Ministère de l'Enseignement Supérieur
et
Universitaire
UNIVERSITE PROTESTANTE DE LUBUMBASHI
FACULTE DES SCIENCES INFORMATIQUES

Vérité & Liberté
PROJET TUTORÉ DE FIN D'ETUDES
Sujet : CONCEPTION D'UN SYSTEME INTELLIGENT
D'ANALYSE
DE CV BASE SUR LE TRAITEMENT DU LANGAGE NATUREL
(NLP) POUR UNE
EVALUATION OPTIMISEE DES
CANDIDATURES : APPLICATION AU DEPARTEMENT
DES
RESSOURCES HUMAINES.
Effectué par NKISSA KUDOLYE JOSPIN Promotion :
BAC3
Filière : IAGE
Août 2025
Ministère de l'Enseignement Supérieur
et
Universitaire
UNIVERSITE PROTESTANTE DE LUBUMBASHI
FACULTE DES SCIENCES INFORMATIQUES

Vérité & Liberté
PROJET TUTORÉ DE FIN D'ETUDES
Sujet : CONCEPTION D'UN SYSTEME INTELLIGENT
D'ANALYSE
DE CV BASE SUR LE TRAITEMENT DU LANGAGE NATUREL
(NLP) POUR UNE
EVALUATION OPTIMISEE DES
CANDIDATURES : APPLICATION AU DEPARTEMENT
DES
RESSOURCES HUMAINES.
Promotion : BAC 3 Filière : IAGE
Dirigé par Professeur MWAMBA KASONGO Dahouda
Co-dirigé par Assistant NGOIE NKAYA Philippe
ANNEE ACADEMIQUE
2024-2025

DEDICACE
À ma famille,
Ce mémoire est le fruit de votre soutien inestimable, de
vos encouragements et de votre amour sans limites.
À mes parents, pour vos sacrifices, votre patience et
votre confiance en moi. Sans vous, rien de tout cela n'aurait été
possible.
NKISSA KUDOLYE JOSPIN

REMERCIEMENTS
Avec un coeur profondément reconnaissant et des mots
chargés d'émotion, je tiens à commencer cette page en
rendant gloire à Jéhovah Dieu, le Soutien suprême de ma
vie. À Lui seul reviennent les louanges éternelles pour le
souffle de vie, la santé préservée, la force quotidienne,
et la protection invisible mais constante dont j'ai
bénéficié tout au long de ce parcours. Sans Sa main
puissante, aucun de mes efforts n'aurait porté de fruit.
Je rends un hommage vibrant à mes chers parents,
Kuudolye Celestin et Kikaina Naomie , véritables artisans de mon avenir,
pour leur amour inconditionnel, leur soutien inlassable, et surtout pour avoir
assuré ma scolarité de façon continue, depuis mes premiers
pas à l'école maternelle jusqu'à ce jour. Vous avez
été et restez mes modèles de persévérance et
de foi. Grâce à vous, je me tiens aujourd'hui debout, fier du
chemin parcouru.
Mes pensées les plus affectueuses vont également
à l'ensemble de ma famille élargie, et tout
particulièrement à mes oncles et tantes actuellement
présents ici à Lubumbashi, pour leur soutien moral de haute
qualité, leur proximité affectueuse, et leurs paroles
réconfortantes aux moments les plus décisifs. Je n'oublierai
jamais les cadeaux précieux que vous m'avez offert avec amour et
fierté après chaque réussite. Vos gestes m'ont toujours
rappelé que je n'étais jamais seul.
Je tiens à exprimer ma gratitude la plus profonde
à mon directeur de mémoire, le Professeur MWAMBA KASONGO Dahouda,
pour ses orientations ingénieuses, sa disponibilité constante, et
sa rigueur académique qui ont largement contribué à donner
de la profondeur et de la qualité à ce travail. Son encadrement
bienveillant a été un véritable phare tout au long de
cette aventure intellectuelle.
Mes sincères remerciements vont également
à mon co-directeur, l'Assistant NGOIE NKAYA Philippe, pour ses conseils
avisés, son écoute attentive, et ses encouragements stimulants.
Son accompagnement méthodique m'a permis de progresser avec assurance et
efficacité.
Je ne saurais oublier mes connaissances, mes amis, et toutes
les personnes merveilleuses qui ont, d'une manière ou d'une autre,
laissé une empreinte positive dans cette aventure. Une mention
spéciale et honorifique à Maître ASIM, un ami exceptionnel
et une source inépuisable d'inspiration depuis l'école SHALOM
jusqu'à UPL avec la devise sanguine « rendre les parentes
fières car nous n'avons aucune seconde d'erreur la science ! la science
! »
À tous ceux et celles qui, par un geste, un mot, un
sourire ou une prière, ont contribué à cette
réussite, je vous dis un immense MERCI. Que
Jéhovah Dieu vous comble de ses bénédictions les
plus riches.

Table des matières
REMERCIEMENTS ii
LISTE DE FIGURES v
LISTE DES TABLEAU vii
INTRODUCTION 1
CHAPITRE 1 : Revue de la littérature 4
I.1 Revue des systèmes 4
CHAPITRE 2 : MÉTHODOLOGIE 11
2.1 Introduction 11
2.2 Présentation des méthodologies de
développement logiciel (SDLC) 11
2.3 Outils et technologies utilisés
15
2.4 Architecture du système 17
2.5 Méthode d'implémentation du NLP
17
2.6 Exigences fonctionnelles et non fonctionnelles
19
2.7 Limites méthodologiques 19
2.8 Conclusion 19
Chapitre 3 Conception du système 20
3.1 Introduction 20
3.2 Modélisation du processus métier
21
3.3 Identification des acteurs 22
3.4 Diagramme de contexte métier 23
3.5 Diagramme de processus métier BPMN (Business
Process Model and Notation) 24
3.6 Diagramme de cas d'utilisation métier
26
3.7 MODELE DU DOMAIN 27
3.7 Analyse du système informatique 28
3.8. Analyse des besoins de conception 32
3.9 Diagramme de séquence 37
3.12. CONCEPTION DU MODÈLE LOGIQUE DE
DONNÉES 60
3.13. DIAGRAMME DE DÉPLOIEMENT 61
Conclusion partielle 64
CHAPITRE 4 IMPLEMENTATION DE LA SOLUTION PROPOSEE
65
4.1. Introduction 65
4.1. Technologies 65
4.2 Rappels théoriques essentiels 68
4.2.1. Introduction au Machine Learning 68
1.2.2 Apprentissage supervisé 68
2.2.3 Apprentissage non supervisé 69
2.3.4 Apprentissage par renforcement 69
iv
2.3.5 Notions de Deep Learning 69
4.3 Récolte de données 74
4.4 Conception et Entraînement du Modèle de
Classification pour l'Analyse CV-Offres 75
4.5. Conclusion 80
CHAPITRE 5. RESULTATS ET EVALUATIONS 81
5.1 Résultats 81
Conclusion Générale 87
Bibliographie 88

LISTE DE FIGURES
Figure 1 Diagramme de contexte métier 24
Figure 2 Diagramme de processus métier BPMN 25
Figure 3 Diagramme de cas d'utilisation métier 26
Figure 4 Diagramme de classes système 28
Figure 5 Présentation du système 33
Figure 6 Diagramme de cas d'utilisation 35
Figure 7 Diagramme de séquence CU1 créer compte
38
Figure 8 Diagramme de séquence CU2 S'authentifier
39
Figure 9 Diagramme de séquence CU 3
Réinitialisation de mot de passe 40
Figure 10 Diagramme de séquence CU 4 Gérer
profil 41
Figure 11 Diagramme de séquence CU 5 Publier offre
42
Figure 12 Diagramme de séquence CU 6 Gérer
l'offre 43
Figure 13 Diagramme de séquence CU 7 Consulter les
offres 44
Figure 14 Diagramme de séquence CU 8
Téléverser un cv 45
Figure 15 Diagramme de séquence CU 9 supprimer ou
modifier un cv 46
Figure 16 Diagramme de séquence CU 10 Analyser un cv
47
Figure 17 Diagramme de séquence CU 12 Afficher
résultat 48
Figure 18 Diagramme de séquence CU 11 AfficherResultat
48
Figure 19 Diagramme de séquence CU 12 afficher
candidatures 49
Figure 20 Diagramme système 51
Figure 21 Diagramme de classe participante CU 2
Authentification 52
Figure 22 Diagramme de classe participante CU 2
Authentification 52
Figure 23 Diagramme de classe participante CU 3
Réinitialisation 53
Figure 24 Diagramme de classe participante CU 4 Gérer
profil 53
Figure 25 Diagramme de classe participante CU 5 publier offre
54
Figure 26 Diagramme de classe participante CU 6 Gérer
offre 55
Figure 27 Diagramme de classe participante CU 7 Consulter
l'offre 56
Figure 28 Diagramme de classe participante CU 8
Téléverser cv 56
Figure 29 Diagramme de classe participante CU 9 Supprimer
modifier cv 57
Figure 30 Diagramme de classe participante CU 10 Analyser cv
58
Figure 31 Diagramme de classe participante CU 11 Afficher
résultat 59
Figure 32 Diagramme de classe participante CU 12 Afficher
candidature 59
Figure 34 Diagramme de déploiement 63
Figure 35 Machine learning, deep learning description 70
Figure 36 Quelques Domaines du nlp 73
Figure 37 Déséquilibre initiale de classe 76
Figure 38 Equilibres de classes 77
Figure 39 Comparaison de la performance des modèles
78
Figure 40 Tableau comparatif des modèles 78
Figure 41 visualisation de la courbe de précision et
perte 79
Figure 42 Matrice de confusion du modèle validé
79
Figure 43 Matrice de confusion normalisé 79
vi
Figure 44 interface d'accueille 81
Figure 45 interface des offres 81
Figure 46 interface des offres avec option de filtre 82
Figure 47 interface de login pour s'authentifier 82
Figure 48 interface pour réinitialiser le mot de passe
83
Figure 49 interface pour la vérification de OTP envoyer
par mail 83
Figure 50 interface pour sur la vue du détaille de
l'offre 84
Figure 51Interface pour uploader le cv 84
Figure 52 Dashboard Entreprise 85
Figure 53 Dashboard chercheur d'emploie 85
Figure 54 Dashboard entreprise avant l'analyse 85
Figure 55Dashboard entreprise l'analyse encours 86
Figure 56 opération Asynchrone avec serveur celery
86
Figure 57 Résultat d'analyse 86
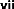
LISTE DES TABLEAU
Tableau 1 Outils et technologies utilisés 15
Tableau 2 Rôles des acteurs 23
Tableau 3 Identification des acteurs du système
d'Analyse de cv basé sur le NLP 33
Tableau 4 Planification des itérations 35
Tableau 5 Contenu du dataset 74
Tableau 6 Algorithmes implémentés 77

INTRODUCTION
Contexte du sujet
Le processus de recrutement constitue un pilier fondamental de
la gestion des ressources humaines, car il détermine la qualité
du capital humain au sein d'une organisation. Avec la numérisation
croissante des candidatures, les entreprises doivent aujourd'hui traiter un
volume massif de CV, ce qui rend les méthodes traditionnelles de
sélection de plus en plus inefficaces.
Cette surcharge d'informations entraîne non seulement
une perte de temps considérable, mais aussi une augmentation du risque
d'erreur humaine ou de biais dans l'évaluation des profils. Si un
recruteur passe une minute au moins pour évaluer un CV. Imaginons que
suite d'une annonce , l'entreprise reçoit 2000 CV, cela voudrait dire
que le recruteur passerait environ 33 heures pour la
sélection de ces CV, ce qui équivaut 4 jours de travail de 8
heures.
Parallèlement, les avancées dans le domaine de
l'intelligence artificielle (IA), et plus particulièrement du
traitement automatique du langage naturel (Natural Language Processing,
NLP), ont ouvert de nouvelles perspectives pour automatiser et
améliorer les processus décisionnels. Le NLP permet aux machines
de comprendre, d'analyser et de générer du langage humain, ce qui
en fait une technologie de choix pour l'analyse de documents non
structurés tels que les CV.
Dans ce contexte, plusieurs solutions intelligentes ont
été proposées dans le monde pour automatiser la
présélection des candidatures. Des systèmes basés
sur la détection de mots-clés, des moteurs de correspondance
sémantique, et plus récemment des modèles d'apprentissage
profond tels que BERT ou GPT ont été mis en oeuvre avec des
résultats encourageants.
À Lubumbashi, le recrutement pour plusieurs structures
reste encore largement manuel, malgré la disponibilité croissante
de CV numériques. Les départements des ressources humaines
manquent souvent d'outils adaptés pour automatiser ce processus, ce qui
ralentit considérablement la sélection des bons profils. Il
existe donc un besoin réel et urgent d'outils intelligents.
Ce mémoire s'inscrit dans cette dynamique. Il vise
à concevoir un système intelligent capable d'analyser
automatiquement des CV numériques rédigés en
français, à l'aide de techniques avancées de traitement du
langage naturel. Ce système pourra ainsi contribuer à rendre le
processus de présélection plus rapide, plus objectif et plus
efficace au sein des entreprises de Lubumbashi.
Objectifs de l'étude
L'objectif principal de cette étude est de
concevoir un système intelligent d'analyse de CV basé sur
le traitement du langage naturel (NLP) permettant d'automatiser
l'évaluation initiale des candidatures au sein d'un département
des ressources humaines.
Les objectifs spécifiques sont :
· D'extraire automatiquement les informations
pertinentes contenues dans les CV (diplômes, expériences,
compétences, etc.).
· De mesurer la correspondance entre les profils et les
offres d'emploi selon des critères définis.
2
· De proposer un classement des candidats en fonction de
leur adéquation avec le poste à pourvoir.
· D'adapter le système au contexte local
congolais, notamment au format des CV rédigés en
français.
Dans un environnement économique de plus en plus
compétitif, les entreprises doivent recruter rapidement les meilleurs
profils. Cependant, les départements RH sont souvent confrontés
à la difficulté de traiter manuellement un grand volume de
candidatures, Ce traitement manuel est non seulement long, mais il peut
également être subjectif et peu reproductible.
Plusieurs outils existent pour aider à cette
tâche, mais ils sont souvent conçus pour des environnements
anglophones, ne tiennent pas compte de la structure des CV francophones, et
nécessitent des ressources techniques importantes. À Lubumbashi,
les petites et moyennes entreprises disposent rarement d'outils intelligents ou
de personnel formé à ce type de technologie.
Dès lors, une question centrale se pose :
comment concevoir un système intelligent, basé sur le
NLP, capable d'analyser automatiquement des CV en français et
d'optimiser le processus de présélection des candidatures
?
Hypothèse
Nous posons l'hypothèse suivante :
L'utilisation d'un système intelligent
basé sur le traitement automatique du langage naturel permet
d'automatiser et d'accélérer le processus de
présélection des CV, tout en améliorant la pertinence des
candidats retenus pour un poste donné.
Importance ou justification de l'étude Ce
travail est justifié par plusieurs besoins :
v Sur le plan pratique, il répond
à une demande réelle d'amélioration des outils RH dans un
contexte local où les ressources sont limitées.
v Sur le plan scientifique, il s'inscrit
dans la dynamique actuelle de recherche autour du NLP appliqué à
des problématiques RH.
v Sur le plan technologique, il explore la
mise en oeuvre de modèles d'IA modernes dans un environnement
francophone et africain, souvent peu représenté dans les bases de
données utilisées pour l'apprentissage automatique.
Portée et limites
La portée de cette étude se limite aux points
suivants :
· Le système ne traitera que des CV
numériques (PDF).
· Seuls les CV rédigés en langue
française seront analysés.
3
· Le système s'arrête à la
phase de présélection : il ne réalise pas
d'évaluation comportementale ni d'entretien.
Les limites incluent :
· L'efficacité du système dépendra de
la qualité des CV (orthographe, structure,
lisibilité).
· Le manque de données locales
annotées pour l'entraînement de modèles peut
limiter la performance initiale.
Structure du travail
Ce mémoire est organisé en cinq chapitres
principaux :
v Chapitre 1 : Revue de la
littérature
Analyse des travaux existants en lien avec l'analyse automatique
de CV, le NLP appliqué aux RH, et les systèmes intelligents
d'évaluation des candidatures.
v Chapitre 2 : Méthodologie
Présentation du modèle de développement
logiciel (SDLC), des techniques NLP adoptées, et des outils mis en
oeuvre.
v Chapitre 3 : Conception du système
Analyse du système informatique (Modélisation des
exigences fonctionnelles et non fonctionnelles ...)
Conception du système informatique (description de
l'architecture, et conception UML ...)
v Chapitre 4 : Implémentation
Description technique de la réalisation du
système, des choix technologiques et des modules
implémentés.
v Chapitre 5 : Résultats et
évaluation
Présentation du système développé,
des tests effectués (fonctionnalité, performance,
utilisabilité ...) et interprétation des résultats
obtenus.
4
CHAPITRE 1 : Revue de la littérature
De nos jours, avec le grand nombre de candidatures que les
entreprises reçoivent, il devient de plus en plus important de trouver
des moyens efficaces pour analyser les CV. C'est dans ce contexte que les
systèmes intelligents, combinant intelligence artificielle, traitement
du langage naturel (NLP) et ressources humaines, prennent tout leur sens. Ce
chapitre propose un regard critique sur les recherches qui ont
déjà été menées dans ce domaine.
Nous allons voir quelles méthodes ont été
utilisées, quels étaient les objectifs, ce qui a
été obtenu et quelles limites ont été
rencontrées. Cela nous permettra d'identifier ce qui manque encore, et
de mieux comprendre pourquoi le projet que nous présentons ici est
pertinent et utile
I.1 Revue des systèmes
Revue (1)
I.1.1 L'intelligence artificielle au coeur du processus de
recrutement E Recrutement 4.0 au Maroc : Etat des lieux et perspectives
[1].
1. Identification des lacunes en matière de
recherche ou de mise en oeuvre
Manque d'application à 100% :
L'e-recrutement 4.0 n'est pas encore pleinement appliqué au Maroc, ce
qui souligne un écart entre les possibilités technologiques et
leur adoption réelle.
Résistance des candidats :
Une grande partie des candidats refuse
d'être évaluée par un robot, en raison :
o du manque de formation numérique,
o de la peur de l'automatisation,
2. Synthèse
L'article synthétise plusieurs travaux
antérieurs en montrant que l'intelligence artificielle apporte :
des gains en efficacité (temps de traitement des CV
réduit de 18h à quelques minutes),
une réduction des erreurs humaines,
une capacité d'analyse de grands volumes de
données (Allal-Chérif et al., 2021).
