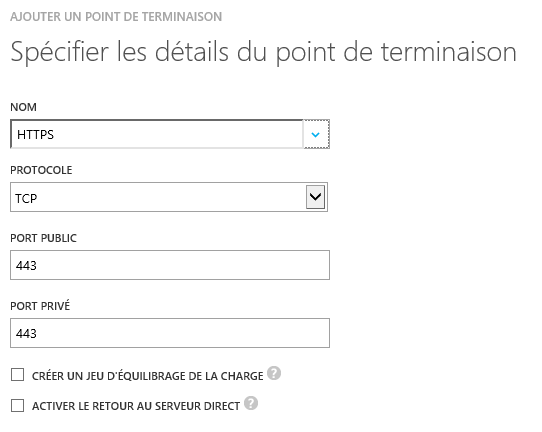
|

REPUBLIQUE DEMOCRATIQUE DU CONGO
MINISTERE DE L'ENSEIGNEMENT SUPERIEUR ET UNIVERSITAIRE
UNIVERSITE REVEREND KIM
Faculté de Siences informatiques de
Gestion
B.P. 171 KIN XX
Kinshasa/Ndjili
« Etude sur le déploiement d'une base
de données locale vers le Cloud »
Cas du SQL AZURE DATABASE
KADIMA MUAMBA Donatien
Directeur : CT. KALOMBO TAMBWE TRUDON
Année Académique 2015-2016
Travail de Fin de Cycle présenté en
vue de l'obtention du titre de Gradué en Sciences informatiques de
Gestion.
EPIGRAPHE
« L'informatique semble encore
chercher la recette miracle qui permettra aux gens d'écrire des
programmes corrects sans avoir à réfléchir. Au lieu de
cela, nous devons apprendre aux gens comment réfléchir »
Anonyme
DEDICACE
A mon père MUAMBA Jean-Louis et ma mère
KABATUSUILE Hélène qui ont inculqué la notion de prendre
au sérieux nos études et qui ont consenti à nos
peines et sacrifices afin de nous assurer une formation universitaire
outre les formations antérieures dont ils nous ont fait
bénéficier toujours au prix de leurs sueurs.
A ma famille biologique: Grace NGALULA ,MUKANYA
Symphorien ,Berthine Tshilanda ,Jean KAZADI,Fernand KAMBA, Symphorien
KAMUENA, ainsi que mon oncle KABEYA et surtout à mes collègues
proches de l'URKIM : KAPYA MUFUNGA Hélène,TSHIMPAKA MADIAYI
Moïse, NYAMABO Hervé ,SESEBE ANDWENG Rose, MWIKA
Dorcas,NGUNGABWI NTUMBA Francia, KINGUNZA DISASI Patrick sans oublier mon
amie personnelle : Schelah JILABU TSHIMANGA .
Donatien KADIMA MUAMBA
REMERCIEMENT
Nous rendons premièrement grâce au seul Dieu
tout puissant créateur du ciel et de la terre, de l'univers visible et
invisible pour ses merveilles et ses multiples bien faits qu'il
continue d'accomplir dans le roman de notre vie et sans qui nous n'aurions rien
pu accomplir de notre existence humaine.
Nous disons merci aux autorités, Professeurs,
Chefs des travaux, Assistants... de l'Université
Révérend Kim pour leur dévouement et leur
générosité dont ils ont fait montrer tout au long de notre
formation académique dans cette pépinière de culture de la
personnalité scientifique et humaine. Nous remercions à titre
personnel le CT KALOMBO Trudon qui a accepté de diriger notre travail de
Fin d'Etude ainsi qu'à tous ceux qui me connaissent.
Donatien KADIMA MUAMBA
LISTE DES ABREVIATIONS
SQL : Structured Query Language
CPU : Central Processing Unit
GSM : Groupe Système Mobile
PC : Personal Computer
FTP : File Transfer Protocole
IEEE : Institute of Electrical and
Electronic Engineer
OSI : Open System Interconnect
TCP-IP : Transmission Control
Protocol/Internet Protocol
OLTP : Online Transaction Processing
OLAP : Online Transaction Processing
SGBD : Système de Gestion de Base
de données
SGBDR : Système de Gestion de Base
de données Relationnel
SGBDO : Système de Gestion de Base
de données Orienté Objet
SLM : Service Level Management
RFC : Request For Comment
SLA : Service Level Agreement
IETF : Internet Engeneering Task Force
ITU : International Telecommunication
Union
CIR : Committed Information Rate
EIR : Equipment Identity Register
LISP : Lost of Insipid and Silly
BCP : Best Current Practice
VM : Virtual Machine
RDP : Remote Desktop Protocol
DAC : Discretionary Access Control
PAC : Proxy Autoconfiguration File
BAC : Backup
LISTE DES FIGURES
Figure 1 - 1 : Topologie en bus
Figure 1 - 2 : Topologie en anneau
Figure 1 - 3 : Topologie en étoile
Figure 1 - 4 : Une architecture
client/serveur
Figure 1 - 5 : Communication entre les
Couches
Figure 3 - 1 : Présentation SQL
AZURE
Figure 3 - 2 : Assistant Migration de la
base de données SQL
LISTE DES TABLEAUX
Tableau 1 - 1 : Les Sept Couches du
Modèle OSI
Tableau 1 - 2 : Correspondance entre les
Couches et Composants Réseau
Tableau 3 - 1 : Récapitulation de
Plan de Migration
O. INTRODUCTION GENERALE
0.1. PRESENTATION DU SUJET
Notre sujet du travail scientifique porte sur
Etude sur le déploiement d'une base de données
locale vers le cloud. « Cas de Sql Azure
DataBase »
0.2. GENERALITE
Aller dans les nuages, a toujours été le
rêve des hommes. Ce domaine était longtemps réservé
aux poètes, et leur offrait la possibilité de s'évader des
problèmes quotidiens qui les assaillaient. Mais depuis le jour où
les avions et autres objets volants, conquirent le grand espace ciel, une
grande majorité de gens pouvait sillonner plusieurs types de nuages. Ce
rêve est également devenu réalité, dans le domaine
de l'informatique. Actuellement, on parle beaucoup de Cloud Computing, et ce
n'est pas par hasard.
Le Cloud, est d'abord un mot anglais qui signifie « nuage
». Et Cloud, est le diminutif de Cloud Computing. C'est un ensemble de
services qui permet à un utilisateur, de transférer ses stockages
et ses traitements informatiques, depuis un ou plusieurs de ses serveurs
locaux, vers d'autres serveurs extérieurs. Ce concept est un peu
difficile à saisir au premier abord. Mais à la demande d'un
utilisateur, le Cloud Computing lui ouvre simplement l'accès à
des ressources informatiques virtuelles, via internet. Ainsi, les
opérateurs en informatiques, les entrepreneurs individuels ou les
sociétés de tailles diverses, deviennent aussi des internautes en
puissance. Ils naviguent comme eux dans les nuages, pour effectuer leurs
travaux de transfert de données informatiques.
A en juger par les nombreuses traductions du Cloud Computing,
le sujet intéresse le monde entier. Il est d'actualité et il est
vaste. Cependant, vu le grand nombre de services qu'il permet, et le grand
nombre de domaines qu'il couvre, on n'arrive pas trop bien à cerner sa
définition. En France, pour le définir, on veut saisir l'image
des nuages, et associer son aspect poétique et magique, à la
rigueur de l'informatique. On parle alors « d'informatique virtuelle
», « d'informatique en nuage », « d'informatique dans les
nuages » ou « d'informatique dématérialisée
». Mais on emploie aussi les termes comme « stockage dans les nuages
», ou « stockage à distance » ou encore «
infonuagique ». Quant à la commission générale de
terminologie et de néologie de France, elle souligne que l'infonuagique,
est un aspect particulier d'administration de l'informatique. Le client qui le
pratique, ne sait pas localiser matériellement ses données. Et
pourtant, il peut accéder facilement au service, par le biais d'une
application classique, tel un navigateur web. Malgré tout, les usagers
préfèrent en général employer le terme Cloud
Computing.
Le client particulier ou l'entreprise, ne gère plus ses
serveurs informatiques. Il peut seulement accéder progressivement
à plusieurs services en ligne, sans contact direct avec l'infrastructure
technologique. Les données ainsi que les applications, sont logés
dans un « nuage », formé de plusieurs serveurs
interconnectés, et distants les uns des autres. L'utilisateur
bénéficie ainsi, de la facilité de fonctionnement du
système, assurée par l'usage d'une bande passante de haute
qualité. On délimiterait alors la définition de Cloud
Computer, par la transposition de l'infrastructure technologique de
l'informatique dans les `'nuages''.
0.3. PROBLEMATIQUE
La problématique est une façon
d'appréhender le sujet en terme de problèmes (1(*)). Elle peut être
définie comme l'ensemble des questions posées dans un domaine
de la science en vue d'une recherche de solution2(*).
Au cours de notre travail, nous ressortissions la grande
problématique liée aux contraintes que rencontrent
les entreprises en nous posant les questions suivantes :
- Est - il nécessaire à une entreprise
d'acheter les serveurs qui coûtent très chers et qui
nécessitent une maintenance mensuelle et annuelle afin de
rendre sa base de données accessible et permanente chez tous les
utilisateurs ?
- Est - ce l'entreprise serait - elle capable de
couvrir les coûts fixes et les dépenses engagés dans
les traitements des informations ?
0.4. HYPOTHESE
Selon le dictionnaire Webster, l'hypothèse est une
affirmation provisoire formulée dans le but de tirer ou de
vérifier ses conséquences logiques ou empiriques.
L'adoption d'un Cloud, apporte des avantages certains pour les
entreprises. Outre la limitation de ses machines informatiques, qui dispense de
toutes les activités de maintenance et de prestations, elles participent
à la sauvegarde de l'environnement. Finis les recherches et les achats
de logiciels, aussi simples que complexes. Finis les licences serveurs et
clientes.
Elles éviteront les batailles avec les
problématiques liés aux données, comme les backups, et
ceux liés aux calculs, comme l'insuffisance des ressources CPU. Elles ne
se soucieront ni des différents tests inhérents aux nouveaux
logiciels, ni de leurs mises à jour, qui prennent beaucoup de temps. Peu
leur importe les changements de normes ou l'internationalisation des SI. La
seule occupation de l'entreprise client, est de sortir ou rentrer ses
données, avec un minimum de suivi interne. L'économie est saine
et nette !
La facturation de votre Cloud ne contient ni abonnement, ni
frais de mise en service, ni frais masqué. Vous règlerez à
chaque fin de mois, uniquement votre consommation réelle du mois.
0.5. METHODES ET TECHNIQUES
a) Méthode
Madeleine GRAWITZ définit la méthode comme
« ensemble des opérations intellectuelles par lesquelles une
discipline cherche à atteindre les vérités qu'elle
poursuit, les démontre, les vérifie».
Selon Larousse encyclopédique, « la
méthode est la démarche rationnelle de l'esprit, raisonnement
tenu pour arriver à la connaissance ou à la démonstration
d'une vérité ».
Il est important de signaler que les informations
utilisées dans notre travail scientifique proviennent des
interviews, des recherches sur Internet, des documents et
mémoires écrits sur le sujet. Nous avons aussi
essayé d'obtenir des renseignements des entreprises qui
fournissent déjà des solutions cloud.
Ainsi, ce travail a fait appel à trois
méthodes :
1. Méthode Structuro -
Fonctionnelle :
Cette méthode est caractérisée par la
recherche des impératifs fonctionnels et structurels pour maintenir
l'équilibre d'un système. Elle nous a permis d'analyser et
d'indiquer la structure organico-fonctionnelle des entreprises et du
déploiement de la base de données.
2. Méthode
Analytique :
Elle consiste à décomposer les
éléments d'un système afin de mieux les définir,
tel a été notre cas.
3. Méthode Historique :
La méthode historique a pour objet l'explication des
époques, des faits et des événements passées et
de leur enchainement pour aboutir à la vérité des faits
et ce pour l'utilisation systématique et la critique des
documents.
b) TECHNIQUE
Une technique est l'ensemble de procédés
exploités par les chercheurs dans la phase de la collecte des
données qui intéressent cette étude.
1. Technique d'observation
directe : Par la technique d'observation directe, nous
entendons celle qui ouvre un contrat, une communication entre des
êtres humains. Elle nous a permis d'être en communication avec
les différentes entreprises.
2. Technique documentaire :
Cette technique est ainsi désignée parce qu'elle met en
présence le chercheur d'une part et de l'autre part des documents
supposés contenir les informations recherchées.
0.6. INTERET ET CHOIX DU SUJET
Le choix de cette étude n'est pas le fait de hasard.
Entant que finaliste en troisième année de graduat en
Informatique de Gestion, il s'agit d'une opportunité de mener une
étude sur le déploiement d'une base de données locale
vers le cloud computing. Et ce travail nous permet d'obtenir le titre
d'analyste programmeur en informatique.
Notre travail à un triple intérêt :
Ø Du point de vue scientifique :
nous estimons que notre travail sera une clé de référence
pour d'autres chercheurs qui vont aller dans ce domaine tout en mettant en
pratique toutes les connaissances acquises au cours de notre formation pendant
trois ans afin d'ajouter une pierre sur la construction du monde
informatique.
Ø Du point de vue pratique :
d'accomplir le devoir qu'a tout étudiant en général et
tout analyste programmeur en particulier au terme de son cycle, celui de
réaliser son étude, en implémentant un système
informatique pouvant permettre le stockage des grandes masses
d'informations.
Ø Du point de vue personnel : de
découvrir ce que nous avons pu acquérir tout au long de notre
premier cycle d'étude universitaire en Informatique de Gestion.
