I.2.4.2. La présentation ou la restitution
Cette dernière étape, également
appelée Reporting, consiste à présenter les
informations à valeur ajoutée de telle sorte qu'elles
apparaissent de la façon la plus lisible possible dans le cadre de
l'aide à la décision. Les données sont principalement
modélisées par des représentations à base de
requêtes afin de constituer des tableaux de bord ou des rapports via des
outils d'analyse décisionnelle.
N.B : IL existe aussi une étape
appelée administration, qui est une fonction transversale
permettant de superviser la bonne exécution de toutes les autres
étapes et ainsi faire le contrôle du système
décisionnel lui-même.
Cette étape pilote le processus de la mise à
jour des données, la documentation sur les données, la
sécurité, les sauvegardes et la gestion des incidents.
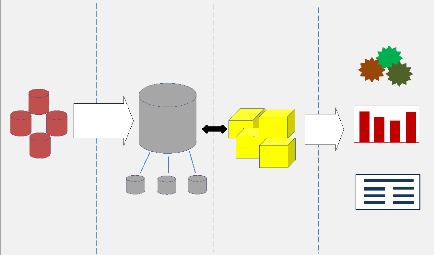
I.2.5. Architecture globale d'un système
décisionnel
Avant d'entrer dans le vif du sujet, et passer à
l'étape explicite des éléments constituant l'environnement
d'un Data warehouse, il serait intéressant de connaitre le
positionnement de ces éléments dans une architecture globale d'un
système décisionnel.
Un système décisionnel est architecturé
globalement de la façon suivante :
· En amont un accès au système transactionnel
en lecture seule
· Un DWH fusionnant les données requises
· Un ETL permettant d'alimenter le DWH à partir des
données existantes
· Des applications d'exploitation de reporting, exploration
et/ou de prédiction
· D'éventuels DM permettant de simplifier le DWH en
vue de certaines applications.
11
Sources des données Stockage des données
Conception des Restitution des
Extraire Transformer Charger
Data Marts Serveur/Cube OLAP
Data
Warehouse
vues métiers
Servir
Analyse & Statistiques
Requêtes & Rapports
vues métiers
Data Mining
? Intégrées
Les données de l'entrepôt proviennent de
différentes sources éventuellement
hétérogènes.
Figure 1: Architecture globale d'un système
décisionnel
I.3. Le Data warehouse
I.3.1. Définition
Selon Bill INMON : « un Data warehouse est
une collection de données orientées sujet,
intégrées, non volatiles et historiées, organisées
pour le support d'un processus d'aide à la décision. »
[4]
? Orientées sujet
Cela signifie que les données collectées doivent
être orientées « métiers » et donc triées
et
réorganisées par thème.
Donc :
? Les données sont organisées autour de sujets
majeurs de l'entreprise ;
? Données pour l'analyse et la modélisation en vue
de l'aide à la décision, et non pas pour
les opérations et transactions journalières ;
? Vue synthétique des données selon les sujets
intéressant les décideurs ;
12
L'intégration consiste à résoudre les
problèmes d'hétérogénéité des
systèmes de stockage, des modèles de données, de
sémantique de données.
? Non volatiles
Tout se conserve, rien ne se perd : cette
caractéristique est primordiale dans les Data warehouses. En effet, et
contrairement aux bases de données classiques, un Data Warehouse est
accessible en ajout ou en consultation uniquement. Les modifications et les
mises à jour ne sont pas autorisées sauf pour des cas
particuliers (correction d'erreurs par exemple). Une même requête
effectuée à intervalle de temps, en précisant la date
référence de l'information donnera le même
résultat.
? Historiées (données
datées)
La conservation de l'évolution des données dans
le temps, constitue une caractéristique majeure des Data warehouses.
Elle consiste à s'appuyer sur les résultats passés pour la
prise de décision et faire des prédictions ; autrement dit, la
conservation des données afin de mieux appréhender le
présent et d'anticiper le futur.
