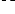Sécurité dans les systèmes temps réel( Télécharger le fichier original )par Thomas Vanderlinden Université Libre de Bruxelles - Licence en Informatique 2007 |

Chapitre 4Récompense et sécurité4.1 Introduction Comme nous l'avons défini au chapitre 2, chaque tâche dans un système temps réel doit se terminer avant une certaine échéance en produisant le résultat attendu. Si le système n'est pas ordonnançable, il faudra alors choisir des parties qui resteront non exécutées de façon à ce que toutes les tâches respectent leur échéance. Le système peut ne plus être ordonnançable suite à une demande de précision trop fine du résultat, par exemple, lors du raffinement de la qualité d'une image ou pour citer notre cas, si le niveau de sécurité attribué aux différentes tâches est trop important. La communauté de recherche dans ce domaine, a mis au point plusieurs techniques. Nous pouvons par exemple « sauter » [11] entièrement certains travaux d'une tâche donnée suivant un facteur de saut qui détermine combien de travaux sur un certain nombre de travaux de cette tâche peuvent être abandonnés par l'algorithme d'ordonnancement. Mais nous supposons dans ce cas, que les données produites par une tâche qui n'a pas été exécutée entièrement ne sont d'aucune utilité. Or, dans de nombreux secteurs comme le traitement d'images, de la voix, le contrôle de robot, et bien d'autres encore, une solution partielle est souvent suffisante. Pour résoudre notre problème de sécurité, nous pourrions également utiliser de telles techniques qui peuvent nous apporter en un temps acceptable, une sécurité partielle mais suffisante. 4.2 Reward-Based Scheduling 4.2.1 Introduction Ce chapitre est basé sur les travaux de H. Aydin [3]. Nous n'envisagerons dans cette section que le cas des tâches périodiques avec un système temps réel à échéance sur requête.
Oi ? mi + tij
Mi mi + oi 0 mi Ti FIG. 4.1 - Partie obligatoire et optionnelle d'un travail 'i-ij de la tâche Ti Comme son nom l'indique, le principe de cet ordonnancement est d'associer une récompense à l'exécution d'une tâche. Chaque tâche Ti peut être décomposée en une sous-tâche (partie) obligatoire (Mi) et une sous-tâche optionnelle (Oi) (voir figure 4.1). La longueur de la partie obligatoire de chaque travail de Ti sera notée mi et oi désignera la longueur maximum que peut prendre la partie optionnelle d'un travail de Ti. Il est primordial que la partie obligatoire se termine avant l'échéance, et nous attribuerons à l'exécution de la partie optionnelle une fonction de récompense non-décroissante. Ce type de technique est basé sur les modèles IRIS [5] (« Increasing Reward with Increasing Service »), ce qui signifie en reprenant notre cas, que plus un travail s'exécutera longtemps, plus la qualité de la sécurité s'en verra améliorée et donc plus la récompense sera importante. Dans le modèle IRIS, la distinction entre partie obligatoire et optionnelle n'est pas faite, on permet uniquement aux tâches d'obtenir une augmentation de la récompense en fonction de l'allongement du temps d'exécution sans imposer de borne supérieure pour celui-ci exceptée bien entendu l'échéance de la tâche. De manière à ne pas continuer à sécuriser une tâche au-delà d'un certain niveau de sécurité maximum, ce qui risquerait de nous empêcher de sécuriser les autres tâches efficacement, nous remarquons qu'il serait préférable dans le cadre de la sécurité, d'utiliser également une borne supérieure pour le temps d'exécution de la partie optionnelle, ce qui est possible avec cette version « Reward Based Scheduling ». Nous allons donner priorité à la partie obligatoire, la partie optionnelle sera ensuite exécutée en utilisant le temps restant avant l'échéance si la partie obligatoire courante d'aucune tâche n'est encore présente dans le système. Conditions d'ordonnançabilité et d'optimalité Un niveau minimum de sécurité sera imposé et sera pris en compte dans la partie obligatoire. Une condition nécessaire pour l'ordonnançabilité du système est que les parties obligatoires et optionnelles se terminent toutes avant l'échéance de manière à fournir une sortie minimale acceptable. Mais il faudra également essayer de maximiser le plus possible la moyenne pondérée des récompenses obtenues par les différentes tâches afin de rendre cet ordonnancement optimal. Malheureusement, ces deux objectifs sont la plupart du temps antagonistes étant donné que si l'on désire respecter les échéances, il faut généralement sacrifier en partie la sous-tâche optionnelle et donc la récompense s'en verra diminuée. 