|

Année académique
2014/2015
RÉPUBLIQUE DU CAMEROUN REPUBLIC OF
CAMEROON
Paix -Travail - Patrie
************
Peace - Work - Fatherland
***************
Ministère de l'Enseignement Supérieur
Ministry of Higher Education
Université de Maroua The University Of
Maroua
Institut Supérieur du Sahel The Higher Institute
of the Sahel
Département d'Informatique et des
Télécommunications
Department of Computer Science and
Telecommunications
INFORMATIQUE ET
TÉLÉCOMMUNICATIONS

Mémoire présenté et soutenu en vue de
l'obtention du
Par
BASSIROU MOHAMET
Ingénieur des Travaux en Informatique
Option
Génie Logiciel
13Z584S
Sous la direction de
Dr
Jean Michel NLONG II
Chargé de cours
Devant le jury composé de :
Président : Prof. DANWE RAÏDANDI
Examinateur : Dr Pascal NTSAMA ELOUNDOU
Rapporteur : Dr Jean Michel NLONG II
Invité : M. BATOURE B. Apollinaire
i
Bassirou Mohamet
DEDICACE
Spécialement à ma mère chérie Zara
Asta.
ii
Bassirou Mohamet
REMERCIEMENTS
Au terme de notre étude, nous tenons à exprimer
notre profonde gratitude envers tous ceux qui, de loin ou de près ont
contribué à sa réalisation.
Nous tenons à remercier particulièrement :
· Notre directeur de mémoire, Dr Jean Michel
NLONG II, pour son apport, ses critiques et ses suggestions constructifs ;
· M. BATOURE B. Apollinaire, notre encadreur industriel,
sans l'initiative duquel ce projet n'aurait été possible. Je
tiens à lui exprimer toute ma reconnaissance pour son dévouement,
la confiance qu'il m'a accordée, sa rigueur et la qualité des
commentaires et suggestions dont il m'a fait part ;
· Pr Michel TCHOTCHOUA, Chef de Département de
Géographie, Directeur du LG, Université de
Ngaoundéré pour ses multiples soutiens, conseils et apports ;
· Les membres du jury pour l'honneur qu'ils me font en
examinant ce modeste travail à sa juste valeur ;
· Ma mère Zara Asta qui ne ménage aucun
effort depuis ma naissance jusqu'aujourd'hui pour faire de moi un homme digne
et intègre. Maman, trouve ici ma reconnaissance inoubliable envers ta
personne, merci ;
· Ma chère épouse, H. Komboussa et mes
enfants pour leur soutien, encouragement et surtout leur présence
à mes côtés durant toute la période de ma formation
;
· L'ensemble du personnel du CDTIC pour leur accueil
chaleureux et leurs conseils constructifs. Nous pensons à MM. S.
Rodrigue et F. IZANE Gaétan ;
· Mon tuteur Hamadou Célestin, tu as
été pour moi plus qu'un père durant tout mon parcours
académique, merci papa ;
· Tous mes frères et soeurs pour leur soutien
affectif, moral et financier, mes pensées vont vers ZECK, MEIMOUNA,
ADAMA, BACHIROU, TOUZING, GBERI... ;
· Dr. VIDEME BOSSOU Olivier, notre Chef du
département, pour ses conseils et ses efforts à nous dispenser
les cours malgré ses multiples préoccupations ;
· Tous mes enseignants de l'ISS pour la formation de
pointe qu'ils nous font ;
· Tous mes camarades de promotion pour le soutien mutuel
au moment critique de notre formation. Je pense à DJIMADOUM Janvier pour
son soutien multiforme et mes co-stagiaires NGUEDOUBOUM Roland, MANG-EGRE,
NGAROUA, HAMIDOULLAH.
TABLE DES MATIÈRES
DEDICACE i
REMERCIEMENTS ii
TABLE DES MATIÈRES iii
LISTE DES SIGLES ET ABRÉVIATIONS vii
RÉSUMÉ... viii
ABSTRACT ix
LISTE DES TABLEAUX x
LISTE DES FIGURES ET ILLUSTRATIONS xi
INTRODUCTION GÉNÉRALE 1
Chapitre I : CONTEXTE ET PROBLÉMATIQUE 3
I.1. CONTEXTE GÉNÉRAL DU SUJET 3
I.2. CADRE DU TRAVAIL 4
I.2.1. Les services offerts par le CDTIC 5
I.2.2. L'encadrement technique 5
I.2.3. Organigramme du CDTIC de l'Université de
Ngaoundéré 6
I.2.4. Localisation et contact 6
I.3. OBJECTIF DU PROJET 7
I.4. MÉTHODOLOGIE 8
Chapitre II : GENERALITÉS SUR LES ENTREPÔTS DE
DONNÉES 9
II.1. L'INFORMATION GÉOGRAPHIQUE 9
II.1.1. Représentation en mode raster 10
II.1.2. Représentation en mode vecteur 11
II.2. LES SYSTÈMES D'INFORMATIONS GÉOGRAPHIQUES
(SIG) 13
II.2.1. Les composants d'un SIG 13
II.2.1.1. Les logiciels 14
II.2.1.2. Les données 14
II.2.1.3. Les matériels informatiques 14
II.2.1.4. Le savoir-faire (la connaissance technique)
14
|
iii
|
Bassirou Mohamet
|
|
II.2.1.5.
|
Les utilisateurs
|
14
|
|
II.3.
|
LES ENTREPÔTS DE DONNÉES
|
15
|
|
II.3.1.
|
Définition
|
16
|
|
II.3.2.
|
L'architecture fonctionnelle des ED
|
16
|
|
II.3.3.
|
Pourquoi un ED à la place d'un SGBD Opérationnel ?
|
18
|
|
II.3.4.
|
Modélisation conceptuelle des entrepôts de
données
|
19
|
|
II.3.4.1.
|
La modélisation par sujet.
|
19
|
|
II.3.4.2.
|
La modélisation dimensionnelle
|
20
|
|
II.3.4.3.
|
Les Faits et Dimensions
|
20
|
|
II.3.5.
|
Structuration des données dans les entrepôts
|
21
|
|
II.3.5.1.
|
Le schéma en étoile
|
22
|
|
II.3.5.2.
|
Le schéma en flocon
|
22
|
|
II.3.5.3.
|
Le schéma en constellation
|
23
|
|
II.3.6.
|
Modélisation logique des entrepôts de données
|
24
|
|
II.3.7.
|
Alimentation des entrepôts de données (ETL)
|
24
|
|
II.3.7.1.
|
Extraction des données sources
|
24
|
|
II.3.7.2.
|
Transformation des données
|
25
|
|
II.3.7.3.
|
Chargement des données (Loading)
|
26
|
|
II.3.7.4.
|
Stratégies d'alimentation de l'ED
|
27
|
Chapitre III : LES ENTREPÔTS DE DONNÉES SPATIALES
ET OUTILS DE MISE EN OEUVRE 29
III.1. CONCEPTS FONDAMENTAUX DES EDS 29
III.1.1. Dimension spatiale et hiérarchie
29
III.1.2. Mesure spatiale 30
III.2. MODÈLES CONCEPTUELS POUR LES EDS 31
III.2.1. Modèle de Pourrabas 31
III.2.2. Modèle de Malinowsky et Zimànyi
31
III.3. SYSTÈME D'AIDE À LA DÉCISION
SPATIALE 32
III.4. OLAP SPATIAL (SOLAP) 33
III.4.1. Définition 34
III.4.2. Architecture SOLAP 35
III.4.3. Les opérateurs spatiaux 35
III.4.4. Les cubes de données spatiales 36
III.5. OUTILS DE MISE EN OEUVRE SOLAP 36
III.5.1. Les outils ETL géospatiaux 36
III.5.1.1. GeoKettle 37
III.5.1.1.1. Vocabulaire de GeoKettle 40
III.5.1.1.2. Composants de GeoKettle 42
III.5.1.1.3. Fonctionnalités spatiales de GeoKettle
42
III.5.1.2. Spatial Data Integrator (SDI) 44
III.5.2. Outils d'entreposages des données spatiales
45
III.5.2.1. MySQL Spatial 45
III.5.2.2. PostgreSQL/PostGIS 45
III.5.2.3. Oracle Spatial 46
III.5.3. Serveurs SOLAP 46
III.5.3.1. GeoMondrian 46
III.5.3.2. Geo Analysis Tool (GAT) 47
III.5.4. Client SOLAP 47
III.5.4.1. SolapLayers 47
III.5.4.2. Jpivot 48
Chapitre IV : CONCEPTION DU SYSTÈME D'ETL SPATIAL
49
IV.1. ÉTUDE DE L'EXISTANT ET ANALYSE DES BESOINS
49
IV.2. CONCEPTION DE l'EDS D'APPLICATION 50
IV.2.1. Choix des dimensions et fait 50
IV.2.2. Dimensions thématiques 50
IV.2.3. Dimension temporelle 51
IV.2.4. Dimensions spatiales 51
IV.2.5. Identification des faits 52
IV.2.6. Modèle multidimensionnel complet
52
IV.3. SGBD D'ENTREPOSAGE SPATIAL 54
IV.4. CONCEPTION DU PROCESSUS D'ETL 54
IV.4.1. Étude et planification 54
IV.4.1.1. Les sources de données 55
IV.4.1.2. Détection des emplacements des données
55
IV.4.1.3. Définition de la périodicité de
chargement 55
IV.4.2. L'architecture du système d'ETL 56
IV.4.3. Processus global d'alimentation de l'entrepôt
57
IV.4.3.1. Processus de chargement des dimensions
57
IV.4.3.2. Processus de chargement des faits 58
IV.4.3.3. Processus de chargement de la dimension « Temps
» 59
Chapitre V : RÉSULTATS ET COMMENTAIRES 61
V.1. Référentiel du système ETL
61
V.2. Différents processus ETL de l'EDS avec GeoKettle
64
V.2.1. Chargement de la dimension «dim_temps»
64
V.2.2. Chargement de la dimension « dim_abonnement
» 64
V.2.3. Chargement de la dimension « dim_transfo »
66
V.2.4. Chargement de la dimension « dim_zone_geo »
67
V.2.5. Chargement des faits « fait_conso »
67
V.3. Création de job 68
V.4. Exécution des transformations et job
69
V.4.1. Exécution avec « carte »
69
V.4.2. Exécution avec « Pan » 70
V.4.3. Exécution avec « Kitchen »
70
V.5. Visualisation des résultats 70
CONCLUSION ET PERSPECTIVES 72
BIBLIOGRAPHIE 73
ANNEXE 76
vii
Bassirou Mohamet
LISTE DES SIGLES ET ABRÉVIATIONS
BD: Base de Données;
BI: Business Intelligence;
CDTIC: Centre de Développement de
Technologies de l'Information et de la
Communication;
ED: Entrepôt de Données;
EDS: Entrepôt de Données
Spatiales;
ENSAI : Ecole Nationale de Sciences
Agro-Industrielles ;
ETL: Extract Transform and Load;
GéoBI: Geospatial Business
Intelligence;
HOLAP: Hybrid Online Analytical
Processing;
IUT: Institut Universitaire de
Technologie;
LG: Laboratoire Géomatique;
MOLAP: Multidimensional Online Analytical
Processing;
OLAP: Online Analytical Processing;
OLTP: Online Transaction Processing;
OSGeo: Fondation Open Source Geospatial.
ROLAP: Relationnal Online Analytical
Processing;
SAD: Système d'Aide à la
Décision;
SADS : Systèmes d'Aide à la
Décision Spatiale ;
SGBD(R) : Système de Gestion de Base
de Données (Relationnelles);
SI: Système D'Information;
SID: Système d'Information
Décisionnelle;
SIG: Système d'Information
Géographique;
SOLAP: Spatial Online Analytical
Processing;
SRS: Système de
Référence Spatiale;
TIC: Technologies de l'Information et de la
Communication;
TICE: Technologies de l'Information et de la
Communication pour l'Enseignement;
UML: Unified Modeling Language;
XML: Extensible Markup Language.
viii
Bassirou Mohamet
RÉSUMÉ
Les décideurs d'entreprises ont souvent besoin des
informations fiables, analysables et synthétiques. Le système
d'aide à la décision est une technologie qui permet aux
entreprises de transformer de précieuses données internes en
informations accessibles aux décideurs. Ceux-ci peuvent alors prendre
des décisions en toute connaissance de cause et en temps utile. L'usage
des entrepôts de données permet d'uniformiser et de stocker les
données provenant des sources diverses.
L'intégration des données provenant des sources
hétérogènes dans l'entrepôt de données
spatiales a conduit au développement des outils ETL spatiaux. Certains
de ces outils existent et permettent la conversion entre formats
géospatiaux. Cependant, peu s'intéressent spécifiquement
aux données géospatiales. Dans ce mémoire, nous
décrivons les différents aspects de mise en oeuvre d'applications
géodécisionnelles. Nous présentons ensuite GeoKettle, un
outil ETL « géo-capable », open source, permettant d'extraire
les données géospatiales, les transformer et les charger dans
l'entrepôt de données spatiales. Nous avons mis sur pied un
système d'ETL qui permet l'exécution des processus ETL de
l'entrepôt de données spatiales pour le suivi des consommations
d'électricité des abonnés de la commune de
Ngaoundéré 2e.
Mots clés : systèmes
d'aide à la décision, Géo-BI, entrepôt de
données spatiales, système d'information géographique,
outils ETL.
ix
Bassirou Mohamet
ABSTRACT
Corporate decision makers often need reliable, analyzable and
synthetic information. The decision support system is a technology that enables
enterprises to transform data into valuable internal information available to
decision makers. These can then make decisions knowingly and timely. The use of
data warehouses allows standardizing and storing data from various sources on a
single DB.
The integration of data from heterogeneous sources in spatial
data warehouse led to the development of spatial ETL tools. Some of these tools
are available and allow the conversion between geospatial formats. However,
none is specifically interested in geospatial data. In this paper, we describe
the different aspects of implementing Geo-BI applications. We then present
GeoKettle, an ETL tool "geo-enabled", and open source, to extract geospatial
data, transform and load into the spatial data warehouse. We have developed an
ETL system that allows the execution of the ETL process of the spatial data
warehouse of electricity consumption of the town of Ngaoundéré
2nd.
Keywords: support systems Decision,
Geo-BI, spatial data warehouse, geographic information system, ETL tools.
x
Bassirou Mohamet
LISTE DES TABLEAUX
Tableau II. 1: Différence entre ED et système
transactionnel 19
xi
Bassirou Mohamet
LISTE DES FIGURES ET ILLUSTRATIONS
Figure I. 1: Organigramme du CDTIC 6
Figure I. 2: Plan de localisation du CDTIC 6
Figure II. 1: Représentation en mode raster 10
Figure II. 2: Représentation en mode vecteur 11
Figure II. 3: Architecture d'un système d'ED 17
Figure II. 4: Modèle conceptuel d'une table de faits et
la représentation du cube associé 21
Figure II. 5: Exemple d'un schéma en étoile
22
Figure II. 6: Exemple d'un schéma en flocon 23
Figure II. 7: Exemple du schéma en constellation 23
Figure II. 8: Exemple d'opérations de transformation
26
Figure II. 9: Objectifs de qualité de données
27
Figure III. 1: Représentation graphique du
modèle des EDS 32
Figure III. 2: Équation SOLAP 33
Figure III. 3: Architecture de SOLAP 35
Figure III. 4 : Processus ETL de GeoKettle 38
Figure III. 5: Fenêtre d'accueil de GeoKettle 40
Figure III. 6: Une transformation avec GeoKettle 40
Figure III. 7: Différents types de liens avec GeoKettle
41
Figure III. 8: Exemple d'un job GeoKettle 42
Figure IV. 1: Diagramme de classes de la base de
données de facturation 49
Figure IV. 2: Dimensions thématiques 50
Figure IV. 3: Dimension temporelle 51
Figure IV. 4: Dimension spatiale 51
Figure IV. 5: Fait suivi de la consommation 52
Figure IV. 6: modèle multidimensionnel en étoile
53
Figure IV. 7: modèle multidimensionnel en flocon 53
Figure IV. 8: Architecture du processus ETL 56
Figure IV. 9: Diagramme d'activité du processus global
d'alimentation 57
Figure IV. 10: Diagramme d'activité ETL des dimensions
58
Figure IV. 11: Diagramme d'activité ETL des faits 59
Figure V. 1: Création du référentiel et
la connexion à la BD 62
Figure V. 2: Valider la création du
référentiel et générer la requête SQL 62
Figure V. 3: Modification de la requête avant son
exécution 62
Figure V. 4: Connexion au référentiel de travail
GeoKettle 63
Figure V. 5: Génération du calendrier et
chargement dans l'EDS 64
Figure V. 6: Génération et chargement de la
table "ABONNE" 65
Figure V. 7: Processus ETL des abonnements 65
Figure V. 8: ETL des transformateurs 66
Figure V. 9: ETL dimension "dim_zone_geo" 67
Figure V. 10: ETL des faits "fait_conso" 68
Figure V. 11: Job du processus ETL 68
Figure V. 12: Configuration serveur carte 69
Figure V. 13: Liste des zones géographiques 70
Figure V. 14: Carte des zones géographiques 71
1
Bassirou Mohamet
Introduction générale
INTRODUCTION GÉNÉRALE
L'informatique décisionnelle (en anglais "Business
intelligence, BI") est née au milieu des années 90. Son objectif
principal était orienté vers l'analyse des données
croissantes dont disposaient les entreprises. Ces dernières investissent
des énormes sommes d'argent pour stocker des gros volumes d'informations
grâce aux systèmes transactionnels (SGBDR). Ces données
sont difficilement exploitables par les décideurs/gestionnaires qui
n'ont besoin que des informations de nature analytique ou décisionnelle
(tableaux de bord, statistiques...). Le BI est un système qui s'appuie
sur les systèmes déjà en place, et ne les remplace pas.
