Le diagramme de déploiement (Deployment Diagram) est
un diagramme structurel UML qui permet de représenter la topologie
physique du système. Il décrit comment les composants logiciels
(code source, bibliothèques, services, modèles NLP, etc.) sont
distribués et déployés sur les noeuds matériels et
logiciels du système (serveurs, navigateurs, bases de données,
etc.).
Ce diagramme est indispensable pour visualiser
l'environnement d'exécution réel de l'application, notamment dans
une architecture client-serveur ou distribuée. Il assure la
compréhension globale de la structure d'hébergement, de
l'accessibilité des services, et des dépendances entre les
différentes couches.
Dans le cas de notre système intelligent d'analyse de
CV basé sur le NLP, le diagramme de déploiement permet de
représenter l'architecture logicielle articulée autour des
technologies suivantes :
· Framework backend Django (Python)
· API REST pour la communication avec le frontend
· Interface utilisateur en React.js + Tailwind CSS
· Moteur NLP BERT embarqué pour l'analyse
sémantique
· SGBD PostgreSQL pour le stockage des données
· Serveur d'applications (Gunicorn / uWSGI)
· Serveur web (Nginx ou Apache)
· Conteneurs (optionnellement Docker)
· Navigateur client (pour l'utilisateur final)
Les principaux éléments à
représenter dans ce diagramme sont :
Ce sont les dispositifs physiques ou virtuels sur lesquels
les composants sont exécutés. Dans notre système, on
distingue notamment :
· Le client utilisateur (navigateur web sur poste ou
mobile)
· Le serveur applicatif (hébergeant l'API Django +
NLP)
· Le serveur de base de données (PostgreSQL)
62
· Un moteur de traitement (pour BERT + PDF parser)
· Une infrastructure d'hébergement (local, Cloud, ou
via conteneurs Docker/Kubernetes)
2. Les Artéfacts (Artifacts) :
Ce sont les artefacts logiciels déployés sur les
noeuds. Exemples :
· Backend : code source Django (.py), modèles BERT,
scripts d'analyse (.py), fichiers de configuration (
settings.py, .env)
· Frontend : fichiers React buildés (index.html,
JS/CSS)
· Base de données : schéma relationnel
PostgreSQL (tables, contraintes)
3. Les Associations :
Ce sont les canaux de communication entre les noeuds, illustrant
les flux de données ou les appels réseau. Exemple :
· HTTPS entre le navigateur client et le serveur web
· REST API (HTTP/JSON) entre React et Django
· Connexion TCP/IP entre Django et PostgreSQL
· Communication interne entre Django et le moteur NLP Le
déploiement de notre système se présente de la
manière suivante :
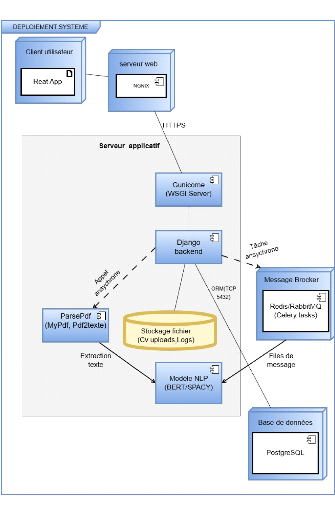
63
Figure 33 Diagramme de déploiement
64
Conclusion partielle
Dans ce chapitre, notre démarche a
débuté par une analyse détaillée du processus
métier de gestion des candidatures et de l'analyse automatisée de
CV. Nous avons ensuite présenté et modélisé le
système intelligent que nous proposons, centré sur
l'automatisation de l'extraction d'informations pertinentes à partir des
CV et leur traitement sémantique à l'aide de techniques NLP.
L'étude a permis d'identifier les exigences
fonctionnelles et non fonctionnelles du système, de décrire les
flux de données, les acteurs impliqués, ainsi que les points
forts et les limitations des approches classiques, justifiant ainsi notre
solution. Les méthodes de collecte, de traitement des CV (parser PDF,
analyse avec BERT), et de restitution des résultats ont
été décrites.
Nous avons également modélisé les
différents aspects du système à l'aide de diagrammes UML
clés : diagrammes de cas d'utilisation, de séquence, de classes,
du modèle logique de données, et enfin le diagramme de
déploiement. Ce dernier illustre l'architecture physique du
système, avec une répartition claire des composants logiciels sur
des noeuds distincts : client (navigateur), serveur web, serveur applicatif,
base de données et broker de messages.
Enfin, la conception globale du système repose sur une
architecture client-serveur hybride intégrant :
· le modèle MVVM côté frontend
(React) pour une meilleure séparation entre l'interface utilisateur et
la logique de présentation ;
· le modèle MVT côté backend
(Django), structurant le traitement des requêtes, la logique
métier, et le rendu des données.
Cette structuration garantit un système modulaire,
scalable et maintenable, capable de traiter efficacement les CV à grande
échelle avec un bon découplage des responsabilités.
65