0.7. DELIMITATION DU SUJET
Etant donné que tout travail scientifique se limite sur
un temps et dans un espace donné. Notre étude couvre une
période de l'évolution de la technologie cloud sur Sql Azure
Database de 2008 à 2014.
0.8. SUBDIVISION DU SUJET
Hormis l'introduction générale et la conclusion
générale, notre travail est subdivisé en trois chapitres
suivants :
- Chapitre I : CONCEPTS DE BASE
- Chapitre II : CLOUD COMPUTING
- Chapitre III : DEPLOIEMENT D'UNE BASE DE
DONNEES VERS LE SQL AZURE
Chapitre I
Concepts de Base
SECTION I :
RESEAU INFORMATIQUE
1.1.1. Définition
1.1.1.1. Définition Générale
Le réseau est une structure, un ensemble qui relie
plusieurs éléments entre eux selon une architecture, afin
qu'ils communiquent, s'échangent intelligemment le travail pour une
meilleure efficacité.
1.1.1.2. Définition Informatique
Un réseau informatique se compose de plusieurs
ordinateurs reliés entre eux par des câbles, afin de pouvoir
échanger des données et partager des ressources, tels que des
imprimantes, de l'espace disque etc..
Il est l'ensemble des équipements informatiques
interconnectés3(*).
1.1.1.3. Objectifs
Un réseau informatique a l'objectif de :
- Le partage de ressources (fichiers, applications ou
matériels, connexion à l'internet, etc.) ;
- La communication entre personnes (courrier
électronique, discussion en direct, etc.) ;
- La communication entre processus (entre des ordinateurs
industriels par exemple) ;
- La garantie de l'unicité et de l'universalité
de l'accès à l'information (bases de données en
réseau).
1.1.2. Classification de réseau informatique
Parmi les réseaux informatiques, on distingue un
certain nombre de réseau dont l'architecture et les technologies se
différencient. On établit ainsi la classification suivant
l'échelle géographique (selon la taille) et la classification
selon le type :
1.1.1.4. La classification selon l'échelle
géographique ou taille
Les réseaux sont divisés en quatre grandes
familles : les PAN, LAN, MAN et WAN ;
a) PAN
Les réseaux personnes ou (Personal Area
Network), interconnectent sur quelque mettre des équipements
personnels tel que terminaux GSM, portable, organiseurs d'un même
utilisateur.
b) LAN
Les réseaux locaux, ou (Local Area Network)
correspond par leur taille aux réseaux intra entreprise.
Ils servent au transport des informations numériques
de l'entreprise. En règle générale, les bâtiments
à câbler s'étendent sur plusieurs centaines de
mettre.
Les débits de ces réseaux vont aujourd'hui de
quelques mégabits à plusieurs centaines de mégabits par
seconde.
c) MAN
Les réseaux métropolitains, ou (Metropolitan
Area Network), permettent l'interconnexion des entreprises ou
éventuellement de particulier un réseau spécial à
haut débit qui est géré à l'échelle
d'une métropole.
Il doit être capable d'interconnecter les
réseaux locaux de différents entreprises pour leur donner la
possibilité de dialoguer avec l'extérieur .
d) WAN
Les réseaux étendus, ou (Wide Area
Network), sont destinés à transporter les données
numériques de distance à l'échelle d'un pays, voire
d'un continent ou de plusieurs continents.
Le réseau est soit terrestre et il utilise dans ce cas
des infrastructures au niveau du sol, essentiellement de grand réseau de
fibre optique, soit hertzienne, comme les réseaux satellitaire.
1.1.1.5. La classification selon la
topologie
Les réseaux peuvent être classés par type
de modèle, architecture utilisé pour relier les machines le
constituant. Il existe autant de topologies que de façons de connecter
les matériels entre eux. Généralement on regroupe toutes
ces possibilités en trois grandes formes de topologies.
Une topologie est l'arrangement physique et logique des
ressources réseau.
Nous avons la topologie physique et logique.
v Topologie physique
La topologie physique est l'arrangement physique des
matériels, c'est-à-dire la configuration ou l'organisation
spéciale du réseau. Parmi les différents types de
topologies physiques, nous avons :
v Topologie en bus : Cette topologie
permet une connexion multipoint. Le bus est le support physique de transmission
de l'information. Les machines émettent simplement sur le câble
est défectueux, cassé, le réseau est paralysé. On
trouve à chaque extrémité d'un brin des bouchons qui
empêchent le signal de se réfléchir.
Figure 1 - 1 Topologie en bus
v Topologie en anneau : Chaque
ordinateur, imprimante, est relié à un noeud central : hub ou
Switch dans le cas d'un réseau Ethernet. Les performances du
réseau vont alors dépendent principalement de ce noeud
central.
Figure 1 - 2 Topologie en anneau
v Topologie en étoile il s'agit de la
topologie en bus que l'on a refermé sur elle-même. Le sens de
parcours du réseau est déterminé-ce qui évite les
conflits. Les stations sont actives : c'est-à-dire qu'elles
régénèrent le signal. Généralement cette
topologie est active avec un deuxième anneau et un système de
bouclage sur les stations. Ainsi si un poste est en passe il est
supprimé logiquement de l'anneau. Ce dernier peut alors continuer
à fonctionner. Ces topologies peuvent être déclinées
en un grand nombre de possibilité en fonction des besoins, du
coût, et de la politique de connexion. Cette possibilité
d'interconnexion totale permet de sécuriser le réseau par contre
elle est couteuse en câble et en matériels. Cette topologie permet
de fiabiliser le réseau et de diminuer la charge réseau sur le
bus principal. Les données circulent toujours dans le même sens.
Chaque matériel reçoit à son tour les données,
teste au niveau de la couche 2 si cela la concerne.

Figure 1 - 3 Topologie en
étoile
1.1.1.6. Classification selon
l'architecture
1.1.1.6.1. L'architecture Client-serveur
L'architecture client-serveur s'appuie sur un poste central,
le serveur, qui envoi des données aux machines clientes. Des programmes
qui accèdent au serveur sont appelés programmes clients (client
FTP, client mail).
a) Avantages de cette architecture
· Unicité de l'information : pour
un site web dynamique par exemple (comme vulgarisation-informatique.com),
certains articles du site sont stockés dans une base de données
sur le serveur. De cette manière, les informations restent identiques.
Chaque utilisateur accède aux mêmes informations.
· Meilleure sécurité :
Lors de la connexion un PC client ne voit que le serveur, et non les autres PC
clients. De même, les serveurs sont en général très
sécurisés contre les attaques de pirates.
· Meilleure fiabilité : En cas de
panne, seul le serveur fait l'objet d'une réparation, et non le PC
client.
· Facilité d'évolution :
Une architecture client/serveur est évolutive car il est très
facile de rajouter ou d'enlever des clients, et même des serveurs.
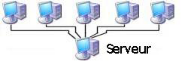
Figure 1.4 Une architecture
client/serveur
b) Inconvénients de cette architecture
§ Un coût d'exploitation
élevé (bande passante, câbles, ordinateurs
surpuissants)
Le client pour recevoir des informations du serveur lui
émet une requête passant par un port du PC (exemple : port 25 pour
les mails, port 80 pour le web et 21 pour le FTP). Le serveur lui envoi ensuite
les informations grâce à l'adresse IP de la machine cliente.
1.1.1.6.2. L'architecture Peer to Peer (égal
à égal)
Cette architecture est en fait un réseau sans serveur
constitué de deux ou plusieurs ordinateurs. Les ressources sont donc
libres de partage ou non.
a) Les avantages du Peer to Peer
Cette architecture propose quelques avantages :
v Un coût réduit
v Simplicité d'installation
v Rapidité d'installation
b) Inconvénients de cette architecture
Les inconvénients sont assez nombreux en ce qui
concerne le Peer to Peer :
v Une sécurité parfois très faible.
(c'est mieux de se protégé avec des firewalls)
v La maintenance du réseau difficile. En effet, chaque
système peut avoir sa propre panne et il devient impossible de
l'administrer correctement.
Cette architecture est donc réservée à
des milieux ne nécessitant pas une grande protection des données
et n'ayant pas beaucoup d'utilisateurs (une quinzaine maximum) :
v Les petites entreprises n'ayant rien à cacher
(sécurité aléatoire)
v Une configuration avec les ordinateurs proches les uns des
autres
v L'entreprise aura moins de 15 utilisateurs (donc
évolution restreinte)
v c) Administration d'un réseau Peer to Peer
L'administration d'un réseau Peer to Peer est faite par
l'utilisateur de l'ordinateur. Elle ne touche que son ordinateur et pas ceux
des autres PC :
v Gestion de la sécurité
v Partage des données
v Actualisation des données
d) Sécurité d'un réseau Peer to Peer
On entend par sécurité bien sûr le fait
qu'un autre utilisateur ne puisse accéder à vos données
sans votre accord. Voici les règles de base :
v Mettez des mots de passe aux données, même si
elles ne se situent pas dans des répertoires partagés.
v Ne partagez qu'un dossier qui contiendra tout ce que vous
souhaitez partager (administration plus facile)
v Utilisez un bon firewall (dans le cas de programmes
d'échanges de fichiers comme kazaa, etc.)
1.1.3. Les réseaux sans fil
1.1.3.1. Définition
Un réseau sans fil (en anglais Wireless Network) est un
réseau dans lequel au moins deux terminaux peuvent communiquer sans
liaison filaire.
Les réseaux sans fil sont basés sur une liaison
utilisant, des ondes radioélectriques (radio et infrarouges) en lieu et
place des câbles habituels.
Il existe plusieurs technologies se distinguant de la
fréquence d'émission utilisée ainsi que le débit et
la portée des transmissions.
Les réseaux sans fil permettent de relier très
facilement, des équipements distants d'une dizaine de mètre
à quelques kilomètres.
1.1.3.2. Les différents types de réseau
sans fil
On distingue plusieurs catégories de réseaux
sans fil, selon la zone de couverture.
v Les réseaux personnels sans fil (WPAN)
Le réseau personnel sans fil (appelé
également réseau individuel sans fil ou réseau domestique
sans fil et noté WPAN : Wireless
Personal Area Network),
concerne les réseaux sans fil d'une faible distance (environ 10
mètres).Il existe plusieurs technologies utilisées pour les
WPAN :
· Les technologies utilisées pour les
WPAN La principale technologie est Bluetooth,
proposant un débit théorique de 1Mbps pour une
portée maximale d'une trentaine de mètres. Bluetooth, connu aussi
sous le nom IEEE 802.15.1.
· Home RF (Home Radio Frequency),
lancée par le HomeRF Working Group (formé notamment par les
constructeurs Compaq, HP, Intel, Siemens, Motorola et Microsoft) propose un
débit théorique de 10 Mbps (une portée d'environ 50
à 100 mètres sans amplificateur. Cette technologie fut
remplacée par le
Wi-Fi
avec incorporation d'un microprocesseur et un adaptateur Wi-Fi)
· La technologie ZigBee (connue sous le
nom IEEE 802.15.4) permet d'obtenir des liaisons sans fil.
v Les réseaux locaux sans fils
(WLAN)
Le réseau local sans fil (WLAN pour Wireless Local Area
Network) est un réseau permettant de couvrir, l'équivalent d'un
réseau local d'entreprise, soit une portée d'environ une centaine
de mètres.
v Les réseaux métropolitains sans fil
(WMAN)
Le réseau métropolitain sans fil (WMAN :
Wireless Métropolitain Area Network) est connu sous le nom de Boucle
Locale Radio (BLR).
Les WMAN sont basés sur la norme IEEE 802.16. La Boucle
Locale Radio offre, un débit utile de 1 à 10 Mbit/s pour une
portée de 4 à 10 Km, ce qui destine principalement cette
technologie aux opérateurs de télécommunication.
v Les réseaux étendus sans fil
(WWAN)
Le réseau sans fil (WWAN : Wireless Wide Area
Network) est également connu sous le nom de réseau cellulaire
mobile.
Il s'agit des réseaux sans fil les plus répandus
puisque tous les téléphones mobiles sont connectes à un
réseau étendu sans fil. Les principales technologies
sont les suivantes :
ü GSM (Global System for Mobile
Communication (Groupe Spéciale Mobile)
ü GPRS (General packet Radio Service)
ü UMTS (Universal Mobile
Telecommunications System)
1.1.4. MODELE OSI (Open System Interconnect)
L'OSI est un modèle de base qui a été
défini par l'International Standard Organisation. Cette organisation
revient régulièrement pour normalisé différents
concepts, tant en électronique qu'en informatique.
Ce modèle définit 7 niveaux différents
pour le transport de données. Ces niveaux sont également
appelés couches.
Modèle fondé sur un principe
énoncé par Jules César : Diviser pour mieux
régner.
Le modèle OSI est un modèle préconisant
un certain nombre de règles à mettre en place pour interconnecter
un ensemble d'équipement. Le modèle OSI est un modèle
abstrait qui définit une terminologie, décompose les
systèmes de communication en sous ensemble fonctionnels appelés
couches.
L'OSI a pour but de spécifier les communications
entre systèmes informatiques ouverts.
L'OSI a décomposé les fonctions
nécessaires à la communication entre systèmes. Ces
fonctions sont réparties en 7 couches hiérarchisées
regroupées dans le "Modèle de référence" (IS 7498).
Ce modèle est avant tout abstrait. Les spécifications
définissent l'interaction entre les systèmes et non pas le
fonctionnement interne des systèmes.
Système très hiérarchisé : 7
couches et plusieurs sous-couches.
· Principes
o Regroupement de fonctions similaires dans une même
couche,
o Interface avec les couches immédiatement
supérieure et inférieure,
o Modifier une couche sans affecter les autres.
Modèle d'architecture générique.
Plusieurs tentatives d'implémentations par les constructeurs.