Ainsi, il offre une possibilité d'analyser des données
historisées, agrégées dans un entrepôt de
données, issues des différentes sources de
données (Bases de données, fichiers, web) quelques soient leurs
types (alphanumériques, géométrie) et l'endroit où
elles se trouvent (local, internet) afin de les présenter sous une forme
exploitable et conforme aux décideurs. Dans ce domaine où les
besoins exprimés se diffèrent des systèmes
transactionnels, l'on ne parle plus de systèmes d'information classique
(SI), mais plutôt de système d'aide à la décision
(SAD). Selon (Franklin, 1992), 80% des données d'entreprise peuvent se
voir rattacher une localisation. De la même façon que le temps,
l'espace (localisation) doit être pris en compte dans l'analyse des
données d'entreprise. Pour cela, on passe du concept décisionnel
au géodécisionnel. Notre travail consiste en la mise en oeuvre
d'un système géodécisionnel (conception, alimentation et
exploitation d'un entrepôt de données spatial).
Il est divisé en deux modules. Le premier consiste à faire
l'extraction et la transformation des informations tirées des sources de
données diverses, et leur chargement dans l'entrepôt de
données préalablement conçu en utilisant l'outil ETL
GeoKettle. Le second module quant à lui va traiter de l'analyse de
données ou de l'aspect visuel coté client en utilisant le serveur
multidimensionnel GeoMondrian.
Ce mémoire traite du premier module et nous
l'appliquerons sur les données de consommation électrique des
abonnés de la commune de Ngaoundéré 2e.
2
Bassirou Mohamet
Introduction générale
Le présent travail est composé de cinq
chapitres. Le premier chapitre traite du contexte et la problématique de
notre sujet. Le second quant à lui se consacre aux
généralités sur les SIG, les entrepôts de
données (ED) et le couplage des deux technologies. Le troisième
chapitre porte sur les outils de mise en oeuvre des entrepôts de
données spatiales. Le quatrième chapitre décrit la
conception de l'EDS et la mise en oeuvre du système d'ETL
géospatial. Le cinquième chapitre, et le dernier, présente
les résultats obtenus et quelques commentaires.
3
Bassirou Mohamet
Chapitre I : Contexte et problématique
Chapitre I : CONTEXTE ET PROBLÉMATIQUE
Ce chapitre présente le contexte général
de notre travail et la problématique
posée par le sujet. Nous présentons aussi la
méthodologie adoptée pour la résolution du problème
posé et les objectifs que cherche à atteindre notre
étude.
I.1. CONTEXTE GÉNÉRAL DU SUJET
De nos jours, la majeure partie des entreprises, si ce n'est
la totalité, évolue dans un environnement fortement complexe et
hautement concurrentiel. Ce climat de forte concurrence exige de ces
entreprises une surveillance très étroite du marché afin
de ne pas se laisser distancer par les concurrents et cela en répondant,
le plus rapidement possible, aux attentes du marché, de leur
clientèle et de leurs partenaires.
Pour ce faire, les dirigeants d'entreprise, quel qu'en soit le
domaine d'activités, doivent se doter d'outils modernes qui leur
permettent de mener à bien les missions qui leur incombent. Ils devront
prendre notamment les décisions les plus opportunes. Ces
décisions, qui influeront grandement sur la stratégie de
l'entreprise et donc sur son devenir, ne doivent pas être prises ni
à la légère, ni de manière trop hâtive,
compte tenu de leurs conséquences sur la survie de l'entreprise. Il
s'agit de prendre des décisions fondées, basées sur des
informations claires, fiables et pertinentes. Le problème est de savoir
donc comment identifier et présenter ces informations à qui de
droit, sachant par ailleurs que les entreprises croulent d'une part sous une
masse considérable de données et que d'autre part les
systèmes opérationnels « transactionnels », (DB, SIG)
qui sont de type OLTP (Online Transactional Processing) s'avèrent
limités, voire inaptes à fournir de telles informations et
constituer par la même occasion un support appréciable à la
prise de décision.
C'est dans ce contexte que les « systèmes
d'information décisionnels » ont vu
le jour. Ils sont nés d'un besoin des entreprises
à fournir à leurs décideurs des moyens d'accéder
aux données de leurs propres systèmes opérationnels dans
le but du pilotage
4
Bassirou Mohamet
Chapitre I : Contexte et problématique
stratégique. Ils offrent donc à ces derniers des
informations de qualité sur lesquelles ils pourront s'appuyer pour
arrêter leurs choix décisionnels. Ces systèmes utilisent un
large éventail de technologies et de méthodes, dont les «
entrepôts de données » (Data Warehouse) représentent
l'élément principal et incontournable pour la mise en place d'un
bon système décisionnel. Mais il se pose deux problèmes
qu'il est important de noter ici : Comment réconcilier les
données émanant de multiples sources
hétérogènes ? Comment personnaliser ces données
pour les applications OLAP spécifiques ? Ce document tentera de
répondre à ces questions posées par intégration de
ces solutions dans le traitement des données de consommation
d'électricité comme échantillon applicatif.
I.2. CADRE DU TRAVAIL
Notre stage s'est déroulé conjointement au
Centre de Développement des TIC
(CDTIC) et au Laboratoire de Géomatique (
www.un-labogeomatique.org)
de l'Université de Ngaoundéré situés dans le campus
universitaire de Dang.
Le CDTIC est un centre d'appui à la
généralisation de l'usage des technologies de l'information et de
la communication et de leur appropriation par la communauté
universitaire de Ngaoundéré. Il a pour mission de
développer toutes les stratégies en matière de TIC de
L'Université de Ngaoundéré et pour d'autres. À ce
titre, il est chargé:
· de définir, mettre en oeuvre et tenir à
jour, en fonction de l'évolution des technologies, la politique
d'informatisation de l'Université de Ngaoundéré;
· d'assurer le fonctionnement du réseau de campus
de l'Université de Ngaoundéré, et sa connexion au
réseau national d'enseignement et de recherche;
· de promouvoir l'égalité d'accès
aux technologies de l'information et de la communication au sein du campus
universitaire;
· de faciliter et d'assurer l'arrimage de
l'Université de Ngaoundéré à la communauté
scientifique nationale et internationale en terme de TICE;
5
Bassirou Mohamet
Chapitre I : Contexte et problématique
· de faciliter la production et le développement de
ressources pédagogiques, informationnelles et des documents
électroniques;
· de contribuer à l'amélioration des
procédures de gestion de l'Université de Ngaoundéré
par un appui à l'informatisation des systèmes de gestion;
· de contribuer à la diminution des coûts par
la mutualisation des ressources;
· de former la communauté universitaire à une
utilisation experte des technologies de l'information et de la communication et
des ressources mises à leur disposition.
I.2.1. Les services offerts par le CDTIC
Le CDTIC offre les différents services suivants à
ses usagers :
· Une Bibliothèque pour une consultation sur place
;
· Des Formations continues à l'utilisation des
logiciels libres, logiciels spécialisés, infographie, internet et
bureautique ... ;
· Une station de radiodiffusion (Radio campus FM 99.0 MHZ)
généraliste pour les informations, débats scientifiques et
animation sur les activités du campus ;
· Un Cybercafé possédant 50 postes, ouvert
6j/7, 11h/j ;
· Une Salle de reprographie destinée aux travaux de
montage, d'impression, de reliure, de photocopie etc... ;
· Une salle de téléenseignement dotée
d'équipement pour les enseignements à distance ;
· Une Académie Cisco.
I.2.2. L'encadrement technique
Pour l'accomplissement de ses missions, le CDTIC comprend les
services opérationnels suivants:
· Le service financier
· Le service formation et certification
· Le service de maintenance et assistance
6
Bassirou Mohamet
Chapitre I : Contexte et problématique
· Le service réseau et mutualisation
· Le service de contenu et communication
· Service de développement
I.2.3. Organigramme du CDTIC de l'Université de
Ngaoundéré
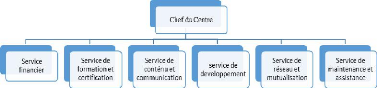
Figure I. 1: Organigramme du
CDTIC
I.2.4. Localisation et contact
Le CDTIC est situé au sein du campus de
l'Université de Ngaoundéré, près du
bâtiment administratif de l'IUT, non loin du
bâtiment de l'ENSAI et de l'entrée principale des
préfabriquées.
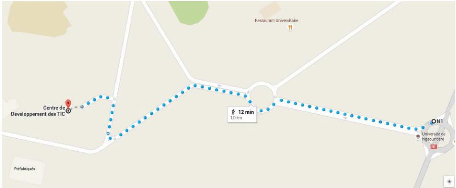
Figure I. 2: Plan de localisation du
CDTIC
Contact:
CDTIC, UNIVERSITÉ DE NGAOUNDÉRÉ
B.P. 454 NGAOUNDÉRÉ, CAMEROUN Téléphone: +237 222
25 42 49
7
Bassirou Mohamet
Chapitre I : Contexte et problématique
Par ailleurs, comme nous l'avons mentionné, nous avons
bénéficié, au cours de
notre stage, de l'appui documentaire du Laboratoire de
Géomatique (LG)1. En effet,
c'est un laboratoire universitaire de recherche en
géomatique rattaché au
Département de Géographie
de la Faculté des Arts, Lettres et Sciences Humaines de
l'Université de Ngaoundéré.
Le LG dispose d'une dizaine de postes informatiques
reliés en réseau sur lesquels les étudiants et les
chercheurs font les divers travaux. Il dispose également d'imprimantes
et scanners de formats A3 et A2. Pour les travaux menés, le LG est
doté de plusieurs images (aériennes, satellitaires, Landsat, ...)
du Cameroun et des pays voisins. On y retrouve également les
données cartographiques au 1/50 000e, 1/200 000e,
1/500 000e...
De nombreux logiciels de géomatique sont
utilisés. Ils sont pour la plupart payants et aux formats
propriétaires. Nous pouvons citer MapInfo, Adobe Illustrator, Inskape,
StatGraphics, etc.
Les objectifs principaux du LG sont la constitution d'un
fonds documentaire alimenté par les mémoires et thèses des
étudiants, la publication d'articles et ouvrages, l'établissement
de partenariats divers, l'expertise, la participation à la gestion de
l'environnement et du développement durable.
Les principaux axes de recherche du LG sont :
· La cartographie assistée par ordinateur ;
· Les SIG, la télédétection et le
géopositionnement ;
· L'analyse, l'intégration des données
spatiales, socio-économiques et les modélisations en vue de
l'aide à la décision ;
· L'utilisation des données multimédia et
gestion partagée des données.
I.3. OBJECTIF DU PROJET
Afin de pallier les problèmes
précédemment cités, notre structure d'accueil a
initié le présent projet. Ce projet a pour but la mise en oeuvre
d'une informatique géodécisionnelle et en particulier le
système d'ETL par l'utilisation de l'outil GeoKettle et son
intégration dans le traitement des données de consommation
1 Source : Mémoire de Batouré, 2011
8
Bassirou Mohamet
Chapitre I : Contexte et problématique
d'électricité dans la Commune de
Ngaoundéré IIe. Les principaux objectifs du projet que
nous nous sommes fixés sont :
· La conception et implantation d'un entrepôt de
données spatiales ;
· La sélection des données devant alimenter
ce dernier ;
· L'extraction des données stratégiques de
consommation ;
· La transformation de ces données ;
· Le chargement des données transformées dans
l'entrepôt de données. Les données seront extraites
à partir des différents fichiers (Excel, shapefile et BD
opérationnelle) mis à notre disposition par le Laboratoire de
Géomatique.
I.4. MÉTHODOLOGIE
Le développement de tout produit logiciel s'appuie, en
respect de la règle de l'art, sur une méthodologie. La mise en
place d'un logiciel suit plusieurs étapes afin de minimiser le risque
d'abandon et le temps de conception. Le domaine de l'analyse et de la
conception des systèmes d'information décisionnels est
très demandeur en techniques et méthodes. Seulement, parmi les
méthodes existantes, aucune n'a fait l'objet d'un standard, presque tout
est resté dans le domaine de la recherche. Quelques-unes des
démarches proposées ne sont presque pas cohérentes les
unes aux autres puisqu'elles ne sont pas orientées réutilisation.
Selon (Aziza, 2012), lorsque l'on veut utiliser des méthodes classiques
de systèmes d'information, on se trouve confronté aux
problèmes de l'inadéquation des modèles de systèmes
d'information (SI) au domaine du décisionnel en raison des
spécificités des besoins des SID. Cependant, dans notre travail,
nous allons utiliser le langage UML et UP7 pour l'analyse et la conception du
système.
Cette partie du document nous a permis de présenter le
contexte général et la
problématique posée par notre sujet. Une
étude du cadre de travail nous a fait découvrir nos structures
d'encadrement du stage et leur mission.
Dans le chapitre suivant, nous allons étudier en
détail quelques généralités sur les concepts
d'entrepôt de données.
9
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
Chapitre II : GENERALITÉS SUR LES
ENTREPÔTS DE DONNÉES ET LES SIG
Pour mieux comprendre les systèmes d'aide à la
prise de décisions, nous avons fait une étude plus ou moins sur
ce que c'est que l'informatique géodécisionnelle. Il existe deux
technologies majeures qui sous-tendent ce vaste concept à savoir les SIG
(Système d' Informations Géographiques) et les ED
(Entrepôts de données ; Data warehouse en anglais : DW) de
façon générale.
Dans cette partie nous aborderons ces points, mais pas sans
toutefois faire une description sommaire de l'information géographique,
parce qu'elle nous permettra de mieux comprendre l'intérêt des SIG
et toutes les technologies et applications y relatives.
II.1. L'INFORMATION GÉOGRAPHIQUE
L'information géographique est la
représentation d'un objet ou d'un phénomène réel ou
imaginaire, présent, passé ou futur, localisé dans
l'espace à un moment donné et quelles qu'en soient la dimension
et l'échelle de représentation. En effet il a été
démontré par Franklin (FRANKLIN, 1992) que la grande partie des
informations que nous utilisons au quotidien possède un aspect
géographique ainsi que 80% des informations stockées dans les
bases de données possèdent une référence
spatiale.
Les informations géographiques sont composées
de données alphanumériques
classiques et des données géométriques,
représentant des points, des lignes et des polygones (INMON, 2000) :
· Les points servent à la représentation
de symboles ponctuels : un quartier sur une carte d'un arrondissement, un arbre
sur une parcelle...
· Les lignes servent à représenter les
routes, rivières, voies de chemin de fer...
· Les polygones servent à représenter tous
les objets surfaciques comme les régions, départements sur une
carte du Cameroun...
Chapitre II : Généralités sur les
entrepôts de données et les SIG
Ces informations géographiques donnent une description
des objets et phénomènes localisés par rapport à un
référentiel sur la terre.
Il existe deux types d'information géographique
à savoir les informations géographiques par nature (soient de
base ou de référence) et les informations géographiques
par destination (ou thématiques). Les informations géographiques
par nature sont celles sur le territoire. Par exemple, un cours d'eau, une
parcelle, une route, etc. Par contre, les informations géographiques par
destination sont soit localisées (décrit par un nom, un
repère, une caractéristique, en référence à
une information géographique par nature) soit localisables
(élément tel qu'un habitant, un client, un hôpital, . . .
localisé en référence à une information
géographique par nature) (BORDIN, 2002).
Il existe deux modes fondamentaux de représentation
numérique des données géographiques. Nous avons le mode
raster ou matriciel et le mode vecteur.
II.1.1. Représentation en mode raster
Le mode raster ou mode matriciel : Ce sont des images, avec
comme unité de base le pixel. Ces images ne permettent pas d'association
avec des données alphanumériques en dehors des attributs de
chaque pixel. Ces attributs sont peu intéressants pour l'utilisateur de
SIG désirant réaliser des cartographies statistiques, puisque
celui-ci ne peut connaitre que les caractéristiques de chaque pixel de
base, et n'a aucune information concernant un secteur géographique plus
vaste. De plus, ces attributs ne sont pas modifiables et ne peuvent pas
être enrichis par d'autres informations.
Figure II. 1: Représentation en mode
raster
11
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
II.1.2. Représentation en mode vecteur
Le mode vecteur, lui il permet une décomposition du
contenu de l'image en traits caractéristiques, contours et
éléments principaux. Ce mode facilite l'accès direct aux
éléments de la carte (routes, parcelles, immeubles, . . .). Les
primitives géométriques sont ici des points, des lignes et des
polygones. Ce mode est celui privilégié dans les SIG. Ainsi,
alors que le mode raster représente implicitement l'objet et
explicitement l'espace ; le mode vecteur représente implicitement
l'espace et explicitement l'objet.