4.2.2 Une fonction de récompense Chaque tâche se voit attribuer une fonction de récompense qui sera utilisée pour tous ses travaux. L'abscisse représente le temps d'exécution utilisé par la partie optionnelle du travail, l'ordonnée retourne la récompense obtenue avec ce temps. Plusieurs types de fonctions de récompense sont modélisables selon le type d'application qui nous intéresse. Types de fonctions: Convexe: Définition fonction convexe [23]: Une fonction f d'un intervalle I vers < est dite convexe si, V x ety E I et tout t dans [0, 1] on a: f(tx + (1 - t) y) = t f(x) + (1 - t) f(y). De manière géométrique, cela correspond
à un graphe dont la partie plus le traitement est important, plus la façon dont la récompense augmente sera importante. Concave: Définition fonction concave [23]: On dit que la fonction f est concave si la fonction opposée est convexe. Cela équivaut à : V x et y E I et tout t dans [0,1] on a: f(tx + (1 - t) y) = t f(x) + (1 - t) f(y). De manière géométrique, la partie bombée est tournée vers le haut, donc la partie la plus importante est située au début de l'exécution, c'est à ce moment que la récompense augmentera le plus rapidement, ce qui est par exemple surtout très utile dans le traitement d'images, où l'amélioration de la qualité est importante au début et faible par la suite. Linéaire : (qui sont des cas particuliers de fonctions concaves et convexes) la récompense augmente uniformément pendant l'exécution de la partie optionnelle. Choix du type de fonction FEISTEL propose en 1973 [15], les paramètres et principes de base pour construire un bon algorithme de chiffrement. Parmi ceux-ci, on retrouve la taille des blocs, la taille de la clé, le nombre de tours dans l'algorithme, la complexité d'un tour et la complexité de génération des sous-clés pour chaque tour. Augmenter ces paramètres élève la sécurité mais diminue la vitesse de chiffrement. Il pourrait donc être intéressant d'augmenter ceux-ci lorsque l'ordonnancement le permet. Nous choisirons ici d'utiliser des fonctions convexes qui se révèlent être intéressantes pour modéliser la valeur en sécurité d'un système en fonction du temps dépensé pour mettre celle-ci en place. En effet, comme nous l'avons vu au chapitre 3, la valeur en sécurité d'un système dépend de la dif~culté à « casser » cette sécurité. Plus la longueur de la clé utilisée pour le chiffrement est importante, plus une recherche exhaustive sur l'ensemble des clés consommera du temps avant de trouver la clé correcte. En rajoutant 1 bit à la clé l, l'espace de toutes les clés possibles et donc le temps mis par une attaque exhaustive sont multipliés par deux. Soit une récompense de 2 pour une clé de 1 bit, la récompense vaudra donc 2l pour une clé de l bits, où la récompense représente le nombre de clés à tester au pire cas. Il reste donc à calculer le temps de chiffrement en fonction de la longueur de la clé et de la taille des données à chiffrer. A l'aide de la librairie crypto++ [4], nous avons calculé la durée de chiffrement d'une quantité de données de 1Mo avec les trois variantes officielles d'AES (voir tableau 4.1). Il est malheureusement impossible de modifier la longueur de la clé bit à bit car l'algorithme n'a pas été prévu pour cela à la base : le nombre de tour, la taille des clés et la taille des blocs sont dépendants les uns des autres.
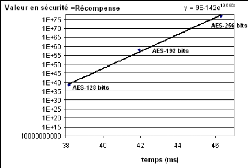
TAB. 4.1 - Calcul de la durée de chiffrement selon la longueur de la clé Sur la figure 4.2 est représentée graphiquement l'évolution de la valeur en sécurité du système en fonction du temps obtenu à partir du tableau 4.1. L'amélioration de la sécurité est si importante que sur le graphique, la différence de récompense n'était plus faite entre la version 128 et 192 bits par rapport à la version 256 bits, nous avons donc opté pour un graphique à l'échelle semilogarithmique. Nous obtenons bien une fonction convexe exponentielle pour représenter l'évolution de la récompense en fonction du temps.
