|
EPIGRAPHE
Les données ne naissent pas intelligentes,
mais elles les deviennent......
DEDICACE
A Toi Seigneur Jésus-Christ, Dieu Tout Puissant,
Créateur de l'univers tout entier, mon seul et unique espoir.
A mes parents, Donatien MAYOMBO KAFUNDA et Jacqueline
BIUMA TSHIBITSHIABU à qui je dois tous les hommages en tant que source
première de la vie, pour les sacrifices consentis pour moi, pour la
force et le courage que vous avez créés en moi, afin de surmonter
les obstacles combien multiples de la vie. Ce travail est la pierre angulaire
que vous avez construite et restera sans doute un monument durable pour les
générations futures.
A mes frères et soeurs, Pierre KAFUNDA et sa femme
Joséphine, Simon BANZA TSHIMUNYI et sa femme Clarisse NGALULA, Willy
KATALAYI et sa femme, Justin MULUMBA et sa femme Anny, Rebecca
BAMONA, Thethe MBUYI, Roger MAYOMBO, Marie NGOYA, Jackie BIUMA, Héritier
NGALULA, Marthe BAMBI.
A mes cousins, cousines, neveux et nièces,
Trésor MBUYI, Yves MULUMBA, Trésor NSINGI, Esther NGUDIA, Rachel
MUTOMBO, Princia BANZA.
A mes oncles et tantes, Thadé KABENGELE, Evariste
MUTOMBO, MBELU NDAYA, Justine MULUMBA.
A tous mes amis et connaissances, Directeur Olivier NKIEMENE,
John CIBAMBE, Rozan MBUNGU, Junior MWANGA, Pascal MUKEBA, Jose NGANZWA, Giresse
TOMBA, Junior MUKANDA KANKOLONGO, Héritier MONGENGE, Borel BOOTO, Herve
MABUAKA, Lionel, Kelly, Charmant MIMPEMBE, Isaac ILUNGA.
A tous les congolais épris de la science et de la
recherche.
KALOMBO MAYOMBO Kalo
AVANT-PROPOS
Ce travail qui couronne la fin de notre cursus universitaire
est le fait du sens de l'abnégation et d'acharnement qui ont
caractérisé notre parcours estudiantin.
Néanmoins, la réalisation de ce travail a
été rendue possible grâce aux divers concours dont nous
avons eu le privilège de bénéficier d'une manière
ou d'une autre. Qu'il soit donc permis en ce moment crucial de notre existence
d'exprimer notre profonde gratitude à tous ceux qui dans la mesure de
leurs possibilités ont eu à nous assister.
Cette dette de reconnaissance pour nous envers tous ceux qui
ne nous ont ménagé ni leurs conseils, ni leur temps, faute de
pouvoir les nommer tous, nous tenons à exprimer plus
particulièrement nos remerciements chaleureux :
Ø Au Directeur du présent travail, le Professeur
MUHINDO G. RUGISHI qui a bien voulu prendre sous sa supervision la direction
de ce travail qu'il nous laisse le plaisir de lui dire grand merci.
Ø A notre encadreur, le Chef de Travaux Pierre KAFUNDA
qui a, dès le départ, encouragé nos travaux et mis
à notre disposition les outils nécessaire pour mener à bon
port nos recherches.
Ø Aux Professeurs, Chefs de Travaux et Assistants qui
ont grandement contribué à ma formation par leurs orientations et
divers conseils, Alain MUSESA, Issa RAMADANI, Jean Didier BATUBENGA, Crispin
BUKANGA, Steve BADIBANGA, Eva KAPINGA, Alex BINTU, Alain KUYUNSA, Willy MUTEBA.
Ø A mes compagnons de lutte : Cédric
MWANGA, Junior MUKUNA KABUENA, Fabrice SONGAMBELE, NTUMBA KABEMBA, Rose
MICIABU, Lionel LIKANGO, Vince MULADI, pour leur solidarité
mécanique ayant caractérisé des moments de vache maigre de
notre amitié.
Ø A ma très chère Rachel META KUPA KUA
NZAMBI.
Que tous ceux qui nous ont aidé de près ou de
loin trouvent ici l'expression de notre parfaite reconnaissance et notre
profonde gratitude.
INTRODUCTION
De nos jours, l'évolution des technologies, la
mondialisation des marchés et le raccourcissement du cycle de vie des
produits rendent la concurrence toujours plus rude. Il devient très
difficile pour une entreprise de conserver sa part de marché en se
basant uniquement sur les prix et les produits.
Le fort déclin de la publicité de masse illustre
cette difficulté à gagner et à conserver des parts de
marché en se focalisant uniquement sur le produit. Dès les
années 80, les techniques de marketing de masse n'apportant guère
de résultats positifs pour les entreprises, elles cèdent leurs
places à un marketing direct, orienté vers le client, qu'il faut
comprendre, satisfaire et avec qui il faut communiquer « directement
» afin d'optimiser le succès futur de l'entreprise. Le CRM (Gestion
de la relation Client, en anglais Customer relationship Manager) s'inscrit
clairement dans cette évolution et représente, d'une certaine
manière, le dernier marketing direct.
Afin de construire une relation avec le client dans le but
d'aboutir à une fidélité de ce dernier, les entreprises
s'orientent donc actuellement et de plus en plus vers la gestion de la relation
client. Le CRM est un processus qui consiste à gagner, à
conserver, à élargir et à fidéliser une
clientèle. Sa stratégie est de placer le client au centre des
préoccupations de l'entreprise en instaurant un dialogue, une relation
de confiance et un respect mutuel avec les clients.
Les clients constituent la principale richesse des
entreprises. Ainsi, une entreprise qui se veut compétitive devrait avoir
les objectifs suivants :
Ø augmenter la rentabilité et la
fidélité de leurs clients
Ø maitriser les risques
Ø utiliser les bons canaux au bon moment pour vendre le
bon produit.
Et l'un des moyens pour y parvenir, c'est la Gestion de la
Relation Client (GRC), en anglais, Customer Relationship Management (CRM).
La Gestion de la Relation Client comprend deux aspects: CRM
analytique et CRM opérationnel. Et la matière première
précieuse, ce sont les données sur les clients. On ne veut plus
seulement savoir : « Combien de clients ont acheté tel produit
pendant telle période ? » Mais : « Quel est leur profil ?
», « Quels autres produits les intéresseront ? », «
Quand seront-ils intéressés ? ».D'ou il y a
nécessité de mieux étudier le comportement des
consommations. Notre étude se basera principalement sur deux axes :
Ø La segmentation du marché ou des clients en
vue de mettre en évidence les groupes de consommateurs homogènes
par rapport à leur préférence ou leur
comportement ;
Ø L'affectation d'offre ou le ciblage d'offre ;
une fois les clients regroupés en groupes homogènes par rapport
à leur comportement.
Connaître l'étendue de son marché,
identifier les différents types de consommateurs, avoir une idée
précise de leurs motivations et de leurs comportements de consommation
ne suffit pas à l'entreprise pour répondre de manière
efficace aux demandes variées, voire contradictoires, des divers groupes
de consommateurs. Pour que son plan de marchéage soit en
cohérence avec la structure du marché, l'entreprise va le
segmenter. Cette opération consiste à découper le
marché pour regrouper les consommateurs en groupes homogènes,
selon des critères quantitatifs ou qualitatifs.
Un segment de marché est donc un ensemble de
consommateurs ayant des besoins et des comportements d'achat identiques. Les
différences entre les segments doivent être suffisamment grandes
pour permettre d'identifier ces derniers et d'agir sur eux. Par ailleurs, la
taille des segments doit être suffisante pour qu'ils constituent une
cible. Plusieurs critères peuvent être appliqués pour avoir
des segments homogènes tels que :
1. des critères démographiques : âge,
taille, sexe du consommateur visé... ;
2. des critères socio-économiques : niveau de
revenu, catégorie socioprofessionnelle, niveau d'instruction du
consommateur visé ;
3. des critères socio-psychologiques :
personnalité, valeurs, croyances... ;
4. des critères géographiques : pays, climat,
caractéristiques régionales, caractère urbain ou rural du
consommateur visé... ;
5. des critères liés à l'acte d'achat :
moment de l'achat, attitude vis à vis du produit...
L'entreprise va utiliser l'un ou l'autre de ces
critères, en fonction de ses besoins, pour segmenter le
marché.
A partir des données ou des groupes homogènes
obtenus à la segmentation, l'entreprise peut adopter plusieurs
stratégies pour offrir ces produits aux différents segments du
marché ou groupes de consommateurs :
Une offre indifférenciée : elle s'adresse
à l'ensemble des segments du marché, sans prendre en compte les
différences existant entre les consommateurs. Son principal avantage
réside dans les coûts de production (fabrication de produits
standardisés) et de politique mercatique (coûts de communication)
qui sont moins élevés. Son principal inconvénient est de
satisfaire imparfaitement la plupart des clients.
Une offre concentrée : l'entreprise propose un seul
produit pour un seul segment et développe une stratégie de niche
dans les segments où elle pense détenir un avantage
compétitif. L'avantage se situe dans la possibilité de concentrer
ses ressources et son action sur une cible plus restreinte. Cette
stratégie présente l'inconvénient de cantonner
l'entreprise à une partie limitée de son marché potentiel
et donc de la fragiliser.
Une offre différenciée : l'entreprise vise les
différents segments du marché pour mieux répondre aux
besoins spécifiques des groupes de consommateurs. L'avantage d'une telle
stratégie est qu'elle permet de mieux lutter contre la concurrence.
L'inconvénient majeur est qu'elle se traduit par un accroissement des
coûts de production et de communication.
Outre l'introduction et la conclusion générale
notre travail se subdivise en quatre chapitres:
Dans le premier chapitre, nous parlerons de la fouille de
données ;
Le deuxième chapitre porte sur la segmentation des
clients à l'aide de l'algorithme de centres mobiles en vue d'obtenir des
groupes homogènes des clients ;
Le troisième chapitre est consacré à
l'apprentissage supervisé, dans ce chapitre il sera question de
prédire le groupe d'un nouveau client en vue de lui offrir le service
qui lui convient.
Le dernier chapitre portera sur la réalisation d'une
application informatique qui effectue une discrimination des clients et une
prédiction à l'aide de la statistique bayésienne.
CHAPITRE I. LA FOUILLE DE
DONNEES [2, 5, 6,10, 11,12]
I.1 Définitions et
historique
Le «data mining» que l'on peut traduire par
«fouille de données» apparaît au milieu des
années 1990 aux États-Unis comme une nouvelle discipline à
l'interface de la statistique et des technologies de l'information : bases de
données, intelligence artificielle, apprentissage automatique («
machine learning »).
David Hand (1998) en donne la definition suivante: « Data
Mining consists in the discovery of interesting, unexpected, or valuable
structures in large data sets».
La métaphore qui consiste à considérer
les grandes bases de données comme des gisements d'où l'on peut
extraire des pépites à l'aide d'outils spécifiques n'est
certes pas nouvelle. Dès les années 1970, Jean-Paul
Benzécri n'assignait-il pas le même objectif à l'analyse
des données ? : « L'analyse des données est un outil pour
dégager de la gangue des données le pur diamant de la
véridique nature ».
On a pu donc considérer que bien des praticiens
faisaient du data mining sans le savoir. On confondra ici le « data mining
», au sens étroit qui désigne la phase d'extraction des
connaissances, avec la découverte de connaissances dans les bases de
données (KDD ou Knowledge Discovery in Databases) .
La naissance du data mining est essentiellement due à
la conjonction des deux facteurs suivants :
Ø l'accroissement exponentiel dans les entreprises de
données liées à leur activité (données sur
la clientèle, les stocks, la fabrication, la comptabilité ...)
qu'il serait dommage de jeter car elles contiennent des informations-clé
sur leur fonctionnement stratégiques pour la prise de
décision.
Ø Les progrès très rapides des
matériels et des logiciels.
L'objectif poursuivi par le data mining est donc celui de la
valorisation des données contenues dans les systèmes
d'information des entreprises. »
Les premières applications se sont faites dans le
domaine de la gestion de la relation client qui consiste à analyser le
comportement de la clientèle pour mieux la fidéliser et lui
proposer des produits adaptés. Ce qui caractérise la fouille de
données (et choque souvent certains statisticiens) est qu'il s'agit
d'une analyse dite secondaire de données recueillies à d'autres
fins (souvent de gestion) sans qu'un protocole expérimental ou une
méthode de sondage ait été mis en oeuvre.
La fouille de données consiste à rechercher et
extraire de l'information (utile et inconnue) de gros volumes de données
stockées dans des bases ou des entrepôts de données. Le
développement récent de la fouille de données (depuis le
début des années 1990) est lié à plusieurs facteurs
:
Ø une puissance de calcul importante est disponible sur
les ordinateurs de bureau ou même à domicile ;
Ø le volume des bases de données augmente
énormément ;
Ø l'accès aux réseaux de taille mondiale,
ces réseaux ayant un débit sans cesse croissant, qui rendent le
calcul possible et la distribution d'information sur un réseau
d'échelle mondiale viable ;
Ø la prise de conscience de l'intérêt
commercial pour l'optimisation des processus de fabrication, vente, gestion,
logistique, ...
La fouille de données a aujourd'hui une grande
importance économique du fait qu'elle permet d'optimiser la gestion des
ressources (humaines et matérielles).
Quand elle est bien menée, la fouille de données
a apporté des succès certains, à tel point que
l'engouement qu'elle suscite a pu entraîner la transformation (au moins
nominale) de services statistiques de grandes entreprises en services de
data mining.
La recherche d'information dans les grandes bases de
données médicales ou de santé (enquêtes,
données hospitalières etc.) par des techniques de data mining est
encore relativement peu développée, mais devrait se
développer très vite à partir du moment où les
outils existent. Quels sont les outils du data mining et que peut-on trouver et
prouver ?
Le datamining peut aussi être défini comme un
processus inductif, itératif et interactif de découverte dans
les bases de données larges de modèles de données
valides, nouveaux, utiles et compréhensibles.
Ø Inductif: Généralisation d'une
observation ou d'un raisonnement établis à partir de cas
singuliers.
Ø Itératif : nécessite plusieurs
passes
Ø Interactif : l'utilisateur est dans la boucle du
processus
Ø Valides : valables dans le futur
Ø Nouveaux : non prévisibles
Ø Utiles : permettent à l'utilisateur de
prendre des décisions
Ø Compréhensibles : présentation
simple
I.2 Les outils
On y retrouve des méthodes statistiques bien
établies, mais aussi des développements récents issus
directement de l'informatique. Sans prétendre à
l'exhaustivité, on distinguera les méthodes exploratoires
où il s'agit de découvrir des structures ou des comportements
inattendus, de la recherche de modèles prédictifs où une
« réponse » est à prédire.
I.3. Les différents types
de données rencontrés
Classiquement, les données sont décrites dans un
tableau individus-variables par une valeur unique. On parlera alors de
« tableau de descriptions univaluées ou
classiques ». Dans les applications réelles, où le
grand souci est de prendre en compte la variabilité et la richesse
d'informations au sein des données, il est courant d'avoir affaire
à des données complexes et hétérogènes (ou
mixtes). Ce qui se traduit par le fait que chaque case du tableau de
descriptions peut tenir non seulement une valeur unique mais également
de valeurs multiple, un intervalle de valeurs ou une distribution sur un
ensemble de valeurs. On dira alors que la classification va porter sur un
« tableau de descriptions symboliques ».
