
29
Introduction
Dans la deuxième partie de notre travail nous
présentons, l?optimisation au niveau de la base de données. Nous
parlerons de l?optimisation au niveau conceptuel de la base de
données.
Ainsi, nous n?allons pas concevoir la base de données,
mais plutôt parler des procédures d?optimisation du modèle
logique de données (MLD), optimisé appliqué au
Système de gestion des bases de données relationnelles (SGBDR)
Pour illuster nos propos, nous nous servirons des exemples bases sur le SGBDR
oracle.

Chapitre I : Modèlisation de données
Ce chapitre ne nous apprend pas à modeliser la base de
données, mais plustôt nous montre à quel niveau de la
modelisation nous pouvons optimiser la base de données.
En fait, l?optimisation d?un modele intervient lors de la fin
de la conception du modèle logique de données (MLD) déduit
du modèle conceptuel de données (MCD).C?est pour quoi cette
étapes intermediaires du modèle logique de données et du
modèle physique de données est appelé modèle
logique de données optimisé.
Ce modèle logique de données optimisé porte
sur les concepts suivants : - les données calculées ;
- les clés secondaires ;
-la redandonse calculé ;
-le rapprochement physique.
Avant de parler de chaque concepts, nous disons que cette
étape consiste à optimiser l?organisation physique de
données afin de la reprendre au niveau traitements de l?application et
d?améliorer les performances des accès logiques en reduissant
leur nombres des R/W.
1-Les données calculées
Pendant la modelisation du MCD, les données
calculées ne sont pas prises en compte dans les entités,
c'est-à-dire ne représentent pas les proprietés des
objets. Car leurs valeurs respectives sont trouvées suités
à des calculés.
Il arrivé que ces valeurs soient calculées
plusieurs fois selon les besoins de l?application, il est mieux de les
mémorise dans la base de données. Cela fait l?optimisation de
MLD.
2-Les clés secondaires
La création des clés secondaires dans les
tables, nous offre une meilleure navigation dans tables de la base de
données. Car la navigation facile, permet la rapidité des
traitements dans l?application.
Pour illustrer ce propos, nous prenons trois tables : clients,
commande et
facture. Les tables client et la facture ne sont pas
liées, mais ells ne sont en
rélation qu?avec la table commande. Si on veut savoir
à quel client appartient la facture, on est obligé de passer par
la table commande, alors qu?on peut directement créer la clé
secondaire référençant le client dans la table facture.
Voici cet exemple :
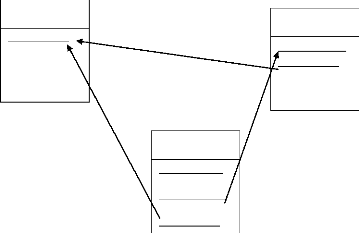
*MCD
Client Commande

NuméroCli
Numérocom
Facture
NuméroFac 1,N
1,1
Associer

1,N 1,1
passer

Client
Commande
NuméroCli
Numérocom NuméroCli
Facture
NuméroFac Numérocom
31
*MLD
Agent
NuméroAg
Affecter
1,N 1,N
Service
NuméroSer


*MLD optimisé
Client
Commande
NuméroCli
Numérocom NuméroCli
Facture
NuméroFac Numérocom NuméroCli
3-Redondance calculée
Ici on se propose de mettre dans une table quelques attributs
d?une autre table afin de réduire le nombre d?accès.
Par exemple, les table agent et service relié par la
relation affectée,l? on aura le MCD suivant :
*MLD
Agent
Service
NuméroSer

NuméroAg

NuméroAg NuméroSer
Affecter
NuméroAg NuméroSer
*MLD optimisé
|
|
Agent
|
Service
|
|
Affecter

33
NuméroAg NuméroSer
4-Rapprochement physique
Le rapprochement physique s?effectue avec des liaisons
paralleles (1,1) dites aussi bijections, il faudra concevoir une table qui
prendra tous les attributs de l?autre table tout en éliminant celle qui
donne ces attributs.
Considérons les entités secteur et charger
d?affaire.L?on a le MCD suivant :
Secteur
NuméroSec NomSec
*MLD
Charger
d?affaire
NuméroCh
1,1 1,1
Couvrir