Figure II. 2: Représentation en mode
vecteur
La représentation cartographique est le mode de
présentation le plus utilisé pour l'information
géographique. Ces informations peuvent être
représentées suivant une ou plusieurs dimensions. Ceci permet,
(Inmon, 1990), de mieux faire ressortir sur des cartes, l'information
souhaitée. La représentation en 2D ressort les objets dans le
plan selon les coordonnées en X et en Y. Par contre, la
représentation 2D1/2 correspond au rattachement d'une coordonnée
Z à chaque point (X, Y). Cette valeur correspond à l'altitude de
l'objet ou du point, ce qui forme une nappe ou relief au-dessus d'une carte 2D.
La différence de la représentation 2D1/2 avec celle 3D est que
l'on peut avoir plusieurs Z pour un point (X, Y) donné, en
représentation 3D. D'autres documentations évoquent
également la représentation 2D1/4 et 2D3/4.
L'information géographique est
caractérisée par trois composantes :
· La composante sémantique : elle représente
l'information relative à la nature,
l'aspect et les propriétés descriptives d'un
objet ou à un phénomène du monde terrestre. Par exemple un
département est décrit par son nom (Vina), sa population
(451800), etc. Cette information peut aussi inclure des relations avec d'autres
objets ou phénomènes, par exemple le département Vina
appartient
12
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
à la région de l'Adamaoua. Un des aspects
sémantiques qui distingue l'information géographique des
données classiques est sa représentation multiple à
différentes échelles ;
· La composante relationnelle : décrit les
relations éventuelle avec d'autre objets ou phénomènes :
c'est le niveau topologique (la contiguïté entre deux communes,
l'adjacence entre les différents noeuds de tronçon constituant
des parcelles cadastrales, etc.) ;
· La composante spatiale ou géométrie :
représente la position sur la surface terrestre et la forme d'un objet
du monde réel. Une position est décrite dans un système de
référence explicite comme par exemple un système de
coordonnées. Cette composante permet de représenter la forme de
l'objet lui-même et de positionner celui-ci par rapport aux autres
phénomènes ou objets du monde réel.
Les données géographiques sont complexes et
constituées de plusieurs types qui
peuvent être numériques, alphabétiques,
images vecteurs ou raster, etc. Ces données sont structurées sous
forme de métadonnées (données sur les données).
Selon (Batouré, 2011), l'information géographique
doit permettre de répondre à un certain nombre de questions :
· Où : où se trouve cet objet ou ce
phénomène ?
· Quoi : que trouve-t-on à cet endroit ?
· Comment : quelles relations existent-il entre ces objets
ou phénomènes ?
· Quand : à quels moments les changements sont-ils
intervenus ?
· Et si : que se passerait-il si tel ou tel scénario
d'évolution se produisait ?
· Pourquoi : qu'est-ce-qui a favorisé la
réalisation de l'événement, comment le prévenir
?
Le besoin de gestion automatique des réponses à
ces questions a conduit à la mise en place des systèmes
d'informations géographiques (SIG).
Chapitre II : Généralités sur les
entrepôts de données et les SIG
II.2. LES SYSTÈMES D'INFORMATIONS
GÉOGRAPHIQUES (SIG)
Les systèmes d'informations géographiques (SIG)
sont apparus à la fin des années 1960. L'idée était
d'utiliser la grande possibilité de calculs des ordinateurs pour saisir,
gérer et analyser toute sorte d'information spatiale (NKWENKEU,
2008).
Un SIG est un système d'information capable
d'intégrer, d'organiser et de présenter des données
alphanumériques spatialement référencées, ainsi que
de produire des plans et des cartes en vue de résoudre des
problèmes d'aménagement, de gestion, d'aide à la
décision, d'étude ou de recherche. Notre travail se positionne
dans la classe d'aide à la décision.
Ainsi les SIG s'appliquent dans plusieurs domaines comme ceux
cités ci-dessous (HABERT, 2000) :
· Le tourisme (gestion des infrastructures,
itinéraires touristiques) ;
· Le marketing (localisation des clients, analyse du site)
;
· La planification urbaine (cadastre, POS, voirie,
réseaux assainissement) ;
· La protection civile (gestion et prévention des
catastrophes) ;
· Le transport (planification des transports urbains,
optimisation d'itinéraires) ;
· La forêt (cartographie pour aménagement,
gestion des coupes et sylviculture) ;
· La géologie (prospection minière) ;
· La biologie (études du déplacement des
populations animales) ;
· La télécoms (implantation d'antennes pour
les téléphones mobiles) ;
· L'hydrologie ...
Les SIG permettent d'accomplir un ensemble
d'opérations liées aux données géographiques comme
l'acquisition, la structuration, la mémorisation, l'analyse et la
visualisation de ces données sous différentes formes. Il est
important de connaitre qu'un SIG est composé de cinq composants
majeurs.
II.2.1. Les composants d'un SIG
13
Bassirou Mohamet
Les SIG sont généralement composés de cinq
éléments suivants :
14
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
II.2.1.1. Les logiciels
Ils assurent les six fonctions suivantes (appelées «
6A ») :
· saisie des informations géographiques sous
forme numérique (Acquisition)
· gestion de base de données
(Archivage)
· manipulation et interrogation des données
géographiques (Analyse)
· mise en forme et visualisation
(Affichage)
· représentation du monde réel
(Abstraction)
· la prospective (Anticipation).
Parmi une pléthore de ces logiciels nous pouvons citer
: MapInfo, Quantum GIS
(QGIS), Map Serveur, Abc-Map, PostGIS, Oracle Spatial, MySQL
Spatial etc...
II.2.1.2. Les données
Ce sont les données géographiques qui sont la
plus part de temps importées à partir de fichiers ou saisies par
un opérateur.
II.2.1.3. Les matériels informatiques
Le traitement des données se fait à l'aide des
logiciels sur un ordinateur de
bureau ou sur un ordinateur durci directement sur le terrain.
L'ordinateur de terrain avec GPS et laser télémètre permet
la cartographie et la collecte des données.
II.2.1.4. Le savoir-faire (la connaissance
technique)
La maîtrise de la technologie fait partie des composants
des SIG. II.2.1.5. Les utilisateurs
Comme tous les utilisateurs de systèmes d'information
géographique ne sont
pas forcément des spécialistes, un tel
système propose une série de boîtes à outils que
l'utilisateur assemble pour réaliser son projet.
15
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
Jusqu'à présent nous avons
présenté les SIG et les données qu'ils utilisent, mais
pour mettre en oeuvre un système d'aide à la décision,
nous avons besoin d'effectuer des traitements multidimensionnels, de
représenter les données sous forme de cube pour mieux les
exploiter. D'où la nécessité d'introduire les
entrepôts de données (ED).
II.3. LES ENTREPÔTS DE DONNÉES
Le concept d'entrepôt de données a
été formalisé pour la première fois en 1990 par
(Inmon, 1990). Il s'agissait de constituer une base de données
orientée sujet, intégrée et contenant des informations
historisées, non volatiles et exclusivement destinées aux
processus d'aide à la décision.
En effet, la simple logique de production (produire pour
répondre à une demande) ne suffit plus pour pérenniser
l'activité d'une entreprise.
Pour faire face aux nouveaux enjeux, l'entreprise doit
collecter, traiter, analyser les informations de son environnement pour
anticiper. Mais cette information produite par l'entreprise est surabondante,
non organisée et éparpillée dans de multiples
systèmes opérationnels hétérogènes et peut
provenir de toutes les places de marchés (mondialisation des
échanges).
L'idée première lors de la mise en place des
entrepôts de données dans les années 90, était
d'aider les entreprises qui regorgeaient d'un grand nombre d'information
archivées, pas toujours bien organisées, de tirer le meilleur
parti de celles-ci afin d'aider à la prise de décisions par
rapport aux faits observés antérieurement. On parle alors de
business intelligence (BI2) en français intelligence
économique.
Il devient fondamental de rassembler et
d'homogénéiser les données afin de permettre l'analyse des
indicateurs pertinents pour faciliter la prise de décisions. L'objectif
de l'entrepôt de données est de définir et
d'intégrer une architecture qui serve de fondation aux applications
décisionnelles (Desnos, 2015).
2 BI : informatique décisionnelle ou DSS : Decision
Support System.
16
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
II.3.1. Définition
Un entrepôt de données ou data warehouse (DW) en
anglais est une collection
de données thématiques (orientées
sujet), intégrées, non volatiles et historisées pour la
prise de décisions (Inmon, 1990).
· Orientées sujet:
thèmes par activités majeures ;
· Intégrées:
données de divers sources de données ;
· Non volatiles: ne pas supprimer
les données du DW ;
· Historisées: trace des
données, suivre l'évolution des indicateurs.
En d'autres termes, c'est une base de données
regroupant l'ensemble des données fonctionnelles d'une entreprise. Son
but est de fournir un ensemble de données servant de
référence unique, utilisée pour la prise de
décisions dans l'entreprise par le biais de statistiques et de rapports
réalisés via des outils de reporting.
L'infrastructure technique mise en oeuvre doit être
capable d'intégrer, d'organiser, de stocker et de coordonner de
manière intelligible des données produites au sein du
Système d'Information (issues des applications de production) ou
importées depuis l'extérieur du SI (louées ou
achetées) dans lesquelles les utilisateurs finaux puisent les
informations pertinentes à l'aide d'outils de restitution et d'analyse
(OLAP3, Data mining).
II.3.2. L'architecture fonctionnelle des ED
L'architecture d'un entrepôt de données
influence plusieurs facteurs comme la disponibilité des données
et l'efficacité des traitements. L'architecture la plus simple consiste
seulement en des bases de données sources, un entrepôt de
données central et plusieurs clients. Parce que les applications des
entrepôts de données sont devenues plus complexes, les
entrepôts sont construits en utilisant des architectures multi-niveaux
afin d'accroître la performance, i.e., il n'y a pas seulement un
entrepôt de données central, mais aussi des « data marts
» (magasins de données) qui permettent de placer les données
le plus proche de l'utilisateur final.
3 Online Analitycal processing (en français:
Traitement Analytique en Ligne).
17
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
La figure ci-dessous nous offre une vision
générale de l'architecture des ED en cinq niveaux (Marlyse D,
2015):
· Data sources : constitué des
sources de données hétérogènes ;
· Back-end tiers : solution d'extraction,
de transformation et de chargement ;
· Data warehouse tiers : entrepôt de
données particulier ;
· OLAP tiers : serveur d'analyse
multidimensionnel tiers ;
· Front-end tiers : interface
GUI4 (tableau de bord du décideur ou analyste).
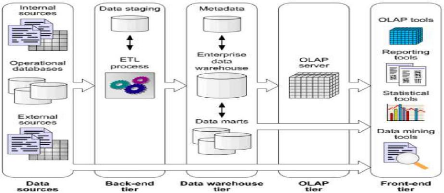
Figure II. 3: Architecture d'un système
d'ED
Un entrepôt de données peut se structurer en
quatre classes de données organisées selon un axe historique et
un axe de synthèse (Desnos, 2015):
Les données agrégées
Les données agrégées correspondent
à des éléments d'analyse représentant les besoins
des utilisateurs. Elles constituent déjà un résultat
d'analyse et une synthèse de l'information contenue dans le
système décisionnel, et doivent être facilement accessibles
et compréhensibles.
Les données détaillées
Les données détaillées reflètent les
événements les plus récents. Les
intégrations régulières des
données issues des systèmes de production vont habituellement
être réalisées à ce niveau.
4 Graphic User Interface (en francais : Interface graphique
utilisateur).
18
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
Les métadonnées
Les métadonnées constituent l'ensemble des
données qui décrivent des règles ou processus
attachés à d'autres données. Ces dernières
constituent la finalité du système d'information.
Les données historisées
Chaque nouvelle insertion de données provenant du
système de production ne détruit pas les anciennes valeurs, mais
créée une nouvelle occurrence de la donnée.
II.3.3. Pourquoi un ED à la place d'un SGBD
Opérationnel ?
Les ED et les SGBD5 opérationnels ont des objectifs
différents et font des traitements différents. Leurs modes de
stockage et leurs types de requêtes sont également
différents. D'où ils doivent être physiquement
séparés pour optimiser leur fonctionnement.
Les SGBD opérationnelles sont des systèmes dont
le mode de travail est transactionnel (OLTP : On-line Transaction Processing).
Ils permettent de faire :
· L'insertion, la modification ;
· L'interrogation rapide des informations et de
manière sécurisée. Les SGBD ont comme objectifs
principaux:
· La sélection, faire des ajouts ;
· De mettre à jour et supprimer des tuples.
Ces opérations doivent être effectuées
très rapidement, et par de nombreux utilisateurs
simultanément.
Les data warehouse quant à eux, sont des
systèmes conçus pour l'aide à la prise de décision
dont le mode de travail est analytique (OLAP On-Line Analytical Processing).
Les ED sont utilisés la plupart du temps en lecture.
Les objectifs principaux sont :
5 Système de gestion des bases de
données
19
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
· Extraire, regrouper, organiser des informations
provenant de sources diverses ;
· Intégrer les informations et les stocker pour
donner à l'utilisateur une vue orientée métier ;
· Retrouver et analyser l'information facilement et
rapidement.
Le tableau ci-dessous présente un récapitulatif
comparatif des ED et SGBD (Batouré, 2011).
Caractéristiques
|
SGBD/Opérationnel
|
Entrepôt de données
|
Applications
|
Production
|
Aide à la prise de décision
|
Utilisateurs
|
Professionnels de l'informatique
|
Décideurs non informaticiens
|
Données
|
Normalisées, non agrégées
|
Dénormalisées, agrégées
|
Requêtes
|
Simples, nombreuses, régulières,
prévisibles, répétitives
|
Complexes, peu
nombreuses, irrégulières, non
prévisibles
|
Nombre tuples invoqués par
requête
|
Des dizaines
|
Des millions
|
Taille données
|
100 MB à 1 GB
|
1 GB à 1 TB et plus
|
Ancienneté des données
|
récente, mises à jour
|
historique
|
|
Tableau II. 1: Différence entre ED et
système transactionnel
II.3.4. Modélisation conceptuelle des
entrepôts de données
II.3.4.1. La modélisation par sujet
Un entrepôt de données est
généralement basé sur un SGBD relationnel. La
modélisation par sujet est une technique de conception logique qui vise
à organiser et classifier les informations des bases légataires
en données classées par sujet fonctionnel. Elle est basée
sur la modélisation " Entité/Relation " et est
préliminaire à la modélisation dimensionnelle. Chaque
sujet correspond à une table gérée au sein de
l'entrepôt. Il faut isoler les données stratégiques,
déterminer les informations de détails nécessaires
(profondeur, granularité) et conserver les métadonnées.
20
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
II.3.4.2. La modélisation dimensionnelle
La modélisation dimensionnelle (modèle
multidimensionnel) souvent appelée modélisation OLAP (CODD, 1993)
se présente comme une alternative au modèle relationnel. Elle
correspond mieux aux besoins du décideur tout en intégrant la
modélisation par sujet. C'est une méthode de conception logique
qui vise à présenter les données sous une forme
standardisée intuitive et qui permet des accès (requêtes)
hautement performants. Elle va de cette façon présenter les
données non plus sous forme de tables mais de cube6 centré sur
une activité. Un cube de dimension n (n > 3) est aussi dit hypercube.
Les données sont ainsi divisées en fait et en dimension.
II.3.4.3. Les Faits et Dimensions
La table de faits est la clé de voûte du
modèle dimensionnel où sont stockés les indicateurs de
performances d'un axe d'analyse. Les faits (mesures) sont
généralement des valeurs numériques provenant des
processus d'affaires. Le concepteur doit s'efforcer de considérer comme
indicateurs les informations d'un processus d'entreprise dans un SI. Les
indicateurs étant les données les plus volumineuses d'un SI, on
ne peut se permettre de les dupliquer dans d'autres tables mais de les
rationaliser au sein de la table de faits. Le terme fait est ainsi
utilisé pour représenter une mesure économique. Enfin,
certaines mesures peuvent être calculées à partir d'autres
mesures ou propriétés de membres. Elles sont appelées
mesures dérivées (Bimonte, 2007). Un fait est tout ce qu'on
voudra analyser (Grim, 2015).
Une mesure peut être :
· Additive : si l'on peut l'appliquer la somme sur toutes
les dimensions ;
· Semi-additive : si la somme a du sens seulement sur
certaines dimensions ;
· Non-additive : si elle n'est sommable sur aucune
dimension.
Les tables de dimensions sont les entités
complémentaires à la conception de la table de faits. Elles
fournissent le contexte (le qui, le quoi, quand, où, le pourquoi et
comment) des faits. Elles contiennent, autant que possible, des attributs sous
forme de descriptions textuelles permettant de qualifier ou d'expliquer
l'activité. Des attributs
6 Cube: Une construction multidimensionnelle formée de la
conjonction de plusieurs dimensions. Chaque cellule est définie par une
seule valeur de chaque dimension.
21
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
de dimensions, nombreux, permettent de varier les
possibilités d'analyse (par tranches ou en dés). Ces attributs
rendent utilisables et intelligibles les données de l'entrepôt de
données. Selon (Grim, 2015), une dimension est tout ce qu'on utilisera
pour faire nos analyses.
En général, les tables de dimensions tendent
à être peu profondes mais elles sont larges (l'inverse de la table
de faits), en d'autres termes elles ont peu de lignes mais beaucoup de
colonnes.
Par exemple, pour une société de vente de
produits à Ngaoundéré, on peut chercher à
comptabiliser les types de produits vendus, leur quantité et le montant
de chaque vente au jour le jour et ceci, pour chaque produit et chaque magasin.
