
REPUBLIQUE DU SENEGAL
ECOLE SUPERIEUREDETECHNOLOGIE ET DE MANAGEMENT DE
DAKAR
DEPARTEMENT INFORMATIQUE
MEMOIRE DE FIN DE CYCLE
Pour l'obtention de la :
Licence Professionnelle Téléinformatique et
Réseaux
THEME
MISE EN PLACE D'UN ENTREPOT
DE DONNEES POUR L'AIDE A LA
DECISION MEDICALE.
Présenté par: Ndioba Syll et
Encadré par : Dr. Fodé Camara
Abdrahmane Aw
Promotion : 2014
Remercîment

A notre encadreur Dr Fodé Camara de par sa
disponibilité, son soutien et surtout ses judicieux conseils, tout au
long de ce mémoire.
Nous voudrons aussi remercier les professeurs et le personnel de
L'ESTM, au
Nous tenons également, à exprimer notre
sincère reconnaissance et notre profonde gratitude à nos
parents.
La réalisation de ce mémoire a été
possible grâce au concours de plusieurs personnes à qui on
voudrait témoigner toute notre reconnaissance.
A l'issue de ce travail, nous remercions, en premier lieu,
ALLAH de nous avoir donné la santé, et le courage de le mener
à terme.
Pr Ibrahima Pierre Ndiaye et tous ceux qui ont
contribués de près ou de loin à la réalisation de
ce mémoire.
Ndioba Syll et Abdrahmane Aw Page2
Avant- Propos

Créée en 2001, l'Ecole Supérieure de
Technologie et de Management de Dakar (ESTM) fait parti de la ligne des
écoles supérieures de formation professionnelle qui ont pour
ambition de former de jeunes cadres africains pour l'excellence dans le domaine
des technologies et la gestion à travers l'informatique et le
management.
Avec un corps professoral des experts de la place dans les
domaines cités, l'ESTM est dans une posture de se démarquer de
ses concurrents directs et indirects pour relever les défit du nouveau
millénaire.
La fin d'une formation est toujours validée par la
soutenance d'un mémoire de fin de cycle. Ainsi, chaque étudiant
devient apte à recevoir un diplôme reconnu par le ministère
de l'enseignement supérieur et par le conseil africain et malgache pour
l'enseignement supérieur(CAMES).
Ndioba Syll et Abdrahmane Aw Page3
Ndioba Syll et Abdrahmane Aw Page4
Résumé
La Business Intelligence (BI) se définit comme
l'ensemble des technologies permettant de traiter, valoriser et
présenter les données à des fins de compréhension
et de décision; elle s'appuie sur un système d'information
spécifique appelé Système d'Information Décisionnel
(SID).
En effet la mise en place de Systèmes d'Information
Décisionnels (SID) dédiés au pilotage de la performance
facilite la prise de décision et l'alignement stratégique des
organisations en recherche d'efficacité et d'efficience. Ces
systèmes assurent la restitution d'informations fiables, précises
et pertinentes au moyen d'indicateurs structurés en tableaux de bord.
Ils s'appuient sur les méthodes du contrôle de gestion et du
pilotage de la performance.
Ils trouvent également une application dans le domaine
de la Gouvernance des Systèmes d'Information où leurs
fonctionnalités sont étendues à la mesure et au pilotage
de la qualité. C'est en combinant des approches fonctionnelles bien
établies, telles que le contrôle de gestion, la mesure de la
qualité et de la performance, avec des technologies
décisionnelles qui s'appuient sur des portails d'entreprise que les
maîtres d'oeuvre des systèmes décisionnels peuvent apporter
une vraie valeur aux organisations, publiques ou privées. Par opposition
aux systèmes d'informations transactionnels. Les SID comportent
plusieurs composants qui se résumaient autrefois en un entrepôt de
données.
Un entrepôt de données est une collection de
données intégrées et historiées qui sont
utilisées pour la prise de décisions stratégiques au moyen
de techniques de traitement analytiques. La majeure partie des outils existants
pour le développement des entrepôts de données se focalise
sur la structure de stockage des données. L'intérêt est
principalement porté à la définition de modèles
« en étoile » ou « en flocons », d'intégrer
des données provenant de sources hétérogènes.
Par ailleurs, peu d'approches dirigées par les
exigences sont proposées pour la conception des SID. Dans une approche
d'ingénierie des exigences pour les SID, le principal but n'est pas de
savoir « où » les données doivent être
stockées mais « comment » elles devraient être
structurées et « pourquoi » elles sont nécessaires. Le
« pourquoi » n'est souvent pas connu et encore moins rattaché
au « quoi ». Pourtant la prise en compte du « pourquoi »
permettrait de justifier le choix des informations opérationnelles
`justes nécessaires, modélisées et utilisées pour
l'aide à la décision.
Ndioba Syll et Abdrahmane Aw Page5
Summary
Business Intelligence (BI) is defined as the set of
technologies for treatment, recovery and present data for purposes of
understanding and decision; it relies on a specific information system called
Intelligence Information System (IIS). Indeed the establishment of Decisional
Information Systems (DIS) dedicated to performance management facilitates
decision-making and strategic alignment of businesses for efficiency and
effectiveness.
These systems provide accurate and relevant through structured
indicators in dashboards restitution of reliable information. They rely on
methods of management control and performance management. They also find
application in the field of Governance Information Systems where their
capabilities are extended to measuring and monitoring quality. By combining
well-established functional approaches, such as controlling, measuring the
quality and performance with decision technologies that rely on enterprise
portals that contractors systems decision can bring real value to
organizations, public or private it gives managers visibility into their
business performance to improve the ability of the latter to react more quickly
than its competitors respond to new opportunities or risks market.
As opposed to transactional information systems, DISs have
several components that summarized previously in a data warehouse. A data
warehouse is a collection of integrated, historical data that are used to make
strategic decisions using techniques of analytical treatment. The majority of
existing tools for developing data warehouse focuses on data storage structure.
The interest is focused on the definition of models "star" or "fluff" to
integrate data from heterogeneous sources.
Furthermore, few approaches led by the requirements are
proposed for the design of DIS. In an approach to requirements engineering for
the DIS, the main goal is not to know "where" the data must be stored, but
"how" they should be structured and "why" they are needed. The "why" is often
not known and even less attached to the "what." However, taking into account
the "why" would justify the choice of operational information 'just needed'
modeled and used for decision support.
Ndioba Syll et Abdrahmane Aw Page6
Table de Matières
Remerciement 2
Avant- Propos 3
Résumé 4
Summary 5
Table de Matières 6
Introduction 9
I. Les entrepôts de données pour l'aide à la
décision 9
II. Problématique et objectif du mémoire 11
2.1. Conception d'un système pour le décisionnel
12
2.2. Gestion de l'évolution des entrepôts 12
2.3. Difficulté à spécifier et formaliser
les exigences décisionnelles 12
2.4. Objectif du mémoire 13
Chapitre I : Etat de l'art sur les systèmes
décisionnels 14
1. Entrepôts de données multidimensionnelles et
aspects temporels 14
1.1. Entrepôts de données 14
1.2. Architecture d'un entrepôt de données 14
1.3. Différence entre Entrepôts et les bases de
données 15
1.4. Modélisation multidimensionnelle 16
1.4.1. Niveaux Conceptuels 17
1.4.1.1. Tables de faits 17
1.4.1.2. Tables de Dimensions 18
1.4.1.3. Hiérarchie 18
1.4.1.4. Granularité 19
Ndioba Syll et Abdrahmane Aw Page7
1.4.2. Niveaux Logiques 20
1.4.2.1. Schéma en étoile 20
1.4.2.2. Schéma en flocon de neige 21
1.4.2.3. Schéma en Constellation 22
1.5. Serveurs OLAP (On-Line Analytical Processing) 23
1.5.1. ROLAP (Relational OLAP) 24
1.5.2. MOLAP (Multidimensional OLAP) 24
1.5.3. HOLAP (Hybrid OLAP) 25
Chapitre II : Conception et mise en place de notre entrepôt
de données 26
2.1. Le cycle de développement 26
2.2. Choix du modèle multidimensionnel 27
2.3. Processus ETL 28
2.3.1. Définition d'un outil ETL 28
2.3.2. La phase d'alimentation 29
2.4. Etude de quelques solutions décisionnelles 29
2.4.1. Spago BI 30
2.4.2. Pentaho 30
2.4.3. Birt 31
2.4.4. Talend Master Management (TMDM) 31
2.4.5. Le serveur Mondrian 32
2.4.6. JPivot 32
2.5. Choix de la solution 32
2.5.1. Présentation de Pentaho 32
2.5.2 Prise en main de Pentaho 35
Ndioba Syll et Abdrahmane Aw Page8
Chapitre lll: Implémentation 37
3.1. Intégration des données avec Pentaho Data
Integration 37
3.2. Alimentation Datamart 44
3.3. Création de rapport avec Pentaho Report Designer
51
3.4. Analyse des données avec la plateforme BI Lite
cube 55
Conclusion 58
ANNEXE 59
Liste des Figures 59
Biographie 61
Ndioba Syll et Abdrahmane Aw Page9
Introduction
Au moment où les technologies se développent, la
concurrence internationale accrue, les méthodes de communication de plus
en plus perfectionnées, les besoins sociaux de plus en plus nombreux,
les structures des entreprises, les hommes (mentalités) doivent
être capables de s'adapter aux changements. Une nouvelle approche est
nécessaire : l'analyse systémique.