Eu égard à ce qui précède, nous
disons qu'un data warehouse ou entrepôt de données est une base de
données dédiée au stockage et à l'ensemble des
données utilisées dans le cadre de la prise de décision et
de l'analyse décisionnelle. Il est une vision centralisée et
universelle de toutes les informations de l'entreprise.
Il s'appuie alors non seulement à la
compréhension du fonctionnement actuel de l'entreprise et son pilotage
mais aussi l'anticipation des actions à venir.
I.3.2. Historique des Data warehouses
Dans une entreprise, le volume de données
traitées croît rapidement avec le temps. Ces données
peuvent provenir des fournisseurs, des clients, de la production, de
l'environnement, etc. Cette quantité de données augmente en
fonction du secteur et de l'activité de l'entreprise.
C'est à la suite des nouveaux besoins des entreprises
et aux quantités importantes de données produites par les
systèmes opérationnels, qu'est apparu pour la première
fois, en 1980 bien entendu le concept de « Data warehouse » ou «
Entrepôt de données ».
13
A cette époque, le Data warehouse était
perçu comme étant un simple environnement ou une nouvelle base
dans laquelle on logerait les informations que l'entreprise n'envisage pas
d'usage immédiat, « concept d'infocentre ».
Ce n'est qu'à partir de 1990 pratiquement, que cet
environnement est reconnu non seulement comme un lieu de collection, de
stockage, d'historisation et de journalisation des informations provenant des
bases de données opérationnelles mais aussi un socle
intégré de données conservées de manière
cohérente pour leur exploitation directe et ainsi permettre la prise des
décisions dans des entreprises.
I.3.3. Structure de données d'un Data
warehouse
Le Data Warehouse a une structure bien définie, selon
différents niveaux d'agrégation et de détail des
données. Cette structure est définie par Inmon comme suit :
? Données détaillées :
ce sont les données qui reflètent les
événements les plus récents, fréquemment
consultées, généralement volumineuses car elles sont d'un
niveau détaillé.
? Données détaillées
archivées : anciennes données rarement
sollicitées, généralement stockées dans un disque
de stockage de masse, peu coûteux, à un même niveau de
détail que les données détaillées.
? Données agrégées :
données agrégées à partir des
données détaillées.
? Données fortement agrégées :
données agrégées à partir des
données détaillées, à un niveau d'agrégation
plus élevé que les données agrégées.
? Métadonnées : ce sont les
informations relatives à la structure des données, les
méthodes d'agrégation et le lien entre les données
opérationnelles et celles du Data warehouse. Les
métadonnées doivent renseigner sur :
· Le modèle de données ;
· La structure des données telle qu'elle est vue par
les développeurs ;
· La structure des données telle qu'elle est vue par
les utilisateurs ;
· Les sources des données ;
· Les transformations nécessaires ;
· Suivi des alimentations.
14
I.3.4. Les composantes d'un Data warehouse
L'environnement du Data Warehouse est constitué
essentiellement de quatre éléments : le système
opérationnel source, la zone de préparation des données,
la zone de présentation des données et les outils d'accès
aux données.
? Les applications opérationnelles
sources
Ce sont les applications du système
opérationnel qui capturent les transactions de l'entreprise. Leurs
principales priorités sont la performance des traitements et la
disponibilité. Ces applications sont extérieures au Data
warehouse.
? Préparation des données
La préparation englobe tout ce qu'il y a entre les
applications opérationnelles sources et la présentation des
données. Elle est constituée d'un ensemble de processus
appelé ETL, « Extract, transform and Load », les
données sont extraites et stockées pour subir les transformations
nécessaires avant leur chargement.
Un point très important, dans l'aménagement
d'un entrepôt de données, est d'interdire aux utilisateurs
l'accès à la zone de préparation des données, qui
ne fournit aucun service de requête ou de présentation.