I.3.1 Description classique
d'une variable
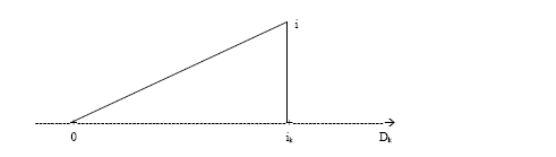
Classiquement, une variable yl est définie
par une application :
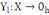
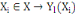
Où : X={X1, X2,..., Xn} est
l'ensemble des individus. L'ensemble d'arrivée 0h est
appelé domaine d'observation de la variable yl. Un individu
est alors décrit sur une variable yl par une valeur unique de
0h.
On distingue schématiquement deux types de
variables : les variables quantitatives dites aussi numériques et
les variables qualitatives dites aussi catégorielles.
I.3.2 Les variables
quantitatives
Définition
Une variable est dite quantitative, lorsqu'elle prend
des valeurs ordonnées (comparable par la relation d'ordre =) pour
lesquelles des opérations arithmétiques telles que
différence et moyenne aient un sens. Une variable quantitative
peut être binaire, continue ou discrète. Les variables binaires ne
peuvent prendre que deux valeurs, le plus souvent associées à
{0,1}, {absence, présence} ou {succès, échec}
(exemple : le sexe d'un nouveau né).
Les
variables continues ou d'échelle sont les variables dont les valeurs
forment un sous-ensemble continu et dans certains cas les valeurs forment un
sous-ensemble infini de l'ensemble R des réels (exemple : le
salaire, le coût du séjour). Les variables discrètes sont
celles dont les valeurs forment un sous-ensemble fini de l'ensemble N des
entiers naturels (exemple : le nombre de jours d'hospitalisation, le
nombre d'enfants).
I.3.3 Variables qualitatives
Définition :
On
entend par une variable qualitative, une donnée dont l'ensemble des
valeurs est finie et qui prend des valeurs symboliques qui désignent des
catégories ou des modalités. Par exemple la couleur de cheveux
est une variable qualitative.
Remarque : On ne peut effectuer des
opérations arithmétiques sur des variables qualitatives.
I.3.4 Description symbolique
d'une variable
L'analyse de données symboliques a été
introduite par Diday en 1991, la définition d'une variable a
été étendue afin de pouvoir décrire un individu par
des variables yh à description symbolique. La
définition a été modifiée de manière
suivante : On notera Äh ce nouvel ensemble
d'arrivée. La variable yh est ainsi définie par
l'application suivante :
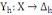
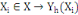
Le domaine d'arrivée Äh peut
s'écrire à partir du domaine de valeurs
élémentaires Oh et nous pouvons distinguer les trois
types de domaine Äh suivants :
Ø Äh= Oh. C'est le cas des
variables de valeurs unique classique présentées dans la section
1.2. On parlera ainsi de variable à description univaluée,
quantitative ou qualitative. Par exemple Yh(Xi) =
rectangle.
Ø Äh= p (Oh) avec p
(Oh) est l'ensemble de parties de Oh . C'est le cas d'une
variable qualitative qui peut être décrite par un intervalle de
valeurs. On parlera alors de descriptions multivaluées. Par exemple
Yh(Xi) = Oh{rectangle, carré}.
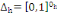 Ø Ø 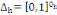 , l'ensemble des fonctions de 0h dans [0,1]. On parlera alors
de description modale. Par exemple, Yh(Xi) est une
distribution de probabilité sur l'ensemble de valeurs {rectangle,
carré}. , l'ensemble des fonctions de 0h dans [0,1]. On parlera alors
de description modale. Par exemple, Yh(Xi) est une
distribution de probabilité sur l'ensemble de valeurs {rectangle,
carré}.
Le tableau 1.2 suivant présente des exemples de
descriptions multivaluées et modales des variables salaire et forme
géométrique.
|
Age
|
Forme géométrique
|
|
Multivaluée
|
[15, 25]
|
{rectangle, carré}
|
|
Modale
|
Densité de la loi normale   (20, ó) (20, ó)
|
Prob (rectangle) = 0,7
Prob (carré) = 0,3
Prob = 0 ailleurs
|
Tableau 1.2 Exemple de
descriptions multivaluées et modales.
I.3.5 Les variables à
descriptions multivaluées
C'est le cas d'une variable Yh qui peut être
décrite par plusieurs valeurs du domaine d'observation 0h.
Ø si le domaine d'observation 0h est
quantitatif (continu, discret) ou qualitatif ordinal, la description
multivaluée de Yh est un intervalle de valeurs et le domaine
d'arrivée Äh de Yh est l'ensemble des
intervalles fermés bornés sur 0h. Par exemple, la
variable Yh = coût d'hospitalisation pour une intervention sur
le rachis peut être Yh (intervention sur le rachis).
Ø Si le domaine d'observation 0h est
qualitatif nominal, la description multivaluée de Yh est un
ensemble de valeurs et le domaine d'arrivé Äh de
Yh est l'ensemble de sous-ensembles de 0h. Par exemple,
la variable Yh= traitements subis au cours d'une hospitalisation
pour le patient jopi peut prendre les valeurs Yh(jopi) =
{Uncusectomie, Foraminotomie}.
I.3.6 Les variables à
descriptions modales
C'est le cas d'une variable Yh qui peut être
décrite par une fonction définie sur le domaine d'observation
0h dans [0,1].
I.3.7 Les variables
taxonomiques ou structurées
Les domaines d'observation des variables de classification
peuvent être munis parfois de connaissances supplémentaires
appelées connaissances du domaine. Ces connaissances
supplémentaires sont définies dans le cas de descriptions
univaluées mais peuvent être prises en compte dans un traitement
sur des descriptions multivaluées (exemple : dans le calcul de la
mesure de ressemblance entre les individus au cours d'un processus de
classification automatique).
Il arrive par exemple qu'un expert puisse fournir une
structuration des valeurs du domaine d'observation sous la forme d'un arbre
ordonné, d'un graphe orienté, etc. Une variable dont le domaine
d'observation est représenté par une structure
hiérarchique est dite variable taxonomique ou encore
structurée.
I.4. Les mesure de
ressemblance
Tout système ayant pour but d'analyser ou d'organiser
automatiquement un ensemble de données ou de connaissances doit
utiliser, sous une forme ou une autre, un opérateur capable
d'évaluer précisément les ressemblances ou les
dissemblances qui existent entre ces données.
La notion de ressemblance (ou Proximité) a fait l'objet
d'importantes recherches dans des domaines extrêmement divers. Pour
qualifier cet opérateur, plusieurs notions comme la similarité,
la dissimilarité ou la distance peuvent être utilisées.
I.4.1 Définition
Nous appelons similarité ou dissimilarité
toute application à valeurs numériques qui permet de mesurer le
lien entre les individus d'un même ensemble. Pour une
similarité le lien entre deux individus sera d'autant plus fort que sa
valeur est grande. Pour une dissimilarité le lien sera d'autant plus
fort que sa valeur de dissimilarité est petite
I.4.2 Indice de
dissimilarité
Un opérateur de ressemblance 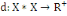 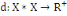 défini sur l'ensemble d'individus défini sur l'ensemble d'individus 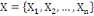 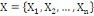 est dit indice de dissimilarité (ou dissimilarité), s'il
vérifie les propriétés suivantes : est dit indice de dissimilarité (ou dissimilarité), s'il
vérifie les propriétés suivantes :
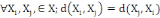 1. 1. 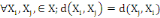 (propriété de symétrie) (propriété de symétrie)
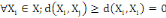 2. 2. 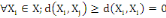 (propriété de positivé) (propriété de positivé)
I.4.3 Distance
Un opérateur de ressemblance 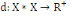 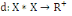 défini sur l'ensemble d'individus défini sur l'ensemble d'individus 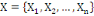 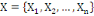 est dit distance, s'il vérifie en plus des deux
propriétés 1 et 2 les propriétés d'identité
et d'inégalité triangulaire suivantes : est dit distance, s'il vérifie en plus des deux
propriétés 1 et 2 les propriétés d'identité
et d'inégalité triangulaire suivantes :
3.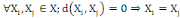 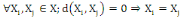 (propriété de d'identité) (propriété de d'identité)
4.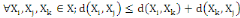 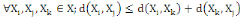 (inégalité triangulaire) (inégalité triangulaire)
1.4.4 Indice de
similarité
Un opérateur de ressemblance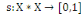 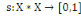 défini sur l'ensemble d'individus défini sur l'ensemble d'individus 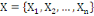 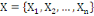 est dit indice de similarité (ou similarité), s'il
vérifie en plus de la propriété de symétrie (1) les
deux propriétés suivantes : est dit indice de similarité (ou similarité), s'il
vérifie en plus de la propriété de symétrie (1) les
deux propriétés suivantes :
5.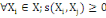 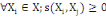 (propriété de positivité) (propriété de positivité)
6.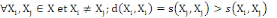 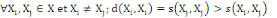 (propriété de maximisation). (propriété de maximisation).
Il convient de noter ici que le passage de l'indice de
similarité s à la notion duale d'indice de dissimilarité
(que nous noterons d), est trivial. Etant donné smax la
similarité d'un individu avec lui-même (smax= 1 dans le cas d'une
similarité normalisée), il suffit de poser :
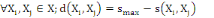
I. 5 Mesure de
ressemblance entre individus à descriptions classiques
Le processus de classification vise à structurer les
données contenues dans X={X1, X2, ...,
Xn} en fonction de leurs ressemblances, sous forme d'un ensemble de
classes à la fois homogènes et contrastées.
L'ensemble d'individu X est décrit
généralement sur un ensemble de m variables Y= {Y1,
Y2,..., Ym} définies chacune par :
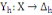
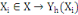
Où Äk est le domaine d'arrivée
de la variable Yh.
En conséquence, les données de classification
sont décrites dans un tableau Individus-variables où chaque case
du tableau contient la description d'un individu sur une des m variables. Ce
tableau Individus-Variables est en général un tableau
homogène qui peut être de type quantitatif (où toutes les
variables sont quantitatives) ou qualitatif (où toutes les variables
sont qualitatives).
I.5.1 Tableau de données
numériques (continues ou discrètes)
La distance la plus utilisée pour les données de
type quantitatives continues ou discrètes est la distance de Minkowski
d'ordre á définie dans Rm par :
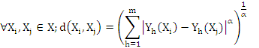
Où 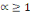 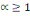 , ,   si : si :
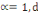 Ø Ø 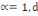 est la distance de city-block ou Manhattan. est la distance de city-block ou Manhattan.
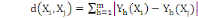 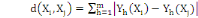
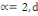 Ø Ø 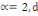 est la distance Euclidienne classique. est la distance Euclidienne classique.
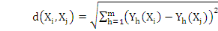 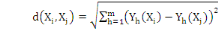
Dans ce travail on ne considérera pas des individus
à description symbolique. C'est pourquoi, nous n'avons pas
définie la mesure de ressemblance correspondante à ce type de
données.
I.6.Le bruit
Il importe de ne pas faire comme si toutes les données
ont une valeur connue, et encore moins une valeur valide ; il faut donc
gérer des données dont certains attributs ont une valeur inconnue
ou invalide ; on dit que les données sont « bruitées ».
La simple élimination des données ayant un attribut dont la
valeur est inconnue ou invalide pourrait vider complètement la base de
données ! On touche le problème de la collecte de données
fiables qui est un problème pratique très difficile à
résoudre. En fouille de données, il faut faire avec les
données dont on dispose sans faire comme si on disposait des valeurs de
tous les attributs de tous les individus.
I.7.Différentes
tâches d'extraction d'information
Le datamining comprend 5 tâches principales
Ø Classification
Ø Clustering (Segmentation)
Ø Recherche d'associations
Ø Recherche de séquences
Ø Détection de déviation
I.7.1. Problème de
classification
Dans les problèmes, chaque donnée est
affectée d'une caractéristique, par exemple une couleur.
Supposons que l'ensemble des couleurs possibles soit fini et de faible
cardinalité. Le problème de classification consiste alors
à prédire la couleur d'un point quelconque étant
donné un ensemble de points colorés.
Géométriquement, cela revient à trouver
un moyen de séparer les points les uns des autres, en fonction de leur
couleur. S'il n'y a que deux couleurs, un simple (hyper)plan peut suffire
à les séparer ; ceux d'une certaine couleur sont d'un coté
de l'hyperplan, les autres étant de l'autre coté. Dans ce cas,
les points sont linéairement séparables (séparables par un
objet géométrique qui ressemble à une droite, un hyperplan
pour être plus précis au niveau du vocabulaire).
Généralement, des points d'une couleur
donnée se trouvent du mauvais coté de l'hyperplan. Cela peut
résulter d'erreurs dans l'évaluation des attributs (on s'est
trompé en mesurant certains attributs, ou en attribuant sa couleur
à la donnée) ; dans ce cas, les données sont
bruitées. Cela peut aussi être intrinsèque aux
données qui ne peuvent pas être séparées
linéairement. Il faut alors chercher à les séparer avec un
objet non hyper planaire.
I.7.2.Problème de
segmentation
Dans les problèmes de segmentation, on dispose d'un
ensemble de points et la tâche consiste à repérer des
groupes de points qui se ressemblent. On verra alors deux ensembles de
techniques : les algorithmes qui proposent une segmentation des données
puis des algorithmes qui construisent une représentation
géométrique interprétable par un humain (dans un plan)
d'un ensemble de données. C'est alors un humain qui détecte les
groupes et effectue la segmentation : l'algorithme de projection est une aide
pour l'humain ; on effectue de la fouille de données assistée par
ordinateur.
I.7.3.Problème de
recherche d'association
Plus généralement, on peut disposer d'un
ensemble de données pour lesquels on veut détecter des relations
entre la valeur de leurs attributs. Il s'agit alors de chercher des
règles d'association.
I.7.4.Recherche de
séquences
Liaisons entre événements sur une période
de temps, extension des règles d'association en prenant en compte le
facteur temps (série temporelle).
Exemple : Achat Télévision ==>
Achat Magnétoscope d'ici 5 ans.
I.7.5 Détection de
déviation
Instances ayant des caractéristiques les plus
différentes des autres, basées sur la notion de distance entre
instances
Expression du
problème :
Temporelle : évolution des instances ?
Spatiale : caractéristique d'un cluster d'instances
?
Notons que dans tous ces problèmes, la notion de «
corrélation » est omniprésente, l'extraction d'information
repose sur la recherche de corrélations entre des données. Ces
corrélations peuvent être linéaires : c'est le cas simple.
En général, on doit chercher des corrélations non
linéaires. Enfin, l'espace de données dans lequel celles-ci nous
sont fournies initialement n'est pas forcément le plus adéquat.
Il s'agît alors de préparer les données pour en faciliter
l'extraction d'information. Cette préparation peut consister en la
diminution du nombre d'attributs, à divers traitements sur les valeurs
d'attributs (lissage, ...), au changement d'espace de représentation des
données (projection dans un espace ou les relations sont plus faciles
à détecter, projection dans un sous-espace plus petit, ou
représentation dans un espace obtenu par combinaison des attributs
initiaux {création de facteurs). La représentation des
données dans un espace inadéquat entraîne lui-aussi du
bruit, différent de celui rencontré plus haut.
