifs
liés aux agents.
b) Analyse de la performance
4. Génération de rapports périodiques
sur l'assiduité, le rendement et l'efficacité.
5. Visualisation des indicateurs clés de performance
(KPI) par bureau, direction ou période.
6. Comparaison des performances entre agents ou services.
c) Gestion des affectations et mutations
+ Suivi des décisions d'affectation, de permutation, ou de
suspension. + Historique complet des mouvements administratifs des agents.
d) Fonctionnalités de recherche
> Recherche multicritère (par nom, matricule, service,
statut, etc.). > Exportation des résultats (PDF, Excel, etc.).
e) Sécurité des accès
5. Authentification par identifiant et mot de passe.
6. Droits d'accès différenciés selon les
profils (administrateur, superviseur, utilisateur simple).
Page | 46
3.2.2 Besoins non fonctionnels
Les besoins non fonctionnels définissent les
qualités que le système doit posséder sans décrire
des fonctions spécifiques.
a) Performance
Réponse rapide aux requêtes d'analyse.
Génération instantanée des rapports et
tableaux de bord.
b) Fiabilité
Taux de disponibilité élevé.
Sauvegarde automatique des données.
c) Sécurité
Protection des données personnelles des agents.
Journalisation des accès et actions des utilisateurs.
d) Facilité d'utilisation
Interface conviviale et intuitive.
Formation minimale nécessaire à l'usage.
e) Portabilité
Accessibilité via navigateur web (interface web).
Possibilité de déploiement sur réseau local ou en
ligne.
4.2 ANALYSE CONCEPTUELLE
Cette phase vise à structurer logiquement le
système décisionnel, en distinguant les environnements OLTP
(transactionnel) et OLAP (analytique). Elle repose sur la
modélisation des données et des traitements à
effectuer.
4.2.1 SYSTÈME OLTP (ONLINE TRANSACTION
PROCESSING)
Le système OLTP représente l'environnement
opérationnel dans lequel les données sont saisies au quotidien.
Il comprend :
· Les entités principales : Agents, Services,
Activités, Présences, Évaluations, Documents.
· Fonctionnalités clés :
+ Gérer la liste des présences
+ Archivage des documents
+ Assurer le suivi des réalisations des
activités
+ Évaluation périodique des agents
+ Et la prise de décision.
Page | 47
Ce diagramme modélise un système d'analyse de la
performance des agents à la Direction Provinciale de la Fonction
Publique.
Grâce à cette structure, le système offre
une vision complète du rendement des agents en comparant les
tâches prévues avec celles réellement effectuées,
tout en assurant le suivi administratif des agents au sein des services.
? CONCEPTION DE DIAGRAMME DE CLASSE
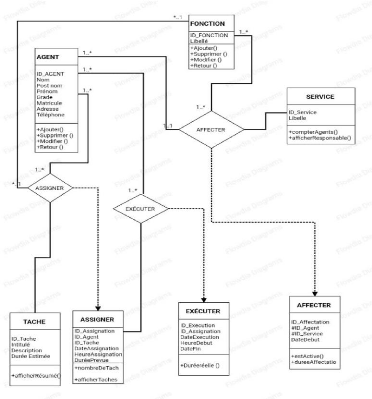
? Analyse (mesurée par le nombre des
tâches réalisées, la durée de la réalisation,
le nombre de tâches assignées, cotes d'évaluation)
Figure IV-1 : Diagramme de classe pour l'analyse de
performance des agents
4.2.2 SYSTÈME OLAP (ONLINE ANALYTICAL
PROCESSING)
Ce système est conçu pour l'analyse
multidimensionnelle des données issues de l'OLTP.
? FAITS :
Page | 48
+ DIMENSIONS :
y' Service
y' Fonction
y' Agent
y' Temps
y' Tâche
Modèle en étoile (schéma
multidimensionnel) :
Table de Faits : F_ANALYSE
La table F_ANALYSE est au coeur du modèle. Elle contient
les indicateurs de performance et les clés permettant de relier les
dimensions contextuelles.
Clés étrangères :
y' ID_SERVICE
y' ID_AGENT
y' ID_FONCTION
y' ID_TACHE
y' ID_TEMPS
Indicateurs :
y' NombreTacheAssignées : nombre de tâches
assignées à l'agent.
y' NombreTâchesRéalisées : nombre de
tâches réalisées.
y' DuréeRéalisation : durée effective de
réalisation.
Tables de dimensions : dim_agent, dim_service,
dim_ fonction, dim_temps.
Ce modèle en étoile représente un
système d'analyse de la performance des tâches à la
Direction Provinciale de la Fonction Publique.
La table centrale F_ANALYSE regroupe les indicateurs
clés comme le nombre de tâches réalisées, la
durée de réalisation et les tâches assignées, tandis
que les tables de dimensions (agents, fonctions, services, tâches, temps)
fournissent le contexte d'analyse.
Ce modèle permet une analyse multidimensionnelle et
facilite la prise de décision basée sur la productivité
des agents, l'efficacité des services, et l'évolution des
performances dans le temps.
