|
RÉPUBLIQUE DÉMOCRATIQUE DU CONGO
ENSEIGNEMENT
SUPÉRIEUR, UNIVERSITAIRE ET
RECHERCHES
SCIENTIFIQUES
(E.S.U.R.S)
UNIVERSITÉ
CHRÉTIENNE BILINGUE DU CONGO

CONCEPTION ET IMPLÉMENTATION D'UN SITE WEB
POUR
L'ARCHIVAGE ET LA COMMANDE EN LIGNE DES JOURNAUX DANS
UNE MAISON DE
PRESSE ÉCRITE : CAS DE L'EDITEUR LES COULISSES A
BENI
Par SALAMA MBALU Stephen
Travail de fin de cycle présenté et défendu
en vu de l'obtention du diplôme de grade en faculté de
Sciences Appliquées, département de
Génie Informatique.
Directeur : Jean Pierre KILUKA SWEDI
Année académique : 2013 -
2014.
i
EPIGRAPHIE
« Notre peur la plus profonde n'est pas que nous ne
soyons pas à la hauteur,
Notre peur la plus profonde est que nous
sommes puissants au-delà de toutes limites.
C'est notre propre
lumière et non notre obscurité qui nous effraie le plus.
Nous nous posons la question... Qui suis-je, moi, pour
être brillant, radieux, talentueux et
merveilleux ?
En fait, qui êtes-vous pour ne pas l'être ?
Vous êtes un enfant de Dieu.
Vous restreindre, vivre petit, ne rend
pas service au monde.
L'illumination n'est pas de vous
rétrécir pour éviter d'insécuriser les
autres.
Nous sommes nés pour rendre manifeste la gloire de Dieu qui
est en nous.
Elle ne se trouve pas seulement chez quelques élus, elle
est en chacun de nous,
Et, au fur et à mesure que nous laissons briller
notre propre lumière, nous donnons
inconsciemment aux autres la
permission de faire de même.
En nous libérant de notre propre peur, notre puissance
libère automatiquement les autres. »
Paroles de Nelson MANDELA,
réécrites par Marianne WILLIAMSON.
ii
REMERCIEMENTS
Nous voici en train de toucher la fin de nos quatre ans de fin
d'études du cycle de graduant à l'université. Au cours de
cette longue période d'études, nous avons
bénéficié d'une assistance de nombreuses personnes et
c'est dans cette optique que nous nous sentons dans l'obligation de
présenter nos sincères remerciements à tous.
Ainsi nous rendons gloire à Dieu le Père
céleste pour la santé et le courage qu'il nous a accordé
pendant cette période d'études.
Qu'il nous soit permis d'exprimer notre gratitude au
comité de gestion de l'Université Chrétienne Bilingue du
Congo, spécialement à monsieur le recteur David MUSIANDE KASALI,
monsieur le recteur A.I. et secrétaire général
académique Honore BUNDUKI KWANI, à tout le staff enseignant et
à tout le personnel de l'Université.
Nous remercions également les dirigeants de la
faculté des Sciences Appliquées dont nommément Monsieur le
Maitre Ir Wilfred MUSHAGALUSA GANZA et SEREKA KATIMIKA Félix qui ont
usé de leur force et leur temps pour nous accompagner et nous diriger
durant toute cette période d'études, ils ont compati pour nous
encadrer et nous soutenir dans différents travaux.
Nos remerciements spéciaux s'adressent au directeur du
présent travail à la personne de Jean Pierre KILUKA SWEDI pour le
dévouement et le courage qu'il a consacré pour
l'effectivité du travail. Celui-ci nous a encadré et
dirigé pendant la réalisation de ce travail que nous avons la
fierté de présenter aujourd'hui. Que le bon Dieu vous
bénisse.
Notre gratitude s'adresse également à mes chers
parents, ma mère Kavira WANZIRE et mon père Paluku MUSAMBAGHANI
Diallon pour l'amour et le soutien qu'ils ont toujours manifesté envers
nous et pour les efforts consentis jusqu'ici, sans oublier mes soeurs et
frères Furaha Mbalu, Kambale Mbalu Joel, Liddy Musambaghani, Marry
Musambaghani, Abigael Musambaghani et Jetro Musambaghani .
Nous ne clôturerons pas cette étape sans
remercier le couple VAGHENI Alexa pour nous ont gardé sous leur toit et
nous ont traité comme leur fils, à tous nos ami(e)s et
connaissances, spécialement à tous les camarades du lutte de la
fameuse promotion de G3
iii
chacun par son nom et à tous les amis du club
universitaire PBU pour les joies et peines partagées ensemble pendant
toute cette période.
Enfin, nous remercions toute personne qui a contribuée
moralement, financièrement et matériellement pour
l'effectivité de nos études universitaires.
iv
SIGLES ET ABBREVIATIONS
CERN : Conseil Européen pour la Recherche
Nucléaire
Dynamic Linked Library
DLL :
DOM : Document Object Model
IDMS : Integrated Data Management System
LDAP : LightWeight Directory Access Protocol
MCD : Modèle Conceptuel de Données
MLD : Modèle Logique de Données
MPD : Modèle Physique de Données
MCT : Modèle Conceptuel de Traitement
SGBD :
SGML : Standard Generalized Markup Language
SVG : Scalade Vector Graphics
W3C : World Wide Web Consortium
Extensible HyperText Markup Language
XHTML :
XML : Extended Markup Language
extensible style Language Transformation
XSLT
:
Système de Gestion de Bases de Données
1
INTRODUCTION
0.1. PROBLEMATIQUE
Le siècle présent est un siècle de
l'information où l'informatique est au centre de toute activité
de l'être humain ; actuellement une tendance de tout numériser et
de tout automatiser s'observe. Les nouveaux concepts de mondialisation et de
village planétaire sont encore un autre besoin qui pousse à une
numérisation de l'information, étant donné que celle-ci
devra circuler sur des réseaux interconnectant des terminaux
informatiques qui traitent de l'information numérisée et se
trouvant dans n'importe quel coin du monde.
Actuellement les gens accèdent à l'information
de différentes manières dont notamment par des programmes
radiodiffusés, par des programmes télévisés, par
des journaux imprimés en dur, voir même via internet etc. C'est
ainsi que dans notre contexte de l'agence de presse écrite Les Coulisses
s'agissant bien d'une agence de publication des journaux, celle-ci produit des
journaux qu'elle met à la disposition des consommateurs selon un
délai de publication tout au moins régulier, ce qui permet aux
consommateurs de bénéficier de l'information en continu. Par
contre, le dit éditeur des journaux n'est pas accessible sur la toile et
donc absent sur internet alors que cela serait avantageux non seulement
à la dite entreprise mais aussi aux consommateurs du produit qui sont
effectivement les lecteurs des journaux publiés par le dit
éditeur. Un client régulier une fois en déplacement loin
du Grand-Nord ou du Nord-Kivu n'a pas la possibilité ou la
facilité de retrouver les nouveaux numéraux publiés par
l'éditeur Les Coulisses alors qu'il y aurait une solution informatique
pour rendre le produit accessible où que l'on soit dans tous les coins
du monde. Il est aussi évident que certains nord-kivuciens de la
diaspora ont parfois l'intension d'avoir accès à
l'actualité de leur milieu d'origine, mais ils n'ont pas la
possibilité car il y a insuffisance des agences de presse
présentes sur la toile. Mais aussi, avec la grande tendance actuelle
d'augmentation du nombre des internautes, il devient de plus en plus
intéressant de rendre disponible un grand nombre des services sur
internet ; dont notamment la commande, la vente ou la consultation des journaux
sur internet, ce qui se fait d'ailleurs pour bon nombre de maisons
d'édition des journaux.
C'est ainsi que notre travail est parti des questions qui
suivent :
? Par quel moyen l'éditeur les Coulisses rendrait-il
disponible les journaux au grand public ou à quiconque qui veut
effectuer des consultations en ligne ?
2
? Quel moyen pourrait faciliter les commandes des journaux
produits par l'éditeur les coulisses par ses consommateurs ?
0.2. HYPOTHESES D'ETUDE
Nos hypothèses se résument en quelques lignes
qui sont les suivantes :
? La mise en place d'un site web prenant en charge l'archivage
des journaux permettrait à l'éditeur de conserver tous les
numéros de journaux parus mais aussi de les rendre disponibles aux
consommateurs pour des éventuelles consultations en ligne.
? La commande des journaux en ligne ou sur internet à
partir d'un site web privé de la maison d'édition les Coulisses
faciliterait la tâche à un grand nombre des consommateurs
d'obtenir des journaux qui leur sont livrés à domicile mais aussi
à la maison d'édition d'élargir la plage de ses
clients.
0.3. CHOIX ET INTERET DU SUJET
En tant qu'étudiant finaliste du premier cycle en
faculté des Sciences Appliquées dans le département de
génie informatique, il est de notre devoir de présenter un
travail de fin de cycle dans le but de démontrer ce à quoi nous
avons été capables tout au long de notre parcours de ce cycle de
graduat. C'est ainsi que nous avons proposé le présent sujet, non
seulement qu'il est bénéfique pour nous seuls, mais aussi
bénéfique pour la communauté.
Le choix de ce sujet n'a pas été un simple
hasard, mais il a plutôt été motivé par des
intérêts que nous avons jugés non négligeables. En
effet, nous nous sommes engagés dans le domaine qui est celui de
l'ingéniorat en informatique pour qu'enfin de compte nous soyons en
mesure d'innover technologiquement dans notre communauté, dans des
entreprises qui nous entourent et partout ailleurs où nous pouvons
contribuer en apportant des solutions informatiques aux multiples
problèmes que nous y rencontrons. C'est ainsi que nous avons
estimé que le présent projet serait déjà une
illustration de notre apport dans le cadre de l'innovation technologique dans
cette entreprise d'édition des journaux.
Il serait aussi important de signaler un autre
intérêt qui nous concerne peut-être directement ; il est en
effet sur qu'à la fin de ce travail nous aurons puisé beaucoup
plus d'aptitudes et d'expériences dans le domaine de la programmation en
général et dans la
3
programmation web en particulier étant donné que
tout au long de ce premier cycle nous n'avons eu aucun cours qui cadre avec la
programmation sur le web. Ce travail nous permet donc de pousser des recherches
au delà même des cours que nous avons appris en classe.
0.4. DELIMITATION DU SUJET
En tant que travail scientifique, notre travail se trouve
délimité tant dans le temps, dans l'espace que dans la
matière à traiter. Voici donc la délimitation en quelques
lignes :
Délimitation dans le temps :
La réalisation du présent travail s'étend
sur une période allant de Janvier 2014 jusqu'au mois de juillet 2014 qui
sera enfin sanctionné par une soutenance en ce même mois de
juillet.
Délimitation dans l'espace :
Les études et recherches concernant le présent
travail se sont déroulées dans la ville de Beni, province du
Nord-kivu en République Démocratique du Congo. Nous nous sommes
limités à une seule entreprise qui est la maison d'édition
des journaux Les Coulisses se situant en ville de Beni.
Délimitation dans la matière :
Le sujet du présent travail étant
intitulé « Conception et implémentation d'une vitrine
web pour l'archivage et la commande en ligne des journaux dans une maison de
presse écrite : Cas de la maison Les Coulisses à Beni
», nous nous sommes fixés des délimitations dans la
matière.
En effet, le travail que nous nous sommes assigné de
réaliser consiste à réaliser un site web dynamique qui
prends en charge les commandes en ligne, l'archivage des journaux pour des
consultations en ligne et éventuellement la publicité. Il ne nous
sera pas facile d'inclure des services tels que les achats en ligne
étant donné le contexte des pays en voie de développement
où nous nous retrouvons. Mais néanmoins nous prévoyons des
abonnements semestriels pour des consultations en ligne des nouveaux ou anciens
numéros. C'est ainsi que nous ne prendrons pas en charge des achats avec
carte bancaire ou de mobile-banking , mais
4
nous prendrons en charge des abonnements pour des
consultations en ligne. Parler totalement d'achat en ligne serait peut
être la prochaine étape. Ce site pourra être, à part
les principales objectifs de ce travail, un site vitrine pour présenter
l'entreprise, partager la passion de l'entreprise et montrer la
différence qu'elle apporte dans le monde des éditeurs des
journaux.
0.5. SUBDIVISION DU TRAVAIL
Hormis l'introduction et la conclusion générale,
le présent travail est subdivisé en trois grands chapitres.
Le premier chapitre se porte sur les considérations
générales concernant le thème du travail. Ici nous
présentons les notions générales et indispensables pour la
compréhension du travail, mais aussi ce chapitre traite de la
présentation de l'entreprise dans laquelle nous avons mené nos
recherches.
Le deuxième chapitre porte de l'étude et analyse
avant conception. Il s'agit ici de présenter la structure et
l'architecture du site web, mais aussi nous allons présenter les
étapes suivies pour la modélisation de la base de données
qui conservera les données sur notre site web. Ce chapitre porte aussi
sur le choix de l'environnement de développement ou de programmation.
Enfin, le troisième chapitre porte sur
l'implémentation de la solution informatique qui est le site web. Ce
chapitre traite de la mise en oeuvre de la base de données sous MySQL,
il porte aussi sur la conception des pages web, de la connexion de la base avec
PHP et de démontrer quelques événements avec PHP et
JavaScript.
Voilà en quelque sorte la présentation sommaire
du travail que nous avons l'honneur de vous présenter.
5
0.6. METHODES ET TECHNIQUES UTILISEES
Tout chercheur effectuant un travail scientifique se sert
nécessairement d'une ou plusieurs méthodes et d'une ou plusieurs
techniques lui permettant de pousser le travail jusqu'au bout.
La méthode est considérée comme
étant un ensemble d'opérations mises en oeuvre pour atteindre un
ou plusieurs objectifs, un corps de principe président à toute
recherché organisée (Grawitz). C'est ainsi que le présent
travail n'étant pas du reste, il nous a été utile de
recourir à certaines méthodes qui ont dirigés nos
recherché dont notamment :
? La méthode analytique : Celle-ci a consisté
à faire une analyse du problème que nous avons eu à
résoudre et analyser le contexte dans lequel nous voulions effectuer nos
recherches.
? La méthode MERISE (Méthode d'Etude et de
Réalisation Informatique pour les Systèmes d'Entreprise) : Elle
nous a permis d'étudier notre système d'information d'une
façon standardisée en utilisant des étapes et normes
d'étude standards.
