INTRODUCTION
La recherche accorde ces dernières années,
beaucoup d'importance au traitement des données textuelles. Ceci pour
plusieurs raisons : un nombre croissant de collections mises en réseau
et distribuées au plan international, le développement de
l'infrastructure de communication et de l'Internet. Les traitements manuels de
ces données s'avèrent très coûteux en temps et en
personnel, ils sont peu flexibles et leur généralisation à
d'autres domaines est presque impossible ; c'est pour cela que l'on cherche
à mettre au point des méthodes automatiques.
Le domaine de la fouille de textes (text mining) s'est
développé pour répondre à volonté à
la gestion par contenu des sources volumineuses de textes. A l'heure actuelle,
de nombreux logiciels de classification de textes sont disponibles, ils ont
fait l'objet de publications et leurs champs d'application
s'élargit de jour en jour. En général, ces
systèmes sont basés sur des algorithmes d'apprentissage
automatique (approche statistique, approche syntaxique et approche
connexionniste).
Nous nous intéressons ici plus particulièrement
aux algorithmes d'apprentissage et nous avons utilisé et comparé
deux algorithmes : les K plus proches voisins (Kppv) et l'algorithme de
Rocchio. Pour pouvoir utiliser de tels algorithmes, il est nécessaire de
transformer les données, initialement en format texte, en une
représentation numérique. Nous avons choisi pour ce faire, la
méthode de sélection des termes les plus pertinents. Une fois ce
prétraitement terminé, nous pouvons effectuer la classification
à l'aide de nos algorithmes ; ensuite nous ferons une étude
comparative entre les deux méthodes.
Nous résumons la présentation de notre travail
ainsi :
· Le chapitre I : résume l'explication de la
catégorisation de texte et ses domaines d'applications.
· Le chapitre II : expose les différents
algorithmes d'apprentissage utilisé pour la catégorisation de
textes et expose en détail les deux algorithmes d'apprentissage
utilisés : les K plus proches voisins (Kppv) et l'algorithme de
Rocchio.
· Le chapitre III, expose l'architecture du logiciel
conçu et son fonctionnement.
· Le chapitre IV, est consacré à
l'implémentation de notre logiciel et quelques exemples de
démonstration
CHAPITRE I
1- Introduction :
L'objet d'étude de ce mémoire : la
catégorisation automatique de textes ; c'est un problème qui
intéresse les chercheurs depuis relativement longtemps. On retrouve des
travaux portant sur ce sujet depuis au moins le début des années
1960.
La recherche dans ce domaine est toujours très
pertinente, car les résultats obtenus aujourd'hui sont encore sujets
à amélioration. Pour certaines tâches, les classificateurs
automatiques performent presque aussi bien que les humains, mais pour d'autres,
l'écart est encore grand. Au premier abord, l'essentiel du
problème est facile à saisir. D'un côté, on est en
présence d'une banque de documents textuels et de l'autre, d'un ensemble
prédéfini de catégories. L'objectif est de rendre une
application informatique capable de déterminer de façon autonome,
dans quelle catégorie classer chacun des textes, à partir de leur
contenu, tel qu'illustré à la figure 1.
[Sim, 2005].
Malgré cette première définition
très simple, la solution n'est pas immédiate et plusieurs
facteurs sont à prendre en considération. Ce chapitre vise donc
à définir plus en profondeur de quoi il en retourne. En premier
lieu, il précise la tâche de Catégorisation
(classification), et le deuxième point présente le choix d'un
mode de représentation adéquat des instances à traiter, en
l'occurrence les textes. Il s'agit d'une étape incontournable en
apprentissage automatique : on doit opter pour une façon uniforme
et judicieuse d'abstraire les données avant de les soumettre à un
algorithme. Comme l'apprentissage joue un rôle dans la
catégorisation automatique de textes, le choix d'un mode de
représentation y devient un enjeu. Par la suite, il sera question de la
sélection d'attributs, presque toujours impliqués en
catégorisation automatique de textes et on éliminera les
attributs jugés inutiles à la classification. [Sim,
2005].