Page | 49
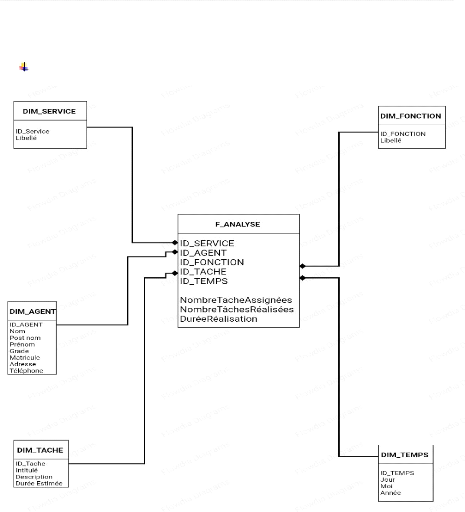
CONCEPTION DE MODELE EN ETOILE
Figure IV-2 Modèle en étoile pour l'analyse de
performance des agents
4.3 ALGORITHME D'ANALYSE DE PERFORMANCE
Dans le but de mettre en oeuvre un système
décisionnel capable d'analyser de manière objective la
performance des agents de la Direction Provinciale de la Fonction Publique, il
est indispensable de définir un algorithme d'évaluation
structuré et cohérent. Cet algorithme repose sur plusieurs
critères clés observés dans le fonctionnement
administratif, notamment la ponctualité,
Page | 50
la présence effective, la réalisation des
tâches, l'appréciation du supérieur hiérarchique, et
l'ancienneté dans le service.
a) Description des critères
d'évaluation
|
Critère
|
Description
|
Poids maximal
|
|
Ponctualité
|
Fréquence d'arrivée à l'heure par rapport
aux jours travaillés
|
20
|
|
Présence (Assiduité)
|
Nombre de jours effectivement prestés sur une
période donnée
|
20
|
|
Tâches accomplies
|
Pourcentage des tâches planifiées
effectivement réalisées
|
25
|
|
Appréciation du
supérieur
|
Note qualitative donnée par le supérieur
hiérarchique (sur 10)
|
25
|
|
Ancienneté
|
Bonus accordé aux agents ayant au moins 5 ans
d'ancienneté
|
10
|
Tableau IV-1 : Critères d'évaluation de la
performance des agents
Le score total maximal est de 100 points. En fonction du score
obtenu, une appréciation globale est donnée à chaque agent
selon la grille suivante :
|
Score obtenu
|
|
Évaluation de la performance
|
|
=
|
85
|
Excellent
|
|
70
|
- 84
|
Bon
|
|
50
|
- 69
|
Moyen
|
|
<
|
50
|
Faible
|
b) Algorithme proposé
Début
Pour chaque agent dans la base de données faire
Initialiser performance = 0
// Ponctualité
Si (taux_de_ponctualité >= 90%) alors
performance += 20
Sinon si (taux_de_ponctualité >= 75%) alors
performance += 15
Sinon
performance += 5
// Présence (Assiduité)
Si (taux_de_presence >= 95%) alors
performance += 20
Page | 51
Sinon si (taux_de_presence >= 80%) alors
performance += 15
Sinon
performance += 5
// Tâches accomplies
Si (taux_taches_realisees >= 90%) alors
performance += 25
Sinon si (taux_taches_realisees >= 70%) alors
performance += 15
Sinon
performance += 5
// Appréciation du supérieur
Si (note_superieur >= 8) alors
performance += 25
Sinon si (note_superieur >= 5) alors
performance += 15
Sinon
performance += 5
// Ancienneté
Si (anciennete >= 5 ans) alors
performance += 10
// Appréciation finale
Si (performance >= 85) alors
Evaluation = "Excellent"
Sinon si (performance >= 70) alors
Evaluation = "Bon"
Sinon si (performance >= 50) alors
Evaluation = "Moyen"
Sinon
Evaluation = "Faible"
Enregistrer performance et Évaluation dans la base de
données Fin Pour
Fin
c) Conclusion
Cet algorithme constitue la base de l'analyse
automatisée de performance dans le système décisionnel.
Grâce à lui, l'administration peut facilement
générer des rapports comparatifs, détecter les agents les
plus performants ou ceux nécessitant un encadrement spécifique,
et prendre des décisions stratégiques fondées sur des
données fiables et objectives.
Page | 52
4.4 IMPLEMENTATION
4.4.1. Présentation de la technologie
utilisée
Nous avons opté Visual C Sharp, comme environnement de
développement de l'application décisionnel pour des raisons de
performance et de souplesse. Il permet de développer des projets aussi
variés que des applications Windows Forms. Il s'agit d'une composante
l'EDI Visual Studio.
4.3.1.1. Présentation de Visual C #
Le langage C# (C Sharp) est un langage objet
créé spécialement pour le framework Microsoft .NET.
L'équipe qui a créé ce langage a été
dirigée par Anders Hejlsberg, un informaticien danois qui avait
également été à l'origine de la conception du
langage Delphi pour la société Borland (évolution objet du
langage Pascal).22
Le Framework .NET est un environnement d'exécution (CLR
Common Language Runtime) ainsi qu'une bibliothèque de classes (plus de
2000 classes). L'environnement d'exécution (CLR) de .NET est une machine
virtuelle comparable a celle de Java.
La rutine fournit des services aux programmes qui
s'exécutent sous son contrôle : chargement/exécution,
isolation des programmes, vérification des types, conversion code
intermédiaire (IL) vers code natif, accès aux
métadonnées (informations sur le code contenu dans les
assemblages .NET), vérification des accès mémoire
(évite les accès en dehors de la zone allouée au
programme), gestion de la mémoire (Garbage Collector), gestion des
exceptions, adaptation aux caractéristiques nationales (langue,
représentation des nombres), compatibilité avec les DLL et
modules COM qui sont en code natif (code non manage).
Les classes .NET peuvent être utilisées par tous
les langages prenant en charge l'architecture .NET. Les langages .NET doivent
satisfaire certaines spécifications : utiliser les mêmes types CTS
(Common Type System), les compilateurs doivent générer un
même code intermédiaire appelé MSIL (Microsoft Intermediate
Language).
Le MSIL (contenu dans un fichier .exe) est pris en charge par
le runtime .NET qui le fait tout d'abord compiler par le JIT compiler (Just In
Time Compiler).