Parlant des techniques que nous avons eu à utiliser,
tout d'abord une technique de recherche est définie comme étant
un ensemble des moyens, et de procédés qui permettent à un
chercheur de rassembler les informations originales de première ou de
seconde main sur un sujet donné. Ce sont des instruments pour arriver
à un résultat. (André Masiala ma Solo, Guide du chercheur
en sciences humaines, 2012). C'est ainsi que nous avons utilisé les
techniques qui sont entre autre :
? La technique documentaire : Elle a consisté à
rassembler tous les documents et ouvrages utiles pour la rédaction du
travail, pour la programmation et l'implémentation de la solution
informatique.
? La technique d'interview : Elle nous a permis d'avoir l'avis
des personnes responsables de la maison Les Coulisses en ce qui concerne le
choix du contenu du dit site web, le choix et l'appréciation des
graphismes ainsi que l'ergonomie afin d'atteindre les objectifs et la vision de
l'entreprise.
6
0.7. DIFFICULTES RENCONTREES
Dans la réalisation de tout travail scientifique, l'on
s'est toujours heurté à des difficultés, selon le contexte
de travail ou selon l'environnement dans lequel on réalise ce travail et
le présent travail n'en est pas du reste.
Dans la réalisation de ce travail, nous avons
été obligés d'utiliser environ quatre langages de
programmation, ce qui nous a amené à les apprendre tous. Ceci n'a
pas été une chose facile surtout que l'apprentissage d'un langage
de programmation demande un temps de concentration et de pratique.
Mais aussi, le programme national ne prévoit aucun
cours de technologie web ni de programmation web dans le cycle de graduat dans
le département de Génie-Informatique en faculté de
Sciences Appliquées, ce qui nous a amené à nous auto
former dans ce domaine.
Nous avons aussi connu des problèmes liées
à l'accès à l'internet et ainsi l'accès aux
bibliothèques en ligne, des problèmes de courant
électrique se sont aussi présentés comme obstacles dans la
réalisation du présent travail étant donné que sa
grande partie nécessite un travail directement sur ordinateur.
7
1. GENERALITES
1.1. Présentation de la maison Les Coulisses
a.Dénomination, Siège et nature du
journal
L'organe de presse sur lequel se sont basées nos
recherches est dénommé Les Coulisses. Il s'agit bien d'un journal
bimensuel francophone et spécialiste des grands lacs.
Le siège du journal Les Coulisses se situe au n° 37 du
Boulevard Nyamwisi dans la concession Dokolo en commune Beu, ville de Beni
(Nord-Kivu, République Démocratique du Congo). Ce siège
abrite la Rédaction Centrale du journal précité.
Ce bimensuel traite et analyse les informations de la RD Congo
et particulièrement celles du Nord-est en évaluant, à
partir des faits, les influences des pays voisins, pour mener des études
sur les phénomènes géopolitiques qui entourent et
focalisent le vécu quotidien de la population des Grands Lacs. Pour un
cas illustratif, en parlant de la flambée du prix des produits
pétroliers, le journaliste fera mention des problèmes
pétroliers des pays voisins (taxes, pénurie de ces produits,...)
susceptibles d'en influencer le prix.
b.Statut juridique
En juin 1995 à Kinshasa l'autorisation de
paraître no MIP/ marque la création du journal Les Coulisses, qui
était alors un hebdomadaire privé de huit pages imprimé en
noir et blanc. Aujourd'hui il est publié sous le
récépissé de la Déclaration de publication no
04/CAB/MIN/PRESS&INFO /024/2004. Cet organe de presse congolais à
part entière est une SPRL.
c.Historique du journal :
Le journal Les Coulisses fut créé en juin 1995
à Kinshasa. Dans ses débuts il était dénommé
Les Coulisses hebdo, la totalité ou, à défaut, l'essentiel
du travail étant concentré à Kinshasa. Pas de journalistes
à l'intérieur du pays (et à l'étranger).
En 1998 la Rédaction Centrale se voit, suite à
la guerre, transférée à Goma, et c'est alors que le
journal prend la dimension de spécialiste des Grands Lacs. Pour les
mêmes raisons-les impératifs de la guerre-et d'une façon
non voulue, la Rédaction Centrale du journal est une
8
fois encore transférée à Beni en 2000
dans un environnement où la liberté de la presse était
inexistante.
Une fois à Beni, Les Coulisses crée des
permanences dans tout le Nord-est de la RD Congo, alors qu'à Goma il
n'en existait que deux : l'une à Kisangani et l'autre à
Bukavu.
d. Du fonctionnement du journal
? La Rédaction Centrale
La Rédaction Centrale du journal Les Coulisses se situe
à Béni sur Boulevard Nyamwisi no 37. Elle est assurée par
l'Editeur Directeur de Publication du journal. Ce service recherche et collecte
les informations au niveau de, compile celles provenant des permanences et des
correspondants, les sélectionne et en fin les met en forme en vue de
leur publication. Ce service joue à la fois le rôle de
Secrétariat de Rédaction et de Rédaction Centrale.
? Le service technique
Le service technique s'occupe des nouvelles technologies de
l'information et de la communication au niveau du journal. Dans les
attributions de ce service figure la saisie des articles (saisie et scannage),
leur mise en page, la fabrication et le maquettage du journal, tout sous la
supervision du Directeur de Publication.
? Le service administratif et financier
Ce service s'occupe de l'administration et de la finance du
journal (tenue de compte, budget, paie des agents,...). Il est aussi en
relation directe avec les permanences.
? Le service de distribution et de vente
C'est ce service qui reçoit les journaux dès
leur arrivée au Congo-car ils sont imprimes en Ouganda- les distribue
aux points de vente de la ville de et en expédie aux permanences
disséminées à travers le pays. Il assure le recouvrement
des journaux dans les points de vente (et les permanences) et se charge de la
communication entre la Rédaction Centrale et les permanences.
9
? Les permanences
Les permanences de Les Coulisses sont ses petites
rédactions se trouvant dans les villes du territoire national où
opèrent les correspondants du journal. Elles forment des
rédactions entières avec tout le matériel permettant
à un journaliste de remplir les missions qui lui sont révolues.
Avec un pouvoir limité, ces permanences assurent la
représentation du journal dans leurs milieux d'implantation.
? L a Réception
Le maintien de l'ordre et de la propreté dans les
locaux sont les tâches dévolues à l'agent chargé de
la Réception.
? Les ressources humaines
Le personnel du journal est très réduit, cela
pour des raisons d'efficacité. Ils sont des agents permanents, des
journalistes et d'autres personnes qui prennent part à la
réalisation du journal. Dans son souci de mieux servir ses lecteurs le
journal accorde une place de choix à l'autoformation. Il sied de
souligner que la difficulté de trouver des personnes qui acceptent
d'oeuvrer dans la pesse écrite justifie ce nombre réduit des
journalistes.
? Les ressources matérielles et
financières
La rédaction Centrale du journal Les Coulisses dispose
de deux locaux et d'une salle pour la mise à niveau du personnel, une
petite salle hébergeant les machines(NTIC), une bibliothèque
à jour, etc. Partant du principe selon lequel le journal est
indépendant et qu'il se veut objectif et impartial, Les Coulisses doit
produire ses propres moyens de financement. Ses ressources financières
proviennent de la vente des journaux, des interviews, des reportages, des
abonnements et, dans une certaine mesure, de la publicité.
10
e. Organigramme
EDITEUR DIRECTEUR DE PUBLICATION
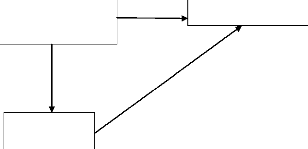
PERMANENCES HORS BENI
SERVICE DE
VENTE ET DISTRIBUTION
REDACTION CENTRALE
SERVICES DE VENTE ET DISTRIBUTION
SERVICE TECHNIQUE ET COMMERCIAL
Fig1. : Organigramme de la maison les Coulisses.
11
1.2. Notion sur le WEB et sur les technologies WEB
1.2.1. L'internet
L'histoire de l'Internet commence avec le démarrage de
recherches en 1969 menées par le département des " projets
avancés " de l'armée américaine qui s'appelait à
l'époque Arpa (et qui s'appelle maintenant Darpa, Defence advanced
research project agency). Il s'agissait alors de relier entre eux des
ordinateurs dans différents centres de recherche en mettant en place un
système de transmission permettant à un terminal unique d'avoir
accès aux ordinateurs distants.
Ce réseau de transmission, appelé ARPANET (Arpa
network, ou réseau Arpa) a vu le jour à l'Université de
Californie à Los Angeles (UCLA) et reliait au début seulement
trois ordinateurs.
Les premiers essais en " vraie grandeur " impliquant une
quinzaine d'ordinateurs à UCLA, SRI, MIT, Harvard, etc., eurent lieu en
1971.
Le travail sur les réseaux en France a
démarré à cette époque par la mise en oeuvre du
réseau Cyclades. Ce réseau avait adopté la technologie de
transmission de données par datagramme similaire à celle de
l'Arpanet mais il n'était pas relié à l'Arpanet.
Dès 1972, un groupe de travail a été mis en place afin
d'étudier une architecture permettant l'interconnexion des
réseaux. Et en 1973, Vint Cerf et Bob Kahn inventèrent le concept
d'Internet. L'idée était d'interconnecter les différents
réseaux par des passerelles et de relayer les messages de réseau
à réseau. Le protocole utilisé par les passerelles fut
appelé le protocole IP (Internet Protocol). La première version
du protocole IP fut publiée en 1978, mais la version devenue standard
(version 4) a été achevée en 1981.
L'utilisation du protocole IP permettant d'interconnecter des
réseaux auparavant isolés, le développement de
technologies de réseaux locaux rapides et peu chers (réseaux
Ethernet), et le développement d'applications multiples (courrier
électronique, transfert de fichiers distants, etc), ont rapidement rendu
l'utilisation des réseaux " intéressante " puis " indispensable
". Ainsi, plus de 1000 ordinateurs étaient déjà
raccordés à l'Arpanet en 1984. En 1986, la NSF (National Science
Foundation) a mis en place un nouveau réseau, le NSFnet, qui agissait
comme une épine dorsale (backbone) couvrant les États-Unis et
reliant entre eux les différents réseaux déjà
existants. Le débit auquel les messages pouvaient être
envoyés sur ce
12
réseau était de 56 000 bits par seconde (56
kb/s). Ce débit paraissait considérable à l'époque,
bien qu'il soit à peine le double du débit des modems disponibles
sur n'importe quel PC récent (sachant en plus que ce débit
était partagé par tous les utilisateurs du
réseau).1
1.2.2. Le WEB
Depuis ces dernières années, les technologies de
l'information et de la communication ont tellement évolué ;
surtout avec l'apparition de l'internet et du WEB. Ces innovations ont
révolutionné le monde des NTIC en rendant disponible une vaste
étendue d'informations présentées sous forme d'archives de
magazines, de pages de livres de bibliothèques publiques et
universitaires, de documentation à usage professionnel,
etc. au grand public du monde entier en
facilitant la consultation des sites internet.
Le World Wide Web (WWW ou W3), appelé plus couramment
le Web, a été développé en 1991 par des
informaticiens, le Britannique Timothy Berners-Lee et le Belge Robert Cailliau,
tous deux chercheurs du Laboratoire européen de physique des particules
(CERN) à Genève. Au départ, cette interface avait pour but
de favoriser le partage d'informations entre des équipes de chercheurs
dispersées dans le monde entier. Mais rapidement, le Web a fait office
de plate-forme internationale pour le développement de logiciels
apparentés, tandis que le nombre d'ordinateurs et d'utilisateurs
connectés s'est accru considérablement. Aujourd'hui, le
rôle principal du Web est d'être la « fenêtre »
d'Internet. Son développement est géré par le consortium
WWW (ou W3C) situé au Massachusetts Institute of Technology
(MIT).2
Le web a été inventé plusieurs
années après Internet, mais c'est lui qui a contribué
à l'explosion de l'utilisation d'Internet par le grand public,
grâce à sa facilité d'emploi. Depuis, le Web est
fréquemment confondu avec Internet alors qu'il n'est en
réalité qu'un de ses services. C'est ainsi qu'il nous importe de
parler brièvement d'une petite historique de l'internet d'abord puis du
web. Le principe de web repose sur l'utilisation d'hyperliens pour naviguer
entre des documents (appelés «pages web»)
grâce à un logiciel appelé. Une page web est ainsi un
simple fichier texte écrit dans un langage de description (appelé
HTML), permettant de décrire la mise
1 Histoire de l'internet sur
http://fr.wikipedia.org/wiki/Histoire_d%27Internet
2 Microsoft ® Encarta ® 2009. (c) 1993-2008 Microsoft
Corporation. Tous droits réservés.
13
3Philippe RIGAUX (2009). Pratique de MySQL et PHP :
Conception et réalisation des sites web dynamiques, Paris,
édition DUNOD, 4e éd, p4.
en page du document et d'inclure des éléments
graphiques ou bien des liens vers d'autres documents à l'aide de
balises.
Au-delà des liens reliant des documents
formatés, le web prend tout son sens avec le protocole HTTP permettant
de lier des documents hébergés par des ordinateurs distants
(appelés serveurs web, par opposition au client que représente le
navigateur). Sur Internet les documents sont ainsi repérés par
une adresse unique, appelée URL, permettant de localiser une ressource
sur n'importe quel serveur du réseau internet.
Serveurs WEB :3
Un site est constitué, matériellement, d'un
ordinateur connecté à l'Internet, et d'un programme tournant en
permanence sur cet ordinateur, le serveur. Le programme serveur est en
attente de requêtes transmises à son attention sur le
réseau par un programme client. Quand une requête est
reçue, le programme serveur l'analyse afin de déterminer quel est
le document demandé, recherche ce document et le transmet au programme
client. Un autre type important d'interaction consiste pour le programme client
à demander au programme serveur d'exécuter un programme, en
fonction de paramètres, et de lui transmettre le résultat.
La figure ci-dessous illustre les aspects essentiels d'une
communication web pour l'accès à un document. Elle s'effectue
entre deux programmes. La requête envoyée par le programme client
est reçue par le programme serveur. Ce programme se charge de rechercher
le document demandé parmi l'ensemble des fichiers auxquels il a
accès, et transmet ce document.