Dans les systèmes d'information modernes depuis
quelques années, un troisième objectif a été
défini : il s'agit de produire une information de connaissance, une
information intelligente (qui n'était pas stockée au paravent
mais qui est le produit du brassage, du croisement de plusieurs informations
d'origines diverses) qui permet la prise de décision, on parle alors du
système d'information décisionnel ou analytique. Ainsi les
entrepôts de données intègrent les informations en
provenance de différentes sources, souvent réparties et
hétérogènes et qui ont pour objectif de fournir une vue
globale de l'information aux analystes et aux décideurs. Ces
applications d'aide à la décision sont de type OLAP (On-line
Analytical Processing ou Analyse en ligne). La construction et la mise en
oeuvre d'un entrepôt de données représentent une
tâche complexe qui se compose de plusieurs étapes. La
première consiste à l'analyse des sources de données et
à l'identification des besoins des utilisateurs. La deuxième
correspond à l'organisation des données à
l'intérieur de l'entrepôt. Finalement, la troisième
consiste à établir divers outils d'interrogation (d'analyse, de
fouille de données ou d'interrogation). Chaque étape
présente des problématiques spécifiques. Ainsi, par
exemple, lors de la première étape, la difficulté
principale consiste en l'intégration des données, de
manière à qu'elles soient de qualité pour leur stockage.
Pour l'organisation, ils existent plusieurs problèmes comme : la
sélection des vues à matérialiser, le
rafraîchissement de l'entrepôt, la gestion de l'ensemble de
données (courantes et historiées), entre autres. En ce qui
concerne le processus d'interrogation, nous avons besoin des outils performants
et conviviaux pour l'accès et l'analyse de l'information.
Notre travail se focalise principalement sur les deux
dernières étapes, ainsi, pour le processus d'organisation, nous
proposons la définition d'un modèle multidimensionnel.
I. Les entrepôts de données pour l'aide
à la décision
L'entrepôt de données, ou le DataWarehouse, est
une collection de données orientées sujet,
intégrées, non volatiles et historiées, organisées
pour le support d'un processus d'aide à la décision. Il
centralise toutes les données de l'entreprise. Il est structuré
pour contenir une
Ndioba Syll et Abdrahmane Aw Page10
volumétrie importante de données, les volumes de
données à collecter étant de plus en plus
conséquents et ne cessant d'augmenter. Ces données sont issues de
sources hétérogènes. Elles peuvent être internes,
bases de données, fichiers, services Web, etc, externes (clients,
fournisseurs, etc.) ou encore non informatisées (lettres, notes de
service, compte-rendu de réunions, etc.).
Nous détaillons ces caractéristiques :
Orientées sujet : Les données des
entrepôts sont organisées par sujet plutôt que par
application. Par exemple, une chaine de magasins d'alimentation organise les
données de son entrepôt par rapport aux ventes qui ont
été réalisées par produit et par magasin, au cours
d'un certain temps.
Intégrées : Les données provenant des
différentes sources doivent être intégrées, avant
leur stockage dans l'entrepôt de données. L'intégration
(mise en correspondance des formats).
Non volatiles : A la différence des données
opérationnelles, celles de l'entrepôt sont permanentes et ne
peuvent pas être modifiées. Le rafraichissement de
l'entrepôt, consiste à ajouter de nouvelles données, sans
modifier ou perdre celles qui existent.
Historiées: La prise en compte de l'évolution
des données est essentielle pour la prise de décision qui,
utilise des techniques de prédiction en s'appuyant sur les
évolutions passées pour prévoir les évolutions
futures.
La construction d'un entrepôt revient à faire
correspondre les besoins des utilisateurs avec la réalité des
informations disponibles. Nous devons d'abord identifier et analyser les
sources de données, ce qui nous permet de proposer les mécanismes
adaptés selon les caractéristiques des informations. Ensuite,
nous devons organiser l'ensemble de données à l'intérieur
de l'entrepôt. Pour cela, nous devons d'abord structurer ces informations
en considérant leur granularité. Ceci nous permet d'aboutir
à la conception d'un schéma multidimensionnel qui permet de
répondre aux besoins des utilisateurs
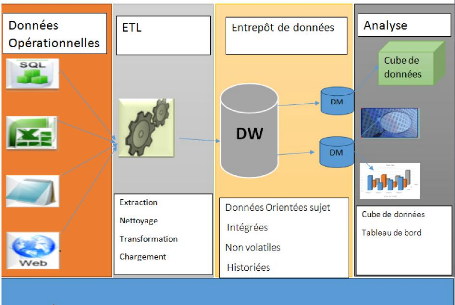
Ndioba Syll et Abdrahmane Aw Page11
Figure 1 : Architecture générale d'un
système décisionnel
II. Problématique et objectif du
mémoire
Les entrepôts de données ont été
conçus pour l'aide à la décision. Ils intègrent les
informations en provenance des différents systèmes
transactionnels de l'entreprise. L'ensemble des données, y compris leur
historique, est utilisé pour faire des calculs prévisionnels, des
statistiques ou pour établir des stratégies de
développement et d'analyses des tendances.
Dans ce mémoire, nous nous proposons d'adapter notre
savoir-faire au problème de la gestion de données
médicales qui constituent un cadre applicatif particulièrement
intéressant. En effet, ces données se trouvent reparties dans une
source qu'il faudra, dans un premier temps, fédérer pour
constituer un entrepôt de données pertinentes pour l'application
visée. Cette étape est importante car elle doit non seulement
identifier la source, mais aussi déterminer comment extraire de celle-ci
les données désirées. En plus, nous devons établir
un mécanisme pour la gestion de l'évolution. Dans ce cas, il
faudra déterminer l'adaptation au niveau : de l'application
d'extraction, des agrégats.
Ndioba Syll et Abdrahmane Aw Page12
En fin, comme tous les autres systèmes, un
système informatique décisionnel (SID) n'est de qualité
que s'il répond aux exigences de la communauté des usagers. Cela
entraine que sa conception n'est pas uniquement dirigée par les
données disponibles dans les SI opérationnels.
2.1. Conception d'un système pour le
décisionnel
La conception d'un entrepôt de données est une
tâche complexe et délicate. Nous trouvons une méthodologie
descendante pour la conception d'un entrepôt.
L'identification des tables de faits et leurs niveaux de
granularités :
Remplacer des valeurs anciennes par des nouvelles dans
l'enregistrement de la dimension, néanmoins, nous perdons la
possibilité de suivre les événements passés.
L'ensemble des mesures :
Créer de nouveaux enregistrements de dimension lors du
changement qui contiennent les nouvelles valeurs de l'attribut. Ceci
équivaut à segmenter l'historique selon l'ancienne et la nouvelle
description.
Créer de nouveaux champs à l'intérieur de
l'enregistrement d'origine de la dimension, tout en conservant en même
temps les premières valeurs enregistrées.
2.2. Gestion de l'évolution des entrepôts
Le problème d'évolution d'un schéma a des
conséquences sur l'application chargée de l'extraction et
l'intégration de données des sources, car elle peut devenir
incomplète ou incohérente vis-à-vis du nouveau
schéma de l'entrepôt. Cette évolution entraine aussi
l'adaptation des agrégats pré-calculés et l'adaptation du
processus de maintenance.
2.3. Difficulté à spécifier et
formaliser les exigences décisionnelles
Il s'avère difficile de spécifier les exigences
décisionnelles. La problématique des exigences exprimées
par les décideurs est qu'elles sont initialement vagues et
incomplètes. Ces exigences sont de niveau stratégique. Elles ne
sont souvent pas claires dans les esprits des
Ndioba Syll et Abdrahmane Aw Page13
décideurs et nécessitent d'être
complétées tout en restant cohérentes quelques soit les
visions ou rôles des décideurs qui les ont formulées. Par
ailleurs, un projet décisionnel implique, également, les
données extraites à partir du SI opérationnel et charge
dans le système celles qui permettent aux décideurs de disposer
des informations nécessaires afin de les aider dans leurs prises de
décision.
2.4. Objectif du mémoire
L'objectif ainsi que le contenu de ce mémoire vise
à expliquer et montrer les apports fonctionnels et techniques de
l'informatique décisionnelle, plus communément connue sous le nom
de business intelligence, aux décideurs pour une meilleure
visibilité des informations et une qualité de service accrue. En
ce sens l'apport de cette nouvelle technologie permettra aux dirigeants
(médecins) de réagir rapidement et efficacement dans le processus
stratégique de prise de décision et de prouver :
Pourquoi construit-t-on un système décisionnel ?
Comment construit-on un système décisionnel ? Nous allons
articuler notre étude au tour de ces points : Le nombre de personnes
atteintes de paludisme par :
? Tranches d'Age
? Sexe
? Lieux (Village, Poste de santé, District) ? Temps
(jours, mois, trimestres, années)
La définition d'un Meta modèle multidimensionnel
qui se compose de trois classes :Cube, Dimension et Hiérarchie.
Ndioba Syll et Abdrahmane Aw Page14
Chapitre I : Etat de l'art sur les systèmes
décisionnels
1. Entrepôts de données
multidimensionnelles et aspects temporels
Les entrepôts de données sont apparus vers les
années 1990 en réponse à la nécessité de
rassembler toutes les informations de l'entreprise en une base de
données unique destinée aux analystes et aux gestionnaires.
L'ensemble des données, y compris leur historique, est utilisé
dans de nombreux domaines, tels que : l'analyse de données et l'aide
à la décision (gestion et analyse de marche, gestion et analyse
du risque, gestion et détection des fraudes,...) ; dans d'autres
applications (recherches dans des textes, dans les documents web, dans
l'astronomie,...).
Dans ce chapitre, nous analysons aussi bien les
caractéristiques des entrepôts que leurs aspects temporels.
1.1. Entrepôts de données
La prise de décision suppose trois
éléments. De ce fait pour prendre une décision il faut :
avoir des objectifs (savoir ce que l'on veut faire), disposer d'informations
suffisantes par rapport à ces objectifs (savoir où l'on en est),
rapprocher ces informations des objectifs pour prendre une décision qui
va entraîner une action (savoir quoi faire).
Il faut donc définir des objectifs qui, pour être
atteints, vont nécessiter des actions appropriées. Pour pouvoir
définir ces objectifs et mesurer l'effet des actions, il faut disposer
d'informations.
C'est là qu'interviennent les systèmes
d'informations décisionnels. Nous présentons d'abord
l'architecture d'un système décisionnel qui se compose de trois
composants : les sources, l'entrepôt et les outils pour l'interrogation
de l'ensemble de données. Nous décrivons aussi les
caractéristiques des entrepôts et les bases de données.
