L'architecture d'un entrepôt de données
influence plusieurs facteurs comme la disponibilité des données
et l'efficacité des traitements. L'architecture la plus simple consiste
seulement en des bases de données sources, un entrepôt de
données central et plusieurs clients. Parce que les applications des
entrepôts de données sont devenues plus complexes, les
entrepôts sont construits en utilisant des architectures multi-niveaux
afin d'accroître la performance, i.e., il n'y a pas seulement un
entrepôt de données central, mais aussi des « data marts
» (magasins de données) qui permettent de placer les données
le plus proche de l'utilisateur final.
3 Online Analitycal processing (en français:
Traitement Analytique en Ligne).
17
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
La figure ci-dessous nous offre une vision
générale de l'architecture des ED en cinq niveaux (Marlyse D,
2015):
· Data sources : constitué des
sources de données hétérogènes ;
· Back-end tiers : solution d'extraction,
de transformation et de chargement ;
· Data warehouse tiers : entrepôt de
données particulier ;
· OLAP tiers : serveur d'analyse
multidimensionnel tiers ;
· Front-end tiers : interface
GUI4 (tableau de bord du décideur ou analyste).
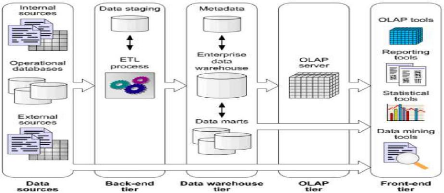
Figure II. 3: Architecture d'un système
d'ED
Un entrepôt de données peut se structurer en
quatre classes de données organisées selon un axe historique et
un axe de synthèse (Desnos, 2015):
Les données agrégées
Les données agrégées correspondent
à des éléments d'analyse représentant les besoins
des utilisateurs. Elles constituent déjà un résultat
d'analyse et une synthèse de l'information contenue dans le
système décisionnel, et doivent être facilement accessibles
et compréhensibles.
Les données détaillées
Les données détaillées reflètent les
événements les plus récents. Les
intégrations régulières des
données issues des systèmes de production vont habituellement
être réalisées à ce niveau.
4 Graphic User Interface (en francais : Interface graphique
utilisateur).
18
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
Les métadonnées
Les métadonnées constituent l'ensemble des
données qui décrivent des règles ou processus
attachés à d'autres données. Ces dernières
constituent la finalité du système d'information.
Les données historisées
Chaque nouvelle insertion de données provenant du
système de production ne détruit pas les anciennes valeurs, mais
créée une nouvelle occurrence de la donnée.


