4.3. Méthodes d'analyse des données
Pour analyser nos données, nous avons utilisé les
méthodes qualitatives et les méthodes quantitatives.
Parmi les méthodes qualitatives, nous avons
utilisé l'analyse de contenu sous sa forme logico sémantique qui
se veut une méthode capable d'effectuer l'exploitation totale et
objective des données informationnelles. Nous nous sommes
également servi du logiciel TROPES pour analyser de façon
minutieuse les discours obtenus auprès des toxicomanes.
Parmi les méthodes quantitatives, nous avons
utilisé les méthodes statistiques car elles nous permettent de
calculer les fréquences, les pourcentages, les indices de relation entre
les variables de nos hypothèses notamment le khi deux (X2),
le coefficient de contingence et l'analyse de la variance.
Pour y parvenir, nous nous sommes servi des logiciels
statistiques EpiData pour saisir nos données et SPSS pour analyser et
traiter ces données.
Le khi deux ÷2
Le but est d'étudier la dépendance entre deux
variables qualitatives. Le khi deux s'obtient par la formule :
( n1 - n1') 2 ( n2 - n2') 2
÷21 = +
n1' n2'
n1 = Effectifobservé
n1'= Effectif de la norme
n2 = Effectif de l'échantillon - Echantillon
observé n2'= Effectif de l'échantillon - Effectif de la norme Il
peut se calculer aussi de la façon suivante :
×2ddl = ? ( ni - ni') 2
ni'
ni = effectif observé
ni' = effectif théorique
ddl = degré de liberté
Lorsque ni < 10 on utilise la correction de Yates : en
remplaçant ( ni - ni')2 par (ni - ni'- 0,5)2
ni ni'
Nos résultats sont lus au seuil 0.05
L'hypothèse nulle (Ho) est celle d'indépendance
entre les indicateurs de deux modalités si le khi deux calculé
est inférieur au khi deux lu sur la table de ce test.
L'hypothèse alternative (Hl) qui
suppose l'existence d'une liaison entre les caractères des deux
modalités si le khi deux calculé est supérieur au khi deux
lu sur la table.
Le coefficient de contingence : C
Il permet de voir si la relation est élevée ou
faible entre les variables étudiées. Elle varie entre 0 et 1
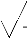
Sa formule est : C = X2
X2 + n
n = Total de toutes les entrées du tableau
L'analyse de la variance à un facteur
Le but est d'étudier la dépendance entre deux
variables dont l'une est quantitative et l'autre qualitative.
Soient J observations: zj ; j = 1 à J,
d'un caractère Z.

On notera z la moyenne de ce caractère,
définie par: z = 1 Ezj
i= 1
J
On notera V(Z) ou ó2 ( Z
) la variance de Z, définie par: V ( Z) = E(
zj-z)2
j= 1
On appellera :
Y la variable quantitative
yik la valeur de Y pour l'observation i du
groupe k.
K le nombre de groupes
Ik le nombre d'observations dans le groupe
k.
K
)
I le nombre total d'observations
réalisées ( I = EIk
k= 1
1
yk = Zdyik
I k i= 1
est la moyenne de Y dans le groupe k.
Ik
1
y = yik
k= 1 i=1
est la moyenne globale de Y.
K Ik

K I
Remarque :y = E
1
E yik
k= 1 I k i= 1 k=1
Ik
) =
K
yk
La moyenne globale est donc une moyenne des moyennes des groupes
pondérées par leurs effectifs.
|
1 Ik
Vk ( Y ) =
ó2k( Y = E( y
k -yk)
I k i = 1
|
2 est la variance de Y à
l'intérieur du groupe k.
|
|
1 K Ik
V (Y ) = ó2 ( Y )
= EE( yik -y)
I k= 1 i=1
|
2 est la variance totale de Y.
|
L'idée est la suivante :
Si le facteur de groupe induisait des différences sur
la variable Y, toutes autres influences mises à part, on
obtiendrait une dispersion de Y qui traduirait ces groupes: On aurait
donc une dispersion entre les groupes petite par rapport à la
dispersion à l'intérieur des groupes.
Mesure de la dispersion :
- La dispersion est mesurée par la variance.
- On peut d'ores et déjà établir une
décomposition intéressante de la variance totale de
Y:
K K
I I
k k
V Y
( ) = V Y
( ) + ( )
y y
-
k k
I
k = I
1 k = 1
|
2
|
|
On remarque que le premier terme de cette somme est la
moyenne des variances internes aux groupes pondérées par leurs
effectifs, il s'agit donc d'une variance interne moyenne, ou: variance
dans les groupes. Quant au second terme, c'est clairement la variance
des moyennes des différents groupes, soit une variance entre
les groupes.
La décomposition ci-dessus de la variance de Y
s'interprète donc tout simplement comme:
Variance totale = Variance dans
les classes + Variance entre les classes On
notera:
K I
- la variance dans les classes: V Y
d ( ) =
k= 1
k
V Y
( )
k
I
K I
-
I ( y k - y
k
) 2
1
la variance entre les classes: V Y
e ( ) =
=
k
Le critère et le test:
dispersion
L'idée est la suivante: si le rapport
est grand, on admet la
entre
dispersion dans
significativité de l'influence dépistée du
facteur de groupe sur la variable Y. Formule du
test
Sous l'hypothèse que le facteur de groupe n'induit aucune
différence sur Y entre les groupes (i.e. aucun effet
spécifique, autrement dit tous les bk = 0), la
statistique suivante: F
V e ( Y ) .K K
V d ( Y) .I I - K

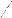
- 1 suit une loi bien précise: la loi de
Fisher à respectivement K-1 et I-K
degrés de liberté, notée F (K-1, I-K).
On calcule donc la statistique F sur les
observations, et l'on regarde si elle est tombée dans une région
"peu probable" de cette loi (i.e. par exemple une région dans laquelle
F ne devrait tomber que dans 5% des cas, et où la
densité de probabilité est faible). Si c'est le cas, on est
enclin à considérer que l'hypothèse de non-influence est
trop peu plausible, et donc à admettre l'hypothèse d'une
influence du groupe sur Y. A contrario, si F est
tombée en dehors de la région "peu probable", tout paraît
normal, et l'on n'a pas à rejeter l'hypothèse de non-influence.
On ne considère donc pas que le groupe ait une influence significative
sur Y.
On compare donc F au fractile d'ordre 95% ou 99% de la
loi F(K-1,I-K), noté f0.95(K-1,I-K) ou
f0.99 (K-1, I-K).
| 

