|
Mémoire professionnel
Master management multimédia Option art
numérique
Christel Morvan
La visualisation des informations
Le mode de transmission de l'information a beaucoup
changé depuis les débuts de l'histoire de la communication.
Durant l'antiquité, les connaissances et savoir-faire étaient
transmis majoritairement par la tradition orale et souvent, le savoir
était réservé aux élites et membres de certaines
écoles de pensée. Les pythagoriciens par exemple, partageaient
leur savoir uniquement de manière orale et secrète, les
initiés étant les seuls à pouvoir y accéder.
L'écriture a ensuite permis l'affranchissement du
support de la voix et du contact : les connaissances purent alors être
mémorisées, stockées et échangées. Mais
c'est seulement avec l'apparition de l'imprimerie que les livres, d'abord
supports de communication, vont devenir des véritables diffuseurs
d'information. Ce procédé a contribué à
démocratiser la connaissance lorsqu'auparavant seuls les clercs
étaient capables de maîtriser les techniques d'écriture et
la lecture des textes qui étaient en latin.
Cette révolution dans la transmission des informations
a provoqué un véritable changement de paradigme1 dans
tous les domaines. Alors que l'impression des textes de l'antiquité
permis une meilleure compréhension de l'histoire et de la philosophie,
l'Ymago mundi2 , entre autres, changea la vision de la
géographie.
Et ces nouvelles connaissances permirent à l'Europe de
se lancer dans des expéditions d'envergure mondiale. Dés lors,
les anciennes cartes devinrent rapidement obsolètes, la
découverte de nouvelles terres et la notion de distances
changèrent la représentation du monde.
Pour se repérer dans ce « nouveau monde », il
s'avéra rapidement nécessaire de le cartographier. Devant le
nombre croissant d'informations à représenter sur les cartes, les
signes conventionnels de la cartographie de simplifièrent. Mappemondes
et atlas vont voir le jour à cet époque, et la géographie
deviendra une science à part entière.
Aujourd'hui, avec l'ère du numérique, le mode de
transmission de l'information a de nouveau changé. Les ordinateurs sont
devenues des outils de calcul, d'aide à la décision, et de
stockage perfectionnés. Internet a permis l'affranchissement des
contraintes spatiales et temporelles, et nous pouvons désormais
accéder rapidement à une quantité innombrable
d'information et de données.
A l'instar des cartographes de la renaissance contraints de
revoir la manière de représenter le monde, nous allons à
notre tour devoir cartographier le réseau foisonnant de données
et d'informations. Si à
1 Un paradigme, viens du grec ancien
ðáñÜäåéãìá /
paradeïgma qui signifie « modèle » ou «
exemple » ici, est une représentation, un modèle de vision
du monde.
2 Pierre d'Ailly, L'Ymago Mundi, imprimé en 1410,
est un ouvrage de 12 traités s'appuyant sur des auteurs tel
Ptolémée, Aristote ou encore Averroès. Il est
agrémenté d'une carte représentant la terre en un globe
divisé en plusieurs zones climatiques. Autre fait nouveau par rapport
aux cartes médiévales, Pierre D'Ailly place le nord en haut de la
carte.
l'époque l'enjeu était de se repérer dans
le monde réel, aujourd'hui l'enjeu est de s'orienter dans les
données pour nous repérer et améliorer la diffusion de
l'informations et des connaissances.
Nous évoluons aujourd'hui dans un monde où les
information sont de plus en plus omniprésente et surabondantes. Comment
les représenter quand celles-ci ne cessent d'augmenter en
quantité et en complexité? Quel système peut nous
permettre de synthétiser l'information, de la rendre plus lisible et
pertinente? L'image est-elle la solution?
Il y a à ces question des ébauches de
réponses techniques et théoriques mais prennent-elles vraiment en
compte tous les aspects et les enjeux de la représentation de
l'information?
Pour comprendre l'importance d'aborder la
représentation des informations sous un angle neuf, nous allons d'abord
analyser l'information en elle-même, en décryptant ses
mécanismes de fonctionnement dans un premier temps, puis en essayant de
cerner ses nouvelles modalités. Nous aborderons ensuite la notion
d'hyperinformation et ses conséquences.
Pour comprendre comment s'opère la transmission de
l'information et donc savoir comment la représenter au mieux, nous
étudierons de manière synthétique la question du langage.