Programme informatique
Texte
Texte classifié, étiqueté
Ensemble de catégories, hiérarchisées
ou non
Figure 1 - La tâche de classification
2- Définition de la catégorisation de
textes :
Le but de la catégorisation automatique de textes est
d'apprendre à une machine à classer un texte dans la bonne
catégorie en se basant sur son contenu. Habituellement, les
catégories font référence aux sujets des textes, mais pour
des applications particulières, elles peuvent prendre d'autres formes.
En effet, on peut résoudre, par des techniques de catégorisation,
des problèmes tels que l'identification de la langue d'un document, le
filtrage du courrier électronique pertinent ou indésirable, ou
encore la désambiguïsation de termes. Un autre
aspect du problème qui varie selon les applications est la
présence ou non d'une contrainte concernant le nombre de
catégories assignables à un document donné. Il se peut
qu'on désire qu'un même texte ne soit associé qu'à
une seule catégorie ou bien on peut permettre que plusieurs
catégories accueillent un même document. Aussi, une
précision supplémentaire est à faire : dans le cadre
de la catégorisation de textes, l'ensemble de catégories
possibles est déterminé à l'avance. Il est à noter
que le problème consiste à regrouper des documents selon leur
similarité.
Dans une catégorisation de texte : la
classification s'apparente au problème de l'extraction de la
sémantique d'un texte, puisque l'appartenance d'un document à une
catégorie est étroitement liée à la signification
de ce texte. C'est en partie ce qui rend la tâche difficile puisque le
traitement de la sémantique d'un document écrit en langage
naturel n'est pas encore solutionné. Une observation mérite aussi
d'être faite concernant le fait que la nature des textes à traiter
influence significativement la difficulté de la tâche de
classification. Prenons l'exemple d'articles de journaux écrits
généralement dans un style direct et contenant de l'information
purement factuelle. Le vocabulaire utilisé s'avère précis
et souvent relativement restreint pour faciliter la compréhension. A
l'opposé, imaginons un corpus de textes d'un style plus
littéraire, utilisant un vocabulaire très varié et
imagé. On peut aisément prévoir que la classification
automatique de ce dernier corpus présentera plus de difficultés
que pour l'autre. Entre ces deux extrêmes, on peut aussi retrouver des
textes scientifiques (où chaque catégorie aura potentiellement un
vocabulaire caractéristique), des pages Web, du courrier
électronique, etc. Chacun de ces types de textes possède des
particularités qui rendent la tâche de classification plus ou
moins ardue. [Sim, 2005].
3- Comment catégoriser un texte ?
Le processus de catégorisation intègre la
construction d'un modèle de prédiction qui, en entrée,
reçoit un texte et, en sortie, lui associe une ou plusieurs
étiquettes.
Pour identifier la catégorie ou la classe à
laquelle un texte est associé, un ensemble d'étapes est
habituellement suivies. Ces étapes concernent principalement la
manière dont un texte est représenté, le choix de
l'algorithme d'apprentissage à utiliser et comment évaluer les
résultats obtenus pour garantir une bonne généralisation
du modèle appris.
Le processus de catégorisation, intégrant la
phase de classement de nouveaux textes, est résumé dans la
figure 2. Il comporte deux phases que l'on peut distinguer
comme suit :
1. l'apprentissage, qui comprend plusieurs
étapes et aboutit à un modèle de prédiction:
a) nous disposons d'un ensemble de textes
étiquetés (pour chaque texte nous connaissons sa
catégorie) ;
b) à partir de ce corpus, nous extrayons les k
descripteurs (mots, termes) (t1; ..; tk) les plus
pertinents au sens du problème à résoudre ;
c) nous disposons alors d'un tableau « descripteurs
× individus », et pour chaque texte nous connaissons la valeur de ses
descripteurs et son étiquette;
2. le classement d'un nouveau texte
dx, qui comprend deux étapes :
a) recherche puis pondération des occurrences
(t1; ...; tk) des termes dans le texte dx
à classer ;
b) application d'un algorithme d'apprentissage sur ces
occurrences et le tableau précédent afin de prédire
l'étiquette de ce texte dx. [Rad, 2003].
