2.4 Stratégie d'Étiquetage Automatique
Approche : Discrétisation des scores de
similarité en 4 classes
Seuils déterminés:
1. Excellent: similarity = 0.7
2. Très bon: 0.6 = similarity <
0.7
3. Bon : 0.5 = similarity < 0.6
4. Faible : similarity < 0.5
Justification :
Les seuils fixes permettent une interprétation
cohérente, tandis que la version basée sur les
quantiles s'adapte automatiquement à la distribution des
données.
2.5 Équilibrage des Classes
Problématique : Distribution
inégale des classes dans les données brutes
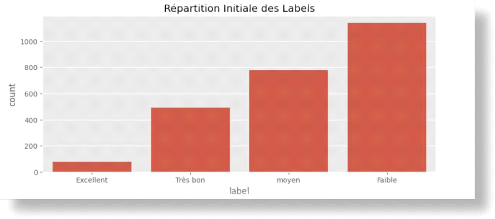
Figure 36 Déséquilibre initiale de classe
Solutions implémentées :
1. Oversampling avec SMOTE
2. Pondération des classes
3. Approche hybride : Combinaison des deux
méthodes pour les modèles sensibles au
déséquilibre
77
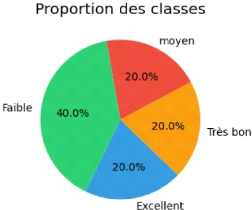
Figure 37 Equilibres de classes
Impact :
Réduction du biais envers les classes majoritaires,
amélioration des métriques sur les classes rares.
3. Modèles de Classification 3.1 Modèles
Traditionnels
Tableau 6 Algorithmes implémentés
Modèle Paramètres Clés
Avantages
|
Random Forest
|
n_estimators=200, max_depth=15
|
Robustesse, sélection de features
|
|
SVM
|
kernel='rbf',
class_weight='balanced'
|
Performances en haute dimension
|
|
Régression
Logistique
|
penalty='elasticnet', solver='saga'
|
Interprétabilité
|
3.2 Réseau de Neurones Profond
Hyperparamètres :
· Taux d'apprentissage : 0.0005 (avec réduction
dynamique)
· Batch size : 64
· Early stopping avec patience=10 Mécanismes
avancés :
· Dropout : Prévention du
surapprentissage
· BatchNorm : Stabilisation de
l'apprentissage
· Callbacks : Optimisation automatique du
LR
78
4. Évaluation des Performances des
modèles
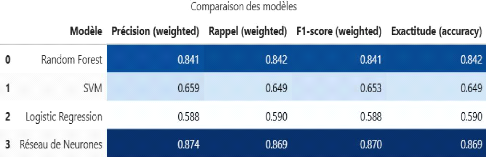
Figure 39 Tableau comparatif des modèles
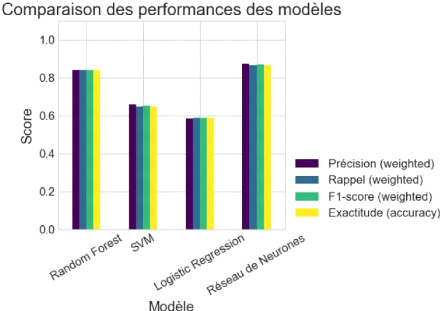
Figure 38 Comparaison de la performance des
modèles
79
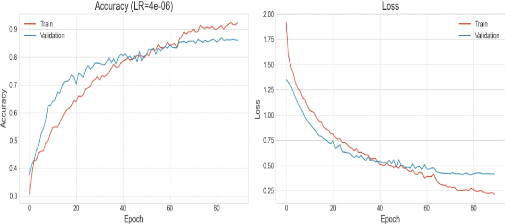
Figure 40 visualisation de la courbe de précision et
perte
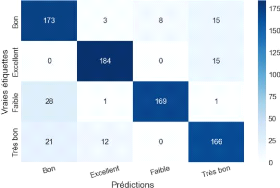
Figure 41 Matrice de confusion du modèle
validé
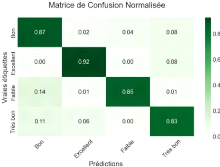
Figure 42 Matrice de confusion normalisé
80
4.5. Conclusion
Dans ce chapitre, nous avons présenté l'ensemble
des outils et technologies ainsi que methodes utilisés pour le
développement de notre système, en mettant l'accent sur les
architectures MVT côté backend (Django) et MVVM côté
frontend (React). L'implémentation a été structurée
de manière modulaire, facilitant la maintenance et
l'évolutivité ainsi que la manières dont nous avons
recoltés nos données et entrainer le model jusqu'au
résultat final. Les tests réalisés ont montré que
la solution est stable, cohérente avec les exigences définies.
81
| 