14
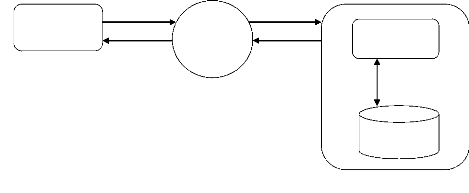
Machine du serveur
Fig2. : Architecture WEB.
Programme client
Machine Cliente
Requêtes
Internet
Document
Programme Serveur
Document(s)
Documents
Protocol http:
Les architectures WEB offrent de nombreuses solutions pour
faire communiquer le navigateur Web avec l'environnement serveur. Ces solutions
peuvent être distinguées de façon suivante:
? Un protocole standard, http, qui permet le transport d'un
langage de présentation (HTML) et de contenus.
? Des protocoles propriétaires, utilisant les
capacités d'évolution du navigateur grâce à l'ajout
de composants lourds (applets, Winforms ou plugins).
Toutes les ressources disponibles sur le Web peuvent être
atteintes grâce à une URL (Uniform Ressource Locator). Cette URL
est constituée avec un schéma générique dont
découlent les URL utilisées dans la communication HTTP:
Protocole://user:password@host:port/path?querystring#fragment
Légende:
- Protocole : protocole d'accès (HTTP, FTP, etc.)
- User, password : infos d'authentification de l'utilisateur,
lorsqu'on utilise les modes
d'authentification propres au protocole (par exemple le mode
BASIC pout HTTP).
- Host : adresse internet de la machine (IP ou nom de
domaine).
- Port : port à ouvrir (facultatif).
15
- Path : chemin vers la ressource.
- Querystring : paramètres de requête
(facultative).
- Fragment : référence vers une zone de la
ressource, si celle-ci est du code HTML.
HTTP est un protocole du niveau application du modèle
OSI, au même titre que les protocoles FTP ou telnet. Les principaux
avantages sont sa simplicité de mise en oeuvre et son
accessibilité.
1.2.3. Les standards du WEB
Le W3C (World Wide Web Consortium) et d'autres groupes et
organismes de standardisation ont établi des technologies pour la
création et l'interprétation du contenu Web. Ces technologies,
que nous appelons «standards du Web», ont été
conçues pour offrir tous les avantages du Web au plus grand nombre tout
en s'assurant de la pérennité de tous les documents
publiés sur le Web.
Les normes W3C définissent une plate-forme Web ouverte
pour le développement d'applications qui a le potentiel sans
précédent pour permettre aux développeurs de créer
des expériences interactives riches, alimentés par de vastes
magasins de données, qui sont disponibles sur n'importe quel appareil.
Bien que les limites de la plate-forme ne cessent d'évoluer, les
dirigeants de l'industrie parlent presque à l'unisson sur la
façon dont HTML5 sera la pierre angulaire de cette plate-forme. Mais
toute la force de la plate-forme repose sur beaucoup plus de technologies que
le W3C et ses partenaires créent, y compris CSS, SVG, WOFF, la pile du
Web sémantique, XML, et une variété d'API.4
Concevoir des sites Web avec ces standards est plus simple
qu'avant leur avènement et contribue à réduire les
coûts de production, tout en offrant des sites accessibles à une
plus large audience et une plus grande diversité de moyens
d'accès à Internet. Les sites développés en suivant
ces principes continueront à fonctionner correctement avec les
navigateurs traditionnels sur les ordinateurs de bureau, alors que de nouveaux
outils d'accès à Internet apparaissent sur le marché.
4 The WEB standards :
http://www.w3.org/standards/
16
a. Le HTML:
HTML (Hypertext Markup Language) et CSS (Cascading Style
Sheets) sont deux des technologies de base pour la création des pages
Web. HTML fournit la structure de la page, la mise en page CSS (visuelle et
auditive), pour une variété de dispositifs. Avec des graphiques
et des scripts, HTML et CSS sont à la base de la construction des pages
Web et des applications Web.
HTML est le langage pour décrire la structure des pages
Web. HTML donne aux auteurs les moyens de publier des documents en ligne avec
des titres, du texte, des tableaux, des listes, des photos, etc.; de
récupérer des informations en ligne via les liens hypertextes, au
clic d'un bouton ; de concevoir des formes pour effectuer des transactions avec
des services à distance, pour une utilisation dans la recherche
d'informations, faire des réservations, commander des produits, etc.
;d'inclure des fiches réparties, des clips vidéo, des clips audio
et d'autres applications directement dans leurs documents. Avec le HTML, les
auteurs décrivent la structure des pages à l'aide de balises. Les
éléments des pièces d'étiquettes de langue de
contenu tels que «paragraphe», «liste», «table»,
et ainsi de suite.
HTML est une des trois inventions à la base du
World Wide Web, avec le Hypertext Transfer Protocol (HTTP) et les adresses
web. HTML a été inventé pour pouvoir écrire des
documents hypertextuels liant les différentes ressources d'Internet avec
des hyperliens. Aujourd'hui, ces documents sont appelés « page web
». En août 1991, lorsque Tim Berners-Lee annonce publiquement le web
sur Usenet, il ne cite que le langage SGML, mais donne l'URL d'un document de
suffixe .html. Dans son livre Weaving the web, Tim Berners-Lee
décrit la décision de baser HTML sur SGML comme étant
aussi « diplomatique » que technique : techniquement, il trouvait
SGML trop complexe, mais il voulait attirer la communauté hypertexte qui
considérait que SGML était le langage le plus prometteur pour
standardiser le format des documents hypertexte. En outre, SGML était
déjà utilisé par son employeur, l'Organisation
européenne pour la recherche nucléaire (CERN). Les premiers
éléments du langage HTML comprennent le titre du document, les
hyperliens, la structuration du texte en titres, sous-titres, listes ou texte
brut, et un mécanisme rudimentaire de recherche par index. La
description de HTML est alors assez informelle et principalement définie
par le support des
17
divers navigateurs web contemporains. Dan Connolly a
aidé à faire de HTML une véritable application de SGML.
C'est quoi le XHTML ?5
XHTML est une variante du HTML qui utilise la syntaxe de XML
(Extensible Markup Language). Le XHTML a tous les éléments du
HTML standard, mais la syntaxe est un peu différente. Comme XHTML est
une application du XML, il peut aussi utiliser quelques outils du XML tel que
le XSLT qui est un langage de transformation de contenu XML.
Le XHTML permet d'améliorer l'accessibilité des
sites internet. L'accessibilité c'est quoi? L'accessibilité,
c'est la capacité à accéder un site Internet via n'importe
quel logiciel capable de naviguer sur un site web : les navigateurs web
traditionnels (firefox, internet explorer, safari...) mais aussi les appareils
de synthèse vocale utilisées par les handicapés, les
navigateurs des téléphones mobiles, le navigateur de mon
frigidaire (qui me proposera d'acheter des oeufs en ligne quand je serai
à cours) ou le navigateur intégré au tableau de bord de ma
voiture (qui peut-être dans un futur proche me proposera une
réservation en ligne d'une chambre de l'hôtel le plus proche),
etc.
L'utilité du XHTML, c'est de réaliser un site et
un site seulement, de manière à ne pas décliner autant de
sites qu'il existe de logiciels capables de naviguer sur un site internet.
Les cinq règles de syntaxe XHTML6
:
y' Toute balise ouvrante doit obligatoirement être
fermée, et les balises dites «vides» sont
écrites avec une barre oblique finale (exemple: <br
/>).
Juste : <span>xhtml</span>
Faux : <span>xhtml<span>
y' Les balises et les attributs doivent être écrits
en minuscule.
Juste : <a href="
http://xhtml.le-developpeur-web.com"
title="xhtml">XHTML</a>
Faux : <A href="
http://xhtml.le-developpeur-web.com"
TITLE="xhtml">XHTML</a>
5 What is XHTML? Sur
http://www.w3.org/standards/webdesign/htmlcss
6Les 5 règles de syntaxe XHTML sur
http://xhtml.le-developpeur-web.com/
18
y' Les valeurs des attributs doivent être entre
guillemet ou apostrophe.
Juste : <span id="monSpan"
class='spanXhtml'>xhtml</span>
Faux : <span id=monSpan
class=spanXhtml>xhtml</span>
y' Chaque attribut doit avoir une valeur.
Juste : <input type="checkbox" cheched="checked" />
Faux : <input type="checkbox" checked />
y' Chaque élément doit être
imbriqué correctement.
Juste : <p>j'aime le
<strong>xhtml</strong></p>
Faux : <p>j'aime le
<strong>xhtml</p></strong>
b. Le CSS:7
CSS est le langage utilisé pour décrire la
présentation des pages Web, y compris les couleurs, mise en page et les
polices. Il permet d'adapter la présentation de différents types
d'appareils, tels que les grands écrans, les petits écrans ou des
imprimantes. CSS est indépendante du langage HTML et peut être
utilisé avec n'importe quel langage de balisage basé sur XML. La
séparation de code HTML CSS rend plus facile à maintenir les
sites, les feuilles de style de l'action à travers des pages et des
pages sur mesure à des environnements différents. Ceci est
désigné comme la séparation de la structure (ou: teneur)
de présentation.
Pour résumer grossièrement l'histoire, CSS est
né en 1996. Grâce à la guerre des navigateurs, qui
commençait déjà à cette époque, les normes
qu'il imposait furent vite l'objectif à atteindre. En effet, chaque
navigateur refusait que ses concurrents puissent s'affirmer comme étant
les plus conformes!
Mais ce n'est qu'en 2000, soit quatre ans plus tard, que
Microsoft réussit le premier à respecter plus de 99% des normes
de CSS1 avec Internet Explorer 5. En parallèle, CSS2 a vu le jour en
1998. Malheureusement trop ambitieux avec des idées comme des affichages
en braille ou des rendus vocaux, le W3C a dû revoir ses objectifs
à la baisse dès 2001 avec un niveau de
correction : CSS2.1. De nouveaux sélecteurs, de
nouvelles propriétés. A force de travail, ce n'est qu'en 2007 que
CSS2.1 devient une recommandation candidate. Un peu comme les logiciels qui
7 What is CSS ? sur
http://www.w3.org/standards/webdesign/htmlcss
19
peuvent avoir une version release candidate, CSS2.1 était
devenue stable, prêt à sortir pour de bon, mais pouvant contenir
encore quelques bogues. Neuf ans après sa création, on n'avait
toujours pas une version 100% stable de CSS2 !
Ce n'est que le 7 Juin 2011 que le W3C a officialisé
ses recommandations : ce n'est que depuis cette date que nous sommes
censés utiliser les propriétés CSS2.1 sans risque de
bogues.
Le développement de CSS3 s'est fait en parallèle
de CSS2.1, dès 1999. Et oui, si tôt ! Selon certaines personnes,
il s'agirait d'une erreur de la part du W3C : établir les normes de deux
niveaux différents mais complémentaires est loin d'être
aisé, il suffit de voir la date de recommandation officielle de CSS2.1
pour s'en rendre compte! Mais maintenant que ce dernier est enfin
finalisé, il ne fait aucun doute que CSS3 sera le prochain objectif du
W3C.8 Il est bien sur à noter que le CSS3 est
déjà implémenté dans presque toutes les
dernières versions des navigateurs répandus tel que Mozila,
Webkit, Operamini, Internet Explorer9, Safari, etc.
c. Le DOM9
Définit comme Document Object Model ou en
français modèle de description de documents
spécifié par le W3C et permettant d'accéder au contenu de
documents HTML et XML. Le Document Object Model est une plate-forme et une
interface de langage neutre qui permettra aux programmes et aux scripts
d'accéder dynamiquement et de mettre à jour le contenu, la
structure et le style des documents. Le document peut être encore
traité et les résultats de ce traitement peuvent être
incorporés de nouveau dans la page présentée. Il s'agit
d'une vue d'ensemble des matériaux DOM liés ici au W3C et sur le
web.
Pourquoi le DOM ?
Le « HTML dynamique » est un vocable utilisé
par centaines personnes pour décrire la combinaison du HTML, feuilles de
style mais aussi des scripts qui permettent l'animation des documents. Le W3C a
reçu plusieurs soumissions et propositions sur la façon dont le
modèle objet des documents HTML devrait être exposé aux
scripts. Ces soumissions ne proposent aucune nouvelle étiquette du HTML
ou une nouvelle technologie pour les feuilles de style.
8Un peu d'histoire :
http://fr.openclassrooms.com/informatique/cours/stylisez-votre-site-avec-
css3/avant-de-commencer-21#r-1615305
9 What is the Document Object Model? Sur
http://www.w3.org/DOM/
20
Le W3C DOM Activity est en train de travailler dur pour
s'assurer de l'interopérabilité et de solutions neutres de
langages de scriptage sont pris en convention. DOM permet de construire une
arborescence de la structure d'un document et de ses éléments. Il
est donc préférable de parcourir et de mémoriser
l'intégralité du document avant de pouvoir effectuer les
traitements voulus. Pour cette raison, les programmes utilisant DOM ont souvent
une empreinte mémoire volumineuse en cours de traitement. À
l'inverse, à partir d'un arbre DOM donné, il est possible de
générer des documents dans le langage de balisage voulu, qui
pourront à leur tour être manipulés par l'interface DOM.
DOM est utilisé pour pouvoir modifier facilement des documents XML ou
accéder au contenu des pages web.
Evolution du DOM :
Avant sa standardisation par le W3C, chaque navigateur web
disposait de son propre Document Object Model. Si le langage de base
destiné à manipuler les documents web a vite été
standardisé autour de JavaScript, il n'en a pas été de
même pour la série précise de fonctions à utiliser
et la manière de parcourir le document. Par exemple, lorsque Netscape
Navigator préconisait de parcourir un tableau indexé nommé
document.layers[], Internet Explorer l'appelait plutôt document.all[], et
ainsi de suite. En pratique, cela obligeait à écrire (au moins)
deux versions de chaque morceau de script si l'on voulait rendre son site
accessible au
plus grand nombre. La standardisation de ces techniques s'est
faite en plusieurs étapes,
lesquelles étendent chaque fois les
possibilités précédentes sans jamais les remettre en
cause. - Le DOM 1 :
La première est le DOM Level 1 publié en 1998
(le niveau 0 étant considéré comme l'implémentation
de base figurant dans Netscape Navigator 2.0), où le W3C a défini
une manière précise de représenter un document (en
particulier un document XML) sous la forme d'un arbre. Chaque
élément généré à partir du balisage
comme, dans le cas de HTML, un paragraphe, un titre ou un bouton de formulaire,
y forme un noeud. Est également définie une série de
fonctions permettant de se déplacer dans cet arbre, d'y ajouter,
modifier ou supprimer des éléments. En plus des fonctions
génériques applicables à tout document structuré,
des fonctions particulières ont été définies pour
les documents HTML, permettant par exemple la
21
gestion des formulaires. Le DOM Level 1 a été
disponible dans sa plus grande partie dès les premières versions
d'Internet Explorer 5 et de Netscape 6.