1.2. Architecture d'un entrepôt de données
L'architecture des entrepôts de données repose
souvent sur un Système de Gestion de Base de Données (SGBD)
séparé du système de production de l'entreprise qui
contient les données de l'entrepôt. Le processus d'extraction des
données permet d'alimenter périodiquement ce
Ndioba Syll et Abdrahmane Aw Page15
SGBD. Néanmoins avant d'exécuter ce processus,
une phase de transformation est appliquée aux données
opérationnelles. Celle-ci consiste à les préparer (mise en
correspondance des formats de données), les nettoyer, les filtrer,...,
pour finalement aboutir à leur stockage dans l'entrepôt.
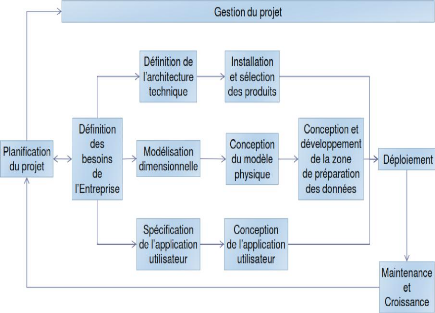
Figure 2 : Méthodologie pour un projet
BI
1.3. Différence entre Entrepôts et les bases
de données
Dans l'environnement des entrepôts de données,
les opérations, l'organisation des données, les critères
de performance, la gestion des métadonnées, la gestion des
transactions et le processus de requetés sont très
différents des systèmes de bases de données
opérationnels. Par conséquent, les SGBD relationnels
orientés vers l'environnement opérationnel, ne peuvent pas
être directement transplantés dans un système
d'entrepôt de données.
Les SGBD ont été créés pour les
applications de gestion de systèmes transactionnels.
Par contre, les entrepôts de données ont
été conçus pour l'aide à la prise de
décision. Ils intègrent les informations qui ont pour objectif de
fournir une vue globale de l'information aux analystes et aux
décideurs.
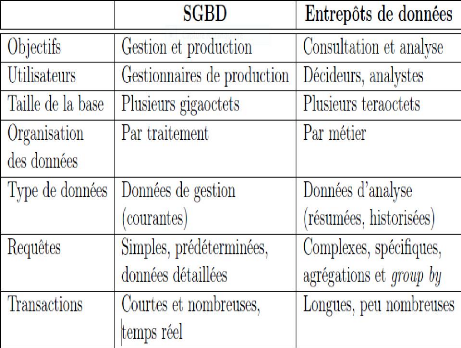
Le tableau1 : différences entre entrepôts et
les bases de données
1.4. Modélisation multidimensionnelle
La modélisation multidimensionnelle consiste à
considérer un sujet d'analyse comme un point dans un espace à
plusieurs dimensions. Les données sont organisées de
manière à mettre en évidence le sujet (le fait) et les
différentes perspectives de l'analyse(les dimensions).
Ndioba Syll et Abdrahmane Aw Page16
Ndioba Syll et Abdrahmane Aw Page17
1.4.1. Niveaux Conceptuels
Un Data Warehouse (DW) est basé sur une
modélisation multidimensionnelle qui représente les
données dans un cube.
Un cube permet de voir les données suivant plusieurs
dimensions.
1.4.1.1. Table de faits
Une table de faits représente l'objet de l'analyse.
Elle contient principalement des mesures sous forme d'attributs
représentant les éléments d'analyse. Les faits les plus
utilisables sont les numériques, les valeurs continues et additives. Une
mesure est un élément de donnée sur lequel porte les
analyses, en fonction des différentes dimensions. Ces valeurs sont le
résultat d'opérations d'agrégation sur les
données.
Exemple : Coût des travaux, Nombre
d'accidents...
Les mesures peuvent être par exemple, nombres de
personnes atteintes, nombres de villes touchées qui sont
résumées ou représentées par une moyenne. Ces
mesures sont reliées chacune à une table de dimension avec des
clés étrangères.
La granularité des tables de faits est une
caractéristique importante expliquée par le niveau de
détail des mesures représentées.

Figure 3 : Représentation d'une table de
Fait
NB : La table de fait contient les valeurs des mesures et les
clés vers les tables de dimensions.
Ndioba Syll et Abdrahmane Aw Page18
1.4.1.2. Table de Dimensions
Une table de dimension est un objet qui inclut un ensemble
d'attributs permettant à l'utilisateur d'avoir des mesures suivant
différentes perspectives d'analyse. Les attributs sont des indicateurs
pour les différentes vues d'analyses possibles. Par exemple, les ventes
de produits médicaux peuvent être analysées suivant
différentes régions d'un pays, suivant des catégories de
produits ou suivant la combinaison de plusieurs de ces dimensions. Ces
dimensions sont connectées à la table de faits par des
clés étrangères. Les attributs (tels que ville, pays)
d'une table de dimension sont appelés des attributs de dimensions. Les
attributs d'une dimension peuvent former entre eux une hiérarchie
(ville/région/pays) permettant à l'utilisateur de voir les
données détaillées ou résumées suivant
l'attribut en question. Une dimension peut avoir aussi des attributs
descriptifs qui ne sont pas utilisés pour l'analyse tels que le
numéro de téléphone, le nom d'un client, l'adresse d'un
client. Les attributs descriptifs sont orthogonaux aux attributs dimensions et
ils les complètent.

Figure 4 : Représentation d'une table de dimension
patient
1.4.1.3. Hiérarchie
Il est important d'avoir des hiérarchies bien
définies dans un SID. L'importance provient du fait que la prise de
décision commence par des vues générales puis les
informations se détaillent de plus en plus. En plus, si des outils OLAP
sont utilisés pour l'analyse des
données, il est ainsi possible de réaliser des
agrégations automatiques des données en s'appuyant sur les
hiérarchies définies.
Exemple
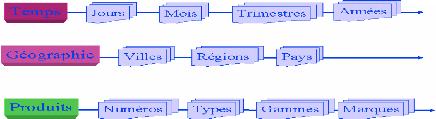
Dimension temporelle : jour, mois, semestre, année
Dimension géographique : agence, ville,
département, région, pays
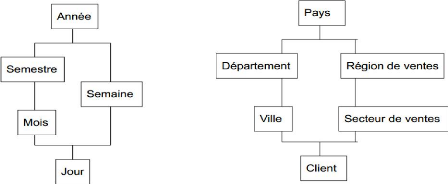
Figure 5 : Représentation des hiérarchies
dans une dimension
1.4.1.4. Granularité
La granularité est le niveau de détail des
données dans un entrepôt de données. La granularité
détermine le volume des données ainsi que le type des
requêtes que l'utilisateur peut poser.
Pour arriver à construire un modèle approprie pour
un entrepôt de données, nous pouvons choisir, soit un
schéma multidimensionnel (cube), soit un schéma relationnel (le
schéma en étoile, en flocon de neige ou en constellation).
Ndioba Syll et Abdrahmane Aw Page19
Ndioba Syll et Abdrahmane Aw Page20
Figure 6 : Représentation de la granularité
de temps de lieu et produit
1.4.2. Niveaux Logiques
Dans les schémas relationnels ou Niveaux Logiques nous
trouvons deux types de schémas. Les premiers sont des schémas qui
répondent fort bien aux processus de type OLTP qui ont été
décrits précédemment, alors que les deuxièmes, que
nous appelons des schémas pour le décisionnel, ont pour but de
proposer des schémas adaptés pour des applications de type
OLAP.
Nous décrivons les déférents types des
schémas relationnels pour le décisionnel.
1.4.2.1. Schéma en étoile
Il se compose du fait central et de leurs dimensions. Dans ce
schéma il existe une relation pour les faits et plusieurs pour les
déférentes dimensions autour de la relation centrale. La relation
de faits contient les déférentes mesures et une clé
étrangère pour faire référence à chacune de
leurs dimensions.
Avantage:
? Facilité de navigation
? Nombre de jointures limité
Inconvénients :
? Redondance dans les dimensions
? Toutes les dimensions ne concernent pas les mesures
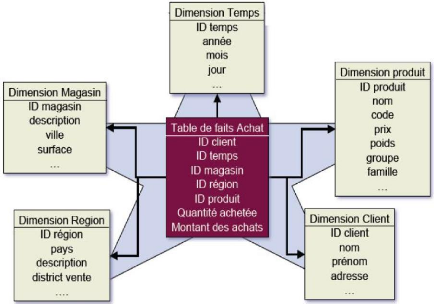
Ndioba Syll et Abdrahmane Aw Page21
Figure 7 : Modélisation en
étoile
1.4.2.2. Le schéma en flocon de neige
(Snowflake)
Il dérive du schéma précédent avec
une relation centrale et autour d'elle les déférentes dimensions,
qui sont éclatées ou décomposées en sous
hiérarchies. L'avantage du schéma en flocon de neige est de
formaliser une hiérarchie au sein d'une dimension, ce qui peut faciliter
l'analyse. Un autre avantage est représenté par la normalisation
des dimensions, car nous réduisons leur taille. Cependant, ce type de
schéma augmente le nombre de jointures à réaliser dans
l'exécution d'une requête réduisant ainsi la navigation.
Ndioba Syll et Abdrahmane Aw Page22
Figure 8 : Modélisation en flocon.
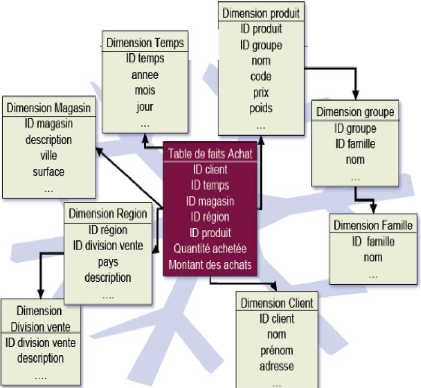
1.4.2.3. Le schéma en constellation
Le schéma en constellation représente plusieurs
relations de faits qui partagent des dimensions communes. Ces
déférentes relations de faits composent une famille qui partage
les dimensions mais où chaque relation de faits a ses propres
dimensions.
