|
Université de Versailles Saint Quentin en
Yvelines
Rapport de Stage
Master 2 Recherche Informatique
Concepts aux Systèmes
Option : Bases de données et Réseaux
Sécurisés
2007-2008
Mutualisation des requêtes XQuery dans un
réseau Pair-à-pair sur des Flux RSS
Réalisé par : Benamira Mohammed
Salah
benamira@ymail.com
Encadré par : Laurent Yeh
Laurent.Yeh@prism.uvsq.fr
Laboratoire d'Accueil :
Laboratoire PRISM
45 avenue des Etats-Unis 78035
VERSAILLES
  RoSeS - Really Open
and Simple Web Syndication
RoSeS - Really Open
and Simple Web Syndication
Résumé :
Ce rapport a été réalisé lors de
mon stage de fin de Master 2 COSY à l'université de Versailles
Saint Quentin en Yvelines. Celui-ci s'est déroulé au laboratoire
PRISM du 01 avril au 30 août 2008. Le but de ce stage concernait
La Mutualisation des Requêtes XQuery sur des flux RSS dans un
réseau Pair à Pair.
Mots clés : Flux RSS, Pair, Mutualisation, XQuery,
DHT.
Remerciements
Je tiens à remercier ici mon maître de stage, M.
Laurent Yeh, pour m'avoir accueilli au sein du laboratoire PRISM, et pour sa
grande disponibilité tout au long du stage. Nous avons eu beaucoup de
discussions très intéressantes qui m'ont permis d'envisager les
choses sous un autre angle.
Je remercie également tous les enseignants-chercheurs,
doctorants et stagiaires du PRISM pour leur aide, ma mère, mes soeurs,
mon frère, mon beau frère, qui m'ont soutenu toute au long de
cette période.
Merci enfin à mon ange, sans qui la vie me semblerait
nettement moins passionnante.
Table des matières
4
5
6
6
7
8
8
8
9
9
9
10
11
11
11
12
12
13
13
14
15
15
17
19
19
21
22
22
23
24
24
25
25
27
28
28
28
30
32
33
34
35
1 Introduction
............................................................................................................
Le contexte du stage
..........................................................................................
Fonctionnement du prototype
...............................................................................
Faiblesses du mini prototype
.................................................................................
L'objectif du stage
............................................................................................
2-Etat de l'art
............................................................................................................
RSS
..............................................................................................................
Domaines d'utilisation
.............................................................................
Fichier RSS
..........................................................................................
Les principales balises
..............................................................
Métadonnées
.........................................................................................
Contenu : Description de chaque article
.......................................................
Les réseaux Pair à Pair
.........................................................................
Objectif du Pair-à-Pair
..............................................................................
Classification des systèmes Pair-à-Pair
.........................................................
Réseaux Pair-à-Pair centralisés
..................................................................
Réseaux Pair-à-Pair décentralisés
et non structurés ...........................................
Les réseaux Pair-à-Pair
décentralisés mais structurés
.........................................
Les réseaux Pair-à-Pair hybrides
.................................................................
Approche e-commerce
......................................................................................
Query Trading ou Commerce de requêtes (QT)
....................................................
L'algorithme QT
.......................................................................................
Exemple
.............................................................................................
Approche StreamGlobe pour le traitement de flux
......................................................
Architecture de StreamGlobe
.....................................................................
Optimisations
.......................................................................................
3-Notre proposition : Mutualisation des requêtes
XQuery ............................................................
Principe de la mutualisation
................................................................................
Fonctionnement de la mutualisation
...........................................................................
Requête semblables (proches)
..................................................................................
Exemples
.................................................................................................
Comment chercher les sources dans le réseau
...........................................................
Exemples
.............................................................................................
Jointure entre Flux RSS, documents XML
....................................................................
Problèmes
...........................................................................................
Solutions
.............................................................................................
Exemple
..............................................................................................
Résultats et comparaison
........................................................................................
Explications des résultats
.........................................................................
4-Conclusion et Perspectives
.............................................................................................
5-Annexes
..................................................................................................................
6-Références
...............................................................................................................
CHAPITRE 1 : INTRODUCTION
1 Introduction
Les flux RSS basés sur les concepts XML du W3C
constituent une nouvelle approche pour la publication d'informations. Du point
de vue utilisateur, la consommation de ces données pose de nouveaux
problèmes. En effet, l'utilisateur ne peut ou ne souhaite lire en temps
réel l'ensemble des données provenant de ces flux. Un utilisateur
peut être rapidement submergé par les données provenant de
nombreux flux. Il doit pouvoir se faire aider par des outils qui lui
synthétisent une information en tenant compte de la dimension
temporelle. Un exemple de requête sur les flux est : «Quels sont les
articles sur les jeux olympiques de pékin durant les trois derniers
jours ?». Pour cela, il est nécessaire de conserver les flux sur
une période de temps [1]. En outre, les requêtes sont fortement
répétitives. A chaque nouvel item produit sur un flux RSS, il est
nécessaire de recalculer les requêtes définies pour un
utilisateur.
Un réseau P2P est utilisé pour les raisons
suivantes :
- Répartition de la charge de traitement (si beaucoup
de pairs veulent exécuter les mêmes requêtes)
- Fiabilité: ne plus dépendre d'un seul
serveur.
- Collaboration : mise en commun de ressources (ex.
Requête)
L'objectif du stage est d'étudier l'exécution de
quelques requêtes XQuery temporelles bien définies sur plusieurs
caches temporels distribués sur plusieurs machines. Un cache temporel
permet d'aspirer un flux et de les conserver suivant une fenêtre
temporelle. La conservation de ces données permet de faire des
requêtes historiques, des requêtes d'agrégats (combien
d'article parle des médaillées d'Or en natation).
Chaque cache peut également stocker les flux RSS
provenant de plusieurs producteurs. Chaque cache est capable d'exécuter
des requêtes XQuery (contient le SGBD eXist). L'utilisation de XQuery est
justifiée par sa puissance et sa simplicité comme langage
d'interrogation. Pour qu'il y ait une interopérabilité entre les
différents caches répartis sur le réseau P2P, Chaque cache
stocke également les clés permettant à d'autres
utilisateurs d'atteindre les enregistrements pertinents qu'ils recherchent. Ces
clés sont similaires aux clés des index traditionnelles (ex.
BTree). Les clés indiquent où sont stockés les
enregistrements.
Les clés sont calculées par une méthode
d'indexation Pair-à-Pair (PàP) (c'est une sorte d'index
distribué).
Pour l'exécution d'une requête XQuery temporelle,
l'idée est d'utiliser l'index pour isoler les sites contenant les
données pertinentes, et d'envoyer aux sites pertinents la requête
XQuery. Vu la forte répétition des requêtes XQuery
(à chaque arrivé d'un item dans un flux RSS, il faut recalculer
le résultat), et pour éviter que tous les pairs exécutent
la même requête (de nombreux utilisateurs peuvent
s'intéresser aux mêmes sujets), l'idée est de mutualiser
ces requêtes sur le réseau P2P. La mutualisation permets un
meilleur équilibrage des charges et d'utiliser les ressources sur un
réseau de manière plus optimum.
