|
République Algérienne
Démocratique et Populaire
Ministère de l'Enseignement Supérieur et de la
recherche Scientifique

École Nationale Polytechnique
d'Oran - Maurice Audin
Mémoire de fin d'étude
Réalisé par : HALLA Assala
En vue de l'obtention du
diplôme de Master 2
Option : Ingénierie et Management des
Systèmes d'Information
IMPLÉMENTATION DES SERVICES DE STOCKAGE D'OBJET ET DE
FICHIERS PARTAGÉS DANS LA SOLUTION CLOUD OPENSTACK
Mémoire soutenu le 16/09/2021 devant le jury
composé de :
Présidente : Mme. DJEBBAR Esma Insaf:
Maître de Conférences classeB
Examinatrice : Mme.
BENDIMERAD Nawel :Maître de Conférence classe B
Encadrante :Mme BOUMEDJOUT Amal :
Maître de Conférences classe A
Co-Encadrant :M. BENDRISS
Lahouari : Responsable du centre de calcul de l'ENPO
Promotion : 2020/2021
Remerciements
Un grand Merci à Dieu le tout puissant de m'avoir
éclairé le chemin et permis de mener à bien ce travail
Au terme de ce projet de fin d'étude, mes vifs
remerciements sont dédiés à tous ceux qui ont
contribué, directement ou indirectement à la réalisation
de ce mémoire de fin d'études.
En premier lieu, je remercie mon encadrante Madame BOUMEDJOUT
Amal de m'avoir aidé,orienter et conduit à soigner constamment la
qualité de ce travail
Mes remerciements s'adressent également à
Monsieur BENDRISS Lahouari d'avoir pris le temps de suivre mon travail et
d'être à l'écoute lors des difficultés techniques
rencontrés dans ce projet.
Mon dernier mot s'adresse aux membres du jury pour l'honneur
qu'ils me font de participer à l'examen de ce travail.
C'est avec une immense fierté que j'adresse mes
remerciements les plus distingués à tous les enseignants du
département SI qui m'ont transmis leur savoir et m'ont assuré la
meilleure des formations
Dédicace
Je dédie ce travail à mes très chers
parents,
Ma mère qui a toujours était présente pour
moi, celle qui m'a soutenu sur tous les plans m'offrant ainsi une
infinité de raisons d'être heureuse
Mon père qui s'est sacrifié pour moi tant
d'années et m'a transféré cet amour de l'informatique
depuis toute petite
Ma soeur qui m'a toujours aidé et encouragé
à faire de mon mieux pour réussir
Mon frère qui réussit toujours à apporter
la graine de joie dans ma vie
Je dédie ce travail à ma petite famille
grâce à laquelle je suis arrivée là où j'en
suis
Résumé
La vitesse avec laquelle le volume des données
informatiques augmente dans les entreprises, les établissements et les
organisations est immense, étant la source de plusieurs
problématiques liées aux stockages, de nombreuses solutions ont
été proposées, dont la plus connue est le Cloud. Ceci dit,
la complexité des modes de stockage ne semble pas être
dépassé, en effet, même en présence d'une
infrastructure virtualisé via un Cloud les technologies de stockage ne
cessent d'augmenter.
Pour répondre à ces besoins en stockage, de
nombreuses organisations développent des systèmes de stockage
dans le Cloud afin de les proposer aux différentes entreprises dont le
nombre qui implémente cette technologie du Cloud ne cesse d'augmenter.
Parmi les systèmes de stockage présents dans le marché on
retrouve les open source : GlusterFS, Ceph, LVM, ZFS, Swift, Cinder,
Manilla, Sheepdog, Kinetic et les propriétaires : IBM et
EMC...etc.
L'objectif de ce mémoire est de traiter la
problématique du stockage en améliorant le système de
stockage d'une solution Cloud privé que nous avons déjà
déployée avec OpenStack. Nous proposons d'implémenter, en
plus du service de stockage en bloc existant, des services de stockage en objet
et en fichier à notre architecture initiale afin de
bénéficier de la diversité de fonctionnalités que
propose ces différents services.
Après une analyse de l'existant, nous avons donc
décidé d'intégrer la combinaison de services : Swift
et Manila au service Cinder présent dans notre Solution Cloud
privé déjà déployée. Cette proposition vise
à rendre le système facilement scalable, à renforcer la
sécurité d'accès aux données, à prendre en
charge tout type de données (structuré, non structurées,
statique, non statiques, binaire, transactionnelle...etc.), à
élargir l'accès jusqu'au services d'OpenStack (auparavant
limité uniquement aux machines virtuelles) et à permettre
l'accès simultanée aux fichiers partagés qui
n'était pas pris en charge avec le système de stockage
initial.
Mots clés: Cloud computing, OpenStack,
Stockage en bloc, stockage en objet, stockage en fichiers, Swift, Cinder,
Manila.
Abstract
The speed with which the volume of computer data is increasing
in companies, institutions and organizations is immense, being the source of
many problems related to storage, many solutions have been proposed, the best
known of which is the Cloud. That said, the complexity of storage modes does
not seem to be outdated, in fact, even in the presence of a virtualized
infrastructure via a Cloud, storage technologies continue to increase.
To meet these storage needs, many organizations are developing
cloud storage systems to offer them to different companies whose number
implementing this cloud technology continues to grow. Among the storage systems
present in the market are open source: GlusterFS, Ceph, LVM, ZFS, Swift,
Cinder, Manilla, Sheepdog, Kinetic and proprietary: IBM and EMC ... etc.
The objective of this thesis is to address the storage issue
by improving the storage system of a private cloud solution that we have
already deployed with OpenStack. We propose to implement, in addition to the
existing block storage service, object and file storage services to our initial
architecture in order to benefit from the diversity of functionalities that
these different services offer.
After an analysis of the existing system, we decided to
integrate the combination of services: Swift and Manila to the Cinder service
present in our already deployed Private Cloud Solution. This proposal aims to
make the system easily scalable, to strengthen the security of data access, to
support all types of data (structured, unstructured, static, non-static,
binary, transactional ... etc.), to expand access to OpenStack services
(previously limited only to virtual machines) and to allow simultaneous access
to shared files that was not supported with the initial storage system.
Key words: Cloud computing, OpenStack, Bloc
Storage, Object Storage, File Storage, Swift, Cinder, Manila.
Table des
matières
Introduction générale
12
Chapitre 1 : Cloud et virtualisation
14
1.1. Introduction
14
1.2. La virtualisation
14
1.2.1. Définitions et concepts
14
1.2.2. Historique de la virtualisation
15
1.2.3. Les principes de la virtualisation
16
1.2.4. Les différents types de la
virtualisation
19
1.2.5. Les avantages et les
inconvénients de la virtualisation
21
1.3. Le Cloud Computing
22
1.3.1. Définitions et concepts
22
1.3.2. Historique du cloud computing
23
1.3.3. Caractéristiques du cloud
24
1.3.4. Les stratégies de
déploiement
25
1.3.5. Les différents modes de
déploiement
29
1.3.6. Avantages et inconvénients du
cloud
32
1.4. Conclusion
33
Chapitre 2 : État de l'art sur les
solutions de stockage dans Openstack
34
2.1. Introduction
34
2.2. Présentation de la solution
OpenStack
34
2.3. Étude et analyse de
l'existant
35
2.4. Synthèse de l'existant
42
2.5. Conclusion
44
Chapitre 3 : Étude analytique et
comparative entre les types de stockages persistant dans la solution
Openstack
45
3.1. Introduction
45
3.2. Les types de stockage dans OpenStack
45
3.2.1. Stockage
éphémère
45
3.2.2. Stockage persistant
46
3.3. Le mode de stockage en objet
« Swift »
46
3.3.1. Vue d'ensemble sur Swift
47
3.3.2. Architecture de Swift :
48
3.4. Le mode de stockage en bloc
« Cinder »
50
4.4.1. Vue d'ensemble sur
« Cinder »
51
4.4.2. Architecture de
« Cinder »
52
3.5. Le mode de stockage en fichier «
Manila » :
53
4.5.1. Vue d'ensemble sur Manila
53
4.5.2. Architecture de Manila
54
3.6. Étude comparative entre les
services Cinder et Swift et Manila
56
3.6.1. Scalabilité et backend
56
3.6.2. Cohérence des
données
57
3.6.3. Accessibilité et
administration
57
3.6.4. Sécurité
58
3.6.5. Redondance et tolérance aux
pannes
59
3.7. Conclusion
60
Chapitre 4 : Implémentation des services
de stockage Swift et Manila
62
3.1. Introduction
62
3.2. Travail réalisé
62
3.2.1. Configuration du service Neutron
63
3.2.2. Implémentation du service de
stockage d'objet (Swift)
68
3.2.3. Implémentation du service de
système de fichiers partagé (Manila)
74
3.2.4. Utilisation privée du stockage
offert par la solution Cloud :
77
3.3. Conclusion
81
Conclusion générale
82
Perspective
84
Bibliographie
85
Annexe A : Commandes d'installations et de
configurations
89
Liste des
figures
Figure 1 : Le concept de la virtualisation
[3]
15
Figure 2 : Historique de la virtualisation [6]
16
Figure 3 : Création des ressources virtuelles
propres à chaque machine virtuelle [5]
17
Figure 4 : Représentation de l'hyperviseur du
type 1 [4]
18
Figure 5 : Représentation de l'hyperviseur de
type 2 [4]
19
Figure 6 : la paravirtualisation [4]
20
Figure 7 : La virtualisation totale et la
paravirtualisation [4]
20
Figure 8 : Vue générale sur le Cloud
[7]
22
Figure 9 : Évolution de l'information vers le
Cloud Computing [14]
24
Figure 10 : L'environnement du Cloud Computing
[15]
25
Figure 11 : Schéma de l'architecture
matérielle du Cloud public [9]
26
Figure 12 : Schéma de l'architecture
matérielle du Cloud privé interne [17]
27
Figure 13 : Schéma de l'architecture
matérielle du Cloud privé externe [17]
27
Figure 14 : Schéma de l'architecture
matérielle du Cloud hybride [9]
28
Figure 15 : Schéma de l'architecture
matérielle du Cloud Communautaire [17]
28
Figure 16 : Les services du Cloud Computing [23]
31
Figure 17 : La répartition des
responsabilités [24]
32
Figure 18 : Le mode de stockage en objet [38]
46
Figure 19 : Organisation logique du service Swift
[39]
47
Figure 20 : Organisation physique du service Swift
[39]
48
Figure 21 : Architecture logique du service Swift
[40]
49
Figure 22 : le mode de stockage en bloc [38]
51
Figure 23 : Architecture logique du service
Cinder [41]
52
Figure 24 : le stockage en mode fichier
[38]
53
Figure 25 : Architecture logique du service Manila
[41]
55
Figure 26 : schéma de l'architecture de
réseau avec le mécanismes Open vSwitch [46]
64
Figure 27 : Topologie simple du réseau
informatique
65
Figure 28 : Topologie graphique du réseau
informatique
66
Figure 29 : Test ICMP & TCP des instances
67
Figure 30 : Présentation du service de
stockage d'objet Swift dans le tableau de bord
68
Figure 31 : création d'un conteneur
69
Figure 32 : chargement des fichiers dans le
conteneur
69
Figure 33 : présentation des fichiers dans le
conteneur privé
70
Figure 34 : La récupération du lien du
conteneur
70
Figure 35 : Liste des objets via le lien du
conteneur - vue par défaut en fichier XML -
71
Figure 36 : téléchargement d'un
fichier depuis un conteneur public
71
Figure 37 : optimisation de la liste des objets avec
des liens cliquables
72
Figure 38 : vue du conteneur depuis un smartphone
non connecté à la plateforme Cloud
72
Figure 39 : présentation du site internet
hébergé dans le cloud
73
Figure 40 : Présentation du service de
fichiers partagés dans le tableau de bord
74
Figure 41 : Création de type de partage
75
Figure 42 : Création d'un partage
76
Figure 43 : Présentation du Partage
76
Figure 44 : Connexion de l'utilisateur au Cloud
depuis un Smartphone
77
Figure 45 : Nom de projet et d'utilisateur
78
Figure 46 : Tableau de bord de l'utilisateur depuis
smartphone
78
Figure 47 : Téléchargement de fichier
dans le conteneur
79
Figure 48 : Liste des objets dans le conteneur de
l'utilisateur
80
Liste des abréviations
AMQP Advanced Message Queuing Protocol
API Application Programming Interface
CERN European Organization for Nuclear
Research
CIFS Common Internet File System
CRUSH Criminal Reduction Utilising Statistical
History
DHCP Dynamic Host Configuration Protocol
HPC High Performance Computer
GPL General Public License
HDFS Hadoop Distributed File System
HTTP Hyper Text Transfer Protocol
IAAS Infrastructure As AService
IDS Inrusion Detection System
IP Internet Protocol
ISCSI Internet Small Computer System
Interface
KVM Kernel-based Virtual Machine
LAN Local Area Network
LDAP Lightweight Directory Access Protocol
LXC Linux Containers
LVM Logical Volume Manager
MAC Multi Access Computer
MySQL My Structured Query Language
NAT Network Address Translation
NAS Network Attached Storage
NASA National Aeronautics and Space
Administration
NFS Network File System
NFV Network Functions Virtualization
OVS Open vSwitch
PAAS Plate-forme As A Service
QEMU Quick EMUlator
RBD RADOS Block Storage
REST REpresentationalStateTransfer
RPC Remote procedure call
SAAS Software As A Service
SAN Storage Area Network
SSH Secure Shell
TCP Transmission Control Protocol
TRC The Research Council
URL Uniform Resource Locator
VLAN VirtualLocal Area Network
VM Virtual Machine
VNC Virtual Network Computing
XML Xtenssible Markup Language
Liste des tableaux
Tableau 1 : Principales caractéristiques
des stratégies de déploiement du cloud [19]
29
Tableau 2 : Synthèse de l'existant
43
Tableau 3 : Tableau de comparaison entre les
services Cinder, Swift et Manila
59
L'énorme croissance des infrastructures des
technologies de l'information (IT) combinée à l'augmentation des
coûts de l'informatique exige une solution de contournement efficace
assurant la réduction des coût associés à ces
infrastructures. De plus, comme la croissance incontrôlée des
données a suscité desinquiétudes pour l'environnement de
l'entreprise, le stockage a été déplacé en dehors
des serveurs vers des environnement virtuels grâce à la
technologie du Cloud Computing.
Le Cloud computing exerce un vrai impacte sur la façon
avec laquelle les informations sont stockées et partagées,
apportant par conséquence un changement majeurau monde économique
et technologique, en effet, des plateformes distribuées ont vu le jour
pour fournir des services au client à la demande, ce dernier est
affecté par le système que génère l'architecture
« pay as you go » adoptée par le Cloud avec laquelle
les ressources sont facturéesselon le modèle et le temps
d'utilisation du Client.
Beaucoup d'organisations informatiqueset fournisseurs de
services se tournent vers la solution OpenStack comme mécanisme
permettant de créer leurs propres Clouds privés ou public.
Openstack fournit un cadre pour proposer des ressources de calcul, de stockage
et de réseau qui peuvent être consommées en tant que
servicesans avoir besoin de gros investissements dans le matériel
physique. OpenStack est actuellement un projet open source et compte des
centaines de contributeurs.
Comme la raison principale du développement du Cloud
est bien le stockage. Il existe en effet trois types de stockage dans le
Cloud : le stockage en objet, en bloc et en fichier. Le stockage en objets
quiconvient aux données statiques non structurés (fichiers
multimédias), en raison de son agilité et de sa nature plate, il
peut être adapté pour prendre en charge des quantités
extrêmement massives de données.Le stockage en mode Bloc est
idéal aux données structurées non statiques, grâce
à sa rapidité il convient mieux aux bases de données qui
nécessitent d'être adapté en permanence, de plus, il offre
un environnement idéal pour le stockage des machines virtuelles. Le
stockage en mode fichiers partagé prend en charge tous les types de
fichiers qu'ils soient structurés ou non offrant la
possibilité d'y accéder même simultanément par
plusieurs machines grâce à la notion de partage.
OpenStack propose divers types de stockages assurés par
plusieurs services, en effet cette plateforme de Cloud a
développé en 2010 un service appelé
« Swift » grâce auquel unstockage en mode objet est
fourni, il a été suivi quelques années plus tard, en 2012,
du service « Cinder » proposant un stockage en mode bloc,
en 2015 le projet OpenStack lance un troisième service de stockage de
fichiers partagés sous le nom de « Manila ».
L'amélioration du stockage au sein d'OpenStack ne se résument pas
uniquement aux services interne, en effet, de nombreuse entreprises ont
développé des alternatives externes qui peuvent être
implémenté à la solution OpenStack, parmi les
systèmes de stockage présents dans le marché on retrouve
les open source : GlusterFS, Ceph, LVM, ZFS, Swift, Cinder, Manilla,
Sheepdog, Kinetic et les propriétaires : IBM et EMC...etc.
proposant chacun des fonctionnalités différentes voire
complémentaires.
Notre travail consiste à réaliser une
étude comparative entre les types de stockage dans le Cloud et à
implémenter un ou plusieurs services de stockages à la solution
Cloud privé que nous avons déployé sous OpenStack dans le
but d'améliorer le système de stockage. Pour cela nous allons
étudier en profondeurles différentes méthodologies de
stockages présentes dans le marchéet plus
précisément celles qui sont open source et qui peuvent
s'intégrer facilement à notre solution OpenStack.
Les objectifs du système de stockage que nous allons
implémenter peuvent se présenter ainsi :
- Garantir la connectivité des instances en
réseau privé et public
- Permettre l'accès depuis l'extérieur au
Cloud
- Fourniture d'un stockage en tant que service au grand
public
- Améliorer la scalabilité et
l'évolutivité du système.
- Agrandir l'accessibilité précédemment
limitée aux machines virtuelles.
- Assurer la protection des données et la
tolérance aux pannes.
- Garantir le stockage d'une diversité de type de
données (Structuré ou non, statique ou non, transactionnelles,
volumineuses, binaires...etc.).
- Fournir un accès simultané aux unités
de stockage.
- Sécuriser l'accès aux données.
Ce mémoire est structuré en quatre
chapitres :
- Dans le premier chapitre, nous présenterons en
détail les deux technologies de Cloud Computing et de la virtualisation,
leurs fonctionnements, leurs types et leurs modes.
- Le second chapitre consiste à réaliserun
état de l'art sur les solutions de stockage Cloud existantsen se basant
sur l'analyse et la synthèse de six (06) support de recherches qui
représentent des sources d'informations fiables à savoir des
articles de recherches, des rapports de conférence, des articles de
journaux ...etc. La présentation des recherches menées sera
suivie d'une analyse des conclusions auxquelles les chercheurs sont
arrivés et d'une synthèse de document.
- Le troisième chapitre présente la solution qui
sera implémentée pour améliorer le système de
stockage, nous présenterons la combinaison de services de stockage qui
répondent aux objectifs cités auparavant ainsi qu'une comparaison
selon plusieurs critères comme : la sécurité, la
cohérence, le Protocol d'accès et le type de données
stockées
- Le dernier chapitre concerne l'installation, la
configuration et l'implémentation des services de stockage ainsi que le
test de fonctionnalités (accès, stockage...etc.) assurées
par ces derniers
Chapitre 1: Cloud et virtualisation
|
1.1.
Introduction
Le volume des données informatiques augmente de
manière exponentielle ce qui exige aux entreprises des moyens
énormes pour gérer leurs infrastructures informatiques. De nos
jours, la priorité principale des entreprises est la possibilité
de réduire les coûts liés à cette gestion
d'infrastructure. Plusieurs techniques ont été utilisées
pour réaliser cette réduction des coûts, parmi lesquels, la
virtualisation, et le Cloud Computing. Ces deux concepts sont différents
mais complémentaires. Dans ce chapitre on détaillera le principe,
les caractéristiques, les avantages et les inconvénients de la
virtualisation ainsi que ceux du cloud pour pouvoir lier leurs usages aux
entreprises.
