Institut Africain d'Informatique
Etablissement Inter - Etats d'Enseignement Supérieur
BP 2263 Libreville (Gabon) Tél. (241) 077 70 55 00 - 077
70 56 00
Site web:
www.iaisiege.org E-mail:
contact@iaisiege.org

Mémoire de fin d'études
En vue de l'obtention du
Diplôme d'Ingénieur
Informaticien
Thème :
EVALUATION DE LA DYNAMIQUE SPATIO-TEMPORELLE DE L'EVOLUTION DE
LA COVID A LIBREVILLE PAR UNE APPROCHE MACHINE LEARNING
|
Réalisé et soutenu le 30 juin 20222 par
RAMADANE BAKARI
|
Jury
Président du jury :Pr
KOUSSOUBE, maitre de conférences. Enseignant permanant à
l'IAI.
Superviseur : M. GUIFO Donacien
Ingénieur Informaticien. Enseignant permanant à l'IAI.
Maître de Stage : Dr. Marius
MASSALA Enseignant Chercheur au LAIMA.
Maître de Stage : Dr. Pierre
MOUKELI Enseignant Chercheur au LAIMA.
Membre : M. Brice ONDJIBOU
Ingénieur Informaticien Enseignant vacataire à IAI.
Rapporteur : M. MATY MAMAN
Ingénieur Informaticien. Enseignant permanant à l'IAI.
Année académique : 2020-
2021

DEDICACE
À la mémoire des 6 millions de morts, victimes
de la pandémie de la covid-19.
À tous les soldats camerounais, tombés sur les
champs d'honneur pour la défense de la patrie, contre les terroristes de
BOKO HARAM et les terroristes sécessionnistes du NOSO.
Au feu : gendarme-Major DAMO DJOMMAILA, tombé les
armes à la main, le 2 juin 2018, en mission commandée, dans le
cadre de la sécurisation des régions du Nord-Ouest et du
Sud-Ouest, en proie aux attaques des terroristes sécessionnistes du
NOSO.
EPIGRAPHE
« Si j'avais une heure pour sauver le monde, je passerais
cinquante-neuf minutes à définir le problème et une
minute à trouver la solution ».
Albert Einstein
REMERCIEMENTS
Nous adressons nos sincères remerciements à
toutes les personnes qui, ont contribué à la réalisation
de ce travail. Nous remercions de façon toute particulière :
· M. EKOMY Clément Achille, le Coordonnateur de
l'IAI, pour le cadre offert afin que cette formation puisse bien suivre son
cours.
· M. GUIFO Donacien, enseignant permanent à l'IAI,
notre superviseur IAI, pour l'excellent suivi du travail ainsi que ses
remarques et suggestions très pertinentes ;
· DR MOUKELI Pierre, enseignant Chercheur au LAIMA, notre
maître de stage au LAIMA, pour l'excellent suivi du travail ainsi que ses
remarques et suggestions très pertinentes ;
· M. MASSALA Marius, enseignant Chercheur au LAIMA, notre
maître de stage au LAIMA, pour l'excellent suivi du travail ainsi que ses
remarques et suggestions très pertinentes ;
· Le corps administratif et enseignant de l'IAI pour leur
encadrement tout au long de notre formation ;
· Tous nos camarades de promotions et toute la
communauté estudiantine de l'IAI .
AVANT-PROPOS
L'Institut Africain d'Informatique créé le 29
janvier 1971 à FORT-LAMY, ancien nom de la capitale politique de la
République du TCHAD, dans le cadre du renforcement de la
solidarité l'unité africaine est une école
inter-état d'enseignement supérieur. L'IAI comprend cinq
(5) filières : Licence, Analystes programmeurs, Maitrise en Informatique
Appliquée à la Gestion des Entreprises (MIAGE), Master et
Ingénieur.
Cette école de renommée internationale,
intègre dans le cursus de formation des ingénieurs de conception
en informatique, en fin de cycle, un stage de formation pratique d'une
durée de 5 (cinq) mois en entreprise ou dans un laboratoire de
recherche. Ce stage de fin d'études vise à mettre les
élèves ingénieurs dans un environnement pratique afin de
leur permettre une intégration en milieu professionnel plus
aisée.
Le présent document constitue donc l'aboutissement de
trois (3) années de formation à l'Institut Africain
d'Informatique de Libreville et cinq (5) mois de stage de recherche
effectué au sein du Laboratoire Africain d'Informatique et de
Mathématiques Appliquées. Il tient lieu de mémoire de fin
de formation d'ingénieurs de conception en Informatique et s'intitule
: « Évaluation de la dynamique spatio-temporelle de
l'évolution de la Covid-19 à Libreville : par une approche
Machine Learning »
RESUME
La crise de la covid-19 a rapidement dépassé le
domaine strictement médical pour impacter l'ensemble des secteurs
d'activités. Le système « Gabon » a été
soumis à une série de chocs majeurs successifs : une crise
sanitaire, suivie d'une crise économique. Relever le défi de la
santé dans un environnement fortement perturbé s'est
imposé aux autorités de santé publique : comprendre le
présent, anticiper le futur, comprendre les leviers d'actions possibles,
étudier des scenarii sont devenus des éléments clés
pour les décideurs. Les prévisions spatio-temporelles des
maladies infectieuses passent rapidement au premier plan des politiques et des
réponses de santé publique en raison de leur rôle
clé dans les stratégies d'atténuation des risques. La
modélisation et la simulation ont ainsi acquis une nouvelle
visibilité liée à ces nouvelles exigences. Mais
très vite des limitations sont apparues dans la seule prise en compte de
la dynamique temporelle de l'épidémie. D'autres facteurs se sont
révélés essentiels : la dimension géographique ou
spatiale. En raison de la complexité du problème
épidémiologique et de la disponibilité des données,
le Machine Learning a récemment attiré l'attention pour la
construction de modèles de prédiction d'épidémie.
Les approches Machine Learning visent à développer des
modèles avec une plus grande capacité de
généralisation et une plus grande fiabilité de
prédiction pour des délais plus longs.
La finalité de ce mémoire est d'explorer
l'application du Machine Learning pour modéliser la pandémie de
la COVID-19. Ainsi il est question d'une part de développer un
modèle de régression, basé sur l'algorithme de «
Facebook Prophet » pour prédire la dynamique temporelle de
l'épidémie dans la ville de Libreville. Ensuite de
développer un modèle de clustering, base sur l'algorithme K-means
et le système d'information géographiques(SIG), pour
déterminer les clusters à risques à l'échelle
d'arrondissements et à l'échelle de quartier. Enfin de concevoir
un tableau de bord intelligent de suivi de la dynamique spatio-temporelle d'une
épidémie
Mots-clés : Covid-19- le machine learning - Facebook
Prophet - K-means - SIG - Cluster - modélisation .
ABSTRACT
The covid-19 crisis quickly went beyond the strictly medical
field to impact all sectors of activity. The "Gabon" system was subjected to a
series of successive major shocks: a health crisis, followed by an economic
crisis. The public health authorities had to take up the challenge of health in
a highly disrupted environment: understanding the present, anticipating the
future, understanding the possible levers of action, and studying scenarios
have become key elements for decision-makers. Modelling and simulation have
thus acquired a new visibility linked to these needs. However, limitations have
appeared in the sole consideration of the dynamics of the epidemic. Other
factors have proved essential: the geographical or spatial dimension. Machine
learning approaches aim to develop models with greater generalisation
capability and prediction reliability for longer time frames.
The aim of this thesis is to explore the application of
Machine Learning to model the COVID-19 pandemic. The aim is to develop a
regression model, based on the "Facebook Prophet" algorithm, to predict the
temporal dynamics of the epidemic in the city of Libreville. Secondly, to
develop a clustering model, based on the K-means algorithm and the geographic
information system (GIS), to determine the risk clusters at the district and
neighbourhood levels. Finally, using an inductive approach, we generalise the
results obtained to all the communes of Libreville, based on data collected at
the University Hospital of Libreville.
Key words: Covid-19- machine learning - Facebook Prophet -
K-means - GIS - Cluster - modelling - simulation- Moran's autocorrelation
test.
SOMMAIRE
DEDICACE
I
EPIGRAPHE
II
REMERCIEMENTS
III
AVANT-PROPOS
IV
RESUME
V
ABSTRACT
VI
SOMMAIRE
VII
TABLE DES ILLUSTRATIONS
VIII
LISTE DES TABLEAUX
X
LISTE DES SIGLES ET ABREVIATIONS
XI
INTRODUCTION GENERALE
1
PREMIERE PARTIE : CONTEXTE GENERAL DE L'ETUDE
2
A. CHAPITRE I : PRESENTATION DE LA STRUCTURE
D'ACCUEIL ET DU SUJET D'ETUDE
3
B. CHAPITRE II : CONCEPTS LIÉS A LA
DYNAMIQUE D'UNE EPIDEMIE
6
C. CHAPITRE III : ETAT DE L'ART DE LA
MODELISATION DES EPIDEMIES
14
DEUXIEME PARTIE : MODELISATION DE LA COVID-19 PAR
UNE APPROCHE MACHINE LEARNING
19
D. CHAPITRE IV : PRESENTATION DU MACHINE
LEARNING
20
E. Chapitre V : démarche Machine
Learning pour la modélisation
25
F. CHAPITRE VI: l'étude de
l'algorithme facebook prophet et conception du modèle de
prédiction
35
TROISIEME PARTIE : REALISATION DU SIMULATEUR
EVAL_EPI
40
G. Chapitre VI : MÉTHODOLOGIE DE
DÉVELOPPEMENT
41
H. Chapitre VII : MISE EN OEUVRE DE LA
SOLUTION
46
QUATRIEME PARTIE : FINALISATION DE LA SOLUTION
66
I. Chapitre VIII : IMPLEMENTATION ET
RESULTATS
67
J. CHAPITRE IX : GESTION DE PROJET ET
BILAN
74
CONCLUSION GÉNÉRALE
78
RÉFÉRENCES BIBLIOGRAPHIQUES
79
ANNEXES
82
TABLE DES ILLUSTRATIONS
Figure 1: Organigramme de l'IAI
2
Figure 2 : la dynamique d'une
épidémie selon le modèle SIR
9
Figure 3: Dynamique temporelle du
modèle SIR, Source: (Avhad, 2020)
9
Figure 4 : Cartographie des cas actif au
Gabon au 17 fevrier 2022 au 19 mai 2022 (COPIL, 2022)
14
Figure 5: diagramme du modèle SEAIRD
(MATONDO MANANGA, 2021)
15
Figure 6: Représentation graphique des
éléments de RdP
16
Figure 7: modèle SVEIR-RDP de LAIMA
17
Figure 8 : Représentation
imagée d'un agent en interaction avec son environnement et les autres
agents, (Ferber, 1995)
18
Figure 9 : Diagramme de classe des
entités COMOKIT (Taillandier, Drogoul, & Gaudou, 2020)
19
figure 10 : branches de l'intelligence
artificielle, (Mohammed, 2019)
22
Figure 11 : cycle de vie du processus
KDD, source : (Swamynathan, 2017)
28
Figure 12 : méthode CRISP-DM,
adapté de (Shearer, 2000)
29
Figure 13 : Capture d'écran des cas
de guérison dans le monde (partiellement)
31
Figure 14 extraction des lignes et colonnes
32
Figure 15 les captures d'écran du
dataset avant et après le nettoyage
33
Figure 16 : partitionnement des données
en données d'entrainement et données de test
33
Figure 17 : les courbes de nombre
cumulés de cas de guérison à Libreville avant et
après le prétraitement
34
Figure 18 : Courbe d'apprentissage du
modèle
40
Figure 19 : code pour tester la
performance du modèle
41
Figure 20 : la courbe de comparaison entre
les valeurs réelles et les valeurs prédites
41
Figure 21 : la schématisation en Y
utilisée pour représenter la méthode de
développement 2TUP, source : Bassim, K.A. et Akaria, R., 2007
45
Figure 22: Les diagrammes d'UML (UMLversion
1.5), source : (Guiochet, 2009)
47
Figure 23 : Diagramme global de cas
d'utilisation
51
Figure 24:Diagramme de cas d'utilisation -
gérer les utilisateurs.
51
Figure 25: Diagramme de cas d'utilisation
« gestion des données »
52
Figure 26 : Diagramme de cas d'utilisation
«Gestion du prétraitement des données »
52
Figure 27 : Diagramme de cas d'utilisation
- Simuler la dynamique spatio-temporelle
53
Figure 28 : Diagramme de cas d'utilisation
- Gérer les indicateurs épidémiologiques.
53
Figure 29: Diagramme de cas d'utilisation -
Gérer des modèles de simulation
54
Figure 30 : Diagramme de cas d'utilisation
- gérer une visualisation
55
Figure 31: diagramme d'activités du cas
d'utilisation «charger les données »
56
Figure 32 : diagramme d'activités
du cas d'utilisation « gestion du prétraitement »
56
Figure 33: diagramme d'activités du cas
d'utilisation «simuler la dynamique épidémique »
57
Figure 34:diagramme d'activités du cas
d'utilisation « calculer un indicateur »
58
Figure 35 : diagramme d'activités
du cas d'utilisation « Visualiser un indicateur »
58
Figure 36 : diagramme d'activités
du cas d'utilisation «ajouter un indicateur»
59
Figure 37 : diagramme d'activités
du cas d'utilisation « modifier un indicateur»
60
Figure 38 : Diagramme de classes
61
Figure 39 : Architecture applicative de
notre solution. (EVAL_EPI)
62
Figure 40 : Architecture logicielle de
notre solution.
65
Figure 41 : Le prototype
général du simulateur EVAL_EPI
66
Figure 42 : Architecture physique de notre
solution.
67
Figure 43 - Interface de RStudio sous
Windows
73
Figure 44- Diagramme de déploiement.
74
Figure 45 : Page d'accueil du logiciel
« EVAL_EPI ».
74
Figure 46 : Capture d'écran d'une
simulation de la dynamique temporelle
75
Figure 47 : Capture d'écran d'une
simulation de la dynamique temporelle
75
LISTE DES TABLEAUX
Tableau 1 : Valeurs des Ro de quelques
maladies et de leur couverture vaccinale v
2
Tableau 2: Etapes du KDD
27
Tableau 3 : récapitulatif des
phases du processus CRISP-DM.
28
Tableau 4 : résumé des
questionnements qui facilitent la compréhension du métier
30
Tableau 5 : description des
données
31
Tableau 6 : récapitulatif des
proportions des valeurs manquantes dans les data set
32
Tableau 7: comparaison de modèle de
Machine Learning la prédiction des séries temporelles
34
Tableau 8 : Performances de Prophet et de ARIMA
selon la metrique R2-score
35
Tableau 9:récapitulatif des
paramètres de performance de prévision
36
Tableau 10 : exemple de réglage des
hyper paramètres du modèle Facebook prophet
39
Tableau 11: gestion de projet suivie le
processus agile ou le processus unifié
44
Tableau 12 : Package des classes de la
simulation de la dynamique d'une épidémie
60
Tableau 13 : Package des classes de la
visualisation des indicateurs épidémiologique
60
Tableau 14: comparaison du MVC et du MVT
63
Tableau 15 : comparaison des
caractéristiques de R et python
69
Tableau 16:comparaison de performance de R et
Python
69
Tableau 17 : outils de stockage et de
manipulation des données
70
Tableau 18 : Les bibliothèques
spécialisées sur la covid-19
70
Tableau 19 : Les bibliothèques
spécialisées sur le Machine Learning
71
Tableau 20 : Les bibliothèques de
manipulation des données geospatiale
71
Tableau 21 : outils
d'implémentation de l'interface graphique
72
Tableau 22 : Découpage du projet en
étapes
77
Tableau 23:récapitulatif des coûts
des charges du projet
77
LISTE DES SIGLES ET
ABREVIATIONS
|
2TUP
|
Two Track Unified Process
|
|
ABM
|
Agent Base Modeling
|
|
CAH
|
Classification Ascendant Hierarchique
|
|
CHUL
|
Centre Hospitalier et Universitaire de Libreville
|
|
COPIL
|
Comité de Pilotage
|
|
COVID-19
|
Corona Virus Desease 2019
|
|
CRISP-DM
|
Cross Industry Standard Process for Data Mining
|
|
DAO
|
Data Access Object
|
|
DBSCAN
|
Density-Based Spatial Clustering of Applications with Noise
|
|
HTML
|
HyperText Markup Language
|
|
HTML
|
HyperText Markup Language
|
|
HTTP
|
Hypertext Transfer Protocol
|
|
IAI
|
Institut Africain d'Informatique
|
|
JHU CSSE
|
Center for Systems Science and Engineering (CSSE)
at Johns Hopkins University
|
|
KDD
|
Knowledge Discovery in Databases
|
|
LAIMA
|
Laboratoire Africain d'Informatique et de Mathématiques
Appliquées
|
|
MVC
|
Modèle-Vue-Contrôleur
|
|
MVT
|
Modèle-Vue-Template
|
|
OMS
|
Organisation Mondiale de la Santé
|
|
PAM
|
Partitionnement Autour des Medoides
|
|
R0
|
Taux de reproduction de base
|
|
RdP
|
Réseau de Pétri
|
|
SARCOV2
|
Severe Acute Respiratory Syndrome Coronavirus 2
|
|
SIG
|
Système d'Information Géographique
|
|
UML
|
Unified Modeling Language
|
|
UP
|
Unified Process
|
INTRODUCTION GENERALE
La pandémie de la covid-19 semble avoir pris de court
la plupart des autorités politiques et sanitaires. Ceci en raison de la
rapidité de la diffusion du virus et de la nécessité de
contrôler l'épidémie, par des mesures de confinement
strict, sans équivalent en temps de paix à une échelle
planétaire. Plus de deux ans après que la COVID-19 a
été identifiée pour la première fois, les
gouvernements continuent d'être confrontés à un besoin
urgent de compréhension du paysage pandémique en
évolution rapide. Par conséquent, une évaluation
précise de la dynamique spatio-temporelle de la COVID-19 devient
cruciale dans une telle situation.
En raison de la complexité du problème
épidémiologique et de la disponibilité des données,
le Machine Learning a récemment attiré l'attention pour la
construction de modèles de prédiction d'épidémie.
Les approches Machine Learning visent à développer des
modèles avec une plus grande capacité de
généralisation et une plus grande fiabilité de
prédiction pour des délais plus longs. Ainsi il est donc possible
d'utiliser le SIG et le Machine Learning pour aider à atténuer
l'épidémie grâce à la masse des données
collectées sur la Covid-19. Ceci en trouvant des corrélations
spatiales avec d'autres variables sociodémographiques et afin
d'identifier la dynamique spatio-temporelle de transmission de la Covid-19
à Libreville. C'est dans cette optique que ce projet nous a
été confié, afin de développer un modèle
épidémiologique permettant d'analyser la propagation de
l'épidémie dans sa dimension spatio-temporelle, notamment
à l'aide de technique de machine Learning, auxquelles, on associe les
méthodes de système d'information géographique et des
méthodes d'analyse spatiale.