Ce rapport s'articulera donc autour de trois axes :
Tout d'abord, nous présenterons le contexte du stage,
le sujet proposé ainsi que les problématiques posées,
Ensuite, un état de l'art de quelques travaux qui nous ont
inspiré dans la réalisation de ce stage sera décrit.
Enfin, le reste du rapport portera sur l'ensemble du travail
effectué : les choix effectués, les résultats obtenus,
leurs analyses et les perspectives envisageables.
1.1 Le contexte du stage
Le stage s'inscrit dans le cadre d'un projet ANR appelé
ROSES.
Comme base de travail, j'ai utilisé une mini plateforme
en pair à pair pour l'interrogation en historique des flux RSS,
réalisée par les étudiants d'ISTY3 dans le cadre de leur
projet annuel de troisième année. Pour ceci cette mini plateforme
stocke de données RSS suivant le temps, pour pouvoir les interroger
après [1].
Cependant, la réalisation du mini prototype
n'intègre pas les fonctionnalités de mutualisation de
requêtes sur le réseau distribué. Ceci est l'objet du
présent stage.
L'architecture générale de cette plateforme est un
réseau pair à pair avec réseau P2P au centre. Ce
réseau est semi réparti. Il sera par la suite totalement
réparti sur les pairs. La représentation des composants
ci-dessous décrit le mini prototype 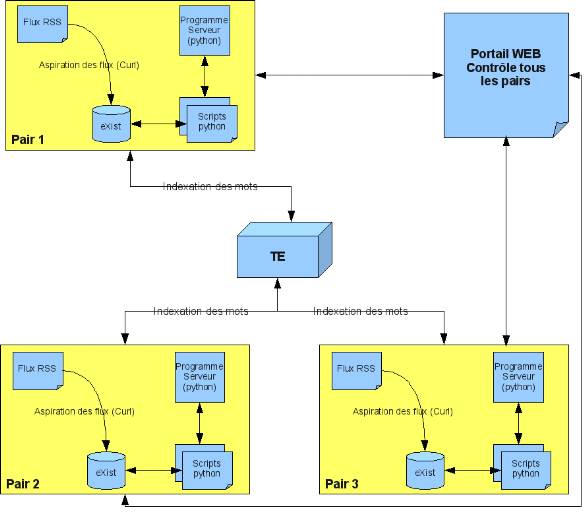
Figure 1 : Architecture du mini prototype
Selon la figure ci-dessous, les composants du réseau
sont:
Ø les pairs : contiennent la base de
données eXist, et aspirent périodiquement des flux RSS.
Ø le réseau P2P (Tour Eiffel) : le contenu
des pairs (flux RSS) est publié dans le réseau, pour pouvoir les
retrouver. Chaque pair possède une portion de code donnant vie au
réseau figurant au centre. Cette portion de code assure les services
comme le routage, le stockage de clés, etc.
Ø Le portail web : il permet de commander les
pairs à distance. Il permet également de visualiser le
comportement des pairs du réseau.
1.2 Fonctionnement du prototype
Si un pair P veut exécuter une requête XQuery Q
sur une période T, P doit interroger le réseau P2P en lui
fournissant comme paramètres quels : flux, mots clés et
période T lui intéressent, le réseau P2P en retour donne
à P les adresses IP des pairs pertinents.
Une fois ceci fait, P envoie la requête Q à
chacun des pairs pertinents, et enfin le résultat serait l'union des
réponses.
1.3 Faiblesses du mini prototype
L'exécution des requêtes XQuery dans le
modèle décrit ci-dessus, engendre plusieurs
problèmes :
Ø Si toutes les réponses des pairs pertinents
sont identiques (redondance), dans ce cas on augmente inutilement la charge du
réseau, donc on risque de l'inonder.
Ø Si d'une manière ponctuelle (ex : Jeux
Olympiques), il y a N pairs (N très grand) voulant exécuter la
même requête Q, selon la logique de fonctionnement décrite
ci-dessus, les N pairs devront faire les mêmes démarches, à
savoir : interroger l'indexeur pour isoler les pairs pertinents, envoyer
la requête Q à ces mêmes pairs, réaliser l'union des
réponses reçues. Ainsi les pairs sources seront vite
saturés.
Ø De plus, pour une requête identique issue de
deux sites différents, compte tenu des temps de transmissions des
données, du temps CPU pour le calcule, il peut s'avérer plus
intéressants de calculer qu'une fois, puis de faire profiter du
résultat à d'autres.
Il y a un vrai problème de répartition de la
charge de traitement des requêtes sur l'ensemble des pairs.
1.4 L'objectif du stage
L'objectif de ce stage est la réalisation d'un
prototype pour l'exécution des requêtes XQuery sur des flux RSS
dans un réseau pair à pair tout en répartissant la charge
de traitement de ces requêtes pour que le réseau s'adapte à
la charge, en utilisant deux approches :
Ø Approche e-commerce (meilleures offres) pour
résoudre le premier problème [3] (à savoir le choix parmi
plusieurs sources possibles)
Ø Mutualisation des requêtes pour résoudre
les derniers problèmes
Ces deux approches seront décrites dans le chapitre
suivant.
CHAPITRE 2 : ETAT DE L'ART
2 Etat de l'art
Ce chapitre présente un état de l'art sur les
Flux RSS, les réseaux P2P, et les approches qui ont inspiré ce
travail. Le lien entre l'état de l'art et le travail effectué,
sera mentionné tout au long du chapitre 3.
2.1 RSS
RSS désigne une famille de formats XML
utilisés pour la syndication de contenu Web. Ce standard est
habituellement utilisé pour obtenir les mises à jour
d'information dont la nature change fréquemment, typiquement cela peut
être des listes de tâches dans un projet, des prix, des alertes de
toute nature, des nouveaux emplois proposés, les sites d'information ou
les blogs. Les Podcasts et vidéocasts sont conçus sur ce
même standard en utilisant la balise 'Enclosure'. Pour les recevoir,
l'utilisateur doit s'abonner au flux, ce qui lui permet de consulter
rapidement les dernières mises à jour, à l'aide d'un
agrégateur, sans avoir à se rendre sur le site.
Trois formats peuvent être désignés par
ces initiales :
· Rich Site Summary (RSS 0.91)
· RDF Site Summary (RSS 0.90 et 1.0)
· Really Simple Syndication (RSS 2.0)
2.1.1 Domaines d'utilisation
Mais on parle aussi souvent de RSS pour désigner
également le format Atom.
La diffusion d'alertes, de nouvelles ou de listes (au sens
large) trouve de nombreuses applications professionnelles en plus de celles que
les blogs ont largement popularisées.
Le standard RSS est notamment utilisé pour la diffusion
d'actualités sur Internet par les blogs professionnels ou
semi-professionnels. Des annuaires répertorient ainsi un grand nombre de
flux d'actualités francophones.
Ces flux peuvent généralement être lus
grâce à des lecteurs en ligne, mais aussi sur des lecteurs de
flux.
Plusieurs navigateurs peuvent également lire les flux
RSS, notamment Maxthon, Mozilla Firefox (d'origine, ou avec les extensions
Wizz RSS News Reader, infoRSS ou Sage), ou encore
Opera et, depuis sa version 7, Internet Explorer, ainsi que, pour Mac OS X,
Safari et Camino.