1.2. La virtualisation
1.2.1.
Définitions et concepts
La virtualisation : représente
une technologie permettant d'exploiter toute la capacité d'une machine
physique en la répartissant entre de nombreux utilisateurs ou
environnements différents.[1] Elle consiste à
dématérialiser le comportement et les données d'un
serveur, de façon à simuler plusieurs instances virtuelles au
sein d'un même matériel physique. Les instances
créées ne doivent pas interférer entre elles et doivent
fonctionner de façon dépendante.
La virtualisation est le processus qui consiste à
créer une version logicielle (ou virtuelle) d'une entité
physique, telle que des applications, des serveurs, des systèmes de
stockage et des réseaux virtuels. Il s'agit du moyen le plus efficace de
réduire les coûts en partageant les ressources, et en
évitant de multiplier l'acquisition de serveurs physiques, tout en
stimulant l'efficacité et l'agilité pour toutes les entreprises,
quelle que soit leur taille.[2]
Lorsqu'un système virtuel n'utilise pas les ressources
d'un système physique, celles-ci peuvent être utilisées par
un autre système virtuel. Dans un environnement non virtualisé,
les ressources du système peuvent être inactives pendant une
période de temps.
La figure suivante illustre le concept de la
virtualisation :
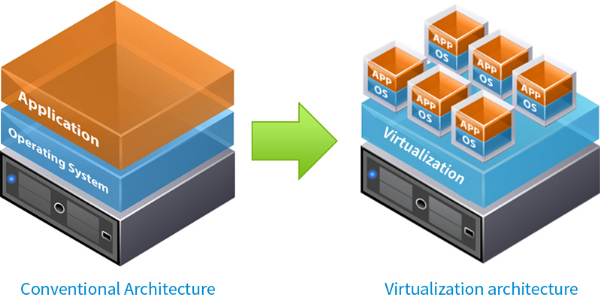
Figure 1 : Le concept de la
virtualisation[3]
La machine virtuelle : Une machine
virtuelle est responsable de la simulation d'une machine physique.Un
système d'exploitation est fait pour s'exécuter sur une
architecture d'ordinateur particulière (type de processeur, drivers
spécifiques, langage assembleur...). Par conséquent, le
système d'exploitation a des restrictions matérielles qui doivent
être respectées pour terminer son travail.Une machine virtuelle
c'est aussi une couche de logiciel qui fournit un ensemble d'instructions au
système d'exploitation qu'elle héberge. Cet ensemble
d'instructions permet au système d'effectuer un accès
matériel au matériel virtuel (matériel
émulé). La machine virtuelle convertit et redirige ensuite ces
appels vers le système hôte pour les exécuter sur du
matériel réel. [4] Aujourd'hui, pour qu'un ordinateur puisse
héberger plusieurs machines virtuelles de façon optimale, il est
nécessaire qu'il soit composé de ressources matérielles
suffisamment puissantes.
En résumé, la virtualisation consiste à
utiliser les technologies de l'information et de la communication,
matérielles et logicielles, dans le but d'héberger plusieurs
systèmes d'exploitation différents sur une unique machine
physique [5].
1.2.2. Historique de
la virtualisation
La virtualisation remonte aux années 1960. À
l'époque, c'est la firme IBM qui créé le premier
système de virtualisation de serveur. Dans ce contexte, l'informatique
est peu présente et les rares sociétés qui
possèdent des systèmes informatiques sont équipées
de gros calculateurs, les Mainframe. Déjà à cette
époque, les soucis d'optimisation des ressources matérielles
d'une machine se posent. En effet, les supers calculateurs sont parfois sous
utilisés. IBM développe alors un produit VM/CMS (Virtual Machine
/ Conversational Monitor System), un système de virtualisation serveurs.
Au cours des années 80-90 apparaît l'architecture x86 et les PC se
déploie auprès d'un grand nombre d'utilisateurs. Le besoin de
virtualiser pour optimiser les machines se fait moins sentir. Mais, dans les
années 90-2000, VMware réussi à virtualiser un poste x86.
Ceci ouvre la porte à plus de possibilité et relance l'envie pour
les sociétés informatiques de développer de nouvelles
fonctionnalités pour optimiser et offrir plus de flexibilité. A
l'heure actuelle, la virtualisation est très connue. On entend parler de
virtualisation de serveur, de VirtualBox, mais aussi de virtualisation de poste
de travail, de VDI, et de virtualisation dans les jeux-vidéos avec les
émulateurs. [5]
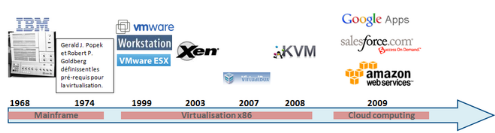
Figure 2 : Historique de la
virtualisation[6]
1.2.3. Les principes
de la virtualisation
La virtualisation suit deux principes de base, à savoir
le cloisonnement et la transparence [6]:
· Le cloisonnement : Chaque
système d'exploitation fonctionne indépendamment et ne peut en
aucun cas interférer.
· La transparence : L'exécution
en mode virtuel ne modifie pas le fonctionnement du système
d'exploitation et des applications.
Le principe de la virtualisation repose sur le
mécanisme suivant :
· Système hôte : il
s'agit d'un système d'exploitation simple installé sur un seul
serveur physique. Le système hôte sera utilisé pour
accueillir plusieurs autres systèmes d'exploitation via un logiciel
appelé hyperviseur. [5]
· L'Hyperviseur : est une sorte de
logiciel de virtualisation qui peut être directement installé sur
le système d'exploitation principal ou le système d'exploitation
hôte, de sorte que plusieurs environnements fermés et
indépendants peuvent être créés. Ces environnements
peuvent également héberger d'autres systèmes
d'exploitation (également appelés systèmes
invités). [5]
Les environnements indépendants ainsi
créés grâce à l'hyperviseur sont des machines
virtuelles.
La figure suivante montre la façon avec laquelle les
ressources virtuelles de chaque machine virtuelle (VM) sont créer.
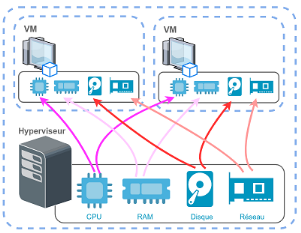
Figure 3 : Création des ressources virtuelles
propres à chaque machine virtuelle[5]
Les types des hyperviseurs :
Nous retrouvons deux types d'hyperviseurs que nous allons
citer ci-dessous :
· Hyperviseurs de type 1 : Ils sont
particulièrement utiles dans les architectures de réseaux de
grandes entreprises qui doivent optimiser les coûts et la maintenance,
tout en améliorant la robustesse aux pannes. Celui-ci s'exécute
directement sur la plate-forme matérielle sans système
d'exploitation intermédiaire. Il gère l'accès à
l'architecture du noyau du système d'exploitation invité
Matériel de base. Pour cela, vous pouvez exécuter plusieurs
systèmes d'exploitation Presque directement sur le matériel, sans
dépendre du système d'exploitation hôte [5]. Les principaux
hyperviseurs de type1 sont les suivants :
· Vmware ESXI
· Microsoft Hyper-V
· Xen
La figure suivante illustre l'hyperviseur de type 1 :
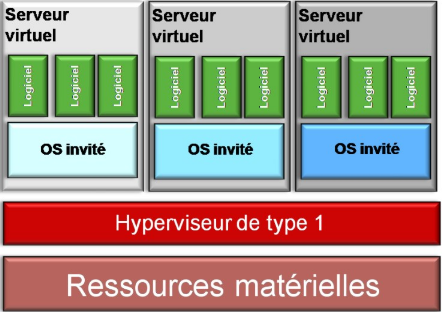
Figure 4 : Représentation de l'hyperviseur du
type 1 [4]
· Hyperviseurs de type 2 : Ils
conviennent vraiment aux petites infrastructures. Généralement,
ils sont adaptés aux situations où vous ne disposez que d'une
seule machine et que vous souhaitez effectuer des tests multiplateformes
(applications, systèmes d'exploitation, communications ...). Les
hyperviseurs de type 2, ou hosted hypervisor (hyperviseur
hébergé), est le plus facile à mettre en place. Il
s'installe comme n'importe quelle application, qui se situe au-dessus de l'OS
hôte. Le système d'exploitation contrôle l'accès au
matériel physique. L'hyperviseur agit comme un système de
contrôle entre le système d'exploitation hôte et les
systèmes d'exploitation invités. Il permet, une fois
installé, de créer des VMs indépendantes de l'OS
hôte [5]. Les principaux hyperviseurs de type 2 sont les suivants :
· Oracle VirtualBox
· VMWare Workstation (Player et Pro) et VMware Fusion
(pour Mac)
· Microsoft VirtualPC (plus maintenu depuis 2011).
La figure suivante illustre l'hyperviseur de type 2 :
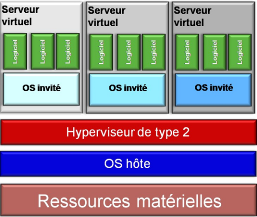
Figure 5 : Représentation de l'hyperviseur de
type 2 [4]
1.2.4. Les
différents types de la virtualisation
Pour pouvoir faire tourner différents systèmes
d'exploitation simultanément sur un même matériel, les
hyperviseurs utilisent différentes technologies de virtualisation, les
plus utilisées sont : la virtualisation complète (Full
Virtualization) et la paravirtualisation
(Paravirtualization).
La virtualisation complète : On parle
de virtualisation complète lorsque le système d'exploitation
invité n'a pas conscience d'être virtualisé. L'OS qui est
virtualisé n'a aucun moyen de savoir qu'il partage le matériel
avec d'autres OS. Ainsi, l'ensemble des systèmes d'exploitation
virtualisés s'exécutant sur un unique ordinateur, peuvent
fonctionner de manière totalement indépendante les uns des autres
et être vu comme des ordinateurs à part entière sur un
réseau. [4]
La paravirtualisation : Par opposition
à la virtualisation, on parle de paravirtualisation lorsque les
systèmes d'exploitation doivent être modifiés pour
fonctionner sur un hyperviseur de paravirtualisation. Les modifications sont en
fait des insertions de drivers permettant de rediriger les appels
système au lieu de les traduire. [4]
Le mécanisme de redirection des appels système
est expliqué par la figure ci-dessous :
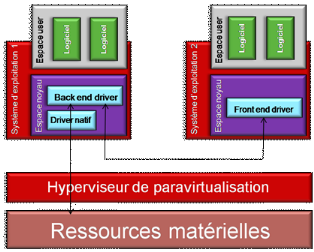
Figure 6 : la paravirtualisation [4]
Le contrôle d'un ou plusieurs matériel(s) est
donné à un des OS virtualisé (celui qui contient le driver
backend), ici le système d'exploitation 1. Une fois cela compris, il
sera simple d'imaginer que l'OS 2, qui souhaite accéder au hardware,
devra passé par son driver front end qui redirigera les appels
système vers l'OS 1. L'inconvénient de cette technique est donc
la dépendance d'un OS virtualisé vis à vis d'un autre qui
se créé par ce mécanisme de driver. En effet si l'OS 1
tombe en panne, l'OS 2 ne pourra plus accéder au matériel. [4]
La figure suivante montre la différence entre la
paravirtualisation et la virtualisation :
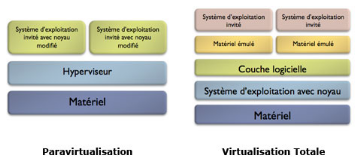
Figure 7 : La virtualisation totale et la
paravirtualisation[4]
1.2.5. Les avantages
et les inconvénients de la virtualisation
Parmi les avantages et les inconvénients de la
virtualisation nous pouvons citer ce qui suit :
Les avantages de la virtualisation :
1. Utilisation optimale des ressources d'un parc de machines
(distribution de machines virtuelles selon la charge respective sur la machine
physique).
2. Installer, tester, développer, interrompre et
redémarrer sans interruption Système d'exploitation
hôte.
3. Isolation des différents utilisateurs
simultanés d'une même machine.
4. Allocation dynamique de la puissance de calcul en fonction
des besoins de chaque application à un instant donné.
Les inconvénients de la virtualisation :
1. L'accès aux ressources des serveurs hôtes via
la HAL (couche d'abstraction matérielle) nuit aux performances, et
l'exécution de n'importe quel logiciel "virtualisé" consommera
davantage de ressources qu'en mode natif.
2. En cas de panne d'un serveur hôte, l'ensemble des
machines virtuelles hébergées sur celui-ci seront
impactées. Mais la virtualisation est souvent mise en oeuvre avec des
redondances, qu'elle facilite.
1.3. Le Cloud Computing
1.3.1.
Définitions et concepts
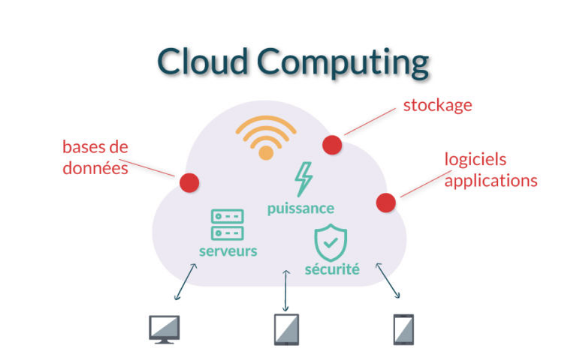
Figure 8 : Vue
générale sur le Cloud[7]
Le cloud est un grand réseau interconnecté de
plusieurs serveurs qui produisent des services à différents
utilisateurs, c'est aussi un modèle permettant l'accès à
un réseau partagé de ressources configurables (p. ex.,
réseaux, serveurs, stockage, applications et services) qui peuvent
être rapidement fournis et publiés avec un minimum d'efforts de
gestion ou d'interaction avec les fournisseurs de services.[8]
Le cloud est devenu une solution fréquemment
utilisée pour fournir un accès facile et à moindre
coût aux ressources informatique externalisées, de nombreuses
organisations (centres de recherche, entreprises ...etc.)
bénéficient du Cloud pour héberger leurs applications en
leur permettant l'exploitation de ces dernières directement en
ligne.[9]
Grace à la virtualisation, le Cloud computing est
capable de traiter avec la même infrastructure physique une grande
clientèle avec des besoins informatiques différents.
Contrairement aux paradigmes (Clusters et Grid computing)1(*) le Cloud n'est pas
orienté application mais plutôt orienté service
[10][11].
1.3.2. Historique du
cloud computing
Dans un speech de MIT en 1960 John McCarthy a indiqué
la possibilité de délivrer les matériels,
équipements et les installations informatiques aux utilisateurs sous
forme de service, ce fut donc la première énonciation du concept
du cloud qui a évolué dans le temps.[12]
En 1999 Salesforce l'entreprise spécialisé dans
le CRM2(*) (Customer
Relationship Management) ou gestion de relation client a commencé la
distribution des applications aux clients à travers un site web.[13]
En 2002 Amazon a lancé Amazon Web Services offrant
ainsi les services de stockage et de calcul. L'entreprise avait constaté
une augmentation des achats en ligne et a donc opté pour une solution
cloud, qui n'étais pas clairement défini à
l'époque, mais qui se résumait en une location des
capacités informatiques disponibles à la demande et accessible
via Internet, en réduisant ainsi la surcharge des serveurs
dédié au commerce en ligne.[12]
En 2009 de nombreuses grandes entreprises tels que Google,
Microsoft, HP, Oracle ont commencer à proposer des services cloud.
De nos jours toutes les personnes utilisant internet sont
certainement en train d'utiliser les services du cloud computing dans la vie
quotidienne. Par exemple Google Photos, Google Drive, ICloud ...etc. La vision
du futur du Cloud est clairement définie, le cloud computing deviendra
une nécessité basique pour toutes les industries de l'information
technologique.
La figure suivante résume l'évolution de
l'informatique vers le Cloud Computing selon Nicholas Carr [14].
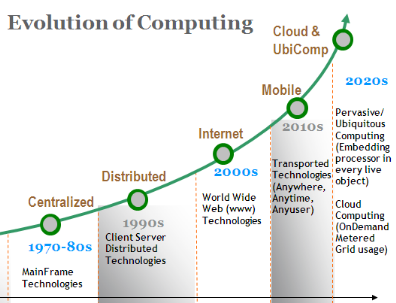
Figure 9 : Évolution de l'information vers le
Cloud Computing [14]
1.3.3.
Caractéristiques du cloud
Dans cette section nous allons décrire les
différentes caractéristiques du cloud qui selon l'institut
national des Standards et de la technologie (NIST) se résument en cinq
formes citées ci-dessous [8]:
1. Un libre-service à la
demande :
La demande des ressources informatiques par le client peut se
faire à tous moments et sera fournie sans nécessitée
d'interaction avec le fournisseur de service.
2. Un accès universel :
Les capacités fournies sont accessibles via le
réseau, les accès qui eux reposent sur des mécanismes
standards et peuvent être initiés par le client de
différentes manières : mobile, tablettes, client
léger, client lourd, etc.
3. La mise en commun de ressources :
Les ressources informatiques mises à disposition sont
communes à tous les clients et partagées entre eux de
façon dynamique suivant la demande, sans qu'ils sachent exactement
où se situe la ressource demandée.
4. Une élasticité rapide :
Les ressources allouées sont automatiquement
ajoutées ou libérées, dans certains cas de façon
automatique, en fonction des besoins du moment. Selon le client ces ressources
fournies paraissent comme étant illimitées et disponibles
à tout moment et à n'importe quelle quantité.
5. La mesure de service fourni :
Les systèmes du cloud contrôlent et optimise
l'utilisation des ressources automatiquement, ces dernières sont
contrôlées, optimisés et parfois facturer à
l'usage.La figure suivante montre l'environnement du Cloud Computing.
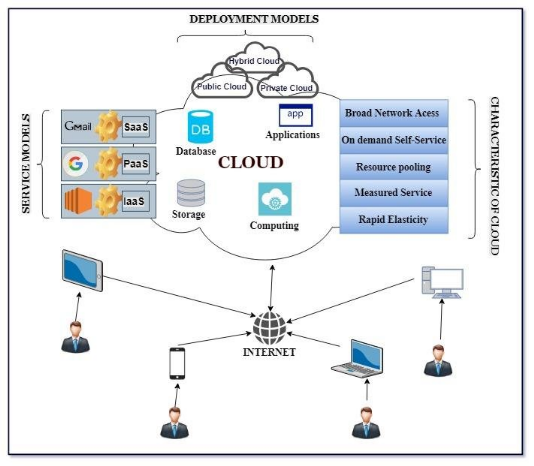
Figure 10 : L'environnement du Cloud Computing
[15]
1.3.4. Les
stratégies de déploiement
Le cloud peut être déployé en utilisant
les stratégies citées ci-dessous :
Le Cloud Public :Le cloud public est une
stratégie de déploiement qui consiste à héberger
des services Cloud dans des datacenter appartenant à un fournisseur de
service tiers, le terme « public » ne signifie pas
« gratuit » or qu'il peut être un peu coûteux.