Ndioba Syll et Abdrahmane Aw Page23
Figure 9 : Modélisation en
constellation
1.5. ServeursOLAP (On-Line Analytical Processing)
Les données opérationnelles constituent la
source principale d'un système d'information décisionnel. Les
systèmes décisionnels complets reposent sur la technologie OLAP,
conçue pour répondre aux besoins d'analyse des applications de
gestion.
L'acronyme FASMI (FastAnalysis of Shared Multidimensional
Information) permet de résumer la définition des produits OLAP.
Cette définition fut utilisée pour la première fois en
1995 et depuis aucune autre définition n'est plus proche pour
résumer le terme OLAP.
Fast : Le temps de réponse aux demandes des
utilisateurs oscille entre 1 et 20 secondes. Les constructeurs utilisent des
pré-calculs pour réduire les durées des requêtes.
Analysis : Le système doit pouvoir faire face à
toutes les logiques d'affaires et de statistiques, ainsi que fournir la
possibilité aux utilisateurs de construire leurs calculs et leurs
analyses sans avoir à programmer. Pour cela, il y a des outils qui
seront fournis par le constructeur.
Ndioba Syll et Abdrahmane Aw Page24
Shared : Le système doit créer un contexte
où la confidentialité est préservée et doit
gérer les cas où plusieurs utilisateurs ont des droits en
écritures. Ce point constitue la plus grosse faiblesse des produits
actuels.
Multidimensional : C'est la caractéristique clé.
Le système doit fournir des vues conceptuelles multidimensionnelles des
données. Il doit supporter aussi les hiérarchies.
Informations : L'ensemble des données et les
informations nécessaires pour un produit OLAP.
Nous exposons dans la suite les divers types de stockage des
informations dans les systèmes décisionnels.
1.5.1. ROLAP (Relational OLAP)
Dans les systèmes relationnels OLAP, l'entrepôt
de données utilise une base de données relationnelle. Le moteur
ROLAP traduit dynamiquement le modèle logique de données
multidimensionnel M en modèle de stockage relationnel R (la plupart des
outils requièrent que la donnée soit structurée en
utilisant un schéma en étoile ou un schéma en flocon de
neige).
La technologie ROLAP a deux avantages principaux : elle permet
la définition de données complexes et multidimensionnelles en
utilisant un modèle relativement simple. Elle réduit le nombre de
jointures à réaliser dans l'exécution d'une
requête.
Le désavantage est que le langage de requêtes tel
qu'il existe, n'est pas assez puisant ou n'est pas assez flexible pour
supporter de vraies capacités d'OLAP.
1.5.2. MOLAP (Multidimensional OLAP)
Les systèmes multidimensionnels OLAP utilisent une base
de données multidimensionnelle pour stocker les données de
l'entrepôt et les applications analytiques sont construites directement
sur elle. Dans cette architecture, le système de base de données
multidimensionnel sert tant au niveau de stockage qu'au niveau de gestions
données. Les données des sources sont conformes au modèle
multidimensionnel dans toutes les dimensions, les différentes
agrégations sont pré-calculées pour des raisons de
performance.
Les avantages des systèmes MOLAP sont basés sur
les désavantages des systèmes ROLAP et elles représentent
la raison de leur création. D'un côté, les requêtes
MOLAP sont très
Ndioba Syll et Abdrahmane Aw Page25
puissantes et flexible en termes du processus OLAP, tandis que,
d'un autre côté, le modèle physique correspond plus
étroitement au modèle multidimensionnel.
Néanmoins, il existe des désavantages au
modèle physique MOLAP. Le lus important, à notre avis, c'est
qu'il n'existe pas de standard du modèle physique.
1.5.3. HOLAP (Hybrid OLAP)
Un système HOLAP est un système qui supporte et
intègre un stockage des données multidimensionnel et relationnel
d'une manière équivalente pour profiter des
caractéristiques de correspondance et des techniques d'optimisation.
Ci-dessous, nous traitons une liste des caractéristiques
principales qu'un système HOLAP doit fournir :
La transparence du système : Pour la localisation et
l'accès aux données, sans connaître si elles sont
stockées dans un SGBD relationnel ou dimensionnel. Pour la transparence
de la fragmentation,...
? Un modèle de données général et un
schéma multidimensionnel global :
Pour aboutir à la transparence du premier point, tant le
modèle de données général que le langage de
requête uniforme doivent être fournis. Etant donné qu'il
n'existe pas un modèle standard, cette condition est difficile à
réaliser.
? Une allocation optimale dans le système de stockage :
Le système HOLAP doit bénéficier des
stratégies d'allocation qui existent dans les systèmes
distribués tels que : le profil de requêtes, le temps
d'accès, l'équilibrage de chargement,...
? Une réallocation automatique :
Toutes les caractéristiques traitées ci-dessus
changent dans le temps. Ces changements peuvent provoquer la
réorganisation de la distribution des données dans le
système de stockage multidimensionnel et relationnel, pour assurer des
performances optimales.
Actuellement, la plupart des systèmes commerciaux
utilisent une approche hybride.
Cette approche permet de manipuler des informations de
l'entrepôt de données avec un moteur ROLAP, tandis que pour la
gestion des datamarts, ils utilisent l'approche multidimensionnelle.
Ndioba Syll et Abdrahmane Aw Page26
Chapitre II : Conception et mise en place de notre
entrepôt de données
2.1. Le cycle de développement
La conduite d'un projet informatique, tel que le
développement d'un système d'information, fait appel à des
méthodes formalisées dont les principales sont : Les
méthodes séquentielles dites en cascade et les méthodes
itératives (évolutive, objet).
Depuis des décennies, les projets sont
gérés avec une approche classique, le plus fréquemment
« en cascade » ou son adaptation « en V », basée sur
des activités séquentielles : on recueille les besoins, on
définit le produit, puis on le développe, ensuite on le test
avant de le livrer au client.
Vu que les besoins évoluent en permanence pour
répondre aux changements du marché, ces approches
prédictives se sont révélées trop « rigides
»parfois, sont alors apparues, dans les années 1990, des
méthodes moins prédictives ; ce sont les méthodes dites
« agiles».
Après une étude exploratoire des méthodes
de conduite de projet et pour répondre aux objectifs fixés en
début, le cycle de développement en « V » s'est
révélé le plus approprié pour ce travail.
Le model en « V » a été imaginé
suite au problème de réactivité du model en cascade. Il
permet en cas d'anomalie de limiter le retour aux étapes
précédentes.
Les phases de la partie montantes doivent renvoyer de
l'information sur les phases en vis -à-vis lorsque des défauts
afin d'améliorer le logiciel.
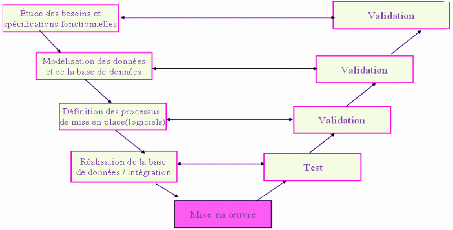
Ndioba Syll et Abdrahmane Aw Page27
Figure 10 : Processus de développement du projet
tiré du modèle en « V »
2.2. Choix du modèle multidimensionnel
Notre choix c'est porté sur le modèle en flacon
de neige car simple à alimenter, celui-ci permet une bonne
lisibilité et une bonne performance des requêtes. Il sera
constitué de tables de dimensions, et d'une table de fait. La table de
fait contiendra des données normalement numériques, puisque
d'ordre quantitatif.
Il s'agira des clés primaires de chaque table de
dimension et des mesures (nombre de personne infecté qui sera
analysé en fonction de chaque dimension). En effet les dimensions
citées précédemment nous serviront d'axes d'analyses pour
les faits enregistrés.
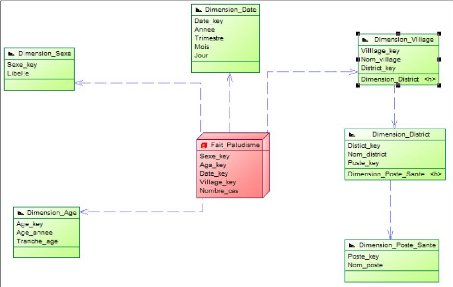
Ndioba Syll et Abdrahmane Aw Page28
Figure 11 : Représentation du modèle en
flacon de neige « pour l'indicateur Paludisme »
2.3. Processus ETL
L'intégration des données est une étape
clé dans la mise en oeuvre de ce projet. En effet, l'objectif de cette
partie est de mener une réflexion sur des solutions et outils afin
alimenter les tables de la base de données. Parmi ces outils, on notera
les ETL (Extract, Transform, Load).
2.3.1. Définition d'un outil ETL
Un ETL est une boite à outil (pro-logiciel) qui permet
ainsi l'Extraction, la Transformation et le chargement (Load) de données
depuis des sources diverses(bases de données, fichiers ,...) vers des
cibles préalablement définies. Les ETL sont communément
utilisés dans l'informatique décisionnelle afin de permettre
l'alimentation des datawarehouses (entrepôts de données).
De nombreux systèmes de gestion de bases de
données sont supportés nativement en lecture/écriture
(Oracle, MSQL Server, DB2, MYSQL,...).De nombreux types de fichiers peuvent
également être lus ou écrits: Csv, Excel, Txt, XML, ...
Ndioba Syll et Abdrahmane Aw Page29
Notons que la plupart des ETL disposent d'une interface graphique
permettant l'élaboration des différents scénarios
d'intégration.
Le travail des développeurs en est ainsi grandement
facilité, tant au niveau de la conception que de la maintenance des
traitements de données.
2.3.2. La phase d'alimentation
Elle se compose des zones de sources de données et
d'extraction, de transformation et de chargement des données.
? La zone des sources de données :
L'entrepôt de données est composé de
différentes tables qu'il va falloir remplir avec des données
provenant souvent de sources diverses et hétérogènes.
C'est ainsi que dans une organisation ou entreprise, les
informations peuvent être stockées sous différentes formes
: soit dans une base de données, dans un fichier, dans un tableau,
etc.
Il existe donc plusieurs sources de données pour alimenter
un entrepôt de données. Les sources de données peuvent
être constituées des différentes bases de données
(MYSQL, Oracle, Access ...), des fichiers Excel, des fichiers textes, pages
web, etc.
