Etude des scénarios de clustering des réseaux 4G de TT pour la migration vers une architecture 5G Cloud-RANpar El Bouhani Abdelbasset FSB - Master 2021 |

ConclusionL'étape de dimensionnement d'un réseau est l'étape cruciale pour la mise en place du réseau dans le but de l'optimisation du déploiement. En effet, dans ce chapitre, nous avons défini le principe de planification radio, particulièrement la phase de dimensionnement de l'eNodeB en se basant sur les différents modèles de propagation ainsi que leur capacité. Nous avons défini tout le calcul nécessaire qui nous sera utile pour la conception et au développement de notre application. 74 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel Chapitre 4 Clustering des BBU basé sur l'intelligenceartificielle IntroductionL'évolution de notre vie quotidienne et notre besoin dans le monde présente développe à partir de nous services qui applique indirectement l'utilisation de l'intelligence pour facilite et gérée nous services qui a le besoin. Dans ce chapitre on va présenter comment l'intelligence facilite et renforce notre réseaux 5g dans la coté service spécialement dans la partie du traitement du réseau qui situer les BBU 1 Base band unit 1.1 BBU Une unité de bande de base (BBU) est un dispositif de réseau de télécommunication utilisé pour traiter les signaux de bande de base. La bande de base est le terme utilisé pour décrire la fréquence d'origine d'une transmission avant la modulation. Le réseau d'accès radio traditionnel (RAN) se compose d'un BBU connecté à une ou plusieurs unités radio distantes (RRU) positionnées à proximité de la ou des antennes. L'unité de bande de base est responsable de la communication via l'interface physique avec le réseau central, tandis que l'unité radio distante exécute les fonctions d'émission et de réception RF. Les deux éléments sont généralement reliés entre eux par fibre optique, La fonctionnalité centralisée et le positionnement fixe au pied de la tour de téléphonie cellulaire sont des aspects du sens BBU traditionnel redéfini par la 5G . L'architecture RAN de nouvelle génération divise la fonctionnalité BBU entre une unité distribuée (DU) pour les fonctions en temps réel et une unité centralisée (CU) pour les fonctions non temps réel telles que le contrôle des ressources radio (RRC). La virtualisation et la désagrégation des unités de bande de base 5G augmentent la capacité et réduisent la latence. 75 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel 1.2 couches Appelée également Radio Cloud Center (RCC) dans certaines architectures, la Baseband Unit(BBU) est composée d'un ensemble de couches et de fonctions, servant à traiter les signaux radio,transitant par le réseau d'accès. Alors qu'elle est associée à l'unité radio (RU/RH) dans un eNodeB dans l'architecture RAN de la 4G, la BBU est séparée de cette même RU (appelée alors RRH/RRU) dans une architecture C-RAN pour être, par la suite, regroupée avec d'autres unités de traitement au sein d'un même élément, appelé pool BBU. Ce dernier est généralement virtualisé et centralisé dans un serveur (ou un mini Datacenter) se trouvant entre les RRH et le réseau coeur (EPC). Le pool BBU fournit ainsi les ressources physiques nécessaires pour le traitement des signaux. La centralisation des unités BBU en un seul pool offre un grand nombre d'avantages, tels que,le partage des ressources virtuelles et matérielles entre les différentes BBU, l'efficience énergétique grâce à la possibilité de désactiver le fonctionnement de certaines unités BBU selon leur charge de traitement, la simplification des opérations de configuration des cellules, l'augmentation de la capacité de calcul pour le traitement des signaux radio, la gestion améliorée de la mobilité des UE ainsi que des opérations de handover, etc. Néanmoins, afin de fournir ces performances, il est nécessaire d'intégrer des algorithmes d'ordonnancement des ressources partagées en sein du pool BBU et de déterminer le bon placement de ce dernier par rapport aux RRH déployées dans le Réseau. Une unité BBU intègre les trois couches protocolaires composant l'eNodeB : la couche physique (PHY/L1), la couche (Media Access Control (MAC)/L2) ainsi que la couche contrôle (Radio Resource Control (RRC)/L3). Les fonctions de chacune de ces couches sont présentées ci-dessous. 