Dans ce mémoire, Il sera question d'abord de
présenter l'environnement de travail en décrivant la structure
d'accueil, ainsi que le projet qui nous a été confié, son
intérêt et les notions y afférentes, suivi d'une
étude sur les modèles épidémiologiques existants et
de la démarche Machine Learning adoptée. Ceci dans la
perspective de proposer un modèle de régression et un
modèle de clustering. Ensuite d'implémenter ces modèles
dans une plateforme web. Ceci dans l'optique de pouvoir faire des
prédictions d'une part sur le nombre de cas de la maladie de la
covid-19 à Libreville. Et d'autre part de déterminer les foyers
épidémiques à risque dans la commune de Libreville.
PREMIERE PARTIE : CONTEXTE
GENERAL DE L'ETUDE
CHAPITRE I : PRESENTATION
DE LA STRUCTURE D'ACCUEIL ET DU SUJET D'ETUDE
Dans ce chapitre, nous présentons d'une part la
structure d'accueil dans laquelle nous avons effectué le stage, d'autre
part ensuite le projet qui nous a été soumis, son utilité,
ses objectifs et la problématique qu'il soulève.
1. Structure d'accueil : le LAIMA
Nous présenterons ici d'abord l'historique du LAIMA,
puis ses missions et enfin l'organigramme de l'Institut Africain d'Informatique
(IAI).
a) Historique du LAIMA
L'Institut Africain d'Informatique (IAI) est une école
inter-état dont le siège est à Libreville au Gabon.
Créée en 1971 à Fort-Lamy (actuel N'Djamena) au Tchad par
plusieurs chefs d'États Africain. L'IAI a à sa tête une
Direction Générale, qui supervise trois directions qui sont :
la Direction des Enseignements, la Direction Administrative et
Financière. L'IAI possède en son sein un Laboratoire Africain
d'Informatique et de Mathématiques Appliquées (LAIMA)
placé sous la Direction de l'étude (DE).
b) Missions du LAIMA
Le LAIMA assure la recherche dans les domaines de
l'informatique et des Mathématiques Appliquées. Ses axes de
recherche sont entre autres : la conception du système d'information,
l'Intelligence artificielle, le Calcul scientifique, l'Optimisation et
l'Informatique décisionnelle... .
c) Structure organisationnelle de L'Institut Africain
d'Informatique (IAI)
L'organigramme de l'Institut Africain d'Informatique se
présente comme suit (figure 1) :
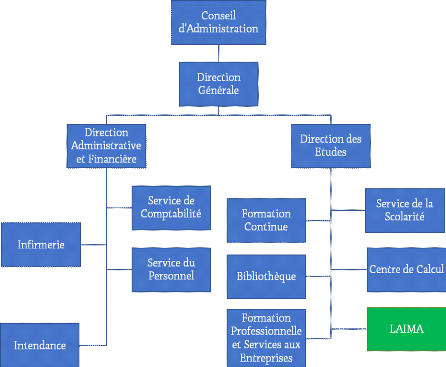
Figure 1: Organigramme de
l'IAI
2. Présentation du sujet et de son
intérêt
a) Contexte du sujet
Le 30 janvier 2020, le Comité d'urgence du
Règlement sanitaire international de l'Organisation Mondiale de la
Santé (OMS) a déclaré l'épidémie de la
maladie appelé COVID-19, comme une "urgence de santé publique de
portée internationale". Le coronavirus, virus responsable de la COVID-19
s'est propagé à tous les continents, devenant une crise de
santé publique sans précédent. A la date du 05 mai 2022,
le Comité de pilotage du plan de veille et de lutte contre la
pandémie à coronavirus au Gabon (COPIL) a fait état d'un
total de plus trois cents décès et de près de
quarante-huit mille cas confirmés sur le territoire Gabonais.Afin de
maitriser et de surveiller la dynamique de propagation de cette
épidémie, il convient de l'analyser dans sa dimension
spatio-temporelle, notamment à l'aide d'un système d'information
géo-référencé, prédictif et intelligent.
b) Problématique
La crise sanitaire causée par la covid-19, a contraint
les décideurs à agir dans l'urgence. Le COVID-19 est un
défi pour l'humanité à bien des égards. Son impact
est destructeur non seulement pour les vies humaines mais aussi pour le
fonctionnement de divers secteurs de la sphère économique et
sociale.
Il est nécessaire de prévoir la propagation de
la maladie pour développer des stratégies de réponse
efficacesau niveau local. Les épidémies locales pourraient
submerger les systèmes de santé publique, les hôpitaux et
les salles d'urgence. Ainsi, les décideurs se tournent vers les
scientifiques, avec cette problématique : quelle est la technologie la
plus adaptée pour suivre, décrire et prédire de la
dynamique spatio-temporelle de l'épidémie de la covid-19 ?
c) Objectifs
A partir des données collectées au CHUL et au
COPIL, Il est question dans ce mémoire :
ï D'abord de proposer un premier modèle de
Machine Learning pour la prédiction du nombre de cas de la maladie de
la covid-19 à Libreville,
ï Ensuite de proposer un deuxième modèle
de Machine Learning pour la détermination des clusters à
l'échelle d'arrondissement ou de quartier à Libreville
ï Enfin de concevoir un simulateur, implémentant
les modèles proposées, et qui permet de suivre et de
prédire l'évolution de la dynamique spatio-temporelle de
l'épidémie de la covid-19 à Libreville.
CHAPITRE II : CONCEPTS
LIÉS A LA DYNAMIQUE D'UNE EPIDEMIE
Il est question dans ce chapitre de
présenterbrièvement le domaine de l'épidémiologie,
puis d'expliciter la notion de dynamique spatio-temporelle.
3. Définitions, méthodes et principes en
épidémiologie
Pour comprendre le domaine de l'épidémiologie,
nous allons exposer tour à tour, la définition de quelques
notions de base, les principes en épidémiologie, les
méthodes et les outils, enfin l'analyse et la maitrise des
épidémiologies.
a) Quelques notions de base
· L'Organisation mondiale de la santé (OMS) a
défini en 1968 l'épidémiologie comme
« une étude de la distribution des maladies et des
invalidités dans les populations humaines, ainsi que des
déterminants qui déterminent cette distribution ».
· Une maladie transmissible ou
infectieuse est une maladie provoquée par la transmission d'un germe
pathogène à un hôte sensible. Les agents infectieux peuvent
être transmis à l'homme :
o directement à partir d'autres personnes
infectés ou,
o indirectement par l'intermédiaire de vecteurs, de
particules en suspension dans l'air ou d'autres supports.
· Foyer épidémique : en
épidémiologie, un foyer épidémique ou un
agrégat spatial ou «cluster» peut être défini
comme un regroupement des cas géographiquement proches, de taille et de
concentration suffisante pour qu'il y ait peu de chance qu'il soit uniquement
dû, au hasard. La détection de tels groupements permet
d'identifier les zones à risque et de dégager des
hypothèses sur la transmission de la maladie.(Guégan, 2009)
b) Principes en épidémiologie
Les termes clés de cette définition
reflètent certains des principes importants de
l'épidémiologie. A savoir : le principe d'étude, le
principe de distribution, et le principe de déterminants
· Principe d'étude :
l'épidémiologie est une discipline scientifique fondée sur
de solides méthodes d'enquête scientifique.
L'épidémiologie est axée sur les données et repose
sur une approche systématique et impartiale de la collecte, de l'analyse
et de l'interprétation des données. L'épidémiologie
s'appuie également sur des méthodes d'autres domaines
scientifiques, notamment la biostatistique et l'informatique.
· Principe de
distribution : l'épidémiologie
s'intéresse à la fréquence et au schéma des
événements de santé dans une population.
· Principe de déterminants :
l'épidémiologie est également utilisée pour
rechercher des déterminants, qui sont les causes et d'autres facteurs
qui influencent l'apparition de maladies et d'autres événements
liés à la santé.
c) Méthodes et outil en
épidémiologie
Il existe en épidémiologie plusieurs
méthodes et outil pour l'Analyse et maîtrise des
épidémies
(1) Outils utilisés en
épidémiologie
Les outils les plus utilisés pour caractériser
l'épidémie sont : la courbe, la carte des points et les
Indicateurs épidémiologiques.
· La courbe
épidémique :c'est un outil important pour
l'investigation de la maladie. Dans la courbe épidémique, la
distribution des cas est tracée sur le temps, généralement
sous forme d'histogramme, avec la date d'apparition des cas sur l'axe
horizontal, et le nombre de cas correspondant à chaque date d'apparition
sur l'axe vertical.
· La carte des points : c'est une
carte de la localité où l'épidémie s'est produite,
sur laquelle l'emplacement des cas est tracé. La carte des points est
souvent utile pour détecter la source d'une épidémie.
(2) Indicateurs
épidémiologiques :
Plusieurs mesures de la fréquence d'une maladie reposent
sur les notions fondamentales de prévalence et d'incidence.
Incidence : fait référence
à la vitesse avec laquelle de nouveaux événements se
produisent dans une population. L'incidence (I) se calcule au moyen de la
formule suivante :

Prévalence :correspond au nombre
de cas observés dans une population déterminée à un
moment donné. La prévalence (P) d'une maladie se calcule au moyen
de la formule suivante :

Taux de létalité : permet
d'apprécier la gravité d'une maladie et se définit comme
la proportion des cas d'une maladie ou d'une infection donnée qui ont
une issue fatale au cours d'une période donnée. Il est
généralement exprimé en pourcentage.

Les séries chronologiques
épidémiologiques :Lorsque les données sont
collectées au fil du temps et que le temps est un aspect des
données contenant des informations importantes, il s'agit d'une
série chronologique. Le suivi temporel de l'apparition de cas malades
est un outil prédictif important, car il permet de déterminer la
dynamique de la maladie qui peut être :
· de type épidémique : forte
augmentation ponctuelle de l'incidence ou,
· de type endémique : la transmission est
stable dans le temps.
d) Analyse et maîtrise des épidémies
L'étude d'une épidémie de maladie
transmissible a pour objet d'identifier sa cause et de recenser les meilleurs
moyens pour la combattre. D'après les recommandations l'OMS, publie dans
Éléments d'épidémiologie, l'analyse et la
maîtrise des épidémies nécessite une démarche
rigoureuse qui comporte les étapes suivantes, appliquées de
manière séquentielle ou simultanée (BONITA &
Beaglehole, 2010):
· entreprendre une enquête
préliminaire : La première étape de
l'enquête consiste à vérifier les diagnostics de
présomption et à confirmer l'existence de
l'épidémie.
· identifier et notifier les cas :
l'identification systématique des nouveaux cas
· prendre en charge la maladie et appliquer des
mesures de lutte :assurer le traitement des cas, enrayer
l'extension de la maladie et surveiller les effets des mesures de lutte
instaurées
· recueillir et analyser des
données : la collecte, l'analyse et
l'interprétation des données
· diffuser les résultats obtenus et
assurer un suivi.
Les critères permettant de sélectionner les
maladies sont entre autres :
· incidence et prévalence,
· indices de gravité (taux de
létalité),
· indice de perte de productivité,
· coûts médicaux,... .
L'épidémiologie cherche aussi à
comprendre la dynamique des épidémies, pour mieux ajuster les
mesures préventives.
4. DYNAMIQUE TEMPORELLE D'UNE EPIDEMIE
La propagation d'un agent infectieux au sein d'une population
est un phénomène dynamique. Les effectifs d'individus sains et
malades évoluent dans le temps, en fonction des contacts.Ceci au cours
desquels l'agent infectieux passe d'un individu infecté à un
individu sain non immuniser en l'infectant à son tour. Un tel
phénomène peut être modélisé par des
équations différentielles. Ainsi dans cette section, nous allons
exposer d'un côté la modélisation de la dynamique
temporelle par et les modèles à base des compartiments et de
l'autre côté les effets de la vaccination sur la dynamique
temporelle.
a) Dynamique temporelle d'une épidémie et les
modèles à base des compartiments
Cette approche permet de compartimenter la population des
individus hôtes selon leur état clinique et consiste à
étudier les flux d'individus entre les différents compartiments.
À savoir le compartiment des susceptibles infectés, ou
même éventuellement des retirés... . Un des modèles
à base des compartiments les plus simples est le modèle de
Kermack et McKendrick dit S.I.R (Figure 2) qui divise la population hôte
en susceptibles (S), infectieux (1) et retirés (R) :
· S désigne, au sein de la population
concernée, les individus Susceptibles d'être infectés,
· I désigne ceux qui sont Infectés,
· R concerne ceux qui sont Rétablis ou immunise
Le modèle décrit la dynamique d'une
épidémie comme suit :
· Les individus susceptibles deviennent infectés
au taux ë communément appelé force d'infection ou taux de
contagiosité et,
· les individus infectés guérissent ou
meurent au taux ã.
· Les flèches entre les boites
représentent les flux d'individus selon les taux indiqués
au-dessus des flèches.
· L'effectif de chacune de ces populations dans un
compartiment varie en fonction du temps

Figure 2 : la dynamique
d'une épidémie selon le modèle SIR
Le système d'équation de la dynamique
temporelle d'une épidémie, selon le modèle SIR est par les
équations suivant :
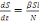 ·
· 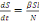
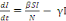 ·
· 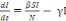
Ces deux équations suffisent pour décrire la
dynamique temporelle d'une épidémie lorsque l'on fait
l'hypothèse que la taille totale de la population hôte N reste
constante. La résolution analytique ou numérique de ce
système d'équations différentielles nous permet de
prédire l'évolution du nombre d'individus hôtes dans
chacune des trois catégories S, let R (Figure 3)
Figure 3: Dynamique temporelle
du modèle SIR, Source: (Avhad, 2020)
b) Détermination du pique de l'épidémie
ou le nombre maximal d'infectés
À partir du modèle S.I.R on peut
également obtenir des informations pertinentes du point de vue de la
santé publique. On peut par exemple déterminer le nombre maximal
d'infectés Imax. Pour cela, on peut réécrire le
modèle sous la forme suivante:
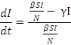
Ou encore si I?0
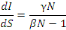
lmax sera obtenu lorsque 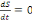
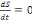 donc pour
donc pour 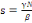
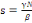 soit:
soit:
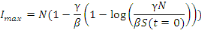
c) Nombre de reproduction de base R0
R0 est le nombre de cas secondaires directement
infectés par une unique personne infectieuse, placée dans une
population totalement susceptible à la maladie. On l'exprime sous la
forme du rapport probabilité de transmission de la maladie ë par
le taux de guérison ã. Il est aussi exprimé sous la
forme des produits du taux de contact "efficace" â, du nombre de
contacts par unité de temps c ; et de la durée de la
période contagieuse d.
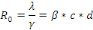
R0 est un seuil en
épidémiologie :
· si R0< 1, alors un individu en infecte en
moyenne moins d'un, la maladie disparaîtra de la population à
terme.
· si R0> 1, alors la maladie peut se
propager dans la population et devenir épidémique.
d) Nombre de reproduction effectif Rt
Pendant les épidémies, la dynamique change en
raison des mesures potentielles qui ont été mises en place pour
réduire les interactions sociales et en raison du pourcentage croissant
de personnes immunisées dans la population. Le taux de reproduction
effectif décrit donc le taux de reproduction à un moment
donné. Une valeur de Rt reflète la propagation
potentielle basée sur les interactions sociales. Il est égale a
au produit du taux de reproduction effectif par la proportion de population
exposée à la maladie.
e) Intervalle intergénérationnel (D) :
Mesure le temps s'écoulant entre la survenue de la
maladie chez un cas dénommé, par convention, le "parent" et la
survenue de la maladie chez les personnes qu'il va infecter
dénommées, par convention, les "enfants". Cet intervalle est
fonction de :
· la durée de contagiosité :
période pendant laquelle un infecte peut transmettre la maladie et,
· du temps de latence : période de temps
entre l'infection et le début des symptômes chez l'agent infecte
f) vitesse de croissance d'une épidémie
À partir du taux de reproduction de base
R0 et de l''intervalle intergénérationnel (D), on peut
estimer la vitesse de croissance d'une épidémie. Le nombre
d'infecte I(t) au cours d'un temps t est donné par la formule :
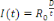
Ainsi on en déduit que l'évolution d'une du
nombre d'infectés au début d'une épidémie est une
croissance exponentielle.
g) Effets de la vaccination sur la dynamique temporelle de
l'épidémie
Une politique de vaccination cherche à protéger
une population dans sa totalité. Ainsi le but d'une politique vaccinale
est de réduire le taux de reproduction de la maladie afin qu'il ne
dépasse pas la valeur de 1. Si la population est vaccinée avec
une couverture vaccinale de v, alors p = 1 - v et la condition pour qu'il n'y
ait pas d'épidémie devient:
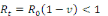
Soit,
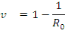
Cette dernière relation nous donne la couverture
vaccinale minimale qu'il faut appliquer pour empêcher le démarrage
d'une épidémie dans une population. On remarque aussi que la
couverture minimale à appliquer dépend du taux de reproduction de
base R0, d'où l'importance de ce paramètre en
épidémiologie. Ainsi plus le Ro est élevé, plus la
couverture vaccinale doit être importante.
Tableau 1 : Valeurs des
Ro de quelques maladies et de leur couverture vaccinale v
|
Maladie
|
Taux de reproduction de base R0
|
Couverture vaccinale v
|
|
Variole
|
3,5 - 6
|
0,71-0,83
|
|
rougeole
|
16-18
|
0,94-0,95
|
|
Ebola
|
2,5-3
|
0,60-0,67
|
Source :(Guégan, 2009)
5. DYNAMIQUE SPATIALE D'UNE EPIDEMIE
Dans cette section il est question de définir ce qu'on
entend par dynamique spatiale d'une part et de présenter le
système d'information géographique (SIG), l'outil de base pour
l'analyse spatiale.
a) Définition de la dynamique spatiale d'une
épidémie
La dynamique spatiale d'une épidémie correspond
à la répartition des cas d'une maladie, que l'on peut trouver sur
un territoire au fil du temps. La science géographique joue un
rôle majeur pour comprendre comment le virus se propage à travers
les régions. La localisation des cas permet d'identifier les
schémas spatiaux tracés par le virus. La compréhension de
ces schémas permet :
· de mieux contrôler de la propagation du
virus,
· de minimise son impact dans les régions
vulnérables,
· d'anticiper sur les épidémies
potentielles oud'élabore des cartes de risques prédictifs.
