|

Je dédie ce mémoire :
· A mon défunt Père : Papa ce
mémoire est pour toi, tu m'as forgé et tu as cru en moi mais tu
es parti sans voir un de tes rêves se réaliser. Je ne te
remercierai jamais assez. Que la terre te soit légère.
· A ma mère, ma complice : ce mémoire
est le fruit de ta générosité, de ton soutien et de la
confiance que tu a toujours portée en moi. Que Dieu te bénisse et
t'accorde longue vie.
· A Alpha, Habib et Souley: vous êtes plus que
des frères pour moi.
· A Babacar, mon frère et professeur, à
Pape, à Laye, à mes grandes soeurs Oumy, Ami, Séné,
Khady et à leur mère pour toutes les années harmonieuses
vécues ensemble.
· A Makhtar et à Seynabou, petit frère et
petite soeur : vous êtes uniques pour moi, je vous adore.
· A toute ma famille : oncles, tantes, cousins,
cousines. Mention spéciale à mon oncle Babacar Loum.
· A mes amis qui se reconnaîtront ; parmi eux
je citerai Mourath Ndiaye, Pape Matar Faye et Médoune Diaw.
· A tous mes camardes avec qui j'ai partagé les
bancs d'écoles.
· A mes camarades-ingénieurs : Niane mon
voiz, Saliou mon partenaire de stage, Omgue mon grand ami, Sow le
maat-maticien, Amar, Issa Baldé, Diaw, Khalifa, Wade,
Mbacké, Souleymane, Bamba..., et à toutes les filles de la
promo.
· A tous mes condisciples avec qui je partage l'amour en
Cheikh Ahmadou Bamba.

Je rends grâce à Dieu pour tous les bienfaits dont
il m'a comblé.
Je remercie cordialement :
· Mes parents : jamais assez de mots pour le faire,
· Monsieur Samuel Ouya, mon professeur encadreur, pour son
soutien, sa disponibilité et ses conseils,
· Monsieur Ahmat Bamba Mbacké, pour sa
disponibilité, sa relecture, ses corrections et ses conseils,
· Tous les professeurs qui nous ont encadrés pendant
ces trois ans : si nous sommes de bons informaticiens c'est grâce
à vous,
· Messieurs Omar Cissé, Mamadou Faye, Djibril
Mané, Maximilien Diouf, Ousmane Cissé pour m'avoir accueilli et
bien intégré dans leur structure : 2SI,
· Messieurs Djibril Mané (Maître de stage) et
Mamadou Faye (directeur technique toujours disponible), pour leur rigueur et
leurs conseils,
· Tout le personnel de 2SI : Mme Sall, Mme Dramé, Mme
Dione, etc.
· Toute l'équipe de développement : Saliou,
Mbodj, Dem, Rougui, Omar, Jean, Morel, Doumboua, Maniang, Martin, Malick,
Adama, Coura, Arame, etc.
· Tous ceux qui ont participé de près ou de
loin à la rédaction de ce mémoire.

Sigles et abréviations
6
Table des figures
7
Avant-propos
9
Résumé....
10
Introduction
11
Première partie : Présentation
générale et choix d'une méthode d'analyse
12
Chapitre 1 : Présentation
générale
13
I. Présentation de la structure
d'accueil
13
1. Présentation de la
société SSI
13
2. Domaines d'activités
13
II. Présentation du sujet
13
1. Problématique
13
2. Objectifs
14
Chapitre 2 : Choix d'une méthode
d'analyse et de conception
15
I. Définition des concepts
16
1. L'analyse
16
2. La conception
16
3. L'implémentation
17
II. Classification des méthodes
d'analyse et de conception
17
1. Les méthodes cartésiennes ou
fonctionnelles
17
2. Les méthodes systémiques
17
3. Les méthodes objet
17
4. Les méthodes agiles
18
III. Choix d'une méthode d'analyse et de
conception
19
1. Aperçu de quelques démarches
existantes
19
2. Choix d'une démarche
21
2.1. Présentation du processus unifié
(UP)
21
2.2. Présentation de l'eXtreme Programming
(XP)
27
2.3. La démarche simplifiée
29
3. Présentation du langage de
modélisation UML
34
Deuxième partie : Analyse et conception
de la solution
44
Chapitre 3 : Le monde des services pour
mobiles
45
I. Définition des concepts du domaine
45
1. Le téléphone mobile
45
2. Les réseaux téléphoniques :
une infrastructure évolutive pour une stratégie orientée
services
46
2.1. Le Réseau GSM
46
2.2. Le réseau GPRS
50
2.3. Le réseau UMTS
52
II. Les services existants dans le domaine du
mobile
56
1. Les acteurs principaux
56
2. L'état des lieux
58
Chapitre 4 : Spécifications
détaillées de notre plateforme
61
I. Le service de sauvegarde de répertoire
61
1. Présentation
61
2. L'application cliente
61
3. L'application serveur
62
II. Le service de billetterie
dématérialisée
62
1. Présentation
63
2. Identification des modules
64
Chapitre 5 : Conception de la plateforme
68
I. Le service de sauvegarde
68
1. Les maquettes
68
2. Fiche descriptive de cas d'utilisation
69
3. Les diagrammes
70
II. Le service de billetterie
dématérialisée
76
1. Les maquettes
76
2. Fiche descriptive
77
3. Les diagrammes
78
Troisième partie : Mise en place de la
solution
85
Chapitre 6 : Choix des outils et des
technologies d'implémentation
86
I. Les plateformes applicatives
86
1. L'architecture J2EE
86
2. La plateforme .Net
87
3. Les environnements basés sur AMP
87
4. Interopérabilité J2EE, .NET, PHP
87
II. Les plateformes de développement pour
clients mobiles
88
1. La diversité des
périphériques
89
2. L'architecture Java 2 Micro Edition (J2ME)
90
2.1. La problématique multi-plateformes et
multi-périphériques de java
90
2.2. Les configurations
91
2.3. Les profils
93
3. L'Architecture Microsoft Windows Embedded
96
4. Conclusion :
97
III. Les sources de données
98
1. MySQL
99
2. Postgresql
99
IV. Les solutions de synchronisation
100
1. Le standard SyncML
100
2. Le serveur de synchronisation
107
V. Choix des outils d'implémentation
adéquats
109
Chapitre 7 : Implémentation de la
solution
111
I. Synthèse de la solution
111
1. Le service de sauvegarde /restauration
111
1.1. Création de la MIDlet
111
1.2. Connecter le serveur à une base de
données MySQL
114
2. Le service de billetterie
dématérialisée
115
2.1 Front-office, back-office,
paiement...........................................115
2.2 Portail
USSD..................................................................115
2.3 Génération et validation du
ticket..........................................115
II. Les environnements de développement
116
III. Diagrammes de composants
119
IV. Diagrammes de déploiement
120
V. Sécurité de la plateforme
121
1. Service de sauvegarde
122
2. Service MTicket
122
Conclusion
128
Bibliographie / Wébographie
129
Glossaire
.............................................................................................................................................130
Annexe .......
131
Sigles et abréviations
|
API
|
Application Programming
Interface
|
|
CDC
|
Connected Device
Configuration
|
|
CLDC
|
Connected Limited
Device Configuration
|
|
CU
|
Cas d'Utilisation
|
|
DTD
|
Document Type
Definition
|
|
GPRS
|
General Packet
Radio Service
|
|
GSM
|
Global System for
Mobile communication
|
|
GUID
|
Global Unique
Identifier - identifiant global unique
|
|
HTTP
|
HyperText
Transfer Protocol
|
|
IDE
|
Integrated Developement
Environment
|
|
IMEI
|
International Mobile
Equipment Identifier
|
|
IP
|
Internet Protocol
|
|
J2EE
|
Java 2 Entreprise
Entreprise Edition
|
|
J2ME
|
Java 2 Micro
Edition
|
|
J2SE
|
Java 2 Standard
Edition
|
|
LUID
|
Local Unique
Identifier - identifiant local unique
|
|
MIDP
|
Mobile Information
Device Profile
|
|
MMS
|
Multimedia Message
System
|
|
MMSC
|
Multimedia Message
System Center
|
|
OBEX
|
OBject EXchange
|
|
OS
|
Operating System
|
|
PIM
|
Personnal Information
Manager
|
|
QoS
|
Quality of
Service
|
|
SI
|
Système d'Information
|
|
SMS
|
Short Message
System
|
|
SVA
|
Service à Valeur
Ajoutée
|
|
UML
|
Unified Modeling
Langage
|
|
UP
|
Unified Process
|
|
USSD
|
Unstructured Supplementary
Service Data
|
|
WAP
|
Wireless Application rotocol
|
|
WSP
|
Wireless Session
Protocol
|
|
WTK
|
Wireless
ToolKit
|
|
XML
|
eXtensible Markup
Language
|
|
XP
|
eXtreme Programming
|
Table des figures et tableaux
Figure 1 : Relation acteur - cas
d'utilisation
22
Figure 2 : Dynamique des modèles du
langage UML
23
Figure 3 : cycle de vie du Processus
Unifié
26
Figure 4 : Cycle de vie de XP
29
Figure 5 : Démarche simplifiée -
étape 1
30
Figure 6 : Démarche simplifiée -
étape 2
30
Figure 7: Démarche simplifiée -
étape 3
31
Figure 8 : Démarche
simplifiée - étape 4
31
Figure 9 : Démarche
simplifiée - étape 5
32
Figure 10 : Démarche
simplifiée - étape 6
33
Figure 11 : Démarche
simplifiée - étape 7
34
Figure 12 : Démarche
simplifiée - étape 8
34
Figure 13 : Evolution des versions
d'UML
35
Figure 14 : Les vues UML
37
Figure 15 : Architecture du
téléphone mobile
45
Figure 16 : Disposition des cellules dans
un réseaux
47
Figure 17 : Architecture du réseau
GSM
48
Figure 18 : Architecture du réseau
GPRS
51
Figure 19 : Chaîne de valeur des
services mobiles end user centric
56
Figure 20 : Evolution trimestrielle du
parc global de la téléphonie mobile
59
Figure 21 : Evolution du taux de
pénétration du mobile au Sénégal
59
Figure 22 : Architecture fonctionnelle
Synchronisation
62
Figure 23 : Architecture fonctionnelle
MTicket
64
Figure 24 : Workabout PRO G2
65
Figure 25 : Maquettes SOS PIN
68
Figure 26 : Diagramme de CU SOS PIN
70
Figure 27 : Modèle du domaine SOS
PIN
71
Figure 28 : Diagramme de classes
participantes SOS PIN
71
Figure 29 : Diagramme de séquence
SOS PIN
72
Figure 30 : Diagramme d'activités
SOS PIN
73
Figure 31 : Diagramme d'interactions SOS
PIN
74
Figure 32 : Diagramme de classes de
conception SOS PIN
74
Figure 33 : Maquette MTicket - portail web
74
Figure 34 : Maquette MTicket - portail
USSD
74
Figure 35 : Diagramme CU MTicket
74
Figure 36 : Modèle du domaine
MTicket
74
Figure 37 : Diagramme de classes
participantes MTicket
74
Figure 38 : Diagramme de séquence
MTicket
74
Figure 39 : Diagramme d'activités
MTicket
74
Figure 40 : Diagramme
d'intéractions MTicket
74
Figure 41 : Diagramme de classes de
conception
74
Figure 42 : Diversité des
périphériques embarqués
74
Figure 43 : Etendue des responsabilités
de CDC et CLDC dans Java
74
Figure 44 : Plateforme JAVA 2
74
Figure 45 : MIDlet, CLDC et MIDP
74
Figure 46 : Cycle de vie d'une Midlet
74
Figure 47 : Communication SyncML entre
client et serveur
74
Figure 48 : Exemple d'ancre SyncML
74
Figure 49 : Architecture du serveur
Funambol
74
Figure 50 : Architecture de l'API SyncML
J2ME
74
Figure 51 : Architecture applicative de
SOS PIN
74
Figure 52 : Architecture applicative de
MTicket
74
Figure 53 : Relation entre les
différentes classes de l'API SyncML
74
Figure 54 : Schéma d'ensemble de
MTicket
74
Figure 55 : NetBeans mobility pack : vue en
mode flow
74
Figure 56 : NetBeans mobility pack : vue en
mode screen
74
Figure 57 : Interface WTK
74
Figure 58 : Diagramme de composants MTicket
74
Figure 59 : Diagramme de composant SOS PIN
74
Figure 60 : Diagramme de déploiement
MTicket
74
Figure 61 : Diagramme de déploiement SOS
PIN
74
Figure 62 : Navigateur en mode HTTPS
74
Figure 63 : Exemple de MMS non
transferable
74
Figure 64 : Interface d'accueil de SOS PIN -
test sur l'émulateur de SUN
74
Tableau 1 : Description des modèles
d'UML
26
Tableau 2 : Apports d'UML2
43
Tableau 3 : Evolution du parc mobile au
Sénégal entre décembre 2006 et décembre 2007
58
Tableau 4 : Les temps de
réalisation des services suivant les types de réseau
60
Tableau 5 : Acteurs du service Sauvegarde
de données
69
Tableau 6 : Identification des CU du
service de sauvegarde
70
Tableau 7 : Acteurs MTicket
74
Tableau 8 : CU MTicket
74
Tableau 9 : Les packages de CLDC
74
Tableau 10 : Les packages de MIDP
74
Tableau 11 : Exemple de message SyncML
74
Avant-propos
Pour l'obtention du Diplôme d'Ingénieur de
Conception (DIC), les étudiants du département informatique de
l'ESP doivent effectuer un stage de cinq (5) mois pour mettre en pratique leurs
connaissances théoriques acquises pendant (3) ans.
C'est dans ce dessein que nous avons intégré la
société 2SI, structure dans laquelle nous avions charge de mener
un projet informatique dont la teneur est consignée dans ce
mémoire.
Résumé
Ce mémoire présente deux nouveaux services, au
Sénégal, dans l'environnement du téléphone
portable, devenu le terminal majeur de communication dans ce pays et dans le
monde.
Le boom de l'utilisation de cet appareil, combiné
à la précarité de sa durée de vie et à
l'importance des données qu'il transporte, pose le problème de
l'intégrité de celles-ci.
Sa portabilité pourrait aussi être
utilisée à des fins autres que la communication
téléphonique uniquement.
Dans ce contexte, 2SI propose de concevoir une plateforme
à même de valoriser ce terminal mobile au grand
bénéfice des propriétaires. Cette plateforme sera
constituée de deux types de services :
· Un service de sauvegarde à distance du
répertoire des contacts des abonnés
· Un service de billetterie
dématérialisée dans lequel le téléphone
jouera le rôle de porte billet électronique.
Introduction
Les progrès technologiques récents ont permis
l'apparition d'une grande variété de nouveaux moyens permettant
à un utilisateur d'accéder et d'utiliser l'information qui
l'intéresse en tout lieu couvert par le réseau et à tout
moment. L'accès au contenu ne s'effectue plus exclusivement de la
même façon ni par les mêmes appareils qu'il y a quelques
années. Ces nouveaux appareils, fruits d'une véritable
révolution technologique, ont pour nom : assistants personnels,
téléphones cellulaires, smartphones, etc. Le nombre
d'utilisateurs de ces nouveaux appareils continue sa croissance exponentielle.
Les moyens d'accès au contenu ont également évolué,
avec de nouveaux réseaux tels que les réseaux sans fil WiFi,
GPRS, UMTS, etc. Ces réseaux se sont développés et se sont
intégrés à l'Internet. L'utilisation du World Wide Web ne
ressemble donc plus à ce qu'elle était à l'origine,
où l'utilisateur accédait à l'information depuis son
ordinateur personnel et à travers le réseau filaire.
Le concept de terminal mobile est ainsi né. Par
définition c'est un appareil qui peut être déplacé ;
par principe c'est un appareil de taille réduite. Cette taille n'est pas
seulement le produit des avancées technologiques mais elle est
tributaire de la puissance, du reste, limitée des terminaux mobiles.
L'embarqué et la mobilité dont les besoins sont aussi divers que
variés : allant de la carte à puce au satellite en passant
par la téléphonie mobile ou le radar automatique, vont être
de plus en plus présents dans notre quotidien du fait de l'explosion du
marché des machines mobiles et de leurs applications.
Conscient de l'utilité et de l'ampleur de plus en plus
grandissantes de ces appareils, 2SI concepteur d'innovations, propose aux
opérateurs de téléphonie une plateforme de services qui
permettra aux mobiles de remplir leur rôle dans la mise en place d'une
société de l'information compétitive et dynamique, au
grand bénéfice des utilisateurs. Cette solution vise à
tirer le maximum de profit de la convergence des technologies et des concepts
vers un seul appareil multimédia.
Ce mémoire s'articulera autour de trois parties :
une première dans laquelle nous présenterons notre structure
d'accueil et camperons notre sujet, une deuxième qui traitera de
l'analyse et de la conception de la plateforme à réaliser et une
troisième qui sera consacrée à l'implémentation et
à la présentation de la solution.
Première
partie : Présentation générale et choix d'une
méthode d'analyse

Cette partie comporte deux chapitres:
Ø La présentation de la structure d'accueil et
du sujet : nous présenterons de manière succincte l'entreprise "
Stratégies et Solutions Informatiques (2SI)" et le sujet que nous avons
traité en posant sa problématique et ses objectifs.
Ø Choix d'une méthode d'analyse et de
conception : Pour mettre en oeuvre la solution proposée, nous
ferons à travers ce chapitre la présentation de méthodes
d'analyse et de conception puis un choix de l'une d'entre elles.

Chapitre 1 : Présentation
générale
I. Présentation de
la structure d'accueil
1. Présentation de la société
2SI
Implantée depuis l'année 2001 par un groupe
d'ingénieurs informaticiens sortis de l'Ecole supérieure
Polytechnique de Dakar, 2SI est leader dans la prestation de solutions et de
services innovants dans le domaine des technologies de l'information et de la
communication destinés aux entreprises, aux organisations et aux
administrations.
Elle est composée d'une dizaine
d'ingénieurs de conception, d'un réseau de partenaires
au Sénégal et à travers le monde (France, USA, Chine, ...)
et offre à sa clientèle un ensemble de solutions métiers,
afin d'augmenter la productivité, de faciliter la prise de
décision et de mettre à niveau les compétences en
entreprise.
2. Domaines d'activités
Les domaines d'activités de la société sont
divers. 2SI intervient en effet dans :
· Ingénierie
logicielle
· Développement web
· Automatisme et
Informatique industrielle
· Services à valeur ajoutée
· Formation et
Perfectionnement
II. Présentation du
sujet
1.
Problématique
Les téléphones mobiles d'aujourd'hui sont
allés au-delà de leur rôle primitif d'outils de
communication et ont progressé pour devenir une extension de la
personnalité de l'utilisateur. Nous assistons à une époque
où ces derniers n'achètent plus ces appareils afin d'être
seulement en contact avec d'autres personnes, mais d'exprimer eux-mêmes,
leurs attitudes, sentiments, et intérêts.
Les clients veulent continuellement plus de leur
téléphone. Ils les utilisent pour stocker leurs données,
jouer, lire des articles de presse, surfer sur Internet, avoir un
aperçu sur l'astrologie, écouter de la musique, consulter leur
solde bancaire, etc.
Ainsi, il existe un vaste monde au-delà de la voix qui
doit être exploré et exploité et toute l'industrie
cellulaire se dirige vers celui-ci pour fournir des options novatrices à
ses clients. Les abonnés ayant l'embarras du choix, ils commencent
à choisir leurs opérateurs sur la base des services à
valeur ajoutée qu'ils offrent. L'importance accrue de SVA a
également incité les développeurs d'applications à
proposer de nouveaux services et concepts.
Dans ce sens, un boom de SVA basés sur les SMS a
été constaté un peu partout dans le monde, au
Sénégal en particulier, laissant en rade d'autres technologies
aussi avantageuses disponibles dans les réseaux actuels de
téléphonie mobile, et répondant globalement aux attentes
des abonnés.
2.
Objectifs
Notre plateforme de services intégrés vise
à atteindre les objectifs suivants :
· Participer à la rentabilisation des
investissements des opérateurs pour la mise en place, de réseaux
téléphoniques évolués en utilisant les
possibilités de ressources de ces réseaux,
· Participer à la rentabilisation des
investissements des abonnés pour l'acquisition de terminaux
onéreux multifonctionnels,
· Etre un allié sûr des propriétaires
de terminaux dans la sauvegarde de leurs données personnelles,
· Etre facilitateur d'accès aux endroits
événementiels,
· Etre un pont efficace entre organisateurs de spectacles
et spectateurs.

Chapitre 2 : Choix
d'une méthode d'analyse et de conception
Un projet informatique, quelle que soit sa taille et la
portée de ses objectifs, nécessite la mise en place d'un
planning organisationnel tout au long de son cycle de vie. C'est ainsi qu'est
apparue la notion de méthode.
Une méthode, dans le contexte informatique, peut
être définie comme une démarche fournissant une
méthodologie et des notations standards qui aident à concevoir
des logiciels de qualité.
Modéliser un système avant sa réalisation
permet de mieux comprendre le fonctionnement du système. C'est
également un bon moyen de maîtriser sa complexité et
d'assurer sa cohérence. Un modèle est un langage commun,
précis, qui est connu par tous les membres de l'équipe et il est
donc, à ce titre, un vecteur privilégié pour communiquer.
Cette communication est essentielle pour aboutir à une
compréhension commune aux différentes parties prenantes
(notamment entre la maîtrise d'ouvrage et la maîtrise d'oeuvre
informatique) et précise d'un problème donné.
Dans le domaine de l'ingénierie du logiciel, le
modèle permet de mieux répartir les tâches et d'automatiser
certaines d'entre elles. C'est également un facteur de réduction
des coûts et des délais. Par exemple, les plateformes de
modélisation savent maintenant exploiter les modèles pour faire
de la génération de code (au moins au niveau du squelette) voire
des allers-retours entre le code et le modèle sans perte d'information.
Le modèle est enfin indispensable pour assurer un bon niveau de
qualité et une maintenance efficace car, une fois mise en production,
l'application va devoir être maintenue, probablement par une autre
équipe et, qui plus est, pas nécessairement de la même
société que celle ayant créée l'application. Le
choix du modèle a donc une influence capitale sur les solutions
obtenues. Les systèmes non triviaux sont mieux modélisés
par un ensemble de modèles indépendants. Selon les modèles
employés, la démarche de modélisation n'est pas la
même.
Dans ce chapitre, nous ferons une étude approfondie de
l'ensemble des méthodes d'analyse et de conception existantes. Enfin
nous effectuerons un choix parmi ces dites méthodes.
I. Définition des concepts
Une méthode fait intervenir essentiellement les concepts
d'analyse et de conception.
1.
L'analyse
Correspondant à la phase qui répond à la
question « que fait le système », l'analyse est
l'une des étapes les plus importantes et les plus difficiles de la
modélisation. Elle permet de modéliser le domaine d'application,
d'analyser l'existant et les contraintes de réalisation. Elle s'effectue
par une abstraction et une séparation des problèmes. Elle peut
être découpée en trois phases que sont :
1.1. La définition des
besoins
Il s'agit d'identifier les acteurs et les cas d'utilisation,
de structurer le modèle, et d'identifier les autres exigences.
1.2. La capture des
besoins
Elle consiste à collecter des informations (interviews,
lecture de documentation) et à la compréhension du domaine et du
problème posé.
A ce niveau il s'agit de restituer les besoins dans un langage
compréhensible par le client et de procéder à
l'identification, à la structuration et à la définition
d'un dictionnaire.
1.3. La spécification
des besoins
Dans cette phase il sera question d'aller à un niveau
de spécification plus détaillé voire même plus
formel des besoins. Elle sera d'une grande utilité pour le client mais
aussi pour le développeur.
A la fin de cette phase d'analyse un modèle conceptuel
sera disponible, lequel modèle sera un outil fondamental lors de la
phase de conception.
2. La
conception
Phase menée à la suite de l'analyse des besoins,
la conception met en oeuvre tout un ensemble d'activités qui à
partir d'une demande d'informatisation d'un processus permettent la conception,
l'écriture et la mise au point d'un produit informatique (et donc de
programmes informatiques) jusqu'à sa livraison au demandeur. Elle a
comme objectifs de répondre à la question « comment
faire le système ?» et de décomposer de façon
modulaire le système à mettre en place. La conception
définit l'architecture du logiciel. Elle définit par la
même occasion chaque constituant du logiciel (Informations
traitées, traitements effectués, résultats fournis,
contraintes à respecter. A la suite un modèle logique utilisable
à la phase d'implémentation est produit.
3.
L'implémentation
Cette phase consiste à la mise en oeuvre des programmes
dans un langage de programmation conformément aux spécifications
définies dans les phases précédentes. Elle renferme en son
sein les phases de test et de mise au point (débogage). A la sortie il
sera produit un modèle physique (collection de modules
implémentés mais non testés, documentation de
programmation expliquant le code).
II. Classification des
méthodes d'analyse et de conception
Malgré la diversité des méthodes
d'analyse et de conception, il est possible de les classer en trois
catégories :
1. Les méthodes
cartésiennes ou fonctionnelles
Avec cette méthode, le système
étudié est abordé par les fonctions qu'il doit assurer
plutôt que par les données qu'il doit gérer. Le processus
de conception est vu comme un développement linéaire. Il y a
décomposition systématique du domaine étudié en
sous domaines, eux-mêmes décomposés en sous-domaines
jusqu'à un niveau considéré élémentaire.
SADT (Structured-Analysis-Design-Technique) en est un exemple.
2. Les méthodes
systémiques
Les méthodes systémiques sont des
méthodes s'appuyant sur une approche systémique. Elles
définissent différents niveaux de préoccupation ou
d'abstraction et proposent de nombreux modèles complémentaires.
Les méthodes systémiques sont souvent
spécialisées pour la conception d'un certain
type de systèmes. Comme exemple de méthode systémique nous
pouvons citer MERISE, AXIAL ...
3. Les méthodes
objet
Ce sont des méthodes consistant à créer
une représentation informatique des éléments du monde
réel auxquels on s'intéresse, sans se préoccuper de
l'implémentation, ce qui signifie indépendamment d'un langage de
programmation. Il s'agit donc de déterminer les objets présents
et d'isoler leurs données et les fonctions qui les utilisent. Pour cela
des méthodes ont été mises au point. Entre 1970 et 1990,
de nombreux analystes ont mis au point des approches orientées objets,
si bien qu'en 1994 il existait plus de 50 méthodes objet. Toutefois
seules 3 méthodes ont véritablement émergé :
· La méthode OMT de
Rumbaugh
· La méthode BOOCH'93 de
Booch
· La méthode OOSE de
Jacobson
4. Les méthodes
agiles
Les méthodes de développement dites
« méthodes agiles » (en anglais
Agile Modeling) visent à réduire le cycle de vie du
logiciel (donc accélérer son développement) en
développant une version minimale, puis en intégrant les
fonctionnalités par un processus itératif basé sur une
écoute client et des tests tout au long du cycle de
développement.
L'origine des méthodes agiles est liée à
l'instabilité de l'environnement technologique et au fait que le client
est souvent dans l'incapacité de définir ses besoins de
manière exhaustive dès le début du projet. Le terme
« agile » fait ainsi référence à la
capacité d'adaptation aux changements de contexte et aux modifications
de spécifications intervenant pendant le processus de
développement. En 2001, 17 personnes mirent ainsi au point le manifeste
agile dont la traduction est la suivante :
· individus et interactions plutôt que processus et
outils
· développement logiciel plutôt que
documentation exhaustive
· collaboration avec le client plutôt que
négociation contractuelle
· ouverture au changement plutôt que suivi d'un
plan rigide
Grâce aux méthodes agiles, le client est pilote
à part entière de son projet et obtient très vite une
première mise en production de son logiciel. Ainsi, il est possible
d'associer les utilisateurs dès le début du projet. Comme
méthode agile nous pouvons citer eXtreme Programming (XP).
III. Choix d'une
méthode d'analyse et de conception
Pour l'analyse et la conception de notre application nous
opterons pour une méthode orientée objet. Une méthode
étant un assemblage d'une démarche et d'un langage de
modélisation, nous allons choisir le tandem le plus adéquat.
1. Aperçu de
quelques démarches existantes
Plusieurs démarches orientées objet existent. Les
plus utilisées sont :
1.1 RAD
RAD (Rapid Application Development) est une méthode de
conduite de projet permettant de développer rapidement des applications
de qualité. Aujourd'hui qualité et réactivité font
partie des objectifs généraux de beaucoup d'entreprises. Cela
entraine un certain nombre de projets, qui tout en apportant satisfaction aux
utilisateurs, doivent être menés dans un délai
court. C'est à cela que répond la méthode RAD.
La méthode RAD propose de remplacer le cycle de vie
classique par un autre découpage temporaire. Le déroulement est
d'abord linéaire, puis il suit le modèle de la spirale. Les
étapes sont au nombre de cinq :
L'étape Initialisation :
l'objectif est de sélectionner les acteurs pertinents, de structurer le
travail en thèmes et d'amorcer une dynamique. Elle ne dépasse pas
15 jours.
L'étape Expression des besoins :
l'objectif est de mettre à jour ce qui sera utile aux utilisateurs. On
utilise la technique du JRP1(*) qui organise le travail en session. La durée de
cette étape est fonction du nombre d'utilisateurs concernés. Elle
ne dépasse pas 30 jours.
L'étape Conception : l'objectif
est de concevoir une solution. Les techniques utilisées sont le
JAD2(*) et le prototypage.
L'étape ne dépasse pas 60 jours.
L'étape Construction : il
s'agit, fonction par fonction, de construire un système viable. Les
techniques utilisées sont la time-box3(*) et le prototypage. Cette étape ne
dépasse pas 120 jours.
L'étape Mise en oeuvre :
des recettes partielles ont été faites à l'étape
construction. Il s'agit ici d'officialiser une livraison globale, de
l'optimiser éventuellement, d'installer le nouveau système et de
faire le bilan du projet.
1.2 DSMD
La méthode DSDM (Dynamic Software
Development Method) a été mise au point en s'appuyant sur la
méthode RAD afin de combler certaines de ses lacunes, notamment en
offrant un canevas prenant en compte l'ensemble du cycle de
développement.
Les principes fondateurs de la méthode DSDM sont les
suivants :
· Une implication des utilisateurs
· Un développement itératif et
incrémental
· Une fréquence de livraison élevée
· L'intégration des tests au sein de chaque
étape
· L'acceptation des produits livrés dépend
directement de la satisfaction des besoins
1.3 UP
La méthode du Processus Unifié
(UP pour Unified Process) est un processus de
développement itératif et incrémental, ce qui signifie que
le projet est découpé en phases très courtes à
l'issue de chacune desquelles une nouvelle version incrémentée
est livrée.
Il s'agit d'une démarche s'appuyant sur la
modélisation UML pour la description de l'architecture du logiciel
(fonctionnelle, logicielle et physique) et la mise au point de cas
d'utilisation permettant de décrire les besoins et exigences des
utilisateurs.
1.4 RUP
RUP (Rational Unified Process) est
une méthode de développement par itérations promue par la
société Rational Software, rachetée par IBM. RUP
propose une méthode spécifiant notamment la composition des
équipes et le calendrier ainsi qu'un certain nombre de modèles de
documents. RUP est l'une des plus célèbres implémentations
de la démarche UP, livrée clé en main, permettant de
donner un cadre de développement logiciel, répondant aux
exigences fondamentales préconisées par les créateurs
d'UML. RUP est une version commerciale d'UP.
1.5 XP
La méthode XP (pour eXtreme Programming)
définit un certain nombre de bonnes pratiques permettant de
développer un logiciel dans des conditions optimales en plaçant
le client au coeur du processus de développement, en relation
étroite avec le client.
L'eXtreme Programming est notamment basé sur les
concepts suivants :
· Les équipes de développement travaillent
directement avec le client sur des cycles très courts d'une à
deux semaines maximum.
· Les livraisons de versions du logiciel interviennent
très tôt et à une fréquence élevée
pour maximiser l'impact des retours utilisateurs.
· L'équipe de développement travaille en
collaboration totale sur la base de binômes.
· Le code est testé et nettoyé tout au long
du processus de développement.
· Des indicateurs permettent de mesurer l'avancement du
projet afin de permettre la mise à jour du plan de
développement.
2. Choix d'une
démarche
Le choix de la démarche se fera en prenant en compte
des critères essentiels de la plateforme à concevoir. Pour des
raisons d'efficacité, de rapidité et d'analyse complète,
nous opterons en effet pour un processus situé à mi-chemin entre
UP (Unified Process), un cadre général
très complet de processus de développement, et
XP (eXtreme Programming), une approche minimaliste à la
mode centrée sur le code.
2.1. Présentation
du processus unifié (UP)
UP (Unified Process) est une méthode
générique de développement de logiciels.
Générique signifie qu'il est nécessaire
d'adapter UP au contexte du projet, de l'équipe, du domaine et/ou de
l'organisation (exemple: R.UP ou X.UP). C'est plus ou moins vrai pour
toute méthode, qu'elle se définisse elle-même comme
générique ou pas.
2.1.1. Le processus
unifié : un cadre général
Le processus unifié est une démarche de
développement logiciel : il regroupe les activités à mener
pour transformer les besoins d'un utilisateur en système logiciel.
Ses principales caractéristiques sont:
o Il est à base de composants,
o Il utilise le langage UML (ensemble d'outils et de
diagrammes),
o Il est piloté par les cas d'utilisation,
o Il est centré sur l'architecture,
o Il est itératif et incrémental.
2.1.2. Le processus
unifié est piloté par les cas d'utilisation
L'objectif principal d'un système logiciel est de
rendre service à ses utilisateurs ; il faut par conséquent bien
comprendre les désirs et les besoins des futurs utilisateurs. Le
processus de développement sera donc centré sur l'utilisateur. Le
terme utilisateur ne désigne pas seulement les utilisateurs humains mais
également les autres systèmes. L'utilisateur représente
donc une personne ou une chose dialoguant avec le système en cours de
développement. Ce type d'interaction est appelé cas d'utilisation
illustré par le schéma suivant :