76 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel
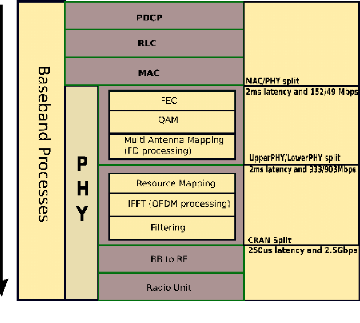
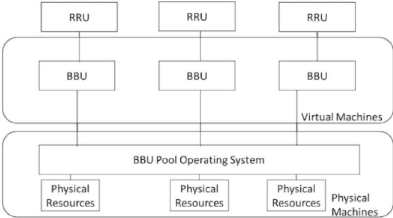
Figure 39.Structure des couches 1.2.1 Couche physique La couche physique représente la couche basse (L1) de la BBU. Elle se charge de la transmission/réception des données IQ à travers le fronthaul grâce à l'exécution des fonctions suivantes : -- Codage de canal : permet de détecter les changements (erreurs) produits sur les bits de données reçues grâce à l'utilisation du code Cyclic Redundancy Check (CRC). Ces erreurs sont par la suite corrigées grâce à l'utilisation des fonctions Forward Error Correction (FEC), lequel permet d'ajouter des bits redondants à la donnée ainsi que de la fonction Automatic Repeat Request (ARQ) qui, en cas d'existence d'erreur, va solliciter une retransmission du paquet de données erroné. -- Adaptation de lien : nommée également Adaptive Modulation and Coding (AMC). Cette fonction permet de moduler les bits à transmettre avec un code rate correspondant à la qualité du canal de transmission. -- Multiple-Input Multiple-Output (MIMO) : technique de multiplexage permettant de transmettre les données vers plusieurs RRH en simultané. 77 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel -- Modulation multiporteuse : permet de transmettre les données modulées sur de multiples porteuses en même temps. -- Mesures radio : estime la qualité du signal et du canal de transmission, ainsi que la puissance des signaux émis par les différentes RRH (cellules). -- Synchronisation : notamment celle des horloges entre la RRH et la BBU. -- Signalisation des informations de contrôle : entre l'UE et les réseaux d'accès. 1.2.2 Couche MAC La Couche MAC, appelée également couche 2 (L2), est composée de trois sous couches qui interviennent pour la transmission des paquets de données (le DP) et pour le CP. La description de chacune de ces sous couches est donnée ci-dessous : -- Packet Data Compression Protocol (PDCP) : intégrant plusieurs fonctions. La sous couche PDCP permet de compresser les entêtes des paquets, en utilisant des mécanismes tels que Robust Header Compression (RoHC) pour améliorer l'efficacité spectrale sur des services de type voix sur IP (VoIP). Elle permet également de chiffrer et de protéger l'intégrité des données de signalisation RRC. Enfin, cette sous couche se charge de la détection et de la suppression des doublons (paquets de données) qui apparaissent généralement lorsqu'un handover se produit entre deux cellules. -- Radio Link Control (RLC) : assure le contrôle des liaisons de données grâce à des fonctions de détection d'erreurs, de retransmission de paquets (en cas d'erreur), d'ordonnancement de ces derniers et d'optimisation des transmissions grâce à l'utilisation de fenêtres d'émission/réception. -- Medium Access Control (MAC) : permet d'accéder et d'adapter la transmission des données au canal de transport correspondant. Pour cela, la sous couche MAC utilise des fonctions d'allo- cation dynamique des ressources radio, de maintien de synchronisation (en lien montant) et de priorisation des flux de données. La sous couche MAC utilise également le mécanisme Hybrid Automatic Repeat Request (HARQ) pour une transmission fiable des paquets. 