II.3.2.Partie quantitative de l'enquête
Le questionnaire élaboré au préalable
sur base des informations tirées de diverses littératures a
été amélioré grâce aux interviews
semi-structurées. Par l'approche du questionnaire, les
différentes informations obtenues auprès des dirigeants des IMF
ont pu améliorer et adapter le questionnaire préalablement
établi à notre étude. Le questionnaire soumis aux IMF
comporte 10 questions et les données récoltées sont
traitées à travers un modèle économétrique
et cela par le logiciel SPSS.
II.2.3. Le modèle économétrique
II.2.3.1.
Présentation
Les chercheurs en sciences sociales rencontrent souvent des
situations où la variable dépendante est une variable
catégorielle, plus précisément binaire (ou dichotomique),
c'est-à-dire une variable pour laquelle on associe la valeur
« 1 » à une caractéristique donnée
(par exemple un succès) et la valeur « 0 » à
l'absence de la caractéristique (un échec). Le modèle de
régression linéaire n'est pas approprié pour
étudier ce genre de situations. Les chercheurs doivent faire appel
à d'autres méthodes que la régression linéaire.
Parmi ces méthodes alternatives, la régression logistique est,
de loin, la plus populaire. La méthode de régression logistique
s'applique aussi aux situations où la variable dépendante est une
variable catégorielle comportant plus de deux attributs
(François PETRY, 2003).
Dans le modèle de régression choisi pour notre
étude, la variable expliquée est qualitative. Les variables
qualitatives appelées également variables dichotomiques,
binaires, artificielles, muettes (dummy) ne prennent que deux valeurs à
savoir :
1 pour signifier la présence de
l'attribut ;
0 pour signifier son absence
Dans le cas où on a une variable binaire sur des
variables quantitatives et ou des variables qualitatives, on distingue quatre
sortes de modèles à savoir : le modèle
linéaire de probabilité, le modèle logit, le modèle
probit et le modèle tobit (Ricco RACOTOMALALA, N.D). Pour notre cas,
comme la variable expliquée est binaire ou dichotomiques, une telle
dichotomie nous conduit au modèle logit ou logistique.
II.2.3.2. La régression logistique
La régression logistique se
définie comme étant une technique permettant d'ajuster une
surface de régression à des données lorsque la variable
dépendante est dichotomique. Cette technique est utilisée pour
des études ayant pour but de vérifier si des variables
indépendantes peuvent prédire une variable dépendante
dichotomique (Julie Desjardins, N.D).
Selon (NEJI & Anne-Helène JIGOREL, ND),
la régression logistique est un modèle statistique
permettant d'tudier les relations entre un ensemble de variables qualitatives
Xi et une variable qualitative Y.
Quant à (Ricco Racotomalala, N.D), il s'agit d'une
technique de modélisation qui, dans sa version plus rependue, vise
à prédire et expliquer les valeurs d'une variable
catégorielle binaire Y (variable à prédire, variable
expliquée, variable dépendante, attribut classe, variable
endogène) à partir d'une collection des variables X continues ou
bien binaires (variables prédictives, variables explicatives, variables
indépendantes, descripteurs, variables exogènes).
Spécification du modèle de
diversification des produits
Avec le codage disjonctif complet, notre variable
expliquée dont la diversification des produits prendra la valeur
« 1 » lorsque les IMF ont diversifié leurs produits
et la valeur « 0 » si non.
Le modèle se présentera alors comme
suite :
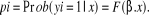
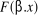 représente la fonction de répartition et représente la fonction de répartition et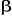 , représente un vecteur des éléments explicatifs
associés au vecteur x. , représente un vecteur des éléments explicatifs
associés au vecteur x.
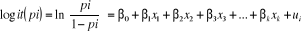 Nous pouvons donc calculer la probabilité pour qu'un
événement ne puisse pas se réaliser, cette
probabilité sera de la forme : Nous pouvons donc calculer la probabilité pour qu'un
événement ne puisse pas se réaliser, cette
probabilité sera de la forme :
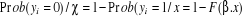
Pour notre modèle, nous aurons la forme suivante :
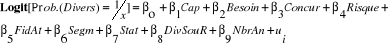
| 