Aujourd'hui le modèle est conservé mais les protocoles sont
abandonnés.
a) Les sept couches du modèle d'OSI
La modélisation qui résulte de l'effort de
normalisation se nomme OSI (Open System Interconnexion), elle permet de
découper un problème de communication et se décompose en
sept couches.
Pour échanger des données entre deux
utilisateurs, différentes fonctions doivent être
réalisées.
Ces fonctions sont regroupées en « couches
».
Une couche est un domaine de normalisation où seront
fixées les règles de communication (les protocoles) qui
permettent aux mêmes couches de deux systèmes différents de
se parler, et des services qui définissent les fonctions de chaque
couche.
Le nom de « couche » montre bien le
cloisonnement de l'architecture. Les couches du modèle OSI sont
numérotées de 1 à 7, chaque couche des sept couches
de ce modèle représente une fonction nécessaire
à la communication. Cette répartition en couche a pour but de
rendre les différentes fonctions aussi distinctes et
indépendantes que possible, de manière à ce qu'une
modification au niveau d'une d'elles ne nécessite pas forcement de
changement au niveau des autres. Dans ce modèle, chaque couche est
censée fournir des services aux couches supérieures et utiliser
des données des couches inférieures.
|
Couches
|
Fonctions
|
|
Niveau 1
Couche Physique
|
La couche physique assure un transfert de
(bits) sur le support physique. Elle regroupe les
entités permettant l'interface avec le support physique aussi bien
mécanique, qu'électrique ou procédural.
|
|
Niveau 2
Couche de Liaison des données
|
La couche de liaison assure, sur la ligne, un service de
transfert de blocs de données (trames), entre deux
systèmes adjacents en assurant le contrôle,
l'établissement , le maintien et la libération du bien logique
entre les entités. Elle permet aussi, de détecter et de
corriger les erreurs inhérentes aux supports physiques.
|
|
Niveau 3
Couche Réseau
|
La couche réseau met en oeuvre les fonctions de
routage de données (paquets) à travers les
différents noeuds d'un sous - réseau, de prévention de
la congestion, l'adaptation de la taille des blocs de données aux
capacités du sous - réseau physique utilisé.
|
|
Niveau 4
Couche Transport
|
La couche transport assure le transfert de bout en bout
(d'utilisateur final à utilisateur final), des informations
(messages) entre les deux systèmes
d'extrémité.
La couche transport doit également assurer aux
couches hautes un transfert fiable quel que soit la qualité du
sous - réseau de transfert utilisé.
|
|
Niveau 5
Couche Session
|
La couche session gère l'échange de
données (transaction) entre les applications
distantes : elle synchronise les échanges et définit
des points de reprise sur incidents.
|
|
Niveau 6
Couche présentation
|
La couche présentation assure la mise en forme des
données, la conversion de codes nécessaires pour
délivrer à la couche supérieure un message
compréhensible.
|
|
Niveau 7
Couche d'application
|
La couche application comprend les programmes
d'applications ainsi que des fonctions applicatives
génériques permettant le développement d'applications
distribuées.
|
Tableau 1 - 1 Les Sept couches du
Modèle OSI
Remarque :
La couche liaison de données est divisée en deux
sous-couches :
§ La couche LLC (Logical Link Control, contrôle de
liaison logique) qui assure le Transport des trames et gère l'adressage
des utilisateurs, c'est à dire des logiciels des couches
supérieures (IPX, IP, ...
§ La couche MAC (Medium Access Control, contrôle
d'accès au support) chaque carte réseau a une adresse physique
unique (adresse MAC)) qui structure les bits de données en trames et
gère l'adressage des cartes réseaux.
b) Communication entre les
couches
La mise en relation d'équipement d'origines
diverses nécessite l'utilisation de technique de connexion
compatibles (raccordement, niveaux électrique, protocoles.....). La
description de ces moyens correspond à une structure de communication
appelé architecture de communication. Architecture de deux
systèmes reliés par des relais (commutateurs ou routeurs). On
remarque que chaque couche à ses propres règles de
dialogues avec son homologue.
Les systèmes relais (réseaux, routeurs, etc....)
peuvent être très nombreux entre les systèmes
d'extrémité (SE) (exp : station connectée sur serveur
Web). Le fait de mettre des relais entre des SE, revient à faire de
l'interconnexion de réseaux.
Application
Présentation
Transfert
Réseau
Session
Liaison données
Physique
Application
Présentation
Transfert
Réseau
Session
Liaison données
Physique
1
2
3
4
6
7
5
1
2
3
4
6
7
5
Support physique de transmission
B
Récepteur
A
Emetteur
Imaginons 2 systèmes voulant se transmettre des
informations.
Figure 1.5 Communication entre les
couches
Une application du système A veut émettre des
données vers une application du système B. L'information va
partir de la couche 7 du système A va atteindre la couche 1 du
système A va passer par le système de transmission (câble,
satellite ...) pour arriver à la couche 1 du système B qui va
faire remonter l'information vers la couche 7 du système B.
L'unité la plus petite est le bit et se situe
au niveau de la couche physique. Aucune donnée n'est directement
échangée d'une couche d'un système A vers une couche d'un
système B hormis au niveau de la couche physique. Par contre
"logiquement", une couche d'un système à discuter avec la
même couche d'un système B.
Les données émises d'un système A
à un autre et encapsulé par le système A. Quand le
système B veut comprendre les données émises par le
système A, il "décapsule" les couches successives.
On distingue plusieurs classes de transport suivant la
qualité des couches précédentes. Plus les couches
inférieures sont complètes, moins la couche transport travaille
et réciproquement.
c) L'encapsulation
Les données des utilisateurs traversent toutes les
couches du modèle OSI jusqu'au niveau physique qui génère
le signal transmis sur le media. Chaque couche rajoute des informations de
contrôle du protocole. C'est l'encapsulation des données.
Cet ajout détériore les performances de débit mais sont
nécessaires pour assurer les services des différentes couches :
adressage, contrôle d'erreurs, contrôle de flux...
A chacun de ces niveaux du modèle OSI, on encapsule
un en-tête et une fin de trame (message) qui comporte les informations
nécessaires en suivant les règles définies par le
protocole utilisé. Ce protocole est le langage de communication pour le
transfert des données (TCP/IP, NetBui, IPX sont les principaux) sur le
réseau informatique. Sur le schéma ci - dessous, la partie qui
est rajoutée à chaque niveau est la partie sur fond blanc. La
partie sur fond grisé est celle obtenue après encapsulation du
niveau précédent. La dernière trame, celle qu'on obtient
après avoir encapsulé la couche physique, est celle qui sera
envoyée sur le réseau.
d) Correspondance entre les couches du
modèle OSI et les types de composants
réseau
|
Couche du modèle OSI
|
Composant réseaux
|
|
Couche 1 + Couche 2 +Couche 3 : Réseau
|
Routeurs
|
|
Couche 1 +Couche 2 : Liaison des données
|
Ponts et commutateurs
|
|
Couche 1 : Physique
|
Câbles et concentrateurs (hub)
|
Tableau 1-2 Correspondance entre les
couches et composants réseau
1.1.4. Notion de Protocole
Un protocole est une série d'étapes à
suivre pour permettre une communication harmonieuse entre plusieurs
ordinateurs. Internet est un ensemble de protocoles regroupés sous le
terme "TCP-IP" (Transmission Control
Protocol/Internet Protocol).
Voici une liste non exhaustive des différents protocoles qui peuvent
être utilisés :
v HTTP : (Hyper Texte Transfert Protocol) :
c'est celui que l'on utilise pour consulter les pages web.
v FTP : (File Transfert Protocol) : C'est un
protocole utilisé pour transférer des fichiers.
v SMTP : (Simple Mail Transfert Protocol) :
c'est le protocole utilisé pour envoyer des mails.
v POP : C'est le protocole utilisé
pour recevoir des mails
v Telnet : utilisé surtout pour
commander des applications côté serveur en lignes de commande
v IP (internet Protocol) : L'adresse IP vous
attribue une adresse lors de votre connexion à un serveur.
Les protocoles sont classés en deux
catégories :
ü Les protocoles où les machines s'envoient des
accusés de réception (pour permettre une gestion des erreurs). Ce
sont les protocoles "orientés connexion".
ü Les autres protocoles qui n'avertissent pas la machine
qui va recevoir les données sont les protocoles "non orientés
connexion"
1.1.5. Base de données
1.1.4.1. Définition
Une base de données (en
anglais : database)
est un outil permettant de stocker et de retrouver l'intégralité
de
données
brutes ou d'
informations en
rapport avec un thème ou une activité ; celles-ci peuvent
être de natures différentes et plus ou moins reliées entre
elles4(*).
Dans la très grande majorité des cas, ces
informations sont très structurées, pour permettre des
opérations, parfois très complexes, de lecture, suppression,
déplacement, tri, comparaison, etc.
La base est localisée dans un même lieu et sur un
même support. Ce dernier est généralement
informatisé.
La base de données est au centre des dispositifs
informatiques de collecte, mise en forme, stockage, et utilisation
d'informations. Le dispositif comporte un
système
de gestion de base de données (abr. SGBD) : un logiciel
moteur qui manipule la base de données et dirige l'accès à
son contenu. De tels dispositifs -- souvent appelés base de
données -- comportent également des logiciels
applicatifs, et un ensemble de règles relatives à l'accès
et l'utilisation des informations
2.
La manipulation de données est une des utilisations les
plus courantes des ordinateurs. Les bases de données sont par exemple
utilisées dans les secteurs de la finance, des assurances, des
écoles, de l'épidémiologie, de l'administration publique
(statistiques notamment) et des médias.
Lorsque plusieurs bases de données sont réunies
sous forme de collection, on parle alors d'un entrepôt de
données (en
anglais : data
warehouse).
1.1.4.2. Différence
entre une base de données et un fichier de données
Par opposition au terme fichier de programme, un fichier de
donnés est un ensemble organisé d'enregistrements, traité
comme une unité et contenant de l'information textuelle et/ou sonore
et/ou graphique sous forme numérique.
Mis à part une différence que nous pouvons tirer
du point de vue des définitions des deux concepts (fichiers de
données et base de données), une différence plus
flagrantes s'impose : « on utilise une BD pour des
données de nature diverses et une BD offre la possibilité de
créer de nombreux liens entre ces données; par contre avec des
fichiers nous ne pouvons utiliser que des données homogènes
même si elles sont importantes en volume ».
1.1.4.3. Typologie des bases de
données
Les bases de données peuvent être
classifiées en fonction du nombre d'usagers un seul, un petit groupe,
voire une entreprise. Dans ce cas on parle de :
· Base de données de
bureau : installée sur un ordinateur personnel au
service d'un seul usager
· Base de données
d'entreprise : installée sur un ordinateur
puissant au service de centaines d'utilisateurs.
· Base de données
centralisée est installée dans un emplacement
unique ;
· base de données
distribuée est répartie entre plusieurs
emplacements5(*)
La typologie la plus populaire des bases de données est
selon l'usage qui en est fait, et l'aspect temporel du contenu:
· Les bases de données dites
opérationnelles ou
OLTP
(de l'anglaise online transaction processing) sont
destinées à assister des usagers à tenir l'état
d'activités quotidiennes. Elles permettent en particulier de stocker sur
le champ les informations relatives à chaque opération
effectuée dans le cadre de l'activité: achats, ventes,
réservations, payements. Dans de telles applications l'accent est mis
sur la vitesse de réponse et la capacité de traiter plusieurs
opérations simultanément6(*).
· Les bases de données
d'analyse dites aussi
OLAP
(de l'anglais online analytical processing), sont
composées d'informations historiques telles que des mesures sur
lesquelles sont effectuées des opérations massives en vue
d'obtenir des statistiques et des prévisions.
· Les bases de données sont souvent des
entrepôts
de données (anglais datawarehouse):
des bases de données utilisées pour collecter des énormes
quantités de données historiques de manière quotidienne
depuis une base de données opérationnelle. Le contenu de la base
de données est utilisé pour effectuer des analyses
d'évolution temporelle et des statistiques telles que celles
utilisées en
management. Dans
de telles applications l'accent est mis sur la capacité d'effectuer des
traitements très complexes et le logiciel moteur (le SGBD) est
essentiellement un moteur d'analyse7(*).
1.1.4.4. Avantage des bases de
données
Les bases de données sont bien plus efficaces lorsqu'il
s'agit de retrouver des informations. Vous pouvez poser une question à
une base de données, par exemple : « Combien de centre
hospitalier le patient a fréquenté durant les 5 dernières
années » ou « Quel patient a souffert de telle
maladie », et recevoir immédiatement la réponse.
Qui dit bases de données, dit également
précision. Dotées de listes déroulantes attractives, de
rubriques renseignées automatiquement et de bien d'autres fonctions
encore, les bases de données accélèrent la saisie des
données et veillent à leur cohérence.
La souplesse des impressions est l'un des autres points forts
des bases de données. Qu'il s'agisse d'imprimer des étiquettes de
publipostage, des rapports, des factures, des badges en vue de l'organisation
d'une manifestation ou de formulaires papier, tout est plus simple avec les
bases de données.
1.1.4.5. Caractéristiques des bases de
données
Les bases de données sont caractérisée
par leur capacité à :
* Ne pas accepter la redondance, c'est-à-dire
aucune donnée ne sera répétée dans la base de
données ;
* Ne pas permettre l'incohérence des
données ;
* Offrir une structuration optimale des
données être dans la base de données ;
* Assurer la sécurité des
informations ;
* Etre indépendante des programmes et des
données et à permettre la prise en compte facile de nouvelles
applications.
1.1.6. Système de gestion des bases de
données
1.1.4.6. Définition
Un système de gestion de base de données
(SGBD) est un ensemble de programmes qui permet la gestion et
l'accès à une base de données. Il héberge
généralement plusieurs bases de données, qui sont
destinées à des logiciels ou des thématiques
différentes8(*).