L'essor récent des outils informatiques, et notamment
des systèmes d'information géographique (SIG), depuis une
vingtaine d'années a grandement simplifié la manipulation de
données facilitant ainsi la prise en compte de la dimension spatiale
dans l'étude et la surveillance des maladies infectieuses.
b) Système d'information géographique (SIG)
Il est question d'exposer tour à tour de la
définition de de la notion de SIG, puis la représentation
d'entités géographiques dans un SIG enfin le système de
Coordonnées géographiques
(1) Définition
La Société française de
photogrammétrie et télédétection définit en
1989, le système d'information géographique comme «
Système informatique permettant, à partir de diverses sources, de
rassembler et organiser, de gérer, d'analyser et de combiner,
d'élaborer et de présenter des informations localisées
géographiquement, contribuant notamment à la gestion de l'espace
». Un SIG est de ce fait un outil complet de connaissance, d'aide
à la décision et de communication. Le SIG permet la collecte et
le stockage, la visualisation, la superposition, l'interrogation et l'analyse
des données géoréférencées.
(2) Représentation
d'entités géographiques dans un SIG
Deux modes de représentation des entités
géographiques sont principalement utilisés: le mode vectoriel et
le mode matriciel ou raster.
· En mode vectoriel, les objets de
chaque couche d'information sont localisés dans l'espace par leurs
coordonnées géographiques et sont représentés sous
forme de points, de lignes ou de polygones.
· En mode matriciel, ou raster, l'espace
est représenté sous forme d'une grille ou matrice, ou image,
composée de cellules de même taille appelées pixels,
présentant des valeurs différentes en fonction de leur nature. Ce
mode de représentation est donc adapté à la
représentation de variables, changeant de manière continue dans
l'espace.
(3) Système de Coordonnées
géographiques
Les coordonnées sont les repères qui permettent
de définir la position d'un point sur le globe terrestre, en latitude et
en longitude.
· La latitude est définie par la
distance angulaire de ce point à l'équateur, mesurée en
degrés.
· La longitude est définie par la
distance angulaire de ce point au méridien d'origine mesurée en
degrés.
6. Quelques propriétés
épidémiologiques de la pandémie de la COVID-19
D'après l'Avis du Conseil scientifique de France sur
la COVID-19 publié le 12 mars 2020, la COVID-19 est une affection
bénigne dans 80% des formes symptomatiques, auxquellesse rajoutent 15%
de formes sévères et 5% de formes critiques nécessitant un
passageen réanimation. La létalité des formes
symptomatiques est estiméeautour de 2 à 5% selon la distribution
par âge des patients, leurs co-morbidités, et lasaturation des
systèmes de santé. La létalité des patients avec
des formes critiques aété estimée à 61% dans une
série de patients hospitalisés à Wuhan. Parmi les patients
décédés, 20% ont moins de 60 ans. Ces
élémentsont un retentissement majeur sur le système de
santé.Il est donc question ici de présenter les origines de la
COVID-19, les symptômes et les modes de transmission.
a) Origines de laCOVID-19
D'après (COPIL, 2022) le virus identifié en
janvier 2020 en Chine est un nouveau coronavirus, nommé SARS-CoV-2. La
maladie provoquée par ce coronavirus a été nommée
COVID-19 par l'OMS. Depuis le 11 mars 2020, l'OMS qualifie la situation
mondiale du COVID-19 de pandémie ; c'est-à-dire que
l'épidémie est désormais mondiale. La COVID-19 est
dangereuse pour les raisons suivantes :
o il est très contagieux : chaque
personne infectée va contaminer au moins 3 personnes en l'absence de
mesures de protection ;
o une personne contaminée mais qui ne
ressent pas encore de symptômes peut contaminer d'autres personnes.
b) Symptômes de la COVID-19
D'après (COPIL, 2022), le COVID-19 peut se manifester
par : la sensation de fièvre, la toux, des maux de tête,
courbatures, une fatigue inhabituelle, une perte brutale de l'odorat, une
disparition totale du goût, ou une diarrhée. Dans les formes plus
graves : difficultés respiratoires pouvant mener jusqu'à une
hospitalisation en réanimation voire au décès.
c) Modes de transmission de la COVID-19.
D'après (COPIL, 2022) la maladie se transmet :
· par projection de gouttelettes contaminées par
une personne porteuse : en toussant, éternuant ou en cas de contacts
étroits en l'absence de mesures de protection.
· par contact direct physique entre une personne porteuse
et une personne saine.
· par contact indirect, via des objets ou surfaces
contaminées par une personne porteuse.
CHAPITRE III : ETAT DE
L'ART DE LA MODELISATION DES EPIDEMIES
La modélisation des épidémies a pour but
essentiel de comprendre et contrôler, la propagation d'une maladie
infectieuse transmissible. Elle consiste à construire un modèle
qui permet de rendre compte de la dynamique de la maladie à partir de
données et d'hypothèses sur la population.Dans cette session nous
allons présenter d'abord les modèles à base de
compartiment, puis les modèles à base de réseaux de
pétri enfin et les modèles à base d'agent.
7. Modèles à base des compartiments
Les modèles à base des compartiments divisent la
population en un certain nombre de compartiments ou classes différents,
correspondant à des statuts épidémiologiques
différents : sensible, infecté, guéri... . Des
équations différentielles expriment alors l'évolution du
nombre de personnes dans chaque compartiment au cours du temps.
a) Travaux connexes sur les modèles à base des
compartiments
MATONDO MANANGA Herman, dans l'article intitulé :
« Modélisation de la Dynamique de Transmission de la Covid-19
en République Démocratique du Congo à l'Aide du
Modèle SEIRS à Six Classes», décrit, dans le
temps, la dynamique de transmission de la Covid-19 en environnement
déterministe au moyen des équations différentielles
ordinaires. Le modèle qu'il proposé est une extension du
modèle classique SEIRS ayant 6 compartiments. Son compartiment E est
éclaté en deux : A correspondant au compartiment des
asymptomatiques et I correspondant au compartiment de symptomatiques. Les
autres compartiments sont : ?? : compartiment des susceptibles, ?? :
compartiment des exposés, ?? : compartiment des guéris et ?? :
compartiment des décédés dû à la Covid-19. La
Figure 5 ci-dessous, est le diagramme de transfert de la population d'un
compartiment à un autre.
Figure 4: diagramme du
modèle SEAIRD(MATONDO MANANGA, 2021)
Le peuplement de différents compartiments
procède comme suit : dans S, un susceptible devient exposé
après un contact adéquat durant une période d'incubation
moyenne de 14 jours, soit il manifeste les symptômes, devient
symptomatique et entre dans le compartiment I ; soit il ne manifeste pas de
symptômes et passe dans la classe des asymptomatiques A. Un
infecté de la classe ?? peut, après un traitement, guérir
et passer à la classe de guéris R ; soit, il peut
également mourir de la Covid19 et passe dans la classe ??. Enfin, un
guéri de la Covid-19 peut de nouveau devenir susceptible avec un taux
??. D'où l'hypothèse selon laquelle tous les asymptomatiques ne
meurent pas du Covid-19 mais tous guérissent de la maladie après
un certain temps. Du diagramme de la figure 5, on déduit le
système d'équations différentielles ci-dessous qui
décrivent la dynamique temporelle de la pandémie de la covid-19
en République Démocratique du Congo.
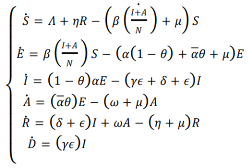
b) Limites des modèles à base de
compartiments
Les réseaux de taille réelle sont difficiles
à modéliser par un jeu d'équations différentielles.
L'introduction de nouvelles populations et l'amélioration du
modèle nécessitent la modification de la plupart des
équations du modèle. Les équations différentielles
ne tiennent pas compte des facteurs spatiaux tels que la variable de la
densité de population et la dynamique de la population. Les
modèles à base de compartiments sont déterministes, donc
ne prennent en compte le caractère aléatoire de
l'épidémie de la covid-19. Ces modèles sont
considérés comme très simplistes.
8. Modèles à base de réseaux de
pétri
Les Réseaux de Petri, en abréviation RdP, ont
été introduits par le mathématicien Allemand Carl Adam
Petri dans sa thèse "Communication avec des Automates" en Allemagne
à Bonn en 1962. Les RdP sont des outils à la fois graphiques et
mathématiques permettant de modéliser le comportement dynamique
des systèmes à évènements discrets. Un RdP est un
graphe orienté comprenant deux sortes de noeuds : des places et des
transitions (figure 6). Ce graphe est constitué de telle sorte que les
arcs du graphe ne peuvent relier que des places aux transitions ou des
transitions aux places.

Figure 5: Représentation
graphique des éléments de RdP
a) Principe de modélisation à base des
réseaux de pétri
En général la modélisation des
épidémies avec les RdP se base sur un certain nombre de principes
simples : les places correspondent aux statuts épidémiologiques
de l'individu. Les transitions représentent les conditions ou les
probabilités de changement de statut épidémiologique ou le
temps nécessaire pour le passage d'un statut
épidémiologique à un autre. Enfin les jetons
représentent les individus. Ces jetons peuvent être colorés
pour distinguer les catégories ou classes d'individus.
b) Avantages de la modélisation à base des
réseaux des pétri
Pour relever les limites des modèles à base de
compartiments, l'on a fait appel aux réseaux de Pétri. En effet
les réseaux de Pétri modélisent aisément le
caractère aléatoire de l'épidémie, notamment les
réseaux de pétri stochastiques. Aussi les RdP modélisent
l'hétérogénéité de la population grâce
aux réseaux de pétri coloré, où chaque couleur de
jeton correspond à un groupe particulier de la population.
c) Travaux connexes sur la modélisation à base
des réseaux des pétri
Les chercheurs du Laboratoire Africain d'Informatique et de
Mathématiques Appliquées (LAIMA), ont modélisé le
phénomène Covid-19 au Gabon grâce aux réseaux des
pétri généralisés (figure 7). Ce modèle est
très réaliste et prend en compte : l'aspect stochastique de
l'épidémie de la Covid-19,
l'hétérogénéité de la population et la
vaccination. Le modèle du LAIMA est une extension du modèle SVEIR
en 8 places : le compartiment E se divise en trois place : la place des
asymptomatiques, la place des hospitalises et la place de la
réanimation. Et le compartiment R se divise en deux places : la place
des guéris et la place des décédés.
Figure 6: modèle
SVEIR-RDP de LAIMA (modèle de KAMANA)
d) Limites des modèles à base des
réseaux de Pétri
Les RdP ont des difficultés à modéliser
la dimension spatiale de la population pourtant essentielle pour une
étude complète d'une épidémie. L'expression de la
dynamique temporelle des épidémies modélisée par
les RdP est sous la forme des systèmes dynamiques, souvent très
complexes.
9. Modèles à base d'agents (ABM)
Ces dernières années témoignent d'un
grand essor dans l'utilisation de la modélisation à base d'agents
pour l'étude des systèmes complexes. Cette approche, qui consiste
à représenter explicitement les entités composant le
système étudié sous la forme d'un ensemble
d'entités informatiques autonomes en interaction appelées agent,
connaît aujourd'hui un grand succès dans de nombreux domaines tels
que l'agronomie, l'écologie, la cartographie ou
l'épidémiologie.
a) Principe de la modélisation à base d'agent
(ABM)
Selon Jacques Ferber, dans « Les
Systèmes Multi Agents: vers une intelligence
collective » : développer un modèle de
simulation à l'aide de l'approche multi-agent consiste, à
modéliser un système un système composé des
'éléments suivants (figure 8):
· Un environnement E,
c'est-à-dire un espace disposant généralement d'une
métrique.
· Un ensemble d'objets O. Ces objets
sont situés, c'est-à-dire que, pour tout objet, il est possible,
à un moment donne, d'associer une position dans E.
· Un ensemble A d'agents, qui sont des
objets particuliers (A ? O), lesquels représentent les entités
actives du système.
· Un ensemble de relations R qui
unissent des objets (et donc des agents) entre eux.
· Un ensemble d'opérations Op
permettant aux agents de A de percevoir, produire, consommer, transformer et
manipuler des objets de O.
· Des opérateurs chargés
de représenter l'application de ces opérations et la
réaction du monde à cette tentative de modification, que l'on
appellera les lois de l'univers
Figure 7 :
Représentation imagée d'un agent en interaction avec son
environnementet les autres agents, (Ferber, 1995)
b) Avantages des modèles à base d'agent
Les systèmes multi-agents apportent une solution
radicalement nouvelle au concept même de modèle et de simulation
dans les sciences de l'environnement :
· En offrant la possibilité de représenter
directement les individus, leurs comportements et leurs interactions.
· L'intérêt de ces simulations est de
pouvoir considérer aussi bien des paramètres quantitatifs
(paramètres numériques) que qualitatifs (des comportements
individuels).
· Enfin, les systèmes multi-agents permettent la
modélisation de situations complexes dont les structures globales
émergent des interactions entre individus.
c) Travaux connexes modèles à base
d'agent :COMOKIT
Les travaux sur la modélisationde
l'épidémie de la covid-19 par une approche des systèmes
multi-agents sont abondants. Mais l'un de ces travaux méritent
d'être cite ici.L'équipe des chercheurs de l'Unité de
Modélisation Mathématique et Informatique des Systèmes
Complexes (UMMISCO), constituée de Kevin Chapuis, Patrick Taillandier,
Benoit Gaudou, Arthur Brugière et Alexis Drogoul, ont mis sur pieds,
l'environnement logiciel COMOKIT (covid-19, modeling kit), qui repose sur un
modèle à base d'agents. COMOKIT est un projet
développé à l'origine pour répondre aux besoins du
gouvernement vietnamien et l'aider à prendre des décisions. Il a
été codé en GAMA, et l'une de ses forces est qu'il est
modulaire et évolutif. Les données peuvent être
modifiées pour étudier d'autres villes, ce qui a
été fait pour étudier la propagation du virus à
Nice. Il a été conçu pour aider à la prise de
décision et a réellement été utilisé pour
cela, notamment au Vietnam. La figure 9 montre le diagramme UML du
modèle COMOKIT, résumant les différents agents inclus.
COMOKIT permet d'explorer l'impact des différentes politiques mises en
place.
Figure 8 : Diagramme de
classe des entités COMOKIT(Taillandier, Drogoul, & Gaudou,
2020)
d) Limites des modèles à base d'agents
(ABM)
Bien que les modèles à base d'agents soient
adaptés pour l'évaluation des politiques sanitaires a priori, ils
présentent un inconvénient majeur : leur consommation en
ressources. En effet ces modèles nécessitent une quantité
importante d'information pour l'estimation des paramètres. Et surtout
les modèles à base d'agents demandent un temps de calculs
très long. Ainsi l'implémentation des modèles à
base d'agents est réputée être plus complexe que pour les
modèles à base de compartiments.
DEUXIEME PARTIE :
MODELISATION DE LA COVID-19 PAR UNE APPROCHE MACHINE LEARNING
CHAPITRE IV : PRESENTATION
DU MACHINE LEARNING
Dans ce chapitre, il est question de présenter la
notion de Machine Learning à travers la définition des termes
clés, puis présenter les types d'apprentissages,
l'évaluation des modèles et enfin exposer quelques
algorithmes.
10. Intelligence artificielle
L'intelligence artificielle est une branche de l'informatique.
Il s'agit de développer des programmes informatiques pour accomplir des
tâches qui nécessiteraient autrement l'intelligence humaine. Les
algorithmes d'intelligence artificielle peuvent aborder l'apprentissage, la
perception, la résolution de problèmes, la compréhension
du langage ou le raisonnement logique.Une intelligence artificielle est
caractérisée par :
· Une Capable de prédire et de
s'adapter : l'intelligence artificielle utilise des algorithmes
qui découvrent des modèles à partir d'énormes
quantités d'informations.
· Une autonomie dans la prise de
décisions :L'intelligence artificielle est capable
d'augmenter l'intelligence humaine, de fournir des informations et
d'améliorer la productivité.
· Une Apprentissage
continu :l'intelligence artificielle utilise des algorithmes pour
construire des modèles analytiques. À partir de ces
algorithmes, la technologie de l'IA découvrira comment effectuer des
tâches à travers d'innombrables séries d'essais et
d'erreurs.
· Une approche
futuriste :L'intelligence artificielle est tournée vers
l'avenir, l'IA est un outil qui permet aux gens de reconsidérer la
façon dont nous analysons les données et intégrons les
informations, puis utilisons ces informations pour prendre de meilleures
décisions.
Une intelligence artificielle est subdivisée en
plusieurs branches parmi lesquelles, figure le Machine Learning (figure
10).
figure 9 : branches de
l'intelligence artificielle,(Mohammed, 2019)
11. Machine Learning
Suite à son invention, Arthur Samuel a formulé
la définition historique du Machine Learning : « Le Machine
Learning est la science de donner à une machine la capacité
d'apprendre, sans la programmer de façon explicite. ». Une
définition formelle couramment citée de l'apprentissage
automatique, proposée par l'informaticien Tom M. Mitchell, dit qu'une
machine apprend si elle est capable de prendre de l'expérience et de
l'utiliser de manière à ce que ses performances
s'améliorent par rapport à des expériences similaires
à l'avenir.
Le Machine Learning est un sous-domaine de l'intelligence
artificielle. Chaque système de Machine Learning peut être
divisé en trois composants: Données, Modèle, Tâche.
Les données sont introduites dans le modèle en tant
qu'entrée, le modèle peut être par exemple une fonction ou
un programme sélectionné spécifiquement pour la
tâche. L'apprentissage automatique est réalisé par un
processus dans lequel, en ajustant le modèle aux données, le
modèle devient meilleur pour la tâche souhaitée.
a) Pourquoi utilise-t-on le Machine Learning ?
Pourquoi avons-nous besoin du Machine Learning plutôt
que de programmer directement nos ordinateurs à réaliser une
tâche spécifique ? Deux aspects d'un problème donné
peuvent faire appel à l'utilisation de programmes capable d'apprendre et
de s'améliorer basée sur leurs expériences : la
complexité du problème et le besoin d'adaptation.
(1) Les tâches qui sont trop
complexes à programmer
· Les tâches effectuées par
humains : Il y a de nombreuses tâches que nous en tant
qu'être humain réalisons habituellement, comme la conduite, la
reconnaissance vocale, la compréhension d'images ... Dans tous ces
exemples, les programmes qui « apprennent à partir de leur
expérience », accomplissent des résultats satisfaisants, une
fois exposés à des données d'entraînements
suffisants.
· Les tâches au-delà des
capacités humaines : Apprendre à détecter des
caractéristiques pertinentes dans de larges et complexes ensembles de
données est un domaine prometteur dans laquelle la combinaison de
programmes qui peuvent s'améliorer avec quasiment une mémoire
illimitée et de plus en plus de vitesse de calcul ouvre de nouveaux
horizons.