Figure 1 : Relation acteur
- cas d'utilisation
Les cas d'utilisation font apparaître les besoins
fonctionnels et leur ensemble constitue le modèle des cas d'utilisation
qui décrit les fonctionnalités complètes du
système.
Les cas d'utilisation ne sont pas un simple outil de
spécification des besoins du système. Ils vont
complètement guider le processus de développement à
travers l'utilisation de modèles basés sur l'utilisation du
langage UML.
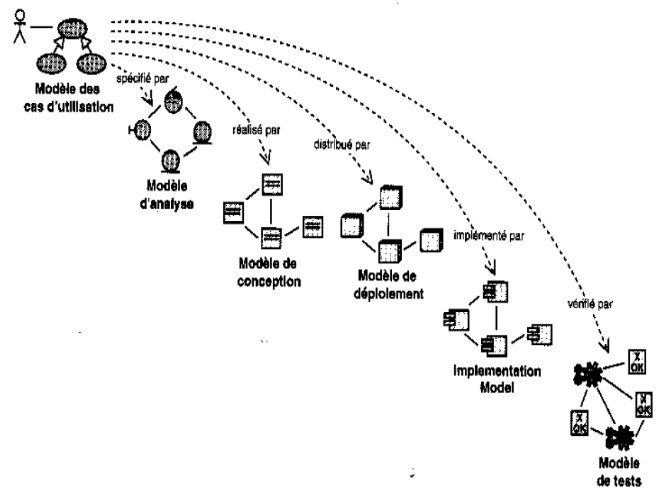
Figure 2 : Dynamique
des modèles du langage UML
Ø A partir du modèle des cas d'utilisation, les
développeurs créent une série de modèles de
conception et d'implémentation réalisant les cas
d'utilisation.
Ø Chacun des modèles successifs est ensuite
révisé pour en contrôler la conformité par rapport
au modèle des cas d'utilisation.
Ø Enfin, les testeurs testent l'implémentation
pour s'assurer que les composants du modèle d'implémentation
mettent correctement en oeuvre les cas d'utilisation.
Les cas d'utilisation garantissent la cohérence du
processus de développement du système. S'il est
vrais que les cas d'utilisation guident le processus de développement,
ils ne sont pas sélectionnés de façon
isolée, mais doivent absolument être développés "en
tandem" avec l'architecture du système.
2.1.3. Le processus
unifié est centré sur l'architecture
Dès le démarrage du processus, on aura une vue
sur l'architecture à mettre en place. L'architecture d'un système
logiciel peut être décrite comme les différentes vues du
système qui doit être construit. L'architecture logicielle
équivaut aux aspects statiques et dynamiques les plus significatifs du
système. L'architecture émerge des besoins de l'entreprise, tels
qu'ils sont exprimés par les utilisateurs et autres intervenants et tels
qu'ils sont reflétés par les cas d'utilisation.
Elle subit également l'influence d'autres facteurs :
§ la plate-forme sur laquelle devra s'exécuter le
système ;
§ les briques de bases réutilisables disponibles
pour le développement ;
§ les considérations de déploiement, les
systèmes existants et les besoins non fonctionnels (performance,
fiabilité...)
a. Liens entre cas d'utilisation et architecture
?
Tout produit est à la fois forme et fonction. Les cas
d'utilisation doivent une fois réalisés, trouver leur place dans
l'architecture. L'architecture doit prévoir la réalisation de
tous les cas d'utilisation. L'architecture et les cas d'utilisation doivent
évoluer de façon concomitante.
b. Marche à suivre :
ü L'architecte crée une ébauche
grossière de l'architecture, en partant de l'aspect qui n'est pas propre
aux cas d'utilisation (plateforme..). Bien que cette partie de l'architecture
soit indépendante des cas d'utilisation, l'architecte doit avoir une
compréhension globale de ceux-ci avant d'en esquisser l'architecture.
ü Il travaille ensuite, sur un sous ensemble des cas
d'utilisations identifiés, ceux qui représentent les fonctions
essentielles du système en cours de développement.
ü L'architecture se dévoile peu à peu, au
rythme de la spécification et de la maturation des cas d'utilisation,
qui favorisent, à leur tour, le développement d'un nombre
croissant de cas d'utilisation.
Ce processus se poursuit jusqu'à ce que l'architecture
soit jugée stable.
2.1.4. Le processus
unifié est itératif et incrémental
Le développement d'un produit logiciel destiné
à la commercialisation est une vaste entreprise qui peut
s'étendre sur plusieurs mois. On ne va pas tout développer d'un
coup. On peut découper le travail en plusieurs parties qui sont autant
de mini projets, chacun d'entre eux représentant une itération
qui donne lieu à un incrément.
Une itération désigne la succession des
étapes de l'enchaînement d'activités, tandis qu'un
incrément correspond à une avancée dans les
différents stades de développement.
Le choix de ce qui doit être implémenté au
cours d'une itération repose sur deux facteurs :
· Une itération prend en compte un certain nombre
de cas d'utilisations qui, ensemble, améliorent l'utilisabilité
du produit à un certain stade de développement.
· L'itération traite en priorité les
risques majeurs.
Un incrément constitue souvent un additif. A chaque
itération, les développeurs identifient et spécifient les
cas d'utilisations pertinents, créent une conception en se laissant
guider par l'architecture choisie, implémentent cette conception sous
forme de composants et vérifient que ceux-ci sont conformes aux cas
d'utilisation. Dés qu'une itération répond aux objectifs
fixés le développement passe à l'itération
suivante. Pour rentabiliser le développement il faut sélectionner
les itérations nécessaires pour atteindre les objectifs du
projet. Ces itérations devront se succéder dans un ordre logique.
Un projet réussi suivra un déroulement direct établi
dès le début par les développeurs et dont ils ne
s'éloigneront que de façon très marginale.
L'élimination des problèmes imprévus fait partie des
objectifs de réduction des risques. Les avantages d'un processus
unifié contrôlé sont :
Ø la limitation des coûts, en termes de risques, aux
strictes dépenses liées à une itération,
Ø la limitation des risques de retard de mise sur le
marché du produit développé (identification des
problèmes dès les premiers stades de développement et non
en phase de test comme avec l'approche « classique »),
Ø l'accélération du rythme de
développement grâce à des objectifs clairs et à
court terme,
Ø la prise en compte du fait que les besoins des
utilisateurs et les exigences correspondantes ne peuvent être
intégralement définis à l'avance et se dégagent peu
à peu des itérations successives.
L'architecture fournit la structure qui servira de cadre au
travail effectué au cours des itérations, tandis que les cas
d'utilisation définissent les objectifs et orientent le travail de
chaque itération. Il ne faut donc pas mésestimer l'un des trois
concepts.
2.1.5. Le cycle de vie du
processus unifié
Le processus unifié répète un certain
nombre de fois une série de cycles. Tout cycle se conclut par la
livraison d'une version du produit aux clients et s'articule en 4 phases :
création, élaboration, construction et transition, chacune
d'entre elles se subdivisant à son tour en itérations.
Chaque cycle se traduit par une nouvelle version du
système. Ce produit se compose d'un corps de code source réparti
sur plusieurs composants pouvant être compilés et
exécutés et s'accompagne de manuels et de produits
associés. Pour mener efficacement le cycle, les développeurs ont
besoin de construire toutes les représentations du produit logiciel :
|
Modèle des cas d'utilisation
|
Expose les cas d'utilisation et leurs relations avec les
utilisateurs
|
|
Modèle d'analyse
|
Détaille les cas d'utilisation et procède
à une
première répartition du comportement du
système entre divers objets
|
|
Modèle de conception
|
Définit la structure statique du système sous
forme de sous système, classes et interfaces ;
Définit les cas d'utilisation réalisés
sous forme de collaborations entre les sous systèmes les classes et les
interfaces
|
|
Modèle d'implémentation
|
Intègre les composants (code source) et la
correspondance entre les classes et les composants
|
|
Modèle de déploiement
|
Définit les noeuds physiques des ordinateurs et
l'affectation de ces composants sur ces noeuds.
|
|
Modèle de test
|
Décrit les cas de test vérifiant les cas
d'utilisation
|
|
Représentation de l'architecture
|
Description de l'architecture
|
Tableau 1 : Description des
modèles d'UML
Tous ces modèles sont liés. Ensemble, ils
représentent le système comme un tout. Les éléments
de chacun des modèles présentent des dépendances de
traçabilité ; ce qui facilite la compréhension et les
modifications ultérieures.
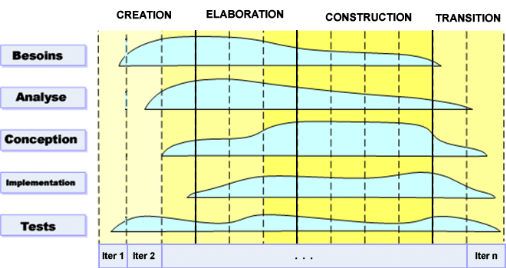
Figure 3 : cycle de vie du
Processus Unifié
o Création
Première phase du cycle de vie du processus
unifié, la création traduit une idée en vision de produit
fini et présente l'étude de rentabilité pour ce produit.
Elle essaie de répondre à un certain nombre de questions :
Que va faire le système pour les utilisateurs ? A quoi peut ressembler
l'architecture d'un tel système ? Quels sont l'organisation et les
coûts du développement de ce produit ? C'est à ce
niveau où les principaux cas d'utilisation seront
spécifiés. L'identification des risques majeurs, la mise sur
place d'une architecture provisoire du système à concevoir et la
préparation de la phase d'élaboration seront les principales
tâches à effectuer durant cette étape de la
création.
o Elaboration
Elle permet de préciser la plupart des cas
d'utilisation et de concevoir l'architecture du système. L'architecture
doit être exprimée sous forme de vue de chacun des modèles.
Lors de cette phase une architecture de référence sera
conçue. Au terme de cette étape, le chef de projet doit
être en mesure de prévoir les activités et d'estimer les
ressources nécessaires à l'achèvement du projet.
o Construction
C'est le moment où l'on construit le produit.
L'architecture de référence se métamorphose en produit
complet, elle est maintenant stable. Le produit contient tous les cas
d'utilisation que les chefs de projet, en accord avec les utilisateurs ont
décidé de mettre au point pour cette version. Celle ci doit
encore avoir des anomalies qui peuvent être en partie résolue lors
de la phase de transition.
o Transition
Le produit est en version bêta. Un groupe d'utilisateurs
essaye le produit et détecte les anomalies et défauts. Cette
phase suppose des activités comme la fabrication, la formation des
utilisateurs clients, la mise en oeuvre d'un service d'assistance et la
correction des anomalies constatées (ou le report de leur correction
à la version suivante).
2.2. Présentation
de l'eXtreme Programming (XP)
L'eXtreme Programming ou XP, est une méthode de
développement de projet mise au point à la fin des années
90 par Kent Beck, Ward Cunningham et Ron Jeffries.
XP doit son nom au fait
qu'elle place l'activité de programmation au centre du projet, et
qu'elle obtient ses résultats en combinant et en poussant à
l'extrême certaines pratiques de développement. XP est un ensemble
de pratiques qui couvre une grande partie des activités de la
réalisation d'un logiciel, de la programmation proprement dite à
la planification du projet, en passant par l'organisation de l'équipe de
développement et les échanges avec le client. Ces pratiques n'ont
en soi rien de révolutionnaire : il s'agit simplement de pratiques de
bon sens, mises en oeuvre par des développeurs ou des chefs de projet
expérimentés, telles que :
· Un utilisateur à
plein-temps dans la salle projet. Ceci permet une communication
intensive et permanente entre les clients et les développeurs, aussi
bien pour l'expression des besoins que pour la validation des livraisons.
· Écrire le test unitaire avant
le code qu'il doit tester, afin d'être certain que le test sera
systématiquement écrit et non pas négligé.
· Programmer en binôme, afin
d'homogénéiser la connaissance du système au sein des
développeurs, ainsi que de permettre aux débutants d'apprendre
des experts. Le code devient ainsi une propriété collective et
non individuelle que tous les développeurs ont le droit de modifier.
· Intégrer de façon
continue, pour ne pas retarder à la fin du projet le risque
majeur de l'intégration des modules logiciels écrits par des
équipes ou des personnes différentes.
· ...
XP s'appuie sur les valeurs suivantes :
Communication : La communication est la
composante fondamentale de tout travail en équipe. XP installe la
communication dans le projet à tous les niveaux.
Simplicité : Communication et
retour d'information : ces dispositions sont menacées, à mesure
que le produit évolue et s'accroît, par la lourdeur et l'inertie
du processus. Pour cette raison, XP érige la simplicité en
véritable discipline, tant au niveau de la conception que du processus
lui-même (scénarios utilisateur, séances de planifications,
propriété collective du code, pas de spécialisations
techniques).
Feedback : Le retour d'information
permet de tracer et d'ajuster le processus en vue d'améliorer la
qualité, la maintenance et la productivité. A chacune des
tâches de production, XP câble un mécanisme ou une pratique
permettant de valider cette production de manière quasiment continue.
Courage : La force d'une équipe
même dotée d'une approche efficace ne se mesure pas tant à
ce qu'elle fait lorsque tout va bien, qu'à la manière dont elle
affronte les difficultés. Pour cette raison XP valorise
également le Courage.
Elle est bien adaptée pour des projets de taille
moyenne où le contexte (besoins utilisateurs, technologies
informatiques) évolue en permanence.

Figure 4 : Cycle de vie de
XP
L'eXtreme Programming repose sur des cycles rapides de
développement (des itérations de quelques semaines) dont les
étapes sont les suivantes :
· une phase d'exploration qui détermine les
scénarios clients qui seront fournis pendant cette
itération ;
· une phase de planning où l'équipe
transforme les scénarios en tâches à réaliser et en
tests fonctionnels ;
· une phase de mise en production où chaque
développeur s'attribue des tâches et les réalise avec un
binôme ;
· une phase de maintenance lorsque tous les tests
fonctionnels passent, le produit est livré.
Le cycle se répète tant que le client peut
fournir des scénarios à livrer. La première livraison est
généralement plus importante et n'est réalisée
qu'après quelques itérations. Après la première
mise en production, les itérations peuvent devenir plus courtes (une
semaine par exemple).
2.3. La démarche simplifiée
La problématique que pose la mise en oeuvre d'UML est
simple : comment passer de l'expression des besoins au code de
l'application ? Comment obtenir le plus efficacement possible un code
informatique opérationnel, complet, testé, et qui réponde
parfaitement aux besoins exprimés par les utilisateurs ?
Figure 5 : Démarche
simplifiée - étape 1
Dans un premier temps, les besoins vont être
modélisés au moyen des cas d'utilisation UML. Ils seront
également représentés de façon plus concrète
par une maquette d'IHM (Interface Homme Machine) destinée à faire
réagir les futurs utilisateurs.
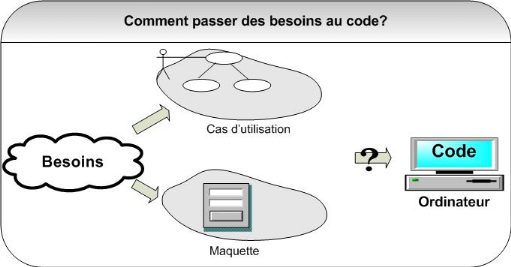
Figure 6 : Démarche
simplifiée - étape 2
Dans le cadre des systèmes orientés-objets, la
structure du code est définie par les classes logicielles et leurs
regroupements en ensembles appelés packages. Nous avons donc besoin de
diagrammes représentant les classes logicielles et montrant les
données qu'elles contiennent (attributs), les services qu'elles rendent
(opérations) ainsi que leurs relations. UML propose les diagrammes de
classes pour véhiculer toutes ces informations.
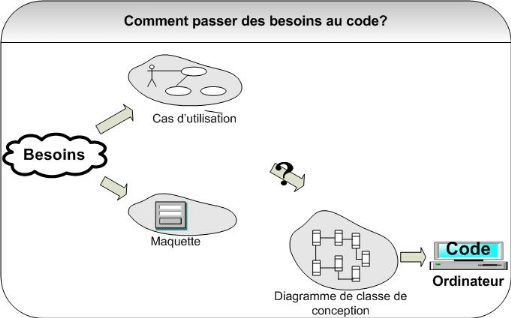
Figure 7: Démarche
simplifiée - étape 3
Les diagrammes de classes de conception représentent
bien la structure statique du code, par le biais des attributs et des relations
entre classes, mais ils contiennent également les opérations
(méthodes) qui décrivent les responsabilités dynamiques
des classes logicielles. L'attribution des bonnes responsabilités aux
bonnes classes est l'un des problèmes les plus délicats de la
conception orientée-objet. Pour chaque service ou fonction, il faut
décider quelle est la classe qui va le contenir. Nous devons ainsi
répartir tout le comportement du système entre les classes de
conception et décrire les collaborations induites.
Les diagrammes d'interactions UML
(séquence ou collaboration) sont
particulièrement utiles au concepteur pour représenter
graphiquement ses décisions d'allocation de responsabilités.
Chaque diagramme d'interaction va ainsi représenter un ensemble d'objets
de classes différentes collaborant dans le cadre d'un scénario
d'exécution du système. Dans ce genre de diagramme, les objets
communiquent en s'envoyant des messages qui invoquent des
opérations sur les objets récepteurs.
On peut donc suivre visuellement les interactions dynamiques
entre objets, et les traitements réalisés par chacun. Les
diagrammes d'interaction aident également à écrire le code
à l'intérieur des opérations, en particulier les appels
d'opérations imbriqués. La figure suivante ajoute une
étape du côté du code, mais ne nous dit pas encore comment
relier tout cela aux cas d'utilisation.
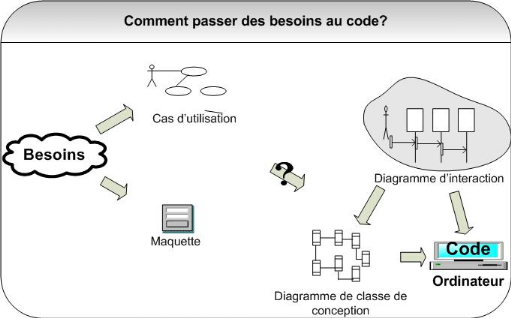
Figure 8 :
Démarche simplifiée - étape 4
Comment passer des cas d'utilisation aux diagrammes
d'interaction ? Ce n'est pas simple ni direct car les cas d'utilisation sont au
niveau d'abstraction des besoins utilisateurs alors que les diagrammes
d'interaction se placent au niveau de la conception objet. Il faut donc au
moins une étape intermédiaire.
Chaque cas d'utilisation est décrit textuellement de
façon détaillée, mais donne également lieu à
un diagramme de séquence représentant graphiquement la
séquence des interactions entre les acteurs et le système vu
comme une boîte noire, dans le cadre du scénario nominal. Nous
appellerons ce diagramme : diagramme de séquence
système.
Par la suite, en remplaçant le système vu comme
une boîte noire par un ensemble choisi d'objets de conception, nous
décrirons l'attribution des responsabilités dynamiques, tout en
conservant une traçabilité forte avec les cas d'utilisation. La
figure ci-après montre ainsi les diagrammes de séquence
système en tant que lien important entre les cas d'utilisation et les
diagrammes d'interaction.
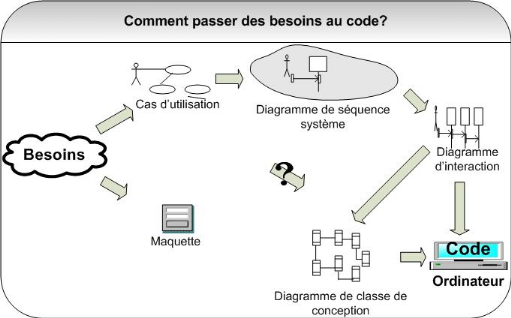
Figure 9 :
Démarche simplifiée - étape 5
Mais comment trouver ces fameuses classes de conception qui
interviennent dans les diagrammes d'interactions ?
Les classes logicielles représentant l'informatisation
des concepts métier manipulés par les experts du domaine et les
utilisateurs sont assez directement trouvées par une analyse du domaine.
Pour matérialiser cette analyse, nous allons construire un
modèle du domaine, sorte de glossaire
détaillé et formalisé en UML des concepts fondamentaux de
l'espace du problème. Ces concepts, leurs attributs et leurs relations
vont être décrits en UML par un diagramme de classes
simplifié utilisant des conventions particulières. Comme
indiqué sur la figure suivante, le modèle du domaine fournit une
partie des classes de conception, celles correspondant directement aux concepts
métier. Il découle des cas d'utilisation et de l'analyse des
besoins
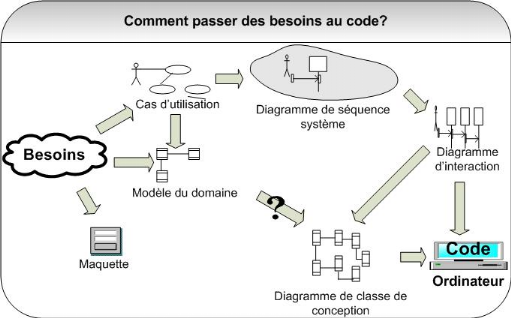
Figure 10 :
Démarche simplifiée - étape 6
Mais le modèle du domaine à lui seul ne permet
pas d'identifier les principales classes d'IHM ni celles qui décrivent
la cinématique de l'application. Le chaînon manquant de notre
démarche s'appelle les diagrammes de classes
participantes. Il s'agit là encore de diagrammes de classes UML
qui décrivent, cas d'utilisation par cas d'utilisation, les trois
principales classes d'analyse et leurs relations.
· Les classes qui permettent les interactions entre
l'application et ses utilisateurs sont qualifiées de «
dialogues ». Ce sont typiquement les écrans
proposés à l'utilisateur : les formulaires de saisie, les
résultats de recherche, etc. Elles proviennent directement de l'analyse
de la maquette.
· Celles qui contiennent la cinématique de
l'application seront appelées « contrôles
». Elles font la transition entre les dialogues et les classes
métier, en permettant aux écrans de manipuler des informations
détenues par un ou plusieurs objets métier.
· Celles qui représentent les règles
métier sont qualifiées d'« entités
». Elles proviennent directement du modèle du domaine,
mais sont confirmées et complétées cas d'utilisation par
cas d'utilisation.
Un avantage important de cette technique pour le chef de
projet consiste en la possibilité de découper le travail de son
équipe d'analyste suivant les différents cas d'utilisation,
plutôt que de vouloir tout traiter d'un bloc. En outre, le modèle
du domaine joue le rôle de référence commune et d'arbitre
en ce qui concerne les entités découvertes par les
différentes équipes. Comme l'illustre la figure ci-après,
les diagrammes de classes participantes sont particulièrement importants
car ils font la jonction entre le les cas d'utilisation, le modèle du
domaine, la maquette et les diagrammes de conception logicielle (diagrammes
d'interaction et diagrammes de classes).
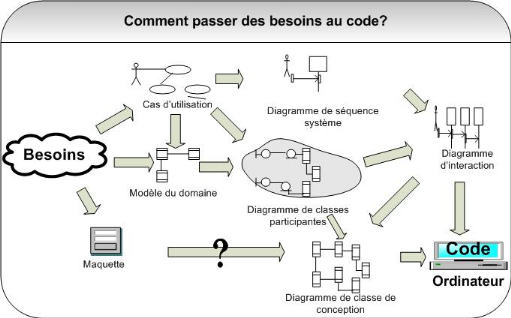
Figure 11 :
Démarche simplifiée - étape 7
Pour que le tableau soit complet, il nous reste à
détailler une exploitation supplémentaire de la
maquette. Elle va nous permettre de réaliser des
diagrammes dynamiques représentant de manière formelle l'ensemble
des chemins possibles entre les principaux écrans proposés
à l'utilisateur. Ces diagrammes s'appellent des diagrammes
d'activités de navigation.
La trame globale de la
démarche est ainsi finalisée, comme indiqué sur la figure
suivante.
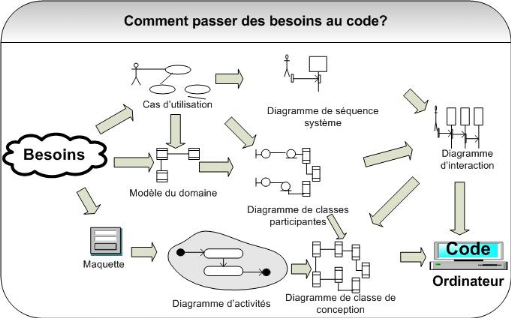
Figure 12 :
Démarche simplifiée - étape 8
3. Présentation du
langage de modélisation UML
3.1. Définition et
historique
UML (en anglais Unified Modeling
Language, « langage de modélisation
unifié ») est un langage graphique de modélisation des
données et des traitements. C'est une formalisation très aboutie
et non-propriétaire de la modélisation objet utilisée en
génie logiciel. UML est l'accomplissement de la fusion des meilleures
approches de la modélisation objet (Booch, OMT, OOSE) effectuée
en 1995. Principalement issu des travaux de Grady Booch, James Rumbaugh et Ivar
Jacobson, UML est à présent un standard défini par l'OMG
(Object Management Group).
UML a démarré avec la version 0.8
intégrant les méthodes BOOCH 93 et OMT. Par la suite il y a eu
l'avènement de la version 0.9 ayant intégré la
méthode OOSE. La version 1.0, proposé à l'OMG en 1996, fut
finalement standardisée en 1997 sous la version 1.1. Depuis cette
année il ya eu quatre révisions du standard (de UML 1.1 à
UML 1.5 en 2003). Les dernières améliorations étant
conséquentes, UML est passé à une nouvelle version :
UML 2.0 (ou UML 2), abrégé souvent en U2. Cette
figure ci-dessous montre l'évolution des versions d'UML depuis sa
genèse.
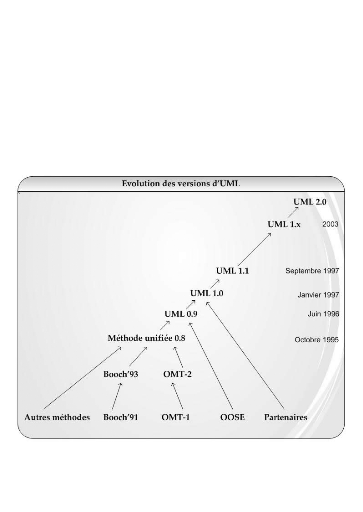
Figure 13 : Evolution
des versions d'UML
3.2. Concepts du
langage
UML se base sur un certain nombre de concepts que sont :
o Objet
On appelle objet un élément matériel ou
immatériel, dans la réalité étudiée, qui
satisfait aux principes de distinction, de permanence et d'activité.
Cela entraine qu'un objet possède une identité, un état et
un comportement. Un objet communique avec ses utilisateurs (ou clients) par le
biais de son interface. L'interface d'un objet est la liste des services qu'il
peut rendre et des ressources qu'il souhaite mettre à la disposition de
ses clients.
o Classe
Une classe est un ensemble d'objet sur lesquels on peut
reconnaître des similitudes dans le champ d'étude. Ces similitudes
portent sur la façon de les identifier, sur les types d'états
qu'ils peuvent prendre et sur le rôle qu'ils jouent.
o Entité
Lors de la modélisation d'un système
d'information certains objets sont porteurs d'informations concrètes,
manipulées, transmises ou mémorisées. On les qualifie
d'objets informationnels. Une entité est donc un ensemble d'objets sur
lesquels on peut reconnaître la même structure et qui sont
gérés de la même façon
o Acteur
UML n'emploie pas le terme d'utilisateur mais d'acteur. Les
acteurs d'un système sont les entités externes à ce
système qui interagissent (saisie de données, réception
d'information, ...) avec lui. Les acteurs sont donc à l'extérieur
du système et dialoguent avec lui. Ces acteurs permettent de cerner
l'interface que le système va devoir offrir à son environnement.
Oublier des acteurs ou en identifier de faux conduit donc nécessairement
à se tromper sur l'interface et donc la définition du
système à produire.
o Processus
Le terme processus vient du latin
« progrès » et signifie littéralement
« aller de l'avant » ; cela évoque
l'idée d'une marche progressive ou d'un plan déterminé
à l'avance. On appelle processus l'organisation d'un ensemble
finalisé d'activités effectuées par des acteurs et mettant
en jeu des entités, pour répondre à un type
d'événement.
3.3. UML et les
vues
Diverses perspectives ou vues peuvent être prises en
compte dans la modélisation d'un système d'informations. Le
langage UML en a défini cinq (05) qui sont complémentaires et qui
guident l'utilisation des concepts objets : il s'agit de l'architecture
4+1 centrée sur la vue utilisateur représentée par la
figure ci-dessous.