La mesure des quantités et des prix de vente s'obtient alors à
l'intersection de toutes les dimensions (produit, magasin, temps). Voir figure
ci-dessous.
Le nombre des dimensions détermine la finesse, la
granularité de la table des faits et indique la portée de
l'indicateur.
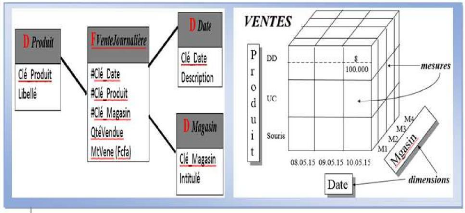
Figure II. 4: Modèle conceptuel d'une table
de faits et la représentation du cube associé
II.3.5. Structuration des données dans les
entrepôts
Dans l'ED, les données sont souvent redondantes et
dénormalisées, ce qui ne respecte pas la modélisation en
troisième forme normale (3NF) et pour cause, cela permet de faciliter
l'utilisation et d'améliorer les performances lors de l'analyse des
données. Il existe deux principaux modèles dans les
entrepôts de données en plus du
Chapitre II : Généralités sur les
entrepôts de données et les SIG
modèle en constellation. Il s'agit du modèle en
étoile et en flocon (AYISSI, 2007). Ces modèles permettent de
diviser les entrepôts de données en magasins de données et
peuvent être vues comme la plus petite unité de l'informatique
décisionnelle. Ce sont les éléments avec lesquels l'on
peut faire des analyses et créer les magasins de données. Ces
derniers mis ensemble, forment un entrepôt de données.
II.3.5.1. Le schéma en étoile
Dans ce schéma, il existe une table centrale de faits
contenant ses mesures et ayant les clefs étrangères qui font
référence aux tables de dimensions. Chaque dimension est
décrite par une seule table (feuille de l'arbre de tables) dont les
attributs représentent les diverses granularités possibles. La
figure ci-dessous illustre à travers un exemple le modèle en
étoile d'un magasin de données sur le suivi de la consommation
d'électricité dans une entreprise de production/distribution.
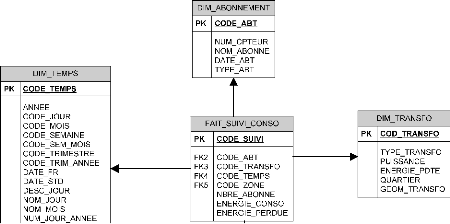
22
Bassirou Mohamet
Figure II. 5: Exemple d'un schéma en
étoile
II.3.5.2. Le schéma en flocon
Dans un schéma en flocon, cette même table de
faits, référence les tables de dimensions de premier niveau, au
même titre que le schéma en étoile. La différence
réside dans le fait que les dimensions sont décrites par une
succession de tables (à l'aide de clefs étrangères)
représentant la granularité de l'information. Ce schéma
évite
Chapitre II : Généralités sur les
entrepôts de données et les SIG
les redondances d'information mais nécessite des
jointures lors de l'agrégation de ces dimensions, chaque dimension
étant dénormalisée.
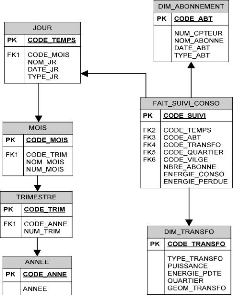
Figure II. 6: Exemple d'un schéma en
flocon
II.3.5.3. Le schéma en constellation
Dans un schéma en constellation, plusieurs
modèles dimensionnels se partagent certaines dimensions. En effet, il
est la fusion de plusieurs modèles en étoile qui utilisent des
dimensions communes. Il comprend en conséquence plusieurs faits et des
dimensions communes ou non. Dans l'exemple de la figure ci-dessous, nous avons
deux dimensions qui sont partagées : les dimensions « TEMPS »
et « GEOGRAPHIE ».
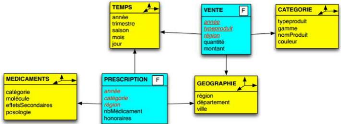
Figure II. 7: Exemple du schéma en
constellation
24
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
II.3.6. Modélisation logique des entrepôts de
données
Le niveau logique des ED présente la description de la
base multidimensionnelle qui sera utilisée selon la technologie choisie.
On distingue trois approches principales pour l'implémentation de
serveurs OLAP : Relational OLAP (ROLAP), Multidimensional OLAP (MOLAP) et
Hybrid OLAP (HOLAP) (Batouré, 2010). Les différents concepts
liés à OLAP sont les cubes de données, les
opérations OLAP.
II.3.7. Alimentation des entrepôts de données
(ETL)
Après la conception, vient la phase d'acquisition pour
alimenter l'entrepôt de données. Il faut déterminer et
recenser les données à entreposer. Nous recherchons ici des
données dans les ressources de l'entreprise. La démarche se
subdivise en un processus défini sous l'acronyme ETL (Extract,
Transform, Load), ETC en français (Extraction, Transformation,
Chargement). Ce processus constitue la phase de migration des données de
production dans le système décisionnel après qu'elles
aient subi des opérations de sélection, de nettoyage et de
reformatage dans le but de les homogénéiser. Cette phase
constitue une étape importante et très chronophage dans la mesure
où on l'estime à environ 80% du temps de mise en place de la
solution décisionnelle. (Simitsis et al., 2010; Jovanovic et al., 2012;
Papastefanatos et al., 2012; Akkaoui et al., 2011; Muñoz et al.,
2009).
II.3.7.1. Extraction des données sources
Selon (Kimball, 2005), « L'extraction est la
première étape du processus d'apport de données à
l'entrepôt de données. Extraire, cela veut dire lire et
interpréter les données sources et les copier dans la zone de
préparation en vue de manipulations ultérieures. »
Avant d'extraire les données des sources, elles subissent d'abord une
sélection afin de déterminer celles qui vont alimenter l'ED. En
effet, toutes les données sources ne sont pas forcément utiles.
Il faut soigneusement trier les données utiles qui feront l'objet
d'extraction pour enrichir l'ED selon les besoins d'analyse de l'entreprise.
25
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
L'extraction peut se faire à travers un outil
d'alimentation qui doit travailler de façon native avec les SGBD qui
gèrent les données sources. Ou alors l'on peut créer des
programmes extracteurs ; seulement, cette approche présente le risque de
faire des extractions erronées, incomplètes et qui peuvent
biaiser l'ED. Il faut alors gérer les anomalies en les traitant et en
gardant une trace.
L'extraction doit se faire conformément aux
règles précises du référentiel. Elle ne doit pas
non plus perturber les activités de production. Il faut faire attention
aux données cycliques. Celles qu'on doit calculer à chaque
période, pour pouvoir les prendre en considération. L'extraction
peut se faire en interne selon l'horloge interne ou par un planificateur ou par
la détection d'une donnée cible (de l'ED) ; ou en externe par des
planificateurs externes. Les données extraites doivent être
marquées par «horodatage» afin qu'elles puissent être
pistées. Il existe trois stratégies de détection de
changement :
· Colonnes d'audit : la colonne
d'audit, est une colonne qui enregistre la date d'insertion ou du dernier
changement d'un enregistrement. Cette colonne est mise à jour soit par
des triggers ou par les applications opérationnelles ;
· Capture des logs : On utilise les
fichiers logs des systèmes sources afin de détecter les
changements (généralement logs du SGBD). En plus de l'absence de
cette fonctionnalité sur certains outils ETL du marché,
l'effacement des fichiers logs engendre la perte de toute information relative
au changement ;
· Comparaison avec le dernier chargement
: le processus d'extraction sauvegarde des copies des chargements
antérieurs, de manière à procéder à une
comparaison lors de chaque nouvelle extraction. Cette méthode permet
d'éviter la perte d'un nouvel enregistrement des données de
production.
II.3.7.2. Transformation des données
La transformation est une suite d'opérations qui a
pour but de rendre les données cibles homogènes afin qu'elles
puissent être traitées de façon cohérente. Par
exemple, soient trois applications ayant des bases de données
différentes qui ont chacune sa structure, la transformation peut
consister à faire des opérations illustrées dans la figure
ci-dessous :
Chapitre II : Généralités sur les
entrepôts de données et les SIG
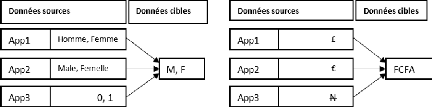
26
Bassirou Mohamet
Figure II. 8: Exemple d'opérations de
transformation
Elle consiste à filtrer les données afin
d'éliminer les données aberrantes: données sans valeurs ou
avec des valeurs manquantes. Souvent dans les bases de production, certaines
données sont sémantiquement fausses. Pour avoir une alimentation
de qualité, il faut avoir une bonne connaissance des données
à entreposer et des règles qui les régissent. Et savoir
corriger les données pour les doter d'un vrai sens sémantique.
Pour ce faire, on peut dédoubler des données pour gagner au
niveau de la cohérence. Les différentes tâches de la
transformation peuvent se résumer en :
· La consolidation des données ;
· La correction des données et élimination de
toute ambiguïté ;
· L'élimination des données redondantes ;
· Compléter et renseigner les valeurs manquantes.
Cette opération se solde par la production
d'informations dignes d'intérêt pour l'entreprise. En effet,
l'ensemble des données sources, après nettoyage ou transformation
d'après des règles précises ou par application de
programmes, seront restructurées et converties dans un format cible. Il
faut synchroniser les données pour que les valeurs
agrégées obtenues soient cohérentes, avant de passer
à la phase de chargement.
II.3.7.3. Chargement des données (Loading)
C'est l'opération qui consiste à charger les
données nettoyées dans l'entrepôt de données. Cette
opération est généralement assez longue en fonction du
volume de données à charger. Il faut alors mettre en place une
stratégie afin d'assurer des bonnes conditions à sa
réalisation.
Chapitre II : Généralités sur les
entrepôts de données et les SIG
II.3.7.4. Stratégies d'alimentation de l'ED
Le processus de l'alimentation peut se faire par l'utilisation
de plusieurs
stratégies. Le choix de la stratégie de
l'alimentation dépend de la disponibilité et
l'accessibilité des données sources. On distingue en effet trois
stratégies:
· Push : la logique de
chargement se trouve dans le système de production. Il « pousse
» les données vers la zone de préparation lorsque c'est
nécessaire. Malheureusement, si le système est occupé, il
ne poussera jamais les données ;
· Pull : contrairement
à Push, la logique du Pull se trouve dans la zone de préparation
des données. Il « tire » les données de la source vers
la zone de préparation. L'inconvénient de cette méthode
est qu'elle peut surcharger le système s'il est en cours
d'utilisation.
· Push-pull : c'est la
combinaison des deux méthodes. La source prépare les
données à envoyer et indique à la zone de
préparation qu'elle est prête. La zone de préparation va
alors récupérer les données.
D'après (Kimball, 2004), le processus ETL doit
répondre à certaines exigences de qualité de
données. Pour ce faire, un processus ETL doit être :
· Sûr : le processus doit assurer
l'acheminement des données et leur livraison.
· Rapide : la quantité de
données manipulées pouvant causer des lenteurs, le processus
d'alimentation doit palier à ce problème et assurer le chargement
du Data Warehouse dans des délais acceptables.
· Correctif : le processus
d'alimentation doit apporter les correctifs nécessaires pour
améliorer la qualité des données ;
· Transparent : le processus doit
être transparent afin d'améliorer la qualité des
données.
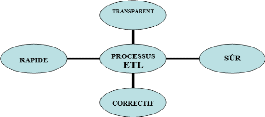
27
Bassirou Mohamet
Figure II. 9: Objectifs de qualité de
données
28
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
Dans ce chapitre, nous avons étudié les SIG, ses
quelques solutions existantes et des différents concepts ou techniques
de mise en oeuvre qui peuvent intervenir lorsque l'on souhaite mettre sur pied
une application dans le domaine du BI. Les approches vues jusque-là nous
présentent distinctivement les SIG et les ED. Dans le chapitre suivant
nous aborderons l'étude des EDS et des outils de mise en oeuvre des
systèmes d'aide à la décision spatiale.
29
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
Chapitre III : LES ENTREPÔTS DE DONNÉES
SPATIALES ET OUTILS DE MISE EN OEUVRE
Les entrepôts de données spatiales permettent
d'intégrer et historiser de très gros volumes de données
(spatiales et non spatiales) provenant de multiples sources pour supporter le
processus de prise de décision au sein d'une organisation (Stefanovic et
al., 2000). Ces entrepôts sont modélisés selon le
modèle spatio-multidimensionnel qui définit les concepts de
mesure spatiale et de dimension spatiale pour prendre en compte la composante
spatiale de l'information géographique. Dans ce chapitre, nous nous
proposons d'étudier les EDS et quelques outils qui permettent la mise en
oeuvre des systèmes
décisionnels/géodécisionnels.
III.1. CONCEPTS FONDAMENTAUX DES EDS
Nous avons décrit dans le chapitre
précédent les différents concepts fondamentaux liés
à l'ED classique. Dans cette partie, nous allons parler des concepts de
base des EDS selon (Béd et al, 05). Il est important de noter qu'un
entrepôt de données spatiales est une reformulation d'un
entrepôt de données conventionnel. Il contient en même temps
des données spatiales et alphanumériques et il reformule les
concepts classiques de dimension et de mesure pour prendre en compte la
composante spatiale de l'information géographique en définissant
les dimensions et les mesures spatiales.
III.1.1. Dimension spatiale et hiérarchie
Le terme de dimension spatiale désigne l'introduction
de l'information spatiale dans une application décisionnelle en tant
qu'axe d'analyse. En plus des dimensions descriptives, les systèmes
SOLAP supportent les dimensions dites spatiales. En effet, ils supportent trois
types de dimensions spatiales [Riv et al, O4] :
1. les dimensions non géométriques
: utilisent une référence spatiale qui est juste
nominale. Exemple : Vina.
2. les dimensions spatiales géométriques :
elles associent une géométrie aux
30
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre

membres de tous les niveaux. Exemple, le département de
la Vina peut être représenté avec
sa carte :

3. les dimensions spatiales mixtes : elles
associent une géométrie aux membres
de certains niveaux définis :
Vina.
Dans (Malinowski et Zimányi, 2005), les auteurs
introduisent le concept de dimension spatiale comme un ensemble de
hiérarchies spatiales. Une hiérarchie est spatiale s'il y a au
moins un niveau qui contient la composante spatiale. Celui-ci est dit niveau
spatial. De plus, entre les membres de deux niveaux spatiaux doit exister une
relation topologique d'inclusion ou d'intersection. Une hiérarchie
spatiale peut être totalement spatiale si tous les niveaux sont spatiaux,
partiellement spatiale s'il y a au moins un niveau non spatial.
III.1.2. Mesure spatiale
Plusieurs auteurs ont défini ce qu'est la mesure
spatiale. D'après (Stefanovic et al. 2000), (Malinowski et
Zimányi, 2004), la mesure spatiale est parfois vue comme une collection
de pointeurs vers des objets spatiaux, comme les résultats
d'opérateurs métriques ou topologiques spatiaux. Par exemple la
distance entre deux régions (Rivest et al., 2001), (Malinowski et
Zimányi, 2004). La mesure spatiale peut également être vue
comme un membre spatial d'une dimension (Marchand et al., 2003). On distingue
deux types de mesures spatiales supportées par SOLAP :
1. Mesures spatiales géométriques :
c'est le résultat d'une opération qui retourne une
géométrie. « il s'agit d'un ensemble de coordonnées
obtenues à partir des opérateurs d'analyse spatiale d'un SIG
» [Bed et al, 05].
2. Mesures spatiales numériques (non
géométriques) : c'est le résultat d'une
opération métrique ou des calculs spatiaux : cumul de longueur
sur un réseau, surface d'un objet, distance minimale avec l'objet le
plus proche...
Avec l'apparition des mesures spatiales, les fonctions
d'agrégation spatiales
sont elles aussi devenues très différentes et
plus complexes que les fonctions classiques (COUNT, SUM, etc.) utilisées
dans les systèmes OLAP. Les systèmes
31
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
SOLAP proposent d'utiliser par exemple l'union, l'intersection
ou le barycentre. Leur utilisation permet d'avoir des descriptions de
synthèse du phénomène spatial.
III.2. MODÈLES CONCEPTUELS POUR LES EDS
Dans cette section nous présentons quelques modèles
formels pour les
bases de données spatio-multidimensionnelles
proposés en littérature, (Sandro Bimonte, 2007).
III.2.1. Modèle de Pourrabas
(Pourrabas, 2003) présente un modèle formel qui
intègre une base de données spatiales objets et une base de
données multidimensionnelles. Cette solution permet de répondre
aux requêtes qui portent sur des données stockées dans une
base de données multidimensionnelle et une base de données
spatiales, de façon transparente à l'utilisateur.
III.2.2. Modèle de Malinowsky et Zimànyi
Le travail présenté dans (Malinowsky et
Zimányi, 2004), (Malinowsky et Zimányi, 2005) et (Malinowsky,
2006) étend le modèle multidimensionnel MultiDim (Malinowsky et
Zimányi, 2004b) avec les concepts de dimension, hiérarchie et
mesure spatiales. Le modèle multidimensionnel est défini comme un
ensemble fini de dimensions et une relation de fait (« fact relationships
»). La figure ci-dessous montre la représentation graphique du
modèle pour entrepôts de données spatiales
présenté dans (Malinowsky et Zimányi, 2004). En (a) les
auteurs présentent les Fait et Mesures. Le dessin (b) représente
la dimension. Les symboles du dessin (c) représentent les
différentes cardinalités. En (d), nous remarquons les dimensions
et leurs niveaux de granularité. Les symboles dans le dessin (e) sont
les icônes spatiales.