- Le DOM 2 :
La seconde étape est le DOM Level 2 (publié en
2000), à présent constitué de six parties (en plus de
Core et HTML, on trouvera Events, Style,
View et Traversal and Range). Dans les évolutions de la
brique de base (Core), on notera la possibilité d'identifier plus
rapidement un noeud ou un groupe de noeuds au sein du document. Ainsi, pour
obtenir un élément particulier on ne le recherchera plus dans un
tableau comme dans les DOM propriétaires précédents, mais
on appellera la fonction getElementById().
- Le DOM 3 et 4 :
Le troisième niveau, publié au printemps 2004, a
ajouté le support de XPath, la gestion d'événements
clavier, et une interface de sérialisation de documents XML. Le
quatrième niveau est en cours de développement, le Last Call
Working Draft ayant été diffusé en février
2014.
1.2.4. Les Technologies WEB :
a. La technologie ASP :10
Active Server Pages (ASP)
est un ensemble de logiciels développés par Microsoft et
utilisés dans la programmation Web.
C'est une suite de logiciels destinée à
créer des sites web dynamiques. Elle nécessite pour fonctionner
une plate-forme Windows avec IIS installé, ou encore une plate-forme
Linux ou Unix avec une version modifiée d'Apache. ASP est une structure
composée d'objets accessibles par deux langages principaux : le VBScript
et le JScript. Il est possible d'utiliser d'autres langages comme le
PerlScript, le REXX, ou encore le Python en ajoutant le moteur
10 Active Server Pages sur
http://fr.wikipedia.org/wiki/Active
Server Pages
ASP.NET permet aux développeurs de
passer plus facilement du développement classique d'applications Windows
au développement d'applications Web en offrant la
22
d'interprétation du langage adéquat à
IIS. À l'inverse de certains langages de programmation (C, C++), cette
technologie n'utilise pas de langages compilés, mais des langages
interprétés. L'ASP utilise COM (aussi appelé ActiveX) pour
communiquer avec des ressources du poste serveur. Il renvoie ensuite de l'HTML
au client via le protocole HTTP.
L'ASP est capable de se connecter à des bases de
données, de lire des fichiers XML et possède des composants pour
la gestion de l'upload (téléchargement), du FTP... Il peut lire
et écrire des documents issus d'Office (Excel, Word...) en passant par
le système COM (Component Object Model, standard de gestion d'objets
distribués, propre à Microsoft), si Office est installé
sur le serveur. Du reste, d'autres langages (comme PHP) peuvent
également utiliser la technologie COM, à condition de tourner
également sur un serveur Windows où les produits Office sont
installés.
Enfin, depuis la technologie .NET, l'ASP est devenu l'ASP.NET.
Bien qu'ASP.NET tienne son nom de l'ancienne technologie de
développement de Microsoft, "ASP", les deux sont assez
différentes. Microsoft a complètement repensé
ASP.NET, en se basant sur le Common
Language Runtime (CLR) partagé par tous les logiciels Microsoft .NET.
Les programmeurs peuvent écrire du code
ASP.NET en utilisant n'importe lequel des
langages de programmation supportés par le Framework .NET,
généralement CU, Visual
Basic.NET,
Delphi.NET ou JScript .NET, mais aussi
d'autres langages "indépendants" de Microsoft tels que Perl et
Python. ASP.NET est, d'après
Microsoft, censé avoir de meilleures performances que d'autres
technologies basées sur des scripts car le code côté
serveur est compilé en quelques simples DLL sur le serveur Web. Lors du
développement, quand le code source est finalisé, la solution est
précompilée avant d'être placée sur le serveur
d'hébergement (publication).
23
possibilité de créer des pages Web
composées de Widget11 (ou zone de contrôle) similaires
à celles des interfaces d'applications Windows habituelles.
b. La technologie PHP:12
Le langage PHP est né en 1994 d'un programme en langage
Perl écrit par Rasmus Lerdorf pour analyser les visites de son CV en
ligne. Il réécrit l'application en langage C puis ouvre son
programme à la communauté du Libre. Ainsi, il pourra
désormais compter sur l'aide de nombreux développeurs. Son
application PHP fusionne avec un moteur de traitement de formulaires, FI, ce
qui donne la version 2. Avec la version 3, les fonctions deviennent nombreuses
et la popularité grandit.
Le PHP est un langage de script en Open Source né en
1994 par Rasmus Lerdorf. PHP signifie tout simplement Personal Home
Page. Sa syntaxe simple (héritée du C et du Perl) et ses
fonctions particulièrement adaptées aux applications Web lui
confèrent une grande productivité. Son excellente documentation
et la profusion des sites qui lui sont consacrés contribuent à la
rapidité de développement.
Parmi les nombreux atouts de PHP il faut noter sa grande
richesse fonctionnelle : PHP dispose d'un grand nombre d'extensions
(disponibles en standard) qui couvrent la totalité des besoins relatifs
aux applications Web (l'ensemble des bases de données, mail, PDF, XML,
LDAP, etc.).
PHP offre aussi des extensions et des librairies pour la
connexion ou l'utilisation d'autres technologies (Java, COM, .NET, Lotus, ...),
ce qui lui donne une très grande interopérabilité et
permet l'implantation d'applications fonctionnant avec PHP dans la plus grande
partie des systèmes d'informations.
PHP est entièrement gratuit, librairies et extensions
comprises (à la différence de langages comme ASP où le
noyau gratuit est très limité et où tout ajout de
composants (upload, mail, crypter des mots de passe, ...) nécessite
leurs achat).
11 Un Widget est un élément
d'une interface graphique à l'exemple des boutons, menus, fenêtre,
etc. (Dictionnaire Jargon Informatique).
12 Jean CARFANTAN, 2009 pp18
24
PHP est portable et s'installe sur quasiment tous les
systèmes d'exploitation et avec les principaux serveurs Web (Apache,
IIS, Iplanet, ...). Au niveau des performances, PHP est 3 à 4 fois plus
rapide que JSP, 3 fois plus rapide que Coldfusion, et 1,5 à 3 fois plus
rapide que le langage ASP. A noter que ces performances sont celles obtenues
avec une simple installation standard de PHP.
En résumé, PHP réduit les coûts de
développement et d'hébergement, il est puissant et performant.
PHP se distingue aussi des outils concurrents du fait que :
? PHP a été créé pour
répondre aux besoins des sites à fort trafic et pour simplifier
le développement.
? PHP est facile d'utilisation : le gain de
productivité des équipes de développement est
important.
? PHP est issu de l'Open Source : les avancées
technologiques sont rapides, le code est de qualité supérieure,
de nombreuses bibliothèques sont déjà écrites et le
support et la documentation sont hors du commun.
? PHP est entièrement gratuit.
Ceci explique que la part de marché de PHP ne cesse de
croître et que la base installée augmente de plus de 20% par
trimestre depuis deux ans. De nombreuses sociétés prestigieuses
ont déjà choisi PHP pour leurs sites web, leurs portails, et
leurs applications critiques : Google, Cisco, France Telecom, Lycos, Vodafone,
Motorola, Siemens, Ericsson, Philips, Air Canada, AirLib, Lufthansa, Deutsche
Bank, NASA, W3C, WorldCom, RedHat, Winamp, Cap Gemini, Siemens, Unilever, US
Army, et bien d'autres.13
c. La technologie JSP :
La technologie JSP permet de séparer la
présentation sous forme de code HTML et les traitements écrits en
Java sous la forme de JavaBeans (composant logiciels écrits en java) ou
de servlets. Ceci est d'autant plus facile que les JSP définissent une
syntaxe particulière permettant d'appeler un bean et d'insérer le
résultat de son traitement dans la page HTML
13 PHP :
http://www.digifactory.fr/info/service.php?docid=308
25
dynamiquement. Les JSP permettent d'introduire du code Java
dans des tags prédéfinis à l'intérieur d'une page
HTML. La technologie JSP mélange la puissance de Java côté
serveur et la facilité de mise en page d'HTML côté client.
Concrètement, les JSP sont basées sur les servlets. Au premier
appel de la page JSP, le moteur de JSP génère et compile
automatiquement une servlet qui permet la génération de la page
web. Le code HTML est repris intégralement dans la servlet. Le code Java
est inséré dans la servlet. C'est quoi une Servlet ? Un servlet
c'est une applet (petit programme conçu pour être
téléchargé via un réseau à chaque fois qu'on
veut l'utiliser et c'est le navigateur qui se charge de l'exécuter)
destinée à être exécutée du coté
serveur et non du cote client.
Versions de JSP14 :
|
Version
|
|
|
0.91
|
Première release
|
|
1.0
|
Juin 1999: première version finale lié à
l'API servlet 2.1
|
|
1.1
|
Décembre 1999 lié à l'API servlet 2.2
|
|
1.2
|
Octobre 2000, JSR 053 lié à l'API servlet 2.3
|
|
2.0
|
Novembre 2003, JSR 152 lié à l'API servlet 2.4
|
|
2.1
|
Mai 2006, JSR 245 lié à l'API servlet 2.5
|
|
2.2
|
Décembre 2009, Maintenance release de la JSR 245
lié à l'API servlet 3.0
|
|
2.3
|
Juin 2013, Maintenance release de la JSR 245 lié à
l'API servlet 3.1
|
14 Les JSP (Java Server Pages) :
http://www.jmdoudoux.fr/java/dej/chap-jsp.htm
26
d. AJAX15:
Ajax se place dans la droite ligne du Web 2.0 car il permet
aux internautes de disposer d'interfaces riches semblables à celles des
logiciels de bureau. L'architecture informatique Ajax (acronyme d'Asynchronous
JavaScript and XML) permet de construire des applications Web et des sites web
dynamiques interactifs sur le poste client en se servant de différentes
technologies ajoutées aux navigateurs web entre 1995 et 2005.
Contrairement à ce que l'on pourrait croire, Ajax n'est pas une
technologie spécifique et innovante mais une conjonction de plusieurs
technologies anciennes. Ainsi, les applications.
Ajax utilisent en général tout ou partie des
technologies suivantes :
· Les feuilles de styles CSS qui permettent d'appliquer
une mise forme au contenu d'une page XHTML.
· Le DOM qui représente la hiérarchie des
éléments d'une page XHTML.
· L'objet XMLHttpRequest de JavaScript qui permet
d'assurer des transferts asynchrones (ou quelquefois synchrones) entre le
client et le serveur.
· Les formats de données XML ou JSON
utilisés pour les transferts entre le serveur et le client.
· Le langage de script client JavaScript qui permet
l'intraction de ces différentes technologies.
p.22.
15 Jean-Marie De France(2008), Premières
applications WEB 2.0 avec AJAX et PHP, Paris, Ed. Eyrolles,
27
2. ETUDE ET ANALYSE DU SYSTEME POUR CONCEPTION
2.1. Architecture et structure du site web
a. Arborescence du site :
L'arborescence est un plan du site, un schéma de la
structure et de l'organisation des contenus. Elle identifie les
différentes pages et sections d'un site, ainsi que les liens entre
elles. Son objectif est d'organiser l'information à communiquer de
façon logique et hiérarchisée. Elle donne une vue
d'ensemble du site Web.
Dans cette section nous présentons l'arborescence
préliminaire du site web qui pourra bien sur être évolutif
selon les nouveaux besoins qui auront à se présenter. Il s'agit
dans un premier temps de faire l'inventaire des contenus du site web et de les
regrouper par thématique afin de constituer des rubriques.
ACCUEIL
ACTUALITES

COMMANDER
JOURNAUX
S'INSCRIRE

A PROPOS
LOCALES
NATIONALES
LOGIN
FORMULAIRE DE COMMANDE
PARUTIONS RECENTES
ANCIENNES PARUTIONS
|
|
|
|
|
INTERNATIONALES
|
Fig.3 : Structure du site.
|
|
|
|
16 Nicolas
Larousse(2009). Création de bases de
données, Paris, éd. Pearson Education France. pp13
28
2.2. La base des données
2.2.1. Généralités sur les Bases de
données :
a. Définitions :
Une base de données est un ensemble structuré
d'informations. On définit une base de données comme étant
l'ensemble des données stockées. Pour les manipuler, on utilise
généralement un logiciel spécialisé appelé
SGBD (Système de Gestion de Bases de Données). Il y a
parfois confusion, par abus de langage, entre base de données et SGBD.
On appelle aussi « système d'information » l'ensemble
composé par les bases de données, le SGBD utilisé et les
programmes associés. Plus formellement, on appelle Base de
Données (BD) un ensemble de fichiers informatiques ou non
structurés et organisés afin de stocker et de gérer de
l'information.16
Un SGBD est un logiciel complexe qui permet de gérer et
d'utiliser les données que l'on stocke en utilisant les
différents modèles de données. (Modèle
hiérarchique, modèle réseau, modèle relationnel,
modèle objet, etc.)
b.Modèles de Bases de données :
Les modèles de données correspondent à la
manière de structurer l'information dans une base de données. Ils
reposent sur les principes et les théories issus du domaine de la
recherche en informatique et permettent de traduire la réalité de
l'information vers une représentation utilisable en informatique.
- Modèle hiérarchique et modèle
réseau :
Le modèle hiérarchique propose une
classification arborescente des données à la manière d'une
classification scientifique. Dans ce type de modèle, chaque
enregistrement n'a qu'un seul possesseur ; par exemple, une commande n'a qu'un
seul client. Cependant, notamment à cause de ce type de limitations, ce
modèle ne peut pas traduire toutes les réalités de
l'information dans les organisations.
29
Le modèle réseau est une extension du
modèle précédent : il permet des liaisons transversales,
utilise une structure de graphe et lève de nombreuses limitations du
modèle hiérarchique.
Dans les deux cas, les enregistrements sont reliés par
des pointeurs : on stocke l'adresse de l'enregistrement auquel il est
lié. Des SGBD de type hiérarchique ou réseau sont encore
employés pour des raisons d'efficacité lorsque la structure des
données s'y prête. On utilise à cet effet des SGBD de
conception ancienne, comme IMS (Bull) pour le modèle réseau ou
IDMS (Computer Associate)17.