22. G. LEBLANC, C# et .NET, Version 2,
Eyrolles, Paris, 2006, pp.7-10.
23. G. LEBLANC, Op.cit.
Page | 53
La compilation en code natif a lieu seulement au moment de
l'utilisation du programme .NET.
Définir un langage .NET revient à fournir un
compilateur qui peut générer du langage MSIL. Les
spécifications .NET sont publiques (Common Language
Spécifications) et n'importe quel éditeur de logiciel peut donc
concevoir un langage/un compilateur .NET. Plusieurs compilateurs sont
actuellement disponibles : C++.NET (version Managée de C++),
VB.NET, C#, Delphi, J#.23
Lors du développement d'applications .NET, la
compilation du code source produit du langage MSIL contenu dans un fichier
.exe. Lors de la demande d'exécution du fichier .exe, le système
d'exploitation reconnait que l'application n'est pas en code natif. Le langage
IL est alors pris en charge par le moteur d'exécution du framework .NET
qui en assure la compilation et le contrôle de l'exécution. Un des
points importants étant que le runtime .NET gère la
récupération de mémoire allouée dans le tas
(garbage collector), a l'instar de la machine virtuelle Java.
"En .NET, les langages ne sont guère plus que des
interfaces syntaxiques vers les bibliothèques de classes."
On ne peut rien faire sans utiliser des types/classes fournis
par le framework .NET puisque le code MSIL s'appuie également sur les
types CTS. L'avantage de cette architecture est que le framework .NET facilite
l'interopérabilité (projets constitues de sources en
différents langages). Avant cela, faire cohabiter différents
langages pour un même exécutable imposait des contraintes de choix
de types «communs» aux langages ainsi que de respecter des
conventions d'appel de fonctions pour chacun des langages utilises.
Particularité de C++.NET : la version .NET de C++ a la
particularité de permettre à l'utilisateur de
générer soit du code natif soit du code manage. Avec Visual C++
Express, le langage C++ a été complété pour
permettre la gestion managée de la mémoire allouée dans le
tas.
Le C# reprend beaucoup d'éléments de syntaxe du
C. Partant du langage C, beaucoup d'éléments de syntaxe sont
familiers :
Le schéma multidimensionnel de la base de
l'entrepôt de données sur disque est le suivant :
Page | 54
Structure des instructions similaires (terminées par ;) :
déclaration de variables, affectation, appels de fonctions, passage des
paramètres, opérations arithmétiques
? Blocs délimités par {}
? Commentaires // ou /* */
? Structures de contrôle identiques : if/else, while,
do/while, for( ;; ) Portée des variables : limitée au bloc de la
déclaration
En C#, on peut déclarer une variable n'importe où
avant son utilisation. Ce n'est pas nécessairement au début d'une
fonction.
4.3.2. Schéma relationnel de la base de
données transactionnelle
Le schéma relationnel est la représentation
réelle de la base de données sur le disque avec la formalisation
de toutes les relations telles qu'elles ont été définies.
Il est le suivant :
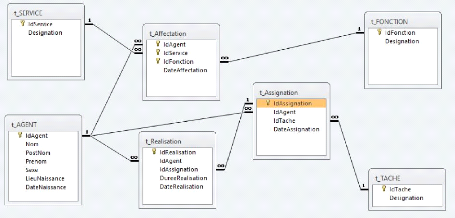
Fig. IV-3 : Schéma
relationnel de la base de données
4.3.3. Schéma multidimensionnel de l'entrepôt
de données
Page | 55
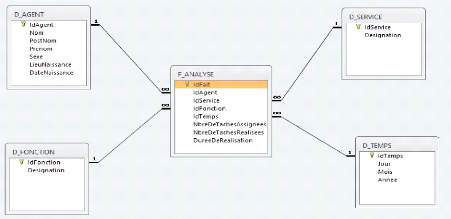
Fig. IV-4 : Base de données
multidimensionnelle
4.4.4. Quelques interfaces graphiques et code source de
l'application 4.3.4.1. Système transactionnel
Dans cette partie nous faisons un extrait des interfaces
graphiques et code source de notre application transactionnelle
implémentée en langage de programmation C#.
A. Extrait des interfaces graphiques
Les formulaires suivants sont les interfaces principales de notre
application. Il s'agit de :
A.1. Le formulaire MDI
Il s'agit ici du formulaire parent qui supporte tous les autres
formulaires de l'application. Il possède des menus qui sont des liens
vers les différentes interfaces de travail. Le voici :
Page | 56
Fig. IV-5 : Formulaire MDI
A.2. Enregistrement de l'agent
Le point de départ est l'identification de l'agent.