Les mécanismes du langage vont nous permettre d'acquérir des
connaissances nécessaires pour transmettre les informations de
manière optimale. Nous allons ensuite étudier les
particularités inhérentes au langage visuel, qui vont nous
aiguiller sur les méthodes à employer pour produire des images
significatives. Dans cette partie, nous essayerons également de savoir
comment créer une image non influencée par une culture, et dont
l'utilisation serait donc universelle. Mais nous verrons par la suite qu'un tel
langage est impossible à réaliser : le langage universel est
irréalisable, qu'il soit visuel ou non.
Une fois cernés les enjeux et les techniques de
production d'une image, nous allons essayer de déterminer de quelle
manière visualiser les informations. Dans un premier temps, nous nous
confronterons à des exemples de visualisations, puis nous
élaborerons les modalités à suivre pour élaborer un
système visuel efficace. Enfin, nous déterminerons les contextes
d'application d'un tel système.
I La donnée et l'information
Depuis l'essor d'internet nous assistons à un profond
changement dans le mode de production et de transmission des connaissances.
Tout paraît plus rapide, accessible. Acquérir une information
aujourd'hui prend le temps qui est nécessaire pour accéder
à internet.
Si le résultat le plus éclatant d'un tel
changement est la démocratisation des informations et de la
connaissance, voir pour certain le début d'un
changement de conscience3, nous ne devons pas
omettre les aspects négatifs qui peuvent surgirent d'une telle abondance
d'informations.
Si nous ne maîtrisons pas le flot d'informations et de
données que nous recevons, nous risquons tout simplement la noyade.
Aujourd'hui, la masse d'informations circulant sur internet est estimée
à plus d'1,8 zettaoctets (1021 octets)4, et ce
chiffre est en croissance exponentielle.
Pour comprendre les enjeux et les risques de cette
surabondance, essayons dans un premier temps de comprendre les
mécanismes relatifs aux données et aux informations circulant sur
internet.
I - 1 Les mécanismes de l'information
Commençons par distinguer clairement donnée et
information pour mettre un terme à la confusion qui existe entre les
deux termes.
Définitions
S'il est important de faire le distinguo entre la
donnée et l'information c'est essentiellement parce que ces deux
éléments de la communication sont très liés, sans
être pour autant synonymes.
La donnée est la représentation - la plupart du
temps en valeur numérique - de quantités, d'objets, de faits, de
transactions, ou encore d'évènements. Elle symbolise une ou des
entités. C'est la description la plus basique et
élémentaire d'un objet en vue d'une interprétation, elle
n'a donc aucune valeur tant qu'elle n'est pas contextualisée et
interprétée.
L'information est une donnée avec un sens
associé, elle est donc la donnée interprétée.
Autrement dit c'est seulement une fois que la donnée est
interprétée, organisée, structurée qu'elle se
transforme en information et peut être porteuse d'un message. La
donnée est pour ainsi dire le lien entre l'objet et l'information.
Prenons un exemple concret : le chiffre 7 en soi ne signifie
pas grand chose, c'est seulement croisé avec d'autres données
qu'il deviendra une information : 7 jours, 7 personnes, 7 accidents...
Le mot information paraît clair pour la plupart,
pourtant en théorie de l'information il a un sens très
précis. C'est ce qui est neuf, inattendu. Une réponse attendue
à une question posée n'a pas valeur d'information. Par
3 Gérard Ayache dans son livre Homo sapiens 2.0,
introduction à une histoire naturelle de l'hyperinformation,
évoque ce changement de paradigme en ces termes : «
L'émergence, (...) de la notion d'information comme structure
fondamentale de l'univers, de la nature et de la vie ouvre des potentiels
considérables dans notre appréciation de la vie, de la conscience
et du développement humain dans son environnement naturel. »
4 Pronostique réalisé par le cabinet d'analyse IDC
en 2008, cf. article de Lucas Maerian, Digital universe and its impact
bigger than we thought, où sont explicités les critères et
techniques employées pour accéder à ce pronostique, et
sont décryptées les conséquences sur nos habitudes
internet.
exemple, si je demande le résultat d'un jet de
dé à six faces et que la réponse donnée est «
entre un et six », l'information est nulle puisque le résultat
n'aurait pu être différent.