2.1.2 Fichier RSS
Le fichier RSS est un langage particulier
du XML. Voici un exemple :
<?xml version="1.0" encoding="iso-8859-1"?>
<rss version="2.0">
<channel>
<title>Mon site</title>
<description>Ceci est un exemple de flux RSS
2.0</description>
<lastBuildDate>Wed, 27 Jul 2005 00:30:30
-0700</lastBuildDate>
<link>http://www.example.org</link>
<item>
<title>Actualité
N°1</title>
<description>Ceci est ma première
actualité</description>
<pubDate>Tue, 19 Jul 2005 04:32:51
-0700</pubDate>
<link>http://www.example.org/actu1</link>
</item>
</channel>
</rss>
2.1.3 Les
principales balises
Le contenu d'un document RSS se situe toujours entre les
balises <rss>. Elles possèdent obligatoirement un attribut version
qui spécifie la version à laquelle le document RSS est
conforme.
Au niveau suivant de cette balise se trouve une unique balise
<channel> qui contiendra les métadonnées du flux RSS,
obligatoires ou non, ainsi que la liste des contenus.
2.1.4
Métadonnées
En ce qui concerne les métadonnées, trois
éléments sont obligatoires dans un channel:
· <title> : Définit le titre du
flux ;
· <description> : Décrit succinctement
le flux ;
· <link> : Définit l'URL du site
correspondant au flux.
D'autres éléments optionnels existent
comme :
· <pubDate> : Définit la date de
publication du flux ;
· <image> : Permet d'insérer une image
dans le flux ;
· <language> : Définit la langue du
flux.
2.1.5
Contenu : Description de chaque article
Pour chaque article, une balise <item> est
ajoutée dans notre document.
Dans cette balise se trouvent les données
correspondantes à l'actualité sous forme de balise. Les balises
les plus courantes sont :
· <title> : Définit le titre de
l'actualité.
· <link> : Définit l'URL du flux
correspondant à l'actualité.
· <pubDate> : Définit la date de
l'actualité.
· <description> : Définit une
description succincte de l'actualité.
· <guid> : Définit de manière
unique l'actualité.
Selon la DTD RSS 2.0, il doit y avoir au moins un
<title> ou une <description> dans un item et le reste des balises
est optionnel.
D'autres balises existent comme :
· <author> : Définit l'adresse
électronique (mail) de l'auteur.
· <category> : Associe l'item à une
catégorie.
· <comments> : Définit l'URL d'une page de
commentaire en rapport avec l'item.
· <namespaces> : C'est une extension des flux RSS
qui permet d'inclure des nouvelles fonctionnalités comme iTunes par
exemple.
2.2 Les réseaux Pair-à-Pair
Une définition du Pair-à-Pair ou P2P ou pair
à pair est : «Pair-à-Pair computing is the
sharing of computer resources and services by direct
exchange between systems» [5]. Une autre définition est :
«Pair-à-Pair refers to a class of systems and
applications that employ distributed resources to perform a
critical function in a decentralized manner» [6].
2.2.1 Objectif Pair-à-Pair
Le modèle P2P étant très
général, des applications de nature très
différentes peuvent l'utiliser, les objectifs sont variés [4] :
· Partage et réduction des coûts entre
les différents pairs ;
· Fiabilité et passage à
l'échelle, l'absence d'élément centralisé pour
l'échange des données permet d'accroître la
fiabilité en supprimant tout point central de panne et
d'améliorer le passage à l'échelle en évitant les
goulots d'étranglement ;
· Localisation des ressources. Ceci permet
l'Agrégation des ressources et interopérabilité, en
mettant en commun des ressources individuelles comme de la puissance de calcul
ou de l'espace de stockage.
· Aucune administration centralisée :
autonomie des pairs en l'absence d'une autorité centrale. Les pairs
peuvent se connectés/déconnectés à tout moment
· Communication ad-hoc et collaborative.
2.2.2 Classification des systèmes
Pair-à-Pair
Plusieurs études essayent de classifier, les
systèmes Pair-à-Pair. Trois grandes catégories
peuvent être identifiées : centralisé,
décentralisé, et hybride. La catégorie
décentralisée peut encore être divisée en
structurée et non structurée. La différence principale
entre ces systèmes est le mécanisme utilisé pour
rechercher des ressources dans le réseau Pair-à-Pair.
2.2.2.1 Réseaux Pair-à-Pair
centralisés
Dans les systèmes Pair-à-Pair
centralisés, la description et l'adresse des ressources sont
stockées dans un annuaire d'un serveur central. Ainsi, les noeuds
envoient des requêtes au serveur central pour trouver quels noeuds ont
les ressources désirées. Le serveur ne fournit que la
capacité de rechercher et négocie les
téléchargements entre clients. De ce fait, le contenu reste du
côté client, ne passant jamais par le serveur. Après avoir
reçu une requête d'un pair, l'index central recherche le meilleur
pair dans son annuaire pour répondre à sa requête. Le
meilleur pair est celui qui est le plus économique, le plus rapide ou le
plus disponible selon les besoins de l'utilisateur. Lorsque le nombre de
participants devient trop grand ce modèle comporte quelques
inconvénients dus à son infrastructure centralisée,
notamment la surcharge de l'annuaire responsable d'accueillir les informations
de tous les participants. Cette catégorie de réseaux
Pair-à-Pair ne peut pas s'étendre à de
très grands réseaux. De plus, l'existence d'un centre unique,
même s'il est dupliqué, ne permet pas une bonne fiabilité
du réseau. Celui-ci peut tomber en panne à cause d'un seul noeud.
Napster a été l'exemple le plus connu reposant sur ce
modèle.
2.2.2.2.a Réseaux Pair-à-Pair
décentralisés et non structurés
Les systèmes décentralisés et non
structurés sont ceux au sein desquels il n'existe ni annuaire
centralisé, ni connaissance où se situent les noeuds du
réseau (la topologie), ni adresse sur l'emplacement des fichiers. Le
logiciel de P2P Gnutella en est un exemple. Ce réseau est formé
de noeuds qui rejoignent le réseau P2P en suivant quelques règles
simples. L'emplacement des fichiers n'est fondé sur aucune connaissance
de la topologie. Pour trouver un fichier, un pair demande tout simplement
à ses voisins qui eux-mêmes vont demander à leurs voisins
s'ils n'ont pas le fichier considéré, et ainsi de suite. Ces
architectures non structurées sont extrêmement résistantes
aux noeuds entrant et sortant du système. Par contre, l'actuel
mécanisme de recherche n'est pas adapté aux très grands
réseaux (on dit que le réseau ne passe pas à
l'échelle) et génère une charge importante sur les
participants du réseau. Les exemples de cette catégorie sont
nombreux comme FreeNet ou Gnutella.
2.2.2.2.b Les réseaux Pair-à-Pair
décentralisés mais structurés
Les systèmes décentralisés mais
structurés n'ont toujours pas de serveur central mais ils sont «
structurés » dans le sens où leur topologie est strictement
contrôlée et les fichiers sont stockés dans des endroits
spécifiques pour faciliter les recherches. Ils sont dits
structurés car les noeuds participants à l'application P2P sont
reliés entre eux selon une structure particulière comme un
anneau. Ce type de réseau a été défini pour rendre
des services de routage et de localisation fondés sur le
Pair-à-Pair.
