5.3. MISE EN PLACE DES MODÈLES
UTILISÉS
5.3.1. Détermination du protocole de
modélisation
Plusieurs auteurs ont proposé une méthodologie pour
la conception de modèles. On peut citer comme exemple les travaux de
Refsgaard (1997) et ceux de Dreyfus et al., (2004).
Pour Dreyfus et al., (2004) la conception d'un
modèle non linéaire type « boîte noire » peut
comprendre trois grandes parties :
i. la sélection des entrées du modèle
qui comprend la réduction de la dimension des données
d'entrée (c'est-à-dire la réduction de la dimension de
l'espace de représentation des variables du modèle) et
l'élimination des variables non pertinentes ;
ii. l'estimation des paramètres du modèle avec
le choix du type de modèle (par exemple les modèles de
Réseaux de neurones, les fonctions polynômes, etc.) et
l'apprentissage ou le calage du modèle précédemment choisi
;
iii. la sélection du meilleur modèle et
l'estimation des performances des modèles. Si le modèle
estimé meilleur n'est pas satisfaisant, on choisit une famille de
fonctions plus ou moins complexe et on revient à la seconde étape
de la tâche précédente.
Cette méthodologie bien qu'elle permette le
développement de modèles, souffre cependant du manque d'une
étape importante : la définition de l'objectif de la
modélisation. En effet, tout modèle est construit pour la
résolution de tâches bien précises. On parle de
modèle de simulation ou de modèle de prévision. L'objectif
assigné au modèle peut alors orienter le modélisateur dans
le choix des variables explicatives et des variables cibles. Pour combler cette
insuffisance, il est intéressant de considérer les étapes
proposées par Refsgaard (1997) qui prend en compte, en plus des
étapes décrites par Dreyfus (2004), la définition de
l'objectif du modèle. Pour cette étude, la méthodologie,
représentée sur la figure 46 suivante,
inspirée des deux auteurs précédemment cités a
été adoptée.
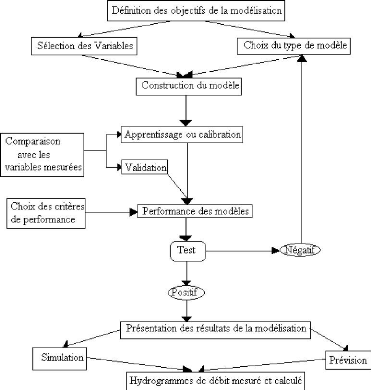
Figure 46 : Protocole de
modélisation adopté des méthodologies de Dreyfus et
al., (2004) et de
Refsgraad (1997)
5.3.2. Définition de l'objet de la
modélisation et choix du pas de temps
Le développement d'un modèle débute
toujours par la définition de ses objectifs. Cette thèse vise la
modélisation de la rélation pluie-débit dans un contexte
perturbé. Il s'agit de mettre en place des réseaux de neurones
capables de :
· Reconstituer des valeurs manquantes dans les
séries de débits sur le Bandama Blanc
(faciliter la
réalisation de certains projets de développement sur la zone
d'étude) ;
· (ii) Prévoir les périodes de basses eaux
et les périodes de hautes eaux sur l'ensemble de la zone d'étude.
Ceci permettra d'aider la classe paysanne dans la gestion de la ressource en
eau. On pourra alors gérer les conflits opposants agriculteurs et
éleveurs dans le Nord de la Côte d'Ivoire. Ce travail vise aussi
à aider la Société de
Distribution d'Eau de la Côte d'Ivoire (SODECI) dans
l'alimentation en eau des localités concernées par
l'étude.
Cette modélisation peut s'effectuer selon plusieurs pas
de temps. Le pas de temps choisi est toujours lié aux objectifs de la
modélisation comme définit précédemment. En
hydrologie, les pas de temps fréquemment utilisés sont l'heure,
le jour, le mois et l'année. Les travaux de Mouelhi (2002) se sont
intéressés à la modélisation au pas de temps
pluriannuel, annuel, mensuel et journalier dans ses travaux de Thèse.
Son objectif était de tirer profit de l'échelle de temps dans la
modélisation pluie-débit en vue d'obtenir des modèles plus
efficaces et plus cohérents entre eux. Huang et al. (2004) ont
fait de la prévision de la rivière Apalachicola (Floride, USA) au
pas de temps journalier, mensuel, trimestriel et annuel. Quant à
Solomatine et Dibike (1999), ils ont fait de la prévision au pas de
temps hebdomadaire en utilisant la pluie, l'évapotranspiration et les
débits. Tous ces exemples montrent que la modélisation
pluie-débit peut se faire sur de nombreux pas de temps.
Une analyse des données de débits fournies par la
Direction de l'Eau (DE) donne les observations suivantes :
i. au pas de temps horaire, les données n'existent pas
;
ii. au pas de temps journalier, les données existent mais
présentent beaucoup de lacunes ;
iii. au pas de temps mensuel, les données sont obtenues
en calculant la moyenne des débits journaliers. Les séries
obtenues présentant peu de lacunes ;
iv. au pas de temps annuel, les données sont obtenues
en calculant les moyennes des débits mensuels. Les débits obtenus
représentent les moyennes des débits mensuels. Les
différentes valeurs de débits sont très lissées au
pas de temps annuels. Les séries de débits annuels obtenues
présentent peu de lacunes.
Il ressort de cette analyse que la Direction de l'Eau ne
dispose que des données au pas de temps journalier et que les
données au pas de temps mensuel et annuels sont obtenues par calcul. Vu
ce qui précède, c'est la modélisation au pas de temps
mensuel qui a été choisie. En effet, ce pas de temps semble
être un bon compromis permettant d'intégrer des données
avec peu de lacunes sans qu'elles soient trop lissées. Le pas de temps
mensuel peut également être considéré comme
opérationnel pour les acteurs concernés par la gestion de la
ressource en eau.
| 