Dés lors, l'information peut être mesurée
: elle est plus importante lorsque le nombre de questions nécessaires
pour dissiper tout ambigüité sur un évènement est
élevé. Précisons qu'il s'agit là de questions de
type binaire, c'est à dire ne laissant la possibilité qu'à
deux états (oui/non, vrai/faux, 0/1). La mesure de l'information se fait
donc en bit (binary digit).5
Il faut encore définir la connaissance, qui est un
ensemble d'informations sur un objet donné pouvant être
expérimentées, et le savoir, qui lui, désigne l'ensemble
des connaissances acquises par un individu.
En somme, l'information est primordiale dans le processus
d'acquisition des connaissances.
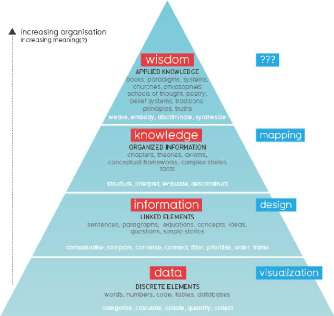
Illustration 1: schéma représentant la
hiérarchie de la compréhension de Davil McCandless
5 Cf. Jean-Marie Klinkenberg, Précis de
sémiotique générale, qui parle de l'information dans la
communication dans le chapitre 2.
Comment reçoit-on l'information?
Comme on l'a vu précédemment, notre rapport
à l'information a changé, nous sommes submergés par sa
masse. Mais d'où provient cette surabondance d'informations, comment la
reçoit t'on et surtout sous quelle forme se présente t'elle?
Contrairement à ce que la plupart des gens pensent,
l'information est partout. Elle peut provenir d'une publicité, du
téléphone, d'un mail, d'une carte, ou même d'une simple
réponse sur un forum. Elle peut se présenter aussi bien sous
forme de texte, de vidéo que de son.
Les Etats-Unis par exemple ont consommé (tous
médias confondus) à peu près 3,6 milliards de teraoctets
d'information en 2008, soit presque 12 heures d'information par jour et par
personne (contre 7,4 heures en 1980). Autant dire que dés que nous
sommes éveillés, nous sommes soumis à un flot
d'information continu.6
Mais concentrons-nous ici sur les supports numériques.
Que ce soit de la page commerciale au site journalistique,
tous les sites internet sont vecteurs d'information. Une page regroupe
d'ailleurs plusieurs informations diverses auquel nous accédons
simultanément, fait quasiment restreint aux usages numériques.
Sur internet, nous pouvons recevoir l'information
volontairement, suite à une recherche, ou involontairement, il s'agit
des informations qui nous sont transmises sans qu'on les ai
attendues7.
Par exemple, une recherche effectuée sur
Google nous donnera plusieurs informations, celles qui sont
susceptibles de répondre à nos questions, celles qui
répondent à nos questions mais sous une forme que nous ne voulons
pas avoir (une réponse trouvée sur un forum n'aura pas
forcément la même valeur informationnelle que celle trouvée
sur un site spécialisé), celles qui ne répondent pas du
tout aux questions, et enfin les « liens commerciaux » et
suggestions.
Autre exemple, sur une page Facebook lambda, nous
allons trouver plusieurs types d'informations. Les publicités, les
informations provenant de nos amis, les informations provenant des
applications, les données concernant notre propre profil, les
suggestions, les évènements, les invitations...
Mais notre cerveau est-il capable de traiter autant
d'informations en même temps?
Comment l'information est-elle produite?
La multiplicité des informations diffusées sur
internet et due à la nature
6 Voir l'article D'Hubert Guillaud, Combien d'informations
consommons nous? publié sur le site d'Internet actu, où
l'auteur met à disposition les détails de l'étude de Roger
Bohn sur la consommation des informations en 2009 aux Etats-Unis.
7 Ce principe est autrement appelé principe de
sérendipité.
du média : produire des informations n'a jamais
été aussi simple qu'à l'heure du numérique. Non
seulement internet offre l'instantanéité, la mobilité,
mais il permet surtout de faire disparaître les processus qui
étaient inhérents à l'écriture sur papier.
Les nouveaux outils numériques réduisent le
délai entre la production et la diffusion des informations. Poster un
billet de blog aujourd'hui prend le temps qu'il est nécessaire de taper
son texte et d'appuyer sur le bouton « envoyer ». Avant, l'acte
d'écriture avait quelque chose d'irréversible. Se tromper en
écrivant sur du papier ou en tapant à l'aide d'une machine
à écrire avait pour conséquence de déchirer le
papier et de recommencer à écrire depuis le début.