Figure 14 : Les vues
UML
§ La vue logique
Cette vue appelée vue de haut niveau se concentre sur
l'abstraction et l'encapsulation. C'est à ce niveau que s'effectue la
modélisation des éléments et mécanismes principaux
du système. La vue logique permet d'identifier les
éléments du domaine, ainsi que les relations et interactions
entre ces éléments : les éléments du domaine
étant le(s) métier(s) de l'entreprise. Ils sont d'une importance
capitale dans la mission future du système, ils gagnent à
être réutilisés (ils représentent un savoir-faire).
Cette vue permet aussi d'organiser, (selon des critères purement
logiques), les éléments du domaine en "catégories"
: pour répartir les tâches dans les équipes, regrouper
ce qui peut être générique, isoler ce qui est propre
à une version donnée, etc.
§ La vue des composants
Cette vue de bas niveau (aussi appelée "vue de
réalisation"), montre : L'allocation des éléments de
modélisation dans des modules (fichiers sources, bibliothèques
dynamiques, bases de données, exécutables, etc.). En d'autres
termes, cette vue identifie les modules qui réalisent (physiquement) les
classes de la vue logique. Elle définit aussi l'organisation des
composants, c'est-à dire la distribution du code en gestion de
configuration, les dépendances entre les composants... Les contraintes
de développement (bibliothèques externes...). La vue des
composants montre aussi l'organisation des modules en
"sous-systèmes", les interfaces des sous-systèmes et
leurs dépendances (avec d'autres sous-systèmes ou modules).
§ La vue processus
Cette vue est d'une très grande importante dans les
environnements multitâches ; elle montre :
o La décomposition du système en termes de
processus (tâches);
o les interactions entre les processus (leur communication);
o la synchronisation et la communication des activités
parallèles (threads).
§ La vue de
déploiement
Cette vue très importante dans les environnements
distribués, décrit les ressources matérielles et la
répartition du logiciel dans ces ressources :
o la disposition et nature physique des matériels,
ainsi que leurs performances,
o l'implantation des modules principaux sur les noeuds du
réseau,
o les exigences en termes de performances (temps de
réponse, tolérance aux fautes et pannes...).
§ La vue utilisateur
Cette vue (dont le nom exact est "vue des cas d'utilisation"),
guide toutes les autres. Dessiner le plan (l'architecture) d'un système
informatique n'est pas suffisant, il faut le justifier ! Cette vue
définit les besoins des clients du système et centre la
définition de l'architecture du système sur la satisfaction (la
réalisation) de ces besoins. A l'aide de scénarios et de cas
d'utilisation, cette vue conduit à la définition d'un
modèle d'architecture pertinent et cohérent. Cette vue est la
"colle" qui unifie les quatre autres vues de l'architecture. Elle motive les
choix, permet d'identifier les interfaces critiques et force à se
concentrer sur les problèmes importants.
3.4. Les diagrammes
UML
UML n'est pas une méthode (i.e. une
description normative des étapes de la modélisation) : ses
auteurs ont en effet estimé qu'il n'était pas opportun de
définir une méthode en raison de la diversité des cas
particuliers. Ils ont préféré se borner à
définir un langage graphique qui permet de représenter, de
communiquer les divers aspects d'un système d'information (aux
graphiques sont, bien sûr, associés des textes qui expliquent leur
contenu). UML est donc un métalangage car il fournit les
éléments permettant de construire le modèle qui, lui, sera
le langage du projet.
Il est impossible de donner une représentation
graphique complète d'un logiciel, ou de tout autre système
complexe, de même qu'il est impossible de représenter
entièrement une statue (à trois dimensions) par des photographies
(à deux dimensions). Mais il est possible de donner sur un tel
système des vues partielles, analogues chacune à une
photographie d'une statue, et dont la juxtaposition donnera une idée
utilisable en pratique sans risque d'erreur grave.
Les versions d'UML 1.x proposaient neuf (09) diagrammes.
UML 2.0 en a rajouté quatre. Ces treize types de
diagrammes représentent autant de vues distinctes pour
représenter des concepts particuliers du système d'information.
Ils se répartissent en deux grands groupes :
Diagrammes structurels ou diagrammes statiques (UML
Structure)
· diagramme de classes (Class diagram)
· diagramme d'objets (Object diagram)
· diagramme de composants (Component diagram)
· diagramme de déploiement (Deployment
diagram)
· diagramme de paquetages (Package diagram)
rajouté par UML 2.0
· diagramme de structures composites (Composite
structure diagram) rajouté par UML 2.0
Diagrammes comportementaux ou diagrammes dynamiques
(UML Behavior)
· diagramme de cas d'utilisation (Use case
diagram)
· diagramme d'activités (Activity
diagram)
· diagramme d'états-transitions (State machine
diagram)
· diagrammes d'interaction (Interaction diagram)
o diagramme de séquence (Sequence diagram)
o diagramme de communication (Communication diagram)
o diagramme global d'interaction (Interaction overview
diagram) rajouté par UML 2.0
o diagramme de temps (Timing diagram) rajouté par
UML 2.0
Ces diagrammes, d'une utilité variable selon les cas, ne
sont pas nécessairement tous produits à l'occasion d'une
modélisation. Les plus utiles pour la maîtrise d'ouvrage sont les
diagrammes d'activités, de cas d'utilisation, de classes, d'objets, de
séquence et d'états transitions. Les diagrammes de composants, de
déploiement et de communication sont surtout utiles pour la
maîtrise d'oeuvre à qui ils permettent de formaliser les
contraintes de la réalisation et la solution technique. Dans la suite
nous allons présenter les diagrammes utilisés dans notre
modélisation.
3.4.1. Diagramme de
classes
Le diagramme de classes est considéré comme le
plus important de la modélisation orienté objet et le seul
obligatoire lors d'une telle modélisation. Il montre la structure
interne d'un système à mettre en place. Il permet de fournir une
représentation abstraite des objets du système qui vont interagir
ensemble pour réaliser les cas d'utilisation. Il est important de noter
qu'un même objet peut très bien intervenir dans la
réalisation de plusieurs cas d'utilisation. Les cas d'utilisation ne
réalisent donc pas une partition des classes du diagramme de classes. Un
diagramme de classes n'est donc pas adapté (sauf cas particulier) pour
détailler, décomposer, ou illustrer la réalisation d'un
cas d'utilisation particulier. Il s'agit d'une vue statique car on ne tient pas
compte du facteur temporel dans le comportement du système. Le diagramme
de classes modélise les concepts du domaine d'application ainsi que les
concepts internes créés de toutes pièces dans le cadre de
l'implémentation d'une application. Chaque langage de Programmation
Orientée Objets donne un moyen spécifique d'implémenter le
paradigme objet (pointeurs ou pas, héritage multiple ou pas, etc.), mais
le diagramme de classes permet de modéliser les classes du
système et leurs relations indépendamment d'un langage de
programmation particulier. Les principaux éléments de cette vue
statique sont les classes et leurs relations : association,
généralisation et plusieurs types de dépendances, telles
que la réalisation et l'utilisation.
3.4.2. Diagramme de cas
d'utilisation
Bien souvent, la maîtrise d'ouvrage et les utilisateurs
ne sont pas des informaticiens. Il leur faut donc un moyen simple d'exprimer
leurs besoins. C'est précisément le rôle des diagrammes de
cas d'utilisation qui permettent de recueillir, d'analyser et d'organiser les
besoins, et de recenser les grandes fonctionnalités d'un système.
Il s'agit donc de la première étape UML d'analyse d'un
système.
Un diagramme de cas d'utilisation capture le comportement d'un
système, d'un sous-système, d'une classe ou d'un composant tel
qu'un utilisateur extérieur le voit. Il scinde la fonctionnalité
du système en unités cohérentes, les cas d'utilisation,
ayant un sens pour les acteurs. Les cas d'utilisation permettent d'exprimer le
besoin des utilisateurs d'un système, ils sont donc une vision
orientée utilisateur de ce besoin au contraire d'une vision
informatique.
Il ne faut pas négliger cette première
étape pour produire un logiciel conforme aux attentes des utilisateurs.
Pour élaborer les cas d'utilisation, il faut se fonder sur des
entretiens avec les utilisateurs.
Les éléments des diagrammes de cas d'utilisation
sont :
· Acteur : un acteur est
l'idéalisation d'un rôle joué par une personne externe, un
processus ou une chose qui interagit avec un système.
· Cas d'utilisation : un cas
d'utilisation est une unité cohérente représentant une
fonctionnalité visible de l'extérieur. Il réalise un
service de bout en bout, avec un déclenchement, un déroulement et
une fin, pour l'acteur qui l'initie. Un cas d'utilisation modélise donc
un service rendu par le système, sans imposer le mode de
réalisation de ce service.
· Association : Une association est
le chemin de communication entre un acteur et un cas d'utilisation.
3.4.3. Diagramme de
séquence
Le diagramme de séquence est une représentation
intuitive lorsque l'on souhaite concrétiser des interactions entre deux
entités (deux sous-systèmes ou deux classes d'un futur logiciel).
Ils permettent à l'architecte/designer de créer au fur et
à mesure sa solution. Cette représentation intuitive est
également un excellent vecteur de communication dans une équipe
d'ingénierie pour discuter cette solution.
Les diagrammes de séquence peuvent également
servir à la problématique de test. Les traces d'exécution
d'un test peuvent en effet être représentées sous cette
forme et servir de comparaison avec les diagrammes de séquence
réalisés lors des phases d'ingénierie. Le diagramme de
séquence permet aussi de représenté un
scénario4(*) d'un cas
d'utilisation.
3.4.4. Diagramme
d'activité
Les diagrammes d'activités permettent de mettre
l'accent sur les traitements. Ils sont donc particulièrement
adaptés à la modélisation du cheminement de flots de
contrôle et de flots de données. Ils permettent ainsi de
représenter graphiquement le comportement d'une méthode ou le
déroulement d'un cas d'utilisation.
Les diagrammes d'activités sont relativement proches
des diagrammes d'états-transitions5(*) dans leur présentation, mais leur
interprétation est sensiblement différente. Les diagrammes
d'états-transitions sont orientés vers des systèmes
réactifs, mais ils ne donnent pas une vision satisfaisante d'un
traitement faisant intervenir plusieurs classeurs et doivent être
complétés, par exemple, par des diagrammes de séquence. Au
contraire, les diagrammes d'activités ne sont pas spécifiquement
rattachés à un classeur particulier. Ils permettent de
spécifier des traitements a priori séquentiels et
offrent une vision très proche de celle des langages de programmation
impératifs comme C++ ou Java.
Dans la phase de conception, les diagrammes d'activités
sont particulièrement adaptés à la description des cas
d'utilisation. Plus précisément, ils viennent illustrer et
consolider la description textuelle des cas d'utilisation. De plus, leur
représentation sous forme d'organigrammes les rend facilement
intelligibles et beaucoup plus accessibles que les diagrammes
d'états-transitions.
Les diagrammes d'activités sont également utiles
dans la phase de réalisation car ils permettent une description si
précise des traitements, qu'elle autorise la génération
automatique du code.
3.5. Apports d'UML
2.0
Adopté en Juin 2004, UML2.0 ou UML2 qui est une
révision majeure d'UML1.x, est déjà supporté par un
nombre important d'ateliers UML.
Le tableau ci-dessous synthétise l'ampleur des
changements intervenus entre UML1.4 et UML2.0. Les éléments
nouveaux ou très impactés sont notés "+++", cependant que
les moins impactés sont notés "-".
|
Modèle
|
Degré d'évolution
|
Commentaire
|
|
Flux d'information
|
+++
|
Nouveauté
|
|
Diagramme d'activité
|
+++
|
Extensions et enrichissement pour la modélisation des
processus et "workflow"
|
|
Diagramme d'interaction
|
+++
|
Structuration et Structures de contrôle sur les
diagrammes
de séquence.
|
|
Diagramme de collaboration
|
++
|
Unification avec "parts" et "ports"
|
|
Diagramme de classes
|
++
|
Nouveautés: parts, ports, structure interne
|
|
Diagramme de déploiement
|
+
|
Refonte et généralisation
|
|
Diagramme d'état
|
+
|
Structuration
|
|
Diagramme d'état de protocole
|
+
|
Formalisation, State invariant, pré et post conditions
|
|
Diagramme des cas d'utilisation
|
-
|
Quasi inchangé pour l'utilisateur final.
|
Tableau 2 : Apports
d'UML2
Les diagrammes de séquence (interaction diagram) ont
été totalement refondus, afin de leur donner plus de
précision et de capacité de modélisation. Il est
maintenant possible de décomposer des diagrammes de séquence en
"sous diagrammes de séquence" et d'employer des structures de
contrôle au sein des diagrammes de séquence. Leur extension a
surtout été inspirée par les besoins des domaines des
télécoms, qui doivent exprimer finement des protocoles. Les
diagrammes de collaboration sont peu utilisés par les praticiens
d'UML1.4. Peu s'intéressent donc à leur évolution, qui du
point de vue de la représentation reste stable. Les diagrammes de classe
ont bénéficié de quelques extensions. Dans une grande
majorité de cas, ceux-ci restent inchangés par rapport à
UML1.4. Lorsque des besoins de modélisation architecturale apparaissent,
alors de nouvelles notions sont utilisées, comme par exemple les
composants, les parts et les ports. Les diagrammes de déploiement
corrigent des insuffisances d'UML1.x. Les notions d'artefact permettent de
modéliser la chaîne de production d'une application, en
décidant des éléments gérés et produits,
comme par exemple des librairies ou des exécutables. Les diagrammes
d'état peuvent être structurés et factorisés pour
être réutilisés. On distingue maintenant les diagrammes
d'état de protocole, qui permet de décrire le cycle de vie des
objets. Les diagrammes de cas d'utilisation enfin, ne présentent pas
d'évolutions notables.
Deuxième
partie : Analyse et conception

Cette partie renferme trois chapitres:
Ø Le monde des services pour mobiles : qui
renferme une étude du soubassement infrastructurel des services
(appareil portable et réseaux mobiles) et un aperçu sur les
services existants.
Ø Spécifications détaillées de
notre plateforme : chapitre où nous exprimons de manière
claire et précise ce que nous voulons de notre plateforme ;
Ø Conception de la plateforme : chapitre dans
lequel nous mettons en pratique la démarche de modélisation
choisie pour concevoir la plateforme.