Cette opération se réalise à travers ce formulaire dont le
point d'entrée est le menu « Gestion », sous-menu «
Nouvel agent » :
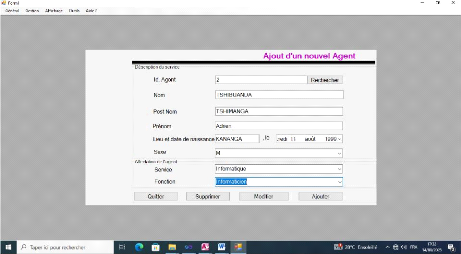
Page | 57
Fig. IV-6 : Formulaire
d'identification de l'agent
A.3. Assignation des tâches
Après avoir identifié l'agent, la prochaine
étape consiste à lui assigner les tâches. Voici le
formulaire permettant de réaliser cette opération :
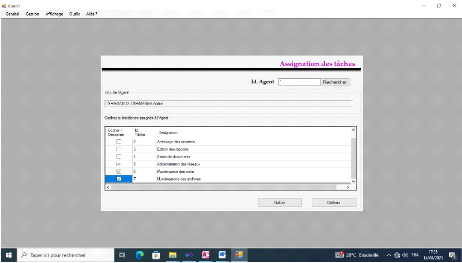
Fig. IV-7 : Formulaire d'assignation des
tâches
A.4. Suivi des réalisations
À ce stade, il faut pouvoir indiquer pour chacune des
tâches assignées, si elle a été
réalisée, la durée. Voici le formulaire permettant de le
faire :
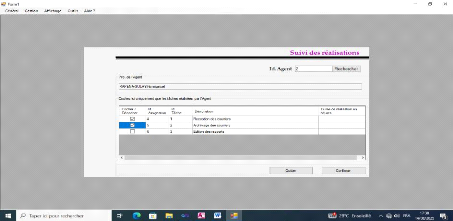
Page | 58
Fig. IV-8 : Formulaire de suivi des
réalisations
A.5. Analyse des performances
Le but de ce système est de pouvoir fournir des
indicateurs précis et claires sur lesquels les décideurs pourront
s'articuler afin de fonder leurs décisions. Nous rappelons en passant
nos trois indicateurs de performances : Nombre de tâches
assignées, nombre de réalisations et la durée de
réalisation. Ce formulaire que nous présentons ici a pour but de
faciliter les analyses sur quatre dimensions : Temps, Agent, Service et
Fonction. Le voici :
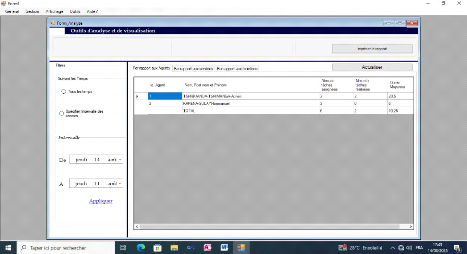
Fig. IV-9 : Formulaire d'analyse
B. Extrait du code source de l'application
Ci-dessous nous présentons l'extrait du code source de
l'application transactionnelle en se basant sur les opérations des mises
à jour et celles liées à l'extraction de données,
transformation et chargement (ETL). Pour des questions d'espace, certaines
méthodes seront présentées uniquement en prototype. La
classe ci-après en donne les détails :
|
class Class_Manip_Bd
{
//Propriétés
private OleDbConnection Connexion_Bd;
|
Page | 59
private OleDbConnection Connexion_Dm;
private OleDbCommand Commande;
private OleDbDataReader Lecture;
private string Requete;
private string Chaine_Connexion_Bd;
private string Chaine_Connexion_Dm;
private string Chaine_Decisionnel;
public Class_Manip_Bd()
{
//this.Requete=requete;
this.Chaine_Connexion_Bd =
@"Provider=Microsoft.ACE.OLEDB.12.0;
Data Source=C:\Gestion_Performance\BD_Performance.accdb";
this.Connexion_Bd = new
OleDbConnection(this.Chaine_Connexion_Bd);
this.Chaine_Connexion_Dm =
@"Provider=Microsoft.ACE.OLEDB.12.0;
Data
Source=C:\Gestion_Performance\DM_Gestion_Performance.accdb";
this.Connexion_Dm = new
OleDbConnection(this.Chaine_Connexion_Dm);
}
/*public Class_Manip_Bd(bool decisionnel, string requete)
{
//System.Windows.Forms.MessageBox.Show("On Y est !");
this.Requete = requete;
this.Chaine_Decisionnel = "server=CARITAS-LUEBO-1; user id=sa;
pwd=CARITAS-LUEBO; database=SD_GETION_REDEVANCES";
this.Connexion = new OleDbConnection(this.Chaine_Decisionnel);
}*/
public void Mise_A_Jour(string r_Bd)
{
//System.Windows.Forms.MessageBox.Show(Requete);
this.Commande = new OleDbCommand(r_Bd, this.Connexion_Bd);
this.Connexion_Bd.Open();
this.Commande.ExecuteNonQuery();
this.Connexion_Bd.Close();
System.Windows.Forms.MessageBox.Show("Mise à jour
effectuée avec succès !");
}
//
public void Mise_A_Jour(string r_Bd, int msg) {
//System.Windows.Forms.MessageBox.Show(Requete); this.Commande =
new OleDbCommand(r_Bd, this.Connexion_Bd); this.Connexion_Bd.Open();
this.Commande.ExecuteNonQuery();
this.Connexion_Bd.Close();
Page | 60
}
//
public void Mise_A_Jour(string r_Dm, bool Dm) {
//System.Windows.Forms.MessageBox.Show(Requete);
this.Commande = new OleDbCommand(r_Dm, this.Connexion_Dm);
this.Connexion_Dm.Open();
this.Commande.ExecuteNonQuery();
this.Connexion_Dm.Close();
//System.Windows.Forms.MessageBox.Show("Mise à jour
effectuée avec succès !");
}
//
public void Mise_A_Jour(string r_Bd, string r_Dm) {
//System.Windows.Forms.MessageBox.Show(Requete);
this.Commande = new OleDbCommand(r_Bd, this.Connexion_Bd);
this.Connexion_Bd.Open();
this.Commande.ExecuteNonQuery();
this.Connexion_Bd.Close();
//
this.Commande = new OleDbCommand(r_Dm, this.Connexion_Dm);
this.Connexion_Dm.Open();
this.Commande.ExecuteNonQuery();
this.Connexion_Dm.Close();
System.Windows.Forms.MessageBox.Show("Mise à jour
effectuée avec
succès !");
}
/*public void Mise_A_Jour(string r_Bd, int msg)
{
//System.Windows.Forms.MessageBox.Show(Requete);
this.Commande = new OleDbCommand(r_Bd, this.Connexion_Dm);
this.Connexion_Dm.Open();
this.Commande.ExecuteNonQuery();
this.Connexion_Dm.Close();
//
}*/
public int Nouveau_Numero(string table, string champ)
{
int nNum = 0;
string snNum = "0";
this.Commande = new OleDbCommand("SELECT MAX("+champ+") AS
nNum FROM "+table, this.Connexion_Bd);
this.Connexion_Bd.Open();