FIG. 4.2 - Valeur en sécurité du système en fonction du temps 4.2.3 Modélisation du système Nous considérons un ensemble S de n tâches périodiques: T1, T2,..., T n de période Pi V i E [1, n] à échéance sur requête et à départ simultané. L'ordonnancement sera testé jusqu'à l'hyperpériode P (définie dans la chapitre 2), ce qui signifie que sur l'intervalle [O, P), chaque tâche Ti enverra bi = Pi P travaux. Dans ce modèle, chaque tâche est donc constituée de bi travaux, nous nous référons au je travail de Ti par ôij. Ici, nous supposerons que les tâches sont toutes indépendantes l'une de l'autre et prêtes à l'instant t = O. Lorsque l'exécution de la partie obligatoire Mi est achevée, la partie optionnelle devient disponible pour l'exécution et s'exécute aussi longtemps que l'ordonnanceur le permet avant l'échéance. 4.2.4 Calcul de la récompense moyenne du système Comme nous l'avons dit dans la section 4.2.2, nous allons associer une fonction de récompense à la partie optionnelle, que nous noterons Ri(tij) et qui retournera la récompense accrue par le travail ôij lorsqu'il reçoit tij unités d'exécution au delà de sa partie obligatoire. {fi(tij) si O = tij = oi Ri(tij) = (4.1) fi(oi) sinon, Où fi est une fonction réelle continue positive non-décroissante et oi représente la longueur maximale de la partie optionnelle. mi+oi représente dans notre cas le temps maximum nécessaire pour sécuriser complètement les informations. Au delà de ce seuil (tij> oi), la récompense ne sera plus augmentée (voir équation 4.1) et la priorité sera alors donnée à un travail qui n'a pas encore suffisamment sécurisé ses informations. La récompense moyenne de Ti sera définie comme: P bi j=1
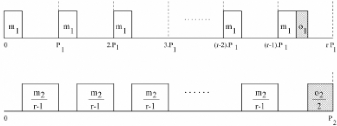
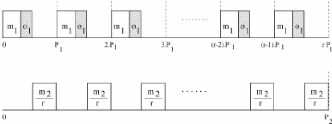
Ri(tij) C'est-à-dire, la moyenne des récompenses accrues par chaque travail de la tâche jusqu'à l'hyperpériode (= P = ppcm{P1, P2, ... Pn}), bi étant le nombre de fois que l'on peut placer la période de la tâche Ti dans cet intervalle (= bi = Pi P ). Pour calculer la moyenne pondérée de la récompense (REWW), nous additionnons les récompenses REWi de chaque tâche Ti à laquelle nous associerons un certain poids selon l'importance de la partie optionnelle de la tâche (voir équation 4.3). Nous intégrerons par la suite ce poids directement dans la fonction fi(tij) sous forme d'un coefficient ki. REWW = Xn wiREWi, (4.3) i=1 4.2.5 Approche Mandatory-First (parties obligatoires d'abord) Dans cette approche, le principe est comme nous l'avons mentionné plus haut, de donner priorité aux parties obligatoires. Nous n'exécuterons les parties optionnelles que si la partie obligatoire de chaque tâche a été complètement exécutée. Diverses techniques utilisant l'approche Mandatory-First existent. Nous pouvons les classer en approches statiques ou dynamiques. Utilisation avec une méthode statique Il existe plusieurs méthodes statiques, nous pouvons citer parmi celles-ci « Rate Monotonic » et « Least Utilization ». Soit l'ordonnanceur donne une plus haute priorité : - aux parties optionnelles de la tâche ayant la plus petite période, cette méthode est appelée « Rate Monotonic » (RM), - soit en utilisant une méthode « Least Utilization » (LU) qui assigne les priorités statiquement aux parties optionnelles selon leur facteur d'utilisation (calculé par: (oi - mi)/Pi). Les tâches possédant un facteur d'utilisation plus faible reçoivent une priorité plus importante [6]. Utilisation avec une méthode dynamique « Best Incremental Return » (BIR) est une des meilleures méthodes dynamiques car à chaque unité de temps, l'algorithme sélectionne la partie Oi qui augmente le plus la récompense en faisant le calcul fi(tij+ Ä) - fi(tij), où Ä est la durée minimum que l'ordonnanceur attribuera à une tâche optionnelle. La fonction qui fournit la plus grande différence est élue et la tâche associée à cette fonction peut exécuter sa partie optionnelle. BIR est la méthode la plus ef~cace en terme de récompense mais est très gourmande en calcul et n'est donc pas utilisée en pratique excepté comme étalon, pour comparer les performances d'autres algorithmes