Chapitre 3 : Le monde
des services pour mobiles
Naguère apanage des
opérateurs de téléphonie et constructeurs d'appareils
portables, les applications pour mobiles sont devenues le domaine de
prédilection des majors de l'informatique au nom de la convergence
informatique - télécommunication. Parmi ceux-ci, nous pouvons
citer Microsoft avec son système d'exploitation Windows Mobile, Google
concepteur d'Androïd et Yahoo pour sa suite Yahoo Mobile.
A côté de ces
majors, de nombreux fournisseurs de service ont aussi investi ce secteur. Nous
allons, ci-après, décrire le soubassement infrastructurel de ces
services, ensuite nous décrirons ces services en tant que tels.
I. Définition des
concepts du domaine
1. Le
téléphone mobile
Un téléphone mobile (ou simplement
mobile), également nommé téléphone portable ou
portable (ce qui peut créer des confusions avec
l'
ordinateur
portable), permet de communiquer par voix sans
être relié par câble à un central.
Figure 15 : Architecture
du téléphone mobile
Les sons ne sont pas
transmis directement. La voix est codée puis resynthétisée
au niveau de la réception. D'où les bruits incongrus parfois en
cas de mauvaise réception (bruit de ressorts). La transmission se fait
par
ondes
électromagnétiques avec un
réseau
spécifique. On peut donc communiquer de tout
lieu où une antenne de relais capte les émissions de l'appareil
utilisé.
Depuis son apparition à aujourd'hui, le
téléphone portable a énormément
évolué. C'est parti d'un objet très simple juste pour
téléphoner, à un objet très complexe qui devient
maintenant télévision. On parle de Smartphones ou
téléphones intelligents.
Cependant l'utilisation de certaines
fonctionnalités repose sur la disponibilité d'un réseau
approprié.
2. Les réseaux
téléphoniques : une infrastructure évolutive pour une
stratégie orientée services
Plusieurs types de réseau se sont
succédés dans le monde de la téléphonie, chacun
apportant des améliorations dans la qualité de service par
rapport à son prédécesseur. Nous allons décrire
dans cette section les principaux réseaux qui ont marqué la
téléphonie et mettre en évidence l'amélioration du
débit mobile à travers leur succession.
2.1. Le Réseau
GSM
2.1.1. Introduction au
standard GSM
Le réseau GSM (Global System for Mobile communications)
constitue au début du 21ème siècle le standard de
téléphonie mobile le plus utilisé. Successeur du Radiocom
2000 depuis le 28 juillet 2000, il s'agit d'un standard de
téléphonie dit « de seconde
génération » (2G) car, contrairement
à la première génération de réseau de
téléphones portables, les communications fonctionnent selon un
mode entièrement numérique.
Il existe d'autres standards 2G tels que le
CDMA (Code Division Multiple Access), utilisant une technique
d'étalement de spectres permettant de diffuser un signal radio sur une
grande gamme de fréquences et le TDMA (Time Division
Multiple Access), utilisant une technique de découpage temporel des
canaux de communication, afin d'augmenter le volume de données transmis
simultanément
Baptisé « Groupe Spécial
Mobile » à l'origine de sa normalisation en 1982, le GSM est
devenu une norme internationale nommée « Global System for
Mobile communications » en 1991. Il utilise les bandes de
fréquences 900 MHz et 1800 MHz. On parle alors de GSM 900 ou GSM 1800
(appelé aussi DCS 1800) suivant la bande utilisée.
La norme GSM autorise un débit maximal de 9,6 kbps, ce
qui permet de transmettre la voix ainsi que des données
numériques de faible volume, par exemple des messages textes
(SMS, pour Short Message Service) ou des messages
multimédias (MMS, pour Multimedia Message
Service).
2.1.2. Notion de réseau
cellulaire
Les réseaux de téléphonie mobile sont
basés sur la notion de cellules, c'est-à-dire
des zones circulaires se chevauchant afin de couvrir une zone
géographique.
Figure 16 :
Disposition des cellules dans un réseaux
Les réseaux cellulaires reposent sur l'utilisation d'un
émetteur-récepteur central au niveau de chaque cellule,
appelée « station de base » (en
anglais Base Transceiver Station, notée BTS).
Plus le rayon d'une cellule est petit, plus la bande passante
disponible est élevée. Ainsi, dans les zones urbaines fortement
peuplées, des cellules d'une taille pouvant avoisiner quelques centaines
de mètres seront présentes, tandis que de vastes cellules d'une
trentaine de kilomètres permettront de couvrir les zones rurales.
Dans un réseau cellulaire, chaque cellule est
entourée de 6 cellules voisines (c'est la raison pour laquelle on
représente généralement une cellule par un hexagone). Afin
d'éviter les interférences, des cellules adjacentes ne peuvent
utiliser la même fréquence. En pratique, deux cellules
possédant la même gamme de fréquences doivent être
éloignées d'une distance représentant deux à trois
fois le diamètre de la cellule.
2.1.3. Architecture du réseau
GSM
Dans un réseau GSM, le terminal de l'utilisateur est
appelé station mobile. Une station mobile est
composée d'une carte SIM (Subscriber Identity
Module), permettant d'identifier l'usager de façon unique, et d'un
terminal mobile, c'est-à-dire l'appareil de l'usager (la plupart du
temps un téléphone portable).
Les terminaux (appareils) sont identifiés par un
numéro d'identification unique de 15 chiffres appelé
IMEI (International Mobile Equipment Identity).
Chaque carte SIM possède également un numéro
d'identification unique (et secret) appelé IMSI
(International Mobile Subscriber Identity). Ce code peut être
protégé à l'aide d'une clé de 4 chiffres
appelés code PIN.
La carte SIM permet ainsi d'identifier chaque utilisateur,
indépendamment du terminal utilisé lors de la communication avec
une station de base. La communication entre une station mobile et la station de
base se fait par l'intermédiaire d'un lien radio,
généralement appelé interface air (ou
plus rarement interface Um).
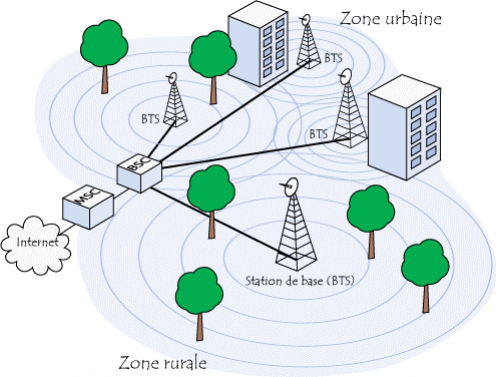
Figure 17 :
Architecture du réseau GSM
L'ensemble des stations de base d'un réseau cellulaire
est relié à un contrôleur de stations (en
anglais Base Station Controller, noté BSC),
chargé de gérer la répartition des ressources. L'ensemble
constitué par le contrôleur de stations et les stations de base
connectées constituent le sous-système radio (en
anglais BSS pour Base Station Subsystem).
Enfin, les contrôleurs de stations sont eux-mêmes
reliés physiquement au centre de commutation du service
mobile (en anglais MSC pour Mobile Switching
Center), géré par l'opérateur
téléphonique, qui les relie au réseau
téléphonique public et à internet. Le MSC appartient
à un ensemble appelé sous-système
réseau (en anglais NSS pour Network
Station Subsystem), chargé de gérer les identités des
utilisateurs, leur localisation et l'établissement de la communication
avec les autres abonnés.
Le MSC est généralement relié à
des bases de données assurant des fonctions
complémentaires :
· Le registre des abonnés locaux
(noté HLR pour Home Location Register): il
s'agit d'une base de données contenant des informations (position
géographique, informations administratives, etc.) sur les abonnés
inscrits dans la zone du commutateur (MSC).
· Le Registre des abonnés
visiteurs (noté VLR pour Visitor Location
Register): il s'agit d'une base de données contenant des
informations sur les autres utilisateurs que les abonnés locaux. Le VLR
rapatrie les données sur un nouvel utilisateur à partir du HLR
correspondant à sa zone d'abonnement. Les données sont
conservées pendant tout le temps de sa présence dans la zone et
sont supprimées lorsqu'il la quitte ou après une longue
période d'inactivité (terminal éteint).
· Le registre des terminaux (noté
EIR pour Equipement Identity Register) : il s'agit
d'une base de données répertoriant les terminaux mobiles.
· Le Centre d'authentification
(noté AUC pour Authentification Center) :
il s'agit d'un élément chargé de vérifier
l'identité des utilisateurs.
Le réseau cellulaire ainsi formé est
prévu pour supporter la mobilité grâce à la gestion
du handover, c'est-à-dire le passage d'une cellule à une
autre.
Enfin, les réseaux GSM supportent également la
notion d'itinérance (en anglais roaming),
c'est-à-dire le passage du réseau d'un opérateur à
un autre.
2.1.4. Conclusion sur le réseau
GSM
La mise en place d'un réseau GSM (en mode circuit)
permettait principalement à un opérateur de proposer des services
de type « voix » à ses clients en donnant
l'accès à la mobilité tout en conservant un
interfaçage avec le réseau fixe RTC (Réseau
Téléphonique Commuté) existant. Délaissé au
profit de nouvelles architectures du fait de sa faible capacité à
transmettre des données numériques, il constitue néanmoins
la base architecturale de tous ses successeurs.
2.2. Le réseau
GPRS
2.2.1. Introduction au
standard GPRS
Le standard GPRS (General Packet Radio
Service) est une évolution de la norme GSM, ce qui lui vaut parfois
l'appellation GSM++ (ou GMS 2+). Etant donné qu'il s'agit d'une norme de
téléphonie de seconde génération permettant de
faire la transition vers la troisième génération (3G), on
parle généralement de 2.5G pour classifier le standard GPRS.
Le GPRS permet d'étendre l'architecture du standard
GSM, afin d'autoriser le transfert de données par paquets, avec des
débits théoriques maximums de l'ordre de 171,2 kbit/s (en
pratique jusqu'à 114 kbit/s). Il vient ajouter un certain nombre de
« modules » sur le réseau GSM sans changer le
réseau existant.
Grâce au mode de transfert par paquets, les
transmissions de données n'utilisent le réseau que lorsque c'est
nécessaire. Le standard GPRS permet donc de facturer l'utilisateur au
volume échangé plutôt qu'à la durée de
connexion, ce qui signifie notamment qu'il peut rester connecté sans
surcoût.
Aussi le standard GPRS utilise l'architecture du réseau
GSM pour le transport de la voix, et propose d'accéder à des
réseaux de données (notamment internet) utilisant le protocole IP
ou le protocole X.25. Le réseau est donc constitué de routeurs
IP.
Le GPRS permet de nouveaux usages que ne permettait pas la
norme GSM, généralement catégorisés par les classes
de services suivants :
· Services point à point (PTP),
c'est-à-dire la capacité à se connecter en mode
client-serveur à une machine d'un réseau IP,
· Services point à multipoint (PTMP),
c'est-à-dire l'aptitude à envoyer un paquet à un groupe de
destinataires (Multicast).
2.2.2. Architecture du
réseau GPRS
L'intégration du GPRS dans une architecture GSM
nécessite l'adjonction de nouveaux noeuds réseau appelés
GSN(GPRS Support Nodes) situés sur un réseau
fédérateur (backbone) :
· le SGSN (Serving GPRS Support
Node, soit en français Noeud de support GPRS de service),
routeur permettant de gérer les coordonnées des terminaux de la
zone et de réaliser l'interface de transit des paquets avec la
passerelle GGSN.
· le GGSN (Gateway GPRS Support
Node, soit en français Noeud de support GPRS passerelle),
passerelle s'interfaçant avec les autres réseaux de
données (internet). Le GGSN est notamment chargé de fournir une
adresse IP aux terminaux mobiles pendant toute la durée de la connexion.
2.2.3. Qualité de service
Le GPRS intègre la notion de Qualité de Service
(noté QoS pour Quality of Service),
c'est-à-dire la capacité à adapter le service aux besoins
d'une application. Les critères de qualité de service sont les
suivants : priorité, fiabilité, délai,
débit.
2.2.4. L'acheminement
en mode paquet
Lorsque le mobile transmet des données vers un terminal
fixe, les données sont transmises via le BSS (BTS + BSC) au SGSN qui
envoie ensuite les données vers le GGSN qui les route vers le
destinataire.
Le routage vers des terminaux (terminal mobile vers terminal
mobile ou terminal fixe vers terminal mobile) utilise le principe
d'encapsulation et des protocoles tunnels (partie grise sur la figure
Figure 18 : Architecture du réseau
GPRS). Les données reçues par le GGSN sont transmises au SGSN
dont dépend le mobile destinataire.

Figure 18 : Architecture du réseau
GPRS
Ainsi les données recueillies en protocole IP de
l'extérieur via un routeur IP pourront être communiquées
dans des paquets X25 par le principe du tunnel encapsulation -
décapsulation. On parle de protocole PDP (Packet Data Protocol),
l'encapsulation consiste ainsi à placer une unité de protocole A
dans une unité de protocole B sans que ce dernier ne se préoccupe
du format des données transportées.
2.2.5. Les apports du
réseau GPRS
Le GPRS peut être vu comme un réseau de
données à part entière qui dispose d'un accès radio
tout en réutilisant une partie du réseau GSM. Les débits
fournis permettent d'envisager des applications comme la consultation de sites
internet ou le transfert de fichiers en mode FTP (File Transfert Protocol).
Dans la première version du GPRS seul un service de
transmission point à point (PTP - Point To Point) a été
proposé. Une information envoyée par un terminal vers un
terminal.
Les services points à multi-points (PTM- Point To
Multi-point) - une information envoyée d'un fournisseur de contenus vers
plusieurs terminaux - seront ensuite proposés à des
communautés ou des zones géographiques. On parle de PTP
Broadcast.
GPRS consolide enfin le service de messagerie entre les
terminaux.
2.2.6. Conclusion sur
le réseau GPRS
Le réseau GPRS permet de considérer le
réseau GSM comme un réseau à transmission de
données par paquets avec un accès radio. Le réseau GPRS
est compatible avec des protocoles IP et X.25. Des routeurs
spécialisés SGSN et GGSN sont introduits sur le réseau.
La transmission par paquet sur la voie radio permet
d'économiser la ressource radio : un terminal est susceptible de
recevoir ou d'émettre des données à tout moment sans qu'un
canal radio soit monopolisé en permanence comme c'est le cas en
réseau GSM.
La mise en place d'un tel réseau permet à un
opérateur de proposer de nouveaux services de type Data avec un
débit de données plus de 10 fois supérieur au débit
maximum du GSM (114 Kbps contre 9,6 kbps).
Baptisé réseau 2,5G, le GPRS a été
amélioré par un facteur quatre (4) par la norme EDGE (Enhanced
Data Rates for Global Evolution), présentée pour l'occasion comme
2.75G devenant ainsi une étape vers les réseaux de données
plus évolués nommés 3G.
2.3. Le réseau
UMTS
Les spécifications IMT-2000 (International Mobile
Telecommunications for the year 2000) de l'Union Internationale des
Communications (UIT), définissent les caractéristiques de la
3G (troisième génération de
téléphonie mobile). Ces caractéristiques sont les
suivantes :
· un haut débit de transmission :
o 144 Kbps avec une couverture totale pour une utilisation
mobile,
o 384 Kbps avec une couverture moyenne pour une utilisation
piétonne,
o 2 Mbps avec une zone de couverture réduite pour une
utilisation fixe.
· une compatibilité mondiale,
· une compatibilité des services mobiles de
3ème génération avec les réseaux de seconde
génération,
La 3G propose d'atteindre des débits supérieurs
à 144 kbit/s, ouvrant ainsi la porte à des usages
multimédias tels que la transmission de vidéo, la
visio-conférence ou l'accès à internet haut débit.
Les réseaux 3G utilisent des bandes de fréquences
différentes des réseaux précédents : 1885-2025
MHz et 2110-2200 MHz.
La principale norme 3G utilisée en Europe et en Afrique
s'appelle UMTS (Universal Mobile Telecommunications
System), utilisant un codage W-CDMA (Wideband Code
Division Multiple Access). La technologie UMTS utilise la bande de
fréquence de 5 MHz pour le transfert de la voix et de données
avec des débits pouvant aller de 384 kbps à 2 Mbps.
2.3.1. Les
équipements d'un réseau UMTS
La mise en place du réseau UMTS implique la mise en
place de nouveaux éléments sur le réseau
2.3.1.1. Le Node
B
Le Node B est une antenne. Répartis
géographiquement sur l'ensemble du territoire, les Nodes B sont au
réseau UMTS ce que les BTS sont au réseau GSM. Les Nodes B
gèrent la couche physique de l'interface radio. Le Node B régit
le codage du canal, l'entrelacement, l'adaptation du débit et
l'étalement.
Les Node B communiquent directement avec le mobile sous
l'interface dénommée Uu6(*).
2.3.1.2. Le RNC (Radio
Network Controller)
Le RNC est un contrôleur de Node B. le RNC est encore
ici l'équivalent du BSC dans le réseau GSM. Le RNC contrôle
et gère les ressources radio en utilisant le protocole RRC (Radio
Ressource Control) pour définir les procédures de communication
entre mobiles (par l'intermédiaire des Nodes B) et le réseau.
Le RNC s'interface avec le réseau pour les
transmissions en mode paquet et en mode circuit.
Le RNC est directement relié à un Node B. il
gère alors :
· Le contrôle de charge et de congestion des
différents Node B
· Le contrôle d'admission et d'allocation des
codes pour les nouveaux liens radio (entrée d'un mobile dans la zone de
cellules gérées...)
Il existe deux types de RNC :
· Le Serving RNC qui sert de passerelle vers le
réseau
· Le Drift RNC qui a pour fonction principale le routage
des données
NB : L'ensemble des Node B et des RNC constitue
l'équivalent de la sous architecture BSS vue précédemment
en réseau GSM. En réseau UMTS, on parlera de sous architecture
UTRAN7(*).
2.3.2. Utilisation des
architectures des réseaux existants
Le réseau coeur de l'UMTS s'appuie sur les
éléments de base des réseaux GSM et GPRS. Le réseau
coeur est en charge de la commutation et du routage des communications (voix et
données) vers les réseaux externes. Dans un premier temps le
réseau UMTS devrait s'appuyer sur le réseau GPRS.
Le réseau coeur se décompose en deux
parties : le domaine circuit et le domaine paquet.
2.3.2.1. Le domaine
circuit
Le domaine circuit permet de gérer les services temps
réels dédiés aux conversations téléphoniques
(vidéo-téléphonie, jeux vidéo, streaming8(*), applications
multimédia). Ces applications nécessitent un temps de transfert
rapide. Le débit du mode domaine circuit est de 384kbps.
L'infrastructure s'appuie sur les principaux éléments du
réseau GSM : MSC/VLR (base de données existantes) et le
GMSC9(*) afin d'avoir une
connexion directe vers le réseau externe.
2.3.2.2. Le domaine
paquet
Le domaine paquet permet de gérer les services non
temps réels. Il s'agit principalement de la navigation sur l'Internet,
de la gestion de jeux en réseaux et de l'accès ou l'utilisation
des e-mails. Ces applications sont moins sensibles au temps de transfert. C'est
la raison pour laquelle les données transitent en mode paquet. Le
débit du domaine paquet est sept fois plus rapide que le mode circuit,
environ 2Mbits/s. L'infrastructure s'appuie sur les principaux
éléments du réseau GPRS : SGSN (base de
données existantes en mode paquet GPRS, équivalent des MSC/VLR en
réseau GSM) et le GGSN (équivalent du GMSC en réseau GSM)
qui joue le rôle de commutateur vers le réseau Internet et les
autres réseaux publics ou privés de transmission de
données.
2.3.3. Les apports du
réseau UMTS
Le réseau UMTS permet à l'opérateur de
proposer à ses abonnées des services innovants. Le GSM
répond aux attentes en termes de communication de type voix et le
réseau GPRS répond aux attentes en termes d'échanges de
données en complément du réseau GSM. L'avènement
des réseaux UMTS sonne l'ère du multimédia portable.
2.3.4. Migration vers
le tout IP
A terme le réseau coeur UMTS pourrait migrer vers une
solution complète IP à condition d'apporter des solutions aux
problèmes de l'IP en termes de service (QoS). Il y a fort à
parier que les opérateurs migreront vers un réseau unique
(domaine paquet et domaine circuit réunis) avec l'utilisation de plus en
plus fréquente de la VOIP10(*).
2.3.5. Conclusion sur
le réseau UMTS
Le réseau UMTS est complémentaire aux
réseaux GSM et GPRS. Le réseau GSM couvre les
fonctionnalités nécessaires aux services de type voix en un mode
circuit, le réseau GPRS apporte les premières
fonctionnalités à la mise en place de services de type Data en
mode paquets, et l'UMTS vient compléter ces deux réseaux par une
offre de services Voix et Data complémentaires sur un mode paquet.
La mise en place d'un réseau UMTS va permettre à
un opérateur de compléter son offre existante par l'apport de
nouveaux services en mode paquet complétant ainsi les réseaux GSM
et GPRS. Face à la convergence très forte entre la voix et la
donnée, l'UMTS ou 3G semble être le réseau de communication
du futur avec sa normalisation au niveau mondial et l'idée d'un
accès aux technologies de l'information et de la communication depuis
n'importe quel endroit couvert de la planète.
II. Les services existants
dans le domaine du mobile
L'évolution du GSM vers l'UMTS est une évolution
technologique poussée par une évolution - marché avec des
demandes orientées service. Il existe deux approches des
services :
· Les services « Telco
centric » destinés à l'opérateur :
ici un fournisseur apporte une solution permettant de réduire des frais
de fonctionnement, de réaliser des économies
d'échelle...). Ici le client du fournisseur de service est
l'opérateur.
· Les services « end user
centric » : des services ou des applications
développés par l'opérateur et ses fournisseurs en vue de
définir un service pour l'abonné (nouveau service,
amélioration de la qualité réseau). Ici le client est
l'abonné.
Nous analyserons dans la suite les services
« end user centric ».
Dans ce type de services, plusieurs acteurs participent
à la création de la valeur pour l'utilisateur final.
1. Les acteurs
principaux

Figure 19 :
Chaîne de valeur des services mobiles end user centric
1.1.
L'opérateur
Un opérateur télécom est une
entité administrative indépendante. Un opérateur, un MNO
(Mobile Network Operator) gère un réseau, un PLMN (Public Land
Mobile Network). L'opérateur est en charge de trois grandes
missions :
· Il gère les abonnés, ses clients
· Il gère ses propres infrastructures radio et
réseau
· Il assure l'interconnexion avec les autres
réseaux nationaux ou internationaux (on parle dans ce cas de roaming
lorsqu'un abonné d'un pays A se rend dans un pays B)
La politique d'un opérateur télécoms
consiste à trouver de nouvelles sources de revenus autres que le canal
« Voix ». Les réseaux de troisième
génération doivent permettre de générer de
nouvelles sources de revenus sur de nouveaux business models11(*) « Data ».
Dans cette optique, l'opérateur peut proposer d'autres services.
1.2. Le fournisseur de
services
Les services à valeur ajoutée sont fournis, en
interne, par les opérateurs de téléphonie mobile
eux-mêmes ou par un tiers fournisseur de SVA (FSAV ou VASP12(*)), également connu sous
le nom de fournisseur de contenu (CP13(*)). Les VASPs sont généralement
connectés à l'opérateur en utilisant des protocoles comme
SMS peer-to-Peer Protocol (SMPP), soit en se connectant directement au centre
de service de messages courts (SMSC) ou, de plus en plus, à une
passerelle de messagerie qui permet à l'opérateur de mieux
contrôler et de prendre en charge les contenus distribués sur son
réseau.
Ils deviennent de plus en plus des éditeurs
d'applications pour mobiles pour le compte des opérateurs.
1.3. L'abonné ou
utilisateur final
Il est le dernier maillon de la chaine de valeur. Il est
détenteur d'un terminal et est abonné à un
opérateur pour le compte duquel il génère un
ARPU14(*) en
utilisant ses services ou ceux proposés par les VASP.
2. L'état des
lieux
Quatre catégories de services sont
définies :
· Communication : permettant
d'entrer en communication au sens large (voix, SMS, WAP)
· SVA : services additionnels
permettant d'accéder à de l'information ou des jeux
· M-commerce : services permettant
un contact e-commerce avec le milieu bancaire et de faire des transactions
financières.
· Service localisés :
ensemble d'applications qui, à l'aide du mobile, permettent de localiser
l'abonné pour l'assister et le surveiller
Le SVA (VAS en anglais) est un terme télécom qui
désigne les services qui ne sont pas coeurs de métiers, par
extension désigne tous les services qui ne sont pas des services de
voix.
De manière conceptuelle, c'est un service additionnel
qui permet de stimuler l'utilisation du téléphone et par
conséquent permet à l'opérateur d'augmenter l'ARPU.
A ce titre le SMS dépasse largement, de par son
utilisation, les autres technologies (WAP, MMS).
Au Sénégal, par exemple, 435 millions de SMS ont
été échangés en 2007 selon l'ARTP15(*). Cela est en grande partie
dû à deux raisons :
· une appropriation du mobile par la population
· de nombreux SVA basés sur le SMS.
Voici quelques statistiques de l'ARTP justifiant ce chiffre
:
|
Téléphonie mobile
|
déc.-06
|
mars-07
|
juin-07
|
sept.-07
|
déc.-07
|
|
Parc total
|
2 982 623
|
3 378 272
|
3 319 616
|
3 434 142
|
4 122 867
|
|
Croissance nette trimestrielle
|
341 512
|
395 649
|
-58 656
|
114 526
|
688 725
|
|
Croissance en %
|
12,93%
|
13,27%
|
-1,74%
|
3,45%
|
20,06%
|
|
Taux de pénétration
|
28,19%
|
31,93%
|
31,38%
|
32,46%
|
38,97%
|
Tableau 3 : Evolution
du parc mobile au Sénégal entre décembre 2006 et
décembre 2007
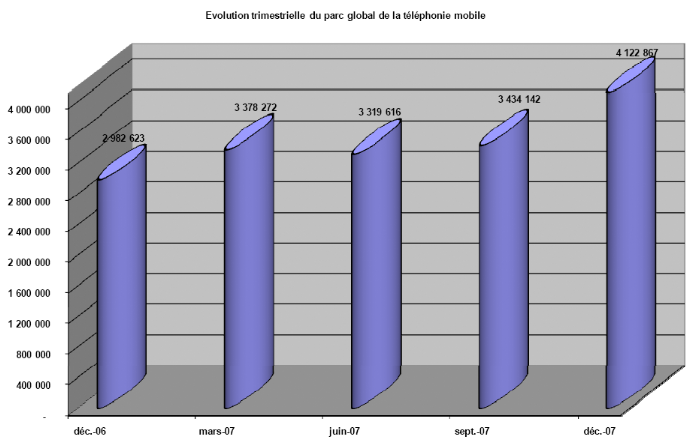
Figure 20 : Evolution
trimestrielle du parc global de la téléphonie mobile
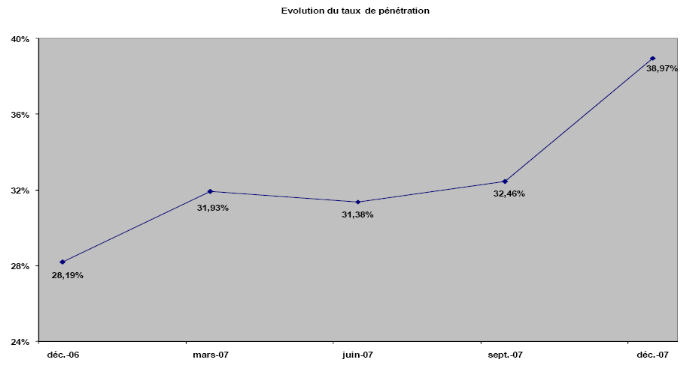
Figure 21 : Evolution
du taux de pénétration du mobile au
Sénégal
Sources des 3 dernières illustrations : ARTP -
OBSERVATOIRE DE LA TELEPHONIE MOBILE, données chiffrées au 31
décembre 2007
Dans le monde, les acteurs historiques du web traditionnel ont
investi le marché du mobile pour accompagner les premiers pas de
l'internet mobile. On entend ainsi parler de portails mobiles tels que Yahoo
Go, Google Mobile, MSN Mobile, AOL Mobile qui visent à apporter la
meilleure expérience possible de l'Internet aux milliards de
consommateurs mobiles dans le monde.
Des cybermarchands ont aussi commencé à se
rapprocher des mobinautes16(*) même si les usages commerciaux du
téléphone tardent à décoller : le marché de
la publicité sur mobile est aujourd'hui encore embryonnaire tandis que
le marché du m-commerce reste limité aux biens digitaux à
faible valeur monétaire (logos et sonneries principalement).
Pour booster l'internet mobile en général, et le
m-commerce en particulier, 2SI compte mettre en place :
- un service de sauvegarde et de restauration du
répertoire d'un abonné
- et un service de vente de tickets sur le mobile de
l'abonné :
Il est à noter que la qualité de ces services,
qui transportent de plus en plus de données, est fortement liée
aux réseaux qui les supportent.
|
services
|
2G
|
2.5G
|
3G
|
|
Fichier E-mail (10Ko)
|
8 secondes
|
0.7 seconde
|
0.04 seconde
|
|
Page web (9Ko)
|
9 secondes
|
0.8 seconde
|
0.04 seconde
|
|
Fichier texte (40Ko)
|
33 secondes
|
3 secondes
|
0.2 seconde
|
|
Rapport (2Mo)
|
28 minutes
|
2 minutes
|
7 secondes
|
|
Clip vidéo (4Mo)
|
48 minutes
|
4 minutes
|
14 secondes
|
Tableau 4 : Les temps
de réalisation des services suivant les types de
réseau
Sources : UMTS - Forum 2001
Ce tableau montre la réalité de l'utilisation de
quelques services. En vert les temps d'accès aux services jugés
« convenables », en rouge, ceux qui sont
« inconcevables ». L'accès rapide aux fichiers de
l'ordre de dizaines de Mo ne peut se concevoir sans un réseau 3G.

Chapitre 4 :
Spécifications détaillées de notre plateforme
Dans un contexte réseau favorable, avec une
clientèle demandeuse, 2SI propose deux types de services dans sa
plateforme :
I. Le service de
sauvegarde de répertoire
Les terminaux mobiles stockent des données importantes
telles que des contacts, des agendas ou bien des listes de tâches.
Cependant ces données peuvent être perdues dès que le
terminal est endommagé ou perdu. Les abonnés ont ainsi besoin de
sauvegarder leurs données et de les récupérer au besoin.
1.
Présentation
SOS-PIN, du nom du service à développer par 2SI,
permettra d'assurer la pérennité des données personnelles.
Il permettra à un abonné de stocker ses données à
partir de n'importe où sur le réseau et de les
récupérer au besoin. Ce service nécessitera l'installation
d'une application, sur le mobile du client, chargée de communiquer avec
l'application installée sur le serveur de l'autre côté du
réseau.
2. L'application
cliente
L'application cliente permet de lancer, au gré de
l'utilisateur du mobile, le processus d'échange de données. Elle
adopte différents comportements selon le mode d'échange entre le
mobile et le serveur. Dans le cas d'une communication "client vers serveur"
(sauvegarde), cette application est chargée de collecter, arranger
et envoyer les données situées sur le terminal.
Dans le cas d'un échange "serveur vers client"
(restauration), elle est chargée de récupérer les
données envoyées par le serveur, de les comparer aux
données existantes et de stocker les bonnes données en
évitant toute redondance.
3. L'application
serveur
Elle est chargée de communiquer avec le client mobile.
Selon les modes d'échanges, elle récupère les
données envoyées par le mobile ou renvoie au client mobile ses
données stockées auparavant. Elle est aussi chargée
d'attribuer à chaque client un espace de stockage de ses
données.
Au terme d'un échange de données entre le
serveur et le client, la base de données cliente et l'espace de stockage
réservé par le serveur à ce client sont identiques. Ce
processus s'appelle la synchronisation.