- Le modèle relationnel :
Ce modèle a été proposé en 1970
par E. F. Codd dans un article resté célèbre : « A
Relational Model of Data for Large Shared Data Banks », CACM 13,
no 6, June 1970. Il cherche à créer un langage d'interrogation
des bases de données plus proche du langage naturel. Dans cette optique,
il fonde sa recherche sur des concepts mathématiques rigoureux, tels que
la théorie des ensembles et la logique du premier ordre. Le
modèle relationnel permet de modéliser les informations contenues
dans les bases de données en utilisant des relations,
c'est-à-dire des ensembles d'attributs. De l'idée de
départ à la réalisation d'un produit utilisable, le laps
de temps est souvent de l'ordre d'une décennie. La mise en oeuvre des
idées de Codd se fait chez IBM dans le cadre du projet de recherche
System-R. Le premier produit commercial sera non pas le fait d'IBM, mais celui
d'Honeywell en 1976. Il sera suivi d'un produit réellement abouti de
chez Relationnel Software en 1980 : Oracle, qui a connu le succès que
l'on sait. De son côté IBM en tirera un produit qui deviendra
DB2.
Le modèle relationnel est aujourd'hui l'un des
modèles les plus utilisés. « Les premiers systèmes de
gestion de base de données (SGBD ou DBMS en anglais) bâtis sur ce
modèle ont été SQL/DS et DB2 de IBM, d'où est
né le langage de manipulation de bases relationnelles, SQL (Structured
Query Language). » Le modèle relationnel est basé sur deux
instruments puissants : l'algèbre relationnelle (c'est-à-dire le
concept mathématique de relation en théorie des ensembles) et la
notion de produit cartésien. Ce modèle définit une
façon de représenter les données, les opérations
qui peuvent être effectuées et aussi les mécanismes pour
préserver la consistance des données. E.F Codd a décrit
les principes et la conception de modèle relationnel
17 Nicolas Larrousse,
Création de bases de données, éd. Pearson Education
France, Paris 2009, pp 16.
30
dans son livre « A relational model of data for large
shared data banks ». Par exemple une bonne utilisation du code
nécessite la redéfinition d'une entité qui va être
exploitable dans la présentation de données.
La modélisation relationnelle permet de
représenter les relations à l'aide de tables (à deux
dimensions) dont chaque colonne a un identificateur qui représente un
domaine. Une ligne du tableau représente donc une entité et
chacune des cases représente un de ses attributs. On appelle attributs
le nom des colonnes qui représentent les constituants de
l'entité. Un attribut (une colonne) est repéré par un nom
et un domaine de définition, c'est-à-dire l'ensemble des valeurs
qu'il peut prendre. On appelle tuple (ou n-uplet) une ligne du tableau.
L'entité voiture pourra par exemple être
représentée par :
? La marque
? Le modèle
? La série
? La plaque minéralogique.
La cardinalité d'une relation est le nombre de tuples
qui la composent. Dans l'exemple ci-dessus la cardinalité est
égale à 3.
La clé principale d'une relation est l'attribut, ou
l'ensemble d'attributs, permettant de désigner de façon unique un
tuple. Dans l'exemple ci-dessus, le numéro de la plaque
minéralogique est une clé principale dans la mesure où la
seule connaissance de cet attribut permet de connaître la voiture. Une
clé étrangère, par contre, est une clé (donc un
attribut permettant d'identifier de façon unique un tuple) faisant
référence à une clé appartenant à une autre
table.
La description d'une relation (d'une table) par ses attributs
(nom et domaine) est appelée schéma d'une relation. On
désigne par le terme schéma d'une base de données
relationnelle l'ensemble des relations qui la composent.
31
La manipulation des éléments de la table se fait
à l'aide d'opérations sur les ensembles. On définit deux
types d'opérations de base:
? Les opérations unaires
? les opérations ensemblistes
- Le modèle objet :18
Les langages de programmation orientés objet sont
apparus dans les années 1960 et sont devenus populaires dans les
années 1980. Les premiers systèmes de gestion de bases de
données (SGBD) objets sont apparus dans les années 1990, en
même temps que se sont répandus les langages de programmation
orientés objet.
Le consortium OMG (Object Management Group) a
été fondé en 1989, dans le but de soutenir et uniformiser
les nouvelles technologies basées sur les objets. Les bases de
données objet sont une des technologies soutenues et
standardisées par ce consortium.
À cette époque, les systèmes de gestion
de bases de données (SGBD) relationnels étaient
déjà bien implantés sur le marché. L'arrivée
des SGBD à objets a poussé plusieurs éditeurs de SGBD
relationnels à modifier leurs produits en vue de leur permettre de
stocker des objets.
En 1997 les parts de marché des SGBD à objets
sont d'environ 3 %, le marché est largement dominé par les SGBD
relationnels. Depuis l'arrivée cette année de SGBD qui manipulent
à la fois des bases de données à objets et relationnelles,
il est très peu probable que les SGBD à objets remplacent un jour
les SGBD relationnels.
Plusieurs raisons, en dehors des qualités reconnues de
l'approche objet, ont conduit à définir une extension objet pour
les bases de données. La première est que le modèle
relationnel, dans sa simplicité, ne permet pas de modéliser
facilement toutes les réalités. La
18 Base de données orientée objet :
http://fr.wikipedia.org/wiki/Basededonnéesorientéeobjet
32
deuxième est qu'un objet permet de représenter
directement un élément du monde réel. Les structures
d'éléments complexes se retrouvent souvent dispersées
entre plusieurs tables dans l'approche relationnelle classique. De plus, le
concept objet est mieux adapté pour modéliser des volumes de
texte importants ou d'autres types de données multimédias (sons,
images, vidéos...). Enfin, il est beaucoup plus commode de manipuler
directement des objets lorsque l'on développe avec un langage à
objet (comme C++ ou Java). Les bases de données, on le rappelle, sont
dorénavant des briques constitutives des applications. Les bases de
données « orientées objet » apportent ainsi aux
applications développées en langage objet la persistance des
objets manipulés : ces derniers peuvent ainsi directement être
réutilisés par l'application d'origine ou par d'autres sans
redéfinition. Ces concepts ont été intégrés
à partir de la version 2 de la norme SQL.
- Le modèle relationnel-objet :
Le modèle relationnel-objet est, en informatique, une
manière de modéliser les informations contenues dans une base de
données qui reprend le modèle relationnel en ajoutant quelques
notions empruntées au modèle objet, venant combler les plus
grosses lacunes du modèle relationnel. La technologie
objet-relationnelle est née en 1992, elle est donc assez nouvelle sur le
marché des SGBD, dominé depuis environ 1970 par les bases de
données relationnelles. Dans le sillage du développement des
langages orientés objet (C++, Java...) dans les années 1980, le
concept objet a été adapté aux bases de données.
Plusieurs raisons, en dehors des qualités reconnues de l'approche objet,
ont conduit à définir une extension objet pour les bases de
données.
33
2.2.2. Analyse avec la méthode merise :
La conception d'un système d'information n'est pas du
tictac car il faut réfléchir à l'ensemble de
l'organisation que l'on doit mettre en place. La phase de conception
nécessite des méthodes permettant de mettre en place un
modèle sur lequel on va s'appuyer. La modélisation consiste
à créer une représentation virtuelle d'une
réalité de telle façon à faire ressortir les points
auxquels on s'intéresse. Ce type de méthode est appelé
analyse. Il existe plusieurs méthodes d'analyse, la
méthode la plus utilisée en France et dans le monde francophone
étant la méthode MERISE qui vient de «Méthode d'Etude
et de Réalisation Informatique pour les Systèmes d'Entreprise
».
a. Etude de l'existant:
La première étape que nous avons eu à
aborder a consisté à étudier et présenter le
système manuel existant, celle-ci étant la première
étape du cycle d'abstraction pour la conception des systèmes
d'information tel que prévu par MERISE.
En effet, la maison de presse écrite les Coulisses ne
dispose pas d'un système d'information informatisé ; tout est
encore manuel sauf que l'outil informatique est quand même utilisé
quand il s'agit bien de traiter les textes et des images.
Modèle conceptuel de communication :
Le diagramme ci-après a pour but de représenter
les flux d'informations entre les acteurs externes et internes selon une
représentation standard.
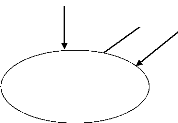
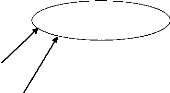
Rédaction
Commander Donner
rapport
Soumettre les journaux
2
1
Service de vente et distribution
34
Réceptionniste
S'adresser à
Client
Orienter
Points de vente et permanences hors Beni.
Service technique
Superviser
Superviser
Directeur de
publicaton
Fig4 : Diagramme de flux pour les Coulisses. Légende :
1 : Soumettre les textes pour la saisie, mise en page et
impression
2 : Fournir et recouvrir les journaux.
b. Expression des besoins
Le service technique au sien de l'agence de presse
écrite Les Coulisses s'occupant bien des nouvelles technologies de
l'information et de la communication au niveau du journal a pour attributions
qui sont entre autre la saisie des articles (saisie et scannage), leur mise en
page, la fabrication et le maquettage des journaux. Il advient un besoin de
plus qui est celui de doter à cette agence une vitrine sur internet qui
prend en charge l'archivage et la commande en ligne des journaux ; ceci
étant avantageux non seulement pour la maison Les Coulisses mais aussi
pour les consommateurs des produits fournis par la dite maison. De plus, il
serait louable de doter le service de vente et distribution d'un outil de plus
qui les aiderait à élargir son réseau de
35
distribution. C'est ainsi que nous avons songé à
doter à la dite maison d'un site web dynamique qui prends en charge
l'archivage des journaux et la commande en ligne.
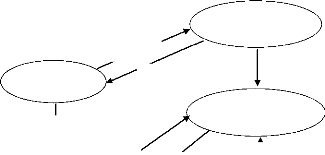
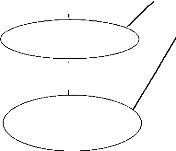
c. Modèle conceptuel de communication (MCC) du
futur système :
Le modèle conceptuel de communication définit
les flux d'informations à prendre compte.
L'entreprise est considérée comme un
système. L'extérieur, avec qui l'entreprise effectue ses
échanges est aussi perçu comme un ensemble de systèmes.
L'entreprise est découpée en systèmes fonctionnels ou
conceptuels. Les systèmes externes et internes sont appelés
intervenants.19
C'est ainsi que dans notre cas, le diagramme conceptuel de
flux se représente de la manière suivante :
Points de vente et
Contacter client et expédier journaux
distribution Directeur de publication
6
5
9
Service de vente et distribution
7
Superviser
Client (Abonné du site)
3
Rédaction centrale
4
Service technique
8
1
2
Superviser
Administrateur du
site
Fig5. : MCC du futur système
19 Michel DIVINÉ(1994), Perlez-vous MERISE ?,
Les éditions du Phénomène, pp26.
36
Légende :
1: Commander ou s'abonner aux consultations en ligne (payer par
mobile money)
2: Envoi accuse réception ou octroyer le code de
consultation.
3: Présenter commandes et abonnements pour les
consultations en ligne.
4: Accepter commandes ;
5: Demande d'expédition des journaux commandés,
fournir journaux ;
6: Donner rapport ;
7: Superviser ;
8 :Soumettre des textes pour saisie et mise en page +
impression.
9 :Payer abonnement pour des consultations en ligne.
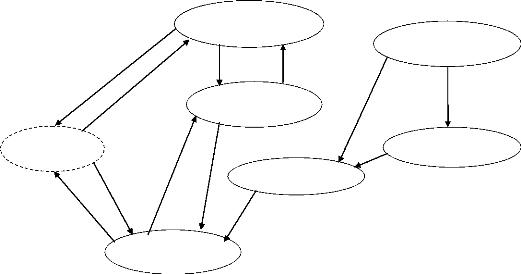
d. Modèle conceptuel de Traitement (MCT):
Le MCT décrit les traitements effectués par
domaine (opération conceptuelle). Il permet de valider les messages du
MCC et de décrire les conditions d'émission des messages
résultats. Le MCT vise à définir le quoi, quels sont les
traitements dans l'organisation, il ne définit pas qui, ou, ni comment
sont effectués les traitements. Il prend en compte des
événements, décrit les opérations qu'ils
déclenchent et les résultats obtenus ; il décrit aussi
dans quel ordre s'enchainent les traitements.
Un événement matérialise une
sollicitation du système d'information : il lui indique que quelque
chose s'est passé et que le système doit réagir. Il
déclenche une ou plusieurs opérations. Un événement
peut être :
- Entrant quand il vient de l'extérieur (visite d'un
client par exemple, réception d'un ordre de souscription),
- Interne quand il vient de l'extérieur du SI et qu'il
reste dans ce SI (ordre de souscription), - Sortant quand il est destiné
à un acteur externe (facture client)
- Temporel (délais, fin de mois, début de
semaine).
Une opération représente un ensemble de
traitements (phases) non interruptibles, effectues en réaction à
un événement.
Une opération est déclenchée par un
événement unique ou bien par une association (synchronisation) de
plusieurs événements.
37
Le déroulement d'une opération ne peut
être interrompu ou suspendu par l'attente d'un événement
externe complémentaire dès qu'elle est activée.
Synchronisation20 : C'est la représentation
d'une pré-condition qui doit être satisfaite pour l'activation
d'une opération à partir de plusieurs événements.
La synchronisation est spécifiée par le nom des
événements et/ou des résultats qui y contribuent et du
prédicat qui précise leur participation. La synchronisation d'une
opération définit une condition booléenne sur les
événements contributifs devant déclencher une
opération. Il s'agit donc de conditions au niveau des
événements régies par une condition logique
réalisée grâce aux opérateurs : OU, ET et NON.