Les données d'un utilisateur ne sont pas visibles contrairement à
ce que le mot « public » pourra signifier, les fournisseurs
de cloud public contrôle l'accès aux données en utilisant
le mécanisme de contrôle d'accès. [9]. Le Cloud public
offre un moyen élastique et économique pour déployer des
solutions.Parmi les fournisseurs de services Cloud gratuits nous
retrouvons : Amazon Elastic Compute Cloud (E), Sun Cloud, IBM's Blue
Cloud, Google App Engine, windows Azure Services Platform.[16]. La figure
suivante illustre l'architecture matérielle d'un Cloud public :
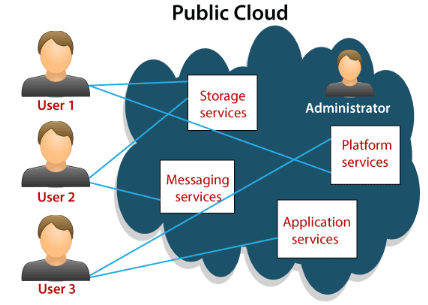
Figure 11 : Schéma de l'architecture
matérielle du Cloud public[9]
Le Cloud Privé : Le cloud privé est un
réseau informatique utilisé en exclusivité par
l'entreprise, les données et les processus sont gérés au
sein de l'organisation sans les restrictions de la bande passante du
réseau, les risques de sécurité que peut présenter
le Cloud public, de plus l'accès est restreint à un nombre
limité des utilisateurs, ce qui améliore la
sécurité et la résilience.Le Cloud privé peut
être géré par l'organisation elle-même comme par un
tiers, mais ne peut être utilisé que par cette organisation. Nous
pouvons donc distinguer deux types de Cloud privé : le Cloud
privé interne et le Cloud privé externe. La figure suivante
montre le schéma de l'architecture matérielle d'un cloud
public.
· Le Cloud privé interne :
C'est un Cloud qui est géré et utilisé au sein de
l'organisation sur des infrastructure lui appartenant.La figure suivante
illustre le cloud privé interne
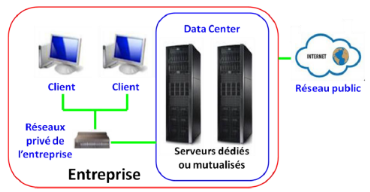
Figure 12 : Schéma de l'architecture
matérielle du Cloud privé interne[17]
· Le Cloud privé externe :
C'est un Cloud utilisé par l'organisation mais
hébergé chez un prestataire. La figure suivante détaille
le schéma matériel du Cloud privé externe
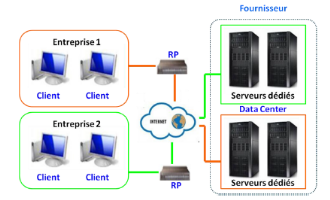
Figure 13 : Schéma de l'architecture
matérielle du Cloud privé externe[17]
Le Cloud Hybride :Le Cloud hybride est
un environnement Cloud qui combine les deux infrastructures des Cloud
privés et Cloud publics connectées entre elles par un
système d'orchestration, l'organisation conserve les services et les
données sensibles sous son contrôle dans un Cloud privé et
héberge les informations non critiques dans un Cloud public [9] . La
figure suivante montre le schéma de l'architecture matérielle du
Cloud hybride.
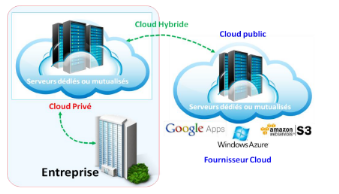
Figure 14 : Schéma de l'architecture
matérielle du Cloud hybride[9]
Le Cloud Communautaire : Le Cloud
communautaire représente un espace Cloud où plusieurs
organisations partagent des ressources et des données qui sont
utilisées uniquement par ces organisations.Parmi les Cloud communautaire
existe la GSA, Amadeus, CMed, DARVA. Par exemple, Amadeus qui est le principal
fournisseur de solutions informatiques à l'industrie du tourisme et du
voyage, a été créé par Air France, Lufthansa,
Iberia et SAS.[18]
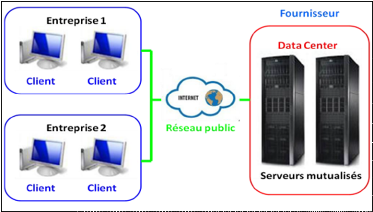
Figure 15 : Schéma de l'architecture
matérielle du Cloud Communautaire[17]
Le tableau ci-dessous compare les stratégies de
déploiement citées auparavant selon plusieurs critères (La
propriété, le contrôle, le coût, la localisation et
la sécurité) [19]
Tableau 1 : Principales caractéristiques
des stratégies de déploiement du cloud[19]
|
Stratégie de déploiement
|
Propriété
|
Control
|
Coût
|
Localisation
|
Sécurité
|
|
Le Cloud public
|
Un tiers
|
Un tiers
|
Faible
|
Hors site
|
Faible
|
|
Le Cloud privé
|
Organisation / tiers
|
Organisation / tiers
|
Élevé
|
Local au site
|
Élevé
|
|
Le Cloud hybride
|
Les deux
|
Les deux
|
Moyen
|
Local au site et Hors site
|
Moyen
|
|
Le Cloud communautaire
|
Organisation / tiers
|
Organisation / tiers
|
Élevé
|
Local au site et Hors site
|
Élevé
|
1.3.5. Les
différents modes de déploiement
Dans cette section du chapitre nous allons étudier les
différents modes de déploiement. Le Cloud peut être
déployer en trois modes différents que nous pourrons nommer
« les services du cloud » qui sont SaaS PaaS et IaaS :
Software-as-a-service (SaaS)
Software-as-a-service (SaaS) ou application fournie comme
service, est un des trois services du Cloud qui consiste à
héberger des applications avec toutes les données
nécessaires à leur bon fonctionnement dans un Cloud et les
fournir par la suite aux utilisateurs à travers le réseau
Internet (l'utilisateur utilise un client léger via un navigateur web)
sous forme de service à la demande, l'entreprise n'achète donc
pas toutes les applications mais plutôt paie par utilisation.[20]
Les applications fournies comme services peuvent prendre
plusieurs formes comme des applications métiers, de
comptabilité, des ERP (Entreprise Ressources Planification), de
facturation, de la gestion de contenu (CM), de la gestion des ressources
humaines (GRH), de la gestion de la relation client (CRM).
Parmi les exemples des Software-as-a-service BPOS, Google
Apps, Salesforce.com ...etc. [21]
Les avantages du Software-as-a-service
(SaaS) :
· Le fournisseur se charge de la maintenance,
l'installation
· Non nécessité d'achat de licence
· Accessible via un abonnement et depuis tous les
ordinateurs
Les inconvénients du Software-as-a-service
(SaaS) :
· Applications génériques qui ne sont pas
toujours appropriées pour une utilisation
· Manque de sécurité
· Dépendance des prestataires
Platform-as-a-service (PaaS)
Platform-as-a-service (PaaS) ou plateforme fournie en tant que
service, dans ce type de cloud le fournisseur héberge dans un cloud un
environnement permettant aux utilisateurs de développer, déployer
et exécuter des applications en utilisant les outils matériels et
les ressources du fournisseur via le réseau
Internet.[22] Le PaaS est aussi un service fourni à la demande, le
paiement se fait donc par utilisation de cet environnement fourni
Les avantages de la Platform-as-a-service
(PaaS) :
· Le fournisseur se charge de la maintenance et de
l'installation
· Développement rapide et à bas
coût.
· Déploiement privé ou public.
Les inconvénients de la Platform-as-a-service
(PaaS) :
· Développement limité au langage et outils
du fournisseur du service. Professionnelle (ex : Python ou Java pour Google
AppEngine, NET pour Microsoft Azure, propriétaire pour force.com)
[16]
· Absence du contrôle des machines virtuelles
sous-jacentes.
· Convient uniquement aux applications Web.
Infrastructure-as-a-service (IaaS)
Il s'agit de la mise à disposition, à la
demande, de ressources d'infrastructures dont la plus grande partie est
localisée à distance dans des Datacenters. L'IaaS permet
l'accès aux serveurs et à leurs configurations pour les
administrateurs de l'entreprise. Le client a la possibilité de louer des
clusters, de la mémoire ou du stockage de données. Le coût
est directement lié au taux d'occupation. Une analogie peut être
faîte avec le mode d'utilisation des industries des commodités
(électricité, eau, gaz) ou des Télécommunications.
Les cibles sont les responsables d'infrastructures informatiques. Amazon E est
le principal qui propose ce genre d'infrastructures. Eucalyptus est un exemple
d'infrastructure. [16]
Les avantages de l'Infrastructure-as-a-service
(IaaS) :
· Permet d'offrir des capacités de stockage
infinies et totalement flexibles au client.
· Contrôle total des systèmes
(administration à distance par SSH : Secure Shell ou Remote
Desktop, RDP).
· Personnalisation.
Les inconvénients de
l'Infrastructure-as-a-service (IaaS) :
· Demande pour les acteurs du Cloud des investissements
très élevés
· Besoin d''un administrateur système pour les
solutions de serveurs classiques sur site.
· Problème de la sécurité.
La figure suivante montre les différents services du
Cloud Computing et ses utilisateurs.
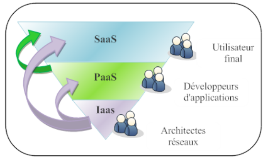
Figure 16 : Les services du Cloud
Computing[23]
Pour mieux illustrer la différence entre les services
du Cloud Computing nous allons découvrir dans la figure suivante la
réparation des responsabilités :
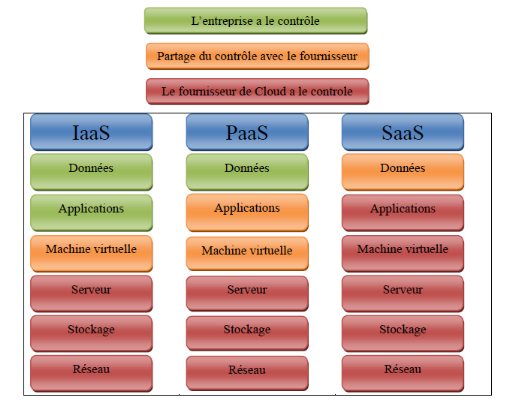
Figure 17 : La répartition des
responsabilités [24]
1.3.6. Avantages et inconvénients du cloud
Nous pouvons tirer les avantages et les inconvénients
que présente le Cloud computing selon différents
critères.
Les avantages du Cloud :
· Un démarrage rapide : Le cloud
computing permet de tester le business plan rapidement, à coûts
réduits et avec facilité.
· L'agilité pour l'entreprise :
Résolution des problèmes de gestion informatique
simplement sans avoir à vous engager à long terme.
· Un développement plus rapide des
produits : Réduisons le temps de recherche pour les
développeurs sur le paramétrage des applications.
· Pas de dépenses de capital :
Plus besoin des locaux pour élargir vos infrastructures
informatiques.
Les inconvénients du Cloud :
· La bande passante peut faire exploser votre
budget : La bande passante qui serait nécessaire pour mettre
cela dans le Cloud est gigantesque, et les coûts seraient tellement
importants qu'il est plus avantageux d'acheter le stockage nous-mêmes
plutôt que de payer quelqu'un d'autre pour s'en charger.
· Les performances des applications peuvent
être amoindries : Un Cloud public n'améliorera
définitivement pas les performances des applications.
· La fiabilité du Cloud : Un
grand risque lorsqu'on met une application qui donne des avantages
compétitifs ou qui contient des informations clients dans le Cloud
· Taille de l'entreprise : Si votre
entreprise est grande alors vos ressources sont grandes, ce qui
inclut une grande consommation du cloud. Vous trouverez peut-être
plus d'intérêt à mettre au point votre propre Cloud
plutôt que d'en utiliser un externalisé. Les gains sont bien plus
importants quand on passe d'une petite consommation de ressources à une
consommation plus importante.
1.4. Conclusion
Dans ce chapitre nous avons présenté le principe
de la virtualisation et son ampleur dans le monde informatique. Cette ampleur
augmente de plus en plus à causes des avantages considérables que
les entreprises acquièrent via cette technologie. En effet la
virtualisation est un moyen efficace qui permet la réduction des
coûts en minimisant l'acquisition d'un nombre important de serveurs. Par
ailleurs, le fait de posséder moins de machines physiques réduit
considérablement l'espace des locaux de l'entreprise et garantie un gain
considérable en énergie. De plus la facilité du
déploiement et la rapidité de la gestion des machines virtuelles
ont permis la réduction du temps ainsi que du coût
d'administration. Néanmoins, l'augmentation immense de la taille des
données ne se contente pas du principe de la virtualisation seulement
mais permet d'étendre la sauvegarde de données sur le Cloud sans
pour cela s'en passer de la technologie de la virtualisation. La virtualisation
permet de réaliser une fondation du Cloud Computing, car elle permet
à ce dernier de traiter avec la même infrastructure physique une
grande clientèle avec des besoins informatiques différents. En
résumé, le Cloud s'appuie sur la technologie de virtualisation
pour atteindre le but de fournir des ressources informatiques selon
l'utilité de façon dynamique.
Chapitre 2 :
État de l'art sur les solutions de stockage dans Openstack
|
2.1. Introduction
La forte augmentation des données chez les entreprises
ou même chez des particuliers fait sujet à de nombreux
problématique en termes de stockages tels que le manque du
matériel de stockage, la gestion des informations internes massives et
les coûtsélevés liés à la maintenance. C'est
pourquoi le stockage dans le cloud est l'un des sujets les plus traité
en recherche. Pour répondre à ces besoins en stockage, de
nombreuses organisations développent des systèmes de stockage
dans le Cloud afin de les proposer aux différentes entreprises dont le
nombre qui implémente cette technologie du Cloud ne cesse d'augmenter.
Parmiles systèmes de stockage présents dans le marché on
retrouve les open source : GlusterFS, Ceph, LVM, ZFS, Swift, Cinder,
Manilla, Sheepdog, Kinetic et les propriétaires : IBM et EMC...etc.
De nombreux chercheurs ont travaillé sur ces types de plateforme de
stockage cloud dans lesquels d'énormes données numériques
(structurés, semi structurés ou non structurés) sont
stockés et contrôlés à distance et enfin
récupérer via le réseau Internet. Dans ce qui suit nous
allons présenter la solution OpenStack et les différentes
recherches qui ont été menées sur les plateformes de
stockages les plus utilisé de nos jours, en tirer des conclusions et des
leçons pour ensuite comparer entre eux en profondeur en respectant des
critères bien précis et importants comme : la
cohérence, les méthodes de placement de données, les
opération de lecture et d'écriture, la sécurité, le
type de stockage proposé, le mieux reste de trouver la ou les meilleures
plateforme de stockage à implémenter dans notre Cloud
privé déployé sous OpenStack.
2.2. Présentation de la solution OpenStack
OpenStack est une plate-forme de cloud computing
développée par le fournisseur de services d'hébergement
Rackspace et la NASA pour aider les fournisseurs de services cloud et les
entreprises à créer des services d'infrastructure cloud [25]. Le
projet OpenStack pourrait être considéré comme un
système d'exploitation cloud. Toute organisation ou tout particulier
peut créer son propre environnement de cloud computing (IaaS)
basé sur OpenStack. Openstack permet la gestion du calcul, du stockage
et du réseau à travers une interface web et visant à
créer une plateforme de Cloud qui soit open source flexible et
élastique. L'architecture d'OpenStack propose de nombreux services dont
les plus importants sont : le service de calcul (Nova), service
d'identité (Keystone), service d'Image (Glance), service de
réseau (Neutron), service de stockage en objet (Swift), service de
stockage en bloc (Cinder), le tableau de bord (Horizon)[26]
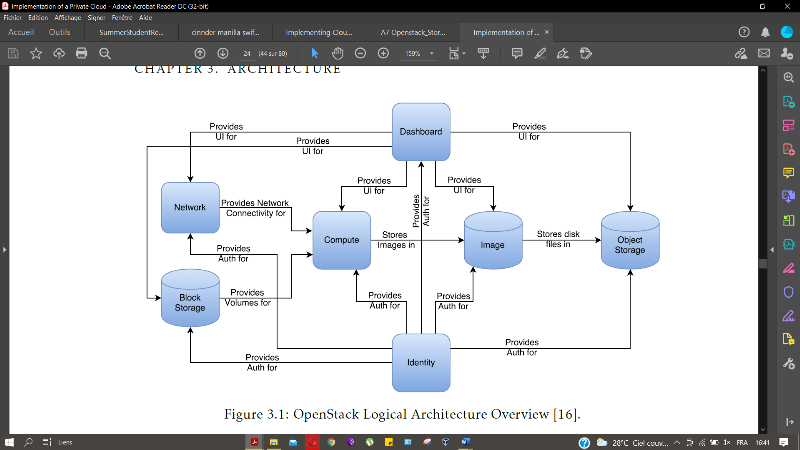
Figure 27 : Architecture des services
d'OpenStack[25]
2.3. Étude et analysede l'existant
Les plateformes de stockage dans le Cloud en existe beaucoup,
certains mieux que les autres et d'autres complémentaire qui peuvent
donc être implémentés et cohabités dans le
même système. Après plusieurs lectures approfondie une
sélection d'article semblait potentiellement intéressante
à aborder dans ce travail qui touchait nécessairement à
ces plateformes de stockage open source dans le Cloud : Swift, Manilla,
Cinder, Ceph, GlusterFS et Sheepdog. Dans ce qui suit nous présenterons
les recherches effectuées et la conclusion tiré des supports de
recherches [27][28][29][30][31][32]pour chacune des plateformes de stockage.
Nous discuterons la combinaison de celles que leur implémentation dans
notre plateforme Cloud est intéressantes.
Les recherches qui ont été menéesau sein
du département IT de l'université des sciences appliqué
sur les établissements d'enseignement supérieur montrent le
développement exponentiel de l'utilisation des données
informatiques au sein de ces établissements provocant ainsi deux
problématiques majeures lié principalement à la
fourniture des ressources informatiques via le matériel physique. En
constatant le changement du monde informatique par le biais de la technologie
du Cloud qui transforme la façon dont fonctionne les datacenter (centres
de traitement de données), de nombreux établissements
d'enseignement supérieur y réfléchissent pour tirer parti
de son potentiel, l'utilité de son implémentation dans
l'infrastructure réside dans sa capacité à fournir des
ressources matérielles virtuelles à savoir des serveurs, des
routeurs et des réseaux avec un mécanisme standard pour leurs
gestion et leurs distributions. Le travail présenté dans la
source [27] qui fait d'ailleurs parti du projet fondé par The
Research Council (TRC) présente une conception et une mise en
oeuvre d'un prototype de Cloud privé pour les établissement
d'enseignement supérieures en utilisant la solution OpenStack qui
fournit une IaaS, permettant ainsi aux étudiants et aux chercheurs de
travailler avec des machines virtuelles en créant leurs propres
ressources virtuelles comme les serveurs, les routeurs et les topologie des
réseaux, cette solution offre la possibilité de faire des
expériences dans un environnement sandbox(environnement de test
pour logiciels ou sites web). Lorsque nous prêtons attention à
l'architecture du déploiement qui finalement est censé
répondre à la problématique de stockage nous remarquons
qu'en plus des services primaires d'OpenStack : Identité, Image,
Réseau, Calcul, Tableau de bord, existe deux autres services de stockage
Cinder pour le stockage en bloc et Swift pour le stockage en objet, nous nous
intéressons plus particulièrement à cette partie du
Cloud : le stockage. Ce que nous pourrons conclure de ce travail est que
les deux services de stockage Cinder et Swift ont chacun leurs propres
fonctionnalités qui peuvent être complémentaire pour
assurer une bonne gestion de stockage dans le Cloud.