L'ordinateur permet l'erreur tout en offrant le pouvoir de défaire,
autrement dit de corriger les erreurs, d'ajouter du contenu, autant de
possibilité qui rendent l'écriture plus abordable.
Internet offre aussi la possibilité à tous de
publier, là où le support papier nécessite de trouver un
éditeur, un journal acceptant de publier l'information.
La production et la diffusion est devenue rapide et surtout
accessible à tous et à tout type d'information, de la plus riche
à la plus vide en passant par la plus controversée. Cela signifie
aussi que nous sommes tous potentiellement des producteurs d'information.
I - 2 Les modalités de l'information
aujourd'hui La forme de l'information
Pour mieux comprendre ce qui motive un internaute à
accéder à une information, nous devons commencer par comprendre
sous quelle forme il veut recevoir cette information.
Pour la plupart des utilisateurs d'internet, l'écrit
serait le meilleur moyen de communiquer des informations. Un sondage
réalisé par l'agence Webcopyplus8 en 2008 avance
même que plus de 63% des utilisateurs Internet considèrent
l'écrit comme le meilleur moyen de communiquer sur le Web. Mais
l'internaute consulte-t-il véritablement les contenus écrits?
Apparemment oui. Du moins dans certains cas. Si les
internautes lisent effectivement, il s'agit surtout de textes cours. Quand aux
textes plus longs, ils sont sujets à une lecture légère,
en priorité des titres et des mots-clef, les lectures plus profondes
sont rares et réservées aux utilisateurs cherchant
véritablement une information. Mais les textes longs sont souvent soit
laissés de côté soit survolés, les supports
numériques n'offrant pas encore un confort visuel nécessaire
à la lecture prolongée.
Pour ce qui est d'une information complexe ou longue,
l'utilisation d'autres médias que le texte est donc très souvent
favorisée.
8 Pour plus d'information, le site de Webcopyplus, où les
résultats de leurs études sont régulièrement mis en
ligne : http://www.webcopyplus.com/
En terme de plateforme, les médias sociaux sont
aujourd'hui largement privilégiés pour la communication et donc
le partage d'informations. Non seulement ils permettent le dialogue direct
entre utilisateurs, mais surtout une transmission et une production des
informations communautaires, autrement dit collaboratives. Sur les
médias sociaux, tout le monde est à la fois diffuseur et cible
potentielle d'un message.
L'utilisateur peut y recevoir son information directement
depuis les autres utilisateurs sans avoir à effectuer des recherches
interminables au préalable. Ce système, qui se rapproche de la
discussion traditionnelle par son instantanéité et par le type de
langage employé n'est cependant pas toujours le moyen le plus pertinent
pour avoir une information. La plupart des réponses sont erronées
ou ont bien peu de valeur. Mais le principal intérêt des
médias sociaux n'est pas tant de communiquer une information que de
discuter autour pour en obtenir divers points de vue.
Antony Mayfield9 qualifie les réseaux sociaux
selon cinq points :
· La participation: les internautes discutent entre eux et
partagent leurs avis, supprimant ainsi la barrière entre le public et
les médias.
· L'ouverture: le principe des médias sociaux est
basé sur l'échange. Tout le monde peut participer et
échanger des informations.
· La conversation: contrairement aux médias
traditionnels, les médias sociaux ne font pas que transmettre un
message, ils encouragent la discussion autour du message.
· La communauté: rassemble des groupes de personnes
ayant les mêmes centres d'intérêt
· L'interconnexion: les réseaux sociaux
récupèrent des informations provenant d'autres sites, et
renvoient l'information ailleurs. L'information se propage.
D'autre part, on peut distinguer plusieurs types de
médias sociaux par où transite l'information: Les réseaux
sociaux qui permettent à l'utilisateur de se connecter à son
réseau de connaissances pour partager des informations ou du contenu.
Les forums sont des véritables zones de discussion en
ligne, souvent centrées autour d'un thème spécifique. Ce
sont des outils puissants et populaires pour les communautés en
ligne.