? La zone d'extraction, de transformation et de chargement des
données (ETL ou Extract Transform and Load)
Pour alimenter l'entrepôt de données, on utilise
un ETL. Cet outil peut être conçu manuellement. Il peut aussi
s'agir de logiciels propriétaires ou open source (code source ouvert et
sans licence) conçus spécialement à cet effet.
Il extrait les données à partir de leur source,
procède aux transformations nécessaires et effectue le chargement
de celles-ci dans l'entrepôt de données. Ainsi il permet de
manière cohérente d'agréger, de classifier, de normaliser,
de qualifier, de nettoyer et de consolider les données extraites.
2.4. Etude de quelques solutions
décisionnelles
Avant de s'orienter vers la création de solutions
décisionnelles complètes, les projets open source se
concentraient chacun sur un point bien précis du décisionnel.
Ndioba Syll et Abdrahmane Aw Page30
Ainsi, les projets BIRT ou Jasper Reports permettent de
composer et générer des rapports, et les projets Mondrian et
JPivot permettent de présenter des données sous forme
multidimensionnelle. Ces projets étaient et sont encore destinés
à être intégrés en tant que « composants »
dans des développements spécifiques. Certaines plateformes
décisionnelles open source se basent sur ces composants
déjà bien rodés et les intègrent de façon
à constituer une solution homogène, dans laquelle toutes les
fonctionnalités sont disponibles dans un cadre unique et rendues
interopérables.
Dans cette partie, nous allons présenter les principaux
composants décisionnels disponibles en open source, que l'on peut
regrouper dans les catégories suivantes :
? ETL : Pentaho Data Integration (ex Kettle), Talend Open
Studio.
? Designer de rapport : BIRT, Jasper Report (i Report) et Pentaho
Report Designer,
Spago.
? Analyse : Mondrian, JPivot, Palo/JedoxBffgvfI.
? Data mining: Weka.
? MDM : Talend MDM.
2.4.1. Spago BI
Spago est une plateforme collaborative dédiée
à l'informatique décisionnelle complètement
réalisée en open source. C'est une suite d'outils
intégrés facilitant le développement et la mise en oeuvre
de solutions de business intelligence quel que soit le métier ou le
secteur d'activité. Cette plateforme fédère plus de vingt
logiciels open source existant. Leur intégration s'est faite en
s'appuyant sur le middleware J2EE Spago Object Web, un serveur de
séparation vues/traitement/données de type MVC, qui comporte des
composants de messagerie et de dialogue XML. Spago couvre un large
périmètre fonctionnel : les analyses OLAP (Mondrian), le
datamining (Weka), les requêtes, la restitution (Open Report). Spago
comporte également
le logiciel d'ETL Enhydra Octopus. SpagoBI permet un
développement très flexible
permettant de « mixer »
l'open source avec des solutions propriétaires. Son grand avantage est
donc sa capacité d'intégration, ce qui permet de travailler
indépendamment par briques séparées et une meilleure
répartition du travail. Son inconvénient principal est que c'est
une solution jeune dans un secteur en pleine évolution, il faut donc se
tenir régulièrement au courant quant à l'ajout de nouveaux
composants et de fonctionnalités.
Ndioba Syll et Abdrahmane Aw Page31
2.4.2. Pentaho
Pentaho est un projet ambitieux visant à créer
une plateforme décisionnelle complète. Son but n'est pas de
proposer une alternative open source en matière de décisionnel,
mais bien concurrencer les leaders du marché BI. Pentaho se fonde sur
des briques logiciels open sources confirmées pour monter une plateforme
robuste. Le projet Pentaho est dirigé par André Boisvert, un des
meilleurs visionnaires du monde décisionnel, qui a dirigé les
principales entreprises de ce secteur depuis 25 ans. A ses côtés,
James Dixon, ancien pilier de Hyperion, et plusieurs autres « pointures
» du décisionnel. Elle seule, cette équipe
crédibilise le projet Pentaho.
2.4.3. Birt
BIRT (Business Intelligence Reporting Tools) est un outil de
Reporting indépendant. Ce logiciel a été
créé en 2005 et fait partie de la communauté Eclipse. BIRT
peut être intégré la suite Pentaho dans son serveur au
travers d'actions spécialement créées pour le
démarrage et le paramétrage de rapports. BIRT est
considéré comme un outil simple d'utilisation tout en fournissant
une série de fonctionnalités facilitant la création de
rapports de type Business Intelligence. Il en va du tableau croisé
jusqu'à la possibilité de représenter un set de
données du rapport sous forme de cube, simplifiant la création
d'agrégations et de regroupements. L'environnement de
développement est doté d'un composant permettant la
prévisualisation des rapports dans Eclipse. Parmi les
inconvénients majeurs de Birt nous pouvons cités la manque de
certaines fonctionnalités ce qui contraint l'utilisateur à
l'associer à un voir plusieurs outils pour bien réaliser un
projet de business intelligence.
2.4.4. Talend Master Management (TMDM)
Talend Master Data Management est une composante de la suite
d'intégration de donnéesopen source Talend. Elle fournit une
plateforme permettant d'intégrer, nettoyer, surveiller etpublier les
données référentielles d'une entreprise.
En s'intégrant dans la suite ETL de Talend, Talend MDM
permet de faire de l'échange en tempsréel entre un
référentiel de données et des bases d'application
hétérogène.
D'un point de vue technique, les données
référentielles sont stockées dans une base de
données XML eXistdb.
Ndioba Syll et Abdrahmane Aw Page32
Le serveur MDM Talend est une application JEE
déployée dans un serveur JBoss donnant accès à de
nombreux services Web. Du point de vue utilisateur, on dispose d'une
application Web permettant d'interagir avec la base de données
référentielle.
2.4.5. Le serveur Mondrian
Le serveur Mondrian fait partie de la catégorie des
serveurs « ROLAP », c'est à dire qu'il accède à
des données contenues dans une base relationnelle .Mondrian
exécute des requêtes utilisant le langage MDX, également
utilisé par d'autres moteurs OLAP, tel que celui de Microsoft SQL
Server. Ce langage permet de créer des requêtes dont
l'équivalent en langue SQL nécessiterait un grand nombre de
requêtes et des temps d'exécution beaucoup plus longs.
Mondrian est particulièrement puissant et permet
d'optimiser les temps de réponse en utilisant des tables
d'agrégats, créées au préalable, mais permet
également de réaliser des calculs complexes, en comparant des
éléments sur la dimension temps ou en gérant des
hiérarchies récursives dissymétriques.
2.4.6. JPivot
JPivot est un client OLAP disposant d'une interface Web. Il
permet de représenter un cube OLAP sous forme de tableau croisé
multidimensionnel et d'effectuer les opérations classiques d'analyse
(drill down, drill up, rotations, filtres ...) de façon interactive.
Il permet également d'afficher un graphique
correspondant aux données présentées entableau, qui est
mis à jour au fur et à mesure de l'exploration. Il est possible
d'exporter tableau et graphique sous forme de fichier PDF imprimable ou de
document Excel afin de réutiliser les données obtenues.
2.5. Choix de la solution
Les Trois plateformes citées plus haut
représentent un grand pas l'open source en matière de
décisionnel car elles offrent désormais des solutions traitant
plusieurs aspect du BI. Cependant notre choix s'est porté sur Pentaho
car cette solution présente plus d'avantages que Spago BI et Birt.
2.5.1. Présentation de Pentaho
Pentaho est une plate-forme décisionnelle open source
complète possédant les caractéristiques suivantes :
Ndioba Syll et Abdrahmane Aw Page33
? une couverture globale des fonctionnalités de la
Business Intelligence :
ETL (intégration de données), reporting,
tableaux de bord ("Dashboards"), analyse ad hoc
(requêtes à la demande), analyse multidimensionnelle
(OLAP);
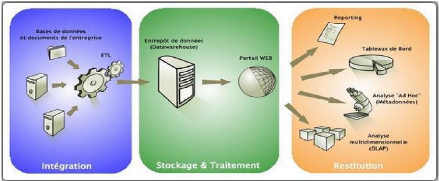
Figure 12 : présentation de Pentaho
? Pentaho permet d'adresser deux typologies d'utilisateurs :
les « one-clic users », utilisateurs de base,
consommateurs d'indicateur prédéfinis, les utilisateurs
avancés, qui ont besoin d'outils d'analyse et d'exploration
avancés ;
? Une architecture Web 2.0 qui se compose :
d'un serveur Web J2EE permettant de mettre à
disposition l'ensemble des ressources décisionnelles et ceci au travers
d'URL Web uniques et standardisées. Le serveur est dénommé
"Pentaho User Console" (PUC), plusieurs clients riches permettant la
conception et la publication des ressources. Ces derniers sont librement
téléchargeables et peuvent être installés sous des
environnements Windows, Linux ou MacOs (clients Java) ;
? le serveur Web Pentaho comporte également une
plate-forme d'administration (Pentaho Administration Console) pour la
gestion des droits d'accès, la planification d'évènements,
la gestion centralisée des sources de données... ;
? Pentaho est reconnue pour être une solution d'une
grande qualité conceptuelle et technique. La plate-forme est
orientée « processus » : au travers de « séquences
d'actions » on peut ainsi modéliser avec Pentaho des workflows BI
avancés ;
Ndioba Syll et Abdrahmane Aw Page34
? il n'est pas besoin de connaître JAVA pour travailler
avec Pentaho : seule la maîtrisedu langage SQL est nécessaire,
ainsi que des connaissances de base en XML, HTMLet JavaScript. Il faut bien
sûr s'auto former (ou être formé) aux clients de conception
;
? une communauté importante et très active
s'anime autour de Pentaho. Celle-cicontribue au codage de nombreux plugins et
de projets communautaires : pluginsKettle, PentahoAnalysisTool, Pentaho
Community Dashboard Framework, etc.
;
Pentaho est une suite décisionnelle open source
commerciale qui reste très « ouverte ».Les différences
fonctionnelles entre la version libre (Community edition) et la versionpayante
(enterprise edition) restent limitée. La version libre de Pentaho permet
d'installer une plate-forme décisionnelle complète !
