II.2. Les protocoles de routage dans les réseaux Ad
Hoc
Le routage dans les réseaux ad hoc est assez
délicat étant donnée la nature changeante de la topologie
de ce type de réseaux. De nombreux protocoles sont proposés pour
résoudre le problème de routage multi saut (multihoping),
chacun fondé sur différents concepts et reposant sur
différentes hypothèses et intuitions. Les protocoles de routage
peuvent être séparés en deux classes principales, à
savoir proactif ou réactif, selon les manières dont les
routes sont créées et maintenues. On pourra
ajouter une troisième classe, celle des protocoles hybrides qui sont une
combinaison des protocoles proactifs et réactifs. Dans ce qui suit, nous
présentons beaucoup plus en détail les principaux protocoles
retenus par le groupe de travail MANET au sein de l'IETF.
II.2.1 Les protocoles de routage proactif
Les protocoles proactifs utilisent
l'échange régulier de messages de contrôle pour maintenir
au niveau de chaque noeud des tables de routage (qui associent à chaque
destination ou groupe de destinations un voisin direct par lequel les paquets
doivent être relayés) vers toute destination atteignable depuis
celui-ci. Ces tables sont maintenues même quand les routes ne sont pas
utilisées, cette approche permet de disposer d'une route vers chaque
destination immédiatement au moment où un paquet doit être
envoyé.
Les deux principales méthodes utilisées sont :
la méthodes Etat de Lien ("Link State") [Per0 1] et la
méthode du Vecteur de Distance ("Distance Vector")
[PBh94]. Les deux méthodes exigent une mise à jour
périodique des données de routage qui doit être
diffusée par les différents noeuds de routage du réseau.
Les algorithmes de routage basés sur ces deux méthodes, utilisent
la même technique qui est celle des plus courts chemins, et permettent
à un hôte donné, de trouver le prochain hôte pour
atteindre la destination en utilisant le trajet le plus cours existant dans le
réseau. Généralement le calcul du plus court chemin entre
deux stations, est basé sur le nombre de n°uds mobile (on dit aussi
le nombre de sauts) que comportent les différents chemins qui existent
entre les deux noeuds. Mais on peut aussi associer des coûts aux liens de
communication. Un coût peut matérialiser le taux de l'utilisation
d'un lien, les délais relatifs de communication etc«.
a. Algorithme du vecteur de distance
Dans le vecteur de distance ou routage de bellman-Ford
(distance vector routing) [Wei], chaque noeud du réseau
maintient une table de routage qui comporte une entrée par n°ud du
réseau, le prochain noeud à att eindre et le coût pour
joindre cette destination. Périodiquement chaque noeud diffuse sa table
de routage à ses voisins. Le n°ud voisin apprend ainsi ce que son
voisin est capable de joindre. À la réception, le n°ud
compare les informations reçues à sa propre base de connaissance
de la façon suivante:
- Si la table reçue contient une entrée qui
n'est pas déjà dans sa propre table, il incrémente le
coût de cette entrée du coût affecté au lien par
lequel il vient de recevoir et met cette entrée dans sa table. Il a
ainsi appris une nouvelle destination et il rediffuse cette nouvelle table
à ces voisins.
- Si la table contient une entrée qu'il connaît
déjà, la procédure est la suivante :
Si le voisin qui a envoyé les mises à jour est
le même figurant dans l'entrée considéré comme
prochain n°ud à atteindre, donc seul le coût du chemin a
changé, alors il met à jour sa table. Bien entendu ceci voudrait
dire que le chemin a changé à partir du deuxième saut.
Sinon
Si Le coût calculé (coût reçu
incrémenté du coût lien) est supérieur ou
égale à l'information qu'il possède, il l'ignore. Dans le
cas contraire il met à jour sa table.
De proche en proche chaque n°ud apprend la configuration
du réseau et le coût des différents chemins. Cet algorithme
n'est pas sans faille. En effet, la convergence des différentes tables
peut être assez longue. De plus, le manque de coordination dans la mise
à jour des tables de routage peut conduire à la modification de
ceux-ci sous la base des données erronées, ce qui peut provoquer
une boucle de routage (routing loops). En plus de cela, le DBF
(Distributed
Bellman-Ford) ne possède pas de
mécanisme précis qui peut déterminer quand est ce que le
réseau doit arrêter l'incrémentation de la distance qui
correspond à une destination donnée, ce problème est
appelé : counting to infinity. Le paragraphe suivant
élucide ces problèmes.
a-1. Boucle de routage :
Considérons la topologie du réseau Ad hoc suivant
(figure 2.2).

A
A
0
B
B
1
2
B
C
B
A
C
B
B
C
0
2
1
B
A
C
A
B
C
0
1
1
Figure 2.2 : Exemple d'utilisation du DBF.
Nous avons trois n°uds qui maintiennent chacun une table
de routage, la première colonne désignant la destination à
atteindre ; la deuxième, le prochain n°ud et la troisième le
coût, en terme du nombre de sauts, pour atteindre cette destination. Bien
entendu, nous supposons que le réseau est déjà stable.
Imaginons maintenant qu'à un moment donné, le lien
entre C et B ne soit plus actif. Apprenant la nouvelle, le
n°ud B met à jour sa table en portant le coût du
lien (B, C) à l'infini pour indiquer qu'il ne peut
plus atteindre ce n°ud, donc ne diffuse plus cette route (la figure
suivante illustre ce fait).
B
|
B
|
0
|
|
C
|
C
|
0
|
A
|
A
|
1
|
|
B
|
B
|
™
|
C
|
C
|
™
|
|
A
|
B
|
2
|
|
A
A
0
B B 1

C B 2
Figure 2.3 : Mises à jour après coupure de lien
dans
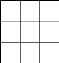
Lors du prochain échange, A informe B
qu'il peut atteindre C à un coût 2, B met
sa table à jour qui devient ainsi :
B
A
C
A
A
B
0
3
1
Nous venons d'aboutir à une boucle, tout paqué que
A reçoit à destination de C, il l'envoie
à B, vice versa tout paqué que B reçoit
à destination de C, il l'envoie àA.
a-2. Contage à l'infini :
Pour illustrer ce concept, considérons l'état
précédent de notre topologie.
À l'échange suivant, A apprend que
joindre C en passent par B a maintenant un coût de 3+1
Soit 4. Il met sa table à jour. À l'échange suivant B
passe le coût à 5, puis A à 6 jusqu'à
ce que le coût devienne l'infini.
| 

