2.8.2. Plan d'analyse des
données
Ø Après le contrôle de qualité, les
données ont été analysées grâce à un
logiciel SPSS 12.0 for Windows, Le logiciel EVIEWS 3.0 nous a servi pour
l'estimation économétrique des modèles retenus.
Ø Avant de procéder à leur analyse
proprement dite, les données ont été organisées
sous forme des tableaux et graphiques, et décrites. Et ceci nous a
permis de faire le choix judicieux des tests statistiques à utiliser.
.
Ø Les mesures statistiques suivantes ont
été calculées :
v les mesures de tendance centrale : la moyenne et les
mesures de dispersion des variables quantitatives (Age, taille, prix,
dépense, revenu ...)
v les mesures de fréquence pour les variables
qualitatives et quantitatives groupées
Ø Statistiques inférentielles et
mesures épidémiologiques
· L'association entre l'utilisation de la MII d'une part
et les variables explicatives qualitatives d'autre part retenues a
été établie par le test Chi Carré
d'indépendance ; la force de cette association est estimée par le
calcul du rapport de cotes pour les variables binaires.
· La statistique Z a été utilisée
pour construire les intervalles de confiance permettant ainsi d'estimer les
paramètres de la population
· L'analyse multivariée a été
utilisée respectivement :
§ La régression linéaire nous a permis de
vérifier la corrélation entre les dépenses
journalières du ménage et le revenu déclaré par le
chef de ménage.
§ La régression logistique comme analyse multi
variée, nous a permis d'identifier et de retenir les déterminants
de l'utilisation de la MII.
2.8.3 Rappel: modèle
Logit
Ø Le modèle Logit permet d'exprimer la relation
entre une variable qualitative à deux modalités (Y) et des
variables explicatives (X) qui peuvent être qualitatives et/ou
quantitatives. Une variable qualitative est une variable non mesurable
numériquement (ou codée) qui a un nombre limité de
modalités.
Par exemple :
Yi = 1 si l'enfant a dormi sous une MII et Yi
= 0 si non (variable dichotomique)
Yi = 0 si le poids de naissance est 2kg ;
Yi = 1 si poids de naissance est inférieur à 2 kg et
Yi = 2 si poids de naissance est supérieur à 2 kg
(variable codée à 3 modalités, dans ce cas, on utilise un
modèle polytomique)
Y = 0 ou 1 peut traduire la prévalence d'une
caractéristique (maladie, etc.) l'apparition d'un
événement (maladie, etc.)
Ø Les modèles Logit permettent ainsi d'expliquer
(et de calculer) la probabilité de dormir sous la MII quand les valeurs
des caractéristiques individuelles X sont connues.
La probabilité que Yi = 1 (dormir sous la
MII) connaissant les caractéristiques individuelles X1i ,
..., Xki , s'écrit : E( Yi = X1i , ...,
Xki ) = P( Yi = 1 = X1i , ..., Xki ) = f
(X1i , ..., Xki ) où E(Yi = X1i, ...,
Xki) est la moyenne de Y conditionnellement aux valeurs prises par les
variables explicatives.
La forme mathématique du modèle Logit
dichotomique à une variable explicative s'écrit:
Soit Yi = 1 si l'individu i a dormi sous la MII et
Yi = 0 sinon, on veut expliquer la probabilité dormir sous la
MII: P(Y=1).
La variable explicative X peut être quantitative
(âge, revenu, degré d'exposition à un facteur de risque,
etc.).
La probabilité que Yi = 1 (être
malade) connaissant la valeur de la variable explicative Xi
s'écrit :
P(Yi = 1 = Xi) =  = =  = f(Xi) = f(Xi)
et peut s'interpréter comme le pourcentage de malades
lorsque la variable X prend une valeur précise.
La fonction logistique f(Xi) a une forme en S qui correspond
à une forme de relation souvent observée entre une dose X et la
fréquence d'une maladie Y (relation dose -effet). Elle décrit
donc l'association entre le degré d'exposition à un facteur de
risque (X) et l'accroissement du risque de maladie.
