II.5 SCHEMAS D'UN DATA WAREHOUSE [8]
Un schéma est un ensemble d'objets de la base de
données tels que les tables, des vues, des vues
matérialisées, des index et des synonymes. La conception du
schéma d'un Data Warehouse est guidée par le modèle des
données source et par les besoins utilisateurs.
L'idée fondamentale de la modélisation
dimensionnelle est que presque tous les types de données peuvent
être représentés dans un cube de données, dont les
cellules contiennent des valeurs mesurées et les angles les dimensions
naturelles de données. Nos conceptions peuvent comporter plus de trois
dimensions. Techniquement, il faudrait parler d'hypercube, bien que le
terme cube de données ait été adopté par
le métier.
a) les objets d'un schéma de Data
Warehouse
Les deux types d'objet les plus courants dans les
schémas de Data Warehouse multidimensionnels sont les tables de faits et
les tables de dimension.
? Tables de faits : une table de faits
comprend généralement des colonnes de deux types : celles qui
contiennent des faits numériques (souvent appelés indicateurs) et
celles qui servent de clé étrangère vers les tables de
dimension. Une table de faits peut contenir des faits détaillés
ou agrégées. Les tables contenant des faits agrégés
sont souvent appelées tables agrégées. une table
de faits contient généralement de faits de même niveau
d'agrégation. La plupart des faits sont additifs, mais ils peuvent
être semi-additifs ou non additifs. Les faits additifs peuvent être
agrégés par simple addition arithmétique. C'est par
exemple le cas des ventes. Les faits non additifs ne peuvent pas être
additionnés du tout. C'est le cas des moyennes. Les faits semi-additifs
peuvent être agrégés selon certaines dimensions mais pas
selon d'autres. C'est le cas, pas exemple des niveaux de stock. Une table de
faits doit être définie pour chaque schéma. Du point de vue
de la modélisation, la clé primaire de la table de faits est
généralement une clé composée qui est formée
de toutes les clés étrangères associées.
? Tables de dimensions et hiérarchies :
une dimension est une structure comprenant une ou plusieurs
hiérarchies qui classe les données en catégories. Les
dimensions sont des étiquettes descriptives fournissant des informations
complémentaires sur les faits, qui sont stockées dans les tables
de dimension. Il s'agit normalement de valeurs textuelles descriptives.
Plusieurs dimensions distinctes combinées avec les faits permettant de
répondre aux questions relatives à l'activité de
l'entreprise. Les données de dimension son généralement
collectées au plus bas niveau de détail, puis
agrégées aux niveaux supérieurs en totaux plus
intéressants pour l'analyse, ces agrégations ou cumuls naturels
au sein d'une table de dimension sont appelés des
hiérarchies. Les hiérarchies
sont des structures logiques qui utilisent les niveaux ordonnées pour
organiser les données. Pour une dimension temps, par exemple, une
hiérarchie peut agréger les données selon le niveau
mensuel, le niveau trimestriel, le niveau annuel.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
19
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Au sein d'une hiérarchie, chaque niveau est
connecté logiquement aux niveaux supérieurs et inferieurs. Les
valeurs des niveaux inferieurs sont agrégées en valeurs de niveau
supérieur.
a) Le Schéma en Etoile
Le schéma en étoile peut être le type le
plus simple de schéma de Data Warehouse, il est dit en étoile
parce que son diagramme entité/relation ressemble à une
étoile, avec des branches partant d'une table centrale. Un schéma
en étoile est caractérisé par une ou plusieurs tables de
faits, très volumineuses, qui contiennent les informations essentielles
du Data Warehouse et par un certain nombre de tables de dimension, beaucoup
plus petites, qui contiennent chacune des informations sur les entrées
associées à un attribut particulier de la table de faits. Une
interrogation en étoile est une jointure entre une table de faits et un
certain nombre de table de dimensions. Chaque table de dimension est jointe
à la table de faits à l'aide d'une jointure de clé
primaire à clé étrangère, mais les tables de
dimension ne sont pas jointes entre elles.