Le projet Pentaho est aujourd'hui un des leaders les plus en
vue des logiciels Open Source pour le Business Intelligence.
Nombreux sont d'ailleurs les projets qui composent la suite
Pentaho à avoir officiellement rejoint le projet : Mondrian, le serveur
OLAP utilisé par toutes les plateformes Open Source faisant du
décisionnel, l'outil d'ETL Kettle et le générateur de
rapports JFree Report. La suite logicielle Pentaho BI est composée de
plusieurs projets de logiciels indépendants s'étant
regroupés en une communauté appelée Pentaho Corporation.
On peut citer :
? Pentaho Data Integration (PDI) : anciennement appelé
Kettle qui est un outil ETL (Extract Transform Load) complet, pouvant
être utilisé indépendamment de la plateforme Pentaho. Il
est comparable à Talend Open Studio en terme de fonctionnalité
;
? Pentaho Design Studio : Client Eclipse de
modélisation de workflows BI (Xactions) propre à Pentaho. Design
Studio permet de mettre en oeuvre de nombreuses ressources BI en minimisant
l'écriture de code (envoi de mails automatisé par ex.) ;
? Pentaho Metadata : Client riche permettant la mise en place
d'une couches émantique d'abstraction (métadonnées) sur la
couche physique (tables et colonnes d'une base de données). Le but est
de rendre les objets d'un SGBD compréhensibles et manipulables par un
utilisateur final afin de lui permettre d'effectuer ses propres requêtes
et ceci sans connaîtrele langage SQL. La couche de
métadonnées peut être utilisée dans le raquetteur
Web ad hoc, dans Pentaho Report Designer et dans Pentaho Design Studio
;
Ndioba Syll et Abdrahmane Aw Page35
Pentaho Report Designer : Client de conception de rapports
avancés. Il s'agit d'unoutil de mise en page similaire à iReport,
Eclipse BIRT, Crystal Reports...Permet de se connecter à de nombreuses
sources de données : SGBD, XML, Excel,CSV, flux de données venant
de Kettle, MDX (OLAP)...
Pentaho SchemaWorkbench : Client riche permettant la
définition des schémas Mondrian à partir d'un
modèle en étoile ou flocon de l'entrepôt de données.
Un autre outil, Pentaho Agrégation Designer (PAD), permet de construire
et de charger automatiquement des tables d'agrégation en vue
d'améliorer les performances lors du requêtage des cubes Mondrian
;
La plateforme Pentaho Business Intelligence : pour la
publication des rapports et la réalisation des analyses OLAP sous forme
de service web. La plupart des outils sont utilisés par d'autres
plateformes (BI ou Business intelligence) comme SPAGO BI ou OPENI. Cependant
ses outils sont indépendants les uns vis-à-vis des autres lors de
l'utilisation et chacun pouvant être démarré
indépendamment de l'autre.
2.5.2. Prise en main de Pentaho
La prise en main de Pentaho est très rapide en effet il
suffit d'abord d'installer une machine virtuelle JDK et de
télécharger les dernières versions de chacune d'entre
elles, puis de les décompresser n' importe où sur le disque dur.
Ainsi après avoir téléchargé PentahoV4, on double
clic sur le dossier contenant PentahoV4 voici le chemin
D:\ABDAAW\memoire2014\Pentaho
v4\data-integration.
On double clic sur le Spoon .bat (fichier de commande Windows)
Figure 13 : lancement Pentaho Data Integration
(PDI)
Une fois que Pentaho est lancé, l'interface d'accueil se
présente à nous.
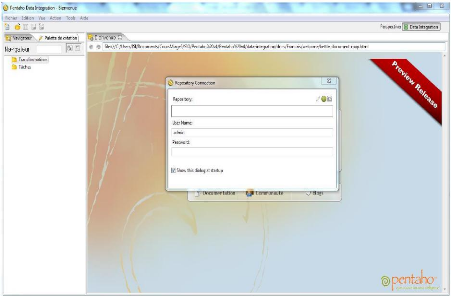
Figure 14 : Représentation de la page d'accueil de
Pentaho Data Integration
Ndioba Syll et Abdrahmane Aw Page36
Ndioba Syll et Abdrahmane Aw Page37
Chapitre lll: Implémentation de la solution
3.1. Intégration des données avec Pentaho
Data Integration
L'intégration des données constitue une
étape très importante car étant le point de départ
de tout système décisionnel. Cette phase commence par le choix
des sources de données. Dans notre cas la source de données
provient d'un fichier Excel.
Nous allons lancer Wamp Server afin de pouvoir créer
nos bases de données MySQL qui servira de L'ODS. L'ODS, c'est une
structure intermédiaire de gestion de données. Elle permet de
stocker des données issues d'un système de production
opérationnelle de manière temporaire, permettant un traitement
ultérieur par des outils spécifiques.
Des données sont récupérées et
intégrées en étant filtrées pour obtenir une autre
base de données. Cette base peut alors subir un traitement
supplémentaire, permettant d'avoir d'autres informations. Nous avons
alors un accès plus rapide, car les données redondantes sont
éradiquées.
Lançons à présent l'outil Pentaho Data
Integration et au niveau de la page d'accueil qui s'affiche,
Cliquer sur le menu Fichier, pointer sur nouveau, une nouvelle
transformation pour créer une transformation.
Cliquer sur l'onglet Navigateur puis pointer sur Connexion et
cliquer sur nouveau voici la fenêtre Database Connexion qui s'affiche.
Dans cette fenêtre on définit le nom de la connexion
(gestion_maladie_2014), le type de base de données (MYSQL), le type de
serveur (localhost) et le type d'utilisateur (root).
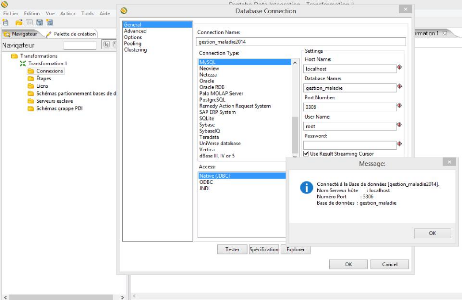
Ndioba Syll et Abdrahmane Aw Page38
Figure 15 : Création de la connexion à la
base de données source
A côté de navigateur se trouve l'onglet palette de
création. Nous allons nous placer sur Extraction qui contient les
étapes pour récupérer différents formats de
données source.
Dans notre cas on fait un drag-drop de l'étape
«Extraction depuis excel» et faire glisser sur l'espace de
travail.
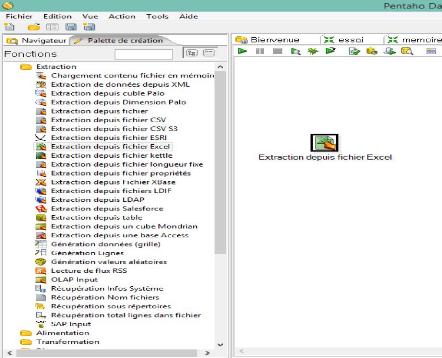
Ndioba Syll et Abdrahmane Aw Page39
Figure 16 : Extraction des donnés de puis
Excel
On ouvre l'étape « Extraction des
donnés de puis excel » pour récupérer notre source d
données en cliquant sur parcourir puis sur ajoute.
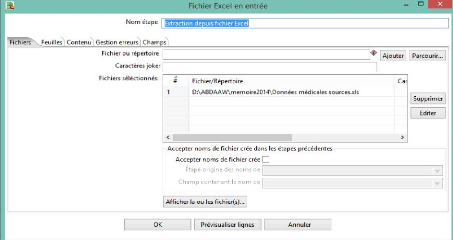
Ndioba Syll et Abdrahmane Aw Page40
Figure 17 : Récupération de la source de
données
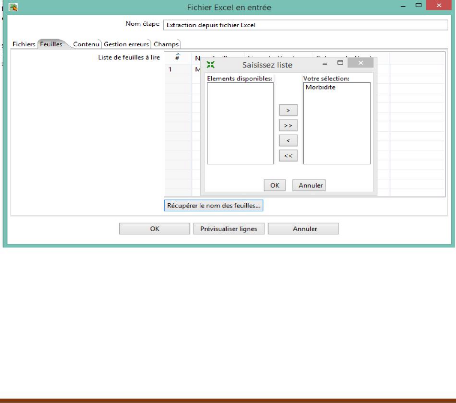
Figure 18 : Récupération des
feuilles
Le menu Feuilles permet d'ajouter une référence
a chaque source ainsi, on clique sur « Récupérer le nom des
feuilles »
Ndioba Syll et Abdrahmane Aw Page41
A tout instant On peut Pré visualiser les champs à
partir de «Prévisualiserlignes » ou aller
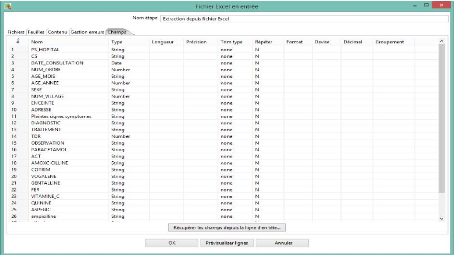
dans le menu Champs pour récupérer les champs et
leurs types grâce à « Récupérer les champs
depuis la ligne d'en tète ».
Figure 19 : Récupération des champs depuis
la ligne d'en tète
Nous ferons de même dans le sous menu Transformation en
choisissant «Altération structure flux» après avoir
établis la liaison entre les deux étapes.


Figure 20 : Transformation des données
Maintenant nous allons cliquer sur Altération structure
flux, sélectionner pour récupérer les champs. Mais aussi
métadonnées toujours pour récupérer les champs et
valider pour finir.