? Présentation des données
C'est le lieu où les données sont
organisées, stockées et offertes aux requêtes directes des
utilisateurs, aux programmes de reporting et autres applications d'analyse. Si
les données de la zone de préparation sont interdites aux
utilisateurs, la zone de présentation est tout ce que l'utilisateur voit
et touche par le biais des outils d'accès.
L'entrepôt de données est constitué d'un
ensemble de Data Mart. Ce dernier est défini comme étant une
miniaturisation d'un Data warehouse, construit autour d'un sujet précis
d'analyse ou consacré à un niveau départemental.
Cette différence de construction, autour d'un sujet ou
au niveau départemental, définit la façon
d'implémentation du Data mart au niveau de l'entrepôt.
15
? Outils d'accès aux données
C'est l'ensemble de moyens fournis aux utilisateurs du Data
warehouse pour exploiter la zone de présentation des données en
vue de prendre des décisions basées sur des analyses.
Ces outils varient des simples requêtes ad hoc aux
outils permettant l'application de forage de données plus complexes en
passant par l'évaluation, la prévision, l'application d'analyse
jusqu'à la génération de rapports. Environ quatre-vingt
à nonante pourcent des utilisateurs sont desservis par des applications
d'analyses préfabriquées, consistant essentiellement en
requêtes préétablies.
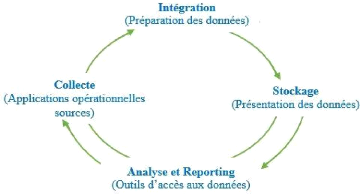
Figure 2: Composants du DWH refermant la boucle
Ce mode de traitement est transactionnel est destiné
aux métiers de l'entreprise pour les assister dans leurs tâches de
gestion.
16
I.3.5. Architecture d'un Data warehouse
La figure suivante nous renseigne de façon globale
l'architecture d'un entrepôt de données, et nous montre la
manière dont les données sont exploitées depuis leur
collecte et intégration jusqu'à leur exploration.
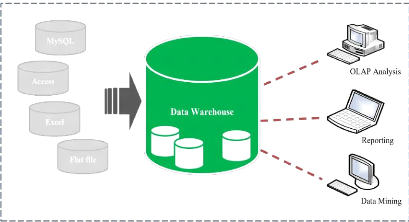
Figure 3: Architecture d'un Data Warehouse
I.4. Comparaison entre les systèmes
transactionnels et systèmes décisionnels
IL serait évident de s'interroger sur le pourquoi de
la réalisation d'une structure informatique décisionnelle alors
qu'il suffirait à l'utilisation d'un simple SGBD.
La réponse est que les objectifs de ces deux
systèmes sont quasiment différents car il y a d'une part un
système dédié aux transactions en temps réel,
à la gestion quotidienne (OLTP) et d'autre part un système
destiné à l'exécution des analyses et des questions
statistiques (OLAP).
I.4.1. OnLine Transaction Processing (OLTP)
Le traitement de transactions en ligne appelé OLTP est
un modèle ou un type d'applications qui s'inscrit dans les
systèmes opérationnels (SGBD).
17
L'objectif d'utilisation d'un tel système est
d'insérer, modifier et interroger rapidement la base de données
en toute sécurité. Ces actions doivent pourvoir être
effectuées en temps réel par des nombreux utilisateurs en
simultané.
I.4.2. OnLine Analytical Processing (OLAP)
Le traitement analytique en ligne appelé OLAP est un
type d'applications couramment utilisé en informatique
décisionnelle, dans le but d'aider la direction à avoir une vue
transversale de l'activité d'une entreprise.
Les applications de type OLAP, utilisées par les
entrepôts de données se fait uniquement en lecture et sont
orientées vers l'analyse sur-le-champ d'informations selon plusieurs
axes, dans le but d'obtenir des rapports de synthèse.
Pour effectuer l'analyse, les programmes consultent une
grande quantité de données. Les principaux objectifs sont de
regrouper et d'organiser des informations à partir de différentes
sources, les intégrer et les stocker afin de donner à l'usager
une vue axée métier, récupérer et analyser
l'information facilement et rapidement.