Les schémas en étoile présentent les
avantages suivants : ils fournissent une correspondance directe et intuitive
entre les entités fonctionnelles analysées par les utilisateurs
et la conception du schéma. Ils sont pris en charge par un grand nombre
d'outils décisionnels. La manière la plus naturelle de
modéliser un Data Warehouse est la représenter par un
schéma en étoile dans lequel une jointure unique établit
la relation entre la table de faits et chaque table de dimension. Un
schéma en étoile optimise les performances en contribuant
à simplifier les interrogations et à raccourcir les temps de
réponse.
Les schémas en étoile présentent
néanmoins quelques limites. La table centrale peut devenir très
volumineuse, sa taille maximale étant déterminée par le
produit des nombres de lignes des tables de dimension. En outre, les tables de
dimension ne sont plus normalisées. Elles sont donc plus volumineuses et
plus difficiles à tenir à jour car elles contiennent beaucoup de
données dupliquées.
|
EX :
|
|
|
|
|
|
|
|
|
|
Dimensions 2 Id_dim2
|
|
Dimensions 1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Id_dim1
|
|
|
|
|
|
|
|
|
|
|
|
|
Table des Faits
|
|
|
|
|
|
|
|
|
Id_f (Pk) Id_dim1 (Fk) Id_dim2 (Fk)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Dimensions 3
|
|
Dimensions 4 Id_dim4
|
|
|
|
|
|
Id_dim3
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Fig.II .1 : schéma d'un modèle en étoile
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
20
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
b) Le Schéma en Flocon
Les schémas en flocons normalisent les dimensions pour
éliminer les redondances. Autrement dit, les données de dimension
sont stockées dans plusieurs tables et non dans une seule table de
grande taille. Cette structure de schéma consomme moins d'espace disque,
mais comme elle utilise davantage de tables de dimension, elle nécessite
un plus grand nombre de jointures de clé secondaire. Les interrogations
sont par conséquent plus complexes et moins performantes.
Dans un schéma en flocon, cette même table de
faits, référence les tables de dimensions de premier niveau, au
même titre que le schéma en étoile.
La différence réside dans le fait que les
dimensions sont décrites par une succession de tables (à l'aide
de clés étrangères) représentant la
granularité de l'information. Ce schéma évite les
redondances d'information mais nécessite des jointures lors des
agrégats de ces dimensions.
Dimensions 1
Id_dim1
Dimensions 4
Id_dim4
Dimensions 5
Dimensions 2
Id_dim5

Table des Faits
Id_dim2
Id_dim 5

Dimensions 3
Id_dim3
Id_dim 6
Id_f (Pk) Id_dim1 (Fk) Id_dim2 (Fk)
Dimensions 6
Id_dim 6
Le principal avantage du schéma en flocons est une
amélioration des performances des interrogations due à des
besoins réduits en espace de stockage sur disque et la petite taille des
tables de dimension à joindre. Le principal inconvénient de ce
schéma est le travail de maintenance supplémentaire imposé
par le nombre accru de tables de dimension. EX :
Fig II.2 : schéma d'un modèle en flocon
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
21
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
d) schéma multi dimensionnel
(CUBE)
Dans le modèle multidimensionnel, le concept central
est le cube, lequel est constitue des éléments appelés
cellules qui peuvent contenir une ou plusieurs mesures. La localisation de la
cellule est faite a travers les axes, qui correspondent chacun a une
dimension.
La dimension est composée de membres qui
représentent les différentes valeurs.
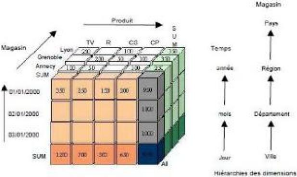
Fig. II. 3:Exemple de schéma multidimensionnel
La figure II. 3, présente un schéma
multidimensionnel pour les ventes qui ont été
réalisées dans les magasins pour les différents produits
au cours d'un temps donné (jour).
| 

