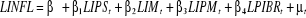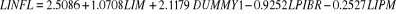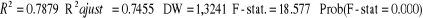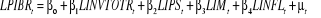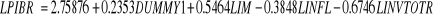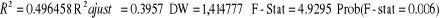L'efficacité de la politique des réformes monétaires sur l'inflation et la croissance économique en RDC (de 1982 à 2007)( Télécharger le fichier original )par Claude RUBONEZA BAHATI MIDAGU Université de Goma - Licence en économie 2008 |

I.3 ESTIMATION DES MODELES DE LONG TERMENous allons présenter par la suite les résultats de chacune de nos variables dépendantes ou endogènes, la politique monétaire sur l'inflation et la politique monétaire de la croissance économique. I.3.1 Modèle de Long Terme de l'impact de la politique monétaire sur l'inflationPartant des tests effectués, nous présentons les résultats de nos tests comme suit : § Le test de RESET sur la forme fonctionnelle indique que l'hypothèse alternative ne peut être rejetée, ce qui implique une erreur de spécification du modèle ; celle-ci a ete corrigée en insérant dans l'équation de régression une variable indicative (DUMMY1) 58(*) § Le test de BREUSH -GODGREY59(*) ne laisse pas entrevoir l'existence d'une dépendance sérielle des erreurs60(*). § Le test de WHITE échoue de rejeter l'hypothèse nulle d'homoscédasticité des erreurs au seuil de 5%.61(*) § La matrice de corrélation indique une forte corrélation entre les variables IM et IPS62(*). Pour éviter le risque de multicollinéarité, l'une d'elles (à l'occurrence IPS) a été enlevée du modèle. § La statistique de JARQUE-BERA montre les résidus du modèle d'inflation sont normalement distribués63(*) Après application de ces tests et correction des problèmes économétriques rencontrés, les résultats définitifs de notre modèle à Long Terme de l'équation d'inflation se présentent comme suit :
I.3.2 modèle à Long Terme l'impact de la politique monétaire sur la croissance
En adoptant la même démarche que celle effectuée dans le précèdent, les tests donnent les résultats suivants : § Le test de RESET sur la forme fonctionnelle indique que l'hypothèse nulle ne peut être rejetée, ce qui implique que la spécification du modèle est valable64(*). Toutefois, l'existence des données aberrantes pour la variable PIBR et INFL a été corrigée par l'introduction d'une variable indicatrice (DUMMY1) qui prend la valeur 1 entre 1993 et 1996 d'intervalle de temps et 0 ailleurs. § Le test de BREUSH -GODGREY ne laisse pas entrevoir l'existence d'une dépendance sérielle des erreurs.65(*) § Le test de WHITE montre que les erreurs du modèle de croissance sont homoscédastiques au seuil de 5% : la probabilité du Multiplicateur de Lagrange (5, 76%) est supérieure au seuil de signification. § La statistique de JARQUE-BERA ne rejette pas l'hypothèse nulle de normalité des résidus du modèle : sa probabilité (82,1%) est supérieure au seuil de signification. Ainsi, après l'application de tous les tests nécessaires, notre modèle à Long Terme de la politique monétaire sur la croissance économique se présente comme suit :
La cointégration de nos séries permet l'application de la méthode de ENGLE et GRANGER dont la deuxième étape porte sur l'estimation du modèle à correction d'erreur ou modèle à CT. * 58 La probabilité associée à la statistique de Fisher ainsi qu'au ratio du log de vraisemblance deviennent alors largement supérieures au seuil de 5 %. Elles s'élèvent respectivement à 88,39 % et 86,52 %. * 59 Le choix de ce test se justifie par le fait qu'il est plus général que celui de Durbin-Watson ; ce dernier n'est valable qu'en présence d'une autocorrélation d'ordre 1 (BOURBONNAIS, 1998). * 60 La probabilité de la statistique de Fisher et celle du Multiplicateur de Lagrange sont supérieures au seuil de 5%, indiquant le rejet de l'hypothèse alternative d'autocorrélation des erreurs. * 61 La probabilité de la statistique de Fisher et celle du Multiplicateur de Lagrange sont supérieures au seuil de 5%, respectivement de 9,81% et 16,97% * 62 Leur coefficient de corrélation s'est élevé à 99,53%, indiquant que ces deux variables véhiculent quasi parfaitement la même information sur la variabilité de la variable dépendante. * 63 La probabilité de cette statistique qui est de 64,61% confirme la normalité des résidus et autorise par conséquent de procéder aux tests d'hypothèse et de construire des intervalles de confiance pour les variables du modèle. * 64 La probabilité associée à la statistique de Fisher ainsi qu'au ratio du log de vraisemblance sont largement supérieures au seuil de 5 %. Elles s'élèvent respectivement à 56,51 % et 50,37 %. * 65 La probabilité de la statistique de Fisher et celle du Multiplicateur de Lagrange sont supérieures au seuil de 5% (respectivement 35,28% et 25,50%), indiquant le rejet de l'hypothèse alternative d'autocorrélation des erreurs. |
|