dans les simulations. De plus, BIR n'est pas optimal étant donné qu'il ne tient pas compte du temps restant avant les échéances. Nous pouvons citer d'autres méthodes d'ordonnancement dynamiques telles « Earliest Deadline First » (EDF) qui donne une priorité plus importante à l'exécution des parties optionnelles de la tâche ayant l'échéance la plus proche ou « Least Laxity First » (LLF) qui sélectionne un des travaux rij prêt à l'instant courant t dont la laxité £ij(t) est la plus faible. La laxité se calcule par la formule 4.4. £ij(t) = dij(t) - remij(t) (4.4) où dij(t) est le temps restant avant l'échéance du travail rij et remij(t) est le temps d'exécution restant de celui-ci calculé à l'instant t. Un travail qui a une échéance proche et qui a encore un temps important d'exécution devant lui est donc plus facilement sélectionné par LLF. « Least Attained Time » (LAT) est une méthode intéressante dans le cas de fonctions concaves car elle donne une plus grande priorité aux parties optionnelles des tâches ayant utilisé le moins de temps processeur (priorité = 1/tij), ce qui permet d'équilibrer le temps d'exécution des parties optionnelles. Résultats de simulations Dans son étude [3] sur le « Reward-Based Scheduling », H. Aydin a effectué des tests sur ces différentes méthodes et a constaté que: - Plus l'utilisation du système par les parties obligatoires augmente, plus l'écart s'accentue entre la récompense accrue par l'algorithme optimal et celle accrue par les méthodes évoquées plus haut (statiques ou dynamiques) utilisées avec une approche Mandatory-First. Cela s'explique par le fait que ces méthodes perdent des occasions d'exécuter des parties optionnelles avantageuses au niveau de la récompense en favorisant constamment les parties obligatoires. Nous reviendrons de manière plus détaillée sur l'algorithme optimal par après. - La récompense accumulée par une méthode LAT se rapproche plus de la méthode BIR lorsque les fonctions de récompense sont concaves. Comme LAT, des fonctions concaves favorisent des temps d'exécution équilibrés pour les parties optionnelles. - L'écart entre la méthode optimale et les approches Mandatory-First est moins important lorsque les tâches possèdent des fonctions linéaires de récompense. En effet, les approches Mandatory First perdent des occasions d'exécuter des premiers slots valables de parties optionnelles. Or, l'exécution d'un premier slot de partie optionnelle est plus important si la fonction est concave vu que c'est à ce moment que la récompense augmente le plus. Exemple d'ordonnancement Schématisons un exemple basé sur un cas d'école afin de montrer les limites d'un algorithme Mandatory-First. Considérons deux tâches où P1=4, m1=1, o1=1, P2=8, m2=3 et o2=5 avec des fonctions de récompenses f1(t1) = k1t1 pour T1 et f2(t2) = k2t2 pour T2, k1 et k2 étant donc les coefficients dans les fonctions linéaires de récompense de T1 et T2 respectivement. Nous supposerons que k2 est négligeable par rapport à k1 (c.-à-d. k1 » k2). Avec une approche Mandatory-First nous obtenons donc l'ordonnancement représenté dans la figure 4.3. Nous observons que quelle que soit l'assignation de priorité (statique ou dynamique) utilisée dans cet exemple avec l'approche Mandatory-First, le processeur sera occupé dans cet exemple par les parties obligatoires jusqu'à l'instant t = 5. Sur l'intervalle inoccupé [5, 8] l'algorithme choisira de planifier O1 complètement (soit une unité) étant donné qu'il fournit une plus grande récompense que O2. Le temps restant (2 unités) sera consacré àO2. Un algorithme optimal produirait cependant l'ordonnancement reproduit sur la figure 4.4. L'exécution de M2 est retardée d'une unité afin de permettre l'ordonnancement de O1 sur la première période de T1, ce qui nous fournirait une plus grande récompense que celle fournie par l'exécution d'une unité supplémentaire de O2 et les échéances des parties obligatoires sont toujours respectées. Comme k1 » k2, on peut conclure que la récompense accrue par l'algorithme Mandatory-First ne peut valoir qu'environ la moitié de celle accrue par l'algorithme optimal.
