Les déterminants de la qualité de l'habitat à Kinshasa. Approche par le modèle Biprobit (Probit Bivarié)( Télécharger le fichier original )par Christian OTCHIA SAMEN Université de Kinshasa (UNIKIN) - Licencié en économie mathématique 2006 |

2.1.5. Spécification du modèleLes modèles de régression logistique permettent d'ajuster une surface de régression à des données lorsque la variable de régression est dichotomique45(*). L'objectif de ces modèles consiste alors à expliquer la réalisation d'un événement considéré en fonction d'un certain nombre de caractéristiques observées pour les individus de l'échantillon. Supposons un échantillon de N individus indicés i = 1, ..., N. Pour chaque individu, on observe si un certain événement s'est réalisé et l'on note Yi la variable codée associée à événement. On pose,
On remarque ici le choix du codage (0,1) qui est traditionnellement retenu pour les modèles dichotomiques. En effet, celui-ci permet définir la probabilité de la réalisation de l'événement comme l'espérance de la variable codée Yi, puisque : E (Yi) = Prob (Yi = 1) × 1 + Prob (Yi = 0) ×0 = Prob (Yi = 1) = pi (2) Les modèles logistiques permettent ainsi d'expliquer (et de calculer) la probabilité de remplir les critères de la qualité de l'habitat quand les valeurs des caractéristiques individuelles X sont connues. La probabilité que Yi = 1 (remplir les critères de la qualité de l'habitat) connaissant les caractéristiques individuelles X1i, ..., Xki, s'écrit : où la fonction F(.) désigne une fonction de répartition dont le choix est à priori non contraint. Toutefois, on utilise généralement deux types de fonctions : la fonction de répartition de la loi logistique et la fonction de répartition de la loi normale centrée réduite. À chacune de ces fonctions correspond un nom attribué au modèle ainsi obtenu : modèle Logit et modèle Probit46(*). 1°) Présentation du modèle ProbitSoit le modèle Dans un modèle Probit, on suppose que la fonction de
répartition F est une loi normale. On note
2°) Estimation du modèle ProbitDans le cas des modèles dichotomiques, plusieurs méthodes d'estimation sont envisageables : il s'agit des méthodes paramétriques (Moindres Carrés Non Linéaires, Maximum de Vraisemblance) et non paramétriques (Méthodes du Score Maximum, Méthode Semi - Paramétrique). La méthode d'estimation utilisée dans ce travail est la méthode du maximum de vraisemblance parce qu'elle fournit des meilleurs estimateurs lorsque la loi des perturbations est connue. Ces estimateurs sont dérivés de la manière suivante : Soit notre échantillon de N individus indicés i
= 1, .., N. Pour chaque individu, on observe si un certain
événement s'est réalisé et l'on note yi
la variable codée associée à événement. On
pose
où
La fonction de vraisemblance associée à l'observation yi s'écrit comme le produit des probabilités et est donnée par l'expression suivante :
Par ailleurs, la vraisemblance associée à l'échantillon de taille N est donnée par l'expression suivante (8), dans laquelle on substitut yi par ses valeurs telles que renseignées dans l'expression (6).
De l'expression (6), on déduit la log-vraisemblance. Elle est simplement égale à la dérivée de la fonction de vraisemblance.
En distinguant les observations yi=1 et celles pour lesquelles yi=0, la log-vraisemblance peut s'écrire sous la forme :
Le vecteur des paramètres â est obtenu en maximisant soit la fonction de vraisemblance L(y, â) soit la fonction de log-vraisemblance log L(y, â). En dérivant la log-vraisemblance par rapport aux éléments du vecteur â, on obtient un vecteur de dérivées G(â) appelé vecteur du gradient.
Où f (.) est la fonction de densité associée
à F (.) et où En mettant l'expression (12) au même dénominateur, on obtient alors :
En outre, on peut aussi exprimer le gradient en distinguant les observations yi=1 et celles pour lesquelles yi=0 de sorte qu'on aie l'expression suivante :
(14) Pour obtenir l'estimateur du maximum de vraisemblance
En remplaçant F par
La probabilité estimée pour chaque individu est donnée par
avec * 45 HOWEL C. David, Méthodes statistiques en sciences humaines, De Boeck, Paris, 1998, p. 615 * 46 Le mot Probit est simplement une forme contractée de l'expression anglaise probability unit. |
|


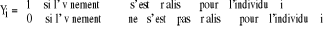 (1)
(1)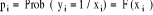
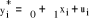 (4),
où
(4),
où 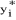 est
une variable latente, c'est-à-dire qu'elle est inobservable comme la
propension à satisfaire l'indicateur de la qualité de l'habitat.
Néanmoins, nous pouvons observer le comportement de l'individu qui a
satisfait l'indicateur de la qualité de l'habitat.
est
une variable latente, c'est-à-dire qu'elle est inobservable comme la
propension à satisfaire l'indicateur de la qualité de l'habitat.
Néanmoins, nous pouvons observer le comportement de l'individu qui a
satisfait l'indicateur de la qualité de l'habitat.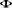 la
fonction de répartition et ö la fonction de densité de la
loi normale centrée réduite N(0,1). Ainsi, la
probabilité Pi est définie de la manière
suivante :
la
fonction de répartition et ö la fonction de densité de la
loi normale centrée réduite N(0,1). Ainsi, la
probabilité Pi est définie de la manière
suivante :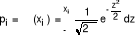 ,
avec
,
avec 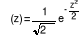 (5)
(5) :
: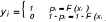 (6)
(6)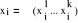 ,
, 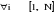 désigne un vecteur de caractéristiques observables et
où
désigne un vecteur de caractéristiques observables et
où
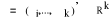 est
un vecteur de paramètres inconnus.
est
un vecteur de paramètres inconnus.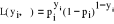 (7)
(7)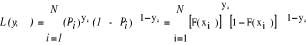 (8)
(8)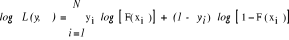 (9)
(9)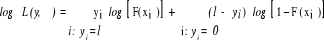 (10)
(10)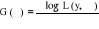 (11)
(11)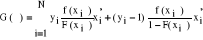 (12)
(12)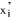 désigne la transposée du vecteur xi.
désigne la transposée du vecteur xi.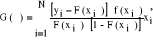 (13)
(13)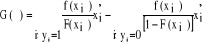

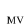 , on
doit résoudre le système d'équations non linéaire
suivant :
, on
doit résoudre le système d'équations non linéaire
suivant :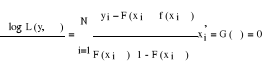 (15)
(15)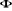 et f
par ö, le système devient :
et f
par ö, le système devient :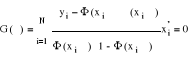 (16)
(16)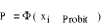 (17)
(17)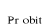 le
vecteur de paramètres du modèle Probit estimé par la
méthode du maximum de vraisemblance
le
vecteur de paramètres du modèle Probit estimé par la
méthode du maximum de vraisemblance