Figure 22 :
Architecture fonctionnelle Synchronisation
II. Le service de
billetterie dématérialisée
Dans ce service, toutes les ressources seront
localisées sur le réseau. Il n'est pas besoin d'installer une
application sur le terminal mais ce dernier doit avoir une configuration
minimale requise.
Ce service est appelé M-ticketing pour
mobile-ticketing.
1.
Présentation
Dans un souci de faciliter l'accès à de grands
spectacles ou à certains endroits au grand public, les
téléphones mobiles peuvent jouer le rôle de porte-billet
électronique en lieu et place du traditionnel billet en papier.
M-ticketing consiste alors en la
dématérialisation des billets de spectacles, transport, etc.
Un ticket est un billet attestant un paiement et donnant droit
à un service, à l'entrée dans un établissement ou
à l'accès à un moyen de transport.
Dans ce qui suit, nous considérerons le cas où
le ticket donne accès à un événement. Ces
événements sont regroupés par type et il existe une ou
plusieurs catégories de tickets donnant accès aux
différents événements d'un même type, chaque
événement définissant ses propres prix par
catégorie.
La dématérialisation est la
transformation d'un flux de documents, ainsi que les traitements qui
lui sont appliqués, en flux et traitements numériques. Elle
consiste à mettre en oeuvre des moyens électroniques pour
effectuer des opérations de traitement, d'échange et de stockage
d'informations sans support papier. Elle n'a aucun effet sur le contenu de ces
informations qui restent ce qu'elles sont indépendamment de la forme
que prend leur support.
En partant du constat que le portable accompagne son
propriétaire partout, il peut jouer facilement le rôle de
porte-billet électronique où les billets sont affichés
à l'écran sous forme de code barres comme celui figurant sur la
majorité des produits en vente dans le commerce.
Après une transaction effectuée à partir
d'un mobile habilité ou sur Internet, le billet est envoyé sur le
terminal du client sous la forme d'un SMS-image ou d'un MMS (selon les
caractéristiques du portable de l'abonné).
En se débarrassant du support papier, ce service
génère plus de confort pour le client. Celui-ci peut en effet
effectuer sa commande jusqu'au dernier moment (contrairement à la vente
à distance de billets papier qui nécessite de s'y prendre
à l'avance). De plus, il facilite le contrôle
d'accès : il suffit juste de faire passer l'écran du mobile
devant un lecteur code barres.
Ce service, outre qu'il est accessible à partir du web,
compte s'appuyer sur le modèle existant de vente de crédit de
recharge où un détaillant (le mobile habilité cité
ci-haut) initie la transaction.
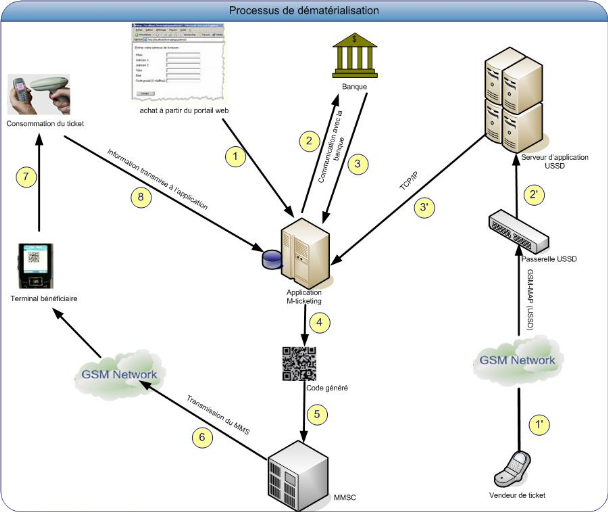
Figure 23 : Architecture
fonctionnelle MTicket
NB : les numéros sur la figure indiquent
l'ordre chronologique des actions effectuées dans ce service.
2. Identification des
modules
L'identification des modules nous permettra de dégager
les tâches à faire, de les planifier et de faire les choix
technologiques nécessaires à leur réalisation.
2.1. Portail web pour
l'achat d'un ticket
A partir de ce portail, un utilisateur pourra acheter autant
de tickets qu'il le désire. Il devra renseigner les numéros de
téléphone des bénéficiaires, les
événements, et les catégories. Il devra en plus renseigner
son numéro de carte bancaire pour le paiement. Ce portail propose, en
outre, à ses visiteurs une vue globale sur l'ensemble des
événements pris en compte.
2.2. Système de paiement en
ligne
Dans le cas de l'achat à partir du portail web, notre
application devra communiquer avec un système de paiement en ligne qui
se chargera d'autoriser la transaction.
2.3.
Génération du code barres
Ce module permettra de générer, de
manière sécurisée, les images (codes barres 1D17(*)) qui représentent les
tickets à partir de numéros reçus en entrée. Ces
numéros seront aussi générés selon un algorithme
précis.
2.4. Envoi du
ticket
Ce module permettra d'envoyer un SMS image ou MMS selon la
compatibilité du terminal du bénéficiaire. Le MMSC de
l'opérateur sera mis en contribution.
2.5. Validation du
ticket
Le bénéficiaire fait passer son terminal sous un
lecteur de code barres. Un dispositif léger récupère
l'information (le numéro du ticket) et informe notre application que ce
ticket vient d'être consommé.
Pour des raisons de mobilité et de performances, nous
utilisons le Workabout Pro G2, un micro-ordinateur prenant en charge
une large gamme de cartes et de modules d'extensions parmi lesquels des
lecteurs de codes barres (voir image 3 ci dessous), des cartes SIM pour
fonction de téléphonie, des extensions WIFI. Elle est
basée sur une architecture (OS) Windows Embedded (Windows CE) ou Windows
Mobile.
1

2

3

Figure 24 : Workabout PRO
G2
2.6. Back
office
Sous forme d'interface web, il sera composé de deux
niveaux :
· Un espace pour l'administration globale du portail :
c'est à ce niveau que sont gérés les
événements (création, suivi, etc)
· Un espace d'administration restreinte à partir
duquel un organisateur ne peut gérer que son événement
2.7. Réception
d'une demande de ticket à partir du serveur d'application de
l'opérateur
Lorsqu'un client désire acheter un ticket à
partir d'un point de vente, le vendeur informe l'opérateur de la
transaction et lui transmet toutes les informations nécessaires
(événement, catégorie, numéro du destinataire) par
USSD. L'opérateur, après avoir vérifié que le
crédit du bénéficiaire est suffisant pour une telle
transaction, informe notre application et lui transmet les paramètres.
L'USSD est un moyen de transmission d'information sur un
réseau GSM, GPRS, UMTS. Il a été défini standard
(standards ETSI, 3GPP [1] [2] [3]) à l'origine pour la commande de
services supplémentaires spécifiques aux opérateurs. Il
offre aujourd'hui en pratiques des possibilités de services beaucoup
plus vastes (accès à des bouquets de services, consultation des
comptes prépayés ou post payés...).
Il offre aussi une connexion orientée session,
half-duplex et bi-directionnelle entre un terminal mobile et un serveur
applicatif USSD. Les sessions peuvent être ouvertes à l'initiative
du mobile par simple appel d'un code de service (i.e numéros courts avec
des * et des #).
Exemples de codes USSD :
*100#
*100*775790221#
L'USSD utilise le canal de signalisation : il est peu gourmand
en ressources réseaux et donc peu coûteux contrairement au SMS qui
est du type store-and-forward et qui nécessite la présence d'un
SMSC (SMS Center) dans le circuit de traitement. Il peut être
assimilé à telnet alors que le SMS est assimilé au
mail.
Cette technologie est entrain d'être largement
acceptée comme le canal idéal de services tels que l'information
par mobile, le commerce sur mobile et tout autre service qui nécessite
une interaction entre le client et l'application. Comparé à
l'IVR18(*), l'USSD
améliore quantitativement les temps de réponse : de 25
à 7 seconds19(*).
Il est typiquement utilisé comme déclencheur
(trigger) pour invoquer des services. C'est le cas des services de
recharge de crédit ou de consultation de solde.

Chapitre 5 : Conception
de la plateforme
Pour mener à bien la conception, nous allons mettre en
pratique la démarche simplifiée présentée à
la page
29, pour les deux services, en partant des besoins
spécifiés dans le chapitre précédent.
I. Le service de
sauvegarde
1. Les
maquettes

Figure 25 : Maquettes SOS
PIN
La première maquette est une interface de choix. A ce
niveau, l'utilisateur peut choisir de sauvegarder ses données, de les
restaurer ou de paramétrer la période de sauvegarde.
La deuxième maquette résulte du choix de
l'option paramétrage en 1. A partir de cette interface l'utilisateur
peut choisir d'automatiser la sauvegarde de son répertoire soit
automatiquement après l'ajout d'un contact soit périodiquement.
Il peut aussi revenir sur le mode manuel dans lequel il déclenche
lui-même l'opération.
Dans la troisième maquette, l'utilisateur est
invité à confirmer l'opération de sauvegarde ou à
l'annuler.
A l'issue de l'opération, un message de succès
est affiché à l'écran : c'est la dernière
maquette.
2. Fiche descriptive de
cas d'utilisation
Nom : Effectuer une sauvegarde de
données
Objectif : A partir d'un terminal
mobile, l'utilisateur pourra effectuer la sauvegarde de ses données
personnelles dans un serveur distant.
Identification des acteurs
|
Acteurs
|
Description
|
Type
|
|
utilisateur
|
Il déclenche le service
|
Secondaire
|
|
client
|
C'est l'application cliente. Il communique avec l'utilisateur via
des interfaces et avec le serveur
|
Principal
|
|
Serveur
|
Il exécute le service demandé (sauvegarde)
|
Secondaire
|
Tableau 5 : Acteurs du service
Sauvegarde de données
Préconditions
Disponibilité du réseau
Application installée au niveau du terminal client
Scénarii :
Afficher un menu (client)
Choisir un service de sauvegarde (utilisateur)
Afficher une demande de confirmation (client)
Confirmer la demande (utilisateur)
Initialiser client (client)
Initialiser serveur (serveur)
Sauvegarder données (client)
Envoyer accusé (serveur)
Notifier utilisateur (client)
Post conditions : La base de
données du serveur de sauvegarde est à jour
Variantes et cas d'erreurs :
En 4. Annulation de la demande : l'application affiche le
menu principal
En 6. Le serveur ne répond pas à l'initialisation
du client, le cas se termine
En 7. Les données n'existent pas sur le mobile ou les
données ne sont pas bien récupérées :
l'application affiche un message d'erreur, le cas se termine.
Identification des cas d'utilisation
|
Cas d'utilisation
|
Description
|
Acteur
|
Relations entre cas
|
|
1. Choisir service de sauvegarde
|
L'utilisateur choisit le service de sauvegarde
|
utilisateur
|
|
|
2. Initialiser client
|
L'application cliente initie la synchronisation
|
client
|
|
|
3. Initialiser serveur
|
Le serveur est prêt à synchroniser
|
serveur
|
|
|
4. Sauvegarder données
|
Le client envoie les données de son répertoire
|
client
|
Inclut 2.
|
|
5. Envoyer accusé
|
Le serveur signifie au client que l'échange s'est bien
déroulé
|
serveur
|
étend 3.
|
|
6. Notifier utilisateur
|
L'application cliente notifie l'utilisateur
|
client
|
étend 4.
|
Tableau 6 :
Identification des CU du service de sauvegarde
3. Les diagrammes
3.1. Diagramme de cas
d'utilisation
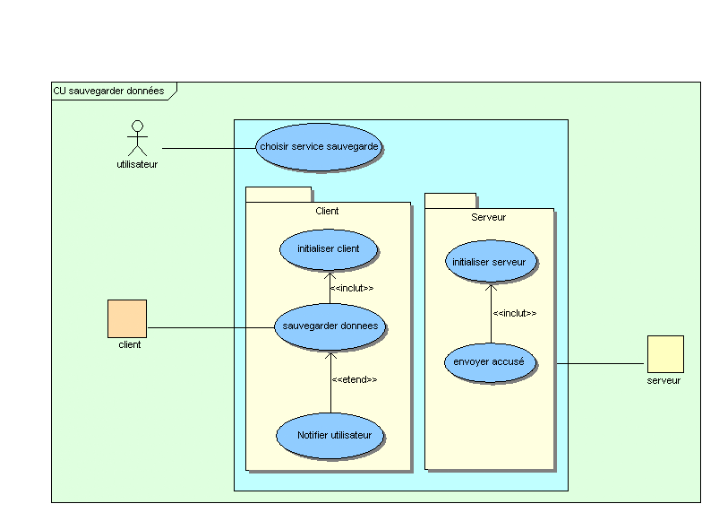
Figure 26 : Diagramme
de CU SOS PIN
3.2. Modèle du
domaine
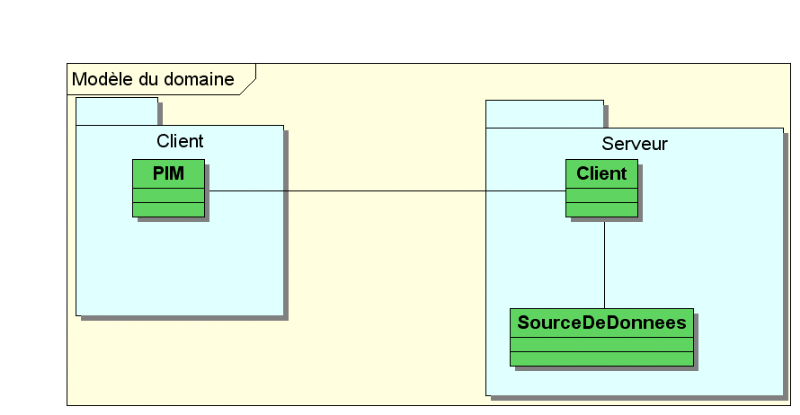
Figure 27 :
Modèle du domaine SOS PIN
3.3. Diagramme de
classes participantes
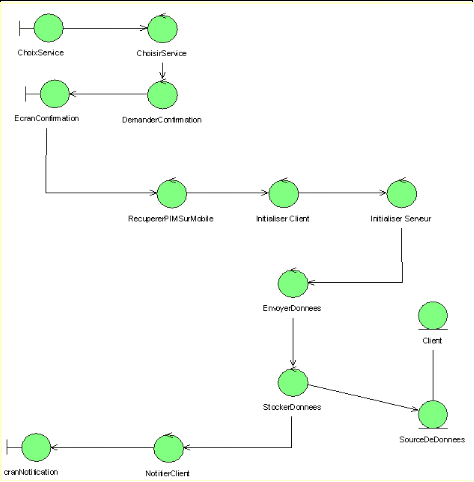
Figure 28 : Diagramme
de classes participantes SOS PIN
3.4. Diagramme de
séquences
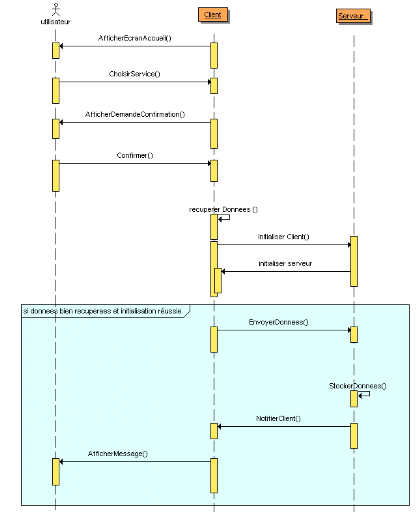
Figure 29 : Diagramme
de séquence SOS PIN
3.5. Diagramme
d'activités
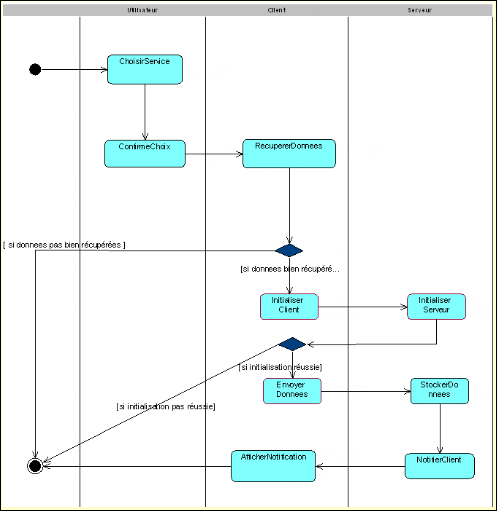
Figure 30 : Diagramme
d'activités SOS PIN
3.6. Diagrammes
d'intéractions
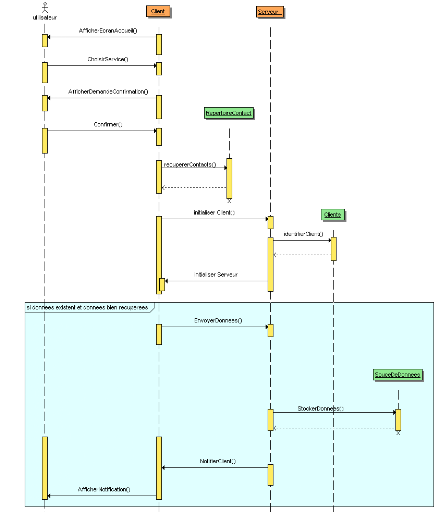
Figure 31 : Diagramme
d'interactions SOS PIN
3.7. Diagrammes de
classes de conception

Figure 32 : Diagramme
de classes de conception SOS PIN
II. Le service de
billetterie dématérialisée
1. Les
maquettes

Figure 33 : Maquette
MTicket - portail web
Le portail web d'achat se divise en 5 zones : 4
latérales et une centrale. En 1, la zone centrale présente une
image des événements pris en compte par l'application.
L'utilisateur peut cliquer sur une image pour accéder aux informations
détaillées de l'événement correspondant et
éventuellement acheter un ticket : ces dernières options
sont accessibles dans la zone centrale de la maquette numéro 2.

Figure 34 : Maquette
MTicket - portail USSD
Ces maquettes définissent l'ordre chronologique du
déroulement de l'achat d'un ticket à partir d'un
détaillant. Dans la première, s'effectue le choix du service.
Ensuite sont choisis l'événement et la catégorie pour
lesquels le ticket est acheté. En fin le numéro de
téléphone du destinataire du ticket est renseigné.
2. Fiche
descriptive
Nom : Acheter du crédit
à partir du portail web
Objectifs : l'acheteur pourra
réserver un ticket qui sera envoyé par MMS sur un mobile
précisé
Identification des acteurs :
|
Acteurs
|
Description
|
Type
|
|
Acheteur
|
C'est le visiteur du portail qui effectue une transaction
|
secondaire
|
|
Client
|
C'est le terminal mobile qui recevra le ticket sous forme
d'image
|
secondaire
|
|
Système de paiement (SP)
|
Il est chargé de contrôler le paiement
|
secondaire
|
|
Serveur MTicket (SM)
|
Il est chargé de générer un ticket et de
l'envoyer au client
|
principal
|
Tableau 7 : Acteurs MTicket
Préconditions :
L'acheteur se présente devant le
portail
Scénarii :
Le système affiche l'écran accueil du portail
L'acheteur choisit l'événement sur lequel porte son
achat
Le système présente un formulaire
L'acheteur remplit le formulaire et valide
Le SP contrôle le paiement
Le système vérifie la compatibilité du
client
Le système génère un ticket
Le système envoie le ticket sous forme de MMS au client
Postconditions :
Le ticket sous forme de code barres s'affiche
sur le terminal client
Variantes :
En 4. l'acheteur ne valide pas le formulaire : le cas se
termine
En 5. le solde de l'acheteur est insuffisant pour la
transaction : le cas se termine
En 6. le client est incompatible : un message est
envoyé au terminal client ; le cas se termine
Identification des cas d'utilisation
|
Cas d'utilisation
|
Description
|
Relation
|
|
1. Choisir ticket
|
L'acheteur choisit le ticket qui lui convient
|
|
|
2. Traiter paiement
|
Le SP contrôle le paiement
|
|
|
3. Vérifier compatibilité terminal client
|
Le SM s'assure que le client peut recevoir un MMS
|
|
|
4. Générer ticket
|
Le SM génère un ticket récupérable
par le client
|
Inclut 3.
|
|
5. Envoyer MMS
|
Le SM envoie le MMS au client
|
Inclut 4.
|
Tableau 8 : CU
MTicket
3. Les diagrammes
3.1. Diagramme de cas
d'utilisation
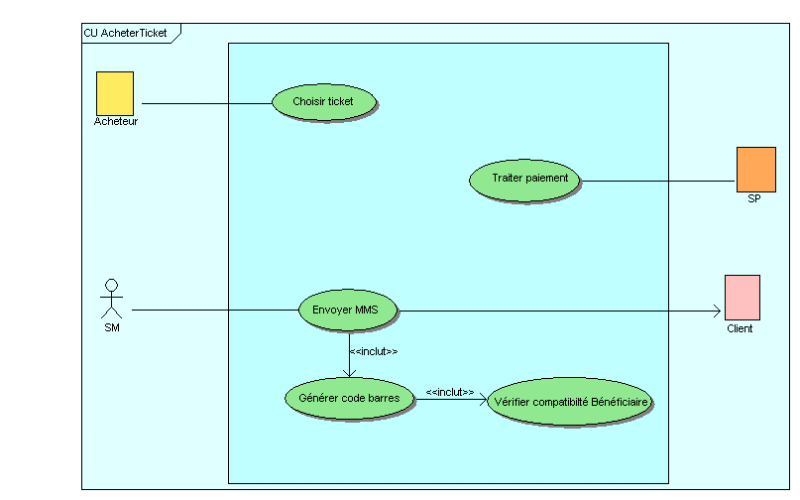
Figure 35 : Diagramme
CU MTicket
3.2. Modèle du
domaine
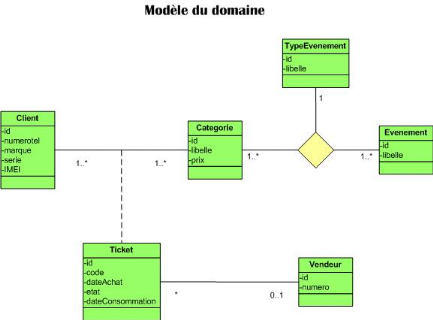
Figure 36 :
Modèle du domaine MTicket
3.3. Diagramme de
classes participantes
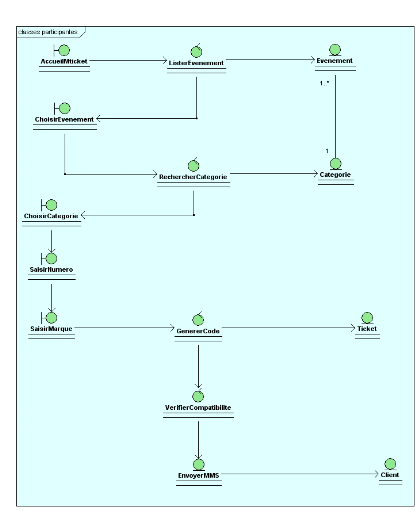
Figure 37 : Diagramme
de classes participantes MTicket
3.4. Diagramme de
séquences
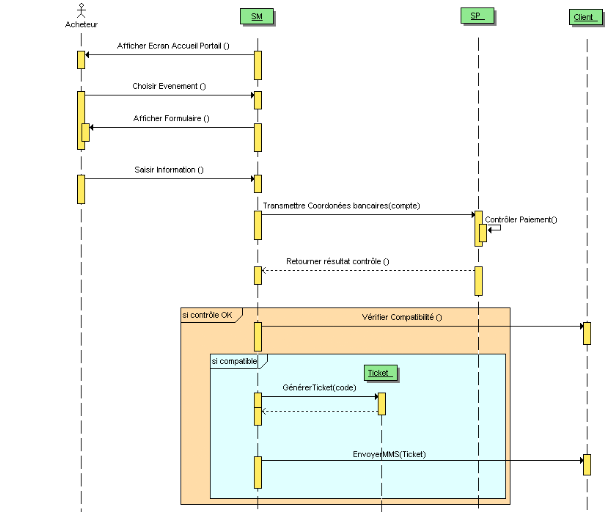
Figure 38 : Diagramme
de séquence MTicket
3.5. Diagramme
d'activités
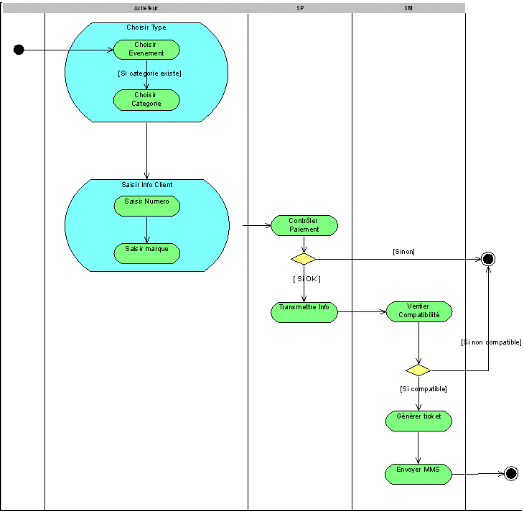
Figure 39 : Diagramme
d'activités MTicket
3.6. Diagrammes
d'intéractions
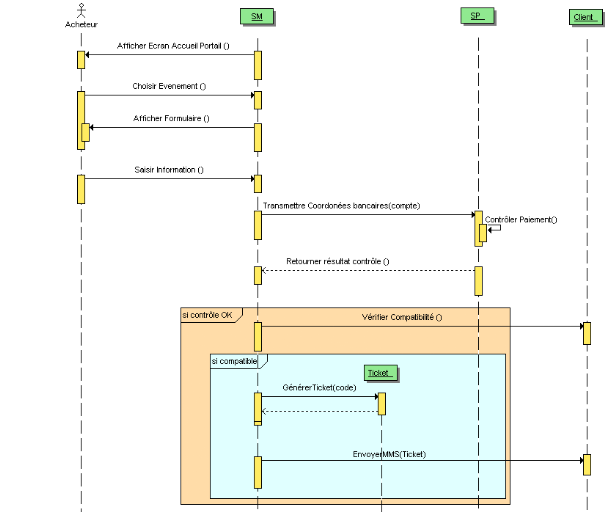
Figure 40 : Diagramme
d'intéractions MTicket
3.7. Diagrammes de
classes de conception
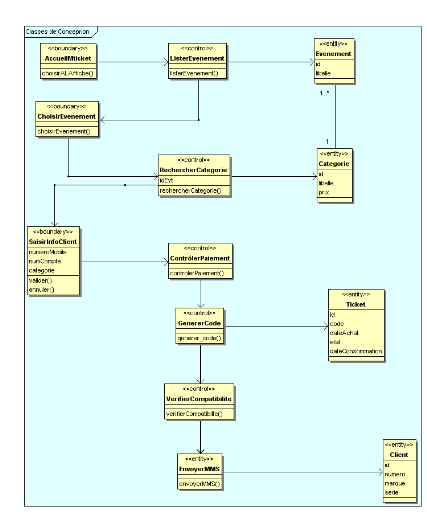
Figure 41 : Diagramme
de classes de conception
Troisième
partie : Mise en place de la solution

Cette partie est composée de deux chapitres qui portent
sur :
Ø Le choix des outils et technologies
d'implémentation : pour la réalisation de chaque tâche, on
présente les différentes possibilités et on en retient une
que l'on va utiliser ;
Ø L'implémentation de la plateforme : Ici
nous présenterons dans les détails la réalisation des
différentes tâches identifiées.