32
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
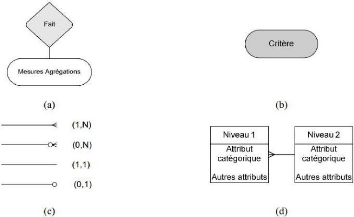

Figure III. 1: Représentation graphique du
modèle des EDS
III.3. SYSTÈME D'AIDE À LA
DÉCISION SPATIALE
Dans le contexte de l'exploration et d'analyse interactive de
données spatiales, qui représentent 80% des données
transactionnelles (Franklin, 1992), les cartes ne sont pas seulement de simples
outils de visualisation, mais elles sont des instruments actifs qui stimulent
l'utilisateur dans son processus mental d'analyse (MacEachren et Kraak, 2001).
Les Systèmes d'Aide à la Décision (SAD), et les
systèmes OLAP en particulier, ne présentent aucun instrument pour
la gestion des données spatiales. Par conséquent, les outils
OLAP, en prenant peu en compte la composante spatiale et son pouvoir
d'expression et d'analyse, manquent d'un instrument fondamental d'analyse et
d'exploration qui peut aider l'utilisateur dans le processus décisionnel
(Caron, 1998). A la base des SIG, il existe une technologie OLTP, contrairement
aux systèmes d'entrepôts de données qui s'appuient sur une
technologie OLAP (voir II.3. ). Les SIG ne peuvent pas être
considérés comme de véritables SAD, car même s'ils
incluent des fonctionnalités avancées d'analyse, ils manquent
d'une interface simple et intuitive pour visualiser et requêter les
données. Les temps d'analyse sont longs et
33
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
ils ne sont pas conçus pour fournir une vision
agrégée des données (Keenan, 1996). Un nouveau type de SAD
a alors été conçu : les Systèmes d'Aide à la
Décision Spatiale (SADS). Un SADS étend les
fonctionnalités des systèmes d'information géographique
(Armstrong et Denshman, 1990), (Goodchild et Denshman, 1990). Ils aident les
décideurs à résoudre de problèmes et prendre de
décisions dans les applications où la composante spatiale joue un
rôle fondamental comme le géomarketing, l'environnement, etc.
Différents types de SADS ont été développés,
comme par exemple les systèmes « Exploratory Spatial Data Analysis
» (Andrienko et al., 2003), qui intègrent des techniques
d'interaction et de visualisation cartographique, et des méthodes
d'analyse spatiales. On note aussi les systèmes « Spatial Data
Mining » (Compieta et al.,2007) qui fournissent des techniques de fouille
de données spatiales et visualisation cartographique. Chacun s'adresse
à des problématiques décisionnelles spatiales
particulières. Parmi ces solutions, on trouve aussi le SOLAP qui vise
à intégrer la donnée spatiale dans l'OLAP.
III.4. OLAP SPATIAL (SOLAP)
Le terme OLAP Spatial (SOLAP) identifie un type de
système d'aide à la décision spatiale qui apporte des
solutions en intégrant les techniques d'analyse de l'OLAP et des SIG. La
figure suivante représente ce qu'on appelle l'équation SOLAP :

Figure III. 2: Équation
SOLAP
SOLAP augmente les capacités d'analyse des
systèmes OLAP classiques et il implique une reformulation des concepts
des entrepôts de données et de l'analyse en ligne d'un point de
vue formel et d'implémentation. La conception d'entrepôts de
données spatiales repose essentiellement sur le modèle en
étoile.
34
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
III.4.1. Définition
Le Spatial OLAP se propose comme un SAD où toutes les
fonctionnalités OLAP sont intégrées avec des
fonctionnalités SIG et avec des techniques de GeoVisualisation (Rivest
et al., 2005). L'introduction dans l'OLAP de la composante spatiale augmente
les capacités d'analyse de l'OLAP classique. La représentation
cartographique peut mettre en évidence des relations spatiales entre
différents faits et/ou mesures, qu'une simple étiquette textuelle
ou un affichage graphique n'aurait jamais montrées. De nombreux auteurs
ont données des définitions et descriptions de la technologie
SOLAP, mais celles données par le Professeur Bedard vont retenir notre
attention.
SOLAP se définit comme « une plate-forme
visuelle spécialement conçue pour supporter rapidement et
facilement des analyses spatio-temporelles et l'exploration des données
selon une approche multidimensionnelle basée sur des niveaux
d'agrégation et permettant des affichages cartographique, graphique et
tabulaire » (Bédard, 1997).
Dans la suite, il dit que SOLAP est: « un type de
logiciel qui permet la navigation facile et rapide dans les bases de
données spatiales et qui offre plusieurs niveaux de granularité
d'information, plusieurs thèmes, plusieurs époques et plusieurs
modes d'affichage synchronisés ou non : cartes, tableaux et
diagrammes.» (Bédard, 2004).
Pour ce qui est de la composante SIG, elle permet de manipuler
et visualiser les données spatiales et d'introduire, dans un contexte
d'analyse multidimensionnel, les outils d'analyse spatiale. Ainsi, l'interface
du client OLAP doit être enrichie par des techniques de visualisation
avancées, formant une interface qui intègre et synchronise
cartographie, représentation tabulaire et graphique dans un
environnement interactif et familier. Les cartes représentent les
dimensions et/ou les mesures spatiales et la visualisation des mesures
alphanumériques dans l'espace. C'est dans cette optique que naisse le
terme système d'aide à la décision spatiale (SADS).
35
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
III.4.2. Architecture SOLAP
Typiquement, une architecture d'entreposage de données
spatiales (Figure ci-dessous) est constituée de trois niveaux :
entrepôt de données spatiales, Serveur SOLAP et Client SOLAP
(Rivest et al., 2001). L'EDS est souvent implémenté en utilisant
un SGBD Spatial. Ce dernier permet de gérer et d'interroger les
données spatiales tout en garantissant le passage à
l'échelle et de bonnes performances. Le serveur SOLAP définit les
hyper-cubes spatiaux en définissant les mesures, les dimensions
(spatiales) et les opérateurs d'agrégation. Enfin, le client
SOLAP permet des analyses pertinentes du contenu de l'EDS, en exploitant divers
types d'affichage: histogrammes, tableaux croisés dynamiques et des
cartes interactives.
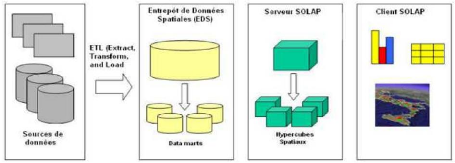
Figure III. 3: Architecture de
SOLAP
III.4.3. Les opérateurs spatiaux
SOLAP dispose des opérateurs spatiaux, que nous pouvons
classer en trois catégories :
1. Les opérateurs SOLAP de forage :
permettent la navigation dans les dimensions géographiques à
partir des cartes. Dans le cas où plusieurs hiérarchies
coexistent, il faudra préciser la hiérarchie de navigation
utilisée.
2. Les opérateurs SOLAP de coupe :
permettent de sélectionner une partie de l'hypercube en utilisant
l'interaction avec la carte et des relations topologiques, métriques
et/ou directionnelles entre les membres spatiaux .
36
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
3. Les opérateurs SOLAP de modification
dynamique de l'hypercube : sont des opérateurs qui permettent
à l'utilisateur de créer de nouveaux membres à la
volée grâce à des opérateurs d'analyse spatiale
(buffer, overlay, clipping).
III.4.4. Les cubes de données spatiales
Les cubes de données SOLAP répondent aux
mêmes principes que les cubes de données OLAP explicités
dans les sections précédentes.
Rappelons que ces cubes sont générés par
le moteur SOLAP mis en place à partir de l'entrepôt de
données stocké dans une base de données relationnelle et
dans les tables de dimension et de faits. Les cubes de données sont
interrogés par les utilisateurs à travers une requête
multidimensionnelle appelé MDX7.
Les dimensions, les hiérarchies et les niveaux sont pour MDX ce que sont
les tables et les colonnes pour SQL.
III.5. OUTILS DE MISE EN OEUVRE SOLAP
La mise en oeuvre d'un système SOLAP nécessite
toute une panoplie d'outils allant de l'ETL à l'analyse SOLAP.
III.5.1. Les outils ETL géospatiaux
Les extracteurs des données aussi appelés ETL
(Extract, Transform and Load) sont des logiciels destinés à
extraire les informations des différentes sources, les transformer et
les charger dans l'entrepôt de données. Ils servent aussi de lien
entre l'entrepôt de données et les sources de données
hétérogènes. Il existe trois catégories d'outils
ETL :
· Engine-based: les transformations
sont exécutées sur un serveur ETL, disposant en
général d'un référentiel. Ce genre d'outil dispose
d'un moteur de transformation ;
· Database-embedded: les
transformations sont intégrées dans la BD ;
7 MultiDimensional eXpressions : Langage d'expression des
requêtes multidimensionnelles.
37
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
· Code-generators: les transformations
sont conçues et un code est généré. Ce code peut
être déployé indépendamment de la base de
données.
Il existe une grande variété de ces outils
existent allant des versions open source aux versions commerciales. On peut
citer entre autre GeoKettle, SDI etc... Comme notre travail impose
l'utilisation de GeoKettle pour nos processus ETL, nous allons pousser une
étude approfondie sur cet outil. Néanmoins, une
présentation sommaire de quelques autres sera faite à la fin de
l'étude de GeoKettle.
III.5.1.1. GeoKettle
GeoKettle est une version «géo-capable»
issue de l'outil ETL Kettle (Pentaho
Data Integration, PDI). C'est une solution open source que
nous allons utiliser pour notre mise en oeuvre.
En effet, PDI est un outil ETL puissant de
catégorie Engine-based, dédié à
l'intégration de différentes sources d'information au sein
d'entrepôts de données. PDI embarque à cet effet la
totalité du code nécessaire dans son noyau et ne traite ainsi que
les flux de données. Ainsi, un traitement Kettle peut être
stocké sous forme de fichier plat (XML, CSV...) ou bien dans un SGBD
("Kettle repository"), ce dernier servant également de
référentiel de travail partagé. Un des attraits de PDI est
son niveau d'intégration avec la plate-forme OSBI Pentaho. Kettle peut
ainsi servir de source de données au moteur de reporting de Pentaho et
même permettre l'élaboration de vues d'analyses
multidimensionnelles avec le concept "Agile BI" et l'outil Pentaho Analyzer.
Kettle est intégré à pentaho depuis 2006, distribué
sous Mozilla public licence ; il dispose d'une interface graphique, un
très bon niveau de packaging et il est multiplateforme. Le niveau de
sécurité est sûrement le meilleur des ETL que nous avons
étudiés. La mise en place d'une console d'administration permet
un niveau de sécurité important, tant au niveau de l'accès
aux métadonnées que sur celui de la création de
scénarios et même sur leur mise à jour. De plus, une
gestion automatisée des logs ainsi que des systèmes de test et de
debugging est prise en charge.
GeoKettle est développé par l'équipe GeoSoa
de Dr Badard de l'université
canadienne Laval au Québec. Il agit comme une surcouche
permettant la manipulation
38
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
des données géographiques. En effet, il permet
l'intégration de différentes sources de données spatiales
pour la constitution et la mise à jour d'entrepôts de
données géospatiales. De ce fait, GeoKettle permet l'extraction
des données de multiples sources, la transformation ces dernières
afin de corriger d'éventuelles erreurs, leur nettoyage afin de les
homogénéiser, le changement de la structure de celles-ci pour les
rendre conformes aux standards définis, ainsi que de permettre le
chargement (Loading) des données transformées dans un SGBD, un
fichier SIG ou un service Web géospatial.
GeoKettle bénéficie aussi des capacités
géospatiales des librairies Open Source
robustes, matures et bien connus comme JTS, GeoTools,
deegree, OGR. La figure ci-dessous illustre les différentes tâches
que GeoKettle peut nous permettre d'effectuer.
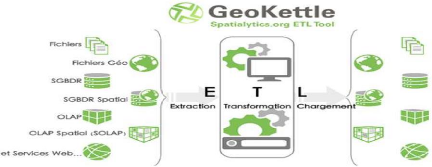
Figure III. 4 : Processus ETL de
GeoKettle
GeoKettle pourrait donc se résumer de la
manière suivante: GeoKettle = Kettle + Extensions spatiales. GeoKettle
permet alors :
· La manipulation des données de type
géométrique (basés sur JTS) ;
· L'accès aux objets de la géométrie
avec JavaScript ;
· La définition des étapes faites sur
commande de transformation par l'utilisateur ;
· La manipulation des attributs topologiques (intersection,
croisement, etc.) ;
· La définition et transformation de Système
de Référence Spatiale (SRS) ;
· L'entrée-sortie avec un certains SGBD spatiales
;
· La communication avec Oracle, PostGIS et MySQL ;
· Une possibilité d'intégration avec MS
SQL Server 2008, Ingres et IBM DB2, sous réserve d'apporter quelques
retouches.
39
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
GeoKettle 2.5 est la version communautaire que nous avons
étudiée. Il est dédié à l'intégration
de données géospatiales dans des systèmes
opérationnels (SIG, SDI, ...) ou des systèmes décisionnels
(GéoBI, SOLAP, ...). Cette version est plus puissante, évolutive,
rapide et conforme aux normes de l'industrie (WFS, WPS, CSW,
...)8.
Les principales nouveautés sont:
· WFS (Web Feature Service de l'OGC): étape
d'entrée pour la récupération de données
géospatiales directement à partir d'un service WFS;
· CSW (Service de catalogue OGC pour le Web):
étapes en entrée et sortie, désormais en mesure de lire
des services Web CSW de Deegree et MDWeb. L'étape de sortie CSW prend
désormais en charge les opérations d'insertion, suppression et
mise à jour de métadonnées, testée avec Deegree et
GeoNetwork;
· WPS (Web Processing Service de l'OGC): une
étape côté client a été ajoutée pour
invoquer des géotraitements distants exposés en WPS et ainsi
bénéficier de nouvelles et inédites capacités de
traitement, testée avec différentes implantations comme Deegree,
GeoServer, PyWPS, 52North WPS et Zoo WPS;
· Utilisation de la nouvelle version (1.9.1) de GDAL/OGR
pour plus de puissances avec les étapes OGR en entrée et
sortie;
· Utilisation de la nouvelle version (1.13) de la
bibliothèque JTS pour de meilleures performances et la correction de
bogues;
· Des nouvelles fonctions de conversion ajoutées
à l'étape «Calcul» (plus de capacités pour la
création et la transformation de fichiers/données WKT, GeoJSON,
GML, KML, ...);
· Mise à jour de la base de données de
projections EPSG (la définition d'une projection sur mesure introduite
dans la version 2.0 reste possible);
· Nouveaux installateurs dédiés selon l'OS
pour Windows, Linux / Debian ou Linux / Red Hat, Macintosh (une version en
fichier .zip est toujours disponible);
· Module Sextante: Ajoute des fonctionnalités
avancées de géotraitements vectoriel basé sur la
bibliothèque Sextante.
GeoKettle est disponible en téléchargement
libre, et selon le type de la plateforme, sur le site
http://www.spatialytics.org/fr/projets/GeoKettle
ou sur le site du projet :
https://www.geokettle.org.
Avant de l'installer, JRE (Java Runtime Environment) doit être
installé sur le système. Si l'on a
téléchargé le .exe, il suffit de faire un double-
8 Source :
www.georezo.net/forum
Chapitre III : Les EDS et outils de mise en oeuvre
clic et poursuivre le processus d'installation. Mais si c'est
l'archive qu'on a téléchargé, il faut le
désarchiver (selon votre version de SE) dans un répertoire de
votre choix (
C:\GeoKettle ou /home par exemple). Il faut
exécuter ensuite spoon.bat pour Windows ou
spoon.sh
pour une distribution Linux. La fenêtre d'accueil
ci-dessous apparaît et nous pouvons créer notre première
transformation.

Figure III. 5: Fenêtre d'accueil de
GeoKettle
III.5.1.1.1. Vocabulaire de GeoKettle
Le monde de l'ETL GeoKettle exige la manipulation de certains
termes qui lui sont propres qu'il est nécessaire d'expliquer ici.
· Transformations : tout processus ETL
;
· Etapes (steps) : Élément
d'une transformation ;
· Liens (hops) : Lien entre deux
étapes ;
·
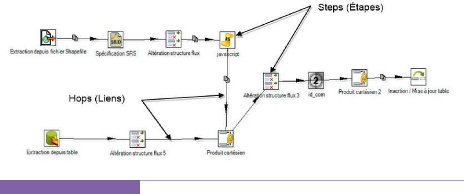
Bassirou Mohamet
40
Figure III. 6: Une transformation avec
GeoKettle
Les étapes sont des threads qui
s'exécutent en parallèle.
41
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
Les steps ont des paramètres de configuration
(double-clic) qui permettent d'indiquer :
· la connexion à la bd source ;
· le nom du fichier à ouvrir ;
· le code source du script (javascript) à
exécuter ;
On distingue plusieurs catégories de steps :
· Entrée/Sortie ;
· Transformation ;
· Scripting ;
· Flux...