Les systèmes Pair-à-Pair
décentralisés mais structurés possèdent un
algorithme de recherche pour lequel une ressource donnée se trouve en un
endroit parfaitement déterminé à l'avance. Cet endroit a
été calculé pour qu'il soit le plus simple d'accès
aux autres peers du réseau.
L'algorithme de recherche est donc complètement
déterministe, et les liens entre les pairs sont faits suivant des
règles bien définies. Cette structure permet la découverte
efficace des fichiers partagés. De plus, elle est
particulièrement appropriée au développement de
réseaux à grande échelle. Dans cette catégorie, on
peut placer Chord, CAN (Content Adressable Network), Tapestry, Pastry, Kademlia
et Viceroy.
2.2.2.3 Les réseaux Pair-à-Pair
hybrides
Les réseaux hybrides permettent de résoudre des
problèmes de l'approche purement distribuée tout en gardant
l'efficacité de la solution centralisée. Les réseaux
fondés sur ces mécanismes de localisation et de routage de
données peuvent supporter un nombre de pairs de l'ordre du million.
Cette solution combine les caractéristiques des modèles
centralisés et décentralisés. La décentralisation
signifie, entre autres, l'extensibilité, la tolérance aux fautes
et le passage à l'échelle. La centralisation partielle implique
quelques centres serveurs qui contiennent des données importantes pour
le système. Chaque utilisateur élit son Super-pair, qui est
« le serveur central » pour « des noeuds locaux » et peut
communiquer avec d'autres Super-pairs. FastTrack, KaZaA, BitTorrent,
eDonkey/eMule en sont quelques exemples.
2.3 Approche e-commerce
C'est une approche pour l'optimisation des requêtes
distribuées [3], inspirée du e-commerce, elle considère
les requêtes et leurs réponses comme des marchandises, les pairs
voulant exécuter des requêtes comme des acheteurs, et ceux qui en
répondent comme des vendeurs.
La marchandise (la réponse) a un prix (coût), ce
dernier prend en compte plusieurs facteurs, à savoir, la fraîcheur
ou la complétude des données, le temps total d'exécution,
ou bien le nombre d'octet de la réponse.... Le prix de la marchandise
varie au cours du temps en fonction de l'offre / demande. Si une marchandise
est trop demandée, son coût augmente, et l'inverse est vrai.
Dans un tel environnement, trouver la réponse d'une
requête nécessite parfois que la requête soit
éclatée en plusieurs sous parties, récupérer les
sous réponses des pairs distants (vendeurs), avec le prix le moins cher,
et les fusionner pour construire la réponse à la requête
initiale.
Pour mieux comprendre cette approche, prenons un exemple d'une
société de télécommunication, qui dispose de
plusieurs bureaux en France. Chacun des ces bureau possède un SGBD
local. Le schéma de la base comprend la relation CLIENT (IDClient,
NomClient, Bureau) qui stocke les informations du client comme son nom, son
identifiant ..., ainsi qu'une autre relation FACTURE (FID, NuméroTel,
IDClient, Montant) détenant l'historique des communications du
client.
Supposant que le manager du bureau de paris, demande le
montant total des factures émises par les bureaux de Lyon et
Metz :
SELECT SUM(Montant) FROM FACTURE F, CLIENT C
WHERE F.IDClient=C.IDClient AND Bureau in (`Lyon',`Metz');
Le bureau de paris va interroger tous les bureaux qu'ils aient
ou non la réponse à la (sous partie) requête. Supposant
que, entre autre, les bureaux Lyon et Metz ont répondu positivement aux
parties de la requête concernant leurs propres clients avec un prix
à 30 et 40 secondes respectivement.
Supposant aussi que les offres de Metz et Lyon soient les
meilleures, et que le prix ici représente le temps d'exécution de
la (sous partie) requête.
Le bureau de paris va comparer ces offres, et il va constater
que la meilleure offre est celle faite par les bureaux Lyonnais et Messins.
On dit ici que le pair parisien (acheteur) a acheté les
réponses (marchandises) des pairs (vendeurs) lyonnais et Messins
à un prix de 30 et 40 secondes respectivement, mais ensuite, il peut
négocier le prix. La négociation sera exposée par la
suite.
2.3.1 Query Trading ou Commerce de requêtes (QT)
Dans QT, la procédure d'optimisation des requêtes
est considérée comme un commerce des réponses entre les
pairs vendeurs, possédant les données relevantes aux
requêtes. Les pairs acheteurs sont les pairs qui ne peuvent pas
répondre à certaines requêtes, soit parce qu'ils manquent
de ressources (CPU, mémoire...), ou bien ils n'ont pas les
données relevantes à la requête localement.
Chaque pair peut jouer le rôle d'acheteur ou de vendeur,
ça dépend de la requête qu'on veut optimiser et des
données que chaque pair détient localement.
Le pair acheteur demande des services aux pairs vendeurs, pour
le calcul de la réponse à la requête, et les pairs vendeurs
répondent en faisant des offres qui contiennent l'estimation du
coût de la réponse à la requête. Cette estimation
pourra être le temps requis pour l'exécution et la transmission
des résultats au pair acheteur, le temps nécessaire pour trouver
la première ligne du résultat, le temps moyen pour
récupérer les lignes du résultat, le nombre total des
lignes du résultat, la fraicheur ou la complétude du
résultat.
L'acheteur classe les offres reçues, et choisit celles
qui minimisent le prix (coût) relatif à la requête.
2.3.2 L'algorithme QT
Son rôle est de trouver la combinaison des offres de
données les plus intéressantes à la requête de
l'acheteur, et ce à moindre coût.
Cet algorithme tourne itérativement et tente
d'améliorer le plan d'exécution d'une requête à
chaque itération.
Dans chaque itération l'acheteur fait un appel d'offre
pour trouver les données relevantes à sa requête, et les
vendeurs répondent avec leurs offres contenant l'estimation des
propriétés de leurs réponses. Les vendeurs peuvent ne pas
avoir la totalité des données nécessaires pour une
requête, c'est pourquoi ils font des offres qui ne concernent que la part
de données qu'ils possèdent localement. A la fin de chaque
itération l'acheteur utilise ces offres pour trouver, si c'est possible,
un meilleur plan d'exécution, et l'algorithme recommence une nouvelle
fois avec un nouvel ensemble de requêtes dans le but de reconstruire un
nouveau plan d'exécution plus optimal que le précédent.
L'algorithme d'optimisation est une sorte de négociation entre le pair
acheteur et les pairs vendeurs.
|
Algorithme coté Acheteur
|
Algorithme coté Vendeur
|
|
B0. Initialisation Q= {{q,C}}
B1.faire une estimation stratégique des coûts
pour requêtes de l'ensemble Q
B2.faire un appel d'offre des requêtes de Q
B3.choisir les meilleures offres {qi,
ci}
B4. En utilisant les meilleures offres, trouver les plans
d'exécution Pm et leurs coûts Cm.
B5. Chercher des sous requêtes qe, et leurs
coûts ce respectifs, si elles existent, elles
peuvent être utilisées à l'étape B.4.