Chapitre 6 : Choix des
outils et des technologies d'implémentation
I. Les plateformes
applicatives
Une plate-forme applicative se présente sous la forme
d'une suite logicielle comprenant l'ensemble des briques nécessaires au
déploiement d'une application client/serveur de haut niveau à
savoir : une application ou plusieurs applications serveur accessibles -
généralement en mode Web - depuis des postes de travail ou des
terminaux Internet.
A chaque élément de la suite son
rôle :
· Le serveur d'applications
gère le noyau de l'application avec pour objectif central
de répondre aux requêtes des utilisateurs s'y connectant.
· Le serveur de données
stocke l'ensemble des données métier et techniques
nécessaires au bon fonctionnement de l'application.
· L'infrastructure de portail a
pour but d'orchestrer les droits d'utilisation de l'application et de
gérer la personnalisation des données et des accès
fonctionnels.
· Le serveur
d'intégration prend en charge les
éventuels flux de données ou composants à prendre en
compte, en provenance d'autres serveurs d'applications ou systèmes.
Dans ce domaine, deux architectures sophistiquées
mènent une rude bataille. Il s'agit de J2EE (pour Java 2 Enterprise
Edition) et .Net. Cependant la combinaison Apache/Mysql/PHP, adossée
à un système d'exploitation, brille aussi de mille feux.
1. L'architecture
J2EE
Lancé par Sun en 1998, autour du langage Java, il
s'articule autour d'une infrastructure standardisée, couvrant les
principales couches d'une plate-forme applicative (serveur d'applications,
infrastructure de portail et serveur d'intégration), ainsi que les liens
avec la base de données (ou persistance). J2EE est aujourd'hui
implémenté par les principaux éditeurs de serveurs
d'applications du marché, parmi lesquels on compte IBM, Oracle et
BEA.
J2EE est portable d'un système d'exploitation à
l'autre. Un point fort qui, dès l'origine, a été mis en
avant par Sun comme l'une des principales valeurs ajoutées de son
infrastructure. Initialement, Java a d'ailleurs été
élaboré pour répondre précisément à
cet enjeu. Dans la même logique, J2EE facilite également le
portage d'une application Java entre serveurs d'applications, pour peu que ces
derniers répondent aux spécifications définies par Sun
dans ce cadre.
2. La plateforme
.Net
Le modèle .Net (lire DotNet) a été
lancé par Microsoft en 2001 en réponse à J2EE. Cette
plate-forme, rebaptisée en 2003 Windows Server System, s'adosse à
la manière de J2EE à une logique de développement et de
déploiement de nouvelle génération (orientée
objets). Son principal point fort : aussi structurante et riche
fonctionnellement que son équivalent Java, elle n'en offrirait pas moins
une approche de travail beaucoup plus simple. Basé sur C#, .Net offre un
autre avantage de taille sur J2EE : son noyau permet d'exécuter des
applications développées dans n'importe quel langage, à
partir du moment où Microsoft a décidé de le supporter.
C'est notamment le cas avec le Python ou encore le Cobol.
Cependant c'est une plateforme trop propriétaire et ne
tourne que sous Windows.
3. Les environnements
basés sur AMP
PHP est un langage de scripts. Il est
interprété, par conséquent il ne nécessite pas
d'être compilé pour obtenir un objet, un exécutable avant
d'être utilisable (comme en C par exemple).
PHP est un module
supporté par le serveur web frontal Apache, le plus
répandu dans le monde (plus de 70% des serveurs web), il est donc
développé pour être facilement utilisable via ce serveur et
s'interface très facilement à MySQL.
Suivant le système d'exploitation utilisé qui
assure l'attribution des ressources aux autres composants de la plateforme, on
parle de LAMP, WAMP, MAMP, SAMP respectivement pour Linux, Windows, Macintosh,
Solaris.
4.
Interopérabilité J2EE, .NET, PHP
Offrir davantage d'ouverture et de compatibilité entre
systèmes informatiques est depuis longtemps un secteur en constante
évolution.
L'avènement des technologies Internet n'a fait
qu'étendre ce vieux concept à des applications distribuées
au delà d'un réseau d'entreprise. Le secteur économique
des TIC (Technologies de l'Information et de la Communication) est bien
évidemment à l'écoute de ce genre de problématique
car fournir des services informatiques intégrables directement, et de
manière transparente, au sein de SI existants intéresse
nécessairement des acteurs, existants ou futurs, de ce marché.
Dans l'absolu, l'interopérabilité consiste
à utiliser conjointement des fonctionnalités d'applications
basées sur des technologies différentes (J2EE, .NET, PHP, C++,
etc.). Une des motivations peut provenir de la volonté de consommer
depuis ses applications des services métier gérés par des
partenaires externes (opérateurs, établissements bancaires,
etc.). C'est un dialogue bilatéral entre deux systèmes.
Le véritable objectif est alors de permettre cette
interopérabilité le plus simplement possible, en abstrayant
à la fois aux utilisateurs finaux et aux développeurs la
complexité et la diversité des environnements.
L'administration technique du SI ne doit cependant pas s'en
trouver complexifiée outre mesure. Il est important que les
équipes responsables de cette administration puissent facilement prendre
le contrôle et gérer ces solutions.
Prenons l'exemple de notre application de MTicketing qui a
besoin de communiquer avec le SI de l'opérateur et, par moment, avec les
établissements bancaires.
Au delà de simples appels de fonctions sur des
applications de ces différents SI, des besoins de sécurité
(paiement en ligne), de gestion transactionnelle (réservation) ainsi que
de transmission de données « brutes » (le code barre
en image) doivent être gérés. Et tout cela de la
manière la plus transparente possible et avec la plus grande
facilité d'administration !
II. Les plateformes de
développement pour clients mobiles
La bataille que se livre actuellement Sun et Microsoft au
sujet des environnements de développement a un impact direct sur les
plateformes embarquées proposées de part et d'autre. D'un
coté, Sun propose Java 2 Micro Edition (J2ME) à
travers son architecture J2SE, et de l'autre, Microsoft
propose Smart Device Extensions (SDE)
basé sur sa plate-forme .NET. Si jusqu'au début
du millénaire, ce marché était essentiellement
représenté par des acteurs très spécifiques de
l'embarqué autour de multiples technologies propriétaires, il
semble acquis aujourd'hui, à la lueur des évènements, que
ces deux leaders mondiaux du logiciel que sont Microsoft et Sun seront
à l'origine des prochaines générations de plateformes
embarquées. Ce recentrage autour de Java et
.NET ne sera pas sans effets. D'une part, l'utilisation de
technologies standards et largement adoptées par l'industrie va tendre
à réduire les risques d'enfermement technologiques et
pérenniser les investissements. D'autre part, cela aura un impact
indéniable en termes de réduction des coûts car les outils,
les compétences et les architectures matérielles se
résumeront à ces deux plateformes maîtrisées. Il va
de soi que le mieux placé sur le terrain des outils de
développement aura un avantage indéniable sur celui de la
production.
A partir de ce constat, nous avons choisi de défricher
les deux solutions prédominantes du moment. Dans un premier temps, nous
nous attacherons à présenter les deux architectures concurrentes,
puis nous porterons notre choix sur l'une d'elles que nous présenterons
plus en détail.
1. La diversité
des périphériques
La mise en place d'une plate-forme technique commune à
tous les périphériques est une opération très
délicate. Chaque appareil possède des spécificités
qui obligent les applications à s'adapter à différentes
caractéristiques d'affichage ou de pointage. Microsoft et Sun n'ont pas
du tout la même approche concernant ce problème. Si J2ME s'attache
à unifier par le biais d'APIs les différents
types d'appareils, Microsoft préfère proposer un ensemble de
briques logicielles dans le cadre de son système d'exploitation
embarqué : Windows CE.

Figure 42 :
Diversité des périphériques embarqués
La liste suivante démontre la variété des
terminaux ciblés par les deux plate-formes :
· Téléphone cellulaire,
Smartphone (Nokia, Ericsson, Alcatel, Siemens, ...)
· Assistant personnel, PDA (Palm Pilot,
PocketPC, ...)
· Appareil d'imagerie numérique
(Caméscope numérique, Appareils photo numérique, ...)
· Appareil automatique industriel (Robot
dans une chaîne d'usinage, Affichage embarqué dans les
automobiles,...)
· Application Internet/Media
· Portail d'entrée automatique
· Appareil de paiement, Web
Pad, Windows Thin Client, ...
Toute la difficulté de concevoir des technologies pour
l'embarqué réside dans cette complexité inhérente
à la diversité de l'offre. Nous verrons que cela aura un impact
important sur la conception interne des environnements proposés de part
et d'autre.
2. L'architecture Java
2 Micro Edition (J2ME)
2.1. La
problématique multi-plateformes et multi-périphériques de
java
Java 2 Micro Edition ou Java ME ou Java
Platform Micro Edition est l'édition de la plateforme Java à
destination de l'électronique grand public. Cette architecture technique
a donc pour but de fournir un socle de développement aux applications
embarquées. L'intérêt étant de proposer toute la
puissance d'un langage tel que Java associé aux services proposés
par une version bridée du Framework J2SE : J2ME.
Les terminaux n'ayant pas les mêmes capacités en termes de
ressources que les ordinateurs de bureau classiques (mémoire, disque et
puissance de calcul), la solution passe par la fourniture d'un environnement
allégé afin de s'adapter aux différentes contraintes
d'exécution. Cependant, comment faire en sorte d'intégrer la
diversité de l'offre à un socle technique dont la cible n'est pas
définie à priori ? La solution proposée par J2ME consiste
à regrouper par catégories certaines familles de produits tout en
proposant la possibilité d'implémenter des routines
spécifiques à un terminal donné. L'architecture J2ME se
découpe donc en plusieurs couches :
1. Les profils : Ils permettent à
une certaine catégorie de terminaux d'utiliser des
caractéristiques communes telles que la gestion de l'affichage, des
évènements d'entrées/sorties (pointage, clavier, ...) ou
des mécanismes de persistance (Base de données
légère intégrée). Ces profils sont soumis à
spécifications suivant le principe du JCP (Java
Community Process)
2. Les configurations : Elles
définissent une plateforme minimale en termes de services concernant un
ou plusieurs profils donnés.
3. Les machines virtuelles : En fonction
de la cible, la machine virtuelle pourra être allégée afin
de consommer plus ou moins de ressources
4. Le système d'exploitation :
L'environnement doit s'adapter au système d'exploitation existant
(Windows CE, Palm Os, SavaJe, ...)
Cette architecture en couches a pour but de factoriser pour
des familles de produits données un ensemble d'APIs permettant à
une application de s'exécuter sur plusieurs terminaux sans modification
de code.
2.2. Les
configurations
Une configuration est un environnement d'exécution Java
complet constitué de trois éléments :
· Une machine virtuelle Java (JVM) pour
exécuter le code Java.
· Le code natif qui compose l'interface avec le
système sous-jacent.
· Un assortiment de classes Java
exécutables.
Pour pouvoir utiliser une configuration sur une machine
donnée, elle doit remplir certaines conditions minimales définies
dans les spécifications officielles. Bien qu'une configuration ne
fournisse pas un environnement Java complet, l'ensemble des classes du
noyau est normalement très petit et doit être enrichi d'autres
classes supplémentaires fournies par les profils de J2ME ou
grâce à l'implémenteur de configuration. En particulier,
les configurations ne définissent aucune classe destinée à
l'interface utilisateur.
J2ME définit deux configurations : la
CLDC et la CDC
2.2.1. La
CLDC
CLDC signifie Connected Limited Device Configuration.
Ce qui peut être traduit par configuration limitée pour appareils
connectés.
Cette configuration s'adresse aux terminaux légers tels
que les téléphones mobiles ou les assistants personnels. Ces
périphériques étant limités en termes de
ressources, l'environnement classique ne permet pas de respecter les
contraintes d'occupation mémoire liées à ces appareils.
J2ME définit donc un ensemble d'API spécifiques à CLDC et
destinées à utiliser les particularités de chaque terminal
d'une même famille (profil). La liste suivante résume l'ensemble
de ses caractéristiques :
· Minimum de 160Ko à 512Ko de
RAM, processeur 16 ou 32 bits, vitesse 16Mhz
ou plus
· Alimentation limitée, prise en
charge d'une batterie
· Connexion réseau non
permanente, sans fil.
· Interface graphique limitée ou inexistante
Définie par un sous-ensemble de classes Java
s'exécutant dans la KVM (KiloByte Virtual Machine), la
CLDC s'inscrit donc dans une logique d'économie de ressources avec une
KVM de 40 à 80 Ko s'exécutant 30 à 80% moins vite qu'une
JVM normale. Il n'y a aucun compilateur Just-In-Time20(*) ni même de prise en
charge des nombres flottants. La KVM omet d'autres caractéristiques
importantes telles que la finalisation. Cependant l'assortiment de classes
exécutables du noyau ne représente qu'une toute petite fraction
des classes du noyau de J2SE - classes de base des paquetages
java.lang, java.io et java.util -
accompagnées de quelques classes supplémentaires issues du
nouveau paquetage javax.microedition.io. Quant au Multi-threading et
au Ramasse miettes, ils demeurent supportés.
La CLDC n'intègre pas, non plus, la gestion des
interfaces graphiques, la persistance ou les
particularités de chaque terminal. Ces aspects ne sont pas de sa
responsabilité. La matrice suivante résume les packages et
classes présents dans cette couche :
|
Liste des packages de CLDC
|
|
Java.io
|
Fournit la gestion des flux d'entrées/sorties
|
|
Java.lang
|
Classes de base du langage (types, ...)
|
|
Java.util
|
Contient les collections et classes utilitaires
|
|
Javax.microedition.io
|
Classes permettant de se connecter via TCP/IP
|
Tableau 9 : Les packages de
CLDC
Le package javax.microedition.io fait partie des briques non
incluses dans J2SE tel qu'illustré dans la figure ci-après. Il
gère les connexions distantes ou entrées/sorties
réseau.
2.2.2. La
CDC
CDC signifie Connected Device Configuration. Ce qui peut
être traduit par configuration pour dispositifs connectés. Elle
spécifie un environnement pour des terminaux connectés de forte
capacité tels que les téléphones à écran, la
télévision numérique, etc.
Les caractéristiques de l'environnement matériel
proposées par la configuration CDC sont :
· Minimum de 512Ko de ROM et
256Ko de RAM, processeur 32 bits
· Une connexion réseau obligatoire
(sans fil ou pas)
· Support des spécifications complètes de la
machine virtuelle Java optimisée, compacte et nommée pour
l'occasion CVM (machine virtuelle C)

Figure 43 : Etendue des
responsabilités de CDC et CLDC dans Java
Cette configuration s'inscrit donc dans le cadre d'une
architecture Java presque complète. C'est la raison pour laquelle elle
requière plus de mémoire que la CLDC et un processeur
plus rapide. La CDC est en fait un sur-ensemble de la CLDC.
2.3. Les
profils
Un profil ajoute à une configuration des classes
spécifiques d'un domaine afin de combler l'absence d'une
fonctionnalité et pour supporter les utilisations spécifiques
d'un dispositif. Par exemple, la plupart des profils définissent des
classes d'interfaces utilisateurs qui permettent de construire des applications
interactives.
Pour pouvoir utiliser un profil, la machine doit satisfaire
à toutes les exigences minimales de la configuration sous-jacente ainsi
qu'à toutes les exigences rendues obligatoires par les
spécifications officielles du profil qui se surajoutent.
Il existe plusieurs profils qui en sont à des stades de
développement variables. Le Mobile Information Device Profile
(MIDP = profil pour dispositifs informatiques mobiles), premier profil
publié, est basé sur la CLDC et conçu pour les
applications tournant sur téléphones
mobiles et les bips interactifs disposant d'un petit
écran, d'une connexion HTTP sans fil et d'une mémoire
limitée. Un autre profil plus évolué basé sur la
CLDC, le Personal Digital Assistant Profile (PDAP = profil
pour assistant numérique personnel), prolonge le MIDP en lui
ajoutant de nouvelles classes et caractéristiques permettant de couvrir
la gamme des appareils de poche plus puissants. En ce qui concerne les profils
de type CDC, le Foundation Profile (FP = profil fondamental)
prolonge la CDC en lui ajoutant des classes de J2SE, le
Personal Basis Profile (PBP = profil personnel de base) prolonge le
FP grâce à l'ajout de classes peu encombrantes
d'interfaces utilisateurs dérivées de l'Abstract Window
Toolkit (AWT = outil qui permet de générer les
fenêtres de dialogue de l'interface utilisateur) et d'un nouveau
modèle d'application, et le Personal Profile prolonge le
PBP avec le support d'applets et des classes d'interfaces utilisateurs
plus encombrantes.
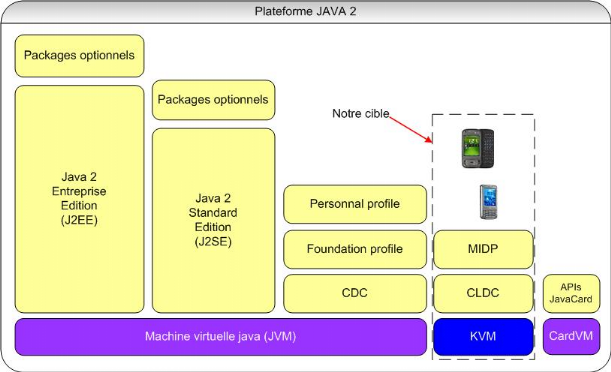
Figure 44 : Plateforme
JAVA 2
2.3.1.
Présentation de MIDP
Le Mobile Information Device Profile (MIDP)
définit un environnement d'exécution pour une classe
d'appareils référencés sous le nom d'appareils mobiles
d'informations (MID = mobile information devices). Cela
correspond aux appareils dotés des caractéristiques minimales
suivantes :
· Suffisamment de mémoire pour exécuter les
applications du MIDP
· Un écran numérique adressable d'au moins 96
pixels de largeur sur 56 pixels de hauteur, qu'il soit monochrome ou
couleur.
· Des pavés numériques, un clavier ou un
écran tactile.
· La capacité d'établir une liaison sans fils
bidirectionnelle.
Il contient des méthodes permettant de gérer
l'affichage, la saisie utilisateur et la
gestion de la persistance (base de données). Il existe
aujourd'hui deux implémentations majeures de profils MIDP : l'une,
plus spécifique, destinée aux Assistants
de type Palm Pilot (PalmOs) et l'autre, totalement générique,
proposée par Sun comme implémentation de
référence (RI).
Voici un tableau présentant les API liés
à ce profil :
|
Liste des packages de MIDP
|
|
javax.microedition.lcdui
|
Fournit la gestion de l'interface utilisateur
(contrôles, ...)
|
|
javax.microedition.midlet
|
Socle technique destiné à gérer le cycle
de vie des midlets
|
|
javax.microedition.rms
|
Base de données persistante légère
|
Tableau 10 : Les packages
de MIDP
L'API lcdui est chargée de gérer
l'ensemble des contrôles graphiques proposés par ce profil. Quant
à la gestion des événements, elle suit le modèle
des listeners du J2SE avec un CommandListener
appelé en cas d'activation d'un contrôle. Pour finir,
rms fournit les routines nécessaires à la prise en
charge d'une zone physique de stockage.
Toute application MIDP est appelée MIDlet et doit
dériver de la classe javax.microedition.midlet. Midlet.
2.3.2. Les
Midlets
Les Midlets sont l'élément principal d'une
application Java embarquée.
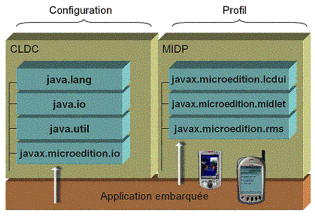
Figure 45 : MIDlet,
CLDC et MIDP
Pour bien saisir leur mode de fonctionnement, il suffit de
prendre comme analogie les Applets ou
les Servlets. Le cycle de vie d'une Applet est
géré par un conteneur, en l'occurrence le Navigateur Web, dont le
rôle est d'interagir avec celle-ci sous la forme de méthodes de
notifications prédéfinies
(init(),paint(),destroyed(),...). Une servlet
possède les mêmes caractéristiques qu'une Applet
excepté le fait que le conteneur est un moteur de servlet (Tomcat,
WebSphere, WebLogic, ...). Quant aux Midlets, ils représentent le
pendant des Applets et des Servlets pour J2ME avec comme conteneur le
téléphone mobile ou l'assistant personnel. Ainsi, en cas de mise
à jour d'une application embarquée, un simple
téléchargement de code Midlet est nécessaire à
partir d'un quelconque serveur. De cette manière, un programme
développé pour un profil donné est en mesure de
s'exécuter sur tous les périphériques correspondant
à cette famille. C'est aussi une manière de découpler le
socle technique des applicatifs puisque le seul lien existant entre les
logiciels embarqués et le terminal est l'API J2ME.
Une MIDlet connaît trois états dans son cycle de
vie : en pause, active et détruite. Une fois créée par le
système d'exploitation du téléphone, son état
devient "en pause". Puis le système invoque la méthode startApp()
qui change l'état en actif. Le retour au premier état a lieu lors
de l'invocation de la méthode pauseApp(). Enfin, à tout moment
l'exécution de la méthode destroyApp() conduit à
l'état détruit. Nous constatons ainsi que la méthode
startApp() peut se voir appelée plusieurs fois au cours du cycle de vie
de l'application. Le constructeur de la MIDlet fera donc office de
méthode main() pour toutes les tâches ne devant s'opérer
qu'une seule fois.

