CHAPITRE 4
1- Fonctionnement du logiciel :
L'architecture suivante représente le fonctionnement
de notre application. Son fonctionnement est composé de plusieurs
étapes qui peuvent être visualisées une par une, ces
étapes principales sont :
Etape1 : L'utilisateur ouvre l'interface principale
(Navigateur, Explorateur). Les vecteurs d'occurrences de textes d'apprentissage
interdits et autorisés sont calculés et transformés en
vecteurs de fréquences automatiquement après l'exécution
de l'application.
Etape2 : L'utilisateur ouvre un fichier local sur le
disque dur
Etape3 : L'algorithme choisi charge le vecteur de mots
clés et représente le texte à classer (vecteurs
d'occurrences).
Etape4 : L'algorithme choisi transforme le vecteur
d'occurrences de texte à classer en vecteur de fréquences selon
le codage de la méthode.
Etape5 : L'algorithme calcule la similarité entre
le texte à classer et les textes d'apprentissage si la méthode
choisie est kPPV ou la similarité entre le texte à classer et les
profils prototypiques des deux classes (médecine/non médecine) en
cas de l'algorithme de Rocchio.
Etape6 : Selon la métrique de prise de
décision de l'algorithme choisi, le fichier sera classé.
2- L'interface du logiciel :
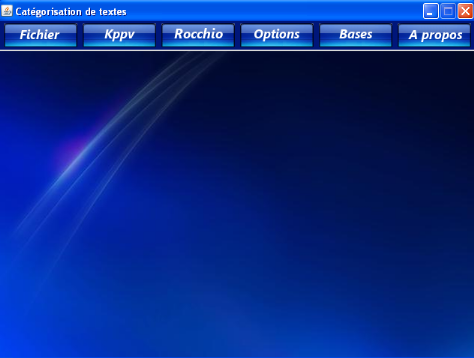
Notre prototype se compose d'une fenêtre principale
à partir de laquelle l'utilisateur peut effectuer les opérations
ou les traitements désirés en sélectionnant un
élément du menu ou en cliquant sur un bouton de la barre.
Cette fenêtre est montrée dans la figure
suivante :

Interface du logiciel:
Le bouton fichier :

Un test avec la méthode KPPV
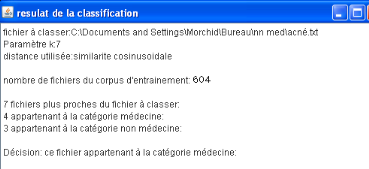
Résultat de la méthode kppv
Un test avec la méthode Rocchio
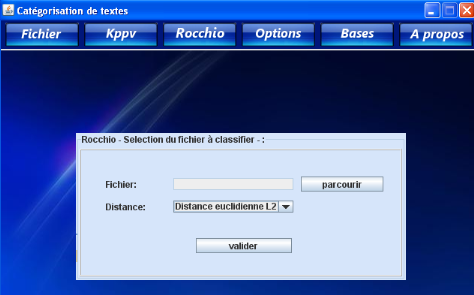
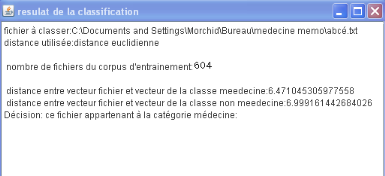
Résultat de la méthode Rocchio
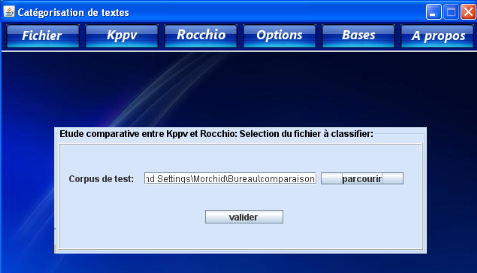
Comparaison
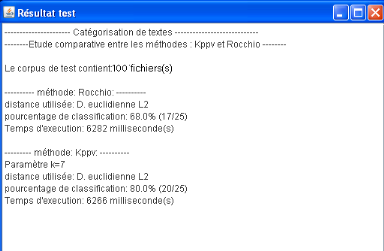
Résultat de la comparaison
Le bouton a propos:
CONCLUSION
Nous avons présenté dans ce mémoire, les
nouvelles approches d'analyse intelligente de
documents qui utilisent les techniques d'apprentissage automatique.
Dans le cadre des méthodes d'apprentissage statistique,
nous avons présenté et discuter deux algorithme Rocchio et k les
plus proches voisins. La démarche générale est
constituée deux étapes, à savoir :
Le pré-traitement du texte
Dans cette dernière phase, la représentation
de texte dans un format adapté aux algorithmes
d'apprentissage ; on utilise souvent la représentation vectorielle.
choix d'une méthode d'apprentissage
Nous avons proposé la méthode Kppv et Rocchio,
qui a donné de bons résultats .
L'algorithme Rocchio est simple, en vu des résultat
obtenu , on peut conclure que la méthode de Rocchio donne de bons
résultats avec un bon taux de précision, l'apprentissage est
rapide, permettant de traiter des données volumineuses, elle convient
donc particulièrement bien au problème de la fouille de
textes.
Il serait maintenant intéressant de poursuivre cette
recherche, qui a permis de découvrir les avantages de ces algorithmes
dans le cadre de la catégorisation de texte. Nous espérons que
cette contribution pourra ouvrir de nouvelles perspectives à d'autres
collègues et d'ouvrir un champ de recherche.
| 