Diagrammes du MCT :
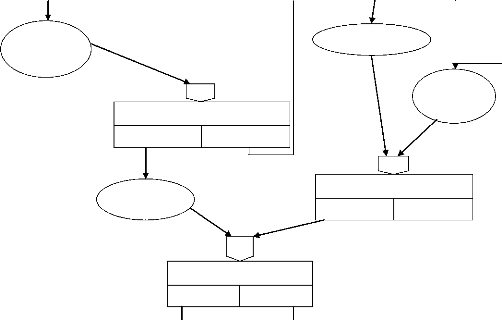
- 1er Cas : Traitement des commandes
20Modèle conceptuel des traitements sur :
http://www.commentcamarche.net/contents/660-merise-modele-conceptuel-des-traitements
38
Inscription
Demande inscription
acceptée
refusée
Commande Client Authentification
ET
|
Commande
|
|
Acceptée
|
Annulée
|
OU
Non dispo
Dispo
Envoi du message de confirmation
Livraison des journaux
Contrôle lot des journaux
Fig.6. Traitement des commandes
Envoi du message de refus
Commande en attente
39
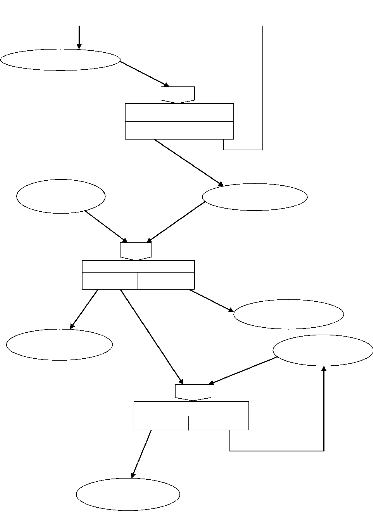
- Deuxième cas: Traitement des archivages
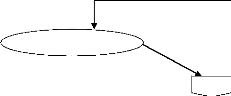
Demande inscription
Inscription
Besoin d'archivage
Nouveau num dispo Pas de nouveau num
Journaux archivés
Code validé
Archivage
Demande du code
Et
Code erroné
Code octroyé
Octroyer code de consultation
Authentification
ET
Code pas octroyé
Paiement abonnement semestriel

Consultation du journal
Fig.7. Traitement des archivages
40
e. Modèle Conceptuel des Données(MCD)
:
Pourquoi cette approche données ? Un grand nombre
d'ensembles d'informations manipulées nécessite un travail de
cohérence indispensable et d'optimisation des coûts de stockage et
de traitement des informations. Cette complexité sur les ensembles
d'informations, que l'on trouve en informatique de gestion, a rendu
nécessaire la création d'une méthode qui prenne en compte
la structure des informations. Cette méthode s'applique aussi bien aux
développements sur microordinateurs qu'à ceux sur grands
systèmes informatiques.
Les informations sont structurées et classées,
sans répétition, en deux types d'ensembles (d'informations), les
individus et les relations.
Un individu est un concept ou un "objet de gestion"
conçu par l'esprit de l'utilisateur lui permettant d'organiser ses
connaissances. Une relation est une association d'individus.
Individus et relations sont étudiés en premier.
Les règles à respecter sur les informations pour obtenir un
modèle de données correct sont ensuite
développées.
Les compléments à apporter au modèle, les
contraintes sont ensuite abordés. Enfin, la vie d'un modèle et
les différents pièges à éviter entre
information, individu et relation seront passés en revue.
? Entité et associations :
Une entité est une population d'individus
homogènes. C'est donc une représentation d'un
élément matériel ou immatériel ayant un rôle
dans le système que l'on désire décrire.
Une association est une liaison qui a une signification.
? Les identifiants :
Un identifiant est un ensemble de propriétés
(une ou plusieurs) permettant de désigner une et une seule
entité. La définition originale est la suivante: L'identifiant
est une propriété particulière d'un objet telle qu'il
n'existe pas deux occurrences de cet objet pour lesquelles cette
propriété pourrait prendre une même valeur. Les attributs
d'une classe d'entité permettant de désigner de façon
unique chaque instance de cette entité sont appelé identifiant
21 Di GALLO Fréderic,
Méthodologie des systèmes d'information-MERISE, CNAM
ANGOULEME 20002001, p20.
41
absolu. Le modèle conceptuel des données propose
de souligner les identifiants (parfois de les faire précéder d'un
#).21
? Les cardinalités :
La cardinalité d'un lien entre une entité et une
association précise le minimum et le maximum de fois qu'un individu de
l'entité peut être concerné par l'association.
Dictionnaire des données :
|
Code Libelle Type Taille
|
|
NomAbonne
|
Nom de l'abonné
|
Chaine de caractères
|
20
|
|
PostNomMembre
|
Le post-nom de l'abonné
|
Chaine de caractères
|
20
|
|
Prenom
|
Le prénom de l'abonné
|
Chaine de caractères
|
20
|
|
Sexe
|
Le sexe de l'abonné
|
Chaine de caractères
|
10
|
|
Pays
|
Le pays de l'abonné
|
Chaine de caractères
|
50
|
|
Ville
|
La ville de l'abonné
|
Chaine de caractères
|
50
|
|
Email
|
L'adresse mail de l'abonné
|
Chaine de caractères
|
50
|
|
Telephone
|
numéro téléphone de l'abonné
|
Chaine de caractères
|
15
|
|
Pseudo
|
Le pseudo de l'abonné
|
Chaine de caractères
|
20
|
|
MotDePasse
|
Le mot de passe de l'abonné
|
Chaine de caractères
|
50
|
|
DesignationGrroupe
|
La désignation du groupe
|
Chaine de caractères
|
20
|
|
DesignationCategorie
|
La catégorie du journal
|
Chaine de caractères
|
20
|
|
IsFree
|
Le journal est gratuit
|
booléen
|
1
|
|
TitreJournal
|
Le titre du journal
|
texte
|
50
|
|
SyntheseJournal
|
La Synthèse du Journal
|
texte
|
255
|
|
url
|
L'url du journal
|
Chaine de caractères
|
255
|
|
ContenuMotClef
|
Le contenu du mot clef
|
Chaine de caractères
|
50
|
|
Quantite
|
La quantité des journaux
|
Chaine de caractères
|
50
|
|
VilleLivraison
|
La ville de livraison
|
Chaine de caractères
|
50
|
|
CommuneLivraison
|
La commune de Livraison
|
Chaine de caractères
|
50
|
|
QuartierLivraison
|
Le quartier de livraison
|
Chaine de caractères
|
50
|
|
CelluleAvenueLivraison
|
La cellule/avenue de livraison
|
Chaine de caractères
|
50
|
|
NumeroResidence
|
Le numéro de résidence
|
entier
|
10
|
|
AutreDetail
|
Les autres détails sur la cmd
|
texte
|
|
|
IdConsultation
|
L'identifiant de la consultation
|
entier
|
10
|
|
IdAbonnement
|
L'identifiant de l'abonnement
|
entier
|
10
|
42
|
IdMembre
|
L'identifiant du membre
|
entier
|
10
|
|
IdGroupe
|
L'identifiant du groupe
|
entier
|
5
|
|
IdLogin
|
L'identifiant du Login
|
entier
|
10
|
|
IdCommande
|
L'identifiant de la commande
|
entier
|
10
|
|
IdConsult
|
L'identifiant de la consultation
|
entier
|
10
|
|
IdCategorie
|
L'identifiant de la catégorie
|
entier
|
10
|
|
IdJournal
|
L'identifiant du journal
|
entier
|
10
|
|
IdCorres
|
L'id. de la correspondance
|
entier
|
10
|
|
IdMotCle
|
L'identifiant du mot clef
|
entier
|
10
|
|
DateConsult
|
La date de consultation
|
Date
|
|
|
DateAbonnement
|
La date d'abonnement
|
Date
|
|
|
TypeAbonnement
|
Le type d'abonnement
|
Chaine de caractères
|
20
|
|
MontantPaye
|
Le montant payé par l'abonné
|
entier
|
10
|
|
|
|
|
|
|
|
|
Diagramme du MCD :
43
1,n
1,n
Consulter
DateConsult
Commander
1,n
DateCommande Quantite
1,n
Effectuer
|
1,n
|
|
1,1
|
Journaux
|
|
Catégories
|
|
IdJournal TitreJournal
SyntheseJournal
|
|
IdCatégorie
DesignationCategori
|
Appartient
|
|
|
|
|
IsFree
|
1,n
|
Url
|
|
Membres
IdMembre Nom Post-Nom Prénom Sexe Pays Ville Email
Téléphone
|

Appartient
1,n
|
Se Connecter
|
1,1
|
Logins IdLogin
Pseudo 1
MotDePasse
|
1,1
|
|
1,1
|
|
|
1,1
1,n
1,n
Abonnements
IdAbonnement DateAbonnement TypePaiement
Groupe
|
IdGroupe
DesignationGroupe
1
|
Fig.8 : MCD
44
2.3. Choix de l'environnement de développement
:
2.3.1. Les pages WEB
Pour le développement de nos pages WEB, nous avons utilise
les outils qui sont :
a. Le HTML comme langage de balisage
Le HTML comme langage de balisage pour éditer nos pages
WEB. Nous avons eu a l'utiliser dans sa version HTML5 ; ceci dans le but de
profiter des nouvelles fonctionnalités qu'offre cette nouvelle version.
Le HTML5 introduit huit nouvelles fonctionnalités dont certaines
risquent bien, si le standard est adopté par tous les navigateurs, de
révolutionner certaines applications Web.
On pense, bien évidemment, à la vidéo,
avec les nouvelles balises multimédias (audio et vidéo). Le
support en natif des streamings risque de porter un coup fatal au Flash Player
d'Adobe, déjà mis à mal par Silverlight de Microsoft.
Cette nouvelle fonctionnalité permet par exemple de changer la taille
d'une vidéo, de lui appliquer des filtres en temps réel, de
naviguer beaucoup plus rapidement, d'y ajouter du texte, etc. Et ce de
manière étonnamment fluide.
Il faut bien avouer que les formulaires traditionnels comme la
ligne ou la zone de texte, les boutons radio, à choix multiples ou
autres boutons de commandes entraînent une lassitude certaine dans
l'aspect visuel de la page. Les apports du Html5 vont révolutionner les
formulaires avec des lignes de texte avec suggestions, des calendriers, des
compteurs numériques, des curseurs, une validation sans passer par le
JavaScript et bien d'autres surprises.
Le Html5 est une évolution du Html. Il en reprend les
grands principes, quitte à en améliorer certains aspects. Il est
conçu pour assurer une rétrocompatibilité avec ce qui a
été fait jusqu'à présent, en termes de publication
sur le Web.
Même si le codage est moins formaliste que le Xhtml5,
l'exigence d'un code propre, respectueux des règles fondamentales du
balisage continue d'être d'actualité.
Par Stephen SALAMA/UCBC-BENI
45
b.Le CSS pour la réalisation de nos feuilles de
style :
Le CSS défini comme Cascading Style
Sheets nous a permis de réaliser les mises en forme sur
nos pages web. Les avantages qui nous ont poussé à opérer
notre choix a les mises en forme avec CSS alors qu'il était possible de
les réaliser avec seulement du HTML sont tel que CSS permet la mise en
forme hors des documents ; Il est par exemple possible de ne décrire que
la structure d'un document en HTML, et de décrire toute la
présentation dans une feuille de style CSS séparée.
Mais aussi dans le cas d'un site web, la présentation
est uniformisée : les documents (pages HTML) font
référence aux mêmes feuilles de styles. Cette
caractéristique permet de plus une remise en forme rapide de l'aspect
visuel. Un avantage de plus est que le code HTML est considérablement
réduit en taille et en complexité, puisqu'il ne contient plus de
balises ni d'attributs de présentation.
c.PHP comme langage de script :
Le langage PHP est né en 1994 d'un programme en langage
Perl écrit par Rasmus Lerdorf pour analyser les visites de son CV en
ligne. Il réécrit l'application en langage C puis ouvre son
programme à la communauté du Libre. Ainsi, il pourra
désormais compter sur l'aide de nombreux développeurs. Son
application PHP fusionne avec un moteur de traitement de formulaires, FI, ce
qui donne la version 2. Avec la version 3, les fonctions deviennent nombreuses
et la popularité grandit.
Pour viser le dynamisme dans notre site web et pour interagir
et communiquer avec les bases de données, nous avons
préféré utiliser le langage de script qui est PHP. En
effet, ce langage présente quelques avantages qui sont notamment :22
- La disponibilité de la documentation et du support
;
22 Luke WELLING (2009). PHP&MySQL, Paris,
ed. Pearson, 4e éd., pp5.
Par Stephen SALAMA/UCBC-BENI
46
- La portabilité : PHP est disponible sur de nombreux
systèmes d'exploitation. Un code PHP bien écrit pourra donc
généralement être utilisé sans modification sur un
autre système.
- Les performances : PHP est très rapide. Avec un seul
serveur d'entrée de gamme, vous pouvez servir des millions de
requêtes par jour. Les tests de performances publiés par Zend
Technologies
- (
http://www.zend.com)
montrent que PHP dépasse tous ses concurrents;
- des interfaces vers différents systèmes de bases
de données ; - des bibliothèques intégrées pour la
plupart des tâches web ; - un faible coût ;
- la disponibilité de son code source ;
- la disponibilité du support et de la documentation.
2.3.2. La base de données :
Pour le développement de notre application, nous avons
choisi le célèbre système de gestion des bases de
données (SGBD) qui n'est autre que MySQL.
Le SGBD MySQL :
MySQL est un système de gestion de
base de données relationnelle (SGBDR). Il est distribué sous une
double licence GPL et propriétaire. Il fait partie des logiciels de
gestion de base de données les plus utilisés au monde, autant par
le grand public (applications web principalement) que par des professionnels,
en concurrence avec Oracle, Informix et Microsoft SQL Server.
MySQL est un Système de Gestion de Bases de
Données (SGBD) qui gère pour vous les fichiers constituant
une base, prend en charge les fonctionnalités de protection et de
sécurité et fournit un ensemble d'interfaces de programmation
(dont une avec PHP) facilitant l'accès aux données.
La complexité de logiciels comme MySQL est due à
la diversité des techniques mises en oeuvre, à la
multiplicité des composants intervenant dans leur architecture, et
également aux
Par Stephen SALAMA/UCBC-BENI
47
différents types d'utilisateurs (administrateurs,
programmeurs, non informaticiens,...) confrontés, à
différents niveaux, au système.
MySQL consiste en un ensemble de programmes chargés de
gérer une ou plusieurs bases de données, et qui fonctionnent
selon une architecture client/serveur (Philippe RIGAUX, Paris 2009).