La même chose sera pour l'étape Insertion et mise
à jour où on définit le nom de la table cible dans Mysql,
puis la clé de recherche
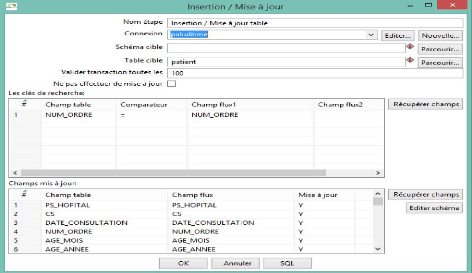
Figure 21 Insertion et mise à jour des
données
A présent, on clique sur SQL pour générer la
requête SQL de création de table
Ndioba Syll et Abdrahmane Aw Page42
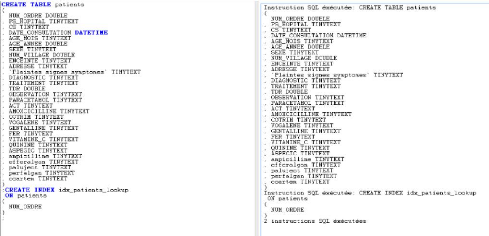
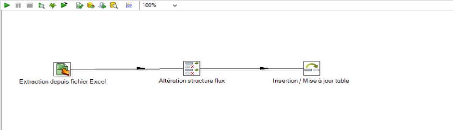
Figure 22 : Création de la table Patient dans
l'entrepôt
|
En fin on clique sur exécuter pour démarrer la
transformation
|
|
|
|
|
|
|
Figure 23 : Processus ETL
Nous allons maintenant exécuter la transformation afin que
les données soient chargées dans l'Opérational Data Store
(l'ODS).
Ndioba Syll et Abdrahmane Aw Page43
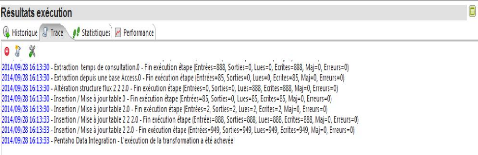
Figure 24 : Visualisation du résultat
d'exécution dans Trace
Lancement de Wamp Serveur pour vérifier que le Data
Warehouse est bien alimenté.
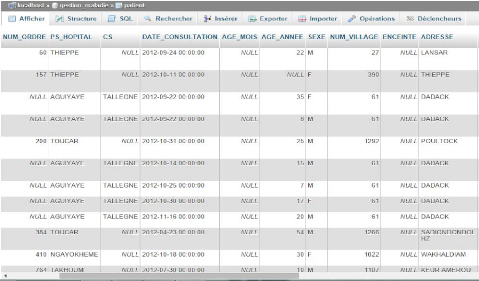
Figure 25 : Vue de l'entrepôt depuis
MySQL
3.2. Alimentation Datamart
Notre transformation consiste à importer des
données à partir de d'une table (table patient) de l'ODS,
à manipuler l'information s'y trouvant et à créer une
nouvelle structure en bout de ligne qui n'est rien d'autre qu'un magasin de
données (Datamart conformément à la modélisation en
flocon de neige de la Figure 11 : Représentation du modèle en
flacon de neige « pour l'indicateur Paludisme ».
Ndioba Syll et Abdrahmane Aw Page44
Ndioba Syll et Abdrahmane Aw Page45
Comme pour le data L'ODS, Une connexion à la base de
données et nécessaire et la source de données sera
l'entrepôt déjà alimenté.
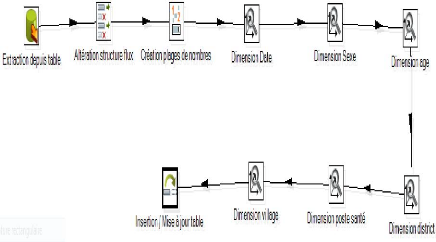
Figure 26 : Représentation du Model
Multidimensionnel
On clique sur Extraction depuis table pour renseigner le champ
« Connexion » en y mettant le nom de la connexion à la base de
données source et la requête SQL qui permettra de
récupérer les champs qui seront extraient depuis la table
concernée.
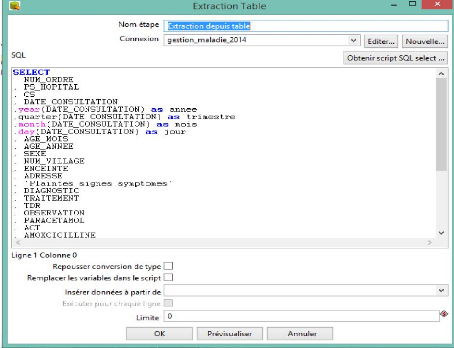
Ndioba Syll et Abdrahmane Aw Page46
Figure 27 : Récupération des
champs
De la même façon que précédemment pour
l'étape « Altération structure flux », il est important
de récupérer les champs. Mais aussi métadonnées
toujours pour récupérer les champs et valider pour finir.
On clique sur l'étape création plages de nombres
afin de définit les champs sources et destinations. Cette étape
permet de définir les tranches d'âge.
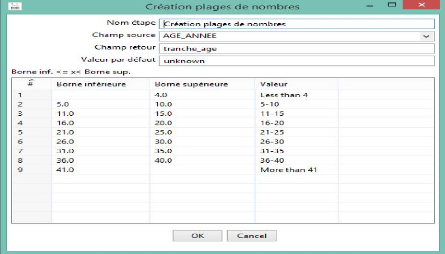
Ndioba Syll et Abdrahmane Aw Page47
Figure 28 : Définitions des tranches
d'âge
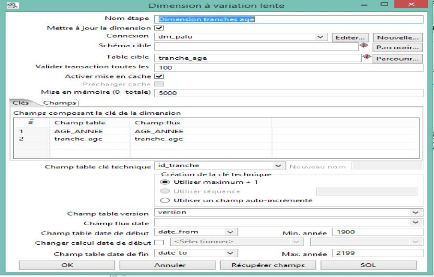
Maintenant pour chaque dimension on définit la
connexion, le nom de la table de dimension et on récupère les
champs composants la clé de dimension sans oublier l'identifiant de
chaque table.
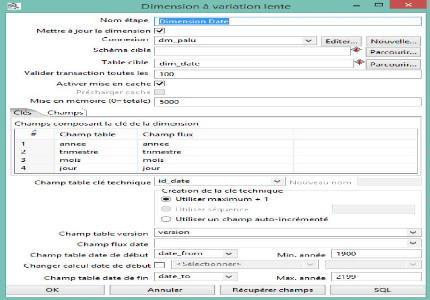
Ndioba Syll et Abdrahmane Aw Page48
Figure 29 : Dimension date
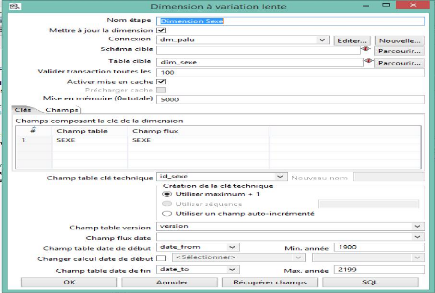
Figure 30 : Dimension Sexe
Ndioba Syll et Abdrahmane Aw Page49
Figure 31 : Dimension Tranche d'Age
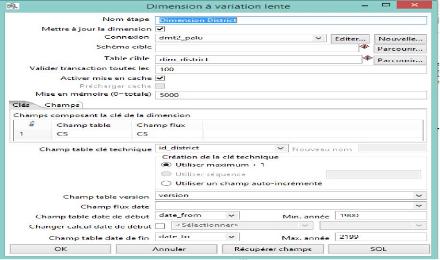
Figure 32 : Dimension District
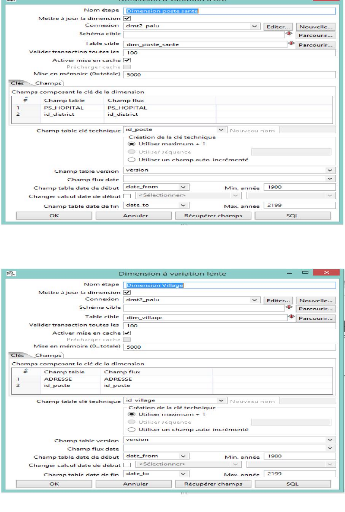
Figure 33 : Dimension Poste Santé
Figure 34 : Dimension village
Ndioba Syll et Abdrahmane Aw Page50
Ndioba Syll et Abdrahmane Aw Page51
Ndioba Syll et Abdrahmane Aw Page52
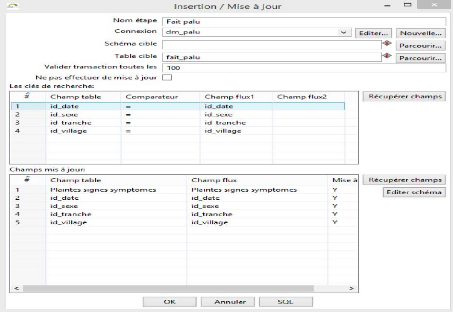
Figure 35 : Table de fait_palu
Regardons dans Wamp Server pour voir et vérifier si la
table de fait a été créée et si les données
ont bien été chargées.
3.3. Création de rapport avec Pentaho Report
Designer
Pour la création de rapports, nous avons choisis
Pentaho Report Designer qui est un outil de conception graphique de rapports
avancés et permet de se connecter à de nombreuses sources de
données : SGBD, XML, Excel, CSV, flux de données.
Il est par ailleurs possible de générer des
rapports en masse en utilisant l'ETL Pentaho Data Integration, dans lequel on
retrouve une étape de génération de rapports faisant appel
au fichier prpt conçu avec PRD.
Pour lancer PENTAHO REPORT DESIGNER, il faut double cliquer
sur le fichier de commande Windows se trouvant dans
D:\ABDAAW\prd-ce-5.1.0.0-752\report-designer,
une page d'accueil guide l'utilisateur vers les étapes indispensables de
création du rapport :

Figure 36 : Interface de Pentaho report
Designer
Figure 37 : Création d'un rapport avec Pentaho
Report Designer
Un assistant, le Report Wizard, permet d'établir une
nouvelle connexion mais également de se connecter à un
méta modèle (dictionnaire de données) de Pentaho :
Ndioba Syll et Abdrahmane Aw Page53
Il s'agit ici d'une avancée importante dans les outils
de reporting open source et PRD a été le premier, fin 2007,
à permettre à un utilisateur de créer un rapport sans
aucune connaissance SQL.