(2) L'adaptation
Une caractéristique des outils programmés est
leur rigidité. Une fois que le programme a été
écrit et installé, il reste inchangé. Pourtant, de
nombreuses tâches changent au fil du temps ou d'un utilisateur à
un autre. Les outils Machine Learning, programmées avec des
comportements qui s'adaptent à leurs données d'entrées,
offrent des solutions à ces problèmes. Ils s'adaptent
naturellement aux changements dans les environnements où ils
interagissent. Des exemples d'applications du Machine Learning à de
tels problèmes incluent : les programmes capables de décoder des
écritures manuscrites, où le programme peut s'adapter à la
variation de l'écriture de différentes personnes, un autre
exemple, les programmes de reconnaissance vocale.Le Machine Learning
développe des algorithmes qui vont apprendre de manière
automatisée des modèles statistiques à partir de
données d'apprentissage. Ceci peut se faire de manière
supervisée, non supervisée, par renforcement ou encore en
profondeur.
b) Types d'apprentissage
Les algorithmes de Machine Learning peuvent être
divisés en quatre groupes principaux : l'apprentissage
supervisé, l'apprentissage non supervisé, L'apprentissage par
renforcement etl'apprentissage en profondeur .
(1) Apprentissage supervisé
L'algorithme de Machine Learning dispose d'un ensemble de
données d'entrée suffisamment grand pour servir d'exemple de
sortie ou d'événement, généralement
préparé en consultation avec l'expert en la matière d'un
domaine donné. L'objectif de l'algorithme est d'apprendre des
modèles dans les données et de construire un ensemble
général de règles pour faire correspondre l'entrée
à la classe ou à l'événement. De manière
générale, il existe deux types d'algorithmes d'apprentissage
supervisé couramment utilisés :
· Régression :La sortie
à prédire est un nombre continu en rapport avec un ensemble de
données d'entrée donné.
· Classification : La sortie
à prédire est une probabilité d'appartenir à une
classe. L'algorithme doit apprendre les modèles dans l'entrée
pertinente de chaque classe à partir de données historiques.
Enfin il doit être capable de prédire des nouvelles classes dans
le futur en tenant compte des données d'entrée.
(2) Apprentissage non
supervisé
Il existe des situations où la classe ou
l'événement de sortie souhaité est inconnu pour les
données historiques. Dans ce cas, l'objectif est d'étudier les
modèles dans l'ensemble de données d'entrée afin de mieux
comprendre et d'identifier les modèles similaires qui peuvent être
regroupés dans des classes ou des événements
spécifiques.
· Regroupement : supposons que les
classes ne soient pas connues à l'avance pour un ensemble de
données donné. L'objectif ici est de diviser l'ensemble de
données d'entrée en groupes logiques d'éléments
connexes.
· Réduction des dimensions :
l'objectif est ici de simplifier un grand ensemble de données
d'entrée en les transposant dans un espace de dimension
inférieure. Par exemple, l'analyse d'un ensemble de données de
grande dimension nécessite des ressources informatiques importantes.
Pour simplifier, il est possible donc de trouver des variables clés qui
contiennent un pourcentage significatif.
(3) Apprentissage par renforcement
Cette technique consiste pour la machine à
améliorer son comportement à partir d'une méthode d'essai
et d'erreur dans un dynamique environnement. Ici, le problème est
résolu par prise de décision approprié dans une certaine
situation pour maximiser le rendement et obtenir les résultats
acquis.
(4) Apprentissage en profondeur
L'apprentissage en profondeur ou le « Deep
Learning » s'appuie sur un réseau de neurones artificiels
s'inspirant du cerveau humain. Ce réseau est composé de dizaines
voire de centaines de «?couches?» de neurones, chacune recevant et
interprétant les informations de la couche précédente.
Une fois un type d'apprentissage a été
implémenté, il est nécessaire de procéder à
une évaluation.
c) Évaluation d'un modèle en Machine
Learning
L'évaluation permet de tester le modèle par
rapport à des données qui n'ont jamais été
utilisées pour l'entrainement. Cela permet de voir comment le
modèle pourrait fonctionner par rapport à des données
qu'il n'a pas encore vues. Ceci est censé être
représentatif de la façon dont le modèle pourrait
fonctionner dans le monde réel. Il existe plusieurs méthodes pour
calculer le score de chaque algorithme pour ensuite choisir le meilleur pour la
prédiction. Voici quelques méthodes de calcul du score.
(1) Score R-carré (R²)
Le R-carré est appelé coefficient de
détermination. C'est un indicateur utilisé en statistiques pour
juger de la qualité d'une régression linéaire.
Mathématiquement, il s'agit de la proportion de la variance d'une
variable dépendante qui s'explique par une ou plusieurs variables
indépendantes dans le modèle de régression. On l'exprime
soit entre 0 et 1, soit en pourcentage. Le R² se calcule à partir
de la formule suivante :
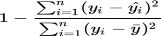
Avec :
· yi la valeur du point i,
· yi la valeur prédite pour le point i
par la régression linéaire,
· ? la moyenne empirique des points donnés.
(2) Erreur quadratique moyenne ou le
« Root Mean Square Error » (RMSE)
L'erreur quadratique moyenne d'un estimateur F d'un
paramètre O de dimension 1 est une mesure caractérisant la «
précision » de cet estimateur. Elle est plus souvent appelée
« erreur quadratique » (« moyenne » étant
sous-entendu) ; elle est parfois appelée aussi « risque quadratique
». L'erreur quadratique moyenne est définie via l'équation
mathématique :
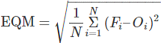
Où
· Fi = les valeurs de la prévision du
paramètre en question
· Oi = la valeur de vérification
correspondante
· N = le nombre de points de vérification dans la
zone de vérification
d) Quelques algorithmes de Machine Learning
(1) ARIMA
Il s'agit d'un modèle de série chronologique
hybride où :
· AR désigne AutoRégressif,
· I dénote pour Intégré et,
· MA dénote pour Moyenne mobile.
Il prend des données historiques en entrée et
produit des résultats futurs en observant la tendance. L'objectif
d'ARIMA est de définir les autocorrélations entre les points de
données.
(2) Prophète
Ce modèle a été conçu et
développé en 2007, par l'équipe Data Scientist de Facebook
dirige par Taylor et Letham, pour prévoir les tendances et la nature
du modèle est additive. Ainsi, le modèle de prophète FB
peut prédire les tendances quotidiennes, hebdomadaires, mensuelles et
saisonnières en fonction des besoins. Fondamentalement, Prophet est un
modèle polyvalent et flexible qui décompose diverses
données de séries chronologiques et produit une sortie
évolutive.
(3) LSTM
Le modèle LSTM a été
développé en 1997 par Hochreiter et Schmidhuber. Il s'agit d'un
modèle spécial de réseau neuronal récurrent (RNN)
spécialisé dans la mémorisation ou le stockage de
données de séquence plus longue pour prédire des tendances
précises. LSTM signifie Long Short-Term Memory network. Cela implique
qu'ils sont très bien adaptés pour recueillir des données
pour des données étendues par rapport à RNN. Le
modèle LSTM appartient à la catégorie des algorithmes
d'apprentissage en profondeur et fournit des résultats optimaux pour un
ensemble de données plus volumineux avec une erreur minimale.
Chapitre V :
démarche Machine Learning pour la modélisation
Dans cette partie il est question de présenter les
deux processus d'extraction de données les plus populaires et largement
pratiqués pour construire des systèmes d'apprentissage
automatique. Ces processus sont les suivants : le processus «Knowledge
Discovery in Databases «(KDD), et le Processus «Cross Industry
Standard Process for Data Mining» (CRISP-DM)
12. Processus «Knowledge Discovery
in Databases «(KDD)
Le processus Knowledge Discovery in Databases (KDD) ou en
français « Bases de données de découverte de
connaissances » est un processus global de découverte de
connaissances utiles, à partir de données. Ce processus couvre
l'ensemble du cycle de vie des données, notamment la manière dont
les données sont stockées, la manière dont on y
accède, la manière dont les algorithmes peuvent être
adaptés efficacement à de base de données gigantesque, la
manière dont les résultats peuvent être
interprétés et visualisés. Le KDD comporte cinq
étapes, présentées dans le tableau 2.
Tableau 2: Etapes du
KDD
|
étape
|
Nom
|
Description
|
|
1
|
Sélection
|
Création des données sur lesquelles la
découverte va s'établir
|
|
2
|
Prétraitement
|
Nettoyage des données pour obtenir des données
consistantes
|
|
3
|
Transformation
|
Transformation des données en utilisant des
méthodes de transformations
|
|
4
|
Data Mining
|
Recherche de modèles en adéquation avec les
objectifs de Data Mining
|
|
5
|
Interprétation/
évaluation
|
Interprétation et évaluation des modèles
trouvés
|
Source: (Swamynathan, 2017)
Le cycle du processus KDD s'apparente à une progression
quasiment linéaire et séquentielle (figure 11).
Figure 10 : cycle de vie
du processus KDD, source :(Swamynathan, 2017)
13. Processus «Cross Industry
Standard Process for Data Mining» (CRISP-DM)
Le Processus CRISP-DM, ou Processus standard interindustriel
pour l'extraction de données, a été établi par le
programme stratégique européen de recherche en technologies de
l'information en 1998. Ceci dans le but de créer une
méthodologie universelle qui ne dépend pas d'un domaine
particulier. Il s'agit d'un processus itératif et
incrémentale, où de nombreuses tâches reviennent sur
celles précédentes et répètent certaines actions
pour apporter plus de clarté. Il y a six phases principales, comme
décrit dans le tableau 3 ci-dessous.
Tableau 3 :
récapitulatif des phases du processus CRISP-DM.
|
Phase
|
objectifs
|
|
Compréhension de l'activité
|
comprendre les objectifs généraux du projet et
les attentes du point de vue de l'entreprise.
|
|
Compréhension des données
|
comprendre les lacunes des données ou leur pertinence
par rapport à l'objectif visé
|
|
Préparation des données
|
Cette phase consiste à nettoyer les données afin
qu'elles soient prêtes à être utilisées pour la phase
de construction du modèle
|
|
Modélisation
|
Choix de l'algorithme en fonction de leur performance
|
|
Évaluation et validation
|
évaluation comparative des différents
modèles choisis et vérification résultats par rapport aux
besoins de l'entreprise identifiés.
|
|
Déploiement
|
L'objectif principal de cette phase est la facilité
d'utilisation des résultats du modèle
|
Source:(Swamynathan, 2017)
Le cycle de vie du processus CRISP-DM est itératif et
incrémentale comme l'indique la figure 10 ci-dessous.
Figure 11: méthode
CRISP-DM, adapté de (Shearer, 2000)
14. Méthodologie choisie : le
processus CRISP-DM
En général, la plupart des chercheurs et des
experts en exploration de données suivent le modèle le processus
CRISP-DM parce qu'il est plus complet et plus précis. CRISP-DM est plus
complet car le flux itératif des connaissances à travers et entre
les phases a été clairement défini. De plus, il couvre
tous les domaines de la construction de systèmes de Machine Learning
fiables. Les avantages de la méthode CRISP DM sont nombreux pour un
projet de Machine Learning. Cette méthode est agile et itérative,
c'est-à-dire que chaque itération apporte de la connaissance
métier supplémentaire qui permet de mieux aborder
l'itération suivante.
15. Mise en oeuvre de la démarche
CRISP-DM
Il s'agit d'appliquer les six étapes du processus CRISP
à notre projet.
a) Compréhension métier
Ici il est question de la définition du
problème. Puis de comprendre : à quoi serviront les
prédictions ? Qui a besoin des prédictions ? Et comment
elles s'intègrent dans l'organisation ? (voir tableau 4)
On commence par une description informelle du problème
dans le but de formuler en une phrase facilement compréhensible le
problème : comment concevoir un modèle de Machine Learning
capable de prédire le nombre des cas de l'épidémie de la
covid-19 ?
Pour la définition formelle du problème, l'on se
base sur la définition de Tom Mitchell en 1997 qui définissait
un programme de Machine Learning comme suit : «on dit qu'un programme
informatique apprend de l'expérience E en ce qui concerne une
tâche T et une mesure de performance P, si sa performance sur T,
mesurée par P, s'améliore avec l'expérience
E. ». En d'autres termes, il va falloir définir le triptyque T
(tâche), P (Performance) et E (Expérience).
· Tâche (T) : prédire le nombre des cas de
l'épidémie de la covid-19.
· Performance (P) : La précision de la
prédiction faite par l'algorithme et le temps d'exécution
raisonnable
· Expérience (E) : Les inventaires des
données réelles sur les cas de la covid-19 au Gabon.
Tableau 4 :
résumé des questionnements qui facilitent la compréhension
du métier
|
questionnement
|
Réponses attendues
|
|
Quelle est le problème à
résoudre ?
|
comment concevoir un modèle de Machine Learning
capable de prédire le nombre des cas de l'épidémie de la
covid-19 ?
|
|
À quoi serviront les prédictions ?
|
Prédire l'évolution de la dynamique
spatio-temporelle de la covid-19
|
|
Qui a besoin des prédictions?
|
les décideurs en santé publique et les
organismes engagés dans la lutte contre la pandémie de la
covid-19.
|
|
Comment sont intégrées les prédictions
dans l'organisation ?
|
Les prédictions seront exploitées sous la forme
d'outils d'aide à la décision
|
b) Compréhension des données
Dans cette phase, nous avons procéder à la
collecte des données initiales, à leur description et à
leur exploration.
(1) Collecte de données
Les données utilisées dans ce projet sont
fournies par :
· Le « Johns Hopkins University Center for Systems
Science and Engineering» (JHU CSSE),
· Le Centre hospitalier et Universitaire de Libreville
(CHUL).
(2) Description des données
Les données utilisées dans ce projet sont
décrits ainsi qu'il suit :
· une partie des données ont été
téléchargées à partir du référentiel
Github qui est géré par l'Université John Hopkins et
l'ensemble de données est public et mis à jour quotidiennement.
Il existe plusieurs fichiers CSV. Pour ce projet, nous extrayons les
données d'un seul fichier à savoir : confirmed_case.csv
· l'autre partie des données
collectéesauprès du CHUL de Libreville sont la forme de fichier
Excel : Chul.civid.xls.
Le tableau 5 ci-dessous récapitule les données
et leurs sources respectives
Tableau 5 : description
des données
|
Fichier
|
Source
|
Données à extraire
|
dimension de la data frame
|
|
confirmed_case.csv
|
JHU CSSE
|
Le nombre cumulé de cas confirmés
|
850 colonnes et 270 lignes
|
|
Chul.covid.xls
|
CHUL
|
Lieu de résidence des cas confirmés à
Libreville.
|
10 colonnes et 1026 lignes
|
(3) Exploration des données
L'inspection des différentesbases de données
nous ont permis de comprendre que :
Pour le fichier provenant l'Université John Hopkins
· Les lignes représentent différents pays
et,
· les colonnes incluent :
o le nom du pays/région et également de la
province/état si disponible,
o la latitude et la longitude du pays et,
o le nombre cumulé de cas du 22 janvier 2020 au 17 mai
2022 (figure13).
Pour les fichiers fournis par le Centre hospitalier et
Universitaire de Libreville
· Les lignes représentent les dates
d'enregistrement
· Les colonnes représentent
o le domicile du patient,
o Le statut épidémiologique,
o L'âge,
o le sexe ...
Figure 12 : Capture
d'écran des cas de guérison dans le monde (partiellement)
Après la phase de compréhension des
données, le prétraitement des données est
effectué, c'est ce qui est expliqué à l'étape
suivante.
c) Préparation des données
Les tâches de préparation comprennent
principalement cinq étapes : l'extraction, le traitement des valeurs
manquantes, l'encodage, la normalisation et le partitionnement des
données
(1) Extraction
On extrait les lignes et les colonnes qui nous seront utiles
pour la suite. Dans notre c'est ligne correspondant au pays Gabon
(figure14).
Figure 13 extraction des
lignes et colonnes
(2) Traitement des valeurs manquantes
et les jours non-ouvrages
Il est a remarqué le comité de pilotage (COPIL)
ne publie pas de rapport sur la situation épidémiologique du
Gabon, les jours fériés et les weekends. Ce qui fait que durant
les jours non-ouvrages on enregistre automatiquement des valeurs manquantes.
Mais les analystes de l'Université John Hopkins, complètent les
jours non ouvrages du comité de pilotage (COPIL) par des zéro.
Ainsi se pose un problème d'interprétation entre les
données manquantes et les valeurs nulles. Les valeurs manquantes de
chaque base de données est résumé dans le tableau 6
ci-dessous.
Tableau 6 :
récapitulatif des proportions des valeurs manquantes dans les data
set
|
Fichier
|
Proportion de données manquantes en %
|
Prétraitement adoptée
|
|
covid19_confirmed_case_Gabon.csv
|
27,57
|
suppression
|
|
Chul.covid.xls
|
14,28
|
suppression
|
Pour les valeurs manquantes et les lignes correspondantes aux
jours non-ouvrables, l'imputation avec la moyenne, la médiane ou le mode
serait incorrecte car ces données représentent les cas
réelssignalés dans le monde entier. Par conséquent, ces
données ont été supprimées (figure 15).
|
|
|
Figure 15a les captures d'écran du dataset avant le
nettoyage
|
Figure 15b les captures d'écran du dataset
après le nettoyage
|
Figure 14 les captures
d'écran du dataset avant et après le nettoyage
(3) Encodage,normalisation et
partitionnement des données
Les données ont été transformé
suivant les formats date pour la colonne date et en forme numérique,
pour la colonne contenant les nombre de cas de la maladie de la covid-19.
Pour la normalisation, les données sur le nombre
cumules de cas confirme forme une série chronologique monotone et
croissante. Ainsi les termes consécutifs sont très proches. Et
par conséquentil n'y a pas des valeurs aberrantes. Donc la normalisation
ou la standardisation ne sont pas nécessaires dans ce cas.
Ensuite nous avons partitionné les données en
deux groupes (voir la figure 16) :
· Les données d'entrainement (75%) et,
· Les données de test (25%)
|
|
|
Figure16a données du test
|
Figure 16b données d'entrainement
|
Figure 15 : partitionnement
des données en données d'entrainement et données de
test
(4) Visualisation
Elle permet d'avoir une idée sur les
propriétés géométriques de la courbe, susceptible
d'être utilisé pour faire la régression. Ainsi cette
visualisation peut orienter le choix de l'algorithme d'entrainement. La figure
17 ci-dessous représente les courbes de nombre cumulés de cas de
guérison à Libreville avant et après le
prétraitement :
|
|
|
Figure 17a Avant le prétraitement
|
Figure 17b après le prétraitement
|
Figure 16 : les courbes
de nombre cumulés de cas de guérison à Libreville avant et
après le prétraitement
16. Modélisation : Choix de
l'algorithme d'entrainement.
Pour ce faire il plusieurs méthodes parmi les lequel
la sélection du modèle par la revue systématique de la
littérature ou la méthode expérimentale avec comparaison
des performances des modèles. Dans le cadre de ce mémoire nous
avons opté pour la revue systématique de la
littérature.