Mais il regroupe aussi les critiques fréquentes :
manque de transparence des décisions algorithmiques,
risques d'erreurs injustes,
Des études de cas (ex. Amazon) et des
témoignages d'experts (Morgane Fantino, 2021).
3. Analyse critique
Points forts : L'étude met en
lumière les avantages tangibles de l'IA dans le
recrutement, comme l'efficacité et la rapidité,
tout en soulignant les défis techniques et culturels.
5
Limites : Les auteurs notent que les travaux
existants se concentrent souvent sur les perspectives des recruteurs,
négligeant parfois la perception des candidats, notamment dans des
contextes spécifiques comme le Maroc.
Contributions : L'article comble
partiellement cette lacune en analysant la perception des candidats
marocains
4. Contextualisation
La revue de la littérature montre que l'e-recrutement
basé sur l'intelligence artificielle améliore la rapidité
et l'efficacité du tri des candidatures. Cependant, ces solutions sont
souvent développées pour des contextes internationaux,
principalement anglophones, et ne s'adaptent pas bien aux
réalités locales.
À Lubumbashi, les CV sont souvent non
structurés, rédigés en français, et les entreprises
disposent de peu de ressources techniques.
Le présent mémoire vise donc à combler ce
vide en développant une solution NLP adaptée au contexte local,
capable d'analyser automatiquement les CV francophones dans un environnement
à faible technicité.
Revue (2)
I.1.2 Diplôme : Master en gestion des ressources
humaines, à finalité spécialisée en "politique et
management RH" [2].
1. Identification des lacunes en matière de
recherche ou de mise en oeuvre
En parcourant les travaux existants, notamment celui de
Martins et Mariana (2022),plusieurs limites apparaissent dans les approches
actuelles d'automatisation du recrutement par le traitement du langage naturel.
Ces recherches, bien qu'intéressantes, restent souvent
éloignées des réalités du terrain dans des
contextes comme celui de Lubumbashi.
Premièrement, la majorité des
études s'appuient sur des données provenant de grandes
entreprises internationales, avec peu de prise en compte des
spécificités locales. Or, dans des villes comme Lubumbashi, les
candidatures présentent une grande diversité de formats parfois
non structurés, manuscrits ou scannés et les entreprises
disposent rarement des moyens techniques nécessaires pour
intégrer des solutions complexes.
Deuxièmement, bien que des
modèles avancés de NLP tels que BERT soient
évoqués, leur application concrète dans l'analyse de CV,
notamment en langue française, reste encore limitée. Leur
potentiel est loin d'être pleinement exploité, surtout dans des
contextes à faible ressource.
Par ailleurs, les systèmes proposés sont
généralement peu personnalisés. Ils utilisent des scores
standards de similarité(TF-IDF), sans véritablement tenir compte
des attentes spécifiques du recruteur ou des exigences du poste à
pourvoir.
6
Ces constats soulignent la nécessité de
concevoir une solution innovante, à la fois intelligente, éthique
et réellement adaptée au contexte local.
Synthèse
L'article explore l'utilisation des outils de traitement
automatique du langage naturel (NLP) dans le domaine des ressources humaines,
notamment pour l'analyse de CV et l'appariement aux offres d'emploi. Il passe
en revue plusieurs systèmes, outils, et méthodes existantes,
comme le TF-IDF ou encore les moteurs de recommandation classiques.
Analyse critique
L'examen du document de référence fait
apparaître plusieurs limites notables dans les approches existantes de
l'analyse automatisée des candidatures.
D'abord, les solutions reposent encore largement sur des
représentations textuelles traditionnelles, comme le modèle
TF-IDF, qui reste limité. Même si des modèles plus
avancés comme BERT sont mentionnés, leur intégration est
encore incomplète ou expérimentale, ce qui réduit leur
impact réel sur la qualité de l'analyse.
Ensuite, on constate un manque de personnalisation et de prise
en compte du contexte. Les systèmes évalués se contentent
souvent d'un appariement générique, sans s'adapter aux
spécificités d'un poste, d'une entreprise, ou aux
préférences individuelles des recruteurs. Cette approche
compromet la pertinence des résultats proposés.
Contextualisation
Dans un monde du travail en pleine transformation
numérique, les départements des ressources humaines cherchent
à moderniser leurs outils pour gagner en efficacité et en
objectivité. Le recours au traitement automatique du langage naturel
(NLP) s'inscrit dans cette dynamique, en permettant d'analyser plus rapidement
et de manière plus cohérente des centaines de candidatures.
Dans ce contexte, le présent travail vise à
combler ce vide en concevant un système intelligent d'analyse de
CV, combinant des techniques de NLP, une approche éthique et
une adaptation aux conditions spécifiques du terrain local.
Revue (3)
I.1.3 Un système intelligent pour l'optimisation du
processus de e-recrutement [3]
Identification des lacunes en matière de recherche
ou de mise en oeuvre
Malgré les avancées importantes dans le domaine
du e-recrutement assisté par l'intelligence artificielle, plusieurs
lacunes persistent dans les travaux antérieurs, notamment :
7
Identification incomplète du profil de
candidat
La majorité des systèmes d'appariement exploitent
uniquement le texte brut des offres d'emploi, sans en extraire formellement les
caractéristiques clés du profil recherché (ex. :
diplôme, expérience, compétences ...). Cela limite la
qualité des recommandations de candidats.
Synthèse
la littérature sur le e-recrutement intelligent se
structure autour :
Extraction d'entités (NER) : Les méthodes
traditionnelles (à base de règles ou d'ontologies) sont
aujourd'hui dépassées par les modèles basés sur
l'apprentissage automatique (BERT). Ces derniers permettent une meilleure
extraction d'informations à partir des offres et des CV.
Analyse critique
Bien que les solutions existantes soient techniquement
avancées, plusieurs critiques peuvent toujours persister :
Les méthodes de Matching sont souvent
dépendantes de la qualité des données textuelles, ce qui
peut jouer négativement sur les résultats.
Contextualisation
Systèmes d'aide à la décision (SAD) de
Ramdani (2021) s'inscrit dans une dynamique de modernisation des processus de
recrutement en ligne, en combinant :
- l'analyse automatique des documents RH (CV, offres)
- l'extraction de caractéristiques pertinentes (profil
recherché) [3].
Revue(4)
1.1.4 Intelligence artificielle appliquée au
processus de recrutement - Les perceptions des recruteurs [4]
Identification des lacunes en matière de
recherche ou de mise en oeuvre Lacunes théoriques :
- Le mémoire souligne que l'IA dans le recrutement est
un sujet émergent, encore peu étudié scientifiquement.
Lacunes pratiques :
- Les entreprises ont encore du mal à intégrer
l'IA dans leur stratégie RH globale, faute de moyens, de
compétences numériques internes, ou de clarté sur les
retours d'investissement.
8
Synthèse
Le mémoire de Mariana Martins explore les perceptions
des recruteurs vis-à-vis de l'IA dans le processus de recrutement. Il
adopte une méthode qualitative à travers des entretiens
semi-directifs. L'étude montre que :
- L'IA est perçue comme un levier d'efficacité,
surtout dans les phases de présélection.
- Elle soulage les recruteurs des tâches
répétitives, permet un meilleur ciblage et accélère
le traitement des candidatures.
Analyse critique
Points forts du mémoire :
Bonne structuration théorique : le mémoire offre
une revue de littérature approfondie sur la GRH, le recrutement et
l'IA.
Limites :
L'analyse pourrait approfondir davantage les enjeux juridiques
et les dimensions éthiques (RGPD Règlement
Général sur la Protection des Données.),
consentement).
Contextualisation
Dans le contexte socio-économique :
Le mémoire s'inscrit dans un moment post-COVID
où le télétravail, le recrutement à distance, et la
transformation digitale accélèrent la mutation des RH.
Revue(5)
I.1.5 Mise en correspondance entre les CV et les offres
d'emploi en utilisant le Deep Learning [5]
Identification des lacunes en matière de recherche
ou de mise en oeuvre. Lacunes en recherche :
- Peu de références sont faites aux enjeux
juridiques et éthiques (comme la confidentialité des
données personnelles ou les biais algorithmiques dans les
systèmes de recrutement).
Lacunes en mise en oeuvre :
- Le système repose sur des données
collectées via web scraping (Indeed), ce qui peut poser problème
légalement si l'usage n'est pas encadré.
Synthèse du mémoire
Ce mémoire propose un système de recommandation
qui met en correspondance les CV et les offres d'emploi à l'aide du
deep learning, notamment :
9
Un réseau de neurones classificateur
pour étiqueter les segments des CV (éducation,
expérience, compétences).
L'utilisation de cosinus de similarité
pour calculer la similarité sémantique entre les
éléments d'un CV et ceux d'une offre d'emploi.
Analyse critique Points forts :
Travail rigoureux et structuré, avec une bonne
maîtrise des outils de traitement du langage naturel (NLP) et du deep
learning.
Limites :
L'ensemble du système repose sur des
données textuelles extraites automatiquement
Contextualisation
Dans le contexte technologique :
L'usage du deep learning dans le NLP est
pertinent et montre l'évolution des outils classiques (mots-clés)
vers des approches plus intelligentes.
Dans le contexte local et académique :
Le mémoire contribue à valoriser
l'application de l'IA dans les systèmes web au sein des
universités algériennes.
Pourquoi faire une revue de la littérature
?
1. Pour mieux comprendre notre sujet :
Avant de concevoir un système intelligent d'analyse de
CV, il est essentiel de comprendre en profondeur les fondements
théoriques liés au traitement du langage naturel et à son
usage dans le domaine des ressources humaines. La revue de littérature
permet d'explorer les travaux antérieurs, d'identifier les
modèles et techniques couramment utilisés (comme Word2Vec ou
BERT), et de mieux cerner les enjeux liés à l'automatisation du
tri des candidatures. Cette compréhension offre non seulement une base
solide à la démarche, mais oriente aussi le choix des
technologies adaptées aux objectifs du projet.
2. Pour identifier les lacunes et les besoins de
recherche :
Analyser les recherches existantes aide à
révéler les limites que rencontrent les systèmes d'analyse
de CV actuels, comme leur difficulté à traiter les formats non
standardisés, leur manque de contextualisation ou leur tendance à
négliger les compétences transversales. En mettant en
évidence ces insuffisances, la revue de littérature ouvre des
pistes concrètes d'amélioration et permet de mieux cibler les
besoins encore insatisfaits, que ce soit en termes techniques, fonctionnels ou
éthiques.
10
3. Pour justifier notre recherche :
La revue de littérature permet aussi de positionner
clairement sa propre contribution. En s'appuyant sur les études
existantes et en soulignant leurs limites, elle montre en quoi le
système proposé se distingue et répond à des
besoins réels. Dans notre cas, l'intégration du NLP pour analyser
intelligemment les CV vise à offrir une solution plus précise,
plus accessible et mieux adaptée aux exigences des recruteurs, notamment
dans des contextes locaux peu représentés dans la recherche
actuelle.
4. Pour faciliter la rédaction d'un travail de
recherche :
Enfin, la revue de littérature joue un rôle
structurant dans la rédaction du mémoire. Elle permet de
construire la problématique, d'alimenter le cadre conceptuel, et de
justifier les choix méthodologiques. Elle sert également de
repère tout au long du projet, assurant cohérence et rigueur
scientifique. Ainsi, elle facilite non seulement la rédaction du
travail, mais renforce également la recherche.
11
CHAPITRE 2 : MÉTHODOLOGIE
2.1 Introduction
En informatique, la méthodologie désigne
l'ensemble des techniques, processus et approches utilisés pour
concevoir, développer, implémenter et maintenir des
systèmes informatiques. Elle s'applique à toutes les
étapes du cycle de vie logiciel, depuis l'analyse des besoins
jusqu'à la maintenance, en passant par la conception, le codage et les
tests. Une méthodologie rigoureuse permet de structurer le travail, de
garantir la qualité du logiciel produit, et de réduire les
risques d'échec du projet.
Dans le domaine de l'ingénierie logicielle, la
méthodologie représente bien plus qu'une simple succession
d'étapes techniques. Elle incarne une vision structurée du
développement logiciel, qui permet de traduire une idée
fonctionnelle en une solution informatique fiable, performante et
évolutive. Concrètement, elle désigne l'ensemble des
techniques, processus et approches utilisées pour analyser, concevoir,
implémenter, tester, déployer et maintenir un système
logiciel.
Chaque projet, quelle que soit sa taille, repose sur une
série de choix méthodologiques qui influencent directement sa
réussite. Sans une démarche rigoureuse et bien définie, le
développement logiciel devient vulnérable aux retards, aux
erreurs de conception, à l'instabilité du code et à
l'inadéquation entre le produit final et les besoins des
utilisateurs.
La méthodologie s'applique donc à toutes les
phases du cycle de vie logiciel -- depuis la formulation des exigences
jusqu'à la maintenance post-déploiement, en passant par la
modélisation, la programmation et l'évaluation des performances.
Elle permet de structurer le travail des développeurs, de coordonner les
efforts de l'équipe projet, et surtout, d'assurer que chaque
décision technique reste alignée avec les attentes fonctionnelles
du client ou de l'utilisateur final.
Mais au-delà de sa dimension technique, la
méthodologie est aussi une démarche humaine. Elle établit
un cadre de collaboration entre les différents acteurs du projet :
développeurs, chefs de projet, analystes métiers, utilisateurs
finaux. Elle définit les rôles, organise la communication,
facilite les feedbacks et favorise l'amélioration continue. Ainsi, elle
devient un levier stratégique pour anticiper les difficultés,
maîtriser les risques et construire des solutions réellement
utiles et durables.
Dans le cadre du présent projet, qui vise à
concevoir un système intelligent d'analyse de CV à l'aide du
traitement automatique du langage naturel (NLP), le recours à une
méthodologie adaptée est indispensable. Le caractère
innovant, technique et évolutif de cette solution nécessite une
démarche de développement souple, progressive et centrée
sur l'utilisateur.
2.2 Présentation des méthodologies de
développement logiciel (SDLC)
Le développement logiciel repose sur des modèles
méthodologiques bien établis, regroupés sous le terme de
SDLC (Software Development Life Cycle). Chaque modèle organise les
différentes phases du développement selon des principes et une
logique propre. Le choix du modèle influence profondément la
manière de gérer le projet, de collaborer en équipe et
d'interagir avec les utilisateurs finaux.
12
Ci-dessous, une présentation des principales
méthodologies :
1. Le modèle en cascade (Waterfall)
Le modèle en cascade est l'un des plus anciens
modèles de développement. Il se caractérise par une
progression linéaire et séquentielle des phases de
développement. Chaque étape (analyse des besoins, conception,
implémentation, test, déploiement, maintenance) doit être
complétée avant de passer à la suivante.
Caractéristiques :
· Rigidité du processus : pas de retour possible en
arrière.
· Documentation exhaustive à chaque phase.
· Adapté aux projets à exigences fixes et
stables. Avantages :
· Simplicité de mise en oeuvre.
· Bonne traçabilité des livrables.
Limites :
· Faible adaptabilité aux changements.
· Risque élevé si les besoins sont mal
définis au départ.
2. Le modèle en spirale
Ce modèle introduit une approche itérative
combinée à une analyse du risque. Chaque cycle (ou spirale)
contient les étapes classiques du développement, mais avec des
boucles successives qui permettent d'améliorer ou de corriger le produit
progressivement.
Caractéristiques :
· Axé sur la gestion des risques.
· Intègre des retours fréquents.
Avantages :
· Bonne maîtrise des risques.
· Adapté aux projets longs ou complexes.
Limites :
· Coûts élevés.
· Nécessite une expertise en évaluation de
risques.
3. Le modèle en V (ou modèle de validation
et de vérification)
C'est une extension du modèle en cascade, avec une
correspondance stricte entre chaque phase de développement et sa phase
de test. Chaque exigence a un plan de test associé.
13
Caractéristiques :
· Vision claire des étapes de validation.
· Phase de tests bien planifiée. Avantages
:
· Haut niveau de qualité logicielle.
· Réduction des erreurs de validation.
Limites :
· Peu flexible.
· Nécessite une très bonne définition
des exigences dès le départ.
4. Le modèle Agile
Le modèle Agile est itératif, incrémental
et collaboratif. Il repose sur une organisation du travail en sprints (courtes
périodes de développement), avec des démonstrations
régulières, des tests continus et une adaptation rapide aux
retours des utilisateurs.
Caractéristiques :
· Priorité à la satisfaction du client.
· Évolution continue du produit. Avantages
:
· Flexibilité aux changements.
· Amélioration continue.
· Forte implication des utilisateurs. Limites
:
· Moins adapté aux projets très
réglementés.
· Risque de dérive si la gestion de projet est
faible.
5. La méthode DevOps
DevOps (Development + Operations) est une culture qui vise
à rapprocher les équipes de développement logiciel et
celles chargées de l'exploitation (déploiement, surveillance).
Elle met l'accent sur l'automatisation, la livraison continue et
l'intégration continue.
Caractéristiques :
· Développement, test et déploiement
automatisés.
· Surveillance et retour immédiat après mise
en production.
14
Avantages :
· Accélère la livraison des
fonctionnalités.
· Améliore la stabilité des systèmes.
Limites :
· Nécessite une infrastructure technique
avancée.
· Transformation culturelle parfois difficile dans les
grandes entreprises. 6. Le modèle Lean
Inspiré du lean manufacturing, cette méthode vise
à éliminer les gaspillages, optimiser la valeur apportée
au client et réduire les délais. Elle repose sur la
simplification des processus, la réduction des tâches inutiles, et
l'autonomie des équipes.
Caractéristiques :
· Centré sur la valeur utilisateur.
· Recherche permanente de l'efficience. Avantages
:
· Gain de temps et de ressources.
· Produit adapté aux besoins réels.
Limites :
· Peut être difficile à mettre en oeuvre sans
expérience.
· Moins structuré que les modèles classiques.
2.3 Justification du modèle choisi : Agile
Compte tenu de la nature évolutive du projet (analyse de
CV et recrutement intelligent), le choix s'est porté sur la
méthodologie Agile. Cette approche permet de :
· Décomposer le développement en sprints
hebdomadaires,
· Intégrer rapidement les retours des RH et
utilisateurs finaux,
· Livrer des fonctionnalités utiles à chaque
itération,
· Réagir rapidement aux imprévus et
changements fonctionnels.