M1 o o M1
O1 1 4 5 6
T1 O2 o 6 8 M2 1 4 T2 FIG. 4.3 - Ordonnancement généré par un algorithme Mandatory-First T1 T2
M2 2 4 FIG. 4.4 - Ordonnancement généré par un algorithme optimal M2 6 7
M1 o o o
O1
O2 M1
O1 Pour poursuivre notre comparaison entre le « meilleur » algorithme MandatoryFirst et un algorithme optimal, nous pouvons prouver qu'au pire cas, la proportion de récompense accumulée par l'approche Mandatory-First par rapport à la récompense obtenue par un algorithme optimal peut être arbitrairement proche de zéro si on prend un r arbitrairement grand dans le théorème 1 issu de l'article d'Aydin [3]. Il n'y a donc pas de garantie de performance des méthodes Mandatory-First. Théorème 1 Il existe une instance du problème d'ordonnancement périodique basée sur la récompense pour lequel la proportion: Récompense du meilleur algoritthme MandatorryFirss 2 = . Récompense d un algoritthme optimal r pour n'importe quel entier r = 2. des fonctions de récompense respectivement: f1(t1) = k1 . t1, f2(t2) = k2. t2 et posons r = P2/P1, k1/k2 = r. (r-1), m2 = 1 2 .(r.o2) et P1 = m1 + o1 + r = m1 + m2 m2 r-1 ce qui implique que o1 = m2 r(r-1) et que P2 est l'hyperpériode du système. Suivant ces hypothèses, nous pouvons observer qu'à chaque période de T1, l'algorithme peut exécuter en plus de la partie obligatoire M1, une partie de O1 et/ou M2. Avec une approche Mandatory-First, le processeur exécute uniquement les parties obligatoires jusqu'à l'instant t = P2 - P1 + m1 (voir figure 4.5). Le temps restant, est utilisé pour ordonnancer tout d'abord O1 entièrement car k1 > k2 (k1 =r.(r-1).k2),etensuitet2= m 2 r = o2 2 unités de O2. Nous calculons donc la récompense moyenne obtenue grâce à l'algorithme Mandatory-First: f1 (o1) RMFA=REW1+REW2= + f2(t2), r d'après les formules 4.2 et 4.3 en sachant que P1 /P = P1 /P2 = 1 /r et P2/P = 1
FIG. 4.5 - Un ordonnancement généré par un algorithme « Mandatory-First ». Un algorithme optimal, aurait choisi quant à lui de retarder l'exécution de M2 de o1 unités à chaque période de T1. Cela permet d'accroître la récompense fournie par T1 à chaque travail. L'ordonnancement résultant est représenté sur la figure 4.6 et la récompense moyenne en utilisant un tel algorithme serait: = f1(o1), r . f1(o1) ROPT = REW1 + REW2 = REW1 = r
FIG. 4.6 - Un ordonnancement généré par un algorithme optimal. Nous obtenons donc la proportion sur la récompense entre les deux algorithmes (Vr ~ 2) en remplaçant les: RMFA + f2 (t2) 1 = r ROPT f1(o1) k2 t2 + 1 = r k1 · o1
Il suffit ensuite de choisir un système avec une constante r tendant vers oc pour que cette proportion tende vers 0. ut 4.2.6 Optimalité Dans cette section nous allons formaliser le problème de maximisation de la récompense sur un ordonnancement de tâches périodiques. Notre objectif, est de trouver les valeurs optimales tij dans l'équation 4.5 qui maximiseront cette récompense. Nous verrons par la suite qu'il peut être intéressant de poser tij = tik Vi, k mais nous analyserons également le cas plus général (où i,j, k tel que tij=6 tik). L'équation 4.5 est construite à partir des équations 4.2 et 4.3, en supposant que le poids wi de la tâche Ti est intégré dans la fonction de récompense Ri(tij). Pi P >2n >2bi j=1 Ri(tij), (4.5) Il faudra ajouter à cette équation quelques contraintes. 1. Il faut imposer que le temps utilisé par toutes les parties obligatoires et optionnelles de chaque tâche jusqu'à l'hyperpériode (P) ne dépasse pas le temps processeur disponible sur celle-ci. Autrement dit, que >2n >2bi (mi + tij) P. i=1 j=1 (réécrit d'une autre manière dans l'équation 4.7) Malheureusement, cette contrainte est nécessaire mais en
aucun cas suf- tij.
Reprenant toutes ces contraintes, le problème que nous appellerons REW-PER est donc de trouver les valeurs optimales pour les tij :
à condition que >2n bimi + >2n >2bi tij P (4.7) i=1 i=1 j=1 0 tij oi i=1, ...,n j=1, ... , bi (4.8) Il existe un ordonnancement faisable avec les valeurs {mi} et {tij}. (4.9) Cette dernière condition 4.9 revient à dire que le système avec les valeurs {mi} et {tij} doit être ordonnançable avec EDF sur l'intervalle [0, P). Nous obtiendrons donc un ordonnancement faisable avec les valeurs mi et des valeurs optimales pour tij. Notons que si la contrainte 4.7 n'est pas satisfaite, la contrainte 4.9 ne l'est pas non plus. Nous aurions donc pu nous limiter à poser la contrainte 4.9, mais 4.7 reste intéressante pour tester la faisabilité. En effet, lorsque 4.7 n'est pas satisfait, nous savons que le système n'est alors pas ordonnançable et il n'est donc pas nécessaire d'effectuer la simulation jusqu'à l'hyperpériode pour tester son ordonnançabilité. H. Aydin nous démontre par le théorème 2 dans son article [3] comment il est possible de supprimer la contrainte 4.9 en utilisant des temps d'exécution des parties optionnelles tij égaux à chaque appel (tij = tik ?i, k). Cette démonstration est applicable uniquement dans le cadre d'une utilisation de fonctions de récompense concaves ou linéaires (qui sont des cas particuliers de fonctions concaves). Nous remarquons intuitivement que si les fonctions sont convexes, il est plus intéressant de prolonger l'exécution de tij pour certains travaux puisque la récompense augmente de manière exponentielle. Théorème 2 Soit un exemple donné du problème REW-PER, il existe une solution optimale où les parties optionnelles d'une tâche Ti reçoivent le même temps d'exécution à chaque travail, c'est-à-dire, tij = tik 1 <j < k < Pi P . De plus, n'importe quelle méthode d'ordonnancement périodique temps-réel qui peut utiliser entièrement le processeur (EDF , LLF , RMS-h) peut être utilisée pour obtenir un ordonnancement faisable avec ces assignations. Démonstration: Abandonnons la contrainte 4.9 sur la faisabilité et appelons MAX-REW le problème REW-PER sans la contrainte de faisabilité. Assertion 1 Posons tijcomme une solution optimale de MAX-REW, 1 < i < n 1 <j <Pi P = bi. Alors, t' ij, en posant ti1 + ti2 + ... + ti bi t' i1 = t' i2 = ... = t' i bi = t' i = bi 1<i<n 1<j<bi, est aussi une solution optimale de MAX-REW.