Le tableau suivant résume de façon non
exhaustive certains éléments de divergence entre les
systèmes transactionnels classiques et les systèmes
décisionnels par rapport à l'usage, aux transactions, au type
d'opérations, à la taille, etc.
Une table de faits est la table centrale d'un modèle
dimensionnel, qui représente un sujet à analyser et où les
mesures de performances sont stockées.
18
Tableau 1: Comparaison entre les systèmes
transactionnels et systèmes décisionnels
Caractéristiques
|
Le système transactionnel
OLTP
|
Le système
décisionnel
OLAP
|
Utilisation
|
-SGBD (Bases de production) -Les opérationnels
(Employés de bureau)
|
-Data Warehouse -Analystes/ décideurs
|
Opération typique
|
· Mise à jour
|
· Analyse
|
Données
|
· Détaillées
|
· Dérivées et agrégées
|
|
· Requêtes complexes et imprévisibles
|
|
· Résumées et globales
|
|
· Orientées sujet
|
|
· Historiques
|
|
· Statiques
|
|
|
Accès aux données
|
-Lecture / Ecriture
|
-Lecture seule
|
|
Transactions
|
-Petites, nombreuses
|
-Grosses, 1 par jour
|
|
Taille BD
|
-Faible (quelques GB)
|
-Importante (pouvant aller jusqu'à plusieurs TB)
|
|
Temps de réponse
|
-Instantané
|
-Réponse moins rapide (seconde à minutes)
|
I.5. Approche générale de la
modélisation dimensionnelle
Lorsqu'on fait un schéma dans la modélisation des
bases de données classiques, on parle de tables et de
relations. Une table étant une représentation
d'entité et une relation une technique pour lier ces entités.
Et bien en Business Intelligence, la modélisation
dimensionnelle parle en termes des Dimensions et des Faits.
Un modèle dimensionnel et/ou multidimensionnel est en fait la
combinaison de dimensions et de faits.
I.5.1. Les faits
C'est un modèle où la table de faits est au
coeur du schéma. Dans ce modèle, toutes les tables de dimension
de la structure sont directement liées à la table principale
(fait) et
19
En complément aux dimensions, les faits sont ce sur
quoi va porter l'analyse. Ce sont des tables qui contiennent des informations
opérationnelles et qui relatent la vie de l'entreprise.
Une ligne d'une table de faits correspond à une ou
plusieurs mesures. Une mesure est un attribut dans une table de faits. Ces
mesures sont généralement des valeurs numériques,
additives ; cependant des mesures textuelles peuvent exister mais sont rares.
Le concepteur doit faire son possible pour faire des mesures textuelles des
dimensions, car elles peuvent êtres corrélées efficacement
avec les autres attributs textuels de dimensions.
Dans les modèles dimensionnels, les tables de faits
expriment des relations de un à plusieurs entre les dimensions. Elles
comportent des clés étrangères, qui ne sont autres que les
clés primaires des tables de dimension.
I.5.2. Les dimensions
Les tables de dimension sont les tables qui permettent
d'interpréter et de raccompagner une table de faits ; elles contiennent
les descriptions textuelles de l'activité.
Le sujet analysé, c'est à dire le fait, est
analysé suivant différentes perspectives. Ces perspectives
correspondent à une catégorie utilisée pour
caractériser les mesures d'activité analysées ; on parle
de dimensions.
Un fait est une table qui contient les données
observables [les faits] que l'on possède sur un sujet et que l'on veut
analyser [les dimensions].
I.5.3. Différents modèles de la
modélisation dimensionnelle
Le concepteur d'un entrepôt de données est
appelé à faire le choix, lequel des modèles dimensionnels
appréhender pour bien représenter sa solution. Avant de faire
notre choix, les lignes qui suivent illustrent consisteront à expliciter
les types de modèles utilisés dans la modélisation
dimensionnelle et/ou multidimensionnelle.