15
2.3 Outils et technologies utilisés
Le projet a mobilisé des technologies modernes,
adaptées aux besoins du NLP et du développement web :
Tableau 1 Outils et téchnologies
utilisés
Catégorie Outils/Technologies
Justification
|
Environnement de
développement
|
Anaconda
|
Distribution Python complète et stable
avec
gestionnaire d'environnements intégrés
(conda),
idéale pour le NLP et la data science
|
|
Langage principal
|
Python
|
Langage flexible, adapté au traitement NLP et
à l'IA
|
|
Framework Web
|
Django
|
Framework rapide, sécurisé, avec
architecture
MVT intégrée
|
|
Traitement du
langage
|
spaCy, Transformers
(BERT)
|
Extraction avancée d'entités,
compréhension
sémantique
|
|
Base de données
|
PostgreSQL
|
Système relationnel robuste, performant et
open
source
|
|
Interface frontend
|
Rectact
|
Design réactif, moderne et facile à
intégrer
avec l'architecture mvvm
|
|
Visualisation
|
Matplotlib, Seaborn
|
Génération de graphiques analytiques clairs
et
personnalisables
|
SECTION : Environnement et outils de
développement
Afin de concevoir un système intelligent d'analyse de
CV basé sur le traitement automatique du langage naturel, nous avons
soigneusement sélectionné une série d'outils,
bibliothèques et environnements adaptés au contexte du projet.
Cette section décrit en détail les choix technologiques retenus
ainsi que leur justification technique et fonctionnelle.
1. Environnement de développement :
Anaconda
L'environnement de développement utilisé dans ce
projet est Anaconda. Il s'agit d'une distribution open source de Python,
largement adoptée dans les domaines de la data science, du machine
learning et du traitement de données. Anaconda fournit un
écosystème intégré comprenant le gestionnaire de
paquets Conda, un environnement isolé et reproductible, ainsi que des
interfaces comme Jupyter Notebook ou Spyder. Ce choix permet de gérer
facilement les dépendances complexes liées aux
bibliothèques NLP (comme spaCy, transformers) et d'assurer une
compatibilité cohérente des versions. De plus, Anaconda facilite
le déploiement sur différents systèmes (Windows, Linux),
ce qui est crucial pour la portabilité du projet.
L'interface web destinée aux utilisateurs (entreprises
et demandeur d'emploie) a été développée en
s'appuyant sur la bibliothèque JavaScript React. Ce
choix technologique permet de
16
2. Langage de programmation principal :
Python
Le langage central utilisé est Python, en raison de sa
grande richesse en bibliothèques dédiées au traitement du
langage naturel, à l'intelligence artificielle et à la science
des données. Python est aujourd'hui considéré comme la
norme dans les domaines du NLP, grâce à des bibliothèques
comme spaCy, NLTK, scikit-learn, TensorFlow ou encore Hugging Face
Transformers. Sa syntaxe claire et son accessibilité favorisent une
productivité accrue et facilitent la collaboration entre
développeurs. De plus, Python est bien supporté dans les
environnements universitaires, ce qui rend son intégration naturelle
dans un cadre académique.
3. Framework Web : Django
Pour le développement de l'application web, nous avons
utilisé le framework Django. Ce framework Python repose sur une
architecture modèle-vue-contrôleur (MVC) qui favorise la
séparation des responsabilités et la maintenabilité du
code. Django est reconnu pour sa sécurité, sa robustesse et sa
rapidité de développement. Il intègre nativement des
modules pour la gestion des utilisateurs, l'administration des données,
les migrations de base de données, ce qui permet un développement
accéléré et structuré de la plateforme. Django est
également bien adapté à l'intégration de composants
d'intelligence artificielle via des APIs.
4. Traitement automatique du langage : spaCy et
Transformers (BERT)
Le coeur du système repose sur l'analyse linguistique
et sémantique des documents textuels (CV, offres d'emploi). Pour cela,
nous avons utilisé deux outils puissants et complémentaires.
D'une part, spaCy permet un traitement linguistique rapide et précis :
tokenisation, lemmatisation, reconnaissance d'entités nommées
(NER), etc. D'autre part, la bibliothèque Transformers de Hugging Face
fournit des modèles de langage pré-entraînés (comme
BERT) capables de produire des représentations sémantiques
profondes des phrases. Ces modèles permettent un appariement intelligent
entre un CV et une offre d'emploi, même lorsque les termes
utilisés diffèrent. Le couplage de spaCy pour la syntaxe et de
BERT pour la sémantique permet une analyse fine, robuste et
contextualisée.
5. Base de données : PostgreSQL
Le système de gestion de base de données
utilisé est PostgreSQL. Il s'agit d'un SGBD relationnel open source
reconnue pour sa fiabilité, sa conformité aux standards SQL et
ses performances, même avec des volumes de données importants.
PostgreSQL permet de stocker les profils candidats, les offres d'emploi, les
résultats d'analyse, ainsi que les historiques d'évaluation. Sa
capacité à gérer des types de données complexes et
à supporter les requêtes avancées (jointures,
agrégats, indexation) en fait un choix idéal pour ce projet. De
plus, son intégration avec Django via l'ORM (Object Relational Mapper)
permet une manipulation fluide des données côté backend.
6. Interface utilisateur (Frontend) : React
17
construire des interfaces utilisateur dynamiques et
réactives, capables de mettre à jour l'affichage en temps
réel en fonction des interactions et des données reçues du
backend.
React crée un système d'interface modulaire,
où chaque composant peut être stylisé de manière
claire et maintenable.
Grâce à cette approche, l'application propose un
tableau de bord interactif, ergonomique et responsive, optimisé pour
différents formats d'écrans (ordinateurs de bureau, tablettes,
terminaux mobiles). L'utilisation de React offre en outre la possibilité
d'implémenter des fonctionnalités avancées, telles que le
rafraîchissement automatique des résultats de matching, la
navigation fluide entre les pages et la gestion centralisée de
l'état de l'application. Enfin, cette architecture frontend garantit une
accessibilité renforcée et une expérience utilisateur
intuitive, en adéquation avec les standards modernes du
développement web.
7. Visualisation de données : Matplotlib et
Seaborn
Pour visualiser les résultats du système
(statistiques de matching, performances,
comparaisons), des bibliothèques de visualisation ont
été utilisées. Matplotlib est la bibliothèque de
base pour créer des graphiques en Python : histogrammes, courbes,
barres,
etc. Seaborn, construite sur Matplotlib, permet d'obtenir des
visualisations plus esthétiques avec moins de code, et une
intégration facilitée avec les DataFrames (pandas). Ces outils
sont particulièrement utiles pour présenter les
résultats des tests, les performances des
modèles NLP, ou encore les distributions de scores de
similarité entre CV et offres.
2.4 Architecture du système
L'architecture logicielle suit une structure client-serveur avec
les modules suivants :
1. Import des données :
Téléversement de CV au format PDF.
2. Extraction et prétraitement :
Conversion en texte brut, nettoyage, tokenisation.
3. NLP : Extraction des entités (NER),
tokenization, lemmatisation, analyse sémantique.
4. Matching et score : Calcul de
similarité entre le profil et une offre d'emploi.
5. Système d'aide à la décision
: Classement des candidats.
6. Dashboard : Interface RH, consultation des
résultats. 2.5 Méthode d'implémentation du
NLP
2.5.1 Extraction et prétraitement
Les CV sont extraits via un module OCR ou extraction PDF directe.
Le texte est ensuite nettoyé :
· Suppression des caractères spéciaux
· Mise en minuscule
· Suppression des stopwords (ex. "le", "et", "de")
· Lemmatisation pour réduire les mots à leur
racine
18
2.5.2 Reconnaissance d'entités (NER)
Le modèle spaCy est utilisé dans
un premier temps pour détecter :
· Les noms et prénoms
· Les diplômes (ex. Licence, Master)
· Les compétences techniques ("Python", "SQL")
· Les dates d'expérience professionnelle
Un modèle BERT pré-entraîné (par ex.
CamemBERT pour le français) vient enrichir cette extraction avec une
meilleure compréhension contextuelle.
2.5.3 Vectorisation et représentation
Chaque CV et chaque offre sont convertis en vecteurs
sémantiques à l'aide d'un encodeur BERT. 2.5.4
Calcul de similarité (cosine similarity)
Contexte : Après extraction des textes du CV et de
l'offre, le système utilise un modèle BERT (ou autre encodeur
NLP) pour transformer ces textes en vecteurs numériques (embedding).
Chaque document devient un vecteur dans un espace sémantique.
But : Mesurer à quel point le CV et l'offre d'emploi sont
proches dans cet espace vectoriel. On utilise pour cela la similarité
cosinus (cosine similarity).
(AxB)
Formule mathématique :
sim(A, B) = (||A||x||B||
Avec :
· A et B : vecteurs denses du CV et de l'offre.
· A · B : produit scalaire des deux vecteurs.
· ?A? et ?B? : norme (longueur) des vecteurs A et B.
Interprétation du score :
· Score = 1 ? les deux vecteurs sont identiques
(même orientation) ? documents très similaires.
· Score = 0 ? les vecteurs sont orthogonaux ? aucune
similarité.
· Score < 0 (rare dans ce contexte) ? vecteurs
opposés ? contradiction ou divergence sémantique.
Mathématiquement par là tous s'expliquent et
facile à démontrer une fois le texte converti en vecteur .
Supposons que l'encodage donne ces vecteurs :
· CV ? A = [0.5, 0.1, 0.4]
· Offre ? B = [0.6, 0.0, 0.3] sim(A, B) donnera = 0.965
19
2.5.5 Classement intelligent
Les candidats sont classés selon leur score, et ce
classement est affiché dans le dashboard RH Entreprise.
2.6 Exigences fonctionnelles et non fonctionnelles
Fonctionnelles
· Upload de CV PDF
· Extraction automatique des données pertinentes
· Matching avec des offres d'emploi
· Dashboard RH (score, export, tri) Non
fonctionnelles
· Réactivité de l'interface
· Sécurité des données
(authentification, cryptage)
· Compatibilité mobile et navigateurs
· Performances (temps de traitement < 2 secondes)
2.7 Limites méthodologiques
Certaine limite à signaler :
· Difficultés de traitement de certains formats PDF
complexes 2.8 Conclusion
La méthodologie déployée combine des outils
modernes, une approche agile et des techniques de NLP puissantes afin de
répondre aux besoins du e-recrutement intelligent. Le prochain chapitre
abordera en détail la conception technique du système et ses
différents composants fonctionnels.
20
Chapitre 3 Conception du système
3.1 Introduction
Dans le cadre de ce mémoire portant sur le
développement d'un système intelligent d'analyse de CV
fondé sur le traitement du langage naturel (NLP), le présent
chapitre constitue une étape fondamentale de la démarche
méthodologique. Il vise à exposer en détail le processus
de conception de l'application envisagée, depuis l'identification des
besoins métier jusqu'à la définition des modèles
logiques et techniques.
La conception d'un système d'information repose sur un
enchaînement structuré d'activités qui permettent de passer
d'un constat problématique à une solution technique fiable et
pertinente. Dans le domaine du recrutement, la gestion des candidatures est
aujourd'hui confrontée à plusieurs difficultés: la
réception massive de CV non standardisés, la lenteur de
l'évaluation manuelle, et la subjectivité inhérente au tri
des candidatures. L'émergence des techniques de NLP, notamment les
modèles pré-entraînés comme BERT (Bidirectionnel
Encoder Représentations from Transformers), ouvre des perspectives
nouvelles pour automatiser l'analyse sémantique des documents et
fiabiliser la sélection des profils.
Le système conçu dans ce travail a pour vocation
de permettre une comparaison objective et automatisée entre le contenu
des CV déposés par les demandeurs d'emploi et
les offres publiées par les entreprises, grâce
à l'intervention du système intelligent
d'analyse. L'originalité du dispositif repose sur la
capacité à traiter des CV au format PDF, à extraire leur
contenu textuel, à encoder l'information en vecteurs numériques
par BERT, et à calculer un score de pertinence par la mesure de
similarité cosinus. Ce score constitue un indicateur objectif de la
correspondance entre un profil et une offre d'emploi.
Le présent chapitre est organisé en plusieurs
sections complémentaires. La première partie expose
l'analyse métier, qui consiste à étudier
le processus actuel de gestion des candidatures, à identifier les
contraintes et les besoins des principaux acteurs (demandeur d'emploi,
entreprise) et à situer le rôle du système intelligent dans
la chaîne de valeur. Cette étape permet de comprendre le contexte
opérationnel et les enjeux concrets auxquels l'application devra
répondre.
La seconde partie présente l'analyse du
système informatique, notamment la définition des
exigences fonctionnelles (extraction des données, calcul de la
similarité, classement des CV, exportation des résultats) et des
exigences non fonctionnelles (performance, sécurité des
données, ergonomie, évolutivité). Ces
spécifications constituent le référentiel de conception
auquel le développement devra se conformer.
La troisième partie détaille la
conception logique et technique: architecture logicielle de
l'application, modélisation UML du système (diagrammes de cas
d'utilisation, diagrammes de séquence, diagramme de classes) et
définition du modèle logique de données. L'ensemble de ces
éléments permet de structurer le système de façon
cohérente, modulaire et évolutive.
Enfin, le chapitre se termine par la présentation du
modèle de déploiement et par la planification
des itérations de développement, qui permettront de valider
progressivement les fonctionnalités principales et d'assurer la
qualité globale du produit final.
En résumé, le chapitre 3 constitue la
colonne vertébrale conceptuelle et technique du
mémoire. Il établit un lien direct entre les besoins
exprimés par les acteurs du processus de recrutement et les
Le recruteur procède alors à une lecture
détaillée du contenu du CV. Cette lecture est suivie d'une
analyse manuelle visant à apprécier l'adéquation du profil
du candidat avec les exigences définies
21
solutions informatiques proposées, en s'appuyant sur
les meilleures pratiques d'architecture logicielle et sur les avancées
récentes du NLP appliqué à la gestion des ressources
humaines.
3.2 Modélisation du processus métier
La modélisation de processus (en
anglais, business process modeling ou BPM) consiste à
structurer et à représenter les activités d'une
organisation, généralement en utilisant une notation
graphique pour représenter visuellement
l'enchaînement des activités. La modélisation peut
s'appuyer sur des méthodes et outils spécialisés, et
mettre en oeuvre des cadres de références de
processus. [6]
Description textuelle du processus manuel de traitement
des candidatures (CV uniquement)
Le processus de traitement manuel des candidatures au sein
d'une entreprise débute dès l'instant où un demandeur
d'emploi manifeste son intérêt pour une offre d'emploi
spécifique. Dans un premier temps, le candidat consulte l'annonce
publiée, qui peut être diffusée en ligne ou par d'autres
canaux de communication (panneaux d'affichage, presse écrite,
réseaux professionnels). Il prend connaissance des conditions
d'accès au poste et des compétences attendues.
Suite à cette consultation, le candidat prépare
son curriculum vitae (CV), document essentiel permettant de présenter
son parcours académique, ses expériences professionnelles, ainsi
que ses principales compétences. Ce travail est réalisé de
manière autonome par le demandeur d'emploi, sans assistance
automatisée.
Une fois le CV finalisé, le candidat procède
à la soumission de sa candidature auprès de l'entreprise. Cette
transmission peut s'effectuer par voie électronique (email ou plateforme
de dépôt en ligne) ou par remise physique (dépôt du
dossier à l'accueil ou envoi postal). Dans certains cas, une
confirmation de réception est adressée au candidat, mais cette
pratique reste facultative et varie selon les entreprises.
La réception du CV par le service des ressources
humaines marque le transfert de responsabilité et l'ouverture du
traitement interne. La première étape consiste en une
vérification attentive de la complétude du document. L'objectif
est de s'assurer que toutes les informations nécessaires sont
présentes et que le format est conforme aux attentes.
À l'issue de cette vérification, une
première décision est prise:
Si le CV est jugé incomplet (par exemple, absence de
coordonnées, imprécisions sur le parcours professionnel), le
recruteur contacte directement le candidat afin d'obtenir les
compléments requis. Cette démarche s'effectue par email ou
téléphone et retarde l'analyse du dossier.
Si le CV est complet, il est intégré au lot des
candidatures en cours de traitement.
22
pour le poste à pourvoir (niveau de qualification,
années d'expérience, maîtrise des compétences
techniques et comportementales).
Dans un second temps, le recruteur compare les candidatures
entre elles, en utilisant généralement un tableau de suivi ou un
dossier papier, afin de mettre en évidence les différences et
d'établir une hiérarchisation des candidatures. Cette comparaison
repose sur des critères qualitatifs, et elle s'accompagne de la
rédaction de notes d'évaluation et d'appréciations propres
à chaque dossier.
Enfin, une seconde décision intervient. En fonction des
éléments analysés, le recruteur statue sur le statut final
du CV :
Si le profil est jugé pertinent et conforme aux
attentes, le CV est marqué comme présélectionné
pour la suite du processus de recrutement (convocation à un entretien,
tests complémentaires, etc.).
Si le profil est jugé non conforme ou moins
adapté, le CV est archivé dans les bases documentaires de
l'entreprise ou classé selon les procédures internes en
vigueur.
Ce processus manuel, qui mobilise l'expertise et le jugement
du recruteur à chaque étape, prend fin une fois que le statut de
l'ensemble des candidatures reçues a été fixé.
3.3 Identification des acteurs 3.3.1 un acteur
Un acteur représente un rôle joué par une
entité externe (utilisateur humain, dispositif matériel ou autre
système) qui interagit directement avec le système
étudié [7].
Un acteur peut consulter et/ou modifier directement
l'état du système, en émettant et/ou en recevant des
messages susceptibles d'être porteurs de données
[7].
o Les acteurs jouent un rôle clé dans le
fonctionnement du système en effectuant des actions ou en recevant des
informations.
23
Tableau 2 Rôles des acteurs
|
N°
|
Acteur
|
Rôle dans le système manuel
|
|
1
|
Demandeur d'emploi
|
- Recherche des offres d'emploi (presse, affichage, site
web)
- Prépare son CV et sa lettre de motivation
- Soumet sa candidature par email, en main propre ou par
courrier
|
|
2
|
Entreprise
|
- Rédige et diffuse l'offre d'emploi
- Réceptionne les candidatures
- Trie manuellement les dossiers
- Lit les CV un à un et note les candidats
- Compare les profils et sélectionne les meilleurs
|
|
3
|
Responsable RH / Service Recrutement
|
- Participe à l'analyse des dossiers
- Transmet les informations à la hiérarchie
- Organise la suite du processus (entretiens, tests, etc.)
|
3.4 Diagramme de contexte métier
Le diagramme de contexte est le premier modèle à
réaliser dans une démarche de modélisation
systémique. En effet, quel que soit le niveau d'analyse choisi par le
modélisateur, toute modélisation nécessite de
représenter et de clarifier en premier lieu la frontière de
l'entité modélisée ainsi que les objets qu'elle va
échanger avec les autres entités qui se trouvent à
l'extérieur de sa frontière et qui composent son environnement
externe [8].