Les blogs, qui sont moins axés sur la discussion,
permettent à l'utilisateur d'ajouter et d'éditer du contenu et
des informations sur luimême et son ou ses domaines
d'intérêt pour ensuite le diffuser aux autres utilisateurs. Les
blogs sont souvent écrits par des spécialistes ou des
passionnés d'un domaine en particulier. Ils ont donc par
définition un plus fort potentiel informationnel que les réseaux
sociaux ou les forums. Certains blogs d'ergonomie et de design rencontrent par
exemple beaucoup de succès
9Antony Mayfield met à disposition ses recherches sur les
médias sociaux dans son e-book intitulé What is social
media
http://www.icrossing.co.uk/fileadmin/uploads/eBooks/What_is_Social_Media_iCrossing_ebook.pdf
dans les milieux professionnels auxquels ils sont
associés. Certaines entreprises possèdent même leurs
propres blogs afin de créer une communauté autour de leur
marque.
Les microblogs sont des blogs de format court. Le but des
microblogs, comme Twitter par exemple, est plus de
récupérer une information pour la diffuser à ses contacts
ou au public. L'utilisateur propage l'information.
Enfin10, le Wiki permet aux gens d'éditer
et d'ajouter du contenu ou de l'information sur un document commun ou une base
de donnée. L'exemple le plus connu de wiki est
Wikipédia.
Wikipedia est une encyclopédie collaborative.
Autrement dit, son contenu est entièrement produit par les utilisateurs.
Cette propriété a souvent été décriée
par les spécialistes de l'information à cause du fort nombre
d'erreurs trouvées sur les articles. En plus des informations
erronées propagées, on voit également apparaître des
actes de vandalisme. Les actes de vandalisme se traduisent par des informations
volontairement erronées, dans le but d'induire les utilisateurs en
erreur, des spams, ou encore des messages personnels laissés sur des
articles.
Malgré tout, Wikipedia reste une des
premières sources d'information sur internet, utilisée par les
étudiants, et même comme base de référence par
certains enseignants.
Michel Serres déclarera lui-même «Je suis
un enthousiaste de Wikipedia. On reproche à Wikipedia
de ne pas produire de l'info, mais les professeurs non plus n'en produisent
pas. Wikipedia est un transmetteur de savoir. Un passeur. Comme les
professeurs, comme les journalistes... Bien-sûr il y a des erreurs, mais
pas plus que dans l'encyclopédie Britanica. Le nombre d'erreurs
contenues dans les livres de la bibliothèque nationale de France est
gigantesque. Qui vérifie le contenu de ces ouvrages? Qui corrige les
erreurs? Sur Wikipedia, la vérité est rétablie
par des bénévoles anonymes et libres. Dans les journaux, les
erreurs se recyclent d'article en article.»11
Et l'avis de Michel Serres semble être plutôt
répandu sur internet. Les internautes ne veulent plus se fier qu'aux
experts, ils veulent avoir plusieurs avis, ils veulent avoir le contrôle
sur ce qu'ils lisent, pouvoir en évaluer la véracité. La
connaissance ne provient plus que des enseignants ou des élites, elle
est partagée entre les utilisateurs. Nous passons d'un système de
transmission des connaissances vertical à un système transversal
et complexe.
Pour résumer l'information aujourd'hui se traduit par:
· Un système de transmission transversal et
complexe.
10Il existe deux autres catégories de médias
sociaux, le podcast et les communautés de partage de contenu (comme
Flickr, Delicious, Deezer), que je n'ai pas
mentionné car ils concernent davantage l'échange de contenu que
d'information.
11 Extrait d'un texte de Michel Serres, de l'académie
française, publié par le Point du 21 juin 2007
· L'instantanéité et la facilité
de création et d'édition.
· Une abondance croissante due au grand nombre
d'émetteurs.
· Une variété dans la qualité des
informations.
Une crise de confiance
En réalité, il s'agit là d'une
véritable crise de confiance. Maintenant que l'internaute a accès
librement à un large panel de connaissances plus seulement
réservées aux élites, spécialistes ou journaliste,
il remet facilement l'information en doute. Dés lors, les informations
sont vérifiables, et les erreurs divulguées dans les journaux ne
passent plus inaperçues.
Un utilisateur de blog ira même jusqu'à dire
« Pour ma part, je n'achète plus le moindre journal tout simplement
parce que je n'ai plus aucune confiance en lui. C'est la même chose pour
la télévision, mais je ne dis pas qu'ils sont inutiles. On oublie
les nouveaux comportements qu'engendre le Web est que le consommateur ne
consomme que ce dont il a besoin. La télévision, la radio, la
presse écrite ne sont devenus que des blogs, des sites parmi les
millions d'autres, et le lecteur n'utilisera que le strict nécessaire.