I.5.4. Le modèle en Etoile
20
représente visuellement une étoile. Ce
schéma est le modèle de référence pour la
construction des data marts.
I.5.5. Le modèle en Flocon
C'est une technique de la modélisation dimensionnelle
dérivée du modèle en étoile qui consiste à
éclater ou à décomposer les dimensions. Dans ce
modèle, il y a des dimensions qui sont directement liées à
la table de faits et d'autres passent via d'autres dimensions, on parle de la
hiérarchie.
I.5.5. Le modèle en Constellation
Il s'agit d'une technique qui consiste à fusionner
plusieurs modèles en étoile et où plusieurs tables de
faits peuvent utiliser une table de dimension.
I.5.6. Les Data marts
Littéralement « Magasin de données »,
ce terme désigne un sous-ensemble du Data Warehouse contenant des
données de ce dernier pour un secteur particulier de l'entreprise.
Il doit être un ensemble de tables de données
organisées dans une structure qui favorise la lecture pour du reporting
analytique sur un historique plus important que celui conservé en
production.
Remarques : Un data warehouse et un data mart
se distinguent par le spectre qu'ils recouvrent:
? Le data warehouse recouvre l'ensemble des
données et problématiques d'analyse
visées par
l'entreprise.
? Le data mart recouvre une partie des
données et problématiques liées à un métier
ou
un sujet d'analyse en particulier.
Un data mart est fréquemment un sous-ensemble du data
warehouse de l'entreprise, obtenu par extraction et agrégation des
données de celui-ci.
21
I.5.7. Le cube OLAP
Le principe de la modélisation multidimensionnelle
stipule qu'un sujet à analyser doit être considéré
comme un point à plusieurs dimensions dans un espace. Les données
sont ensuite organisées de manière à mettre en
évidence le sujet analysé et les différentes perspectives
de l'analyse.
Le cube OLAP est donc une catégorie de logiciels
axés sur l'exploration et l'analyse rapide des données selon une
approche multidimensionnelle à plusieurs niveaux
d'agrégation. Il est aussi considéré
comme étant une méthode de stockage de données
sous
forme multidimensionnelle, généralement à des fins des
rapports.
I.5.8. Les attributs
Ce sont les éléments caractéristiques des
tables pour un modèle dimensionnel. Les tables de dimension et de faits
doivent avoir dans le cas échéant des clés techniques, des
clés de substitution, de clés étrangères et bien
d'autres attributs.
I.5.8.1. La clé technique ou de
substitution
Appelée parfois clé artificielle ou encore
clé de remplacement (surrogate key de l'anglais), la clé
technique désigne la clé primaire de la table de dimension car
elle est utilisée pour faire le lien avec la table de faits.
Indépendante du système source, cette clé est du type
entier et est généralement incrémenté
automatiquement à chaque insertion.
I.5.8.2. La clé fonctionnelle ou
opérationnelle
Appelées aussi clés des systèmes source,
les clés fonctionnelles permettent d'identifier de manière unique
un enregistrement de la dimension dans un système source.
I.6. Cycle de vie d'un modèle
dimensionnel
Avant d'étudier de plus près les
spécifications de la conception, du développement et du
déploiement d'un data warehouse, il faudrait exposer une
méthodologie globale tout en présentant le cycle de vie
dimensionnel.
Modélisation dimensionnelle
Définition de
l'architecture technique
Sélection et
installation des
produits
Conception physique
Mise en route
Spécification de
l'application
d'analyse

Plan ning
du projet
Conception/Dév.
de la préparation
de
données
Maintenance et évolution
22
Le schéma suivant représente la succession des
tâches de haut niveau nécessaires à la conception, au
développement et au déploiement d'entrepôt de
données efficaces. Il décrit le cheminement du projet dans son
ensemble ; chaque rectangle sert de poteau d'indicateur ou de borne.
|
Définition des
besoins de
l'entreprise
|
|
Développement des applications
d'analyse
|
Gestion du projet
Figure 4: Digramme du cycle de vie d'un modèle
dimensionnel
I.7. Alimentation du Data warehouse
L'alimentation est une opération qui consiste à
effectuer la migration et la préparation des données provenant
des systèmes opérationnels vers l'entrepôt. Nous pouvons
conclure à notre niveau qu'alimenter un Data warehouse c'est simplement
lui intégrer les données des bases de production.