1.1.4.7. Fonctionnement d'un SGBD
On distingue couramment les SGBD classiques, dits SGBD
relationnels (SGBDR), des SGBD orientés objet (SGBDO). En fait, un SGBD
est caractérisé par le modèle de description des
données qu'il supporte (relationnel, objet etc.). Les données
sont décrites sous la forme de ce modèle, grâce à un
Langage de Description des Données (LDD). Cette description est
appelée schéma. Une fois la base de données
spécifiée, on peut y insérer des données, les
récupérer, les modifier et les détruire. Les
données peuvent être manipulées non seulement par un
Langage spécifique de Manipulation des Données (LMD) mais aussi
par des langages de programmation classiques.
Actuellement, la plupart des SGBD fonctionnent selon un mode
client/serveur. Le serveur (sous-entendu la machine qui stocke les
données) reçoit des requêtes de plusieurs clients et ceci
de manière concurrente. Le serveur analyse la requête, la traite
et retourne le résultat au client.
Quel que soit le modèle, un des problèmes
fondamentaux à prendre en compte est la cohérence des
données. Par exemple, dans un environnement où plusieurs
utilisateurs peuvent accéder concurremment à une colonne d'une
table par exemple pour la lire ou pour l'écrire, il faut s'accorder sur
la politique d'écriture. Cette politique peut être : les lectures
concurrentes sont autorisées mais dès qu'il y a une
écriture dans une colonne, l'ensemble de la colonne est envoyée
aux autres utilisateurs l'ayant lue pour qu'elle soit rafraîchie.
1.1.4.8. Typologie d'un SGBD
Les premiers S.G.B.D. sont apparus dans les années 1960
lorsqu'on s'est rendu compte que pour stocker les données d'une
application sur des fichiers il fallait, chaque fois, un grand effort pour
l'encodage et la gestion des informations. L'utilisation de formats de fichiers
spécifiques à chaque application était également
une barrière importante pour le partage d'informations entre plusieurs
applications. L'idée principale fut alors d'introduire, entre le
système d'exploitation et les applications, une couche de logiciel
spécialisée dans la gestion de données structurées.
L'un des premiers systèmes de grande ampleur à implanter une
telle couche fut le système IMS avec le langage DL/1 (data language
one), basé sur un modèle hiérarchique pour la
représentation des données.
a. Modèle hiérarchique
Le modèle hiérarchique, premier modèle de
SGBD, est un formalisme de base de données dont le système de
gestion lie les enregistrements dans une structure arborescente où
chaque enregistrement n'a qu'un seul possesseur. Elle a été
utilisée dans les premiers systèmes de gestion de base de
données de type mainframe et a été inventé par la
NASA.
b. Modèle réseau
Ce modèle est une extension du modèle
précédent (hiérarchique), et est en mesure de lever de
nombreuses difficultés du modèle hiérarchique grâce
à la possibilité d'établir des liaisons de type n-n
(plusieurs enregistrement pour plusieurs possesseurs) en définissant des
associations entre tous les types d'enregistrements.
Les deux paradigmes (hiérarchie et réseau)
étaient fondés sur des
langages navigationnels qui nécessitaient une
connaissance fine de la structuration des données pour leur exploration
et leur interrogation.
c. Modèle relationnel
En 1970, Ted Codd (A. M. Turing Award 1981), proposa
de faciliter et d'optimiser l'interaction avec les S.G.B.D. en utilisant le
modèle relationnel pour la représentation des données.
Dans ce modèle ensembliste, l'information est
organisée en plusieurs tables
ou relations homogènes qui peuvent être
interrogées et combinées grâce à des
opérateurs ensemblistes. Le succès du modèle relationnel
dans les S.G.B.D. modernes tient à sa simplicité (on n'est pas
obligé de connaître les détails d'implémentation
pour interroger la base), ses fondements logiques et son efficacité (il
existe des algorithmes et des structures de données efficaces pour
manipuler les données)9(*).
Le modèle relationnel est destiné à
assurer l'indépendance des données et à offrir les moyens
de contrôler la cohérence et d'éviter la redondance. Comme
dit ci-haut, Il permet de manipuler les données comme des
ensembles et
d'effectuer des opérations de la
théorie
des ensembles. Les règles de cohérence qui s'appliquent
aux bases de données relationnelles sont l'absence de redondance ou de
nul des
clés
primaires, et l'
intégrité
référentielle. Depuis 2010 la majorité des SGBD
sont quasiment de type relationnel:
d. Orienté objet(SGBDO)
Le modèle SGBDO est un modèle
relationnel mais auquel on rajoute des notions objets, avec stockage ou non des
objets dans des tables.
Vous vous demandez c'est quoi un objet ? Pas de soucis.
En
informatique, un
objet est un conteneur symbolique, qui possède sa
propre existence et incorpore des informations et des
mécanismes10(*),
éventuellement en rapport avec une chose tangible du monde réel,
et manipulés dans un
programme.
C'est le concept central de la
programmation
orientée objet.
Il existe d'autres types de SGBD non
référencés ou cités dans ce travail et dont
l'apparition remonte dans les années 1990. Il s'agit des modèles
semi-structurés, mieux adaptés à la gestion et à
l'intégration de documents hétérogènes tels qu'ils
sont publiés sur le Web. Le standard XML est un représentant de
ce type de modèles.
Chapitre II
Le Cloud Computing
Le Cloud est apparu, pour satisfaire l'exploitation des
services et des espaces de stockage informatiques disponibles chez un
fournisseur, par des clients qui sont des entreprises externes. Les
méthodes utilisées pour finaliser le service entre un fournisseur
et un client final, se présentent sous quatre formes : l'application, la
plate-forme, l'infrastructure et les données. L'application reste en
contact direct avec le client. La plate-forme réalise l'application.
L'infrastructure supporte la plate-forme et les données sont
délivrées sur demande.
Les services offerts par le Cloud Computing, proviennent
d'énormes centrales numériques appelées datacenters, qui
utilisent des logiciels basés sur les techniques virtuelles. A cause de
leur coût d'investissement initial, ces types d'appareils ne sont
accessibles que par des grosses sociétés. Elles sont alors mises
à la disposition des clients, par leurs intermédiaires.
Cependant, après l'adoption du Cloud, les usagers se soucient beaucoup
du problème de performance, de disponibilité d'accès des
données, de leur sécurité et de leur
intégrité.
Si vous êtes intéressés, les
possibilités informatiques qui vous sont présentées, ont
en général des dimensions modulables au cours du temps. Sans
avoir à acheter de grosses unités avec de gros serveurs, vous
disposez d'une capacité de stockage infinie. Il vous suffirait de
quelques minutes pour actionner un nouveau serveur dans le Cloud. Vos pointes
de charges sont facilement absorbées, grâce aux processeurs et aux
réseaux de haute performance. La disponibilité des ressources est
assurée par contrat type SLA ou Service Level Agreement. Le fournisseur
peut vous garantir par exemple, une indisponibilité inférieure
à 5 minutes par an, sinon il vous rembourse.
Le respect de la qualité de service dans un Cloud, fait
appel à la mise en place d'un moyen de mesure fiable et impartial, par
le biais d'une approche réseau. C'est le SLM ou Service Level
Management, qui accompagne le SLA. Dans un premier temps, vous pouvez opter
pour l'installation d'un processus de tests sur le plan protocolaire. Pour les
réseaux IP par exemple, deux familles, la RFC 2330 pour l'IETF et
l'Y.1540 pour l'ITU-T, ont apporté la Qualité de Service des
réseaux IP. Par ailleurs, les équipes travaillant pour un Cloud,
restent présentes sur site en 24 x 7. Ce principe permet de satisfaire
tous les clients du monde, indépendamment des décalages
horaires.
La correction de la norme RF544, prévue pour suivre les
performances d'un matériel particulier au niveau Ethernet, apporta
l'IUT-TY.1564. Ce dernier amena des services, des débits de tests, le
CIR, l'EIR et l'Overshoot. Il donna également, deux types de test pour
la configuration et la performance, et quatre métriques pour le
débit, la latence, la gigue et la perte.
L'adoption d'un Cloud, apporte des avantages certains pour les
entreprises. Outre la limitation de ses machines informatiques, qui dispense de
toutes les activités de maintenance et de prestations, elles participent
à la sauvegarde de l'environnement. Finis les recherches et les achats
de logiciels, aussi simples que complexes. Finis les licences serveurs et
clientes.
Elles éviteront les batailles avec les
problématiques liés aux données, comme les backups, et
ceux liés aux calculs, comme l'insuffisance des ressources CPU. Elles ne
se soucieront ni des différents tests inhérents aux nouveaux
logiciels, ni de leurs mises à jour, qui prennent beaucoup de temps. Peu
leur importe les changements de normes ou l'internationalisation des SI. La
seule occupation de l'entreprise client, est de sortir ou rentrer ses
données, avec un minimum de suivi interne. L'économie est saine
et nette !
2.1. DEFINITION
Le coud computing est un ensemble de services qui permet
à un utilisateur, de transférer ses stockages et ses traitements
informatiques, depuis un ou plusieurs de ses serveurs locaux, vers d'autres
serveurs extérieurs.
2.2. BREF APERCU DU CLOUD
Le cloud computing est une expression
imagée désignant un ensemble de technologies matérielles
et logicielles qui offrent à un utilisateur ou à une entreprise
le moyen d'accéder en libre-service, n'importe quand et n'importe
où, à des fichiers personnels, des applications logicielles
opérationnelles ou toute autre ressource numérique au travers
d'une infrastructure réseau fiable et sécurisée11(*). Traduit en français
par informatique dans les nuages, informatique
dématérialisée ou encore informatique virtuelle, ce
concept rend possible l'externalisation de la puissance de calcul et de
stockage. Il permet de déporter, sur des serveurs distants, des
traitements informatiques traditionnellement exécutés sur la
machine locale de l'utilisateur.
L'intérêt d'une telle approche est double :
la machine client de l'utilisateur devient un simple terminal peu gourmand en
ressources, et la gérance informatique n'est plus assurée
localement sur chaque poste mais de manière globale et unifiée
par un prestataire tiers. L'utilisateur a virtuellement les avantages d'un
accès garanti à une capacité de calcul et à un
espace de stockage modulables (voire infinis), sans les inconvénients
d'installation, de maintenance logicielle, de sécurisation et de
sauvegarde de données.
Pour l'entreprise, le cloud computing correspond à une
utilisation systématique et raisonnée de technologies
éprouvées avec pour objectif de diminuer considérablement
les coûts associés à la gestion des ressources et des
services informatiques. La charge de cette gestion peut même être
confiée comme mission à une entreprise externe
spécialisée, en partie ou en totalité. En cela, le cloud
computing est avant tout un principe économique et non technologique.
2.3. HISTORIQUE
Comme tous les concepts relevant autant de l'économie
que de la technologie, il est difficile de dire avec précision quand a
été inventé le cloud computing12(*). Selon certains, il faut
remonter en 1960, avec les travaux de l'Américain John McCarthy
(1927-2011), un des pionniers de l'intelligence artificielle qui
considérait d'emblée l'informatique comme un service. Selon une
autre source, c'est l'avènement des réseaux dans les
années 1970 qui a rendu possible l'exécution
déportée des tâches informatiques.
D'autres enfin mentionnent le fait qu'Amazon, site de commerce
électronique de dimension mondiale, a trouvé dans le cloud
computing une solution élégante à la sous-utilisation de
son parc de serveurs informatiques en dehors des périodes de fête
(qui représentent en termes de commandes un pic temporel ponctuel
d'utilisation). En louant ses serveurs à la demande et en proposant
à ses clients ses outils S3 (simple storage service) et E
(elastic compute cloud), qui offrent respectivement des services de
stockage de données et de calcul, Amazon a pu rentabiliser ses propres
investissements en matériel informatique.
L'expression « cloud computing » a, quant
à elle, été citée pour la première fois en
1997 par un professeur en systèmes de l'information, Ramnath Chellappa,
qui a défini les limites de l'informatique non en termes techniques mais
en termes économiques. D'autres sociétés, comme
Salesforces, Google 101, ou IBM ont commencé dès 1999, à
développer une économie numérique fondée sur ces
principes. Toutes ces entreprises de dimension mondiale participent de
manière active à la création de centres
(data-centers ou clusters) offrant une puissance de calcul et de stockage
inégalée. Ces data-centers sont un des enjeux stratégiques
majeurs de la décennie 2015-2025.
2.4. ENJEUX ECONOMIQUES
Selon le cabinet d'études IDC, les dépenses en
matière de Cloud Computing vont croître au cours des 5 prochaines
années, aussi bien dans le domaine du Cloud public que dans celui du
Cloud privé. Comment aborder, financièrement, ce passage au Cloud
en entreprise ?
« Malgré les incertitudes économiques
actuelles, IDC prévoit que les fournisseurs de services Cloud - à
la fois publics et privés - seront parmi les plus dépensiers
parmi les fournisseurs de produits et services IT », avance Richard
Villars, vice- président systèmes de stockage chez IDC. Une bonne
nouvelle pour les fournisseurs du secteur du Cloud. Voici les objectifs
financiers majeurs à garder à vue pour une entreprise se tournant
vers le Cloud.
· Stockage local et infrastructures
internes
Le premier point concerne logiquement le stockage local. Bien
entendu, les frais liés au stockage local des données sont
amenés à diminuer lors du passage au Cloud. Cette transition va
ainsi abaisser les coûts permanents associés à l'archivage
d'informations à long terme.
Dans un second temps, cela peut également amener une
restriction voire une disparition des investissements internes en
matière d'infrastructure informatique lors de charges de travail
imprévisibles : l'entreprise peut facilement et rapidement exploiter une
solution PaaS ou SaaS.