Figure 46 : Cycle de
vie d'une Midlet
3. L'Architecture
Microsoft Windows Embedded
A travers le temps, l'approche de Microsoft concernant le
monde de l'embarqué a considérablement évolué. De
Microsoft Embedded Visual Tools (eVB et C++), nous sommes passé à
la plate-forme .NET et les différents langages qui l'accompagnent
(C#, VB.NET, ...). Même s'il est vrai
que l'engouement autour de cet univers des terminaux légers est
allé croissant dès lors que les PDA et autres
téléphones mobiles ont fait leur apparition, il n'en demeure pas
moins que ce segment de marché a toujours été
délaissé par le géant éditeur de logiciels.
Aujourd'hui, l'offre de Microsoft est essentiellement basée sur son
système d'exploitation embarqué : Windows
CE.
Microsoft Embedded propose une approche plus orientée
« système » de l'embarqué. Un constructeur
désireux d'intégrer un environnement Windows dans un terminal
donné, devra extraire les briques logicielles d'une version standard en
fonction des caractéristiques du récepteur. Par exemple, dans le
cas d'un périphérique sans fil, les composants embedded
« wireless » accompagnés des drivers adéquats
seront proposés à l'intégrateur. Lorsque le terminal
nécessite une base de données embarquée, il suffira de
générer une image du Système
d'exploitation prenant en compte cette contrainte. Bref, Microsoft propose une
panoplie de composants systèmes en tout genre et adaptés à
tout type de besoin, charge ensuite à l'intégrateur de
définir sa propre configuration. Cette approche comparée à
Java est donc sensiblement différente.
Avec l'avènement du Framework .NET, la
partie embarquée de l'offre de Microsoft a subi quelques
évolutions majeures. Ainsi, le .NET Compact Framework
(.NET CF) a fait son apparition au sein de l'architecture avec une philosophie
proche de J2ME pour Java : Un ensemble d'API allégés
permettant de répondre aux exigences des périphériques en
termes de ressources. Mais .NET CF se destine aux plateformes Windows CE.
4. Conclusion
:
J2ME et Microsoft embedded Architecture ont une approche
totalement différente dans leur manière d'aborder le
développement embarqué. Si Java privilégie l'aspect
Multi-périphériques et Multi-OS, Microsoft préfère
concentrer ses efforts sur Windows CE, son système d'exploitation
maison.
Malgré tous ces efforts, force est de constater que la
technologie Microsoft ne parvient pas à rivaliser avec J2ME, ce dernier
conservant de loin la première place en termes de taux de
pénétration sur le terrain des logiciels mobiles. La plupart des
grands constructeurs de téléphones portables au premier rang
desquels figure Nokia demeurent en effet fidèle à
l'infrastructure de Sun. Principal point fort de J2ME : sa
portabilité. Une caractéristique qui le rend des
plus attractifs pour les fournisseurs de services embarqués, qui
cherchent à rendre leurs applications indépendantes des machines
sous-jacentes.
De plus, il est à noter qu'il existe des machines
virtuelles Java permettant d'exécuter une application J2ME sur Windows
CE.
III. Les sources de
données
Une source de données est une installation de stockage
des données. Elle peut être aussi sophistiquée qu'une base
de données complexe, un annuaire ou un entrepôt de données
pour une grande entreprise ou aussi simple qu'un fichier avec des lignes ou des
colonnes. Une source de données peut être localisée sur un
serveur distant ou bien disponible en local sur une machine de bureau.
Une base de données (son abréviation est BD, en
anglais DB, database) est une entité dans laquelle il est possible de
stocker des données de façon structurée et avec le moins
de redondance possible. Ces données doivent pouvoir être
utilisées par des programmes, par des utilisateurs différents.
Afin de pouvoir contrôler les données ainsi que
les utilisateurs, le besoin d'un système de gestion s'est vite fait
ressentir. La gestion de la base de données se fait grâce à
un système appelé SGBD (système de
gestion de bases de données) ou en anglais DBMS (Database management
system). Le SGBD est un ensemble de services (applications logicielles)
permettant de gérer les bases de données,
c'est-à-dire :
· permettre l'accès aux données de
façon simple
· autoriser un accès aux informations à de
multiples utilisateurs
· manipuler les données présentes dans la
base de données (insertion, suppression, modification)
Les systèmes qui emploient le modèle relationnel
pour contrôler la base de données sont nommés SGBDR
(système de gestion de base de données relationnel).
De manière basique, tous les SGBD disponibles sur le
marché intègrent ces fonctionnalités. D'autres raisons
présideront alors au choix de l'un ou de l'autre parmi eux.
Notre étude portera sur deux d'entre eux disponibles en
open source.
1.
MySQL
Disponible sou licence GPL sous Linux, Windows, MacOSX, Unix,
BSD, MySQL en est à sa version 5.0.15 (beta 5.1). Ses principaux
avantages sont :
· Solution très courante en hébergement
public
· Très bonne intégration dans l'environnement
Apache/PHP
· OpenSource
· Facilité de déploiement et de prise en
main.
· Plusieurs moteurs de stockage adaptés aux
différentes problématiques.
Il présente cependant quelques inconvénients :
· Ne supporte pas entièrement des standards SQL-92
· Support incomplet des triggers et procédures
stockées
· Assez peu de richesse fonctionnelle
· Manque de robustesse avec de fortes volumétries
· Pas d'héritage de tables
· Pas de vue matérialisée
· Pas d'ordonnanceur intégré
· Pas de partitionnement
2.
Postgresql
C'est un SGBDR fonctionnant sur des systèmes de type
UNIX et sur Windows. Ses avantages sont :
· Open Source et gratuit
· Fiable et relativement performant, tout en restant simple
d'utilisation
· Supporte la majorité du standard SQL-92 et
possède en plus un certain nombre d'extensions (Java, Ruby, PL-SQL).
· Très riche fonctionnellement, notions
d'héritage de tables, multitude de modules
· Simple d'utilisation et d'administration
· Héritage de tables
Il présente néanmoins quelques
inconvénients :
· Sauvegardes peu évoluées
· Supporte les bases de moyenne importance
· Pas de services Web
· Pas de support XML
· Pas d'ordonnanceur intégré
· Pas de vue matérialisée
· Permissions seulement au niveau de la table, pas au niveau
de la colonne
IV. Les solutions de
synchronisation
La synchronisation offre la possibilité à un
terminal de se connecter à un réseau afin de mettre à jour
à la fois l'information de l'appareil et l'information du réseau
pour que les deux soient identiques et à jour.
Devant la prolifération d'appareils mobiles et de
protocoles propriétaires ainsi que la demande croissante d'accès
à de l'information en situation de mobilité, les
sociétés leader sur le domaine ont compris l'intérêt
de créer un langage standard et universel décrivant les actions
de synchronisation entre les terminaux et les applications. Elles ont
formé un consortium pour sponsoriser cette initiative et pour
créer ce langage.
Actuellement, le consortium SyncML a été
adopté et incorporé à l'Open Mobile Alliance, un
regroupement de plus de 300 sociétés qui supporte plusieurs
projets collaboratifs portant sur les technologies et les protocoles.
1. Le standard
SyncML
1.1. Qu'est ce que
SyncML
SyncML ou Synchronization Markup Language est le
protocole standard, basé sur XML, de synchronisation de données
au travers d'une multitude de réseaux, de plates-formes et de terminaux.
SyncML a été démarré en tant qu'initiative en 2000
par de grandes sociétés comme Ericsson, IBM, Palm Inc., Lotus,
Matsushita Ltd. (Panasonic), Motorola, Nokia, Openwave, Starfish Software,
Psion et Symbian. Leur but était la création d'un langage
universel à partir de la myriade de protocoles de synchronisation
propriétaires utilisés par les appareils mobiles et de fournir un
ensemble complet de fonctionnalités de synchronisation pour les futurs
terminaux. Le consortium a sorti la version 1.0 en décembre 2000. Ils
ont développé de nouvelles fonctionnalités et
résolu les problèmes découverts avec cette version,
finalisant le protocole avec la version 1.1 en février 2002.
Le protocole SyncML a été conçu en
gardant ces objectifs à l'esprit :
· Garder en cohérence deux ensembles de
données
· Être indépendant du transport
· Être indépendant de la donnée
synchronisée (PIM, email, fichier, ....)
SyncML comprend des commandes client et serveur
définies par des DTD.
1.2. Principes de
SyncML
Voici quelques éléments de vocabulaire :
· Client - le terminal mobile, son application et sa base
de données locale.
· Serveur - un système distant communiquant avec
la base de données du système ou de l'application.
· Modifications - les données dans les champs
d'une base de données qui sont modifiées.
· Synchronisation - le client et le serveur
échangent des messages SyncML avec des commandes.
· Package - Balises XML conformes à la DTD de
SyncML décrivant les requêtes ou actions qui doivent être
effectuées par un client ou un serveur SyncML. Un package est un
ensemble d'actions à effectuer.
· Message - La plus petite unité de balise SyncML.
Les grands packages sont découpés en messages
séparés.
· Mapping - Utilisation d'un identifiant
intermédiaire pour lier deux informations. Exemple: Disons que 'vert'
c'est '5', et '5' c'est bien. Qu'est-ce qui est bien ? Si vous
répondez 'vert', vous êtes tombé juste. vous avez
réalisé un mapping !
1.2.1. Messages et
Packages
Un message est un ensemble de commandes SyncML transmises (en
une seule fois) vers le client ou le serveur. La taille maximale d'un message
est définie par la Meta données MaxMessageSize. Si un message
à transmettre dépasse cette taille on le découpe en
plusieurs messages. On parle alors de Multiple Message in Package. Un package
correspond à un ensemble de messages pour effectuer une des
étapes de la synchronisation. Les packages sont les suivants: pkg1 =
initialisation du client (authentification, échange des devinf, des
informations sur les bases à synchroniser), pkg2 = initialisation du
serveur, pkg3 = modification côté client, pkg4 = modification
côté serveur, pkg5 = mis à jour des données et
statuts, pkg6 = mapping des ids client et serveur.
1.2.2. Communication
entre client et serveur
SyncML est basé sur XML mais supporte obligatoirement
un protocole de transport, par exemple HTTP, OBEX21(*) ou WSP22(*). Mais SyncML ne change pas
quelque soit le protocole de transport. Une session SyncML est
constituée de 4 phases :
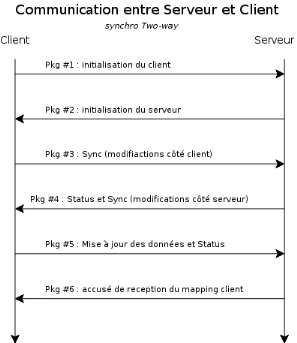
Figure 47 :
Communication SyncML entre client et serveur
1. La phase d'alerte du serveur, qui est
optionnelle et peut être considérée comme une phase de
pré-initialisation. Son principal objectif est de permettre au serveur
d'alerter le client sur une probable session à démarrer.
2. L'initialisation de la synchronisation qui
est un passage obligatoire pour le client et le serveur avant d'entamer une
synchronisation. La première étape est que le client et serveur
parlent le même langage, en s'échangeant l'un et l'autres leurs
capacités (définies par le matériel, comme la
quantité de mémoire, et le protocole définit par la DTD).
La seconde étape est l'identification des bases de données
à synchroniser. Ensuite, les deux doivent décider du type de
synchronisation. La troisième et dernière partie est
l'authentification. Une fois que cette étape à été
complétée avec succès, la synchronisation à
proprement parler peut commencer.
3. L'échange de données :
normalement le client commence par envoyer ses modifications. Le serveur les
reçoit, détecte et résout les conflits avant d'envoyer ses
modifications.
4. La phase de finalisation dans laquelle
s'effectuent le mapping, la mise à jour des ancres et l'envoi
d'accusé de réception.
1.2.3. Authentification
Le client s'identifie puis se met d'accord avec le serveur sur
les principes d'échanges.
1.2.4.
Adressage
L'adressage est réalisé au travers des balises
<Source> et <DocURI>. Un serveur aura une URI du genre
http://www.2si.syncml.com/sync et le terminal mobile client
aura un numéro d'identification IMEI comme ceci
354101000208403.
1.2.5. Mapping ou
Correspondance
SyncML est basé sur l'idée que les clients et
les serveurs peuvent avoir leur propre méthode pour faire correspondre
les informations dans leur base de données. Aussi, les clients et les
serveurs doivent avoir leur propre ensemble d'identifiants uniques.
Par gain de place, certains terminaux mobiles ne peuvent
accepter, en effet, des id trop longs, ils vont alors définir leur
propres id, et envoyer au serveur le mapping à effectuer à l'aide
de la balise <Map>. De cette manière, le mobile ne stocke que l'id
qu'il a choisi (généralement assez court) et le serveur, lui,
stocke les deux, ce qui lui permet de s'adresser au mobile avec l'id que le
mobile connait. Le serveur conserve l'ensemble des id indéfiniment.
Dans les futurs échanges, le mobile utilisera seulement
l'id qu'il connait, et le serveur se chargera d'effectuer les mappings
correspondants.
· Les identifiants locaux uniques (LUID - Locally Unique
Identifiers) sont des nombres assignés par le client à une
donnée dans la base de données locale (comme un champ ou une
ligne). Ce sont des nombres non réutilisables assignés à
ces objets par le client SyncML.
· Les identifiants globaux uniques (GUID - Globally
Unique Identifiers) sont des nombres assignés à une donnée
utilisés dans une base de données distante. Cet identifiant est
assigné par le serveur.
Le serveur va créer une table de correspondance pour
lier les LUID et GUID ensemble.
Données côté client
|
LUID
----
5
|
Data
----
Green
|
Données côté serveur
|
GUID
----
5050505
|
Data
----
Green
|
Correspondance sur le serveur
|
GUID
----
5050505
|
LUID
----
5
|
1.2.6. Journaux de
modification (change logs)
Les change logs sont une manière pour
un dispositif (client ou serveur) de déterminer la liste des
modifications dans la base depuis la dernière synchronisation
1.2.7. Les
ancres
Les ancres servent à savoir si la dernière
synchronisation s'est bien passée. Au début de session, le client
envoie ses ancres (last et next). Le serveur stocke la next du client. A la fin
de la session (s'il n'y pas eu d'interruption), le client met à jour ses
ancres (last = next et il incrémente next). Lors de la prochaine
session, le client envoie son next et last. Le serveur vérifie que le
last du client vaut le next qu'il a stocké précédemment.
Si c'est le cas, c'est OK, on continue. Sinon ça ne va pas du tout et le
serveur peut forcer une slow sync.
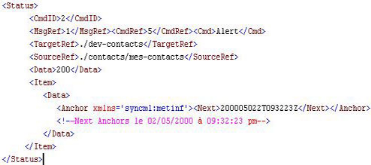
Figure 48 : Exemple d'ancre
SyncML
1.3. Types de
Synchronisation
Dans sa version 1.1, le langage SyncML définit 7 types
de synchronisation. La section ci-dessous définit ces différents
types:
1. Two-way Sync (Synchronisation
bi-directionnelle) - Le client et le serveur s'échangent des
informations relatives aux données modifiées. Le client transmet
les modifications en premier.
2. Slow sync (Synchronisation lente) - Le
client renvoie l'intégralité de ses
données. Le serveur calcule le delta (avec les siennes) et le
renvoie au client. Ce type de synchronisation est généralement
utilisé lors d'une première synchro, lors d'une interruption, ou
lorsque l'une des deux parties le demande.
3. One-way sync, client only (Synchronisation
uni-directionnelle, Client uniquement) - Le client transmet ses
modifications. Le serveur les accepte puis met à jour les données
sans transmettre en retour ses modifications.
4. Refresh sync from client (Synchronisation de mise
à jour avec les donnés du client) - Le client transmet
sa base de données entièrement au serveur. Le serveur remplace la
base de données cible par celle transmise par le client.
5. One-way sync, server only (Synchronisation
uni-directionnelle, Serveur uniquement) - Le serveur transmet ses
modifications au client. celui ci les accepte puis met à jour ses
données locales sans transmettre en retour ses modifications.
6. Refresh sync from server (Synchronisation de mise
à jour avec les donnée du serveur) - Le serveur transmet
l'intégralité des informations de sa base de données. La
base de données du client est entièrement remplacée.
7. Server alerted sync - Le serveur
télé-commande au client d'initier un des modes de synchronisation
présentés ci-dessus. De cette façon, le client est
contrôlé à distance par le serveur.
1.4. Structure d'un
message SyncML
Comme SOAP, il y a deux parties dans un message SyncML, un
en-tête <SyncHdr> et un corps <SyncBody>. L'en-tête
contient des méta-informations sur la requête comme la base de
données cible <Target> et la base de données source
<Source>, les informations d'authentification <Cred>, l'identifiant
de session <SessionID>, l'identifiant du message <MsgID>, et la
déclaration de la version de SyncML <VerDTD>. Le corps contient
les commandes SyncML (les statuts des commandes du message
précédent, et toutes les autres commandes prévues par
SyncML).
Un Exemple de message SyncML
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
|
Tableau 11 : Exemple
de message SyncML
Notez que les lignes {1} et {18} débutent le fichier
SyncML par la balise racine. Ensuite, le SyncHdr est défini par les
lignes {2} et {8}. Il contient :
- les lignes {3,4} qui définissent des informations
concernant la version de SyncML utilisée,
- la ligne {5} définit l'identifiant de session
(sessionID) qui permet d'identifier de façon unique le dialogue qui est
en cours entre le client et le serveur,
- la ligne {6} représente l'identifiant du message
(MsgID) qui permet d'identifier de façon unique cet ensemble de
requêtes (toutes ces balises) qui vont être exécutées
par l'application réceptrice.
- la ligne {7}, on trouve la balise Cred (demande
d'authentification, non détaillée ici) qui fait également
partie de l'entête.
- La ligne {8} est la fermeture du SyncHdr (entête).
Le SyncBody (Corps du message) commence à la ligne {9}.
Dans cette partie du message SyncML, on trouve :
- le statut de l'application/l'appareil {10},
- la source et la cible de la requête (source/target)
{12,13},
- et les actions demandées comme la synchronisation
elle-même entre les lignes {11,16}.
Aux lignes {14,15}, on peut voir les commandes Add
et Replace qui commandent respectivement l'ajout et le remplacement de
données dans la base de donnée cible.
2. Le serveur de
synchronisation
La synchronisation offre la possibilité à un
terminal de se connecter à un réseau afin de mettre à jour
à la fois l'information de l'appareil et l'information du réseau
pour que les deux soient identiques et à jour.
Convaincus de l'utilité de pouvoir disposer, au besoin,
de données à jour sur son mobile, plusieurs éditeurs de
logiciels se sont lancés dans la production d'une panacée :
un serveur de synchronisation où l'information sur les
mobiles serait stockée et centralisée.
On distingue deux grandes catégories de
sociétés positionnées sur ce segment : les pure
players23(*) d'une
part, les éditeurs généralistes d'autre part.
Présents sur le marché depuis quelques années
déjà, les premiers proposent des solutions
généralement basées sur des technologies
propriétaires et principalement articulées autour
d'environnements de développement et d'exécution Java. Les
éditeurs généralistes sont les derniers à explorer
ce domaine.
Dans le monde de l'open source, un produit a
fait le vide derrière lui : il s'agit de Funambol. Ce serveur est
l'implémentation standard, de facto, de l'OMA. Il fournit, en plus du
moteur de synchronisation, des API en C++ ou J2ME, pour le développement
d'applications clientes. Ces API cachent au développeur toute la
complexité de SyncML.
Funambol DS (Data Synchronisation) est contenu dans Tomcat et
gère la communication http, la manipulation des sessions,
l'échange de données avec le client et beaucoup d'autres
fonctionnalités. Son architecture est construite autour du sync
engine (moteur de synchronisation). Il transforme les messages SyncML
reçus des clients et construit les messages destinés aux clients
en guise de réponse. Le moteur de synchronisation permet au
développeur de se focaliser sur la source de données à
synchroniser avec l'application mobile.

Figure 49 :
Architecture du serveur Funambol
La figure ci-dessus montre l'architecture du serveur Funambol
composé de six éléments principaux:
1. L'adaptateur de synchronisation (sync adaptator ou
transport mapper) qui reçoit les messages de SyncML HTTP et les
convertit en une représentation interne qui sera envoyée avec
HTTP.
2. L'input pipeline manager effectue un traitement
supplémentaire du message SyncML entrant. En général il
vérifie si la représentation interne est correcte pour être
traitée par le moteur de synchronisation
3. L'output pipeline manager est similaire au
précédent. Ses traitements se font sur les messages sortants
4. Le moteur de synchronisation est le coeur de Funambol. Il
fournit la fonctionnalité applicative pour le protocole SyncML
5. Le moteur a accès à une source persistante
dans laquelle il stocke les informations qu'il tient entre les sessions sur
l'état de synchronisation des périphériques.
6. La source de synchronisation (sync source) est
utilisée pour accéder à la source de données
à laquelle un appareil mobile synchronise ses données.
L'atout majeur de ce serveur, l'API pour J2ME, se
présente comme suit :
Figure 50 : Architecture de
l'API SyncML J2ME
Une application cliente interagit principalement avec deux
entités de l'API: le SyncManager et le SyncSource. Le
SyncManager est le composant qui gère toute la communication. Il cache
la complexité des processus de synchronisation en fournissant une
interface simple à l'application cliente. Le SyncSource
représente la collection d'objets stockés dans le
répertoire local. Il contient la logique métier du client pour
découvrir les éléments à envoyer au serveur et pour
stocker ceux obtenus à partir du serveur. Le client alimente le
SyncSource avec les éléments changés du côté
client, tandis que le SyncManager l'alimente avec les données
reçues du serveur.
V. Choix des outils
d'implémentation adéquats
Pour chacun de nos deux services, nous aurons à faire
des choix technologiques sur les différents segments de sa
réalisation. Le service formant un tout, malgré son
découpage en modules, un choix sur un segment peut influer sur le choix
dans la réalisation d'un autre module.
Ainsi dans le cas du service de sauvegarde, le choix du
serveur Funambol, basé sur le critère de l'open source et la
fourniture d'APIs, a conditionné l'adoption du J2ME, du reste plus
portable que SDE, comme technologie de développement de l'application
cliente. De plus la disponibilité d'un connecteur à une base de
données MySQL ou un annuaire LDAP fait sortir ces deux sources du lot.
Cependant l'objectif même de la synchronisation, qui consiste à
mettre à jour à chaque transaction le client et le serveur, joue
en défaveur de LDAP prévu pour être plus sollicité
en lecture qu'en écriture.
Le standard SyncML, supporté par HTTP, sera
adopté comme langage de synchronisation car les APIs fournis par le
serveur de synchronisation cachent, derrière leur utilisation, la
manipulation complexe de ce langage.
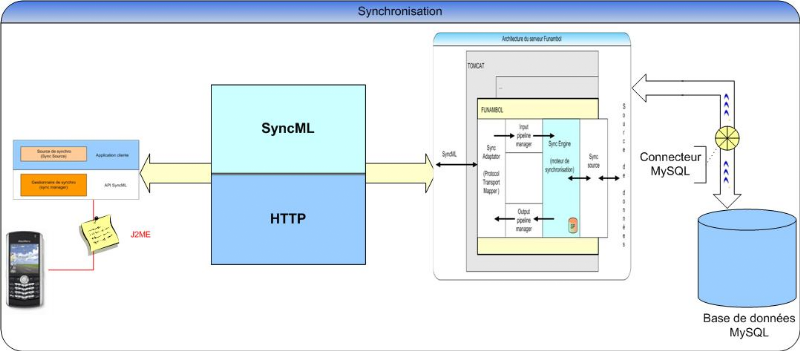
Figure 51 :
Architecture applicative de SOS PIN
Pour le service de billetterie
dématérialisée, une plateforme LAMP est utilisée
pour le serveur MTicket. Son caractère totalement open source, la
quantité des données manipulées, ainsi que les
accès web à réaliser justifient ce choix.
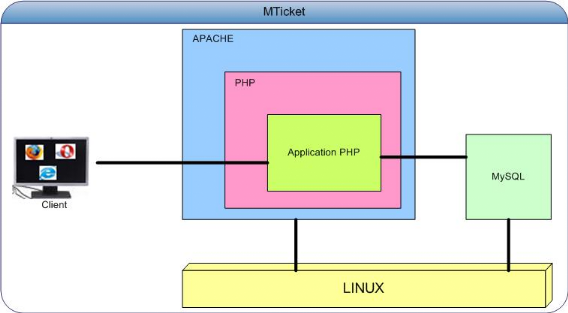
Figure 52 :
Architecture applicative de MTicket
Cependant nous mettrons en oeuvre les principes
d'interopérabilité pour des raisons de sécurité (la
génération d'un ticket par un code php rendrait cette
opération visible à partir d'un navigateur) et pour assurer la
communication sécurisée avec les tiers, étant donné
que la réalisation de certains modules (tels que l'envoi du ticket
image, le traitement d'un message USSD) est dévolue à des acteurs
externes. Java sera alors utilisé pour réaliser certaines de ces
tâches.
Le process de validation sera quand à lui
implémenté avec la plateforme .NET CF étant donné
que le Workabout Pro G2 tourne sous Windows CE.

Chapitre 7 :
Implémentation de la solution
I. Synthèse de
la solution
1. Le service de
sauvegarde /restauration
Il s'agit en définitive, d'une part d'écrire une
midlet capable de synchroniser avec le serveur installé en utilisant
le SDK24(*) Funambol JavaME
(entendre par là l'API SyncML cité supra), et d'autre part
connecter le serveur à une base de données MySQL.
1.1. Création de
la MIDlet
Les pré requis sont :
· Ant et Antenna
Ant est un projet open source de la fondation Apache
écrit en Java qui vise le développement d'un logiciel
d'automatisation des opérations répétitives tout au long
du cycle de développement logiciel, à l'instar des logiciels
Make.
Antenna fournit un de jeu de tâches Ant adéquates
pour le développement d'applications destinées au MIDP. Antenna
permet de compiler, prévérifier, packager et exécuter les
applications MIDP.
· L'API SyncML : c'est le SDK évoqué
plus haut. Il est téléchargeable
ici
· L'API Common qui vient en appoint pour
l'exécution de certaines tâches telles la sérialisation. Il
est disponible en téléchargement
ici
Les classes clé de l'API sont :
SyncManager : c'est la classe principale
qui contrôle le process de synchronisation et fait appel aux
méthodes de la classe SyncSource
SyncConfig : classe utilisée pour
instancier le SyncManager avec la configuration du client (URL,login, mot de
passe, etc)
Implémentation de SyncSource :
c'est l'implémentation de l'interface SyncSource qui est le lien entre
le moteur de synchronisation (du côté du serveur) et le client.
C'est la source des données du client à synchroniser.
SyncItem : représente l'objet
échangé entre le SyncSource et le moteur de synchronisation, il
peut transporter n'importe quel type d'information.
1.1.1.
Implémentation de notre SyncSource
C'est l'interface entre le client et le moteur de
synchronisation. En implémentant cette méthode de la
manière la plus convenable pour accéder à la source de
données cliente, nous pouvons synchroniser tout type de données
à partir du mobile.
Nous pouvons implémenter cette interface directement ou
bien nous pouvons étendre la classe abstraite
BaseSyncSource , où une partie du travail est
déjà réalisée. Les méthodes abstraites
à implémenter sont les initXXXitems() pour
initialiser les tableaux d'éléments à synchroniser
(SyncItem), selon le mode de synchronisation, où XXX peut
signifier :
all : il s'agit, dans ce cas, de tous
les éléments stockés dans la base de données
cliente. Il est utilisé dans le cas d'un slow sync ou d'un
refresh from client
new : c'est pour récupérer
le tableau des éléments ajoutés chez le client depuis la
dernière synchronisation
upd : c'est le tableau des
éléments modifiés depuis la dernière
synchronisation
del : c'est le tableau des
éléments supprimés de la base cliente depuis la
dernière synchronisation
Pour gagner de la place en mémoire, il est important
que ces tableaux ne contiennent que des informations sur les
éléments, sans leur contenu qui pourra être
récupéré par un appel à la méthode
getItemContent(). Cette méthode est appelée pour chaque
élément à synchroniser.
1.1.2. Création
du SyncManager
Une instance de SyncManager doit être
créée avant d'entamer n'importe quelle synchronisation. Un
SyncManager propose un constructeur recevant un
SyncConfig en paramètre, qui doit être rempli
lors de l'appel avec l'URL, un login et un mot de passe. Les autres
informations peuvent être optionnelles.
Le SyncConfig contient aussi la classe
DeviceConfig, un simple conteneur d'informations relatives
à l'appareil telles que le manufacturier, etc.
Voici, sous forme de diagramme de classe, les relations entre
les principales classes de l'API :
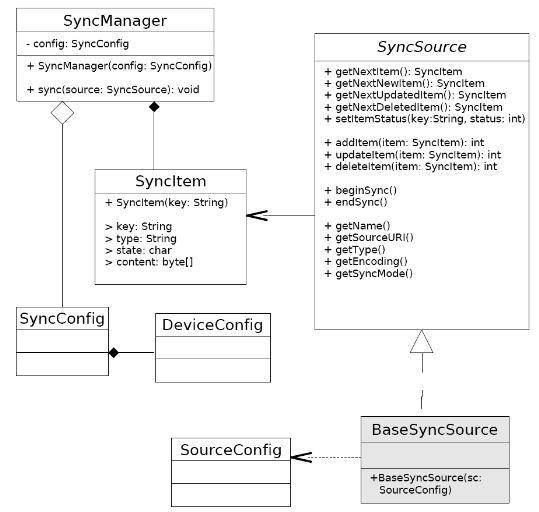
Figure 53 : Relation entre
les différentes classes de l'API SyncML
1.1.3. Démarrage
de la synchronisation
Une fois que nous avons instancié le
SyncManager, nous pouvons démarrer la synchronisation
par la méthode sync en passant le SyncSource en
paramètre. La synchronisation sera lancée avec le mode de
synchronisation stocké dans le SourceConfig .
En JavaME, nous exécuterons la synchronisation dans un
thread séparément. L'implémentation minimale de la
méthode run est la suivante :
import com.funambol.syncml.protocol.SyncML;
import com.funambol.syncml.spds.SyncManager;
import com.funambol.syncml.spds.SyncSource;
import com.funambol.syncml.spds.SyncConfig;
import com.funambol.syncml.spds.SourceConfig
import com.funambol.storage.NamedObjectStore;
import com.funambol.util.Log;
public void run() {
SyncConfig conf = new SyncConfig();
conf.syncUrl = "http://2sisyncml.com";
conf.username = "user";
conf.password = "pass";
SourceConfig sc = ClientStore.loadMySourceConfig();
MySyncSource myss = new MySyncSource(sc);
SyncManager sm = new SyncManager(conf);
sm.sync(sc);
ClientStore.saveMySourceConfig();
}
Dans ce thread MySyncSource représente
l'implémentation de notre SyncSource.
1.2. Connecter le
serveur à une base de données MySQL
Pour mener à bien cette tâche, il suffit de
suivre les étapes suivantes :
installer la version bundle du serveur de synchronisation
disponible en téléchargement
ici (http://funambol.com/opensource/download.php?file_id=funambol-6.5.14.exe).
Le répertoire d'installation sera nommé FUNAMBOL_HOME. Par
défaut ce sera C:/Programme files/Funambol/
sous Windows.
· créer sur le serveur MySQL une base de
données nommée funambol et un utilisateur
· lancer le script sql install_funambol-ds-server_schema.sql
pour créer les tables du DS server
· lancer le script sql
install_funambol-foundation_schema.sql
· Arrêter le serveur lorsqu'il tourne
· Modifier les fichiers
<FUNAMBOL_HOME>\tools\tomcat\conf\Catalina\localhost\funambol.xml et
<FUNAMBOL_HOME>\tools\tomcat\conf\Catalina\localhost\webdemo.xml :
Spécifier les valeurs correctes pour les attributs de
l'élément ressource ; c'est-à-dire :
<Resource name="jdbc/fnblds" auth="Container" type="javax.sql.DataSource"
username="funambol" password="funambol" driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost/funambol" />
· Copier dans le répertoire
<FUNAMBOL_HOME>\tools\tomcat\common\lib le MySQL JDBC
(c'est-à-dire mysql-connector-java-5.*.*-bin.jar))
2. Le service de
billetterie dématérialisée
Dans ce service, il s'agit de mettre en place un portail web
pour la consultation des événements et l'achat d'un ticket, en
plus d'un portail d'administration, d'un portail USSD et d'un module de
validation.
2.1. Front office, back office et
paiement
Toutes les pages sont réalisées en php.
Lorsque l'utilisateur veut acheter un ticket, il remplit les
formulaires adéquats. Parmi ceux-ci, nous avons le formulaire pour le
paiement en ligne. Ces informations seront transmises au partenaire de paiement
(PayBox) qui entre en contact avec la banque du client et nous renvoie
l'autorisation de faire la transaction.
2.2. Portail USSD
L'achat de ticket à partir des revendeurs
nécessite l'apport de l'opérateur. Ce dernier devra ajouter notre
service à son serveur d'application USSD. Lors d'un achat, son serveur
d'application USSD transmettra à notre serveur MTicket une URL contenant
l'ensemble des informations de la transaction.
2.3. Génération et validation du
ticket
Le ticket, après avoir été
généré en java, sous un format image standard (.jpg), est
envoyé au bénéficiaire par l'intermédiaire d'une
MMG25(*) qui permet
l'envoi de messages.
A la validation, notre dispositif (Workabout Pro G2) lit le
code barres sur le téléphone puis le transmet à notre
serveur :
· Soit par SMS grâce à la fonction de
téléphonie intégrée.
· Soit par HTTPS via un réseau WIFI si disponible.
Il s'agira pour nous d'éditer un programme en .NET CF
capable d'assurer cette transmission.
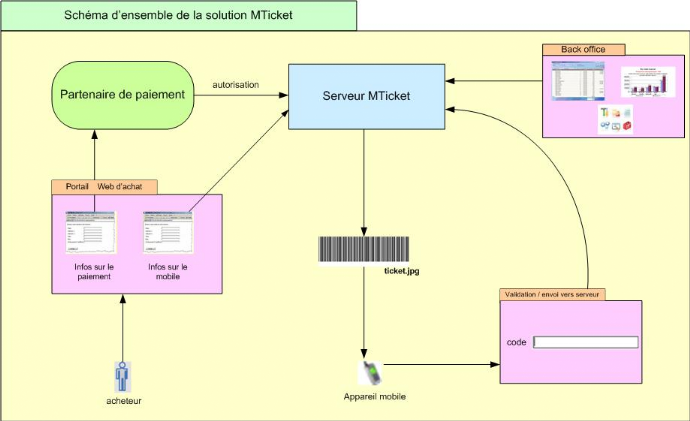
Figure 54 :
Schéma d'ensemble de MTicket
II. Les environnements
de développement
Dans le cadre du service de sauvegarde /
restauration, nous développons avec l'IDE Netbeans, dans sa
version 6.0.1, combiné avec son Mobility pack.
Netbeans est un environnement de développement pour
java, placé en open source par Sun sous licence CDDL26(*). En plus de Java, NetBeans
permet également de supporter différents autres langages.
Il comprend toutes les caractéristiques d'un IDE
moderne (éditeur en couleur, projets multi-langage, refactoring,
éditeur graphique d'interfaces et de pages web).
NetBeans est lui-même développé en Java,
ce qui peut le rendre assez lent et gourmand en ressources mémoires.
Mobility pack est le plug-in propre à Netbeans qui
permet le développement d'applications J2ME reposant sur MIDP en
utilisant un Wireless Toolkit. Il permet surtout l'édition graphique des
MIDlets. C'est la raison pour laquelle nous avons préféré
NetBeans à Eclipse27(*) combiné avec son plugin EclipseME.
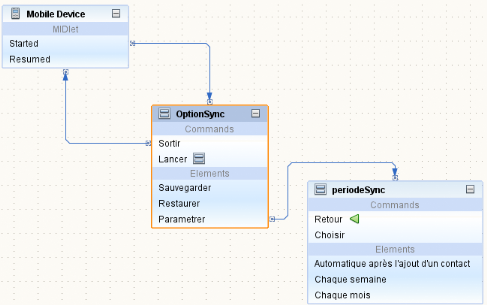
Figure 55 : NetBeans
mobility pack : vue en mode flow
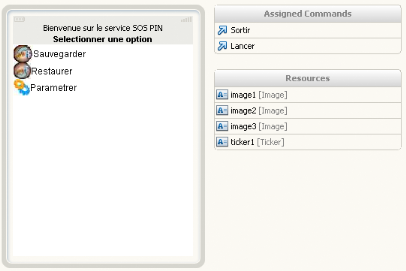
Figure 56 : NetBeans
mobility pack : vue en mode screen
Le Sun Java Wireless Toolkit (anciennement Wireless Toolkit)
ou WTK est l'ensemble des outils proposés par Sun pour développer
des applications basées sur une configuration CLDC. Il existe
également un Sun Java Toolkit pour CDC.
L'interface graphique est sommaire, il faut un éditeur
tiers pour créer le code source, mais toutes les fonctionnalités
sont là, c'est pour cela que la plupart des IDE sont des
frontends28(*) pour le
WTK.
Figure 57 : Interface
WTK
Ø
Fonctionnalités de WTK
· Toute la chaine de création jusqu'au test via un
émulateur.
· Signature des MIDlets
· Gestion des certificats
· Emulation OTA29(*)
· Emulation Push registry
· Nokia's Scalable Network Application Package (SNAP)
· ...
Ø APIs
supportées par WTK
La version 2.5.2 du toolkit, que nous utilisons d'ailleurs,
supporte les API suivantes :
· Mobile Service Architecture (JSR30(*) 248)
· Java Technology for the Wireless Industry (JTWI) (JSR
185)
· Connected Limited Device Configuration (CLDC) 1.1 (JSR
139)
· Mobile Information Device Profile (MIDP) 2.0 (JSR 118)
· PDA Optional Packages for the J2ME Platform (JSR 75)
· Java APIs for Bluetooth (JSR 82)
· Mobile Media API (MMAPI) (JSR 135)
· J2ME Web Services Specification (JSR 172)
· Security and Trust Services API for J2ME (JSR 177)
· Location API for J2ME (JSR 179)
· SIP API for J2ME (JSR 180)
· Mobile 3D Graphics API for J2ME (JSR 184)
· Wireless Messaging API (WMA) 2.0 (JSR 205)
· Content Handler API (JSR 211)
· Scalable 2D Vector Graphics API for J2ME (JSR 226)
· Payment API (JSR 229)
· Advanced Multimedia Supplements (JSR 234)
· Mobile Internationalization API (JSR 238)
· Java Binding for the OpenGL(R) ES API (JSR 239)
III. Diagrammes de
composants
Le diagramme de composants décrit
l'organisation du système du point de vue des modules de code (fichier
source, exécutable, bibliothèque). Ce diagramme permet de mettre
en évidence les dépendances entre les composants (qui utilise
quoi ?) et ainsi de mieux organiser les modules.
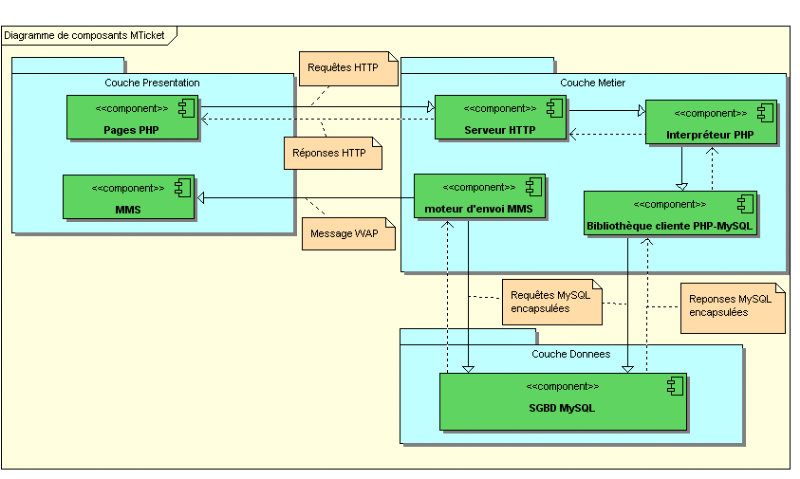
Figure 58 : Diagramme de
composants MTicket
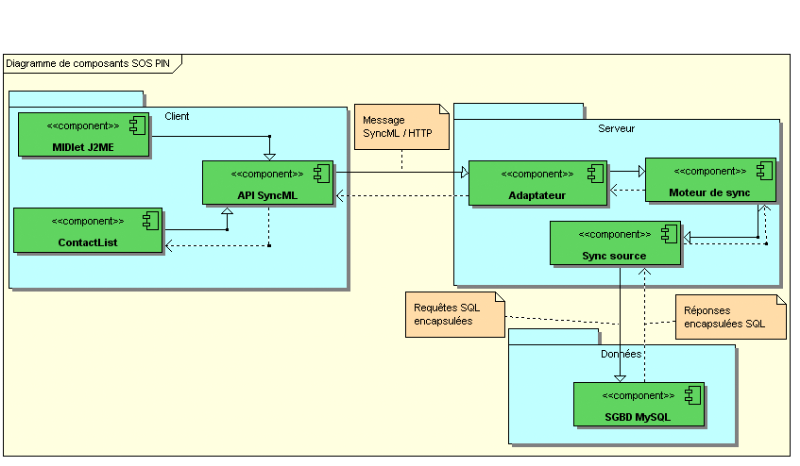
Figure 59 : Diagramme de
composant SOS PIN
IV. Diagrammes de
déploiement
Un diagramme de déploiement est une
vue statique qui sert à représenter l'utilisation de
l'infrastructure physique par le système et la manière dont les
composants du système sont répartis ainsi que
leurs relations entre eux. Les éléments utilisés par un
diagramme de déploiement sont principalement les
noeuds (représentation d'une ressource
matérielle), les composants, les
associations et les artefacts31(*). Les
caractéristiques des ressources matérielles physiques et des
supports de communication peuvent être précisées par
stéréotype.