B.6 mettre à jour l'ensemble Q avec les sous
requêtes {qe, ce}.
B.7 soit P* le meilleur plan d'exécution
parmi Pm. Si P* est meilleur que celui produit dans la
précédente itération de l'algorithme, ou bien si
l'étape B6 a modifié l'ensemble Q, alors aller à
l'étape B.1.
B.8 informer les pairs vendeurs, qui, leurs requêtes
sont utilisées dans le meilleur plan d'exécution P*,
qu'ils commencent l'exécution de ces requêtes.
|
S1.pour chaque requête q dans l'ensemble Q
faire :
S2.1 trouver les sous requêtes qk de q qui
peuvent être exécutées localement.
S2.2 faire une estimation pour chaque sous requête
qk
S2.3 faire offre et essayer de vendre les requêtes de
l'étape S2.1
|
Figure 2 : L'algorithme QT
La figure 2 représente le détail de l'algorithme
d'optimisation des requêtes. L'entrée de cet algorithme est une
requête q, et la sortie est le meilleur plan d'exécution
P* et son coût C* (étape B8).
L'algorithme au niveau de l'acheteur tourne itérativement
(étape B1 à B7). Chaque itération commence avec un
ensemble Q de pairs et de requêtes et leurs coûts correspondant,
que l'acheteur veut acheter. Dans la première étape (B1),
l'acheteur estime stratégiquement le coût qu'il doit demander
concernant les requêtes dans l'ensemble Q, et lance après un appel
d'offre aux pairs distants (étape B2). Les vendeurs (candidats)
après avoir reçu cet appel d'offre, ils vont faire leurs offres
qui contiennent les réponses concernant des parties des requêtes
dans l'ensemble Q (étapes S2.1 - S2.2). Ensuite les offres gagnantes
seront sélectionnées (étapes B3 S3). Le pair acheteur
utilise ces offres afin de trouver un ensemble de plans d'exécution
candidats Pm et leurs coûts respectifs Cm (étape B4), et enrichit
l'ensemble Q avec de nouvelles requêtes et leurs coûts
(qe, ce) (étape B5 B6), qui peuvent être
utilisées dans la prochaine itération pour améliorer
davantage les plans d'exécution produits dans l'étape B4.
Finalement, à l'étape 7, le meilleur plan d'exécution
P*, parmi les plans d'exécution candidats Pm est
sélectionné. Si P* n'est pas meilleur par rapport au
plan d'exécution produit dans la précédente
itération (amélioration impossible) et à l'étape
B5, il n'y a pas eu de nouvelles requêtes, alors l'algorithme
s'arrête.
Exemple :
Considérons l'exemple précédant de la
société de télécommunication, et la requête
posée par le bureau de paris :
q=SELECT SUM(Montant) FROM FACTURE F, CLIENT C
WHERE F.IDClient=C.IDClient AND Bureau in (`Lyon',`Metz');
Etape B0 :
Q={q,c}
Etapes B1, B2:
Regarder figure 3
Etape S1 :
Etape S2.1 :
Les pairs lyonnais et Messins répondent à
l'appel d'offre de l'acheteur respectivement avec q1, q2
q1=SELECT SUM(amount) FROM invoiceline i, customer c
WHERE i.custid=c.custid AND office=`Lyon';
q2= SELECT SUM(amount) FROM invoiceline i, customer c
WHERE i.custid=c.custid AND office=`Metz';
Etape S2.1, S2.3 :
Regarder figure 3
Etape B3 :
Supposant que les pairs Lyonnais et Messins aient fait les
meilleures offres pour répondre à la requête du bureau de
Paris {{q1, c1}, {q2, c2}}
Etape B4 :
Le meilleur plan d'exécution P* comprend q1 et q2.
Etapes B5, B6:
Mettre à jour l'ensemble Q avec les nouvelles sous
requêtes
Q= {{q, c}, {q1, c1}, {q2, c2}}
Etape B7:
Puisqu'il s'agit de la première itération, il
n'y a pas encore de plan d'exécution aller à B1
v La prochaine itération de l'algorithme va faire un
appel d'offre des requêtes de l'ensemble Q, et va essayer
d'améliorer P*.
o Si amélioration possible c'est-à-dire le plan
d'exécution de la deuxième itération est mieux que P*
aller à B1.
o Sinon aller à B8.
2.4 Approche StreamGlobe pour le traitement de flux
Cette partie présente le système StreamGlobe
[2]. Ce système permet de construire un réseau pair-à-pair
(P2P) faisant transiter des flux XML continus, potentiellement infinis. Ce
système doit permettre à n'importe quel utilisateur
(c'est-a-dire périphérique) de s'abonner aux différents
flux qu'il souhaite et ce, sans limitations vis-à-vis de ses
capacités. De plus, dans un souci de performances, cette partie
décrit les optimisations intégrées à StreamGlobe
pour exploiter au mieux les ressources du réseau dont il se sert,
réduire le trafic réseau et éviter sa congestion,
réduire la charge sur les pairs. Nous verrons dans une première
partie l'architecture de StreamGlobe. Puis nous verrons les optimisations
faites et leurs impacts.
2.4.1 Architecture de StreamGlobe
StreamGlobe définit deux grandes catégories de
pairs :
Ø Les Thin-Peers : ce sont des pairs ayant peu de
capacité de calculs (par exemple : téléphone cellulaire,
PDA, ...)
Ø Les Super-Peers : ce sont de pairs pouvant faire des
calculs complexes (par exemple : des serveurs, des ordinateurs personnels
fixes, ...). Ils forment le backbone du réseau.
L'architecture de StreamGlobe est découpée en
une série de couches. Le nombre de couches présent chez un pair
diffère selon sa capacité de calculs.
Il y a en tout 4 couches :
La première, la plus basse de toutes, est obligatoire
sur chaque pair. Il s'agit d'un middleware de grille nommé Globus
Toolkit (GT). Ce middleware est construit avec une approche orientée
services. Il vise les environnements dynamiques
hétérogènes à large échelle et il permet de
garantir une certaine QOS. Parmi les différents services qu'il propose,
StreamGlobe utilise principalement le mécanisme de communication
(données XML) et de services de GT. Cependant, comme il s'agit d'un
middleware de grille (chaque machine peut échangée avec n'importe
quelle autre machine du réseau), la sémantique des réseaux
P2P n'est pas respectée (chaque pair dialogue avec son entourage proche
qui forme son voisinage). C'est précisément là où
la seconde couche intervient. Cette couche est présente sur chaque pair
obligatoirement. Elle permet de recréer une topologie P2P en
recréant un voisinage entre les pairs. Il est à noter que
StreamGlobe n'impose aucune topologie P2P particulière (P2P
structuré ou non).
Les deux couches supérieures sont spécifiques au
traitement du flux de données et aux optimisations. Elles sont
optionnelles et ne sont présentes que sur les pairs possédant
suffisamment de ressources de calculs. Au-dessus de ces deux dernières
couches se trouve l'interface de StreamGlobe. Elle permet aux pairs de
s'abonner à un flux en faisant connaitre les informations qu'ils
souhaitent recevoir (sous forme de requête XQuery). Les pairs serveurs
successifs du réseau (ie. les Super-Peers) vont transformer le flux de
données selon le schéma XML transmis par le pair client. Ainsi,
le flux livré sera exactement conforme aux volontés de ce
dernier.