Ensuite, en passant à une interface SaaS
développée selon le mode de fonctionnement de l'entreprise,
celle-ci peut également permettre une optimisation des applications de
gestion de l'information au sein d'une entreprise. Ainsi, les mails, les
services de messagerie instantanée ou encore un Intranet
transférés dans le Cloud sont disponibles plus facilement,
à un coût d'accession moindre.
· Quantifier le gain de productivité :
mission impossible ?
Enfin, une dernière donnée plus difficilement
quantifiable est à prendre en compte lors d'un éventuel passage
d'une entreprise vers le Cloud : le gain de productivité et de temps.
Avec une information accessible plus facilement et plus rapidement,
combiné à une flexibilité importante en matière
d'infrastructure informatique sans oublier l'externalisation de gestion du
stockage des informations, cela permet aux différents acteurs de se
recentrer sur leur tâche principale, et ce à tous les
échelons de l'entreprise.
Cependant, il faut garder à l'esprit que le passage au
Cloud implique également une attention forte pour ne pas perdre,
après quelques mois d'utilisation, les gains économiques
envisagés. Dans le Cloud comme au sein d'un Service Informatique (SI)
classique, la gestion des identités et de leur contrôle sur le
service exploité est essentielle pour aboutir à une
maîtrise durable des coûts.
2.5. ARCHITECTURES
Le Cloud est donc ainsi, la mise en disponibilité, ou
la flexibilité de ces quatre formes qui ne peuvent pas s'imbriquer. On
trouve en général les termes suivants, pour désigner la
transformation en Cloud de ces formes. Le « Software as a Service »,
ou SaaS, qui est le découpage de l'application en services. La «
Platform as a Service » ou PaaS, est la plate-forme granulaire. «
L'Infrastructure as a Service » ou IaaS, est l'infrastructure
virtualisée et le « Data as a Service » ou le DaaS, concerne
les données livrées à un endroit précis13(*).
a) IaaS (Infrastructure as a
Service)
Dans le modèle IaaS, seul le
matériel (serveurs, baies de stockage, réseaux) qui constitue
l'infrastructure est hébergé chez un prestataire ou un
fournisseur. Avec l'IaaS, l'entreprise bénéficie d'une
infrastructure mutualisée (pour des raisons évidentes de
coûts des matériels) et automatisée. Avec un modèle
IaaS très flexible, l'entreprise peut diminuer ou augmenter ses
ressources IT en fonction de ses besoins actuels et futurs.
b) Paas (Platform as a Service)
Le modèle
PaaS
se place sur le niveau supérieur de l'IaaS en offrant aux entreprises un
environnement leur permettant de déployer leurs développements.
Le PaaS fournit ainsi des langages de programmation, des bases de
données et différents services pour faire fonctionner leurs
applications. De plus, il automatise entièrement le déploiement
(mises à jour, correctifs, etc.) et la montée en charge.
c) SaaS (Software as a
Service)
Le modèle SaaS fournit des
applications à l'utilisateur sous la forme d'un service prêt
à l'emploi qui ne nécessite aucune maintenance : les mises
à jour étant régulièrement faites par
l'éditeur. Il est donc perçu, à juste titre par les
utilisateurs, comme un modèle de consommation des applications.
d) DaaS (Data as a Service)
Le Data as a Service (DaaS) est le
service du cloud qui permet aux entreprises d'accéder à des bases
de données distantes pour y lire et écrire des données. Le
DaaS est un service de stockage de données qui offre aux utilisateurs de
très fortes garanties d'intégrité (aucune perte ou
altération de données ; politiques de sauvegarde
quotidienne, hebdomadaire mensuelle et annuelle, sur supports persistants).
Comme il peut s'agir de quantités de données énormes
(plusieurs giga/téraoctets), les fournisseurs DaaS (quelques centaines
à travers le monde) appliquent des tarifs de location fondés sur
le volume, le type des données transférées, la
politique et
la fréquence des archivages.
Dans certains cas, les clients sont facturés en
fonction de la quantité de données qu'ils utilisent, en
consultation comme en stockage. Dans d'autres, les données sont
classées par type (financier, organisationnel, historique,
géographique, etc.) et une valeur marchande est associée à
chaque type. Les prestataires de service DaaS imposent souvent des quotas de
transfert ainsi que des tailles d'espace de stockage.
Le DaaS souffre des mêmes inconvénients que le
SaaS et repose sur la capacité du prestataire cloud à offrir une
qualité de service irréprochable (absence de pannes, débit
de données suffisant, cohérence des bases de données,
archivage, etc.). Une autre critique souvent formulée à
l'encontre du DaaS est la nécessité de télécharger
à chaque session de travail des données qui pourraient être
facilement stockées sur la machine locale une fois pour toutes, mais qui
courent le risque de devenir à la longue incohérentes avec la
base de données de référence qui est, par nature,
perpétuellement mise à jour sur le serveur distant.
2.6. LES PROTOCOLES UTILISES DANS LE CLOUD
Le IaaS (Infrastructure As A Service) permet d'offrir
à un client un ensemble de serveurs virtualisés managé en
grande partie par lui-même. Il est du ressort de nuage de mettre à
disposition les machines virtuelles, avec un réseau public ou
privé en fonction des besoins exprimés14(*).
Les techniques habituelles de segmentation Ethernet (comme les
VLANs) ne sont plus assez efficaces pour répondre à ce besoin et
il devient nécessaire de se pencher vers de nouveaux protocoles.
Ces problèmes doivent répondre aux besoins
suivants :
· la sécurisation des flux entre les clients et
l'infrastructure ;
· la mobilité des machines virtuelles ;
· la dynamique sur la gestion de l'infrastructure.
On peut distinguer deux cas de figure :
· la mise à disposition d'IPs publiques ;
· la création de réseaux privés
entre les machines virtuelles d'un IaaS.
L'utilisation de LISP pour la mise à disposition d'IPs
publiques offre de nombreux avantages, mais le principal dans une offre Cloud
est la séparation de l'identification et de la localisation au niveau de
l'adresse IP. Ces deux notions sont habituellement corrélées en
routage IP « classique », ici l'identification est
l'adresse IP publique et la localisation est l'emplacement réel de la
machine virtuelle sur l'infrastructure. Ainsi, lorsque la machine change
d'emplacement sur l'infrastructure, le protocole LISP pourra optimiser son
routage interne afin de pouvoir la suivre rapidement.
Pour créer des réseaux privés sur des
infrastructures cloud, plusieurs protocoles ont vu le jour, notamment
NVGRE (Network Virtualization using Generic
Routing Encapsulation), VXLAN (Virtual
EXtensible LAN), STT (Stateless Transport
Tunnelling) ou encore TRILL (TRansparent
Interconnection of Lots of Links). Chacun a ses particularités,
mais tous peuvent permettre l'ajout de nouveaux réseaux privés
sans modifier l'infrastructure coeur. Tous ces protocoles vont permettre de
créer un réseau niveau 2 (Ethernet) sur un réseau existant
(de niveau 2 à 4). La configuration de ces types de réseau se
fait dynamiquement, permettant de faciliter la gestion, l'ajout d'une nouvelle
machine virtuelle ne demandant pas de provisioning spécifique sur la
partie réseau.
NVGRE utilise les tunnels GRE sur IP et est en cours de
standardisation par Microsoft et intégré à Hyper-V. Le
problème de NVGRE est que le standard définit uniquement un
« data plane » en laissant le
« control plane » libre en fonction des
constructeurs. Ceci limite fortement son adoption par le manque
d'interopérabilité.
VXLAN est une encapsulation niveau 2 sur UDP/IP qui est
également en cours de standardisation. Contrairement à NVGRE la
spécification du protocole est complète, tant sur le
« data plane » que sur le « control
plane ». VXLAN utilise le multicast afin de gérer
l'apprentissage des adresses MAC.
NVGRE et VXLAN s'affranchissent de la limite du tag VLAN
à 4096 valeurs maximum, en utilisant un tag sur 24bit, permettant de
segmenter plus librement le réseau entre les différents
réseaux privés ou IaaS.
Il existe aussi le protocole STT qui se rapproche de VXLAN et
NVGRE disponible dans VMWare NSX. Son objectif est d'exploiter les fonctions
accélératrices des cartes réseaux existantes en utilisant
un « faux entête TCP ». Il utilise également
un tag sur 32bit afin de pouvoir partitionner le réseau. NVGRE ne
prévoit rien concernant l'apprentissage des adresses MAC dans le
« control plane » et est laissé aux choix
des éditeurs/constructeurs. STT a l'avantage de pouvoir facilement
exploiter « l'equal-cost multi-path » mis en place
sur le niveau 3.
Cependant au même titre que NVGRE et en raison de la
structure de leur « data plane« , ils passent
difficilement les pare-feux, ce qui peut être un désavantage lors
de déploiements de grande envergure ou lorsque le réseau n'est
pas maîtrisé.
En revanche, TRILL sert avant tout à remplacer le
protocole STP (Spanning Tree Protocol), gérant les boucles sur
un réseau Ethernet. Il permet l'exploitation optimale d'un maillage
Ethernet, contrairement au STP qui bloquait obligatoirement certains chemins.
De plus, des extensions dans TRILL sont possibles pour segmenter le
réseau en différents IaaS. L'avantage de TRILL sur les autres
protocoles d'encapsulation Ethernet sur IP est sa restriction au niveau
Ethernet, avec les avantages en terme d'efficacité dans l'utilisation du
canal et dans le temps de commutation.
Tous ces protocoles viennent bouleverser le monde du
réseau, puisqu'ils apportent la sécurité nécessaire
à la livraison de services réseau souhaitée dans nuage.
Aujourd'hui, les protocoles en plein essor sont surtout ceux ayant des
spécifications complètes tels que TRILL, LISP et VXLAN. Ceux-ci
garantissent une interconnexion avec d'autres systèmes et constructeurs
et font l'objet de développements au sein de la communauté
Linux.
Comme nous venons de le voir, et en pleine conformité
avec son cahier des charges initial, nuage fait appel uniquement à des
protocoles libres, sécurisés et standardisés.
Cela permet un excellent niveau de résilience au sein
de nuage, le Cloud solidaire et responsable.
2.7. LES PRINCIPAUX ACTEURS DANS LE CLOUD
Le marché
de l'hébergement dit « Cloud » est
devenu pléthorique depuis quelques temps mais il existe des mastodontes
qui font office d'institution. Autant dire que les Datacenter qui les
hébergent sont colossaux.
v
SalesForce : a été la première
offre CRM online. Suivant l'adage « premier arrivé,
premier servi » cette société est rapidement
devenue leader sur un marché vacant.
v Amazon Web
Service : est une
collection de produits étiquetés Cloud Computing avec
notamment
Amazon Elastic Compute Cloud (Amazon
E), qui permet d'exécuter des applications dans un environnement
dont la puissance s'adapte automatiques aux besoins du moment et
Amazon Elastic
MapReduce, système de bases de données non
transactionnelle utilisé pour de très grosses quantités de
données.
v Google : Si le moteur de
recherche n'est plus à présenter,
Google offre une liste
impressionnante de services. En faire la liste exhaustive nécessiterait
plusieurs articles et le mieux mais pour les découvrir je vous invite
à aller voir ces deux pages :
Google Products &
Google Labs.
v Windows Azure : Microsoft
s'implique aussi dans le monde du Cloud.
Windows
Azure est un ensemble de solution avec une approche type PAAS.
Cette plate-forme propose un socle assez riche de
fonctionnalités.
2.8. SECURITE DANS LE CLOUD
Malgré les projets d'investissement des entreprises
dans les applications de collaboration et de service à la
clientèle, CRM, il subsiste des craintes dans le domaine de la
sécurité et de disponibilité. Selon un sondage
effectué par le Cloud Industrie Forum en 2011, sur 300 entreprises, 62%
sont préoccupées par la sécurité des
données. Elles la placent comme la première condition d'adoption
d'un Cloud.
Heureusement, ces craintes sont compensées par les
avantages apportés par les investissements. Le Virtual Private Cloud ou
VPC d'Amazon semble garantir un contrôle de la sécurité
dans le Cloud. Il nécessite des pare-feu entrants obligatoires à
états (stateful firewalls), et comporte des pare-feu sortants. Ainsi,
toute entrée et sortie de la machine est contrôlable. AWS renforce
la sécurité au niveau de l'hyperviseur, mais il appartient
également au client, de définir son niveau de tolérance
sur l'exposition de l'information. Le « coffre-fort numérique
» existe également. Une fois que les données sont
chiffrées, à part le détenteur du code, même le
fournisseur ne peut pas y accéder. Vous avez donc le devoir de choisir
les outils de sécurité à mettre en service. Il y a de plus
en plus d'offres de MDM sur le marché.
Les prestataires de soins restent plutôt prudents, car
6% seulement des leurs responsables IT, attribuent 10% de leur budget au Cloud
Computing. Ils exigent que les infrastructures restent privées, à
cause de la sécurité des données, et de la
nécessité de normaliser l'audit vis-à-vis des exigences
légales.
2.9. AVANTAGES ET INCONVENIENTS
a) Avantages
L'adoption d'un Cloud, apporte des avantages certains pour les
entreprises. Outre la limitation de ses machines informatiques, qui dispense de
toutes les activités de maintenance et de prestations, elles participent
à la sauvegarde de l'environnement. Finis les recherches et les achats
de logiciels, aussi simples que complexes. Finis les licences serveurs et
clientes.
Elles éviteront les batailles avec les
problématiques liés aux données, comme les backups, et
ceux liés aux calculs, comme l'insuffisance des ressources CPU. Elles ne
se soucieront ni des différents tests inhérents aux nouveaux
logiciels, ni de leurs mises à jour, qui prennent beaucoup de temps. Peu
leur importe les changements de normes ou l'internationalisation des SI. La
seule occupation de l'entreprise client, est de sortir ou rentrer ses
données, avec un minimum de suivi interne. L'économie est saine
et nette !