Les différents types de liens que l'on peut rencontrer
sont :
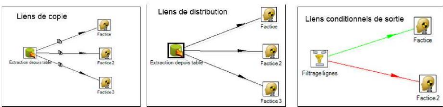
Figure III. 7: Différents types de liens
avec GeoKettle
Un job est une série de
tâches séquentielles à exécuter.
Ces tâches peuvent être :
· Des transformations ;
· Des requêtes SQL ;
· Des opérations sur les fichiers (copie,
suppression, téléchargement) ;
· Des tests conditionnels ;
· Des scripts (shell, javascripts) ;
· Envoi/réception des e-mails ;
· D'autres jobs ...
42
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
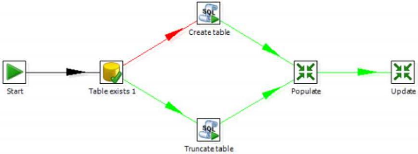
Figure III. 8: Exemple d'un job
GeoKettle
III.5.1.1.2. Composants de GeoKettle
GeoKettle est composé des différents outils
suivants : spoon, chef, pan, kitchen
et carte.
· Spoon: environnement graphique pour
l'édition des transformations et des jobs ;
· Pan: lancement (automatisation) en ligne
de commande des transformations ;
· Kitchen: lancement en ligne de commande
des jobs ;
· Chef: gestion automatique des
tâches complexes de transformations ;
· Carte: serveur web pour exécution
à distance des transformations et jobs.
III.5.1.1.3. Fonctionnalités spatiales de
GeoKettle
GeoKettle intègre de manière cohérente des
géométries vectorielles :
· Utilisation de type de données Geometry :
géométrie vectorielle (JTS), point, ligne, polygone.

· Conversions transparentes entre types de données
:
o Geometry <-> String: depuis et vers WKT (Well Known
Text) ;
o Geometry <-> Binary: depuis et vers WKB (Well Known
Text) ;
· Support des SGBD Spatiaux intégrés dans le
noyau d'E/S pour SGBD
43
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
(utilisation de JDBC). Tous les steps pouvant accéder
au BD supportent les colonnes géométriques de manière
transparente.
GeoKettle gère très correctement la lecture et
l'écriture des géométries. Il supporte les SGBD spatiaux
suivants :
· PostreSQL/PostGIS ;
· MySQL Spatial ;
· Oracle Spatial / Locator.
Il n'y a pas de steps distincts et dédiés
spécifiquement à chaque SGBD puisque tous les steps de BD
existants ont accès aux colonnes géométriques.
Il supporte les formats de fichiers SIG suivants :
· Shapefile ;
· KML ;
· GML.
Avec GeoKettle, on peut effectuer différentes analyses
spatiales :
· Scripting sur objets géométriques en
JavaScript ;
· Utilisation des fonctions d'analyses spatiales :
o Prédicats topologiques: INTERSECTS, TOUCHE, WITHIN...
exploitables à partir de steps de jointure et de filtrage ;
o Fonctions spatiales : UNION, INTERSECTION, LENGHT, BUFFER...
et toutes celles offertes par la librairie JTS accessibles en JavaScript;
GeoKettle assure la gestion des systèmes de
référence spatiaux (SRS) et projection.
· Gestion native des SRS dans les
métadonnées des champs Geometry en utilisant la librairie
GeoTools;
·
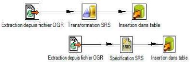
Reprojection : changement de SRS :
· Affectation d'un SRS à un flux de
données :
44
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
· Lecture et écriture des métadonnées
de SRS :
o Lecture des SRS depuis les sources de données : SGBD
et Shapefile (fichier .prj) ;
o Validation du SRS lors de l'insertion de données
dans PostGIS et Oracle ;
o Écriture du fichier .prj lors de la création
d'un Shapefile ;
Cette étude nous aidera au moment de la pratique pour la
mise en place de nos applications.
III.5.1.2. Spatial Data Integrator (SDI)
SDI est un ETL spatial open source basé sur Talend Open
Studio (TOS) et développé par la société
CampToCamp. Cet ETL est de type générateur de code (Java, Perl).
C'est-à-dire que pour chaque tâche réalisée sur
l'interface graphique, un code spécifique est
généré. En plus de la centaine de connecteurs natifs
(Sugar CRM, SalesForce...) disponibles dans TOS, SDI ajoute la
possibilité de lire et/ou écrire des données au format WFS
(Lecture) et GPX (Lecture/Écriture) ainsi que de réaliser des
traitements cartographiques (simplification, changement du sens des lignes...).
De plus, il peut également être couplé à la
bibliothèque Sextante afin de travailler sur
du raster. Enfin, la visualisation des données peut se faire directement
depuis Udig. SDI est proche de GeoKettle et permet un
accès à des sources de données très
diversifiées et l'intégration des fonctions de filtrage,
d'agrégation etc... La gestion des métadonnées est
centralisée. Le traitement des données est quant à lui de
très bonne qualité car bien qu'il existe la possibilité
d'ajouter de nouvelles fonctions, de nombreuses fonctions de transformation des
dates, nombres ou de statistiques avancées sont déjà
incorporées. De plus, il supporte les jointures de flux.
Le niveau de sécurité rivalise presque avec
celui de GeoKettle. Doté des mêmes caractéristiques, SDI se
distingue cependant par l'absence de sécurité sur le lancement
des tâches, d'un système de test et de débuggage en temps
réel ainsi qu'un type de sécurité propriétaire. SDI
est disponible en téléchargement sur son site à travers le
lien:
http://www.spatialdataintegrator.com
45
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
III.5.2. Outils d'entreposages des données
spatiales
III.5.2.1. MySQL Spatial
Apparu en 1995, MySQL a été initialement
développé par la société MySQL AB, récemment
rachetée par Sun Microsystem. Il est disponible pour la plupart des
systèmes d'exploitation, et est distribué sous licence GPL.
Soutenu par une communauté très importante, MySQL apparaît
comme un incontournable de la base de données Open source. Simple de
configuration, de déploiement et d'utilisation, il s'avère
être grandement utilisé lors de la conception de sites Web, et
c'est pour cela que la plupart des hébergeurs gratuits le supportent.
Néanmoins, de nombreuses structures professionnelles l'utilisent
également comme base de données interne, et non pour l'usage
unique de site Web. En effet, MySQL traite aisément les données
d'une masse volumique assez importante. Mais, bien que très performant
et rapide, ses avantages ont également le revers de la médaille.
Par exemple, il ne gère pas l'intégrité
référentielle, ce qui le rend plus rapide. Avec son module MySQL
Spatial, il intègre la gestion des données spatiales et devient
de ce fait un SGBD géographique.
III.5.2.2. PostgreSQL/PostGIS
La première version du projet PostgreSQL, appelé
Postgre à l'origine, remonte à 1986. Il est devenu libre et
distribué sous licence BSD depuis 1996. Réputé pour ses
excellentes performances, il possède de solides références
chez les grands comptes, comme Météo France. Le fait que ce
projet ne fonctionnait pendant longtemps que sous système UNIX explique
les raisons d'une communauté plus faible que chez MySQL.
Néanmoins, depuis la version 8.0, il est disponible sous Windows. Un peu
plus complexe de prise en main que MySQL, il traite les masses de
données importantes et garantie une cohérence de la
quasi-totalité des données car il gère
l'intégrité référentielle. Il utilise un puissant
plugin spatial PostGIS. Il constitue la meilleure plateforme d'entreposage des
données spatiales du marché. Nous allons nous servir de cet outil
pour la mise en oeuvre de notre entrepôt de données spatiales.
46
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
III.5.2.3. Oracle Spatial
Oracle Spatial est une solution développée par
Oracle permettant la gestion
complète de l'information traditionnelle et
géographique, et constitue la plateforme de données spatiales.
Elle est composée de 3 modules :
· Oracle Locator : Module
standard qui fournit les fonctionnalités cartographiques de base ;
· Oracle Spatial : Module qui
étend le module Oracle Locator et qui fournit les fonctionnalités
cartographiques avancées telles que le géocodeur, le routeur, le
stockage de données raster, le modèle de données
réseaux, le modèle de données topologique, les web
services, les requêtes complexes, la gestion de la 3D et la segmentation
dynamique (LRS) ;
· Oracle MapViewer : Serveur de
rendu cartographique en ligne.
Oracle Spatial permet l'utilisation d'un dépôt
unique pour les données spatiales et attributaires, ce qui donne
accès à l'ouverture, l'évolution, la
sécurité et la performance. En effet, en stockant les
données géospatiales et descriptives dans une base de
données unifiée, le niveau de fiabilité et de
disponibilité est largement supérieur à celui fourni par
de simples fichiers. Cela permet de minimiser les coûts par rapport
à l'exploitation et le stockage hybride qu'il est nécessaire de
faire si ces données sont stockées dans des bases de
données distinctes. En outre, cela permet également de rendre les
données interopérables entre les différents outils du SIG.
Enfin, Oracle permet le stockage et la gestion de gros volumes de
données, fréquemment rencontré dans le domaine des
SIG.9
III.5.3. Serveurs SOLAP
III.5.3.1. GeoMondrian
GeoMondrian est sans doute le premier serveur SOLAP Open Source.
C'est une
version « géo-capable » du serveur OLAP
Mondrian de Pentaho (Pentaho Analysis
9 Source :
http://www.oscars-sa.eu/fr/les-plus-doracle-spatial
47
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
Services). En effet, Mondrian est un serveur OLAP
écrit en Java qui ne permet pas l'intégration des données
de type géométrique. GeoMondrian vient palier à ce
manquement en permettant une intégration consistante d'objets spatiaux
(géométrie) dans la structure de données en cube
plutôt que de devoir les obtenir ailleurs, à partir d'un SGBD
spatial, un Service Web ou des fichiers SIG. GeoMondrian intègre
cependant les premières extensions spatiales au langage de requête
MDX ajoutant ainsi de puissantes capacités de requêtes et
d'analyse spatiale venant valoriser l'intelligence spatiale dans les cubes. Il
ne supporte que le SGBD PostgreSQL avec sa cartouche spatiale PostGis.
GeoMondrian est une réalisation de l'équipe de
recherche du groupe GeoSOA à l'université de Laval au
Québec. Les termes de la licence de GeoMondrian correspondent à
ceux de la licence EPL (Eclipse Public License). C'est l'outil que le
deuxième module de notre projet utilisera pour l'exploitation.
III.5.3.2. Geo Analysis Tool (GAT)
Geo Analysis Tool est un serveur open source qui permet
d'effectuer des analyses multidimensionnelles spatiales (OLAP Spatial). GAT est
un outil qui permet de réunir en une seule interface un outil d'analyse
OLAP tabulaire comme JPivot, et un outil entièrement spatial permettant
de travailler sur l'aspect spatialisé des données habituellement
traitées par le requêteur OLAP. Il s'appuie sur les composants
open sources : PostgreSQL/PostGis, GeoMondrian, OLAP4J, Open Layers,
Jpivot...
III.5.4. Client SOLAP
III.5.4.1. SolapLayers
SOLAPLayers est un composant cartographique open source,
capable d'afficher des cartes dont les résultats sont directement issus
d'une analyse OLAP de GeoMondrian. Il permet surtout une navigation
géo-spatiale dans le cube de données à l'aide du serveur
GeoMondrian. Ce composant cartographique vise aussi à être
intégré dans différents Frameworks, de tableau de bord
afin de produire de véritables tableaux de bord géo-analytiques
interactifs. Il permet encore la
48
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
représentation cartographique de mesures et de membres
d'une dimension spatiale sous la forme de cartes à intervalles fixes ou
à intervalles égaux dynamiques.
SOLAPLayers utilise les librairies OpenLayers et Dojo et
peut, évidemment se connecter au serveur spatial GeoMondrian.
III.5.4.2. Jpivot
Jpivot est plutôt un client OLAP disposant d'une
interface Web permettant de représenter un cube OLAP sous forme de
tableau croisé multidimensionnel. Il est particulièrement la
solution la plus utilisée dans le monde open source. Avec Jpivot, on
peut réaliser plusieurs opérations d'analyse
complémentaires telles que le drill down/drill up, les rotations,
l'exportation des tableaux sous forme de fichiers PDF ou de document Excel.
Pour permettre la visualisation et l'exploration des données tabulaires,
GeoMondrian l'utilise.
Ce chapitre nous a permis d'étudier les concepts de
l'EDS et quelques outils de mise en oeuvre dont la liste n'est pas exhaustive.
Parmi les outils étudiés ici, certains font partie d'une suite de
solution complète. D'autres peuvent être utilisés
indépendamment. L'objet de notre mémoire étant la mise en
oeuvre de système ETL spatial par l'utilisation de GeoKettle, cet outil
aura retenu plus notre attention dans cette étude. Le chapitre suivant
traitera de la conception et la mise en oeuvre de ce système.
49
Bassirou Mohamet
Chapitre IV : Conception du système d'ETL
Spatial
Chapitre IV : CONCEPTION DU SYSTÈME D'ETL
SPATIAL
Après l'étude des SIG, ED, EDS et les outils de
mise en oeuvre des EDS, nous entrons dans la partie du travail qui traite de la
mise en oeuvre de notre système. Dans ce chapitre, les
différentes démarches à suivre pour la mise en place d'un
système d'ETL spatial seront présentées.
IV.1. ÉTUDE DE L'EXISTANT ET ANALYSE DES
BESOINS
Le Laboratoire de Géomatique de l'Université de
Ngaoundéré nous a recommandé d'appliquer notre
étude aux données de consommation d'électricité
dans la Commune de Ngaoundéré 2e. Alors ne disposant pas d'une
base de données de production de l'entreprise qui distribue
l'électricité. Le LG nous a pourvus de quelques fichiers (Excel,
shapefile...) résultant de leurs études antérieures. Nous
avons aussi complété ces informations par quelques fichiers
(shapefile) du découpage administratif du Cameroun,
téléchargés sur le site
http://www.sogefi-sig.com/donnees-sig/137-donnees-sig-openstreetmap.
Nous nous sommes basés sur ces données pour concevoir et mettre
sur pied une base de données de production test pour la facturation et
la gestion des abonnements. Le diagramme de la figure ci-dessous illustre le
modèle de cette base de données.
Figure IV. 1: Diagramme de classes de la base de
données de facturation
Le SGBD MySQL a été utilisé pour
l'implémentation de ce schéma. Ensuite, nous avons
généré quelques données fictives pour enrichir
cette base de données.
Chapitre IV : Conception du système d'ETL
Spatial
IV.2. CONCEPTION DE l'EDS D'APPLICATION
Un système d'information décisionnelle (SID)
doit s'appuyer sur d'autres systèmes en place dits opérationnels,
pour pouvoir fonctionner. N'ayant pas ces systèmes, nous allons nous
appuyer sur les données de test que le LG a mis à notre
disposition et la base de données de facturation que nous avons
implantée, afin de concevoir le modèle de données
multidimensionnelles.
IV.2.1. Choix des dimensions et fait
Dans un entrepôt de données, la plus part des
données sont chargées dans les dimensions qui constituent les
axes d'analyses, auxquels sont liés les indicateurs que l'on peut
observer. Lorsqu'il s'agit d'un EDS, trois types de dimension au minimum
doivent y participer. Nous devons avoir les dimensions thématiques,
temporelles et spatiales.
IV.2.2. Dimensions thématiques
Ces dimensions peuvent être vues comme les plus
classiques dans un entrepôt. Elles contiennent très souvent des
attributs textuels distincts, et permettent d'avoir plus de détails sur
un objet lors des analyses. Après l'étude et l'analyse des
différentes sources mises à notre disposition, nous avons retenu
les dimensions suivantes :
· ABONNEMENT avec ses attributs
clés : numéro compteur, type d'abonnement, le nom de
l'abonné, la date de branchement ;
· TRANSFO avec ses attributs
clés : type, puissance, quartier et l'énergie produite.
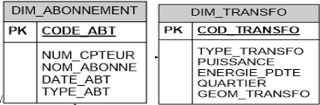
Figure IV. 2: Dimensions
thématiques
Chapitre IV : Conception du système d'ETL
Spatial
IV.2.3. Dimension temporelle
Dans le cadre de la mise en oeuvre de notre système,
nous avons une dimension
temporelle « Temps » avec les
attributs: Jour, jour de la semaine, mois, code mois, mois de l'année
trimestre, année....

Figure IV. 3: Dimension
temporelle
IV.2.4. Dimensions spatiales
Cette dimension fait intervenir l'espace dans notre contexte
comme axe d'analyse.
Nous l'appelons ici « Localisation
» pour exprimer la zone géographique qui fera l'objet de
l'analyse.

51
Bassirou Mohamet
Figure IV. 4: Dimension spatiale
Chapitre IV : Conception du système d'ETL
Spatial
IV.2.5. Identification des faits
Après avoir ressorti les différents types de
dimensions à partir des sources des
données, nous cherchons à définir les
attributs et les mesures qui vont constituer les indicateurs d'analyse du
système à mettre en place. Trois mesures ont été
retenues :
· Nombre d'abonné : cette mesure
permet de connaitre l'effectif des abonnés suivant une dimension
quelconque (localisation, temps...) ;
· Énergie consommée :
elle permet de retracer la consommation de chaque abonné ;
· Énergie perdue : c'est la
mesure qui indique la différence entre l'énergie produite au
niveau d'un transformateur et la somme d'énergie consommée par
les abonnés connectés sur ce dernier.