Textes catégorisés
Textes à classifier
Représentation
Textes d'apprentissage
Représentation
Modèle de catégorisation
Prédiction de la catégorie
Figure 2: Processus de la catégorisation de
textes
Notons que les k descripteurs les plus pertinents
(t1; ...; tk) sont extraits lors de la première
phase par analyse des textes du corpus d'apprentissage. Dans la seconde phase,
celle du classement d'un nouveau texte, nous cherchons simplement la
fréquence de ces k descripteurs (t1; ...; tk) dans
le texte à classer.
Les deux phases seront développées dans le
chapitre 2.
La figure 3 illustre le processus de
classification d'un nouveau document.
Sélection d'attributs et Représentation des
documents
Texte à classer
ti
Représentation abstraite du texte {ai,k}
Classification par le programme
Texte classifié, étiqueté
<ti, f(ai,k)>
Figure 3 - Classification d'un nouveau
document
4- Représentation et codage des textes :
Un codage préalable du texte est nécessaire,
comme pour l'image, le son, etc., car il n'existe pas actuellement de
méthode d'apprentissage capable de traiter directement des
données non structurées, ni dans la phase de construction du
modèle, ni lors de son utilisation en classement.
Pour la majorité des méthodes d'apprentissage,
il faut transformer l'ensemble des textes en un tableau croisé
« Individus-Variables » :
- L'individu est un texte (un document) dj,
étiqueté lors de la phase d'apprentissage, il est classé
dans la phase de prédiction.
- Les variables sont les descripteurs (les termes)
tk qui sont extraits des données textuelles.
- Le contenu du tableau (les
éléments wkj), au croisement du texte j et du terme k,
représente le poids de ce terme k dans le document j.
Le principal enjeu de la catégorisation de texte, par
rapport à un processus d'apprentissage classique, réside dans la
recherche des descripteurs (ou termes) les plus pertinents pour le
problème à traiter. Différentes méthodes sont
proposées pour le choix des descripteurs et des poids associés
à ces descripteurs. Certains chercheurs utilisent, à titre
d'exemples, les mots comme descripteurs, tandis que d'autres
préfèrent utiliser les lemmes (racines lexicales); ou encore des
stemmes (la suppression d'affixes). [Rad, 2003].
5- Applications de la catégorisation de
texte:
La catégorisation de textes est utilisée dans de
nombreuses applications. Parmi ces domaines figurent : l'identification de la
langue, la reconnaissance d'écrivains, la catégorisation de
documents multimédia, et bien d'autres.
La catégorisation de textes peut être un support
pour différentes applications parmi lesquelles le filtrage, qui consiste
à déterminer si un document est pertinent ou non (décision
binaire), par exemple la détection de spams (les courriers
indésirables) pour ensuite les supprimer, le routage qui permet
d'affecter un document à une ou plusieurs catégories parmi n, par
exemple la diffusion sélective d'information. Lors de la
réception d'un document l'outil choisit à quelles personnes le
faire parvenir en fonction de leurs centres d'intérêt. Ces centres
d'intérêt correspondent à des profils individuels.
[Rad, 2003].
6- Lien avec la recherche documentaire:
La catégorisation de texte est proche de la recherche
documentaire. En recherche documentaire, on doit retrouver les documents qui
correspondent à une requête, ce qui revient à
classer tout le corpus en deux classes : les textes correspondant
à la requête d'une part, les autres d'autre part. En
catégorisation, il s'agit d'attribuer les documents à un
ou plusieurs groupes, en fonction des informations qu'ils
contiennent.
La recherche documentaire est à l'origine de nombreux
modèles de catégorisation de textes. La distinction entre les
deux domaines n'est pas facile à établir car ils peuvent
être vus tout deux comme des problèmes de
classement. [Rad, 2003].
7- Approches pour la représentation des
textes :
7-1- Introduction :
Les algorithmes d'apprentissage ne sont pas capables de
traiter directement les textes, plus généralement, les
données non structurées comme les images, les sons et les
séquences vidéo. C'est pourquoi une étape
préliminaire dite représentation est nécessaire. Cette
étape consiste généralement en la représentation de
chaque document par un vecteur, dont les composantes sont par exemple les mots
contenus dans le texte, afin de le rendre exploitable par les algorithmes
d'apprentissage. Une collection de textes peut être ainsi
représentée par une matrice dont les lignes sont les termes qui
apparaissent au moins une fois et les colonnes sont les documents de cette
collection. [Rad, 2003].