D'abord le chef-ouvre de Zenah ALZUBAIDI, consignés
dans leurs travaux de recherche pour le mémoire de Master de Institut de
technologie de Rochester de Dubaï, sur le thème : «A
Comparative Study on Statistical and Machine Learning Forecasting
». Elle a procédé à une étude
comparative des modèles de prédictions les plus usuelles et a
établi les avantages et les inconvénients de ces modèles
qui sont résumés dans le tableau 7 suivant :
Tableau 7: comparaison de
modèle de Machine Learning la prédiction des séries
temporelles
|
Avantages et inconvénients des
prévisions du modèle S/ARIMAAvantagesIncontinentsPeut
gérer les composants de tendance et de saisonnalitéSuppose que la
série chronologique ne contient pas d'anomaliesPrévisions
impartiales et niveaux de confiance réalistesLes paramètres du
modèle et le terme d'erreur sont constantsAvantages et
inconvénients des prévisions du modèle
FBPAvantages Incontinents Robuste aux points de données
manquants et aux valeurs aberrantesLes modèles multiplicatifs ne peuvent
pas être utilisés dans le prophètePrend en compte les
effets de vacancesRéglage manuellement pour des données à
saisonnalité multiple Avantages et inconvénients des
prévisions du modèle LSTMAvantages Incontinents Capable
d'apprendre la saisonnalité et les oscillations dans les données
nécessite une grande quantité de données historiques pour
créer de prédiction fiable Utile pour les données
séquentiellesNécessite une Grande capacité mémoire
de calcul nécessaire.
|
Source:(ALZUBAIDI, 2020)
En effet une bonne partie des travaux de prédiction de
la covid-19 à l'aide du modèle de Facebook Prophet ont
donné des résultats satisfaisants. Parmi ceux travaux trois
méritent d'êtrecités ici.
· D'abord les travaux du Dr Zahra Taheride
l'université de Téhéran, dans l'article intitulé
« Spread Visualization and Prediction of the Novel Coronavirus
Disease COVID-19 Using Machine Learning »où elle a
testé une dizaine de modèle de Machine Learning sur des
données de la Covid-19 provenant de l'Université de Johns
Hopkins. Elle est parvenu à la conclusion suivante : sur l'ensemble
de données de la covid-19, Facebook Prophet avait en moyen un temps
d'exécution plus faible et une bonne performance par aux autres
modèle comme ARIMA.
· Ensuite les travaux de BOULEKCHER Rachida et KABOUR
Oussama, consignés dans leurs travaux de recherche pour le
mémoire de Master, sur le thème : « Une approche
basée Machine Learning pour la prédiction du Covid-19 en
Algérie ». Ils ont réussi a montré que le
modèle FacebookProphet était plus performant et plus
adapté que le modèle ARIMA, pour la prédiction de la
Covid-19, selon la métrique R2-score (tableau 8).
Tableau 8 : Performances de
Prophet et de ARIMA selon la metrique R2-score
|
Prophet
|
ARIMA
|
|
Cas confirmées en Algérie au 23/04/2021
|
0.904
|
0.846
|
Source : (BOULEKCHER & KABOUR, 2021)
Enfin les travaux de Arnau Gispert BECERRA,
consignés dans ses travaux de recherche pour le mémoire de
« bachelor's degree in telecommunications technologies and
services engineering », sur le thème : «Time
series forecasting using SARIMA and SANN models». Où il a pu
montrer que sur un dataset de 1000 entrées, le modèleFacebook
Prophet (FBP)était 7 sept fois plus rapide que le modèle SARIMA
et 40 fois plus rapide que le modèle LTSM (voir le tableau 9).
Tableau 9:récapitulatif
des paramètres de performance de prévision
|
Modèle
|
Temps d'exécution en seconde
|
Erreur moyenne absolue (MAE)
|
Erreur quadratique moyenne (RMSE)
|
|
ARIMA saisonnier
|
7,962
|
0,721
|
0,965
|
|
LSTM
|
43,912
|
0,906
|
1,172
|
|
prophète
|
1,992
|
0,640
|
0.802
|
Source: (Becerra, 2021)
On peut retenir de cette revue de la littérature que
Prophet s'efforce de fournir un modèle simple à utiliser et
suffisamment sophistiqué pour fournir des résultats
significatifs. La robustesse, la facilité de configuration et la
rapidité d'installation de Prophet attirent les non-experts et les
utilisateurs ayant des connaissances statistiques limitées pour
déployer Prophet au sein de leur organisation.
Au final nous avons choisi l'algorithme facebook prophet pour
concevoir le modèle de prédiction proposée. En
effet :
· Prophet est fort dans le traitement des données
manquantes, capturant les changements de tendance et les grandes valeurs
aberrantes.
· Prophet arrive à une estimation raisonnable des
données mixtes sans effort manuel.
· Prophet est optimisé pour les prévisions
commerciales observées sur le réseau socialFacebook.
a) Évaluation et validation
A la fin de cette phase, une décision sur
l'utilité des résultats des modèles de Machine Learning
conçus doit être prise. Pour ce faire, nous allons évaluer
les métriques du modèle. Pour le modèle de Facebook
Prophet, nous allons utiliser comme métrique le Rscore2 et le RMSE (voir
le chapitre suivant).
b) Déploiement
Le modèle sera implémenté dans un
simulateur : une application web interactive (voir la partie suivante).
Cette application devra être capable de simuler la dynamique
spatio-temporelle de l'épidémie de la covid-19 à
Libreville, de déterminer les zones potentiellement à risque et
de faire des prédictions à court terme.
CHAPITRE VI:l'étude
de l'algorithme facebook prophet et conception du modèle de
prédiction
Ce chapitre sera principalement axé sur la
présentation du mode de fonctionnement de l'algorithme Facebook
prophet, puis de concevoir le modèle prédictif.
17. Principe détaillé du
fonctionnement de Facebook prophet.
La procédure Prophet est une méthode de
régression additive qui appartient à la famille des
modèles additifs avec les composants et la forme fonctionnelle
suivants :
Où :
· g(t) capture la tendance dans la série
chronologique, c'est-à-dire qu'il modélise les changements non
périodiques dans la série chronologique.
· s(t) capture la saisonnalité de la série
chronologique, La saisonnalité représente les changements
périodiques que soit journalière, hebdomadaire, mensuelle ou
même annuelle dans la série chronologique.
· f(t) capture les vacances ou les
événements spéciaux dans la série chronologique et,
· åt est un terme d'erreur
irréductible.
a) Modélisation de la tendance g(t)
La tendance peut être modélisée de deux
manières différentes dans Prophet, soit par un modèle
linéaire par morceaux, soit par un modèle de croissance
exponentielle.
Le modèle linéaire par morceaux est donné
par :
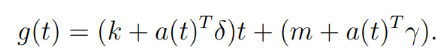
Où :
· le taux de croissance est désigné par k,
· les ajustements de taux sont désignés par
ä,
· ã est un ensemble pour rendre la fonction
continue et,
· m est un paramètre de décalage.
Le modèle de croissance exponentielle est donné
par :
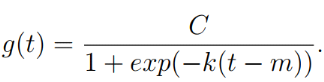
Où
· C : est la capacité de charge,
· K : est le taux de croissance et,
· m : est un paramètre de décalage.
b) Modélisation de la saisonnalité
La saisonnalité est modélisée avec des
séries de Fourier. Les effets saisonniers sont approximés
par :
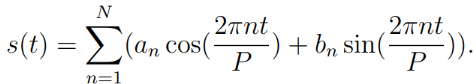
Où P est une période régulière
attendue dans les données.
L'ajustement des composantes saisonnières
nécessite l'estimation de a1, . . . ,
aNet b1, . . . ,
bN...
c) Modélisation des vacances
Les jours fériés sont modélisés
par une fonction indicatrice. Supposons que L est le nombre de jours
fériés imputé, alors :
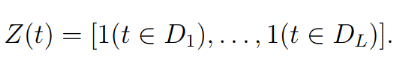
La méthode Prophet utilise une technique d'ajustement
de courbe pour l'ajustement des séries chronologiques.
18. Réglage des hyper
paramètres
Dans l'apprentissage automatique, les hyper paramètres
sont des paramètres qui sont définis avant l'entraînement
de l'algorithme et ces paramètres sont ajustés en fonction des
caractéristiques de l'ensemble de données. Le modèle
Prophet contient 16 hyper paramètres différents. Cependant,
seulement 4 d'entre eux sont recommandés pour régler selon la
documentation officiel de Facebook Prophet . Les hyper paramètres qu'il
est recommandé de régler sont répertoriés
ci-dessous.
a) Paramètre du point de changement de tendance.
Ce paramètre détermine la flexibilité de
la tendance et comment la tendance change aux points de changement de
tendance.
b) Paramètre de saisonnalité.
En plus de l'échelle précédente du point
de changement, ce paramètre détermine la flexibilité de
la saisonnalité. Des valeurs plus grandes permettent au modèle de
s'adapter à des fluctuations plus importantes.
c) Paramètre de vacances.
Ce paramètre spécifie la flexibilité des
effets de vacances et est similaire au paramètre de
saisonnalité
d) Paramètre du mode de saisonnalité.
Ce paramètre définit si la saisonnalité
est soit additive, soit multiplicatif. Par exemple, si la saisonnalité
croît le long de la tendance, le mode multiplicatif peut être
envisagé.
Il existe de nombreuses façons d'optimiser ces hyper
paramètres (tableau 10). Prophet a une méthode
intégrée pour le réglage des hyper paramètres
appeléevalidation croisée parallèle.
Tableau 10 : exemple de
réglage des hyper paramètres du modèle Facebook
prophet
|
Paramètres
|
point de changement de tendance
|
saisonnalité
|
mode de saisonnalité
|
|
Réglage 1
|
0.01
|
0.1
|
additif
|
|
Réglage 2
|
0.1
|
1
|
multiplicatif
|
19. Construction de notre
modèle
Dans notre projet, les colonnes «Date» ont
été renommées en «ds» et la variable cible,
c'est-à-dire les cas confirmés, a été
renommée en «y» conformément aux configurations du
modèle. Les modèles de données ont été
soumis aux caractéristiques d'entrée (ds, y) et à la
sortie sous forme de valeurs prédites ajoutées au cadre de
données pour les dates respectives. Le résumé du
modèle implémenté ainsi que sa configuration sont
présentés ci-dessous : le modèle de prophète
Facebook est plus facile à mettre en oeuvre car il s'agit d'un
modèle préformé où nous avons juste besoin de
fournir les configurations nécessaires.
a) Etape 1 importer les bibliothèques
|
library(covid19.analytics)
library(dplyr)
library(prophet)
library(lubridate)
library(ggplot2)
library(caret)
library(caretForecast)
|
b) Etape 2 configuration des données
|
#Etape 2.1 configuration
|
|
ds<-Laima_pre$Date
y<-Laima_pre$Cas_gueri_cumules
df<-data.frame(ds,y)
|
|
Etape 2.2 partitionnement des données en données
d'entrainement et données de test
|
|
train = df %>%
filter(ds<ymd("2021-01-23"))
test = df %>%
filter(ds>=ymd("2021-01-23")
|
c) Etape 3 configuration du modèle
|
# Etape 3.1 configuration et entrainement du modèle
|
|
m<-prophet(train)
#prediction
future<-make_future_dataframe(m,periods = 28)
forecast<-predict(m,future)
tail(forecast[c('ds', 'yhat',
'yhat_lower', 'yhat_upper')])
|
|
# Etape 3.2 règlage des hyperparamètres
|
|
additive = prophet(train,seasonality.mode = 'additive')
add_fcst = predict(additive,future)
|
d) Etape 4 évaluation de la performance du
modèle
|
# Etape 4.1 la validation croisee
|
|
df.cv <- cross_validation(m, initial = 500, period = 7,
horizon = 100, units = "days")
head(df.cv)
|
|
# Etape 4.2 visualisation
|
|
df.cv %>%
ggplot()+
geom_line(aes(ds,y)) +
geom_point(aes(ds,yhat,color=factor(cutoff)))+
theme_bw()+xlab("Date")+
ylab("deces_cumules")+ scale_color_discrete(name = 'Cutoff')
plot_cross_validation_metric(df.cv, metric = 'rmse')
plot_cross_validation_metric(df.cv,metric = 'mae')
|
Le graphe de la courbe d'entrainement montre que le
modèle fait moins d'erreur sur la prédiction de moins de 25
jours. Puis les nombres d'erreur atteinte un pique pour une période de
prédiction de 75 jours (figure 16)
Figure 17 : Courbe
d'apprentissage du modèle
e) Etape 5 Test du modèle
La figure 17 ci-dessous représente le code R
permettant de tester la prédiction de notre modèle sur une
période de 28 jours.
Figure 18 : code pour
tester la performance du modèle
Et la figure 18ci-dessous représente la courbe de
comparaison entre les valeurs réelles et les valeurs prédites
Figure 19 : la courbe de
comparaison entre les valeurs réelles et les valeurs
prédites
TROISIEME PARTIE :
REALISATION DU SIMULATEUR EVAL_EPI
Chapitre VI :
MÉTHODOLOGIE DE DÉVELOPPEMENT
Une méthodologie de développement logiciel est
une manière de gérer un projet de développement logiciel.
Ainsi dans ce chapitre nous présenterons d'une part une étude
comparative entre la famille des processus agile et la famille des processus
unifiés. D'autre part nous allons procéder à une
présentation détaillée de la méthode choisie.
20. Étude comparative entre la
famille des processus agile et la famille des processus unifiés
Les processus modernes de développement des logicielles
appartiennent majoritairement a la famille des processus agile ou à la
famille des processus unifiés
a) Présentation de la famille des processus
agile
Les méthodes agiles sont conçues pour s'adapter
à l'évolution des exigences, minimiser les coûts de
développement et fournir des logiciels de qualité raisonnable.
Les projets agiles se caractérisent par de nombreuses versions
incrémentales générées chacune dans un laps de
temps très court. Généralement, tous les membres de
l'équipe sont impliqués dans tous les aspects de la
planification, de la mise en oeuvre et des tests. Ceci est
généralement utilisé par de petites équipes,
peut-être neuf ou moins, qui peuvent avoir une interaction quotidienne en
face à face. Les équipes peuvent inclure un représentant
du client.
(1) Exemple de processus agile
· SCRUM :C'est actuellement la mise
en oeuvre la plus populaire des idéaux agiles. Les
fonctionnalités sont ajoutées en de courts sprints
généralement 7 à 30 jours et de courtes réunions
fréquentes permettent aux gens de rester concentrés. Les
tâches sont généralement suivies sur un tableau Scrum. Le
groupe est auto-organisé et géré en collaboration, bien
qu'il y ait un scrum master chargé de faire respecter les règles
et de protéger l'équipe de distractions extérieures.
· Extreme Programming (XP) : C'est
une méthodologie de développement dans laquelle les
développeurs travaillent par paires pour une révision continue du
code. Cela donne un logiciel très robuste et de haute qualité, au
prix du double du coût de développement. L'accent est mis sur le
développement piloté par les tests.
(2) Inconvénients des
méthodes Agiles
Les inconvénients des méthodes Agiles sont
qu'ils fonctionnent mal pour des projets avec des centaines de
développeurs, ou qui durent des décennies, ou lorsque les
exigences mettent l'accent sur une documentation rigoureuse et une conception
et des tests bien documentés.
b) Famille des processus unifiés
C'est un processus de développement interactif pour des
équipes de développement plus importantes, souvent plus
bureaucratiques. L'accent est mis sur les cas d'utilisation,
qui à leur tour suggèrent des exigences. L'accent est
également mis sur le choix de la meilleure
architecture. Les tâches les plus risquées sont
effectuées en premier afin de donner un point d'arrêt
précoce où le projet peut être annulé s'il est
voué à l'échec. Le bassin de main-d'oeuvre est
utilisé efficacement en ayant souvent divers pourcentages d'exigences,
de conception, de mise en oeuvre et de test exécutés en
parallèle.
(1) Exemple de processus
unifié :
· Rational Unified Process (RUP) : Cette
implémentation du processus unifié est un produit IBM
composé d'une documentation, d'outils logiciels de gestion, d'une
formation et de certifications.
· La méthode 2TUP2 : Ce processus
préconise un cycle de vie en Y qui dissocie et parallélise la
résolution des questions fonctionnelles et techniques. Le cycle de vie
de 2TUP s'apparente à un cycle en cascade mais introduit une forme
itérative interne à certaines tâches. 2TUP préconise
des formes de recherche de qualité et de performance
intéressantes telles que les services réutilisables et la
conception générique.
(2) Inconvénients des processus
unifiés :
Ces processus sont caractérisés par une
documentation abondante à chaque étape de développement.
Et plus ils restent plutôt superficiel sur les phases situées en
amont et en aval du développement: la capture des besoins et le suivi
de la maintenance.
Le tableau 11suivant récapitule les
caractéristiques des deux familles de processus
étudiés.
Tableau 11: gestion de projet
suivie le processus agile ou le processus unifié
|
la famille des processus unifiés
|
la famille des processus agile
|
|
Facteur de succès
|
Finir en temps et dans le budget.
|
Fournir une valeur ajoutée.
|
|
Type de projet
|
Besoins connus et stables.
Incidence critique.
Grand projet.
|
Besoins changeants.
Incidence peu critique.
Livraison rapide.
|
|
Planification
|
Détaillée pour l'ensemble du projet.
|
Grossière pour l'ensemble, détaillée pour
l'itération.
|
|
Gestion du risque
|
Suivi plus rigoureux.
|
Courtes itérations favorisant le plus grand risque au
départ.
|
|
Délais de livraison
|
À la fin du projet ou dès la première
itération, pouvant dépasser 6 mois.
|
De deux semaines à quatre mois.
Généralement un mois.
|
Source : (TREMBLAY, 2007)
21. Présentation
détaillée de méthode choisie : le processus 2tup couple au
langageUML
Après description des différentes processus
faisant ressortir leurs avantages et leurs
Inconvénients, la méthode 2TUP parait
intéressante pour les raisons suivantes:
· Peu exigeante par rapport à la
disponibilité du client,
· La séparation des besoins fonctionnels et
Architecturaux,
· Suivi plus rigoureux Gestion du risque, surtout
pour les projets aussi complexe que les projets de Machine Learning.
· Le besoin de documentation de la conception pour
faciliter la maintenance future, et surtout que nos clients sont des services
relevant de l'administration publique. Donc ils ont donc une culture de
bureaucratie.
a) Présentation détaillée du processus
2tup
Le processus 2TUP insiste sur la non-corrélation
initiale des aspects fonctionnel et technique. « 2 Tracks »
signifient littéralement que le processus suit deux chemins. Il s'agit
des chemins « fonctionnel» et « d'architecture technique »,
comme le présente la figure 19.
Figure 20 : la
schématisation en Y utilisée pour représenter la
méthode de développement 2TUP, source : Bassim, K.A. et Akaria,
R., 2007
Les deux branches d'étude fusionnent ensuite pour la
conception du système, ce qui donne la forme d'un processus de
développement en Y. la séparation initiale permet à la
fois de capitaliser la connaissance métier sur la branche gauche et de
réutiliser un savoir-faire technique sur la branche droite.
