III. La classification par la méthode des
"k-means"
III.1. Objectif de la méthode des "k-means"
La méthode des "K-means" reste actuellement la
méthode la plus utilisée surtout pour les grands fichiers de
données qui contiennent plus de 40 000 individus. En effet, cette
méthode a été utilisée pour classer 40 000
personnes. Ceux-ci ont répondu à une enquête sur les ventes
par correspondance d'une entreprise afin d'obtenir des profils types de
clientèle [Celeux, G., et al., (1989)].
Cette méthode à l'instar de la méthode
hiérarchique, a l'avantage d'être efficace et très rapide.
La classification hiérarchique a l'inconvénient d'user toutes les
ressources de l'ordinateur. Elle procède par le calcul pour chaque point
sa distance à tous les autres. Elle effectue ensuite un tri et enfin
elle agrège les individus les plus proches. La méthode
hiérarchique est itérative et elle est inefficace pour les grands
fichiers de données. Le principe de la méthode des
"k-means" c'est que la classification se fait sur la base du
critère des plus proches voisins. Celui-ci signifie que chaque individu
est affecté à une classe s'il est très proche de son
centre de gravité.
La particularité de la méthode des "k-means"
c'est que le nombre de classes doit être spécifié
préalablement. La méthode la plus utilisée pour estimer ce
nombre c'est de mener une classification hiérarchique sur un
échantillon représentatif de l'ensemble I des individus. Une
autre manière de procéder est de se baser sur le nombre de
classes obtenues par des classifications ayant les mêmes objectifs que la
présente étude.
III.2. L'algorithmes de la méthode des
"k-means"
1) Algorithme
Dans la méthode des "k-means", le choix des centres
initiaux s'effectue sur la base d'un tirage aléatoire sans remise de
k individus à partir de la population à
classifier. La partition des classes est modifiée avec chaque
affectation d'un individu i de I.
Les individus sont géométriquement
représentés dans l'espace vectoriel P
muni d'une distance notée d. L'algorithme de la
méthode des "k-means" se déroule comme suit :
Etape -0- 1- On
choisit par un tirage aléatoire sans remise k individus parmi n
individus composant l'ensemble I. Ces k centres notés 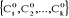 sont provisoires. sont provisoires.
2- Chaque individu i de
I est affecté à une classe et une seule. Chacune de ces
classes est localisée par son centre. La procédure d'affectation
est la suivante : i est affecté à la classe notée 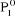 de centre de centre 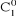 si et seulement si si et seulement si 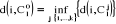 . .
Après avoir affecté tous les
individus on obtient k classes notées  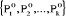 de centres respectifs de centres respectifs 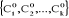 . .
Etape -1- En considérant les k
classes obtenues à l'étape -0-, on calcule ses centres de
gravité. On obtient donc k nouveaux centres notés 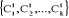 . On utilise la même règle d'affectation qu'à
l'étape -0-, on obtient k nouveaux classes . On utilise la même règle d'affectation qu'à
l'étape -0-, on obtient k nouveaux classes 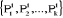 de centres respectifs de centres respectifs 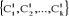 . .
Etape -h- On détermine k
nouveaux classes en calculant les centres de gravité des classes
obtenues à l'étape (h-1). La règle d'affectation reste la
même qu'à l'étape précédente et on obtient
par la suite une nouvelle typologie de l'ensemble I : 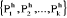 de centres respectifs de centres respectifs 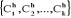
2) L'arrêt de l'algorithme
L'arrêt de l'algorithme de la méthode des
"k-means" se fait
· Lorsque deux itérations successives conduisent
à une même partition.
· Lorsqu'on fixe un critère d'arrêt tel que
le nombre maximal d'itérations.
Remarques
La lecture de cet algorithme suggère les remarques
suivantes
1- La méthode des " k-means" est fortement liée
au nombre de k classes fixées a priori. Cependant la classification en l
classes avec l > k peut être largement différente de la
classification en k classes.
2- La classification utilisant cette méthode
dépend du choix des centres initiaux. Deux tirages aléatoires des
centres peuvent engendrer deux différentes typologies.
3) Justification de l'algorithme
La justification de cet algorithme est donnée par le
critère de stabilité ou de convergence suivant
A une certaine étape le moment centré
d'ordre 2 intra-classe cesse de décroître entre l'étape
( h ) et ( h +1).
En effet, soit 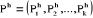 la partition obtenue à l'étape h, ses centres de
gravité sont respectivement la partition obtenue à l'étape h, ses centres de
gravité sont respectivement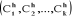 . Le moment centré d'ordre 2 intra-classe de la partition
Ph est donné par la quantité suivante . Le moment centré d'ordre 2 intra-classe de la partition
Ph est donné par la quantité suivante
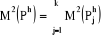 avec avec 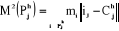
mi étant la masse de l'individu i.
Soit donc 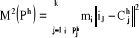
D'après l'algorithme, les centres de gravité des
classes 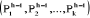 serviront pour former la partition serviront pour former la partition 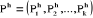 . On considère donc la quantité suivante . On considère donc la quantité suivante
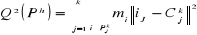
On appliquant le théorème de Huygens, on obtient
l'égalité suivante
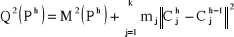
donc on aurait 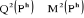 . .
D'autre par en considérant maintenant les moments
centrés d'ordre 2 suivants
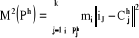
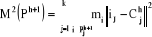
Sachant que les centres de gravité de la partition
Ph serviront pour la formation de la partition Ph+1 alors
les points seront plus proche de 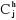 dans dans 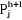 que dans que dans 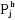 donc donc 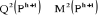 . .
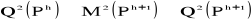
Donc on a l'égalité suivante
qui indique la décroissance simultanée du
critère du moment centré d'ordre 2 intra-classe.
Conclusion
La classification hiérarchique et la méthode
des "k-means" sont deux méthodes itératives et ont des principes
différents. Pour cette dernière raison qu'il est difficile de
comparer entre l'output des deux méthodes appliquées à un
même input.
Ces deux méthodes se caractérisent par le fait
que l'une complète l'autre. En effet, pour mener une classification en
utilisant la méthode des "k-means", il serait préférable
de commencer par lancer une classification sur un échantillon plus
réduit que l'échantillon initial. Ensuite, on dégage le
nombre de classes qui serait utilisées pour l'affectation des individus
aux classes les plus proches. C'est l'une des propriétés de ces
méthodes qui leur permet d'être les méthodes de
classifications les plus utilisés pour la segmentation de la population.
| 