Secteur
NuméroSec NomSec NuméroCh
Charger
d?affaire
NuméroCh NuméroSec
*MLD optimisé
Charger
d?affaire
NuméroCh NuméroSec NomSec

35
Chapitre II : Principe de l?optimisation de la base de
données
Les principaux points d?optimisation de la base de
données sont les suivants :
-Organiser les données pour obtenir une base de
données fonctionnant avec de bonnes performances ;
-le modèle logique de données que l?on
déduit du modèle conceptuel de données ne coïncide
pas toujours avec une bonne organisation optimale des données dans le
disque. Il faut réaliser le modèle logique de données
optimisé pour reprendre avec le besoin du système
d?information.
Ainsi, nous disons que la réalisation d?une base de
données surtout quand elle doit contenir de très nombreuses
données, nécessite fréquemment une nette modification au
niveau modélisation optimale afin de garantir la fiabilité, voir
les qualités d?une application.
Cette modification résulte d?une optimisation de la
base de données avec les méthodes précises et des
possibilités qu?offre le système de gestion de base de
données rélationnelle comme dans le cas d?oracle.

Chapitre III : Méthode d?optimisation de la base de
données
Les méthodes que nous pouvons retenir partant des
principes pour d?optimisation d?une base données sont :
-l? évaluation générale des performances
d?une application ; -les paramètres d?enregistrement ;
-la démarche d?optimisation de la base de
données.
1-Evaluation générale des performances d?une
application
Il y a deux éléments essentiels pour
évaluer la performance d?une application. Ces éléments
sont :
-le temps de réponse qui se passe lors du lancement de
chaque traitement et l?obtention des résultats correspondant attendu.
-la fiabilité qui détermine la capacité
de la base de données à réagir de façon stable et a
ne pas provoquer de perte d?informations ou données en cas de
problème et aussi d?enpêcher des accès intempestifs
à son contenu.
En plus de ce qui vient d?être dit, la qualité
d?une application réside aussi de ces capacités à
évaluer à moindre coût. Car la maintenance d?une
application est facile que si elle a été conçue clairement
et qu?elle est bien documentée.
Certains choix technique élaboré peuvent en
particulier améliorer la performance d?une application en faisant migrer
la base de données de celui-ci vers un système de base de
données à une autre.
2-Les paramètres d?enregistrements
Le temps de réponse dans les applications informatiques
est souvent influencé par des paramètres agissants sur un
élément essentiel qui est le disque dur.
Le disque est constitué de surfaces planes en
rotation, sur lesquelles on enregistre les données dans les emplacements
bien définis appelés les secteurs.
Pour effectuer la lecture, ou l?écriture d?un secteur
disque, il faut que le bras de lecture/écriture se déplace puis
attendre que la rotation du disque amène le secteur à lire devant
la tête de lecture/écriture portée par le bras. Cette
action ralentie les traitements.
Ainsi, nous pouvons retenir deux paramètres
d?enregistrements des données dans le disque :

37
-l?accès séquentiel ; -l?accès direct.
a-L?accès séquentiel
Ce paramètre permet de parcourir ou de lire la table
de la base de données depuis sa première ligne d?enregistrement
jusqu'à trouver la donnée recherchée. Ceci afin
d?accéder à autant d?enregistrement sur le disque.
b-L?accès direct
Il nécessite les connaissances de l?adresse de
l?enregistrement se trouvant dans un secteur disque pour retrouver chaque
donnée trouvée, chaque donnée voulue. Cette astuce, est
impossible dans les applications de gestions courantes. Par contre le SGBD
fournit un accès accéléré grâce à des
index et des blocs de données créent par l?administrateur de la
base de données.
3-La démarche d?optimisation
Pour optimiser une base de données, il faut : - optimiser
le MLD selon les traitements ; -optimiser le MPD selon le SGBD.
Voici un tableau résumant ces propos :

Base de départ
|
Actions d?optimisations
possibles
|
Résultat
d?optimisation
|
|
Optimisation logique selon la logique des traitements :
|
|
|
-groupement des tables ;
|
|
MLD
|
|
|
|
-définition des index ;
|
|
|
|
MLD optimisé
|
|
-élimination des tables
volumineuses.
|
|
|
Optimisation physique selon
des caractéristiques du
|
|
|
SGBD :
|
|
Tables logiquement
|
-définition des tailles de
|
|
optimisées
|
bloc ;
-répartition des tables par bloc ;
|
Tables physiquements
optimisées
|
|
-paramétrage des index.
|
|
|