78 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel 1.2.3 Couche Radio Resource Control (RRC) Troisième couche de la pile protocolaire, RRC assure la configuration et le contrôle des couches sous-jacentes. Elle est ainsi responsable des fonctions suivantes : -Diffusion et décodage des informations système liées aux couches Access Stratum (AS) et Non-Access Stratum (NAS). -Gestion des envois/réceptions de radio messagerie (paging), -Gestion des connexions entre les couches RRC de l'UE et de l'unité de traitement. -Établissement, configuration et maintenance des connexions point à point des Radio Access Bearer (RAB). -Gestion des fonctions et des clefs de sécurité. -Gestion et contrôle de la mobilité des UE en mode connecté et en mode veille. -Gestion de la QoS et des mesures de l'UE. 2 Concept de virtualisation La technologie de virtualisation facilite l'isolement logique des ressources tandis que les ressources physiques sont partagées de manière dynamique et évolutive. Ces ressources incluent les ressources de réseau, de calcul ou de stockage. À partir de ces ressources, la virtualisation du réseau est essentielle dans C-RAN et ses architectures de déploiement. La virtualisation de réseau consiste en plusieurs noeuds et liens déployés sur la même machine physique. Ainsi, une telle technologie permet un mécanisme de contrôle flexible, des ressources efficaces, un faible coût et des applications diverses. Dans le contexte du C-RAN, la virtualisation du réseau se fait au niveau du pool BBU. Chaque BBU est un noeud virtuel tandis que la communication entre eux se fait par des liens virtuels. Le pool fonctionne sur une seule machine physique partageant les ressources CPU, mémoire et réseau 79 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel entre plusieurs BBU. La figure au-dessus illustre le partage de ressources dans un pool BBU où le pool est déployé dans une machine physique tandis que les BBU sont sur des machines virtuelles. Les RRU connectent essentiellement le pool BBU qui les distribue sur les BBU dans sa machine virtuelle. Une telle technologie présente de nombreux avantages, notamment la réduction des coûts, la réduction du temps requis pour la communication BBU et, surtout, l'évolutivité. L'ajout ou la suppression de BBU devient plus facile car ces BBU sont des machines virtuelles qui sont beaucoup plus faciles à désactiver et à activer que les machines physiques. Comme C-RAN est principalement concerné par la virtualisation du réseau, la section suivante discutera des approches pour y parvenir.
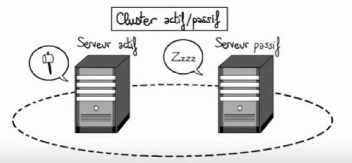
Figure 40.Virtualisation du pool BBU dans C-RAN 2.1 Coopération BBU Les BBU d'un même pool doive coopérer afin de prendre en charge le partage des données des utilisateurs, la planification et la collecte des commentaires des canaux. Une telle coopération n'est pas définie et présente un défi quant à la manière de gérer la confidentialité des utilisateurs, une bande passante élevée et une communication à faible latence entre ces BBU. 80 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel 2.2 Types de coopération en mode grappe 4 Grappe actif /passif Dans le grappe actif/passif, les BBU sont démarrées mais seul BBU traite les requetés, c'est le serveur actif et les autres BBU bien que démarrés est en sommeil (les BBU passif)
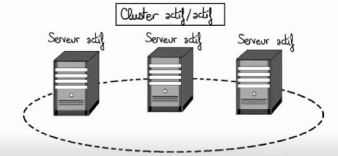
Figure 41.Cluster actif/passif 4Grappe actif-actif Le principe est de redonder le BBU actif avec d'autre BBUs similaires, dans le grappe actif-actif tous les BBU sont actifs. La charge de travail est donc répartie entre BBU actifs, si un BBU du cluster tombe, ce sont les autres BBUs qui doit prendre le relais et supporter une montée de charge pour compenser la défaillance du serveur indisponible. il permet de gérer la montée en charge.