Les autres attributs sont les identifiants des dimensions qui
lui sont liées. Ces
identifiants représentent les clés
étrangères. La figure ci-dessous présente le modèle
de la table des faits de notre entrepôt de données spatial.
52
Bassirou Mohamet
Figure IV. 5: Fait suivi de la
consommation
IV.2.6. Modèle multidimensionnel complet
Après la modélisation de toutes ces
entités (dimensions, fait), nous sommes parvenus à ce
modèle multidimensionnel qui est représenté en
étoile et en flocon dans les figures ci-dessous. Mais compte tenu de la
volumétrie des données spatiales, nous implémenterons le
modèle en étoile pour éviter les jointures qui peuvent
ralentir le fonctionnement du système d'analyses géospatiales
lors des navigations.
Chapitre IV : Conception du système d'ETL
Spatial
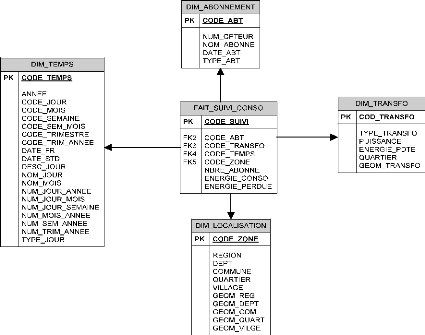
Figure IV. 6: modèle multidimensionnel en
étoile
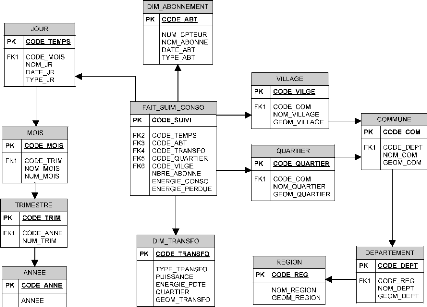
Figure IV. 7: modèle multidimensionnel en
flocon
54
Bassirou Mohamet
Chapitre IV : Conception du système d'ETL
Spatial
IV.3. SGBD D'ENTREPOSAGE SPATIAL
Le choix du SGBD spatial s'est fait suivant plusieurs
critères. Premièrement nous devons travailler dans un
environnement open source. De plus, il nous a fallu un système
performant pouvant supporter un très grand volume de données
spatiales. Ainsi, nous avons choisi d'implémenter notre entrepôt
de données sous le SGBD open source PostgreSQL/PostGIS.
IV.4. CONCEPTION DU PROCESSUS D'ETL
L'ETL est l'une des étapes la plus importantes dans le
processus de mise sur pied d'un système de GéoBI. Beaucoup
d'auteurs de commun accord, estiment à 80% sa charge de travail. En
effet, son objectif principal est d'assurer le transfert de données des
systèmes source jusqu'à l'entrepôt de données, en
passant par les différentes phases de nettoyage et de transformations
nécessaires.
La conception du processus d'alimentation nécessite les
phases suivantes :
· Étude et planification ;
· Choix de l'architecture du système d'ETL ;
· Conception des processus de chargement des tables:
o Dimension ;
o Faits ;
o Temps.
IV.4.1. Étude et planification
C'est la phase préliminaire de l'ensemble du processus.
Elle consiste à :
· Étudier les sources de données ;
· Détecter les emplacements des données
source ;
· Définir la périodicité du chargement
des données.
55
Bassirou Mohamet
Chapitre IV : Conception du système d'ETL
Spatial
IV.4.1.1. Les sources de données
Dans la section de l'étude de l'existant, nous avons
souligné que les sources des données de notre entrepôt sont
:
· Une base de données de production de
facturation que nous avons implémentée ;
· Des fichiers (shapefile, Excel) mis à notre
disposition par le Laboratoire de Géomatique ;
· Des fichiers shapefile du territoire Camerounais
téléchargés sur le site :
http://www.sogefi-sig.com/donnees-sig/137-donnees-sig-openstreetmap.
IV.4.1.2. Détection des emplacements des
données
L'étude des différentes informations que le
Laboratoire de Géomatique, à travers notre encadreur industriel,
a mises à notre disposition nous a permis de déterminer les
emplacements des données source et d'en choisir ceux qui sont
pertinentes et plus fiables.
Au vu des volumes importants de données que nous
avions à étudier et le
manque de systèmes opérationnels, cette
tâche n'était pas facile à réaliser.
Néanmoins, après la réalisation du schéma
étoile de l'EDS, nous devons :
· Lister les données nécessaires pour l'EDS
;
· Lister les emplacements de chaque donnée ;
· Choisir la source la plus fiable et la valider comme
source de chargement ;
· Dresser un tableau, selon (Kimball, 2004), qui
établit le lien entre données sources et donnée cibles
avec les transformations nécessaires.
IV.4.1.3. Définition de la
périodicité de chargement
Pour définir la périodicité de
chargement des données, il faut prendre en considération quelques
contraintes suivantes :
· La quantité de données à charger
;
· La période d'inactivité des systèmes
sources.
Chapitre IV : Conception du système d'ETL
Spatial
Supposons que le système de facturation fonction
à partir du milieu du mois courant. Dès cet instant, le
chargement de l'EDS peut commencer. Mais à quel moment de la
journée ou avec quelle fréquence ? L'EDS ou tout au moins le
magasin de données que nous avons implanté concerne la Commune de
Ngaoundéré 2e où le nombre d'abonnés
nous semble peu important. De ce fait, un chargement mensuel n'aura pas un
très grand volume de données. Donc nous allons procéder au
chargement mensuel dans la période d'inactivité du système
de production, c'est-à-dire entre dix-huit heures et huit heures.
IV.4.2. L'architecture du système d'ETL
L'élaboration d'une architecture du système d'ETL
au début de tout projet
d'alimentation est très importante. En effet,
d'après (FILALI, 2010), le choix d'une architecture affecte pratiquement
toutes les composantes du projet.
Il devient donc nécessaire d'élaborer une
architecture consistante qui prendra en charge toutes les contraintes
auxquelles on doit faire face.
Le processus de l'ETL peut se faire de différentes
manières. Dans notre cas, nous avons choisi la méthode
«Pull». D'autant plus que nous avons
décidé du chargement mensuel et à des heures
d'inactivité du système de production. La figure suivante
illustre l'architecture du processus d'alimentation que nous avons
adoptée dans le cadre de ce travail.
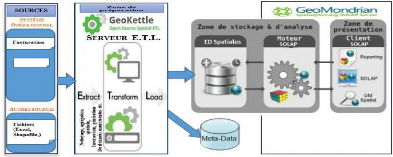
Figure IV. 8: Architecture du processus
ETL
57
Bassirou Mohamet
Chapitre IV : Conception du système d'ETL
Spatial
Au niveau du serveur ETL, les données sont extraites
à partir des sources de données. Quelques transformations seront
appliquées pour les préparer au chargement dans l'EDS qui se
trouve dans la zone d'entreposage. Après chaque chargement, il faut
mettre à jour les Meta Data.
Afin de détecter les changements effectués sur
les données sources, il est impératif de
développer une sentinelle et de l'implémenter
au niveau des sources. C'est elle qui enverra le signal au système ETL
pour déclencher le processus.
IV.4.3. Processus global d'alimentation de
l'entrepôt
Le diagramme d'activités défini dans la figure
IV.9 ci-dessous décrit de manière globale le processus
d'alimentation de l'EDS.
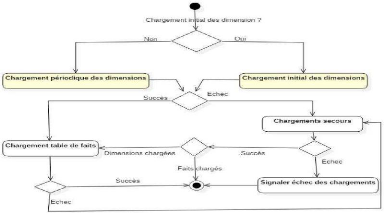
Figure IV. 9: Diagramme d'activité du
processus global d'alimentation
IV.4.3.1. Processus de chargement des dimensions
Les dimensions constituent le contexte des faits. Une
dimension est généralement constituée d'une clé
artificielle, d'une clé naturelle et des attributs. Le processus de
chargement de dimensions doit, non seulement transformer et charger les
données, mais aussi assurer :
· La gestion des clés artificielles: affectation
des clés et mise en correspondance avec les clés naturelles ;
58
Bassirou Mohamet
Chapitre IV : Conception du système d'ETL
Spatial
· La gestion de l'évolution de dimension :
gérer les changements que subissent les dimensions. Il existe trois
types de traitements par rapport à l'évolution d'une dimension
:
1. « Écraser l'ancien
enregistrement» : consiste à mettre à jour
l'attribut qui a subi le changement ;
2. «Créer nouvel
enregistrement» : consiste à créer un nouvel
enregistrement afin de sauvegarder tout le cycle d'évolution de la
dimension ;
3. «Déplacer l'ancienne valeur qui a
changé dans un attribut ancien» : consiste à
prévoir des attributs pour enregistrer les changements éventuels.
Il permet de sauvegarder un nombre défini de changements.
Le diagramme d'activité représenté dans
la figure ci-dessous illustre le processus de chargement des dimensions dans
l'EDS.
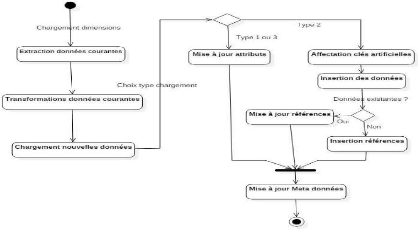
Figure IV. 10: Diagramme d'activité ETL des
dimensions
IV.4.3.2. Processus de chargement des faits
L'extraction des faits s'effectue avec les clés
naturelles utilisées dans le système opérationnel.
L'étape qui précède le chargement des faits consiste
à remplacer les clés naturelles par les clés
artificielles. La substitution peut se faire directement par le biais des
dimension, mais c'est très lent. Pour résoudre le problème
de lenteur, on peut utiliser des tables de référencement.
59
Bassirou Mohamet
Chapitre IV : Conception du système d'ETL
Spatial
Le processus de chargement de la table des faits doit garantir
l'intégrité référentielle vis-à-vis des
dimensions.
Le processus de chargement de faits est illustré par le
diagramme d'activité suivant.
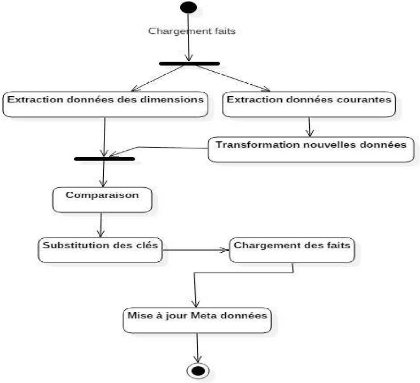
Figure IV. 11: Diagramme d'activité ETL des
faits
IV.4.3.3. Processus de chargement de la dimension
« Temps »
La dimension « Temps »
contient uniquement des dates qui ne sont pas forcément extraites
à partir du système opérationnel. Mais il doit avoir un
attribut « date » dans le système opérationnel
permettant de faire des comparaisons et référencer la dimension
temps. En effet cette dimension doit contenir toutes les dates qui peuvent
coïncider avec un fait quelconque. Elle assure l'historisation. Il est
donc conseillé de construire un calendrier selon (Kimball, 2004) :
60
Bassirou Mohamet
Chapitre IV : Conception du système d'ETL
Spatial
«La dimension date est plus souvent construite comme
étant un calendrier avec une granularité
journalière».
L'objectif principal d'un processus ETL est l'extraction, la
transformation et la livraison de données conformes, cohérentes
et correctes. Tout ceci avec des meilleures performances. Pour garantir le
succès de notre processus ETL, nous nous sommes fixés quelques
objectifs à savoir :
· Alimenter l'EDS avec des données de qualité
;
· Ne pas nuire aux performances des systèmes sources
;
· Utiliser autres sources de données que le
système opérationnel ;
· Suivre l'avancement des chargements et déboguer en
cas d'erreur ;
· Mise à jour des Meta données, pour la
maintenance et l'assurance de la qualité de données.
Dans le chapitre qui suit, nous présenterons
l'implémentation du processus ETL
que nous avons conçu. Quelques commentaires suivront cette
présentation.
61
Bassirou Mohamet
Chapitre V : Résultats et commentaires
Chapitre V : RÉSULTATS ET COMMENTAIRES
Ce chapitre s'intéresse à la présentation
des résultats de notre travail. Nous avons implémenté
notre système ETL en utilisant GeoKettle et en nous appuyant sur la
conception réalisée dans le chapitre précédent.
Nous allons présenter les principaux processus ETL
développé. Mais avant, pour assurer l'aspect
sécurité, nous allons créer un référentiel
de stockage des transformations et des jobs du système ETL.
V.1. Référentiel du système
ETL
Généralement, les transformations et les jobs
sont stockés dans des fichiers XML (.ktr/.kjb). Mais il existe une
alternative pour garantir la sécurité du processus. On stocke un
référentiel dans une base de données. En effet, les
transformations, jobs et paramètres de connexions aux sources et aux
destinations sont stockés dans une base de données
dédiée appelée
référentiel.
Pour créer un référentiel, il suffit de
démarrer GeoKettle. Dès que la première fenêtre
s'ouvre, sur «Référentiel»,
il faut cliquer sur «Nouveau ». Une
nouvelle fenêtre apparaît nous invitant à choisir la
connexion à la base de données du référentiel. Nous
entrons le nom et la description du référentiel. Nous cliquer
ensuite sur le bouton «Nouveau». La
fenêtre de création de la connexion à la BD s'affiche. Il
faut renseigner les paramètres de la connexion et tester celle-ci. Il
faut noter que nous avons au préalable créé notre base de
données du référentiel sur PostgreSQL. Si le test passe
avec succès, on valide la connexion pour revenir à la
fenêtre des informations du référentiel. Nous cliquons sur
le bouton « Créer ou Mettre à niveau
». Nous validons en cliquant sur « Oui » et
ensuite « Oui » pour évaluer la requête SQL
générée afin de créer les différentes tables
du référentiel. Les différentes figures ci-dessous
illustrent le processus que nous venons de décrire ci-dessus.
Chapitre V : Résultats et commentaires
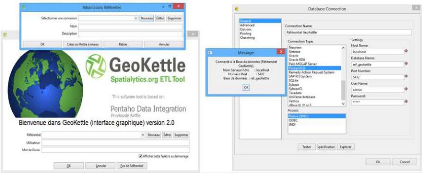
Figure V. 1: Création du
référentiel et la connexion à la BD
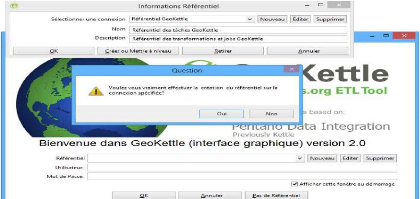
Figure V. 2: Valider la création du
référentiel et générer la requête
SQL
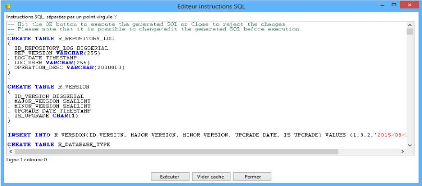
Figure V. 3: Modification de la requête avant
son exécution
Chapitre V : Résultats et commentaires
Dans cette dernière figure, l'on peut copier le code
généré dans un éditeur pour procéder
à quelques modifications si possible. Nous cliquons alors sur «
Exécuter » pour lancer l'exécution du code. Si tout se passe
bien, en ouvrant la base de données du référentiel, nous
devons disposer de 42 tables où l'on va stocker les différentes
tâches ETL comme l'illustre cette figure.
Nombre de tables du référentiel
Nous validons alors en cliquant sur une suite de « Ok
» pour revenir à la fenêtre principale de démarrage de
GeoKettle. Il faut maintenant renseigner les champs « utilisateur »
et « mot de passe » pour se connecter au référentiel et
commencer alors le processus ETL. Par défaut, l'utilisateur et le mot de
passe c'est « admin », on peut modifier ces
paramètres après le démarrage.
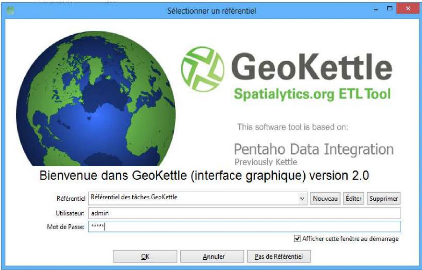
Figure V. 4: Connexion au référentiel
de travail GeoKettle
64
Bassirou Mohamet
Chapitre V : Résultats et commentaires
V.2. Différents processus ETL de l'EDS avec
GeoKettle
Dans cette section, nous allons décrire les
différents processus : extraction
(génération si les données n'existent pas),
transformation et de chargement des dimensions et faits en utilisant l'atelier
ETL GeoKettle.
V.2.1. Chargement de la dimension «dim_temps»
Pour charger la dimension temps, nous avons construit un
calendrier de cent
ans à compter du 1er janvier 2014. La
transformation illustrée dans la figure ci-dessous présente le
processus de génération des données de cette dimension.