La branche fonctionnelle comporte:
· la capture des besoins fonctionnels, qui produit un
modèle des besoins focalisé sur le métier des
utilisateurs.
· l'analyse, qui consiste à étudier
précisément la spécification fonctionnelle de
manière à obtenir une idée de ce que va réaliser le
système en termes de métier.
La branche technique comporte:
· la capture des besoins techniques, qui recense toutes
les contraintes et les choix dimensionnant la conception du système.
· la conception générique, qui
définit ensuite les composants nécessaires à la
construction de l'architecture technique.
La branche du milieu comporte:
· la conception préliminaire, qui
représente une étape délicate, car elle intègre le
modèle d'analyse dans l'architecture technique de manière
à tracer la cartographie des composants du système à
développer;
· la conception détaillée, qui
étudie ensuite comment réaliser chaque composant;
· l'étape de codage, qui produit ces composants et
teste au fur et à mesure les unités de code
réalisées;
· l'étape de recette, qui consiste enfin à
valider les fonctions du système développé.
b) CHOIX DE LA MODELISATION AVEC UML
Il est difficile d'envisager le processus 2TUP sans recourir
à UML comme support. Le recours à la modélisation est
depuis longtemps une pratique indispensable au développement, car un
modèle est prévu pour anticiper les résultats du
développement.
Un modèle est, en effet, une représentation
simplifie de la réalité, dont le but est de collecter ou
d'estimer les informations d'un système.
UML comporte une dizaine de diagrammes dépendants
et hiérarchiques. Ils se complètent de façon à
permettre la modélisation d'un projet tout au long de son cycle de vie
(figure 20) :
· Les diagrammes statiques permettent de
représenter les éléments du système,
· les diagrammes comportementaux illustrent les
interactions possibles entre les différents éléments et
les acteurs et enfin,
· les diagrammes dynamiques reflètent les
enchaînements successifs de ces interactions.
En fonction du type d'application développé,
les différents types de diagrammes ne sont pas tous utiles. En dehors de
son utilité pour l'analyse des besoins et de la conception, cette
modélisation est une documentation indispensable à la maintenance
future de l'application.
Figure 21: Les diagrammes
d'UML (UMLversion 1.5), source : (Guiochet, 2009)
Chapitre VII : MISE EN
OEUVRE DE LA SOLUTION
Ce chapitre présente l'analyse des besoins de l'outil,
l'étude des contraintes et sa conception. L'analyse de l'outil s'est
soldée par des diagrammes de cas d'utilisation et de des diagrammes
d'activité. La phase de conception quant à elle a permis de
réaliser les architectures de notre outil et le schéma de
données qui seront recueillies du simulateur.
22. Analyse du besoin
Partant du modèle de Machine Learning proposé,
notre travail consiste à développer une application web
interactif pour les administrations en charge de la santé publique, qui
permettra d'atteindre deux grands objectifs à savoir :
ï Simuler l'évolution de la dynamique
spatio-temporelle d'une épidémie en s'appuyant sur une collecte
préalable des données.
ï Analyser les résultats produits à
l'étape précédente avec des outils d'exploration de
données interactifs pour extraire l'information utile aux
autorités en charge de la santé.
Le simulateur prédit l'évolution de la dynamique
spatio-temporelle d'une épidémie sur une
périodicité bien définie. A l'issus de cette simulation,
des données représentant l'état prévisionnel de la
situation épidémique d'une zone d'étude bien
déterminée, et sur la plage de jours préalablement
précisée sont générées. Les données
simulées seront analysées et interprétées pour
servir d'outils d'aide à la décision aux autorités en
charge de la santé publique.
a) Besoins du système
Les besoins du système informatique représentent
la description de ce que le système doit faire, des services qu'il doit
offrir et des contraintes liées à ses opérations. Ces
besoins sont classés en deux catégories : les besoins
fonctionnels et les besoins non-fonctionnels.
(1) Besoins fonctionnels
Le simulateur EVAL-EPI qui fait l'objet de notre travail a un
double objectif.
· Premièrement permettre de simuler
l'évolution de la dynamique spatio-temporelle d'une
épidémie et,
· Deuxièmement offrir des outils d'aide à
la décision aux autorités en charge de la santé publique,
à travers des indicateurs épidémiologiques extraites
à l'aide d'une analyse des données issues de la simulation.
Nous pouvons par conséquent distinguer six grands
groupes de fonctionnalités à ce niveau :
1. Les fonctionnalités liées à la
simulation de l'évolution de la dynamique spatio-temporelle d'une
épidémie.
2. Les fonctionnalités liées à la gestion
des indicateurs épidémiologiques à suivre.
3. Les fonctionnalités liées à
l'exploration des données issues de la simulation.
4. Les fonctionnalités liées à gestion
des utilisateurs
5. Les fonctionnalités liées à gestion
des modèles de simulations
6. Les fonctionnalités liées à gestion de
la visualisation
(a) Fonctionnalités liées
à la simulation de l'évolution de la dynamique spatio-temporelle
d'une épidémie
L'idée est de permettre à l'utilisateur de
simuler la dynamique spatio-temporelle de l'épidémie, en se
basant sur les données d'inventaires, les paramètres de la
dynamique de l'épidémie ainsi que les paramètres de
simulation qu'il a fournie.
Les données d'inventaires sont des données de
suivi journalier de l'évolution des cas d'infecté, de
décès, d'hospitalisation ... qui sert de base de données
d'entrainement du modèle de Machine Learning.
Les paramètres liés à la simulation
sont :
· La date de début de la simulation.
· Les localités sur lesquelles la simulation aura
lieu.
· La période de prédiction de la
simulation
· La période de comparaison des données
simulées avec les données réelles.
· Le modèle utilisé pour la simulation
· Les métriques d'évaluation de la
performance des modèles,
· Pourcentage des données d'entrainement
Dans cette section un utilisateur a la possibilité
de :
· configurer les données d'inventaire
préalablement chargées,
· procéder au prétraitement des
données d'inventaire préalablement chargées,
· choisir un modèle de simulation,
· ajuster les hyper paramètres d'un modèle
de simulation,
· saisir les paramètres de simulation.
Une fois les données d'inventaires chargées,
les paramètres saisis, et validés par l'utilisateur, une
vérification de la cohérence et la conformité de
données chargée et des paramètres saisies par
l'utilisateur sera effectuée, avant de procéder au
prétraitement des données et enfin le lancement effectif de la
simulation. Si la vérification échoue ou s'il se produit une
erreur durant la simulation, un message doit être renvoyé
à l'utilisateur afin de lui permettre de la corriger.
(b) Fonctionnalités liées
à la gestion des indicateurs épidémiologiques :
Dans cette section un utilisateur a la possibilité
d'ajouter ou de modifier les informations d'un indicateur qu'il voudrait suivre
pendant la simulation afin de visualiser son évolution dans le temps et
dans l'espace. Un indicateur est caractérisé dans notre
système par les informations suivantes:
· Le nom de l'indicateur
· L'expression de la fonction mathématique ou un
programme de calcul.
(c) Fonctionnalités liées
à la gestion des modèles de simulation :
Dans cette section un utilisateur a la possibilité de
choisir ou d'ajouter ou de modifier les informations d'un modèle de
simulation qu'il voudrait expérimenter pendant la simulation. Un
modèle est caractérisé dans notre système par les
informations suivantes :
· Le nom de l'indicateur
· L'expression de la fonction mathématique ou le
système dynamique ou le modèle de régression
associé.
(d) Fonctionnalités liées
à l'exploration des données issues de la simulation :
Cette partie des fonctionnalités est la plus importante
pour les autorités en charge de la santé car elle consiste
à fournir à ceux-ci des informations pertinentes leurs permettant
d'avoir une vue prévisionnelle sur un ensemble d'indicateurs pertinents
de la gestion des épidémies.
Dans cette section un utilisateur a la possibilité
de :
· D'évaluer les valeurs prévisionnelles des
indicateurs,
· Déterminer et de suivre l'évolution d'un
foyer épidémique,
· Faire des statistiques sur une situation
prévisionnelle de l'épidémie.
(e) Fonctionnalités liées
à gestion de la visualisation
Dans cette section un utilisateur a la possibilité de
visualiser les résultats sous la forme des graphes, des cartes ou des
tables. Aussi il a la possibilité de visualiser les résultats en
mode animation ou statique.
(f) Fonctionnalités liées
à gestion des utilisateurs
Dans cette section l'administrateur a la possibilité
de :
· gérer les comptes des utilisateurs
· gérer des profils des utilisateurs.
b) Besoins non fonctionnels
A côté des besoins fonctionnels, se trouvent les
besoins non fonctionnels ; ce sont des besoins secondaires représentant
des contraintes liées aux services offerts par le système.
Il s'agit dans ce cas de besoin tels que :
· Le logiciel doit être simple, facile
d'utilisation et offrir la plus grande convivialité possible.
· Il doit également être facile à
installer et doit pourvoir fonctionner sur un environnement Windows.
· Il doit effectuer et fournir les résultats de la
simulation de la dynamique d'une épidémie dans un temps
raisonnable.
· L'utilisation du moteur de simulation
implémentant le modèle de Machine Learning
développé, précédemment dans le cadre de ce
projet.
· Le logiciel doit s'assurer de la validité des
données d'entrée à savoir :
o Tous les types de données attendues doivent
être remplies et conformes;
o Définir les valeurs par défaut pour orienter
l'utilisateur dans le remplissage de certains paramètres.
c) Acteurs
Dans notre système nous distinguons trois acteurs
principaux :
· L'administrateur, qui a pour rôle de gérer
les utilisateurs,
· Le scientifique qui s'occupe de la simulation et,
· Le décideur qui peut visualiser les
résultats et les rapports des différentes simulations.
d) Cas d'utilisation
Nous donnons dans cette section une description
détaillée de tous les cas d'utilisations accompagnés de
leurs représentations graphiques.
(1) Diagramme global de cas
d'utilisation
Le Diagramme global de cas d'utilisation (voir Figure 23)
représente une vue globale de notre système, en terme de
fonctionnalités offertes à l'utilisateur. Nous avons huit
principaux cas d'utilisation :
1. Gestion des utilisateurs,
2. Gestion des données,
3. Gestion du prétraitement des données
d'entrée
4. Gestion de la simulation,
5. Gestion des indicateurs épidémiologiques,
6. Gestion de la visualisation.
7. Gestion des modèles de simulation,
Figure 22 : Diagramme
global de cas d'utilisation
(2) Gestion des utilisateurs
Dans ce cas d'utilisation (figure 24) il s'agit de donner la
possibilité l'administrateur de :
· Attribuer un profil d'utilisateur
· Ajouter un compte utilisateur
· Modifier un compte utilisateur
· Supprimer un compte utilisateur
· Attribuer un rôle
Figure 23:Diagramme de cas
d'utilisation - gérer les utilisateurs.
(3) Gestion des données.
La gestion des données consiste ici (voir figure 25) :
· Charger des données
· Stocker des données
· Analyser des données
· Exporter des données
L'application peut télécharger des
données sous forme des fichiers aux formats suivants:
· valeurs séparées par des virgules (.csv
ou .txt),
· valeurs séparées par des tabulations
valeurs (.tsv ou .txt),
· valeurs séparées par des points-virgules
(.txt).
· Fichier Excel (.xls)
· Fichier JavaScript Object Notation (JSON)
Le fichier de données, sélectionné, peut
être modifié à tout moment lors de l'utilisation des
applications en sélectionnant simplement un nouveau fichier de
données.
Figure 24: Diagramme de cas
d'utilisation « gestion des données »
(4) Gestion du prétraitement des
données d'entrées de la simulation.
Le troisième groupe se charge du prétraitement
des données entrées par le scientifique :
· Supprimer une ligne ou une colonne avec des valeurs
manquantes.
· Remplacer une valeur manquante par une valeur
numérique.
· Encoder les données catégorielles
· Normaliser les données
· Standardiser les données (voir la figure 26)
Figure 25 : Diagramme de
cas d'utilisation «Gestion du prétraitement des données
»
(5) Gestion de La simulation de la
dynamique spatio-temporelle :
Cette catégorie regroupe tous les services qui entrent
en jeu dans la simulation de l'évolution de l'épidémie
à savoir (voir figure 27) :
· Faire une prédiction
· Faire un clustering
· Faire une classification
Figure 26 : Diagramme de
cas d'utilisation - Simuler la dynamique spatio-temporelle
(6) Gestion les indicateurs
épidémiologiques
Pour généraliser l'extraction des informations
des données simulées, nous avons ajouté la
possibilité d'étendre la liste des indicateurs à suivre
par l'utilisateur. Un indicateur est caractérisé par son nom et
l'expression mathématique ou le programme de calcul, qui lui est
associée. L'unicité d'un indicateur étant
identifiée sur le nom de l'indicateur. La gestion des indicateurs
consiste ici à l'ajout, le calcul, le chargement, la modification ou
même la suppression des indicateurs comme le montre la Figure 28.
Figure 27 : Diagramme de
cas d'utilisation - Gérer les indicateurs
épidémiologiques.
(7) Gestion des modèles de
simulation
Pour que le simulateur puisse s'adapter à
l'évolution des données, nous avons ajouté la
possibilité d'étendre la liste des modèles de simulation
par l'utilisateur. Ainsi la gestion des modèles consiste ici à
l'ajout, la modification, la suppression et l'évaluation de la
performance d'un modèle comme le montre la Figure 29.
Figure 28: Diagramme de cas
d'utilisation - Gérer des modèles de simulation
(8) Gestion de la visualisation
Elle concerne l'exploitation des résultats de
simulation pour fournir à l'utilisateur une interface de gestion
présentant la valeur des indicateurs et leur évolution dans le
temps au de la simulation. Pour évaluer la gestion d'une
épidémie, les autorités en charge de la santé
publique peuvent se baser sur l'évolution de certains indicateurs dans
le temps et dans l'espace. Ceux-ci permettent d'optimiser la gestion des
ressources humaines, matérielles et financières. Ainsi cette
fonctionnalité permet de :
· Visualiser un indicateur : consulter sa courbe
d'évolution ainsi que les données générées
par les simulations et qui ont servi à construire la courbe.
· Visualiser sur un fond de carte de la zone
d'étude avec les statistiques de résultats de la simulation.
· Exporter les résultats (graphes, données,
carte, rapport) sous forme d'un fichier image ou fichier Portable Document File
(PDF) (voir figure 30).
Figure 29 : Diagramme de
cas d'utilisation - gérer une visualisation
23. Diagrammes d'analyse
a) Diagrammes d'activités
Il est question de réaliser le diagramme
d'activité de quelques cas d'utilisation à savoir :
· Le diagramme d'activités du cas d'utilisation
« charger des données »
· Le diagramme d'activités du cas d'utilisation
« gestion du prétraitement »
· Le diagramme d'activités du cas d'utilisation
« simuler la dynamique épidémique »
· Le diagramme d'activités du cas d'utilisation
«calculer un indicateur épidémiologique»
· Le diagramme d'activités du cas d'utilisation
« Visualiser un indicateur »
· Le diagramme d'activités du cas d'utilisation
«ajouter un indicateur épidémiologique»
· Le diagramme d'activités du cas d'utilisation
« modifier un indicateur »
(1) Le diagramme d'activités du
cas d'utilisation « charger des données »
Le processus de chargement des données par le
scientifique se fait ainsi qu'il suit (figure 31) :
· Tout d'abord, il faut fournir un fichier des
données d'inventaires
· Ensuite le système vérifier le format du
fichier contenant les données d'inventaire
· Puis le système vérifier la forme et le
contenu des paramètres de dynamique
· Enfin le système contrôler
l'adéquation des fichiers d'inventaires.
Figure 30: diagramme
d'activités du cas d'utilisation «charger les données
»
(2) diagramme d'activités du cas
d'utilisation « gestion du prétraitement »
Le diagramme d'activités du cas d'utilisation (figure
32) « gestion du prétraitement» représente la
séquence d'action à suivre pour effectuer un prétraitement
des données avant la simulation.
· Tout d'abord, il faut fournir un fichier des
données d'inventaires.
· Ensuite le système vérifie si les
données acquises contiennent des valeurs manquantes.
· Si oui, l'utilisateur est invité à
choisir le mode de traitement des valeurs manquantes
· Si non, le système vérifie si les
données acquises contiennent des valeurs catégorielles.
· S'il y a des valeurs catégorielles,
l'utilisateur est invité à choisir le mode d'encodage
· Si non, l'utilisateur est invité à
choisir le mode de transformation.
· Enfin Il peut dès lors lancer le
prétraitement.
Figure 31 : diagramme
d'activités du cas d'utilisation « gestion du prétraitement
»
(3) Le diagramme d'activités du
cas d'utilisation « faire une
prédiction »
Le diagramme d'activités du cas d'utilisation «
faire une prédiction » représente la séquence
d'action à suivre pour effectuer une prédiction de la dynamique
spatio-temporelle d'une épidémie (figure 33) :
· Tout d'abord, il faut configurer les données
d'inventaires prétraité.
· Ensuite la configuration est vérifiée et
validée par le système.
· L'utilisateur doit ensuite entrer les
paramètres de la simulation.
· Enfin Il peut dès lors lancer la simulation.
Le processus est effectif si les vérifications des
entrées ne renvoient aucune erreur sinon on revient sur le point
aberrant.
Figure 32: diagramme
d'activités du cas d'utilisation «simuler la dynamique
épidémique »
(4) Le diagramme d'activités du
cas d'utilisation « calculer un indicateur
épidémiologique »
Calculer un indicateur revient, à évaluer sa
valeur à partir des données simulées. Ceci en utilisant
sa fonction mathématique. Ainsi les séquences d'activité
s'enchainent comme suit (figure 34) :
· En premier, il faut choisir l'indicateur,
· Ensuite préciser la localité et la
période de prédiction.
· Après validation par l'utilisateur, une
vérification est effectuée et s'il n'y a pas d'erreurs,
l'indicateur est calculé.
· Le cas contraire, le simulateur retourne au choix des
paramètres et indiquant l'erreur survenue.
Figure 33:diagramme
d'activités du cas d'utilisation « calculer un indicateur
»
(5) Le diagramme d'activités du
cas d'utilisation « Visualiser un indicateur
épidémiologique »
Visualiser un indicateur revient, à consulter sa
représentation graphique, ou sa projection sur une carte. Ainsi les
séquences d'activité s'enchainent comme suit :
· En premier, il faut choisir l'indicateur,
· Ensuite préciser la localité et la
période de prédiction.
· Après validation par l'utilisateur, une
vérification est effectué et s'il n'y a pas d'erreurs,
l'indicateur est calculé et affiché à l'utilisateur.
· Le cas contraire, le simulateur retourne au choix des
paramètres et indiquant l'erreur survenue.
L'utilisateur peut consulter un film temporel, il devra, puis
choisir l'indicateur, la période, la localité. Enfin choisir
l'option `animation' dans les paramètres et cliquer sur le bouton de
visualisation. Le schéma suivant représente la séquence
d'actions décrites (figure35).