Le Cloud vous soulagera des problèmes relatifs aux
données. Il a une Haute disponibilité, un espace de stockage
pratiquement illimité, et une sécurité absolue de
l'installation. Vous ne risquez pas de perdre vos données, et aucun
intrus physique ne pourra dérober vos travaux ou votre logiciel. Vous
n'avez pas à craindre les pannes éventuelles, soit de votre
installation, soit de votre logiciel. Comme vous n'avez pas à
acquérir un quelconque logiciel, vous économiserez en temps et en
coût d'installation, et en coût d'acquisition. On peut citer le
coût d'achat ou de location de serveur, le coût des licences de
logiciels et le coût des administrateurs des systèmes qui le
soutiennent.
b) Inconvénients
Si vous acceptez le transfert de vos données au cloud,
vous devriez procéder à l'audit de votre système
d'information. Après sélection des serveurs que vous souhaiteriez
déplacer dans le cloud, vous effectuerez le choix des fournisseurs de
cloud qui vous semblent les plus adaptés à vos attentes. Vous
vous chargerez des comparaisons de coûts, avant de prendre les
décisions finales.
Vous ne pourriez pas effectuer trop rapidement vos transferts.
Vous le feriez progressivement, pour éviter toute action brutale au
niveau de votre entreprise. En effet, la mutation d'un ou plusieurs de vos
serveurs, entraînera une diminution de matériels et de
prestations. A titre d'exemple, la suppression de votre serveur de mails
Microsoft Exchange, vous obligera à réduire votre personnel
administrateur en conséquence. La disponibilité des services, est
offerte uniquement par contrat avec le fournisseur de Cloud Computing.
Le contrat doit inclure le régime de protection de vos
données et que vous aurez à définir. A ce propos, la
Directive 95/46/CE du 24 Octobre 1951reste applicable en Europe. En France, la
loi du 6 Août 2004, a permis d'aligner la loi informatique et
Libertés (LIL) du 6 Janvier 1978 avec cette Directive. La LIL
régit le traitement des données personnelles et stipule que le
responsable du traitement est le client, et le « Cloud Provider » est
l'organe de traitement.
Chapitre III
Déploiement d'une base de données vers
SQL AZURE
3.1. Présentation de SQL AZURE
SQL Azure est un système de gestion de base de
données dans le Cloud, qui se base sur SQL Server 2008.
Dans les grandes lignes, utiliser SQL Azure revient à
utiliser une base de données SQL Server, avec un coût de licence
grandement diminué, et une couverture quasiment complète des
fonctionnalités de SQL Server 2008.
Il est possible d'accéder à ces données
de la même façon que l'on accéderait à une base de
données SQL Server classique, que ce soit depuis des applications
hébergées dans Windows Azure, ou depuis toute autre application
capable de s'interfacer avec SQL Server.

En parallèle à SQL Azure, un ensemble d'outils
sont en cours de développement, ou déjà disponibles, pour
étendre les fonctionnalités de base d'un SGBD.
Figure 3 - 1 : Présentation
SQL AZURE
SQL Azure Data Sync permet de synchroniser les données
entre plusieurs bases de données SQL Azure, à l'intérieur
d'un Data Center, ou entre Data Centers (actuellement, il existe 6 Data Centers
Azure dans le monde). Data Sync est actuellement en CTP1
SQL Azure Reporting devrait être disponible en fin
d'année 2010, et fournir un équivalent dans le Cloud à
Reporting Services.
3.2. INTRODUCTION AU DEPLOIEMENT
3.2.1. MODE DE DEPLOIEMENT
3.1.1.1. Cloud Public
Le Cloud public est une plate-forme Cloud Computing,
gérée par des entreprises spécialisées15(*). Elles louent ensuite leurs
services à plusieurs autres entreprises. Le principe de cette
plate-forme est basé sur l'hébergement d'applications, web en
général, sur une plate-forme accessible uniquement par internet.
Les ressources y sont mutualisées au maximum.
Le Cloud public, permet ainsi, la création de
multitudes d'environnements d'exécution, sur une même plate-forme.
Pour utiliser ce type de stockage, il vous suffirait de choisir les domaines ou
instances de calculs, de composer vos projets par le biais de l'interface
gestion, ou à travers vos scripts basés sur le web service
correspondant. Chaque domaine ouvert est compté par heure. La
facturation de votre Cloud ne contient ni abonnement, ni frais de mise en
service, ni frais masqué. Vous règlerez à chaque fin de
mois, uniquement votre consommation réelle du mois.
Cependant, le Cloud public ne permet pas l'hébergement
de toute une infrastructure informatique. Dans cette forme de stockage, vous
pouvez découvrir par exemple, des utilisations en ressources
supplémentaires, pour l'absorption de forts trafics ponctuels pendant
une période bien définie. L'accès à ces ressources
s'arrête dès que le trafic retourne à la normale.
3.1.1.2. Cloud Privé
La définition du Cloud privé est sujette
à des controverses. Les grandes entreprises fournisseurs,
considèrent que l'implémentation d'un Cloud privé,
consiste à transformer, grâce à des technologies de
virtualisation et d'automatisation, l'infrastructure interne d'un
système informatique. L'objectif à atteindre ainsi, est de
fournir rapidement à des clients, à la demande et d'une
manière simple, des services et des ressources. Parfois, vous pouvez
entendre parler d'internal Cloud. Ce terme est traduit par Cloud privé
interne ou Cloud interne.
Du côté hébergeur, une telle plate-forme
est perçue comme la mise à la disposition à un client,
d'un ensemble de ressources, telle une Mémoire, un CPU, un Disque, un
Réseau et autre, qui lui permet d'installer une infrastructure
complète. Dans cette situation, on parlera de cas d'offre IaaS, ou
Infrastructure as a Service.
Le Cloud privé est prévu pour offrir aux
entreprises, des services qui leur permettront de mieux maîtriser leurs
ressources informatiques. L'entreprise peut gérer son infrastructure en
solitaire, au rythme de ses besoins, ou passer par la mutualisation. Ce type de
stockage peut être ainsi considéré d'une part, comme
l'installation d'un réseau informatique propriétaire. D'autre
part, on peut le désigner comme un centre de données qui fournit
des services hébergés pour un certain nombre d'usagers. Il leur
délivre des accès, particulièrement favorables pour leurs
applications hébergées.
On distingue les Cloud privés internes, utilisés
par une entreprise pour satisfaire ses propres besoins. Ils sont
administrés en interne par l'entreprise même. Il y a aussi les
Cloud privés externes, destinés à satisfaire les besoins
propres d'une entreprise cliente. Leurs gestions sont confiées à
un prestataire extérieur. On parle alors de gestion externalisée.
Dans ce cas, une partie de ses services externalisés, est prise en
charge par un prestataire de confiance.
3.1.1.3. Cloud Hybride
L'idée de combiner le Cloud privé avec le Cloud
public, a entraîné la conception d'un autre pseudo-type de Cloud,
le Cloud hybride ou mixte. En réalité, ce type de plateforme
hybride n'est pas un Cloud à part entière. Puisqu'on cherche
à mettre ensemble et à faire communiquer les deux modes
précités, le Cloud hybride sert donc uniquement de liaison entre
eux. La tendance actuelle des services de stockage s'oriente vers l'adoption du
Cloud hybride. Dès que vous pensez déployer un Cloud
privé, vous devez considérer également celui public en
excès, en prévision des surcharges de vos capacités
internes. Et l'hybride vient compléter l'ensemble. Mais la mise en place
d'une plate-forme de fédération des identités, ou
l'utilisation d'un service Cloud, n'est pas un Cloud hybride.
Des problèmes techniques peuvent surgir lors de
l'installation du système hybride.
L'hybride est souvent employé, pour englober les pics
de charges ponctuelles comme avec le public, tout en restant lié
à un privé. Les deux infrastructures communiquent donc ainsi, et
forment un Cloud hybride. C'est alors un moyen de combiner, les avantages
apportés par les deux plateformes. On peut mentionner la souplesse des
infrastructures, la facilité de déploiement d'une application,
ainsi que la réalisation d'économies. Il y a en plus,
l'amélioration de la performance et la sécurité du
système d'information interne.
Les entreprises intéressées, doivent analyser
leur niveau d'activité, leur périodicité, leur
système d'information et leurs besoins, avant de penser à
transférer l'ensemble de leur infrastructure dans un Cloud public. Bien
que les Cloud privés soient très sécurisés, leur
manque de flexibilité ne doit pas empêcher leur intégration
dans des systèmes hybrides. Les hybrides, peuvent associer les
ressources physiques et virtuelles, celles virtuelles et propriétaires,
ou celles hébergées et internalisées.
3.1.1.4. Cloud Communautaire
Le Cloud Communautaire, est un Cloud utilisé par
plusieurs entités ou organisations, qui sont animées de besoins
communs. Il peut être employé pour des applications
génériques, avec des particularités ajustées aux
contraintes du groupe. Vous pouvez trouver en exemple le stockage Communautaire
monté par la GSA aux Etats Unis, pour les organisations gouvernementales
américaines. Ce type de plateforme peut héberger une application
métier spécifique, louée en commun par plusieurs
entreprises.
Les solutions Cloud Communautaires se sont
démarquées par la possibilité à résoudre la
complexité grandissante des processus de réservations. On
retrouve celles-ci, non seulement pour le trafic aérien, mais aussi pour
les hôtels, les locations de voitures... Les vols effectués le
même jour, par plusieurs compagnies différentes avec des voyageurs
de destinations diverses, sont autant de facteurs difficiles à
gérer. Ainsi, une compagnie aérienne logique, ne cherchera plus
à créer sa propre application de réservation.
3.3. MIGRATION VERS SQL SERVER DANS LES MACHINES
VIRTUELLES AZURE
3.3.1. Plan de Migration
Le tableau suivant récapitule les options de
déplacement de données vers SQL Server sur une machine
virtuelle Azure.
Tableau 3 - 1 :
Récapitulation Plan de Migration
Notez que ce document suppose que les commandes SQL sont
exécutées à partir de SQL Server Management Studio ou
Visual Studio Database Explorer.
ü Configuration requise
Ce didacticiel part du principe que vous disposez de :
· Un abonnement Azure. Si vous
n'avez pas d'abonnement, vous pouvez vous inscrire à un
essai
gratuit.
· Un compte de stockage Azure. Dans
ce didacticiel, vous allez utiliser un compte de stockage Azure pour
stocker des données. Si vous ne possédez pas de compte de
stockage Azure. Après avoir créé le compte de
stockage, vous devrez obtenir la clé du compte utilisée pour
accéder au stockage.
· Approvisionnement d'un serveur SQL Server
sur une machine virtuelle Azure. Pour obtenir des instructions.
· Azure PowerShell installé
et configuré localement. Pour obtenir des instructions.
ü Déplacement des
données à partir d'un fichier plat source vers SQL Server
sur une machine virtuelle Azure
Si vos données se trouvent dans un fichier plat (au
format ligne/colonne), les méthodes suivantes permettent de les copier
dans l'instance SQL Server VM on Azure :
1.
Utilitaire
de copie en bloc à ligne de commande (BCP)
2.
Requête
SQL Bulk Insert
3.
Utilitaires
graphiques intégrés dans SQL Server (Importation/Exportation,
SSIS)
§ Utilitaire de copie en bloc à ligne de commande
(BCP)
BCP est un utilitaire à ligne de commande,
installé avec SQL Server. C'est l'un des outils les plus rapides pour
déplacer des données. Il fonctionne sur les trois variantes
de SQL Server (instance SQL Server locale, SQL Azure et machine
virtuelle SQL Server sur Azure).
Remarque :
Où mes données doivent-elles se trouver
pour BCP ?
Ce n'est pas une obligation, mais le transfert est
plus rapide si les fichiers contenant les données source résident
sur la même machine que l'instance SQL Server cible (débit du
réseau par rapport au débit d'E/S du disque local). Vous pouvez
déplacer les fichiers plats contenant les données vers la machine
hébergeant SQL Server, en utilisant différents outils de copie,
tels que
AZCopy,
Azure Storage
Explorer ou le copier/coller Windows via le protocole RDP (Remote
Desktop Protocol).
1. Vérifiez que la base de données et les tables
sont créées dans la base de données SQL Server cible.
Voici un exemple montrant comment faire à l'aide des commandes Create
Database et Create Table :
Copy
CREATE DATABASE <database_name>
CREATE TABLE <tablename>
(
<columnname1> <datatype> <constraint>,
<columnname2> <datatype> <constraint>,
<columnname3> <datatype> <constraint>
)
2. Générez le fichier de format qui
décrit le schéma de la table, en exécutant la commande
suivante dans la ligne de commande de la machine où BCP est
installé.
bcp dbname..tablename format nul -c -x -f
exportformatfilename.xml -S servername\sqlinstance -T -t \t -r \n
3. Insérez les données dans la base de
données, en utilisant la commande BCP suivante. Cette commande
fonctionne à partir de la ligne de commande, si SQL Server est
installé sur la même machine :
bcp dbname..tablename in datafilename.tsv -f
exportformatfilename.xml -S servername\sqlinstancename -U username -P password
-b block_size_to_move_in_single_attemp -t \t -r \n
§ Parallélisation des
insertions pour accélérer le déplacement des
données
Si le volume de données déplacées est
important, vous pouvez accélérer l'opération en
exécutant plusieurs commandes BCP simultanément dans un script
PowerShell.
Remarque :
Traitement de volumes importants de
données pour optimiser le chargement de volumes importants et
très importants de jeux de données, partitionnez vos tables de
base de données physiques et logiques en utilisant plusieurs groupes de
fichiers et tables de partition.