this.Lecture = this.Commande.ExecuteReader();
while (this.Lecture.Read())
Page | 61
{
snNum+=this.Lecture[0].ToString();
}
this.Lecture.Close();
this.Connexion_Bd.Close();
nNum=(int.Parse(snNum))+1;
return nNum;
}
public int Nouveau_Numero(string table, string champ, bool Dm)
{
int nNum = 0;
string snNum = "0";
this.Commande = new OleDbCommand("SELECT MAX(" + champ + ")
AS nNum FROM " + table, this.Connexion_Dm);
this.Connexion_Dm.Open();
this.Lecture = this.Commande.ExecuteReader();
while (this.Lecture.Read())
{
snNum += this.Lecture[0].ToString();
}
this.Lecture.Close();
this.Connexion_Dm.Close();
nNum = int.Parse(snNum) + 1;
return nNum;
}
public bool Rechercher(string r_Bd, int n,
System.Windows.Forms.TextBox[] txt)
{
bool trouver = false;
this.Commande = new OleDbCommand(r_Bd, this.Connexion_Bd);
this.Connexion_Bd.Open();
this.Lecture = this.Commande.ExecuteReader();
int i = 0;
while (this.Lecture.Read())
{
while (i < n)
{
txt[i].Text = this.Lecture[i].ToString(); i++;
}
trouver = true;
}
this.Lecture.Close();
this.Connexion_Bd.Close();
return trouver;
Page | 62
}
public bool Rechercher(string r_Dm, int n,
System.Windows.Forms.TextBox[] txt, bool Dm)
{
bool trouver = false;
this.Commande = new OleDbCommand(r_Dm, this.Connexion_Dm);
this.Connexion_Dm.Open();
this.Lecture = this.Commande.ExecuteReader();
int i = 0;
while (this.Lecture.Read())
{
while (i < n)
{
txt[i].Text = this.Lecture[i].ToString(); i++;
}
trouver = true;
}
this.Lecture.Close();
this.Connexion_Dm.Close();
return trouver;
}
public void Charge_Combo_Au_Chargement(string r_Bd,
System.Windows.Forms.ComboBox Combo)
{
Combo.Items.Clear();
this.Commande = new OleDbCommand(r_Bd, this.Connexion_Bd);
this.Connexion_Bd.Open();
this.Lecture = this.Commande.ExecuteReader();
while (this.Lecture.Read())
{
Combo.Items.Add(this.Lecture[0].ToString());
}
this.Lecture.Close();
this.Connexion_Bd.Close();
}
public void
Charge_Taches_Data(System.Windows.Forms.DataGridView
dt)
{
dt.Rows.Clear();
this.Commande = new OleDbCommand("SELECT IdTache, Designation
FROM t_TACHE", this.Connexion_Bd);
this.Connexion_Bd.Open();
this.Lecture = this.Commande.ExecuteReader();
while (this.Lecture.Read())
Page | 63
|
{
dt.Rows.Add();
dt.Rows[dt.Rows.Count - 1].Cells[1].Value =
this.Lecture["IdTache"].ToString();
dt.Rows[dt.Rows.Count - 1].Cells[2].Value =
this.Lecture["Designation"].ToString();
}
this.Lecture.Close();
this.Connexion_Bd.Close();
}
//
public void Charge_Assignations_Agent_Data(int
idAgent,System.Windows.Forms.DataGridView dt)
{
dt.Rows.Clear();
this.Commande = new OleDbCommand("SELECT IdAssignation,
t_Assignation.IdTache, Designation FROM t_TACHE INNER JOIN
t_Assignation
ON t_Assignation.IdTache=t_TACHE.IdTache WHERE
IdAgent="+idAgent,
this.Connexion_Bd);
this.Connexion_Bd.Open();
this.Lecture = this.Commande.ExecuteReader();
while (this.Lecture.Read())
{
dt.Rows.Add();
dt.Rows[dt.Rows.Count - 1].Cells[1].Value =
this.Lecture["IdAssignation"].ToString();
dt.Rows[dt.Rows.Count - 1].Cells[2].Value =
this.Lecture["IdTache"].ToString();
dt.Rows[dt.Rows.Count - 1].Cells[3].Value =
this.Lecture["Designation"].ToString();
}
this.Lecture.Close();
this.Connexion_Bd.Close();
}
public void
Charge_Data_Au_Chargement(System.Windows.Forms.DataGridView
Liste)
{
Liste.Rows.Clear();
this.Commande = new OleDbCommand(this.Requete,
this.Connexion_Bd);
this.Connexion_Bd.Open();
this.Lecture = this.Commande.ExecuteReader();
string[] Ligne = new string[7];
while (this.Lecture.Read())
{
Ligne[1] = this.Lecture[0].ToString();
|
Page | 64
Ligne[2] = this.Lecture[1].ToString(); Ligne[3] =
this.Lecture[2].ToString(); Ligne[4] = this.Lecture[3].ToString();
Liste.Rows.Add(Ligne);
}
this.Lecture.Close();
this.Connexion_Bd.Close();
Liste.Columns[5].DefaultCellStyle.BackColor =
System.Drawing.Color.Fuchsia;
Liste.Columns[6].DefaultCellStyle.BackColor =
System.Drawing.Color.Fuchsia;
}
public void
Par_Rapport_AuxAgents(System.Windows.Forms.DataGridView Tableau)
{
int totalAssignations = 0;
int totalRealisations = 0;
double totalDuree = 0;
string[] ligne = new string[5];
Tableau.Rows.Clear();
//
Tableau.ColumnCount = 5;
Tableau.Columns[0].HeaderText = "Id. Agent";
Tableau.Columns[1].HeaderText = "Nom, Post nom et
Prénom";
Tableau.Columns[1].Width = 400;
Tableau.Columns[2].HeaderText = "Nbre de tâches
assignées";
Tableau.Columns[3].HeaderText = "Nbre de tâches
réalisées";
Tableau.Columns[4].HeaderText = "Duree Moyenne";
this.Commande=new OleDbCommand("SELECT D_AGENT.IdAgent,
Nom, PostNom, Prenom FROM D_AGENT",this.Connexion_Dm);
this.Connexion_Dm.Open();
this.Lecture = this.Commande.ExecuteReader();
int n=0;
while (this.Lecture.Read())
{