La source [28]partage les idées du travail
élaboré dans le projet du TRC et se focalise principalement sur
le service Swift qui propose un stockage en objet. Ce travail exploite
complètement les solutions open source existantes pour
accélérer l'effort de développement et construit un
prototype local de Cloud basé sur base d'une architecture de service de
stockage cloud en Objet (COS3) que des entreprises et des organisations peuvent
se l'approprier. L'architecture COS3 est flexible, simple et modulaire avec une
conception hiérarchique composée de trois couches : stockage
de données, transformation et routage de données, accès
aux données. L'article souligne grandement l'utilité du service
de stockage choisi en expliquant que Swift fournit un stockage rentable,
évolutif et redondant grâce à l'utilisation des clusters,
permet la prise en charge des application web et mobiles ainsi que la
sauvegarde et l'archivage actif des données qui peuvent être
récupérées via une API REST. Swift adopte une architecture
de cohérence à terme (eventual consistency en anglais)
qui le rends idéal pour la construction d'infrastructure massives et
hautement distribuées avec de nombreuses données non
structurées, avec Openstack Swift fournit en plus trois types de
authentification : TemAuth, Swauth et keystone, TempAuth étant le
service d'authentification par défaut de Swift, il stokce les noms des
utilisateurs et leurs mots de passes en texte clair, il n'est donc pas
fortement recommandé de l'utiliser, Swauth en revanche utilise des droit
d'accès configurés pour sécuriser les mots de passe, il
est utilisé principalement dans les environnements d'expériences
et de test contrairement à keystone qui est utilisé dans
n'importe quel environnement que ce soit en test ou en production, c'est le
service qui gère l'accès dans Openstack utilisant les tokens il
propose une meilleure sécurité des mots de passes. L'organisation
des données comme expliquée dans l'article [28] est construite
selon une hiérarchie de : Compte, Conteneur et objet, le compte
étant au niveau supérieur de la hiérarchie, le conteneur
comme les buckets (seaux) et les objets comme magasin de stockage de
donnée : documents, images, vidéos ...etc. Les objets
stockés dans Swift ont une URL que les applications utilisent pour
stocker et récupérer des données, ils peuvent aussi avoir
des métadonnées étendues qui sont indexées et
recherchées, ces objets sont stockés avec plusieurs copies
(généralement trois) pour éviter de les perdre. Cet
article estime que le benchmarking (techniques de test des performances) de
l'implémentation d'un Cluster Swift est essentiel avant le
déploiement de ce dernier pour une utilisation en production. Pour se
faire ils se sont basés sur une configuration d'un cluster de stockage
répartie sur six serveurs (noeuds) : l'un de ces noeuds est un
serveur proxy qui expose les requêtes aux entités de stockage, et
les autres sont es noeuds de stockage à savoir Compte, Conteneurs et
Objet. Ils ont ensuite utilisé« Swift-bench » qui
est un outil de benchmarking en lignes de commande fournit avec la distribution
Swift utilisé comme générateur de charge de travail pour
comparer Swift en termes d'opération #PUT par seconde,
d'opération #GET par seconde et d'opération DELETE par seconde.
Ils ont constaté à la fin que les opération #PUT et
#DELETE sont dominantes dans le cluster Swift.
La conférence ayant eu lieu en mars 2016 à
l'université de Manitoba à Winnipeg au Canada s'intéresse
au problème de mise en oeuvre et d'évaluation des performances
des données critiques dans le marché du Cloud, et plus
précisément à la gestion des incidents [29], cette
conférence présente les travaux qui ont été faits
afin de sélectionner la meilleure stratégie de stockage
permettant la reprise des services en cas de défaillance du
système due à une catastrophe naturelle ou humaine pour une
organisation utilisant un Cloud privé. L'idée était de
créer un nouveau système de proposé une nouvelle
stratégie de réplication pour la duplication des données
dans un Cloud privé basé sur openstack. Pour cela ils ont
construit un Cloud privé à l'aide d'une solution logicielle open
source basée sur OpenStack suivie d'un déploiement d'une
application financières sur des machine virtuelles. Le but était
de provoquer un déclenchement d'un sinistre pour repérer lequel
des deux services de stockage d'Openstack Cinder ou Swift est le meilleur en
cas de défaillance du système (i.e. lequel possède la
meilleure technique de réplication des données). Parmi les
multiples plans de reprise de travail qui existent dans le domaine du
Cloud : sauvegarde du système uniquement, transfert de
données hors site, sauvegarde à la fois du système et des
donnée...etc. la dernière a été choisie, pour se
faire, une technologie de snapshots (une sauvegarde de l'état d'un
système à un instant donné)a été
adopté.Pour récapituler leur expérience, ils ont
créé des scripts qui planifient les captures des snapshots,
ensuite ils ont déclenché une machine virtuelle avec des erreurs
de configuration suivis de la mise hors tension de cette dernière,
à cet instant-là, les snapshots sont
récupérés et le bloc de données passif est
activé ce qui produit un système de réplication de la
machine virtuelle. L'analyse expérimentale des deux
stratégies de stockage s'est basée sur d'autres scripts
créés pour déterminer premièrement laquelle des
deux est rapide en termes de création et déploiement de snapshot
et en quantité de données associé à chaque
itération et deuxièmement laquelle des méthodologies
garantit le plus la cohérence des données en mesurant le nombre
d'octet de données perdus à chaque itération.
D'après les résultats de cet analyse Cinder est 53fois plus
rapide que Swift en termes de création, déploiement et sauvegarde
des données (i.e. Cinder 53 fois mieux que Swift en termes de
récupération du système après un sinistre) un
deuxième constat est tiré de cette analyse, il s'agit de la
cohérence des données, en effet les deux stratégies de
stockage : Cinder et Swift fournissent des données
cohérentes. En conclusion s'il y a un choix à faire entre le
stockage en bloc Cinder et le stockage en objet Swift pour assurer la
fiabilité des données critiques et la reprise des services en cas
de sinistre mieux vaut opter pour Cinder.
Le projet Openstack contient plusieurs composants comme Cinder
qui est dédié au stockage en bloc et qui comme déjà
montré précédemment améliore les performances des
machines virtuelles, ou même Swift qui propose un stockage en objet
offrant ainsi plusieurs fonctionnalités complémentaire avec
Cinder, cependant la création des volumes ne se fait pas uniquement en
local sur OpenStack, il existe en vrai d'autres système de stockage dits
à distance, qui offrent plus ou moins des fonctionnalités pareils
voire absents dans les système de stockage en local : Cinder,
Swift...etc. ces systèmes peuvent être open source comme LVM, NFS,
Ceph ou GlusterFS ou propriétairescomme EMC et IBM.Les chercheurs dans
l'article [30] affirment que le stockage local d'OpenStack n'est pas assez
puissant ni facile à étendre et que son
hétérogénéité rend la gestion et la
maintenance du système complexe, ils constatent qu'il présente un
taux de fiabilité bas. Leur stratégie est composée de deux
partie la première était d'intégrer une solution libre de
stockage distribuée délivrant des services de stockage à
la fois en Bloc, en Objet mais aussi en fichier : Ceph RBD (Rados
Block Device en anglais, dispositif de stockage en bloc en
français) avec les services de calcul (nova), d'image (Glance) et de
stockage en bloc (Cinder) dans Openstack. La deuxième consistait
à construire trois plateformes de stockage : RBD_OpenStack,
Local_OpenStack et GSR_OpenStack avec des backend de stockage différent
(LVM, GlusterFS, LocalFS, RBD)afin de les analyser et les comparer visant
à trouver la meilleure plateforme open source parmi eux. Les analyses
et les calculs de performances de la première partie de
l'expérience ont montré que le système de stockage RBD
réduit le temps de déploiement des machine virtuelles et de leurs
migrations, de plus ils ont trouvé qu'il améliore
l'efficacité de la lecture et de l'écriture sur les volumes de
stockage. L'évaluation des stockages dans la deuxième partie
s'est basée sur trois critères : concernant le temps de
déploiement de la machine virtuelle, le mode de stockage RBD est le plus
rapide suivi du GSR et ensuite du mode Local car le
téléchargement des images disques dans le local se fait à
chaque création d'une machine virtuelle, une seule fois dans le mode GSR
contrairement au mode RBD dans lequel le service de Calcul et d'Image partage
le même backend de stockage unifié ; le deuxième
critère sur lequel ce sont basé les analyses est le temps de
la migration à chaud de la machine virtuelle le temps de la migration
à chaud des machines virtuelles, les modes de stockage partagé
RBD et GSR prennent une seule seconde pour faire cette action contrairement au
mode Local qui nécessite une copie des fichier d'image disque entre les
noeuds de calcul en prenant plus de temps à savoir 121.4 secondes.
Concernant le troisième critère, les performances en lecture et
en écriture de la machine virtuelle dans un volume de stockage sont
élevées dans le RBD car il ne dépend que du transfert de
données dans le cluster Ceph, contrairement au mode Local et GSR qui eux
dépendent des performances I/O (Input/Output, entrée/sortie) du
disque physique ainsi que du trafic du réseau. La conclusion à
relever de ces expériences présentées dans l'article [30]
est que RBD Ceph est la meilleure solution de stockage à mettre en place
en termes de vitesse de déploiement et de migration des machines
virtuelles ainsi qu'en lecture et écriture sur les disques de
stockage.
L'immense quantité de données structurés,
non structurés et semi structuré présente dans le Cloud
est stockée dans un serveur ou un cluster de stockage, ce dernier est
configuré avec un système de stockage Cloud comme GlusterFS,
Ceph, LVM, ZFS etc. l'article [31] discute en premier temps la vue d'ensemble
de ces plateformes et compare par la suite entre les deux plateformes les plus
utilisé : Ceph et Swift, en profondeur et en respectant certains
critères tels que la cohérence, la méthode de placement
des données, opération de lecture, opération
d'écriture, sécurité et autres. GlusterFS est un
système NAS (Network Attached Storage), cette plate-forme fonctionne
avec du matériel à faible coût et convient aux
données non structurées, par exemple : documents, courriers
électroniques, massages, images, fichiers multimédias et fichiers
journaux, etc.[31]Le système ZFS est un système de fichiers avec
gestionnaire de volume logique, il est basé sur l'idée des pools
de stockage pour gérer le stockage physique. ZFS offre des performances
efficaces et une intégrité des informations, ainsi qu'une
administration simple[31].LVM permet au système de fichiers d'être
redimensionné efficacement, il prend des snapshots pour la sauvegarde.
Il peut créer un volume virtuel unique à partir de
différents volumes réels ou d'un disque dur entier et permet le
redimensionnement du volume[31]. Ceph est une plateforme de stockage cloud
distribuée et open source qui prend en charge le stockage en objets, en
blocs et en fichiers, elle est nécessairement conçue pour
atteindre la fiabilité, l'évolutivité avec de meilleures
performances tout en s'exécutant sur du matériel de base sans
point de défaillance unique. [31] Swift fournit une plateforme de
stockage distribuée afin que les clients puissent stocker et
accéder à des informations ou à des objets à l'aide
d'API REST, elle est développée pour assurer
l'évolutivité, la durabilité, la disponibilité et
la simultanéité sur l'ensemble des données.[31]
après avoir comparé entre ces cinq plateformes de stockage ils
ont été classé selon leurs types de stockages, en effet,
Swift assure uniquement le stockage en objet, LVM et ZFS uniquement le stockage
en Bloc, Gluster assure quant à lui le stockage en fichier et en objet
et enfin la plateforme Ceph qui assure les trois type de stockage : en
bloc, en objet et en fichier.
Après cette vue d'ensemble et comparaison
générale présenté dans l'article de journal [31],
les chercheurs ont étudié en profondeur les deux systèmes
Ceph et Swift, en terme de type de stockage Swift fournit un stockage en objet,
accessible via une API RESTful http, il utilise des rings (anneaux) pour
surveiller et fournir des information sur l'emplacement des informations
stockées dans un conteneur, pour se connecter les clients se connectent
via des serveurs proxy aux noeuds de stockage (ce qui crée un goulot
d'étranglement : un point d'un système limitant les
performances globales, et pouvant avoir un effet sur les temps de traitement et
de réponse), pour répartir le travail entre les noeuds de
stockage, Swift utilise la technique de Load Balancer qui consiste à
répartir uniformément les charges de travail sur plusieurs
servers afin d'optimiser le rendement, la fiabilité et la
capacité du réseau. La cohérence étant la
capacité du système à refléter sur la copie d'une
donnée les modifications intervenues sur d'autres copies de cette
donnée, le système Swift est fondé sur un type de
cohérence dit « à terme », ce type de
cohérence consiste à répondre immédiatement aux
demandes de lecture (i.e. faible latence) avec un risque d'envoi de
données obsolètes. Concernant Ceph en fournissant trois type de
stockage : en bloc, en objet et en fichier, il est accessible via l'API
Amazon S3 et l'API de Swift, utilisant pour calculer l'emplacement des objets
stocké dans le cluster un algorithme appelé CRUSH (The Controlled
Replication Under Scalable Hashingen anglais, La réplication
contrôlée sous hachage évolutifenfrançais),
son architecture permet au client de se connecter directement aux noeuds de
stockages (i.e. meilleures performances entrée/sortie), il
possède des serveurs dits Ceph Monitor qui surveillent le cluster en
sauvegardant les données liées à ce dernier, et enfin, par
rapport à Swift il utilise une autre forme de
cohérence appelée « la cohérence
forte » qui certainement réponds aux demandes de lecture
tardivement (latence élevé) mais qui assure que l'information
envoyé soit mise à jours. Pour conclure le travail des chercheurs
présenté dans cet article, nous retiendrons que Ceph et Swift ne
sont pas des concurrents, chacun possède des fonctionnalité
complémentaire à l'autre et peuvent cohabiter dans un seul
système pour profiter des deux offres, cependant à retenir que
Ceph est moins sécure que Swift car les clients communiques directement
avec le cluster de stockage et sur le même réseau Ceph utilise un
trafic de réplication non chiffré (i.e. un pirate pourrait
facilement observer le trafic sur le réseau de stockage).
Les futurs travaux décrits dans l'article [30] dans
lequel des chercheurs ont intégrer le système de stockage Ceph
avec le service du stockage en bloc d'Openstack : Cinder, consistent
à intégrer ce même système avec les services de
stockage en objet : Swift et avec celui du stockage en fichier :
Manila. Un projet au sein du département IT de CERN (nommé
maintenant : l'Organisation Européenne pour le Recherche
Nucléaire) a été réaliser en 2019 pour
l'infrastructure Cloud Openstack du CERN[32], une partie de ce projet
consistait à décrire les fonctionnalités et les avantages
d'une implémentation d'un service de stockage autre que celui du mode
« bloc » : Cinder et du mode
« objet » : Swift, il est nommé Manila et offre
à l'infrastructure Cloud de CERN un service de fichier partagé,
il permet aux utilisateurs de créer et gérer des partages de
fichiers, son utilité principale est son autorisation aux machines
virtuelles d'accéder simultanément à ces fichiers
partagés ( fonctionnalités qui n'est pas prise en charge par
Cinder). À l'heure actuelle, ce service est utilisé pour le
cluster de calcul haute performance qui utilise ces partages de fichiers comme
stockage partagé pour ses charges de travail de calcul. Le service est
également utilisé pour remplacer les fichiers NFS car il
simplifie la gestion de ces machines dédiées. Une fois les
partages de fichiers créés, l'utilisateur peut utiliser le
protocole CephFS pour accéder aux données. CephFS étant le
système de fichier de Ceph.
2.4. Synthèse de l'existant
Afin de tirer le maximum d'information de ces supports
d'informations présentés et analysés, une synthèse
a été réalisée sous la forme d'un tableau afin de
bien structurer les conclusions auxquelles les chercheurs sont
arrivés.
Tableau 2 : Synthèse
de l'existant
|
Conclusion de l'article
|
Les deux services de stockage Cinder et Swift ont chacun leurs
propres fonctionnalités qui peuvent être complémentaire
pour assurer une bonne gestion de stockage
|
L'objectif de Swift est de fournir un système de
stockage à long terme pour une grande quantité de données
statiques.
|
Cinder plutôt que Swift en cas de défaillance du
système.
|
Ceph RBD est le meilleur. En termes de (vitesse de
déploiement et de migration de la VM et en lecture et
écriture)
|
Ceph et Swift ne sont pas des concurrents, chacun
possède des fonctionnalités complémentaires à
l'autre et peuvent cohabiter dans un seul système
|
Manila permet de créer des partages, utilisé
pour ses charges de travail de calcul, remplace les fichiers NFS
|
|
Méthodologie de l'article
|
Déploiement d'un Cloud privé avec les services
de stockages Swift et Cinder
|
Déploiement d'un service de stockage en objet
basé sut la solution Openstack + benchmaarking du cluster Swift
|
Implémenter Swift et Cinder, déclencher un
sinistre, comparer les résultats
|
Construire 3 plateformes de cloud (RDB Openstack, Local
openstack GSR openstack) avec différents backend
|
Étudier GlusterFS, Ceph, LVM, ZFS
Comparaison entre Ceph et Swift
|
Description et présentation du service de
systèmes de fichiers partagé au sein d'OpenStack : Manila
|
|
But de l'article
|
Fournir des ressources informatiques virtualisé facile
à gérer aux institutions d'enseignement supérieur
|
Virtualiser l'infrastructure d'un laboratoire
d'étude
|
Le meilleur service en cas de sinistre
|
Montrer la supériorité de Ceph RBD par rapport
aux autres solutions par rapport à la vitesse de migration,
fiabilité
|
Comparer entre Ceph et Swift en termes de cohérence, de
méthode de placement des données, des opérations de
lecture et d'écriture, de sécurité
|
Améliorer l'infrastructure Cloud Openstack du CERN
|
|
Titre de l'article
|
Design and Implementation of Private Cloud for Higher
Education using OpenStack[27]
|
Building an Object Cloud Storage Service System using
OpenStack Swift[28]
|
Comparing Replication Strategies for Financial Data on
Openstack based Private cloud[29]
|
Construction and Performance Analysis of Unified Storage Cloud
Platform Based on OpenStack with Ceph RBD[30]
|
A comparative Review on Ceph and Swift Open-Source Cloud
Storage Platform[31]
|
Advanced features of the CERN OpenStack Cloud[32]
|
|
Numéro
|
01
|
02
|
03
|
04
|
05
|
06
|
2.5. Conclusion
La vitesse avec laquelle le volume des données
informatiques augmente dans les entreprises, les établissements et les
organisations est immense, étant la source de plusieurs
problématiques liées aux stockages, de nombreuses solutions ont
été proposées, dont la plus connue est le Cloud. Ceci dit,
la complexité des modes de stockage ne semble pas être
dépassée, en effet, même en présence d'une
infrastructure virtualisé via un Cloud les technologies de stockage ne
cessent d'augmenter. Les article et les comptes rendus des conférences
que nous avons étudié et analyser précédemment nous
ouvre des portes vers l'amélioration du système de stockage d'une
infrastructure Cloud déjà déployé auparavant sous
OpenStack, ayant uniquement une intégration d'un stockage en mode
bloc : Cinder. Nous envisageons l'améliorer pour non seulement
supporter les autres types de stockage : en objet (avec Swift) et en
fichier (avec Manila), mais aussi profiter de la fonctionnalité de
partage des stockages. Swift, un système de stockage d'objets simple et
basé sur des composants fiables permettrad'avoir une persistance
élevée des données, une architecture système
complètement symétrique et une évolutivité
illimitée, sans point de défaillance unique. Manila, ce service
de stockage en fichier supportant un système de partage de fichier
surmontera certaines des limitations de Cinder et Swift, apportant plus de
fonctionnalités à OpenStack. Même si les recherches
auparavant menées ont montré l'excellente opportunité que
présente la solution Ceph en termes d'amélioration de stockage,
Swift, Cinder et Manila offrent quand même de nombreuses
fonctionnalités qui sont en perpétuelle évolution et
amélioration, d'autant plus qu'ils bénéficient de leur
intégration approfondie à OpenStack et des contributions de la
communauté OpenStack. Nous avons donc décidé
d'intégrer la combinaison de services : Swift et Manila au service
Cinder présent dans notre Solution Cloud privé déjà
déployée. Dans ce qui suit nous présenterons en
détail les architecture et les fonctionnalités de chacun des
service Cinder, Swift et Manila afin de maitriser leur déploiement.