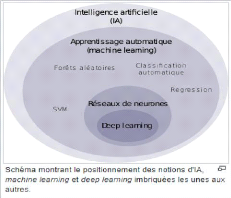
Figure 42.Cluster actif/actif 81 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel 2.3 Regroupement de cellules Le regroupement optimal des cellules et l'assignable du pool BBU avec une surcharge minimale et un gain maximal restent un défi. Un pool de BBU doit atteindre le nombre maximal de canaux d'envoi et de réception tout en minimisant le délai et les frais généraux du fronthaul. En outre, une BBU doit prendre en charge plusieurs emplacements géographiques distribués, tels que des bureaux dans différents États, afin de les consolider en une seule BBU. Par conséquent, ce regroupement et cette affectation BBU sont toujours un défi à résoudre dans les systèmes C-RAN. 3 Intelligence artificiel C'est Un ensemble des théories et des technique mises en oeuvre en vue de réaliser des machines capables de simuler l'intelligence humaine, elle correspond donc à un ensemble de concepts et de technologie endurée Pour la construction de programmes informatiques qui s'adonnent à des taches qui sont, pour l'instant, accomplies de façon plus satisfaite par des êtres humains. Il Ya deux type principale connue d'intelligence artificiel défini par la suite : 3.1 Les types d'intelligence artificiel 4 Intelligence artificiel fort Le terme d'intelligence artificiel fort défini non seulement de produire un comportement intelligent, notamment de modéliser des idées abstraites, aussi d'éprouver une impression d'une réelle conscience, de vrais sentiment et une compréhension de ses propres raisonnements. 4Intelligence artificiel faible La notion d'intelligence artificielle faible a pour construire des systèmes de plus en plus autonome des algorithmes capables de résoudre des problèmes d'une certaine classe .la machine simule l'intelligence, elle semble agir comme si elle était intelligente. 3.2 Distinction entre intelligence artificiel, machine Learning et deep Learning 82 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel Il y a une déférence ente les deux domaines de machine Learning et deep Learning se sont des notions ne sont pas équivalentes mais les deux sont imbriquées sou le non de l'intelligence artificielle comme indique la photo suivante :
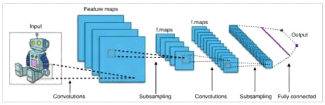
Figure 43.Schéma générale des notions de l'intelligence artificielle - L'intelligence artificiel a été utilisée dans une variété de domaines par exemple : - domaine de finance et banques, certaine banque utilise des systèmes experts dévaluation de risque lié à l'octroi d'un crédit, la vérification et la récupération des informations. - domaine de militaire, utilisation des systèmes tels que les drones, les systèmes de commandement et d'aide à la décision. -domaine médecine, comme les systèmes de diagnostic ou détection d'anomalie. Ilya d'autre domaine aussi utilise l'intelligence comme le domaine de droit, renseignement Policier, logistique et transports, industrie, robotique. 3.2.1 Machine Learning Le machine Learning est une technique de programmation informatique qui utilise des probabilités statistiques pour donner aux ordinateurs la capacité d'apprendre par eux-mêmes sans programmation explicite. La notion de machine Learning contient plusieurs d'apprentissages pour applique 83 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel L'intelligence, et par la suit ont expliquent les types d'apprentissages. 3.2.2 Les types d'apprentissage 4Enseignement supervise C'est la tâche d'apprentissages automatique consistant à apprendre une fonction qui mappe une entrée a une sortie basée sur des exemples de paires de d'entrée-sortie, un algorithme d'apprentissages supervise analyse les données d'apprentissages et produit une fonction déduite, qui peut être utilisée pour cartographier de nouveaux exemples. 4 Apprentissage non supervise Est un type d'algorithme qui apprend des modelés à partir de données non etiquetees.la machine soit obligée de construire une représentation interne compacte de son monde et de générer ensuite un contenu imaginatif, il présente une auto-organisation qui capture des modèles comme des prédilections neuronales ou des densités de probabilités. 4 Apprentissage semi supervise L'apprentissage semi-supervise se suite entre l'apprentissage non supervise et supervise. Certains exemples de formation manquent d'étiquette de formation, lorsqu'elles sont utilisées avec une petite quantité de données étiquetées, peuvent produire une amélioration considérable de la précision de l'apprentissage. 4 Apprentissage par renforcement L'apprentissage par renforcement est un domaine de l'apprentissage automatique qui concerne la façon dont les agents logiciels doivent entreprendre des actions dans un environnement afin de maximiser une certaine notion de récompense cumulative. 3.3 Deep Learning Une classe d'algorithme d'apprentissages automatique qui utilisent différentes couches d'unité de traitement non linéaire pour l'extraction st la transformation des caractéristique, les algorithmes 84 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel peuvent être supervisés et leur application comprennent la reconnaissance de modèles et la classification statique L'apprentissage profond utilise des couches cachées de réseaux de neurones artificiels et des séries de calcules proportionnels complexes. Exemple d'un CNN :