Ce n'est pas en bloquant quelques titres prestigieux qu'on va décourager
le lecteur, car il sait pertinemment qu'il y aura toujours quelqu'un pour lui
donner l'info gratuitement»12.
Mais la crise de confiance que traverse l'information ne se
traduit pas seulement par de la méfiance et du scepticisme. Le scandale
engendré par Wikikeals en est un symbole.
Wikileaks est un site mettant à disposition
des documents, des analyses gouvernementales et sociétales. Mais le but
avoué du site est aussi de divulguer les fuites d'information. Cette
démarche a pour but d'apporter de la transparence journalistique et
gouvernementale là ou le secret existe. De cette manière,
plusieurs affaires ont été portées publiques, la plus
connue à ce jour reste l'affaire Irak War Logs13. Si
ce n'est pas la première fois qu'un scandale gouvernemental est
révélé au grand jour, c'est en tout cas la première
fois qu'un site dédié à l'information fait tellement de
bruit parmi le public et les gouvernements.
Pour Olivier Cimelière, cela s'explique par un
phénomène en pleine croissance, la défiance sociale :
« Si l'onde de choc de WikiLeaks n'en finit pas aujourd'hui de se
propager, c'est avant tout parce qu'elle intervient dans un contexte
sociétal encore plus délétère qu'auparavant
où la récusation des élites et les méfiances envers
les pouvoirs sont devenus le métronome
12Extrait du billet Une étude montrant
l'étendue de la crise du journalisme paru dans le blog Maniac
Geek en 2010
13Le 23 octobre 2010, WikiLeaks a mis en ligne 391 832
documents secrets sur l'Irak, portant sur une période du 1er
janvier 2004 au 31 décembre 2009, et révélant, notamment,
que la guerre avait fait environ 110 000 morts pour cette période, dont
66 000 civils, et indiquant que les troupes américaines auraient
livré plusieurs milliers d'Irakiens à des centres de
détention pratiquant la torture.
presque systématique d'une frange importante de la
société civile. »14
L'internaute doute, il estime qu'on lui doit l'information,
et fait de moins en moins confiance à l'état ou aux experts, qui,
sous couvert de leur statut, peuvent faire croire tout et n'importe quoi au
public lambda. Il a besoin de voir s'exprimer une plus grande part de la
population, d'avoir des avis divers, de prendre connaissance des affaires qui
l'intéressent par le biais de multiples points de vue, et donc de
multiples intervenants. Il ne se contente plus de l'avis du spécialiste,
il désire des informations plus brutes et moins
synthétisées, venant des témoins, passionnés
d'actualité, journalistes amateurs et autres figures d'habitude mises en
retrait par le journalisme plus traditionnel.
Ce phénomène se cristallise justement par le
succès des modèles comme Wikipedia, les modèles
dits de crowdsourcing.
Le crowdsourcing, littéralement traduit
«approvisionnement par la foule, ou par un grand nombre de personnes»
est un travail effectué collectivement, approvisionné par
plusieurs personnes, majoritairement par le grand public. Ce système est
représentatif des nouveaux modes de distribution de l'information,
puisqu'il permet à chacun de devenir producteur de contenu. Si
wikipédia et son encyclopédie collaborative en est
l'exemple le plus connu, le modèle se répand. Jeff
Howe15 nous explique que maintenant, les chaînes de
télévision américaines cherchent de plus en plus à
diffuser les programmes basés sur des productions vidéos
d'amateurs.
Ce qui fait le succès du crowdsourcing, c'est
dans un premier temps le faible cout de la formule, mais aussi le fait de tirer
des ressources d'un nombre important de gens, ce qui permet de
récupérer et d'analyser une plus large gamme de connaissances et
d'expériences, autrement dit, il s'agit de tirer partie de
l'intelligence collective.
En journalisme, le crowdsourcing est aussi
utilisé pour collecter des informations: les sites comme
ushahidi16 proposent ainsi à n'importe quel
utilisateur de rapporter son information, de recenser des
évènements. Ainsi, sur cette plateforme, suite à la
catastrophe d'Haiti, plus de 3 500 évènements auraient
étés recensés.