En réalisant le diagramme de contexte, le
modélisateur va pouvoir définir clairement les frontières
de l'objet modélisé et ses interfaces avec l'environnement
externe et/ou interne. Le diagramme de contexte est une représentation
de l'entité pour répondre à un problème
particulier. En d'autres termes, il peut y avoir différents types de
diagramme de contexte selon la finalité qui est visée par le
modélisateur [8].
24
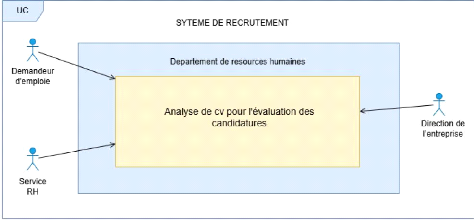
Figure 1 Diagramme de contexte métier
3.5 Diagramme de processus métier BPMN (Business
Process Model and Notation)
Le Business Process Model and Notation (BPMN) ou norme de
modélisation des processus métier en français, est une
méthode de logigramme qui modélise de A à Z les
étapes d'un processus métier planifié.
Élément clé de la gestion d'un processus métier, il
permet de représenter visuellement une séquence
détaillée des activités commerciales et des flux
d'informations nécessaires à la réalisation d'un processus
[9].
Mais aussi il est constituéé d'un schéma qui
peut se révéler bien plus facile à comprendre qu'un texte.
Il permet de communiquer et de collaborer plus facilement pour atteindre un
processus efficace, produisant un résultat de grande qualité. Il
contribue également à la communication menant à la
création des documents XML (Extensible Markup Language)
nécessaires à l'exécution de divers processus.
Figure 2 Diagramme de processus métier BPMN
25
Demandeur d'emploi Entreprise
1 Accusé réception du 16, candidature
A
T
Non
F
ro ntacter le candidat
tVérfication de la
complétude du
CV
ailikk Le CV est-il complet ?
Oui
Lecture du cv
Consulter I offre d'emploi
e
o-
n
Demandeur
d'emploi intéressé
Préparer le CV
Envoyer le cv pour postuler
Comparer plusieurs CV
i
Rédiger des notes et
appréciations
Le candidat est-il retenu ?
V
Oui J
I
Marquer comme
présélectionné
[tom] Candidature valider
Non
Archiver le CV
busines process use case model
26
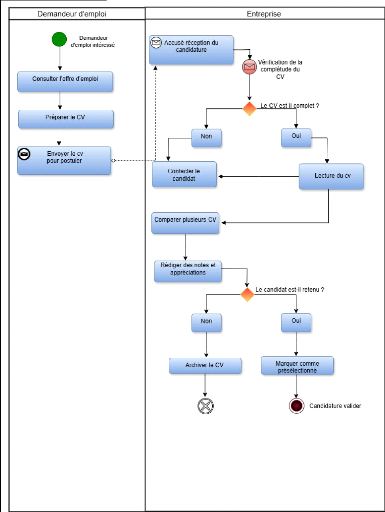
3.6 Diagramme de cas d'utilisation métier
Les diagrammes de cas d'utilisation (DCU) sont des diagrammes
UML utilisés pour une représentation du comportement fonctionnel
d'un système logiciel. Ils sont utiles pour des présentations
auprès de la direction ou des acteurs d'un projet, mais pour le
développement, les cas d'utilisation sont plus appropriés. En
effet, un cas d'utilisation (use cases) représente une
unité discrète d'interaction entre un utilisateur (humain ou
machine) et un système. Ainsi, dans un diagramme de cas d'utilisation,
les utilisateurs sont appelés acteurs (actors), et ils apparaissent dans
les cas d'utilisation [10].
Ils permettent de décrire l'interaction entre l'acteur
et le système. L'idée forte est de dire que l'utilisateur d'un
système logiciel a un objectif quand il utilise le système ! Le
cas d'utilisation est une description des interactions qui vont permettre
à l'acteur d'atteindre son objectif en utilisant le système. Les
use case (cas d'utilisation) sont représentés par une
ellipse sous-titrée par le nom du cas d'utilisation
(éventuellement le nom est placé dans l'ellipse). Un acteur et un
cas d'utilisation sont mis en relation par une association
représentée par une ligne [10].
Figure 3 Diagramme de cas d'utilisation métier
27
3.7 MODELE DU DOMAIN
Le modèle du domaine est une
représentation des concepts clés du
système, de leurs caractéristiques et des liens qui les
unissent. Il s'agit d'un diagramme de classes
simplifié, destiné avant tout à faciliter la
compréhension des entités fondamentales du domaine métier,
indépendamment de toute considération technique ou de mise en
oeuvre. Ce modèle décrit de manière claire et
structurée les objets qui interviennent dans le fonctionnement du
système, tels que les candidats, les offres d'emploi, les CV ou encore
les entreprises, ainsi que les relations logiques qui les relient.
L'objectif principal du modèle du domaine est
d'établir un vocabulaire commun et partagé entre les parties
prenantes du projet (maîtrise d'ouvrage, développeurs,
utilisateurs finaux), afin de s'assurer que la conception technique
reflète fidèlement la réalité métier et
réponde aux besoins exprimés.
Le diagramme de classes est quant à
lui un outil essentiel qui permet de modéliser la structure
statique du système. Il représente les objets ou
entités du domaine, leurs attributs, leurs méthodes principales,
ainsi que les relations de dépendance, d'association ou
d'héritage qui les relient. Ce diagramme joue un rôle central dans
la démarche de conception: il sert de point de référence
pour la définition des structures de données, la conception de la
base de données relationnelle, et la génération des
squelettes de code objet.
Dans le cadre de ce projet, le diagramme de classes facilite
la visualisation des entités principales du système (Entreprise,
Offre d'emploi, Demandeur d'emploi, CV), de leurs propriétés (par
exemple les coordonnées, les dates de publication ou les scores de
pertinence) et des cardinalités des associations (une entreprise peut
publier plusieurs offres, un demandeur peut déposer plusieurs
candidatures, etc.).
28
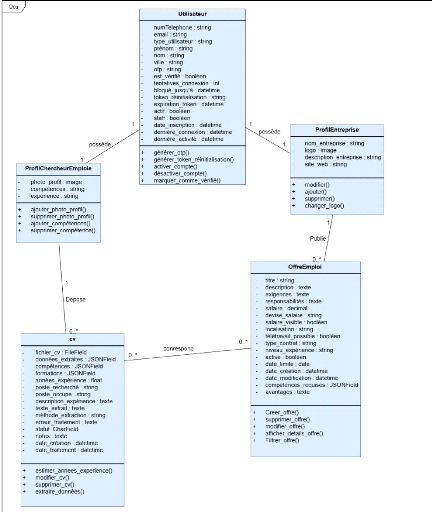
Figure 4 Diagramme de classes système 3.7
Analyse du système informatique
Cette section présente l'analyse
détaillée du système informatique envisagé.
L'objectif est de spécifier les exigences auxquelles la solution doit
répondre, afin d'assurer son adéquation aux besoins métier
identifiés et de guider la conception technique. L'analyse porte
à la fois sur les exigences fonctionnelles, qui
décrivent les services attendus du système, et sur les
exigences non fonctionnelles, qui fixent les contraintes de
qualité, de performance et de sécurité.
Avec plaisir. Voici une version bien structurée et
rédigée de la section :
Ø Exigences fonctionnelles du système existant
(manuel)
29
Cette section présente les exigences fonctionnelles du
système actuel, c'est-à-dire le processus manuel tel qu'il est
observé avant toute informatisation ou automatisation. Il s'agit
d'identifier les tâches que les acteurs réalisent aujourd'hui sans
l'aide d'un système intelligent, afin de mieux comprendre les limites du
fonctionnement actuel et de motiver la mise en place d'une solution
numérique.
o Exigences fonctionnelles identifiées dans le
système existant :
1. Publication manuelle des offres d'emploi
§ Les offres d'emploi sont rédigées et
publiées via des canaux classiques : affichage physique, annonces dans
la presse, groupes WhatsApp ou e-mail.
§ L'offre est souvent sous forme de document Word ou
texte simple.
2. Réception des candidatures
§ Les candidats envoient leur CV par e-mail, sur support
physique (clé USB, papier) ou les déposent en personne.
§ Aucun système centralisé ne gère
la réception : chaque dossier est stocké manuellement.
3. Lecture et analyse des CV
§ Le responsable RH lit chaque CV un par un.
§ L'analyse repose sur l'expérience du recruteur
: vérification manuelle des diplômes, expériences,
compétences.
4. Tri manuel des dossiers
§ Les recruteurs trient les candidatures selon des
critères internes (souvent non formalisés).
§ Les profils sont classés manuellement dans des
dossiers : "retenus", "à revoir", "refusés".
5. Sélection
§ Une liste de candidats
présélectionnés est rédigée sur papier ou
dans un fichier Excel.
§ Le classement est subjectif, sans outil de mesure
formel.
6. Absence de retour automatique
§ Les candidats ne reçoivent souvent pas de retour
formel.
§ Le suivi des candidatures est rarement
automatisé.
7. Archivage des CV
§ Les CV sont stockés dans des dossiers
informatiques ou physiques sans étiquetage standardisé.
§ Il est difficile de retrouver un ancien CV ou de
réutiliser une base de données de candidats.
30
Remarque :
Aucune de ces étapes n'est automatisée, ce qui
engendre des pertes de temps, des oublis, et un manque d'objectivité
dans la sélection.
Suggestion
Pour rendre le processus de recrutement plus simple, rapide et
objectif, nous proposons une application web d'analyse intelligente des
candidatures basée sur le traitement automatique du langage naturel
(NLP). Cette solution aidera les entreprises à identifier plus
efficacement les profils pertinents en comparant automatiquement les CV soumis
aux exigences des offres d'emploi grâce à un modèle BERT de
similarité sémantique.
Ce système permettra aux entreprises de simplifier
leurs démarches de présélection sans avoir à
traiter manuellement de grandes quantités de candidatures, ce qui
réduit considérablement le temps d'analyse et le risque d'erreur
humaine. De plus, l'application offrira aux demandeurs d'emploi la
possibilité de postuler directement en ligne, de recevoir un
accusé de réception et d'assurer une meilleure
traçabilité de leur candidature.
L'authentification sécurisée par OTP garantira
la confidentialité des informations sensibles et la protection des
données personnelles des utilisateurs.
Accessible depuis tout appareil connecté (ordinateur,
tablette, smartphone), l'application couvrira l'ensemble du processus de
dépôt, d'analyse et de classement des CV, assurant une
organisation plus rigoureuse et une expérience utilisateur moderne et
fluide.
3.7.1 Spécification des exigences o Exigences
fonctionnelles
Les exigences fonctionnelles définissent les
principales fonctionnalités que le système doit offrir. Elles
couvrent l'ensemble du cycle de traitement des candidatures, depuis la
publication des offres jusqu'à l'analyse automatique des CV et la
restitution des résultats aux utilisateurs.
Exigences fonctionnelles identifiées : Gestion des
utilisateurs
Le système doit permettre aux entreprises de
créer un compte, de s'authentifier de manière
sécurisée et de gérer leur profil.
L'authentification devra inclure un mécanisme
d'authentification forte via OTP (One-Time Password)
envoyé par email pour renforcer la sécurité lors de la
connexion. Les demandeurs d'emploi doivent pouvoir créer un compte, se
connecter avec OTP, et mettre à jour leurs informations personnelles.
v Publication des offres d'emploi
Les entreprises doivent pouvoir créer, modifier et
supprimer des offres d'emploi via une interface conviviale.
Chaque offre doit comporter au minimum les informations
suivantes: Titre du poste
Description détaillée
31
Compétences requises Niveau d'études
souhaité Type de contrat
Lieu
Date limite de candidature Ect
Consultation des offres
Les demandeurs d'emploi doivent pouvoir consulter la liste des
offres disponibles. Ils doivent pouvoir accéder aux détails
complets de chaque offre avant de postuler.
v Dépôt de candidatures
Les demandeurs d'emploi doivent pouvoir déposer leur CV
au format PDF en réponse à une offre
sélectionnée.
Le système doit confirmer automatiquement la
réception de chaque candidature.
v Extraction et analyse automatique des CV
Le système doit extraire le contenu textuel des CV
déposés.
Il doit générer un vecteur d'embedding à
l'aide du modèle BERT pré-entraîné. Il doit comparer
le contenu du CV avec l'offre d'emploi et calculer un score de
similarité.
v Classement et restitution des résultats
Le système doit afficher la liste des candidatures
reçues pour chaque offre, triée par ordre décroissant de
pertinence.
Il doit permettre d'exporter les résultats au format
Excel et PDF.
v Tableau de bord administratif
Le système doit fournir un tableau de bord de suivi avec
les indicateurs suivants :
Nombre d'offres publiées
Nombre de candidatures reçues
Taux moyen de pertinence des candidatures Statistiques des
dépôts par période
o Exigences non fonctionnelles
Les exigences non fonctionnelles précisent les
contraintes techniques, ergonomiques et organisationnelles auxquelles le
système doit se conformer.
32
Exigences non fonctionnelles identifiées
:
v Sécurité
Les données personnelles des utilisateurs doivent
être protégées conformément aux
réglementations en vigueur.
L'authentification doit être sécurisée avec
un mot de passe chiffré et une vérification par OTP
lors de la connexion.
L'accès aux fonctionnalités sensibles doit
être contrôlé selon le rôle (entreprise, candidat,
administrateur).
v Performance
Le système doit être capable d'analyser un CV et
de générer un score en moins de seconde
après le la soumission de cv.
La navigation doit rester fluide même en cas de forte
affluence.
v Compatibilité
L'application doit être compatible avec les principaux
navigateurs (Chrome, Firefox, Edge).
L'interface doit être responsive, adaptée aux
écrans mobiles et tablettes.
v Ergonomie
L'interface doit être claire et intuitive, avec une
navigation facilitée par des menus explicites et des indications
visuelles.
Les messages d'erreur doivent être précis et guider
l'utilisateur pour corriger les actions.
v Maintenance
Le système doit être conçu de façon
modulaire afin de faciliter son évolution. 3.8. Analyse des
besoins de conception
3.8.1 Présentation du système d'analyse de cv
basé sur NLP
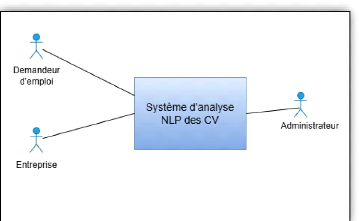
33
Figure 5 Présentation du système
3.8.2 Identification des acteurs du système
d'analyse de cv basé sur le NLP
Un acteur représente un rôle joué par une
entité externe (utilisateur humain, dispositif matériel ou autre
système) qui interagit directement avec le système
étudié. Un acteur peut consulter et/ou modifier directement
l'état du système, en émettant et/ou en recevant des
messages susceptibles d'être porteurs de données [11].
Pour le cas de notre nouveau système, nous recenser les
acteurs ci-après :
Tableau 3 Identification des acteurs du système
d'Analyse de cv basé sur le NLP
|
N° ACTEURS DESCRIPTION
|
|
1
|
Demandeur
|
Toute personne à la recherche d'un emploi qui peut
créer un compte, consulter
|
|
d'emploi
|
les offres, déposer son CV au format PDF et suivre le
statut de sa candidature.
|
|
2
|
Entreprise
|
Organisation ou recruteur autorisé à publier des
offres d'emploi, consulter les candidatures reçues et visualiser les
scores de correspondance générés par le système.
|

3.8.3. Identification des cas d'utilisation
Dans le cadre de la conception du système
proposé, nous avons défini un ensemble de cas d'utilisation
reflétant les principales fonctionnalités attendues. Ces cas
décrivent les interactions entre les différents utilisateurs du
système (demandeurs d'emploi, entreprises, administrateur) et visent
à automatiser efficacement la gestion des candidatures ainsi que
l'analyse intelligente des CV via le NLP.
34
Les différents cas d'utilisation recensés
pour notre système sont les suivants :
1. Créer un compte Permettre aux
utilisate
urs (entreprises, demandeurs d'emploi) de s'inscrire sur la
plateforme.
2. S'authentifier
Connexion sécurisée avec mot de passe et OTP.
3. Gérer le profil utilisateur
Modifier les informations personnelles et les paramètres
de compte.
4. Publier une offre d'emploi
Créer une nouvelle offre avec tous les détails
requis.
5. Gérer les offres d'emploi
Modifier ou supprimer des offres existantes.
6. Téléverser un CV
Envoyer un CV PDF en réponse à une offre.
7. Recevoir la confirmation de candidature
Accuser réception automatiquement au candidat.
8. Analyser le CV
Extraction du texte, génération de l'embedding NLP
et calcul de la similarité.
9. Afficher les candidatures
Voir la liste triée des CV par pertinence.
10. Exporter les résultats
Télécharger les classements au format Excel et
PDF.
3.8.3 Diagramme de cas d'utilisation
Les diagrammes de cas d'utilisation servent à
identifier et à répertorier les principales
fonctionnalités d'un système. Ils permettent de visualiser de
manière synthétique comment les acteurs (utilisateurs ou autres
systèmes) interagissent avec le système, quelles actions ils
réalisent, et quelles sont les fonctionnalités offertes par le
système en réponse à ces actions. En résumé,
les diagrammes de cas d'utilisation sont un outil puissant pour comprendre et
documenter les exigences du projet de
35
manière compréhensible pour toutes les parties
prenantes. Il représente une fonctionnalité du système
visible de l'extérieur du système.
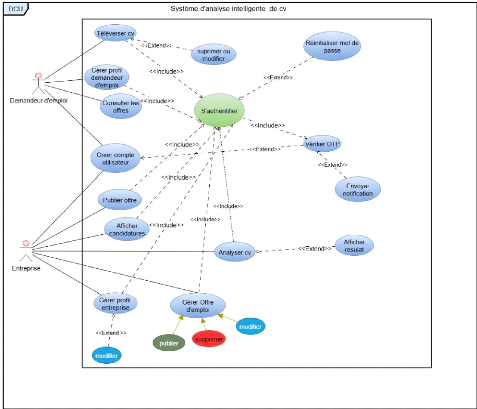
Figure 6 Diagramme de cas d'utilisation 3.8.5
Planification des itérations
Le tableau de Planification des itérations permet de
répartition des cas d'utilisation par cycle, selon leur priorité
et risque, afin d'assurer un développement progressif.