ligne[0] = this.Lecture["IdAgent"].ToString();
ligne[1] =
this.Lecture["Nom"].ToString()+"-"+this.Lecture["PostNom"].ToString()+"-"+this.Lecture["Prenom"].ToString();
OleDbCommand Cmd = new OleDbCommand("SELECT
SUM(NbreDeTachesAssignees) AS nbAssignations, SUM(NbreDeTachesRealisees) AS
nbRealisations, AVG(DureeDeRealisation) AS moyenneDuree FROM F_ANALYSE WHERE
IdAgent=" + ligne[0], this.Connexion_Dm);
OleDbDataReader Lire = Cmd.ExecuteReader(); while
(Lire.Read())
Page | 65
|
{
ligne[2] = Lire["nbAssignations"].ToString();
ligne[3] = Lire["nbRealisations"].ToString();
ligne[4] = Lire["moyenneDuree"].ToString();
}
Lire.Close();
totalAssignations += int.Parse("0"+ligne[2]);
totalRealisations+=int.Parse("0"+ligne[3]);
totalDuree+=double.Parse("0"+ligne[4]);
n++;
Tableau.Rows.Add(ligne);
}
this.Lecture.Close();
this.Connexion_Dm.Close();
ligne[0] = "";
ligne[1] = "TOTAL";
ligne[2] = totalAssignations.ToString();
ligne[3] = totalRealisations.ToString();
ligne[4] = (totalDuree / n).ToString();
Tableau.Rows.Add(ligne);
}
|
4.5. Conclusion partielle
Ce chapitre a été entièrement
consacré au déploiement et à l'implémentation du
système d'aide à la décision pour la gestion des
performances des travailleurs. Nous avons commencé par le
déploiement du système OLTP avant de chuter sur le système
OLAP. Un système OLTP dans ce contexte joue le rôle de source de
données pour le système OLAP. Les interfaces graphiques et codes
sources pour chacun de ces systèmes ont été
présentés.
? Centraliser les données relatives aux agents de la
Fonction Publique,
Page | 66
CONCLUSION GENERALE
Le présent mémoire avait pour thème :
« Modélisation et implémentation d'un système
décisionnel pour l'analyse de performance des agents de la Direction
Provinciale de la Fonction Publique du Kasaï Central ».
À travers ce travail, nous avons cherché
à répondre à une problématique centrale : «
quel système mettre en place en vue de fournir aux décideurs des
indicateurs clairs et précis sur base auxquels ils pourront se pencher
afin de prendre des décisions jugées rationnelles, à ce
qui concerne la gestion leur personnel ? »
Dans le premier chapitre, nous avons présenté
les généralités sur les systèmes
décisionnels, leurs concepts fondamentaux, leurs composantes et leur
importance dans le processus de gestion moderne.
Le deuxième chapitre a permis d'approfondir la notion
de data warehouse, en montrant son rôle structurant dans la collecte,
l'organisation et l'analyse multidimensionnelle des données.
Le troisième chapitre s'est consacré à
l'analyse du contexte organisationnel de la Direction Provinciale de la
Fonction Publique. Cette étape a permis d'identifier les faiblesses du
système existant, caractérisé par une gestion manuelle et
peu fiable, et de spécifier les besoins fonctionnels et non fonctionnels
du futur système décisionnel.
Enfin, dans le quatrième chapitre, nous avons
proposé la conception et l'implémentation d'un système
décisionnel basé sur un modèle en étoile,
intégrant à la fois un environnement OLTP pour la gestion
transactionnelle et un OLAP pour l'analyse multidimensionnelle. Des algorithmes
d'évaluation des performances ont été définis, et
une application a été développée en langage C# pour
matérialiser cette solution.
Les résultats de ce travail montrent qu'il est
possible, grâce à un système décisionnel, de :
Page | 67
? Améliorer la rapidité et la fiabilité des
traitements administratifs, ? Fournir des indicateurs de performance
pertinents,
? Aider les décideurs à prendre des
décisions stratégiques fondées sur des données
objectives.
Cependant, certaines limites doivent être reconnues. Le
système proposé, bien qu'efficace sur le plan conceptuel et
expérimental, devra être renforcé par une infrastructure
technologique adaptée, une volonté politique soutenue et une
formation continue des utilisateurs pour garantir son succès.
En perspective, il serait souhaitable d'intégrer des
technologies plus avancées telles que l'intelligence artificielle pour
affiner l'évaluation des performances, d'ouvrir le système
à une interconnexion nationale entre les différentes directions
provinciales, et d'explorer des solutions cloud pour assurer une meilleure
accessibilité et évolutivité.
En définitive, ce mémoire constitue une
contribution modeste mais significative à la modernisation de la gestion
de la Fonction Publique en République Démocratique du Congo. Il
démontre que la science informatique, et plus particulièrement
les systèmes décisionnels, peuvent servir d'outils puissants pour
améliorer l'efficacité administrative et promouvoir une
gouvernance publique transparente et performante.
