CHAPITRE III :PATIENTS,
MATERIELS ET METHODES
III.1 PATIENTS
Notre étude a porté exclusivement sur les cas de
dépression
Critères d'inclusion
· Avoir consulté au service de neuropsychiatrie en
ambulatoire ou en hospitalisation pour des symptômes plaidant en faveur
d'une dépression (critères DSM - IV - TR)
· Avoir un dossier médical complet avec un
diagnostic définitif de dépression (quelle que soit la forme
clinique).
Critères d'exclusion
· Patients dont les fiches étaient
incomplètes.
· Patients dont le diagnostic de dépression n'a
pas été retenu à l'admission ou durant le suivi
évolutif du cas.
· Patients avec épisode dépressif mais
avec un antécédent de manie ou d'hypomanie.
III.2 MATERIELS
La récolte des données a fait recours aux fiches
de consultation et d'hospitalisation ainsi qu'aux registres de service de
neuropsychiatrie de l'Hôpital Général de
Référence Jason Sendwe et du Centre Neuropsychiatrique Joseph -
Guislain.
Pour l'analyse des données, nous avons utilisé
le logiciel Epi-info version 7.0.9.7, Microsoft Excel et Microsoft Word
2010.
Les paramètres démographiques et cliniques ont
été retenus pour notre étude.
III.3 METHODES
Notre étude est rétrospectivedescriptive
transversale, nous avons fait recours à des méthodes
statistiques pour l'analyse des données ; le groupement en classe,
l'effectif ainsi que la fréquence.
Les données en série ont été
groupées en classes (K). On a ensuite déterminé
l'amplitude de classes (a) et enfin la limite inférieure de la
première classe à l'aide des formules de STURGE :
K = 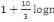 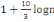
a= 
Avec W = Xmax - Xmin
Linf = Xmin - 
Avec :
W : intervalle de variation.
n : taille de l'échantillon.
Xmax : la valeur maximale.
Xmin : la valeur minimale.
K : nombre de classes
a : amplitude de classes
Nous avons regroupé notre échantillon selon
l'âge, le sexe, la provenance des patients,le niveau d'étude, le
statut marital, les antécédents psychiatriques, le tableau
clinique, les signes physiques associés, les habitus, la forme clinique
de dépression, les facteurs étiologiques etc. Et pour chaque
rubrique, nous avons fait ressortir l'effectif et avons calculéla
fréquence relative en pourcentage. Nous avons aussi calculé la
moyenne. Le calcul de la valeur p a été retenu comme test
statistique pour la comparaison des résultats (différence
significative si p<0,05)
| 