36
Tableau 4 Planification des itérations
N° Cas d'utilisation Acteur Priorité Risque
Itération
|
1
|
Créer compte utilisateur
|
Demandeur/ Entreprise
|
Haute
|
Moyen
|
1
|
|
2
|
S'authentifier (avec OTP)
|
Tous
|
Haute
|
Moyen
|
1
|
|
3
|
Réinitialiser mot de passe
|
Tous
|
Moyenne
|
Moyen
|
2
|
|
4
|
Gérer profil utilisateur
|
Tous
|
Moyenne
|
Faible
|
2
|
|
5
|
Publier offre
|
Entreprise
|
Haute
|
Moyen
|
3
|
|
6
|
Gérer offre d'emploi
|
Entreprise
|
Moyenne
|
Moyen
|
3
|
|
7
|
Consulter les offres
|
Demandeur d'emploi
|
Moyenne
|
Faible
|
3
|
|
8
|
Téléverser CV
|
Demandeur d'emploi
|
Haute
|
Moyen
|
4
|
|
9
|
Supprimer ou modifier CV
|
Demandeur d'emploi
|
Moyenne
|
Faible
|
4
|
|
10
|
Analyser CV
|
Entreprise
|
Haute
|
Élevé
|
5
|
|
11
|
Afficher résultat de l'analyse
|
Entreprise
|
Haute
|
Moyen
|
5
|
|
12
|
Afficher candidatures
|
Entreprise
|
Haute
|
Moyen
|
5
|
|
Dans le cadre de la modélisation du système
proposé, le plan d'itérations permet de structurer le
développement progressif des différentes fonctionnalités
en regroupant les cas d'utilisation par étapes logiques et prioritaires.
Chaque itération correspond à une unité de temps de
développement (souvent une à deux semaines), au cours de laquelle
plusieurs cas d'utilisation sont implémentés de manière
cohérente. Les numéros d'itérations peuvent ainsi se
répéter dans le tableau car plusieurs fonctionnalités
connexes ou complémentaires sont développées
simultanément au sein d'une même phase.
Par exemple, les fonctionnalités liées à
l'authentification des utilisateurs, comme la création de compte et
l'envoi d'un code OTP, sont toutes prévues dès l'itération
1 afin de garantir l'accès sécurisé au système.
L'itération 2 regroupe les opérations de gestion du profil
utilisateur, tandis que l'itération 3 introduit les premières
interactions avec les offres d'emploi, notamment la publication et la
consultation. Les itérations suivantes étendent progressivement
les capacités du système, notamment l'analyse intelligente des
CVs via un moteur NLP, la visualisation des scores de correspondance et
l'export des résultats. Cette organisation permet d'avoir un
développement incrémental, où chaque itération
aboutit à une version partiellement fonctionnelle et testable de
l'application.
37
3.9 Diagramme de séquence
Est un diagramme UML qui représente la séquence
de messages entre les objets au cours d'une interaction. Il permet de
modéliser les interactions possibles entre les objets et les acteurs du
système en fonction du temps. Il montre comment les objets collaborent
entre eux pour atteindre l'objectif d'un cas d'utilisation ou d'un processus.
Un diagramme de séquence comprend des lignes de vie, qui
représenter les objets, est des messages, qui représentent les
échanges entre les objets.
3.9.1 Description textuelle des cas d'utilisation et leurs
diagrammes
1. Titre : Créer un compte utilisateur
Résumé : Permet à un demandeur d'emploi ou
une entreprise de s'inscrire sur la plateforme.
Acteurs : Demandeur d'emploi, Entreprise
Précondition : L'utilisateur ne possède pas encore
de compte.
Scénario nominal :
1.1. L'utilisateur accède à la page
d'inscription.
1.2. Il remplit les champs requis.
1.3. Le système vérifie les données, envoie
un code OTP.
1.4. L'utilisateur valide le code, et le compte est
créé.
Postcondition : Le compte est activé.
38
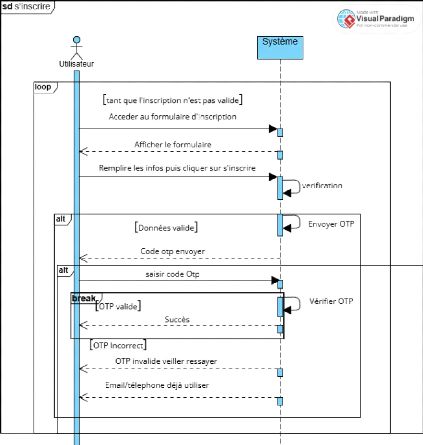
Figure 7 Diagramme de séquence CU1 créer
compte
2. Titre : S'authentifier
Résumé : Permet aux utilisateurs inscrits de se
connecter.
Acteurs : Demandeur d'emploi, Entreprise
Précondition : Compte déjà
créé.
Scénario nominal :
2.1. L'utilisateur saisit ses identifiants.
2.2. Le système vérifie les identifiants.
2.3. Si valides, l'accès est accordé.
Postcondition : Session ouverte.
39
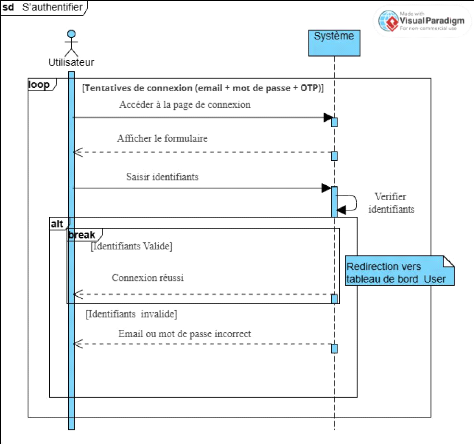
Figure 8 Diagramme de séquence CU2 S'authentifier
3. Titre : Réinitialiser le mot de passe
Résumé : Permet à un utilisateur de
récupérer son accès. Acteurs : Tous
Précondition : L'utilisateur a perdu ses identifiants.
Scénario nominal :
3.1. L'utilisateur clique sur « Mot de passe oublié
». 3.2. Un lien ou OTP est envoyé.
3.3. L'utilisateur crée un nouveau mot de passe.
Postcondition : Mot de passe mis à jour.
Figure 9 Diagramme de séquence CU 3
Réinitialisation de mot de passe
40
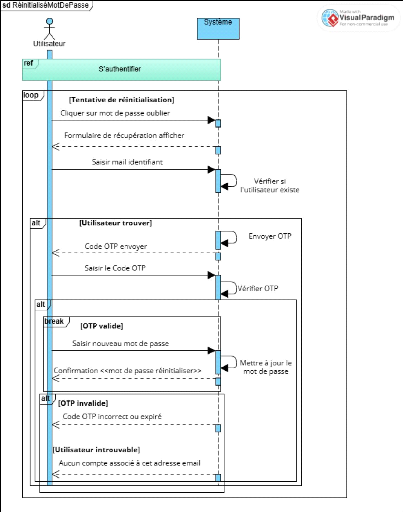
41
4. Titre : Gérer profil utilisateur
Résumé : Mettre à jour ses informations
personnelles.
Acteurs : Tous
Précondition : Être connecté.
Scénario nominal :
4.1. L'utilisateur accède à « Mon profil
».
4.2. Il modifie ses informations.
4.3. Le système enregistre les modifications.
Postcondition : Profil mis à jour.
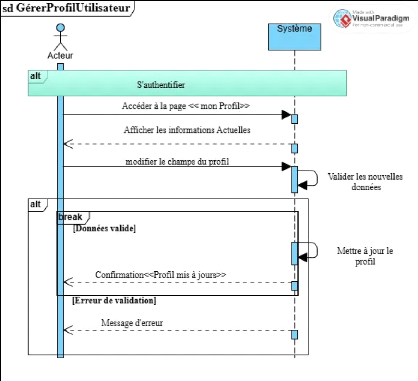
Figure 10 Diagramme de séquence CU 4 Gérer
profil
42
5. Titre : Publier une offre
Résumé : Une entreprise peut créer une
nouvelle offre d'emploi.
Acteurs : Entreprise
Précondition : Être connecté.
Scénario nominal :
5.1. L'entreprise clique sur « Nouvelle offre ».
5.2. Elle saisit les détails de l'offre.
5.3. Le système enregistre et affiche l'offre.
Postcondition : Offre disponible pour consultation.
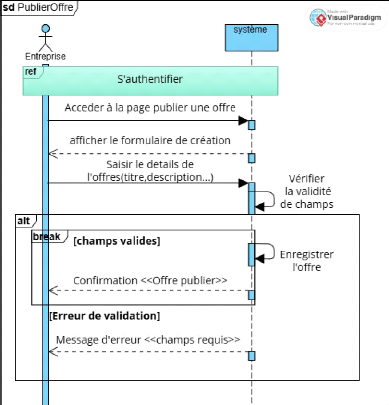
Figure 11 Diagramme de séquence CU 5 Publier
offre
6. Titre : Gérer offres d'emploi
Résumé : Modifier ou supprimer une offre
publiée.
Acteurs : Entreprise
Précondition : Offre déjà existante.
Scénario nominal :
43
6.1. L'entreprise sélectionne une offre. 6.2. Elle peut la
modifier ou la supprimer. 6.3. Le système met à jour ou retire
l'offre. Postcondition : Offre publiée.
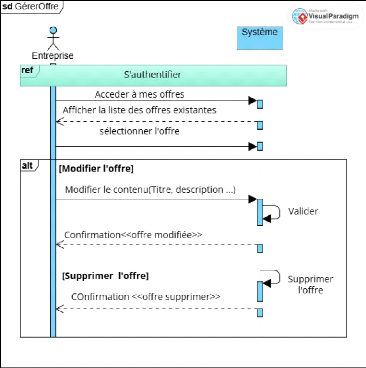
Figure 12 Diagramme de séquence CU 6 Gérer
l'offre
7. Titre : Consulter les offres d'emploi
Résumé : Toute personne (connectée ou non)
peut voir les offres sur la page d'accueil.
Acteurs : Demandeur d'emploi
Précondition : Offres publiées
Scénario nominal :
7.1. L'utilisateur accède à la liste des offres.
7.2. Le système affiche les offres.
7.3. Il peut filtrer ou rechercher.
Postcondition : Offres visibles publiquement.
44
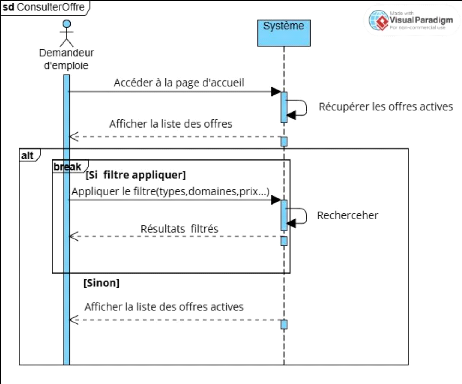
Figure 13 Diagramme de séquence CU 7 Consulter les
offres
8. Titre : Téléverser un CV
Résumé : Permet au demandeur de postuler via un
CV en PDF.
Acteurs : Demandeur d'emploi
Précondition : Être connecté.
Scénario nominal :
8.1. L'utilisateur sélectionne une offre.
8.2. Il choisit un fichier PDF.
8.3. Le système vérifie, enregistre, puis
déclenche l'analyse.
Postcondition : CV analysable.
45
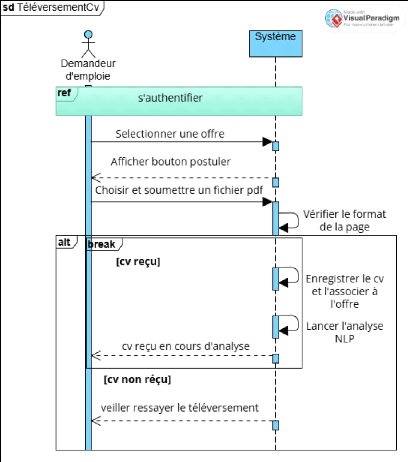
Figure 14 Diagramme de séquence CU 8
Téléverser un cv
9. Titre : Supprimer ou modifier un CV
Résumé : Modifier ou retirer un CV
déjà téléversé.
Acteurs : Demandeur d'emploi
Précondition : Être connecté et CV
existant.
Scénario nominal :
9.1. Le candidat accède à ses CVs.
9.2. Il en supprime ou modifie un.
Postcondition : Modification prise en compte.
46
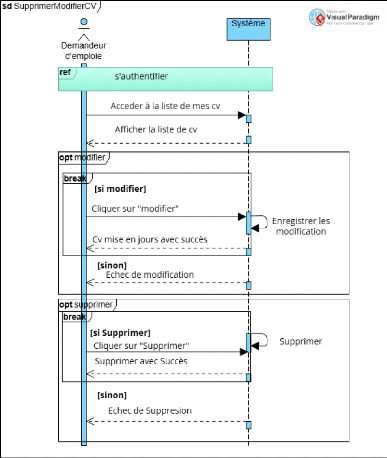
Figure 15 Diagramme de séquence CU 9 supprimer ou
modifier un cv
10. Titre : Analyser un CV
Résumé : Le système traite le CV avec le
NLP.
Acteurs : Système (automatique)
Précondition : CV téléchargé.
Scénario nominal :
10.1. Le système extrait le texte.
10.2. Il génère les vecteurs BERT.
10.3. Il calcule la similarité.
Postcondition : Score disponible.
47
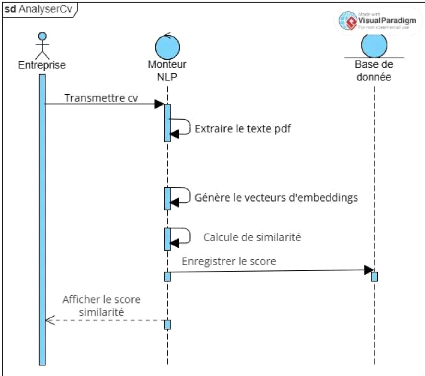
Figure 16 Diagramme de séquence CU 10 Analyser un cv
11. Titre : Afficher résultat de l'analyse
Résumé : Affiche tous les CVs reçus pour une
offre. Acteurs : Entreprise
Précondition : Des candidats ont postulé.
Scénario nominal :
11.1. L'entreprise accède à la liste des
candidatures. 11.2. Elle consulte les informations et scores. Postcondition :
Liste disponible.
48
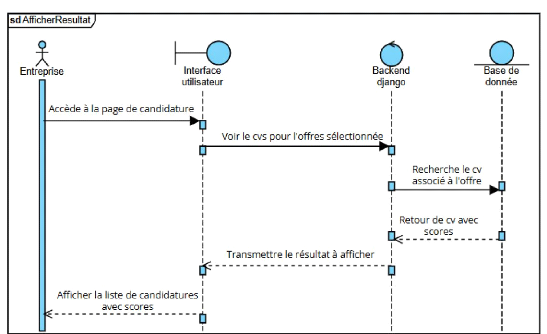
Figure 18 Diagramme de séquence CU 11 AfficherResultat
13. Titre : Afficher candidatures
Résumé : Affiche tous les CVs reçus pour une
offre. Acteurs : Entreprise
Précondition : Des candidats ont postulé.
Scénario nominal :
13.1. L'entreprise accède à la liste des
candidatures. 13.2. Elle consulte les informations et scores. Postcondition :
Liste disponible.
49
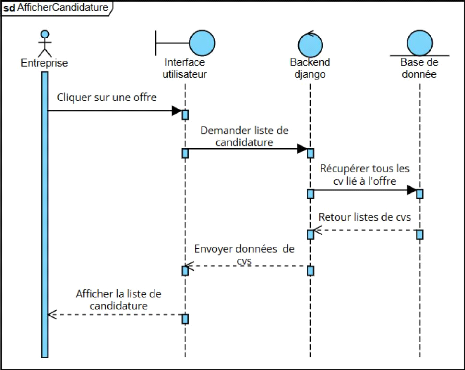
Figure 19 Diagramme de séquence CU 12 afficher
candidatures 3.10. Diagramme de classe de conception
Le diagramme de classes de conception constitue un outil
fondamental de modélisation, permettant de représenter la
structure statique d'un système d'information. Il offre une vision
structurée des entités qui composent l'application, en
précisant leurs attributs, leurs méthodes ainsi que les relations
qui les relient.
Dans le cadre de ce projet, ce diagramme formalise les
entités centrales, notamment les comptes utilisateurs, les CV, les
offres d'emploi, ainsi que les résultats d'analyse
générés par le moteur NLP. Il joue également un
rôle clé dans la conception de la base de données
PostgreSQL et l'implémentation des modèles dans Django.
Éléments clés dans un diagramme de
classes
1. Classe
Une classe est représentée par un rectangle
divisé en trois compartiments :
· Le nom de la classe (ex. : CV, Offre, Utilisateur,
Analyse)
· Les attributs (ex. : email, mots_clés, score)
· Les méthodes ou opérations (ex. :
générer_otp(), analyser_cv())
50
2. Attributs
Ils représentent les données propres à
chaque entité.
Exemple : La classe CV possède des attributs tels que
fichier_pdf, compétences, années_d'expérience.
3. Opérations ou Méthodes
Ce sont les comportements internes à chaque classe.
Exemple : La classe Utilisateur peut avoir des
méthodes telles que authentifier(), vérifier_otp(), ou
réinitialiser_mot_de_passe().
4. Visibilité
Elle détermine l'accessibilité des
éléments :
· public : accessible depuis toute autre classe
· privé : accessible uniquement à
l'intérieur de la classe
· protégé : accessible aux classes
héritées Types de relations entre les classes
a.Association
Lien logique entre deux entités. Exemple : Une
Entreprise publie plusieurs Offres. Un Demandeur d'emploi peut
téléverser plusieurs CV.
b. Héritage
(généralisation)
Une classe spécialisée hérite d'une classe
plus générale.
Exemple : La classe Utilisateur est générique
et donne naissance aux classes Entreprise et Demandeur d'emploi.
c. Composition
Relation forte : la suppression de la classe principale
entraîne celle de la dépendante.
Exemple : Une Analyse dépend d'un CV. Si ce dernier est
supprimé, l'analyse devient obsolète.
d. Agrégation
Relation souple : l'entité liée peut exister
indépendamment.