I .8.Méthodes
Utilisées
La fouille de données est au centre de plusieurs
domaines tels que :
Ø Intelligence artificielle et apprentissage
Ø Bases de données
Ø Analyse de données (statistiques)
Ø Visualisation
Ø Recherche opérationnelle et optimisation
Ø Informatique parallèle et distribuée
Nous nous intéresserons aux méthodes d'analyse
de données qui nous permet d'atteindre nos objectifs.
I.8.1. Analyse de
données
L'analyse des données a pour but de fournir,
grâce à l'ordinateur, un outil ou un ensemble de techniques
permettant d'explorer le contenu de grandes bases de données en
utilisant une représentation graphique facilement accessible par
l'utilisateur. Pour Jambu M., l'analyse de données désigne
l'ensemble des méthodes à partir desquelles on collecte,
organise, résume, présente et étudie des données
pour permettre d'en tirer des conclusions et de prendre des décisions.
Il existe généralement deux grandes familles de méthodes
d'analyse de données :
I.8.1.1 les méthodes factorielles.
Dans cette famille, on cherchera à réduire le
nombre de variables en les résumant en un petit nombre de composantes
synthétiques c'est-à-dire de passer d'un espace de dimension n
(n>3), à un espace de dimension 3 ou 2 de préférence,
dans cette catégorie nous pouvons citer :
Ø l'ACP, Analyse en Composantes Principales si les
variables sont quantitatives
Ø l'AC, Analyse des Correspondances si les variables
sont qualitatives, où on cherchera les liens entre les
modalités
Ø l'AFC Analyse Factorielles des Correspondances
(simples) dans le cas où on dispose de variables qualitatives ;
I.8.1.2 Les méthodes de
classification
Dans cette famille on chercher à réduire la
taille de l'ensemble des individus en les regroupant en un petit nombre de
groupes homogènes en tenant compte d'un certain nombre de
critères, dans cette famille, nous avons :
Ø CAH, Classification Ascendante Hiérarchique
...
Ø CDH, Classification Descendante Hiérarchique
...
Ø les méthodes de partitionnement ;
Ø L'Analyse Discriminante.
I.8.1.1.1 Analyse en composante principale
Le but de l'A.C.P est de transformer un jeu de variables
corrélées en des variables non corrélées, qui, dans
un contexte idéal (Gaussien) pourraient être
interprétées comme des facteurs indépendants sous-jacents
au phénomène. C'est pourquoi ces quantités orthogonales
seront appelées «facteurs», bien que cette
interprétation ne soit pas toujours parfaitement adéquate.
I.8.1.1.1.1 Principes de l'ACP
L'Analyse en Composante Principale (ACP) fait partie des
analyses descriptives multivariées. Le but de cette analyse est de
résumer le maximum d'informations possibles en perdant le moins
possible pour :
Ø Faciliter l'interprétation d'un grand nombre
de données initiales,
Ø Donner plus de sens aux données
réduites
L'ACP permet donc de réduire des tableaux de grandes
tailles en un petit nombre de variables (2 ou 3 généralement)
tout en conservant un maximum d'information. Les variables de départ
sont dites « métriques ». L'idée de l'ACP est
de déterminer un nouveau repère de 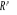 associé de manière naturelle à la structure du
nuage considéré, de façon à pouvoir l'y examiner
plus commodément. associé de manière naturelle à la structure du
nuage considéré, de façon à pouvoir l'y examiner
plus commodément.
Pour s'affranchir des effets d'échelle dus à
l'hétérogénéité éventuelle des
variables, ces dernières sont en général
normalisées, c'est à dire que chaque colonne est divisée
par son écart-type; toutes sont dès lors exprimées dans la
même échelle standard.
D'autre part, l'origine est placée au centre de
gravité du nuage. C'est le nuage ainsi transformé qui est en fait
considéré; l'utilisateur n'a cependant pas à se
préoccuper de ces transformations préalables, sauf demande
contraire elles sont exécutées automatiquement par les logiciels
d'ACP.
I.8.1.1.1.2 Directions principales - plans principaux
et Représentation des individus
Le nuage présente généralement des
directions d'allongement privilégiées, celle d'allongement
maximal D1 est dite première direction principale (axe
principal) (du nuage), la suivante D2 parmi toutes celles
perpendiculaires à D1 est la seconde direction principale, la suivante
D3 parmi toutes celles perpendiculaires à D1 et
D2 est la troisième direction principale, etc.
On choisit un vecteur unitaire 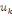 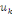 sur chaque direction sur chaque direction 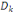 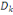 (le choix du sens est libre et décidé arbitrairement par
le logiciel utilisé) et on obtient une base orthonormée de (le choix du sens est libre et décidé arbitrairement par
le logiciel utilisé) et on obtient une base orthonormée de 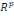 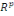 , c'est la base principale du nuage. , c'est la base principale du nuage.
On appelle plan principal i j le plan vectoriel
déterminé par les directions 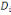 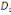 et et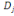 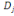 . En général, le nuage est approximativement situé
dans un sous-espace de . En général, le nuage est approximativement situé
dans un sous-espace de 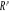 de faible dimension, engendré par les premières directions
principales; l'examen de ses projections sur quelques plans principaux bien
choisis (12, 13, etc.) permet alors de découvrir ses
particularités et de décrire sa structure assez
précisément. de faible dimension, engendré par les premières directions
principales; l'examen de ses projections sur quelques plans principaux bien
choisis (12, 13, etc.) permet alors de découvrir ses
particularités et de décrire sa structure assez
précisément.
b) Composantes principales - représentation des
variables
De même que les variables initiales sont
associées aux axes canoniques de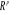 , de nouvelles variables appelées composantes principales sont
associées aux axes principaux: la composante principale , de nouvelles variables appelées composantes principales sont
associées aux axes principaux: la composante principale 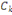 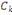 est le vecteur de est le vecteur de 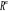 qui donne les coordonnées des individus sur l'axe principal qui donne les coordonnées des individus sur l'axe principal 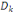 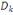 muni du vecteur unitaire muni du vecteur unitaire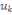 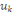 . .
Les composantes principales sont naturellement des
combinaisons linéaires des variables initiales, on montre qu'elles sont
centrées et non corrélées.
L'examen des corrélations entre les variables initiales
et les composantes principales permet d'interpréter ces dernières
et les axes principaux correspondants.
Les programmes usuels permettent de représenter ces
quantités dans le cercle des corrélations. Cette
représentation n'est pas de même nature que celle des individus
sur les plans principaux. Et si certains logiciels superposent les deux sur les
mêmes graphiques, il faut garder à l'esprit que la position des
points-variables par rapport aux points-individus n'y est pas directement
interprétable.
Une présentation alternative de l'ACP,
privilégiant les variables mais équivalente, l'introduit comme la
recherche de nouvelles variables (les composantes principales) non
corrélées entre elles, et les plus corrélées avec
l'ensemble des variables initiales.
Les composantes principales sont parfois vues comme des
variables cachées non-observables, que la méthode permet donc de
mettre en évidence derrière les variables initiales, seules
observables. Elles permettent par ailleurs de résumer, par les
premières d'entre elles, une information répartie sur un grand
nombre de variables (cela est parfois utilisé en régression
linéaire pour échapper à la
multi-colinéarité).
c) Aides à l'interprétation
L'art de l'analyste est celui de l'interprétation des
résultats, cela nécessite à la fois la
compréhension des méthodes employées et la connaissance du
domaine des données étudiées.
L'interprétation s'appuie sur l'examen de
différentes quantités calculées et éditées
par les logiciels d'ACP.
Inertie
Un individu i du nuage (supposé muni des poids
uniformes   = 1) a une inertie I(i) : = 1) a une inertie I(i) :
I(i) =  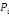 O O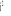 = O = O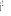
Si 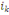 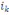 est la projection de i sur l'axe principal est la projection de i sur l'axe principal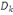 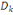 , l'inertie de i suivant cet axe est: , l'inertie de i suivant cet axe est:  (i) = (i) =  O O
L'inertie de i se décompose en la somme de ses inerties
suivant les différents axes principaux 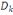 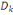 (perpendiculaires): (perpendiculaires):
I(i)=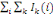 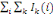
L'inertie totale suivant l'axe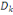 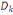 , est: , est:
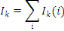
Et l'inertie totale du nuage est :
I=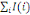 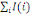 = =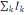 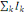
Les directions principales d'allongement du nuage sont en fait
les directions perpendiculaires successives d'inertie maximum du nuage.
Taux d'inertie
Il s'agit des inerties successives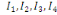 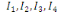 etc. suivant les axes principaux etc. suivant les axes principaux 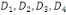 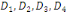 etc. du nuage. Leurs valeurs relatives traduisent l'importance de
l'allongement suivant ces directions successives. On édite les taux
relatifs etc. du nuage. Leurs valeurs relatives traduisent l'importance de
l'allongement suivant ces directions successives. On édite les taux
relatifs 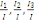 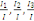 etc., ainsi que les taux relatifs cumulés etc., ainsi que les taux relatifs cumulés 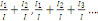 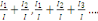
Lorsque ces derniers approchent 100%, on considère que
l'on a assez d'axes principaux pour représenter convenablement le
nuage.
Contributions des individus aux axes (CTR)
Il s'agit des ratios tels que :
CTR(i, k) =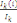 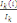 qui mesure la part prise par l'individu i dans la détermination
de l'axe principal qui mesure la part prise par l'individu i dans la détermination
de l'axe principal 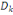 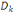
On a: 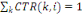 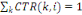
Ces quantités sont les carrés de celles
figurées dans le cercle des corrélations utilisé pour
représenter graphiquement les variables.
Contributions des variables aux axes (CTR)
Il s'agit des ratios tels que:
CTR(j, k) = 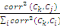 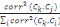 corr2(ck, x.j) / S corr2(ck, x.i) corr2(ck, x.j) / S corr2(ck, x.i)
On a: 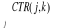 = 1 = 1
L'observation des premiers plans principaux ne permet aucune
conclusion, et peut même être source de contresens, si elle ne
s'accompagne pas de l'examen des quantités précédentes. Il
faut donc toujours les faire éditer par le logiciel utilisé et
les consulter.
I.8.1.1.1.3 Analyse des résultats d'une
ACP
Analyser les résultats d'une ACP, c'est répondre
à trois questions :
1. Les données sont-elles factorisables ?
2. Combien de facteurs retenir ?
3. Comment interpréter les résultats ?
CHAPITRE II. LA SEGMENTATION [1, 4, 5, 12, 15, 18, 22]
L'objectif de la classification est le suivant : on dispose de
données non étiquetées. On souhaite les regrouper par
données ressemblantes. Cette manière de définir
intuitivement l'objectif de la classification cache la difficulté de
formaliser la notion de ressemblance entre deux données. Au-delà
des algorithmes existants, une bonne partie de l'art à acquérir
consiste ici à imaginer cette formalisation. Ainsi, soit un ensemble X
de N données décrites chacune par leurs P attributs. La
classification consiste à créer une partition ou une
décomposition de cet ensemble en groupes telle que :
Critère 1 : les données appartenant au
même groupe se ressemblent ;
Critère 2 : les données appartenant
à deux groupes différents soient peu ressemblantes.
Clairement, la notion de « ressemblance » doit
être formalisée. Cela est fait en définissant une distance
entre tout couple de points du domaine D. Toute la difficulté est
là : définir correctement cette distance. De là
dépend le résultat de la segmentation. Si l'utilisation d'une
distance euclidienne est a priori une bonne idée, ce n'est pas la seule
possibilité, loin s'en faut. En particulier, on a rarement
d'informations concernant la pertinence des attributs : seuls les attributs
pertinents doivent intervenir dans la définition de la distance. De
plus, dans la segmentation que l'on aimerait obtenir, la pertinence des
attributs peut dépendre du groupe auquel la donnée appartient.
Ne connaissant pas les critères de partitionnement a priori, on doit
utiliser ici des algorithmes d'apprentissage non supervisés : ils
organisent les données sans qu'ils ne disposent d'information sur ce
qu'ils devraient faire.
Il existe deux grandes classes de méthodes :
Ø non hiérarchique : on décompose
l'ensemble d'individus en k groupes ;
Ø hiérarchique : on décompose l'ensemble
d'individus en une arborescence de groupes.
On peut souhaiter construire une décomposition :
Ø telle que chaque donnée appartienne à
un et un seul groupe : on obtient une partition au sens mathématique du
terme ;
Ø dans laquelle une donnée peut appartenir
à plusieurs groupes;
Ø dans laquelle chaque donnée est
associée à chaque groupe avec une certaine probabilité.
Notons que le problème de segmentation optimale en k
groupes est NP- complet. Il faut donc chercher des algorithmes calculant une
bonne partition, sans espérer être sûr de trouver la
meilleure pour les critères que l'on se sera donnés.
Idéalement, dans un processus de fouille de données, la
segmentation doit être une tâche interactive : une segmentation est
calculée et proposée à l'utilisateur qui doit pouvoir la
critiquer et obtenir, en fonction de ces critiques, une nouvelle segmentation,
soit en utilisant un autre algorithme, soit en faisant varier les
paramètres de l'algorithme, ...
Définition 1 :
Soit X un ensemble de données, chacune
décrite par P attributs. On nomme « centre de gravité »
g de X une donnée synthétique dont chaque attribut est
égal à la moyenne de cet attribut dans X. Soit, g = (a1, a2, ...,
a3).
Hartigan, est un des premiers à discuter
différents choix possibles du nombre de classes. Au fil des
années, plusieurs statistiques ont été proposées
afin de décider le nombre de classes à choisir et peuvent
être utilisées comme règle d'arrêt dans le cadre des
méthodes hiérarchiques. Elles utilisent
généralement les sommes des carrés inter - groupes, ainsi
que les sommes des carrés intra - groupes, notées respectivement
par B et W pour une partition P en k
classes {c1....Ck}:
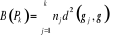
Où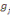 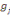 , j = 1, ..., k, est le centre de gravité de la classe Cj
et g le centre de gravité de l'ensemble des objets. , j = 1, ..., k, est le centre de gravité de la classe Cj
et g le centre de gravité de l'ensemble des objets.
Nj représente le poids de la classe
Cj
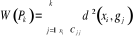
Où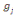 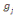 , j = 1, ..., k, est le centre de gravité de la classe Cj
On peut également exprimer ces mesures à l'aide des notions
d'inertie d'un groupe. , j = 1, ..., k, est le centre de gravité de la classe Cj
On peut également exprimer ces mesures à l'aide des notions
d'inertie d'un groupe.
Soit P, une partition en k classe {C1... Ck} alors
on obtient :

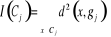
Où   , j = 1, ..., k, est le centre de gravité de l'ensemble des
points de Cj avec g = , j = 1, ..., k, est le centre de gravité de l'ensemble des
points de Cj avec g = 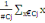 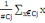 avec avec
#Cj représentant le nombre de points dans Cj.