Chapitre 3 :
Étude analytique et comparative entre les types de stockages persistant
dans la solution Openstack
3.1. Introduction
Améliorer le système de stockage dans un
environnement de Cloud peut être réalisé par plusieurs
méthodes qui sont présents avec plus ou moins de performances
dans le marché de la technologie. Notre proposition est
d'implémenter le service de stockage en objet
« Swift » et le service de système de fichiers
partagés « Manila » pour améliorer le
stockage dans la solution Cloud que nous avons préalablement
déployé sous OpenStack avec uniquement un service de stockage en
bloc « Cinder ». Avant cela nous allonsprésenterplus
en détails les fonctionnalités et leurs architectures
internesainsi que leurs fonctionnements qui seront suivi d'une
synthèsecomparative selon des critères précis.
3.2. Les types de stockage dans OpenStack
D'après le Red Hat OpenStack Platform (RHOSP)
répondre aux exigences de stockageOpenStack est assuré selon deux
type de stockage : le stockage éphémère et le
stockage persistant [33]. Ce que nous allons réaliser comme travail
(Swift, Cinder et Manila) se trouve dans la catégorie de stockage
persistant, néanmoins une présentation des deux formes de
stockage : éphémère et persistant s'avère
nécessaire pour une meilleure compréhension du stockage
d'OpenStack.
3.2.1. Stockage
éphémère
Le stockage éphémère appelé aussi
le stockage non persistant, comme son nom l'indique, il ne garde pas les
disques associés à une machine virtuelle une fois éteinte
[34]. Ce type de stockage est utile pour les exigences d'exécution de
base, telles que le stockage du système d'exploitation de l'instance (la
machine virtuelle) [35].
3.2.2. Stockage
persistant
Le stockage persistant, en revanche, est conçu pour
persister, indépendamment de toute instance en cours d'exécution,
son éteinte n'affectera donc pas les données stockées
contrairement au stockage éphémère. Ce stockage est
utilisé pour toutes les données qui doivent être
réutilisées, soit par différentes instances, soit
au-delà de la durée de vie d'une instance spécifique[34].
Openstack prend en charge trois type de stockage persistant : le stockage
en objet, le stockage en bloc et le stockage en fichier, avec leurs noms de
codes : Swift, Cinder et Manila respectivement.
3.3. Le mode de stockage en objet
« Swift »
Lors de la sortie d'OpenStack en 2010, Rackspace a fourni le
code source de son produit « Cloud Files » en tant que code initial
pour le composant de stockage d'objets OpenStack Object Storage (maintenant
Swift). Le but est de fournir un stockage redondantet massivement
évolutif sur toutes les plates-formes matérielles de base. Le
modèle de basede ce service s'inspire des serveurs de stockage Amazon S3
et est géré de la même manière[36].Le stockage en
mode objet est une structure plate dans laquelle les fichiers sont
décomposés en éléments et répartis sur du
matériel. Avec le stockage en mode objet, les données sont
décomposées en petites unités distinctes appelées
objets et sont conservées dans un référentiel unique[37].
La figure suivante schématise le mode de stockage en objet :
Accès direct
URL
Figure 18 : Le mode de
stockage en objet [38]
3.3.1. Vue
d'ensemble sur Swift
Le stockage ne mode objet permet à l'utilisateur de
stocker les données sous formes d'objets en utilisant une API RESTful
http, ces objets sont stockés de façon vaste et plate, il
n'existe donc aucune hiérarchie ou structure particulière
contrairement à un système de stockage traditionnel. Ce mode de
stockage en objet n'est pas conçu ni adapté aux exigences des
hautes performances ou de données structurées qui sont
fréquemment modifiées (telles que les bases de données).
En effet ce système de stockage est conçu pour de grandes
quantités de données binaires ou statiques qui peuvent être
récupérées et mises à jour, et il est idéal
pour stocker des données non structurées qui peuvent
croître sans limite (telles que les fichiers multimédias, des
données volumineux et des images disque). Les principales notions
caractérisant le stockage en objet sur Swift sont les notions de
Compte, Conteneur et Objet. Ils forment l'organisation logique du service, en
effet, chaque compte possède un ou plusieurs conteneurs, et chaque
conteneur contient un ou plusieurs objets, comme décrit dans la figure
suivante :
Objets
Compte
Conteneur
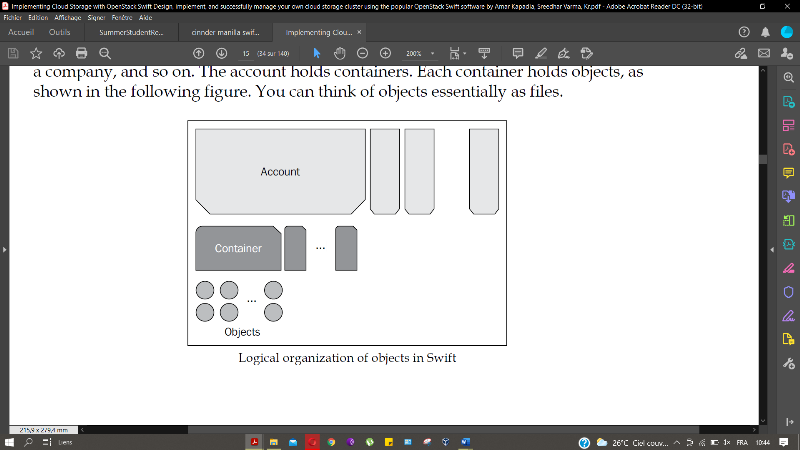
Figure 19 : Organisation
logique du service Swift[39]
- Le Compte :L'emplacement de stockage
du compte est une zone de stockage possédant un nom unique qui contient
les métadonnées (informations descriptives) sur le compte
lui-même ainsi que la liste des conteneurs du compte. Dans Swift, un
compte n'est pas une identité d'utilisateur mais une zone de
stockage.
- Le Conteneur :L'emplacement de
stockage du conteneur est la zone de stockage définie par l'utilisateur
dans un compte où les métadonnées sur le conteneur
lui-même et la liste des objets dans le conteneur seront
stockées.
- L'Objet :L'emplacement de stockage
d'objet est l'endroit où l'objet de données et ses
métadonnées seront stockés.
3.3.2. Architecture
de Swift :
Swift abstrait complètement l'organisation logique des
données -précédemment présentée- de
l'organisation physique [39]. Nous commençons par examiner
l'organisation physique des données, puis la façon dont Swift
assure la circulation des données.
3.3.2.1. L'organisationphysique du service Swift :
Swift classe l'emplacement physique dans une
hiérarchie, en effet la région et au sommet suivi des zones puis
des serveurs de stockage ensuite des disques, comme illustré dans la
figure suivante :
Serveur
Région
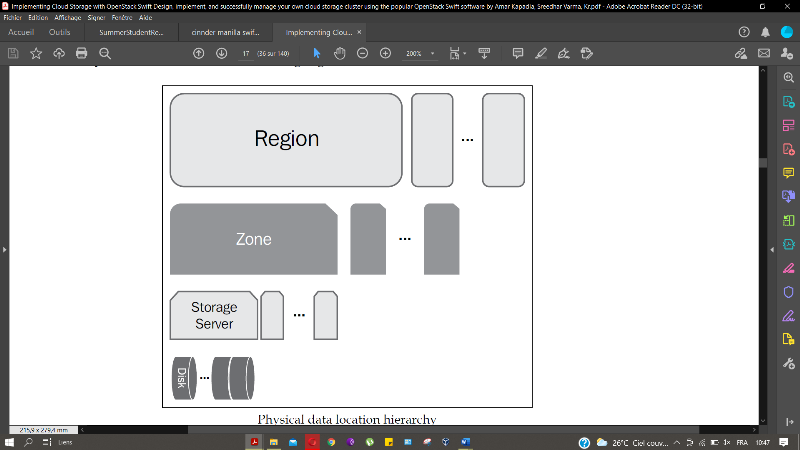
Figure 20 : Organisation
physique du service Swift[39]
- La région : Au niveau le plus
élevé, Swift stocke les données dans des régions
géographiquement séparées et qui souffrent donc d'un lien
à latence élevée. Un utilisateur ne peut utiliser qu'une
seule région, par exemple, si le cluster n'utilise qu'un seul centre de
données[39].
- La zone : au sein des régions,
il existe des zones. Les zones sont un ensemble de noeuds de stockage qui
partagent différentes caractéristiques de disponibilité.
La disponibilité peut être définie comme différents
bâtiments physiques, sources d'alimentation ou connexions réseau.
Cela signifie qu'une zone peut être un serveur de stockage unique, un
rack ou un centre de données complet en fonction de vos besoins. Les
zones doivent être connectées entre elles via des liens à
faible latence. Rackspace recommande d'avoir au moins cinq zones par
région[39].
- Les serveurs de stockage : Une zone
est constituée d'un ensemble de serveurs de stockage allant d'un seul
à plusieurs racks[39].
- Les disques (ou périphériques)
: les lecteurs de disque font partie d'un serveur de stockage. Ceux-ci
peuvent être à l'intérieur du serveur ou connectés
via un JBOD[39].
3.3.2.2. Architecture logique du service Swift:
Swift est un système de stockage deux-tiers
composé d'un niveau proxy, qui gère toutes les demandes
entrantes, et d'un niveau de stockage d'objets où les données
réelles sont stockées. Swift utilise une structure de
données appelée « anneau » pour acheminer
l'URL d'un objet vers un emplacement particulier dans le cluster où
l'objet est stocké. La figure suivante montre Les composants de
Swift.
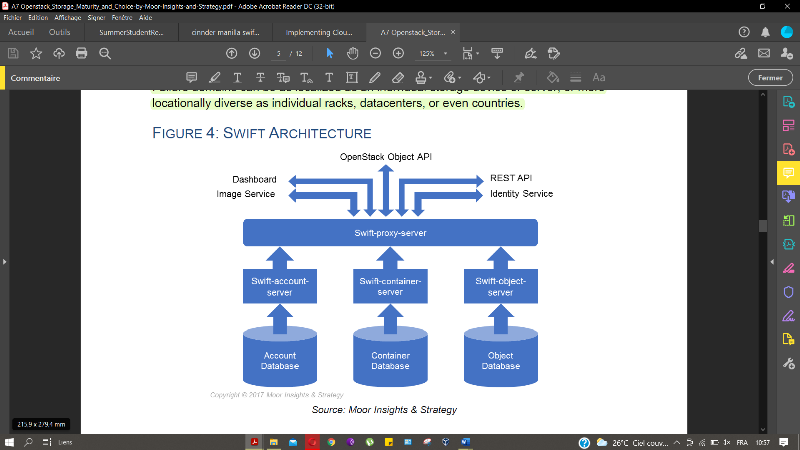
Figure 21 : Architecture
logique du service Swift [40]
- Le serveur :
o Swift-Proxy : accepte les requêtes
entrantes via soit l'API d'objets OpenStack, ou simplement le HTTP brut. Il
accepte les téléchargements de fichiers, des modifications de
métadonnées ou la création de conteneurs. De plus, il sert
également des fichiers ou des listes de conteneurs au navigateur Web. Le
serveur proxy peut également s'appuyer sur éventuellement sur le
cache, qui est généralement déployé avec Memcached
qui améliore les performances.
o Swift-account : gère le compte qui
est défini avec l'objet service de stockage. Il décrit son propre
descriptif (métadonnées) et la liste des conteneurs du compte.
o Swift-container : gère un mappage
des conteneurs dans le compte serveur. Un conteneur fait
référence à la zone de stockage définie par
l'utilisateur dans un compte serveur, il définit une liste d'objets
stockés dans le conteneur. Un conteneur peut être conceptuellement
similaire à un exemple de dossier dans un système de fichiers
traditionnel.
o Swift-object : gère un objet
réel au sein d'un conteneur, stocke les données des objets et
leurs métadonnées. L'objet doit appartenir à un
conteneur[34].
- Les backends
o Base de données
« Account » : Stocke les informations des
comptes.
o Base de données
« Container » : Stocke les informations des
conteneurs.
o Base de données
« Object » : Stocke les informations des
objets.
3.4. Le mode de stockage en bloc
« Cinder »
Le projet OpenStack Nova avait à l'origine un composant
appelé "nova_volume" qui a été séparé de
Nova en 2012 pour fonctionner indépendamment comme un service de
stockage en Bloc sous le nom de « Cinder » afin de fournir
un service de stockage persistant en bloc autogéré aux
utilisateurs.Le stockage en mode bloc rassemble les données en blocs qui
sont stockés en tant qu'éléments séparés.
Chaque bloc de données se voit attribuer un identifiant unique, qui
permet au système de stockage de conserver les petits
éléments à l'emplacement le plus pratique, chaque bloc
existe de manière autonome et peut être partitionné de
manière à être accessible depuis un système
d'exploitation différent, l'utilisateur bénéficie donc
d'une liberté totale pour la configuration de ses données[37].
La figure suivante schématise le mode de stockage en
bloc.
Bloc
Segment
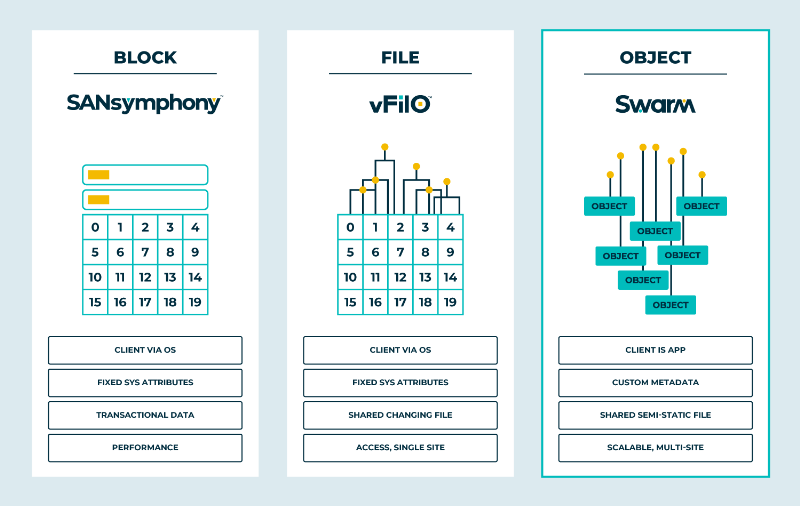
Figure 22 : le mode de
stockage en bloc[38]
4.4.1. Vue
d'ensemble sur « Cinder »
Cinder est un outil de stockage persistant pour OpenStack dont
les volumes exposent un bloc brut de stockage qui peut être
attaché à des instance et qui stocke des données de
manière permanente. De plus Cinder gère les snapshots qui sont
donc des copies ponctuelles d'un volumes, cependant il existe une
possibilité de sauvegarde rapide et temporaire qui se fait en copiant
entièrement les données d'un volume et les stocker dans le
système de sauvegarde[34]. Le service de stockage Cinder virtualise la
gestion des périphériques de stockage par blocs et fournit aux
utilisateurs finaux une API en libre-service pour demander et consommer les
ressources sans avoir besoin de savoir où leur stockage est
réellement déployé ou sur quel type de
périphérique.Nous pouvons conclure 3 ressources de base fournit
par le service Cinder :
- Les volumes : ressources de stockage
de blocs allouées qui peuvent être attachées aux instances
en tant que stockage secondaire ou peuvent être utilisées comme
magasin racine pour démarrer les instances[41].
- Les Snapshots : les snapshots sont une
copie ponctuelle en lecture seule d'un volume. Le snapshot peut être
créé à partir d'un volume actuellement utilisé ou
dans un état disponible. Le snapshot peut ensuite être
utilisé pour créer un nouveau volume[41].
- Les sauvegardes : copie archivée
d'un volume actuellement stocké dans OpenStack[41].
4.4.2. Architecture de
« Cinder »
Cinder est composé de deux service, deux démons
(un programme informatique ou un processus qui n'est pas contrôlé
par l'utilisateur et qui s'exécute en arrière-plan) et deux
backends importants [42]. La figure suivante illustre les composant du service
Cinder :
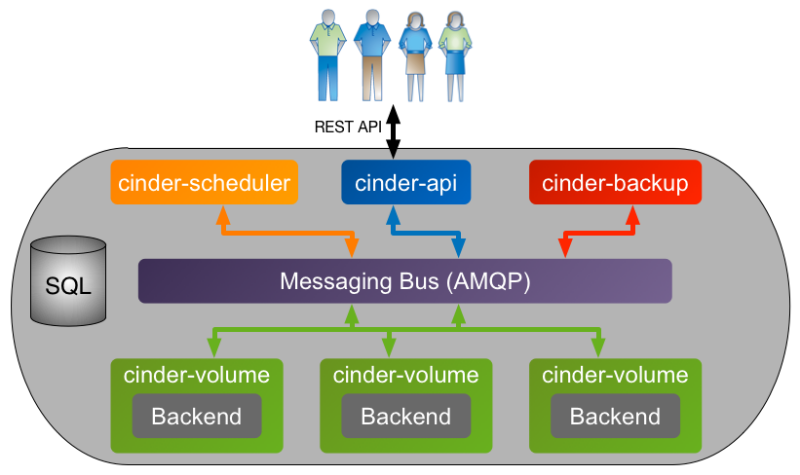
Figure 23 :
Architecture logique du service Cinder [41]
- Les services :
o Cinder-api : Gère les
requêtes API et les achemine vers le volume de cendres à
traiter[42].
o Cinder-volume driver : Liaison principale
entre les démons de cendre, elle est responsable des requêtes de
lecture et d'écriture[42].
- Les démons :
o Cinder-scheduler :Choisit le meilleur noeud
de stockage sur lequel créer le volume[42].
o Cinder-backup :Il crée des
sauvegardes de volumes sur les noeuds de stockage de sauvegarde[42].
- Backends :
o File d'attente : Achemine les
informations entre les processus Block Storage.
o Base de données :
Utilisée pour stocker les informations de bloc.
3.5. Le mode de stockage en fichier « Manila
» :
OpenStack a vu l'ajout de Manila sous la version Liberty en
2015 comme un projet expérimental indépendant facilitant le
stockage des fichiers et proposant la fonctionnalité de partage de ces
derniers avec un support complet[40].Le stockage en mode fichier consiste
à stocker les données en tant qu'élément unique
d'information à l'intérieur d'un dossier, ces données sont
organisées et récupérées à l'aide de
quelques métadonnées qui indiquent où le fichier se
trouve. Le système fonctionne comme un catalogue de
bibliothèque[37]. Dans la figure suivante un schéma de ce type
de stockage est présenté :
Fichiers
Accès hiérarchique
Répertoires
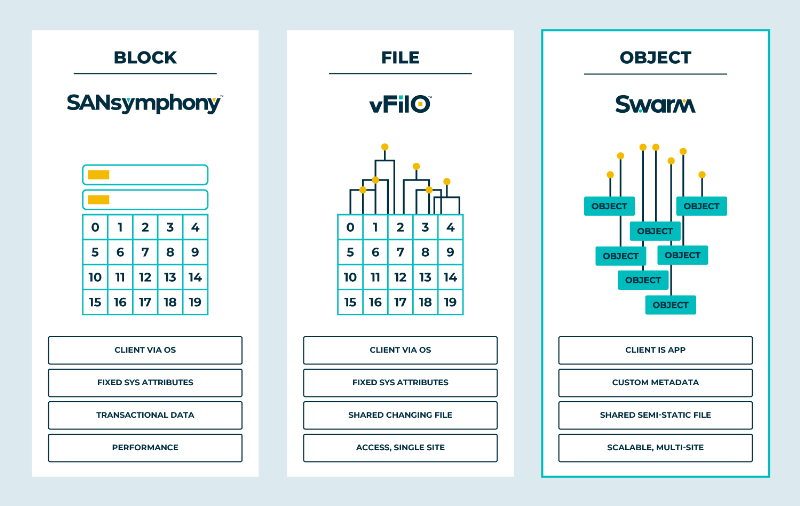
Figure 24 : le stockage
en mode fichier [38]
4.5.1. Vue
d'ensemble sur Manila
Manila apporte des fonctionnalités pour combler les
lacunes de Cinder et Swift, en effet, pendant que Cinder ne prends pas en
charge l'accès simultané au stockage et que même si les
objets Swift sont excellents pour stocker et gérer de gros objets, ils
ne sont pas bien adaptés à un environnement
transactionnel où il représente, en informatique, un
environnement dans lequel les informations sont enregistrées à
partir des séquences d'échange d'information (des transactions),
le service Manila vient donc proposer le système de partage de fichiers
accessibles à plusieurs utilisateurs simultanément[40]. La notion
principale dans ce service est celle du partage et du réseau de
partage.