Page | 68
11) S. Kelly ; Data Warehousing - The Route to Mass
Customization, John Wiley & Sons, 1996, p.13
RÉFÉRENCES BIBLIOGRAPHIQUES
1. OUVRAGES
1) C. LAUDON et JANE P. LAUDON ; Management Information
Systems : Managing the Digital Firm, 17e éd., 2008, p.122
2) EFRAIM TURBAN et JAY E. ARONSON; Decision Support Systems
and Intelligent Systems, 7e éd., 2005, p.33
3) FREYSSINET J. ; Méthode de recherche en Sciences
Sociales, éd. Mont Chrétien, Paris, 1997, p.12
4) G. LEBLANC ; C# et .NET, Version 2, Eyrolles, Paris, 2006,
pp.7-10
5) Groupe EVOLUTION (Bret, Cruanees, Guessarian, Metais,
Rousset, Schwer, Teste, Zurfluh) ; Ingénierie des systèmes
d'information, HERMES, 2001, p.38
6) INMON W.-H. ; Building the Data Warehouse, QED Publishing
Group, 1992, p.57
7) Jarke M., Lenzerini M., Vassiliou Y., Vassiliadis P. ;
Fundamentals of Data Warehouses, Springer Verlag, 1999, p.187
8) Laudon, K. C., & Laudon, J. P. ; Management
Information Systems: Managing the Digital Firm, 15e éd., 2018
9) R. Kimball, L. Reeves, M. Ross, W. Thornthwaite ;
Concevoir et déployer un data warehouse, Eyrolles, Paris, 2000,
p.79
10) R. SHARDA, D. DELEN, E. TURBAN ; Business
Intelligence: A Managerial Perspective on Analytics, 3e éd., 2014,
p.37-42
Page | 69
2. NOTES DE COURS
1. TSHIMANGA Célestin ; Cours d'info centre, UNIKAN L2
info, 2025
3. TRAVAUX SCIENTIFIQUES
1. AHMED T., MIQUEL M., LAURINI R. ; Continuous Data
Warehouse: Concepts, Challenges and Potentials, Proc. of the 12th Int. Conf. on
Geoinformatics, 2004, p.157-164
2. Bertino E., Ferrari E., Guerrini G., Merlo I. ; Extending
the ODMG Object
Model with Composite Objects, OOPSLA'98, Vancouver, 1998,
p.56
3. Bret F., Teste O. ; Construction Graphique d'Entrepôts
et de Magasins de Données, INFORSID'99, La Garde, 1999
4. Chaudhuri S., Dayal U. ; An Overview of Data Warehousing
and OLAP Technology, ACM SIGMOD Record, 26(1), 1997, p.112
5. Dayal U., Blaustein B. T., Buchmann A. P., Chakravarthy U.
S., Hsu M., Ledin R., McCarthy D. R., Rosenthal A., Sarin S. K., Carey M. J.,
Livny M., Jauhari R. ; The HiPAC Project: Combining Active Databases and Timing
Constraints, ACM SIGMOD Record, 17(3), Chicago, 1988, p.312-322
6. Dihia LANASRI ; AI et Data Analytics Manager, 2015,
p.10
7. Samos J., Saltor F., Sistrac J., Bardés A. ;
Database Architecture for Data Warehousing: An Evolutionary Approach, DEXA'98,
Vienna, 1998, p.72
4. DICTIONNAIRE / WEBOGRAPHIE
1.
https://www.memoireonline.com
Page | 70
TABLE DES MATIERES
EPIGRAPHE III
IN MEMORIAM IV
DEDICACE V
REMERCIEMENTS VI
SIGLES ET ABRÉVIATIONS VII
LISTE DES FIGURES ET TABLEAUX VIII
0. INTRODUCTION GÉNÉRALE 1
0.1. CHOIX ET INTÉRÊT DU SUJET 1
0.1.1. CHOIX DU SUJET 1
0.1.2. INTÉRÊT DU SUJET 1
0.2. ÉTAT DE LA QUESTION 2
0.3. PROBLÉMATIQUE ET HYPOTHÈSES 2
0.3.1. PROBLÉMATIQUE 2
0.3.2. HYPOTHÈSES 2
0.4. MÉTHODES ET TECHNIQUES 3
0.4.1. MÉTHODES 3
0.4.2. TECHNIQUES 3
0.5. OBJECTIF DE LA RECHERCHE 3
0.6. DÉLIMITATION DE LA RECHERCHE 4
0.7. SUBDIVISION DU TRAVAIL 4
CHAPITRE I : GÉNÉRALITÉS SUR LE
SYSTÈME DÉCISIONNEL 5
1.0. INTRODUCTION 5
1.1 DÉFINITION DU SYSTÈME DÉCISIONNEL 5
1.1.1 ARCHITECTURE DE SYSTÈMES DÉCISIONNELS 5
Page | 71
1.2 OBJECTIFS PRINCIPAUX D'UN SYSTEME DECISIONNEL DANS LE
CADRE DE
LA GESTION PUBLIQUE. 7
1.2.1 Améliorer la prise de décision 7
1.2.2 Optimiser la gestion des ressources humaines 7
1.2.3 Favoriser la transparence et la
responsabilité 7
1.2.4 Support à la planification et à la
prévision 8
1.2.5 Améliorer la gestion financière
8
1.2.6 Faciliter la gestion des projets publics 8
1.2.7 Soutenir la gestion des crises et des situations
exceptionnelles 8
1.2.8 Renforcer la coopération