L'exemple de script PowerShell ci-dessous montre comment
effectuer des insertions en parallèle à l'aide de BCP :
Copy
$NO_OF_PARALLEL_JOBS=2
Set-ExecutionPolicy RemoteSigned #set execution policy for the
script to execute
# Define what each job does
$ScriptBlock = {
param($partitionnumber)
#Explictly using SQL username password
bcp database..tablename in datafile_path.csv -F 2 -f
format_file_path.xml -U username@servername -S tcp:servername -P password -b
block_size_to_move_in_single_attempt -t "," -r \n -o
path_to_outputfile.$partitionnumber.txt
#Trusted connection w.o username password (if you are
using windows auth and are signed in with that credentials)
#bcp database..tablename in datafile_path.csv -o
path_to_outputfile.$partitionnumber.txt -h "TABLOCK" -F 2 -f
format_file_path.xml -T -b block_size_to_move_in_single_attempt -t "," -r \n
}
# Background processing of all partitions
for ($i=1; $i -le $NO_OF_PARALLEL_JOBS; $i++)
{
Write-Debug "Submit loading partition # $i"
Start-Job $ScriptBlock -Arg $i
}
# Wait for it all to complete
While (Get-Job -State "Running")
{
Start-Sleep 10
Get-Job
}
# Getting the information back from the jobs
Get-Job | Receive-Job
Set-ExecutionPolicy Restricted #reset the execution policy
§ Requête SQL Bulk Insert
La requête
d'insertion en bloc SQL permet d'importer des données provenant
de fichiers à lignes/colonnes dans la base de données (les types
pris en charge sont présentés dans la section
Préparer les
donner pour l'exportation ou l'importation en bloc (SQL Server)).
Voici quelques exemples de requêtes Bulk Insert :
1. Analysez vos données et configurez les options de
personnalisation souhaitées avant de procéder à
l'importation, pour vérifier que la base de données SQL Server
attend le même format pour les champs particuliers, comme les dates.
Voici un exemple de configuration du format de date année-mois-jour (si
vos données contiennent des dates dans ce format) :
Copy
SET DATEFORMAT ymd;
2. Importez des données avec des instructions import en
bloc :
Copy
BULK INSERT <tablename>
FROM
'<datafilename>'
WITH
(
FirstRow=2,
FIELDTERMINATOR =',', --this should be column separator in your
data
ROWTERMINATOR ='\n' --this should be the row separator in your
data
)
§ Utilitaires intégrés dans SQL Server
Vous pouvez utiliser l'utilitaire SSIS (SQL Server
Integrations Services) pour importer les données d'un fichier plat dans
SQL Server VM on Azure. SSIS est disponible dans deux environnements
Studio.
ü Déplacement des
données à partir d'un serveur SQL Server local vers un
serveur SQL Server sur une machine virtuelle Azure
Vous pouvez également utiliser les stratégies de
migration suivantes :
1.
Assistant
de déploiement d'une base de données SQL Server sur une machine
virtuelle Microsoft Azure
2.
Exporter
dans un fichier plat
3.
Assistant
Migration de la base de données SQL
4.
Sauvegarde
et restauration de base de données
Chacune de ces étapes est décrite
ci-après :
ü Assistant de déploiement
d'une base de données SQL Server sur une machine virtuelle Microsoft
Azure
L'Assistant de déploiement d'une base de
données SQL Server sur une machine virtuelle Microsoft
Azure est une méthode simple et recommandée pour
déplacer des données d'une instance SQL Server locale vers
un serveur SQL Server sur une machine virtuelle Azure.
ü Exporter dans un fichier plat
Plusieurs méthodes peuvent être utilisées
pour exporter en bloc des données à partir d'un serveur
SQL Server local et sont documentées dans la section
Importation et
exportation de données en bloc (SQL Server). Une fois les
données exportées dans un fichier plat, il est possible de les
importer en bloc dans une autre instance SQL Server.
1. Pour exporter les données de l'instance SQL
Server locale vers un fichier à l'aide de l'utilitaire BCP,
procédez comme suit :
bcp dbname..tablename out datafile.tsv -S
servername\sqlinstancename -T -t \t -t \n -c
2. Créez la base de données et la table sur la
machine virtuelle SQL Server sur Azure à l'aide de create database et de
create table pour le schéma de table exporté à
l'étape 1.
3. Créez un fichier de format décrivant le
schéma de table des données exportées ou importées.
Les détails du fichier de format sont décrits dans
créer un
fichier de Format (SQL Server).
Génération du fichier de format en cas
d'exécution de BCP à partir de la machine SQL Server
Copy
bcp dbname..tablename format nul -c -x -f
exportformatfilename.xml -S servername\sqlinstance -T -t \t -r \n
Génération du fichier de formation en cas
d'exécution de BCP à distance sur une instance SQL Server
Copy
bcp dbname..tablename format nul -c -x -f
exportformatfilename.xml -U username@servername.database.windows.net -S
tcp:servername -P password --t \t -r \n
4. Utilisez l'une des méthodes décrites dans la
section
Fichiers
plats pour déplacer les données de fichiers plats vers
une instance SQL Server.
ü Assistant Migration de la base de données
SQL
Assistant Migration de la base de
données SQL Server fournit une manière conviviale pour
déplacer des données entre deux instances de SQL Server. Il
permet à l'utilisateur de mapper le schéma de données
entre les tables sources et cibles, de choisir les types de colonne et
d'utiliser d'autres fonctionnalités. Il exécute BCP en
arrière-plan. Voici une copie de l'écran d'accueil de SQL
Database Migration Wizard :
Figure 3 - 1 : Assistant de
Migration de la base de données SQL
ü Sauvegarde et restauration de base de
données
SQL Server prend en charge :
1. La
fonctionnalité de sauvegarde et de restauration de base de
données (dans un fichier local ou par exportation d'un bacpac
dans un objet blob) et les
applications de
la couche Données (à l'aide de bacpac).
2. La possibilité de créer directement des
instances SQL Server VM on Azure avec une base de données copiée
ou de copier une base de données SQL Azure.
3.3.2. Gestion des machines virtuelles dans AZURE

Rendez- vous dans la console de gestion Azure, puis cliquez sur
Machines virtuelles :
Vous y visualisez la liste des machines crées :

Cliquez sur la flèche à droite du nom pour ouvrir
la gestion de la VM :
§ Le premier écran contient des ressources sur le web
:
Le menu Surveiller vous permet de consulter l'historique
d'utilisation des ressources par la VM :
Les Points de terminaison sont les ports (IP) ouverts pour
vous connecter à une machine virtuelle :

Par défaut un accès en Powershell (port 5986) et un
accès RDP (sur un numéro de port aléatoire) sont
ouverts.
Pour ajouter un point, cliquez sur le menu Ajouter.

Choisissez Ajouter un point de terminaison autonome :
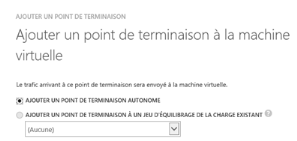
Précisez ensuite les ports et protocoles
utilisés, ici par exemple pour un accès https :
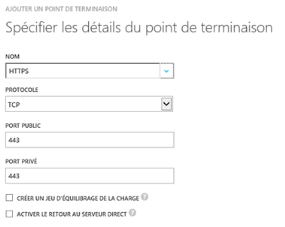
Validez votre choix et vérifiez l'ouverture du port.
Le menu Configurer vous permet de modifier la taille de la
machine et son éventuelle appartenance à un groupe de
disponibilité :
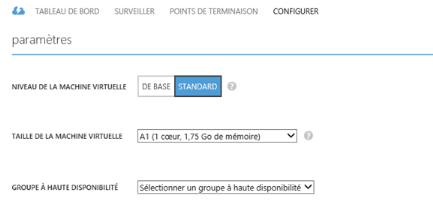
Accès au bureau de votre VM
Par défaut un point de connexion a été
créé pour accéder au bureau à distance de votre
serveur, pour y accéder, cliqué sur le menu

Il suffit ensuite de confirmer le
téléchargement du fichier RDP puis de l'ouvrir.
Après avoir ouvert votre session, vous allez
découvrir votre machine virtuelle, sur la quelle Microsoft à
penser à installer le premier composant que j'installe aussi BGinfo ,
qui permet d'identifier rapidement votre machine virtuelle.
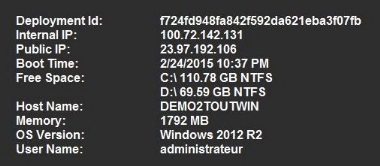
Un rapide coup d'oeil dans l'explorateur vous permettra de
découvrir deux disque virtuels : le disque C, contenant Windows le
disque D, qui comme son nom l'indique est un espace temporaire, non
restauré en cas de redémarrage de votre machine virtuelle, mais
non facturé.

3.3.3. Déploiement de la base
Utilisez l'Assistant Déploiement de base de
données dans SQL Azure16(*) pour déployer une base de
données entre une instance du Moteur de base de données et un
serveur Base de données Azure SQL, ou entre deux serveurs Base de
données Azure SQL.
L'Assistant utilise un fichier d'archive d'application de la
couche Données (DAC) BACPAC pour déployer les données et
les définitions des objets de base de données. Il effectue une
opération d'exportation DAC de la base de données source, et une
importation DAC vers la destination.
Par défaut, la base de données
créée pendant le déploiement aura tous les
paramètres par défaut de l'instruction CREATE DATABASE. Le
classement de base de données et le niveau de compatibilité sont
définis aux valeurs de la base de données source et font
exception.
Les options de base de données, telles que TRUSTWORTHY,
DB_CHAINING et HONOR_BROKER_PRIORITY, ne peuvent pas être ajustées
dans le cadre du processus de déploiement. Des propriétés
physiques, telles que le nombre de groupes de fichiers ou le nombre et la
taille des fichiers, ne peuvent pas être modifiées dans le cadre
du processus de déploiement. Une fois le déploiement
terminé, vous pouvez utiliser l'instruction ALTER DATABASE, SQL Server
Management Studio ou SQL Server PowerShell pour personnaliser la base de
données.
L'Assistant Déploiement de base de
données prend en charge le déploiement d'une base de
données :
· D'une instance du Moteur de base de données vers
Base de données Azure SQL.
· D'une instance de Base de données Azure SQL vers
une instance du Moteur de base de données.
· Entre deux serveurs Base de données Azure SQL.
L'Assistant ne prend pas en charge le déploiement de
bases de données entre deux instances du Moteur de base de
données.
Une instance du Moteur de base de données doit
exécuter SQL Server 2005 Service Pack 4 (SP4) ou version
ultérieure pour fonctionner avec l'Assistant. Si une base de
données sur une instance du Moteur de base de données contient
des objets qui ne sont pas pris en charge sur Base de données Azure SQL,
vous ne pouvez pas utiliser l'Assistant pour déployer la base de
données dans Base de données Azure SQL. Si une base de
données sur Base de données Azure SQL contient des objets qui ne
sont pas pris en charge par SQL Server, vous ne pouvez pas utiliser l'Assistant
pour déployer la base de données sur des instances de SQL
Server.
Pour améliorer la sécurité, les
connexions d'authentification SQL Server sont stockées dans un
fichier DAC BACPAC sans mot de passe. Lorsque le fichier BACPAC est
importé, la connexion est créée en tant que connexion
désactivée avec un mot de passe généré. Pour
activer les connexions, connectez-vous à l'aide d'une connexion qui
possède l'autorisation ALTER ANY LOGIN et utilisez ALTER LOGIN pour
activer la connexion et affecter un nouveau mot de passe pouvant être
communiqué à l'utilisateur. Cela n'est pas nécessaire pour
les connexions d'authentification Windows car leurs mots de passe ne sont pas
gérés par SQL Server.
L'Assistant a besoin d'autorisations d'exportation DAC dans la
base de données source. La connexion requiert au minimum des
autorisations ALTER ANY LOGIN et VIEW DEFINITION de la portée de la base
de données, ainsi que des autorisations SELECT sur
sys.sql_expression_dependencies. L'exportation d'une DAC peut
être réalisée par les membres du rôle serveur fixe
securityadmin également membres du rôle de base de données
fixe database_owner dans la base de données à partir de laquelle
est extraite la DAC. Les membres du rôle serveur fixe sysadmin ou le
compte d'administrateur système intégré de SQL Server
nommé sa peuvent également exporter une DAC.
L'Assistant a besoin d'autorisations d'exportation DAC sur
l'instance ou le serveur de destination. La connexion doit être membre
des rôles serveur fixes sysadmin ou
serveradmin, ou du rôle serveur fixe
dbcreator et disposer d'autorisations ALTER ANY LOGIN. Le
compte d'administrateur système SQL Server intégré
nommé sa peut également importer une DAC.
L'importation d'une DAC avec des connexions à Base de données SQL
requiert l'appartenance aux rôles loginmanager ou serveradmin.
L'importation d'une DAC sans connexions à Base de
données SQL requiert l'appartenance aux rôles dbmanager ou
serveradmin.
Pour migrer une base de données à l'aide de
l'Assistant de déploiement de base de données
1. Connectez-vous à l'emplacement de la base de
données à déployer. Vous pouvez spécifier une
instance du Moteur de base de données ou un serveur Base de
données Azure SQL.
2. Dans l'Explorateur d'objets,
développez le noeud pour l'instance qui contient la base de
données.
3. Développez le noeud Bases de
données.
4. Cliquez avec le bouton droit sur la base de données
que vous voulez déployer, sélectionnez
Tâches, puis sélectionnez Déployer
la base de données dans SQL Azure...
5. Renseignez les boîtes de dialogue de
l'Assistant :
o
Page
Introduction
o
Paramètres
de déploiement
o
Page
Résumé
o
Résultats
Cette page décrit les étapes de l'Assistant
Déploiement de base de données.