- Le partage :est une unité de
stockage avec un protocole une taille et une liste de control d'accès,
il représente une allocation d'un système de fichierspersistent,
lisible, inscriptible et montable auquel plusieurs hôtes et utilisateurs
peuvent accéder en même temps, une fois créé il doit
être associé à un réseau pour pouvoir être
répertorié, interrogé, mis à jour ou
supprimé. Afin de réaliser le lien entre le consommateur du
partage et le service Manila (qui fournit ce partage) il est nécessaire
d'associer à un partage n'importe quel système de fichiers[43],
notamment le système de fichiers en réseau (NFS : Network
File System), le système de fichiers Internet commun (CIFS : Commun
Internet File System), le système de fichiers Gluster (GlusterFS :
Gluster File System), le système de fichiers distribué Hadoop
(HDFS : Hadoop Distributed File System) ou le système de fichiers
Ceph (CephFS : Ceph File System), l'utilisateur peut alors accéder
au partage en utilisant les techniques et commandes usuelles appropriées
au protocole sélectionné[33].
- Le réseau de partage : Le
réseau de partage est un objet qui définit une relation entre le
réseau/sous-réseau d'un locataire (tel que défini dans un
service réseau OpenStack : Neutron ou Nova-Network) et les partages de
Manila créés par le même locataire. Un exemple
d'utilisation d'un réseau de partage serait le désir de
provisionner des partages qui ne seront disponibles que pour les instances
connectées à un réseau particulier défini par
OpenStack[43].
4.5.2. Architecture
de Manila
La scalabilité et l'aisance d'implémentation
sont les deux importantes caractéristiques qui forme la vision
derrière le projet OpenStack, Manila, ce système de fichiers
partagé adopte une architecture alignée avec la vision globale
d'OpenStack. Il se compose de trois services, détaillé en bas de
la figure, une file de message et une base de données pour stocker les
informations[43].
La figure suivante montre l'architecture de ce service.
Figure 25 : Architecture
logique du service Manila [41]
- Les services
o manila-api : c'est une application
qui accepte et valide les requêtes REST provenant des clients pour
ensuite les cheminervers les autresprocessus de Manila selon les besoins
à travers un bus de messagerie[43].
o manila-schedular : détermine
quel backend sert comme destination pour une demande de création
d'unpartage, maintient un état non-persistant pour les pools et les
backends, comme la capacité disponible et les spécifications
supplémentaires prises en charge[43].
o manila-share :accepte les demandes
d'autres processus de Manila et sert de conteneur d'opérations pour les
pilotes de Manila[43].
- Le backend : Un backend Manila est
l'objet de configuration qui représente un fournisseur unique de pools
de ressources sur lequel les demandes d'approvisionnement pour les
systèmes de fichiers partagés peuvent être satisfaites. Un
backend communique avec le système de stockage via un pilote[43].
3.6. Étude comparative entre les services Cinder et
Swift et Manila
Chaque type de stockage est conçu pour répondre
à des exigences de stockage spécifiques. Les conteneurs sont
conçus pour un accès large et, en tant que tels,
présentent le débit, l'accès et la tolérance aux
pannes les plus élevés parmi tous les types de stockage. L'usage
des conteneurs est davantage orienté vers les services. D'autre part,
les volumes sont principalement utilisés pour la consommation. Ils ne
bénéficient pas du même niveau d'accès et de
performances que les conteneurs, mais ils disposent d'un ensemble de
fonctionnalités plus étendu et de fonctionnalités de
sécurité natives plus nombreuses que les conteneurs. Les partages
sont similaires aux volumes à cet égard, sauf qu'ils peuvent
être consommés par plusieurs instances simultanément.
Dans ce qui suit nous allons comparer l'architecture et les
fonctionnalités de chaque type de stockage selon des critères de
stockage spécifiques, à savoir : la scalabilité,
backends, la cohérence, l'accessibilité, l'administration, la
sécurité, la redondance et la reprise d'activité
après un sinistre.
3.6.1.
Scalabilité et backend
Le service de stockage en bloc Cinder peut utiliser plusieurs
solutions de stockage en tant que backends discrets. La capacité peut
être évoluée en ajoutant d'autres backends et en
redémarrant le service. Le service Block Storage propose
également une grande liste de solutions back-end prises en charge, dont
certaines disposent de fonctionnalités d'évolutivité
supplémentaires (NFS, CIFS, GlusterFS, CephFS)[44].
Le service de stockage en objet Swift peut évoluer d'un
serveur unique à de très grands clusters (un groupe de serveurs
agissant comme un seul système) simplement en ajoutant des
noeuds[45].
Le service de système de fichiers partagé
provisionne les partages sauvegardés par le stockage d'un pool de
stockage séparé. Ce pool (qui est généralement
géré par un service backend tiers) fournit au partage un stockage
au niveau du système de fichiers. Peu importe le système de
fichier déployé, la mise à l'échelle implique
l'ajout de volumes supplémentaires au pool[45].
3.6.2.
Cohérence des données
Le stockage en objet utilise la cohérence dite
« à terme » c'est une cohérence
immédiate : dès que l'utilisateur demande à recevoir
une données la requête est rapidement répondue (faible
latence), en revanche si d'une autre part cette même données a
subi un changement avant la demande de lecture d'un petit temps, cette mise
à jour ne sera pas envoyée, certes cette cohérence
répond immédiatement mais elle prend le risque d'envoyer des
données erronées.
Le stockage en mode Bloc et en mode Fichiers partagé
utilisent la cohérence dite « Forte » c'est une
cohérence qui prends le temps de mettre à jour une données
qui à subit des modification instantanément et sans interrompre
l'activité, si un utilisateurs envoi une requête demandant une
donnée qui est en train d'être mise à jour, le stockage en
bloc et en fichiers partagé, la mettent en attente (on parle alors de
latence élevé) donc même si ces deux mode tardent à
répondre (le temps est calculé par secondes) les données
envoyés aux utilisateurs sont certainement fiable et à jours.
3.6.3.
Accessibilité et administration
Les volumes sont consommés uniquement via des instances
et ne peuvent être attachés et montés que dans une instance
à la fois. Les utilisateurs peuvent créer des instantanés
de volumes, qui peuvent être utilisés pour cloner ou restaurer un
volume à un état précédent[45].
Comme les volumes, les partages sont consommés via des
instances. Cependant, les partages peuvent être directement montés
dans une instance et n'ont pas besoin d'être attachés via le
tableau de bord ou la CLI (interface en ligne de commande). Les partages
peuvent également être montés par plusieurs instances
simultanément. Le service de système de fichiers partagés
prend également en charge les Snapshots (instantanées) de partage
et le clonage[45].
Les objets d'un conteneur sont accessibles via l'API REST et
peuvent être rendus accessibles aux instances mais pas uniquement, en
effet, contrairement des volumes et des partages, les objets sont aussi
accessibles aux autres services dans le cloud. Cela les rend idéaux
comme référentiels d'objets pour les services ; par exemple,
le service Image (openstack-glance) peut stocker ses images dans des conteneurs
gérés par le service Object Storage[45].
3.6.4.
Sécurité
Le service Block Storage (Cinder) offre une
sécurité de base des données grâce au cryptage de
volume. Avec cela, lors de la création des types de volume, une
configuration l'option de chiffrement via une clé statique est possible
; la clé est ensuite utilisée pour chiffrer tous les volumes
créés à partir du type de volume configuré[45].
La sécurité des objets et des conteneurs est
configurée au niveau du service et du noeud. Le service Object Storage
(Swift) ne fournit aucun chiffrement natif pour les conteneurs et les objets.
Au lieu de cela, le service Object Storage donne la priorité à
l'accessibilité au sein du cloud et, en tant que tel, s'appuie
uniquement sur la sécurité du réseau cloud pour
protéger les données des objets[45].Il existe plusieurs
façons de sécurisé le stockage en objets : Keystone,
Tempauth et Swauth.sont les plus utilisé. Keystone étant le
service d'identification par défaut d'OpenStack, Tempauth est un type
d'authentification qui ne chiffre pas les mots de passe mais les stockent en
mode texte. Swauth est un Middleware intergiciel : logiciel agissant comme
passerelle entre les applications) prend en charge les ACL pour autoriser les
requêtes d'accès doit être installé manuellement.
Le service de système de fichiers partagés
(Manila) peut sécuriser les partages via des restrictions
d'accès, que ce soit par instance IP, utilisateur ou groupe, ou
certificat TLS3(*). En
outre, certains déploiements de services de systèmes de fichiers
partagés peuvent comporter des serveurs de partage distincts pour
gérer la relation entre les réseaux de partage et les partages ;
certains serveurs de partage prennent en charge, voire nécessitent, une
sécuritéréseau supplémentaire. Par exemple, un
serveur de partage CIFS nécessite le déploiement d'un service
d'authentification LDAP4(*),
Active Directory ou Kerberos5(*)[45].
3.6.5. Redondance
et tolérance aux pannes
Le service de stockage en bloc propose une sauvegarde et une
restauration de volume, offrant une récupération après
sinistre de base pour le stockage utilisateur. Les sauvegardes permettent de
protéger le contenu du volume. En plus de cela, le service prend
également en charge les Snapshots (instantanés) ; Outre le
clonage, les instantanés sont également utiles pour restaurer un
volume à un état antérieur[45].
Le service Object Storage ne fournit aucune
fonctionnalité de sauvegarde intégrée (réplication
des données). Ainsi, toutes les sauvegardes doivent être
effectuées au niveau du noeud. Le service, cependant, présente
une redondance et une tolérance aux pannes plus robustes ; même le
déploiement le plus basique du service Object Storage réplique
les objets plusieurs fois[45].
Le service de système de fichiers partagés ne
fournit aucune fonctionnalité de sauvegarde intégrée pour
les partages, en revanche il permet de créer des instantanés pour
le clonage et la restauration[45].
Le but de décrire les fonctionnalités de chaque
service en tenant compte de certains critères est de pouvoir classifier
les services selon leurs impacts et le type de problèmes auxquels il
répond. Le tableau suivant résume ce que nous avons
présenté tout au long de ce travail :
Tableau 3 : Tableau de
comparaison entre les services Cinder, Swift et Manila
|
Spécification
|
Type de stockage
|
|
Service de stockage en objet
« Swift »
|
Service de stockage en bloc
« Cinder »
|
Service de stockage en fichier
« Manila »
|
|
Type de stockage
|
Objet
|
Bloc
|
Fichier
|
|
Placement de données
|
Conteneur
|
Volumes
|
Partage
|
|
Type de données stocké
|
Statiques et non structurées
|
Structurées et non statiques
|
Tous types de données
|
|
Forme de présentation de
données
|
Structure plate (Horizontale)
|
Volumes de taille égale
|
Hiérarchie de fichiers
|
|
Persistance
|
OUI
|
OUI
|
OUI
|
|
Scalabilité
|
En rajoutant des noeuds
|
En ajoutant d'autres backends
|
L'ajout de volumes supplémentaires au pool
|
|
Cohérence
|
Cohérence « À terme »
|
Cohérence « Forte »
|
Cohérence « Forte »
|
|
Accès
|
Instances &accès public
|
Instance
|
Instance
|
|
Protocole d'accès
|
API REST (http)
CLI
Client Swift
|
Depuis une instance via le tableau de bord ou la CLI
|
Tableau de bord ou la CLI
|
|
Protection des données & tolérance
aux pannes
|
Réplication
|
Sauvegarde & Snapshot
|
Snapshots
|
|
Sécurité
|
La sécurité du réseau cloud (https, liste
d'accès selon l'IP)
Tempauth, Swauth
|
Cryptage de volume
|
Restrictions d'accès (Certificat, AD, liste
d'accès)
|
|
Cas et domaines d'utilisation
|
Hébergement de sites
Web application
Stockage en tant que service
Jeux vidéo
|
Stockage des serveurs
Volumes d'exécutions de machines
|
Partages de cloud hybride
NFV/Telco
Big Data
|
3.7. Conclusion
Swift fournit une prise en charge du stockage d'objets,
ce qui le rend adapté au stockage de gros objets binaires à
grande échelle. Cependant, le stockage Swift ne convient pas aux
données transactionnelles ou au stockage de machines virtuelles, car les
objets sont généralement immuables et mis à jour dans leur
intégralité. Les magasins d'objets ne conviennent
généralement pas aux petits objets en raison des frais
généraux liés aux méthodes de protection des
données, telles que le codage par effacement, et sont relativement
inefficaces lors de l'utilisation d'approches de protection simples, telles que
les répliques.
Le stockage par blocs offre un accès hautes
performances aux machines virtuelles (VM) et aux données, mais un volume
Cinder est limité à l'accès par un seul invité Nova
(machine virtuelle). Cette restriction existe car il n'y a pas de processus de
verrouillage ou de synchronisation inhérent intégré aux
protocoles de niveau bloc. Les appareils en bloc ont également des
restrictions de capacité, ce qui les rend difficiles à augmenter
et presque impossibles à réduire.
Manila comble le fossé entre le bloc et l'objet en
offrant la possibilité de mapper des systèmes de stockage
externes à l'aide de protocoles NAS basés sur des systèmes
de fichiers. Les partages de fichiers peuvent être répartis entre
les instances, car le protocole NAS gère les processus de verrouillage
et d'intégrité des données requis pour fournir plusieurs
accès simultanés aux données.
Dans le chapitre suivant, nous présenterons le travail
réalisé soit donc : la configuration du service de
réseau et l'implémentation des services de stockage en objet
(Swift) et de système de fichiers partagés (Manila) dans la
plateforme Cloud privé préalablement réalisée avec
seulement le service de stockage en bloc (Cinder), nous introduisant
l'environnement de déploiement, les étapes d'installation et le
test des fonctionnalités de chacun des services
implémentés.
Chapitre 4 : Implémentation des services de
stockage Swift et Manila
|
3.1. Introduction
Un Cloud proprement fonctionnel permet la création des
instances (machines virtuelles) par des utilisateurs
pré-enregistrés, les instances ont accès à internet
et peuvent être accessibles depuis internet (dans le cas d'une instance
qui héberge un site internet public). Un Cloud propose aussi un service
de stockage d'objet permettant de stocker, télécharger, supprimer
et modifier des fichiers. Notre travail ne s'est paslimité à
l'implémentation des services de stockage en objet (Swift) et du service
de système de fichier partagés (Manila), en effet une
améliorationdu service de réseaux (Neutron) a été
appliquée afin de permettre l'accès depuis l'extérieur
(Internet) à une instance hébergeant un site Internet.
3.2. Travail réalisé
Le déploiement du Cloud privé sur lequel nous
avons établie de nouveau changements pour but d'amélioration
était basé sur trois noeuds (trois serveurs) le noeud Compute qui
assure le calcul, le noeud contrôleur (Controller) qui exécute le
tableau de bord, le service de réseau et d'autres services, et en
dernier le noeud de stockage en bloc (Cinder). La raison pour laquelle nous
avons choisi ce mode de déploiement en plusieurs noeuds était
d'apprendre au mieux le fonctionnement et les étapes de configuration.
Maintenant que nous avons acquis ces compétences, nous pouvons choisir
un déploiement sur un seul noeud et une installation avec paquets, et
apporter des changements aux fichiers de configuration installé par
défaut, nous économiserons le temps d'installation des services
et les ressources matérielles de notre machine physique. Cette
dernière est un ordinateur portable de type HP PROBOOK avec une espace
de stockage disque 500Go HDD, une RAM de 16Go et un processeur Intel®
Core™ i5-7200U CPU @ 2.50GHz. Sachant que les ressources en mémoire
(RAM) consommées par les trois noeuds de nos déploiements
étaient de 6Go pour le Contrôleur et le Compute et 1Go pour le
stockage en Bloc, nous nous retrouvons seulement 3Go de mémoire
disponible ce qui ne permet pas une installation des deux noeuds du service de
stockage d'objet puisque cette dernière demande au minimum deux noeud de
2Go de RAM chacun. La solution était d'utiliser packstack qui est un
utilitaire qui utilise des modules Puppet pour déployer automatiquement
diverses parties d'OpenStack sur un ou plusieurs serveurs
préinstallés via SSH, de cette façon nous aurons à
notre disposition tous les services précédemment cités
(Identité, Image, Réseau, Calcul, Stockage en Bloc) en plus du
Tableau de bord et des services secondaire (file de message, base de
données...etc.) Cette installation est faite en un seul noeud consomme
moins de ressource matérielles(soit 6Go de RAM), avec ce mode de
déploiement nous allons gagner de temps d'installation et les ressources
matérielles disponibles pour nous investir pleinement dans la
configuration des fichiers de chaque service de manière à
améliorer le fonctionnement de notre Cloud.
3.2.1.
Configuration du service Neutron
Le service de réseau appelé Neutron dans
OpenStack, contient des agents qui vont se charger d'établir la
connectivité au sein de notre plateforme de Cloud. L'ancienne
configuration a été réalisé avec les composants
suivants : Le Plugin ML2, L'agent L2, L'agent Linuxbridge, L'agent L3,
L'agent DHCP, L'agent Metadata. Après plusieurs manipulations et
recherches nous avons trouvé que le problème se posait au niveau
du Plugin ML2 et l'agent L3. En effet, la configuration du Plugin ML2 est
réalisée avec les drivers de mécanisme
« Linuxbridge » et « l2 population »
pour construire l'infrastructure du réseau virtuel layer-2 (Bridging et
Switching) pour les instances et la configuration de l'agent L3 manque de la
notion du bridge externe. Ce que nous avons décidé de faire
était d'utiliser un autre mécanisme de drivers pour le plugin ML2
qui est l'Open vSwitch (OVS), contrairement à LinuxBridge, ce dernier
permet la configuration du bridge externe (br-ex) qui est un pont OVS
utilisé pour connecter des ports physiques (comme eth0), afin que le
trafic IP flottant pour les réseaux de projet puisse être
reçu de l'infrastructure du réseau physique (et Internet) et
acheminé vers les ports réseau du projet en libre-service.
Les étapes de configuration sont
présentées dans l'annexe et la nouvelle configuration est
désormais comme suit :
Figure 26 : schéma de
l'architecture de réseau avec le mécanismes Open
vSwitch[46]
Dans notre projet nous avons créé un
réseau externe qui est le même réseau physique auquel
l'ordinateur portable est connecté (192.168.1.0/24) suivit d'une
création d'un projet dans lequel on dispose d'un ensemble de ressources
(donnée par l'administrateur et manipulées par les utilisateurs
de ce projets) comme les réseaux virtuels, les routeurs, le stockage, la
mémoire Ram...etc. Nous avons donc créé un réseau
privé (10.0.1.0/24) relié au réseau externe via un routeur
virtuel, à ce même réseau virtuel nous avons attaché
des instances qui ont chacune une adresse IP (privée) 10.0.1.17 et
10.0.1.42. Une troisième instance de test é été
ajoutée avec l'adresse 10.0.1.31.