D'après le théorème de Koeng - Huygens, l'inertie totale T
ne dépend pas de la partition choisie et est exprimée par T = W +
B et vaut T= 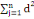 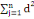 (xi, g). L'inertie intra- classe W est un critère
classique d'évaluation d'une partition, mesurant
l'homogénéité des classes de la partition. Par
conséquent, il suffit de trouver une partition qui minimise
W(Pk). De manière équivalente, on cherchera à
maximiser B(Pk) l'inertie interclasse qui mesure la
séparation des classes. Dans ce cas, une partition vérifie les
principes de cohésion interne et d'isolation externe (xi, g). L'inertie intra- classe W est un critère
classique d'évaluation d'une partition, mesurant
l'homogénéité des classes de la partition. Par
conséquent, il suffit de trouver une partition qui minimise
W(Pk). De manière équivalente, on cherchera à
maximiser B(Pk) l'inertie interclasse qui mesure la
séparation des classes. Dans ce cas, une partition vérifie les
principes de cohésion interne et d'isolation externe
II.1.La segmentation
hiérarchique
Il s'agit de représenter des individus sur un arbre
hiérarchique, dont chaque noeud porte le nom de ''Palier'' ; chaque
palier d'une hiérarchie sur I correspond à un groupe d'individus
de I. Ces individus sont plus proches entre eux (au sens de la mesure de
ressemblance choisie) que les niveaux de palier correspondant sont bas. On peut
détenir une hiérarchie de la manière suivante :
Soit X une matrice de données n x p définie par
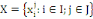 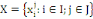 où I est un ensemble de n objectifs (lignes,
observations, instances, individus) et J est un ensemble de p variables
(colonnes, attributs) où I est un ensemble de n objectifs (lignes,
observations, instances, individus) et J est un ensemble de p variables
(colonnes, attributs)
II.1.1 Définition
Soit I un ensemble fini non vide.
H est une hiérarchie de I s'il satisfait aux axiomes
suivants :
Hi : axiome d'intersection
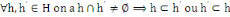

L'ensemble I tout entier, ainsi que toutes les parties
réduites à un élément appartiennent à H.
I H
Une hiérarchie peut être vue comme un ensemble de
partitions emboitées. Graphiquement, une hiérarchie est souvent
représentée par une structure arborescente
représentée par un arbre hiérarchique dit aussi
dendrogramme
Partitions emboitées
e
d
c
f
b
a
g
Dendrogramme
f,g
d,e
b,a
c
Il existe deux types de familles de méthodes : une
descendante, dite divisive, et une ascendante dite agglomérative. La
première moins utilisée, consiste à partir d'une seule
classe regroupant tous les objets, à partager celle-ci en deux. Cette
opération est répétée à chaque
itération jusqu'à ce que toutes les classes soient
réduites à des singletons. La seconde qui est la plus couramment
utilisée consiste, à partir des objets (chacun est dans sa propre
classe), à agglomérer les classes les plus proches,
jusqu'à obtenir une classe qui contient tous les objets.
II.1.3. Construction d'une
hiérarchie
II.1.3.1. Indice d'agrégation
La construction d'une hiérarchie nécessite la
connaissance d'une mesure de ressemblance entre groupes ; cette mesure est
appelée indice d'agrégation. Il existe plusieurs sorte d'indice
d'agrégation ; les plus utilisées sont : indice
d'agrégation du lien minium, indice d'agrégation de la moyenne de
distance, indice d'agrégation de centre de gravité, l'indice
d'agrégation de Ward (ou indice de moment centré d'ordre 2)
II.1.3.2. Proposition
En agrégation deux classes h1,
h2, l'inertie intra classe augmente de :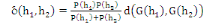 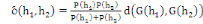 (1.9) (1.9)
II.1.3.3 Algorithme général de la
classification ascendante hiérarchique
1) Partir de la partition P0
2) Construire une nouvelle partition minimisant ä
(h1, h2)
3) Recommencer les classes pour qu'elles soient réunies
en une seule.
II.1.4. La Classification
Descendante Hiérarchique
Les méthodes de classification descendante
hiérarchique sont itératives et procèdent à chaque
itération au choix du segment de l'arbre hiérarchique à
diviser, et au partitionnement de ce segment. La différence entre les
méthodes divisives, développées jusqu'à
présent dans la littérature, figure dans les critères
qu'elles utilisent pour choisir le segment à diviser ainsi dans la
manière dont elles divisent le segment. Le choix de tels critères
dépend généralement de la nature des variables
caractérisant les individus à classer.
II.2. Les méthodes
monothéiques
Les méthodes nomothétiques divisent un segment
(classe C) de l'arbre hiérarchique en deux sous-segments (sous-classes
C1 et ) en fonction d'une variable et de deux groupes de valeurs de cette
variable.
Si la variable est quantitative le segment est divisé
suivant la réponse à la question de la forme "valeur de la
variable inferieur ou égal à c?". Le premier sous-segment C1
contient les individus pour lesquels la valeur de la variable est
inférieure ou égale à c, et l'autre les individus pour
lesquels la valeur de la variable est strictement supérieure à c.
Si la variable est qualitative, un individu est affecté au premier
sous-segment C1 si sa description pour cette variable appartient à un
premier groupe de modalités, sinon il est affecté au
deuxième sous-segment .
La stratégie utilisée par ces méthodes
pour choisir la variable de division (parmi celles caractérisant les
individus) ainsi que la valeur de coupure (c pour les variables quantitatives,
et les groupes de modalités pour les variables qualitatives) repose sur
l'optimisation d'un critère d'évaluation bien
déterminée (par exemple le diamètre d'une partition
donné par la plus grande dissimilarité entre deux individus d'une
même classe: ainsi nous choisissons la classe et la coupure qui
fournissent une partition de petit diamètre).
Les classifications autour de centres mobiles ou
partitionnements, consistent à agréger les individus autour des
noyaux qui, au départ, sont proposés par l'utilisateur ou
tirés au hasard. On aboutit à une première partition qui
dépend beaucoup du tirage des premiers noyaux. On recommence donc en
prenant cette fois pour noyaux les centres de gravité des classes
obtenues à l'étape précédente, et ainsi de suite
jusqu'à la stabilisation des classes. Le résultat de l'algorithme
est une partition unique.
II.3. Segmentation non
hiérarchique
Dans cette approche, on souhaite obtenir une
décomposition de l'ensemble de données X en K groupes non
hiérarchisés que l'on notera
G1, G2,... GK. On a : X =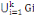 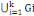 plusieurs méthodes existent dans cette catégorie. plusieurs méthodes existent dans cette catégorie.
II.3.1 La méthode des
centres mobiles.
L'algorithme des centres mobiles est également
dénommé k-moyennes, ou centroides. L'objectif est de segmenter
les données en k groupes, k étant fixé a priori.
L'idée de cet algorithme est très intuitive et, de fait, cet
algorithme a été réinventé à plusieurs
reprises. Il en existe de nombreuses variantes, en particulier l'algorithme
bien connu des « nuées dynamiques ». L'idée de
l'algorithme des centres mobiles est la suivante : on part de K données
synthétiques (c'est-à-dire des points de l'espace de
données D ne faisant pas forcément parti du jeu de
données) que l'on nomme des « centres ». Chaque centre
caractérise un groupe. A chaque centre sont associés les
données qui lui sont les plus proches ; cela crée un groupe
autour de chaque centre. Ensuite, on calcule le centre de gravité de
chacun de ces groupes ; ces k centres de gravité deviennent les nouveaux
centres et on recommence tant que les groupes ne sont pas stabilisés,
c'est-à-dire. Tant qu'il y a des données qui changent de groupe
d'une itération à la suivante ou encore, tant que l'inertie varie
substantiellement d'une itération à la suivante. Cet algorithme
converge en un nombre fini d'itérations. 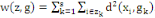 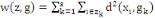
Où g = (g1, . . . ,gs), 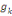 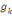 est le centre de la classe est le centre de la classe 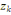 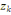 . Rappelons que le critère W(z,g), qui est simplement la somme
des inerties des s classes, est appelé inertie intra classe. La
méthode des centres mobiles consiste à chercher la partition
telle que le W soit minimal pour avoir en moyenne des classes bien
homogènes, ce qui revient à chercher le maximum de l'inertie
interclasse. . Rappelons que le critère W(z,g), qui est simplement la somme
des inerties des s classes, est appelé inertie intra classe. La
méthode des centres mobiles consiste à chercher la partition
telle que le W soit minimal pour avoir en moyenne des classes bien
homogènes, ce qui revient à chercher le maximum de l'inertie
interclasse.
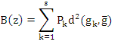
Avec   le centre de gravité de l'ensemble I et le centre de gravité de l'ensemble I et 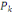 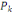 est le poids de la classe est le poids de la classe
Algorithme de centres mobiles.
Nécessite: 2 paramètres : le jeu de
données X, le nombre de groupes à constituer
K €N
Prendre K centres arbitraires ck € D
Répéter
pour k € {1....K} faire
Gk ?Ø
Fin pour
pour i = {1....N} faire
k* =arg min k={1....K} d(xi;
ck)
Gk? Gk  xi xi
Fin pour
pour k € {1....K} faire
Gk ? centre de gravité de
Gk
Fin pour
I ? IW
Calculer IW
Jusque I - IW < seuil.
Quelques remarques sur les centres
mobiles
La segmentation obtenue dépend des centres initiaux
Lors de l'initialisation de l'algorithme, on prend K points dans l'espace de
données au hasard. La segmentation calculée par les centres
mobiles dépend de cette initialisation.
Pour contrer ce problème, on exécute plusieurs
fois l'algorithme en prenant à chaque fois des centres
initialisés différemment. On compare les segmentations obtenues
à chaque itération et on retient celle dont l'inertie intra
classe est la plus faible. En général, un certain nombre de
données se trouvent toujours regroupées ensemble, alors que
d'autres ne le sont pas. On peut considérer que les premières
indiquent nettement des regroupements, alors que les secondes correspondent
à des données éventuellement atypiques, ou à des
données bruitées. De toute manière, cette information est
intéressante.
Le nombre de groupes
Le K choisi peut être mauvais. On peut tester plusieurs
valeurs de K en exécutant plusieurs fois l'algorithme avec des K
croissants. Pour chaque valeur.
II.3.2 Les nuées
dynamiques
La méthode dite des nuées dynamiques est l'une
des méthodes de partitionnement dite de
« réallocation » pouvant avantageusement s'appliquer
sur une grande population (grand ficher numérique ou grand tableau) avec
un critère de qualité de la partition obtenue. Les algorithmes
des nuées dynamiques sont itératifs et optimisent un
critère mathématique.
Cette méthode a été
développé par Diday dans [Diday, 1971] se distingue
principalement des approches précédentes par le mode de
représentation des classes appelé aussi noyau. Ce dernier peut
être son centre de gravité (dans ce cas nous retrouvons l'approche
des centres mobiles), un ensemble d'individus, une distance (l'approche des
distances adaptatives, une loi de probabilité, la décomposition
de mélanges), etc.
II.3.2.1 Bases théoriques de l'algorithme
Soit, un ensemble de n individus. Chaque individu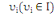 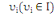 , muni de sa masse , muni de sa masse 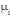 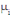 est caractérisé par p variables. est caractérisé par p variables.
Le problème posé est de trouver sur l'ensemble I
une partition en k (k fixé à priori) classes au maximum
satisfaisant un critère global de qualité.
Principe
général de la méthode
Soient :
- I : l'ensemble de n individus à partitionner en
k classes au maximum ;
- P(I) = {P0, P1, ...,
Pm, ..., Pk} : ensemble des parties de
I ;
- A : un ensemble de k noyaux Ai ;
- On suppose que l'espace Rp supportant les n
points individus est muni d'une distance appropriée ; notée
d ;
Chaque classe est représentée par son centre
Ai, également appelé noyau, constitué du petit
sous-ensemble de la classe qui minimise le critère de dissemblance. Les
éléments constitutifs d'un noyau sont appelés
étalons. Ce genre de noyau a pour certaines applications, un meilleur
pouvoir descriptif que des centres ponctuels.
Chaque individu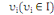 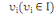 , est par conséquent, caractérisé par sa masse , est par conséquent, caractérisé par sa masse
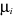 et par la distance et par la distance 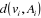 qui le sépare du noyau de sa classe. qui le sépare du noyau de sa classe.
La méthode des nuées dynamiques consiste
à trouver deux applications 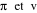 sur lesquelles repose l'algorithme. Ces deux fonctions de base sont
telles que: sur lesquelles repose l'algorithme. Ces deux fonctions de base sont
telles que: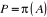 . La fonction de réallocation . La fonction de réallocation 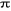 a pour rôle de former une partition, c'est à dire
d'affecter chaque individu a pour rôle de former une partition, c'est à dire
d'affecter chaque individu 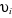 du nuage N(I) aux centres d'attractions que forment les noyaux. du nuage N(I) aux centres d'attractions que forment les noyaux.
A = v(P)
La fonction de recentrage v a pour rôle de recalculer
les nouveaux noyaux à partir des classes déjà
formées.
L'algorithme est une succession d'appels à ces deux
fonctions, il se présente de la manière suivante :
a) Initialisation
Ø Le choix (au hasard ou non) des k premiers noyaux,
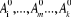 , induisant la première partition , induisant la première partition 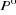 de l'ensemble I et k classes de l'ensemble I et k classes 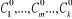 . .
b) Recherche de la meilleure partition
Ø Par l'exécution de 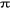 sur ces noyaux et on poursuit les autres étapes jusqu'à
l'arrêt de l'algorithme. sur ces noyaux et on poursuit les autres étapes jusqu'à
l'arrêt de l'algorithme.
L'algorithme se termine soit lorsque deux itération
successives conduisent à la même partition, soit lorsqu'un
critère judicieusement choisi (par exemple, la mesure de la variance
intra classes) cesse de décroître de façon sensible
(convergence), soit encore lorsqu'un nombre maximal d'itération
fixé à priori est atteint.
II.3.2.3 Choix des fonctions  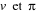
Le choix de deux fonctions de base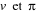 , de l'algorithme, est guidé par des considérations
suivantes : , de l'algorithme, est guidé par des considérations
suivantes :
1°) 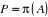
Avec 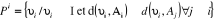
Chaque individu est associé au noyau le plus proche.
2°) A = v(P), A = {A1, ..., Ak}
Avec Ai, un ensemble de
ni éléments qui minimisent une fonction L(v i, I,
P)
3°) la fonction L(v i, I, P) induit une notion de
« distance » de l'individu v i à la classe
Cm de la partition P ;
On peut alors définir un critère de
qualité de la partition P autour d'un ensemble de noyaux A par :
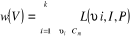
CHAPITRE III. CIBLAGE DES
OFFRES [3,7]
III.1 Définition
Définition 1
On dispose d'un ensemble X de N données
étiquetées. Chaque donnée xi est
caractérisée par P attributs et par sa classe yi € Y. Dans
un problème de classification, la classe prend sa valeur parmi un
ensemble fini. Le problème consiste alors, en s'appuyant sur l'ensemble
d'exemples
X =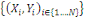 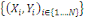 À prédire la classe de toute nouvelle donnée x À prédire la classe de toute nouvelle donnée x
  D. D.
On parle de classification binaire quand le nombre de classes
|Y| est 2 ; il peut naturellement être quelconque. Dans tous les cas, il
s'agît d'un attribut qualitatif pouvant prendre un nombre fini de
valeurs.