Mais si ce modèle est populaire, c'est aussi parce
qu'il permet à tout le monde d'avoir le droit d'expression. Le site
ipaidabribe17 - littéralement je paie un pot de vin
- propose de lutter contre la corruption en Inde en invitant ses utilisateurs
à dénoncer ces actes. Jusqu'ici, 3011 rapports on
été enregistrés sur le site. Autrement dit, le
crowdsourcing permet dans certains cas de lutter contre la censure et
le travestissement des informations. Il contribue aussi à éviter
le contrôle des médias et des images.
L'internaute participe donc. Mais un internaute engagé
ne fait pas que
14 Extrait de l'article d'Olivier Cimelière,
Wikileaks : que penser après la colère et la fureur
médiatique?
15 Jeff Howe nous explique la montée et les enjeux du
crowdsourcing dans un article paru sur le site de WIRED, The Rise
of Crowdsourcing, paru en 2006.
16 Voir le site http://www.ushahidi.com/
17 Voir le site http://ipaidabribe.com/
participer, il veux aussi accéder aux sources de
l'information, il veut analyser lui-même et tirer ses propres
conclusion.
La libération des données
Dans quelles mesures avoir toute l'information? Tous les
points de vue, même ceux semblant les plus insignifiants? Comment
être sur que les informations que l'on nous donnes sont complètes
et fiables? En accédant à la source de l'information : la
donnée.
Aujourd'hui, ce que veut l'internaute, c'est avoir
accès aux données brutes, qui auparavant étaient
réservées aux spécialistes. Cette tendance de «
l'open data », littéralement la donnée ouverte est justement
née de la perte de confiance de l'internaute face aux médias
détenteurs de l'information, élites et gouvernements.
En 2006, le Gardian'technology, dans un article
intitulé Give us back our crown jewels, appelle les
gouvernements à rendre leurs données publiques18.
Selon le journal, les études réalisées pour collecter ces
données doivent appartenir au public puisqu'elles sont entre autre
financées par les taxes. Contre-coup de cet appel : certains
gouvernements ont finalement rendu leurs données accessibles. Les
Etats-Unis mettent en place un site sur lequel ils rendent certaines de leurs
données accessibles, DataGov, encourageant les autres gouvernements
à faire de même. Finalement, ouvrir les données d'un pays
s'avère augmenter - ou restaurer - la confiance des gens en celui-ci.
Après avoir essuyé des scandales sur la gestion de sa
trésorerie par exemple, le Royaume-Uni décide de rendre
accessible la base de données de sa trésorerie,
Coins19.
Les gouvernements aujourd'hui ont une pression qui les incite
à publier leur données brutes. Ce qui était encore
confidentiel il y a quelques années est maintenant à la
portée du grand public. Pour Simon Rogers, journaliste au Guardian,
« ce qu'il faut comprendre c'est que les gouvernants n'ont rien à
perdre. Aux USA, au Royaume Uni, en Australie ou en Nouvelle-Zélande, le
monde ne s'est pas écroulé parce que les données
gouvernementales ont été rendues publiques ! Cela a tout
simplement rendu les choses plus ouvertes et plus transparentes à une
époque où on ne fait plus confiance aux politiciens, on ne fait
plus confiance à la politique. Vous voulez qu'on vous fasse confiance ?
Il faut être ouvert. Rendre ses données publiques c'est essentiel
pour cela, il faut le faire dans un format pratique pour encourager les gens
à s'investir. »20
Les données publiques se qualifient selon 4
critères : ce sont des données collectées par des
organismes publics, non-nominatives, c'est à dire
18 Pour soutenir cette demande, un site est mis à
disposition des internautes :
freeyourdata.org,
actuellement toujours disponible.
19 Coins est actuellement disponible sur le site
Data.gov, site sur lequel le gouvernement
américain met à disposition ses propres bases des données
ainsi que celles provenant d'autres pays.
20 Extrait de l'entretient avec Simon Rogers publié sur
l'Atelier des Médias par Ziad Maalouf le 12 Novembre 2010.
qu'elles n'appartiennent pas à un individu en
particulier, et elles ne relèvent ni de la vie privée, ni de la
sécurité. Autant dire que par leur nature intrinsèque, ces
données sont faites pour être partagées. Mais si certains
gouvernements pratiquent la libération des données, ceux-ci
restent malgré tout minoritaires. En août 2010, seul 7 pays se
sont engagés à rendre leur données publiques en mettant en
place des plateformes locales, régionales et nationales.