Cette phase utilise une série d'outils logiciels pour
la découverte, l'extraction, la transformation et le chargement des
données.
I.8. Les outils du décisionnel
La réalisation d'une architecture décisionnelle
exige un certain type d'outils et de logiciels pour sa mise en oeuvre, en voici
les principaux :
I.8.1. Extraction Transformation Loading
L'ETL pour ?Extraction Transformation Loading» ou
Extraction Transformation Chargement en Français, est un processus qui
permet de charger un data warehouse à partir
23
de données externes généralement issues de
bases transactionnelles. Son rôle est de récupérer ces
données et de les traiter pour qu'elles correspondent aux besoins du
modèle dimensionnel.
En général, les données sources doivent
être "nettoyées" et aménagées pour être
exploitables par les outils décisionnels.
Un processus ETL est simplement une copie des données
depuis les tables du système transactionnel vers les tables du
modèle dimensionnel.
Ce processus remplit trois fonctions principales :
I.8.1.1. L'extraction
Elle est la première phase du processus d'apport de
données à l'entrepôt. C'est une opération qui
consiste à cibler et à importer les données depuis une BD
extérieure vers la zone de préparation en vue de subir la
transformation.
I.8.1.2. La transformation
Elle est la deuxième phase du processus qui a
naturellement pour but de rendre les données cibles homogènes
afin qu'elles soient chargées de façon cohérente. Il faut
noter que les données sources qui alimentent le système
d'information décisionnel sont issues des systèmes
transactionnels de production, le plus souvent sous diverses formes.
La transformation est une phase qui effectue les
opérations de filtrage, d'agrégation, de conversion et de mise en
correspondance des données.
I.8.1.3. Le chargement
C'est la troisième et dernière phase du
processus ETL ou de l'alimentation de l'entrepôt. Elle consiste
simplement à charger les données nettoyées et
homogénéisées dans le DWH.
24
I.8.2. Les outils de Reporting
L'ensemble d'outils d'analyse décisionnelle qui
permettent de modéliser des représentations à bases de
requêtes afin de constituer les rapports, les tableaux de bord, s'appelle
le Reporting. Le reporting est l'application la plus utilisée
dans l'informatique décisionnelle, il permet aux décideurs de
:
+ Sélectionner des données par période,
production, secteur de clientèle, etc ;
+ Trier, regrouper ou répartir ces données selon
des critères de choix ;
+ Réaliser des calculs (totaux, moyennes, sommes,
pourcentages, écarts, comparatif, ...) ; + Présenter les
résultats de manière synthétique ou
détaillée, généralement sous forme de
graphiques.
Les programmes utilisés pour le reporting permettent de
faire varier certains critères pour affiner l'analyse. Des instruments
de type tableau de bord équipés de fonctions d'analyses
multidimensionnelles de type OLAP sont aussi utilisés sur cette
dernière partie du SID.
I.8.3. Les outils de data mining
Au sens littéral du terme, le Data mining signifie
« Forage de données ». C'est un ensemble de techniques
d'exploration et d'analyse d'une masse importante de données dans le but
de découvrir des tendances cachées ou des règles
significatives.
Les objectifs du data mining consistent à :
+ Prédire les conséquences d'un
événement ou d'une décision, se basant sur le
passé. + Découvrir de règles cachées : des
règles associatives, entre différents événements. +
Confirmer des hypothèses : des hypothèses proposées par
les analystes et décideurs, et les doter d'un degré de
confiance.