La seconde fonction de cette couche est l'enregistrement de
flux continus par une source. Là encore, la source transmet le
schéma XML et les données brutes (provenant majoritairement de
capteurs) pour que les Super-Peers remettent en forme le flux selon les
attentes du schéma.
Au sein de chacune des trois dernières couches (couche
réseau, traitement de flux, optimisation), une partie est
dédiée à la gestion des métadonnées. Elles
permettent par exemple de tenir les informations sur le voisinage réseau
pour la couche réseau. Pour un Super-Peers, ces
métadonnées pourront intervenir dans la construction de la
topologie de son sous réseau local, etc... Ces métadonnées
permettent le bon fonctionnement de StreamGlobe.
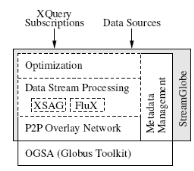
Figure 3 : Architecture StreamGlobe.
2.4.2 Optimisations
Dans la partie précédente, nous avons
décrit l'architecture de StreamGlobe.
Dans cette partie nous nous intéressons plus
précisément aux deux dernières couches optionnelles (les
deux couches supérieures dans la figure 3).
Comme StreamGlobe doit réduire la charge des pairs de
bordure (Thin-Peers), les auteurs ont fait en sorte que le réseau prenne
en charge la gestion et le routage des données que les Thin-Peers
souhaitent acquérir.
De plus, pour des raisons évidentes d'optimisation de
la charge réseau, les auteurs ont introduit dans StreamGlobe quelques
nouvelles idées. La première concerne l'agrégation de
flux. Les Super-Peers peuvent assembler deux flux différents en un seul
si ces flux ont des caractéristiques semblables. Ceci est
déterminé par le schéma XML du flux. Une autre
optimisation consiste à filtrer les flux. Par exemple si dans un flux,
un champ n'est pas utilisé par aucun abonnement, celui-ci peut
être supprimé. Deux opérations sont disponibles pour cela
:
Ø Projection : permet de supprimer les champs non
utilisés dans les abonnements.
Ø projection-sélection : permet de supprimer les
champs non utilisés et de modifier (changer de schéma) ceux qui
restent.
Une nouvelle optimisation consiste à agréger
plusieurs requêtes XML en une seule (on parle alors de Multi-Query
evaluation). Plusieurs requêtes similaires de différents
Thin-Peers peuvent être traitées en même temps si ces
dernières sont « semblables ».
Comme les flux sont continus et potentiellement infinis,
StreamGlobe introduit un moteur de requêtes appelé FluX. Il est
basé sur les événements (équivalent à un
parseur SAX) pour limiter l'espace mémoire requis pour extraire les
informations désirées d'un flot. S'il existe une
possibilité de saturer la mémoire (cas de buffers infinis), alors
StreamGlobe fait appel à une fenêtre (WXQuery) pour
découper le flux.
CHAPITRE 3 : NOTRE PROPOSITION
3 Notre proposition : Mutualisation des
requêtes XQuery
Afin de résoudre la problématique citée
dans le chapitre 1, nous avons proposé une solution qui marie les deux
approches « Mutualisation des requêtes XQuery » et
« e-commerce » en s'inspirant fortement des deux approches
décrites dans l'état de l'art.
3.1 Principe de la mutualisation
Le principe de la mutualisation est le suivant : un pair
P calcule une requête XQuery sur un flux RSS et les autres pairs voulant
calculer la même requête s'abonnent à P et
récupèrent le résultat.
On veut factoriser au maximum les calculs dans le
réseau pair à pair.
Avant d'aborder le principe de fonctionnement de notre
proposition, voyons maintenant quelques définitions :
l Base : Ensemble de flux RSS aspirés
l Cache : Ensemble de XQueries prises en charge
(calculées).
l Vue : XQuery calculée à partir du
cache.
Comme le mentionne la figure ci-dessous, une requête
XQuery peut être exécutée directement sur une Base si elle
n'a pas été prise en charge, sinon elle peut être
exécutée sur un Cache produisant une Vue
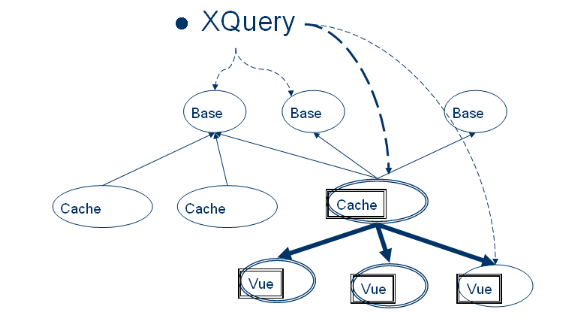
![]()
Figure 4: Exécution d'une requête XQuery
3.2 Fonctionnement de la mutualisation
Tout pair ayant exécuté une requête, doit
publier les prédicats de cette requête avec un coût dans la
DHT. En d'autres termes, faire savoir aux autres que cette requête a
été exécutée.
Si un pair P veut exécuter une requête Q, avant
d'aller chercher les sources, il doit chercher dans la DHT, s'il y a un pair
qui a déjà pris en charge cette requête ou une
requête semblable. les requêtes semblables [2] seront
expliquées plus loin.
Ici on a 2 cas :
Ø Cas 1 : si aucun pair n'a pris en charge cette
requête alors chercher les sources, en d'autres termes,
trouver les meilleures bases pour calculer la requête Q.
Ø Cas 2 : si un pair P' a pris en charge la
requête Q (ou une sous partie) alors :
- Si le pair P' peut accepter un nouveau client (coût
intéressant proposé par P'), alors le pair P s'abonne à P'
pour mutualiser la requête Q.
- Sinon chercher les sources, en d'autres termes, trouver les
meilleures bases pour calculer la requête Q.
Notre originalité réside dans
l'intégration du coût dans la DHT, ainsi le pair P va
connaître le coût directement, sans avoir à envoyer des
messages à P' pour connaître le coût.
3.3 Requête semblables (proches)
Deux requêtes sont semblables [2] ou proches, si le
résultat de l'une est inclus dans l'autre
Exemple 1 :
Q1= For $i in document(`Equipe.xml')/rss/channel/item
Where contains($i/title, `Foot') and
contains($i/title, `PSG')
Return $i
Q2= For $i in document(`Equipe.xml')/rss/channel/item
Where contains($i/title, `Foot') and contains($i/title,
`PSG')
and contains($i/title, `2008')
Return $i
Exemple 2 :
Q1= For $i in document(`Equipe.xml')/rss/channel/item
Where contains($i/title, `Foot')
Return $i
Q2= For $i in document(`Equipe.xml')/rss/channel/item
Where contains($i/title, `Foot')
Return $i/description
Dans les deux exemples ci-dessus, le résultat de Q2 est
bien inclus dans le résultat de Q1, donc pour factoriser les calculs au
maximum afin de réduire la charge des pairs, si le pair P1 a pris en
charge la requête Q1, et s'il y a un pair P2 qui veut exécuter Q2,
il suffit que P2 s'abonne à P1, et que ce dernier exécute Q2 sur
le résultat de Q1.