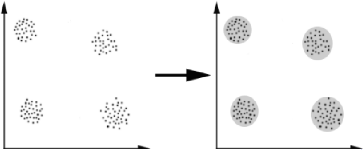
Figure 44.CNN ?Domaine d'application L'apprentissage profond s'applique à divers secteurs des technologies communication par exemples : la communication La reconnaissance visuelle, la robotique, la bio-informatique, la sécurité, la sante ect. 4 La classification automatique « Clustering » Un cluster est un groupe d'objets, de nombres, de points de données (informations) Dans ce chapitre cette application nous permettre de faire un regroupement non superviser Dans notre cas on va développer un module l'intelligent du clustering du BBU. Un « Cluster » est donc une collection d'objets qui sont « similaires » entre eux et qui sont « dissemblables » par rapport aux objets appartenant à d'autres groupes. On peut voir cette définition clairement graphiquement dans l'exemple suivant : Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel
85 Figure 45.llustration de regroupement en clusters 5 Déférente algorithme Le domaine du machine Learning regorge d'algorithmes pour répondre à différents besoins, il y a plusieurs d'algorithmes de machine Learning mais nous présentent les algorithmes les plus basique et redoutables par la suite : Linear régression : les algorithmes de régression linéaire modélisent la relation entre des variable prédictives et une variable cible, elle va trouver une fonction sous forme de droite pour estimer la relation Logistique régression : est une méthode statistique pour effectuer des classifications binaires, elle prend en entrée des variables prédictives qualitatives et/ou ordinales. Support vector machine (svm) : est aussi un algorithme de classification binaire choisira la séparation la plus nette possible entre deux classes, aussi nommée classifieur aux marges larges. Naïve bayes : utilisé pour les classifications de texte basse sur le nombre d'occurrence de mots. -anomalie détection : pour détecter des patterns anormaux, cet algorithme est très utile pour la détection de fraudes dans les transactions bancaires et les détection d'intrusion. décision trees : est algorithme qui se base sur un modèle de graphe (les arbres) pour définir la décision finale. Chaque noeud comporte une condition, et les branchements sont en fonction de cette condition (vrai ou faux). Plus on descend dans larbre, plus on cumule les conditions. Neurals networks : ils permettent de trouver des patterns complexes dans les données. Ces réseaux de neurones apprennent une tache spécifique en fonction des données d'entrainement. 86 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel Dans ces réseaux on trouve le tiers d'entrée (input layer) qui va recevoir les données, il va propager les données par la suite aux tiers caches (hidden layers). Finalement le tiers de sortie (output layer) permet de produire le résultat de classification. Chaque tiers du réseau de neurones est un ensemble d'interconnexions des noeuds d'un tiers avec ceux des autres tiers. -k-means : un algorithme de clustering en apprentissage non supervise. On lui donne un ensemble d'éléments, et un nombre de groupes k. k-means va segmenter en k groupes les éléments. Le groupement s'effectue en minimisant la distance euclidienne entre du cluster et un élément donne. -gradient descent : un algorithme itératif de minimisation de fonction de cout. Cette minimisation servira à produire des modelées prédictifs comme la régression logistique et la régression linéaire. 6 Réalisation 1 les besoins Dans la réalisation de notre cluster ont besoin de classer les paramètres en deux parties les entre et les sorties Paramètres d'entrée -base de donnée qui contient tous les informations du BBU -outils d'apprentissage Paramètres de sortie -les cluster 2 Environnement de travail: 2.1 Environnement matériel: ? Fabriquant: Lenovo ideapad110. ? Processeur: Intel(R) Core (TM) i3-4005U CPU@ 1.70 GHz ? Mémoire RAM: 6 Go. ? Disque dure: 500 Go 87 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel ? Système d'exploitation: Windows 10. 2.2 Environnement Logiciel: -navigateur anaconda
Figure 46.Logo anaconda Anaconda est une distribution libre et open source des langages de programmation Python et R appliqué au développement d'applications dédiées à la science des données et à l'apprentissage automatique, qui vise à simplifier la gestion des paquets et de déploiement. -Jupyter notebook
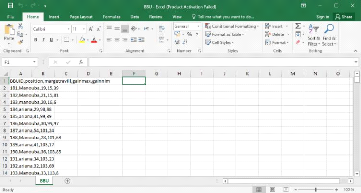
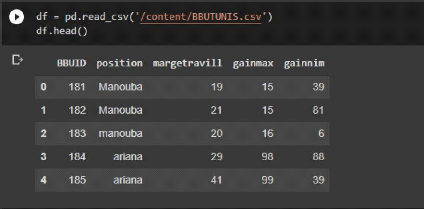
88 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel Figure 47.Logo jupyter est une application web utilisée pour programmer dans plus de 40 langages de programmation, dont Python, Julia, Ruby, R, ou encore Scala. C'est un projet communautaire dont l'objectif est de développer des logiciels libres, des formats ouverts et des services pour l'informatique interactive. Jupyter est une évolution du projet IPython. Jupyter permet de réaliser des calepins ou notebooks, c'est-à-dire des programmes contenant à la fois du texte en markdown et du code. Ces calepins sont utilisés en science des données pour explorer et analyser des données. 3 Principales bloc du module avec description - préparation de la base de données La base de données qu'on nous somme utilise est un fichier Excel de type .csv qui contient les ID du BBU et sa position, capacité, etc.