I.8.4. Les outils d'analyse
Comme on peut le voir, ses outils permettent d'effectuer
l'analyse statistique des données en mettant en évidence leurs
tendances ou corrélations entre les données non évidentes
à priori. Cette analyse prend effet après l'utilisation des cubes
dimensionnels ou cubes OLAP.
25
I.9. Conclusion
Voilà que nous avons pris connaissance des concepts
généraux et théoriques de la Business Intelligence, il est
temps pour nous de voler et de prendre une nouvelle allure considérable
pour le data warehousing.
Cependant une étude sur l'existant doit être de
mise, c'est-à-dire une étude perspicace sur la façon dont
les données sont stockées et la manière dont l'information
est manipulée dans l'entreprise ciblée.
C'est pourquoi nous réserverons le chapitre suivant
à cette besogne. A ce niveau, nous essayerons de découvrir une
quantité des données utilisées et en faire les
données conséquentes et importantes qui seront par la suite
intégrées dans la base décisionnelle.
26
CHAPITRE II : LE STOCKAGE DE DONNEES A LA
BRASIMBA
II.1. Introduction
L'analyse préalable est la première
étape dans l'élaboration du projet de type informatique ; elle
est une étude globale relativement grossière du problème
à traiter.
Elle consiste à inventorier les données et les
traitements actuellement utilisés dans le système en vue de
dégager les besoins et d'envisager l'opportunité d'optimiser
certaines tâches.
C'est en s'inscrivant dans ce même ordre d'idées
que ce chapitre aura l'objectif de s'intéresser sur comment s'effectue
le stockage des informations dans cette société, quels sont les
SGBD utilisés à cette fin, tout en faisant un rappel sur les BD
opérationnelles.
L'analyse des processus qui aboutissent à la vente
sera aussi effectuée dans cette partie de notre travail. Nous nous
intéresserons au processus de vente car c'est elle qui aura une
influence remarquable sur la décision de la production des marchandises
à la Brasimba.
II.2. Aperçu sur les systèmes
transactionnels
Avant de nous lancer sur l'étude pertinente des
éléments qui constituent les processus du système et son
enchainement, nous raflons d'abord sur cette partie qui consistera à
expliciter les éléments et les concepts liés à la
théorie sur les bases de données classiques, lesquelles bases de
données ont donné naissance aux entrepôts de
données.
II.2.1. Qu'est-ce qu'une base de
données
Plusieurs auteurs ont essayé de donner des
définitions plus ou moins parallèles sur les bases de
données, cela nous a conduit à dire qu'il n'existe pas une
définition nette et exacte de ce concept.
Mais la définition générale dit
simplement qu'une base de données pourrait être un ensemble
organisé d'informations ayant un objectif commun.
Peu importe le support utilisé pour rassembler et
stocker les données (papiers, fichiers...), dès lors que des
données sont rassemblées et stockées d'une manière
organisée
27
dans un but spécifique, nous pouvons parler d'une base
de données. Bien entendu, dans le cadre de ce travail, nous nous
intéressons aux bases de données informatisées.
Nous disons donc qu'une base de données
informatisée est un ensemble de données structurées,
organisées, enregistrées dans un support et accessibles par un
ordinateur dans le but de satisfaire une communauté d'utilisateurs
géographiquement repartis.
II.2.2. Problématique de la cohérence des
données
La création d'une base de données répond
aux besoins de rassembler les données qui possèdent un lien entre
elles, dans le but de retrouver l'information en utilisant des critères
de recherche basés sur le contenu de cette information. [5]
La condition sine qua non pour garantir la faisabilité
et la qualité d'une recherche de données par le contenu est la
cohérence des données. Certaines données non
cohérentes souffrent de plusieurs problèmes qui compromettent
leur consultation.
La cohérence des données est la
problématique fondamentale des bases des données. La
première et la plus importante des réponses à ce
problème consiste à limiter au maximum la redondance
d'informations. Il existe évidemment un nombre important de
méthodes qui permettent d'assurer la cohérence des
données.