Le schéma suivant représente la topologie du
réseau informatique dans la plateforme de Cloud
précédemment détaillée.
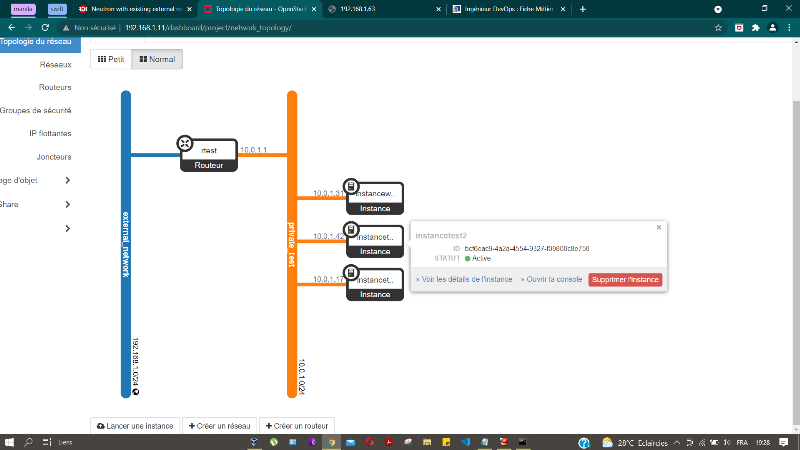
Figure 27 : Topologie simple
du réseau informatique
Nous pouvons représenter graphiquement notre
déploiement du cloud par rapport au réseau externe comme
cela :
Machines virtuelles
Réseau physique
Cloud privé
Réseau virtuel
Routeur virtuel
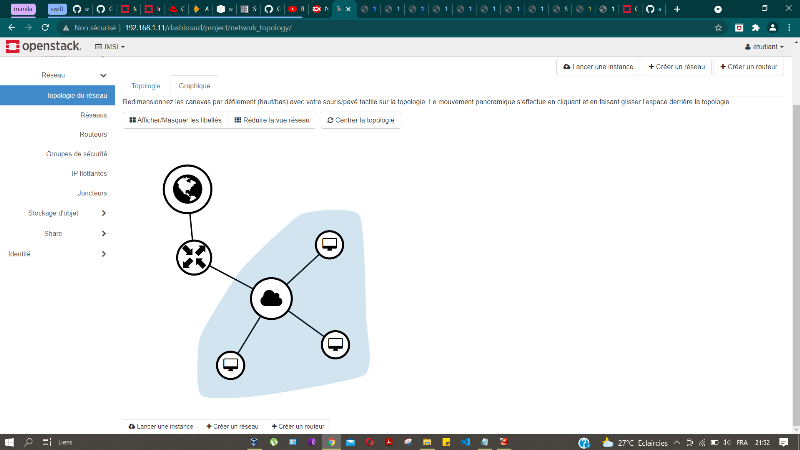
Figure 28 : Topologie
graphique du réseau informatique
Cette nouvelle configuration du réseau nous permet
d'avoir une meilleure connectivité du réseau, Afin de tester la
connectivité et la disponibilité des instance nous avons
autorisé l'accès ICMP/TCP dans les règles de
sécurité associé à ces instances, ce qui les rends
être accessible via Internet (en utilisant leurs adresses IP flottantes
associés) et via SSH (en utilisant les paires de clés) tout en
accédant au réseau internet. Nous pouvons après
héberger dans une instance un site internet et y accéder depuis
le navigateur Web. La figure suivante montre ces fonctionnalités :
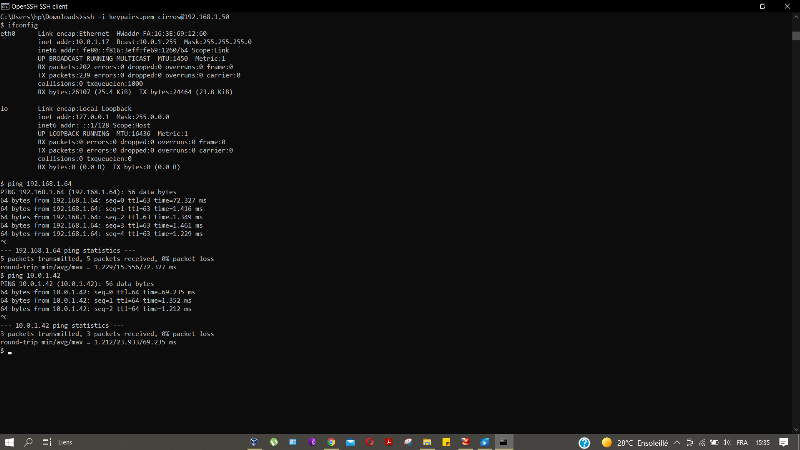
Figure 29 : Test ICMP &
TCP des instances
Sur l'invité de commande cmd de Windows nous avons pu
accéder à la première instance (10.0.1.17) et depuis cette
dernière nous avons lancé la commande ifconfig qui
montre bien l'adresse IP de cette machine (en effet l'instance ne se rends pas
compte qu'elle dispose d'une adresse IP flottante, la sortie de cette commande
le montre bien) pour la deuxième instance (10.0.1.42) nous avons pu lui
lancer un Ping depuis la première.
3.2.2.
Implémentation du service de stockage d'objet (Swift)
L'installation du service de stockage en objet par Packstack
met à notre disposition des fichiers à configurer afin
d'exploiter au mieux les fonctionnalités proposées. En principe
ce service permet aux utilisateurs de créer des conteneurs pour y
stocker des objets (des images, vidéos, son, textes...etc.).
Figure 30 :
Présentation du service de stockage d'objet Swift dans le tableau de
bord
Lors de la création du conteneur l'utilisateur
décide si ce dernier sera privé (accessible uniquement aux
utilisateurs du projet sur lequel le conteneur est créé) ou
public (accessible à toute personne possédant le lien URL
attribué par défaut au conteneur.
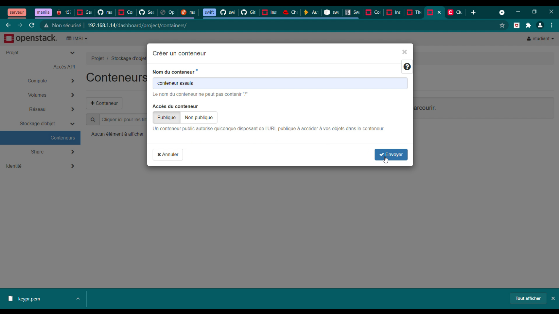
Figure 31 : création
d'un conteneur
Après la création du conteneur, qu'il soit
public ou privé, permet à l'utilisateur de charger des fichiers
comme le montre la figure suivante :
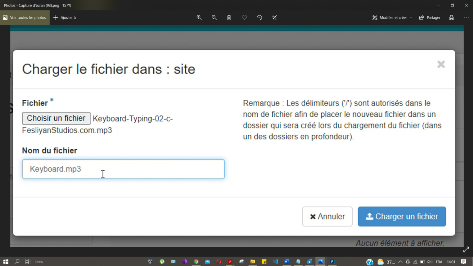
Figure 32 : chargement des
fichiers dans le conteneur
Dans le cas où le conteneur est privé, les
objets ne pourront être consulter que via la plateforme du Cloud et
uniquement pour les utilisateurs du même projet.
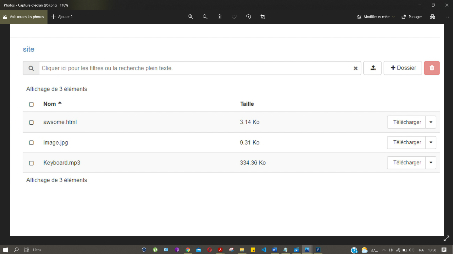
Figure 33 :
présentation des fichiers dans le conteneur privé
Lorsque le conteneur est public il dispose d'un lien URL
permettant l'accès via le Protocol HTTP :
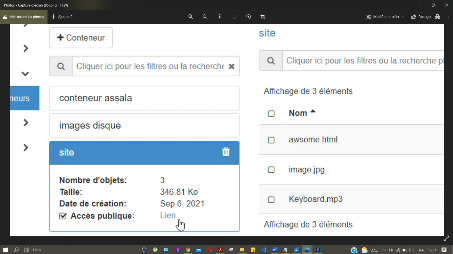
Figure 34 : La
récupération du lien du conteneur
La fonctionnalité qui nous intéresse le plus est
celle du conteneur public, où toute personne possédant le lien du
conteneur pourra le consulter et télécharger son contenu. La
sortie de ce lien par défaut est un fichier XML exposant les objets et
leurs métadonnées.
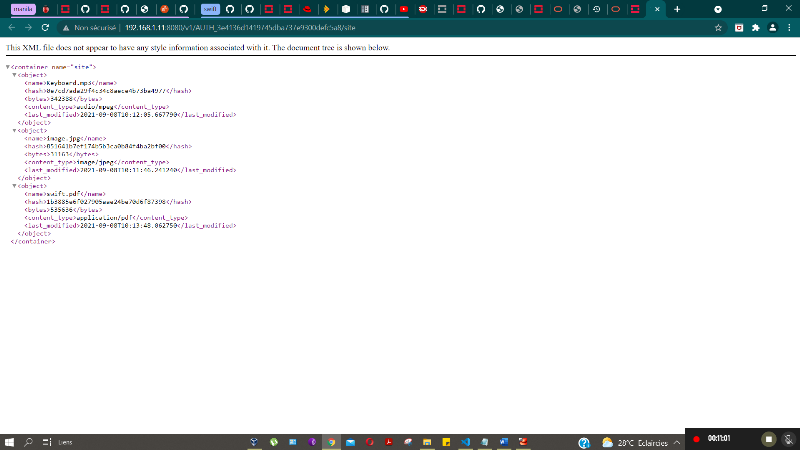
Figure 35 : Liste des
objets via le lien du conteneur - vue par défaut en fichier XML
-
Afin de télécharger un quelconque objet il
suffit de mettre le nom de l'objet à la fin de l'URL du conteneur
(URLdu conteneur/nomdufichier) ici nous souhaitons
télécharger un fichier mp3 comme le montre les figures
suivantes :
Figure 36 :
téléchargement d'un fichier depuis un conteneur
public
À ce stade là le service de stockage d'objet est
fonctionnel. Cependant nous souhaitant lister les objets de manière
présentable et facilement manipulée par les consultants de ce
conteneur. Pour cela nous avons travaillé sur les Access Control List
(ACL ou liste de control d'accès) et sur les métadonnées
du conteneur que nous présenterons dans la partie Annexe plus en
détail. Cette figure montre le changement que nous avons apporté
à la version par défaut que propose le service Swift :
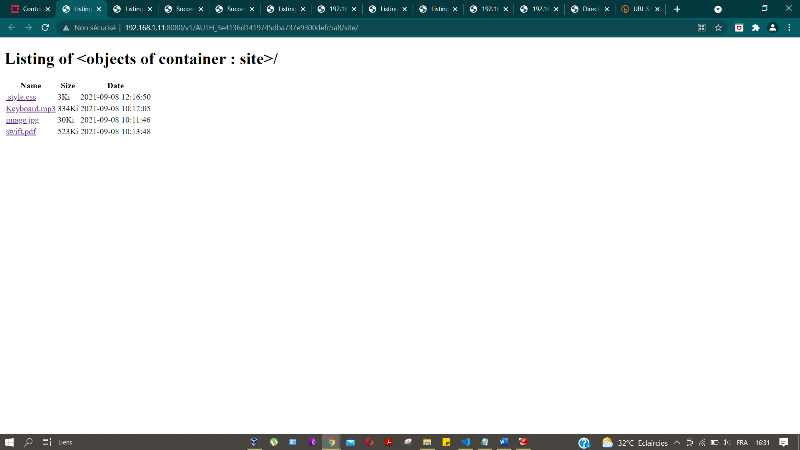
Figure 37 : optimisation de
la liste des objets avec des liens cliquables
Un accès depuis un téléphone portable
avec le lien du conteneur « site » permet la consultation
et le téléchargement des fichiers comme le montre la figure
suivante :

Figure 38 : vue du conteneur
depuis un smartphone non connecté à la plateforme
Cloud
Le service de stockage d'objet Swift contrairement à
Swift permet l'hébergement des sites internet de telle façon
à ce que le lien URL d'un conteneur public donné pointe vers un
fichier de type index.html affichant par conséquence le site internet
généré par le code html, sans pour autant publier le
contenu du conteneur. Pour présenter ceci nous allons travailler en
parallèle avec les ACL et les métadonnées sur une
requêteHeader afin de permettre au conteneur de pointer
directement sur le site internet hébergé. Les commandes
associées sont dans la partie annexe, et le résultat se
présente ainsi :
Figure 39 :
présentation du site internet hébergé dans le
cloud
3.2.3.
Implémentation du service de système de fichiers partagé
(Manila)
Ce service est lancé en 2015 afin de combler certaines
failles du service Cinder et du service Swift, dont la plus importante et la
notion de partage. Ce qui veut dire qu'une fois un partage créé
et monté sur une ou plusieurs instances ces dernières peuvent
tous partager l'accès aux fichiers et même accéder
simultanément. La vérité sur ce service c'est qu'il est en
plein développement et qu'une fonctionnalité pareille n'apporte
pas un grand changement ni un intérêt au grand public c'est un
service qui est en plein développement et que son exploitation ne peut
affecter en force l'utilisation du Cloud, n'empêche qu'il reste un
service intéressant à connaitre.
Figure 40 :
Présentation du service de fichiers partagés dans le tableau de
bord
Manila supporte plusieurs types de backends de drivers et de
protocole de partage, par défaut il utilise le backend et le driver
Genericque nous pouvons travailler avec ou alors le changer pour
utiliser d'autres comme GlusterFS, NetApp, CephFS ...etc. Le backend Generic
est utilisé à des fins de test accompagné du Protocol
NFS.
Avant de pouvoir créer un partage, l'administrateur
doit créer un type de partage afin que l'utilisateur en serve pour
créer le partage. Manila supporte deux types de partage un type qui
prends en charge les serveurs de partage, et un type qui ne les prend pas en
charge. Par défaut il existe un type de partage qui prends en charge les
serveurs de partage. Cela nécessite la création d'un serveur de
partage et d'un réseau de partage. Nous allons créer un type qui
ne les prend pas en charge c'est-à-dire que le réseau de partage
sera géré par Neutron. Cette figure montre la création du
type de partage :
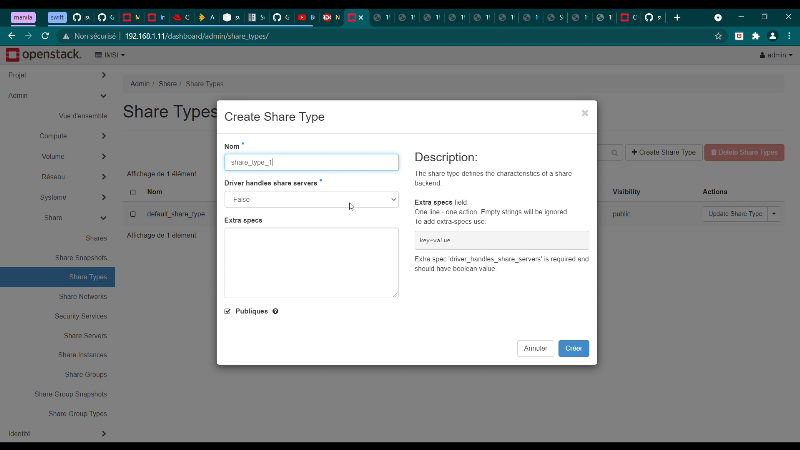
Figure 41 : Création
de type de partage
L'utilisateur pourra donc créer des partages, en
précisant le protocole à utiliser (NFS dans notre cas), la taille
et le type de partage comme suit :
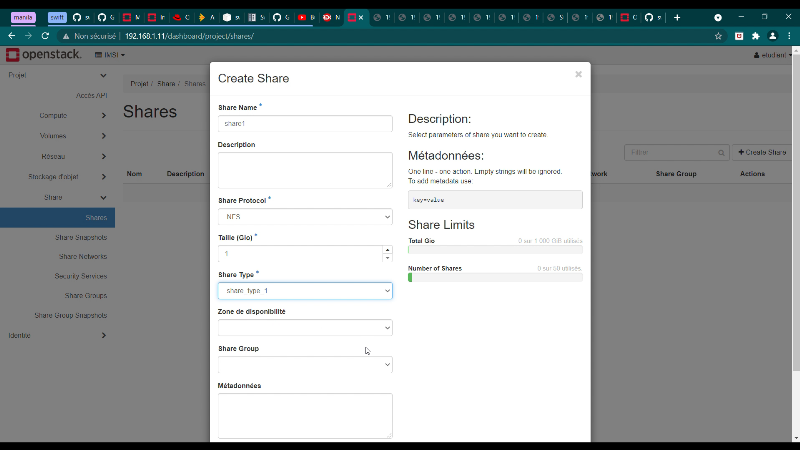
Figure 42 : Création
d'un partage
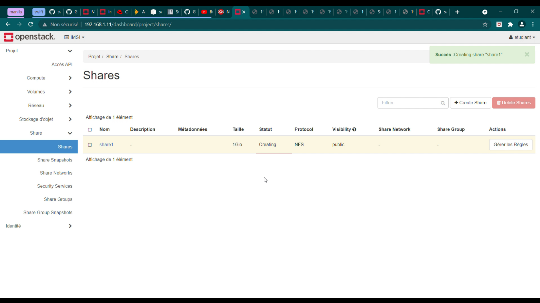
Figure 43 :
Présentation du Partage
3.2.4. Utilisation
privée du stockage offert par la solution Cloud :
Le stockage offert par notre Cloud peut être exploiter
pour des fins personnelles et privées, de telle sorte que l'utilisateurs
se connecte à la plateforme Cloud et utilise le stockage offert par
l'administrateur pour sauvegarder ses propres données (Documents,
images, vidéos ...etc). Nous avons créé un projet (un
ensemble de ressources) pour l'attribuer à un utilisateur en tant
qu'administrateur (i.e. l'administrateur ne pourra pas consulter les
données stockées dans le projet). Les figures suivantes montrent
comment un utilisateur se connecte, stocke et consulte ses données via
un smartphone.
Figure 44 : Connexion de
l'utilisateur au Cloud depuis un Smartphone
L'administrateur crée un projet avec le nom de
« Documents_personnels » et l'utilisateur avec le nom
« assalahalla » en tant qu'administrateur de son projet.