Figure 34 : diagramme
d'activités du cas d'utilisation « Visualiser un indicateur
»
(6) Diagramme d'activités du cas
d'utilisation «ajouter un indicateur épidémiologique
»
Ajouter un indicateur revient, à créer nouvel
indicateur, en indiquant son nom, son code et sa formule mathématique.
Ainsi les séquences d'activité s'enchainent comme suit :
· En premier, il faut saisir le nom et le code de
l'indicateur,
· Après validation par l'utilisateur, une
vérification est effectuée et s'il n'y a pas d'erreurs, le nom et
le code du nouvel indicateur sont enregistrés.
· Le cas contraire, le simulateur retourne à
l'étape de saisir de nom et du code de l'indicateur et indiquant
l'erreur survenue
· Puis saisir la formule mathématique du nouvel
indicateur,
· Après validation par l'utilisateur, une
vérification est effectué et s'il n'y a pas d'erreurs, la formule
du nouvel indicateur est enregistrer.
· Le cas contraire, le simulateur retourne à
l'étape de la saisie de la formule mathématique. et indiquant
l'erreur survenue (figure 36).
Figure 35 : diagramme
d'activités du cas d'utilisation «ajouter un
indicateur»
(7) diagramme d'activités du cas
d'utilisation « modifier un indicateur épidémiologique
»
Modifier un indicateur revient, à mettre à jour
sa formule mathématique. Ainsi les séquences d'activité
s'enchainent comme suit :
· En premier, il faut choisir l'indicateur,
· Puis Saisir la nouvelle formule mathématique,
· Après validation par l'utilisateur, une
vérification est effectué et s'il n'y a pas d'erreurs, la formule
de l'indicateur est mise à jour.
· Le cas contraire, le simulateur retourne au choix des
paramètres et indiquant l'erreur survenue (figure 37).
Figure 36 : diagramme
d'activités du cas d'utilisation « modifier un
indicateur»
b) Diagramme de classe
Nous avons un diagramme de classe composé de deux sous
diagrammes de classe correspondant aux cas d'utilisation : la simulation de la
dynamique d'une épidémie(voir tableau 12) et la visualisation des
indicateurs épidémiologique (voir tableau 13).
Tableau 12 : Package des
classes de la simulation de la dynamique d'une épidémie
|
Diagramme
|
description
|
|
simulation
|
La classe représentant l'interface de la simulation
|
|
Donnée d'inventaire
|
La classe correspondant aux données d'inventaire
|
|
donnéessimulées
|
La classe correspondant aux données simulées
|
|
Modèle
|
La classe correspondant à tous les modèles de
simulation
|
Tableau 13 : Package des
classes de la visualisation des indicateurs
épidémiologique
|
Diagramme
|
description
|
|
I'indicateur
|
L'interface de généralisation des
indicateurs.
|
|
Visualisation
|
La classe représentant le mode et le type de
simulation
|
|
Utilisateur
|
La classe représentant tous les utilisateurs
|
|
Statistique
|
La classe représentant les statistiques sur les
données simulées
|
De l'analyse effectuée, on peut ressortir les classes
suivantes (figure 38) :
Figure 37 : Diagramme de
classes
24. Conception de la solution
Dans cette section, il s'agit de présenter les indicateurs
épidémiologiques choisis pour le simulateur, architecture
applicative, architecture logicielle, la couche de présentation et
l'architecture physique
a) Choix des indicateurs épidémiologiques
Nous avons pu ressortir pendant la phase d'analyse une liste
de ces indicateurs que nous fournirons comme outils d'aide à la
décision dans notre solution. Ce sont des indicateurs plus
utilisés par les épidémiologistes et les décideurs
en santé publique, pour évaluer la dynamique d'une
épidémie, son ampleur et aussi estimer l'efficacité des
mesures sanitaires adoptées. Voici ci-dessous cités les
indicateurs de cette liste : Incidence, incidence cumulée,
prévalence, taux de reproduction effective, taux de
létalité et les séries chronologiques
épidémiologiques.
b) Architecture applicative
Nous avons opté pour une architecture en couche dans
laquelle nous avons :
· notre boite noire, le moteur de simulation, qui est
constitué du modèle de Machine Learning, qui reçoit des
paramètres rentrés par l'utilisateur à partir de notre
interface graphique.
· Après la simulation, les données en
sortie sont stockées dans une base de données par
l'intermédiaire d'une couche de persistance DAO (Data Access
Object).
· Le modèle DAO propose de regrouper les
accès aux données persistantes dans des classes à part,
plutôt que de les disperser. Il s'agit surtout de ne pas écrire
ces accès dans les classes "métier", qui ne seront
modifiées que si les règles de gestion métier changent.
· Les données simulées sont
analysées par le module d'analyse de données.
· le module d'analyse de données utilisera
l'interface graphique pour afficher les résultats obtenus.
La Figure 39 représente le schéma de cette
architecture applicative.
Figure 38 : Architecture
applicative de notre solution. (EVAL_EPI)
ï L'extracteur de données : est
le bloc chargé d'extraire de l'ensemble des données en sortie du
simulateur, les valeurs de l'indicateur l'on voudrait visualiser.
ï L'analyseur : est le bloc de calcul
qui utilise les méthodes de la statistique descriptive telles que : la
médiane, la moyenne, l'ecart-type, le mode etc pour estimer la valeur
de l'indicateur épidémiologique à partir des valeurs des
différentes simulations.
ï Estimation d'erreur : est le bloc de
calcul de l'intervalle de confiance des valeurs d'un indicateur
épidémiologique donné. Pour chaque valeur xit
au temps t de la simulation i, la borne supérieure de l'intervalle de
confiance est le quantile à 97.5% au temps t et la borne
inférieure est le quantile à 2.5% au temps t de toutes les
valeurs xit de toutes les simulations i au temps t.
ï Le gestionnaire des indicateurs : est
chargé d'enregistrer, de modifier ou de supprimer des indicateurs, et
enfin de sauvegarder toutes ces informations. C'est dans ce bloc que se passe
la transformation des expressions mathématiques en une fonction
correspondant au langage d'implémentation.
ï Le simulateur : est le bloc de
calcul qui permet de faire des prédictions ou de clustering.
c) Architecture logicielle de
« EVAL-EPI »
D'après (AYMEN, 2018 )L'architectured'un logiciel
contient la description du système en termes de ses composantes ainsique
ses relations et interactions. Ainsi plusieurs techniques de
modélisation sont appliquées pour l'architecture logicielle des
applications Web interactives. Ici nous présenterons les deux
architectures usuelles :
· le « Modèle-Vue-
contrôleur » et,
· le « Modèle -Gabarit-Vue (MVT).
(1) Modèle-Vue-
contrôleur (MVC)
Il s'agit d'un modèle de conception logicielle
utilisé pour implémenter des interfaces utilisateurs et qui met
l'accent sur la séparation de la représentation des
données des composants qui interagissent et traitent les
données.Il comporte 3 composants et chaque composant a un objectif
spécifique :
· Le modèle est le composant central
de cette architecture. Il gère les données, la logique ainsi que
d'autres contraintes de l'application.
· La vue traite de la façon dont les
données seront affichées à l'utilisateur et fournit divers
composants de représentation des données.
· Le contrôleur manipule le
modèle et rend la vue en agissant comme un pont entre les deux.
(2) Modèle -Vue-Gabarit (MVT)
Il est également utilisé pour implémenter
des interfaces et des applications Web mais contrairement à MVC, la
partie contrôleur est prise en charge par le framework lui-même.Il
comporte trois composants et chaque composant a un objectif
spécifique :
· Le modèle similaire à
MVC : il est responsable du traitement réel des données,
comme la connexion à la base de données, l'interrogation de la
base de données, la mise en oeuvre des règles métier.
· La vue exécute la logique
métier et interagit avec le modèle. Il accepte la requête
HTTP, puis renvoie les réponses HTTP.
· Le Gabarit ou
« template » en anglais, est le composant qui rend le MVT
différent du MVC. Le Gabarit agit comme la couche de
présentation et est essentiellement du code HTML qui restitue les
données. Le contenu de ces fichiers peut être statique ou
dynamique.
(3) Différence entre MVC et
MVT
Le tableau 14 ci-dessous résume les principales
différences entre le MVC et le MVT.
Tableau 14: comparaison du MVC et
du MVT
|
« Model View Controller »
(MVC)
|
« Model View Template »
(MVT)
|
|
MVC a un contrôleur qui pilote à la fois le
modèle et la vue.
|
MVT a des vues pour recevoir une requête HTTP et renvoyer
une réponse HTTP.
|
|
La vue indique comment les données de l'utilisateur seront
présentées.
|
Le « template » indique comment les
données de l'utilisateur seront présentées.
|
|
Fortement couplé
|
Faiblement couplé
|
|
Le flux est clairement défini donc facile à
comprendre
|
Le flux est parfois difficile à comprendre
|
Source :(geeks, 2022)
(4) Architecture logicielle
choisie : le modèle MVC
Les avantages de l'utilisation du modèle MVC dans les
applications Web sont :
· Séparer le code en catégories telles que
modèles, vues et contrôleur conduire à une base de code
plus facile à gérer et plus lisible, lorsqu'une partie de
l'application doit être corrigé, testé ou étendu.
· Le modèle architectural de conception MVC favorise
la cohésion de classes.Or les avantages d'une cohésion
élevée sont :
o la réduction de la complexité des modules,
o l'augmentation de la maintenabilitéet,
o de la facilité dans la réutilisabilité
des modules du système (Forte, 2016).
En s'inspirant du patron de conception M.V.C et des
différents blocs de notre architecture applicative, notre outil peut
être représenté par une architecture composée de
trois couches:
ï La couche de traitement (Modèle)
: elle représente la couche dans laquelle se passe tous les
traitements liés à la simulation ou à l'analyse des
données pour le calcul des indicateurs
épidémiologiques.
ï La couche de présentation (Vue)
: c'est la couche visible par l'utilisateur, elle reçoit les
données venant de ce dernier et lui présente les résultats
produits à la suite de l'exécution d'un cas d'utilisation.
ï La couche de persistance (contrôleur)
:étant le point d'entrée principal de l'application, il
établitle lien entre l'utilisateur et le système. De plus, il
manipule la Vue et traduit l'interaction de l'utilisateur au Modèle. En
outre,le Contrôleur communique directement avec le Modèle et doit
être capablede changer son état.
Bien que MVC se décline en différentes couches,
le flux de contrôle fonctionne généralement comme
suit :
1. L'utilisateur interagit avec l'interface utilisateur (par
exemple, l'utilisateur appuie sur un bouton)
2. Le contrôleur gère l'événement
d'entrée à partir de l'interface utilisateur
3. Le contrôleur accède au modèle,
éventuellement en le mettant à jour d'une manière
appropriée à l'action de l'utilisateur.
4. la vue utilise le modèle pour générer
une interface utilisateur appropriée.
5. L'interface utilisateur attend d'autres interactions de
l'utilisateur, ce qui recommence le cycle.
Une représentation graphique de cette architecture est
donnée à la Figure40.
Figure 39 : Architecture
logicielle de notre solution.
d) Conception de la couche de présentation
La couche de présentation est la première partie
de notre application en contact directe avec notre utilisateur. Il est donc
primordial de la concevoir à travers un prototypage avec un choix bien
mesuré des couleurs de cette dernière. Nous avons adopté
une structure simple en matière de graphisme en vue de permettre
à l'utilisateur de retrouver et d'accéder facilement aux
informations. L'interface comporte trois parties principales à savoir :
l'entête, le bloc latéral et le bloc central.
· L'entête : La bande bleue
au-dessus comportant simplement le nom que nous avons attribué à
l'application à savoir : « EVAL-EPI». C'est un bloc statique,
il reste fixe durant toute la navigation de l'utilisateur.
· Le bloc latéral : La bande
verticale noire comportant les différentes fonctionnalités de nos
modules et les différentes rubriques de notre application. Nous les
avons présentés ici sous forme de menu : «Accueil »,
« données »,« prétraitement » «
Simulation », « indicateur », « Visualisation »
«paramètre », « Aide ».
· Le bloc central :C'est à
l'intérieur du bloc central que les informations liées à
chaque rubrique sont affichées. C'est le seul bloc dynamique de
l'application. Il est utilisé le plus souvent pour interagir avec
l'application. Le prototypage dans le cadre de la conception des interfaces a
été réalisé avec le logiciel « Pencil ».
Le prototype général est présenté sur la Figure
41.
Figure 40 : Le prototype
général du simulateur EVAL_EPI
e) Architecture physique
Dans le souci de mette en place une solution pouvant
s'exécute tant bien en local sur un PC qu'en mode distribué entre
plusieurs utilisateurs nous avons opté pour une architecture physique
client-serveur en utilisant :
ï un serveur web pour servir les pages
web de notre simulateur,
ï une base de donnéespour stocker
les données de la simulation et celles des indicateurs à
visualiser et,
ï un serveur de fichiers pour stocker
les fichiers de l'application.
Les utilisateurs peuvent via un réseau accéder
à notre application, en passant par le serveur web. Cette architecture
peut aussi bien être déployée sur un PC en local, en y
installant tous les outils nécessaires pour le fonctionnement de
l'architecture.La représentation graphique de notre architecture est
donnée à la Figure 42.
Figure 41 : Architecture
physique de notre solution.
QUATRIEME PARTIE :
FINALISATION DE LA SOLUTION
Chapitre VIII :
IMPLEMENTATION ET RESULTATS
25. CHOIX DES OUTILS
a) Choix de la Plateforme logiciel
Le projet a été implémenté en
utilisant le langage de programmation R version 4.1.2 et en utilisant la
plateforme RStudio version 4.1.2
(1) Pourquoi le langage de programmation
R ?
R est un environnement de simulation libre pour
l'informatique statistique et graphique crée par Ross Ihaka et Robert
Gentleman. R et Python sont aujourd'hui les bases indispensables du data
scientist. Il existe néanmoins des différences qui sont notables
et qui orienterons vos choix lors de la décision du langage à
utiliser pour un projet.
Emmanuel Jakobowicz, dans son ouvrage « python
pour le data scientist » a fait une étudecomparative
entre R et python sur les caractéristiques intrinsèques de chaque
langage dont les conclusions sont résumés dans le tableau 15
suivant :
Tableau 15 : comparaison
des caractéristiques de R et python
|
Propriété
|
R
|
Python
|
|
Analyse de données
|
Très bien adapté (FactoMineR)
|
manque d'outils de visualisationadaptés
|
|
Visualisation
|
Capacités fortes (ggplot2)
|
Bonnes capacités (Matplotlib et Seaborn)
|
|
Applications« web »
|
En avance grâce au package shiny
|
Quelques packages se mettent en place avecBokeh et Dash
|
Source : (Jakobowicz, 2018)
En outre Ricco Rakotomalala, dans son article intitule :
«R et python performance comparées » a montré
pour certains taches de prétraitements des données et des
statistiques descriptifs, R avait en moyenne un temps d'exécution
nettement inférieur à celui de python (voir tableau 16)
Tableau 16:comparaison de
performance de R et Python
Source : (Rakotomalala)
(2) Les limites du langage de
programmation R
D'après (Odhiambo, juillet 2020) , les
inconvénients majeurs du langage R sont :
· La Difficulté à apprendre le langage
R : les fonctions peuvent avoir la fâcheuse habitude de renvoyer un
type d'objet imprévu.
· La syntaxe pour résoudre certains
problèmes peut ne pas être si évidente. Cela est dû
au grand nombre de bibliothèques.
b) Choix des outils de manipulation des données
Pour le choix des outils de stockage et de manipulation des
données nous nous sommes penchés vers des solutions qui ne
nécessitaient aucune configuration quelconque. Le langage R
utilisé dans le cadre de l'implémentation de cet outil nous offre
déjà des outils de stockage de données sous le format
*.RData et des packages très puissant de manipulation de ces
données (voir les tableaux17, 18,19 et 20):
(1) Le package « data.table
»
Le package data.table est un package développé
par Matthew Dowle, C'est un package qui permet de lire et de manipuler les
données. Il permet d'importer des données assez volumineuses avec
la fonction fread() et leur manipulation comme tout autre data.frame .
L'importation des données volumineuse avec ce package est très
rapide (par exemple 20Go, soit à peu près 200 millions
d'individus, en8mn alors qu'avec python ou d'autres simulateurs, ça
prendrait des heures).
(2) Les autres packages pour la
manipulation des données
Tableau 17 : outils de
stockage et de manipulation des données
|
bibliothèques
|
description
|
|
Dplyr(Davood, 2022)
|
Manipulation et analyse des données sous R
|
|
data.table
(Dowle, Srinivasan, & Gorecki, 2021)
|
L'importation des données volumineuses avec ce package
est très rapide. Il a servi à lire et manipuler les
entrées utilisateurs comme les données d'inventaires.
|
Tableau 18 : Les
bibliothèques spécialisées sur la covid-19
|
bibliothèques
|
description
|
|
covid19.analytics
(Ponce, 2021)
|
Charger et analyser les données de la pandémie
de COVID-19 en temps réel.
|
|
EpiEstim (Cori, 2013)
|
un package pour estimer les nombres de reproduction variant
dans le temps à partir de courbes épidémiques.
|
Tableau 19 : Les
bibliothèques spécialisées sur le Machine Learning
|
bibliothèques
|
description
|
|
Prophet
(Taylor, 2021)
|
Implémente une procédure de prévision des
données de séries chronologiques basée sur un
modèle additif dans lequel les tendances non linéaires sont
ajustées à la saisonnalité annuelle, hebdomadaire et
quotidienne, ainsi qu'aux effets des jours fériés.
|
|
Dbscan
(Hahsler, 2022)
|
Une réimplémentation de plusieurs algorithmes
basés sur la densité de la famille DBSCAN. Comprend les
algorithmes de clustering DBSCAN (clustering spatial basé sur la
densité d'applications avec bruit) et HDBSCAN (DBSCAN
hiérarchique)
|
Tableau 20 : Les
bibliothèques de manipulation des données geospatiale
|
bibliothèques
|
description
|
|
leaflet
(Cheng, 2022)
|
Production des cartes interactives avec peu de code. Ils
transforment R en un serveur cartographique complet. Ils sont facilement
intégrables avec un shiny.
|
|
Sf
(Pebesma, 2022)
|
En plus de couvrir plusieurs types de données spatiales
(fichiers csv, shapefile, base de données spatiales), il offre un grand
nombre de méthodes d'analyses spatiales.
|
|
Ggmap
(Kahle, 2019)
|
Une collection de fonctions pour visualiser des données
et des modèles spatiaux.sur des cartes statiques provenant de diverses
sources en ligne (par exemple, Google Maps et Stamen Plans)
|
|
tmap
(Tennekes, 2022)
|
Ce package offre une approche flexible, basée sur des
couches et facile à utiliser pour créer les cartes
thématiques, telles que les choroplèthes et les cartes à
bulles.
|
c) Choix des outils d'implémentation de l'interface
graphique
(1) Le package « shiny » :
outil de création de l'interface graphique
Le package « shiny » est un nouveau package de R
permettant de construire des applications web interactives :
· Il permet de construire des interfaces web avec
seulement des lignes de codes sans l'utilisation de JavaScript.