j=1fi(tij) = bifi(t i) si fi(t) est une fonction concave (incluant le cas des fonctions linéaires). Le lecteur intéressé peut consulter cette démonstration que nous avons reprise dans l'annexe A. ut Nous pouvons dès lors simplifier le problème MAX-REW et le réécrire comme une: maximisation de Xn fi(ti) (4.10) i=1
0=tij =oi i=1, ... , n. (4.12) (mi+ti) La contrainte 4.11 peut encore être simplifiée comme >In Pi = 1. Ce qui i=1 Ci est équivalent à exprimer la condition U = >In Pi = 1 nécessaire et suffisante i=1 sur l'utilisation pour qu'une politique d'ordonnancement périodique classique (comme par exemple EDF, LLF,...) permette d'obtenir un ordonnancement faisable avec n tâches pour lesquelles le temps d'exécution Ci = mi + ti? i E [1, n]. Cela nous permet de ne pas devoir tenir compte de la contrainte de faisabilité 4.9 du problème REW-PER. Limites de l'optimalité Malheureusement l'optimalité avec tij = tik?j,k ne tient pas dans tous les cas. Il faudra donc poser quelques hypothèses sur le système de tâches pour que le système fournisse une récompense optimale avec des parties optionnelles ayant des temps d'exécution identiques à chaque période, tout en satisfaisant la contrainte de faisabilité. Ces hypothèses sont démontrées à chaque fois par un contre-exemple dans l'article [3]. Récapitulons ces hypothèses :
Nous allons maintenant voir comment résoudre le problème MAX-REW sur un système constitué de tâches périodiques à échéance sur requête avec une fonction linéaire de récompense associée à chaque tâche. Les parties optionnelles seront de même taille de manière à garantir l'optimalité (voir théorème 2) et l'ordonnancement sera basé sur une règle d'assignation dynamique des priorités, « Earliest Deadline First » (EDF). Nous respecterons donc toutes les hypothèses citées ci-dessus. Nous nous baserons sur un algorithme présenté dans [3]. Celui-ci est optimal lorsque les fonctions de récompense sont linéaires, il nous assure donc d'obtenir la meilleure récompense possible. Cependant, cet algorithme n'est plus optimal lorsqu'une des fonctions de récompense est convexe. Il sera présenté à la section 4.2.7 et utilisé dans le chapitre suivant comme étalon afin de le comparer à des méthodes heuristiques. 4.2.7 Optimalité avec des fonctions linéaires de récompense Soit une fonction linéaire de récompense de la forme : fi(ti) = kiti, en augmentant la valeur ti de i unités de temps, la récompense accrue augmentera de kii mais nous utiliserons bii unités de la laxité disponible d. Nous noterons par bi (4.14) le nombre de travaux de la tâche Ti qu'il est possible de placer dans l'hyperpériode. Donc, la valeur apportée au système par la tâche Ti par unité consommée sur la laxité est wi = kiÄ biÄ = ki bi avec bi = Pi P Définition laxité :
Nous définissons la laxité d au début de
l'exécution de l'al- nelles jusqu'à l'hyperpériode, soit: d = P - Xn mi·bi (4.13) i=1 P avecbi= (4.14) Pi Nous allons donc calculer la valeur apportée wi pour chaque tâche Ti. Ensuite les tâches seront triées par rapport à cette valeur, les tâches ayant un wi plus important seront favorisées. Posons T1 comme la tâche ayant la plus grande valeur wi, T2 la suivante, et ainsi de suite. Si le fait de choisir le temps maximal o1 pour les parties optionnelles des travaux de la tâche T1 ne nous fait pas dépasser d (b1 ·o1 = d), nous fixons le temps optionnel t1 à o1 et la laxité restante est diminuée de b1 · o1. Ensuite, on recommence la même procédure avec la tâche T2, T3,. . . jusqu'à ce qu'à la ie étape, la laxité restante soit insuffisante pour accepter de prendre oi comme temps optionnel. Dans ce cas, la laxité restante est divisée par le nombre de travaux (bi) de Ti jusqu'à l'hyperpériode. Cette valeur est attribuée comme temps optionnel ti et toute la laxité est alors consommée, l'utilisation du processeur, parties obligatoires et optionnelles confondues (U) vaut donc dans ce cas 1, ce qui permet d'ordonnancer le