Figure 60 : Diagramme de
déploiement MTicket

Figure 61 : Diagramme de
déploiement SOS PIN
V.
Sécurité de la plateforme
1. Service de
sauvegarde
L'utilisation de SyncMl et du serveur Funambol sont un gage de
sécurité car ils gèrent de nativement la
sécurité des transactions.
Dans la phase d'authentification, le serveur envoie au client
un message contenant la balise <Chal> qui représente une demande
d'authentification (Challenge en anglais) pour les
informations auxquelles le client tente d'accéder. Le client doit alors
répondre et donner le login et mot de passe dans une balise <Cred>
(Credential en anglais).
SyncML peut utiliser l'accès authentifié par le
hachage md5. Le client et le serveur échangent leurs identifiants durant
la phase d'authentification, retournant un code d'erreur si le processus
s'arrête quelque part. La balise <Cred> est utilisée dans le
<SyncHdr> pour fixer le type d'authentification qui sera utilisé
dans la phase d'authentification. (Il y a le hachage md5, mais aussi l'encodage
base64 et d'autres... Il faut donc que le serveur informe le client du type
d'authentification utilisée).
Au niveau du serveur, la résolution des conflits de
synchronisation (modification d'une même donnée à la fois
sur le client et le serveur) revient à la charge du Sync Engine (moteur
de synchronisation) et s'effectue en s'appuyant sur les ancres.
2. Service
MTicket
La stratégie de sécurité pour ce service est
déployée à plusieurs niveaux :
Ø Accès des utilisateurs au
portail
L'administrateur se connecte au portail grâce à
un login et un mot de passe crypté par hachage MD5. Il peut ainsi
procéder aux tâches qui lui sont dévolues (gestion des
événements, création d'un nouveau compte pour
l'organisateur d'un nouvel événement).
L'organisateur d'événement peut aussi se
connecter grâce à son login et son mot de passe. Sa vue est
cependant restreinte à son cadre d'organisation, c'est-à-dire
qu'il ne peut voir et agir que sur son événement.
Une trace des différentes connexions est toujours
gardée par le système.
Ø Paiement en ligne
La sécurité de ce module est totalement
assurée par le partenaire de paiement (Paybox). L'ensemble des phases de
paiement à réaliser entre l'acheteur et le système est
entièrement crypté et protégé. Le protocole
utilisé est SSL32(*) couplé à de la monétique
bancaire. Il nous suffit juste de nous mettre en HTTPS33(*). Dans ce cas, un cadenas
fermé apparaît en bas de la fenêtre du logiciel de
navigation.

Figure 62 : Navigateur en
mode HTTPS
Ø Génération des tickets
Pour s'assurer que le numéro généré
pour ce ticket est unique, nous utilisons la fonction uniqid()
de php :
string uniqid ( string prefix
, bool more_entropy )
Cette fonction retourne un identifiant préfixé
unique, basé sur l'heure courante, en micro-secondes. Le
paramètre prefix est optionnel mais peut servir à
identifier facilement différents hôtes, si nous
générons simultanément des fichiers depuis plusieurs
hôtes, à la même micro-seconde. Depuis PHP 4.3.1,
prefix peut prendre jusqu'à 114 caractères.
Si le paramètre optionnel more_entropy est TRUE ,
uniqid() ajoutera une entropie "combined LCG" à la fin
de la valeur retournée, ce qui renforcera encore l'unicité de
l'identifiant.
Sans prefix (préfixe vide), la chaîne
retournée fera 13 caractères. Si more_entropy est
à TRUE , elle fera 23 caractères. En combinant cette
méthode au hachage md5, nous obtenons un code de 32
caractères :
// meilleur, difficile à deviner
$code =
md5(uniqid(rand(), true));
Le code généré, ainsi que les autres
références du ticket, sont stockés au niveau de la base de
données. Un process java plus sécurisé se chargera de
parcourir la base et générer les tickets en instance. Une
génération avec un script php rendrait l'opération visible
au niveau de la page web.
Ø MMS non transférables
Le MMS transmis à un bénéficiaire,
après une transaction, ne peut plus être utilisé par un
autre appareil mobile, en d'autres termes ce MMS ne peut plus être
transféré. Pour cela, l'Open Mobile Alliance (OMA) a
spécifié un modèle de gestion des droits [OMADRM34(*)], dont la version 1 actuelle
prévoit trois niveaux de protection :
· Niveau 1, Forward Lock :
- l'usage du contenu téléchargé est
illimité (ex : autant d'écoutes que l'on veut)
- le contenu ne peut être transmis.
· Niveau 2, Remise Combinée (Combined
Delivery) :
- l'usage du contenu téléchargé est
régi par des droits (ex : 3 écoutes maximum).
- les droits d'accès au contenu sont
véhiculés avec le contenu
- le contenu ne peut être transmis.
· Niveau 3, Remise Séparée
(Separate Delivery) :
- l'usage du contenu téléchargé est
régi par des droits (ex : 3 écoutes maximum).
- les droits d'accès au contenu sont
véhiculés indépendamment du contenu
- le contenu peut être transmis (sans les droits),
possibilité de marketing viral.
On doit néanmoins mettre l'accent sur le fait que tous
les terminaux n'ont pas encore intégré de mécanisme de
protection des droits. En outre, malgré la normalisation par l'OMA, il
existe encore un certain nombre de modèles ayant une
implémentation propriétaire des DRM. Cependant, un contenu
protégé par un DRM, mais envoyé sur un mobile ne
supportant pas ce DRM, est rejeté.
Une seconde version de DRM est prévue par l'OMA,
utilisant un cryptage des droits d'accès par une clé publique
(PKI).
Pour protéger un fichier par Combined Delivery (pour
rendre le message, entre autres, non transférable) celui-ci doit
être encapsulé dans une enveloppe de type :
application/ vnd.oma.drm.rights+xml
Exemple:
Content-Type:
application/vnd.oma.drm.rights+xml
boundary="----123456789"
----123456789
Content-Type: image/jpeg; name="Ticket.jpg"
Content-Transfer-Encoding: base64
Content-Location: Ticket.jpg
/9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAUDBAQEAwUEBAQFBQUGBwwIBwcHBw8LCwkMEQ8S
etc.etc.etc.etc.etc.etc..etc.etc.etc.etc
etc.etc.etc.etc.etc.etc.etc.etc
5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREA
----123456789--
Figure 63 : Exemple de
MMS non transferable
VI. Captures d'écrans
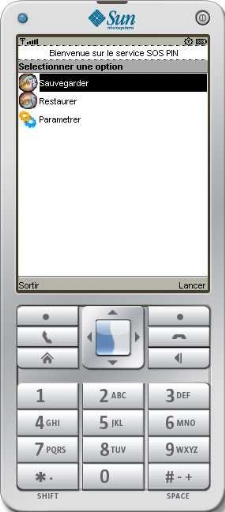
Figure 64 : Interface
d'accueil de SOS PIN - test sur l'émulateur de SUN
C'est à partir de cette interface que l'abonné
choisit de sauvegarder ou restaurer ses données, ou bien de
paramétrer ce service. Il peut choisir une de ces options en utilisant
les touches haut et bas de son téléphone. Pour valider un choix,
il peut appuyer sur le bouton situé en haut à droite (option
" lancer "). Pour sortir de cet écran, il suffit d'utiliser
l'option "sortir".
Cet écran est le front-office de MTicket permettant
à un internaute d'acheter un ticket pour un des événements
représentés par une image cliquable.
Cet écran du backoffice de MTicket permet d'avoir une
vue sur les événements présentés au niveau du
front.
Conclusion
2SI compte, à travers cette plateforme, poser les
jalons de nouveaux types de SVA.
Il s'agissait, d'une part, d'assurer la
pérennité des données stockées dans le
téléphone mobile. Ceci a été réalisé,
en partie, dans le service SOS PIN avec la sauvegarde des contacts. En
perspective, il peut être extensible à une sauvegarde de tous les
types de données du mobile en manipulant le système de gestion
des fichiers du terminal grâce aux packages adéquats
proposés par J2ME.
D'autre part, la plateforme propose de
dématérialiser les tickets permettant d'accéder à
des services, en particulier des évènements. L'acquisition d'un
ticket virtuel est possible désormais à partir du portail web. Il
reste cependant la contribution de l'opérateur pour implanter ce
service au niveau de son serveur d'application pour le rendre utilisable
à partir du réseau de recharge de crédit. L'achat d'un
ticket en mode WAP ou par serveur vocal est aussi prévu pour multiplier
les modes d'accès au service MTicket.
L'utilisation des codes-barres ouvre, quant à elle,
l'ère de la portabilité d'un certain type d'information :
ici il s'agissait d'un numéro de ticket. L'intégration des codes
barres 2D pourrait largement augmenter ce volume : une chaine
d'informations complète sur un objet précis.
La réalisation de cette plateforme, ainsi
articulée autour des services pour téléphones mobiles nous
a permis d'explorer ce vaste domaine en approfondissant notre connaissance en
réseaux pour mobiles, en synchronisation de données et en
programmation java pour l'embarqué, trois concepts fondamentaux dans
l'informatique d'aujourd'hui.
Bibliographie /
Wébographie
Bibliographie
· UML 2 - Modéliser une application Web, Pascal
Roques - Edition Eyrolles
· Java 2 Micro Edition: Professional Developer's Guide,
Eric Giguere
Wébographie
Documentation UML /UP,
http://fdigallo.online.fr/cours/uml.pdf
Documentation sur la démarche simplifiée,
http://www.dotnetguru.org/articles/Methodes/AgileDotNet.htm
Documentation sur XP,
http://www.jprojet.net/extreme-programming.html
Documentation sur les réseaux et services pour
téléphonie mobile,
http://www.girodon.com/telech/telcos/telcoworld.htm
Documentation SyncML,
http://fr.wikibooks.org/wiki/Programmation_XML/SyncML
Documentation J2ME et SDE,
http://www.dotnetguru.org/articles/J2MEvsSDE/J2MEvsSDE.htm
Documentation serveur Funambol,
http://download.forge.objectweb.org/sync4j/Funambol_DSServer_Overview.pdf
Documentation API SyncML,
http://download.forge.objectweb.org/sync4j/sync4j_java_API_J2ME_developer_guide.pdf
Glossaire
A
API : Ensemble de fonctions courantes de
bas niveau permettant de programmer des applications de haut niveau.
B
Back-office : partie d'un
portail web ou d'un
système informatique qui permet à d'administrer et de
gérer ce dernier.
C
Conteneur : Désigne une classe de
fichiers qui renferme des informations codées de façon
variable.
E
Emulateur : Classe de logiciel permettant de
faire fonctionner un système comme un autre.
Embarqué : se dit d'un
système informatique destiné à fonctionner dans un
véhicule ou un appareil portable comme un avion ou un PDA.
F
Front-office : désigne la partie qui
prend en charge l'interface d'une application. Dans les sites web commerciaux
il permet de commander en ligne
H
Hachage: méthode permettant de diviser
une liste de données en listes plus petites contenant les
éléments de la première qui ont des points en commun.
I
IDE : environnement de développement
intégré réunissant tous les outils nécessaires
à la création d'application, aussi complexe qu'elles soient.
M
Machine virtuelle : machine abstraite
simulée au sein d'une autre machine bien réelle celle-là,
et utilisée comme environnement d'exécution d'un langage portable
de haut niveau.
Module : partie constitutive d'un système
informatique
Monétique : ensemble des traitements
électroniques, informatiques et télématiques
nécessaires à la gestion de cartes bancaires ainsi que des
transactions associées.
O
Open Source : Licence de logiciel qui autorise
la modification et la redistribution gratuite.
P
Plateforme : Ensemble de logiciels
facilitant le développement ou l'exploitation de programmes
PIM : type d'application qui fonctionne
comme un organiseur de données personnelles, par extension, signifie ces
données.
S
Session : Désigne la durée
écoulée entre la mise en route d'un processus et son
arrêt.
T
Transaction: ensemble d'opérations
modifiant des données, devant être effectuées toutes en
même temps ou une par une.
W
WAP : Protocole d'application sans fil qui
permet de se connecter à Internet grâce à un
téléphone mobile.
Annexe
Décision fixant la
liste des valeurs ajoutées au Sénégal
LE DIRECTEUR GENERAL DE L'ART,
Vu la loi n° 2001-15 du 27 décembre 2001 portant code
des télécommunications ;
Vu la loi n°2002-23 du 4 septembre 2002 portant cadre de
régulation des entreprises concessionnaires de services publics ;
Vu le décret n° 2003-63 du 17 février 2003
fixant les règles d'organisation et de fonctionnement de l'Agence de
Régulation des Télécommunications ;
Vu le décret n° 2003-64 du 17 février 2003
relatif aux fréquences et bandes de fréquences
radioélectriques, aux appareils radioélectriques et aux
opérateurs de ces équipements ;
Vu le décret n°2003-215 du 17 avril 2003 nommant les
membres du Conseil de Régulation de l'Agence de Régulation des
Télécommunications ;
Vu le décret n°2003-361 du 28 mai 2003 portant
nomination du Directeur Général de l'Agence de Régulation
des Télécommunications ;
Vu l'avis du Conseil de Régulation en sa séance du
23 avril 2004 ;
DECIDE:
Article premier : La liste des services à
valeur ajoutée visés à l'article 19 du code des
télécommunications est fixée comme suit :
1/ Messagerie électronique :
L'échange, la lecture et le stockage d'informations, sous
forme de messages de données, entre des machines se trouvant dans des
sites distants. Le destinataire du message n'est pas nécessairement
présent au moment de l'envoi du message.
Elle est régie par les recommandations de l'Union
Internationale des Télécommunications X-400 et X- 500 de
l'UIT-T.
2/ Messagerie vocale :
L'échange (la réception et/ou l'envoi) et
l'enregistrement de messages vocaux dans des serveurs vocaux, accessibles
à partir d'équipements terminaux appropriés.
Elle est régie par la recommandation de l'Union
Internationale des Télécommunications X-485 de l'UIT-T.
3/ Audiotex :
La mise à la disposition des usagers d'accès
à des serveurs, interactifs ou non, pour enregistrer, lire ou
écouter des messages à partir d'équipements terminaux
appropriés.
4/ Echange de données informatisé (EDI)
:
L'échange de données formatées de
manière standard entre les différentes applications tournant sur
les ordinateurs de partenaires commerciaux avec un minimum d'interventions
manuelles.
5/ Télécopie améliorée
:
La mise en place de serveurs permettant de transmettre et de
reproduire à distance divers documents (lettres, photos et dessins) avec
la possibilité d'archivage et d'accès à ces documents.
6/ Services d'information on-line :
L'accès à des informations en ligne, en temps
réel et sans intervalles d'attente.
7/ Services d'accès aux données, y compris
la recherche et le traitement des données :
L'accès à des informations stockées dans des
serveurs et/ou des bases de données en utilisant notamment
l'infrastructure du réseau téléphonique public ou des
réseaux de transmission de données et des interfaces
d'adaptation.
8/ Transfert de fichiers et de données
:
Le transport et l'échange de fichiers et de données
informatiques, constitués de textes et d'images, éventuellement
animées, entre des machines hétérogènes se situant
sur des sites distants. Il permet également le
téléchargement de fichiers et de données à partir
de machines distantes.
9/ Conversion de protocoles et de codes :
L'adaptation des protocoles utilisés par des machines
différentes, dont la représentation interne des données
est différente, afin de permettre la communication entre ces
machines.
10/ Services Internet:
La messagerie électronique, le transfert de fichiers, la
connexion à une machine distante, le dialogue sous forme de messages
écrits sur des sujets variés entre des groupes d'utilisateurs en
temps réel et la recherche d'informations dans des serveurs.
11. Services mobiles :
Il s'agit des services suivants :
- le SMS : message texte envoyé vers un
téléphone mobile depuis un autre téléphone mobile
ou depuis un ordinateur ;
- le WAP (Wireless Application Protocol) : Protocole
d'application sans fil qui permet de se connecter à Internet grâce
à un téléphone mobile ;
- l'I-Mode : permet à ses utilisateurs un accès
Data à des services au travers d'Internet. service destiné
à l'univers des télécoms, il peut être
également déployé sur des terminaux aussi divers que les
consoles de jeux, les télévisions, etc. ;
- Le MMS (Multimedia Messaging Service) : service de messagerie
pour les appareils mobiles qui s'apparente au SMS. Le MMS permet l'envoi
automatique et immédiat de messages multimédias
personnalisés de téléphone à
téléphone ou d'un téléphone à un compte
e-mail. Outre les contenus textuels habituels des messages courts, les messages
multimédias peuvent aussi contenir des photos, des graphiques, des clips
audio et vocaux.
Article 2 - Cette liste fera l'objet d'une
révision annuelle.
Article 3 - Les prestataires des services
à valeur ajoutée peuvent demander à tout moment au
Directeur général de l'ART, la reconnaissance d'un nouveau
service de télécommunications comme service à valeur
ajoutée. En cas d'accord, le nouveau service pourra immédiatement
faire l'objet d'une offre au public et sera intégré dans la liste
des services à valeur ajoutée à la prochaine
révision.
Article 4 - La présente décision
entre en vigueur à la date de sa signature et sera publiée et
communiquée partout où besoin sera.
FAIT A DAKAR, LE 28 AVRIL 2004
Le Directeur Général de l'ART
Malick F. M. GUEYE
 
* 1 Joint Requiement
Planning : Technique d'aide à l'expression des besoins par les
utilisateurs
* 2 Joint Application
Development : Cette technique organise le processus de conception de
façon à y faire participer les utilisateurs
* 3 Time-box : cette technique
limite la durée de la réalisation à une enveloppe-temps
maximale
* 4 Un scénario est une
instance d'un cas d'utilisation
* 5 Un des diagrammes dynamique
du langage UML
* 6 Uu : interface radio
entre l'UTRAN (UMTS Terrestrial Radio Access Network) et l'UE (User Equipement
- Equipement de l'utilisateur)
* 7 UTRAN : UMTS Terrestrial
Radio Access Network
* 8 Streaming : envoi de
flux continu d'informations qui seront traitées instantanément
avec la possibilité d'afficher les données avant que
l'intégralité du fichier ne soit
téléchargée, l'objectif étant de gagner en
rapidité
* 9 GMSC (Gateway
MSC) : MSC en GSM qui possède des fonctions de passerelles
* 10 VOIP (Voice Over
IP) : voie sur IP
* 11 Ensemble des
mécanismes permettant à une entreprise de créer de la
valeur à travers la proposition de valeur faite à ses clients
* 12 Value added service
provider
* 13 CP : Content provider
* 14 Average revenu per
user : revenu moyen par utilisateur
* 15 Agence de
Régulation des Télécommunications et des Postes
* 16 Nom donné aux
utilisateurs du téléphone mobiles
* 17 1D :
unidimensionnel
* 18 IVR : interactive
voice request - système de réponse automatique personnalisable
proposant à l'appelant une liste de services
* 19source O2
Sicap USSD gateway :
www.sicap.com/store/attachments/00038.pdf
* 20 Compilation à la
volée : technique visant à améliorer la performance de
systèmes bytecode compilés par la traduction du bytecode en code
machine natif au moment de l'exécution
* 21 OBject
EXchange est un protocole de l'IrDA (Infrared Data
Association) proche d'une version binaire de HTTP. Initialement
créé par l'IrDA pour les transports sur faisceaux infrarouges, il
a été par la suite adapté à d'autres canaux
à bande passante réduite, notamment Bluetooth.
* 22 La couche WSP
(Wireless Session Protocol) est la couche session du WAP
* 23 Les entreprises
qualifiées de pure players sont des
entreprises exerçant uniquement leurs activités sur internet :
elles ne possèdent pas de réseau de distribution physique.
* 24 SDK : Software
Development Kit
* 25Multimedia Mobile
Gateway: plate-forme de messagerie de bout en bout pour les échanges de
données mobiles sur plusieurs supports. Elle permet de connecter des
réseaux de télécommunication ayant des architectures, des
protocoles ou des services différents.
* 26 Community Developement and
Distribution Licence
* 27 Un autre IDE open
source, extensible, universel et polyvalent, permettant potentiellement de
créer des projets mettant en oeuvre n'importe quel langage de
programmation.
* 28 Interfaces grafiques
associés à des programmes en ligne de commande
* 29 Over The Air
Programming (OTA) est une méthode de distribution de logiciels et de
mises à jour destinée aux appareils mobiles
(téléphone portable, smartphone...). L'avantage d'une
installation via OTA est que l'acquisition du programme se fait depuis le
réseau sans-fil de l'appareil (WAP, MMS...).
* 30 Java Specification
Requests émises par le Java
Community Process, qui décrivent les
spécifications et technologies proposées pour un ajout à
la plateforme Java
* 31 composant consommé
ou créé durant l'une des étapes du processus de
déploiement.
* 32 Secure Sockets Layers
-couche de sockets sécurisée- est un
procédé de sécurisation des transactions effectuées
via Internet
* 33 http
sécurisé : protocole http sécurisé avec SSL
* 34 OMA Digital Rights
Management - gestion des droits numériques
| 