Dans le modèle Logit , les coefficients ne sont pas
directement interprétables : le signe du coefficient de X permet de
savoir si la probabilité expliquée est fonction croissante ou
décroissante de la variable X.
Par définition, dans le modèle Logit,
Pi = P(Yi = 1 = Xi) = 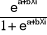 = =  est la probabilité qu'a l'individu i de connaître
l'événement Yi = 1 étant donnée la valeur de la
variable explicative X et est la probabilité qu'a l'individu i de connaître
l'événement Yi = 1 étant donnée la valeur de la
variable explicative X et
1 - Pi = P(Yi = 0 = Xi) = 1 -  = =  est la probabilité qu'a l'individu i de connaître
l'événement Yi = 0 étant donnée la valeur de la
variable explicative X. est la probabilité qu'a l'individu i de connaître
l'événement Yi = 0 étant donnée la valeur de la
variable explicative X.
Lorsqu'on pose Zi = + Xi, la probabilité P(Yi = 1 =
Xi) =  peut être écrite comme suit : P(Yi = 1 = Xi) = peut être écrite comme suit : P(Yi = 1 = Xi) = 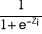 . .
Cette équation peut se
réécrire comme : eZ = pi /1-
pi
En prenant le logarithme, il vient : Zi=
log (pi /1- pi) = + Xi qui fait
apparaître le modèle logistique comme un modèle
linéaire.
En donnant la valeur 0 et 1 à Pi, on peut donc
constater que les probabilités seront soient nulles soient infinies. Ce
qui rend l'estimation des paramètres par la MCO impossible. Il faut donc
choisir la méthode d'estimation appropriée en distinguant le cas
des données non groupées et le cas des données
groupées.
En ce qui concerne notre estimation
économétrique, nous avons estimé un modèle de
régression logistique sur un échantillon de 320 ménages
retenus. Comme dit précédemment, la variable qualitative est
une variable non mesurable numériquement (ou codée) qui a un
nombre limité de modalités. Le modèle Logit permettra
ainsi d'expliquer (et de calculer) la probabilité d'utiliser la MII
quand les valeurs des caractéristiques individuelles Xi sont connues.
Ainsi, pour le cas de notre travail, ce modèle se
présente comme suit :
Yi = f (Xi)
Où Yi = utiliser ou non la MII
Xi = ensemble de variables exogènes ou
indépendantes (coût de MII, disponibilité de MII, niveau
de connaissance de la population sur les MII, niveau d'instruction du chef de
ménage, taille du ménage, Age du chef de ménage...).
Il revient donc de calculer P(Y=1/Xi) qui décrit la probabilité de
Y=1 pour une valeur Xi donnée.
Spécification du
modèle :
L'estimation économétrique a été
utilisée pour identifier les facteurs explicatifs de la
prévalence de l'utilisation de MII (UTIL) dans la communauté.
Ainsi les paramètres à vérifier étaient :
- le niveau d'instruction (NIVET) ;
- degré d'exposition au message (CONMII) ;
- la connaissance de la maladie (CONMAL) ;
- la taille du ménage (TAILLE) ;
- l'age du chef de ménage (Age) ;
- la disponibilité de MII (DISPO) ;
- les autres alternatives à la MII pour lutter contre
les piqûres des moustiques (ALTER),
- le niveau de vie de ménage représenté
par les dépenses journalières (DEPENSE).
L'estimation économétrique s'est
présenté comme suit :
UTIL = 1-@LOGIT(-(C(1) + C(2)*AGE + C(3)*NIVET + C(4)*TAILLE +
C(5)*CONMAL + C(6)*ALTER + C(7)*CONMII + C(8)*DISPO + C(9)*DEPENSE))
C (1) représente l'utilisation autonome,
indépendante de tous les facteurs.
Dans ce modèle, sont incluses des variables quantitatives,
qualitatives binaires et polytomique.
| 