3.4 Comment chercher les sources pertinentes dans le
réseau
Pour réguler la charge de traitement des requêtes
par les pairs, on s'est inspiré de l'approche
E-commerce [3].
Un pair P voulant exécuter une requête Q, sur une
période T, alors que cette requête n'a pas été
prise en charge par d'autres pairs (mutualisation impossible), il doit chercher
les données relevantes à sa requête dans le réseau
(bases).
Il localise à l'aide de la DHT, les sources pertinentes.
Connaissant les pairs et la période qu'ils peuvent satisfaire, le pair P
leur demande un coût. Une fois les coûts reçus, le pair P
sélectionne les pairs qui ont fait les offres les moins coûteuses,
et leurs envoie la requête Q.
Le coût ici, reflète la charge de travail du pair,
et change en fonction de ce dernier. Si un pair a beaucoup de travail
(aspiration flux RSS, plusieurs abonnées lui sont rattachés,
espace disque et espace mémoire insuffisants,.....), il augmente son
coût, et inversement (si son espace disque se libère, il baisse
son coût)
Exemple:
For $i in document(`Equipe.xml')/rss/channel/item
For $j in document(`Sport.xml')/rss/channel/item
Where $i/title = $j/title and contains($i/title, `Foot') and
contains($j/title, `PSG')
Return $i
Temps Valide = 1 à 15
1. Etape 1 : localise les sources pertinentes à
l'aide de la DHT
Get<h(Equipe.xml),
h(/rss/channel/item/title/'Foot'), [1..15]>
- Connaissant les pairs et l'intervalle qu'ils peuvent
satisfaire, demander aux pairs un coût
- Exemple de réponses :
§ P1 : contient `Foot' dans l'intervalle [1, 10] avec un
coût = 5
§ P2 : contient `Foot' dans l'intervalle [11,15] avec un
coût = 3
§ P3 : contient `Foot' dans l'intervalle [1,15] avec un
coût = 20
§ P4 : contient `PSG' dans l'intervalle [1,15] avec un
coût = 10
§ P5 : contient `PSG' dans l'intervalle [1,15] avec un
coût = 8
§ P6 : contient `Euro' et `PSG' dans l'intervalle [1,15]
avec un coût = 20
2. Etape 2 : Sélection des meilleures offres sous
deux contraintes: l'intervalle et le coût
· C.P1+C.P2 +C.P4 = 18
· C.P1+C.P2 +C.P5 = 16
· C.P3+C.P4 = 30
· C.P3+C.P5 = 28
· C.P6 = 20
3. Sélection des meilleures offres sous deux
contraintes : l'intervalle et le coût
· C.P1+C.P2 +C.P4 = 18
· C.P1+C.P2 +C.P5 = 16
· C.P3+C.P4 = 30
· C.P3+C.P5 = 28
· C.P6 = 20
v Meilleures offres P1, P2, P5
4. Étape 3: récriture de la requête:
- Q1 = for $i in document (`Equipe')/rss/channel/item
where contains($i/title, `Foot') and pubDate>=1 and
pubDate<=10 return $i Envoyer (P1)
- Q2 = for $i in document (`Equipe.xml')/rss/channel/item
where contains($i/title, `Foot') and pubDate>=11 and
pubDate<=15 return $i Envoyer (P2)
- Q3 = for $i in document (`Sporte.xml')/rss/channel/item
where contains($i/title, `PSG') and pubDate>=1 and
pubDate<=15 return $i Envoyer (P5)
5. Étape 4 : effectuer la jointure (résultat
final)
- R=R(Q1) union R(Q2)
- For $i in R/rss/channel/item
For $j in R(Q3)/rss/channel/item
Where $i/title= $j/title
Return $i
3.5 Jointure entre Flux RSS et document XML
Pour permettre plus d'opérations sur les flux RSS et de
les compléter avec des données plus riches, on a ajouté
l'option qui permet à un pair d'exécuter une jointure entre un
flux RSS et des sources XML.
Pour mieux comprendre l'utilité de cette option, prenons
l'exemple d'un utilisateur qui s'intéresse au flux RSS
«voitures», et plus précisément qu'à un certains
nombre de voitures.
Pour recevoir que ce qu'il veut, l'utilisateur stocke les noms
des voitures qui lui intéressent dans un fichier XML et le publie dans
la DHT, qu'il appelle «mes_voitures.xml», et effectue la jointure
entre le flux RSS« voitures» et le document XML
«mes_voitures.xml».
Exemple :
L'utilisateur s'intéresse aux voitures
monospaces qui ont été publiées les 5 derniers jours
(d'où la clause Temps Valide=5) :
For $i in document (`voitures')/rss/channel/item
For $j in document (`mes_voitures.xml')/voiture
Where contains($i/title, $j/nom) and contains($j/type,
`Monospace')
Return $i
Temps Valide = 5 jours
3.5.1 Problèmes
Dans l'exemple précédent, on a supposé que
le pair qui va exécuter la requête possède le flux RSS et
le document XML.
PB1. Il se peut que le pair qui a fait la meilleure offre pour
fournir le flux RSS, ne soit pas celui qui possède le document XML. En
d'autres termes, le flux RSS et le document XML ne sont pas sur le même
pair, ceci constitue un frein pour notre travail.
PB2. Un autre problème se pose aussi, si on regarde
l'exemple ci-dessus, on va constater que pour rechercher la source `voitures',
on ne dispose pas de mot clé associé c'est-à-dire d'un
paramètre qui garantie une recherche pertinente de sources, on ne
dispose que du chemin ($i/title).
3.5.2 Solution
Pour résoudre le premier problème, on s'est
inspiré de l'approche e-commerce, en procédant à un
éclatement de la requête en deux parties [3], une partie RSS et
une autre XML, grâce à la DHT, on cherche les pairs qui
contiennent la source RSS, ensuite ceux qui ont fait les meilleures offres,
pareil pour la source XML.
Pour le second problème, on s'est contenté de
publier les chemins. Ainsi, pour la requête ci- dessus, pour chercher le
flux `voitures', on ne cherche que le chemin $i/title.
Pour mieux comprendre les deux solutions décrites
ci-dessus, voyons cet exemple.
Exemple :
L'utilisateur s'intéresse aux voitures monospaces qui
sont publiées les cinq derniers jours, mais, après la
sélection des meilleures offres, il s'avère que, le flux
`voiture' est localisé sur le pair P1 et le document XML
`mes_voitures.xml' est localisé sur le pair P2.
For $i in document (`voitures')/rss/channel/item
For $j in document (`mes_voitures.xml')/voiture
Where contains($i/title, $j/nom) and contains($j/type,
`Monospace')
Return $i
Temps valide = 5 jours
Ø Eclatement de la requête :
Q1= For $i in document (`voitures')/rss/channel/item
Where dateToday-5 <= $i/pubDate <= dateToday
Return $i
Q2= For $j in document (`mes_voitures.xml')/voiture
Where contains ($j/nom, `Monospace')
Return $j/nom
Ø Envoi des requêtes :
Envoyer Q1 P1= Résultat1
Envoyer Q2 P2= Résultat2
Ø Reconstitution du résultat final :
For $i in document (`Résultat1')/rss/channel/item
For $j in document (`Résultat2')/voiture
contains($i/title, $j/nom)
Return $i
Remarque :
Dans la requête Q2, on a effectué la restriction
et la projection au plus haut niveau, pour que transitent dans le réseau
que les données nécessaires, dans le but de réduire au
maximum la charge du réseau [2].