39
Chapitre IV : Optimisation du SGBDR
Pour parler de l?optimisation SGBDR, nous avons choix le SGBDR
oracle, car il fournit un grand nombre d?éléments
nécessaires pour notre étude.
Ainsi, disons que oracle est un système de gestion de
base de données relationnel puissant et utilisé aussi dans les
grandes organisations ou entreprises, pour ces possibilités de
sécurité, de performances...
Il fournit quelques paramètres essentiels pour une
meilleure optimisation de la base de données, que nous citons comme suit
:
-les implantations des index ;
-enregistrement des données sur les mémoires de
masses et des accès concurrentiels ;
-les reprises après panne ;
-l?optimisation des requêtes ;
Les transactions dans les bases de données reparties.
1-Implementation des index
Un index est un objet informatique qui contient des
clés utilisées dans oracle, pour accéder rapidement
à une ou plusieurs lignes de la table et accélérer une
jointure ou une recherche d?informations dans la base.
Le principe clé des index est de limiter le nombre des
accès disque pour trouver une clé de la table.
On distingue trois types des index dans oracles. A savoir :
v' B-arbes qui sont les plus utilisés et pour
l?optimisation, la taille du noeud (le nombre minimum et maximum des
clés) doit être un multiple de la taille du secteur disque.
v' L?index bitmaps réservé aux données
qui peuvent être modifiées rarement. Ils sont performants sur les
combinaisons et /ou des critères ;
v' Index appelé table hachage, qui ne sont presque pas
moins utilisés dans les nouvelles versions d?oracle.
2-Enregistrement des données et accès
concurrents
Dans ce contexte, les données de la base sont
enregistrées dans les fichiers du système d?exploitation. Or le
SGDB enregistre les données des tables, des vues... dans le
système de fichiers. Il arrive parfois que le SGDB pour l?enregistrement
de données puisse s?en passer complètement du système de
fichier du système d?exploitation. Oracle utilise le fichier REDOLOG
pour les enregistrements système et le segment ROLLBACK or le
système, mais dans la base de données.
Pour les accès concurrentiels, oracle utilise des BUFFERS
en mémoire centrale pour les opérations de
lectures/écritures.
En ce qui concerne les performances, Oracle fournit Les
COMMIT pour éviter d?écrire dans la base de données
placé dans les BUFFERS et si ces BUFFERS sont pleins, les données
non validées peuvent être enregistrées dans la base de
données sans problème.
3-Reprise après panne
Nous constatons souvent les pannes dues aux : -les logiciels
installés ;
-les matériels utilisés ;
-l? implantation du réseau.
Ces pannes peuvent endommager ou non les fichiers.
> Si les fichiers sont corrects, la reprise après
panne du fonctionnement de SGBD permet de déterminer les transactions
validées qui ne sont pas finies et annulées ces transactions non
validées (ROLLBACK, on panne avant le COMMIT) ;
> Si les fichiers sont abîmés ou
endommagés, l?administrateur doit commencer par récharger la
dernière sauvegarde complète de la base de données et
ensuite, en redemarrant les actions enregistrées des images après
depuis la dernière sauvegarde. Sinon, il faut recommencer les commandes
perdues.
4-Optimisation de requêtes
L?optimisation des requêtes est basée sur :
-les considérations logiques en réduisant la
taille des données, c'est-à-dire faire des sélections ou
les projections avant les jointures ;
41
-l?implantation physique des données comme l?existence des
index et des clusters ;
-de faire des statistiques sur les données contenus dans
les tables (nombre de ligne, de valeur...).
5-Base de données reparties
Les processus du SGBD sont souvent repartis sur les machines
tandis que les données sont sur plusieurs sites. Il est
nécessaire d?utiliser les COMMITS distribués pour les
transactions distantes. Or, il arrive parfois aussi des pertes de performances
dues au réseau.
Pour résoudre ce problème, il est faut
gérer en temps réel des données locales en faisant
utiliser des copies des données distantes.

| 