Exemple : Une Offre est associée à une Entreprise,
mais l'Entreprise peut exister sans offre.
e. Dépendance
Lien temporaire utilisé pour l'exécution d'une
tâche ponctuelle.
Exemple : ExportService utilise les données des CV et des
scores pour générer un fichier (PDF, Excel), sans lien permanent
avec ces classes.
Ce diagramme de classes constitue une représentation
synthétique de l'architecture du système, facilitant le passage
vers l'implémentation technique avec Django. Il assure une
compréhension claire des rôles et responsabilités de chaque
entité, tout en garantissant une maintenabilité
et une extensibilité optimales du projet.
51
DC Système
OffreEmploi
- titre : string
description : texte
exigences : texte
responsabilités : texte - salaire : decimal
devise_salaire : string salaire_visible : booléen
- localisation : string
télétravail_possible : booléen
- type_contrat : string
niveau expérience : string
_
active booléen
- date_limite : date
- date_création : datetime date modification : datetime
compétences_ requises : JSONField avantages : texte
+ Creer offre()
+ supprirner_offre()
+ modifier_offre()
+ afficher_details_offre()
+ Hltreroffre()
CV
fichier_cv: FileField
données_extraites: JSONField compétences :
JSONField formations: JSONField a nnées_expérience : float
poste_recherche : string poste_occupe : string description_expérience :
texte texte_extrait : texte méthade_exhachon : string erreur
traitement:texte statut :CharField
notes : texte
date_création : datetime date traitement: datetime
= estimer_annees_experience[.: + modifier_cv0
+ supprimer cv()
+ extraire données[:
|
|
ProfilEntreprise
|
|
|
|
|
PrafilChercheurErnploie
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
nam_entreprise : string logo : image descriptian_entreprise :
string site_web : string
+
|
|
|
|
photo_profil : image compétences : string
expérience : string
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
+ ajouter_phota_proFil()
+ supprimer_photo_prehl()
+ ajouter_compétences(} +
supprimer_compétence()
|
+
|
|
modifier()
+ ajouter()
+ supprimer()
+ changer logo()
|
+
|
+
|
+
|
+
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Utilisateur
|
|
|
|
|
|
|
|
|
|
|
email : String
numero_telephone : String type_utilisateur: String prenorn :
String
nom : String
ville : String
code_otp : String es# vedfie : Boolean tentatives connexion :
Integer token_reinitialisation : String est_actif : Boolean
est_membre_personnel : Boolean date inscription : Date derniere_connexion :
Date derniere_activite : Date
|
|
|
|
|
|
|
+ générer_otp()
+ générer_token réinitialisation()
+ activer compte()
+ désactiver_compte()
+ marquer_camme vérifié()
+ norn_cornplet() : String
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 Reçoit
|
|
|
|
|
|
|
|
|
|
|
|
O..'
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Notification
|
|
|
|
|
|
|
|
|
|
|
|
titre : String message : String lue : Boolean uri : LIRL date
creation : Date
|
|
|
|
|
|
|
|
|
|
|
+ marquer_lue(j : void
+ marquer_non_lue(): void
-F envoyer par email()
|
|
|
|
|
|
|
|
Genére
O..
ResultatAnalyseCV
score : String
date_analyse Date
+ enregistrer envoil)
+ get_categorie_score()
Trace
t]'
JoumalEnvoiEmail
- destinataire : String - statut : String
- message_erreur : String - date envoi : Date
+ enregistrer envoi()
Figure 20 Diagramme système
52
3.11. DIAGRAMME DE CLASSES PARTICIPANTES
Le diagramme de participants, également appelé
diagramme de communication ou diagramme de collaboration, est un diagramme
d'interaction en UML. Il illustre les objets impliqués dans une
interaction ainsi que les messages échangés entre eux afin de
réaliser un scénario spécifique,
généralement dérivé d'un cas d'utilisation.
Contrairement au diagramme de séquence qui met l'accent sur la
chronologie des événements, le diagramme de participants
privilégie la structure statique des échanges en
représentant les rôles des objets et les relations de
communication entre eux.
Ce type de diagramme permet de modéliser les
collaborations entre les différentes classes d'analyse, notamment les
classes de type boundary (interface utilisateur), control (logique
métier ou coordination) et entity (gestion des données). Il
fournit ainsi une vue claire et synthétique de l'architecture logique du
système dans le cadre d'un traitement donné.
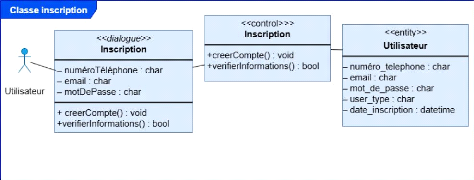
Figure 21 Diagramme de classe participante CU 1
inscription
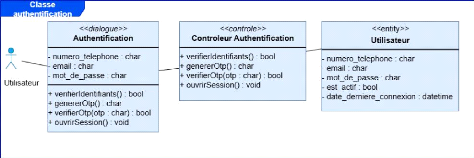
Figure 1 22
Diagramme de classe participante CU 2
Authentification
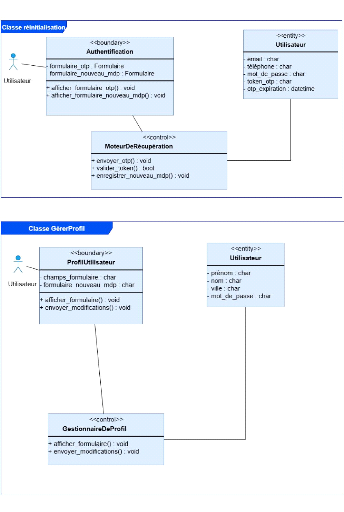
53
Figure 23 Diagramme de classe participante CU 3
Réinitialisation
Figure 24 Diagramme de classe participante CU 4 Gérer
profil
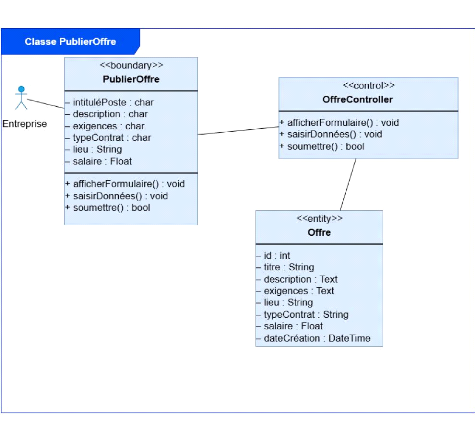
54
Figure 25 Diagramme de classe participante CU 5 publier
offre
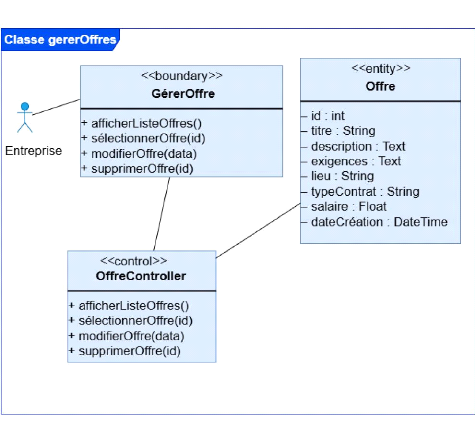
55
Figure 26 Diagramme de classe participante CU 6 Gérer
offre
56
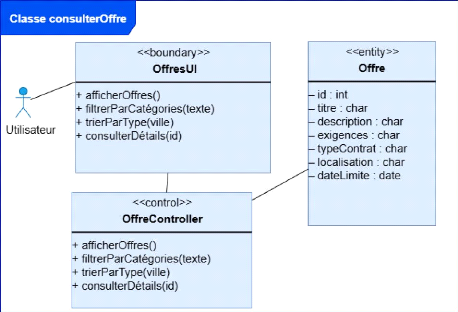
Figure 27 Diagramme de classe participante CU 7 Consulter
l'offre
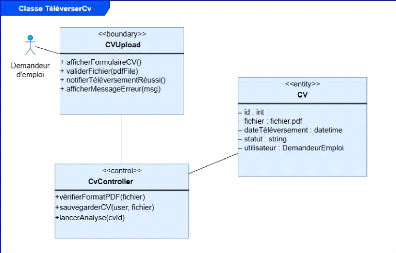
Figure 28 Diagramme de classe participante CU 8
Téléverser cv
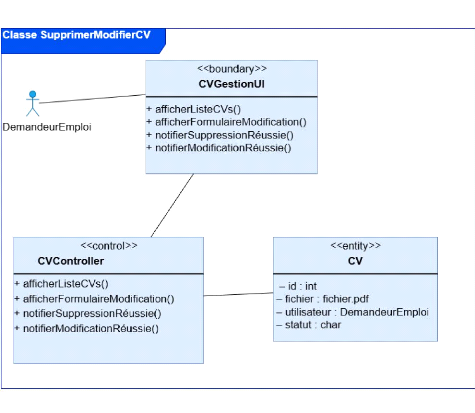
57
Figure 29 Diagramme de classe participante CU 9 Supprimer
modifier cv
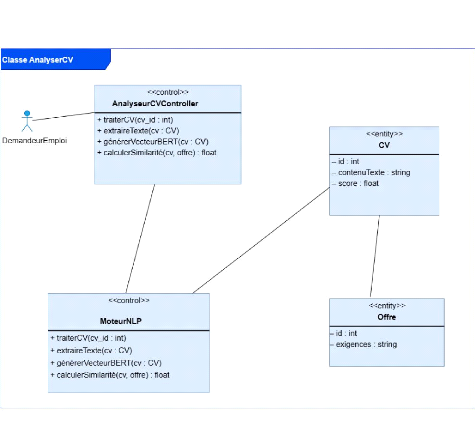
58
Figure 30 Diagramme de classe participante CU 10 Analyser
cv
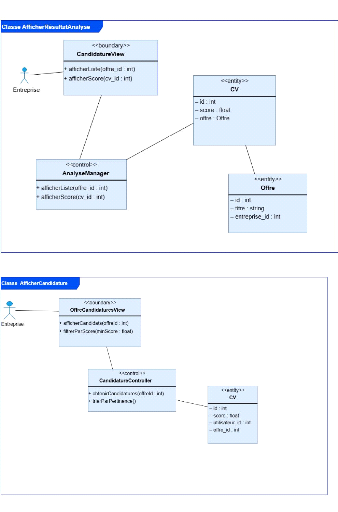
59
Figure 31 Diagramme de classe participante CU 11 Afficher
résultat
Figure 32 Diagramme de classe participante CU 12 Afficher
candidature
60
3.12. CONCEPTION DU MODÈLE LOGIQUE DE
DONNÉES
Le Modèle Logique de Données (MLD) constitue une
étape clé de la conception d'un système d'information. Il
permet de structurer les données à manipuler en respectant les
exigences fonctionnelles exprimées lors de la phase d'analyse. Le MLD
traduit les concepts métiers identifiés dans le Modèle
Conceptuel de Données (MCD) en éléments techniques
compatibles avec un système de gestion de base de données
relationnelle (SGBDR), ici PostgreSQL.
Ce modèle sert de fondement à la
génération ultérieure du Modèle Physique de
Données (MPD), qui correspond à la structure finale
implémentée dans la base.
Caractéristiques principales :
· Les entités métiers (par exemple :
Utilisateur, CV, Offre, Analyse) sont transformées en tables
relationnelles.
· Les attributs de ces entités deviennent les
colonnes des tables, avec un typage explicite adapté (exemples : VARCHAR
pour les chaînes de caractères, INTEGER pour les entiers, BOOLEAN
pour les booléens, TIMESTAMP pour les dates).
· Les identifiants des entités deviennent des
clés primaires (PK), souvent nommées id ou identifiant, avec
auto-incrément ou UUID selon la stratégie choisie.
· Les associations entre entités sont
modélisées soit :
§ Par des clés étrangères (FK),
lorsqu'il s'agit de relations de type 1,N ou N,1 (ex : un CV appartient
à un seul utilisateur),
§ Ou par des tables d'association
supplémentaires, lorsqu'il s'agit de relations N,N (ex : un CV peut
correspondre à plusieurs offres, et une offre peut recevoir plusieurs
CVs).
· Les contraintes d'intégrité
(unicité, non-null, relations référentielles) sont
définies afin de garantir la cohérence et la validité des
données.
Exemple d'application :
Pour ton système, les entités clés suivantes
deviennent des tables principales du MLD :
· Utilisateur (CustomUser) ? Table utilisateur
· ProfilEntreprise ? Table entreprise
· ChercheurEmploi ? Table chercheur_emploi
· Offre ? Table offre
· CV ? Table cv
· Analyse NLP ? Table analyse_cv (si
séparée)
· Notifications ? Table notification ou email_log
61
Chaque table contient une clé primaire (ex : id), des
colonnes typées (ex : phone_number : VARCHAR(13), is_verified :
BOOLEAN), et des clés étrangères (ex : user_id,
entreprise_id).
Les relations complexes comme le lien CV et Offre sont
représentées par une table d'association (ex : cv_offre) avec
deux clés étrangères pointant respectivement vers la table
cv et la table offre.
Ce modèle permet d'assurer la persistance des
données, la normalisation, l'intégrité et
l'extensibilité du système, tout en facilitant
l'implémentation avec un ORM comme Django Models.
3.13. DIAGRAMME DE DÉPLOIEMENT
Le diagramme de déploiement (Deployment Diagram) est
un diagramme structurel UML qui permet de représenter la topologie
physique du système. Il décrit comment les composants logiciels
(code source, bibliothèques, services, modèles NLP, etc.) sont
distribués et déployés sur les noeuds matériels et
logiciels du système (serveurs, navigateurs, bases de données,
etc.).
Ce diagramme est indispensable pour visualiser
l'environnement d'exécution réel de l'application, notamment dans
une architecture client-serveur ou distribuée. Il assure la
compréhension globale de la structure d'hébergement, de
l'accessibilité des services, et des dépendances entre les
différentes couches.
Dans le cas de notre système intelligent d'analyse de
CV basé sur le NLP, le diagramme de déploiement permet de
représenter l'architecture logicielle articulée autour des
technologies suivantes :
· Framework backend Django (Python)
· API REST pour la communication avec le frontend
· Interface utilisateur en React.js + Tailwind CSS
· Moteur NLP BERT embarqué pour l'analyse
sémantique
· SGBD PostgreSQL pour le stockage des données
· Serveur d'applications (Gunicorn / uWSGI)
· Serveur web (Nginx ou Apache)
· Conteneurs (optionnellement Docker)
· Navigateur client (pour l'utilisateur final)
Les principaux éléments à
représenter dans ce diagramme sont :
1. Les Noeuds (Nodes) :
Ce sont les dispositifs physiques ou virtuels sur lesquels
les composants sont exécutés. Dans notre système, on
distingue notamment :
· Le client utilisateur (navigateur web sur poste ou
mobile)
· Le serveur applicatif (hébergeant l'API Django +
NLP)
· Le serveur de base de données (PostgreSQL)
62
· Un moteur de traitement (pour BERT + PDF parser)
· Une infrastructure d'hébergement (local, Cloud, ou
via conteneurs Docker/Kubernetes)
2. Les Artéfacts (Artifacts) :
Ce sont les artefacts logiciels déployés sur les
noeuds. Exemples :
· Backend : code source Django (.py), modèles BERT,
scripts d'analyse (.py), fichiers de configuration (
settings.py, .env)
· Frontend : fichiers React buildés (index.html,
JS/CSS)
· Base de données : schéma relationnel
PostgreSQL (tables, contraintes)
3. Les Associations :
Ce sont les canaux de communication entre les noeuds, illustrant
les flux de données ou les appels réseau. Exemple :
· HTTPS entre le navigateur client et le serveur web
· REST API (HTTP/JSON) entre React et Django
· Connexion TCP/IP entre Django et PostgreSQL
· Communication interne entre Django et le moteur NLP Le
déploiement de notre système se présente de la
manière suivante :
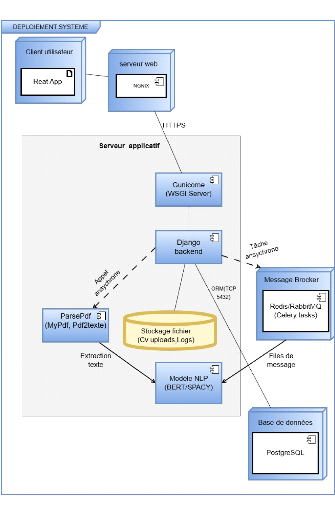
63
Figure 33 Diagramme de déploiement
64
Conclusion partielle
Dans ce chapitre, notre démarche a
débuté par une analyse détaillée du processus
métier de gestion des candidatures et de l'analyse automatisée de
CV. Nous avons ensuite présenté et modélisé le
système intelligent que nous proposons, centré sur
l'automatisation de l'extraction d'informations pertinentes à partir des
CV et leur traitement sémantique à l'aide de techniques NLP.
L'étude a permis d'identifier les exigences
fonctionnelles et non fonctionnelles du système, de décrire les
flux de données, les acteurs impliqués, ainsi que les points
forts et les limitations des approches classiques, justifiant ainsi notre
solution. Les méthodes de collecte, de traitement des CV (parser PDF,
analyse avec BERT), et de restitution des résultats ont
été décrites.
Nous avons également modélisé les
différents aspects du système à l'aide de diagrammes UML
clés : diagrammes de cas d'utilisation, de séquence, de classes,
du modèle logique de données, et enfin le diagramme de
déploiement. Ce dernier illustre l'architecture physique du
système, avec une répartition claire des composants logiciels sur
des noeuds distincts : client (navigateur), serveur web, serveur applicatif,
base de données et broker de messages.
Enfin, la conception globale du système repose sur une
architecture client-serveur hybride intégrant :
· le modèle MVVM côté frontend
(React) pour une meilleure séparation entre l'interface utilisateur et
la logique de présentation ;
· le modèle MVT côté backend
(Django), structurant le traitement des requêtes, la logique
métier, et le rendu des données.
Cette structuration garantit un système modulaire,
scalable et maintenable, capable de traiter efficacement les CV à grande
échelle avec un bon découplage des responsabilités.
65
CHAPITRE 4 IMPLEMENTATION DE LA SOLUTION PROPOSEE
4.1. Introduction
Dans ce chapitre, nous présentons les
différents outils et techniques utilisés tel que le NLP pour
implémenter notre système intelligent d'analyse de CV.