système avec EDF. Il est aussi possible que la laxité soit suffisante pour appliquer ti ? oi à toutes les tâches, U est alors inférieur à 1 et donc le système est également ordonnançable avec EDF. Les dernières tâches de la liste triée, n'ayant pas un poids wi suffisamment important, reçoivent 0 comme temps optionnel. Voici l'algorithme 3 exprimé de façon plus formelle, utilisé pour définir la taille optimale des ti? i E [1, n]: Entrées : Ensemble des n tâches avec leurs caractéristiques (k, b, m, o) et l'hyperpériode P Sorties : Vecteur des temps optionnels ti calculés pour chaque tâche Ti Tri des tâches en fonction des valeurs wi = ki bi ; i -- 1; //Indice des tâches dans la liste triée. d-- P-->n i= 1mi.bi; Tant que (i n ET d> 0) faire Si (bioi < d) Alors ti -- oi; d-- d--bioi; Sinon ti -- bi d; d--0; Fin Si i--i+1; Fait //les tâches restantes n'exécutent pas leur partie optionnelle Tant que (i n) faire ti--0; i--i+1; Fait Algorithme 3: Recherche des ti optimaux - Cas linéaire Après au plus n itérations de la première boucle, la latitude (ou laxité) d est complètement consommée. En plus de ce parcours qui possède une complexité au pire cas en O(n), nous devons effectuer un tri dont la complexité du meilleur algorithme est en O(nlogn). La complexité de l'algorithme est donc identique à celle du tri, soit O(nlog n). Deux types de simulation Nous constatons, que la taille des ti peut être un nombre rationnel positif. En effet, le résultat de bi dn'est pas forcément une valeur entière. Nous nous sommes confrontés à ce problème en réalisant l'implémenta- tion1 de cet algorithme. En effet, le fait que les temps ne soient pas des valeurs entières nous a forcés à utiliser une technique de simulation « orientée évènement » (« Event driven ») plutôt qu'une simulation basée sur une horloge où le temps progresse de façon linéaire d'une unité à chaque tour de boucle du simulateur. Explications: Dans la simulation orientée évènement, chaque évènement est rajouté par une insertion triée dans une file à priorité par rapport à l'instant auquel l'évènement doit se déclencher. Un évènement peut être:
Dans ce type de simulation, on fait donc uniquement appel à l'ordonnanceur lorsqu'un évènement se produit, ce qui permet de ne pas réveiller l'ordonnanceur continuellement sur des périodes oisives et sur les longues périodes durant lesquelles un travail pourrait s'exécuter sans être préempté. Nous évitons donc ainsi les tours de boucle inutiles dans lesquels aucun évènement important ne se produit à l'exception de l'augmentation de Lït unités d'exécution du travail en cours d'exécution. Soit Lït, l'incrémentation du temps à chaque tour de boucle de l'ordonnanceur dans une simulation basée sur une horloge, le fait d'utiliser la notion d'évènements a comme avantage majeur qu'il ne faut pas choisir un Lït très petit, par exemple Lït = 0.001 afin de gérer les décimales ce qui provoquerait également des erreurs de précision. Nous expliquerons plus en détail la simulation basée sur les évènements dans le chapitre suivant lorsque nous décrirons notre simulation complète. 4.2.8 Optimalité avec des fonctions convexes de récompense Dans le cas où les fonctions de récompense sont de type convexe, des temps d'exécution optimaux pour les parties optionnelles sont beaucoup plus complexes à obtenir au niveau du temps de calcul. H. Aydin [3] nous démontre 1Le code C++ de la simulation et de l'algorithme 3 sont fournis dans l'annexe B (méthode linOPT()) que c'est un problème NP-difficile même lorsque les parties optionnelles sont identiques d'une instance à l'autre. Problème NP-difficile, NP-complet Les problèmes sont séparés en plusieurs classes de complexité, citons parmi celles-ci les 2 classes les plus connues : - Classe P : Le problème peut être résolu de manière déterministe en un temps polynomial. - Classe NP : Le problème peut être résolu de manière non-déterministe en un temps polynomial. Le caractère