Dans l'absolu, une donnée peut appartenir à
plusieurs classes : c'est alors un problème multi-classes. Ici, on
considère que chaque donnée appartient à une et une seule
classe.
Définition 2
Un exemple est une donnée pour laquelle on dispose
de sa classe. On utilise donc un ensemble d'exemples classés pour
prédire la classe de nouvelles données ; c'est une tâche
d'« apprentissage à partir d'exemples », ou de «
apprentissage supervisé ».
Définition 3
Un « classeur » est une procédure (un
algorithme) qui, à partir d'un ensemble d'exemples, produit une
prédiction de la classe de toute donnée.
D'une manière générale, un classeur
procède par « induction » : à partir d'exemples (donc
de cas particuliers), on construit une connaissance plus
générale. La notion d'induction de connaissances implique la
notion de « généralisation » de la connaissance :
à partir de connaissances éparses, les exemples, on induit une
connaissance plus générale. Naturellement, même si l'on
suppose que la classe des étiquettes n'est pas erronée, il y a un
risque d'erreur lors de la généralisation ; ce risque est
quantifié par la notion de « taux d'échec », ou
d'« erreur en généralisation ».
Quand on tente d'induire de la connaissance, il faut
déterminer, au moins implicitement, la pertinence des attributs pour la
prédiction de l'étiquette d'une donnée quelconque : c'est
cela « généraliser ». D'une manière ou d'une
part, explicitement ou pas, généraliser implique de construire un
modèle des données.
La taille de ce modèle est un paramètre
important. à l'extrême, il est aussi gros que l'ensemble des
exemples : dans ce cas, on n'a rien appris, rien
généralisé et on est incapable d'effectuer une
prédiction fiable pour une donnée qui ne se trouve pas dans
l'ensemble des exemples : on a sur-appris.
A un autre extrême, on peut n'avoir appris que les
proportions des différentes étiquettes dans l'espace des
données : par exemple, 1=3 des données sont bleues et les autres
sont rouges, cela sans lien avec la description des données ;
prédire la classe revient alors à tirer la classe au hasard avec
ces proportions un tiers/deux tiers : on a pris trop de recul et on n'est plus
capable d'effectuer une prédiction fiable pour une donnée
particulière.
Entre ces deux extrêmes, il y a un juste milieu ou le
modèle a pris du recul par rapport aux exemples, a su extraire les
informations pertinentes du jeu d'exemples pour déterminer
l'étiquette de n'importe quelle donnée avec une
probabilité élevée de succès ; le modèle est
alors de taille modérée et la probabilité d'erreur de ce
modèle est la plus faible que l'on puisse obtenir : on a un
modèle optimisant le rapport qualité/prix, i.e.
probabilité d'effectuer une prédiction correcte/coût du
modèle. La recherche d'un modèle optimisant ce rapport est
l'objectif de l'apprentissage automatique, lequel est l'un des outils
indispensables pour la réaliser de la fouille de données.
On distingue deux grands types de classeurs :
Ø ceux qui utilisent directement les exemples pour
prédire la classe d'une donnée ;
Ø ceux pour lesquels on a d'abord construit un
modèle et qui, ensuite, utilisent ce modèle pour effectuer leur
prédiction.
Le problème de classification présente de
nombreuses difficultés ou problèmes à résoudre tels
que :
Ø Méthode d'induction du classeur ;
Ø Comment utiliser le classeur obtenu ;
Ø Comment évaluer la qualité du classeur
obtenu : taux d'erreur ou de succès ;
Ø Comment traiter les attributs manquants dans le jeu
d'apprentissage ;
Ø Comment traiter les attributs manquants dans une
donnée à classer ;
Ø Estimer la tolérance au bruit : le bruit
concerne ici la valeur des attributs de l'exemple avec lequel on construit le
classeur.
III.2. CLASSIFIEUR BAYESIEN [1,
5, 14]
III.2.1 RAPPELS SUR LA
STATISTIQUE
III.2.1.1 Notions de probabilité
Il existe plusieurs manières de définir une
probabilité. Principalement, on parle de probabilité inductive ou
expérimentale et de probabilités déductives ou
théoriques. On peut les définir comme suit :
Ø Probabilité expérimentale ou
inductive : la probabilité est déduite de toute la
population concernée. Par exemple, si sur une population d'un million de
naissances, on constate 530 garçons et 470 filles, on dit que
P[garçons]=0.53
Ø Probabilité théorique ou
inductive : cette probabilité est connue grace à
l'étude du phénomène sous-jacent sans
expérimentation. Il s'agit donc d'une connaissance à priori par
opposition à la définition précédente qui faisait
plutôt référence à une notion de probabilité
à posteriori. Par exemple, dans le cas classique du dé parfait,
on peut dire sans avoir à jeter un dé, que P[Obtenir un
4]=1/6.
Comme il n'est pas toujours possible de déterminer des
probabilités à priori, on est souvent amené à
réaliser des expériences. Il faut donc pouvoir passer de la
première à la deuxième solution. Ce passage est
supposé possible en termes de limite.
III.2.1.2 Épreuve et
Evénement
Une expérience est dite aléatoire si ses
résultats ne sont pas prévisibles avec certitude en fonction des
conditions initiales.
On appelle épreuve la réalisation d'une
expérience aléatoire, on appelle événement la
propriété du système qui une fois l'épreuve
effectuée est ou n'est pas réalisée.
III.2.1.3 Espace probabilisable, Espace
probabilisé
Une expérience aléatoire définit un
ensemble d'événements possibles ? appelé univers.
Définition : on appelle
tribu sur ? tout sous-ensemble ? de P(?) tel que :
1. ?   ? ?
2. Si A  ? alors ? alors   ? ?
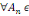 3. 3. 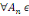 ?, on a ?, on a 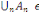 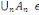 ? ?
(?   ?) est un espace probabilisable ?) est un espace probabilisable
Définition :
Soit (?   ?) est un espace probabilisable. On appelle probabilité sur (? ?) est un espace probabilisable. On appelle probabilité sur (?
  ?) toute application P de ? dans [0,1] telle que ?) toute application P de ? dans [0,1] telle que
1. P(?)=1
2. Pour toute famille (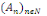 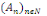 d'élément deux à deux disjoint de F, on a : d'élément deux à deux disjoint de F, on a :
P(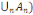 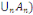 = =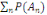 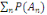 (?, ?,P) est un espace probabilisé (?, ?,P) est un espace probabilisé
P est appelée loi de probabilité
Si ? est fini, la tribu ? est le plus souvent égale
à l'ensemble des parties de ?
Propriétés
élémentaires
De l'axiomatique de Kolmogorov, on peut déduire les
propriétés suivantes :
1. P ( 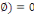
2. P (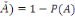 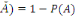
3. P(A)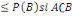 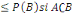
4. P(A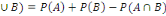 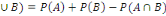
5. P (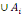 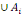 ) )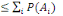 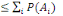
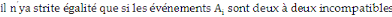
III.2.1.4 Probabilité
conditionnelle
Soient deux événements A et B
réalisés respectivement n et m fois au cours de N
épreuves. On a donc P(A)=n/N et P(B)=m/N. si de plus A et B sont
réalisés simultanément k fois, on a P(A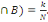 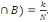 Que peut-on déduire sur la probabilité de
l'événement B sachant que l'événement A est
réalisé? Cette probabilité est appelée
probabilité conditionnelle de B sachant A et se note Que peut-on déduire sur la probabilité de
l'événement B sachant que l'événement A est
réalisé? Cette probabilité est appelée
probabilité conditionnelle de B sachant A et se note
P (B/A). Dans notre cas, on P (B/A)=k/n
Par définition on a : P(B/A)=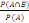 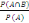
Conséquence
Deux événements A et B sont dits
indépendants si P(A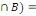 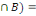 P(A).P(B) ou encore si P(B/A)=P(B) (l'information sur la
réalisation de A n'apporte rien à l'événement B) et
P(A/B)=P(A) P(A).P(B) ou encore si P(B/A)=P(B) (l'information sur la
réalisation de A n'apporte rien à l'événement B) et
P(A/B)=P(A)
III.2.1.5 Notion d'indépendance stochastique ou
indépendance en probabilité des
événements
Soient A, A1, A2, .........,
Ai, ........., An des événements dans ?
a) ces n événements sont indépendants en
probabilité 2 à 2(ou stochastiquement indépendants 2
à 2) si et seulement si 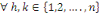 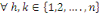 l'ensemble des indices, avec h l'ensemble des indices, avec h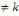 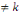 : IP (Ah Ak ) =
IP(Ah).IP(Ak) : IP (Ah Ak ) =
IP(Ah).IP(Ak)
b) ces événements sont indépendants en
probabilité (ou stochastiquement indépendants) k à k,
avec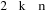 , si et seulement combinaison de k éléments
(i1, i2, .......ik) de l'ensemble , si et seulement combinaison de k éléments
(i1, i2, .......ik) de l'ensemble 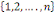 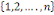 on a : on a : 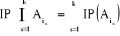
c) ces n événements sont indépendants en
probabilité dans leurs ensembles (ou stochastiquement
indépendants dans leur ensemble ou mutuellement indépendants) ssi
k   combinaisons combinaisons 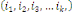 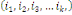 des éléments des éléments 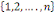 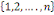
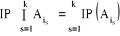
III.2.1.6. Théorèmes fondamentaux du
calcul des Probabilités
III.2.1.6.1 Théorème de la
multiplication des probabilités
Hypothèse :
- Soient des événements A1,
A2, ..., An en nombre fini
- Supposons que les événements A1,
A2, ..., An-1 ne sont pas incompatibles.
Thèse :
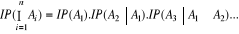 = = 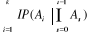 ; où A0 = Ù. ; où A0 = Ù.
III.2.1.6.2 Théorème (ou
Formule) des probabilités totales
Hypothèse :
Soient les événements A1,
A2, ..., An formant un système complet
(c'est-à-dire n événement totalement exclusifs),
c'est-à-dire :
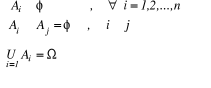
Supposons qu'un autre événement B ne puisse se
réaliser qu'en combinaison avec l'un des événements
Ai, (i = 1, 2, ..., n) c'est-à-dire
B =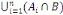 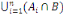
Thèse : IP (B) =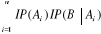
III.2.1.7 Théorème (ou formule) de
Bayes
Hypothèse : Mêmes hypothèses que pour
le théorème des probabilités totales.
Thèse :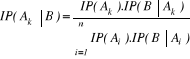 où k ? {1, 2, ..., n} et B ?Ø. où k ? {1, 2, ..., n} et B ?Ø.
Remarque :
v Le théorème de Bayes s'appelle encore
théorèmes des probabilités de causes.
v Le théorème de Bayes s'appelle encore
théorèmes des probabilités à posteriori, en effet
les IP (Ai), (i = 1, 2, ......, n) sont des probabilités
à priori ou données à l'avance tandis que les
IP (Ai B), (i = 1, 2, ......, n) se calculent
après que l'événement B se soit produit.
III.2.1.8 VARIABLES ALEATOIRES ET LOIS DE
PROBABILITE
III.2.1.8.1 La tribu Borélienne sur IR
notée â
â est une famille d'éléments de IR tel
que :
Ø Axiome: IR ? â ;
Ø Axiome: Si B ? â alors 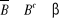 : stabilité par rapport à la
complémentarité ; : stabilité par rapport à la
complémentarité ;
Ø Axiome: Si Bi ? â, (i = 1, 2, ...),
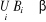 : stabilité par rapport à l'union
dénombrable. : stabilité par rapport à l'union
dénombrable.
Les éléments de â sont appelés des
Boréliens et notés B1, B2
,...,Bi ,...
Définition Un
Borélien est tout ensemble numérique
Exemples : Un ensemble dénombrable des
Réels. Ainsi tout intervalle de IR est un Borélien, mais la
réciproque n'est pas vraie : tout Borélien n'est pas un
intervalle de IR.
III.2.1.8.2 Définitions de Variable
Aléatoire
Nous noterons les Variables Aléatoires les
dernières lettres majuscules de l'alphabet :
Y, Z, U,..., Xj (j=1,2,...)
Soient (Ù, ?, IP), IR l'ensemble des Réels et
la classe de tous les intervalles de IR ;
Définition 1: On appelle
Variable Aléatoire X sur l'espace probabilisé (Ù, ?, IP),
l'application X :(Ù, ?, IP) ? IR vérifiant la
condition : intervalle I ? ,
X-1(I) ? ? ou encore X-1() ?.
Remarque :
1°) X-1(I) = {ù ? Ù tel que X
(ù) ? I}.
2°) En réalité une V.A.X est une
application de Ù dans IR, X : Ù? IR tel que I?, 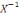 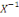 (I) ??. (I) ??.
Définition 2 :
On appelle Variable Aléatoire X une application
numérique
X :(Ù, ?, IP) ? IR vérifiant la condition B
?â, X-1(B) ? ? ou encore X-1(â) ?
Remarque :
1. X-1(B) = {ù ? Ù tel que X
(ù) ? B}.
2. (IR, â) est un espace mesurable ; en partant de
X et de la mesure de IP au sens de Kolmogorov on va définir une autre
mesure de IP qui sera notée IPX IP o X-1, cette
mesure sera appelée distribution de probabilité de la V.A.X.
Cas particuliers de variable
aléatoire
Soit X une variable aléatoire définie sur
(Ù, ?, IP) ; on appelle X (Ù) domaine de variation de X sur
Ù ensemble de toutes les valeurs que prend X sur Ùl'espace-
image de la V.A.X sur Ù.
Il y a deux classes de variable aléatoire :
1. Variable Aléatoire Discrète ou Variable
Aléatoire Discontinue (V.A.D.) : lorsque X (Ù) est au plus
dénombrable, c'est-à-dire lorsque 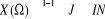 ; ;
2. Variable Aléatoire Continue (V.A.C.) lorsque X
(Ù) n'est pas dénombrable, c'est-à-dire lorsque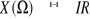 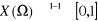
III.2.1.8.3 Lois de Probabilité
univariée
Nous distinguons deux lois de probabilité
univarieés relatives à une variable aléatoire X sur
un espace probabilisé (Ù, ?, IP). Il s'agit de IPX
appelée distribution de probabilité de la variable
aléatoire x et de FX appelée fonction de
répartition de la variable aléatoire x
Remarque :
Ø IPX est définie sur â
c'est-à-dire IPX est une fonction des ensembles
numériques (les Boréliens).
Ø FX est définie sur IR
c'est-à-dire FX est une fonction des points de IR.
III.2.1.9 VECTEURS ALEATOIRES ET LOIS DE PROBABILITE
MULTIVARIEES
III.2.1.9.1 Vecteur Aléatoire
Définition : On appelle
Vecteur Aléatoire à n composantes, le
n - uple des V.A : X= (X1, X2,
..., Xn).
Exemples
(1) Z = (X, Y) ; où X et Y sont des V.A., est un
couple de V.A. ; donc Z est un Vecteur Aléatoire à 2
composantes.
(2) X = (X1, X2) ; où
X1 mesure la taille et X2 le poids des étudiants
de l'UPN
X1(Ù) = { x11,
x12, ..., x1n} ; X2(Ù) = {
x21, x22, ..., x2n}
Où n = #Ù = nombre total
d'étudiants de l'UNIKIN.