Un grand nombre de chercheurs dans le domaine ont choisi
d'utiliser une représentation vectorielle dans laquelle chaque texte est
représenté par un vecteur de n termes
pondérés. A la base, les n termes sont tout simplement
les n différents mots apparaissant dans les textes de
l'ensemble d'entraînement.
7-2- Choix de termes :
Dans la catégorisation de textes, comme dans la
recherche documentaire, on transforme le document dj en un vecteur
dj = (w1j, w2j, ...,w|T|j),
où T est l'ensemble de termes (descripteurs) qui apparaissent au moins
une fois dans le corpus (la collection) d'apprentissage. Le poids
wkj correspond à la contribution du termes tk
à la sémantique du texte dj. [Rad,
2003].
7-3- Représentation en « sac de mots
» :
La représentation de textes la plus simple a
été introduite dans le cadre du modèle vectoriel elle
porte le nom de « sac de mots ». L'idée est de transformer les
textes en vecteurs dont chaque composante représente un mot. Les mots
ont l'avantage de posséder un sens explicite. Cependant, plusieurs
problèmes se posent.
Il faut tout d'abord définir ce qu'est « un mot
» pour pouvoir le traiter automatiquement.
On peut le considérer comme étant une suite de
caractères appartenant à un dictionnaire, ou bien, de
façon plus pratique, comme étant une séquence de
caractères non délimiteurs encadrés par des
caractères délimiteurs.
Les composantes du vecteur sont une fonction de l'occurrence
des mots dans le texte. Cette représentation des textes exclut toute
analyse grammaticale et toute notion de distance entre les mots : c'est
pourquoi cette représentation est appelée « sac de mots
» (figure 4) ; d'autres auteurs parlent d'« ensemble
de mots » lorsque les poids associés sont binaires. [Rad,
2003].
On appelle "langage
informatique" un langage destiné
à décrire l'ensemble des actions consécutives qu'un
ordinateur doit exécuter. Les langages
naturels (par exemple l'anglais ou le français) représentent
l'ensemble des possibilités d'expression partagé par un groupe
d'individus. Les langages servant aux
ordinateurs à communiquer n'ont rien
à voir avec des langages
informatiques, on parle dans ce cas de
protocoles de communication, ce sont deux
notions totalement différentes. Un langage
informatique est une façon pratique pour nous (humains)
de donner des instructions à un
ordinateur.
6
3
3
...
...
...
...
...
2
1
1
langage
informatique
ordinateur
protocole
instruction
communi
Figure 4 - Exemple de la représentation d'un
texte en « sac de mots »
7-4- Représentation des textes par des
phrases :
Malgré la simplicité de l'utilisation de mots
comme unité de représentation, certains auteurs proposent
plutôt d'utiliser les phrases comme unité. Les phrases sont plus
informatives que les mots seuls, car les phrases ont l'avantage de conserver
l'information relative à la position du mot dans la phrase.
Logiquement, une telle représentation doit obtenir de
meilleurs résultats que ceux obtenus via les mots. Mais les
expériences présentées ne sont pas concluantes car, si les
qualités sémantiques sont conservées, les qualités
statistiques sont largement dégradées. [Rad,
2003].
7-5- Représentation des textes avec des racines
lexicales et des lemmes :
Dans le modèle précédent
(représentation en «sac de mots»), chaque flexion d'un mot est
considérée comme un descripteur différent et donc une
dimension de plus; ainsi, les différentes formes d'un verbe constituent
autant de mots. Par exemple: les mots «déménageur,
déménageurs, déménagement,
déménagements, déménager, déménage,
déménagera, etc.» sont considérés comme des
descripteurs différents alors qu'il s'agit de la même racine
« déménage »; les techniques de
désuffixation (ou stemming), qui consistent à
rechercher les racines lexicales, et de lemmatisation cherchent
à résoudre cette difficulté.