Options
· Ne plus afficher cette page : cochez
la case pour ne plus afficher la page Introduction à l'avenir.
· Suivant - Passe à la page
Paramètres de déploiement.
· Annuler - Annule l'opération et
ferme l'Assistant.
Utilisez cette page pour spécifier le serveur de
destination et fournir des détails sur votre nouvelle base de
données.
ü Hôte local :
· Connexion serveur - Spécifiez les
détails de connexion au serveur, puis cliquez sur Se
connecter pour vérifier la connexion.
· Nouveau nom de la base de données
- Spécifiez un nom pour la nouvelle base de données.
ü
Paramètres de base de données Base de données
SQL :
· Édition Base de données SQL
- Sélectionnez l'édition de Base de données SQL dans le
menu déroulant.
· Taille maximale de base de données
- Sélectionnez la taille maximale de la base de données dans le
menu déroulant.
ü
Autres paramètres :
Spécifiez un répertoire local pour le fichier
temporaire, qui est le fichier d'archive BACPAC. Notez que le fichier est
créé à l'emplacement spécifié et qu'il y
reste une fois l'opération terminée.
Utilisez cette page pour passer en revue la source
spécifiée et les paramètres ciblent de l'opération.
Pour terminer le déploiement à l'aide des paramètres
spécifiés, cliquez sur Terminer. Pour annuler le
déploiement et quitter l'Assistant, cliquez sur
Annuler.
Cette page affiche une barre de progression indiquant
l'état de l'opération. Pour afficher l'état
détaillé, cliquez sur l'option Afficher les
détails.
Cette page signale la réussite ou l'échec de
l'opération de déploiement, affichant les résultats de
chaque action. Toute action pour laquelle une erreur s'est produite aura un
lien dans la colonne Résultat. Cliquez sur le lien pour
consulter le rapport d'erreur de cette action.
Cliquez sur Terminer pour fermer l'Assistant.
Pour déployer une base de données à
l'aide des méthodes DacStore, Export()
et Import() dans une application .NET Framework.
1. Créez un objet serveur SMO et définissez-le
sur l'instance ou le serveur qui contient la base de données à
déployer.
2. Ouvrez un objet ServerConnection et
connectez-vous à la même instance.
3. Utilisez la méthode Export de type
Microsoft.SqlServer.Management.Dac.DacStore pour exporter la
base de données dans un fichier BACPAC. Spécifiez le nom de la
base de données à exporter, ainsi que le chemin d'accès au
dossier où le fichier BACPAC doit être placé.
4. Créez un objet serveur SMO et définissez-le
sur l'instance ou le serveur de destination.
5. Ouvrez un objet ServerConnection et
connectez-vous à la même instance.
6. Utilisez la méthode Import de type
Microsoft.SqlServer.Management.Dac.DacStore pour importer le
fichier BACPAC. Spécifiez le fichier BACPAC créé par
l'exportation.
Conclusion Générale
De l'informatique utilitaire des années 60, au
service bureau des années 70, tout en passant par
l'émergence d'internet et des avancées de virtualisation, le
Cloud Computing comme les tendances nous le conforme, est promis à
un bel avenir.
Le Cloud met en oeuvre l'idée d'informatique
utilitaire du type service public, proposée par John McCarthy. Il
peut aussi être comparé au cluster de calcul dans lequel
un groupe d'ordinateurs se relient pour former un ordinateur
virtuel unique permettant le calcul de haute performance (HPC), mais
aussi à l'informatique en grille (Grid Computing) où des
ordinateurs reliés et repartis géographiquement permettent
la résolution d'un problème commun.
Le Cloud Computing n'impose aucune dépense en
immobilisation puisque les services sont payés en fonction de
l'utilisation. Cela permet aux entreprises de ne plus se focaliser sur
la gestion, la maintenance et l'exploitation de l'infrastructure ou des
services applicatifs. Les fortes avancées dans le domaine de la
virtualisation ont rendu possible le Cloud Computing. Cette virtualisation
permet d'optimiser les ressources matérielles en les partageant
entre plusieurs environnements (« time - sharing »). De
même, il est possible de coupler l'application (et son
système d'exploitation) et le matériel (encapsulé dans
la machine virtuelle), cela assure également un
« provisionning », c'est-à-dire la capacité
de déploiement d'environnement, de manière automatique.
Le Cloud couplé, aux technologies de virtualisation,
permet la mise à disposition d'infrastructures et de plate-forme
à la demande. Mais le Cloud ne concerne pas seulement l'Infrastructure
(IaaS), il bouleverse la plate-forme d'exécution (PaaS).
Etant donné que le Cloud computing repose sur un
ensemble de machines interconnectées et massivement
distribuées, cela permet d'être tolérant face aux
défaillances matérielles et logicielles (par des
mécanismes de redondance, réplication, SLA). De plus, le Cloud
permet une élasticité, une flexibilité. Ainsi la
puissance de calcul ou les capacités de stockages peuvent
être très facilement augmentées par l'installation
de nouveaux équipements au sein ou en dehors du Cloud, la charge
sera alors répartie en fonction de ces nouveaux
équipements. Il en va de même avec les applications et les
données : elles pourront être hébergées
à différents « endroits ». En cas de
montée en charge, le Cloud créera plusieurs instances afin
d'y répartir la charge et d'assurer une disponibilité
maximale.
Force de constater que dans un Datacenter classique, le
taux moyen d'utilisation peine à dépasser les 25% (le but
est de saturer la charge serveur pour exploitation optimale), la
moyenne étant de 10%. Les serveurs sont sous - utilisés et en
cas de pic de charge, il faut acheter de nouveaux serveurs pour
pallier à la demande. Cela signifie donc que le nouveau
matériel restera en exploitation même inutilisé
après les pics. Ces infrastructures sont monolithiques dans le
sens où elles ne permettent aucune exploitation dynamique et
flexible, nécessitant une lourde administration et des coûts
induits.
Avec le Cloud , cela devient obsolète : au lieu
de faire tourner vos applications vous - même , le tout est
géré par un « Virtual Datacenter »
partagé. Lorsque le besoin se fait ressentir de déployer
une nouvelle application, il suffira de s'identifier sur le Cloud, de
sélectionner dans un catalogue de services ou d'envoyer directement
l'application souhaitée, puis de la personnaliser et de
lancer. En quelques minutes, (voire quelques secondes), l'application sera
fonctionnelle et pourra être consommée. C'est aussi valable
pour une infrastructure ou une plate-forme. Si une entreprise a
besoin, de trois serveurs Windows et d'un serveur Linux, il suffira de
sélectionner dans le catalogue et d'instancier cette
infrastructure « à la demande ».
BIBLIOGRAPHIE
A. OUVRAGES
1) C. Moyer, Applications de Cloud Computing.
Concepts, design patterns et développement, ibid.,
2011, P.80
2) J. Barr, Le Cloud computing avec Amazon
Web Services. L'informatique en nuage pour votre site Web, coll.
Référence, Pearson, Paris, 2011, P.23
3) Nick Dowling, Database Design And Management
Using Access, Cengage Learning EMEA - 2000,(
ISBN
9781844801091)
4) Dictionnaire petit Larousse Ed. 2006
5) Thomas M. Connolly - Carolyn E. Begg, Database
systems: a practical approach to design, implementation, and
management,Pearson Education - 2005,(
ISBN
9780321210258)
6) Bhuvan Unhelkar, Practical Object Oriented
Analysis, Thomson Learning Nelson - 2005, (
ISBN
9780170122986).
B. NOTES DE COURS
ü KAFUNDA Pierre, Cours de base de
données, G2 Info, UNIVERSITE DE
MBUJIMAYI ,2012-2013.
ü J.A. MVIBUDULU K, L.D. KONKFIE IPEPE,
Technique des bases de données Etude de cas,
2eme Edition corrigée et révisée, Kinshasa,
CRIGED, janvier 2010
ü BUKANGA, Cours de Séminaire
Informatique1, G3 Infos, Université Révérend
KIM, 2015 - 2016, P.78
C. WEBOGRAPHIE
ü
http://www.nuage-france.fr/les-protocoles-du-cloud-dans-nuage,
[consulter le 20/03/2016 à 15h02]
ü URL:
http://www.universalis.fr/encyclopedie/cloud-computing-informatique-dans-les-nuages/
[consulté le 31 mars 2016]
ü
http://www.yeswecloud.fr/cloud/cloud-public-prive-et-hybride-637.html
TABLE DES MATIERES
Titre
|
|
Page
|
|
|
|
|
EPIGRAPHE
|
.......................................
|
I
|
|
DEDICACE
|
.......................................
|
II
|
|
REMERCIEMENT
|
.......................................
|
III
|
|
LISTE DES ABREVIATIONS
|
.......................................
|
IV
|
|
LISTE DES FIGURES
|
.......................................
|
V
|
|
LISTE DES TABLEAUX
|
.......................................
|
VI
|
INTRODUCTION
|
.......................................
|
1
|
0.1. Présentation du sujet
|
.......................................
|
1
|
0.2. Généralité
|
.......................................
|
2
|
0.3. Problématique
|
.......................................
|
2
|
0.4. Hypothèse
|
.......................................
|
3
|
0.5. Méthodes et Techniques
|
.......................................
|
4
|
0.6. Intérêt et Choix du sujet
|
.......................................
|
5
|
0.7. Délimitation du sujet
|
.......................................
|
5
|
0.8. Subdivision du sujet
|
.......................................
|
6
|
Chapitre I : CONCEPTS DE BASE
|
.......................................
|
7
|
1.1.1. Définition
|
.......................................
|
7
|
1.1.2. Classification de Réseau Informatique
|
.......................................
|
7
|
1.1.3. Les réseaux sans fil
|
.......................................
|
12
|
1.1.4. Modèle OSI
|
.......................................
|
14
|
1.1.5. Notion des Protocoles
|
.......................................
|
18
|
1.1.6. Base de données
|
.......................................
|
19
|
1.1.7. Système de gestion de base de
données
|
.......................................
|
23
|
Chapitre II : LE CLOUD COMPUTING
|
.......................................
|
26
|
2.1. Définition
|
.......................................
|
28
|
2.2. Bref Aperçu du Cloud
|
.......................................
|
28
|
2.3. Historique
|
.......................................
|
29
|
2.4. Enjeux Economiques
|
.......................................
|
30
|
2.5. Architectures
|
.......................................
|
31
|
2.6. Les Protocoles utilisés dans le Cloud
|
.......................................
|
33
|
2.7. Les Principaux acteurs dans le Cloud
|
.......................................
|
35
|
2.8. Sécurité dans le Cloud
|
.......................................
|
35
|
2.9. Avantages et Inconvénients
|
.......................................
|
36
|
Chapitre III : DEPLOIEMENT D'UNE BASE DE DONNEES VERS LE CLOUD
|
.......................................
|
38
|
3.1. Présentation de SQL AZURE
|
.......................................
|
39
|
3.2. Introduction au déploiement
|
.......................................
|
40
|
3.3. Migration vers le SQL Server dans les machines virtuelles AZURE
|
.......................................
|
42
|
CONCLUSION GENERALE
|
.......................................
|
59
|
BIBLIOGRAPHIE
|
.......................................
|
62
|
|
TABLE DE MATIERES
|
.......................................
|
63
|
|
|
|
|
|
|
|
|
|
* 1 J. Claude
ROUVEYRAN, Le guide de la thèse et du Mémoire du
projet à soutenance, Paris, Ed. MAISONNEUVE A LA ROSE, 2011, p.
151 - 152
* 2 Dictionnaire
Aristide Quillet, Ed. Aristide Quillet, 2000, P. 345
* 3 L. NGIENGI KWENGU
et A. MUMBANZA MUSUNGA, Note de Cours de Système
d'exploitation réseau, (Texte inédit), Kinshasa, 2014 -
2015, P. 3
* 4 (en)Colin Ritchie,
Database Principles and Design, Cengage Learning EMEA - 2008, (
ISBN
9781844805402)
* 5 Carlos Coronel, Steven
Morris et Peter Rob, Database Systems: Design, Implementation, and
Management, Cengage Learning - 2012, (
ISBN
9781111969608)
* 6 Nick Dowling, Database
Design And Management Using Access, Cengage Learning EMEA - 2000,(
ISBN
9781844801091)
* 7Nick Dowling, Database
Design And Management Using Access, Cengage Learning EMEA - 2000,(
ISBN
9781844801091)
* 8
http://www.futura-sciences.com/magazines/high-tech/infos/dico/d/informatique-sgbd-2525/
* 9 (en) Thomas M. Connolly -
Carolyn E. Begg,Database systems: a practical approach to design,
implementation, and management,Pearson Education - 2005,(
ISBN
9780321210258)
* 10 Bhuvan Unhelkar,
Practical Object Oriented Analysis, Thomson Learning Nelson - 2005, (
ISBN
9780170122986).
* 11 François
PÊCHEUX, « CLOUD COMPUTING ou INFORMATIQUE DANS LES
NUAGES », Encyclopædia Universalis [en ligne],
consulté le 31 mars 2016.
URL :
http://www.universalis.fr/encyclopedie/cloud-computing-informatique-dans-les-nuages/
* 12 J. Barr, Le Cloud
computing avec Amazon Web Services. L'informatique en nuage pour votre site
Web, coll. Référence, Pearson, Paris, 2011, P.23
* 13 C. Moyer,
Applications de Cloud Computing. Concepts, design patterns et
développement, ibid., 2011, P.80
* 14
http://www.nuage-france.fr/les-protocoles-du-cloud-dans-nuage,
consulter le 20/03/2016 à 15h02
* 15
http://www.yeswecloud.fr/cloud/cloud-public-prive-et-hybride-637.html
* 16
https://msdn.microsoft.com/fr-fr/library/jj554810%28v=sql.120%29.aspx,
consulté le 04/03/2016 à 05h08
|