Figure 48.Base de données BBU - Installation et préparation du l'environnement La préparation du l'environnement consiste a installé les bibliothèques et les outils d'apprentissages Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel
Figure 49.Installation de les l'outils -installé la base de donne et définir leur extension
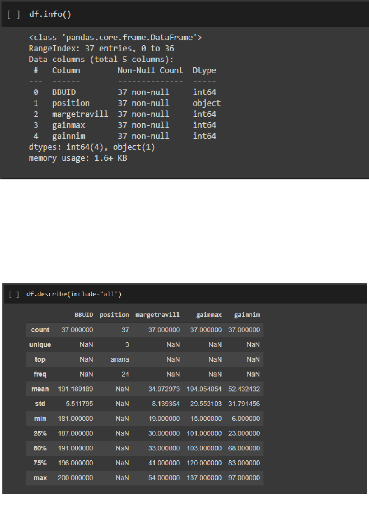
Figure 50.Chemin d'accès à la base 89 -cette commande pour afficher les informations de la base de donné
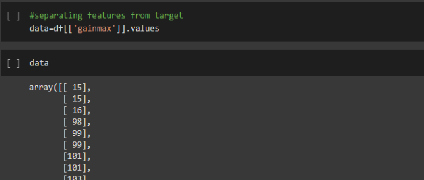
Figure 51.Information sur la base Figure 52.Décris la base 90 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel
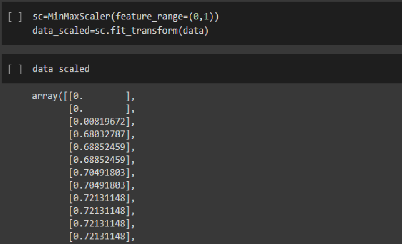
Figure 53.Séparation du cible -cette fonction a pour rôle d'escaladé les donné entre 0 et 1
91 Figure 54.Donné escaladé
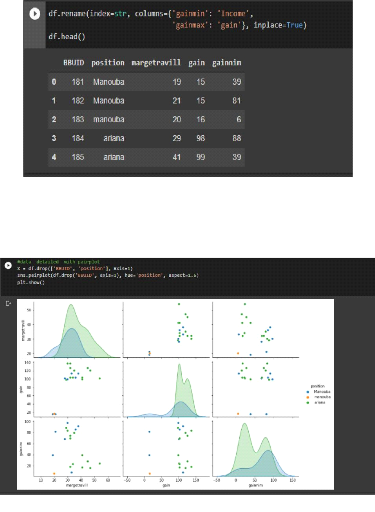
Figure 55.Préparation du paramètre Figure 56.Data détaillé avec pair plot 92 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel
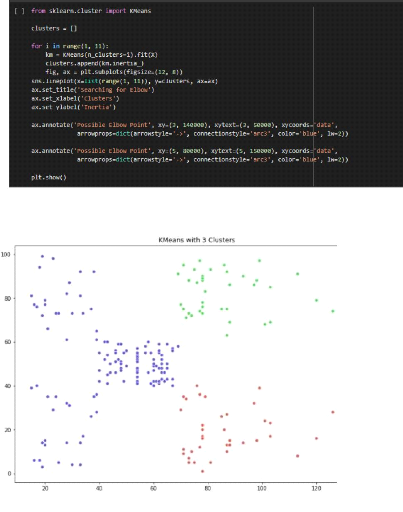
Figure 57.Implémenté le cluster Figure 58.Donné cible classé 93 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel 94 Chapitre 4 : Clustering des BBU basé sur l'intelligence artificiel |
|