Pour la recherche des racines lexicales, plusieurs algorithmes
ont été proposés; l'un des plus connus pour la langue
anglaise est l'algorithme de Porter.
La lemmatisation consiste à remplacer les verbes par
leur forme infinitive, et les noms par leur forme au singulier. Un algorithme
efficace, nommé TreeTagger, a été développé
pour les langues anglaise, française, allemande et italienne.
L'extraction des stemmes repose sur des contraintes
linguistiques bien moins fortes; elle se base sur la morphologie flexionnelle
mais aussi dérivationnelle. De ce fait, les algorithmes sont beaucoup
plus simplistes et mécaniques que ceux permettant l'extraction des
lemmes; ils sont donc plus rapides; mais leur précision et leur
qualité sont naturellement inférieures. [Rad,
2003].
7-6- Codage des termes :
Une fois que l'on choisit les composantes du vecteur
représentant un texte j, il faut décider comment coder
chaque coordonnée de son vecteur dj.
Il existe différentes méthodes pour calculer le
poids wkj. Ces méthodes sont basées sur les deux
observations suivantes:
1. Plus le terme tk est fréquent dans un
document dj, plus il est en rapport avec le sujet
de ce document.
2. Plus le terme tk est fréquent dans une
collection, moins il sera utilisé comme discriminant
entre documents.
Soient :
· #(tk, dj) le nombre d'occurrences
du terme tk dans le texte dj ,
· |Tr| le nombre de documents du corpus
d'apprentissage,
· #Tr(tk) le nombre de documents de cet
ensemble dans lesquels apparaît au moins une fois le terme tk.
Selon les deux observations précédentes, un
terme tk se voit donc attribuer un poids d'autant plus fort qu'il
apparaît souvent dans le document et rarement dans le corpus complet.
La composante du vecteur est codée f(#(tk, dj)),
où la fonction f reste à déterminer. [Rad,
2003].
Deux approches peuvent être utilisées :
La première consiste à attribuer un poids
égal à l'occurrence du terme dans le document :
Wkj = #(tk, dj)
(1)
Et la deuxième approche consiste tout simplement
à associer une valeur binaire (1 si le mot est présent dans le
texte, 0 sinon) :
1 Si #(tk,
dj) > 1
Wkj = (2)
0 Sinon
7-7- Codage Term frequency ×
inverse document frequency (TF × IDF):
Les deux fonctions (1) et
(2) précédentes sont rarement utilisées
car ces codages appauvrissent l'information : la fonction (2)
ne prend pas en compte la fréquence d'apparition du terme dans le texte,
(fréquence qui peut constituer un élément de
décision important) ; la fonction (1) ne prend pas en
compte la fréquence du terme dans les autres textes. [Rad,
2003].
Le codage TF × IDF (acronyme pour «term
frequency × inverse document frequency») a
été introduit dans le cadre du modèle vectoriel, il donne
beaucoup d'importance aux mots qui apparaissent souvent à
l'intérieur d'un même texte, ce qui correspond bien à
l'idée intuitive que ces mots sont plus représentatifs du
document. Mais sa particularité est qu'elle donne également moins
de poids aux mots qui appartiennent à plusieurs documents : Pour
refléter le fait que ces mots ont un faible pouvoir de discrimination
entre les classes. [Sim, 2005].
Le poids d'un terme tk dans un document
dj est calculé ainsi :
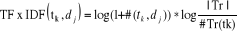 (3) (3)
· # (tk, dj) :
Nombre d'apparition de terme tk dans le document
dj.
· |Tr| le nombre de documents du corpus
d'apprentissage,
· #Tr(tk) le nombre de documents de cet
ensemble dans lesquels apparaît au moins une fois le terme tk.
7-8- Codage TFC :
Le codage TF × IDF ne corrige pas la longueur des
documents. Pour ce faire, le codage TFC est similaire à celui de
TF×IDF : mais, il corrige la longueur des textes par la normalisation
en cosinus, afin de ne pas favoriser les documents les plus longs.
[Rad, 2003].

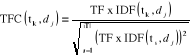 (4) (4)
| 