Après une justification approfondie des choix technologiques (langages,
frameworks, SGBD), nous détaillons l'architecture
d'implémentation adoptée, qui repose sur une approche
client-serveur hybride articulée autour des modèles MVT
(Model-View-Template) pour le backend (Django) et MVVM (Model-View-ViewModel)
pour le frontend (React). Nous exposons ensuite les différents modules
développés et les tests réalisés pour
évaluer le bon fonctionnement de la solution et quelques rappelles
important pour sur les notions de machines learning, deep learning et nlp .
4.1. Technologies
1. Choix des langages de programmation
· JavaScript (React) : utilisé
côté client pour concevoir une interface dynamique en architecture
MVVM. Le modèle (données), la vue (UI) et la logique de liaison
(état via hooks ou Redux) sont clairement séparés.
· Python (Django) : choisi pour son
efficacité dans le développement web côté serveur et
son intégration native avec des bibliothèques NLP (BERT, Spacy).
Django suit le modèle MVT, facilitant la structuration du backend.

· Tailwindcss: utilisés pour
structurer et styliser l'interface dans les composants React.
2. Frameworks
· React.js : framework JavaScript moderne, basé
sur le modèle MVVM, permettant une gestion efficace des vues et de
l'état via composants, props et hooks.
· Django : framework Python robuste, structuré
selon le modèle MVT, utilisé pour la logique métier, les
API REST, la sécurité et l'interface avec la base de
données via ORM.
· Tailwind CSS : bibliothèque CSS utilitaire,
utilisée pour styliser l'interface sans compromettre la
séparation des vues et de la logique.
· PyTorch / Transformers (Hugging Face) : frameworks
utilisés pour charger et exploiter le modèle BERT dans l'analyse
sémantique des CV.
· PyMuPDF / pdfminer : bibliothèques Python
utilisées pour parser et extraire le contenu textuel des CV en PDF.
66
3. Base de données
Le système utilise PostgreSQL comme SGBD relationnel
robuste, performant et bien adapté à l'architecture Django. Le
modèle de données est défini à travers des
modèles Django (ORM), avec une structure logique respectant
l'intégrité des relations (utilisateurs, offres, CV
analysés...).
4. Environnement de développement
· Visual Studio Code (VS Code) : utilisé comme
éditeur principal, avec intégration d'extensions pour Python,
React, Tailwind, etc.
5. Approche d'implémentation
Nous avons adopté une approche modulaire avec
séparation claire des responsabilités entre frontend, backend,
NLP et base de données.
Côté client :
· Le frontend React est structuré selon
MVVM, avec :
o Model : état local / global (via Redux)
o View : composants d'interface (formulaires CV, tableau de
bord, résultats)
o ViewModel : gestion logique (soumissions, appels API)
Côté serveur :
· Django suit l'approche MVT, où :
o Model : définit la base de données via ORM
o View : fonctions ou classes retournant JSON
o Template : utilisé uniquement pour endpoints HTML
(admin), sinon nous avons utilisé un API REST + React
Modules clés développés
· Module Authentification (utilisateurs, entreprises,
chercheurs d'emploi)
· Module de dépôt et parsing de CV (upload,
extraction PDF)
· Module d'analyse sémantique avec BERT
· Dashboard interactif pour les recruteurs (via React +
Chart.js)
· Système de notification (emails)
· Module de gestion des rôles (permissions Django)
Ces Technologies ont était choisi car c'est adapter
pour développer les applications qui utilises le modèle de
machine Learning .
67
6. Étude et mise en oeuvre d'un serveur
Celery
Dans le domaine du développement d'applications web et
distribuées, il est fréquent de rencontrer des traitements lourds
ou longs à exécuter, tels que l'envoi massif d'e-mails, la
génération de rapports volumineux ou le traitement d'images.
L'exécution synchrone de ces tâches dans le processus principal
d'une application entraîne souvent une dégradation significative
des performances et de l'expérience utilisateur. Pour répondre
à ce problème, la communauté Python a
développé Celery, un système de gestion de tâches
asynchrones permettant d'exécuter ces traitements en arrière-plan
grâce à un mécanisme de file d'attente et à des
workers indépendants.
· Définition de Celery
Celery est un framework Python open-source
dédié à la gestion de tâches
distribuées et à leur exécution asynchrone. Il s'appuie
sur un système de messagerie intermédiaire appelé
broker qui joue le rôle de file d'attente.
Dans ce modèle, l'application principale
délègue l'exécution des tâches à un ou
plusieurs workers Celery qui les traitent de manière
indépendante, permettant ainsi à l'application de rester
réactive.
· Architecture générale
L'architecture de Celery repose sur quatre composants principaux
:
1. Le Producteur (Application principale)
o Rôle : Définir et envoyer les tâches
à exécuter.
Pour ce projet le serveur celery se charge de faire l'ORC du cv
et offre provenant du pdf mais aussi il affiche le résultat provenant du
modèle pour ce qui est de cosine similaty et par-dessus tous, ils
gère les envoient de mail en arrière-plan.
2. Le Broker (Serveur de messagerie)
o Rôle : Transmettre les tâches via une file
d'attente.
o Outils fréquents : Redis, RabbitMQ.
3. Les Workers Celery
o Rôle : Récupérer et exécuter les
tâches en arrière-plan.
o Fonctionnement : Chaque worker écoute une file
d'attente et traite les tâches dès qu'elles sont disponibles.
4. Le Backend de résultats (optionnel)
o Rôle : Stocker le résultat des tâches pour
une consultation ultérieure.
o Support : Redis, base de données relationnelle, etc.
68
5. Avantages de cette approche
· Réduction du temps de réponse
: L'utilisateur n'attend pas que le traitement soit fini.
· Scalabilité : Plusieurs workers
peuvent traiter les tâches en parallèle.
· Résilience : Les tâches
peuvent être relancées en cas d'échec. 4.2 Rappels
théoriques essentiels
4.2.1. Introduction au Machine Learning
L'apprentissage automatique est un sous-ensemble de
l'intelligence artificielle dans le domaine de l'informatique qui utilise
souvent des techniques statistiques pour donner aux ordinateurs la
capacité d'apprendre (c'est-à-dire améliorer
progressivement les performances sur une tâche spécifique) avec
des données, sans être explicitement programmées.
L'apprentissage automatique est la conception et l'étude d'artefacts
logiciels qui utilisent l'expérience passée pour prendre des
décisions futures. C'est l'étude de programmes qui apprennent
à partir de données. L'objectif fondamental de l'apprentissage
automatique est de généraliser, ou pour induire une règle
inconnue à partir d'exemples d'application de la règle. Les
systèmes d'apprentissage automatique sont souvent décrits comme
apprenant par l'expérience, avec ou sans surveillance par l'homme
[12].
Voici les trois styles d'apprentissage de base différents
dans les algorithmes d'apprentissage automatique :
1.2.2 Apprentissage supervisé
Un modèle est préparé par le biais d'un
processus d'entraînement dans lequel il doit faire des prédictions
et est corrigé lorsque ces prédictions sont fausses. Le processus
de formation continue jusqu'à ce que le modèle atteigne le niveau
de précision souhaité sur les données
d'entraînement. Un programme prédit une sortie pour une
entrée en apprenant à partir de paires d'entrées
étiquetées et les résultats, le programme apprend à
partir d'exemples de bonnes réponses [12].
1. Les données d'entrée sont appelées
données d'entraînement et ont une étiquette ou un
résultat connu, tel que spam/non-spam ou un cours d'action à la
fois.
2. Des exemples de problèmes sont la classification et la
régression. 3.Algorithmes supervisés couramment
utilisés
L'apprentissage supervisé repose sur l'utilisation
d'algorithmes qui apprennent à partir d'exemples
étiquetés, c'est-à-dire des données dont les
résultats attendus sont connus. Voici une description
détaillée des principaux algorithmes supervisés
utilisés dans le domaine médical :
v Régression logistique : Cet algorithme
est utilisé pour des tâches de classification binaire. Il
modélise la probabilité qu'une observation appartienne à
une classe donnée.
69
La sortie est comprise entre 0 et 1, ce qui permet de
l'interpréter comme une probabilité. Il est simple, rapide, et
efficace pour des jeux de données linéairement
séparables.
v Arbres de décision (Decision Trees)
: Ce modèle fonctionne en divisant les données en
sous-ensembles selon des conditions basées sur les attributs. Il produit
un arbre hiérarchique où chaque noeud représente une
condition de décision. Faciles à interpréter, les arbres
de décision sont efficaces mais sensibles au surapprentissage
(overfitting).
v K-Nearest Neighbors (K-NN) : Cet
algorithme classe une nouvelle observation selon la majorité des classes
de ses k plus proches voisins dans l'espace des caractéristiques. Il ne
nécessite pas de phase d'entraînement, mais peut être lent
sur de grands ensembles de données. Il est également sensible
à l'échelle des variables.
v Support Vector Machines (SVM) : Le SVM
cherche à trouver l'hyperplan qui sépare au mieux les classes
dans un espace à plusieurs dimensions. Il est efficace dans les cas
où les classes ne sont pas parfaitement séparables, en utilisant
des noyaux pour transformer les données.
v Réseaux de neurones artificiels (ANN)
: Inspirés du fonctionnement du cerveau humain, les ANN sont
constitués de couches de neurones interconnectés. Chaque neurone
applique une fonction d'activation pour transmettre les informations. Ces
réseaux sont capables de modéliser des relations complexes entre
les variables, surtout lorsqu'ils sont profonds (deep learning). Ils sont
utilisés dans les applications d'imagerie médicale, de
reconnaissance vocale et de traitement du langage naturel.
2.2.3 Apprentissage non supervisé
Un modèle est préparé en déduisant
les structures présentes dans les données d'entrée. Il
peut s'agir d'extraire des règles générales. Il peut
s'agir d'un processus mathématique visant à réduire
systématiquement la redondance, ou d'organiser les données par
similarité. Un programme n'apprend pas à partir de données
étiquetées. Au lieu de cela, il tente de découvrir des
modèles dans les données [12].
Ici les données ne sont pas étiquetées,
L'objectif principal de l'apprentissage non supervisé est de permettre
à l'algorithme de trouver des patterns, des regroupements ou des
relations entre les données d'entrée, sans intervention
humaine.
2.3.4 Apprentissage par renforcement
L'apprentissage par renforcement (Reinforcement
Learning, en anglais) est une forme d'apprentissage automatique dans
laquelle un agent autonome apprend à prendre des décisions en
interagissant avec un environnement dynamique. Cet agent n'apprend pas à
partir d'un ensemble de données déjà
étiqueté (comme en apprentissage supervisé), mais à
travers des essais et des erreurs, en recevant des récompenses ou des
pénalités selon la qualité de ses actions.
2.3.5 Notions de Deep Learning
Le Deep Learning ou apprentissage profond est une branche
avancée de l'apprentissage automatique (machine learning) qui repose sur
l'utilisation de réseaux de neurones artificiels profonds,
composés de plusieurs couches. Ces architectures sont capables de
modéliser des relations complexes et de traiter des données de
grande dimension comme les images, les sons ou les textes non structurés
[13].
70
Figure 34 Machine learning, deep learning description
Un réseau de neurones est une structure inspirée
du fonctionnement du cerveau humain. Il est constitué de plusieurs
neurones artificiels.
Les approches classiques de Machine Learning
nécessitent peu de données pour fonctionner efficacement. Elles
s'appuient sur des architectures comme les arbres de décision, SVM ou
KNN, et offrent de bonnes performances lorsqu'elles sont appliquées
à des données structurées. Leur entraînement est
généralement rapide et peu coûteux.
En revanche, les modèles de Deep Learning sont
particulièrement adaptés aux données complexes telles que
les textes, les images ou les sons. Ils reposent sur des réseaux de
neurones profonds et exigent de grandes quantités de données pour
atteindre leur plein potentiel. Leur entraînement demande plus de temps
et mobilise davantage de ressources.
Cas d'usage du Deep Learning dans le traitement de
CV
L'usage du Deep Learning dans le traitement des curriculum
vitae (CV) constitue une avancée majeure dans l'optimisation des
processus de recrutement. Cette technologie, grâce à sa
capacité à traiter des données textuelles
hétérogènes et non structurées, permet de
répondre à des enjeux stratégiques liés à la
sélection automatisée et à la correspondance entre
candidatures et offres d'emploi.
1. Extraction des informations pertinentes à partir
de données non structurées
Les architectures de Deep Learning telles que BERT, SBERT et
les pipelines de traitement linguistique comme spaCy, intégrant la
reconnaissance d'entités nommées (NER), facilitent l'extraction
automatisée de données essentielles, notamment :
· L'identité du candidat
· Les diplômes et le niveau académique
· Les expériences professionnelles
antérieures
· Les compétences techniques (ex. : langages de
programmation, systèmes d'exploitation)
· Les langues maîtrisées
71
· Les certifications obtenues
Cette démarche permet de convertir des documents
textuels non standardisés en représentations structurées
exploitables par des systèmes décisionnels.
2. Évaluation sémantique de la pertinence
entre CV et offres d'emploi
La correspondance automatisée entre le profil d'un
candidat et les exigences d'un poste repose sur la vectorisation
sémantique des contenus textuels. Les modèles comme Sentence-BERT
(SBERT) transforment le CV et l'offre en vecteurs dans un espace latent
partagé. La mesure de similarité cosinus entre ces vecteurs
permet d'évaluer le degré de correspondance. Ce processus
constitue une étape essentielle dans la mise en oeuvre de
systèmes intelligents de recommandation et de
présélection.
2.3.6 Traitement automatique du langage naturel (NLP)
Le NLP pour Natural Language Processing ou Traitement du
Langage Naturel est une discipline qui porte essentiellement sur la
compréhension, la manipulation et la génération du langage
naturel par les machines. Ainsi, le NLP est réellement à
l'interface entre la science informatique et la linguistique. Il porte donc sur
la capacité de la machine à interagir directement avec l'humain.
[14]
À quelles problématiques répond le
NLP ?
Le NLP est terme assez générique qui recouvre un
champ d'application très vaste. Voici les applications les plus
populaires :
Ø Traduction automatique
Le développement d'algorithmes de traduction
automatique a réellement révolutionné la
manière dont les textes sont traduits aujourd'hui. Des applications,
telles que Google Translator, sont capables de
traduire des textes entiers sans aucune intervention humaine.
Le langage naturel étant par nature ambigu et variable, ces applications
ne reposent pas sur un travail de remplacement mot à mot, mais
nécessitent une véritable analyse et modélisation de
texte, connue sous le nom de Traduction automatique statistique (Statistical
Machine Translation en anglais) [14].
Ø Sentiment analysis
Aussi connue sous le nom de « Opinion
Mining », l'analyse des sentiments consiste
à identifier les informations subjectives d'un texte pour
extraire l'opinion de l'auteur [14].
À titre exemple, lorsqu'une marque lance un nouveau
produit, elle peut exploiter les commentaires recueillis sur les réseaux
sociaux pour identifier le sentiment positif ou négatif globalement
partagé par les clients.
De manière générale, l'analyse
des sentiments permet de mesurer le niveau de satisfaction des clients
vis-à-vis des produits ou services fournis par une entreprise ou un
organisme. Elle peut même s'avérer bien plus efficace que
des méthodes classiques comme les sondages [14].
En effet, si l'on rechigne souvent à passer du temps
à compléter de longs questionnaires, une partie
croissante des consommateurs partage aujourd'hui fréquemment leurs
opinions sur les réseaux sociaux. Ainsi, la recherche de textes
négatifs et l'identification des principales plaintes permettent
d'améliorer les produits, d'adapter la publicité et de
réduire le niveau d'insatisfaction des clients [14].
72
Ø Marketing
Les spécialistes du marketing utilisent également
le NLP pour rechercher des personnes étant susceptible d'effectuer un
achat [14].
Ils s'appuient pour cela sur le comportement des
internautes sur les sites, les réseaux sociaux et les
requêtes aux moteurs de recherche. C'est grâce à ce type
d'analyse que Google génère un profit non négligeable en
proposant la bonne publicité aux bons internautes. Chaque fois qu'un
visiteur clique sur une annonce, l'annonceur reverse jusqu'à 50 dollars
!
De manière plus générale, les
méthodes de NLP peuvent être exploitées
pour dresser un portrait riche et complet du marché existant, des
clients, des problèmes, de la concurrence et du potentiel de croissance
des nouveaux produits et services de l'entreprise.
Les sources de données brutes pour cette analyse
comprennent les journaux de ventes, les enquêtes et les médias
sociaux...
Ø Chatbots
Les méthodes NLP sont au coeur du
fonctionnement des Chatbots actuels. Bien que ces systèmes ne soient pas
totalement parfaits, ils peuvent aujourd'hui facilement gérer
des tâches standards telles renseigner des clients sur des
produits ou services, répondre à leurs questions, etc. Ils sont
utilisés par plusieurs canaux, dont l'Internet, les applications et les
plateformes de messagerie. L'ouverture de la plateforme Facebook
Messenger aux chatbots en 2016 a contribué à leur
développement [14].
Autres domaines d'application
· Classification de texte : cela
consiste à attribuer un ensemble de catégories
prédéfinies à un texte donné. Les
classificateurs de texte peuvent être utilisés pour organiser,
structurer et catégoriser à ensemble de textes.
· Reconnaissance de caractères :
Cela permet d'extraire, à partir de la reconnaissance
des caractères, les principales informations des
reçus, des factures, des chèques, des documents
de facturation légaux, etc.
· Correction automatique : la plupart
des éditeurs de texte sont aujourd'hui muni d'un correcteur
orthographique qui permet de vérifier si le texte contient des fautes
d'orthographe.
73
Figure 35 Quelques Domaines du nlp Parmi les
principales étapes, on retrouve :
· Nettoyage : Variable selon la source des
données, cette phase consiste à réaliser des tâches
telles que la suppression d'urls, d'emoji, etc.
· Normalisation des données:
o Tokenisation, ou découpage du texte en
plusieurs pièces appelés tokens. Exemple : «
Vous trouverez en pièce jointe le document en question » ; «
Vous », « trouverez », « en pièce jointe »,
« le document », « en question ».
o Stemming : un même mot peut se
retrouver sous différentes formes en fonction du genre (masculin
féminin), du nombre (singulier, pluriel), la personne (moi, toi, eux...)
etc. Le stemming désigne généralement le processus
heuristique brut qui consiste à découper la fin des mots dans
afin de ne conserver que la racine du mot. Exemple : « trouverez
» -> « trouv »
o Lemmatisation : cela consiste à
réaliser la même tâche mais en utilisant un vocabulaire et
une analyse fine de la construction des mots. La lemmatisation permet donc de
supprimer uniquement les terminaisons inflexibles et donc à isoler la
forme canonique du mot, connue sous le nom de lemme. Exemple : «
trouvez » -> trouver
o Autres opérations : suppression des
chiffres, ponctuation, symboles et stopwords, passage en minuscule.