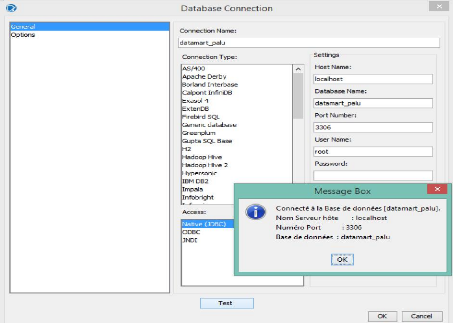
Figure 38 : Connexion au Datamart
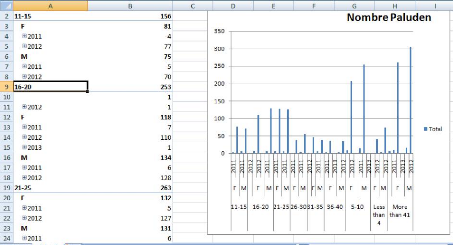
Le rapport suivant montre le nombre de paludéens suivant
la dimension Sexe.
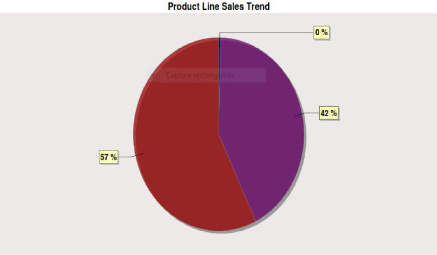
Figure 39 : Le Nombre de Paludéen Suivant la
Dimension Sexe
Et maintenant, nous allons voire le nombre de paludéens
suivant la dimension trimestre.
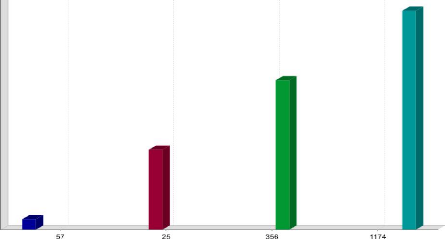
Ndioba Syll et Abdrahmane Aw Page54
Figure 40 : Le Nombre de Paludéens Suivant la
Dimension trimestre
Ndioba Syll et Abdrahmane Aw Page55
Pentaho Report Designer est un outil simple à
manipuler, bien intégré à la suite décisionnelle
Pentaho pour la gestion des paramètres ou la publication sur la
plateforme web. On regrettera cependant dans PRD l'impossibilité de
créer des tableaux croisés sauf à pointer sur un
schéma Mondrian existant.
3.4. Analyse des données avec la plateforme Bi
lite Cube
Bi-Lite-il Zero est un constructeur OLAP Cube disponible dans
un certain nombre d'édition, qui permet créer des cubes à
la porté de quiconque qui est familier avec MS Access ou SQL Serveur.
En tant qu'utilisateur Bi-Lite Cube offre une méthode
rapide et efficace de produire des prototypes entièrement
fonctionnels
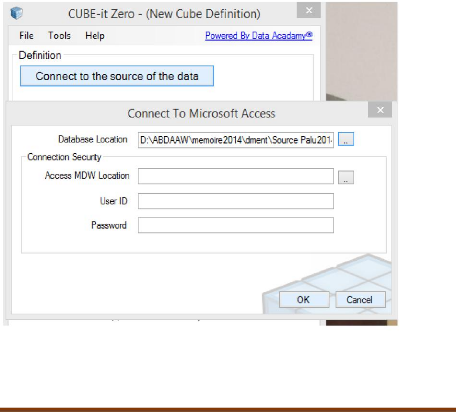
Figure 41 : Connexion à notre base de
données Access
On va transformer notre Datamart MYSQL en une base Access
grâce à notre outil PDR tout en se référent à
la Figure 26 : Représentation du Model Multidimensionnel
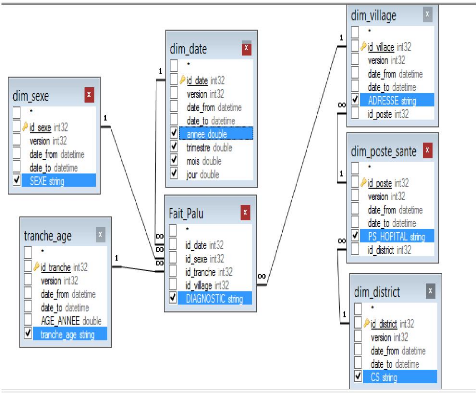
Figure 42 : Concevoir la requête de rapport
à l'aide du concepteur visuel de requêtes
Ndioba Syll et Abdrahmane Aw Page56
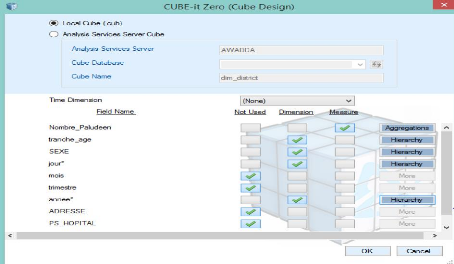
Ndioba Syll et Abdrahmane Aw Page57
Figure 43 : Définir le contenu de votre
cube
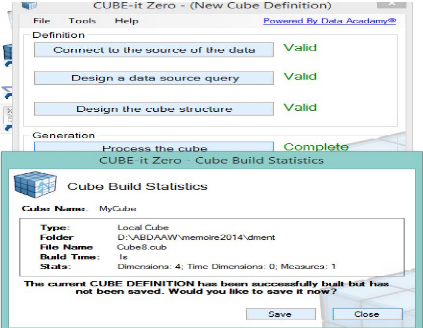
Figure 44 : Traiter et construire le cube en un seul
clic
Ndioba Syll et Abdrahmane Aw Page58
Figure 45 : Analyse multidimensionnelle
Conclusion
La prise de décision dans de multiples domaines, tels
que le management, l'évaluation de la performance d'un processus
business ou la prise de décision stratégique dans l'entreprise,
exige la manipulation et l'analyse de grandes quantités de
données qui sont généralement dispersées dans
l'entreprise. Il est, ainsi, nécessaire de les rassembler et de les
intégrer d'une manière cohérente afin de pouvoir restituer
l'information requise.
Pour la réalisation de ce travail notre choix s'est
porté sur la plate forme Pentaho qui est un outil Open source de
Business Intelligence.
Ainsi nous avons pu réaliser au cours de notre travail
les taches qui nous ont été confiées à savoir :
L'agrégation de donnée dans l'entrepôt de
donnée
La création des datamarts
La réalisation de cube pour une analyse
multidimensionnelle.
En fin ce travail nous à permis de comprendre
l'importance du système d'information décisionnel (SID) qui doit
être capable d'assurer quatre fonctions fondamentales : la collecte,
l'intégration, la diffusion et la présentation des
données. À ces quatre fonctions s'ajoute une fonction
d'administration
Ndioba Syll et Abdrahmane Aw Page59
ANNEXE
Table des Figures et Tableaux
Figure 1 : Architecture générale d'un
système décisionnel 11
Figure 2 : Méthodologie pour un projet BI 15
Le tableau1 : différences entre entrepôts et les
bases de données 16
Figure 3 : Représentation d'une table de Fait 17
Figure 4 : Représentation d'une table de dimension
patient 18
Figure 5 : Représentation des hiérarchies dans
une dimension 19
Figure 6 : Représentation de la granularité de
temps de lieu et produit 20
Figure 7 : Modélisation en étoile 21
Figure 8 : Modélisation en flocon 22
Figure 9 : Modélisation en constellation 23
Figure 10 : Processus de développement du projet
tiré du modèle en « V » 27
Figure 11 : Représentation du modèle en flacon de
neige « pour l'indicateur Paludisme » 28
Figure 12 : présentation de Pentaho 33
Figure 13 : lancement Pentaho Data Integration (PDI) 36
Figure 14 : Représentation de la page d'accueil de
Pentaho Data Integration 36
Figure 15 : Création de la connexion à la base de
données source 38
Figure 16 : Extraction des donnés de puis Excel 39
Figure 17 : Récupération de la source de
données 40
Figure 18 : Récupération des feuilles 40
Figure 19 : Récupération des champs depuis la
ligne d'en tète 41
Figure 20 : Transformation des données 41
Figure 21 : Insertion et mise à jour des données
42
Ndioba Syll et Abdrahmane Aw Page60
Figure 22 : Création de la table Patient dans l'entre
42
Figure 23 : Processus ETL 43
Figure 24 : Visualisation du résultat
d'exécution dans Trace 43
Figure 25 : Vue de l'entrepôt depuis Mysql 44
Figure 26 Représentation du Model Multidimensionnel
45
Figure 27 : Récupération des champs 46
Figure 28 : définitions des tranches d'âge 47
Figure 29 : Dimension date 48
Figure 30 : Dimension Sexe 48
Figure 31 : Dimension Tranche d'Age 49
Figure 32 : Dimension District 49
Figure 33 : Dimension Poste Santé - 50
Figure 34 : Dimension village 50
Figure 35 Table de fait_palu 51
Figure 36 Interface de Pentaho report Designer 52
Figure 37 : Création d'un rapport avec Pentaho Report
Designer 52
Figure 38 : Connexion au Datamart 53
Figure 39 : Le Nombre de Paludéen Suivant la Dimension
Sexe 54
Figure 40 Le Nombre de Paludéen Suivant la Dimension
Trimestre 54
Figure 41 : Connexion à notre base de données
Access 55
Figure 42 : Concevoir la requête de rapport à
l'aide du concepteur visuel de requêtes 56
Figure 43 : Définir le contenu de votre cube 57
Figure 44 : Traiter et construire le cube en un seul clic
57
Figure 45 : Analyse multidimensionnelle 58
BIBLIOGRAPHIE
? Pentaho Data Integration 4Cookbook, Adrián Sergio
Pulvirenti et María Carina Roldán
Sites internet
http://www.smiler.fr/
http://support.pentaho.com
http://www.pentaho.com/
Ndioba Syll et Abdrahmane Aw Page61