· C'est une manière simple et efficace de
créer des applications interactives où les sorties se mettent
à jour au fur et à mesure que les entrées sont
modifiées sans nécessiter un rechargement du navigateur.
· Il est également possible d'intégrer La
conception d'application web avec shiny sépare au niveau du code le
client (fichier ui.R) et le serveur (fichier server.R) responsable du
traitement des requêtes clientes et de la gestion des
évènements.
· Il est facile d'utilisation et offre de nombreuses
facilités de déploiement aussi bien en ligne qu'en local.
La conception d'une interface avec ce package de R repose sur
deux fichiers :
ï un fichier pour l'aspect graphique de l'interface
(ui.R) et,
ï un fichier pour l'aspect contenu et gestion des
évènements sur l'interface (server.R)
La même structure est suivie par les fichiers
appelés par le script server.R. La logique suivie dans la conception de
cette structure est vraiment simple :
· diviser un problème complexe en problèmes
plus petits et plus faciles à gérer.
· Chaque "problème" à résoudre
c'est-à-dire chaque fonctionnalité qu'EVAL_EPI fait, a une
interface utilisateur et quelques calculs et fonctions réactives qui le
font fonctionner.
· Par conséquent, chaque petite partie du
problème, chaque partie d'EVAL_EPI a besoin de son propre fichier
d'interface utilisateur et de son propre fichier de serveur.
· La structure sortant du fichier server.R est donc la
même que celle de UI-body.R.
Le tableau 21 ci-dessous résume les autres outils
utilise pour l'implémentation de l'interface graphique.
Tableau 21 : outils
d'implémentation de l'interface graphique
|
bibliothèques
|
description
|
|
Shiny (Chang, 2021)
|
Facilite incroyablement la création d'un site Web
interactifapplications avec R.
|
|
ggplot 2
(Wickham, 2016)
|
Créez des visualisations de données
élégantes à l'aide de la grammaire des graphiques
|
|
Factoextra
(Kassambara, 2020)
|
Extraire et visualiser les résultats des analyses de
données multivariées
|
(2) Choix de l'IDE Integrated
Development Environment (environnement de développement
intégré).
RStudio est un environnement intégré libre,
gratuit et qui fonctionne sous Windows, Mac Os et Linux. Il complète R
et fournit un éditeur de script avec coloration syntaxique, des
fonctionnalités pratiques d'édition et d'exécution du code
comme l'auto-complétion, un affichage simultanée du code, de la
console R, des fichiers, des graphiques et pages d'aide, une gestion des
extensions, une intégration avec des systèmes de contrôle
de version comme git, etc. Il intègre de base, divers outils comme par
exemple la production de rapports au format Rmarkdown(Figure 43). Il est en
développement actif et de nouvelles fonctionnalités sont
ajoutées régulièrement. Son principal défaut est
d'avoir une interface uniquement anglophone.
Figure 42 - Interface de
RStudio sous Windows
26. DEPLOIEMENT
Nous avons développé notre solution
entièrement avec le langage de programmation R qui ne peut fonctionner
sans l'existence du simulateur R. Nous lui avons associé une extension
shiny qui nous permet de développer et d'exécuter des
applications web par l'intermédiaire d'un navigateur web. Notre
architecture physique prévoit l'utilisation d'un serveur web pour servir
les pages web de notre application qui ont été
développé avec le package shiny et le simulateur R. Le serveur
sous R qui permet de jouer ce rôle est « Shiny Server »
(Combinaison entre le simulateur R et le package shiny). Nous avons
conçu notre diagramme de déploiement (Figure 44) en
prévoyant :
· un serveur contenant « Shiny Server »,
· un serveur de fichierspour stocker les fichiers de
l'application et,les fichiers binaires constituant notre base dedonnées
et,
· la machine du client contenant un navigateur web.
Figure 43- Diagramme de
déploiement.
27. PRESENTATION DE QUELQUES
RESULTATS
Dans cette section nous présenterons quelques captures
d'écran du fonctionnement du simulateur : Page d'accueil du
simulateur et Module de simulation de la dynamique spatio-temporelle de la
covid-19
a) Page d'accueil d'EVAL-EPI
C'est la page qui s'affiche dès le lancement de
l'application. A l'intérieur du bloc central, le seul bloc dynamique de
l'application, nous retrouvons le logo du projet EVAL_EPI et le logo du COPIL
et une petite description de l'outil comme le montre la Figure 45.
Figure 44 : Page
d'accueil du logiciel « EVAL_EPI ».
b) Module de simulation de la dynamique spatio-temporelle de
la covid-19
Nous avons regroupé les fonctionnalités
liées à ce module dans le menu « Simulation
». Pour simuler la dynamique d'une spatio-temporelle de
la covid-19, ici l'utilisateur doit :
· D'une part charger les données d'inventaire sur
les cas de la maladie de la covid-19
· D'autre part préciser un certain nombre de
paramètres liés à l'étude de la dynamique de cette
épidémie dans le temps et dans l'espace comme le montre les
Figure 46 et 47
Figure 45 : Capture
d'écran d'une simulation de la dynamique temporelle
Figure 46 : Capture
d'écran d'une simulation de la dynamique temporelle
CHAPITRE IX : GESTION DE
PROJET ET BILAN
Dans ce chapitre, il sera abordera d'une part la gestion du
projet et d'autre part le bilan et les perspectives.
28. Gestion du projet
Conduire un projet, c'est prendre toutes les mesures
nécessaires pour faire en sorte que le projet atteigne ses objectifs. La
gestion du projet s'articule autour de trois éléments :
· Les intervenants,
· le découpage du projet et,
· l'estimation des charges.
a) Les intervenants
Il existe deux principaux acteurs dans la gestion d'un
projet :
· La maitrise d'ouvrage :
o Le maître d'ouvrage : est la personne physique ou
morale qui est propriétairede l'ouvrage. Il fixe les objectifs,
l'enveloppe budgétaire et les délais souhaités pour le
projet.
o Dans le cadre de notre projet, ce rôle a
été joué par le responsable du LAIMA de l'IAI, structure
dans laquelle nous avons effectué notre stage.
· La maitrise d'oeuvre :
o est la personne physique ou morale qui reçoit la
mission du maître d'ouvrage pour assurer la conception et le
contrôle de la réalisation d'un ouvrage conformément au
programme préétabli.
o Dans le cadre de notre projet, ce rôle nous a
été attribué.
b) Découpage du projet
L'Agence Française de la Norme (AFNOR) a
proposé un découpage type classique des projets informatiques (NF
Z67-101, 1984) en cinq phases :
1. Étude préalable,
2. Conception détaillée,
3. Etude technique,
4. Réalisation,
5. Mise en oeuvre et Évaluation.
De ce fait, nous avons divisé notre projet en plusieurs
tâches comme suit (voir tableau 22):
Tableau 22 :
Découpage du projet en étapes
|
Étapes
|
Libellé
|
Responsable
|
Début
|
Fin
|
|
1
|
Étude préalable,
|
Dr MOUKELI Pierre,
Dr MASSALA Marius et
M. RAMADANE Bakari
|
Semaine 1
|
Semaine 2
|
|
Recherche Documentaire
|
M. RAMADANE
M. MADZOU
|
Semaine 3
|
Semaine 3
|
|
3
|
Conception détaillée
|
M. RAMADANE
|
Semaine 4
|
Semaine 8
|
|
4
|
Etude technique
|
M. RAMADANE
|
Semaine 9
|
Semaine 10
|
|
5
|
Réalisation
|
M. RAMADANE
|
Semaine 10
|
Semaine 16
|
|
6
|
Mise en oeuvre et Évaluation
|
Dr MASSALA Marius et
M. RAMADANE Bakari.
|
Semaine 15
|
Semaine 16
|
|
7
|
Rédaction du mémoire
|
Mr GUIFO et M. RAMADANE
|
Semaine 16
|
Semaine 20
|
Diagramme de Gantt
Diagramme de GANTT prévisionnel
c) Estimation des charges
Le tableau 23 suivant présente le récapitulatifs
des coûts des charges nécessaires à la réalisation
de notre projet.
Tableau
23:récapitulatif des coûts des charges du projet
|
Charges
|
COÛT PROJET
|
COUT REEL
|
|
Ordinateur portable acer, Windows 10
|
600.000 F CFA
|
600.000 F CFA
|
|
Connexion internet
|
100.000 FCFA
|
80.000 FCFA
|
|
autoformation
|
600.000 FCFA
|
500.000 FCFA
|
|
Indemnité de stage
|
1.800.000 FCFA
|
750.000 F CFA
|
|
TOTAL
|
3.100.000 FCFA
|
1.930.000 FCFA
|
29. Bilan et perspective du projet
Il est question de dresser un bilan sur l'état
d'avancement du projet, de présenter les apports du stage, les
difficultés rencontrées et enfin de donner quelques
orientations sur les travaux futurs.
a) Etat d'achèvement du projet
L'objectif principal du projet était
· d'abord de Comprendre la dynamique de la propagation de
la covid-19.
· Puis prédire l'évolution future de la
covid-19, afin d'anticiper sur la fin probable de l'épidémie.
· En outre de déterminer les clusters a risque
dans l'optique de mieux orienter la politique relative aux mesures de
protection de la population.
· Enfin de maitre sur pied une application
implémentant les modèles de Machine Learning proposé.
Cette application générique et évolutive, devra être
capable d'évaluer la dynamique spatio-temporelle de
l'épidémie de la covid-19 en particulier, de toute autre
épidémie en générale.
Cela étant, les travaux effectués durant ce
stage peuvent attester que l'objectif principal a été atteint. Et
l'achèvement du projet est estime à 75% de réalisation.
Toutefois, le projet étant conçu suffisamment
générique et modulaire, peut faire l'objet d'amélioration
continu des performances de l'application.
b) Apports du stage
Ce stage a été d'un apport considérable
dans l'accomplissement de la formation :
· D'abord les échanges avec une équipe
pluridisciplinaire d'experts en collaborant au sein du projet. Ceci constitue
une preuve supplémentaire du rôle incontournable de
l'informatique, dans la résolution des crises d'une ampleur mondiale.
· Le quotidien dans un laboratoire de recherche est
toujours enrichissant en expériences nouvelles.
· Ce stage a été une occasion unique de
découvrir le domaine de l'épidémiologie, qui à la
première vue semble être très éloignée de
l'informatique.
c) Difficultés Rencontrées
Comme le dit le célèbre écrivain Japon,
TOM ICHIRO « une vie pleine de difficulté et qui a un sens, a
une saveur très particulière ». C'est pour dire que
dans la vie d'un élève-ingénieur en stage, les
difficultés sont incalculables et indénombrables. Mais il est
important de relever ici les difficultés qui semblent être les
plus insurmontables.
· D'une part le manque de culture de chiffres et
de données en Afrique. Alors que les données
constituent la matière première du Machine Learning, la
disponibilité, l'accessibilité et la fiabilité des
données sur la covid-19, ont constitué le plus grandobstacle
dans ce projet.
· D'autre part l'obstacle linguistique.
En général le monde scientifique est dominé par la culture
anglo-saxonne. Et parmi toutes les disciplines scientifiques, l'informatique
est celle qui a le plus adopté l'anglais comme langue de communication.
Ainsi la quasi-totalité des langages de programmation ou les articles
scientifiques les plus pertinentes sont en anglais.
d) Perspectives
Notre travail a permis de réaliser des modèles
de Machine Learning pour la prédiction et le clustering. Ces
modèles ont été implémentésafin de simuler
la dynamique de l'épidémie de la covid-19 à Libreville.
Nous envisageons de perfectionner ce modèle en intégrant des
algorithmes de Deep Learning. Ces algorithmes basés sur le réseau
des neurones artificiels, sont plus performants et plus précis.
CONCLUSION
GÉNÉRALE
Pour aborder le développement du simulateur EVAL_EPI,
nous avons étudié les concepts liés au domaine et avons
analysé rigoureusement les modèles épidémiologiques
existants. Sur la base des méthodes et techniques de Machine Learning
choisis, nous avons proposé deux modèles d'intelligence
artificiel. Le premier modèle est basé sur l'algorithme de
Facebook Prophet, et est spécialisé pour la prédiction du
nombre de cas cumulées d'infection à Libreville. Le second
modèle utilise l'algorithme K-means pour déterminer les foyers
épidémiques dans la commune de Libreville.
En outre nous avons proposé une plateforme web qui
implémente ces modèles de Machine Learning proposés. La
conception et la modélisation de l'application ont été
faites en utilisant une méthode construite aÌ l'aide du langage
UML et d'un processus « two track unified process
(2TUP) »
L'implémentation de notre plate-forme a
été faite avec des bibliothèques de R telle que
« shiny » (pour l'application web et le tableau
de bord) et « leaflet »pour le serveur des cartes et
le logiciel de conception Argo-UML, pour l'édiction des diagrammes
UML.
Au terme de ce stage, nous considérons que l'objectif
fixé a été atteint. Le système mis en place permet
de simuler la dynamique spatio-temporelle d'une épidémie,
d'apprécier son ampleur afin de prendre des mesures anticipatives.
RÉFÉRENCES
BIBLIOGRAPHIQUES
ALZUBAIDI, Z. (2020). A Comparative Study on Statistical and
Machine Learning Forecasting . Dubaï: Rochester Institut of
Technology.
Avhad, A. A. (2020). Predictive Analysis and Effects of
COVID-19 on India.Pune, India: Deccan Education Society's Fergusson
College.
AYMEN, D. ( 2018 ). ÉTUDE DES PATRONS ARCHITECTURAUX
DE TYPE MVC DANS LES APPLICATIONS ANDROID.MONTRÉAL:
UNIVERSITÉ DU QUÉBEC.
Becerra, A. G. (2021). times series forecasting using sarima
and sann model.Prague, République Tchèque: Universitat
Polit`ecnica de Catalunya.
BONITA, R., & Beaglehole, R. (2010).
éléments d'épidemiologie deuxieme édition.
Genève : L'Organisation mondiale de la Santé.
BOULEKCHER, R., & KABOUR, O. (2021). Une approche
basée Machine Learning pour la prédiction du Covid-19 en
Algérie . universite de Larbi M'hidi.
Chang, W. (2021). Web Application Framework for R.
Boston (USA): CRAN.
Cheng, J. (2022). Create Interactive Web Maps with the
JavaScript 'Leaflet'.Boston (USA): CRAN.
COPIL. (2022, mai 24). COMITÉ DE PILOTAGE DU PLAN DE
VEILLE ET DE RIPOSTE CONTRE L'ÉPIDÉMIE À CORONAVIRUS.
Retrieved from infocovid gabon: www.infocovid.ga
Cori, A. (2013). EpiEstim: a package to estimate time varying
reproduction numbers from epidemic curves. Boston: CRAN.
Davood, A. (2022). Data Manipulation in R with
dplyr.Boston (USA): CRAN.
Delfraissy, J.-F., Atlani-Duault, L., & Cauchemez, S. (2020).
Avis du Conseil scientifique COVID-19.Paris .
Dowle, M., Srinivasan, A., & Gorecki, J. (2021).
Extension of `data.frame. Boston, USA: CRAN.
Ferber, J. (1995). Les Systèmes Multi Agents: vers une
intelligence collective .InterEdiction.
Forte, L. (2016). BUILDING A MODERN WEB APPLICATION USING AN
MVC FRAMEWORK.Oulu: Université des sciences appliquées
d'Oulu.
geeks, g. f. (2022, mai 24). difference between mvc and mvt
design patterns. Retrieved from geeks for geeks:
www.geeksforgeeks.org/difference-between-mvc-and-mvt-design-patterns
Guégan, j.-F. (2009). Introduction à
l'épidémiologie intégrative des maladies infectieuses et
parasitaires. Bruxelles: De Boeck.
Guiochet, J. (2009). Le Processus Unifié Une
Démarche Orientée Modèle.Toulouse ,FRANCE:
Université Paul Sabatier Toulouse III.
Hahsler, M. (2022). Density-Based Spatial Clustering of
Applications with Noise.Boston (USA): CRAN.
Jakobowicz, E. (2018). Python pour le data
scientist.Malako, (France): Dunod.
Johns_Hopkins_University. (2022, 05 25). COVID-19
Dashboard. Retrieved from JHU.edu: https://coronavirus.jhu.edu/map.html
Kahle, D. (2019). Spatial Visualization with
ggplot2.Boston (USA): CRAN.
Kassambara, A. (2020). Extract and Visualize the Results of
Multivariate Data Analyses.Boston: CRAN.
MATONDO MANANGA, H. (2021). Modélisation de la
Dynamique de Transmission de la Covid-19 en République
Démocratique du Congo à l'Aide du Modèle SEIRS à
Six Classes.Kinshasa (RDC): Université de Kinshasa.
Mohammed, Z. (2019). Artificial Intelligence Definition,
Ethics and Standards. Cairo: British University in Egypt.
O.M.S. (2022, 05 25). WHO Coronavirus (COVID-19)
Dashboard. Retrieved from who.int: https://covid19.who.int/
Odhiambo, J. O. (juillet 2020). An analytical comparison
between python_Vs_R. Nairobi: Université de Nairobi.
Pebesma, E. (2022). Simple Features for R. Boston (USA):
CRAN.
Ponce, M. (2021). Load and Analyze Live Data from the
COVID-19 Pandemic.Boston (USA): CRAN.
Rakotomalala, R. :. (n.d.). R et Python : Performances
comparées.Lyon (France): Université de Lyon 2.
Swamynathan, M. (2017). Mastering Machine Learning with
Python in Six Steps. Bangalore, Karnataka, India: Library of Congress.
Taheri, Z. (2020). Spread Visualization and Prediction of the
Novel Coronavirus Disease COVID-19 Using Machine
Learning.Téhéran, Iran: l'université de
Téhéran.
Taillandier, P., Drogoul, A., & Gaudou, B. (2020).
COMOKIT: a modeling kit to understand, analyze and compare the impacts of
mitigation policies against the COVID-19 epidemic at the scale of a
city.
Taylor, S. (2021). Automatic Forecasting Procedure.
Boston (USA): CRAN.
Tennekes, M. (2022). Thematic Maps.Boston (USA):
CRAN.
TREMBLAY, R. (2007). IMPLANTATION D'UNE MÉTHODE AGILE
DE DÉVELOPPEMENT LOGICIEL EN ENTREPRISE.QUÉBEC, CANADA:
UNIVERSITÉ LAVAL.
Wickham, H. (2016). ggplot2: Elegant Graphics for Data
Analysis. Springer-Verlag. New York.
Wien, I. f. (2022, 05 25). The Comprehensive R Archive
Network. Retrieved from cran.r-project.org: https://cran.r-project.org
ANNEXES