Cas particuliers des vecteurs
aléatoires
(1) Vecteur Aléatoire Discret (ou Vecteur
Aléatoire Discontinu) :
X= (X1, X2, ..., Xn) est un
Vecteur Aléatoire discret ssi ses composantes X1,
X2, ..., Xn sont des V.A.D. définies sur
même (Ù, ?, IP).
Dès lors, les lois de probabilité
(IPX et FX) d'un Vect. al. Discret X= (X1,
X2, ..., Xn) sont des lois discrètes (ou
discontinues).
(2) Vecteur Aléatoire Continu :
Le Vecteur Aléatoire X= (X1, X2,
..., Xn) est Continu si et seulement ses composantes X1,
X2, ..., Xn sont des V.A.C. définies sur
même (Ù, ?, IP).
III.2.1.9.2 lois de probabilité
usuelles
Il est toujours possible d'associer à une variable
aléatoire une probabilité et définir ainsi une loi
de probabilité. Lorsque le nombre d'épreuves augmente
indéfiniment, les fréquences observées
pour le phénomène étudié tendent
vers les probabilités et les distributions observées
vers les distributions de probabilité ou loi de probabilité.
Identifier la loi de probabilité suivie par une variable
aléatoire donnée est essentiel car cela conditionne le choix des
méthodes employées pour répondre. Nous pouvons distinguer
deux catégories de lois particulières :
Ø Lois discrètes : Par définition,
les variables aléatoires discrètes prennent des
valeurs entières discontinues sur un intervalle donné. Ce sont
généralement le résultat de dénombrement.
Ø Lois continues : Par définition, les
variables aléatoires continues prennent des valeurs
continues sur un intervalle donné.
III.2.1.9.2.1 Loi normale
1. Définition : Une variable
aléatoire continue sera distribuée selon la loi normale de
moyenne m et d'écart type ó si sa fonction de fréquence
(ou densité de probabilité) fX est définie
par :
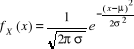 , x ? IR. , x ? IR.
Remarque :
1°) On vérifie par calcul direct que fX
est une fonction de fréquence :
fX (x) = 0 x ? IR et 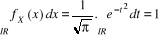 , par changement de variable d'intégration. , par changement de variable d'intégration.
2°) On vérifie par calcul direct :
v La moyenne est définie par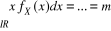 ; le premier paramètre de la loi normale N(m, ó) ; ; le premier paramètre de la loi normale N(m, ó) ;
v La variance est définie par 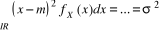 ; le carré du second paramètre de la loi normale
N(m, ó) ; ; le carré du second paramètre de la loi normale
N(m, ó) ;
3°) Pour toute variable aléatoire X de moyenne m
et d'écart type ó fini, la variable aléatoire
définie par 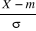 s'appelle variable aléatoire réduite ou variable
aléatoire centrée réduite correspondant à X ;
on a aussi : IE( s'appelle variable aléatoire réduite ou variable
aléatoire centrée réduite correspondant à X ;
on a aussi : IE(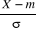 ) = 0 ; Var ( ) = 0 ; Var (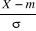 ) = 1 ; c'est-à-dire toute variable aléatoire
réduite a pour moyenne 0 et pour écart type 1. ) = 1 ; c'est-à-dire toute variable aléatoire
réduite a pour moyenne 0 et pour écart type 1.
4°) Si X est une V.A. N(m, ó), alors la variable
aléatoire Z = 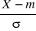 est donc une V.A. N(0 ; 1). est donc une V.A. N(0 ; 1).
III.2.2 CLASSIFIEUR
BAYESIEN
Soient k classes et X vecteur caractéristique de taille
M
On choisit la classe 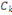 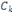 qui maximise P(Ck /X), probabilité que X appartienne
à qui maximise P(Ck /X), probabilité que X appartienne
à 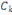 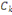 : P ( : P (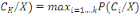 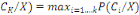 avec : avec :
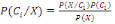 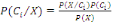 ; ;
P(X)=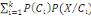 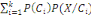 et et
P(Ci) =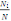 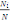 est la probabilité d'observer la classe est la probabilité d'observer la classe 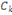 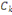 étant donné l'ensemble étant donné l'ensemble
D'exemples N. Ou encore P(Ci)=1/k.
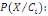 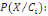 La vraisemblance de l'événement « observer la
donnée x » si elle est de classe La vraisemblance de l'événement « observer la
donnée x » si elle est de classe 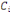 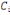 en disposant des exemples de taille N. Ce terme est plus difficile
voir impossible à estimer que le précédent. En absence
d'autre information, on utilise « L'hypothèse de Bayes naïve
» en disposant des exemples de taille N. Ce terme est plus difficile
voir impossible à estimer que le précédent. En absence
d'autre information, on utilise « L'hypothèse de Bayes naïve
»
III.2.2.1 HYPOTHESE DE BAYES NAIVE
La donnée x est une conjonction de valeur d'attributs ;
cette hypothèse consiste à supposer que les attributs sont des
variables aléatoires indépendantes, c'est-à-dire que les
valeurs de ses attributs ne sont pas corrélées entre-elle.
Clairement, cette hypothèse n'est à peu près
jamais vérifiée; cependant, elle permet de faire des calculs
simplement et, finalement, les résultats obtenus ne sont pas sans
intérêt d'un point de vue pratique
Avec
· Ni le cardinal de la classe i ;
· N le cardinal de l'ensemble de données
· K le nombre de classe.
III.2.2.2 ESTIMATION DE 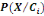 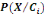
Quand les variables aléatoires sont issues d'une
séquence d'événements aléatoires, leur
densité de probabilité prend la forme de la loi normale, N(  , ,   ). Ceci est démontré par le théorème de la
limite centrale. Il est un cas fréquent en nature. ). Ceci est démontré par le théorème de la
limite centrale. Il est un cas fréquent en nature.
Les paramètres de N(  , ,  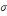 ) sont les premiers et deuxième moments des exemples. Donc, on
peut les estimer pour n'importe quel nombre d'exemples. On peut même
estimer les moments quand il n'existe pas les bornes (Xmax-Xmin) ou quand X est
une variable continue. ) sont les premiers et deuxième moments des exemples. Donc, on
peut les estimer pour n'importe quel nombre d'exemples. On peut même
estimer les moments quand il n'existe pas les bornes (Xmax-Xmin) ou quand X est
une variable continue.
Dans ce cas, p( ) est une "densité" et il faut une
fonction paramétrique pour p().
Dans la plupart des cas, on peut utiliser N (  , ,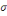 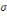 ) comme une fonction de densité pour p(x). ) comme une fonction de densité pour p(x).
p(x) 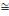 N(x; N(x;  , ,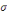 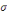 )= )= 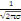 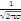 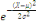 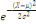
Le base "e" est : e = 2.718281828....
Le terme 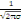 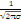 sert à normaliser la fonction en sorte que sa surface est 1. sert à normaliser la fonction en sorte que sa surface est 1.
Estimation d'un vecteur de variables
aléatoires
Pour un vecteur de D propriétés
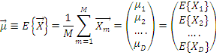
Pour D dimensions, la covariance entre les variables xi et xj est
estimée à partir de M observations  
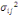 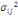 =E{( =E{(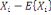 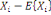 )( )(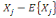 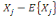 )} )}
  = =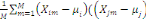 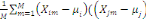 Et encore, pour éviter le biais, on peut utiliser : Et encore, pour éviter le biais, on peut utiliser :
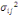 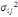 = =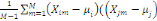 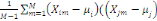
Ces coefficients composent une matrice de covariance. C
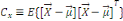
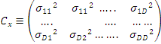
Dans le cas d'un vecteur de propriétés,   , la loi normale prend la forme : , la loi normale prend la forme :
p(x)  N(x; N(x;   , , 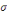 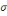 )= )= 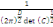 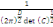 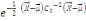 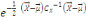
Le terme 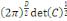 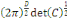 est un facteur de normalisation. est un facteur de normalisation.
En vertu de la loi des grands nombres, nous avons :
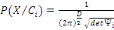 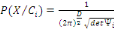 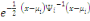 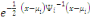
Avec
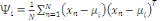 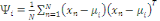 : la matrice de variance covariances : la matrice de variance covariances
Hypothèse :
Distribution normale à l'intérieur de chaque classe
Ci
Les variables sont corrélées entre elles
III.3 EVALUATION DE RISQUE
Toutes les décisions n'ont pas le même impact
· Prêter à un client à haut risque
comparativement à ne pas prêter à un client à faible
risque
· Diagnostic médical : impacts possibles de la
non-détection d'une maladie grave
· Détection d'intrusion
· Cibler un client qui n'est pas intéressé par
le produit
· Affecter un consommateur dans une autre classe de
consommateur qui ne présente pas les mêmes
caractéristiques.
Toutes ces questions nous amènent à évaluer
le risque d'une mauvaise affectation des individus. Ce risque peut être
quantifié par la fonction de perte : L (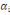 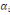 ; Cj ) ; Cj )
Effectuer une action 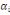 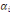 alors que la classe véritable est Cj alors que la classe véritable est Cj
Le Risque
Le risque espéré d'une action 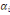 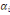 est évaluée de la façon suivante : est évaluée de la façon suivante :
R(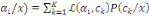 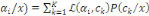
Action minimisant le risque :
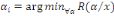
Modifier la fonction de perte modifie le risque :
I Modifier le coût associé à un faux
négatif relativement au coût d'un faux positif.
Matrice de confusion
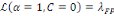
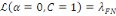
Fonction de perte zero-un d'une matrice en k
classes :
L (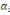 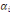 , ,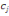 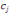 )= )=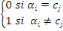 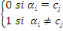
Le risque correspondant est alors :
R (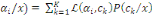 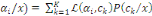
=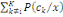 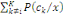
=1-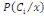 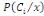
CHAPITRE IV. APPLICATION
[4]
Dans ce qui suit, nous présentons la conception de notre
outil d'aide à la décision. Notre solution est constituée
de trois volets, le premier est consacré à la conception d'une
application transactionnelle, le deuxième, à l'utilisation d'une
technique de datamining basée sur un algorithme de classification
automatique, et le troisième nous utiliserons une technique de
prédiction basée sur la statistique de bayes. Nous utiliserons
des diagrammes UML, pour illustrer les aspects statiques, dynamiques et
fonctionnels de notre conception.
IV.1. Les Diagrammes UML
IV.1.1. Diagrammes de cas
d'utilisation :
Le gestionnaire, étant l'acteur principal. Les cas
d'utilisation de base qui vont être mis en évidence pour
l'assister dans la constitution des décisions ou la prise de
décision seront :
Ø Accéder à l'application transactionnelle.
Ø Visualiser les données des clients à
classifier.
Ø Appliquer les centres mobiles pour la segmentation.
Ø Analyse les classes obtenues.
Ø Appliquer la statistique bayesienne pour la
prédiction.
Ø Proposer un marketing au client.
Ø Visualiser les rapports

IV.1.2 Diagrammes de
séquence:
Dans cette phase de notre développement, après
identification des cas d'utilisation, et des scénarios associés
à chaque cas, nous représentons quelques cas à l'aide des
diagrammes de séquence :
IV.1.2.1 Diagramme de séquence Appliquer les
centres mobiles pour la segmentation
Ø IV.1.2.2 Diagramme de séquence
Appliquer la statistique bayesienne pour la prédiction

IV.3 Module de la conception
Data Mining
La deuxième phase de notre solution est
consacrée à la création des groupes des clients
homogènes en utilisant l'algorithme des centres mobiles permettant de
construire des groupes de clients en fonction de critères de
similarité. Avant de détailler la modélisation de notre
algorithme de partitionnement, il faut éclaircir certains points et
rappeler quelques définitions de base utilisées dans les
étapes de calcul des groupes d'individus.
IV.4. Implémentation et
mise en oeuvre
Notre travail consiste à analyser le comportement des
clients ou consommateurs des produits fabriqués par une entreprise. Le
but ultime de ce travail est de voir la distribution de clients de la
société, leur profil, leur comportement ou habitude d'acheter tel
ou tel autre produit, en fin à l'aide de la statistique bayesienne
prédire la classe qu'un nouveau client peut appartenir en vue de mettre
une stratégie qui permet à l'entreprise de garder ce client.
IV.4.1 Architecture du
système
L'architecture montre l'ensemble des composants, outils et
matériels interconnectés permettant d'obtenir une architecture
simple.
L'architecture est composée de parties
différentes :
Ø La première partie constitue l'interface de notre
application permettant d'effectuer les opérations de vente,
d'enregistrement des informations
Ø La deuxième partie permet de classifier les
clients en groupes homogène en utilisant l'algorithme des centres
mobiles,
Ø et enfin la prédiction de groupe de nouveau
client.
IV.5 Etude de cas et interfaces
de l'application
IV.5.1. Etude de cas
Le cas que nous présenterons concerne
l'analyse de la base de données commerciales. Les tableaux qui suivent
montrent une partie de la structure de la base de données de la Bralima.
Le tableau suivant constitue une partie de la base de données à
la quelle nous travaillons.
|
Age
|
Revenu
|
Montant
|
Sexe
|
Codeclient
|
|
25
|
36000
|
50400
|
1
|
1
|
|
29
|
42000
|
14500
|
0
|
10
|
|
25
|
35000
|
14500
|
1
|
11
|
|
28
|
45000
|
5400
|
1
|
12
|
|
25
|
48000
|
4500
|
1
|
13
|
|
21
|
65000
|
59500
|
0
|
14
|
|
29
|
485000
|
29500
|
0
|
15
|
|
39
|
24000
|
14500
|
1
|
16
|
|
38
|
68500
|
14500
|
0
|
17
|
|
30
|
100000
|
54000
|
1
|
18
|
|
21
|
35000
|
45000
|
0
|
19
|
|
28
|
45000
|
26000
|
1
|
2
|
|
28
|
480000
|
45200
|
1
|
20
|
|
25
|
145000
|
85000
|
1
|
21
|
|
28
|
145000
|
45000
|
1
|
22
|
|
30
|
254000
|
45000
|
1
|
23
|
|
20
|
65800
|
45000
|
0
|
24
|
|
36
|
24500
|
15000
|
1
|
25
|
|
35
|
256000
|
299000
|
0
|
26
|
|
34
|
482000
|
145000
|
1
|
27
|
|
34
|
685000
|
14500
|
0
|
28
|
|
21
|
354000
|
145000
|
1
|
29
|
|
30
|
254000
|
49400
|
0
|
3
|
|
29
|
452000
|
145000
|
0
|
30
|
|
25
|
485000
|
45000
|
1
|
31
|
|
28
|
365000
|
785000
|
0
|
32
|
|
25
|
65000
|
45000
|
0
|
33
|
|
21
|
45000
|
75000
|
0
|
34
|
|
29
|
685000
|
45000
|
1
|
35
|
|
39
|
45000
|
85000
|
1
|
36
|
|
38
|
758000
|
75000
|
0
|
37
|
|
30
|
85000
|
15000
|
1
|
38
|
|
21
|
485000
|
78500
|
1
|
39
|
|
20
|
45000
|
25600
|
1
|
4
|
|
28
|
685000
|
8500
|
1
|
40
|
|
26
|
45000
|
54000
|
1
|
41
|
|
36
|
24000
|
25400
|
0
|
5
|
|
35
|
152000
|
25600
|
1
|
6
|
|
34
|
254000
|
15200
|
1
|
7
|
|
34
|
45000
|
14500
|
1
|
8
|
|
21
|
95000
|
14500
|
0
|
9
|
Le montant correspond au cumul des achats effectués par un
client pendant une période.