interinstitutionnelle 9
1.2.9 Améliorer la qualité des services publics
9
1.3 DIFFERENCE ENTRE UN SYSTEME D'AIDE À LA DECISION
(SAD) ET UN
SYSTEME D'INFORMATION DE GESTION (SIG). 9
1.3.1 Système d'Aide à la
Décision (SAD) 10
1.3.3 Composants principaux d'un SIG : 11
1.3.4 Différences entre un SAD et un SIG
12
1.3.5 Relation entre un SAD et un SIG 12
1.3.6 Types de systèmes décisionnels : 13
1.4 COMPOSANTS D'UN SYSTEME DECISIONNEL 13
1.6 LES DIFFÉRENTS ÉLÉMENTS CONSTITUTIFS
DU SYSTÈME DÉCISIONNEL 14
1.7 LES SOURCES DE DONNÉES DANS UN SYSTÈME
DÉCISIONNEL 15
1.8 AVANTAGES D'UN SYSTÈME DÉCISIONNEL DANS
LA GESTION DE LA
PERFORMANCE DES AGENTS 16
I.9. LES APPORTS DES SYSTÈMES DÉCISIONNELS 17
1.10 LES ENJEUX DE L'INFORMATIQUE DÉCISIONNELLE 18
1.11 LES FONCTIONS ESSENTIELLES DE L'INFORMATIQUE
DÉCISIONNELLE 18
1.12. DÉFINITION DES MODÈLES DE DONNÉES
DÉCISIONNELS 19
Page | 72
Conclusion partielle 20
CHAPITRE II: LE DATA WAREHOUSE 21
2.0 INTRODUCTION 21
2.1 DÉFINITION D'UN DATA WAREHOUSE (DW) 21
2.2 OBJECTIF DU DATA WARE HOUSE 22
2.3. LES COMPOSANTS DE BASE DU DATA WAREHOUSE 23
2.4. CARACTÉRISTIQUES D'UN DATA WAREHOUSE 25
2.5 ARCHITECTURE D'UN DATA WERAHOUSE 25
3.6 L'ETL 25
2.7 ENTREPÔTS ET BASES DE DONNÉES 26
2.7.1 Rôle d'un entrepôt de données 27
2.7.2 Systèmes transactionnels et systèmes
décisionnels 27
2.8 LA PROBLÉMATIQUE DE L'ENTREPRISE 28
2.9. SCHÉMAS D'UN DATA WAREHOUSE 29
2.9.1 Tables des faits : 29
2.9.2 Tables des dimensions : 29
2.10. MODELISATION MULTIDIMENSIONNELLE 30
2.10.1 Le Schéma en Etoile 30
2.10.2 Le Schéma en Flocon 31
2.10.3 schéma multi dimensionnel 31
2.11 LE DATA MART 32
2.11.1 Introduction 32
2.11.2 Les définitions 32
2.11.3 La place du datamart dans l'entreprise 33
2.11.4 Data warehouse Et Data mart 33
2.11.5. Architecture d'un Datamart 34
Page | 73
CONCLUSION PARTIELLE 34
CHAPITRE III : ANALYSE PRÉALABLE ET SPÉCIFICATION
DES BESOINS 35
3.0 INTRODUCTION 35
3.1. PRÉSENTATION DU CADRE D'ÉTUDE 35
3.1.1. Situation géographique 35
3.1.2. Historique 35
3.1.3. Statut juridique 36
3.1.4. Objet social de la DPFP 36
3.1.5. Durée d'existence de la DPFP 36
3.1.6. Rôles de la Direction Provinciale de la Fonction
Publique 36
3.1.7. Projets d'avenir de la DPFP 36
3.1.8. Organisation et fonctionnement 37
3.1.8.1. Organigramme de la DPFP 37
3.1.8.2. Fonctionnement de la DPFP 37
3.1.9 ORGANIGRAMME 39
3.2 ANALYSE DE L'EXISTANT 40
3.2.1 DEFINITION GLOBALE DU PROBLEME 40
3.2.2 LANGAGE DE MODELISATION DE L'EXISTANT 41
3.2.3 DIAGNOSTIC DE L'EXISTANT, CRITIQUES ET PROPOSITIONS
DES
SOLUTIONS 44
Conclusion partielle 44
CHAPITRE IV. CONCEPTION ET IMPLEMENTATION 45
4.0 INTRODUCTION 45
4.1 ANALYSE DES BESOINS 45
3.2.1 Besoins fonctionnels 45
3.2.2 Besoins non fonctionnels 46
Page | 74
4.2 ANALYSE CONCEPTUELLE 46
4.2.1 SYSTÈME OLTP (ONLINE TRANSACTION PROCESSING) 46
? CONCEPTION DE DIAGRAMME DE CLASSE 47
4.2.2 SYSTÈME OLAP (ONLINE ANALYTICAL PROCESSING) 47
? CONCEPTION DE MODELE EN ETOILE 49
4.3 ALGORITHME D'ANALYSE DE PERFORMANCE 49
a) Description des critères d'évaluation 50
b) Algorithme proposé 50
c) Conclusion 51
4.4 IMPLEMENTATION 52
4.4.1. Présentation de la technologie utilisée
52
4.3.1.1. Présentation de Visual C # 52
4.3.2. Schéma relationnel de la base de données
transactionnelle 54
4.3.3. Schéma multidimensionnel de l'entrepôt de
données 54
4.4.4. Quelques interfaces graphiques et code source de
l'application 55
4.3.4.1. Système transactionnel 55
A. Extrait des interfaces graphiques 55
B. Extrait du code source de l'application 58
4.5. Conclusion partielle 65
CONCLUSION GENERALE 66
RÉFÉRENCES BIBLIOGRAPHIQUES 68
TABLE DES MATIERES 70
| 