3.6 Résultats et comparaison
Pour tester l'efficacité de notre travail, on a
utilisé comme plateforme celle réalisée par les
étudiants des ISTY3 qui est constituée de 3 pairs. Notre
proposition a été implémentée en PYTHON.
La performance de notre travail ne dépend pas du nombre
des pairs du réseau, mais du nombre des pairs qui vont répondre
à l'appel d'offre [3].
Pour effectuer les mesures, on a choisi une requête XQuery
avec 1 seule restriction, et on a mesuré la performance de notre
proposition dans le cas où un, deux et trois pairs veulent
exécuter cette requête, en terme de, nombre de messages
échangés via le réseau, et de la quantité des
données y transitant, et on l'a comparée avec celle des ISTY3.
Nbre de messages
Nbre de pairs
Nbre de messages
60
120
180
1
2
3
1
2
3
Nbre de pairs
60
120
180
Figure 5 : Nbre de message VS Nbre de pairs voulant
exécuter la cuté r la même requête en la
mutualisant.
Figure 6 : Nbre de message VS Nbre de pairs voulant
exécuter lcuté r la même requête ISTY3
![]()
3000
Nbre de pairs
Qté données (Ko)
1000
2000
1
2
3
1
2
3
Nbre de pairs
1000
2000
3000
Qté données (Ko)
Figure 7 : quantité des données (Ko) VS
Nbre de pairs voulant oulant exécuter la même requête en la
mutualisant.
Figure 8 : quantité des données (Ko) VS
Nbre de pairs voulantoulant exécuter la même requête
ISTY3.
![]()
3.6.1 Explications des résultats
D'après les figures 5 et 6, qui montrent le nombre de
messages échangés en fonction du nombre de pairs exécutant
une même requête, on constate que notre proposition (mutualisation)
a réussi à baisser significativement le nombre de messages
lorsque le nombre de pairs voulant exécuter la même requête
augmente. Ceci peut être expliqué par le fait, que dans notre
proposition, le premier pair va émettre et recevoir les messages
nécessaires pour la localisation des sources pertinentes, et les
messages destinés aux appels d'offres, par contre les autres pairs,
n'ont qu'à récupérer le résultat en envoyant 3
messages : le premier message pour chercher s'il y a un pair qui a
déjà pris en charge cette requête, le deuxième pour
s'abonner, et le troisième pour récupérer le
résultat.
A l'opposé du travail des ISTY3, où on remarque
une augmentation linéaire du nombre de messages. Ceci est due au fait
que tous les pairs échangent le même nombre de message pour
l'exécution de la même requête.
D'après les figures 7 et 8, on constate également
que grâce à la mutualisation, la quantité des
données échangées via le réseau a nettement
baissé, et si on la compare avec la quantité des données
échangées sans mutualisation (ISTY3), on peut dire que notre
proposition a diminué d'un taux de 85 % la quantité des
données transitant via le réseau. On peut expliquer cette baisse
pour le premier pair, par l'utilisation de l'approche e-commerce, qui mobilise
que les pairs qui ont fait les meilleures offres. Et pour les autres pairs, par
la mutualisation, c'est-à-dire que les autres pairs n'ont qu'à
récupérer le résultat de chez le premier pair. A
l'opposé de la figure 6, où chaque pair mobilise tous les pairs,
ce qui engendre une redondance entraînant une augmentation vertigineuse
de la quantité des données échangées via le
réseau.
4 Conclusion et Perspectives
Tout au long de ce rapport nous avons présenté
les divers volets du travail réalisé pendant les cinq mois du
stage dans Master 2 COncepts aux Systèmes. Le sujet abordé
était la Mutualisation des requêtes XQuery sur des flux RSS dans
un environnement Pair à Pair.
Le réseau pair à pair coopère sur les
requêtes XQuery afin de réaliser la mutualisation, il a permis
grâce à la DHT, de mettre en relation les pairs qui partagent les
même requêtes XQuery.
Nous envisageons dans nos travaux futurs, d'améliorer
la fonction de coût, pour qu'elle prenne en compte d'autres facteurs:
fraîcheur des données, latence du réseau, ceci afin de
réguler avec une grande précision la charge de traitement des
requêtes dans le réseau.
Nous souhaitons également, afin de rendre notre
réseau de plus en plus coopératif, faire, en plus du commerce des
requêtes, le commerce des ressources pour exécuter les
requêtes. C'est-à-dire après avoir trouvé les
sources pertinentes pour répondre à la requête (commerce de
requêtes), on va également chercher de nouveaux pairs qui
disposent de ressources (CPU, mémoire,....) afin qu'ils se chargent de
l'exécution des requêtes.
Annexes
Ø DHT : Une table de
hachage distribuée (ou Distributed Hash Table), est
une technologie permettant l'identification et l'obtention, dans un
système réparti, comme certains réseaux P2P, d'une
information. L'ensemble de la table de hachage est constituée
virtuellement par tous ces constituants répartis sur tous les
éléments du réseau, qui en possèdent chacun une
partie.
Les tables de hash réparties sont utilisées
notamment dans les protocoles Chord, protocole P2P CAN, Tapestry, Kademlia
(utilisé par eMule), Ares Galaxy. Système aussi utilisé
dans de nombreux clients récents pour le protocole BitTorrent comme
Azureus, Bitcomet ou encore uTorrent (prononcer Mu Torrent). Le premier client
BitTorrent à utiliser le DHT était Azureus, suivi du client
officiel BitTorrent, c'était deux versions différentes. La
version officielle fut alors appelée Mainline DHT. Dorénavant la
plupart des clients supportent la version Mainline DHT.
Ø XQuery ou XML Query
est un langage de requête permettant donc d'extraire des informations
d'un document XML.
XML Query est une spécification du W3C.
Sémantiquement proche de SQL, XML Query utilise la
syntaxe XPath pour adresser des parties spécifiques d'un document
XML.
5 Références :
[1] Sujoe Bose, Leonidas FegarasData. Stream Management for
Historical XML Data
[2] Bernhard Stegmaier, Richard Kuntschke, Alfons Kemper.
StreamGlobe: Adaptive Query Processing and Optimization in Streaming P2P
Environments
[3] FRAGKISKOS PENTARIS and YANNIS IOANNIDIS. Query
Optimization in Distributed Networksof Autonomous Database Systems
[4] Dejan S. Milojicic, Vana Kalogeraki, Rajan Lukose, Kiran
Nagaraja, Jim Pruyne, Bruno Richard, Sami Rollins, Zhichen Xu,
Pair-à-Pair Computing HP,
http://www.hpl.hp.com/techreports/2002/HPL-2002-57.pdf
[5] http://www.p2pwg.org
[6] Karl Aberer, Manfred Hauswirth, ICDE 2002,
Pair-à-Pair information systems: concepts and models, state-of-the-art,
and future systems http://lsirwww.epfl.ch
| 