II.2.3. Système de gestion de base de
données
La gestion et l'accès à une base de
données sont assurés par un ensemble de programmes qui
constituent le Système de Gestion de Base de Données. Un
SGBD héberge généralement plusieurs bases de
données, qui sont destinés à des logiciels ou à des
thématiques différentes.
En définitive, un SGBD est un ensemble coordonné
de logiciels ayant pour tâche de créer, de gérer,
d'interroger une base de données et permettre les opérations
d'insertion, de modification et de suppression des données de
celle-ci.
28
Les principaux objectifs des SGBD pour les données sont
d'assurer leur indépendance physique et logique, l'accès,
l'administration centralisée, la non-redondance, la cohérence, le
partage, la sécurité et la résistance aux pannes.
II.2.4. Enjeux des bases de données
Les bases de données jouent un rôle central et
croissant dans le développement des technologies de l'information depuis
plus d'une trentaine d'années. Les SGBD sont actuellement l'une des
technologies de l'Informatique les plus répandues et matures. Au
début, les bases de données se cantonnaient uniquement aux
systèmes d'information des entreprises.
Actuellement, il y a non seulement les entreprises mais nous
pouvons aussi observer que toute application informatique moderne utilise,
directement ou indirectement une base de données.
II.2.5. Modèle de données
relationnel
Le modèle relationnel représente la base de
données comme un ensemble de tables, sans préjuger de la
façon dont les informations sont stockées dans la machine. Les
tables constituent donc la structure logique du modèle relationnel.
Au niveau physique, le système est libre d'utiliser
n'importe quelle technique de stockage dès lors qu'il est possible de
relier ces structures à des tables au niveau logique. Les tables ne
représentent donc qu'une abstraction de l'enregistrement physique des
données en mémoire. De façon informelle, le modèle
relationnel peut être défini de la manière suivante :
? Les données sont organisées sous forme de tables
à deux dimensions ;
? Les données sont manipulées par des
opérations de l'algèbre relationnelle ;
? L'état cohérent de la base est défini par
un ensemble de contrainte d'intégrité.
29
II.2.6. Eléments constitutifs d'un modèle
relationnel
Tableau 2: Eléments constitutifs d'un modèle
relationnel
|
Eléments
|
Significations
|
|
Attribut
|
Est un identifiant (un nom) décrivant une information
stockée dans une base.
|
|
Domaine
|
Est un ensemble de valeurs qu'un attribut peut prendre.
|
|
Relation
|
|
|
Schéma de relation
|
Précise le nom de la relation ainsi que la liste des
valeurs avec leurs domaines.
|
|
Degré
|
Le degré d'une relation est son nombre d'attributs.
|
|
Occurrence
|
Est un élément de l'ensemble figuré par
une relation. Autrement dit, une occurrence est une ligne de la table qui
représente une relation.
|
|
Cardinalité
|
La cardinalité d'une relation est son nombre
d'occurrences. Cela veut dire le nombre de fois qu'une rela5on participe dans
une relation.
|
|
Clé candidate
|
La clé candidate d'une relation est un ensemble minimal
des attributs de la relation dont les valeurs identifient à coup
sûr une occurrence.
|
|
Clé primaire
|
La clé primaire d'une relation est une de ses
clés candidates.
|
|
Clé étrangère
|
Une clé étrangère dans une relation est
formée d'un ou plusieurs attributs qui constituent une clé
candidate dans une autre relation.
|
|
Schéma relationnel
|
Il est constitué par l'ensemble de schéma de
relation avec mention des clés étrangères.
|
II.3. Description des processus
Dans une entreprise de vente et de production, il existe
plusieurs étapes et processus à exécuter pour enfin avoir
un produit fabriqué qui sera ensuite vendu aux consommateurs. Ces
étapes sont généralement perpétuelles et suivent un
certain enchainement.
Nous éveillons notre intérêt à
expliciter sur les processus par les quels on passe pour que la
société aie un produit fini prêt à vendre ou
à écouler.
30
| 