Afin de pouvoir appliquer les méthodes de Machine
Learning aux problèmes relatifs au langage naturel, il est indispensable
de transformer les données textuelles en données
numériques. Il existe plusieurs approches dont les principales
sont les suivantes :
· Term-Frequency (TF) : cette
méthode consiste à compter le nombre d'occurrences des
tokens présents dans le corpus pour chaque texte.
74
· Chaque texte est alors représenté par un
vecteur d'occurrences. On parle généralement
de Bag-Of-Word, ou sac de mots en français.
Néanmoins, cette approche présente un
inconvénient majeur : certains mots sont par nature
plus utilisés que d'autres, ce qui peut conduire le modèle
à des résultats erronés.
· Term Frequency-Inverse Document Frequency
(TF-IDF) : cette méthode consiste à compter le
nombre d'occurrences des tokens présents dans le corpus pour
chaque texte, que l'on divise ensuite par le nombre d'occurrences total de ces
même tokens dans tout le corpus.
Dans le cadre de ce travaille nous avions utiliser le
modèle Sbert(paraphrase-multilingual-MiniLM-L12-v2) pour l'encodage de
texte et non (TF-IDF) ni
(TF)
4.3 Récolte de données
Nous avions récolté nos données sur
kaggle(Automated Resume Job Categorization ) le dataset est
nomé `' clean_resume_data.csv `'
df.shape : (2484, 2)
Description du Dataset - Automated Resume Job
Categorization
Ce jeu de données est utilisé dans le cadre de
projets de classification automatique des curriculum vitae selon les
catégories d'emploi correspondantes. Il est fréquemment
mobilisé dans les systèmes de recommandation d'offres d'emploi ou
de mise en correspondance entre profils candidats et descriptions de postes.
Tableau 5 Contenu du dataset
Attribut Description
Resume
|
|
Contient le texte brut du CV, généralement sous
forme de paragraphe ou d'ensemble de phrases non structurées.
|
Category
|
Étiquette associée à chaque CV,
représentant le domaine professionnel (ex. : "Data Science", "HR",
"Advocate", "Design", etc.).
|
|
Statistiques générales
Voici un aperçu typique basé sur ce jeu de
données
· Nombre total de CVs : 2484
· Nombre de catégories transformer en offre
d'emplois : environ 24
· Format : CSV
· Colonnes : Resume, Category
· Taille moyenne d'un CV : entre 200 et 500 mots
· Langue du contenu : anglaise
75
Objectif du projet avec ce dataset
Former un modèle capable de prédire la
catégorie de job la plus pertinente à partir du contenu
textuel d'un CV non structuré.
Ce dataset nous l'avions modifié en le traduisant en
français et en changeant la catégory en offre via le
modèle Helsinki-NLP/opus-mt-en-fr.
4.4 Conception et Entraînement du Modèle de
Classification pour l'Analyse CV-Offres
Dans ce bloc nous allons décrire en détail la
conception, l'architecture, l'entraînement et l'évaluation d'un
système de classification automatique permettant d'évaluer la
pertinence entre des CV et des offres d'emploi. Le modèle combine des
techniques avancées de traitement du langage naturel (NLP)
1 Architecture Globale du Système
Le système complet se compose des étapes suivantes
:
1. Prétraitement des données textuelles
(nettoyage, normalisation).
2. Encodage sémantique avec un
modèle SBERT (Sentence-BERT).
3. Calcul de similarité entre les
embeddings CV et offres.
4. Classification avec plusieurs algorithmes
(Random Forest, SVM, Réseau de Neurones).
5. Évaluation et optimisation des
performances.
o Prétraitement des Données
Ø Netoyage robuste
Un prétraitement minimaliste est choisi pour
préserver au maximum la richesse sémantique
originale, les
modèles modernes comme SBERT étant robustes aux variations de
formatage.
2. Encodage Sémantique avec SBERT
Modèle utilisé :
paraphrase-multilingual-MiniLM-L12-v2 Caractéristiques
techniques :
· Modèle Transformer
pré-entraîné sur plusieurs langues
· Taille des embeddings : 384 dimensions
· Capacité à capturer la sémantique
des phrases complètes
· Optimisé pour les tâches de
similarité textuelle Optimisations :
· Traitement par lots pour gérer la
mémoire
· Barre de progression avec tqdm
· Concatenation efficace des résultats
76
3. Calcul de Similarité
Métrique utilisée :
Similarité cosinus
2.4 Stratégie d'Étiquetage Automatique
Approche : Discrétisation des scores de
similarité en 4 classes
Seuils déterminés:
1. Excellent: similarity = 0.7
2. Très bon: 0.6 = similarity <
0.7
3. Bon : 0.5 = similarity < 0.6
4. Faible : similarity < 0.5
Justification :
Les seuils fixes permettent une interprétation
cohérente, tandis que la version basée sur les
quantiles s'adapte automatiquement à la distribution des
données.
2.5 Équilibrage des Classes
Problématique : Distribution
inégale des classes dans les données brutes
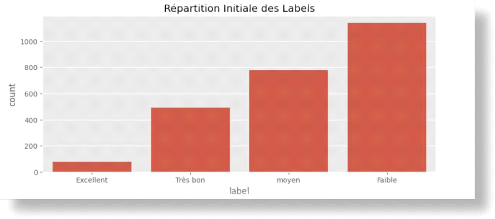
Figure 36 Déséquilibre initiale de classe
Solutions implémentées :
1. Oversampling avec SMOTE
2. Pondération des classes
3. Approche hybride : Combinaison des deux
méthodes pour les modèles sensibles au
déséquilibre
77
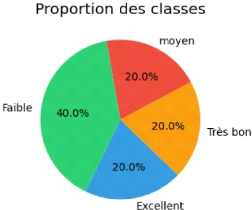
Figure 37 Equilibres de classes
Impact :
Réduction du biais envers les classes majoritaires,
amélioration des métriques sur les classes rares.
3. Modèles de Classification 3.1 Modèles
Traditionnels
Tableau 6 Algorithmes implémentés
Modèle Paramètres Clés
Avantages
|
Random Forest
|
n_estimators=200, max_depth=15
|
Robustesse, sélection de features
|
|
SVM
|
kernel='rbf',
class_weight='balanced'
|
Performances en haute dimension
|
|
Régression
Logistique
|
penalty='elasticnet', solver='saga'
|
Interprétabilité
|
3.2 Réseau de Neurones Profond
Hyperparamètres :
· Taux d'apprentissage : 0.0005 (avec réduction
dynamique)
· Batch size : 64
· Early stopping avec patience=10 Mécanismes
avancés :
· Dropout : Prévention du
surapprentissage
· BatchNorm : Stabilisation de
l'apprentissage
· Callbacks : Optimisation automatique du
LR
78
4. Évaluation des Performances des
modèles
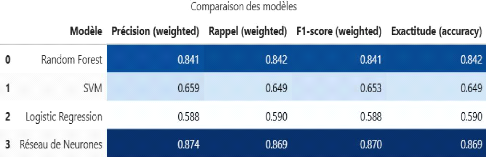
Figure 39 Tableau comparatif des modèles
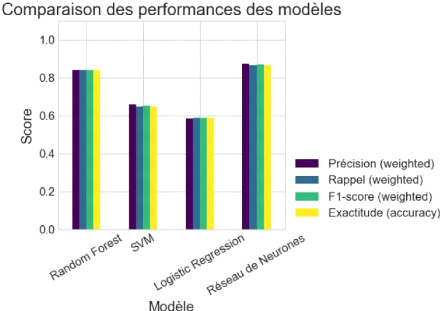
Figure 38 Comparaison de la performance des
modèles
79
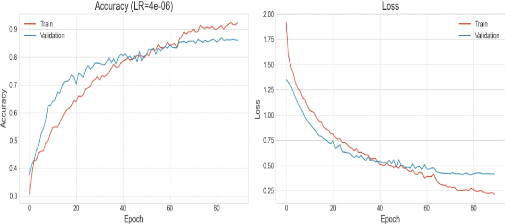
Figure 40 visualisation de la courbe de précision et
perte
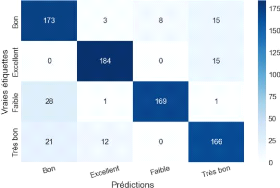
Figure 41 Matrice de confusion du modèle
validé
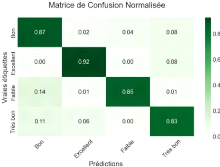
Figure 42 Matrice de confusion normalisé
80
4.5. Conclusion
Dans ce chapitre, nous avons présenté l'ensemble
des outils et technologies ainsi que methodes utilisés pour le
développement de notre système, en mettant l'accent sur les
architectures MVT côté backend (Django) et MVVM côté
frontend (React). L'implémentation a été structurée
de manière modulaire, facilitant la maintenance et
l'évolutivité ainsi que la manières dont nous avons
recoltés nos données et entrainer le model jusqu'au
résultat final. Les tests réalisés ont montré que
la solution est stable, cohérente avec les exigences définies.
81
CHAPITRE 5. RESULTATS ET EVALUATIONS
5.1 Résultats
a) Présentation de l'application
Figure 43 interface d'accueille
Cette page est la page d'accueil accessible à tous les
utilisateurs
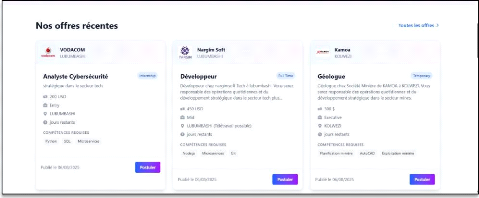
Figure 44 interface des offres
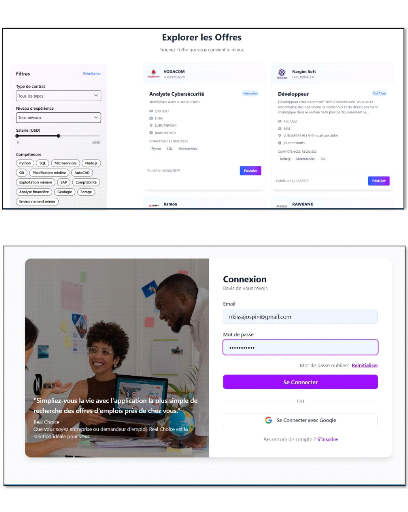
82
Figure 45 interface des offres avec option de
filtre
Figure 46 interface de login pour
s'authentifier
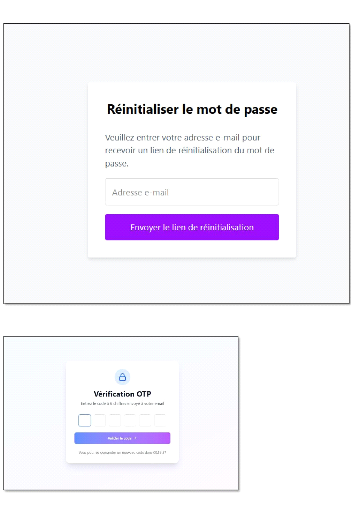
83
Figure 47 interface pour réinitialiser le mot
de passe
Figure 48 interface pour la vérification de OTP
envoyer par mail
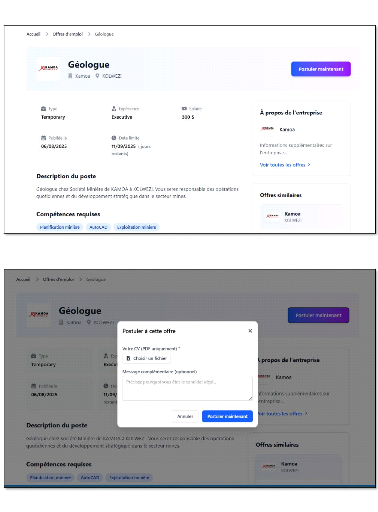
84
Figure 49 interface pour sur la vue du
détaille de l'offre
Figure 50Interface pour uploader le cv
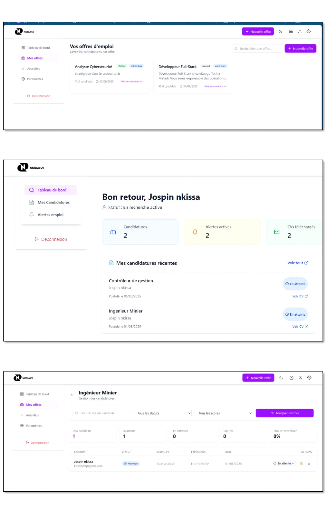
85
Figure 51 Dashboard Entreprise
Figure 52 Dashboard chercheur d'emploie
Figure 53 Dashboard entreprise avant l'analyse
86
Figure 54Dashboard entreprise l'analyse encours
Figure 55 opération Asynchrone avec serveur
celery
Figure 56 Résultat d'analyse
87
Conclusion Générale
Au terme de ce travail de recherche et de
développement, nous avons pu concevoir et implémenter un
système intelligent d'aide au recrutement basé sur l'analyse
automatique de CV et le matching sémantique avec les offres d'emploi.
Cette étude s'inscrit dans une dynamique actuelle de digitalisation des
processus RH, et répond à un besoin croissant d'automatisation
dans le traitement des candidatures, tant du point de vue des recruteurs que
des demandeurs d'emploi.
Dans une première phase, nous avons mené une
analyse approfondie du métier et des besoins fonctionnels, en nous
basant sur les pratiques existantes et les insuffisances observées dans
les systèmes traditionnels de gestion des candidatures. L'analyse
métier a permis de définir les acteurs clés, les cas
d'utilisation pertinents, ainsi que les exigences fonctionnelles et non
fonctionnelles du système à concevoir.
Sur le plan technique, nous avons mis en oeuvre une
architecture web basée sur des technologies modernes (Django, React) et
avons intégré des techniques avancées de traitement
automatique du langage naturel (NLP), notamment via des modèles
d'embedding comme BERT, pour évaluer la correspondance sémantique
entre les profils des candidats et les offres publiées. Cette
démarche a permis de passer d'un système basé sur des
mots-clés à un moteur intelligent d'analyse contextuelle, plus
pertinent et plus performant.
L'application développée offre ainsi aux
entreprises une plateforme intuitive pour publier et gérer des offres
d'emploi, recevoir des candidatures, analyser automatiquement les CV et
visualiser les scores labelisé. Du côté des chercheurs
d'emploi, le système permet de consulter les offres, de
téléverser leur CV, de suivre l'état de leur candidature
et d'accéder à des services fluides, accessibles et ergonomiques.
L'intégration de fonctionnalités telles que l'authentification
OTP, la traçabilité des actions et le tableau de bord statistique
apporte une valeur ajoutée significative à l'application, en
renforçant la sécurité, la transparence et la
facilité de gestion.
Ce mémoire a également permis de mettre en
évidence les limites rencontrées, notamment en ce qui concerne
l'analyse des CV très hétérogènes ou mal
structurés, ou encore les défis liés à la
constitution d'un jeu de données représentatif pour
entraîner les modèles. Toutefois, les résultats obtenus
sont prometteurs et laissent entrevoir plusieurs perspectives
d'amélioration, telles que l'intégration d'un moteur de
recommandation de profils, l'apprentissage automatique supervisé ou non
supervisé, ou encore la prise en compte de critères
socio-professionnels plus larges.
En définitive, ce travail constitue une contribution
concrète à l'optimisation des processus de recrutement à
l'ère numérique, et ouvre la voie à de nombreuses
évolutions futures. Il témoigne également de l'importance
croissante de l'intelligence artificielle dans les systèmes
d'information décisionnels, notamment dans le domaine des ressources
humaines.
Nous espérons que cette application servira de base
pour d'éventuels déploiements en milieu réel, ou à
tout le moins, qu'elle stimulera une réflexion plus large sur les
opportunités offertes par l'automatisation intelligente au service de
l'employabilité.
88
Bibliographie
[1] S. HATTAB, «zenodo,» [En ligne]. Available:
https://zenodo.org/records/7945078.
[Accès le 1 4 2025].
[2] U. d. Liège, «matheo,» Université de
Liège , [En ligne]. Available:
https://matheo.uliege.be/handle/.
[Accès le 3 4 2025].
[3] H. Ramdani, «
hal.univ-lorraine.fr,»
[En ligne]. Available:
https://hal.univ-lorraine.fr/tel-04213881/file/DDOC_T_2021_0366_RAMDANI.pdf.
[Accès le 4 4 2025].
[4] M. Martins Oliveira, «
matheo.uliege.be,»
Liège University, 2021-2022. [En ligne]. Available:
https://matheo.uliege.be/bitstream/2268.2/16352/4/s162904MartinsMariana2022.pdf.
[Accès le 5 4 2025].
[5] Y. ELMOHRI,
dspace.univ-medea.dz,
Algérienne : Université Yahia Fares de Médéa,
2023-2024.
[6] «wikipedia,» [En ligne]. Available:
https://fr.wikipedia.org/wiki/Mod%C3%A9lisation_de_processus.
[Accès le 9 5 2025].
[7] «
clicours.com,» [En ligne].
Available:
https://www.clicours.com/cours-uml-et-exercices-corriges/.
[Accès le 1 6 2025].
[8] Université du Québec à Montréal,
[En ligne]. Available:
https://www.studocu.com/.
[Accès le 28 5 2025].
[9] «
www.lucidchart.com,»
lucidchart, [En ligne]. Available:
https://www.lucidchart.com/.
[Accès le 5 29 2025].
[10] «wikipedia,» wiki, [En ligne]. Available:
https://fr.wikipedia.org/wiki/Logiciel.
[Accès le 30 06 2025].
[11] «clicours,» [En ligne]. Available:
https://www.clicours.com/cours-uml-et-exercices-corriges/.
[Accès le 1 6 2025].
[12] «machinelearning101,» [En ligne]. Available:
https://machinelearning101.readthedocs.io/en/latest/_pages/01_introduction.html.
[Accès le 1 7 2025].
[13] IBM, «
www.ibm.com,» [En ligne].
Available:
https://www.ibm.com/fr-fr/think/topics/deep-learning.
[Accès le 7 7 2025].
[14] «
datascientest.com,» [En
ligne]. Available:
https://datascientest.com/introduction-au-nlp-natural-language-processing.
[Accès le 7 7 2025].