IV.5.1.1 Représentation des clients
Les clients sont représentés par des vecteurs de
 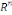 , où n et le nombre de variables (dimensions) ou les
caractéristiques retenues pour décrire les clients dans notre
module. On associe à chaque client, un vecteur. Nous
considérons que chaque individu est muni d'un poids pi
avec pi > 0 et , où n et le nombre de variables (dimensions) ou les
caractéristiques retenues pour décrire les clients dans notre
module. On associe à chaque client, un vecteur. Nous
considérons que chaque individu est muni d'un poids pi
avec pi > 0 et 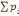 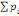 =1. =1.
Sélection des variables
La première étape consiste à
sélectionner les variables à considérées pour
décrire les clients. Nous retenons l'âge du client, le sexe, le
montant acheté, Revenu et le niveau d'instruction
Nuage d'individus ou des clients
Dans l'espace des individus, l'ensemble N
= 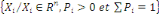 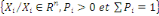 est appelé nuages des clients. est appelé nuages des clients.
Centre de gravité
Le centre de gravité g d'un
nuage N ou encore le « Barycentre »
des points Xi (ou Xi et le
ième client du nuage N)
affectés aux poids pi est
donné par la formule suivante :
G=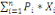 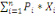 qui peut être écrit à la manière
suivante : qui peut être écrit à la manière
suivante :
G=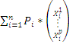 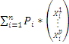 = =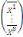 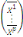
D'autres quantités telles qu'inertie totale, inertie
inter classe et inertie intra classe sont définies dans le chapitre
II.
Remarque :
Ø Dans notre travail, nous avons considérer le
point associé à chaque client égale à un.
Ø Seules les variables quantitatives seront
traitées dans notre algorithme parmi les variables
sélectionnées.
Ø Pour la mise en oeuvre de notre algorithme nous avons
utilisé la distance euclidienne qui est donnée par la formule
suivante :
D(x,y)=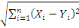 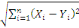 avec X et Y deux vecteurs de avec X et Y deux vecteurs de  
Principe général :
L'algorithme consiste à grouper les clients selon un
critère bien déterminé par exemple : par catégorie
d'achats (i.e. le vecteur x représentant la quantité
achetée de chaque produit). L'entrée de l'algorithme est le
nombre k de groupes (représentant les catégories de clients). Une
fois le nombre de groupes saisi, l'algorithme choisit arbitrairement k clients
comme centres « initiaux » des k groupes. L'étape suivante
consiste à calculer la distance entre chaque individu (client) et les k
centres ; la plus petite distance est retenue pour inclure cet individu dans le
groupe ayant le centre de gravité le plus proche. Une fois tous les
clients groupés, on aura k sous-nuages disjoints du nuage total. Pour
chaque groupe (sous-nuage), l'algorithme calcule le nouveau centre de
gravité.
L'algorithme s'arrête lorsque les groupes construits
deviennent stables. Dans notre cas, notre algorithme va s'arrêter
lorsque l'inertie intra classe dévient inférieure à notre
seuil fixé à 0.05
IV.5.1.2 Résultats de la segmentation
Premier groupe
|
Age
|
Revenu
|
Montant
|
sexe
|
codeclient
|
classe
|
|
25
|
36000
|
50400
|
1
|
1
|
1
|
|
21
|
65000
|
59500
|
0
|
14
|
1
|
|
30
|
100000
|
54000
|
1
|
18
|
1
|
|
21
|
35000
|
45000
|
0
|
19
|
1
|
|
25
|
145000
|
85000
|
1
|
21
|
1
|
|
20
|
65800
|
45000
|
0
|
24
|
1
|
|
35
|
256000
|
299000
|
0
|
26
|
1
|
|
34
|
482000
|
145000
|
1
|
27
|
1
|
|
21
|
354000
|
145000
|
1
|
29
|
1
|
|
29
|
452000
|
145000
|
0
|
30
|
1
|
|
28
|
365000
|
785000
|
0
|
32
|
1
|
|
25
|
65000
|
45000
|
0
|
33
|
1
|
|
21
|
45000
|
75000
|
0
|
34
|
1
|
|
39
|
45000
|
85000
|
1
|
36
|
1
|
|
26
|
45000
|
54000
|
1
|
41
|
1
|
Deuxième groupe
|
Age
|
revenu
|
montant
|
sexe
|
Code client
|
classe
|
|
29
|
42000
|
14500
|
0
|
10
|
2
|
|
28
|
45000
|
5400
|
1
|
12
|
2
|
|
25
|
48000
|
4500
|
1
|
13
|
2
|
|
29
|
485000
|
29500
|
0
|
15
|
2
|
|
38
|
68500
|
14500
|
0
|
17
|
2
|
|
28
|
45000
|
26000
|
1
|
2
|
2
|
|
28
|
480000
|
45200
|
1
|
20
|
2
|
|
28
|
145000
|
45000
|
1
|
22
|
2
|
|
30
|
254000
|
45000
|
1
|
23
|
2
|
|
34
|
685000
|
14500
|
0
|
28
|
2
|
|
30
|
254000
|
49400
|
0
|
3
|
2
|
|
25
|
485000
|
45000
|
1
|
31
|
2
|
|
29
|
685000
|
45000
|
1
|
35
|
2
|
|
38
|
758000
|
75000
|
0
|
37
|
2
|
|
30
|
85000
|
15000
|
1
|
38
|
2
|
|
21
|
485000
|
78500
|
1
|
39
|
2
|
|
20
|
45000
|
25600
|
1
|
4
|
2
|
|
28
|
685000
|
8500
|
1
|
40
|
2
|
|
35
|
152000
|
25600
|
1
|
6
|
2
|
|
34
|
254000
|
15200
|
1
|
7
|
2
|
|
34
|
45000
|
14500
|
1
|
8
|
2
|
|
21
|
95000
|
14500
|
0
|
9
|
2
|
Troisième groupe
|
Age
|
Revenu
|
Montant
|
sexe
|
Code client
|
classe
|
|
25
|
35000
|
14500
|
1
|
11
|
3
|
|
39
|
24000
|
72500
|
1
|
16
|
3
|
|
36
|
24500
|
75000
|
1
|
25
|
3
|
|
36
|
24000
|
127000
|
0
|
5
|
3
|
IV.5.1.3 Analyse des résultats
Après la segmenta le problème reviendra à
étiqueter les classes obtenues c'est-à-dire donner la
signification de chaque groupe de clients. Nous constatons que les clients sont
beaucoup plus influencés par le montant de leur achat et le revenu. En
marketing, un marché est le produit que l'entreprise a mis sur le
marché des biens, nous donnerons une interprétation de ces
classes par rapport au mouvement d'achat effectué par chaque client
vis-à-vis d'un produit.
|
Produit
|
Classe
|
Description classe
|
Catégorie
|
|
COCA
|
|
|
|
|
2
|
Cette classe contient des grands
Consommateurs de ce produit,
le
Marketing ne serait pas opportun
|
Grand
|
|
1
|
Cette Classe contient des consommateurs Moyens du produit, Le
marketing Pourrait aider à accroitre la
Rentabilité
|
Moyen
|
|
3
|
Cette Classe contient des faibles consommateurs du produit, Le
marketing Pourrait aider à augmenter leur
achat
|
Faible
|
|
PRIMUS
|
|
|
|
|
1
|
Cette classe contient des grands Consommateurs de ce produit, le
Marketing ne serait pas opportun
|
Grand
|
|
2
|
Cette Classe contient des consommateurs Moyens du produit, Le
marketing Pourrait aider à accroitre la
Rentabilité
|
Moyen
|
|
3
|
Cette Classe contient des faibles consommateurs du produit, Le
marketing Pourrait aider à augmenter leur
achat
|
Faible
|
|
TURBO
|
|
|
|
|
1
|
Cette classe contient des grands Consommateurs de ce produit, le
Marketing ne serait pas opportun
|
Grand
|
|
3
|
Cette Classe contient des consommateurs Moyens du produit, Le
marketing Pourrait aider à accroitre la
Rentabilité
|
Moyen
|
|
2
|
Cette Classe contient des faibles consommateurs du produit, Le
marketing Pourrait aider à augmenter leur achat
|
Faible
|
Ce tableau regroupe les clients à contacter pour un
marketing ciblé des différents produits.
|
Produit
|
Code Client
|
Nom du client
|
Avenue
|
Numéro de Contact
|
|
COCA
|
|
|
|
|
|
11
|
xxxxxx
|
xxxx
|
09985252260
|
|
16
|
xxxxxx
|
xxxxxx
|
0898754521
|
|
25
|
xxxxx
|
xxxxxx
|
09986858752
|
|
5
|
xxxxx
|
xxxxxxxx
|
|
|
PRIMUS
|
|
|
|
|
|
11
|
xxxxxx
|
xxxx
|
09985252260
|
|
16
|
xxxxxx
|
xxxxxx
|
0898754521
|
|
25
|
xxxxx
|
xxxxxx
|
09986858752
|
|
5
|
xxxxx
|
xxxxxxxx
|
|
|
TURBO
|
|
|
|
|
|
10
|
xxxxx
|
xxxx
|
0895685120
|
|
12
|
xxxxx
|
xxxxxx
|
0999850254
|
|
13
|
xxxxx
|
x
|
0816535261
|
|
15
|
xxxxxx
|
xxxxxx
|
09966585210
|
|
17
|
xxxxxx
|
xxxxx
|
089542410
|
|
2
|
xxxx
|
xxxxxx
|
0898775654
|
|
20
|
x
|
xxxxxx
|
08965853520
|
|
22
|
xxxxxx
|
xxxxxx
|
0998564251
|
|
23
|
xxxxxx
|
xxxxxx
|
0898754621
|
|
28
|
xxxx
|
xxxxxx
|
0996536325
|
|
3
|
xxxx
|
xxxxxx
|
0998452321
|
|
31
|
xxxxx
|
xxxxxx
|
0897865852
|
|
35
|
xxxx
|
xxxxxx
|
0898658251
|
|
37
|
xxxxxx
|
xxxxxx
|
089582560
|
|
38
|
xxxxxxx
|
xxxxxxx
|
08956253520
|
|
39
|
xxxxxxx
|
xxxxxx
|
0897565412
|
|
4
|
xxxxxxx
|
xxxxxx
|
0856421442
|
|
40
|
xxxxxxxx
|
xxxxx
|
0898542543
|
|
6
|
xxxxxx
|
xxxxxx
|
|
|
7
|
xxxxx
|
xxxxxx
|
|
|
8
|
xxxx
|
xxxxxxx
|
|
|
9
|
xxxxx
|
xxxxx
|
|
Le tableau suivant donne la part de chaque groupe de clients
à la clientèle de l'entreprise
|
Classe
|
Nombre de Clients
|
Part du Marche en %
|
Total de clients
|
|
1
|
15
|
31.914893617021278
|
47
|
|
2
|
22
|
46.808510638297875
|
47
|
|
3
|
4
|
8.51063829787234
|
47
|
IV.5.1.4. Affectation
Cette tâche consiste à prédire le groupe d'un
nouveau client qui se présente à l'entreprise, la classe est
prédite après que le client ait effectué son premier
achat.
Ce tableau montre les valeurs d'attributs de ce client
|
code client
|
age
|
revenu
|
montant
|
sexe
|
|
100
|
45
|
450000
|
2800
|
1
|
Résultat du classifieur Bayésien
|
Code client
|
P(C1/X)
|
P(C2/X)
|
P(C3/X)
|
Décision ou Classe
|
|
100
|
0.3967275958099037
|
0.32315485060502985
|
0.2801175535850664
|
1
|
L'individu est affecté dans la classe ou la
probabilité est maximale. Dans ce cas, le client est affecté dans
la classe 1. Le tableau suivant donne la liste des produits à l'offrir
accompagné d'un service de marketing.
|
PRODUIT
|
|
COCA
|
|
PRIMUS
|
|
TURBO
|
Le logiciel propose d'autres analyses sur le client et sur les
produits fabriqués par l'entreprise.
IV.5.1.5 Analyse des Résultats avec
SPAD
IV.5.1.5.1 Résultats de la segmentation
Hiérarchique de la base de données
Liste des trois meilleure(s) partition(s) entre 3 et 10
classes
Ø partition en 4 classes
Ø partition en 6 classes
Ø partition en 7 classes
Première Coupure de l'arbre en 4
classes
FORMATION DES CLASSES (INDIVIDUS ACTIFS)
|
| CLASSE
|
EFFECTIF
|
POIDS
|
CONTENU
|
|
Classe 1
|
7
|
548194
|
1 à 7
|
|
Classe 2
|
14
|
********
|
8 à 21
|
|
Classe 3
|
14
|
996316
|
22 à 35
|
|
Classe 4
|
5
|
325652
|
36 à 40
|
PROGRESSION DE L'INERTIE INTER-CLASSES
|
ITERATION
|
I.TOTALE
|
| I.INTER
|
QUOTIENT
|
|
0
|
0.13612
|
0.12706
|
0.93337
|
|
1
|
0.13612
|
0.12738
|
0.93581
|
|
2
|
0.13612
|
0.12783
|
0.93912
|
|
3
|
0.13612
|
0.12815
|
0.94144
|
|
4
|
0.13612
|
0.12815
|
0.94144
|
|
5
|
0.13612
|
0.12815
|
0.94144
|
La consolidation de la partition Autour des 4
centres de classes est réalisée par 10 itérations a
centres mobiles.
IV.5.1.5.2 Nuage des points
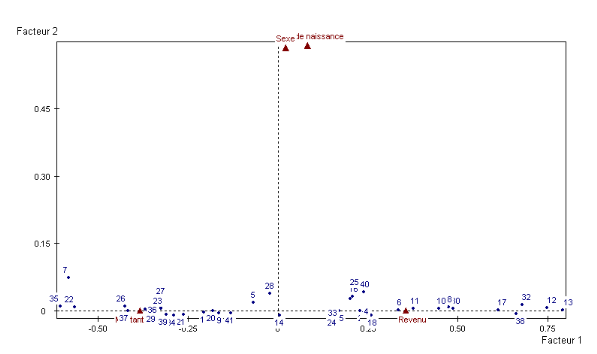
Interprétation : Les nuages
projetés sur les deux premiers axes montrent un certain regroupement des
individus autour des variables Montant et Revenu, donc ce sont ces deux
variables qui influencent les individus.
IV.5.1.6 Comparaison des résultats
La méthode utilisée par SPAD pour segmenter ces
clients nous donne beaucoup de classes par rapport à chaque coupure que
nous pouvons effectuer de l'arbre, le plus petit nombre de classes est quatre,
mais l'interprétation que nous avons fait des ces classes donne lieu
à un regroupement autour des trois classes, Le critère
utilisé est pour la convergence de cet algorithme pour consolider les
classes est celui de la fixation de nombre d'itérations.