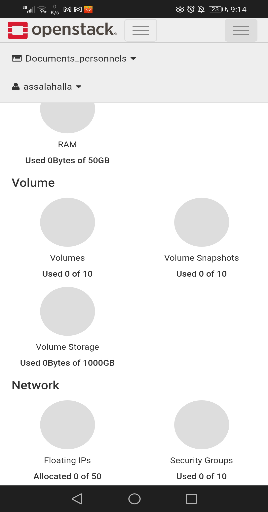
Figure 45 : Nom de projet et
d'utilisateur
Le tableau de bord se présente ainsi :
Figure 46 : Tableau de bord
de l'utilisateur depuis smartphone
Lorsque l'utilisateur décide par exemple
d'héberger ses fichiers dans le Cloud, il n'a qu'à se rendre sur
l'onglet « stockage d'objets » puis conteneur, il pourra
ensuite créer des conteneurs « images »
« vidéos » « documents » ...etc.
comme le montre la figure suivante :
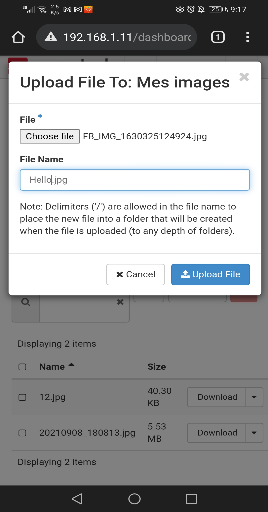
Figure 47 :
Téléchargement de fichier dans le conteneur
L'utilisateur pourra donc consulter son espace de stockage et
pet choisir de rendre l'accès public à un conteneur donné,
comme le montre la figure suivante
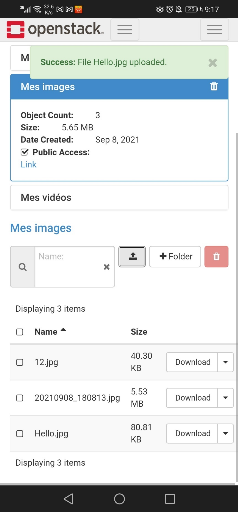
Figure 48 : Liste des objets
dans le conteneur de l'utilisateur
3.3. Conclusion
Le travail réaliser dans le but de
l'amélioration des services de stockage se résume en trois
points, premièrement un changement dans la configuration du service
Neutron a été apporté pour permettre l'accès au
Cloud depuis son URL et assurer la connectivité entre les instances et
l'extérieur (Internet) en adoptant le mécanisme de driver Open
vSwitch qui permet de configurer un pont extérieur à l'interface
de réseau, deuxièmement l'implémentation du service de
stockage en objet Swift permettant ainsi aux utilisateur de créer
télécharger supprimer et consulter et modifier leurs fichiers
(images, vidéos, son, textes, PDF...) et la manipulation des ACLs,
métadonnées et headers afin de proposer une consultation fluide
et présentable des objets du conteneurset dernièrement nous avons
implémenter le service de systèmes de fichiers partagé qui
permet de créer des partage de fichiers entre les instances.
Conclusion
générale
La gestion efficace des données informatiques internes
est l'une des plus importantes problématiques rencontrées chez
les entreprises, les organisations et les institutions. Bien que les solutions
de services de Cloud soient de plus en plus nombreuses, celles de services de
stockage le sont plus. En effet le marché de la technologie a connu une
énorme hausse de systèmes dédiés au stockage dans
les environnements du Cloud, nous retrouvons les systèmes de stockages
open source : LVM, NFS, Ceph, Gluster ou payant : EMC et IBM.
Les systèmes de stockage dans le Cloud sont
répartis en trois catégorie de services, ils offrent soit le
stockage en bloc ou en objet ou en fichiers partagés, il existe des
solutions qui propose deux types de stockages
comme « Gluster » et d'autre qui supportent les trois
stockages tel que la solution Ceph. Chaque type de stockage utilise une
manière qui lui est propre afin de stocker des données qui sont
elles-mêmes différentes d'un type à un autre (i.e. chaque
type de stockage prend en charge des types de données
spécifique).
Notre travail consiste donc à étudier, analyser
et puis comparer entre les services de stockages Cloud open sources existants
afin de sélectionner et implémenter la meilleure des solutions
proposant le stockage en objet et en fichiers partagé dans la
plateformeCloud OpenStack.De plus, nous avons réussis à rendre le
Cloud accessible à tout le monde (lorsque le serveur est allumé).
Cette étape nous était essentielle puisqu'après
l'implémentation des services de stockage d'objets et de partage, il
était intéressant d'offrir un stockage en tant que service aux
utilisateurs finaux. Pour cela nous avons,en premier lieu, améliorer le
système de réseau qui assure la connectivité des instances
et le système de stockage car avec l'architecture initiale les instances
n'étaient pas accessibles depuis l'extérieur, de plus notre Cloud
ne pouvait pas être exploité que depuis notre machine physique, ce
qui n'est plus le cas maintenant : notre Cloud est maintenant accessible
depuis l'extérieur.
Afin d'assurer la meilleure scalabilité du
système, la fiabilité des données, la
sécurité d'accès aux Cloud et la prise en charge des
données souvent modifiés et non structurés nous avons
opté pour le service Swift, afin de permettre grâce à son
architecture plate le stockage de données volumineux,
l'hébergement des sites internet et des Web applications et la libre
consultation du contenu des conteneurs par le grand public grâce à
l'API REST (http). Cependant, puisque Swift ne propose pas des volumes
bootables, il ne permet pas l'exécution des machines virtuelles,
d'où l'importance de le combiner avec le stockage Cinder. En dernier
nous avons implémenter le service de systèmes de fichiers
partagé « Manila » avec le backend
Generic qui propose des fichiers partageables entre les instances
comblant la lacune du stockage en bloc (la non prise en charge de partage de
volume). Concernant le service de réseau nous avons opté pour le
mécanisme de driver Open vSwitch qui propose un port externe (br-ex)
permettant l'accès aux instances de l'extérieur
Après avoir modifier la configuration du réseau
les instances sont désormais accessibles via les protocoles ICMP et TCP.
De plus, suite à l'implémenter les services
« Swift » « Manila » en plus de
« Cinder », l'utilisateur a donc la possibilité
d'accéder au Cloud et utiliser les différents types de
stockage : des volumes pour les attacher aux machines virtuelles, des
partages montés sur des machine virtuelles pour créer des
fichiers facilement consultables par d'autres instances (machines virtuelles)et
des conteneurs afin de stocker et consulter ses données.
Perspective
Comme perspectives de ce projet, il serait intéressant
de travailler sur :
- Le développement d'application
web : en utilisant HTML, PHP, CSS et JavaScript, des outils tels
que les plateformes Angular et NodeJs et Django. Ces applications Web vont
être hébergées dans les conteneurs du service Swift afin de
profiter de ses fonctionnalités en termes de puissance,
sécurité, scalabilité et l'haute disponibilité.
- L'intégration du service de stockage d'objet
de Ceph avec Keystone : RADOSGW est le service de stockage
d'objet de Swift, il peut remplacer Swift après son intégration
avec keystone (le service d'identité par défaut d'OpenStack).
- L'intégration du CephFS comme un backend de
Manila : il est intéressant de changer le backend Generic
utilisé dans ce travail pour le remplacer avec CephFS étant
donné qu'OpenStack prend en charge le système de stockage
distribué Ceph.
Bibliographie
|
[1]
|
«Qu'est-ce que la virtualisation ?. Redhat.
https://www.redhat.com/fr/topics/virtualization/what-is-virtualization».
|
|
[2]
|
«Virtualization Technology & Virtual Machine Software :
What is Virtualization? (2021, 14 janvier). VMware.
https://www.vmware.com/fr/solutions/virtualization.html».
|
|
[3]
|
«http://www.yottatech.co.kr/eng/sub/sub.php?code=007001,»
[En ligne].
|
|
[4]
|
«Virtualisation des serveurs
https://www-igm.univ-mlv.fr/~dr/XPOSE2008/virtualisation/definitions.html».
|
|
[5]
|
«Cours cloud & virtualisation , Soumia zertal ,
université Larbi Ben Mhidi
https://www.researchgate.net/publication/338925290_Cours_cloud_virtualisation».
|
|
[6]
|
«Mise en place d'un système de virtualisation des
serveurs dans un réseau informatique avec vsphere server (cas de Sri/uni
lu)
https://www.memoireonline.com/01/20/11542/Mise-en-place-d-un-systeme-de-virtualisation-des-serveurs-dans-un-reseau-informatique-a».
|
|
[7]
|
«https://www.cogitime.fr/le-marche-du-cloud-computing-en-plein-essor-une-opportunite-pour-les-tpe-pme/,»
[En ligne].
|
|
[8]
|
«NIST. (2011, Septembre). «The NIST Definition of Cloud
Computing (Draft)».».
|
|
[9]
|
K. S. R. D. Q. J.SRINIVAS1, «CLOUD COMPUTING BASICS,»
International Journal of Advanced Research in Computer and Communication
Engineering Vol. 1, Issue 5, july July 2012.
|
|
[10]
|
V. K. N. P. Garbacki, «Efficient Resource virtualization and
sharing strategies for heterogeneous Grid environments,» in Proc.
IFIP/IEEE IMSymp, p. pp 40_49, 2007.
|
|
[11]
|
E. A. D. a. M. G. R. Aoun, «Resource provisioning for
enriched services in Cloud environment,» IEEE CloudCom Conf, p.
296_303, 2010.
|
|
[12]
|
http://www.cloud-entreprise.info/historique-cloud-computing/.
|
|
[13]
|
«https://www.salesforce.com/news/stories/the-history-of-salesforce/».
|
|
[14]
|
«Tim, M. (2009, Octobre). «Security and Privacy».
Publier par: O'Reilly Media, édition 1, USA.».
|
|
[15]
|
«A Systematic Review on Cloud Computing - Scientific Figure
on ResearchGate. Available from:
https://www.researchgate.net/figure/Overview-of-Cloud-Computing_fig1_329555455
[accessed 6 Sep, 2021]».
|
|
[16]
|
«Vincent Kherbache and all, Cloud Computing,» IUT
Nancy Charlemagne, 2009/2010.
|
|
[17]
|
M. B. GUELTOUM, «Sécurité des applications
métiers au niveau du Cloud Computing : Contrôle d'accès au
niveau des APIs du Cloud Computing».
|
|
[18]
|
«Amadeus. (2014, Juin). «The Amadeus Data
Centre».».
|
|
[19]
|
«Liliana, F. et al. (2013, Octobre). «Cloud Security:
State of the Art», publier dans: Security, Privacy and Trust in Cloud
Systems, Springer Berlin Heidelberg, 2014. (pp.3-44).».
|
|
[20]
|
M. Jayasurya, «Cloud Computing-Basics,»
International Journal of Engineering Research & Technology (IJERT) ,
2015.
|
|
[21]
|
Rajkumer, B. et al. (2013, Mai). «Mastering Cloud Computing:
Foundations and Applications Programming». Publier par: Morgan Kaufmann..
|
|
[22]
|
«Dan C. Marinescu. (2013, Mai). «Cloud Computing:
Theory and Practice» . Amesterdam: Livre publier par Morgan Kaufmann,
ELsevier.».
|
|
[23]
|
«Wygwam Bureau d'expertise technologique de Aur'elien
Prunier. Le Cloud Computing: Réelle révolution ou simple
évolution ? 2012».
|
|
[24]
|
«Pascal Sauliere, Cloud et sécurité, Microsoft
tech.days, 2011.».
|
|
[25]
|
«site officiel d'OpenStack. http://www.openstack.org».
|
|
[26]
|
M. Armbrust, A. Fox, R. Griffith, et al., A view of Cloud
Computing..
|
|
[27]
|
I. A. N. S. A. R. J. A. M. Guarav Bhatia, «Design and
Implementation of Private Cloud for Higher Education using OpenStack,»
2018.
|
|
[28]
|
M. Sridevi Bonthu, «Building an Object Cloud Storage Service
System using OpenStack Swift,» International Journal of Computer
Applications, 2014.
|
|
[29]
|
R. K. T. Deepak Bajpai, «Comparing Replication Strategies
For Financial Data on Openstack based Private cloud,» chez The seventh
iInternational Conference on Cloud Computing, GRIDs, and virtualization,
Winnipeg Canada, 2016.
|
|
[30]
|
C. G. F. L. Y. C. Weichao Ding, «Construction and
Performance Analysis of Unified Storage Cloud Platform Based on OpenStack with
Ceph RBD,» IEEE International Conference on Cloud Computing and Big
Data Analysis, 2018.
|
|
[31]
|
M. S. R. P. P. V. R. Kulkarni, «A comparative Review on Ceph
and Swift Open Source Cloud Storage Platform,» International
Conference on Global Trends in Signal Processing, Information Computing and
Communication, 2016.
|
|
[32]
|
J. C. LEÓN1, «Advanced features of the CERN OpenStack
Cloud,» EPJ Web of Conferences 214, 07026, p. 3, 2019.
|
|
[33]
|
Red Hat OpenStack Platform, «Storage Guide, Understanding,
using and managing persistent storage in OpenStack,» [En ligne].
|
|
[34]
|
O. khedher, Mastering openstack Design Deploy and manage a
scalable Openstack infrastrucutre.
|
|
[35]
|
Understanding, using, and managing persistent storage in
OpenStack.
|
|
[36]
|
Oak Ridge National Laboratory, Tennessee Technological
University, «Secure storage architectures,» US DEPARTMENT OF ENERGY,
Janvier 2015.
|
|
[37]
|
Red Hat, «Stockage en mode fichier, bloc ou objet ?,»
[En ligne]. Available:
https://www.redhat.com/fr/topics/data-storage/file-block-object-storage.
|
|
[38]
|
A. HERRERA, «Developing a software-defined foundation with
the pillars of block, file, and object storage,» 29 janvier 2012. [En
ligne]. Available: https://www.datacore.com/blog/go-beyond-object-storage/.
[Accès le 24 août 2021].
|
|
[39]
|
Amar Kapadia, Sreedhar Varma, Kris Rajana, Implementing Cloud
Storage with OpenStack Swift, Packt Publishing, May 2014.
|
|
[40]
|
G. L. J. P. John Fruehe, «Scalable & Flexible Storage
Options Help Drive Cloud Adoption on Openstack,» Moor Insights &
Strategy.
|
|
[41]
|
NetApp, Inc, «OpenStack Deployment and Operations
Guide,» NetApp, Inc, September 2017.
|
|
[42]
|
D. L. B. Alves, «Implementation of a Private Cloud,»
univrsity of lisbon, Setembre 2016.
|
|
[43]
|
M. Patrascoiu, «Manila - OpenStack File Sharing
Service,» CERN openlab Summer Student Report, August 2015.
|
|
[44]
|
OpenStack Documentation Team, «Understanding, using, and
managing persistent storage in OpenStack,» [En ligne]. Available:
https://access.redhat.com/documentation/en-us/red_hat_openstack_platform/16.1/html-single/storage_guide/index.
|
|
[45]
|
r, «Storage services: OpenStack Cinder and Swift,» chez
RCSIS USER guide, West Cambridge Data Centre, Research Computing
Services at the University of Cambridge.
|
|
[46]
|
Red Hat, «OpenStack Networking Overview,» [En ligne].
Available: https://access.redhat.com/articles/1146173.
|
Annexe A : Commandes
d'installations et de configurations
Installation d'Openstack Train
sur Centos 7 :
Modifier le fichier etc/environment
vi /etc/environment
LANG=en_US.utf-8
LC_ALL=en_US.utf-8
Vérifier le statut du firewall puis le stopper et le
désactiver
systemctl status firewalld
systemctl stop firewalld
systemctl disable firewalld
Vérifier le statut de NetworkManager puis le stopper et
le désactiver
systemctl status NetworkManager
systemctl stop NetworkManager
systemctl disable NetworkManager
Désactiver puis activer le réseau
systemctl enable network
systemctl start network
Désactiver SELINUX
vi /etc/selinux/config
SELINUX=disabled
Rebooter le système
reboot
installer openstack Train
sudo yum install -y centos-release-openstack-train
Mettre à jour les package
sudo yum update -y
Installer packstack
sudo yum install -y openstack-packstack
En effet depuis la version Stein d'Openstack (avril 2019) si
on ne prise pas le backend openvswitch(OVS), packstack l'installe avec OVN.
Notre version d'Openstack est Train (Octobre 2019) raison pour laquelle nous
avons précisé le backend dans la commande de packstack
suivante :
packstack -allinone--os-neutron-l2-agent=openvswitch
--os-neutron-ml2-mechanism-drivers=openvswitch
--os-neutron-ml2-tenant-network-types=vxlan
--os-neutron-ml2-type-drivers=vxlan,flat -os-manila-instal=y --provision-demo=n
--os-neutron-ovs-bridge-mappings=extnet:br-ex
--os-neutron-ovs-bridge-interfaces=br-ex:eth0
Redémarrer le service de réseau
service network restart
Configuration du service de réseau Neutron
Configurer le fichier ml2_conf.ini
Vi /etc/neutron/plugins/ml2/ml2_conf.ini
[ml2]
type_drivers = flat,vlan,vxlan,gre
mechanism_drivers = ovs
Configurer les scripts suivants
Vi /etc/sysconfig/network-scripts/ifcfg-br-ex:
DEVICE=br-ex
TYPE=OVSBridge
DEVICETYPE=ovs
ONBOOT=yes
NM_CONTROLLED=no
BOOTPROTO=none
Vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
DEVICE=enp0s3
TYPE=OVSPort
DEVICETYPE=ovs
OVS_BRIDGE=br-ex
ONBOOT=yes
NM_CONTROLLED=no
BOOTPROTO=none
Configuration du service de stockage en
objet
Configurer le proxy-server.conf de telle façon à
contenir les informations de sécurité et à prendre en
charge l'hébergement des sites web static
Vi /etc/swift/proxy-server.conf
Configuration du service de systèmes de
fichiers partagés
Installer le plugin de l'interface graphique de Manila dans le
Dashboard avec cette commande :
yum install openstack-manila-ui -y
Redémarrrer le service httpd
Systemctl restart httpd
Redémarrer le service de memcache
Systemctl restart memcached
Configurer le fichier manila.conf de telle façon
à indiquer le protocol et le backend à utiliser :
Vi /etc/manila/manila.conf
Transformer le format d'affichage du conteneur du XML
vers une liste avec lien cliquables
Source les crédentiels
source keystonerc_admin
Créer des ACL de lecture avec cette commande
swift post -r '.r:*,rlistings' nomduconteneur
Créer des métadonnées avec la
requête post :
swift post -m 'web-listings: true' nomduconteneur
Créer le Héader afin de modifier le titre du
lien d'affichage
swift post -H "X-Container-Mea-web-Listings-Label: < List
des objets du conteneur>
Transformer la vue basique de la liste d'objet du conteneur
avec un fichier CSS importé dans le conteneur :
swift post -m 'web-listings-css: nomdufichiercss'
nomduconteneur
Héberger un site internet dans le Conteneur du
service Swift
Importer tous les documents et fichiers lié aux site
internet dans un conteneur via le dashboard
Rendre le conteneur public avec la commande suivante :
swift post -r '.r:*,rlistings' nomduconteneur
utilizer les métadonnées suivantes :
swift post -m 'web-listings: true' nomduconteneur
Indiquer le fichier html du site internet avec la commande
suivante :
swift post -m `web-index:index.html'
Indiquer le fichier css du site avec la commande suivante
swift post -m 'web-listings-css:style.css' nomduconteneur
* 1 Les termes « grid
computing » et « cluster computing » ont été
utilisés de manière presque interchangeable pour décrire
des ordinateurs en réseau qui exécutent des applications
distribuées et partagent des ressources. Ils ont été
utilisés pour décrire un ensemble si diversifié de
solutions informatiques distribuées que leur signification est devenue
ambiguë. Les deux technologies améliorent les performances des
applications en exécutant des calculs parallélisables
simultanément sur différentes machines, et les deux technologies
permettent l'utilisation partagée des ressources distribuées.
* 2 Le CRM ou gestion de la
relation client (Customer Relationship Management) est une stratégie de
gestion des relations et interactions d'une entreprise avec ses clients ou
clients potentiels
* 3Un certificat TLS
(Transport Layer Security), également nommé certificat SSL
(Secure Sockets Layer) est un certificat numérique que l'on associe
à un nom de domaine ou une URL. Il permet d'établir avec
certitude le lien entre le site internet et son propriétaire
(entreprise, marchand ou individu).
* 4LDAP (Lightweight
Directory Access Protocol) est un protocole ouvert et multiplateforme
utilisé pour l'authentification des services d'annuaire. LDAP fournit le
langage de communication utilisé par les applications pour communiquer
avec d'autres serveurs de services d'annuaire
* 5Kerberos est un protocole
d'authentification réseau qui repose sur un mécanisme de
clés secrètes (chiffrement symétrique) et l'utilisation de
tickets, et non de mots de passe en clair, évitant ainsi le risque
d'interception frauduleuse des mots de passe des utilisateurs.
| 