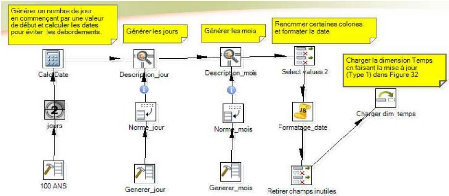
Figure V. 5: Génération du calendrier
et chargement dans l'EDS
V.2.2. Chargement de la dimension « dim_abonnement
»
Pour charger cette dimension, il nous a fallu
générer un certain nombre d'abonnés puisque nous ne
disposions pas de la base de données de production. Comme nous avons mis
sur pied une base de données de production de facturation pour le besoin
de test, nous avons d'abord chargé celle-ci. Après nous avons
donc extrait les données sur les abonnés et leur branchement pour
charger enfin la dimension « dim_abonnement
» dans l'entrepôt de données spatial. Les deux
processus sont illustrés dans les figures ci-dessous. Dans la Figure V.
6, nous
Chapitre V : Résultats et commentaires

Bassirou Mohamet
65
Figure V. 6: Génération et chargement
de la table "ABONNE"
Figure V. 7: Processus ETL des
abonnements
générons un nombre d'abonnés pour
alimenter la table « abonne » dans la base
de données de production que nous appelons « bdprod
» implémentée dans MySQL. La Figure V. 7, quant
à elle présente le processus d'extraction des abonnés et
leur branchement à partir de « bdprod » pour
les charger dans la table de dimension « dim_abonnement
» au niveau de l'entrepôt de données
nommé « edgeo_ndere ».
Chapitre V : Résultats et commentaires
V.2.3. Chargement de la dimension « dim_transfo
»
Quelques données sur les transformateurs nous ont
été fournies par le LG dans un fichier Excel. Cependant, pour
avoir une bonne cohérence des données, nous devons charger la
base de données de production et l'entrepôt de données
spatiales. Le processus devient un peu complexe. Nous avons extrait les
données du fichier Excel, et la table « quartier ». Nous les
avons croisées afin de récupérer les identifiants des
quartiers. D'une part, après quelques transformations nous avons
procédé au chargement dans la table « Transformateur »
au niveau de la base de données de production. D'autre part, à
partir de l'étape de la jointure, des procédures de
transformation ont été nécessaires pour permettre le
chargement dans la dimension « dim_transfo
» et créer en même temps un fichier de forme
(transfo.shp). La Figure V. 8 ci-dessous illustre le processus que nous venons
de décrire.
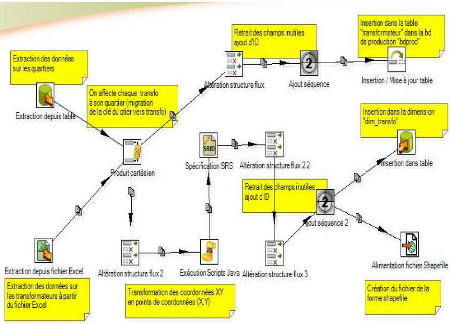
Figure V. 8: ETL des
transformateurs
67
Bassirou Mohamet
Chapitre V : Résultats et commentaires
V.2.4. Chargement de la dimension « dim_zone_geo
»
Comme nous avons dit dans la section de l'étude des
sources, les fichiers de forme (.shp) du Cameroun ont été
téléchargés sur le site
http://www.sogefi-sig.com/donnees-sig/137-donnees-sig-openstreetmap.
Notamment les fichiers sur les communes, les départements et les
régions. Après avoir extrait quelques données de la BD de
production, nous les avons jointes avec les fichiers de forme afin de localiser
par exemple un abonné, un transformateur ou tout simplement un
branchement. Quelques transformations ont été nécessaires
pour enfin charger les données épurées dans la dimension
« dim_zone_geo ». La Figure V. 9 présente le processus ETL de
cette dimension.
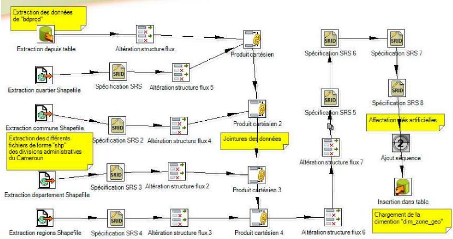
Figure V. 9: ETL dimension
"dim_zone_geo"
V.2.5. Chargement des faits « fait_conso »
Dans le file du processus d'un système ETL,
l'extraction, la transformation et le chargement des faits est la
dernière procédure à s'exécuter. En effet, les
différentes clés étrangères qui peuplent ses champs
doivent provenir des dimensions. Ainsi, l'existance des données dans les
dimensions devient une condition sinéquanone pour le processus de
chargement de la table des faits. La Figure V. 10 illustre ce processus dans
GeoKettle.
68
Bassirou Mohamet
Chapitre V : Résultats et commentaires
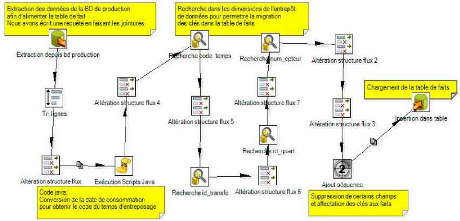
Figure V. 10: ETL des faits
"fait_conso"
V.3. Création de job
Comme nous avons dit dans les sections précédentes,
un job (ou une tâche) est
une série de tâches séquentielles à
exécuter (voir III.5.1.1.1. ). Dans le cas présent de notre
travail, nous avons mis sur pied un job.
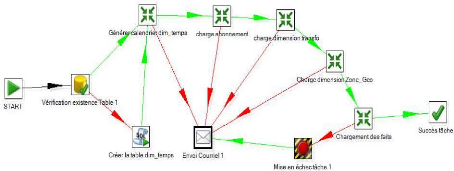
Figure V. 11: Job du processus ETL
Avec ce job, nous pouvons exécuter toutes les autres
transformations de manière séquentielle.
69
Bassirou Mohamet
Chapitre V : Résultats et commentaires
V.4. Exécution des transformations et job
On peut exécuter les différentes tâches
GeoKettle en utilisant ses composants ou directement sur l'interface spoon en
cliquant sur le bouton «play».
V.4.1. Exécution avec « carte »
La section (III.5.1.1.2. présente les différents
composants de GeoKettle. Toutes les tâches que nous avons
développées jusqu'ici ont été
réalisées avec le composant spoon. Carte est un mini-serveur web
permettant d'exécuter toutes les tâches à distance. Pour le
démarrer, il faut le créer à partir de l'interface de
spoon. Pour ce faire, on se positionne sur un job et on fait un clique-droit
sur « Serveurs esclave » et on clique sur « Nouveau ». Une
fenêtre s'ouvre et dont on doit renseigner. La figure ci-dessous montre
cette fenêtre remplie dans notre environnement de travail.
Figure V. 12: Configuration serveur
carte
Pour permettre l'exécution des tâches à
travers carte, on démarre d'abord le serveur en ligne de commande
suivante:
C:\GeoKettle 2.5>carte 10.45.33.24
8082
Lorsque le serveur est bien démarré, nous
retournons à l'interface de spoon pour associer nos tâches
à ce dernier. On va lancer l'exécution de la tâche et
cocher la case « Exécuter à distance » et choisir par
la suite le serveur que nous avons créé. La gestion de
l'exécution de cette tâche peut se faire maintenant à
travers un navigateur web. Par exemple :
http://10.45.33.24:8082/kettle/startJob/?name=ETL_system
Chapitre V : Résultats et commentaires
V.4.2. Exécution avec « Pan »
Pan permet d'exécuter les transformations en ligne de
commande. Exemple:
C:\GeoKettle 2.5>pan.bat
/rep:Referentiel_ETL_Ndere2 /user:bassirou /pass:password
/trans:dim_temps_gen
V.4.3. Exécution avec « Kitchen »
Kitchen quant à lui permet l'exécution des jobs
en ligne de commande :
C:\GeoKettle 2.5>kitchen.bat
/rep:Referentiel_ETL_Ndere2 /user:bassirou /pass:password
/job:ETL_system
V.5. Visualisation des résultats
Après avoir exécuté les
différentes tâches du processus ETL, nous pouvons visualiser les
données dans notre entrepôt de données par l'utilisation du
logiciel SIG QGIS. Il suffit, pour ce faire, de se connecter à
l'entrepôt de données et de charger les dimensions ayant un
attribut géométrique pour observer les différentes
données. Les figures ci-dessous illustrent les différentes
couches géographiques, allant de la région aux quartiers, que
nous avons chargées.
Figure V. 13: Liste des zones
géographiques
71
Bassirou Mohamet
Chapitre V : Résultats et commentaires
VINA
Figure V. 14: Carte des zones
géographiques
Dans ce chapitre, nous avons présenté les
différents processus ETL implémentés avec GeoKettle et
leur exécution. Nous remarquons l'incroyable rapidité avec
laquelle les différentes tâches s'exécutent. Ce qui prouve
les performances de cet outil ETL et justifie notre choix.
72
Bassirou Mohamet
Annexes
CONCLUSION ET PERSPECTIVES
L'informatique géodécisionnelle se lance comme
défi majeur, l'exploitation des données, a priori,
géospatiales de sources hétérogènes de l'entreprise
afin de mettre à la disposition des décideurs leur
synthèse. Les décideurs peuvent alors travailler dans un
environnement informationnel homogénéisé et
historisé. Ce qui les affranchit des problèmes
d'hétérogénéité des systèmes
opérationnels.
Il nous a été demandé de mettre sur pied
un système ETL géospatial par l'utilisation de l'outil open
source GeoKettle. Pour ce faire, une étude des concepts fondamentaux
liés au système géodécisionnel s'est
avérée importante. Nous avons appliqué notre étude
au cas de traitement des données de consommation
d'électricité dans la commune de Ngaoundéré
2e en concevant un EDS à cet effet. Par la suite, nous avons
conçu et réalisé des routines ETL formant ainsi le
système.
Par ailleurs, ce système ne charge qu'un seul data
mart. Cependant, une extension afin de prendre en compte d'autres magasins de
données dans le but de couvrir l'étendue du territoire national
sont des perspectives à venir.
73
Bassirou Mohamet
Annexes
BIBLIOGRAPHIE
Ouvrage spécialisé :
[1] FRANKLIN Carl. An Introduction to Geographic Information
Systems: Linking Maps to. USA, 2002.
[2] INMON W.H. OLAP and Data Warehouse. USA:
Photogrammetric Engineering & Remote, 2000.
[3] BORDIN P. SIG : concepts ; outils et
données. Quebec: Hermes Sciences Publications.
[4] PETER SHAW . GIS Succinctly. Syncfusion, Inc.,
2013
[5] KIMBALL & CASERTA. The Data Warehouse ETL Toolkit.
Wiley, 2004
Article :
[6]. Kamal Boulil, Sandro Bimonte, François Pinet
: Un modèle UML et des contraintes OCL pour les entrepôts de
données spatiales. De la représentation conceptuelle à
l'implémentation, RSTI - ISI - 16/2011, 2011, page 3.
[7]. Khalissa Derbal Amieur, Ibtissem Frihi, Kamel Boukhalfa,
Zaia Alimazighi : De la Conception d'un Entrepôt de Données
Spatiales à un Outil Géo-Décisionnel pour une Meilleure
Analyse du Risque Routier, 2013-33, 2013, page 2-4.
Thèse :
[8]. Faiza GHOZZI JEDIDI, conception et manipulation de
bases de données dimensionnelles a contraintes, thèse de
doctorat, université Toulouse III, 2004.
[9]. SANDRO BIMONTE, Intégration de l'information
géographique dans les entrepôts de données et l'analyse en
ligne : de la modélisation à la visualisation, thèse,
Institut National des Sciences Appliquées de Lyon (INSA), 2007.
Mémoire :
[10]. BATOURE Apollinaire (2011) : Conception d'un
modèle multidimensionnel pour la gestion des données urbaines au
Cameroun, Mémoire de Master II SLED, Université de
Ngaoundéré, Faculté des sciences, 2010/2011.
[11]. Marie-Dominique Van Damme : Entrepôts de
données dans le domaine spatial pour l'inventaire forestier,
mémoire de fin d'étude master II, Centre d'Enseignement Principal
d'Orléans, 2009-2010.
[12]. BATOURE Apollinaire (2010) : Réalisation de
la base de données urbaines de Ngaoundéré,
Mémoire de Master es Sciences de l'Ingénieur en Informatique
Appliquée aux SIG, Université de Douala / ENSG-Paris,
2009-2010.
74
Bassirou Mohamet
Annexes
[13]. NDJOH MESSINA Calvin : Étude exploratoire des
Systèmes d'Informations Géographiques décisionnels (SIG
décisionnels) (outils open source GeoKettle, GeoMondrian, ...),
Université de douala, 2010-2011.
[15]. TAPSOBA Dieudonné : Gestion des
Infrastructures et équipements Communautaires sur les sites de
recasement (Yagma et Basseko) des sinistrés du 1er Septembre 2009,
master II, Institut International d'ingénierie de l'eau et de
l'environnement, Sénégal 2009-2010.
Atelier:
[16] Alice Marascu, Alzennyr Da Silva, Florent Masseglia :
8èmes Journées Francophones Extraction et Gestion des
Connaissances : Fouille de données complexes dans un processus
d'extraction des connaissances, INRIA, Sophia Antipolis, 2008.
[17] CHRISTOPHE LEGG, projet de contrôle de crise
des cultures en utilisant diva gis, Ibanda, nigéria, 2007.
[18] IGN, Schema transformation of administrative data
with GeoKettle, INSPIRE KEN & EUROSDR, 8th October 2013.
[19] Guillaume fantino, un outil de gestion de
l'information Spatiale, observation des sédiments du rhônes,
CNRS-ENS.
[20] Dr. Thierry Badard, CTO: GeoKettle: A powerful
spatial ETL tool for feeding your Spatial Data Infrastructure (SDI),
Workshop, Denver, CO, USA, September 12, 2011
[21] IAAT (institut Atlantique d'Aménagement de
Territoires), Méthodologie sur la mise en oeuvre d'un SIG,
2003.
[22] Marlyse Dieungang - Ghilani Khaoula : Datawarehouse:
Cubes OLAP. cubes OLAP. Support de cours :
[23] Mélanie Herschel : Bases de Données
OLAP, Laboratoire de recherche en informatique, Université Paris
Sud, 2013-2014.
[24] NEGRE Elsa : entrepôt de données,
Université Paris-Dauphine, 2014-2015.
Webographie :
[25]
www.georezo.net/forum/viewtopic.php?id=84811
[26]
www.apachefriends.org/fr/download.html
[27]
www.forum.spatialytics.com/discussion/207/a-guide-for-geomondrian#Item_2
[28]
www.docs.spatialytics.com/doku.php?id=en:spatialytics_olap:002_installation
[29]
www.guide.ubuntu-fr.org/server/tomcat.html
[30]
www.spatialytics.org/fr/projets/geomondrian/
75
Bassirou Mohamet
Annexes
[31] www.forum.spatialytics.com/
[32]
www.mondrian.pentaho.com/documentation/installation_fr.php
[33]
www.forum.spatialytics.com/discussion/207/a-guide-for-geomondrian#Item_2
[34]
www.spatialolap.scg.ulaval.ca/concepts.asp
[35]
www.geosoa.scg.ulaval.ca/en/index.php?module=pagemaster
[36]
www.spatialytics.org/fr/.
[37] http://www.expertbi.net/
[38]
http://www.open-source-guide.com/Solutions
[39]
http://wiki.pentaho.com
[40]
http://www.developpez.net/forums/d510726/logiciels/solutions-d-entreprise/business-intelligence/pentaho/kettle-pdi/installation-kettle/
[41]
http://www.spatialdataintegrator.com
[42]
http://www.spatialytics.org/fr/projets/GeoKettle
[43]
https://www.geokettle.org
[44] http://www.geocameroun.cm/
[45] http://www.sogefi-sig.com/
76
Bassirou Mohamet
Annexes
ANNEXE
Liste des logiciels utilisés pour notre
application
1- GeoKettle 2.5 : Outil ETL géospatial.
· Lien :
www.spatialytics.org/fr/projets/GeoKettle,
www.geokettle.org
2- Schéma Workbench-1.0 : outil pour la construction
de la structure du cube multidimensionnelle)
· Lien :
http://sourceforge.net/projects/geomondrian/files/geomondrian-1.x/1.0/workbench.zip/download.
3- PostgreSQL 9.4 : SGBD utilisé pour l'entreposage des
données.
· Lien :
www.postgresql.org/download.
4- PostGis 2.1 : extension pour la prise en compte des
données de type spatial dans PostgreSQL.
· Lien :
www.postgis.refractions.net/download.
5- QGIS 2.10: Logiciel SIG libre multiplateforme.
· Lien :
https://www.qgis.org/en/site/forusers/download.html
6- GeoMondrian 1.0 : serveur OLAP Spatial.
· Lien :
http://sourceforge.net/projects/geomondrian/files/geomondrian-
1.x/1.0/geomondrian.war/download.
7- Géo Analysis Tool 0.6-alpha : serveur web de
navigation spatiale.
· Lien :
http://geoanalysistool.googlecode.com/files/GAT-0.6-alpha.zip.
8- Apache tomcat 7.0.6 : serveur pour le
déploiement d'applications.
· Lien :
https://tomcat.apache.org/download-70.cgi.
9- OSGeo-Live-8.5 : distribution linux basée sur
Ubuntu 14.04 dédié à la géomatique et
équipée de tous les outils géospatiaux.
· Lien :
http://sourceforge.net/projects/osgeo-live/files/8.5/osgeo-live-
8.5.iso/download
| 