Les avantages23 :
- MySQL dispose d'un système de sécurité
permettant de gérer les personnes et les machines pouvant accéder
aux différentes bases ;
- Le serveur MySQL est très rapide ;
- MySQL est beaucoup plus simple à utiliser que la
plupart des serveurs de bases de données commerciaux ;
- MySQL dispose d'un système de sécurité
permettant de gérer les personnes et les machines pouvant accéder
aux différentes bases.
Ainsi, les avantages qu'offre le SGBD MySQL font de lui le
système le plus utilisé sur le WEB ou tout simplement sur
internet ; c'est ainsi que nous n'avons pas été du reste, nous
n'avons pas trouvé meilleure solution que d'utiliser ce fameux
système.
2.4. Modèle logique des données :
23 Présentation de MySQL :
http://www-igm.univ-mlv.fr/~dr/XPOSE/FcollinMySQL/mySQLindexfichiers/presentation.htm
Par Stephen SALAMA/UCBC-BENI
48
|
Journaux
#IdJournal int (10) TitreJournal (text 50)
SyntheseJournal (text) Url (varchar 50)
# IdCatégorie (int 10)
|
|
|
|
Catégories
|
|
|
|
#IdCatégorie (int 10)
DesignationCategorie (varchar 20) IsFree (Boolean 1)
|
|
|
|
|
|
|
|
|
|
|
|
Commandes
|
Membres
#IdMembre (int 10) Nom (varchar 20) Post-Nom (varchar 20)
Prénom (varchar 20) Sexe (varchar 10) Pays (varchar 50) Ville (varchar
20) Email (varchar 50) Téléphone (varchar 15)
|
|
|
|
Groupe
|
|
|
|
|
#IdGroupe (int 5)
DesignationGroupe (varchar 20)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Logins
#IdLogin (int 10) Pseudo (varchar 20) MotDePasse (varchar
50) #IdMembre (int 10) #IdGroupe (int 5)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#IdCommande (int 10) #IdJournal int (10) #IdMembre
(int 10) Quantite (varchar 50) DateCommande (date) VilleLivraison (varchar 20)
CommuneLivraison (varchar 20) QuartierLivraison (varchar 20)
Cellule/AvenueLivraison (varchar 20) NumeroResidance (int 10) AutresDetails
(text 255)
Abonnements
#IdAbonnement (int10) DateAbonnement(date) #IdMembre (int
10) TypeAbonnement(varchar 20) MontantPaye (int 10)
Consultations
#IdConultation(int10) #IdJournal int (10)
DateConsult(date) #IdAbonnement(int10)
Fig.9: MLD
Par Stephen SALAMA/UCBC-BENI
49
2.5. CAHIER DES CHARGES :
Pour réaliser un projet informatique dans le processus
d'informatisation d'une entreprise, il a toujours été d'une
grande utilité de présenter un cahier de charge.
En effet, notre projet étant axé dans le domaine
de la programmation web, nous avons présenté les besoins tant
matériels que financiers qui sont entre autre :
Des besoins liés au développement de l'application
: Ces besoins se résument en ceux liés à
l'approvisionnement en environnement logiciel et ceux liés au coût
de développement. Pour ce qui est de l'environnement logiciel, les
logiciels utilisés sont gratuits, ce qui fait
à ce que l'entreprise ne va rien acheter ; mais aussi
le système ne sera pas hébergé
localement, pour dire
que l'achat des logiciels tel que MySQL et le serveur web (APACHE) ne sera pas
nécessaire.
En ce qui concerne le coût de développement,
l'application a été développée dans un contexte
pédagogique ou académique, ce qui a fait à ce que nous
procédions déjà au développement de l'application
depuis que nous avions eu l'aval de la dite entreprise. Dans le cas où
la maison se décidait de budgétiser le projet (ce qui est
d'ailleurs une promesse déjà faite), le cout de
développement s'évaluerait autours de deux cent dollars
américains, étant donné que nous reconnaissons aussi que
la Maison Les coulisses nous a tellement aidée dans nos recherches, cela
inclurait les frais de développement et la main d'oeuvre.
Des besoins liés à l'hébergement du site
:
Pour ce qui est de l'hébergement du site, nous avons
choisi l'hébergeur PlanetHoster (
www.planethoster.net) qui
offre une espace mémoire de 60 Go, un trafique illimité et un nom
de domaine gratuit à un cout de 7.99 euros par mois.
Ce même hébergeur offre un abonnement d'une
espace mémoire illimitée, un trafique illimité et un nom
de domaine gratuit à un cout de 10.99 euros par mois. Cette offre a un
avantage d'obtenir un espace mémoire illimité. Elle serait la
meilleure offre pour nous étant donné que nous pourrons conserver
des fichiers pdf sur notre site et bien plus de fonctionnalités qui
adviendraient dans le futur seraient facilement pris en charge. En
défaut, l'offre de 7.99 euros le mois reste aussi quand même une
bonne offre dans un premier temps étant donné que jusqu'ici et
jusqu'à preuve du contraire cet espace pourra être suffisant.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
50
Des besoins liés à l'administration du site et
aux mises en jour : Il serait possible de former le personnel existant pour
chaque fois effectuer des mises à jour ; mais étant donné
que le site web est juste à l'étape où de nouvelles
fonctionnalités seront en train d'être ajoutées, il serait
préférable d'avoir un administrateur du site ou un webmaster qui
serait en train de suivre de près l'évolution. A défaut,
un agent interne serait formé pour cette fin.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
51
CHAPITRE 3. IMPLEMENTATION DE L'APPLICATION
Dans cette section, nous abordons les étapes et techniques
suivies pour l'implémentation de l'application web. Nous allons tout
d'abord traiter de la base de données puis de l'interface web.
3.1. La base des données :
3.1.1. Modèle physique des données :
Le modèle physique est le modela qui montre l'implanation
pratique de notre MCD.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
#IdConsultation #IdJournal DateConsult #IdAbonnements
Consultations
#IdCommande #IdJournal #IdMembre Quantite DateCommande
VilleLivraison CommuneLivraison QuartierLivraison Cellule/AvenueLivraison
NumeroResidance AutresDetails
Abonnements #IdAbonnement DateAbonnement
#IdMembre TypeAbonnement MontantPaye
Commandes
52
Catégories
#IdCatégorie
DesignationCategorie IsFree
Journaux
|
#IdJournal TitreJournal
SyntheseJournal Url
# IdCatégorie
|
Groupe
#IdGroupe
DesignationGroupe
Logins
#IdLogin Pseudo MotDePasse #IdMembre #IdGroupe
Membres
|
#IdMembre Nom Post-Nom Prénom Sexe Pays Ville Email
Téléphone
|
Fig.10 : MPD
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel: +221765630372
53
3.1.2. Implémentation dans MySQL
Tel que dit dans les sections précédentes, le
SGBD utilise dans notre application est bel et bien MySQL. Pour monter notre
base de données, nous nous sommes servis du paquet logiciel qui est
WAMP Server qui nous fournit une combinaison de logiciels qui
sont le service phpMyAdmin, un logiciel de gestion de serveur ou serveur web
qui est Apache. Dans le nom WAMP, la lettre A
désigne tout simplement Apache, la lettre M
désigne MySQL et la lettre P désigne
PHP.
PhpMyAdmin est un outil qui nous a servi comme interface
graphique dans la mise en place de la base de données.
Voici donc comment se présente la page d'accueil
phpMyAdmin :
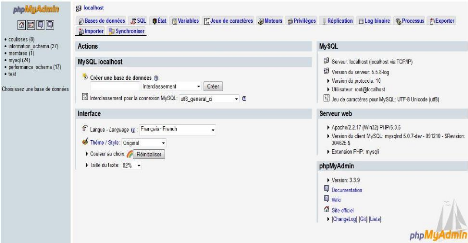
Fig.11 : page d'accueil phpMyAdmin dans Wamp Server.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
54
Création de la base :
Tel que nous le voyons sur la figure ci- dessus, pour
créer la base de données il nous suffit d'écrire le nom de
la base dans le champ qui porte l'étiquette «créer une
base de données », puis de cliquer sur le bouton «
créer ». Ici le nom de notre base est `Coulisses' :
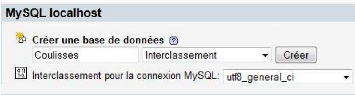
Fig.12 : Formulaire de création de la base dans
phpMyAdmin.
Apres avoir cliqué sur le bouton «
créer », la base est créée mais elle ne
contient aucune table jusqu'ici. Pour la créer, il faut
sélectionner la base vide c.-à-d. en cliquant dessus puis se
présentera l'interface ci-dessous :

Fig.13 : interface pour la création d'une table dans
phpMyAdmin.
Et là il se présente des champs qui nous permettent
de créer des colonnes dans notre
table :
Fig.14 : interface pour la création des colonnes dans une
table dans phpMyAdmin.
Dans la colonne nommée « colonne », on
écrit le nom du champ, dans la colonne nommée « type »
on définit le type de données que va recevoir le champ (Ex :
varchar, int, text, date, blob, etc.).
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
55
Voici quelques types de données dans MySQL :
- INT : nombre entier.
- VARCHAR : court texte (entre 1 et 255 caractères).
- TEXT : long texte (on peut y stocker un roman sans
problème).
- DATE : date (jour, mois, année).
- NUMERIC : ce sont les nombres. On y trouve des types
dédiés aux petits nombres
entiers (TINYINT), aux gros nombres entiers (BIGINT), aux
nombres décimaux, etc. - DATE and TIME : ce sont les dates et les
heures. De nombreux types différents
permettent de stocker une date, une heure, ou les deux
à la fois.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
56
- STRING : ce sont les chaînes de caractères. Ici,
il y a des types adaptés à toutes les tailles. - SPATIAL : cela
concerne les bases de données spatiales, utile pour ceux qui font de la
cartographie (Mathieu Nebra 2011).
Dans la colonne « Taille » on écrit la taille
c.-à-d. le nombre de caractères qui peuvent y être
stockés, dans la colonne « Défaut » on peut y
introduire une valeur par défaut si le champ n'est pas renseigné,
la colonne « interclassement » c'est pour les différentes
encodages mais celle-ci nous l'avons laissé vide car elle ne nous est
pas très utile, dans la colonne « Index» nous
spécifions s'il s'agit bien d'une clé primaire ou d'une ou d'une
valeur unique ou alors elle reste vide dans d'autres cas, la colonne «
Commentaires» nous pouvons ajouter des commentaires qui concernent le
champ. Les deux boutons radio nous permet de spécifier que le champ peut
rester vide ou qu'il s'agit d'une valeur qui s'auto incrémente.
Voici par exemple la structure de notre table « Membres
» :
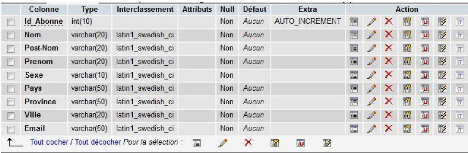
Fig.15 : structure de la table abonnes dans phpMyAdmin.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
57
3.2. LES PAGES WEB
Php est un langage de script qui s'exécute du
coté serveur et non du coté client. Les pages web que nous
concevons doivent ainsi porter l'extension .php car elles contiennent des codes
php. WAMP server nous permet d'avoir un serveur WEB en local, ce qui nous
facilite la tâche dans les tests pendant la création de nos pages
web. Dans WAMP SERVER, les pages ainsi créées doivent être
placées dans le dossier www qui a pour dossier parent le dossier wamp
qui lui se crée automatiquement pendant l'installation. C'est donc
là que seront stockées toutes les pages web que nous auront
à concevoir et donc tout le site web. Pour notre cas, nous avons encore
créé un autre dossier que nous avons intitulé MonProjet
pour le différencier d'autres projets existant dans ce dossier www.
Ainsi, dans les sections qui suivent nous présentons
quelques pages réalisées jusqu'ici.
3.2.1. La constitution générale de toutes les
pages :
a. L'entête :
Le doctype utilisé dans nos pages est celui du html5 :
<!DOCTYPE html> <!-- Le doctype pour html version 5-->
Comme nous pouvons le constater, le doctype de html 5 est
ridiculement simple, contrairement à celui de la version 4.1 de html ou
de XHTML 1.0 qui se présente de la manière :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"
http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
>
La balise doctype permet de renseigner au navigateur la version
du html utilisé. Code pour l'entête :
<tr id="entete">
<td class="section-td">
<table class="section-table" align="center">
<tbody>
<tr>
<td><h1 id="image-entete"><a
href="Index.php"><img id="seal"
src="Images/coulisse.png"
align="left"></a></h1></td>
<td> <a href = "Login.php"><div class =
"login">Se Connecter
</div></a></td>
<td> <a href = "Deconnexion.php"><div class =
"login1">Deconnexion
</div></a></td>
</tr>
</tbody>
</table>
</td> </t >
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
58
Ce code est isolé dans un fichier php que nous appellons
sur la page par l'instruction php qui est :
<?php include ("Includes\Entete.php")?>
Ceci signifie que « Entete.php » se trouve dans le
dossier nommé « Includes ». Cela permet de ne pas
réécrire le même code à chaque fois que nous voulons
placer l'entête sur une page.
b. la structure générale du code HTML pour
nos pages
<!DOCTYPE html> <!-- Le doctype pour html version
5-->
<!-- Accueil pour les coulisses -->
<html>
<head>
<meta http-equiv="content-type" content="text/html;
charset=windows-1252">
<title>Journal Les Coulisses</title>
<meta name="description" content="">
<meta name="keywords" content="">
<link rel="stylesheet" type="text/css"
href="StyleSheets/common.css"> <!-- lien vers
la feuille de style commune a toutes les pages -->
<link rel="stylesheet" type="text/css"
href="StyleSheets/index.css"> <!-- lien vers la
feuille de style de la page d'accueil seulement -->
</head>
<body onload="setCurrentTab()">
<table border="0" cellspacing="0" width="100%">
<tbody>
<!-- $$$$$$$ Entete $$$$$$$ -->
<?php include ("Includes\Entete.php")?> <!-- ici nous
incluons
l'entete dans cette page, l'entete qui est aussi une page php que
nous avons
mis a part-->
<!-- Barre de Navigation -->
<?php include ("Includes\Navigation.php")?>
59
|
<!-- Corps -->
<tr id="main">
<td class="section-td">
<table class="section-table" id="main-table" align="center"
cellspacing="0">
<tbody>
<tr>
<td id="section-table-td">
<div id="Titre_Contenu">
<p>Presentation du journal Les COULISSES</p>
</div>
<table id="main-table-content">
<tbody>
<tr>
<td id="menu">
<table class="menu-table" cellspacing="0">
<tbody>
<tr><td><a href="#"><div
class="menu-button"
id="Culture">Culture</div></a></td>
</tr>
<tr><td><a href="#"><div
class="menu-button"
id="Environnement">Environnement</div></a></td></tr>
<tr><td><a href="#"><div
class="menu-button"
id="Sport">Sport et
Loisirs</div></a></td></tr>
<tr><td><a href="#"><div
class="menu-button"
id="Conferences">Conferences et
Exposés</div></a></td></tr>
<tr><td><a href="#"><div
class="menu-button"
id="Forum">Forum des
discussions</div></a></td></tr>
</tbody> </table>
|
<td class="content"
<!-- Nous placons ici le contenu de la page-->
</td>
</tr> </tbody>
</table>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
<!-- Debut Pied de page -->
<?php include ("Includes\PiedDePage.php")?>
</tbody>
</table>
</body>
</html>
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
60
Dans ce code, nous avons fait appel à deux fichiers php
qui sont Navigation.php,
PiedDePage.php et Entete.php.
c. Les écrans
? L'accueil

? Page pour l'inscription :
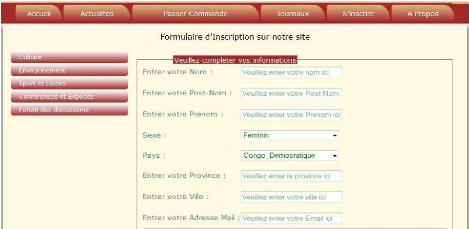
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
61
Fig.16 : Page pour l'inscription au site.