Par contre, notre logiciel à trois groupes d'individus et
le critère de convergence utilisé est celui de la minimisation de
l'inertie intra classe qui explique l'homogénéité entre
les individus d'une même classe, c'est-à-dire la distance qui
sépare chaque individu à son centre de gravité
IV.5. 2.Quelques Interfaces de
l'application
IV.5.2.1 Formulaire Principal

IV.5.2.2 Formulaire de Chargement de données
à segmenter
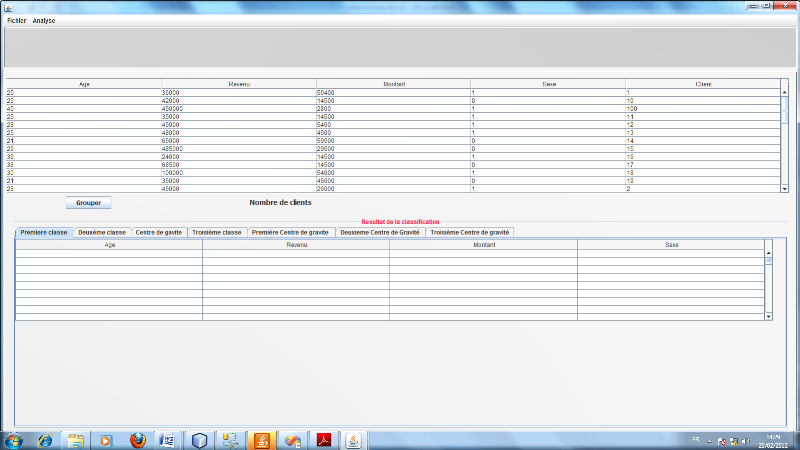
IV.5.2.3. Formulaire d'interprétation et
Exploration
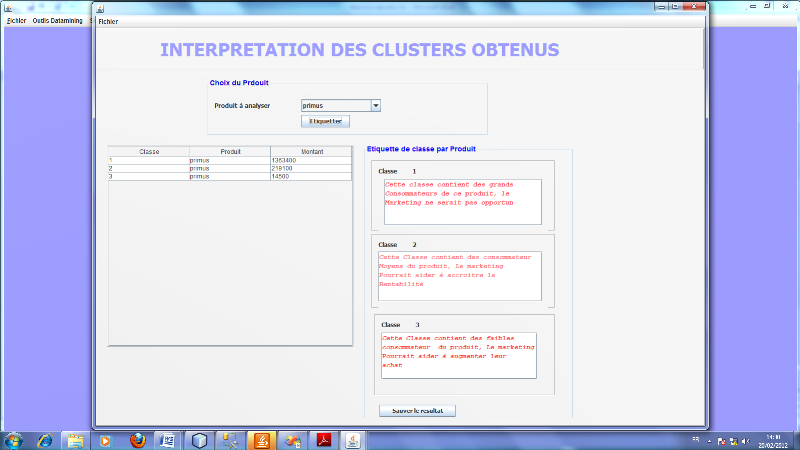
IV.5.2.4. Formulaire de Prédiction
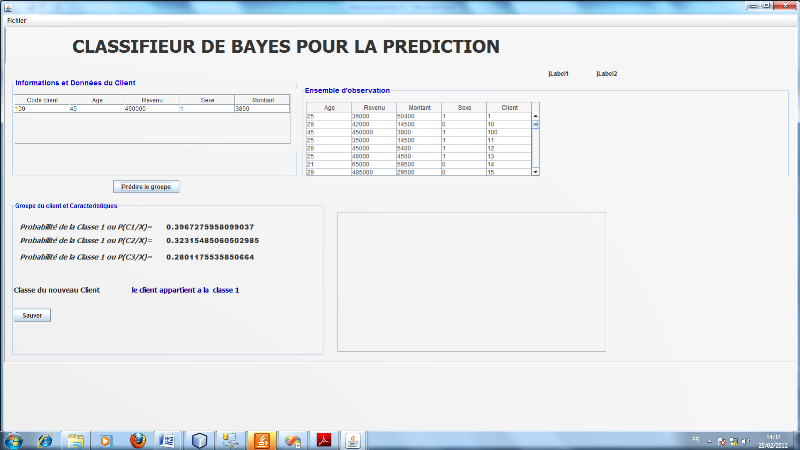
IV.5 Les codes de
l'application
package datateam;
/**
*
* @author kalo
*/
public class Algorithme {
public Double [] centregravite(int n,Double[][] tableau){
Algorithme t=new Algorithme();
Double [] re=new Double [4];
Double[] som=new Double[n];
for(int i=0;i<4;i++){
for(int j=0;j<n;j++){
som[j]=tableau[j][i];
}
re[i]=t.moyenne(n, som);
}
return re;
}
public Double moyenne(int n,Double[]tab){
Double rep=0.0;
Double som=0.0;
for(int i=0;i<n;i++){
som=som+tab[i];
}
rep=som/n;
return rep;
}
public Double inertie(Double [][]individu,Double
[]centre){
Double ret=0.0;
Double[] t=new Double[4];
Double som=0.0;
Algorithme r=new Algorithme();
for(int i=0;i<individu.length;i++){
for(int j=0;j<4;j++){
t[j]=individu[i][j];
}
som=som+r.distance(t, centre);
}
ret=som;
return ret;
}
public Double distance(Double []individu,Double []centre){
Double retour=0.0;
Double somecart=0.0;
for(int i=0;i<centre.length;i++){
somecart=somecart+Math.pow(((centre[i]-(individu[i]))),(int)2);
}
retour=somecart;
return retour;
}
public Double inertieintraclasse(int k,Double[] poid,Double
inertiegroupe,Double []individu,Double []centre){
Double retour=0.0;
Double Iw=0.0;Double resulta;
Algorithme r=new Algorithme();
for(int i=0;i<k;i++){
// resulta=r.inertie(individu, centre);
// Double t=poid[i]*resulta;
// Iw=Iw+t;
}
return retour;
}
public Double inertieinterclasse(int k,Double[] poid,Double
[]centregroupe,Double []centre){
Double retour=0.0;
Double Ib=0.0;Double resulta;
Algorithme r=new Algorithme();
for(int i=0;i<k;i++){
resulta=r.distance(centregroupe, centre);
Double t=poid[i]*resulta;
Ib=Ib+t;
}
return retour;
}public Double minimum(Double x,Double y,Double z){
Double ret=0.0;
Double min=x;
if(Double.compare(x, y)<0 && Double.compare(x,
z)<0){
ret=x;
}else{}
if(Double.compare(y, x)<0 && Double.compare(y,
z)<0){
ret=y;
}else{}
if(Double.compare(z, x)<0 && Double.compare(z,
y)<0) {
ret=z;
}else{}
return ret;
}
public double minimums(double x,double y,double z){
double ret=0.0;
double var;
var=x;
if (x<y && x<z) {
ret=x;
}else if(y<x && y<z){
ret=y;
}else{
ret=z;
}
return ret;
}
public double maximum(double x,double y,double z){
double ret=0.0;
double var;
var=x;
if (x>y && x>z) {
ret=x;
}else if(y>x && y>z){
ret=y;
}else{
ret=z;
}
return ret;
}
}
CONCLUSION
Le travail présenté dans le cadre du
mémoire en vue de l'obtention du titre de licencié en sciences
groupe informatique consiste à donner une contribution de la fouille de
données à la segmentation du marché et au ciblage des
offres.
Les clients constituant la richesse première d'une
entreprise, comme on dit-on que ce sont les clients qui payent nos salaires,
une entreprise qui aspire voir sa croissance doit se préoccuper de
comprendre les comportements de ses clients. L'intérêt principal
d'un tel outil est triple :
Ø d'offrir aux décideurs une meilleure vision de
leurs clients leur permettant ainsi, une meilleure gestion et une meilleure
satisfaction des clients en lui proposant des produits susceptibles
d'être acheter par ces derniers.
Ø Faire le marketing ciblé ou une offre
particulière à un groupe des clients présentant des
caractéristiques similaires et ayant des comportements de consommation
Ø Connaître quoi à offrir au nouveau
client qui se présente à l'entreprise en lui affectant à
un groupe des clients dans lequel les habitudes ou les
préférences de vis-à-vis d'un produit ou d'un groupe des
produit sont connues.
Le logiciel développé permet à toute
personne expert ou non d'effectuer quelques tâches de datamining comme la
classification automatique et la prédiction. Cet outil constitue une
aide efficace pour interpréter les résultats de l'analyse
effectuée.
Comme perspective à ce travail, nous proposons un
enrichissement du module data mining en intégrant d'autres techniques de
classification telles que une classification des variables qualitatives avec
les centres de profil qui est une version de centres mobiles traitant de
données qualitatives, quant à la statistique bayesienne nous
espérons introduire le méthodes de simulation de monte Carlo pour
estimer la vraisemblance au cas où les méthodes numériques
ne marcheraient pas ou lorsque l'hypothèse de la normalité n'est
pas vérifiée.
BIBLIOGRAPHIE
1. Ouvrage
1. ALAIN BACCINI et PHILIPPE BESSE,
« Statistique descriptive
multidimensionnelle, Version Juillet
1999 »
2. ANNE BOYER, «
Introduction au datamining » ;
3. CHRISTINE FRODEAU, « Data mining,
outil de predictiondu comportement du
consommateur le 08 juin 2006 » ;
4. CLERMONT FERRAND, « Algorithmes
de Data Mining Distribués le 05
juillet 2006»
5. E-G. TALBI, « Fouille de
données (Data Mining) » ;
6. GILBERT SAPORTA, « Data mining
» ou fouille de données, le 05 Janvier
2004 » ;
7. HANS WACKERNAGEL, « Cours de
Géostatistique Multivariable le 03 février
2001 »
8. LINE FORTIN, « Analyse de la
segmentation de la clientèle, le 08 Mars
2005 »
9. NAZIH SELMOUNE, SAIDA BOUKHEDOUMA et ZAIA ALIMAZIGHI,
« Conception d'un outil décisionnel pour la
gestion de la relation client dans un site de e-commerce
le 27 Mar 2005 »
10. OLIVIER DECOURT, « DataMining, Le
datamining, qu'est ce que c'est et comment
l'apprehender le 18 juin 2006 »
11. PHILIPPE BESSE, « Apprentissage
Statistique Datamining Version Juillet 2009 »
12. PHILIPPE PREUX, « Fouille de
données Notes de cours, 31 aôut
2009 »
13. PROFESSEUR Dr. Andreas Meier, « Le
CRM analytique Les outils d'analyse OLAP et le Data
Mining, le 26 avril 2008 »
14. RICCO RAKOTOMALALA, « Analyse
discriminante lineaire, une approche pour rendre calculable p(y/x) le 28
Janvier 2008 »
15. STÉPHANE TUFFÉRY,
« Data mining et statistique cisionnelle,
25/12/2006 »
II. Cours
1. Eugène MBUYI MUKENDI, analyse de données,
Cours inédit L1 informatique, UNIKIN, 2007.
2. Leonard MANYA NDJAJIL, Statistique II, cours inédit
G2 informatique, UNIKIN, 2007.
3. Nathanaél KASORO MULENDA, Analyse de données,
cours inédit L1 informatique Gestion,
UNIKIN, 2009.
4. Saint Jean DJUNGU, Génie Logiciel Cours
inédit L1 informatique, UNIKIN 2009.
III. WEBOGRAPHIE
5.
www. kdnuggets.com, consulté le
12 septembre 2001
6.
http://www.cs.bham.ac.uk/~anp/TheDataMine.html,
consulté le 12 septembre
7.
http://www-stat.stanford.edu/~jhf/ftp/dm-stat.ps, consulté le 05
Janvier 2012
8.
http://www.univ-lille3.fr/grappa, consulté le 10 Janvier 2012
9. :http://www.cairn.info/article_p.php, consulté le 12
Janvier 2012
10.
http://www.journaldunet.com/solutions/0301/030108_olap.shtml,
Consulté le 30 Décembre 2011
TABLE DES MATIERES
Pages :
EPIGRAPHE.............................................................................................
Erreur ! Signet non
défini.
DEDICACE
2
AVANT-PROPOS
3
INTRODUCTION
4
CHAPITRE I. LA FOUILLE DE DONNEES [2, 5, 6,10,
11,12]
7
I.1 Définitions et historique
7
I.2 Les outils
9
I.3. Les différents types de données
rencontrés
9
I.3.1 Description classique d'une variable
9
I.3.2 Les variables quantitatives
10
Définition
10
I.3.3 Variables qualitatives
10
Définition :
10
I.3.4 Description symbolique d'une variable
11
Tableau 1.2 Exemple de descriptions
multivaluées et modales.
12
I.3.5 Les variables à descriptions
multivaluées
12
I.3.6 Les variables à descriptions
modales
12
I.3.7 Les variables taxonomiques ou
structurées
12
I.4. Les mesure de ressemblance
13
I.4.1 Définition
13
I.4.2 Indice de dissimilarité
13
I.4.3 Distance
14
1.4.4 Indice de similarité
14
I. 5 Mesure de ressemblance entre individus
à descriptions classiques
14
I.5.1 Tableau de données numériques
(continues ou discrètes)
15
I.6.Le bruit
15
I.7.Différentes tâches d'extraction
d'information
16
I.7.1. Problème de classification
16
I.7.2.Problème de segmentation
16
I.7.3.Problème de recherche
d'association
17
I.7.4.Recherche de séquences
17
I.7.5 Détection de déviation
17
I .8.Méthodes Utilisées
18
I.8.1. Analyse de données
18
CHAPITRE II. LA SEGMENTATION [1, 4, 5, 12, 15, 18,
22]
25
Définition 1 :
26
II.1.La segmentation hiérarchique
27
II.1.1 Définition
28
I H
28
II.1.3. Construction d'une hiérarchie
29
II.1.4. La Classification Descendante
Hiérarchique
29
II.2. Les méthodes monothéiques
30
II.3. Segmentation non hiérarchique
30
II.3.1 La méthode des centres mobiles.
31
II.3.2 Les nuées dynamiques
32
Principe général de la
méthode
33
Avec Ai, un ensemble de ni
éléments qui minimisent une fonction L(v i, I, P)
35
CHAPITRE III. CIBLAGE DES OFFRES [3,7]
36
III.1 Définition
36
III.2. CLASSIFIEUR BAYESIEN [1, 5, 14]
38
III.2.1 RAPPELS SUR LA STATISTIQUE
38
III.2.2 CLASSIFIEUR BAYESIEN
46
III.3 EVALUATION DE RISQUE
48
CHAPITRE IV. APPLICATION [4]
50
IV.1. Les Diagrammes UML
50
IV.1.1. Diagrammes de cas d'utilisation :
50
IV.1.2 Diagrammes de séquence:
52
IV.3 Module de la conception Data Mining
53
IV.4. Implémentation et mise en oeuvre
54
IV.4.1 Architecture du système
54
IV.5 Etude de cas et interfaces de
l'application
55
IV.5.1. Etude de cas
55
IV.5. 2.Quelques Interfaces de l'application
63
IV.5 Les codes de l'application
67
CONCLUSION
69
BIBLIOGRAPHIE
70
TABLE DES MATIERES
72
| 