non-déterministe de la classe NP signifie que le problème peut être représenté par un arbre, sur lequel à chaque étape (chaque noeud) il y aurait un choix à faire entre plusieurs actions et la machine devant résoudre ce problème ne pourrait en effectuer qu'une, sans être certain que la branche choisie soit la bonne. Le problème est donc exponentiel selon la taille des données. Si une machine pouvait tester tous les noeuds fils en même temps à chaque étape (ce qui est encore théorique mais non applicable en pratique), un problème de la classe NP pourrait être résolu en un temps polynomial. Définition Problème NP-difficile (241: :Un problème est NP-difficile s'il est au moins aussi dur que tous les problèmes dans NP. Soit un problème ii- et un algorithme permettant de réduire en un temps polynomial (dans P) ce problème à un problème ii-', il est donc possible de résoudre ii-' si l'on sait résoudre ii-, ce qui rend ii- aussi difficile à résoudre que ii-'. ii- est alors NP-difficile si pour tout problème ii-' de NP , ii-' se réduit en un temps polynomial à ii-. Définition Problème NP-complet (241: :Un problème est NP-complet si il est dans NP et est NP-difficile. Pour prouver que notre problème est NP-difficile, tentons de faire l'analogie de celui-ci au problème subset-sum, également appelé le problème du sac à dos, bien connu pour être NP-complet. Si cette analogie est correcte, l'hypothèse sera prouvée. Premièrement, définissons le problème subset-sum. Définition Problème Subset-sum : Pour un ensemble S donné {s1, s2, ... , sn} de nombres entiers positifs et le nombre entier M, existe-t-il un ensemble SA ? S tel que >siESAsi = M? Démonstration: Construisons un ensemble de n tâches de même période M sans partie obligatoire. Ce qui simplifie la contrainte 4.11 du problème MAXREWpar l'équation 4.16 car mi = 0 V i. Posons W = >n i=1si avec si = oi et choisissons comme fonction de récompense la fonction fi(ti) = t2 i+ (W - si)ti qui est strictement convexe si ti = 0. Elle peut être réécrite comme ti(ti - si) + Wti. Etant donné que la période M est identique pour chaque tâche, l'hyperpériode P dans MAX-REW peut être remplacée par M et nous pouvons réécrire le problème MAX-REW ainsi: maximisons Xn ti(ti-si)+ W Xn ti (4.15) i=1 i=1 à condition que Xn ti = M (4.16) i=1 0 = ti = si. (4.17) Nous observons que si 0 < ti < si, alors ti(ti - si) < 0 ce qui ne maximise clairement pas la récompense car si ti = 0 ou ti = si nous obtenons la quantité ti(ti - si) = 0. Et donc, la première partie de l'équation 4.15 peut être supprimée, il reste à maximiser W>n i=1 ti. La récompense totale que nous noterons Rew = W. M à cause de la contrainte 4.16. Résoudre la question « Rew est-elle égale à W. M ? » revient à résoudre la question « Existe-il un ensemble de ti tel que>ni=1 ti = M, chaque ti étant égal à 0 ou àsi ? », autrement dit Rew = W. M si et seulement s 'il existe un ensemble SA ç S tel que >si?SAsi = M. L'analogie au problème Subset-Sum est faite, ce qui implique que MAX-REW et donc REW-PER avec des fonctions convexes de récompense est NP-difficile. ut 4.3 Conclusion Nous avons développé dans ce chapitre, la méthode de H. Aydin : le « RewardBased Scheduling ». Dans son travail [3], cette méthode est appliquée avec des fonctions concaves de récompense, nous avons montré pourquoi dans le cadre de la sécurité, les fonctions convexes semblent plus appropriées. Il a été démontré que le problème est NP-complet avec de telles fonctions. Cependant, même s'il n'existe pas encore à ce jour de méthodes déterministes et polynomiales en temps pour résoudre le problème 2 avec des fonctions convexes de récompense, nous analyserons dans le chapitre 5 des méthodes heuristiques afin de trouver une solution au problème se rapprochant le plus possible de la solution optimale. 2étant donné qu'à l'heure actuelle, l'égalité NP = P n'a pas encore été démontrée est récompensée par 1 000 000$ à celui qui la prouvera |
|