? La page pour les commandes :

Fig.17 : Page pour les commandes en ligne.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
62
3.2.2. Connexion de PHP à MySQL :
Pour nous connecter à la base de données, nous
utilisons le code php suivant :
|
<?php
$Connexion = mysql_connect("localhost", "root", ""); if
(!$Connexion) {
die("Echec de connexion: ".mysql_error());} else {
$msg= "connexion réussie <br />";} $db_select =
mysql_select_db("coulisses"); if (!$db_select) {
die("Database selection
failed!!!".mysql_error());
}
else {
$msg= "Database selected with success.<br
/>";
}
?>
|
Nous utilisons la fonction PHP mysql_connect() qui permet
d'accéder à une base de données MySQL et donc de
communiquer avec MySQL.
Nous nous connectons au serveur local (localhost) avec
l'utilisateur « root » et le mot
de passe « vide ».
S'il y a échec de connexion, MySQL nous rapportera une
erreur avec le message « Echec de connexion » et s'il n'y a pas
erreur le message devient « connexion réussie ».
Dans la ligne de code $db_select =
mysql_select_db("coulisses"); nous sélectionnons la base de donnees avec
la fonction PHP mysql_select_db() et nous affectons la valeur dans la variable
que nous avons nommé $db_select. Ensuite nous testons si la
sélection de la base a réussie ou non.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
<?php
require 'includes/connect_db.php'; //ici on se connecte a la
base de données
$Nom= $_POST['Nom'];
$Post_Nom= $_POST['Post_Nom'];
$Prenom= $_POST['Prenom'];
$Sexe= $_POST['Sexe'];
$Pays= $_POST['Pays'];
$Province= $_POST['Province'];
$Ville= $_POST['Ville'];
$email_addr= $_POST['email_addr'];
$Telephone = $_POST['telephone'];
$pseudo = $_POST['pseudo'];
$PassWord = $_POST['PassWord'];
// la requete SQL pour l'enregistrement dans la base
$sql = "INSERT INTO abonnes VALUES ('', '".$Nom."',
'".$Post_Nom."',
'".$Prenom."', '".$Sexe."', '".$Pays."', '".$Province."',
'".$Ville."',
'".$email_addr."', '".$Telephone."')";
mysql_query($sql) or die('Erreur
SQL
!'.$sql.'</br>'.mysql_error());
$Id_Abonne = "SELECT MAX(Id_Abonne) AS IdAbonne FROM abonnes";
$dd = mysql_query($Id_Abonne) or die('Erreur
SQL
!'.$Id_Abonne.'</br>'.mysql_error()); //syntaxe pour executer la
requête
$donnees = mysql_fetch_array($dd);
63
3.2.3. Quelques événements PHP :
a. Evénements pour l'inscription au site :
|
$sql1 = "INSERT INTO logins VALUES ('', '".$pseudo."',
'".$PassWord."', '3', '".$donnees[IdAbonne]."')";
mysql_query($sql1) or die('Erreur SQL
!'.$sql1.'</br>'.mysql_error());
echo ('Félicitations!!!Vos infos on été
ajoutées.'); mysql_close();
header('Location: Inscription.php');
|
Nous trouvons donc que le seul formulaire enregistre dans la
table « abonnes » mais aussi dans la table « logins ». En
même temps que l'utilisateur s'enregistre sur le site, nous profitons de
cette occasion pour récupérer aussi son pseudo et son mot de
passe pour constituer son compte d'utilisateur.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
64
3.3. DE LA SECURITE :
La sécurité doit faire partie intégrante
de la conception et c'est un effort sans fin qui se poursuit même
après le déploiement de l'application et lorsque
l'activité de développement a ralenti ou cessé.
Il nous est donc un peu difficile de parler de la vraie
sécurité du site pour l'instant étant donné les
transactions que nous traitons pour l'instant comme les commandes en ligne et
l'archivage des journaux.
Pour ce qui est de l'archivage des journaux, il s'agit ici des
anciens numéros que la maison Les Coulisse se déciderait de
déployer sur le site et qui ne présentent pas beaucoup
d'exigences pour les visiteurs du site pour y accéder ou pour consulter
ces journaux. Ainsi donc il n'est pas très utile d'user d'une
très grande sécurité.
Néanmoins, étant donné que nous
développons sur le web où tout le monde peut accéder, il
serait imprudent de prévoir des mesures minimales de
sécurité.
Chez les programmeurs du web, il y a un adage qui dit ne
jamais faire confiance aux données entrées par l'utilisateur.
Ainsi tout ce qui vient de l'utilisateur doit être traité avec la
plus grande méfiance. Certains pirates de mauvaise intension peuvent se
donner le luxe de pirater un site web et donc d'entrer dans les champs des
formulaires des balises html qui sont en mesure de provoquer le
disfonctionnement de votre site web.
C'est ainsi que nous avons utilisé la fonction php
htmlspecialchars() pour protéger les chaînes de caractères,
comme dans cet extrait de code :
<?php echo htmlspecialchars($_SESSION['Pseudo'])?> qui
nous permet d'afficher le nom de l'utilisateur connecté.
Un autre problème de sécurité a aussi
été géré par la sécurisation de certaines
pages où pour y accéder il faut d'abord s'authentifier.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
65
CONCLUSION
Etant à la fin de notre travail, nous croyons avoir
atteint l'essentiel de nos objectifs bien qu'il reste encore à faire
surtout du coté de l'application étant donné que la
programmation d'une application est progressive. Nous avons géré
les inscriptions au site web, les commandes en ligne et la disponibilisation de
certains journaux en ligne, ces derniers étant seulement accessibles par
les membres inscrits et abonnés (abonnement semestriel pour des
consultations en ligne) du site web.
Nous sommes partis de la problématique, nous nous
sommes fixés des hypothèses, nous avons étudié le
système existant, nous avons proposé un nouveau système et
nous nous sommes servi de notre méthode d'étude qui est la
méthode MERISE pour pouvoir parvenir au résultat final qui est la
mise en place de l'application web et de la base de données pour notre
projet et ainsi en définitif procéder à la mise en place
du système qui n'est rien d'autre que l'implémentation du site
web.
Cette vitrine web permet non seulement à la maison Les
Coulisses de donner la possibilité aux clients de faire des commandes en
ligne et d'effectuer des consultations des journaux en ligne une fois qu'ils
s'y abonnent, mais aussi elle lui permet de se mettre en jour par rapport au
siècle présent qui est un siècle de l'information et de la
numérisation.
Ainsi, la vitrine web est maintenant en place et elle regorge
déjà centaines fonctionnalités et surtout celles qui ont
fait l'objet de notre étude qui sont entre autre la gestion des
commandes en ligne et l'archivage des journaux pour des éventuelles
consultations en ligne. Mais aussi à part ces fonctionnalités,
cette vitrine web servira dans la publicité de la maison Les Coulisses,
elle permettra aux consommateurs de donner leurs avis par rapport au produit
mis à leur disposition et de partager avec d'autres consommateurs du
produit.
Ainsi, nous prévoyons dans le futur de pouvoir
gérer beaucoup pus de fonctionnalités tel que les achats en
ligne, les consultations en ligne de tous les journaux parus et voire
même beaucoup plus selon que les besoins seront en train de se
présenter.
Le présent travail n'a pas été seulement
bénéfique à la maison Les Coulisses ou aux consommateurs
de leurs produits, mais aussi il nous a permis nous en tant qu'étudiant
aspirant
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
66
au titre d'ingénieur d'élargir nos connaissances
et expériences dans le domaine de la programmation sur le web et dans la
conception des bases de données.
Ainsi donc, il nous a été d'une très
grande utilité d'aborder ce travail vu les avantages qu'il
présente pour nous-mêmes et pour les bénéficiaires
directs et indirects.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
67
BIBLIOGRAPHIE :
a. Livres :
1. Philippe RIGAUX (2009), Pratique de MySQL et PHP :
Conception et réalisation des sites web dynamiques, Paris,
éd. DUNOD.
2. Guillaume PLOUIN, Julien SOYER, Marc-Eric TRIOULLIER
(2004), Sécurité des architectures WEB, Paris,
éd. Dunod.
3. Nicolas Larousse (2009),
Création de bases de données, Paris, éd. Pearson
Education France.
4. Philippe RIGAUX (2009). Pratique de MySQL et PHP :
Conception et réalisation des sites web dynamiques, Paris,
édition DUNOD, 4e éd.
5. Jean CARFANTAN (2009). PHP&MySQL et CSS,
Paris, éd. Micro Application.
6. Di GALLO Fréderic, Méthodologie des
systèmes d'information-MERISE, CNAM ANGOULEME 2000-2001.
7. Luke WELLING, Laura THOMSON (2009). PHP & MySQL,
Paris, edition Pearson, 4e Ed. Disponible sur Google Books,
http://books.google.fr
8. Michel DIVINÉ(1994), Perlez-vous MERISE ?,
Les éditions du Phénomène.
9. André MASIALA ma SOLO, A. MULUMA Munanga, L. MAMBU
Mvumbi (2012). Guide du chercheur en sciences humaines Rédaction et
présentation d'un travail scientifique, Kinshasa, Centre
éducatif Congolais.
10. Jean-Marie De France(2008), Premières
applications WEB 2.0 avec AJAX et PHP, Paris, Ed. Eyrolles, p.22.
b. Cours et articles :
1. Mathieu Nebra(2011), Concevez votre site web avec PHP et
MySQL : Téléchargeable sur
www.siteduzero.com.
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
68
c. Ressources sur internet :
1. The web Standards sur
http://www.w3.org/standards/.
2. A quoi sert doctype : récupéré sur
http://coin.des.experts.pagespersoorange.fr/reponses/faq964.html
3. Luke WELLING, Laura THOMSON, PHP & MySQL,
edition Pearson, 4e ed., Paris 2009, pp 7. Disponible sur Google
Books,
http://books.google.fr
4. What is the Document Object Model? Sur
http://www.w3.org/DOM/
5. Active Server Pages sur
http://fr.wikipedia.org/wiki/ActiveServerPages
6. PHP :
http://www.digifactory.fr/info/service.php?docid=308
7. Les JSP (Java Server Pages) :
http://www.jmdoudoux.fr/java/dej/chap-jsp.htm
8. Base de données orientée objet :
http://fr.wikipedia.org/wiki/Basededonnéesorientéeobjet
9. Modèle conceptuel des traitements sur :
http://www.commentcamarche.net/contents/660-merise-modele-conceptuel-des-traitements
10. Introduction au HTML 5 :
http://www.jchr.be/html/manuel.htm
11. Maquette site web :
http://laurent.hohl.free.fr/bcma/maquette
site web.pdf
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
69
TABLE DES MATIERES
Année académique : 2013 - 2014. i
EPIGRAPHIE i
REMERCIEMENTS ii
SIGLES ET ABBREVIATIONS iv
INTRODUCTION 1
0.1. PROBLEMATIQUE 1
0.2. HYPOTHESES D'ETUDE 2
0.3. CHOIX ET INTERET DU SUJET 2
0.4. DELIMITATION DU SUJET 3
0.5. SUBDIVISION DU TRAVAIL 4
0.6. METHODES ET TECHNIQUES UTILISEES 5
0.7. DIFFICULTES RENCONTREES 6
1. GENERALITES 7
1.1. Présentation de la maison Les Coulisses 7
a. Dénomination, Siège et nature du journal 7
b. Statut juridique 7
c. Historique du journal : 7
d. Du fonctionnement du journal 8
e. Organigramme 10
1.2. Notion sur le WEB et sur les technologies WEB 11
1.2.1. L'internet 11
1.2.2. Le WEB 12
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
70
1.2.3. Les standards du WEB 15
1.2.4. Les Technologies WEB : 21
2. ETUDE ET ANALYSE DU SYSTEME POUR CONCEPTION 27
2.1. Architecture et structure du site web 27
a. Arborescence du site : 27
2.2. La base des données 28
2.2.1. Généralités sur les Bases de
données : 28
2.2.2. Analyse avec la méthode merise : 33
2.3. Choix de l'environnement de développement : 44
2.3.1. Les pages WEB 44
2.3.2. La base de données : 46
2.5. CAHIER DES CHARGES : 49
CHAPITRE 3. IMPLEMENTATION DE L'APPLICATION 51
3.1. La base des données : 51
3.1.1. Modèle physique des données : 51
3.1.2. Implémentation dans MySQL 53
3.2. LES PAGES WEB 57
3.2.1. La constitution générale de toutes les pages
: 57
3.2.2. Connexion de PHP à MySQL : 62
3.2.3. Quelques événements PHP : 63
3.3. DE LA SECURITE : 64
CONCLUSION 65
BIBLIOGRAPHIE : 67
TABLE DES MATIERES 69
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
71
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel:
+221765630372
Contacts : stephensalama2@
gmail.com, Watsapp :
+243994753393, Tel: +221765630372.
| 