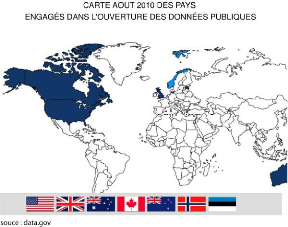
Illustration 2:
Car il ne faut pas confondre données publiques et
données ouvertes. Les données ouvertes ne concernent pas
forcément des documents publiques, en revanche, ce sont des
données partagées et libérées, c'est à dire
autorisées à la modification et la manipulation.
Pour comprendre exactement ce qui caractérise une
donnée ouverte et les attributs qu'elles doivent prendre, le groupe de
travail « open Government Data »21 définira en 2007
les huit principes d'accessibilité aux données :
· Elles doivent être complètes, exception
faite de celles relevant de la sécurité ou de la vie
privée.
· Primaires, c'est à dire relevées
à la source. Elles ne doivent par conséquent pas être
synthétisées, interprétées, agrées, ou
modifiées. Ce sont des données brutes, sous leur forme la plus
rudimentaire.
· Opportunes, c'est à dire publiées au moment
où elles sont pertinentes et actuelles, où elles ont de la
valeur.
21 Voir le site :
opengovdata.org
· Accessibles à tous.
· Exploitables par ordinateur ou lisibles par des
machines (sous une forme permettant le traitement automatisé). Les
formats de fichiers préconisés en ce sens sont le .csv et le
.xls.
· Non discriminatoires.
· Non propriétaires.
· Libres de droit.
En prenant en compte ces propriétés, le W3C
déterminera en 2009 les principaux avantages de la donnée ouverte
: transparence, participation, collaboration, inclusion,
interopérabilité, innovations, efficience,
économies.22
Par ses fonctionnalités, la données ouverte
rassure les utilisateurs et inspire confiance. Non seulement il s'agit d'avoir
accès aux sources de l'information qui étaient auparavant tenues
secrètes ou en tout cas inaccessible au grand public, mais c'est aussi
son caractère non traité qui enthousiasme le plus les gens.
Rappelons que la donnée n'est ni synthétisée, ni
interprétée.23 Pour le public, cela signifie donc que
la donnée est objective, transparente. Aucun risque de corruption, de
travestissement des informations, ni d'erreur journalistique.
En ayant accès à la donnée brute,
l'utilisateur peut accéder à toutes les parts et donc à
n'importe quelle part de l'information. Cela signifie qu'il peut
connaître des données qui l'intéressent personnellement ou
qui auraient pu paraître inintéressantes aux yeux du journaliste,
les chiffres les plus précis, dans leurs détails. Autrement dit,
il est en relation directe avec la donnée, sans intermédiaire.
L'autre avantage de la donnée ouverte est de pouvoir
faire participer le grand public en mettant en place des applications
collaboratives et évoluant en temps réel.
La libération des données s'étend
maintenant à d'autres domaines que la politique, ces domaines
d'application sont divers et variés. Il peut s'agir de statistiques sur
des usages domestiques, d'évènements
météorologiques, de rapports scientifiques.
Dans son dossier sur la réutilisation des informations
publiques au service de l'innovation et de la proximité sorti en 2010,
la FING propose une liste de données partageables avec les citoyens
concernant la ville24 :
· La description du territoire
· L'occupation des
ressources et
(cartes, cadastre...) des capacités (voirie,
bâtiments,
|
|
22 Voir le rapport du W3C sur les enjeux de la donnée
ouverte :
http://www.w3.org/TR/govdata/
23 Se reporter à la définition de la donnée
vue précédemment p. 3
24 La réutilisation des informations publiques au
service de l'innovation et de la proximité : une démarche
à destination des territoires publié en février 2010
est disponible sur le réseau social de la FING. Voir
reseaufing.org
· Des fonds documentaires (études,
réglementation, statistiques...)
· Les données de la décision publique
(projets, enquêtes, délibérations, subventions...)
· Le fonctionnement des réseaux urbains (eau,
énergie, transports, logistique, télécoms...)
· La localisation et les horaires d'ouverture des
services et des commerces
espaces, parkings...)
· Des mesures (environnement, trafic...)
· Des événements (culture, sports...)
· Des informations touristiques, culturelles, des
données d'archives
· Les flux urbains (circulation...)
· Des données de surveillance...
| 

